
4
Evaluation Methods and Issues
Chapter 3 identified three types of questions: monitoring the well-being of the low-income population, tracking and documenting what types of programs states and localities have actually implemented, and formally evaluating the effects of welfare reform relative to a counterfactual. In this chapter we consider only the last of these types of questions. The proper methods for conducting monitoring studies and for determining what policies have actually been implemented are primarily data collection issues; there is no evaluation methodology component to these questions. They are discussed in Chapter 5 in connection with data issues.
This chapter has five sections. In the first, we provide an overview of evaluation methodologies (discussed in more detail in our interim report [National Research Council, 1999] and in evaluation texts). The second section discusses the relative advantages and disadvantages of alternative evaluation methods in relation to each of the different evaluation questions of interest identified in Chapter 3. The third part of the chapter discusses several specific evaluation methodology issues in more detail: the reliability of nonexperimental evaluation methods, statistical power in nonexperimental methods, generalizability, process and qualitative research methods to complement formal evaluation analyses, and the importance of welfare dynamics for evaluation. The fourth part assesses the evaluation projects currently under way (discussed in Chapter 2) in light of the findings that have been presented on the different evaluation methods. The final part of the chapter briefly considers ways in which federal and state agencies can improve evaluations of welfare reform.
We note that recommendations of appropriate evaluation methodologies are sometimes influenced by data availability, for the two are necessarily intertwined.
Chapter 5 presents our major discussion of data issues and data needs; it follows this chapter because data needs should be dictated by what is needed for evaluation. However, a discussion of the strengths and weaknesses of evaluation methods is inevitably influenced by the types of data currently available, likely to be available, or remotely possible to collect; in that context, data issues do arise in this chapter.
OVERVIEW OF EVALUATION METHODS
Formal evaluation studies are those that attempt to estimate the “effect” of a policy change, or the impact of the change on those outcomes which are of interest. By common usage of the word “effect,” this implies that it must be determined what would have happened to those outcomes if the policy change had not occurred. Thus, a formal evaluation study requires the estimation of two quantities: the outcomes that have actually occurred following a policy change, and those that would have occurred if the policy had not changed. The latter is called the “counterfactual.” The basic difficulty in all evaluation studies is that the counterfactual is not naturally or directly observed—it is impossible to know with certainty what would have happened if a policy change had not occurred.1 All evaluation methodologies attempt, implicitly or explicitly, in one way or the other, to estimate those counterfactual outcomes. In experimental methods, the outcomes are estimated by means of a control group to which individuals have been randomly assigned. In nonexperimental methods, the outcomes are estimated by means of a comparison group, a group of individuals that are not randomly assigned to a comparison group, but who are considered to be similar to those who received the policy.
The different types of policy alternatives of interest to different audiences all fit within the counterfactual conceptual framework. Comparing PRWORA in its entirety to its precursor, AFDC, constitutes one pair of policy alternatives, for example, that we concluded would be of interest to many observers. Comparing PRWORA in its present form to a modified PRWORA that might result if its components were altered or improved in some way, constitutes another pair of alternatives in which many policy makers and others are interested. Sometimes, three alternatives are considered, such as the case when the goal is to compare (say) two alternatives (Policy A and Policy B) to current policy. Most of the general issues we discuss for different evaluation methods are the same regardless of which of these policy comparisons is of interest.
Experimental Methods
Randomized experiments have a long history in welfare reform evaluation and have produced some of the most influential results in past reform eras. The strength of the experimental method is that it has a high degree of credibility because randomization assures that those who do experience the policy change (the experimental group) are alike, in all important ways, to those who do not experience it (the control group), except for the difference in treatment (the policy) itself. In evaluation terminology, well-run and well-conducted experiments have strong “internal validity” because they have considerable credibility in generating correct estimates of the true effect of the policy tested in the location and on the population of individuals enrolled in the experiment. The experimental method is also influential because it is simple and easy to understand by policy makers.2
Despite these strengths, the experimental method has weaknesses as well (see Burtless [1995] and Heckman and Smith [1995] for discussions of these issues). A common weakness is that the results of the experiment may not generalize to types of individuals other than those enrolled in the experiment, or to different areas with different economic and programmatic environments, or to policies that differ slightly from those tested in the experiment. In evaluation terminology this is the “external validity” problem. The severity of this problem can be reduced if a large number of experiments are conducted in multiple sites, on different populations, and with different policy features. The expense of doing so is generally prohibitive. A related problem is that experiments are ill suited to estimating the effects of large-scale policy changes which are intended to change the entire culture of a welfare system. If the program is only tested on a small group of individuals in a few cities, the culture will not be affected. However, if the program is enacted nationwide with only a small group of individuals still subject to the old program as a control group, the cultural effects will occur but they will also affect the control group. The experimental method is also not well positioned to estimate so-called “entry effects,” effects that occur because a policy change affects the likelihood of becoming a welfare recipient in the first place. This problem may occur because most welfare experiments draw their experimental and control samples from welfare recipients and not from individuals who are not currently receiving welfare, but who may later do so. A somewhat related problem with experiments is that they usually take a relatively long time to design and implement, so that the policy change tested in the experi-
ment may not be of interest to policy makers by the time the results are completed. Finally, experiments often have practical difficulties when they are conducted in real-world environments with on-going programs and when they require the cooperation and effort of agencies engaged in running current programs.
Despite these weaknesses, the strengths of experiments for answering some types of questions cannot be overemphasized. Even if they may not be completely generalizable and even if they do not always capture all the relevant effects of the program, they provide more credible evidence than other methods for the effects of the programs in one location and on one population. In a policy environment where little credible evaluation research is available, even a small number of experimental results can contribute a great deal to knowledge.
Nonexperimental Methods
Nonexperimental methods are more diverse and heterogeneous than experimental methods, which is one of the reasons that there is often confusion about their nature and value. In all cases, however, nonexperimental methods require that the outcomes experienced by a group of individuals after a policy change be compared with the outcomes that occur for some other group—the comparison group that did not experience the policy change.
A key difference between experimental methods and nonexperimental methods is that an experiment implements a particular policy or program and therefore ensures that it is exactly the one of interest (although, as noted, the time lag in obtaining results may significantly reduce this advantage, and, like nonexperimental studies, the exact policy of interest may not actually be implemented as intended). Nonexperimental methods are necessarily more passive—they can only estimate the effects of programs and policy changes that have actually been implemented, which may not be those of greatest interest. This approach can be advantageous, however, if a wide variety of policy changes have been implemented in different areas, in different environments, and at different times, because a wider range of policies can be studied and generalization is easier. In evaluation terms, nonexperimental evaluations, if they make use of this range, have a greater potential for external validity than do experiments. This potential for external validity must be balanced against the weaker internal validity of nonexperimental methods—that is, the risk that the comparison group is not comparable to the group receiving the policy or program so the correct effects are not estimated.
There are several generic types of nonexperimental evaluations used in welfare evaluations. Perhaps the most traditional is a “cross-area” comparison, which compares outcomes of similar individuals in different geographical areas where different types of policies have been implemented and attributes differences in their outcomes to the differences in policy. A variation on this approach, which is still essentially cross-area in nature, follows individuals over time in
different areas where policy is changing in different ways and observes the outcomes across areas. All these methods can be formulated as econometric models in which individual differences in characteristics are controlled for statistically. This method is not available if all areas are affected by the same policy changes at the same time. In addition, even when there is cross-area variation, there is some danger that not all relevant differences in states’ outcomes, either at a given time or over time, are controlled for; omitted state differences may be correlated with policy choices, either by chance or by design.3
Another, cruder evaluation method is a pure time-series analysis—also called an interrupted time series or before-and-after method—which examines the pattern of outcomes for a group of individuals before and after a policy change. For this method, the “comparison group” is simply the population prior to the policy change. This approach can be implemented either with aggregate data or with micro data—that is, data at the level of the individual or family. In the latter case, the data follow the individuals or families over time before and after a policy change to see how outcomes change. These are among the weakest nonexperimental methods because outcomes change over time for many reasons other than the policy change (for example, changes in the economy and in other policies) which are difficult to control for fully. Outcomes may also change for a given cohort of individuals simply because those individuals age. However, the cohort comparison method (or simply the use of aggregate data, which implicitly uses different cohorts) circumvents this problem by examining a population at the same age at each point in time.
The cohort comparison method examines the outcomes over time of multiple groups of individuals (cohorts) who experience different policies because policy is changing over time.4 If the analysis is conducted in only one area, or in the nation as a whole, the method is essentially a time series. It differs from pure time-series analysis only inasmuch as the cohorts are assumed to be alike in other respects because they are of the same age or are on welfare at the same time. The cohort comparison method can be combined with the cross-area method by comparing changes for different cohorts in different areas where policy has been changing, leading to a cross-area cohort comparison method.
An issue in the cohort comparison method when applied to welfare reform concerns how the cohorts should be defined. If two cohorts are drawn from the welfare rolls at different times—say, one cohort before the legislation and one after—there is a danger that the two cohorts are noncomparable. Noncompara-
bility can arise if (for example) the caseload is falling and those still receiving welfare after the legislation goes into effect are different—for example, more disadvantaged—than those in the first cohort. The exit rate of the second, more disadvantaged cohort is likely to be lower than the first cohort. This lower exit rate is not due to a policy change, but rather because the cohort of welfare recipients has itself changed. This difference can make it difficult to distinguish “true” effects of the legislation on exit rates—that is, whether it really does cause a given recipient to leave welfare sooner than she would have otherwise—from spurious “selection” effects, which arise if the exit rate in the second cohort differs from the first solely because of differences in the make-up of the caseloads.
Another set of nonexperimental methods enjoying some popularity are “difference-in-difference” methods. This method compares the evolution of outcomes over time for different individuals in the same area where a single policy change has occurred, but for which some individuals are in a position to be affected by the change while others are not (Meyer, 1995). Those assumed not to be affected by the policy change constitute the comparison group. In most implementations of the method in welfare reform evaluations, the comparison group is chosen to be a group of individuals ineligible for welfare, or at least ineligible for the policy change in question. Common comparison groups are single women without children, married women with or without children, and men, groups that are mostly ineligible for AFDC or TANF. Sometimes single mothers who are more educated and hence of higher income are used as a comparison group for low-income single mothers because the former group is generally ineligible for welfare. The key assumption in the method is that the evolution of outcomes of the group affected by the policy change (e.g., single mothers) would be the same as that of the comparison group in the absence of the policy change. The major threat to the credibility of this method is that the two groups are sufficiently different in their observed and unobserved characteristics (although observed characteristics can be controlled for) that these differences, and not the policy difference, account for the differences in outcomes.
Another nonexperimental evaluation method that is quite similar to the difference-in-difference method, but that is implemented quite differently and actually predates it, is the method of matching.5 In this method, comparisons are made within given areas between those who are directly affected by a new reform and a comparison group of individuals (or sometimes populations) who are, for one reason or another, not directly affected. Although in principle the types of individuals used to construct a comparison group could be quite similar to those just mentioned for the difference-in-difference method, in practice the method of
matching follows the exact opposite strategy of seeking a comparison group that is as similar in observed characteristics to the affected group as possible. Typically, the group will be drawn from the population of eligibles (usually those not participating in the program) rather than the population of ineligibles, as in the difference-in-difference method. The two groups are matched on observable characteristics (age, education, earnings and welfare history, geographic location, etc.) to eliminate differences resulting from those factors. Like the difference-in-difference method, this method can be implemented in a single area with a single policy change, and does not require cross-area or over-time variation in policy in order to estimate effects.
Also like the difference-in-difference method, the major threat to the matching method is that there are unmeasured characteristics that differ between the two groups and related to the reason that one group was subjected to the policy and the other was not. Because there is no policy variation per se—all individuals reside in the same area, under a single policy—comparison groups have to be constructed from individuals who are, for example, not on welfare, or who are on welfare but are exempted from the new reform by reason of some characteristic they possess (e.g., very young children). Learning whether the members of the comparison group are really comparable to those who were made subject to the new policy—in the sense of having the same outcomes as they would have had in the absence of the policy—is difficult.
The major disadvantage of nonexperimental methods in that it is difficult to assess the degree of bias in the estimates of a policy’s or a program’s effects because of threats to internal validity from the choice of a comparison group. This problem has been given extensive attention in the research literature on nonexperimental evaluation methods. The most convincing approach is simply to conduct formal sensitivity analyses that reveal how different degrees of bias that are thought to be present, on a priori grounds or on the basis of other information, affect the estimates of program effects.6
The magnitude of the effect of a policy change is also important because any given amount of bias is less likely to affect the sign (positive or negative) and policy importance of the estimate if the magnitude is large. This truism underlies the common supposition that nonexperimental methods have greater credibility in cases in which a large effect of the program under study is expected and less credibility in cases when a small effect is likely, for in the latter case it is more likely that any bias in the estimate will swamp the true effect.
Despite the threats to internal validity in all nonexperimental methods, they can be very useful when carefully implemented. Pure time-series methods, the crudest of the nonexperimental approaches, are useful as a descriptive piece of evaluation showing whether, given the other changes over time that can be controlled for, a policy change is correlated with a deviation from the trend in outcomes. Cross-area methods have credibility when the groups of individuals examined in each area are strongly affected by policy, when the policy measures in each area are adequately measured, and when there is a reasonable judgment that the existence of different policy changes is not correlated with outcomes. Difference-in-difference methods have some credibility, particularly for large systemwide changes. Only matching methods suffer from an inherent inability to judge credibility, because they depend on untestable assumptions about unobserved characteristics (we discuss some methods for testing the validity of the matching method below). For all nonexperimental methods, credibility is increased if the expected magnitude of the effects is large. The major advantage of nonexperimental methods is that they have greater generalizability, across a great diversity of areas and population groups, than experiments. These methods can also be used to capture entry effects. Nonexperimental methods are, therefore, a necessary part of welfare reform evaluation.
Process Analysis and Qualitative Methods
Implementation and process analyses collect information on the implementation of policy changes; how those changes are operationalized within agencies, often at the local level; what kinds of services actually get delivered and how they get delivered; and, sometimes, how clients perceive the services. They can be used in conjunction with either experimental or nonexperimental analyses, although analysts disagree about their role in formal evaluations. At one level, they can be seen merely as providing a more accurate description of what is being evaluated: in evaluation language, they provide a more precise description of the policy treatment. This is, indeed, the way many process and implementation evaluations are used.7
A more ambitious role for process and implementation analyses is to assess the effects of experimentally varied or nonexperimentally observed differences in policy implementations. For example, one could have a randomized trial in which the actual policy or program treatment offered is the same for both experimental and control groups, but for which the implementation differs. Or, in a nonexperimental analysis that correlates program variation with outcomes across a number of areas, measures of implementation might be used to characterize each area’s program, in addition to the formal program descriptions. The effects
of implementation differences could then be estimated. This more ambitious goal has not been attempted in any systematic way in welfare reform evaluations thus far, partly because of the difficulty in constructing measures of implementation that are comparable across areas (see below).8
Implementation and process analysis can also play an important informal role in interpreting the estimated effects from analysis of the official treatment. Implementation and process analysis can reveal features of a program that have been carried out successfully—in the way the program designers intended and expected them to be carried out—and it can also reveal features that are not carried out successfully. If difficulties or failures of implementation are found, these can be used to consider why the estimated effect of a program was larger or smaller than anticipated or even why the program had no apparent effect. This interpretative, hypothesis-generating function of implementation and process analysis can be quite valuable when formal effect estimates come out differently than expected.9
More broadly, qualitative methods can be used not only as a method of collecting information for process and implementation analyses, but also to study the behavior of individuals and families. Qualitative methods may involve collecting data through focus groups, semi-structured interviews (sometimes longitudinally with the same individuals or families over time), open-ended questions in surveys, and ethnographic observations of individuals (Newman, 2001). A process study may also use one of these methods to collect data on how caseworkers are implementing a particular policy.
Qualitative methods used to collect information on individuals and families can serve multiple roles in evaluation settings and in a different dimension than process and implementation analysis. To some extent, such data may simply provide a better measure of outcomes than data collected through formal survey or administrative data outcome measurements because they provide much more in-depth information on how individuals and families are affected. In principle, it is possible that formal evaluations of different programs could yield similar estimates of outcomes but that quite different outcomes would be found with the qualitative analysis. This provides a valuable insight into how seemingly similar program effects are not the same. In addition, like implementation and process analysis, qualitative data can also provide insights into the precise mechanism by which policy affects individuals’ lives (or, perhaps more commonly, fails to
affect those lives). Just as implementation and process analyses can discover what works or does not in the delivery of program services, qualitative data can reveal the mechanisms and processes by which program services or offers of services are translated or incorporated into the lives of individual families. Formal survey and administrative data outcomes typically are too crude to ascertain the details of that mechanism. By studying the complexity of individual experiences, qualitative data can both illuminate more clearly how successful programs achieved their successes or illuminate why some programs have been unsuccessful or have had unexpected outcomes. This information can then be used to design improved programs or programs that are differently configured so as to avoid the undesirable outcomes. (In Chapter 5, we discuss how qualitative and ethnographic studies can also be used to enhance survey data collection.)
EVALUATION METHODS FOR THE QUESTIONS OF INTEREST
In Chapter 3 we delineated three formal evaluation questions of interest:
-
What are the overall effects of structural welfare reform?
-
What are the effects of individual, broad components of a welfare reform?
-
What are the effects of alternative detailed strategies of welfare reform within each of the broad components?
In this section, we discuss the evaluation methods that are appropriate to answer each of these questions. We begin with a key conclusion.
Conclusion 4.1 Different questions of interest require different evaluation methods. Many questions are best addressed through the use of multiple methods. No single evaluation method can effectively and credibly address all the questions of interest for the evaluation of welfare reform.
Table 4–1 gives a summary of how this conclusion plays out for the questions of interest and evaluation methods available.
Estimating the Overall Effects of Structural Welfare Reform
Estimating the overall effects of structural welfare reform of the type that has occurred in the 1990s—that is, a reform that bundles together a number of significant changes in the program whose joint impact is to change the basic nature of the welfare program(s) involved—is perhaps the most challenging question for evaluators. Structural reform affects the entire programmatic environment, from the top policy level to the way that local welfare offices operate. In a structural reform, families and individuals in low-income communities (both those on and
TABLE 4–1 Alternative Evaluation Methodologies for Different Questions of Interest
|
|
Questions of Interest |
||
|
Evaluation Methods |
Overall Effects |
Effects of Individual Broad Components |
Effect of Detailed Strategies |
|
Experimental |
Poorly suited |
Moderately well suited |
Well suited |
|
|
Problems: contamination of control group; macro and feedback effects; entry effects; generalizability from only a few areas |
Need to be complemented with nonexperimental analyses for entry effects and generalizability |
Need to be complemented with nonexperimental analyses for generalizability and, possibly, entry effects |
|
Nonexperimental |
Moderately well suited |
Moderately well suited |
Poorly suited |
|
|
Time-series modeling and comparison group designs using ineligibles are the most promising |
Cross-area comparison designs, followed over time, are the most promising |
Within-area matching designs may be the most appropriate, followed by cross-area comparison designs |
|
Problems: lack of cross-area program variation; data limitations |
Problems: lack of cross-area program variation; measurement of policies; data limitations |
Problems: extreme data limitations and lack of statistical power; uncertainty of matching reliability |
|
off welfare) change their expectations about welfare programs; the level of community and neighborhood resources are affected; governments involved in the program (federal, state, and local) alter their spending and taxation levels and the types of services they offer; and other agencies and private organizations that serve the low-income population change, often restructuring themselves to meet new demands for their services.
In such a changed environment, neither experimental methods nor most traditional nonexperimental methods can provide reliable estimates of what would have happened to individuals and families in the absence of the reform having taken place. As noted previously in our discussion of the drawbacks to experimentation when cultural effects are part of the outcome, a control group in a randomized experiment that has been chosen just prior to the initiation of the reform will almost surely be affected by the broad effects created by the reform, thereby contaminating their outcomes as representing those that would occur in the absence of reform. This makes experimental comparisons subject to unknown bias. Nonexperimental methods that rely on cross-area variation are also
generally inadequate because the welfare systems in all areas are changed simultaneously: there is no “no change” area with which the “change” areas can be compared. Similarly, within-area matching methods that compare welfare-eligible nonrecipients to welfare recipients and attempt to control for differences through matching are also unlikely to be reliable because the nonrecipients are almost surely affected by the overall reform.
There are only two possible methods of evaluation in this circumstance, both of which have problematic aspects. One is a pure time-series analysis or its cousin, the cohort comparison method. The second method is the difference-in-difference method.
The time series and cohort comparison methods would be used in combination with either aggregate data or individual data on outcomes before and after the reform and attribute the change in outcomes to the reform. Individual data are generally preferred because individual and family characteristics can be controlled for in the analysis or used to stratify the analysis into different types of individuals and families. At the individual level, panel data that follow individuals over time (from pre- to post-reform) are suitable for this type of analysis. Repeated cohorts of different individuals before and after the reform are also suitable. In either case, it is necessary to estimate the trends in outcomes that occurred over the prereform period, and to implicitly or explicitly extrapolate those outcomes to the postreform period—in other words, to estimate what the course of outcomes would have been in the absence of reform. Then, those extrapolated outcomes are compared with the actual outcomes.
The time-series method requires that changes in the economy and other changes in policy that occur simultaneously with the welfare reform be explicitly controlled for and that their influence be estimated indirectly in one way or another. Thus, for example, the influence of the business cycle must be controlled by econometric methods that use data from past business cycles to estimate their effects and to project what outcomes would have been during the period of reform if only the business cycle had changed. Effects of other reforms, such as Medicaid expansions and the Earned Income Tax Credit must be estimated and controlled for as well. General trends in outcomes, including those that may be different for different types of individuals and families (e.g., trends in the demand for labor for people with modest job skills or extremely limited job skills) must also be controlled.
This type of exercise has been attempted, with limited success, in the econometric modeling literature.10 It is very difficult to control adequately for all the changes in the social and economic environment and in policies, and to estimate their effects accurately. It can also be difficult to assess exactly when a policy was implemented in different areas to make a pre- and post-policy change dis-
tinction and it can be difficult to distinguish any lagged effects of previous policy changes from the effects of the current policy change of interest. Despite these heavy qualifications, time-series models can be of considerable value in providing “ballpark” estimates of the overall effect of a welfare reform. In part, this is because the expected magnitude is usually large so that the biases in nonexperimental methods are outweighed by the magnitude of effects. If the estimates are interpreted as approximate effects rather than precise ones and if they are treated as having a possibly significant margin of error, they can be quite informative, particularly if large effects are detected.
The second method that can be used in this context is the difference-in-difference method, which requires the availability of a comparison group that, with reasonable assurance, has not been affected by the reform. The comparison group serves as the counterfactual to the group affected by reforms, and its outcomes are presumed to be comparable with what the outcomes of the group affected by the policy change would have been in the absence of reform. Studies that have used this method typically compare the changes in prereform to postreform outcomes of one group with those for a comparison group for which the policy did not change. For example, changes in outcomes for single mothers have been compared with those for married women (either with or without children), with those of single women without children, or with those for men (married or unmarried, with or without children) or changes in outcomes for less educated single mothers are compared with those for more educated single mothers or more educated women as a whole (Ellwood, 2000; Meyer and Rosenbaum, 1999, 2000; Schoeni and Blank, 2000). Because the various comparison groups are by and large ineligible for, and therefore presumably unaffected by AFDC or TANF, the trends in their outcomes may be a reasonable indication of the trends in outcomes that single mothers would experience had the reforms not been implemented.
The difficulty with this method is that the comparison group may be affected by a systemwide reform or it may have experienced changes in outcomes that are not the same as those that would have occurred for single mothers (and other people eligible for welfare). To the extent that structural and systemwide reform of welfare for single mothers affects marriage rates and the economic support received by men, for example, the outcomes for men will be affected. Likewise, the pool of married women with children may change as single mothers marry and thereby affect the outcomes of married women who are supposed to comprise the control group. These threats to the credibility of the method can be minimized by comparing low-income single mothers with high-income men and married women. However, this then increases the risk that the two groups are experiencing other different economic and social changes. Thus, there is a tradeoff in using this method between picking comparison groups that are close in socioeconomic characteristics and geographic location to the group of policy interest (in this case, single mothers) and picking comparison groups that are
significantly different in socioeconomic characteristics and geographic location. If the estimates of program effects differ depending on the comparison group chosen, there is little guidance on which estimate is best. Finally, this method must also confront changes in the economic and policy environment that occur at the same time as welfare reform, although in this case only for those that differentially affect single mothers and those in the chosen comparison group. For example, differential effects are likely to occur if overall changes in the policy environment (such as the enactment of a new program that affects everyone in the population) interact with the tax, transfer, and other programs facing the comparison group, because those programs are generally different than the programs being assessed and for which the group is serving as the control.
Nevertheless, as with time-series modeling, the results of this method contribute information to the effects of welfare reform if they are treated as generating approximate estimates and if they are considered as capable only of detecting large effects. Their value also depends on the credibility of the comparison group, as well as whether there is a sufficiently long time series to provide a reasonably reliable indication that the outcomes of the comparison groups were not trending at different rates than those of single mothers.
Aside from these two methods, there are other nonexperimental methods that could occasionally be used to evaluate overall effects, although all have disadvantages. For example, some econometric studies have used variation in the date at which states implemented PRWORA to estimate the effects of reform (Council of Economic Advisers [CEA], 1999). Unfortunately, most states adopted PRWORA within a fairly narrow time interval, and the few states that did not are likely to be different in other ways.11 Other studies estimate the effects of PRWORA-like policies from waivers that were adopted pre-PRWORA, because in that period there was considerable variation in the time at which states adopted waiver policies and because a few states never adopted waivers (prior to 1996). This method, of course, requires that the PRWORA legislation and waivers be sufficiently similar. Unfortunately, there were quite a few important differences between them, which threaten the credibility of this method.
Implementation, process, and qualitative analyses are very important when considering overall effects. Because the available quantitative methods provide, at best, only approximate estimates that almost certainly contain some degree of bias, data obtained from the individuals involved in or affected by the welfare system are important as confirmatory evidence for the more formally estimated quantitative estimates. To be credible, large estimated effects obtained from the nonexperimental methods would require that the evidence from welfare administrators, front-line workers, and from welfare recipients (and welfare leavers) is
consistent with such large effects. Small estimated effects from a formal model should likewise find support in the evidence from those same groups. While the qualitative data cannot by their nature provide formal evidence on what would have happened in the absence of reform, information from the people involved on what has changed and, from their perspective, why it has changed, provide at least some evidence for the issue. The combination of the quantitative results with qualitative data when both point in the same direction is considerably more powerful than either taken separately.
Although many of the threats to valid conclusions of studies that use time-series and differences-in-differences methods are inherent in their designs, the problems can also be reduced with good data. Time-series modeling, for example, is heavily dependent on the availability of good historical data at the individual level on welfare histories, labor market experiences, and other demographic events and at the area level on historical data on policies and measures of the economic environment. Controlling for differences across individuals in their welfare and labor market experience, for example, is important to predicting postreform outcomes and hence to separating what would have occurred from what did occur because of reform. Policy measures and economic measures over time are needed in order to estimate the effects of those forces and project them to a postreform period. These same data requirements manifest themselves in the difference-in-difference group method as well, for which comparisons at the individual level are also important and for which individual, programmatic, and environmental histories on the individuals in the program and comparison groups are needed to control for differences in their histories. In both methods, a fairly detailed geographic disaggregation is needed in order to compare individuals, either cross-sectionally or over time, who live in the same areas and hence are experiencing the same environmental influences.
Unfortunately, as we discuss in more detail in Chapter 5, it is not possible to meet these data requirements with the data infrastructure for welfare evaluation currently in place in the United States. Some of the main national level survey data sets used for evaluation, such as the CPS and the Urban Institute’s National Survey of America’s Families (NSAF), are not longitudinal and hence, do not track individuals over time. Other data sets have little or no information pre-PRWORA. Those longitudinal data sets that do have pre-PRWORA information have relatively small sample sizes (discussed more below), difficulties with high rates of nonresponse, or slow rates of public release. Administrative databases at the state level are often not available in usable individual form and sometimes do not go back far enough because some welfare agencies have not archived old records.12 Measures of the policy environment are particularly difficult to gather
historically and at a disaggregated geographical level. Thus, time-series modeling and difference-in-difference methods of comparison groups of ineligibles are handicapped by the availability of rather crude data to estimate program effects.
Studies that use pre-PRWORA cross-area variation in waiver policies face data difficulties of another type, which is overly small sample sizes in the major data sets available. We consider this problem further below in the context of estimating the effects of broad individual components with cross-area variation.
Estimating the Effects of Individual Broad Reform Components
The possibilities for evaluating the effects of individual broad reform components are greater than for evaluating overall effects. There are both traditional experimental and nonexperimental methods that can be used for this type of evaluation, albeit not without difficulties.
Experiments for example, are usually suited for the evaluation of the effects of adding or subtracting, or otherwise changing, the individual components of welfare reform. Experimental and control groups that differ only in the availability of single components, or combinations of components, are more feasible and credible because it is unlikely that macro and systemwide effects would contaminate the outcomes in the control group, which is the main problem in using these methods to assess the overall effects of a reform. It should be immediately noted, however, that experiments that changed only one feature of the old AFDC program, and not any others (such experiments were not conducted) would not have had the systemwide effects intended by welfare reform advocates and, hence, would have had more limited interest, however feasible. Now that systemwide change has occurred, testing individual component reforms is both feasible and interesting to a wide range of policy makers. Incremental reforms in the current welfare reform structure are eminently testable with experimental methods.
As noted above, however, experiments also have certain inherent drawbacks that are still present in the case of estimations of the effects of individual component changes. The difficulty of incorporating entry effects into the analysis is one example, for entry effects are likely to be important if any major component of a welfare program is eliminated or added. The problem of generalizing the results of an experiment to populations and environments different from the ones in which the experiment is conducted is also a major issue; hence, the inability for cost reasons to test reforms nationwide or separately in most states and areas is a significant drawback. Therefore, for future changes in broad components, experimental methods will still need to be supplemented by nonexperimental methods to obtain a complete and generalizable picture of effects.
Nonexperimental evaluations of the effects of individual program components can also rely on traditional methods, such as the cross-area method discussed above, at least to the extent that there is cross-state variation in those components. Family caps, for example, are not present in all states. This differ-
ence affords an opportunity to estimate their effects by a comparison of outcomes for individuals in states with and without those caps. In comparison with experiments that test the effects of family caps, the nonexperimental strategy is likely to yield a broader range of environments and policies to estimate and hence increase the ability to generalize. The price is that all other differences across areas must be adequately controlled for (a requirement that is necessarily met by a well-run experiment). Nonexperimental evaluations of effects of family caps can, in addition, capture entry effects in a way that experiments cannot. In principle, they can also capture macro and feedback effects. Thus, nonexperimental evaluations are necessary to fill in some of the holes that experimental evaluations leave. However, like experiments, nonexperimental estimates of the effect of the addition or subtraction of individual broad components obtained from cross-area variation in policies can only produce estimates of the incremental effects of such provisions given an overall program structure. For example, family caps added on top of the old AFDC program would likely have had quite a different effect than family caps added post-PRWORA.
The cross-area nonexperimental method cannot be used if there is no cross-sectional policy variation in a individual component. For example, it is not suitable to evaluate broad components like work requirements and time limits, which are necessarily present in some form in all states because they were mandated by PRWORA.13 Time-series and cohort comparison methods are likewise not appropriate to estimate the effects of broad components if those components are introduced in all states at the same time. Even difference-in-difference methods can rarely be used because they require comparison groups of people ineligible for welfare who are unaffected by the component in question. Finding such comparison groups is typically very difficult because ineligibles—say, those exempted from time limits or work requirements—differ from eligibles in some other important characteristic (e.g., the presence of a young child). Separating the effects of the other characteristics from the effect of the component is difficult and requires various assumptions. Within-area matching usually cannot be used for the same reason, for rarely are those who do not have the component in question imposed on them likely to be similar in unobserved ways to those who do have it imposed on them. Although cases may be found where these circumstances are met, it is not a general solution to the estimation of individual reform components.
As with the discussion of methods in the previous section, good data are important to strengthening the conclusions that can be drawn from the evaluation of the effects of individual broad components of welfare reforms. Data issues are typically more important for nonexperimental evaluation than for experimental
evaluations. To be able to test differences in policies across areas, a good nonexperimental evaluation requires good data on the individual components of policies; on the characteristics of different areas; and on the individuals in those areas. For many data sets, such as those drawn from administrative records, cross-state comparability is a major data problem that limits the application of these methods (see Chapter 5 for more discussion). Data over time is particularly useful for tracking the effects of changes in policy combining the cross-section and time-series methods, in contrast to using just a pure cross-section method. Nonexperimental evaluations usually rely at least in part, on data collected for purposes other than the study of interest, while data collection for experimental studies is usually designed specifically for the study, and may not be ideally suited for use in some cases. Finally, sample sizes are critically important in making reliable inferences on the subpopulations affected by the particular individual component in question.
Estimating the Effects of Detailed Reform Strategies
The effects of detailed strategies, such as different types of work and employment strategies, different time limit structures, different sanctions rules, and other such variations are important parts of the welfare reform evaluation effort for certain audiences, as discussed in Chapter 3.
For the evaluation of alternative detailed strategies, randomized experiments are generally the strongest evaluation methodology.14 Macro and other feedback effects, for example, are unlikely to be large when only a detailed strategy is altered within a particular broad component and within a given overall welfare structure. Entry effects are likely to be smaller than those that follow the introduction or deletion of a broad reform component, although reforms that markedly affect the welfare experience may have entry effects.15
Generalizability to different environments and different populations is likely to remain a problem when conducting experiments to learn the effects of particular detailed strategies. Typically, experiments about strategies are quite localized, conducted at the local office level or in one or only a few sites, and usually only on particular populations (e.g., only on the recipients on the rolls at a particular time in the business cycle or only on applicants). This problem could be reduced significantly if sufficient numbers of experiments in different areas, at different points in the business cycle, and on different populations (recipients,
applicants, nonwelfare participants, etc.) were conducted. However, this is rarely feasible for cost reasons and hence the generalizability of experiments on detailed strategies is still likely to be in question. Again, complementary nonexperimental evaluations are one route to fill in the need for generalizability, by either aiding in the extrapolation of experimental results to different populations, environments, and programs, or to directly estimate the effects of alternative detailed strategies across those same variations. Process and implementation studies at each experiment site might also help in assessing the generalizability of experiments. For example, process studies across sites that reveal that experiments were implemented in the same way in each site may support the generalizability of results or cast doubt on the generalizability if the process studies reveal that the experiments were not implemented in the same way. (We discuss the issue of generalizability in more detail in the next section.)
It is possible to use nonexperimental evaluations for the evaluation of detailed strategies, but there are difficulties in doing so. Cross-area comparison methods that examine different detailed strategies on a particular welfare component (e.g., different strategies for increasing employment) in different areas require, for accurate estimation, that all other components of the programs in the different areas be controlled. This is likely to be a problem because the detailed strategies are typically only one component of a larger welfare structure that varies in multiple and complex ways and are difficult to measure and control for. When the need to control for differences in the economic and social environments across areas is also considered, as well as the need to control for other differences in program policies, the difficulties of cross-area program comparisons can quickly become insurmountable. These difficulties are made worse because most nonexperimental data sets have insufficient numbers of areas, each with insufficient sample sizes, to adequately estimate the effects of large numbers of other factors affecting outcomes. The difficulty lies partly in the expectation that the effects being estimated may be relatively small compared with the effects of the other cross-area variations that are not controlled. Thus, nonexperimental estimation is not a promising evaluation method for gauging the effects of alternative detailed strategies.
One alternative nonexperimental methodology that may be more promising for this question is the within-area matching method. Time-series and cohort comparison methods are unlikely to be useful for evaluating detailed strategies for the same reasons they were unlikely to be useful for evaluating broad components. They require areas where the detailed strategy is changed over time, leaving all other components of the welfare program unchanged. Although this is possible in principle, it is unlikely in practice. Difference-in-difference methods are difficult as well because they require the construction of comparison groups of ineligibles for multiple detailed strategies, which is generally unlikely. As mentioned above, the main challenge to this method is finding a group of individuals in the same area as those who were subjected to the reform who have, for
reasons related only to their observable characteristics (age, education, labor force, and welfare history) and not to any unobservable trait, not been subjected to the reform. Usually this group is drawn from the population of people who are eligible for, but not participating in the program. Although this requirement is particularly problematic because it is unlikely that all the factors affecting their participation status are observable, the method is now under active research and there is some evidence in its support (Dehejia and Wahba, 1999). Because it is the only nonexperimental method that is likely to be possible for the evaluation of detailed strategies, it needs more investigation (see below).
Conclusions
Conclusion 4.2 Experimental methods could not have been used for evaluating the overall effects of PRWORA and are, in general, not appropriate for evaluating the overall effects of large-scale, systemwide changes in social programs.
Conclusion 4.3 Experimental methods are a powerful tool for evaluating the effects of broad components and detailed strategies within a fixed overall reform environment and for evaluating incremental changes in welfare programs. However, experimental methods have limitations and should be complemented with nonexperimental analyses to obtain a complete picture of the effects of reform.
Conclusion 4.4 Nonexperimental methods, primarily time-series, and comparison group methods, are best suited for gauging the overall effect of welfare reform and least suited for gauging the effects of detailed reform strategies, and as important as experiments for the evaluation of broad individual components. However, nonexperimental methods require good cross-area data on programs, area characteristics, and individual characteristics and outcomes.
ISSUES IN EVALUATION METHODOLOGY
The panel devoted special attention to several specific issues in evaluation methodology that are often more technical than the general principles just adduced. This section contains the panel’s findings on these specific issues: (1) ways to assess the reliability of nonexperimental evaluation methods; (2) the power of cross-sectional comparison methods to detect welfare reform effects with available data sets; (3) generalizability, which comes up repeatedly in discussing the usefulness of experiments and the combination of nonexperimental and experimental methods; (4) details regarding the use of process and qualitative analysis in evaluation; and (5) the importance of an understanding of welfare
dynamics for evaluation of welfare reform. Readers not interested in these special issues may wish to move to the assessment of current evaluation efforts.
Assessing the Reliability of Nonexperimental Evaluation Methods
Given the importance of nonexperimental methods for many of the evaluation questions surrounding welfare reform, it is desirable to have methods of assessing the reliability of nonexperimental methods for their accuracy. The most important threat to the validity of nonexperimental methods is that the comparison group used is dissimilar in some respect to the group affected by the reform (i.e., that internal validity is weak) and therefore that the outcomes for the comparison group do not properly represent what would have happened to the group affected by the reform if it had not occurred. Methods that focus on this key issue and assess the validity of the comparison group are needed. The same issue arises when multiple types of nonexperimental methods are used and yield different estimates of program effects. In this section we discuss three strategies for assessing the reliability of nonexperimental methods: specification tests, sensitivity testing, and benchmarking to experiments.
Specification Tests
Specification tests are used whenever some of the assumptions made to ensure that one is estimating the true effect can be relaxed and an alternative estimator that does not require those assumptions can be used (see Greene, 2000, pp. 441–444, and 827–831 for a textbook discussion of specification testing). A common example of this type of test arises in program estimates using the cross-area method, where the assumption needed for internal validity is that the different areas would have the same values of the outcome variable in the absence of any variation in policy. This assumption would be incorrect if those areas differ in unobserved and hence unmeasured ways that happen to be related to the policy variation. For example, states differ in their income levels, poverty rates, and other factors, and the differences in policies across states usually account for only a fraction of these differences. The assumption can be tested if data on the areas are available from some prior time, before any policies were adopted in any area, for if the areas differ for reasons unrelated to policy, those differences are likely to have appeared earlier as well. A formal specification test can be developed for assessing whether the pre-policy differences are related to policy variation across areas and hence create problems for the cross-area estimate.16 Similar tests can
be performed for other nonexperimental methods—cohort comparison, time series, and others.
This example illustrates the need for data to conduct specification tests, in this case, data from before the policy was implemented. Although specification tests can occasionally be developed with the same data used for the initial estimate, supplemental data are usually needed to be able to test the key assumptions in the model.
Specification tests are not without limitations. The need for additional data may often be unmet, and there may be no alternative ways to test the specification. More fundamentally, there can be no guarantee when obtaining two separate estimates from alternative models that one is correct and that one is not, for both could be incorrect or the more general estimator may be incorrectly specified. For example, the outcomes at a prior time may be a misleading indicator of what current outcomes would be in the absence of the policy. This means the conclusions from the tests are somewhat uncertain and highlights the fact that all such tests are based, themselves, on additional assumptions that may or may not be correct. Nevertheless, specification tests are a valuable tool and can be informative for many nonexperimental methods and estimators. They are underused in welfare program evaluation, and they need to be refined and developed further for best use.
Sensitivity Testing
A second method of assessing reliability is sensitivity testing, in which the critical assumptions underlying the nonexperimental estimates are relaxed to some degree, or a range of plausible assumptions is examined to determine how much the estimate of the policy effect is sensitive to those assumptions. The extent to which the assumptions are relaxed is based on intuition and general credibility, not on any formal evidence or statistical procedure. For example, in the cross-state example discussed above, one could assume that 10 percent of the difference in outcomes across states existed prior and was unrelated to the effect of policy variation, and then subtract that from the estimated effect. This is the type of implicit sensitivity testing done when an analysis yields a large estimate of a program’s effect. It is implicitly understood that even if some bias exists in that estimate, the true effect is still likely to be large. Sensitivity testing in less obvious circumstances, where an auxiliary assumption that only indirectly contributes to the estimation of the program effect is tested, is more common and constitutes the typical contribution of the method.17
Sensitivity testing also has limitations, mostly concerning the necessity for some arbitrariness in deciding which assumptions should be subject to sensitivity testing and how much they can credibly be varied. The bounds of sensitivity testing must be set by the individual analyst or group on the basis of intuition and outside information, not on the basis of formal tests.18 Nevertheless, sensitivity testing is, like specification testing, all too rarely undertaken in welfare reform studies and should be used more often.
Applying Nonexperimental Methods to Experimental Data
A third method for assessing the reliability of nonexperimental methods is to apply them to data from an experiment where the “true” answer is known. The typical approach is to obtain data on both the experimental and control groups from an experimental evaluation, and then to construct a comparison group using one or more of the available nonexperimental methods. The effect of a program is then estimated by comparing the outcomes of the experimental group to those of the comparison group instead of the control group to determine if the “right” answer is obtained. The indirect method of simply comparing the true control group to the chosen comparison group is an equivalent way of ascertaining the accuracy of the nonexperimental method chosen. Studies of this type include Fraker and Maynard (1987), Friedlander and Robins (1995), Heckman et al. (1997, 1998), Heckman and Hotz (1989), and Lalonde (1986).
The advantages of this approach are that the experiment allows the analyst to know the “truth” to which the effect using nonexperimental methods can be compared. However, the approach has a number of limitations as well. Aside from the issue of whether the experiment itself has internal validity—that is, that it is well executed and does not suffer from problems of attrition or contamination—a general limitation is that the approach is necessarily restricted to those nonexperimental methods that estimate the types of effects as those estimated with experimental methods. As we noted earlier, it is not feasible to estimate some types of effects with experiments. Thus, for example, time series, difference-in-difference, and cross-area methods cannot be tested against experiments because they often capture entry and macrocultural effects, which cannot be feasibly captured with experiments. Likewise, if no experiments have been conducted to estimate the effects of broad components of welfare reform, as we noted previously is the case, nonexperimental methods that aim to estimate those
effects cannot be tested with this approach. The generalizability, or external validity problem of experiments also limits the benefits of this approach. Even if a particular nonexperimental method that replicates the effect of an experiment tested on one particular subpopulation and in one or only a few locations can be found, it may not have many implications for whether that or any other nonexperimental method would be useful for other populations or areas.
A less obvious problem with the approach is that the services received by the control group in an experiment are often not formally characterized and described, for an experiment is generally designed only to estimate the effect of a new policy relative to the entire existing environment of policies. However, if the policy options available to the control group differ from those available to a nonexperimentally constructed comparison group, it may appear that the nonexperimental method has failed when in reality it has simply yielded an alternative, equally valid estimate—but an estimate of the effect of the new policy relative to a different counterfactual policy environment.
Despite these limitations, the inherent advantage of the method is revealed by the studies that have used it to date (see previously cited studies). The most recent studies in this area have compared experimental estimates with nonexperimental estimates using the method of matching. While the results of these studies are interesting, much more needs to be done. Rules for determining when a nonexperimental method is or is not likely to be valid need to be developed to go beyond single examples and illustrations of cases in which particular nonexperimental methods do or do not work in particular cases. The problem of characterizing the policy environment needs to be faced more squarely. The method also needs to be applied to the difference-in-difference method by constructing comparison groups from ineligibles rather than eligibles—an approach that has not yet been attempted.
The research using results from experimental studies to assess the reliability of estimates from nonexperimental studies has been primarily applied to training programs not welfare reform. ACF has recently funded one project in this general area, however, which is a good start. ASPE has also shown interest in the general issue of choice of nonexperimental method, and has worked with an external group of experts to develop an approach. Much more needs to be done in this direction and more progress needs to be made given the importance of nonexperimental methods to welfare program evaluation.
Recommendation 4.1 The panel recommends that ASPE sponsor methodological research on nonexperimental evaluation methods to explore the reliability of such methods for the evaluation of welfare programs. Specification testing, sensitivity testing, and validation studies that compare experimental estimates to nonexperimental ones are examples of the types of methodological studies needed.
Analysis of Statistical Power of Cross-State Comparison Methods
The cross-area method has been used heavily in the analysis of pre-PRWORA waiver effects to examine both the effects of an entire bundle of reforms and the effects of broad components (Council of Economic Advisers, 1997; Figlio and Ziliak, 1999; Moffitt, 1999; Wallace and Blank, 1999; Ziliak et al., 1997). It has been used to a lesser extent in the analysis of post-PRWORA outcomes to study the effects of broad components, generally examining variations in discretionary components or aspects of components across states (Council of Economic Advisers, 1999). The method can be used either with pure cross-section data, comparing states at a single time, or with either panel data or repeated cross-section data over time to control for state fixed effects (that is, to compare changes over time across states, as policies change). The cross-state methodology has a long history in evaluations of the effects of public programs and fits very much in the spirit of a federal system that uses states as laboratories for learning about which programs and policies work.
An issue in the application of this method to welfare reform evaluation that has received little attention concerns the sample sizes needed in order to have sufficient statistical power to detect reasonably sized effects of welfare reform, either overall or of broad components. The power of a statistical hypothesis test (e.g., a test of whether the policy had an effect or not) is the probability that the test will conclude that there is a relationship (or effect) when a true relationship or effect actually exists. The best applications of the cross-area method use individual microdata to compare individuals across states who are similar in characteristics (age, education, etc.) and who are members of the target population for the policies in question. Thus, adequate sample sizes are needed not so much on the general population in each state, but on the specific strata of the population in which one is interested.19
An important statistical and policy question arises in analyses of this kind in defining a proper target population to compare across states. A tradeoff exists between defining the target population narrowly or broadly. Defining the target population narrowly—for example, including only single mothers with young children who have income below the poverty line—is attractive because that is for whom the effects of the policy, if any, are presumed to be the greatest. But defining the population narrowly reduces the sample size in the analysis, risks
bias from endogeneity—particularly if income if used as a stratifier—and adds uncertainty about generalizing to broader groups.20 Defining the population more broadly reduces problems of sample size and endogeneity but diffuses any effects of the program over a larger group of people and reduces power for hypothesis testing. We shall focus here not on the bias question but only on the statistical power question, although generally bias is an issue highly relevant for the issue of power.
In most of the cross-state analyses conducted on pre-PRWORA and post-PRWORA outcomes, the Current Population Survey (CPS) has been used—often only the March survey because it contains income and welfare recipiency information for the prior calendar year. The CPS is the largest of the nationally representative, general-purpose social science data sets available. It is also available over a longer time period than other surveys, which is an advantage for nonexperimental analysis as we discussed above. A disadvantage of the March CPS is that it provides only annual data and also is subject to underreporting of welfare participation. (We discuss these data sets in more detail in Chapter 5.)
In Appendix C, Adams and Hotz report the results of a power analysis for two of the cross-state analyses in the literature, the analysis of the CEA (1997) and of Moffitt (1999). The former used aggregate data to estimate the effect of pre-PRWORA waivers on AFDC caseloads and the latter used the CPS to estimate those effects for both AFDC participation and other outcomes. Moffitt estimated only the overall effect of welfare reform; the CEA also estimated the effect of individual broad components as well. The sample size in the CEA analysis was 969 and the sample size in the Moffitt analysis was 15,504.
Figure 4–1, taken from the Adams-Hotz analysis, shows the power of the CEA aggregate analysis for different effect sizes (see Appendix C for details). The upper line denotes the power of detecting the overall effect of pre-PRWORA waivers, measured as the regression coefficient on a dummy variable for whether the state had a statewide waiver of any type, “Any Waiver.” The effect size is a little over 5 percent, for which there is 60 percent power (i.e., 60 percent of the time an estimated effect would be found to be statistically significant). This is a moderately high level of power but not nearly as high as one would want. The lower lines in the figure show the power curves of detecting the effect of indi-
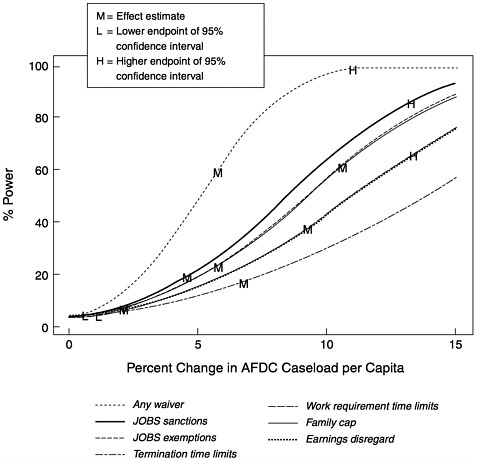
FIGURE 4–1 Power for Council of Economic Advisers analysis.
vidual components (sanctions, time limits, etc.) and demonstrate unacceptably low levels of power.
Figure 4–2 shows the power of detecting waiver effects on the probability of AFDC participation, using the larger CPS data set employed by Moffitt (see Appendix C for details). The power to detect a true effect equal to 1 percent is almost 80 percent, much superior to that of the aggregated CEA model.21 The lower curve shows the power of the effects for education subgroups, each of which had the same sample size and hence the same power. Because each subgroup has a lower sample size than that for the total sample, power is neces-
sarily lower than 80 percent. However, the estimated effect size for the least educated group (those with fewer than 12 years of education) is quite high, even higher than the effect for the entire population.
Contrary to these rather favorable results for detecting overall welfare reform effects on the probability of welfare participation using the CPS, the Adams-Hotz analysis showed that the power of detecting effects on other outcomes in the CPS—employment, earnings, family income-is much less, almost always less than 50 percent, an unacceptably low figure (see Appendix C). This lower power is a result of a much higher variability of these outcomes in the population.
Finally, Adams and Hotz consider the effect on power of doubling the CPS sample size. The power of detecting the overall effects of welfare waivers on AFDC participation rises, at Moffitt’s estimated effect size, from 80 percent to more than 95 percent. Considerably smaller effects could be detected at the initial 80 percent level as well, but “small” effects could still not be detected.
These results are quite discouraging for the use of existing household surveys to detect the effects of welfare reform using cross-state comparison methods—the dominant method in the econometric research on welfare reform in the 1990s. The sample sizes in the CPS are adequate only to detect the overall effect of welfare reform on low-variance outcomes, such as the AFDC participation rate. They are inadequate to detect the effect on individual economic outcomes at acceptable levels. In addition, the analysis of the CEA model strongly suggests
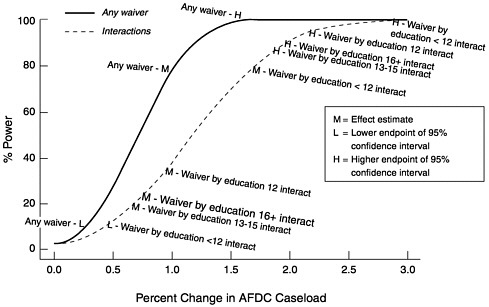
FIGURE 4–2 Power for Current Population Survey data set.
that detecting the effects of broad welfare reform components (time limits, work requirements, etc.) is also unacceptably low at CPS sample sizes.
Estimating the effects of individual welfare components, which Adams-Hotz showed to have unacceptably low power for the aggregate CEA analysis, may be problematic for the CPS as well. Some increase in power would result if the true effects of individual reform components were larger than the overall effect that Adams-Hotz examined with the CPS. But power would also be reduced by the presence of correlation between different state policies and because the implicit amount of variation of policies is less (arising only from those states, among all, who had a particular type of policy). If the individual policies were assumed to affect only a subset of the population, that would further reduce sample size and power. The problem is likely made worse by the crude characterizations of very complex state policies. Thus, it is quite likely that power will continue to be an issue when estimating the effects of reform components.
The CPS is one of the largest national survey data sets currently available. Therefore, the problem of power is likely to be even worse for other data sets. The only data set significantly larger than the CPS is the still-developing American Community Survey (ACS). It, therefore, holds the greatest promise for conducting similar nonexperimental analyses of future welfare reforms.
There are several avenues that can be explored to address these important issues. First, a more detailed analysis of the ACS is needed to assess its reliability for the estimation of welfare reform effects in the future. Although, it holds promise for relieving these sample size constraints, it would be very useful to know exactly what power it has to detect differently sized effects. Second, expansions or supplements to the CPS should be considered to increase its power. Adams and Hotz note that a simple doubling of the CPS would not be the most efficient way to increase sample size if detecting welfare reform were the only goal of the increase, for it would be more efficient to increase sample disproportionately in different states and demographic subgroups. Supplementing the CPS with state-level data sets, somewhat along the lines of the Iowa project (Nusser, Fletcher, and Anderson, 2000), is also worth exploring. Third, the power of state-level administrative data sets for estimating cross-state nonexperimental welfare effects models should be investigated. Administrative data sets are larger than the CPS when pooled across states and therefore hold promise in this regard (see Chapter 5).
Conclusions 4.5 Existing household surveys are of inadequate sample size to estimate all but the largest overall effects of welfare reform on individual outcomes using cross-state comparison methods. Research is needed to address this problem by considering the American Community Survey, state level administrative data sets, and supplements and additions to the CPS or other surveys to increase their capacity to detect welfare reform impacts in the future.
Generalizability of Evaluation Results
The issue of generalizability has emerged as an important one for many of the evaluation methods discussed thus far. There are two separate and distinct problems of generalizability. One is the problem of generalizing the results of a policy evaluation to areas, groups, and populations that were not included in the evaluation. The second is generalizing the results to policies that were not directly evaluated. With regard to the first, experimental methods, for example, are typically applied to only a few localities and on specific populations. The generalizability of their results to a national or even state population is consequently in question. Experiments also, as we previously noted, typically cannot capture entry effects or macrocultural effects and, therefore, may also not be generalizable because the total effect of the program is not measured. In this case, generalizing the experiment to a larger area and population-the nation as a whole, for example—has effects that are not captured in the small-scale study. Nonexperimental methods are typically estimated on more comprehensive groups of the population and in more areas, and sometimes capture entry and macrocultural effects. However, they too are sometimes not fully representative or complete. But nonexperimental methods more often suffer from the second problem of generalizability—to new policies—because those methods are necessarily applied only to policies that have actually been implemented. Nonexperimental methods, therefore, can yield no direct evidence on the effects of new policies. This is particularly important in the case of PRWORA, where, for example, a cross-state analysis on data after 1996 cannot estimate the total effects of PRWORA—it can only estimate the effects of differences across states because all have PRWORA in place in one form or another. Experimental methods often have the policy generalizability problem as well, but at least have the potential to estimate the effects of any policy that can be experimentally operationalized, even if it has never been implemented on a larger scale.
The most common method of addressing these problems of generalizability is through the method of microsimulation.22 Microsimulation models ar con-
structed by selecting a database containing records on individuals and families and simulating the effects of different policies on the population. In the simplest accounting microsimulation models, the eligibility and benefit rules of each program are applied separately to each individual (or family) and the individual’s participation in the program as well as the amount of benefit received is simulated. In more behavioral simulations, responses of recipients to participation in the program are estimated, using results from existing research on the behavioral responsiveness to program parameters. Microsimulation is a complex and often expensive tool and requires experience and sophistication in its use, particularly for calibration and validation (National Research Council, 1991). It can also lead to erroneous predictions, particularly when the model structure and equations depart too far from what empirical evidence supports. However, it is also a powerful tool because it can incorporate multiple relationships that interact in situations in which interactions among programs and markets are complex, and because it can generalize evaluation results to virtually any population or alternative program.
The most transparent advantage of microsimulation is in the generalization of any research results to populations and areas other than those upon which the original evaluations were conducted. Because there is no direct evidence for whether policy effects would be the same or different in areas in which they have not been tested or estimated, this type of exercise necessarily involves extrapolation of evaluation results beyond the range of their data. This, in turn, implies that the degree of certainty associated with simulated outcomes is necessarily lower than that for the actual outcomes in the evaluations. This difficulty can be reduced if evaluations are available for even a small number of different areas and populations from which some of the determinants of variability can be studied and ascertained. Many microsimulation models in other contexts also take information on variation in program effects across individuals and families of different socioeconomic characteristics and use that to generalize policy impacts to individuals in other areas and populations who have similar characteristics. In the end, of course, sensitivity testing is required, as it is in all microsimulation, to determine the range of uncertainty involved in the extrapolation.
Likewise, microsimulation models have the capability to generalize results to new policies not previously tested. However, this explicitly requires that policies be parameterized or characterized by its features and that the effects of individual features alone be estimated. This is required if, for example, a new policy with a different combination of components is of interest.
Extrapolation to both new populations and policies is made easier if the underlying evaluation studies whose results are the basis for calibrating a microsimulation model are conducted in a way that aids generalizability. For example, evaluations that estimate the impact of a unique program on a unique population and that do not attempt to estimate the way in which outcomes vary by program characteristics—e.g., by the estimation of outcomes as a smooth function of those
characteristics—are difficult to use directly in microsimulation without assumptions on whether the same results would apply if the program and population characteristics were different. Often microsimulation developers must obtain the underlying data and estimate new models in order to make extrapolation possible.
A less obvious advantage of microsimulation is in the combination of experimental and nonexperimental results, each with its own advantages, to achieve a result that is superior to either individually. For example, entry effects, which are typically not estimated in experiments, can be estimated from nonexperimental data and applied to a dynamic microsimulation model containing entry and exit from the TANF rolls. Effects of the policy on those who are on the rolls, once they are on, could be drawn from experimental evaluation estimates. The model could be calibrated to both types of evaluation estimates.
Microsimulation can be large scale or small scale, for it can attempt to capture all behavioral relationships and policies affecting the population or it can focus only on a few. Given the complexity of welfare reform evaluation, it is not clear which approach would be best for this purpose. It is quite likely that a small scale model focusing on the delineation of key aspects of the welfare system but representing other programs in the policy environment less precisely, would be the most appropriate way to proceed.
While microsimulation has a long history in social science research and in government agencies (National Research Council, 1991), it has not been used on any significant scale for simulating the effects of PRWORA. However, the diversity of the types of evidence that welfare reform research is generating— ranging from econometric studies to experiments to monitoring studies of leavers, each generating estimates for different groups and different aspects of welfare reform—gives microsimulation more potential than it would have otherwise. When no single type of study can, or is intended to, provide evidence on more than one piece of the response to welfare reform, microsimulation is one means by which to incorporate all the pieces together into a coherent and internally consistent whole. Microsimulation thus could play a role in the synthesis of results, when those results come from very different types of studies.23
Conclusions 4.6 The problem of generalizability of the evidence from welfare reform evaluations on specific populations, areas, and relationships to more general populations, to a national level, and to
new policies, has not been sufficiently addressed. More use of microsimulation models as a tool to address generalizability is needed. Microsimulation is also needed to assist in the synthesis of diverse types of results.
Process and Qualitative Analysis
The complexity of the current welfare program system has led the panel to conclude that multiple research methods need to be used in order to answer key evaluation questions of interest. Research should include process and implementation methods and qualitative and ethnographic research methods, which have become increasingly important in welfare program evaluations. Features of PRWORA and the subsequent changes that have been implemented on a state and local level have fueled the growing importance of process evaluations. The initial period after PRWORA has been characterized by a wide variety of evolving programs and practices as states adjusted their programs to meet their own goals and to fit the needs of their populations. It is during this period of an evolving programmatic environment in which process studies can be especially useful to help inform administrative decisions and to fine-tune implemented programs. Process analyses are an important tool for going beyond descriptions of legislated programs because they provide a more realistic picture of how programs are actually implemented and how services are actually delivered to participants.
Similarly, ethnographic and qualitative studies are becoming increasingly important tools to aid evaluations. Policy makers and administrators are recognizing the value of these methods to learn about early reaction to new policies and for understanding how a policy actually affects clients’ lives. Evaluators are recognizing that qualitative and ethnographic methods can be used to help interpret study results or to generate hypotheses for further exploration and to guide further data collection or research. These potential payoffs to process and qualitative studies lead the panel to conclude that both methods have important roles to play in evaluating welfare reform.
Chapter 2 described several process studies that are under way in welfare policy research. The U.S. Department of Health and Human Services has sponsored process evaluations targeted to programs serving specific subpopulations of low-income families (families with infants and toddlers) and specific program features (welfare-to-work screening and assessment practices and mental health and employment program practices). These studies will provide useful descriptions of the specific program implementations. They do not, however, comprehensively cover TANF programs and are being conducted in only a limited number of states and sites or cover only special services for specific subpopulations. The Rockefeller Institute’s State Capacity Study and its extension, the Front-line Management and Practice Study (which has funding from ACF), are probably the
largest efforts to document state policy implementations. The State Capacity Study covers program implementation in 20 states and the Front-line Management study will cover, among other things, program implementation in 12 local areas of four states. In addition, implementation studies are being conducted in conjunction with monitoring and outcome studies in each of the four metropolitan areas of Urban Change Project, and in the 13 states of the Assessing the New Federalism Project.
However, there is no a systematic effort to conduct process evaluations of how states and local areas have implemented TANF policies, and process studies are not routinely used in conjunction with outcome evaluations. Although it would be impossible to conduct process studies for every local area, a more comprehensive effort is needed. Studies of implementations at both the state and local levels should be sponsored in as many areas as possible and across areas with a wide range of characteristics: for example, across regions of the country; urban and rural areas; areas with different approaches to TANF policies; areas with different special subpopulations such as immigrants; areas with different macroeconomic conditions; or perhaps on a random sample of sites. The panel believes that such an effort will be valuable for understanding how states and local areas have used their block grant funds and leverage for program design to implement programs, information that is now only being provided on a limited basis.
Recommendation 4.2 The panel recommends that U.S. Department of Health and Human Services sponsor process research in a number of service delivery areas to better understand how service delivery administrations have implemented new welfare programs and the benefits and services families and children are receiving under these new programs.
Despite the growing potential for process studies to provide needed information about what is happening in program implementation, methodological improvements in how process studies are conducted are needed for them to be maximally effective. Currently, there are no standard protocols for methods to conduct process studies and, as a result, they are often of uneven quality. Part of this lack of protocols stems from the nature of process studies in that they typically rely on qualitative and subjective data sources (e.g., caseworker interviews concerning problems that arise in delivering services). But too often process studies are conducted on an informal basis, do not carefully design their studies, visit only a few convenient sites or talk to only a few key administrators and as a result, are not reproducible. Carefully designed and credible process studies that use such techniques as formal fieldwork protocols for observation and data collection, repeat visitation or data collection at one site, and data collection across multiple sites are needed.
Integration of process evaluations with impact evaluations at the level where results of process evaluations are used to describe or are part of the planned variation of the policy treatment are, thus far, limited. This lack of integration is due in part to the difficulty of measuring program processes in a quantifiable way. Furthermore, because the processes may vary considerably across sites, common terms for different processes are needed, but, they are not easily agreed to.
Recommendation 4.3 Process and implementation studies have grown in number and importance in the evaluation of welfare reform but often have design defects and are insufficiently integrated with outcome evaluations. As a consequence, their potential use in evaluation has not been fully reached. The panel recommends that the U.S. Department of Health and Human Services sponsor methodological research on process and implementation studies to improve methods for systematizing the documentation of program policies and practices, to develop protocols and best practices, and to further integrate them with impact evaluations.
Ethnographic and other qualitative studies can complement quantitative evaluations. They have become increasingly popular as an aid to program evaluation and have augmented both nonexperimental and experimental welfare reform studies. They are also an important component of several of the current major studies to monitor and evaluate welfare reform (Urban Change, Three-City Study).
In the period following major changes in policy, such as PRWORA, qualitative studies may be particularly useful. For example, the new program rules and implementations may not be well understood by potential or current program participants. Qualitative studies can be used to determine what information and attitudes administering offices are sending to potential program participants (e.g., program outreach or diversion). Focus groups could be used by local or state benefit administering agencies to understand, for example, how well policies of the agency are understood by relevant populations or what barriers some groups face to self-sufficiency.
Information gained from qualitative studies is often complemented with results from statistical evaluations of policies to help interpret results by providing more textured information about the experiences of a sample of cases that are part of the larger evaluation study or a sample of similar cases that are not part of the study. Such efforts might be particularly useful in conjunction with smaller scale or single-site studies, perhaps in conjunction with experimental studies or matching studies, because it will be easier to specifically target a small population for in-depth interviews. In analyses of the effects of treatment bundles, researchers may have difficulty identifying which treatment had the most profound effect on
the outcome of interest. Qualitative studies focused on individual clients can provide information as to which of the treatments may have had the greatest effect. This information could also be valuable for guiding future evaluations and data collection efforts or about future designs of experimental or nonexperimental evaluations. Finally, qualitative and ethnographic studies can also provide more elaborate outcome measures. For example, surveys may include open-ended questions that can provide detailed information from respondents to complement quantitative data. This type of information might be used in monitoring or evaluation studies, as well as to frame hypotheses for quantitative studies.
Recommendation 4.4 Qualitative and ethnographic studies of the low-income population and its relevant subpopulations and of social service agencies that provide services to these populations are an important part of the overall welfare program evaluation framework. The panel recommends the further use of well-designed qualitative and ethnographic studies in evaluations of welfare programs to complement other evaluation methods.
The Importance of Welfare Dynamics to Evaluation
As we emphasized in our interim report (National Research Council, 1999: Ch. 2, pp.22–26), a caseload dynamics perspective is important to welfare reform research. It has long been recognized that an understanding of welfare dynamics—entry and exit from the rolls and the length of spells on welfare—is necessary for an understanding of the welfare population. It has also long been recognized that different welfare recipients exhibit different patterns of participation, and that this reflects their general abilities to exit welfare. As we noted in our interim report, the most common classification of patterns is that which divides recipients into long-termers, short-termers, and cyclers (Ellwood and Bane, 1994). Long-termers have a few long uninterrupted spells on welfare; short-termers have short spells and spend only a brief period of their lives on welfare; and cyclers have short spells but tend to return to welfare frequently after leaving and hence may end up spending a substantial proportion of time on welfare.
These distinctions are essentially just a simple way to classify what is really a continuum of welfare program use. Which of these three groups a welfare recipient falls into is generally presumed to be an indirect indicator of a host of other characteristics of the recipient and so serves as a convenient proxy for those characteristics. Generally, long-termers are presumed to have the lowest job market skills, the most difficult life circumstances, and therefore, the lowest probability of leaving welfare. Short-termers have the best job market skills, the least difficult life circumstances, and therefore the highest probability of leaving welfare. Cyclers are somewhere in between, having job market skills and life circumstances that permit them to leave welfare but not sufficiently favorable to
prevent them from returning. Knowing the composition of the welfare population with respect to these welfare “experience” measures provides an indirect indication of the heterogeneity of the welfare population and how many recipients are the hardest to serve. Other indicators—levels of education, work experience, poverty status, health, transportation and day care problems, and other variables—are additional indicators of need and may become more useful indicators of disadvantage as time limits take effect and people can no longer continue to receive cash assistance. However, we focus on welfare experience because it is a useful overall classification that is an indirect indicator of many other features of a recipient’s degree of disadvantage and because of its particular relevance to studies of specific welfare populations—welfare leaver and diversion studies.
The level of welfare experience is important to the study of welfare reform because some groups are more likely to be affected by reform than others. Leavers are presumably more likely to be short-termers or cyclers, for example, meaning those who stay on welfare may be disproportionately long-termers. Some long-termers leave the rolls, however, and it should be expected that their outcomes after leaving may be worse than those of other leavers. For those who stay on the rolls, the effects of new work requirements and other provisions of PRWORA are also important issues, particularly whether work-first policies are successful. This information is valuable to welfare administrators who must decide how to target their resources across these different groups. Indeed, one of the goals of PRWORA legislation was to reduce the problem of welfare “dependency,” which could be interpreted as a goal primarily aimed at long-termers and cyclers.
In this section we report the results of three explorations of these issues. Two are included in our companion volume (Moffitt, 2001; Ver Ploeg, 2001) and one consists of an unpublished paper prepared for the panel (Stevens, 2000). The analysis by Moffitt uses a nationally representative data set of young women (the National Longitudinal Survey of Youth 1979 [NLSY]) to document the proportions of long-termers, short-termers, and cyclers on AFDC and how their labor market and other characteristics differ. The analysis by Stevens uses an administrative data set from one state (Maryland) that contains merged data on AFDC recipiency and unemployment insurance (UI) wage data to present the same sort of analysis conducted by Moffitt—documenting the proportions of long-termers, short-termers, and cyclers—but for multiple cohorts over time, thereby demonstrating how the composition of the caseload has been changing. The analysis by Ver Ploeg focuses on leaver studies by analyzing data on welfare leavers from Wisconsin to explore how leaver outcomes differ for long-termers, short-termers, and cyclers and how other aspects of a leaver analysis are affected by incorporating the caseload dynamics perspective.
The analysis by Moffitt tests alternative definitions of long-termer, short-termer, and cycler in the NLSY data. He finds that approximately one-third of the caseload in the 1980s and early 1990s (of those who had at least one spell of
receipt) was composed of each of these three types and that these compositions were fairly consistent across most definitions of long-termers, short-termers, and cyclers. A somewhat unexpected finding is that the degree of total welfare dependence—measured as the total time a woman spends on welfare in a long nineteen-year period, 1979–1997, was greater for cyclers than for long-termers. This is contrary to expectations for the ordering of recipients. The greater number of spells experienced by cyclers led them to a longer total time on welfare than long-termers. Some long-termers had one or two long spells but then left welfare for the rest of the period. This finding raises the issue of defining long-termers, cyclers, and short-termers; it is discussed more thoroughly by Moffitt (2001).24 In examining the characteristics of the three groups, Moffitt found, as expected, that short-termers had the highest earnings when off welfare and the highest levels of education. However, again rather surprisingly, he found that cyclers had about the same levels of education as long-termers but lower levels of earnings off welfare. Thus, cyclers in his analysis seem to be the most disadvantaged of the three experience groups.
Stevens used Maryland administrative data and decomposed the AFDC-TANF caseload from 1985 to 1998 into the three experience groups (using all AFDC cases opened and closed sometime during this period). He disaggregated the data into four separate birth cohorts, each observed for a 10-year period, within this time interval. Using similar definitions to those of Moffitt, Stevens found that almost 50 percent of the Maryland caseload were short-termers (a higher fraction than Moffitt found), about a third were long-termers, and the smallest group (about 20 percent) were cyclers. Moreover, he found that the fraction of short-termers had fallen slightly over time and the fraction of cyclers had risen, perhaps the result of welfare reform or changes in the economy. When he examined earnings off welfare for the three experience groups, he found the expected ordering—highest earnings for short-termers, lowest for long-termers, and in between for cyclers, at least for the majority black population. However, for the white population, he found a changing ordering over time, beginning with the expected ordering (as for blacks), but, by the last cohort, cyclers had lower off-welfare earnings than long-termers. This interesting result, combined with the increase in the number of cyclers, suggests that many of the more disadvantaged women on welfare have become cyclers, again possibly as a result of welfare reform or changes in the economy.
Ver Ploeg analyzed the welfare leaver data used in one of the well-known Wisconsin leaver studies (Cancian et al., 2000). The sample included all those who received AFDC July 1995, some of whom subsequently left welfare and some of whom stayed on welfare. AFDC and earnings records for the years 1989–1995 were used to classify leavers and stayers by their pre-1995 welfare experience, using similar definitions to those of Moffitt and Stevens. Ver Ploeg found that about 50 percent were long-termers, about 35 percent were short-termers, and the residual (about 15 percent) were cyclers. These percentages are different than those of either Moffitt and Stevens and suggest that there is considerable diversity across states in the composition of the welfare caseload. Ver Ploeg also found that long-termers were much less likely to be leavers than were stayers, short-termers were much more likely to be leavers, and cyclers were somewhat more likely to be leavers than stayers. When looking at other characteristics, Ver Ploeg found that those who were more welfare-dependent—longer spells and those with less work experience—were considerably less likely to leave the rolls subsequent to 1995 than those with less welfare dependency— shorter spells and more work experience.
When looking at the differential wage and employment outcomes of leavers, she found, perhaps surprisingly, differences by the three welfare experience groups that were quite modest: virtually all three groups had employment rates of 55–65 percent and all had approximately the same level of earnings. However, there were much stronger and more marked differences in leaver outcomes by the level of past work experience. Ver Ploeg also defined a “high barrier” group of initial recipients who had low levels of education, weak employment histories, and high levels of welfare dependency, and she found that they had much lower leaving rates and much worse outcomes after leaving than others. Overall, although Ver Ploeg failed to find as strong a correlation of earnings off welfare with welfare-experience groups as found by Moffitt and Stevens, she found high levels of heterogeneity between welfare stayers and leavers and between different types of leavers. This substantiates many of the points made in our interim report (National Research Council, 1999) about the need to differentiate leavers into different subgroups and to make comparisons within such groups across states, rather than comparing of overall averages.
The lessons of these three studies for the importance of welfare dynamics for welfare reform are many. First and foremost, these studies show that the welfare caseload is extremely heterogeneous with respect to welfare experience, employment history, and other key variables. They further suggest that this heterogeneity is quite different across different states, which could lead to differences in outcomes as a result of that heterogeneity.25 Second, two of the studies show that heterogeneity in welfare experience is strongly correlated with employment and
earnings off welfare and that heterogeneity in general is highly correlated with those variables. Third, the Ver Ploeg study demonstrated specifically for a leavers study the importance of disaggregating the caseload by heterogeneity measures, and how variable leaver outcomes are for different groups. These studies are the first in the welfare reform literature to focus on these issues and show the value of disaggregation along these dimensions. The panel recommends that this perspective be incorporated into more welfare reform studies, both within and across states, in future research and evaluation.
Recommendation 4.5 A welfare dynamics perspective should be incorporated into more welfare reform studies, including leaver studies. In general, more disaggregation by levels of heterogeneity among leavers and stayers is needed given the importance of disaggregation for outcomes on and off welfare.
ASSESSMENT OF CURRENT EVALUATION EFFORTS
The scope, volume, and diversity of existing studies on welfare reform described in Chapter 2 is impressive. However, a large fraction of those studies, if not the majority, are not concerned with formal outcome evaluation. Many are concerned with monitoring the well-being of the low-income population or segments of it and are not aimed at estimating any of the effects or outcomes discussed in this chapter. The National Survey of America’s Families, the Devolution and Urban Change Study, the Three-City Study, and many of the studies using census and other data sets to track the progress of the low-income population are not intended to formally evaluate the effects of welfare reform but, instead, have as their primary purpose the monitoring of different welfare-affected groups.26 Although some have evaluation, neither these studies nor the many excellent implementation studies of welfare reform mentioned in Chapter 2 are reviewed here, for their goal is not formal evaluation.
There are only three major types of existing projects whose primary goal is formal evaluation. These are studies of welfare leavers; randomized experiments; and caseload and other econometric studies. Even the first of these— leaver studies—is included only for discussion purposes, for most analysts agree that they are not intended as formal evaluations, at least as presently conducted.
Leaver Studies
The most common type of welfare reform study is the welfare leaver study, which examines the outcomes of a group of welfare recipients who have left the
welfare rolls in the postreform era. Taken as an evaluation methodology rather than a monitoring method, the question such studies aim to answer is that of the overall effects of structural welfare reform, rather than the effect of any individual component or detailed strategy. For this purpose, these studies are weak and do not deserve the emphasis that they have received in the discussion of the effects of welfare reform. Aside from problems of the underlying data, (see Chapter 5 and also National Research Council [1999]), leaver studies suffer from a narrowness of focus, lack of cross-state comparability, and, most obviously, lack of a comparison group. The narrowness of focus results from examining only a subset of the population affected by reform, generally ignoring stayers as well as divertees, rejected applicants, and discouraged nonapplicants. ASPE has begun to address the latter problem by funding projects to study applicants and diversion, but these efforts have yet to produce results and need to be strengthened and reinforced. The lack of cross-state comparability in the way leavers are defined, (who is classified as a leaver and who is not) and how outcomes are measured is a major barrier to being able to compare effects across areas and to correlate those with policy differences. The grantees whom ASPE funded to conduct new leaver studies have made some decisions on uniformity of definition. While ASPE deserves credit for this, it falls short of what is needed, for there remain many differences in composition across states.
Finally, the lack of a comparison group makes the results of leaver studies difficult to interpret because it is not known whether their outcomes are any different from these for welfare leavers prior to welfare reform. This problem has also begun to be addressed by ASPE as part of its encouragement of multiple cohort designs. However, few states have embraced this method and thus few results are available.
Constructing a comparison group for current leavers from past cohorts of leavers is more difficult than it may appear. Most of the multiple cohort studies discussed in Chapter 2 compare early post-PRWORA leavers to later post-PRWORA leavers, but what is needed is a comparison of post-PRWORA leavers to pre-PRWORA leavers. In addition, using pre-PRWORA leavers is problematic if a statewide welfare waiver was in place prior to 1996, for in that case even cohorts leaving AFDC just prior to PRWORA may have been affected by welfare reform. Another problem in the existing multiple cohort studies is that the question to be answered with such cohorts is not clearly defined. Most multiple cohort studies take any evidence of changing outcomes for leavers over time— such as, lower employment rates—as an indication that more women with low skills are leaving the rolls over time. However, this interpretation ignores the original purpose of multiple cohort designs, which is to estimate the effect of a policy change on the outcomes that a given recipient or type of recipient would have. Differences in leaver outcomes could reflect either changes in the characteristics of those who leave welfare or the true effects of a change in policy. None of the cohort studies conducted thus far attempt to separate these alternatives, nor
do many even acknowledge that it is an issue. Finally, even with a correct cohort definition, more than one pre-PRWORA cohort is needed. Estimating the effects of the unemployment rate and other policy developments requires several cohorts over time.
Conclusion 4.7 Studies of the outcomes of welfare leavers contribute only one part of the story of welfare reform and, as an evaluation method, have been disproportionately emphasized relative to other methods. Studies that compare current leavers to those who left welfare prior to welfare reform and studies of divertees, applicants, and nonapplicant eligibles need more emphasis.
Recommendation 4.6 More methodological research is needed to assess and improve the credibility of the multiple cohort method of evaluating the overall effects of welfare reform. This research needs to study the best method to control for the time-series effects of other policies and the economic environment and how many cohorts are enough to do this.
Randomized Experiments
The number of randomized experiments about welfare has declined in number since the passage of PRWORA. Most of the experiments in the early 1990s were the result of requirements by DHHS that any state granted a waiver from federal AFDC regulations was obligated to conduct an evaluation of that waiver, usually a randomized experiment. Since PRWORA, the federal government has lost its authority to mandate experiments; as the task of evaluation has moved to the states, there have been fewer experiments.
To a considerable degree, this decline has been a natural result of the recognition that experimentation is not particularly appropriate, for assessing the overall impact of a state’s new welfare program. Another reason for the decline of experiments has been a lack of interest among many state policy makers in using the old AFDC program as a counterfactual, for their general belief is that a return to the AFDC program is unlikely. Still another reason for the decline in experimentation is that most states have been doing considerable work in developing new programs in the post-PRWORA environment and have not faced a sufficiently settled and stable policy environment to consider experimentation.
There are a number of experiments ongoing from the pre-PRWORA waiver phase of experimentation and even one experiment that was initiated after the 1988 Family Support Act to evaluate the JOBS program. These experiments are of mixed usefulness for a number of reasons. In many cases the policy environment has changed. In addition, the many systemwide changes that have occurred over the 5 years since PRWORA was passed have unquestionably had spillover effects into the control groups, whose members are now unlikely to have out-
comes that are the same as would have occurred if welfare reform had not taken place. This problem is particularly acute when a reform in question is implemented statewide, and the control group on the old AFDC program is only a small group of recipients in the context of a statewide altered programmatic environment.
The experiments that have been undertaken over the past decade have generally been aimed at estimating the overall effects of a bundle of separate welfare reforms, including work requirements, sanctions, time limits, and other provisions, all enacted and tested simultaneously. With rare exceptions, there have been no experiments that have isolated individual broad components or detailed strategies, varying each while holding all the other features of welfare reform fixed.27 Although experiments of similar policy bundles have often been tested in more than one site, there has been no attempt to coordinate those bundles in a way that would permit isolation of broad components or detailed strategies (i.e., with two sites differing only in one respect). Thus, although it would be advantageous to examine the effect of broad components, experiments have not been designed to do so.
Although the recent experiments on welfare reform therefore have many problems of usefulness and validity, there is considerable scope for new experimentation on alternative detailed strategies and, to some extent, broad components. As noted above, experiments have their greatest advantage in doing so because incremental change is of most interest and the overall welfare environment would be more settled. As states continue to study the issues of what works and for whom, experiments should play an increasingly prominent role in evaluation efforts. ACF is planning experiments on alternative employment retention strategies, which is a good example of tests of detailed strategies. Such experiments need to be supplemented by nonexperimental data collection in order to reach a complete picture of reform effects and to provide adequate generalizability. Experiments are also, in principle, still one of the better methods to test the effects of individual broad components—time limits, work requirements, sanctions, and other provisions—while holding other components fixed. Whether they should be used to do so depends on the degree of policy interest in those components. When they are appropriate, well designed and conducted, and with an adequate sample size, experiments offer uniquely strong evidence.
Recommendation 4.7 Experimental methods are underused in current designs of new welfare policy evaluations and should be employed in future studies evaluating different detailed reform strategies and different individual broad components.
One of the obstacles to using experimental methods is that evaluation is predominantly now in the hands of state welfare administrators, who do not have a great deal of experience in designing experiments or know the operational implications of conducting experiments. Historically, state welfare agencies have not conducted much evaluation of their programs (although there are notable exceptions, many times including partnerships of state administrators with universities). Most evaluation has been initiated at the federal level and conducted by national research organizations. The devolution of legal authority for program design embodied in PRWORA was accompanied by a devolution of program evaluation, for the most part. Consequently, the lack of experienced evaluation personnel at the state level is a significant barrier to the use of experimentation, and to evaluation in general, on welfare reform.
Much welfare evaluation expertise still remains in academia or with federal agencies, particularly in ASPE and ACF. It is therefore natural for those federal agencies to continue to play an active role in sponsoring experiments at the state level and to promote such activities. In the absence of a strong federal presence, the lack of experienced personnel at the state level will result in many lost opportunities for fruitful experimentation. The federal government has a role in assisting in the design of an overall coherent strategy of controlled variation across different states. A study within one state can be a substantial benefit to that state and can contribute to the overall pool of knowledge about programs and their effects; a cross-state experimental evaluation program with comparable studies can go further in yielding generalizability of findings and can subsequently benefit all states.
Recommendation 4.8 The federal government should take a proactive role in sponsoring experiments at the state and local levels and should encourage planned variation and cross-state comparability to yield the maximum general knowledge.
Caseload and Other Econometric Models
A number of caseload and other econometric models have been used in evaluating welfare reform, as described in Chapter 2. All of them aim to estimate the overall effects of welfare reform, and a few attempt to estimate the effects of individual broad components as well. Perhaps the most distinguishing feature of these studies is that they are the only welfare reform studies that have attempted to control for economic conditions and to isolate the effect of welfare reform from those conditions.
While ambitious and deserving of investigation, these modeling efforts have thus far yielded a mixed record of success. They have produced some interesting findings and, in fact, the only findings on the overall effect of PRWORA controlling for the business cycle. However, there are significant problems with the studies that cast doubt on their validity. One problem is that the majority of the
studies have used cross-state and over-time variation in pre-PRWORA programs to estimate the effects of welfare reform. Although the pre-PRWORA waiver programs are of significant interest in and of themselves, in most cases they cannot yield reliable information about PRWORA. PRWORA accelerated and greatly strengthened most of the provisions that were in waiver plans and also created overall structural changes in the welfare system. In addition, the sample sizes available in the major data sets are only barely capable of capturing welfare reform effects of the size to be expected. Thus, data limitations significantly reduce the value of these studies.
A handful of studies have been conducted using comparison-group designs with ineligibles and differences-in-differences methods (see Chapter 2). These studies have yielded significant and interesting results of overall effects. However, the validity of these comparison groups (see discussion of this method above) has not received sufficient examination, leaving the results from these studies in a state of considerable uncertainty.
Despite the problems with the existing caseload and other econometric models to estimate overall effects, they have yielded reasonably credible estimates because they have found significant effects on the outcomes that would be expected and because the magnitude of the expected effect is large. Thus, there is a reasonable chance that the biases that may exist are outweighed by the size of the effects.
The record of the econometric studies in estimating the effects of individual broad components is considerably worse. These studies have used pre-PRWORA cross-area variation in those components, in some cases, and post-PRWORA variation in a smaller set of policies (namely, those that vary cross-sectionally post-PRWORA). The results in these studies for the effects of components is highly variable in magnitude, sign, and significance, and are generally not robust to specification changes. The results often do not accord with sensible expectations, an indication of a underlying misspecification. It is quite probable that the combination of poorly measured policies at the broad component level, combined with sample size problems, have produced this result.
Conclusion 4.8 Caseload and other econometric models have produced a mixed set of results, partly because of data limitations and partly because of an inherent lack of policy variability. They have done somewhat better at producing ballpark estimates of the overall effects of welfare reform than at producing estimates of the effects of individual broad components.
Summary
Despite the large number of studies that have been and are being conducted on welfare reform, the record on evaluation of the three major questions we have
put forth is not impressive. For the overall effect of PRWORA, a number of econometric models provide approximate estimates on individual outcomes and state caseloads, but these studies are weakened by data limitations and lack of policy variability. Experimental tests of the overall effects of PRWORA have also been conducted, have many limitations. There have also been econometric estimates of the effect of individual broad components of welfare reform, but these have more serious problems than those estimating the overall effects. Thus far, the results are not very reliable and lack credibility. There have been no experimental tests of the effects of adding or subtracting broad components. For detailed strategies, there have been almost no formal evaluations that isolate one strategy from all others (holding the others fixed) to determine the effect of the isolated strategy alone. There have been a few experiments of detailed strategies (e.g., the NEWWS demonstration), but these have the problem of control group contamination.
NEXT STEPS
For a mature society like the United States, with over 40 years of experience in evaluating social welfare programs, the record of accomplishment for a major piece of social legislation to date is not sufficient.
There are several evaluation studies in process that can help address some of these gaps (see Chapter 2). The multiple cohort leaver studies already funded by ASPE and their other studies of stayers and divertees, rejected applicants, and discouraged nonapplicants will be valuable additions. The experiments planned by ACF will begin the process of testing alternative detailed strategies.
Nevertheless, major new evaluation efforts are needed at the federal and state levels if the questions of interest for welfare reform research identified in Chapter 3 are to be addressed. The current set of evaluation efforts is an uncoordinated collection of disparate efforts without any overall coherence. Consequently, there are major gaps in the evaluation structure. Some private foundations have attempted to coordinate evaluation studies, but this is a role that should be played by DHHS because it is the agency with responsibility for program operations, access to details about the program and related programs, and the entity that is the most likely to have a long-term commitment to evaluation of the program. Setting forth a clear and carefully considered agenda for the questions to be asked and the evaluation methods that should be brought to bear on each of the questions would go a long way toward ensuring that the necessary analysis is conducted. A leadership role in this area is needed.
Recommendation 4.8 The federal government, taking all agencies as a whole, has produced and funded a great deal of valuable monitoring research and a much smaller volume of evaluation research. A greater effort to produce a comprehensive evaluation framework
for social welfare programs that considers the major questions of interest and the evaluation methods appropriate for each is needed. A comprehensive framework for evaluation should be developed and used to guide the evaluation efforts under way by private and other public evaluation organizations. This should be an on-going effort as new issues emerge and is a responsibility that should be taken on by ASPE in the U.S. Department of Health and Human Services.
In addition, the annual report to Congress recommended in Chapter 3 should include both a discussion of the important questions of welfare reform we outlined and a presentation of the alternative evaluation methods that are currently being used to study these questions, including those studies funded by ASPE as well as by others. The report should discuss the relative mix of experimental and nonexperimental methods being used and should present the agency’s views on whether the appropriate balance and mix is being achieved, in light of the relative strengths and weaknesses of each evaluation method. It should discuss which nonexperimental methods are being used and whether there is an appropriate balance for them. It should also relate ASPE’s own research agenda on evaluation methods to the overall landscape of evaluation and should present what it sees as its own role in support of good evaluation methods.
Recommendation 4.9 In its annual report to Congress, ASPE should review the existing landscape of evaluation methods, whether the appropriate balance of experimental and different nonexperimental methods is being achieved, and how evaluation methodology fits into its own research agenda.
At the state level, the capacity to conduct evaluations is very weak, both experimental and nonexperimental evaluations. This situation must be addressed if better and more appropriately focused and directed evaluations are to take place. Here we recommend again that the federal government exert a leadership role in assisting states. In fact, both ASPE and ACF already expend some portion of their personnel and resources toward such assistance, for example, through the welfare reform research and welfare outcomes conferences they have hosted for the past 3 years. But much more capacity-building effort is needed.
Conclusion 4.9 The panel finds that state capacity and resources to conduct evaluations of their own welfare reform programs is often below the level needed for such an important change in policy.
Recommendation 4.10 The panel recommends that the U.S. Department of Health and Human Services continue and expand its efforts to build capacity for conducting high-quality program evaluations at the state level through the provision of technical assistance,
convening of research conferences, promoting the exchange of technical assistance among the states, and other capacity building mechanisms.
Finally, given the decentralized nature of the evaluation of PRWORA, and given the disparate methods that have been and will be used and the diversity of different approaches to evaluation that have been conducted, a major attempt to synthesize findings will be needed. Reconciling conflicting findings, combining experimental and nonexperimental results when appropriate, weighing the results of different studies considering their strengths and weaknesses, combining quantitative and qualitative data, drawing lessons from monitoring studies as well as evaluation studies, and identifying and filling gaps in knowledge in order to arrive at a comprehensive, best-guess judgment on the different effects of welfare reform will be a challenging task. But it is a necessary one. Once again, we recommend that the federal government, whose interests are those of the nation as a whole as charged by the electorate, take a leadership role in this regard and fulfill the synthesizing function. ASPE, as the policy evaluation and development arm of DHHS, is the most appropriate agency to fill this role.
Recommendation 4.11 The panel recommends that ASPE be the primary agency responsible for synthesizing findings from studies of the consequences of changes in welfare programs.
















































