
6
Evaluations of County Estimates
The development of model-based estimates for small areas is a major, continuing research and development effort for which extensive evaluation is required. For updated estimates of poor school-age children for counties, a thorough assessment of all aspects of the estimation procedure is necessary to have confidence in the estimates–whether the estimates are used by the Department of Education to allocate Title I funds to counties (as was the practice before the 1999-2000 school year) or whether they are used to develop estimates for school districts.
The Census Bureau's county estimates of poor school-age children are produced by using a county regression model and a state regression model (see Chapter 4).1 A comprehensive evaluation of these two components of the estimation procedure should include both “internal” and “external” evaluations.
The first test of a regression model is that it perform well when evaluated internally, that is, for the set of observations for which it is estimated. Such an internal evaluation is primarily an investigation of the validity of the model's underlying assumptions and features, which for a regression model is typically based on an examination of the residuals from the regression–the differences between the predicted and reported values of the dependent variable for each observation.
|
1 |
Population estimates of school-age children are provided to accompany the estimates of poor school-age children to permit calculating poverty rates–see Chapter 8 for a description of the methods used for postcensal population estimates and for evaluation results. |
In an external evaluation, the estimates from a model are compared with target or “true” values that were not used to develop the model. Ideally, an internal evaluation of regression model output should precede external evaluation. Changes made to the model to address concerns raised by the internal evaluation would likely improve its performance in the external evaluation.
Since there are no absolute criteria for what are acceptable evaluation results, one method for determining if the performance of a model can be improved is to examine alternative models. Such comparisons may indicate changes that would be helpful for a model; they may also suggest that an alternative model is preferable. Both internal and external evaluations should be carried out for alternative models.
OVERVIEW OF EVALUATIONS
1993 Estimates
When the original 1993 county estimates of poor school-age children were provided to the panel, the Census Bureau had not had time to complete a full evaluation of them. Subsequently, the panel developed a set of evaluation criteria, and the panel and the Census Bureau conducted a series of internal and external evaluations. The focus of the evaluation effort was on alternative county models, particularly the assumptions underlying the regression equations and how the estimates of poor school-age children in 1989 from each model compared with 1990 census estimates. The state model was examined as well, both directly and as it contributed to the county estimates of poor school-age children. The evaluations included:
-
internal evaluation of the regression output for alternative county models estimated for 1993 and 1989;
-
comparison of estimates of poor school-age children for 1989 from alternative county models with 1990 census estimates, a form of external evaluation;
-
examination of the original 1993 county estimates to identify possibly anomalous estimates that were then reviewed with knowledgeable local people, another form of external evaluation; and
-
evaluation of the state model, including examination of regression output and external evaluation in comparison with 1990 census estimates.
The internal evaluation of regression output and the comparison of modelbased estimates of poor school-age children for 1989 with 1990 census estimates–evaluations (1) and (2) above–were carried out for the four single-equation county models that were considered serious candidates to produce re-
vised 1993 county estimates of poor school-age children (see Chapter 5 and Appendices B and C):
-
log number model (under 21), the original model that the Census Bureau used to produce the original 1993 county estimates of poor school-age children;
-
log number model (under 18), the revised model that the Census Bureau used to produce the revised 1993 county estimates of poor school-age children;
-
log rate model (under 21); and
-
log rate model (under 18).
In addition, the 1990 census comparisons (2) were performed for some other estimation procedures that relied much more heavily than did the four candidate models on estimates from the 1980 census (see below, “Comparisons with 1990 Census Estimates”). Since the Department of Education used estimates of poor school-age children from the previous census for allocations of Title I funds prior to the 1997-1998 school year, these estimation procedures were included in the evaluation in order to see how well the regression models compared with some simple procedures for updating the census estimates.
The internal evaluation of regression output (1) and the comparison of estimates of poor school-age children for 1989 with 1990 census estimates (2) examined residuals and model differences from the census, respectively, for categories of counties. The following characteristics were used for categorizing counties: census geographic division; metropolitan status of county; population size in 1990; population growth from 1980 to 1990; percentage of poor school-age children in 1980; percentage of Hispanic population in 1990; percentage of black population in 1990; persistent poverty from 1960 to 1990 for rural counties; economic type for rural counties; percentage of group quarters residents in 1990; number of households in the CPS sample in 1988-1991 (or whether the county had sampled households); and (for 1990 census comparisons only) percentage change in the poverty rate for poor school-age children from 1980 to 1990 (see details in Table 6-4, below).
1995 Estimates
Because the 1995 county estimates were developed by using a procedure similar to that used to develop the revised 1993 county estimates, the focus of the evaluation effort for the 1995 estimates shifted to how the state and county models behaved over several time periods, and specifically, to determining whether there were persistent biases or other problems. The evaluations of the 1995 county estimates included:
-
internal evaluation of the regression output for the 1995 county model estimated for 1995, 1993, and 1989 (using uncorrected and corrected tax return data);
-
comparison of estimates of poor school-age children that were developed from the 1995 form of the county model for 1995, 1993, and 1989 with CPS estimates for groups of counties, a form of external evaluation; and
-
evaluation of the state model, including examination of regression output for 1996, 1995, 1993, 1992, 1991, 1990, and 1989 and consideration of the state raking factors by which county model estimates are adjusted to make them consistent with the state model estimates.
COUNTY MODEL INTERNAL EVALUATION
1993 Evaluations
The panel and the Census Bureau examined the underlying assumptions and other features of the four models, (a)-(d), that were considered candidates for producing revised 1993 county estimates of poor school-age children, through evaluation of the regression model output for 1989 and 1993.2 Although such an evaluation is not likely to provide conclusive evidence with which to rank the performance of alternative models, particularly when they use different transformations of the dependent variable, examination of the regression output is helpful to determine which models perform reasonably well.
The assumptions and features investigated for the four models fall into two groups: those concerning the functional form of the regression model and those concerning the error distribution. Because properties of the error distribution affect the ability to fit a model, studies of these two types of assumptions are not entirely separable.3
The assumptions and features examined in the first group are linearity of the relationship between the dependent variable and the predictor variables; constancy of the assumed linear relationship over different time periods; and whether
|
2 |
The evaluation of the county regression output pertains to the regression models themselves, that is, before the predictions are combined with the direct CPS estimates in a “shrinkage” procedure or raked to the estimates from the state model (see Chapter 4). For these models, the regression output comprises the model predictions for counties with at least one household with poor school-age children in the CPS sample. For the two log number models, the predictions are the log number of poor school-age children; for the two log rate models, the predictions are the log proportion of poor school-age children. |
|
3 |
These assumptions were also examined for the analogous 1990 census regressions. However, since the census equations only affected the weights for the weighted least squares regression and the extent of “shrinkage” in combining model estimates and direct estimates for counties with households in the CPS sample, analyses of the 1990 census regressions are not discussed here. |
any of the included predictor variables are not needed in the model and, conversely, whether other potential predictor variables are needed in the model. The assumptions examined in the second group are normality (primarily symmetry and moderate tail length) of the distribution of the standardized residuals;4 whether the standardized residuals have homogeneous variances, that is, whether the variability of the standardized residuals is constant across counties and does not depend on the values of the predictor variables; and absence of outliers. Each assumption is discussed in terms of the methods used for evaluation and the results of the evaluation for the four candidate models.
Linearity of the relationships between the dependent variable and the predictor variables was assessed graphically, by observing whether there was evidence of curvature in the plots of standardized residuals against the predictor variables in the model. In addition, plots of standardized residuals against CPS sample size and against the predicted values from the regression model were also examined for curvature.
The only evidence of nonlinearity is for the log number (under 21) model (a) for 1989. For that year, the standardized residuals appear to have a very modest curvature when plotted against the predicted values.
Constancy over Time of the assumed linear relationship of the dependent and predictor variables was assessed through comparison of the regression coefficients on the predictor variables for 1989 and 1993. While major changes in economic conditions are expected to cause some changes in the coefficients, a relatively stable regression equation would be desirable.
Table 6-1 shows the regression coefficients for the predictor variables for the four candidate models for 1989 and 1993. In the log number models (a, b) for 1989 and 1993, the coefficients for the three “poverty level” predictor variables— child exemptions reported by families in poverty on tax returns (column 1), food stamp recipients (column 2), and poor school-age children from the previous census (column 5)—are similar. There are substantial differences across the two time periods in the estimated coefficients for the other two variables—population (under age 21 or under age 18, column 3) and total number of child exemptions on tax returns (column 4). However, the sum of these two coefficients is generally close to 0 in each model in each year. Because these two variables are highly positively correlated, the predictions from equations with a similar sum for the two coefficients will be similar.
|
4 |
The standardization of the residuals involved estimating the predicted standard errors of the residuals, given the predictor variables, and dividing the observed residuals by the predicted standard errors. The predicted standard error of the residual for a county is a function of the estimated model error variance and the estimated sampling error variance (see Belsley, Kuh, and Welsch, 1980). |
TABLE 6-1 Estimates of Regression Coefficients for Four Candidate County Models for 1989 and 1993
|
Predictor Variablesa |
||||||
|
Model |
Counties(Number) |
1 |
2 |
3 |
4 |
5 |
|
(a) Log Number (under 21) |
||||||
|
1989 |
1,028 |
0.52 |
0.30 |
0.76 |
−0.81 |
0.27 |
|
(.07) |
(.05) |
(.22) |
(.22) |
(.07) |
||
|
1993 |
1,184 |
0.31 |
0.30 |
0.03 |
0.03 |
0.40 |
|
(.08) |
(.07) |
(.21) |
(.21) |
(.09) |
||
|
(b) Log Number (under 18) |
||||||
|
1989 |
1,028 |
0.50 |
0.23 |
1.79 |
−1.80 |
0.32 |
|
(.06) |
(.05) |
(.27) |
(.27) |
(.07) |
||
|
1993 |
1,184 |
0.38 |
0.27 |
0.65 |
−0.59 |
0.34 |
|
(.08) |
(.07) |
(.24) |
(.24) |
(.09) |
||
|
Predictor Variablesb |
||||||
|
(c) Log Rate (under 21) |
||||||
|
1989 |
1,028 |
0.32 |
0.29 |
−0.73 |
0.40 |
|
|
(.07) |
(.04) |
(.19) |
(.07) |
|||
|
1993 |
1,184 |
0.23 |
0.31 |
−0.07 |
0.41 |
|
|
(.08) |
(.06) |
(.18) |
(.09) |
|||
|
(d) Log Rate (under 18) |
||||||
|
1989 |
1,028 |
0.29 |
0.26 |
−1.13 |
0.43 |
|
|
(.07) |
(.04) |
(.24) |
(.07) |
|||
|
1993 |
1,184 |
0.26 |
0.30 |
−0.42 |
0.38 |
|
|
(.08) |
(.06) |
(.20) |
(.09) |
|||
|
NOTES: All predictor variables are on the logarithmic scale for numbers and rates. Standard errors of the estimated regression coefficients are in parentheses. The four models were estimated for each year with maximum likelihood. The original 1994 population estimates were used for the 1993 models; 1990 census population estimates were used for the 1989 models. aPredictor variables: (1) number of child exemptions reported by families in poverty on tax returns; (2) number of people receiving food stamps; (3) population (under age 21 or under age 18); (4) total number of child exemptions on tax returns; (5) number of poor school-age children from previous (1980 or 1990) census. bPredictor variables: (1) ratio of child exemptions reported by families in poverty on tax returns to total child exemptions; (2) ratio of people receiving food stamps to total population; (3) ratio of total child exemptions on tax returns to population (under age 21 or under age 18); (4) ratio of poor school-age children to total school-age children from previous (1980 or 1990) census. |
||||||
The sum of all coefficients in each equation for models (a) and (b) ranges from 1.04 to 1.07 and is significantly greater than 1. A sum equal to 1 would mean that county population size itself has no effect on the estimated number of poor school-age children and that the model is expressible as a model with the poverty rate as the dependent variable and rates as predictor variables. Because the sum is greater than 1, the estimated number of poor school-age children is a larger percentage of the population in the larger counties. While this result is difficult to explain as a function of county size, it may be that size reflects the effects of variables not included in the models.
In the log rate models (c, d), the coefficients for the three “poverty rate” predictor variables—ratio of child exemptions reported by families in poverty on tax returns to total child exemptions (column 1), ratio of food stamp recipients to the total population (column 2), and ratio of poor school-age children to total school-age children from the previous census (column 4)—are all positive and about the same size.5 The coefficients for the ratio of total child tax exemptions to the population (under age 21 or under age 18, column 3) are negative, as is also generally the case for the coefficients of the related variable (total number of child tax exemptions) in the log number equations. There are substantial differences in the estimated coefficients for the ratio of total child tax exemptions to the population in the log rate models across time periods and some differences between the coefficients in the two models.
Inclusion or Exclusion of Predictor Variables The possibility that one or more predictor variables should be excluded from a model was assessed by looking for insignificant t-statistics for the estimated values of individual regression coefficients.6 The need to include a predictor variable, or possibly to model some categories of counties separately, was assessed by looking for nonrandom patterns, indicative of possible model bias, in the distributions of standardized residuals displayed for the various categories of counties.7
The only predictor variables with nonsignificant t-statistics are the population under age 21 (column 3 in Table 6-1) and total child exemptions on IRS income tax returns (column 4) for the log number (under 21) model (a) in 1993, and the ratio of child tax exemptions to the population under age 21 (column 3) for the log rate (under 21) model (c) in 1993. All other regression coefficients are
|
5 |
The coefficients are also similar to the coefficients for the corresponding variables—number of child exemptions reported by families in poverty on tax returns, number of food stamp recipients, and number of poor school-age children from the previous census—in the log number equations. |
|
6 |
Although the performance of a predictive regression model is best assessed in terms of the joint impact of the predictor variables, examining the individual predictor variables can suggest ways in which a model might be improved. |
|
7 |
The distributional displays examined for this and other model assumptions were box plots. |
significantly different from 0 at the 5 percent level. Application of Akaike's information criterion (AIC) confirmed the superiority of using the population under age 18 as a predictor variable in preference to the population under age 21 in the log number model. (The test was not performed for the log rate model.)
For most ways of categorizing counties, the standardized residuals do not exhibit systematic patterns. The exceptions are that all four models in 1989 tend to overpredict poor school-age children in counties with a high percentage of Hispanic residents (i.e., the standardized residuals tend to be negative for these counties) and that the log number (under 21 and under 18) models (a, b) in 1993 and 1989 tend to overpredict poor school-age children in counties that are in metropolitan areas but are not the central county in the area.
Normality of the standardized residuals was evaluated through use of Q-Q plots, which match the observed distribution of the residuals with the theoretical distribution, and other displays of the distribution. All four models exhibit some skewness in their standardized residuals, with the log rate models (c, d) showing somewhat more skewness than the log number models (a, b). For none of the models does the skewness appear sufficiently marked to be a problem.
Homogeneous Variances The homogeneity of the variance of the standardized residuals was assessed using a variety of statistics and graphical displays (see Appendix B). Examination of them clearly demonstrates some variability in the size of the absolute standardized residuals as a function of the predicted value (number or proportion of poor school-age children) and the CPS sample size for all four models. With regard to CPS sample size, one would expect the standardized residual variance to remain constant over the distribution of CPS sample size; however, it increases with increasing CPS sample size.
The heterogeneity of the variance of the residuals suggests that there may be a problem with the model specification or in the assumptions that were used to calculate the standardized residuals. However, adjusting a model to remove this type of heterogeneity is likely to have only a small effect on the estimated regression coefficients or the model estimates. The effect on estimates of poor school-age children would stem from two factors: a shift in the weights assigned to each county in fitting the regression model, which would very likely result in only a modest change in the estimated regression coefficients; and a change in the weight given to the direct estimates, which could have an appreciable effect on the estimates only for the few counties with large CPS sample sizes.
Outliers The existence of outliers was evaluated through examination of plots of the distributions of the standardized residuals and plots of standardized residuals against the predictor variables and through analysis of patterns in the distribution of the 30 largest absolute standardized residuals for the various categories of counties. However, it is difficult to evaluate the evidence for outliers
that results from a least squares model fit, which has the property that it may miss influential outliers. In addition, since the four models are so similar and make use of the identical data, it is unlikely that an observation that was a marked outlier for one model would not also be a marked outlier for the other models.
An examination of the distributions of the standardized residuals suggests that none of the four models is especially affected by outliers, although the 1993 models have more outliers than the 1989 models, and nonrural counties and metropolitan counties that are not central counties have somewhat more outliers than other categories of counties. This analysis is only a start. It would be useful to extend this analysis, using other statistics and various graphical techniques, to identify the counties that are not well fit by robustly estimated versions of these models in order to determine any characteristics that outlier counties have in common.
Summary The panel concluded that the analysis of the regression output for the four candidate county models for 1989 and 1993 largely supports the assumptions of the models: there is little evidence of important problems with the assumptions. The analysis does not strongly support one model over another, although it does support use of the population under age 18 instead of the population under age 21 as a predictor variable in the log number model.
All of the models exhibit a few common problems. First, they all behave somewhat differently for larger urban counties and counties with large percentages of Hispanic residents than for other counties. Second, all models show evidence of some variance heterogeneity with respect to both CPS sample size and the number or proportion of poor school-age children.
1995 Evaluations
The internal evaluation for the 1995 county model, which is essentially the log number (under 18) model (b) evaluated above, focused on comparisons of the properties of the model when estimated for different time periods. The analysis looked in particular at three characteristics: the constancy of the regression coefficients for the predictor variables over time; distributions (box plots) of the standardized residuals for categories of counties to determine if there were any nonrandom patterns that persisted over time; and the phenomenon observed in the 1993 evaluations by which the variance of the standardized residuals was related to CPS sample size and the predicted value of the dependent variable (variance heterogeneity).
Constancy of the Regression Coefficients Because the county model is refitted for each prediction year, constancy of the regression coefficients for the predictor variables over time is not as important as it would be if the estimated regression coefficients from the model were used for predictions for subsequent
years. Also, major changes in economic conditions would be expected to cause some changes in the coefficients. Nonetheless, it is desirable for the coefficients to be in the same direction and not fluctuate wildly in size over time.
TABLE 6-2 Estimates of Regression Coefficients for Census Bureau 1995 County Model, Estimated for 1989, 1993, and 1995
|
Predictor Variablesa |
||||||
|
Year |
No. of Counties |
(1) |
(2) |
(3) |
(4) |
(5) |
|
1989 (revised IRS data) |
1,028 |
0.52 |
0.29 |
1.55 |
−1.56 |
0.26 |
|
(.06) |
(.06) |
(.31) |
(.30) |
(.06) |
||
|
1989 (original IRS data) |
1,028 |
0.50 |
0.23 |
1.79 |
−1.80 |
0.32 |
|
(.06) |
(.05) |
(.27) |
(.27) |
(.07) |
||
|
1993 |
1,184 |
0.38 |
0.27 |
0.65 |
−0.59 |
0.34 |
|
(.08) |
(.07) |
(.24) |
(.24) |
(.09) |
||
|
1995 |
985 |
0.31 |
0.29 |
0.88 |
−0.80 |
0.33 |
|
(.10) |
(.08) |
(.25) |
(.25) |
(.09) |
||
|
NOTE: All predictor variables are on the logarithmic scale for numbers. Standard errors of the estimated regression coefficients are in parentheses. aPredictor variables: (1) number of child exemptions reported by families in poverty on tax returns; (2) number of people receiving food stamps; (3) population under age 18; (4) total number of child exemptions on tax returns; (5) number of poor school-age children from previous (1980 or 1990) census. |
||||||
Table 6-2 shows the regression coefficients for the predictor variables for the 1995 county model estimated for 1995 and 1993 and for 1989 with both the original and revised IRS data (see Chapter 4).8 The coefficients for the three “poverty level” predictor variables—child exemptions reported by families in poverty on tax returns (column 1), food stamp recipients (column 2), and poor school-age children from the previous census (column 5)—are fairly similar in the equations for all three time periods. There are more substantial differences across the three time periods in the size of the estimated coefficients for the other two variables—population under age 18 (column 3) and total number of child exemptions on tax returns (column 4). However, the sum of these two coefficients is close to zero in each year. Because the two variables are highly posi-
|
8 |
The regressions for 1995 and for 1989 with corrected IRS data also used modified food stamp data (i.e., the county food stamp data were raked to the adjusted state food stamp data, as described in Chapter 4). |
tively correlated and close in magnitude, the predictions from equations with a similar sum for the two coefficients will be similar.
Finally, the sum of all the coefficients is close to 1 for all 3 estimation years: 1.01 for 1995, 1.05 for 1993, and 1.06 for 1989 with the revised IRS data. It is desirable for the coefficients in a model of this form to sum to 1, which indicates that the model predictions do not vary by the scale of the predictor variables. If the sum of the coefficients is much greater than or less than 1, the model should be examined to determine if additional predictor variables or other changes in the model may be needed.
Patterns of Residuals Given typical random variation, it is likely that the distributions of standardized residuals will display apparently nonrandom patterns for some categories of counties in a particular year. However, if the distributions display the same patterns across years, it is evidence of model bias. The persistence of the same patterns should be investigated to determine ways to eliminate or reduce the bias, for example, by adding a variable to the equation. (There are ample degrees of freedom in the county model to permit the inclusion of additional predictor variables.)
Investigation of the standardized residuals for categories of counties for the county model estimated for 1995, 1993, and 1989 reveals little evidence of persistent bias. However, there is some suggestion that the model tends to consistently overpredict the number of poor school-age children in smaller size counties (i.e., the model estimates are somewhat higher than the CPS direct estimates for smaller counties). It also tends to overpredict the number of poor school-age children in counties that are in metropolitan areas but are not the central county in the area. These patterns, while not strong, are evident in the regression output for all 3 years. The tendency for the model to overpredict the number of poor school-age children in counties with a high percentage of Hispanics that was evident for 1989 in the 1993 model evaluations did not persist over time.
Variance Heterogeneity The regression output for the 1995 county model clearly demonstrates variability in the size of the absolute standardized residuals as a function of the predicted value (log number of poor school-age children) and the CPS sample size. If the variance estimates for the model are correct, then the standardized residual variance should remain constant over the distribution of CPS sample size. However, it increases with increasing CPS sample size. This phenomenon was evident in the evaluations conducted for the 1993 county model, and it is evident in all 3 years for which the 1995 county model was estimated.
As noted for the 1993 evaluations above, adjusting a model to remove this type of heterogeneity is likely to have only a small effect on the estimated regression coefficients or the model estimates (although it will affect the estimated confidence intervals around the model estimates). Nonetheless, it is clear that the current method for estimating the variance of the sampling errors—ai in equation
(1) in Chapter 4—in the county model is incorrect. The current approach estimates the model error variance from a 1989 equation in which 1990 census data form the dependent variable, and then uses the estimate for the model error variance in the CPS-based county equation (see Chapter 4). Taking this estimated model error variance as fixed, the total sampling error variance is obtained together with estimated regression coefficients using a maximum likelihood procedure. Finally, the total sampling error variance is distributed to counties by assuming that the sampling error variance in a county is inversely proportional to the county's CPS sample size. An alternative approach for estimating the sampling error variance that might remove the variance heterogeneity in the regression residuals is discussed in Chapter 9 (see also National Research Council, 2000:Ch.3).
Summary The panel concluded that the analysis of the regression output for the 1995 county model estimated for 1989, 1993, and 1995 largely supports the assumptions of the model: there is little evidence of important problems with the assumptions. However, the model does exhibit a few minor problems that appear to persist over time. First, it tends to overpredict the number of poor school-age children in smaller counties and metropolitan counties that are not the central county. The differences are not marked, but research should be conducted to determine possible ways to modify the model to eliminate or reduce this problem. Second, the model shows evidence of variance heterogeneity with respect to both CPS sample size and predicted number of poor school-age children. Improvements in estimating the model error and sampling error variances should be sought to reduce or eliminate this problem.
COUNTY MODEL EXTERNAL EVALUATION
Comparisons with 1990 Census Estimates
For external evaluation of alternative models that were considered for 1993 estimates, the panel and the Census Bureau compared the estimated number and proportion of poor school-age children for 1989 for the four candidate models with 1990 census estimates.9 The evaluation examined the overall difference
|
9 |
The county estimates reflect the effects of the state model and the county population estimates as well as the county regression model, but the differences in model performance vis-à-vis the census in the evaluation are due to the particular form of the county model. The models for which the 1990 census comparisons were performed were estimated with the method of moments. Maximum likelihood was used to estimate the log number (under 18) model (b) for the revised 1993 county estimates and the 1995 county estimates of poor school-age children. The differences in the estimates from the two techniques are small. |
between the estimates from a model and the census and the differences for groups of counties categorized by various characteristics.
Evaluation by comparison with the 1990 census is not ideal because the census estimates are not true values. They are affected by sampling variability and population undercount; also, the census measurement of poverty differs from the CPS measurement in ways that are not fully understood (see Chapter 3). In addition, there is only one census-based validation opportunity: because of the lack of IRS and Food Stamp Program data for counties for 1979, it is not possible to evaluate model-based estimates by comparison to the 1980 census. Reliance on a single validation using the 1990 census is a problem because a model may perform better or worse in any one validation than it would on average over multiple validations. For this reason, if it were possible to compare model estimates with census or other estimates for 1993 instead of 1989, the results might turn out differently. Nonetheless, in the absence of other means of external validation, the panel and the Census Bureau relied heavily on the 1990 census comparisons to understand the performance of alternative models.
Evaluation by comparison with the 1990 census is intended to assess the accuracy of model estimates for the prediction year (i.e., 1989). The evaluation does not address the issue that model-based estimates for a given year are used for Title I allocations about 3 years later.
The 1990 census estimates that are used in the comparisons are ratio adjusted by a constant factor to make the census national estimate of poor school-age children equal the 1989 CPS national estimate. This adjustment removes the difference of about 6 percent between the CPS and census estimates of total poor school-age children for 1989. Consequently, the differences between a model and the 1990 census in estimating poor school-age children for groups of counties can be interpreted as differences in shares. This feature is useful because the Title I allocation formula distributes funding as shares (percentages) of a fixed total dollar amount.
In addition to the four candidate models, the 1990 census comparisons were performed for four estimation procedures that rely much more heavily on 1980 census estimates. Given the substantial changes in the number and proportion of poor school-age children between the 1980 and 1990 censuses (see Chapter 3), one would expect these procedures to perform less well than the candidate models in predicting poverty for school-age children in 1989.10 In a period of less pronounced change, one or more of them might perform relatively well. The census comparisons were done for the following procedures:
|
10 |
Although the interval was only 4 years instead of 10, substantial changes in the number and proportion of poor school-age children also occurred between 1989 and 1993, and such changes continued to be observed through 1999 (see Chapter 3). |
-
Stable shares procedure, in which the county estimates of poor schoolage children for 1989 are the 1980 census estimates for 1979 after ratio adjustment to make the 1980 census national estimate equal the CPS national estimate for 1989. This simple procedure assumes no change over the decade in each county's share of the total number of poor school-age children nationwide: this is the same assumption that underlies previous practice for Title I allocations, in which estimates from the decennial census were used in the formulas each year until the results from the next census became available.11
-
Stable shares within state procedure, in which the county estimates of poor school-age children for 1989 are the 1980 census estimates for 1979 after raking the estimates for the counties in each state to the estimates from the Census Bureau's state model for 1989. (The national raking employed in the state model also adjusts the total to equal the CPS national estimate for 1989.) This procedure assumes no change over the decade in each county's share of the total number of poor school-age children in its state.
-
Stable rates within state procedure (with conversion), in which the county estimates of poor school-age children for 1989 are developed by converting 1980 census estimates of the proportions of poor school-age children for 1979 to estimated numbers by use of 1990 county population estimates of total school-age children 5-17 and then raking the estimated numbers to the Census Bureau's state model estimates for 1989.
-
Averaging procedure, in which the county estimates of poor school-age children for 1989 are developed from an average of estimates from the 1980 census and the log number (under 21) model (a) for 1989. 12
The rest of this section first discusses overall absolute differences from the 1990 census estimates for the four candidate models and the four procedures that rely more heavily on the 1980 census. It then discusses differences for categories of counties for the four candidate models and two of the procedures: the stable shares procedure and the averaging procedure. Differences for categories of
|
11 |
However, the estimates from the 1990 census that were previously used for Title I allocations were not adjusted to the current CPS national estimate of poor school-age children, which could affect the allocations for some counties. For example, some counties might meet the threshold test for a concentration grant if the census estimates were adjusted to the current CPS national estimate but not if the estimates were unadjusted. |
|
12 |
More precisely, the estimates are developed by averaging the proportions of poor school-age children from the 1980 census and the log number (under 21) model (a) for 1989, converting the estimates to numbers by the use of 1990 county population estimates of total school-age children, and making an overall ratio adjustment to the CPS national estimate for 1989. This procedure is analogous to the panel's recommendation for averaging 1990 census and 1993 model-based estimates for use in Title I allocations for the 1997-1998 school year. However, the panel's recommendation did not include raking the average estimates to the CPS national estimate of poor school-age children in 1993 (see National Research Council, 1997:38). |
counties for the other two procedures, which are intermediate in their reliance on 1980 census estimates, are provided in Appendix C.
Absolute Differences Between Model and Census County Estimates
Table 6-3 presents measures of the overall absolute difference between the model-based county estimates and the 1990 census county estimates of poor school-age children in 1989 for the four candidate models and the four procedures that rely more heavily on the 1980 census. If the 1990 census estimates are reasonably accurate, a good model will produce estimates that differ little from the census estimates, and the absolute differences will be less than for other reasonable models. Also, a good model will perform significantly better than a simple procedure that relies heavily on the previous census.
Column 1 of Table 6-3 is the average absolute difference for county estimates of the number of poor school-age children in 1989, measured as the sum for all counties of the absolute difference (ignoring the direction of the difference) between the model estimate and the 1990 census estimate for each county, divided by the total number of counties. Column 2 of Table 6-3 is the average proportional absolute difference for county estimates of the number of poor school-age children, measured as the sum for all counties of the absolute difference between the model estimate and the 1990 census estimate as a proportion of the census estimate for each county, divided by the total number of counties and expressed as a percentage. Column 3 is the average proportional absolute difference for county estimates of the proportion of poor school-age children. Column 3 is of interest because the proportion of poor school-age children is used as an eligibility threshold for Title I grants.
The measure in column 1 assesses the difference between a model and the 1990 census in terms of numbers of poor children; the measures in columns 2 and 3 assess the difference in terms of percentage errors for counties. To illustrate the difference between absolute and proportional absolute differences, consider two counties, one with an estimated 10,000 poor school-age children from the census and an estimated 9,600 poor school-age children from the model and the other with an estimated 1,000 poor school-age children from the census and an estimated 1,400 poor school-age children from the model. The absolute difference in the number of poor school-age children is the same for both counties (400), but the proportional absolute difference is only 4 percent for the first county and 40 percent for the second.
From a national perspective, it can be argued that absolute differences are more important for effective Title I allocations because Title I funds are primarily distributed in proportion to the number of children in a county; therefore, the amount of funds that are misallocated depends primarily on the number of children rather than the percentages by county. For example, an error of 5 percent in the number of school-age children in poverty in a large county could correspond
TABLE 6-3 Comparison of Model Estimates and Other Procedures with 1990 Census County Estimates of the Number and Proportion of Poor Related Children Aged 5-17 in 1989
|
Average Absolute Difference |
Average Proportional Absolute Difference, in Percent |
||
|
1 |
2 |
3 |
|
|
Model |
Number of Poor Children Aged 5-17a |
Number of Poor Children Aged 5-17b |
Proportion of Poor Children Aged 5-17c |
|
Candidate Models |
|||
|
(a) Log number (under 21) |
272 |
15.4 |
16.4 |
|
(b) Log number (under 18) |
268 |
16.4 |
17.7 |
|
(c) Log rate (under 21) |
275 |
17.5 |
17.1 |
|
(d) Log rate (under 18) |
283 |
18.8 |
18.6 |
|
Procedures that Rely More Heavily on the 1980 Census |
|||
|
(i) Stable shares |
570 |
30.1 |
N.A. |
|
(ii) Stable shares within state |
380 |
27.1 |
N.A. |
|
(iii) Stable rates within state, with conversion |
381 |
26.2 |
N.A. |
|
(iv) Average of 1980 census and 1989 log number (under 21) model (a) |
286 |
19.0 |
N.A. |
|
NOTES: The census estimates are controlled to the CPS national estimate for 1989. See text for definitions of models and measures; N.A.: not available. aThe formula where there are n counties (i), is ∑(|Ymodeli − Ycensusi|) / n. bThe formula is ∑ [(|Ymodeli − Ycensusi |) / Ycensusi ] / n. cThe formula is ∑ [(|Pmodeli − Pcensusi |) / Pcensusi ] / n. SOURCE: Data from U.S. Census Bureau. |
|||
to tens of thousands of children and have more impact on the allocation of funds than errors of 5 percent in several smaller counties. However, from the county perspective, proportional errors are also important. Ideally, a model will perform well on both types of measures.
The panel drew several conclusions from Table 6-3:
-
The performance of the four candidate models is similar, which is not surprising, given that they are variations of the same basic formulation. Thus, the range of the average absolute difference in the estimated number of poor school-age children (column 1) is from 268 children (model b) to 283 children (model d). The average county had about 2,500 poor school-age children for 1989, so that the average absolute difference ranges from 10.7 to 11.3 percent. The range of the average proportional absolute difference in the estimated number of poor school-age children (column 2) is somewhat larger, from 15.4 percent (model a) to 18.8 percent (model d).
-
The log number models (a, b) have somewhat lower average absolute differences for estimates of numbers of poor school-age children than do the log rate models (c, d). This is expected because the estimates from the log rate models must be converted to numbers by use of population estimates of total school-age children, which themselves contain error (see Chapter 8). It was expected for the same reason that the log number models would have higher average absolute differences for estimates of proportions of poor school-age children than would the log rate models because population estimates must be used to convert the estimated numbers from the log number models to estimated proportions. However, model (a) shows lower and model (b) shows not appreciably higher average proportional absolute differences for estimates of poverty rates compared with the better log rate model (c)—see column 3 of Table 6-3.
-
The four candidate models substantially outperform the three procedures (i-iii) that rely solely or largely on 1980 census data. For example, the largest average absolute difference for the four candidate models is 283 poor school-age children (11% of the average number) for the log rate (under 18) model (d), while the smallest average absolute difference for procedures (i-iii) is 380 poor school-age children (15% of the average number) for the procedure that assumes stable poverty shares within state (ii). The differences are even somewhat larger for the average proportional absolute difference for estimates of the number of poor school-age children: 18.8 percent for the worst candidate model, model (d), compared with 26.2 percent for the best procedure of these three, the procedure that assumes stable poverty rates within state with conversion (iii).
-
The four candidate models also perform better than the procedure (iv) that averages 1980 census estimates with estimates from the log number (under 21) model (a) for 1989, although the differences are not large.
Category Differences in Numbers of Poor School-Age Children
Table 6-4 shows the difference in the number of poor school-age children from the 1990 census for categories of counties for each of the four candidate models and two of the procedures that rely more heavily on the 1980 census—the stable shares procedure (i) and the averaging procedure (iv). The measure shown is the algebraic difference by category, which is the sum for all counties in a category of the algebraic (signed) difference between the model estimate of poor school-age children and the 1990 census estimate for each county, divided by the sum of the census estimates for all counties.13 Counties are grouped into five or six categories for each of 11 characteristics—those that were considered in the assessment of the county model regression output discussed above.14
The measure in Table 6-4 expresses model-census differences for groups of counties in terms of numbers of poor children, similar to the overall average absolute difference in column 1 of Table 6-3. However, the category difference is expressed as an algebraic measure in which positive differences (overpredictions) within a category offset negative differences (underpredictions). The measure is intended to identify instances of potential bias in a model's predictions. For example, the model may over(under)predict, on average, the number of poor school-age children in larger counties relative to smaller counties.
If the census estimates are a reasonably accurate standard for comparison, sizable category differences between model and census estimates would be disturbing. They would indicate that the errors in the model estimates are not random errors (which occur in any set of estimates), but occur in part because the model systematically over(under)predicts poverty in certain types of counties. Indeed, bias, in terms of over(under)prediction for different types of counties, is arguably more important than the overall absolute difference in evaluating a model that is used repeatedly because there is the risk that the bias will operate for the same areas on each occasion.15 Although one would not want to use a model that had a large overall absolute difference from the standard of comparison, a model that performed somewhat worse in overall terms but exhibited fewer and less severe biases than another model would be preferable to it.
|
13 |
The formula for counties (i) in each category (j) is ∑i (Ymodelij− Ycensusij) / ∑iYcensusij. |
|
14 |
In addition to the algebraic difference for each category for the four candidate models and four procedures, Appendix C shows for each of them the average proportional algebraic difference; that is, the category difference expressed in terms of percentage errors for counties instead of numbers of poor children (see Table C-1 and Table C-2). Differences between the two measures can help identify particular types of counties within a category for which a model performs less well than others. |
|
15 |
A search for potential biases is also important to identify possible approaches to model improvement. |
TABLE 6-4 Comparison of Model Estimates with 1990 Census County Estimates of the Number of Poor School-Age Children in 1989: Algebraic Difference by Category of County (in percent)
|
Model |
Other Procedures |
||||||
|
Log Number Under 21 |
Log Number Under 18 |
Log Rate Under 21 |
Log Rate Under 18 |
Stable Shares |
Average of Census and (a) |
Number of Countiesa |
|
|
Category |
(a) |
(b) |
(c) |
(d) |
(i) |
(iv) |
|
|
Census Divisionb |
|||||||
|
New England |
−2.9 |
−2.9 |
−2.9 |
−2.9 |
35.9 |
7.8 |
67 |
|
Middle Atlantic |
−2.8 |
−2.8 |
−2.8 |
−2.8 |
27.1 |
4.4 |
150 |
|
East North Central |
−0.2 |
−0.2 |
−0.2 |
−0.2 |
−2.8 |
−5.6 |
437 |
|
West North Central |
1.7 |
1.7 |
1.7 |
1.7 |
−1.8 |
−2.1 |
618 |
|
South Atlantic |
0.5 |
0.5 |
0.5 |
0.5 |
14.8 |
8.1 |
591 |
|
East South Central |
−4.5 |
−4.5 |
−4.5 |
−4.5 |
14.1 |
2.1 |
364 |
|
West South Central |
−2.7 |
−2.7 |
−2.7 |
−2.7 |
−18.1 |
−6.3 |
470 |
|
Mountain |
4.3 |
4.3 |
4.3 |
4.3 |
−23.2 |
−3.1 |
281 |
|
Pacific |
6.5 |
6.5 |
6.5 |
6.5 |
−21.3 |
0.2 |
163 |
|
Metropolitan Status |
|||||||
|
Central county of metropolitan area |
2.4 |
1.6 |
−0.1 |
−0.5 |
−1.6 |
0.4 |
493 |
|
Other metropolitan |
−6.6 |
−5.0 |
5.1 |
6.3 |
3.2 |
3.4 |
254 |
|
Nonmetropolitan |
−4.2 |
−2.8 |
−0.3 |
0.4 |
3.3 |
−1.4 |
2394 |
|
1990 Population Size |
|||||||
|
under 7,500 |
−9.0 |
−2.3 |
−1.9 |
2.3 |
16.5 |
1.3 |
525 |
|
7,500-14,999 |
−4.4 |
0.5 |
2.5 |
5.5 |
10.9 |
2.2 |
630 |
|
15,000-24,999 |
−5.1 |
−2.6 |
0.3 |
1.9 |
6.2 |
−0.6 |
524 |
|
25,000-49,999 |
−4.2 |
−2.9 |
0.6 |
1.3 |
2.4 |
−1.3 |
620 |
|
50,000-99,999 |
−3.5 |
−5.1 |
−1.2 |
−2.3 |
−2.5 |
−3.3 |
384 |
|
100,000-249,999 |
−1.8 |
−4.4 |
−1.8 |
−3.5 |
−4.9 |
−3.3 |
259 |
|
250,000 or more |
3.3 |
3.2 |
0.5 |
0.5 |
−0.6 |
1.8 |
199 |
|
1980 to 1990 Population Growth |
|||||||
|
Decrease of more than 10.0% |
−1.9 |
0.6 |
−3.4 |
−1.9 |
9.1 |
−3.4 |
444 |
|
Decrease of 0.1-10.0% |
−0.6 |
−0.5 |
−1.9 |
−1.8 |
7.5 |
−2.7 |
972 |
|
0.0-4.9% |
−2.8 |
−2.8 |
−3.2 |
−3.1 |
11.0 |
−0.2 |
547 |
|
5.0-14.9% |
0.0 |
−1.0 |
0.2 |
−0.6 |
6.1 |
2.1 |
620 |
|
15.0-24.9% |
7.7 |
5.8 |
5.5 |
4.6 |
−12.8 |
2.4 |
260 |
|
25.0% or more |
−4.0 |
−1.4 |
1.7 |
3.1 |
−21.2 |
1.0 |
292 |
|
Percent Poor School-Age Children, 1980 |
|||||||
|
Less than 9.4% |
−4.0 |
−4.5 |
0.0 |
0.2 |
2.4 |
−1.1 |
516 |
|
9.4-11.6% |
−0.5 |
−1.0 |
−1.6 |
−1.8 |
−9.9 |
−3.6 |
524 |
|
11.7-14.1% |
3.6 |
2.3 |
1.8 |
1.0 |
−4.2 |
0.2 |
530 |
|
14.2-17.2% |
0.9 |
1.2 |
−1.2 |
−1.4 |
−5.0 |
−1.8 |
523 |
|
17.3-22.3% |
1.8 |
1.7 |
0.3 |
−0.1 |
10.7 |
4.2 |
519 |
|
22.4-53.0% |
−2.2 |
0.8 |
1.3 |
2.8 |
12.3 |
4.1 |
523 |
|
Percent Hispanic, 1990 |
|||||||
|
0.0-0.9% |
−3.4 |
−3.3 |
−1.6 |
−1.5 |
10.7 |
0.2 |
1770 |
|
1.0-4.9% |
0.5 |
0.1 |
0.4 |
0.1 |
0.2 |
−0.4 |
847 |
|
5.0-9.9% |
−1.4 |
−0.6 |
−1.1 |
−0.8 |
6.7 |
1.7 |
193 |
|
10.0-24.9% |
2.2 |
1.8 |
0.7 |
0.5 |
−5.7 |
0.1 |
181 |
|
25.0-98.0% |
3.9 |
4.6 |
2.2 |
2.7 |
−16.8 |
−0.4 |
150 |
|
Percent Black, 1990 |
|||||||
|
0.0-0.9% |
−1.2 |
0.3 |
3.9 |
4.9 |
−3.7 |
−0.5 |
1446 |
|
1.0-4.9% |
−0.7 |
−2.0 |
1.3 |
0.5 |
−6.3 |
−2.9 |
615 |
|
5.0-9.9% |
−2.9 |
−2.5 |
−0.7 |
−0.6 |
−8.4 |
−1.8 |
294 |
|
10.0-24.9% |
2.0 |
1.2 |
−1.0 |
−1.3 |
−2.6 |
0.2 |
381 |
|
25.0-87.0% |
1.0 |
1.7 |
−1.8 |
−1.4 |
16.5 |
3.7 |
405 |
|
Persistent Rural Poverty, 1960-1990c |
|||||||
|
Rural, not poor |
−4.0 |
−3.7 |
−1.2 |
−1.0 |
0.1 |
−3.4 |
1740 |
|
Rural, poor |
−5.0 |
−2.1 |
0.7 |
2.1 |
9.8 |
1.2 |
535 |
|
Not classified |
1.7 |
1.2 |
0.3 |
0.0 |
−1.2 |
0.7 |
866 |
|
Economic Type, Rural Countiesc |
|||||||
|
Farming |
−5.5 |
−2.5 |
−1.6 |
0.7 |
13.2 |
1.1 |
556 |
|
Mining |
−10.7 |
−5.1 |
−6.3 |
−3.6 |
−8.9 |
−10.6 |
146 |
|
Manufacturing |
−6.2 |
−5.9 |
−1.7 |
−1.0 |
12.1 |
−0.2 |
506 |
|
Government |
2.1 |
−1.3 |
6.3 |
3.2 |
−0.9 |
0.0 |
243 |
|
Services |
−3.9 |
−3.0 |
−1.8 |
−1.2 |
−5.8 |
−4.3 |
323 |
|
Nonspecialized |
−3.7 |
−1.0 |
−0.1 |
1.4 |
2.2 |
−1.5 |
484 |
|
Not classified |
1.7 |
1.2 |
0.3 |
0.0 |
−1.2 |
0.7 |
883 |
|
Percent Group Quarters Residents, 1990 |
|||||||
|
Less than 1.0% |
−6.7 |
−2.7 |
2.0 |
4.7 |
−1.4 |
0.3 |
545 |
|
1.0-4.9% |
0.3 |
0.7 |
−0.3 |
0.1 |
−0.4 |
0.1 |
2187 |
|
5.0-9.9% |
2.3 |
−4.4 |
0.5 |
−5.2 |
7.8 |
−0.8 |
299 |
|
10.0-41.0% |
14.2 |
−3.2 |
7.4 |
−7.5 |
1.8 |
−2.2 |
110 |
|
Status in CPS, 1989-1991 |
|||||||
|
In CPS sample |
1.4 |
1.0 |
−0.2 |
−0.5 |
−0.6 |
0.5 |
1028 |
|
In CPS, no poor children aged 5-17 |
−2.6 |
−1.9 |
7.3 |
7.8 |
10.0 |
5.9 |
246 |
|
Not in CPS sample |
−4.1 |
−2.8 |
−0.1 |
0.6 |
0.6 |
−2.3 |
1867 |
|
Change in Poverty Rate for School-Age Children, 1980-1990 |
|||||||
|
Decrease of more than 3.0% |
7.5 |
10.4 |
16.2 |
18.1 |
51.6 |
30.0 |
536 |
|
Decrease of 0.1-3.0% |
2.1 |
1.9 |
3.1 |
2.9 |
29.2 |
12.1 |
649 |
|
0.0-0.9% |
−2.6 |
−0.8 |
−0.4 |
0.5 |
4.3 |
3.1 |
272 |
|
1.0-3.4% |
3.8 |
2.2 |
3.4 |
2.6 |
−5.1 |
0.2 |
621 |
|
3.5-6.4% |
−1.2 |
−2.4 |
−3.8 |
−4.3 |
−14.3 |
−8.3 |
532 |
|
6.5-38.0% |
−7.2 |
−5.2 |
−8.7 |
−7.8 |
−25.2 |
−14.5 |
523 |
NOTES: The census estimates are controlled to the CPS national estimate for 1989. The algebraic difference by category is the sum for all counties in a category of the algebraic (signed) difference between the model estimate of poor school-age children and the 1990 census estimate for each county, divided by the sum of the census estimates for all counties in the category. See text for definitions of models.
a3,141 counties are assigned to a category for most characteristics; 3,135 counties are assigned to a category for 1980-1990 population growth and 1980 percent poor school-age children; 3,133 counties are assigned to a category for 1980-1990 percent change in poverty rate for school-age children.
bCensus division states: New England: Maine, New Hampshire, Vermont, Massachusetts, Rhode Island, Connecticut Middle Atlantic: New York, New Jersey, Pennsylvania East North Central: Ohio, Indiana, Illinois, Michigan, Wisconsin West North Central: Missouri, Minnesota, Iowa, North Dakota, South Dakota, Nebraska, Kansas South Atlantic: Delaware, Maryland, District of Columbia, Virginia, West Virginia, North Carolina, South Carolina, Georgia, Florida East South Central: Kentucky, Tennessee, Alabama, Mississippi West South Central: Arkansas, Louisiana, Oklahoma, Texas Mountain: Montana, Idaho, Wyoming, Colorado, New Mexico, Arizona, Utah, Nevada Pacific: Washington, Oregon, California, Alaska, Hawaii
cThe Economic Research Service, U.S. Department of Agriculture, classifies rural counties by 1960-1990 poverty status and economic type. Counties not classified are urban counties and rural counties for which a classification could not be made.
SOURCE: Data from U.S. Census Bureau.
The panel drew several general conclusions from Table 6-4 about the performance of alternative county models in predicting numbers of poor school-age children for categories of counties:
-
The performance of the four candidate models is similar. However, the log number (under 18) model (b) performs somewhat better than the log rate (under 21) model (c), which in turn performs better than the other two, the log number (under 21) model (a) and the log rate (under 18) model (d).
Performance in this instance is evaluated principally in terms of the spread among the differences for categories of counties (the spread between the largest positive and negative category differences for a characteristic). A better performing model has a narrower spread for a greater number of characteristics than other models. As an example (see Table 6-4), the spread among the category differences for counties classified by percentage of group quarters residents is 5.1 percentage points for model (b), 7.7 percentage points for model (c), 12.2 percentage points for model (d), and 20.9 percentage points for model (a).
Also entering into the panel's judgment is consideration of the magnitude and pattern of differences: a better performing model has smaller differences from the census and exhibits fewer obvious patterns across categories than other models. Continuing with the same example from Table 6-4, there is no pattern to the category differences for counties classified by percentage of group quarters residents for model (b), whereas model (a) exhibits a strong monotonic pattern in which the number of poor school-age children is overpredicted for counties with higher percentages of group quarters residents relative to counties with lower percentages. Also, the magnitude of the category differences for counties classified by percentage of group quarters residents is small for model (b)—no difference is larger than 5 percent in either direction. In contrast, the category differences for model (a) are as high as 14 percent for one of the categories.
-
There are characteristics for which some or all models exhibit poor performance in terms of the spread between the largest and smallest category differences, the pattern of the differences across categories, or the magnitude of the differences (see below, “Category Differences for Specific Characteristics”). There are also some characteristics for which all four models perform well: percentage of poor school-age children in 1980; percentage of black population in 1990; and whether a rural county was persistently poor from 1960 to 1990.
-
The four candidate models perform better on most characteristics than the four procedures that rely more heavily on the 1980 census. This is generally true, as discussed below, even for characteristics on which the candidate models perform poorly. However, the averaging procedure (iv), which averages 1980 census estimates and estimates from model (a), performs reasonably well for many characteristics. In contrast, the stable shares procedure (i), which simply ratio adjusts the 1980 census estimates to the CPS national estimate for 1989, performs
-
substantially worse than all of the models and other procedures on almost every characteristic.
Category Differences for Specific Characteristics
Category differences from the 1990 census estimates are discussed below for characteristics for which Table 6-4 shows that some or all four candidate models exhibit poor performance in comparison with the census in estimating the number of poor school-age children: percentage change from 1980 to 1990 in the poverty rate for school-age children; population growth from 1980 to 1990; 1990 population size; percentage of Hispanic population in 1990; percentage of group quarters residents in 1990; and census geographic division.
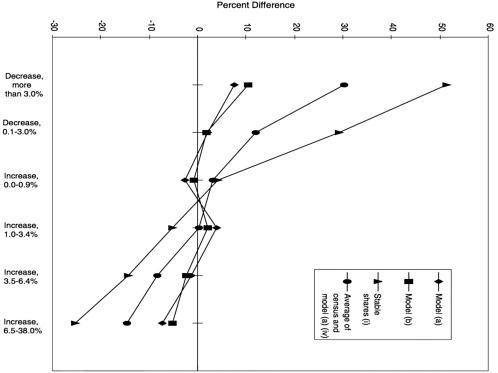
Percentage Change from 1980 to 1990 in Poverty Rate for School-Age Children All four candidate models show a pronounced pattern of overpredicting the number of poor school-age children in counties that experienced the greatest decline in the poverty rate for school-age children from 1980 to 1990 and, conversely, underpredicting the number of poor school-age children in counties that experienced the greatest increase in the poverty rate for school-age children in that period. The category differences are smaller for the log number models (a, b) than for the log rate models (c, d): the spread between the largest positive and largest negative differences is 15-16 percentage points for models (a) and (b) and 25-26 percentage points for models (c) and (d).
One would not expect any of the candidate models to perform particularly well in predicting the number of poor school-age children for the counties at the extremes of the distribution of change in the poverty rate from 1980 to 1990. This variable is closely related to the variable that the models are trying to estimate, and the process of fitting a regression line to all of the data will generally not result in good predictions for the extreme values of the distribution. In other words, one would expect the models to perform less well for counties that experienced the largest changes (increase or decrease) in the poverty rate for school-age children.
Despite the large differences for some categories of this characteristic, however, the four candidate models perform substantially better than the procedures that rely more heavily on the 1980 census—see Table 6-4. (See also Figure 6-1, which shows the category differences for percentage change in the school-age poverty rate from 1980 to 1990 for the log number (under 21) model (a), the log number (under 18) model (b), the stable shares procedure (i), and the averaging procedure (iv).) The stable shares procedure performs very poorly: because it assumes the same proportional distribution of poor school-age children in 1989 as in 1979 (from the 1980 census), by definition it will miss any change in poverty rates that occurred over time. The procedure (iv) that averages the estimates from the 1980 census and the log number model (under 21) for 1989
performs better than the stable shares procedure but not nearly as well as the four candidate models (two not shown in Figure 6-1).
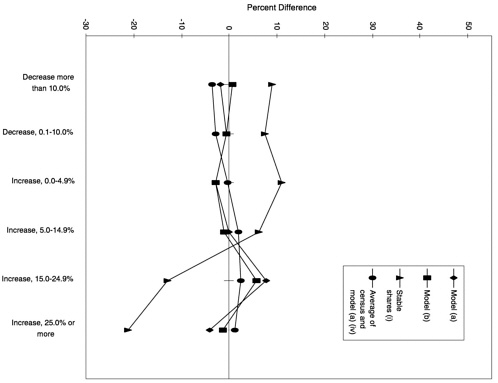
Population Growth from 1980 to 1990 All four candidate models tend to overpredict the number of poor school-age children in counties that experienced larger population increases from 1980 to 1990 relative to counties that experienced smaller increases or declines in population. The exception to a generally monotonic pattern is that the four models underpredict the number of poor school-age children for counties that experienced population increases of 25 percent or more relative to counties that experienced increases of 15-25 percent. The log number (under 21) model (a) has the largest spread in category differences for this characteristic of the four candidate models—12 percentage points between the largest positive and negative differences.
The stable shares estimation procedure (i) performs very poorly on this characteristic. In contrast to the four candidate models, it overpredicts the number of poor school-age children in counties that experienced declines or smaller increases in population from 1980 to 1990 relative to counties that experienced larger population increases. The spread between the largest positive and negative category differences for the stable shares procedure is 32 percentage points. The averaging procedure (iv) exhibits small differences for population growth categories (see Figure 6-2).
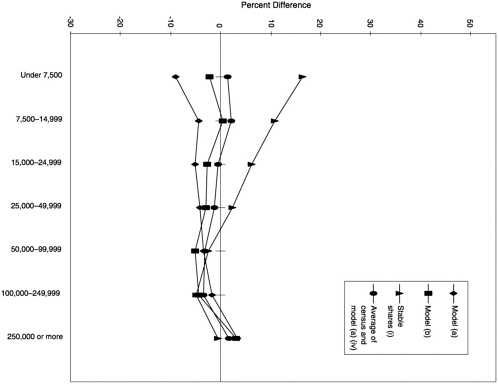
1990 Population Size The four candidate models vary in their performance for counties classified by population size. The log number (under 21) model (a) tends to overpredict the number of poor school-age children in larger size counties relative to smaller size counties. The log number (under 18) model (b) and the log rate (under 21) model (c) do not show a particular pattern to the category differences for this characteristic, and the category differences are not large. The four candidate models perform better than the stable shares model (i), which relies solely on 1980 census data. However, the model (iv) that averages 1980 census estimates with estimates from the log number (under 21) model (a) for 1989 performs reasonably well in predicting numbers of poor school-age children for county population size categories (see Figure 6-3).
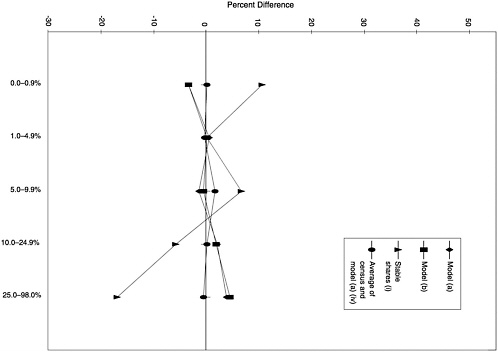
Percentage of Hispanic Population in 1990 All four candidate models tend to overpredict the number of poor school-age children in counties with larger percentages of Hispanics relative to counties with smaller percentages, but the spread between the largest positive and negative differences is small. When the category differences are measured in proportionate terms for counties instead of in terms of numbers of poor school-age children, the models tend to underpredict the number of poor school-age children in counties with larger percentages of Hispanics (see Appendix C). The different patterns of the two category differ
ence measures suggest that the models may perform differently for small counties with many Hispanics (primarily rural border counties) and large counties (cities).
The stable shares procedure (i), which relies solely on the 1980 census estimates, performs poorly on this characteristic. However, the averaging procedure (iv) performs reasonably well (see Figure 6-4).
Percentage of Group Quarters Residents in 1990 The four candidate models vary in their performance for counties classified by percentage of group quarters residents. The log number (under 21) model (a) substantially over-predicts the number of poor school-age children in counties with larger proportions of group quarters residents relative to other counties. The log rate (under 21) model (c) shows a similar but less pronounced pattern of category differences. The log rate (under 18) model (d) shows the opposite pattern, in which it underpredicts the number of poor school-age children in counties with larger proportions of group quarters residents relative to other counties. In contrast, the category differences for the log number (under 18) model (b) are small and do not show a pronounced pattern across categories of this characteristic.
When the evident bias in predicting the number of poor school-age children in counties relative to their percentage of group quarters residents was discovered in the first round of evaluations of model (a), the Census Bureau developed model (b) to ameliorate the problem, with the desired result. The reasoning was as follows. In model (a), the two predictor variables—total child exemptions (assumed to be under age 21) from IRS tax records and the population estimate of the under 21 age group—are used together to estimate the number of people under age 21 in families that do not file tax returns. These families are assumed to be poorer, on average, than families that file tax returns. As can be seen from Table 6-1 and Table 6-2, the regression coefficients for these two variables are of similar magnitude but of opposite sign.
However, in counties with large percentages of group quarters residents under age 21, primarily college students and military personnel, the relationship between the IRS variable and the population estimate may be distorted. To the extent that college students and military personnel under age 21 live in a county that is not the same as the county in which their parents reside or file tax returns, they will not be recorded as child exemptions in their county of residence. Consequently, there will be an overestimate of the number of people under age 21 in families that do not file returns in these counties and a corresponding overestimate, through the model, of the number of school-age children in poverty.
Model (b) replaces the population estimate for the under 21 age group as a predictor variable with the population estimate for the under 18 age group. This change not only eliminates the pattern of overpredicting the number of poor school-age children as a function of the percentage of group quarters residents that is so pronounced in model (a), but it also causes model (b) to perform better than model (a) on a number of other characteristics (e.g., population size). For
reasons that are not clear, the under 18 formulation does not improve the performance of the log rate model; in fact, the log rate (under 18) model (d) generally performs worse than the log rate (under 21) model (c).
Interestingly, the procedures that rely more heavily on the 1980 census (i-iv)—even the stable shares procedure—perform reasonably well in predicting the number of poor school-age children for counties categorized by percentage of group quarters residents (see Figure 6-5).
Census Division All four candidate models show differences from the census for counties categorized by census division. In particular, the four models overpredict the number of poor school-age children in counties in the West (in the Mountain Division and, particularly, in the Pacific Division) relative to counties in other areas. The spread between the largest positive and negative differences is 11 percentage points.
Because the county estimates from the four candidate models are raked to the state estimates from the Census Bureau's state model and census divisions are combinations of states, category differences on this characteristic must be attributable to the state model.16 As discussed later, the category differences by area in the state model occurred also in several other years and warrant further investigation (see below, “State Model”). Yet the state raking procedure, which is done for the four candidate models and for the procedures that assume stable shares within state and stable rates within state (ii, iii), results in substantially better performance on this characteristic than the stable shares procedure (i). The averaging procedure (iv), which partly reflects the effects of the state raking, also performs better than the stable shares procedure (see Figure 6-6).
Differences in Proportions of Poor School-Age Children
The panel examined category differences in estimates of proportions (rather than numbers) of poor school-age children in a form similar to Table 6-4 and reached the same conclusions. Comparisons were performed only for the four candidate models, not for the other procedures.
First, the performance of the four candidate models is similar. Second, the two models that performed best in estimating the number of poor school-age children—log number (under 18) model (b) and log rate (under 21) model (c)—also perform best in estimating the proportion of poor school-age children. However, model (c) performs slightly better than model (b) in estimating proportions,
|
16 |
The category differences are the same for all four candidate models because they are raked to the same set of state estimates (see Table 6-4). The average proportional category differences shown in Appendix C vary somewhat because they are calculated relative to each county 's 1990 census estimated number of poor school-age children before being summed (see Table C-2). |
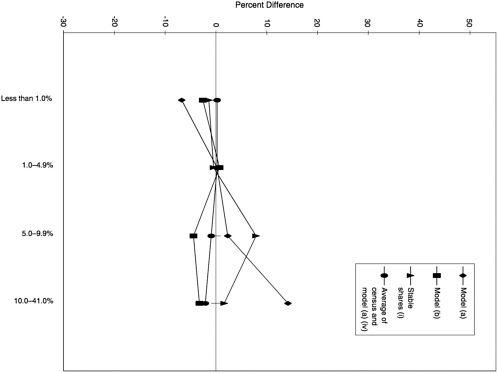
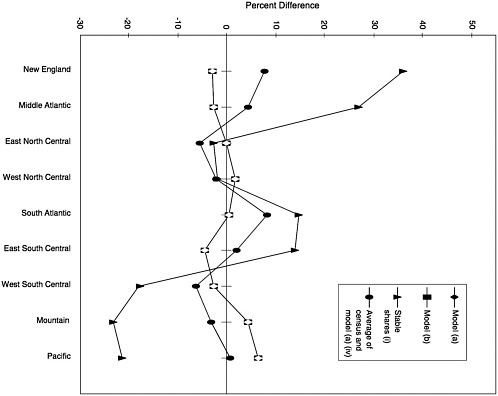
FIGURE 6-6 Census division: Category differences from the 1990 census.
while model (b) performs slightly better than model (c) in estimating numbers of poor school-age children. This reversal is expected because the use of population estimates for children aged 5-17, which themselves contain errors, to convert estimated numbers to estimated proportions from the log number models puts these models at a disadvantage for comparisons of proportions. Conversely, the
use of population estimates for children aged 5-17 to convert estimated proportions to estimated numbers from the log rate models puts these models at a disadvantage for comparisons of numbers (see Chapter 8).
Poverty rates (proportions poor) of school-age children enter the Title I allocation formulas as thresholds, so the panel and the Census Bureau examined the correspondence between each of the four candidate models and the 1990 census in classifying counties and school-age children into three poverty rate categories: 0 to 15 percent; 15 to 30 percent; and 30 percent or higher. (See Table 6-5; no comparisons were performed for the other procedures.) A poverty rate of 15 percent or higher is an eligibility threshold for concentration grants; 15 percent and 30 percent poverty rates are thresholds for hold-harmless provisions of the allocation formulas.
When there are two poverty rate categories, 0 to 15 percent and 15 percent or higher, each of the four candidate models performs equally well, assigning about 87 percent of the counties, which include about 92 percent of the poor school-age children, to the same category as the 1990 census (column 5, top half and bottom half of Table 6-5). When there are three poverty rate categories, 0 to 15 percent, 15 to 30 percent, and 30 percent or higher, each of the four candidate models assigns about 81 percent of the counties, which include about 88 percent of the poor school-age children, to the same category as the 1990 census (column 6, top half and bottom half of Table 6-5).
CPS-Census Differences
A possible explanation of some of the category differences identified in the 1990 census comparisons just described may be, not that a model is in error, but that measurement of poverty differs systematically between the census and the CPS because of the many differences in data collection procedures (see Chapter 3). The Census Bureau performed chi-square tests to determine if there were significant differences between estimates from the March 1990 CPS and the 1990 census of the number of school-age children and the number and proportion poor in this age group in 1989 for county groupings (Fay, 1997).17 More specifically, the tests determined if the ratios of the CPS and census estimates for categories of a characteristic, such as county population size, were significantly different from each other. The characteristics tested were those examined in the 1990 census comparisons.
The tests generally show inconclusive results. However, there is some evidence that, when compared with the 1990 census, the March 1990 CPS estimates
|
17 |
The March 1990 CPS estimates for the categories involved are direct estimates produced using the CPS weights. |
TABLE 6-5 Agreement Between Model Estimates for 1989 and 1990 Census County Estimates for Proportions of School-Age Children in Poverty in 1989 (in percent)
higher numbers and proportions of poor school-age children in metropolitan counties and larger-size counties relative to medium-size counties. (CPS estimates for small-size counties have low reliability because of the relatively small proportion of the population in such counties and the small number of these counties in the CPS sample.) Also, while not significant, a pattern is evident in which the March CPS, when compared with the 1990 census, tends to estimate higher numbers and proportions of poor school-age children in counties with higher percentages of Hispanic population. These results for population size and percentage of Hispanic population parallel the results from the 1990 census comparisons described above. They suggest that at least some portions of the category differences for the candidate models for these two characteristics arise from differences in the CPS measurement of poverty and are not due to model error as such. Whether similar CPS-census differences would be present for 1993 or 1995 is, of course, not known.
Summary
Keeping in mind the limitations of a single census-based validation opportunity, the panel concluded that the four candidate models perform substantially better in predicting the number and proportion of poor school-age children for counties for 1989 than the simple stable shares procedure (i), which relies solely on estimates from the previous (1980) census and the current (1989) CPS national total. Using the state model to rake the 1980 census county estimates for consistency with updated estimates of poor school-age children in each state, as is done in procedures (ii) and (iii), is an improvement over procedure (i). However, the four candidate models, which use a county regression model together with the state model, perform much better than procedures (ii) and (iii). Finally, the four candidate models perform better in many respects than procedure (iv), which averages the 1980 census estimates and the 1989 estimates from the log number (under 21) model (a), although this averaging procedure shows good performance on some characteristics. Overall, the comparisons with the procedures that rely more heavily on the 1980 census provide significant evidence in favor of a model-based approach for updated estimates of poor school-age children and against using estimates that derive solely or largely from the previous census.
The panel further concluded that, while the performance of the four candidate models in comparison with the 1990 census is broadly similar, when consideration is given to measures of overall absolute difference and differences for categories of counties, for estimates of numbers and estimates of proportions of poor school-age children, the log number (under 18) model (b) and the log rate (under 21) model (c) perform better than the other two. Comparing models (b) and (c), model (b) performs somewhat better, and the Census Bureau used this model to prepare the revised county estimates of poor school-age children in 1993. The comparisons also identify areas of performance of model (b) that
deserve further examination in an ongoing research program to continue to improve model-based estimates of poverty for small geographic areas.
Comparisons with the CPS
For the 1995 county model external evaluations, the emphasis shifted to finding a way to look for persistent bias. An apparent bias identified in a single validation, such as the 1990 census comparisons summarized above, may be a one-time effect that will not occur in other years for which a model is estimated. For any particular year, it is almost inevitable that the differences between the model estimates and target values will be somewhat larger for some categories of counties than others. But if such differences persist for the same categories of counties over time, some areas may continually receive more funding and other areas may continually receive less funding than if the true values were known.
As a type of external validation by which the issue of persistent bias could be examined, the panel and the Census Bureau compared estimates of poor school-age children from the 1995 county model for categories of counties for 1989, 1993, and 1995, with CPS direct estimates for those categories for the three periods. Three years of CPS data were used to form the weighted estimates in each case in order to reduce the sampling variability.18
Table 6-6 shows the difference in the number of poor school-age children from the county model, estimated for 1989 (using corrected IRS data), 1993, and 1995, and the weighted 3-year CPS direct estimates centered on those years for categories of counties. The measure shown is the algebraic difference by category, which is the sum for all counties in a category of the algebraic (signed) difference between the model estimate of poor school-age children and the weighted CPS direct estimate, divided by the sum of the weighted CPS direct estimates for the category.
Comparisons with weighted CPS direct estimates have the advantage over comparisons with the census that they can be performed for multiple years. They have the disadvantage that the sample sizes for CPS estimates, even aggregated for 3 years, are small for many categories of counties, thus making the comparisons much more uncertain than the 1990 census comparisons because of the much greater variability in the standard of comparison. Also, in analyzing the CPS comparisons, one must keep in mind that the model estimates are raked to the state estimates, which are developed from a single year of the CPS.
The model-CPS aggregate differences in Table 6-6 differ widely among
|
18 |
This analysis is not the same as the analysis of regression output described above, in which the standardized residuals from the model for counties with sampled households in the CPS—representing the standardized differences between the model estimates and the direct estimates on the log scale—were examined for categories of counties. |
TABLE 6-6 Comparison of County Model Estimates with CPS Aggregate Estimates of the Number of Poor School-Age Children, 1995, 1993, and 1989: Algebraic Difference by Category of County (in percent)
|
No. of Countiesa |
Model-CPS, 1995b |
Model-CPS, 1993b |
Model-CPS, 1989b |
Sample Size, CPS 1996c |
|
|
Category |
(1) |
(2) |
(3) |
(4) |
(5) |
|
Census Regiond |
|||||
|
Northeast |
217 |
−2.87 |
0.81 |
−4.36 |
10,708 |
|
Midwest |
1,055 |
−0.49 |
0.61 |
−4.31 |
11,393 |
|
South |
1,425 |
4.05 |
−0.13 |
4.48 |
15,440 |
|
West |
444 |
−4.16 |
−0.95 |
−0.43 |
12,141 |
|
Census Divisiond |
|||||
|
New England |
67 |
−13.51 |
1.87 |
27.07 |
3,696 |
|
Middle Atlantic |
150 |
0.05 |
0.54 |
−9.79 |
7,012 |
|
East North Central |
437 |
−6.10 |
−0.64 |
−3.04 |
6,841 |
|
West North Central |
618 |
18.31 |
4.25 |
−7.44 |
4,552 |
|
South Atlantic |
591 |
1.82 |
0.83 |
4.12 |
8,150 |
|
East South Central |
364 |
−5.53 |
−5.85 |
9.32 |
2,529 |
|
West South Central |
470 |
12.00 |
1.90 |
2.44 |
4,761 |
|
Mountain |
281 |
−3.91 |
19.87 |
0.84 |
5,543 |
|
Pacific |
163 |
−4.24 |
−6.48 |
−0.92 |
6,598 |
|
Metropolitan Status |
|||||
|
Central county of metropolitan area |
493 |
−2.75 |
−0.91 |
−3.53 |
34,343 |
|
Other metropolitan |
254 |
53.75 |
−3.64 |
8.44 |
2,801 |
|
Nonmetropolitan |
2,394 |
1.24 |
3.50 |
8.32 |
12,538 |
|
1990 Population Size |
|||||
|
Under 7,500 |
525 |
−17.21 |
57.03 |
0.74 |
933 |
|
7,500-14,999 |
630 |
19.82 |
−23.67 |
−0.19 |
1,550 |
|
15,000-24,999 |
524 |
2.94 |
6.24 |
17.02 |
2,289 |
|
25,000-49,999 |
620 |
30.46 |
−0.23 |
−4.46 |
4,204 |
|
50,000-99,999 |
384 |
−2.52 |
4.99 |
22.47 |
5,979 |
|
100,000-249,999 |
259 |
17.27 |
12.12 |
−3.88 |
8,263 |
|
250,000 or more |
199 |
−7.24 |
−2.49 |
−3.10 |
26,464 |
|
1980 to 1990 Population Growth |
|||||
|
Decrease of more than 10.0% |
444 |
−2.71 |
−22.03 |
−4.29 |
2,170 |
|
Decrease of 0.1-10.0% |
972 |
−4.31 |
2.44 |
−1.32 |
10,655 |
|
0.0-4.9% |
547 |
6.04 |
3.41 |
3.18 |
8,015 |
|
5.0-14.9% |
620 |
1.12 |
5.97 |
4.61 |
11,590 |
|
15.0-24.9% |
260 |
−0.07 |
−4.11 |
−10.44 |
9,305 |
|
25.0% or more |
292 |
−0.52 |
−2.27 |
10.31 |
7,947 |
|
Percentage of Poor School-Age Children, 1980 |
|||||
|
Less than 9.4% |
516 |
2.74 |
7.22 |
−1.07 |
14,980 |
|
9.4-11.6% |
524 |
1.39 |
5.28 |
4.35 |
12,291 |
|
11.7-14.1% |
530 |
−10.01 |
−6.49 |
−6.72 |
9,837 |
|
14.2-17.2% |
523 |
1.28 |
−5.82 |
0.44 |
5,217 |
|
17.3-22.3% |
519 |
9.32 |
17.41 |
0.23 |
4,623 |
|
22.4-53.0% |
523 |
1.05 |
−14.81 |
4.11 |
2,734 |
|
Percentage Hispanic, 1990 |
|||||
|
0.0-0.9% |
1,770 |
1.26 |
−0.75 |
3.13 |
12,848 |
|
1.0-4.9% |
847 |
9.33 |
1.45 |
4.32 |
16,966 |
|
5.0-9.9% |
193 |
−2.81 |
17.24 |
6.38 |
6,999 |
|
10.0-24.9% |
181 |
−4.02 |
−5.14 |
−8.29 |
7,236 |
|
25.0-98.0% |
150 |
−7.90 |
−3.29 |
−5.26 |
5,633 |
|
Percentage Black, 1990 |
|||||
|
0.0-0.9% |
1,446 |
8.32 |
8.02 |
5.09 |
10,929 |
|
1.0-4.9% |
615 |
7.41 |
1.04 |
−1.83 |
10,630 |
|
5.0-9.9% |
294 |
5.41 |
−2.07 |
0.95 |
8,646 |
|
10.0-24.9% |
381 |
−4.89 |
−0.75 |
3.51 |
13,437 |
|
25.0-87.0% |
405 |
−6.85 |
−2.82 |
−6.30 |
6,040 |
|
Persistent Rural Poverty, 1960-1990e |
|||||
|
Rural, not poor |
1,740 |
−2.62 |
1.53 |
5.47 |
9,734 |
|
Rural, poor |
535 |
22.45 |
−0.15 |
14.81 |
1,698 |
|
Not classified |
866 |
−1.28 |
−0.28 |
−2.68 |
38,250 |
|
Economic Type, Rural Countiese |
|||||
|
Farming |
556 |
−24.56 |
−29.31 |
−12.41 |
1,634 |
|
Mining |
146 |
46.97 |
27.59 |
40.67 |
901 |
|
Manufacturing |
506 |
−7.10 |
−3.58 |
−1.51 |
2,369 |
|
Government |
243 |
120.13 |
27.59 |
59.39 |
1,661 |
|
Services |
323 |
−12.18 |
−12.42 |
−11.86 |
2,760 |
|
Nonspecialized |
484 |
6.99 |
18.35 |
23.89 |
2,018 |
|
Not classified |
883 |
−1.18 |
−0.20 |
−2.59 |
38,339 |
|
Percentage of Group Quarters Residents, 1990 |
|||||
|
Less than 1.0% |
545 |
3.32 |
22.03 |
16.60 |
3,494 |
|
1.0-4.9% |
2,187 |
−1.58 |
−1.27 |
−1.84 |
41,648 |
|
5.0-9.9% |
299 |
11.90 |
−1.22 |
4.51 |
3,980 |
|
10.0-41.0% |
110 |
49.44 |
−6.28 |
17.02 |
560 |
categories of counties, in large part because of the small sample sizes for the CPS estimates, even when aggregated for 3 years. Some of the differences are very large, larger than any of the differences seen in the model-1990 census comparisons above. Generally, the larger model-CPS aggregate differences are for categories of counties with smaller numbers of CPS sample households. For example, the model-CPS aggregate differences often exceed 5 percent for counties grouped into the nine geographic divisions, but they are all less than 5 percent for counties grouped into the four geographic regions.19
In addition, the model-CPS aggregate differences for 1989 frequently differ from the model-1990 census differences. This finding is expected, given that the measurement of poverty differs between the census and the CPS because of the many differences in data collection procedures.
Despite the sample size limitations, Table 6-6 can inform an assessment of the performance of the county model if the results are used with caution. Of particular interest are instances in which the model-CPS aggregate differences are both large and in the same direction (plus or minus) for all 3 years for which the county model is estimated. Such findings suggest a possible systematic bias in the model that should be investigated to determine the nature of the bias and what steps could be taken to eliminate or reduce it (e.g., by adding a predictor variable to the model). Several persistent patterns are evident in the model-CPS aggregate differences:
-
The model shows a tendency to underpredict the number of poor school-age children in the largest counties, those with 250,000 or more population. This finding is consistent with the results from analyzing the distribution of the standardized residuals from the regression output. The extent of the underprediction is not large, but it appears to be significant given the large number of CPS households in the largest counties.
-
The model shows a tendency to underpredict the number of poor school-age children in counties with large percentages of Hispanic residents (10% or more). There is a similar, although less pronounced, tendency for the model to underpredict the number of poor school-age children in counties with large percentages of blacks. It is likely that counties with large percentages of Hispanics or blacks are not homogeneous (e.g., large-percentage black counties include both inner-city and rural areas). Hence, further research is needed to determine whether the underprediction is more or less pronounced for particular subgroups of these counties and, consequently, what steps are appropriate to ameliorate the bias in the model.
|
19 |
For future evaluations of this type, the standard errors of the differences should be computed so that significant differences between the model estimates and the CPS 3-year aggregate estimates can be identified. |
-
The model estimates are consistently very different from the weighted CPS estimates for some categories of rural counties classified by economic type. In particular, the model estimates for rural counties characterized as government are much higher than the corresponding weighted CPS estimates. Although the comparisons by economic type are based on small CPS sample sizes, it seems worthwhile to examine some of these counties to see if a reason for these large differences can be found.
-
Finally, the model shows a tendency to underpredict the number of poor school-age children in counties that experienced the largest declines in the poverty rate for school-age children from 1980 to 1990. As was noted above, this finding is consistent with the knowledge that any regression model can only partially predict which cases will have the most extreme values of the outcome variable.
Local Assessment of 1993 County Estimates
The panel performed another type of external evaluation of the original 1993 county estimates of poor school-age children—the use of local knowledge.20 Using the original 1993 model estimates for all 3,143 counties in the United States, the analysis first sought to identify groups of counties for which the 1993 estimates seemed unusually high or low in relation to prior levels and trends (e.g., from 1980 to 1990) in the number and proportion of poor school-age children and known social and economic trends for these groups of counties. Then, local informants—including staff and members of local councils of government, economic development authorities, welfare agencies, state demographic units, state data centers, and other agencies—were contacted to obtain their assessment of the reasonableness of the implied trends in poverty for school-age children given their knowledge of local socioeconomic conditions.21
County Analysis
Changes in the number and proportion of poor school-age children implied by the 1993 estimates were examined for counties categorized by several characteristics, including: population size and metropolitan status; population change; percentage of immigrants; college-dominated counties; reservation and Native American counties; for nonmetropolitan counties, whether predominantly agri-
|
20 |
This evaluation was carried out at the University of Wisconsin-Madison by Dr. Paul Voss, a member of the panel, with the assistance of Richard Gibson and Kathleen Morgen (see Voss, Gibson, and Morgen, 1997). |
|
21 |
The discussion refers to “implied” trends because the Census Bureau's county model is not designed to directly estimate change over time. |
cultural; and several classifications by geographic location (e.g., state and the regions identified by the U.S. Department of Agriculture).
The analysis identified a number of categories of counties for which further investigation of the reasonableness of the 1993 estimates seemed warranted:
-
Large metropolitan central city counties had a high implied percentage change in the number of school-age children in poverty between 1989 and 1993—42 percent. This change declined systematically with decreasing size for metropolitan counties and continued to decline to the most remote, rural nonmetropolitan counties, for which the implied change in the number of school-age children in poverty was −6 percent.
-
Counties with higher levels of international immigration had higher implied increases in the number and proportion of poor school-age children.
-
Counties with higher percentages of Native Americans had lower implied increases in the number and proportion of poor school-age children. There was no particular pattern for counties with reservations.
-
Farm counties had an implied decline in the number and proportion of poor school-age children, while nonfarm metropolitan counties had an implied increase.
-
When the country was divided into the 26 regions identified by the U.S. Department of Agriculture, several regions were identified on the extremes of change in the number and proportion of poor school-age children. High implied increases were found in the Northern Metropolitan Belt, the Florida Peninsula, the Southwest, Northern New England, Mohawk New York and Pennsylvania, Lower Great Lakes Industrial, Southern Piedmont, and the Northern Pacific Coast. Small implied increases were found in the Central Corn Belt, the Southern Appalachian Coal Region, the Coastal Plain Cotton Region, the Northern Great Plains, and the Rockies, Mormon, Columbia River Region. The single region with an implied decrease in the number and proportion of poor school-age children was the Mississippi Delta.
Some of these implied changes are apparently related to the general effect of population size, discussed above. However, the findings in this regional analysis, in particular, suggested which states and counties to follow up in discussions with local officials.
Local Input
When counties that share certain characteristics appeared also to share a common pattern of change in the number and proportion of poor school-age children, a variety of individuals with local knowledge were contacted. Initially, 70 individuals associated with state data centers or state data center affiliate units were contacted; they provided a series of responses and referrals to other state
and local officials. In addition, 26 states that appeared to have a sizable number of counties that shared a common implied trend in poverty for school-age children were targeted for intensive contact.
The nature of responses varied considerably. In some states, the original 1993 county estimates released by the Census Bureau had not been examined, and there appeared to be little interest in discussing them. In other states, the estimates had been looked at, but the general admonitions about standard errors that accompanied their release had dampened interest in studying them in detail. In contrast, several states had carried out in-depth analyses of the estimates. Of the 26 states targeted for intensive follow up, 8 provided detailed explanations (supported by examples) of trends suggested by the original 1993 county estimates, and 7 more states provided in-depth responses supported by their own analyses.
Almost every state agency contacted expressed specific doubts about the original 1993 estimates for one or more counties—too high here, too low there. In general, however, there was no consensus that the trends implied by the original 1993 county estimates were wrong, even in states for which large numbers of counties experienced apparent declines in the number and proportion of poor school-age children. Of the 26 states, 21 provided explanations as to why the original 1993 estimates appeared to show poverty trends in a specific direction or why the direction of change is too difficult to know. The most common explanations included comments about the size of the county, its rural agricultural nature, the fact that it is a diverse metropolitan county, immigration from abroad, and economic growth or economic decline. Occasionally, reference was made to a military base, an Indian reservation, or a university as an explanation for an apparent trend in poverty for school-age children. In three states, concern was expressed about the role of Food Stamp Program data in the estimation model, as these data were deemed to be unreliable.
In summary, a high level of concern was expressed by individuals with local knowledge about the statistical reliability of the original 1993 county estimates, which is largely due to the Census Bureau 's own cautions in this regard, coupled with specific county estimates that seem on the basis of local knowledge to be highly doubtful. These concerns notwithstanding, no categories of counties were identified that experienced apparent trends in the number and proportion of poor school-age children between 1989 and 1993 that were not accepted by local informants. Although the trends for a few counties were not accepted locally, the analysis found no strong indicators of potential bias for groups of counties sharing common characteristics in the county model.
Summary
Considering the external evaluations of alternative models that were conducted by comparison with 1990 census estimates, the external evaluations of 3
years of estimates that were conducted for the 1995 county model by comparison with weighted direct CPS estimates, and the local assessment of the 1993 county estimates, the panel concluded that the county model is working reasonably well. However, further investigation is needed of categories of counties for which the model appears to overpredict or underpredict the number of poor school-age children, particularly when that phenomenon is evident for several periods.
STATE MODEL EVALUATION
The state model plays an important role in the production of county estimates of poor school-age children. Evaluations conducted of the state model for the assessment of the revised 1993 county estimates included an internal evaluation of the regression output for 1989 and 1993 and an external evaluation that compared 1989 estimates from the model with 1990 census estimates of proportions of poor school-age children. The results in each case supported the use of the model. However, the state model evaluations were more limited than the county model evaluations, as alternative state model formulations were not evaluated explicitly.
For the assessment of the 1995 county estimates, further evaluations were conducted of the state model. In particular, the model was estimated for 7 years—1989, 1990, 1991, 1992, 1993, 1995, and 1996—and the regression output for those years was examined to determine if there were any systematic biases in the model estimates. (The model was not estimated for 1994 because the redesign of the CPS sample, consequent to the 1990 census, was partly but not completely phased in for the March 1995 CPS.) Also, there was an evaluation of the state raking factors for 1993 and 1995.
State Model Regression Output
The state regression model is a poverty rate model with the variables not transformed (see equation (2) in Chapter 4). The analysis of the regression output for the state model, estimated for each year from 1989 through 1993 and for 1995 and 1996, examined the same assumptions that were examined for the 1995 county model estimated for 1989, 1993, and 1995. The analysis is somewhat less informative for the state model than for the county model because there are about 1,000 counties with poor school-age children in the CPS, but only 51 states (including the District of Columbia), and states are collectively much more homogeneous than counties with respect to poverty rates and other characteristics. In addition, with respect to both internal and external evaluation, some categories of states do not contain enough states for analysis, thereby reducing the utility of evaluation.
Nonetheless, examination of the regression output for the state model helps assess the validity of its assumptions. With a few exceptions, the analysis sup-
ports the assumptions underlying the state model (see below); there is little evidence of significant problems with the model formulation (although there may be other models that fit just as well).
Linearity
Plots of standardized residuals against the four predictor variables in the state model—the proportion of child exemptions reported by families in poverty on tax returns, the proportion of people receiving food stamps, the proportion of people under age 65 who were not included on a tax return, and a residual from the analogous regression equation using the previous census estimate as the dependent variable—support the assumption of linearity. Furthermore, the standardized residuals, when plotted against the model's predicted values, provide no evidence of the need for any transformation of the variables. This result helps justify the decision not to use the log transformation of the proportion poor as the dependent variable.
Constancy Over Time
Table 6-7 shows the regression coefficients for the predictor variables for the state model for each of the years from 1989 to 1996, excluding 1994. The coefficients for all four poverty-rate predictor variables are positive in all 7 years and generally similar across all years. All of the coefficients are significant at the 5 percent level except that the coefficient of the proportion of people under age 65 who were not included on an income tax return (column 3) is not significant in 1989.
Inclusion or Exclusion of Predictor Variables
The standardized residuals for the state regression model were grouped into four categories for each of the following characteristics: census region, population size in 1990, 1980 to 1990 population growth, percentage of black population in 1990, percentage of Hispanic population in 1990, percentage of group quarters residents in 1990, and percentage of poor school-age children in 1979 (from the 1980 census). The distributions of the standardized residuals for each category were then displayed using box plots. For none of these box plots is there an obvious pattern to the standardized residuals across categories, with one exception: in 1989, 1990, 1991, and 1993, the model underpredicts the proportion of poor school-age children in the West Region (i.e., the model estimates are lower than the CPS direct estimates for this group of states). The Census Bureau experimented with adding a West Region indicator predictor variable to the model. The coefficient of this variable has a negative sign for all 7 years; however, it is significant for only 1991, 1992, and 1993. For those 3 years, the
TABLE 6-7 Estimates of Regression Coefficients for the 1995 State Model, Estimated for 1989-1993, and 1995-1996
|
Predictor Variablesa |
||||
|
Year |
(1) |
(2) |
(3) |
(4) |
|
1989 |
0.52 |
0.71 |
0.23 |
0.71 |
|
(.09) |
(.20) |
(.13) |
(.34) |
|
|
1990 |
0.46 |
0.65 |
0.42 |
1.07 |
|
(.09) |
(.20) |
(.15) |
(.36) |
|
|
1991 |
0.46 |
0.52 |
0.59 |
0.84 |
|
(.10) |
(.21) |
(.14) |
(.37) |
|
|
1992 |
0.41 |
0.71 |
0.42 |
1.38 |
|
(.10) |
(.21) |
(.13) |
(.37) |
|
|
1993 |
0.28 |
1.14 |
0.51 |
1.24 |
|
(.12) |
(.25) |
(.14) |
(.39) |
|
|
1995 |
0.57 |
0.79 |
0.32 |
1.54 |
|
(.12) |
(.25) |
(.13) |
(.36) |
|
|
1996 |
0.37 |
0.97 |
0.59 |
1.02 |
|
(.12) |
(.26) |
(.14) |
(.36) |
|
|
NOTES: All predictor variables are in terms of rates. Standard errors of the estimated regression coefficients are in parentheses. aPredictor variables: (1) ratio of child exemptions reported by families in poverty on tax returns to total child exemptions; (2) ratio of people receiving food stamps to total population; (3) ratio of people under age 65 who were not included an income tax return to total population under age 65; (4) residual from a regression of poverty rates for school-age children from the prior decennial census (1980 or 1990) on the other three predictor variables. |
||||
model with the West Region variable performs better for states in the West Region. A further examination of the residuals from the state model without the West Region predictor variable for individual Western states reveals that the model fairly consistently underpredicts the proportion of poor school-age children in some Western states but just as consistently overpredicts the proportion of poor school-age children in other Western states. Further investigation is needed to explain these patterns.
Normality, Homogeneous Variances, and Outliers
The distribution of the standardized residuals from the state regression model shows some small degree of skewness, especially in the 1992 equation. However, the skewness does not appear sufficiently marked to be a problem. Also, the residual plots and the box plots of the distributions of the standardized residuals against the categories of states show little evidence of any heterogenous variance. Finally, there is no evidence of outliers from examination of the residual plots or displays of the distributions of the standardized residuals from the state regression model.
Model Error Variance
One problem in the state model concerns the variance of the model error (ui in equation (2) in Chapter 4). In the state model, the variances of the sampling errors (ei in equation (2)) are estimated directly from the CPS data using a generalized variance function. The total model error variance is calculated using maximum likelihood estimation. The result of this calculation is an estimate of zero for the model error variance in the equation for every year except 1993. This result, which implies (absent sampling variability) that the model gives perfect predictions of state poverty rates for school-age children, is not credible. In the shrinkage estimate, it produces a zero weight for the direct estimates even when those estimates are quite precise, as is the case for several large states in the CPS sample. Even a small model error variance can substantially change the weight on the relatively high-precision direct estimates when they are combined in a shrinkage procedure with the model estimates.
To evaluate the effects of using zero model error variance in the estimation, the panel examined tables that compared the model estimates of the proportion of poor school-age children to the CPS direct estimates by state for 1989-1993 and 1995-1996; as an illustration, Table 6-8 shows this comparison for 1995. This examination demonstrated two important points. First, there are some appreciable differences between the model estimates and the direct estimates. For example, for Mississippi in 1995, the difference is over 7 percentage points. Therefore, if a non-zero estimate for model error variance is produced, it might have important consequences for the state estimates of poor school-age children. Second, while there are some appreciable differences, the model estimates were within two standard errors of the direct estimates for almost all states in each year. The range of model estimates that exceeded that limit in either a positive or negative direction was from one state in 1992 to six states in 1996. (Mississippi's difference in 1995 was not statistically significant at the 5 percent level.) For no single state did the model estimates exceed two standard errors of the direct estimates for more than 3 of the 7 years for which the state model was estimated. (And this analysis ignores the variance of the model estimates, which means that
TABLE 6-8 CPS Direct Estimate and Regression Model Estimate of Percentage of School-Age Children in Poverty by State, 1995
|
CPS Direct Estimate |
Lower Confidence Bound on Direct Estimate |
Upper Confidence Bound on Direct Estimate |
State Model Regression Estimate |
Regression Estimate Minus Direct Estimate (4) – (1) |
|
|
State |
(1) |
(2) |
(3) |
(4) |
(5) |
|
Alabama |
22.2 |
16.5 |
27.9 |
23.4 |
1.2 |
|
Alaska |
6.3 |
1.6 |
11.1 |
10.9 |
4.5 |
|
Arizona |
23.0 |
16.8 |
29.2 |
21.1 |
−1.9 |
|
Arkansas |
21.4 |
14.0 |
28.7 |
24.0 |
2.6 |
|
California |
22.5 |
19.4 |
25.7 |
21.5 |
−1.0 |
|
Colorado |
9.4 |
5.1 |
13.8 |
11.8 |
2.3 |
|
Connecticut |
15.6 |
7.3 |
24.0 |
12.6 |
−3.0 |
|
Delaware |
15.6 |
8.3 |
23.0 |
12.8 |
−2.8 |
|
District of Columbia |
30.2 |
17.9 |
42.4 |
33.8 |
3.7 |
|
Florida |
21.1 |
16.8 |
25.4 |
20.7 |
−0.4 |
|
Georgia |
14.8 |
8.2 |
21.3 |
21.4 |
6.7 |
|
Hawaii |
14.1 |
7.9 |
20.3 |
11.9 |
−2.2 |
|
Idaho |
15.4 |
9.9 |
20.9 |
12.7 |
−2.7 |
|
Illinois |
19.4 |
14.6 |
24.2 |
15.7 |
−3.7 |
|
Indiana |
12.9 |
9.0 |
16.8 |
12.6 |
−0.4 |
|
Iowa |
15.2 |
8.9 |
21.4 |
11.2 |
−3.9 |
|
Kansas |
10.6 |
4.8 |
16.4 |
12.7 |
2.1 |
|
Kentucky |
18.9 |
13.4 |
24.4 |
22.9 |
4.0 |
|
Louisiana |
24.2 |
15.6 |
32.9 |
28.0 |
3.8 |
|
Maine |
10.7 |
4.1 |
17.4 |
13.8 |
3.1 |
|
Maryland |
12.8 |
5.0 |
20.5 |
11.5 |
−1.3 |
|
Massachusetts |
16.5 |
11.5 |
21.5 |
13.3 |
−3.2 |
|
Michigan |
14.2 |
10.0 |
18.3 |
17.2 |
3.0 |
|
Minnesota |
9.5 |
5.5 |
13.4 |
10.0 |
0.6 |
|
Mississippi |
34.9 |
25.6 |
44.3 |
27.4 |
−7.6 |
|
Missouri |
9.4 |
3.5 |
15.2 |
17.0 |
7.7 |
|
Montana |
17.4 |
9.4 |
25.3 |
18.4 |
1.0 |
|
Nebraska |
11.4 |
7.1 |
15.7 |
10.0 |
−1.4 |
|
Nevada |
9.8 |
4.0 |
15.6 |
11.8 |
2.0 |
|
New Hampshire |
4.2 |
0.6 |
7.8 |
6.5 |
2.3 |
|
New Jersey |
9.3 |
6.5 |
12.0 |
12.3 |
3.0 |
|
New Mexico |
34.0 |
27.8 |
40.3 |
28.6 |
−5.5 |
|
New York |
22.7 |
19.1 |
26.3 |
23.1 |
0.4 |
|
North Carolina |
19.7 |
13.8 |
25.5 |
17.1 |
−2.6 |
|
North Dakota |
10.3 |
5.3 |
15.2 |
14.1 |
3.8 |
|
Ohio |
16.6 |
11.1 |
22.2 |
15.1 |
−1.5 |
|
Oklahoma |
22.6 |
13.1 |
32.1 |
22.5 |
−0.1 |
|
Oregon |
12.5 |
7.1 |
17.9 |
12.4 |
−0.1 |
|
Pennsylvania |
16.1 |
12.5 |
19.7 |
15.3 |
−0.9 |
|
Rhode Island |
16.4 |
10.7 |
22.2 |
15.1 |
−1.3 |
|
South Carolina |
30.8 |
21.9 |
39.7 |
21.9 |
−8.9 |
a yet smaller number of differences are statistically significant.) These results suggest that the state model is performing reasonably well: differences between model and direct estimates are neither unusually large nor strongly persistent. However, more work should be conducted to evaluate the current procedures for estimating the sampling error variance of the state model and the effects on the model estimates.
1990 Census Comparisons
Fay and Train (1997) compare 1989 estimates of the proportion of poor school-age children from the state model with 1990 census estimates. They find that the differences between the model and census estimates are much smaller than the differences between the 1989 CPS direct estimates and the 1990 census estimates and considerably smaller than the differences between the 1980 census estimates and the 1990 census estimates. These findings, which are presented graphically in Fay and Train (1997), support the use of a model-based approach to producing updated state estimates of poor school-age children instead of relying on estimates from the previous census or from the CPS alone. Similarly, a formal hypothesis test performed for the state model (Fay, 1996) supports the conclusion that the model-based estimates for 1993 are preferable to estimates
from the 1990 census.22 Comparable evaluations have not been performed for alternative state models or for categories of states.
State Raking Factors
The final stage in producing updated estimates of the number of poor school-age children for counties is to ratio adjust, or rake, the estimates from the county model for consistency with the estimates from the state model. The county model-1990 census comparisons found that the raking procedure was beneficial to the county estimates. The raking factors vary considerably across states. For 1995, the raking factors range from 0.71 to 1.14 (two-thirds fall between 0.88 and 1.06); for 1993, the raking factors range from 0.91 to 1.31 (two-thirds fall between 0.98 and 1.16).
The Census Bureau determined that the correlation between the raking factors for states in 1993 and 1995 is low, which implies that there is little systematic variation by state across these years. Also, some variation in the raking factors is expected given the form of the county model and the need to transform the predicted log values of poor school-age children to estimated numbers before the raking is performed. Other sources of this variability could include the use of 3-year averages of CPS estimates as the dependent variable in the county model versus single-year estimates in the state model, sampling variability, and, possibly, individual state effects that are not captured in the county model (see Chapter 9 and National Research Council, 2000:Ch.3). Preliminary work by the panel suggests that a large proportion of the variation in the state raking factors is due to sampling variability. Further investigation should be carried out to better understand the causes of this variation.
|
22 |
The test assumes that the objective is to predict poverty rates that reflect the CPS measurement of poverty and not the decennial census measurement. |




















































