
Executive Summary
Americans drink millions of gallons of tap water each day, usually with an unquestioning faith in its safety. Indeed, the provision and management of safe drinking water throughout the United States have been major triumphs of public health practice since the turn of the twentieth century. Despite advances in water treatment, source water protection efforts, and the presence of several layers of local, state, and federal regulatory protection, many sources of raw and finished public drinking water in the United States periodically contain chemical, microbiological, and other types of contaminants at detectable and sometimes harmful levels. Furthermore, the production and use of new chemicals that can reach water supplies and the discovery of emerging microbial pathogens that potentially can resist traditional water treatment practices and/or grow in distribution systems pose a regulatory dilemma: Where and how should the U.S. government focus its attention and limited resources to ensure safe drinking water supplies for the future? The availability of increasingly powerful analytical methods for the detection and identification of smaller amounts of chemicals and microorganisms in the environment, many of them never before detected, complicates these decisions.
To help address these difficult issues, one of the major requirements of the Safe Drinking Water Act (SDWA) Amendments of 1996 is that the U.S. Environmental Protection Agency (EPA) publish a list of unregulated chemical and microbial contaminants and contaminant groups every five years that are known or anticipated to occur in public water systems and that may pose risks in drinking water. The first such list, called the Drinking Water Contaminant Candidate List (CCL), was published in March 1998. The primary function of the CCL is to provide the basis for deciding whether to regulate at least five new contaminants from the CCL every five years. However, since additional research and
monitoring need to be conducted for most of the contaminants on the 1998 CCL, the list is also used to prioritize these related activities.
This is the third report by the Committee on Drinking Water Contaminants (jointly overseen by the National Research Council’s [NRC’s] Water Science and Technology Board and Board on Environmental Studies and Toxicology). The committee was formed early in 1998 at the request of EPA’s Office of Ground Water and Drinking Water to provide advice regarding the setting of priorities among drinking water contaminants in order to identify those contaminants that pose the greatest threats to public health. The committee is comprised of 14 volunteer experts in water treatment engineering, toxicology, public health, epidemiology, water and analytical chemistry, risk assessment, risk communication, public water system operations, and microbiology.
In its first report, Setting Priorities for Drinking Water Contaminants, the committee recommended a phased decision-making process, time line, and related criteria to assist EPA efforts to set priorities and decide which contaminants already on a CCL should be subjected to regulation development, increased monitoring, or additional health effects, treatment, and analytical methods research. That report also includes a review of several past approaches to setting priorities for drinking water contaminants and other environmental pollutants. The committee later organized and conducted an NRC workshop on emerging drinking water contaminants and subsequently published a second report entitled Identifying Future Drinking Water Contaminants. That report includes a dozen papers presented at the workshop by government, academic, and industry scientists on new and emerging microbiological and chemical drinking water contaminants, associated analytical and water treatment methods for their detection and removal, and existing and proposed environmental databases to assist in their proactive identification and potential regulatory consideration. Notably, the workshop papers are preceded by a short committee report that provides a conceptual approach to the creation of future CCLs. In this regard, the committee strongly urged EPA in its second report to consider the benefits of a more carefully considered and detailed description of the requirements of a CCL development process.
For this report, EPA asked the committee—which was partially reconstituted after the second report to include a new chair—to evaluate, expand, and revise as necessary the conceptual approach to the generation of future CCLs and any related conclusions and recommendations documented in the second report. In addition, EPA asked the committee
to explore the feasibility of developing and using mechanisms for identifying emerging microbial pathogens (using what the committee now terms virulence-factor activity relationships, or VFARs) for research and regulatory activities—also as recommended in the second report. The contents, conclusions, and recommendations in this report are based on a review of relevant technical literature, information gathered at three committee meetings, and the expertise of committee members. As in its first two reports, the committee continues to emphasize the need for expert judgment throughout all CCL-related processes and for a conservative approach that errs on the side of public health protection.
The committee chose this perspective because public health is the basis for the SDWA and its amendments. Further, this report takes the position that scientific disagreements about the public health effects of contaminants and their relative severity are the norm and do not signal a deviation from sound science. For example, when data are sparse they may often appear consistent and coherent, but data gaps usually become evident as a problem is examined more fully by different methods and from different perspectives. The EPA faces a challenging task in assessing the available scientific information about contaminant risks and, based on that assessment, making decisions about which contaminants should be placed on a CCL for future regulatory and research consideration. Throughout this process, there is no replacement for policy judgments by EPA. As in its first report, the committee has purposely declined to define what constitutes “sufficient” or “adequate” data for making such decisions because this remains a matter of judgment that will vary with context.
RECOMMENDED APPROACH FOR THE DEVELOPMENT OF FUTURE CCLS
Because of the time constraints stipulated by the amended SDWA for publication of the first CCL, EPA was forced to rapidly develop and utilize a decision-making process for the creation of the 1998 CCL. The committee feels that the process used to develop the first CCL, although appropriate for the circumstances at the time, is not suitable as a long-term model. The process used in the future should be made more defensible and transparent, and its development should take place with increased opportunities for public input and comment. Similar comments
can be made about policy decisions. These limitations are identified and discussed in Chapter 2 and provide a foundation for much of this report.
In its first report, the committee concluded that a ranking (rule-based) scheme that attempts to sort a relatively small number of drinking water contaminants already on a CCL in a specific order for regulation development, research, or monitoring is not appropriate. However, the committee subsequently concluded that such ranking schemes may be useful for sorting larger numbers of potential contaminants to determine which ones should be included on future CCLs. In its second report, the committee recommended that EPA develop a two-step process for the creation of future CCLs.
Two-Step Approach
Despite EPA’s constrained resources, the lack of a comprehensive list of potential drinking water contaminants, and poor or nonexistent data on health effects, occurrence, and other attributes of the vast majority of potential contaminants, the committee continues to recommend that EPA develop and use a two-step process for creating future CCLs as illustrated in Figure ES-1. In summary, a broadly defined universe of potential drinking water contaminants is first identified, assessed, and culled to a preliminary CCL (PCCL) using simple screening criteria and expert judgment. All PCCL contaminants are then assessed individually using a “prototype” classification tool in conjunction with expert judgment to evaluate the likelihood that they could occur in drinking water at levels and frequencies that pose a public health risk to create the corresponding CCL. The committee also continues to recommend that this two-step process be repeated for each CCL development cycle to account for new data and potential contaminants that inevitably arise over time. In addition, all contaminants that have not been regulated or removed from the existing CCL should automatically be retained on each subsequent CCL.
It is important to note that although the basic concept for the CCL development approach has not changed, many of the associated guidelines and recommendations for its design and implementation have necessarily been revised and expanded in accordance with the most recent committee deliberations. The committee also notes that the amended SDWA specifically allows EPA to circumvent the CCL process and issue
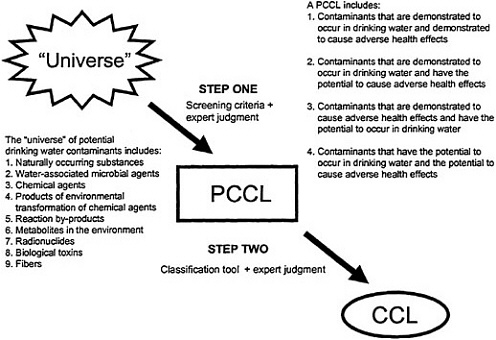
FIGURE ES-1 Recommended two-step process for developing future CCLs.
interim regulations for any drinking water contaminant that is determined to pose an “urgent threat” to humans.
Sociopolitical Considerations
The committee recognizes that the development of a PCCL from the universe of potential drinking water contaminants, as well as the movement from a PCCL to the corresponding CCL, is a complex task requiring numerous difficult classification judgments in a context where data are often uncertain or missing. Due to data gaps and uncertainties, evaluating contaminants using widely varying data will often entail making assumptions. Because of this complexity, the committee be-
lieves that to be scientifically sound as well as publicly acceptable, the process for developing future CCLs must depart considerably from the process used to develop the first CCL. The committee recommends that the process for selecting contaminants for future CCLs be systematic, scientifically sound, and transparent. The development and implementation of this process should involve sufficiently broad public participation. Transparency should be incorporated into the design and development of the classification and decision-making process for future CCLs in addition to being an integral component in communicating the details of the process to the public. Otherwise, the public may perceive the process as subject to manipulation to achieve or support desired results. Therefore, sufficient information should be provided so that private citizens can place themselves in a similar position to decision-makers and arrive at their own reasonable and informed judgments. This may require making available to the public the software and databases used in the CCL development process. The central tenet that the public is, in principle, capable of making wise and prudent decisions should be recognized by EPA and reflected in the choice of a public participation procedure to help create future CCLs. A “decide-announce-defend” strategy that involves the public only after the deliberation process is over is not acceptable. Substantive a public involvement should occur throughout the design and implementation of the process. In this regard, EPA should strive to “get the right participation” (i.e., broad participation that includes the range of interested and affected parties) as well as to “get the participation right” (e.g., incorporating public values, viewpoints, and preferences into the process).
The ultimate goal of the contaminant selection process is the protection of public health by providing safe drinking water to all consumers. To meet this goal, the selection process must place high priority on the protection of vulnerable subpopulations as intended by the SDWA Amendments of 1996. The committee recommends that not only should the definition of vulnerable subpopulations comply with the amended language of the SDWA, but it should also be sufficiently broad to protect public health; in particular, EPA should consider including (in addition to those subgroups mentioned as examples in the amended SDWA) all women of childbearing age, fetuses, the immuno-compromised, people with an acquired or inherited genetic disposition that makes them more vulnerable to drinking water contaminants, people who are exceptionally sensitive to an array of chemical contaminants, people with specific medical conditions that make them more suscepti-
ble, people with poor nutrition, and people experiencing socioeconomic hardships and racial or ethnic discrimination.
Universe to PCCL
While the contaminants included on the first (1998) CCL certainly merit regulatory and research consideration, a broader approach to contaminant selection could potentially identify higher-risk contaminants. Although the committee was not able to deliberate extensively on the first step of the CCL development process (going from the universe of potential drinking water contaminants to a PCCL) due to time constraints, some initial guidance and several related recommendations can be provided, many of which reiterate and expand on those made in its second report:
-
EPA should begin by considering a broad universe of chemical, microbial, and other types of potential drinking water contaminants and contaminant groups (see Table 3–1). The total number of contaminants in this universe is likely to be on the order of tens of thousands of substances and microorganisms, given that the Toxic Substances Control Act inventory of commercial chemicals alone includes about 72,000 substances. This represents a dramatically larger set of substances and microorganisms to be considered initially in terms of types and numbers of contaminants than that used for the creation of the 1998 CCL.
-
EPA should rely on databases and lists that are currently available and under development, along with other readily available information, to begin identifying the universe of potential contaminants that may be candidates for inclusion on the PCCL. For example, EPA should consider using the Endocrine Disruptor Priority-Setting Database (EDPSD) to help develop future PCCLs (and perhaps CCLs). Although relevant databases and lists exist for many categories of potential drinking water contaminants, other categories have no lists or databases (e.g., products of environmental degradation). Thus, EPA should initiate work on a strategy for filling the gaps and updating the existing databases and lists of contaminants for future CCLs. This strategy should be developed with public, stakeholder, and scientific community input.
-
As an integral part of the development process for future PCCLs and CCLs, all information used from existing or created databases or lists should be compiled in a consolidated database to provide a consistent mechanism for recording and retrieving information on the contaminants under consideration. Such a database could function as a “master list” that contains a detailed record of how the universe of potential contaminants was identified and how a particular PCCL and its corresponding CCL were subsequently created. It would also serve as a powerful analytical tool for the development of future PCCLs and CCLs. As a starting point, the committee recommends that EPA review its developing EDPSD to determine if it can be expanded and used as this consolidated database or whether it can serve as a model for subsequent development of such a database. The (re)design, creation, and implementation of such a database should be made in open cooperation with the public, stakeholders, and the scientific community.
-
To assist generally in the identification of the universe of potential contaminants and a PCCL, the committee recommends that EPA consider substances based on their commercial use, environmental location, or physical characteristics (see Table 3–5). EPA should be as inclusive as possible in narrowing down the universe of potential drinking water contaminants for the PCCL. The committee envisions that a PCCL would contain on the order of a few thousand individual substances and groups of related substances, including microorganisms, for evaluation and prioritization to form a CCL. However, the preparation of a PCCL should not involve extensive analysis of data, nor should the PCCL itself directly drive EPA’s research or monitoring activities.
-
The committee recommends the use of a Venn diagram approach (Figure ES-2) to conceptually distinguish a PCCL from the broader universe of potential drinking water contaminants. Because of the extremely large size of the universe of potential drinking water contaminants, well-conceived screening criteria remain to be developed that can be applied rapidly and routinely by EPA in conjunction with expert judgment to cull that universe to a much smaller PCCL. Thus, the PCCL should include those contaminants that are demonstrated to occur or could potentially occur in drinking water and those that are demonstrated to cause or could potentially cause adverse health effects.
-
Regarding the development of screening criteria for health effects, the committee recommends that human data and data on
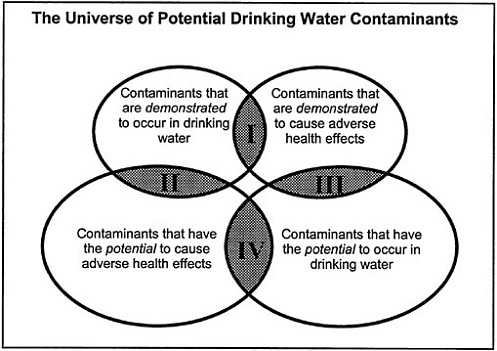
FIGURE ES-2 Conceptual approach to identifying contaminants for inclusion on a PCCL through the intersection of their demonstrated and potential occurrence in drinking water and their ability to cause adverse health effects. Note, the sizes of the intersections and rings are not drawn to scale and do not represent an estimate of the relative numbers of contaminants in each area.
-
whole animals be used as indicators of demonstrated health effects and that other toxicological data and data from experimental models that predict biological activity be used as indicators of potential health effects.
-
A variety of metrics could be used to develop screening criteria for the occurrence of contaminants in drinking water. These are identified in a hierarchical framework in the committee’s first report and include (1) observations in tap water, (2) observations in distribution systems, (3) observations in finished water of water treatment plants, (4) observations in source water, (5) observations in watersheds and aquifers, (6) historical contaminant release data, and (7) chemical production
-
data. The committee recommends that the first four of these should be used as indicators of demonstrated occurrence and information that comes from items 5 to 7 should be used to determine potential occurrence. For commercial chemicals, their potential for occurrence in drinking water may be estimated using a combination of production volume information and water solubility (see Figure 3–2). Most likely occurrence would involve high-production-volume chemicals with high water solubility.
-
Each PCCL should be published and thereby serve as a useful record of past PCCL and CCL development and as a starting point for the development of future PCCLs.
-
Development of the first PCCL should begin as soon as possible to support development of the next (2003) CCL; each PCCL should be available for public and other stakeholder input (especially through the Internet) and should undergo scientific review.
PCCL to CCL
The intrinsic difficulty of identifying potentially harmful substances or microorganisms for movement from a PCCL onto a CCL raises the question of what kind of process or method is best suited to this judgment. As previously noted, the sorting of perhaps thousands of PCCL contaminants into two discrete sets—one (the CCL) to probably undergo research or monitoring of some sort preparatory to an eventual regulatory decision and another much larger set that will not—is an exercise in classification. The committee considered three broad types of strategies for accomplishing this task: expert judgment, rule-based systems, and prototype classifiers (see Chapter 5 for further information).
Based on this review, the committee decided that a prototype classification approach using neural network or similar methods would seem to be an innovative and appropriate approach for EPA to consider. This strategy recognizes that in ordinary practice, one does not usually classify objects on the basis of a fixed algorithm (such as a rule-based scheme) but instead uses criteria based on prior classification of examples or prototypes. As such, prototype classifiers take advantage of the prototyping activity at which humans generally (and intuitively) excel. In simplest terms, a neural network is a mathematical representation of the complex network of biological neurons in higher organisms such as
humans. Neural networks and similar methods start with prototypes (a “training set”) that embody the kinds of outcomes one might wish to achieve. In this case, the training set would consist of chemicals, microorganisms, and other types of potential drinking water contaminants that clearly belong on the CCL, such as currently regulated chemicals (if they were not already regulated), and those that clearly do not, such as some food additives generally recognized as safe by the U.S. Food and Drug Administration. For each contaminant in the training set, its “features” or attributes must be characterized. Using the training set, the neural network constructs the mode of combining and weighting the prototype attributes that best differentiate between the two categories. Thus, what has traditionally been accomplished a priori through the use of a ranking scheme that was most likely designed by experts and required the extensive use of expert judgment throughout would now be conducted on the basis of data that differentiate prototype examples. This a posteriori determination of weights on the basis of features sets prototype classification methods apart from such rule-based methods and expert judgment.
Contaminant Attributes
The committee recommends that EPA develop and use a set of attributes to evaluate the likelihood that any particular PCCL contaminant or group of related contaminants could occur in drinking water at levels and frequencies that pose a public health risk. These contaminant attributes should be used in a prototype classification approach, such as that described in Chapter 5, and in conjunction with expert judgment to help identify the highest-priority PCCL contaminants for inclusion on a CCL. A scoring system and related considerations for a total of five health effect and occurrence attributes are presented in Chapter 4, along with several “scored” examples of chemicals and microorganisms, to illustrate the utility of the recommended approach. For health effects, the committee identified severity and potency as key predictive attributes; prevalence, magnitude, and persistence-mobility comprise the occurrence attributes.
Although the committee spent a great deal of time deliberating on the number and type of contaminant attributes that should be used in the recommended CCL development approach, ultimately it decided that the five attributes listed above constitute a reasonable starting point for EPA
consideration. Furthermore, the scoring metrics and related considerations for each attribute should be viewed in an illustrative manner. Thus, the committee does not explicitly or implicitly recommend these five (or that there necessarily should be five) attributes or that the related scoring metrics be directly adopted for use by EPA. Should EPA choose to adopt a prototype classification approach to the development of future CCLs, the committee recommends that options for developing and scoring contaminant attributes should be made available for public and other stakeholder input and should undergo scientific review. The committee also makes the following related recommendations:
-
The assessment of severity should be based, when feasible, on plausible exposures via drinking water. The committee also recommends that EPA give consideration to different severity metrics such as a ranking through use of either quality adjusted or disability adjusted life-years lost from exposure to a contaminant.
-
Regarding the assessment of contaminant prevalence, in some cases (particularly where contaminants have been included on a PCCL on the basis of potential rather than demonstrated occurrence), insufficient information will be available to directly assess temporal or spatial prevalence (or both). Thus, EPA should consider the possibility of including information on temporal and regional occurrence to help determine (score PCCL) contaminant prevalence. When prevalence cannot be assessed, this attribute must then go unscored and the attribute persistence-mobility used in its stead. The issue of changing (or incorporating) “thresholds” for contaminant detection, rather than relying on continually decreasing detection limits, is one that requires explicit attention and discussion by EPA and stakeholders.
-
Because existing and readily available databases may not be sufficient to rapidly and consistently score health effect and occurrence attributes for individual PCCL contaminants, all information from existing or created databases or lists used in the development of a CCL and PCCL should be compiled in a consolidated database (as previously recommended).
-
Contaminant databases used in support of the development of future CCLs should report summary statistics on all data collected, not only the quantifiable observations. In this regard, EPA should formalize a process for reporting means and/or medians from data with large num-
-
bers of “nondetect” observations. In addition, EPA may want to consider providing other measures of concentration in water supplies such as the 95th percentile of contaminant concentration.
Developing and Implementing a Prototype Classification Approach
Chapter 5 presents a framework for how existing contaminant data and past regulatory decisions could be used by EPA to develop a prototype classification algorithm to determine, in conjunction with expert judgment, whether or not a particular drinking water contaminant is of regulatory concern. More specifically, the committee demonstrates how a prototype classification approach—which must first be “trained” (calibrated) using a training data set containing both contaminants “presumed worthy of regulatory consideration” and those that are not—can be used in conjunction with expert judgment to predict whether a new (PCCL) contaminant should be placed on the CCL or not. The framework is intended to serve as a model of how EPA might develop its own prototype classification scheme for the creation of future CCLs. Use of the majority of currently regulated drinking water contaminants in the training data set to serve as contaminants presumed to be worthy of regulatory consideration can be simply described as “making decisions that are consistent with and build upon what has been done in the past.”
The committee presents two alternative models for use in the scheme—a linear model and a neural network. Although the neural network performed better than the linear model (with respect to minimizing the number of misclassified contaminants), the committee cannot at this time make a firm recommendation as to which model EPA should use due to uncertainties in the training data set employed by the committee. Thus, the committee recommends that EPA explore alternative model formulations and be cognizant of the dangers of overfitting and loss of generalization. That is, EPA must be careful to avoid developing undue confidence in the precision of the training data sets ultimately used and being overzealous in finding an algorithm that produces no classification error in representing these data. The committee warns that this will impose “false structure” in the mapping and not truly capture the functional dependencies. Additionally, the danger of overfitting is especially present in neural network modeling because of the tremendous flexibility in the underlying mathematical relationships—resulting
in a sacrifice of generalization (predictive) ability.
To adopt and implement the recommended approach to the creation of future CCLs, EPA will have to employ or work with persons knowledgeable of prototype classification methods and devote appreciable time and resources to develop and maintain a comprehensive training data set. In this regard, the committee strongly recommends that EPA greatly increase the size of the training data set used illustratively in this report to improve predictive capacity. One way in which EPA can expand the training data set and classification algorithm is to allow for the expected case of missing data. That is, purposefully include in the training data set drinking water contaminants for which the values of some attributes are unknown and develop a scheme that allows prediction of contaminants for which some attributes are unknown. EPA will also have to accurately and consistently assign attribute scores for all contaminants under consideration (i.e., contaminants in the training data set as well as contaminants to which the prototype classification algorithm will be applied for a classification determination). To do this, EPA will have to collect and organize available data and research for each PCCL contaminant and document the attribute scoring scheme used to help ensure a transparent and defensible process. As previously recommended, the creation of a consolidated database that would provide a consistent mechanism for recording and retrieving information on the contaminants under consideration would be of benefit. EPA will also have to withhold contaminants from inclusion in the training data set to serve as validation test cases that can assess the predictive accuracy of any classification algorithm developed for use in the creation of future CCLs.
If neural networks are ultimately used by EPA to establish a prototype classification approach for the creation of future CCLs, the transparency in understanding which contaminant attributes determine the contaminant category will be less than that of a linear model or more traditional rule-based scheme. However, if one acknowledges that the underlying process that maps attributes into categorical outcomes is very complex, there is little hope that an accurate rule-based classification scheme can be constructed. The fact that the nonlinear neural network performed better than the linear classifier is itself a strong indicator that the underlying mapping process is complex, and it would be a difficult task for a panel of experts (including this committee) to accurately specify the rules and conditions of such mapping. Furthermore, the decrease in transparency from using a neural network is not inherent or arbitrary,
but rather derives from the difficulty in elucidating the mapping.
The committee notes that the underlying mapping in a neural network classifier can be examined just as one would conduct experiments to probe a physical system in a laboratory. Through numerical experimentation, one can probe a neural network to determine the sensitivity of the output to various changes in input data. Although a sensitivity analysis was not conducted due to time constraints, the committee recommends that EPA should use several training data sets to gauge the sensitivity of the method as part of its analysis and documentation if a classification approach is ultimately adopted and used to help create future CCLs.
Finally, the committee emphasizes that it is recommending a prototype classification approach to be used in conjunction with expert judgment for the selection of PCCL contaminants for inclusion on future CCLs. Thus, transparency is less crucial (though no less desired) at this juncture than when selecting contaminants from the CCL for regulatory activities as discussed in the committee’s first report.
IDENTIFYING AND ASSESSING EMERGING WATERBORNE PATHOGENS
As noted in the committee’s first report and discussed in greater detail in Chapter 6 of this report, the current approach to identifying and controlling waterborne disease is fundamentally limited in that the identification of pathogens is traditionally tied to the recognition of an outbreak. The committee feels strongly that this ongoing practice is not an effective or proactive means for protecting public health. Furthermore, current regulatory practice requires that methods to culture organisms of interest be developed before occurrence data can be gathered. Thus, a microorganism must ordinarily first be identified as a pathogen, and be capable of in vitro culture, before occurrence data are collected. This long-standing paradigm makes it very difficult or impossible to develop a database of potential or emerging pathogens. The committee feels that this constitutes a severe bottleneck to identifying and addressing potentially important emerging microbial contaminants in drinking water. Thus, a new approach to assessing pathogens could help overcome this serious and ongoing problem.
Virulence-Factor Activity Relationships
A virulence-factor activity relationship is the known or presumed linkage between the biological characteristics of a microorganism and its real or potential ability to cause harm (pathogenicity). The term is rooted in a recognition of the utility of using (quantitative) structure-activity relationships (QSARs or SARs) to compare the structure of new chemicals to known chemicals to enable prediction of their toxicity. Chapter 6 of this report responds to EPA’s request that the committee explore the feasibility of developing VFARs for their construction and use in EPA’s drinking water program. Furthermore, the committee provides a framework, initial guidance, and recommendations on the necessary steps for their construction and use to help identify emerging waterborne pathogens and predict their ability to cause disease in exposed humans.
For pathogenic microorganisms, besides the cell or organism itself, there are many levels of morphological components that can sometimes be used to identify pathogens. In addition to these large structures, there are smaller biochemical components including proteins, carbohydrates, and lipids that are related directly to the virulence of a particular microorganism. (In this report, virulence is defined broadly as the quality of being poisonous or injurious to life [i.e., virulent].) Some examples of these biochemical components include the outer coat of some bacteria (the lipid polysaccharide coat), attachment and invasion factors, and bacterial toxins. Together, these structures and compounds can generally be termed “virulence factors” and the blueprints for them are the genetic code of an organism. For this reason, a principal topic of Chapter 6 is the genetic structure of various microorganisms because of its direct relationship to virulence factors.
Owing to recent advances in molecular biology, the genetic structures of many thousands of microorganisms (especially bacteria and viruses) have been identified, reported, and stored in what are commonly called gene banks. Sophisticated computer programs allow for the sorting and matching of genetic structures and specific genes. The discipline that organizes and studies these genes is known as bioinformatics. Two other growing areas of related interest are functional genomics (i.e., understanding the specific role of genes in terms of the function of the organism) and proteomics (i.e., the science related to the study of the proteins made when the genomic blueprint is actually translated into functional molecules). The need and the ability to use these tools to ad-
dress microbial contamination of drinking water are also reviewed in Chapter 6.
Framework
The central concept is to use microbial characteristics to predict virulence through VFARs. Microbial VFARs would function in much the same way as QSARs do—that is, to assist in the early identification of at least several potential elements of virulence. Research has increasingly shown certain common characteristics of virulent pathogens such as the production of specific toxins, specific surface proteins, and specific repair mechanisms that enhance their ability to infect and inflict damage in a host. Recently some of these “descriptors” (terminology often used in QSARs) have been tied to specific genes, and it has become evident that the same can be done for other descriptors as well. Identification of these descriptors, either directly or through analysis of genetic databases, could become a powerful tool for estimating the potential virulence of a microorganism. This is particularly true for two important aspects of virulence: potency and persistence in the environment. The committee conceives of VFAR as being the relationship that ties specific descriptors to outcomes of concern (see Figure ES-3).
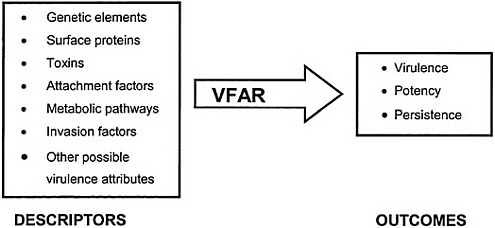
FIGURE ES-3 Schematic drawing of VFAR predicting outcomes of concern (virulence, potency, persistence) using the presence or quality of descriptor variables.
Feasibility
For the VFAR concept to be ultimately adopted and used by EPA in the agency’s drinking water program, it must be feasible. This committee strongly believes this to be the case. Chapter 6 includes a review of several aspects concerning feasibility, including scientific validity and applicability; actual technological feasibility; the application of these technologies to studying disease in humans (validation); the degree to which these methodologies are being universally adopted within the scientific community; and the need for their development and use to adhere to the principles of transparency, public participation, and other sociopolitical considerations reviewed in Chapter 2. To one extent or another, each of these elements affects the ability of the VFAR concept to be developed, used, or validated. These elements either are present or can reasonably be expected to be available in the near future, so the committee concludes that the use of VFARs is indeed feasible.
While the technology, methodology, and even the genetic databanks exist, the application of a VFAR approach to assess waterborne pathogens would require considerable effort and expenditure of resources by EPA in conjunction with the Centers for Disease Control and Prevention, National Institutes of Health, and other federal and state health organizations. Such a “Waterborne Microbial Genomics” project would also require extensive expertise in bioinformatics, molecular microbiology, environmental microbiology, and infectious disease.
The committee fully recognizes that even the initial development of such a program (excluding its maintenance and expansion) is likely to require at least a five-year commitment and significant cooperation and expenditure of resources by EPA and other participating organizations. However, the opportunities for rapid identification of microbial hazards in water afforded by such a program would greatly improve the ability of EPA to quickly and successfully protect public health and improve water quality.
VFAR Conclusions and Recommendations
Despite the identification and discussion of some necessary caveats and limitations, the committee concludes that the construction and eventual use of VFARs in EPA’s drinking water program is feasible and merits careful consideration. More specifically, the committee makes the following recommendations:
-
Establish a scientific VFAR Working Group on bioinformatics, genomics, and proteomics, with a charge to study these disciplines on an ongoing basis and periodically inform the agency as to how these disciplines can affect the identification and selection of drinking water contaminants for future regulatory, monitoring, and research activities. The committee acknowledges the importance of several practical considerations related to the formation of such a working group within EPA, including how it should be administered and supported (e.g., logistically and financially) or where it could be located. However, the committee did not have sufficient time in its meetings to address these issues or make any related recommendations.
-
The findings of this report and those of the Biotechnology Research Working Group (BRWG, 2000: Interagency Report on the Federal Investment in Microbial Genomics) should be made available to such a working group at its inception. The committee views the activities of a VFAR Working Group as a continuing process in which developments in the fields of bioinformatics, genomics, and proteomics can rapidly be assessed and adopted for use in EPA’s drinking water program.
-
The working group should be charged with the task of delineating specific steps and related issues and time lines needed to take VFARs beyond the conceptual framework of this report to actual development and implementation by EPA. All such efforts should be made in open cooperation with the public, stakeholders, and the scientific community.
-
With the assistance of the VFAR Working Group, EPA should identify and fund pilot bioinformatic projects that use genomics and proteomics to gain practical experience that can be applied to the development of VFARs while it simultaneously dispatches the charges outlined in the two previous recommendations.
-
EPA should employ and work with scientific personnel trained in the fields of bioinformatics, genomics, and proteomics to assist the agency in focusing efforts on identifying and addressing emerging waterborne microorganisms.
-
EPA should participate fully in all ongoing and planned U.S. government efforts in bioinformatics, genomics, and proteomics as potentially related to the identification and selection of waterborne pathogens for regulatory consideration.



















