
Appendix I
Description of Different Codes
-
ECMWF's IFS (Integrated Forecast System)
The ECMWF's IFS code is a parallel spectral weather model that is also used for seasonal climate prediction. Its structure is similar to climate codes from NCAR, including CCM, but its parallel execution model is highly evolved. It uses domain decomposition in two-dimensions and performs both spectral and Legendre transformations on the grid data. The sustained rates reported for IFS are in units of forecast days per day (in other words, the ratio of simulated time to real wall-clock time). The two machines compared with this code are the T3E (600-MHz Alpha processors) and the Fujitsu VPP5000. A single processor of the VPP5000 achieves 48 times the sustained speed of a single Cray T3E processor. In parallel configurations this ratio (of sustained rates per processor) increases to 57 when IFS executes on 1408 T3E processors and 98 VPP5000 processors. Notice that only 98 VPP5000 processors are nearly four times faster than 1,408 T3E processors.
Analysis of the performance of the IFS code (at T213 L31 resolution) on a variety of machines, (both microprocessor- and vector-based) indicates that machines with small numbers of fast vector processors are superior to highly parallel microprocessor-based SMPs (Fig. A-1).
-
Environment Canada's MC2
MC2 is a regional, non-hydrostatic weather model. It uses a variety of sophisticated solvers and is structured somewhat like a global spectral model. In Table 4-3 we show the sustained performance in Mflops of MC2 for the Origin 2000 (250-MHz R10000 processors with 4-MB caches) ver-
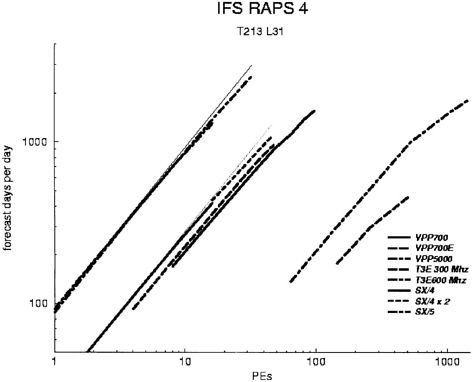
FIGURE A-1 Performance of the IFS code (at T213 L31 resolution) on a variety of machines, both microprocessor- and vector-based. The figure shows that machines with small numbers of fast vector processors are superior to highly parallel microprocessor-based SMPs. Courtesy of D. Dent, European Centre for Medium-range Weather Forecasts.
sus the NEC SX-5, a Japanese VPP. Like the IFS code, the MC2 code executes nearly 50 times faster (on a per-processor basis) on the SX-5 compared to the R10000. The aggregate performance achieved on 28 SX-5 processors is 95,200 Mflops, almost 50% of the potential peak speed of the SX-5 in this parallel configuration. These speeds dwarf the 840 Mflops achieved on a smaller 12-processor configuration of the Origin.
-
NCAR's MM5
MM5 is a grid-based, hydrostatic mesoscale model originally developed at Penn State. Its performance on a single Alpha 667-MHz processor is 360 Mflops, about 27% of peak performance. This is a much higher percentage of the peak microprocessor speed than is achieved by most weather models and is due primarily to MM5's good cache useage. When parallel execution of MM5 is considered, the AlphaServer cluster (128 4-processor machines connected together into a 512-processor configuration) is about 60% faster than a 20-processor VPP5000.
The per-processor speed ratio between the 512-processor Alpha and 20 processor VPP5000 is 16 in favor of the vector machine, much less than the 50-times difference found with the other codes. However, the lower ratio is consistent with the MM5, which attains sustained-to-peak performance a factor of 3 higher than the other codes.
-
German Weather Service's LM and GME
Only limited performance data was available for the local (LM) and global (GME) weather models used by the German Weather Service (Deutscher Wetterdienst). LM is a regional model, while GME is a global model developed using an icosahedral-hexagonal grid. Both these models execute nearly 50 times faster (either serial or parallel) on a VPP5000 than on a Cray T3E.
The actual performance of real weather and climate codes support our contention that currently Japanese parallel vector supercomputers significantly outperform American-manufactured MPPs based upon microprocessor technology. If VPPs are not available, it is more difficult to get good performance. This is particularly true for “capability computing ” (see Section 3-1). As was demonstrated above, Amdahl's law requires a very high degree of parallelism in a model to achieve effective speedups on large numbers of processors. Recognizing this, SMP vendors have been moving to a hybrid architecture that places multiple processors on each node. SMP clusters typically have nodes that contain 2–16 processors sharing uniform memory access (UMA) via a bus or, when the number of processors exceeds 8, a higher-performance intra-node network. To take advantage of this UMA feature the preferred intra-node programming model is OpenMP threads, an evolving standard for what was once known on CRI VPP machines as “multi-tasking.” MPI is used for the non-
uniform memory access (NUMA) inter-node communications. Although this hybrid programming model adds another layer of complexity, it offers a useful path to parallelism if it can be efficiently implemented. For example, rather than doing two-dimensional domain decomposition in longitude and latitude, with the hybrid model one might decompose and use MPI only in latitude while treating parallelism in longitude with threads spread across the processors on each node.
Important considerations from a software standpoint are
-
optimizing the placement of data with respect to the processor(s) that will use it most;
-
minimizing the number and maximizing the size of messages sent between nodes;
-
maximizing the number of operations performed on data that is in cache, while minimizing the amount of data required to be in cache for these operations to occur.
Normally, one expects the operating system or job scheduler to take care of “1” automatically. If data is not localized on the same node as the processor that will use it most often, performance will suffer and is likely to be quite variable from run to run. Item “2” requires careful planning of MPI calls. Item “3” requires the most code changes, such as subdividing the computational domain into blocks small enough so that all data for any single block will fit into cache. More radical steps involve converting from Fortran 90 to Fortran 77 in order to get explicit do-loops, re-ordering array and loop indices, in-lining subroutine calls, fusing loops, and other optimizations that would be left to the compilers if only they were capable.




