
3
Workshop Discussion
DEFINING HEALTH, MEASURES OF HEALTH AND HEALTH CARE, AND DATA NEEDS FOR A FUTURE HEALTH STATISTICS SYSTEM
Through a myriad of methods, health data have been and continue to be collected that provide information on the health status and health care utilization of our population. Although these data are used to answer important and necessary research and policy questions, they are also often used to answer questions that they may never have been intended to answer. The current health statistics system, in particular, has evolved to meet many needs, but perhaps, with minimal vision to the evolution. One of the goals of the workshop was to identify current and future data gaps with respect to the health and policy questions the future health statistics system should be able to answer. In her introductory remarks at the workshop, Margaret Hamburg, Assistant Secretary for Planning and Evaluation at the U.S. Department of Health and Human Services (DHHS), stated that the focus on data for decision making was one of three top priorities for the Secretary of Health. Edward Sondik followed with the charge to workshop participants, “we really need to be looking ahead and not looking back. If we can’t anticipate the future, we don’t know what information it is that we need to collect.” Continuing his introductory comments, Sondik reminded participants that “the goal in all of this is ultimately to improve health status, whether we are talking about issues of disparities, issues of health
care organization, or health care research.” So, in addition to identifying existing data needs inherent to the current health statistics system, many workshop participants suggested new data that be should be collected in a health statistics system that perhaps better defines the vision of health for the future.
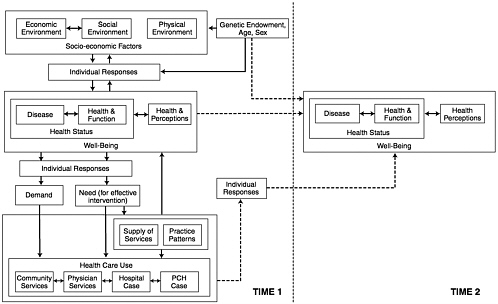
If a goal of a health statistics system is to improve health status, then the question of what is health is raised. It was argued by some workshop participants that, as a starting point for determining data content, it is important to develop a common understanding of the concept of health and of the factors that contribute to health. Prior to discussions that outlined specific data needs, several participants offered their perspectives on this issue. Charlyn Black, of the Manitoba Centre for Health Policy and Evaluation at the University of Manitoba, emphasized in her presentation that health is more than the product of an interaction with the medical care system. She considered health to be influenced by a variety of interactions within the larger ecosystem. Black suggested that if the focus is health and improving health, then the broad range of factors that influence health must be considered. Whereas a major model for health statistics has been to examine the utilization of health care as an indicator of overall health, the Canadian model, as expressed by Evans and Stoddard (1990), focuses more on other factors that influence health status and health-related quality of life. An overreliance on data concerning the utilization of health care, they argue, also results in a lack of appreciation for and knowledge of the outcomes of care. Black stated that it is incumbent upon a national health information system to provide information on both the impact of health care on the health status of patients and the effects of other factors on this health status (see Figure 3-1). She labeled this approach a “population health perspective.” Black suggested that it will be necessary to provide data to respond to a change in the policy discussions from a focus on what health care services are being provided to a focus on what is being done to improve health. The concern that health information systems are relying too heavily on medical care utilization information to describe the health of a population was suggested by others in attendance at the workshop. Richard Kronick, from the University of California at San Diego, commented that without knowing if medical care has much effect on health status, researchers will not know if it is worthwhile to continue to investigate medical care as a major determinant of health. He cited as an example the fact that no one has been able to produce a reasonable estimate of the effects of the Health Security Act on the health status of the U.S. population.
In describing her experience with measuring children’s health, Lorraine Klerman, of the University of Alabama, Birmingham, emphasized the need to convey to legislators that other things affect the health of children, in particular, besides medical care. Klerman described the State Children’s Health Insurance Program (SCHIP), and noted that the policy goals of SCHIP were focused more on ensuring participation by low-income uninsured children in SCHIP without extensive displacement of private coverage, coverage that includes benefits appropriate for children, continuity of coverage, and effective coordination with Medicaid, rather than goals emphasizing the improvement of the health of children. She noted that the focus on health promotion and disease prevention has not been accompanied by the development of indicators that would measure positive health, rather than illness or injury. Klerman outlined the need for data on children’s health and emphasized the need for measures of child health rather than disease. However, even the measures of disease should be reconsidered when children are beingstudied. For example, mortality data do not really help us figure out how healthy children are; hospitalization data are not sufficient because hospitalization of children is relatively rare, and individual diseases are relatively infrequent. She noted that several national surveys that contain questions on children’s health, such as the National Hospital Discharge Survey, the National Ambulatory Medical Care Survey, and the National Hospital Ambulatory Medical Care Survey, are not able to distinguish child health from child ill-health. Therefore, it would appear necessary, according to Klerman, to refocus attention toward positive measures of child health such as quality of life and level of functioning. Only then will an accurate portrayal of the effects of a program such as SCHIP on child well-being be achieved.
Other participants also suggested the idea that health is more than presence or absence of a negative state. For example, Dorothy Rice, from the University of California at San Francisco, in her opening remarks at the conference commented that a refocusing on positive health measures is needed (see Chapter 2). Burton Singer, from Princeton University, proposed a model that represented health as a more positive state than has generally been described in the past. Referring to data that he and his colleague, Carol Riff, have collected and analyzed, Singer focused on six dimensions of psychological well-being: positive relationships, autonomy, personal growth, self-acceptance, purpose in life, and environmental mastery. Singer acknowledged that although psychological well-being is a subjective indicator of health status, he explained how researchers could use his
model to appropriately measure the effect of psychological well-being on overall health status, thus using it as an indicator of physical health.
Robert Kaplan, from the University of California at San Diego, suggested that there are two main approaches to measuring health and illness: the psychometric approach and the weighted approach. Currently, the most widely used psychometric measurement instrument is the SF36, which provides measurements of a person’s physical limitations and how those limitations may or may not affect how they function physically, socially, and emotionally. The SF36 also measures changes in health status as well as overall well-being, including energy level, incidence of pain, and emotional well-being. The SF36 is considered an easy measure to use, and it provides a quality-of-life profile with the complexity that researchers desire. However, the SF36 cannot be employed easily in an economic analysis and may not be sensitive to minor variations in wellness. Kaplan described a weighted approach to measuring health and illness. In general, life expectancy and traditional survival analysis have been good generic ways to look at population health, but they have limitations. For example, in traditional survival analysis, if a person is alive, a point of credit is given or a score of 1.0 is entered in the computer; if the person is dead, 0 is entered. The difficulty is that survival analysis doesn’t make very obvious distinctions; the healthy person scores 1.0, as does the person in a coma. Kaplan proposed an adaptation of traditional survival analysis that accounts for the difference in quality of life and tries to fill in this continuum between optimal functioning and death. Dorothy Rice mentioned, to general assent, that the standardization of whatever measures and definitions we use is extremely important.
Clyde Hertzman, from the University of British Columbia, contended that health is determined in an important way by factors outside of the health care system. To explain, he described an ecological model of the determinants of health that basically conceives of a given society in three levels. At the macro-level is the national socioeconomic environment, consisting of the level of wealth of a society and how resources are distributed. In the meso-level, there is the civil society, which would encompass issues of voluntary associations, questions of institutional responsiveness, neighborhood safety and cohesion, occupational health and safety, and access to organized child care. At the microsystem level is the informal social support network. Intersecting through that is the individual human life cycle, and what we understand about differences in health status between populations in other countries. Hertzman stressed that it would be important for
researchers to examine the determinants of health, health status, and health services utilization on these various socio-levels before they could draw any firm conclusions about what is driving the health outcome measures. Using this model, the population health effects could be measured, for example, when welfare policies change, when unemployment insurance changes, or when the unemployment rate changes. Such a health system would have to allow simultaneous analysis of multiple outcomes, because health status has multiple influences, such as health services utilization. Hertzman also suggested that having too many health indicators can have the negative effect of polluting the health information system. Instead, a few good-quality measures that get at the essence of health status are needed.
The need for data on subpopulations, such as children and minorities, was expressed in the workshop discussions. As mentioned earlier, Lorraine Klerman emphasized the need for data on children’s health. In fact, she stated that she found it discouraging that in the early part of the workshop discussions the issue of the measurement of children’s health had not been mentioned. A question was then posed in the discussions as to how the data for determining the health status of children are different from those required for determining the health status of adults. Klerman responded by pointing out that ignoring the special physical and psychological developmental problems and needs that children and adolescents face could raise serious questions about the validity of conclusions that are reached about this special subpopulation, noting that other subpopulations may also have different subjective notions of what health status means. Olivia Carter-Pokras, from the Office of Minority Health in the Office of the Secretary, U.S. Department of Health and Human Services, followed up this thought by stressing the importance of the system to routinely provide data on ethnic minority groups.
Researchers and policy makers should identify beforehand what the research or policy questions are, before deciding what data will be needed to effectively answer those questions. Similarly, when defining a new vision for a health statistics system, the desired goals of the system should also be identified and be used to generate the appropriate questions to be answered. The concept of what it is we should measure—the definition of health and the measures of health that are appropriate to employ—is an important first consideration in the development of the components of a health information system. With the idea that a proposed goal of a health statistics system is to improve health status, there was much discussion at the workshop on the definition of health and measures of health. Some
defined health from a negative consequence perspective, focusing on illness, whereas others want to move away from a deficit model and toward a positive health model that would involve research of how various factors interact to influence the health status and well-being of patients as well as nonpatients. Although there was no real consensus among workshop participants on whether or not to collect data on illness versus measures of good health, participants did agree that there are many dimensions of health that should be collected, and then those data can be used to answer different research and policy questions. However, there should be a reasoned agreement concerning what data are to be gathered together in a national health data system prior to focusing on the issues of data collection and infrastructure.
HEALTH DATA: WHO ARE THE USERS AND WHAT ARE THEIR NEEDS?
Participants at the workshop noted that the potential users of health data represent numerous areas of the health industry: governments at the local, state, and federal levels; employers who supply health benefits for their workers; insurers; medical care providers; and consumers of health care, to name a few. Government officials at the federal, state, and community levels all need health information to guide them in their public policy decision making. In general, there was a recognition that health data are frequently not given as important a role in public policy decision making as they often merit and that there is a need to interest legislators and elected officials in the value of data collection and evaluation.
Other important nongovernmental players in the health care industry, such as insurers, have their own agendas. Insurance companies seek to run the most cost-efficient program possible. Therefore, they will look for cost-benefit analyses, combined with other measures such as medical care usage. The consumers of medical care usually want to know what the most effective treatments are for their particular needs (e.g., the best treatment for diabetes or cancer). Regardless of the differences in these agendas, each of these sets of decision makers should have data to inform their decisions.
David Fleming suggested that, in many situations, there is a “fundamental disconnect between the data and information side and the policy and program side of our system in the United States.” At the workshop, the SCHIP program was cited as an example of the inconsistent use of data-driven information by Congress when considering legislation. Data
came from several sources: government reports, such as from the Congressional Budget Office, the Congressional Research Service, and the Government Accounting Office; staff- and member-level support from the Congressional Research Service; congressional committee hearings; and fact sheets and other materials from nongovernment organizations. It was suggested that the problem with these information sources was that they often did not contain timely and data-driven material. For instance, some of the sources did not cite the NCHS’s National Health Interview Survey (NHIS), which has included family health coverage questions for several years. The information that was used revolved mainly around cost and access to health care, not whether increased access would result in better health status.
Deficits in health information are present in the private sector, as well. Jacqueline Kosecoff, from Protocare, Inc., discussed the types of data that are needed for her clients, the private sector of the health care industry. Of the various types of data sets that are available (see Table 3–1), each has its advantages and disadvantages. Joseph Newhouse, from Harvard University, made the point that certain national-level surveys, such as the NHIS, Medical Expenditure Panel Survey (MEPS), and Medicare Current Beneficiary Survey (MCBS), are used to monitor big-picture national trends, but they may not be as relevant for state- or community-level needs. This deficit in local and community data underscores the fact that, as many at the workshop noted, there is not presently a single data set that can be used to answer all health policy questions.
An issue that arose repeatedly in the discussion of potential data users was the proper identification of the data needs of these users. One need that appeared to be agreed upon widely by the workshop participants was for data to estimate the effects of programs on health status. As mentioned above, Congress did not, for example, have this information when deciding how to craft an effective child health protection program. A similar lack of appropriate data was evident in the process of developing the Health Security Act, proposed by President Clinton in 1993. Although there were data contributing to the estimates of how many people would be covered by the Health Security Act, how much it would cost the government, whether the cost of health care would increase or decrease, and whether the proposal would affect employment; there were few, if any, data contributing to the question of whether or not the HSA would actually improve the health status of Americans.
There was general agreement among workshop participants on the need for more research to better inform policy makers, but it became a
matter of debate at the workshop as to what level of data needs to be collected and reported in order for that research to be useful to the health policy decision makers. Participants suggested that there had been, to some extent, a shift away from the federal government to the state and local levels, and some mentioned that national-level data are not especially relevant to community- and state-level policy decisions even if aggregated by state or region. Indeed, John Lumpkin, from the Illinois Department of Public Health, suggested in his presentation that not even state data are specialized enough for the public health field. Local community-level data are needed, because public health issues generally occur at that level. The presentation by Alonzo Plough, from the Seattle-King County Health Department, emphasized that community-level data are needed to investigate, among other things, disparities in health outcomes that might be present in the local level. Jacqueline Kosecoff suggested that the data collection system as it presently exists in the private sector has turned into a two-class system, in which those that can afford high-quality data, like pharmaceutical companies, have access to good information, while the less fortunate researchers and data users do not. Kosecoff proposed an idea of a population-based claims database managed by a private, publicly funded group, to which all health plans would be required to submit 5 percent of their data annually so that private data would be available to everyone. Though participants seemed to like this idea, some questioned if health plans have enough of the requisite data, particularly in the capitated sector.
Several participants at the workshop argued, without denying the importance of state-level data, that national surveys give valid information that can be generalized to all states or be aggregated to specific settings and populations. These speakers pointed out that states and communities do not have the infrastructure to handle large-scale surveys and that the cost would be too high to create such a system. At a broader level, some workshop participants mentioned international comparisons as an important component of health information analysis. To do this well, we have to collect and coordinate data on an international level, requiring a large infrastructure.
Several workshop participants stated that regardless of the level at which health data are collected, if the information is not gathered and disseminated in a timely manner, it will cease to be relevant to decision makers— not only the government decision makers but also insurers, health care providers, and consumers.
The completeness and coverage of the data are also important factors
TABLE 3-1 Data from the Private Sector
|
Type of Data |
Description |
Characteristics |
|
Administrative Data |
Routinely submitted billing data (Cost, Dx, Px, Rx, Beneficiary) |
- Longitudinal, population-based complete view of care - Available without additional collection - Complete view of all utilization/costs * office visits * referrals * tests * procedures * medications |
|
Enhanced Administrative Data |
Administrative data + lab results |
- Longitudinal administrative data - Linkage of key laboratory values to patients’ diagnoses and services (e.g., hemoglobin, WBC, liver/renal function) |
|
Medical Records |
Routine patient charts |
- Indepth clinical information, complete patient history (all inpatient, outpatient, Rx. and beneficiary) * physical exam findings * laboratory results * diagnostic tests * surgical interventions * medications - Typically smaller data sets than administrative data |
|
Uses |
Limitations |
|
- Quantify cost/utilization - Population level outcomes and quality information |
- No information about symptoms, functional status, physical exam, or laboratory findings: can document extent of anti-depressant switching, but not why it occurs (e.g., sexual dysfunction, weight gain) - Capitated payment systems may “hide” certain services patients receive - No capture of OTC medication use |
|
- Answer more clinically sophisticated questions requiring understanding of where drug or disease impacts specific lab values (relationship of hemoglobin Alc to adverse outcomes and drug use) - Show how quickly Lipitor impacts cholesterol compared to its competition |
- Difficult to create (payers do not have lab data, providers do not have data from the full “episode” —hospital, ER, specialists, pharmacy) - Unable to answer questions about symptoms or those requiring detailed clinical information |
|
- Track how care is currently provided and changing patterns of care - Document clinical outcomes and adverse events |
- Minimal data on patient symptoms, quality of life, or compliance - Variability of documentation (“what you see is what you get”) - Hard to find complete data - Not standardized (can’t get data you need on all patients collected in same way) |
|
Type of Data |
Description |
Characteristics |
|
Patient “Living” Registries |
Ideal data set |
- Collect specific data in a standardized way * trained data collectors * richer and more accurate than medical records * can readily revise data collected - Ability to continuously track patients across providers and insurance plans - Simulates clinical trials quality data |
|
SOURCE: Data from Jacqueline Kosecoff, Protocare, Inc. (personal communication) |
||
in using data for decision making. For example, as many workshop participants suggested, data about subpopulations, including children with special problems and ethnic minority groups, are needed to give an accurate depiction of the health status and health care needs of all Americans. Furthermore, the lack of longitudinal data can call into question the validity of health care usage and expenditure decisions. Several workshop participants recommended conducting large-scale longitudinal studies composed of several age cohorts, thus controlling for historical and cohort differences. It was noted that that there have been longitudinal studies in the past, including the NHANES I Epidemiologic Followup Study and the Longitudinal Study on Aging, but those were conducted on a relatively short-term basis. Longer series of observation would be more useful.
Dorothy Rice also made the point that, although the quality of government-based data has continually improved, private-sector health data have been erratic. Sampling, reporting, processing, and nonresponse errors plague private-sector data and therefore “the improvement of the quality and reliability of health statistics in the private sector is most urgently needed.” Moreover, peer-reviewed studies are not immune from drawing conclusions from possibly invalid data. In a review of studies dealing with managed care and quality of care, Miller and Luft (1997) found that many of those studies used data that were several years old, based on a relatively
|
Uses |
Limitations |
|
- Document drug’s impact on symptoms, work loss, and cost of care - Determine which symptoms and QOL issues matter most to patients (target DTC advertising) - Assess perceived and actual side effects of drugs on an ongoing basis - Help plan clinical trials - Answer fundamental questions about diseases and therapies - Relate findings back to other data sets |
|
small sample size, and based on “ad hoc data collection.” In addition, participants suggested that the quality of insurance coverage and health care can vary greatly, so that simple utilization rates of health care do not necessarily provide a good indicator of health status. Although some of these data can be audited, some cannot, and therefore it is important to provide adequate incentives to those who are collecting data on all levels.
In summary, many different decision makers need health data, e.g., government officials, legislators, insurers, health care providers, and consumers. Simply providing data to these groups of decision makers is not enough, however. The data must be relevant to the questions being asked and must be given in a timely manner. The relevance of data is often affected by the level at which data are collected. Meeting the needs of all users is, in fact, a gigantic task, and one in which the data collection and integration procedures are very important.
HEALTH DATA: COLLECTION AND INTEGRATION
Two schools of thought emerged from the workshop concerning the collection of health data. One group of participants felt that there are major gaps in the present federal, state, and private sector data sets and that new data collection methods and strategies are needed to fill these gaps.
The second group agreed that there are gaps in the data, but believed that the answers did not necessarily lie in developing new data collection activities. This second group felt that by examining the data that already exist and consolidating and integrating existing data one could compensate for most of what is lacking.
There certainly is currently a great deal of health data in the public domain. Several federal agencies and systems take part in epidemiological and other studies that accumulate health-related data, many of them in the form of surveys. The National Institute of Occupational Safety and Health, the Food and Drug Administration, the National Cancer Institute, the Centers for Disease Control, and the Consumer Product Safety Commission are just a few of the agencies that conduct national surveys. According to the presentations and comments of workshop participants, it was clear that via systems such as these, information is gathered on a broad range of health topics. For example, the National Immunization Survey provides data on the immunization rates of children 19–35 months of age; the Medical Expenditure Panel Survey provides data on health status; the National Household Survey on Drug Abuse provides data on the incidence and prevalence of drug use; the National Health Interview Survey provides national data on noninstitutional samples for acute illness, accidental injury, illness prevalence, health utilization; and the National Health and Nutrition Examination Survey provides national data obtained from physical examinations and physiologic and biomedical measurements. When you take into account all of the available sources that provide health data, you have an imposing collection of health data at the federal level (see Table 3-2). Furthermore, the federal government is not the only entity conducting these types of data collection. The private sector, including corporations, consulting firms, and hospitals, also conduct their own surveys.
Although having such a wealth of varied information might seem to be a positive outcome, Dorothy Rice along with several other workshop participants expressed concern that the overlap and duplication of data results in inefficiency with regard to cost and information. She stated, “Despite improvements, health statistics production in this country presents a picture of fragmented data collection, lack of common definitions, duplicative and overlapping systems, and resistance to data sharing.” Several participants at the workshop referred to this model of data collection and storage as creating a collection of separate silos, each housing fragmented statistical data and not easily relating to the others. The problem at the federal level, at least, was well characterized by Janet Norwood, who said, “The impor-
tant thing, I think, is that there is not a single place in the United States government to which one can turn for a definitive answer [to questions concerning health statistics] and explanation of the different data sets.”
Dorothy Rice reported on a program within DHHS created as part of the Reinventing Government, Part II, initiative, that resulted in the formation of an interagency working group whose purpose was to explore ways to consolidate various DHHS surveys into a single framework. As a result of this activity, for example, MEPS, NHANES, and the National Survey of Family Growth (NSFG) are all now using the sampling frame of the NHIS. Although this represents a major step forward in reducing overlap and increasing efficiency in DHHS data systems, according to Dr. Rice, there is still a long way to go before fragmentation and overlap are eliminated. Several workshop participants echoed these sentiments. H.R. 2885, the Statistical Efficiency Act, currently under consideration in Congress, would be another step in increasing efficiency in federal statistical systems. This act, if passed by the Congress, would designate eight federal statistical agencies as data centers and allow for limited sharing of that data. Janet Norwood cited another step toward data consolidation and coordination taken by DHHS—the creation of a Data Council reporting to the Office of the Secretary. Jennifer Zelmer, from the Canadian Institute for Health Information, pointed out that many countries (e.g., Canada, England, and Australia) regularly perform analyses that “take advantage of those data that can already be integrated consistently.” For example, the population-based information systems known as POPULIS employed in Manitoba and described in the presentation by Charlyn Black demonstrates the advantage of considering the possibilities for data linkages when planning population based health surveys.
Private sector databases generally revolve around health care information obtained from administrative data, medical records, and patient registries. Jacqueline Kosecoff cited the need for enhanced administrative data in the private sector. An example would be data that incorporate lab results with administrative data and allow for longitudinal analyses and linkages of key lab data to patients’ diagnoses and services, as a means of attaining more efficient information collection and the ability to answer more clinically sophisticated questions. For instance, can using lab results from diabetics answer such questions as whether the diabetic is healthier in a capitated plan, or healthier when treated by a diabetologist versus a family physician, or whether the age of the physician impacts care, or whether female diabetics do better with female physicians? Kosecoff and others at
TABLE 3-2 Data Sources for Health Indicators Included in the Candidate Sets
|
Health Indicator |
Data Source |
Level of Availability |
|
Mortality |
||
|
Infant |
Vital Statistics |
Local, State, National |
|
Maternal |
Vital Statistics |
Local, State, National |
|
Motor vehicle crash |
Vital Statistics, FARS |
Local, State, National |
|
Alcohol-related motor vehicle crash |
FARS |
State, National |
|
Work injury |
CFOI |
State, National |
|
Suicide |
Vital Statistics |
Local, State, National |
|
Homicide |
Vital Statistics |
Local, State, National |
|
Firearm fatality |
Vital Statistics |
Local, State, National |
|
Lung cancer |
Vital Statistics |
Local, State, National |
|
Breast cancer |
Vital Statistics |
Local, State, National |
|
Cardiovascular disease |
Vital Statistics |
Local, State, National |
|
Stroke |
Vital Statistics |
Local, State, National |
|
Diabetes |
Vital Statistics |
Local, State, National |
|
Unintentional injury |
Vital Statistics |
Local, State, National |
|
Residential fire |
Vital Statistics |
Local, State, National |
|
Morbidity |
||
|
HIV |
NNDSS |
Local, State, National |
|
AIDS |
NNDSS |
Local, State, National |
|
TB |
NNDSS |
Local, State, National |
|
Measles |
NNDSS |
Local, State, National |
|
Syphilis |
NNDSS |
Local, State, National |
|
Gonorrhea |
NNDSS |
Local, State, National |
|
Hypertension |
BRFSS, NHANES, NHIS |
State, National |
|
Hypercholesterolemia |
BRFSS, NHANES, NHIS |
State, National |
|
End-stage renal disease |
HCFA |
State, National |
|
Asthma hospitalization |
NHDS |
Some State, National |
|
Cumulative trauma disorders |
ASOII |
Some State, National |
|
Depression |
NCS, ECAS |
National |
|
Reported disability |
BRFSS, NHIS |
State, National |
|
Hospital days/100,000 |
NHIS |
Some State, National |
|
Years potential life lost |
Vital Statistics |
Local, State, National |
|
Emerging infectious diseases |
NNDSS |
State, National |
|
Food/water-borne diseases |
NNDSS |
State, National |
|
Hospital admissions |
NHDS |
Local, State, National |
|
Service Delivery |
||
|
Childhood immunizations |
NIS, NHIS |
MSA, State, National |
|
Pneumonia/flu immunization |
BRFSS,NHIS |
State, National |
|
Cervical cancer screening |
BRFSS, NHIS |
State, National |
|
Mammography |
BRFSS, NHIS |
State, National |
|
Preventive services delivery |
PCPS |
National |
|
Primary care linkage |
PCPS |
National |
|
Other Risk Conditions and Factors |
||
|
Low birth weight incidence |
Vital Statistics |
Local, State, National |
|
Teen intercourse |
NSFG,YRBS |
National |
|
Teen pregnancy |
Vital Statistics, NSFG |
Local, State, National |
|
Teen births |
Vital Statistics |
Local, State, National |
|
Condom use |
NSFG, YRBS |
National |
|
First trimester prenatal care |
Vital Statistics |
Local, State, National |
|
Breastfeeding |
Ross Labs, NSFG |
State, National |
|
Cigarette smoking/sales |
NHSDA/NHIS/YRBS/MFS |
National |
|
Smokeless tobacco |
NHSDA/NHIS/YRBS/MFS |
National |
|
Alcohol misuse/emergency room visits |
NHSDA/NHIS/YRBS/MFS |
National |
|
Illicit drug use/emergency room visits |
NHSDA/NHIS/YRBS/MFS |
National |
|
Seatbelt use |
NHIS |
State, National |
|
Firearm storage |
BRFSS, NHIS |
State, National |
|
Overweight |
BRFSS, NHANES |
State, National |
|
Sedentary pattern |
BRFSS, NHANES, NHIS |
State, National |
|
Untreated dental caries |
NHANES |
National |
|
Air quality exposure |
AIRS |
(Non-attainment areas) |
|
Health insurance/loss |
NHIS, Census, MEPS |
State, National |
|
High school graduation rate |
NCES |
State, National |
|
Childhood poverty |
Census |
State, National |
|
Key: |
|
AIRS=National Air Quality and Emissions Trends Report/Aerometric Information Retrieval System |
|
ASOII=Annual Survey of Occupational Injuries and Illnesses |
|
BRFSS=Behavioral Risk Factor Surveillance System |
|
CFOI=Census of Fatal Occupational Injury |
|
ECAS=Epidemiologic Catchment Area Study |
|
FARS=Fatality and Analysis Reporting System |
|
HCFA=Health Care Financing Administration |
|
MCBS=Medicare Current Beneficiary Survey |
|
MEPS=Medical Expenditure Panel Survey |
|
MFS=Monitoring the Future Study (University of Michigan) |
|
NCES=National Center for Educational Statistics, Department of Education |
|
NCS=National Comorbidity Survey |
|
NHANES=National Health and Nutrition Examination Survey |
|
NHDS=National Hospital Discharge Survey |
|
NHIS=National Health Interview Survey |
|
NHSDA=National Household Survey on Drug Abuse |
|
NIS=National Immunization Survey |
|
NNDSS=National Notifiable Disease Surveillance System |
|
NSFG=National Survey of Family Growth |
|
NSWHPA=National Survey of Worksite Health Promotion Activities |
|
PCPS=Primary Care Provider Survey |
|
YRBS=Youth Risk Behavior Survey |
|
SOURCE: Department of Health and Human Services (1998). |
the workshop encouraged the development of a greater connection between federal agencies and the private sector, so that each sector could have additional, useful information that it would be unable to collect on its own, and so that costly overlap among the public and private sectors could be reduced.
Discussion of linkage of government and private sector resources high-lights an interesting question: At what level or levels should linkages of health data take place? Interagency linkage and consolidation is in its infancy in the United States and is used considerably more in other nations. The private/public partnership that several workshop attendees mentioned is another level of linking data, as is linkage among community, state, and federal agencies, not just interagency connections on the federal level. By linking data at all three levels of governmental organization, a more com-
plete picture can be had and less fragmentation of health data will result. Clyde Hertzman emphasized the importance of data integration at the international level. The power and diversity of the data that would result from international partnerships would be valuable. Hertzman also suggested that an important potential partnership is that between universities and government agencies, such that sample data collected in university settings and broad, population data collected in agency settings could be effectively integrated.
According to several workshop participants, a variety of problems can arise with data partnerships. There may be concern that one organization or agency will control the data in opposition to the desires of the other data partners. As an example, many workshop participants mentioned that state-level government agencies might be—or are—hesitant to share data with federal agencies because of fear that the federal agencies will hold all the data and impede the dissemination process. Another major obstacle to integration and linkage of data cited was the lack of standardization in data collection among the levels of data collection mentioned above. Many workshop participants agreed that some sort of standardization in data collection is needed in terms of procedure, definitions of terms, and populations sampled. Some argued that the diversity resulting from not having such standardization can be beneficial, but acknowledged that lack of standardization leads to many inefficiencies. The differing responsibilities of agencies can also inhibit data collaboration. Dr. Kenneth Thorpe from Emory University stated, “It is not a tremendous surprise that, when you see the proliferation of data sets and overlap of data systems, these are often driven by the agency’s differing set of responsibilities.” Not discusssed at the workshop was the topic of legal restrictions that apply to the flow of certain data away from the government and that go hand in hand with the government’s legal authority to collect particular data.
New technologies to facilitate data collection are continuously emerging. As William Eddy from Carnegie Mellon University stated in his presentation, “Communication is the key.” New data collection procedures continually improve the possibilities for gathering data from hard-to-reach populations and hard-to-measure variables, and provide opportunities for improving response rates. Dorothy Rice provided a brief overview of the changes that have occurred over the years in regard to data collection. From in-home interviews to random-digit telephone dialing, computer-assisted telephone surveys, and computer-assisted interviews, the progress of technology in general has had positive effects on health statistics. With the
increase in use of the Internet, further improvements in data collection (e.g., Web-based surveys) are probably not far behind. Participants cautioned, however, that there is always the possibility that more advanced technology may not produce the most valid information. For instance, Lorraine Klerman mentioned that experts tend to agree that household interviews are more valid than surveys conducted by telephone or questionnaire, but questioned if there would be any difference when using the Internet. An added benefit of increased computer technology is, of course, the ease with which data can be shared. Websites can be designed to disseminate timely data analyses rapidly. Complex databases could be formed that consolidate several different surveys and automatically remove any overlapping or duplicative data. Workshop participants noted that a major consideration in the use of technology for these purposes will be the ability of the architects of the system to assure that the privacy and confidentiality of the data in the system are appropriately protected at all times.
PRIVACY AND CONFIDENTIALITY
The protection of privacy and the assurance of confidentiality are important for both the individual and the data collector in any data system. In addition to the obvious ethical and legal responsibilities on the part of the data collector for the assurance of privacy and confidentiality, a lack of secure feelings among the survey participants regarding their privacy and confidentiality can adversely affect the data collection process. As many workshop participants mentioned, obtaining sensitive information is not an easy task. When there is a distrust among survey participants concerning how their information will be used by federal, state, and local governments or by private organizations, the data collection process will inevitably become more difficult and incomplete. Dorothy Rice summarized these difficulties by stating that “both individuals and businesses are questioning how the information is used and who has access to it. At the same time, data users, especially those outside of government, are increasingly frustrated by limits on the amount of detailed information they can obtain from statistical agencies” (see Chapter 2). Not only might survey participants be reluctant to provide accurate data if they feel their privacy would be compromised, but, more important to the health of each individual, they might not cooperate in a treatment setting for fear that information obtained would be made available to others.
The ethical background of health care professionals plays an important
role in protecting the privacy of data. For example, workshop participants pointed to the Hippocratic oath (i.e., “Whatever in connection with my professional practice or not in connection with it I may see or hear in the lives of my patients which ought not be spoke abroad I will not divulge, reckoning that such should be kept secret”) or to the American Medical Association’s Principles of Medical Ethics (i.e., “A physician shall respect the rights of patients, of colleagues, and of other health professionals, and shall safeguard patient confidences within the constraints of the law”). However, not all health researchers, of course, are physicians, and although several professional organizations, such as the American Psychological Association, have their own standards of ethics, many do not. Furthermore, George Duncan of Carnegie Mellon University pointed out in his remarks these two statements of ethical standards are based on the assumption that the paradigm will be one of physician and patient only. These standards are not as relevant to complex systems in which multiple data sources containing information about patients outside any one doctor’s domain are available via various communication streams. Duncan suggested that a more relevant ethical standard to have would be “autonomy and respect for the individual patients.” Whatever the standards, though, the increase in information technology makes data theft a more plausible outcome. Linkages from various databases, easy dissemination using the Internet and other communications technology, and the ease of finding information through user-friendly search engines exacerbate the potential problems.
The storage of data can be made more secure by technological innovations. Just as improved technology creates the potential of nonsecured data sets being broadcast over various communication lines, other technology is being developed to help prevent security breaches. Federal legislation is aimed at insuring that privacy and confidentiality are protected. John Eisenberg, Director of the Agency for Healthcare Research and Quality (formerly known as the Agency for Health Care Policy and Research), reported to the workshop attendees that the DHHS has been developing privacy regulations in connection with the Health Insurance Portability and Accountability Act (HIPAA) legislation.1 These regulations would,
|
1 |
The Health Insurance Portability and Accountability Act of 1996, Public Law 104– 191, was signed into law on August 21, 1996. Having its roots in the 1993 Clinton health care reform proposals, the primary intent of HIPAA is to provide better access to health insurance, to limit fraud and abuse, and to reduce administrative costs. The Administrative Simplification aspect of that law requires DHHS to develop standards and requirements for maintenance and transmission of health information that identifies individual patients. |
among other things, govern the electronic transfer of data used in federal health programs, such as Medicare. George Duncan presented several ideas regarding potentially useful methods for the protection of the privacy and confidentiality of research participants. One method would be to limit the access to and disclosure of the data. A consensus on the appropriate limits to access and disclosure is often very difficult to reach, however, given the potentially conflicting objectives of the interested parties. For example, J. Michael Fitzmaurice, from the Agency for Healthcare Research and Quality, suggested that a possible problem with the HIPAA legislation might be overly strict rules that would have the unwanted effect of keeping important data away from ethical researchers. Furthermore, Jacqueline Kosecoff suggested that in many circumstances health plans need to submit data that are scrambled and “scrambled data are really hard to link with previously scrambled data.” John Eisenberg commented that he considered the proposed regulations to be “a terrific document. It really does bring together control and assurance to the public that their data is being held confidential, and yet a recognition that there are certain goods that we have to keep in mind.”
George Duncan summarized the problem of protecting the privacy and confidentiality of health data by stating that the goal is to “satisfy the customer and deter the shoplifter.” Full data access would result in high-disclosure risk and go above the maximum level of tolerance that an individual would allow (see Figure 3-2). The managers of the data system “have to provide access to the data. At the same time, they have to provide confidentiality protection. If one of these pillars disappears, the whole edifice collapses. That is the framework in which we operate.”
Confidentiality can be protected in ways other than by simply not allowing people to access the information.2 For instance, data masking can be employed to make the data anonymous. This can be accomplished by
|
2 |
In October 1999, the Committee on National Statistics convened a workshop that reviewed the benefits and risks of providing public-use research data files and explored alternative procedures for restricting access to such data, particularly longitudinal survey data that have been linked to administrative records. Please see the summary report of that workshop, in which the tradeoffs between researcher and other data user needs and confidentiality requirements are well articulated, as are the relative advantages and costs of data perturbation techniques versus restricted (physical) access as tools for improving security (National Research Council, 2000). |
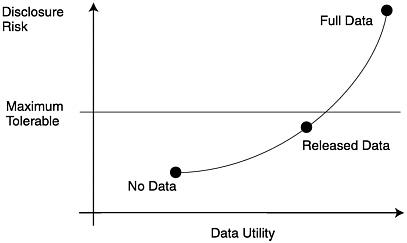
FIGURE 3-2 Data disclosure risk and individual tolerance level.
SOURCE: Data from George Duncan (personal communication).
removing identifiers, restricting reporting of cases and variables, systematically altering the data, and matrix masking. Matrix masking involves transforming the data by receding or releasing only subsets of the data, but leaving the essence of the data in tact. One of the difficulties with this approach is that anonymity is not always assured by simply removing identifiers or variables from the data sets. The use of synthetic data provides another option for restricting access. In this process, the key idea is that descriptive models (usually parametric) are estimated from the data, and then samples are generated from the model. The main problems of this method are the complexity of putting it into practice and the fact that there is no direct link between the original data and the data that are eventually released. However, the essence of the information remains, and attaching data to individual patients is nearly impossible.
In summary, issues of confidentiality are important for both patients and other individuals who supply the data and for health information analysts, decision makers, and others who use the data. If either set of interests is not appropriately taken into account, then the health information system will be filled with frustrations and inefficiencies. Steps have to be taken to ensure that privacy and confidentiality will remain intact while making the data accessible for legitimate uses. Approaches such as using masked or
synthetic data, restricting access to a particular database, or requiring passwords for Web-based access are examples of the methods that can be used, either solely or in combination, to protect confidentiality.
HEALTH DATA SYSTEMS: LESSONS FROM OTHER COUNTRIES
When reviewing the health systems in other countries, some of the characteristics and methodologies regarding the collection and utilization of health data could serve as examples for developing an improved system in the United States. Several presenters at the workshop discussed health information systems that are being implemented in other countries, and suggested that these systems might be viewed as potential models for the American system. Each of these systems featured as core components a central coordinating body, linkage of data sources, and standardization of data and data collection.
Charlyn Black described the POPULIS program, a population-based health information system housed in the Manitoba Centre for Health Policy and Evaluation, which is a university-based research group. The purpose of POPULIS is to provide “accurate and timely information to managers, decision-makers, and providers, in order to support them in offering health care services….” Through its system of data sets, organization, and analysis models, POPULIS is designed to allow evaluation of the components that “influence health, the state of health, and the availability and utilization of health and other services,” thus enabling researchers to address complex questions. Another important feature of using a population-based system is that it “enables the user to simultaneously relate characteristics that affect a populations need for health care to that populations use of health care, to that area’s supply of health care resources, and finally, to the health status of a population.” Black suggested that a prerequisite of a strong health information system is a strong health data system. The data system used by POPULIS is a population-based research registry that captures data provided by the Manitoba provincial health insurance administration system. Black pointed out that a data system is not sufficient by itself, however, to produce a quality information system. An appropriate conceptual model for analysis of the data is very important, as well. The model the POPULIS program employs recognizes that there are a multitude of factors that can contribute to the health status of the population. Health status can, in turn, have its own impact on each of those factors—for example, poor
health status can affect socioeconomic status, and vice versa. This model allows for “rich and complex population-based analysis.” POPULIS uses data obtained from the administration and payment for services delivered to estimate the key concepts under investigation such as health status, health care utilization, and supply. Black noted, “there is a unique identifier within the research registry to maintain privacy and confidentiality. It is scrambled, it is anonymized, and we maintain a parallel and different set of data.” Data from many files, such as hospital data, data from the medical community-based services, pharmaceutical data, vital statistics, and aggregate census data, exist in an unlinked format, and the use of the unique identifier allows for very rich microdata at the level of individualized, anonymized people. Black emphasized that when designing population-based health surveys, the possibility for linking data and conducting validity studies using administrative data should be foreseen and incorporated into study design. In Manitoba, with the expansion of national, longitudinal, population health services, there has been explicit consideration given to the potential to link detailed data from surveys to the population-based study that comes from the administrative registry information. Through the work of the POPULIS program, Black added, they have been able to transform an administrative medical care data system into an information system that focuses on the population’s health, use of the health care system, and cost of the health care system. The system is much more responsive and useful in anticipating policy needs, monitoring trends, and understanding connections, and has been instrumental in changing the focus of policy discussions from what health care services are provided to what is being done to improve health.
Jennifer Zelmer presented a summary of the health information systems that have been created in Australia, Canada, France, Finland, England, and Denmark. She spoke of tenets that have been followed in each country’s efforts. A common theme in each case is that the activities are coordinated by an independent agency that is responsible not only for coordinating the statistical activities at the national level but also for coordinating the health information. For instance, in Australia, the task of oversight has been given to the Institute of Health and Welfare; in Canada, this responsibility is handled by the Institute for Health Information; in France, it is the Direction de la recherche, des études, de l’évaluation, et des statistiques; and, in Finland, the efforts are coordinated by the National Research and Development Centre for Health and Welfare. These coordinating bodies do not act alone, but actively collaborate with federal, pro-
vincial, and territorial governments, and other relevant decision makers. In Canada, for instance, Statistics Canada is an important partner in the health information process. The Danish, Canadian, and Finnish systems integrate microlevel data across time, which allows for complex analyses. More localized efforts can be seen in Canada, where several provincial research institutes have collaborated in order to bring together a wide range of data. Collaborations also exist on the international level. For instance, the European office of the World Health Organization has acted as the coordinating body to bring together national and subnational statistics in that region in order to facilitate international analysis. Other collaborations include the European and international standardization committees, joint health statistics meetings between the World Health Organization and the European Economic Community (EEC), and several initiatives that fall under the Global Healthcare Applications Project.
Efforts to facilitate the collection and linkage of administrative and respondent data are continuously being explored and the information technology continuously upgraded in most developed countries. Data integration and linkage, of course, carry with them a risk of infringement on individuals’ privacy. Finland has attempted to solve this problem by encryption of identifiers and data integration by a third party. Switzerland uses anonymous linkage codes for each hospital patient and destroys the data after 10 years. As in the United States, many countries have implemented specific legislation to protect the rights to data privacy and confidentiality. The legislation is generally modeled on the principles outlined by the Organization for Economic Cooperation and Development. However, with the progression of information technology, countries have realized that more should be done in this area and have sought to develop innovative technologies to aid in the protection of privacy.
Merwyn Greenlick, from the Oregon Health Sciences University, spoke about his Utopian view of what an American health information system should look like in the twenty-first century. Termed a humanistic health care system, Greenlick’s ideal would link each individual to the health care system based on the individuals needs, desires, aspirations, risks, disease condition, and health functional status. In order to meet this need, the health care system must ensure a sense of trust, overcome knowledge deficits, and have a powerful reimbursement method in place. Greenlick pointed to Kaiser Permanente as an example of an organization that has developed a micro image of what a system should possess. Using innovative information technologies, doctors can communicate using computers
to refer, schedule, and even treat patients. Patients could even be given information that they can use to help treat themselves. Greenlick stated that this would place a piece of the treatment of decision making into the hands of the patient. This type of system would also allow for doctors to practice within a population-based clinical practice. Eileen Peterson, from United Health Care, a private-sector health care organization, proposed a private managed health care data system for the United States. The system would be a managed care data repository and reporting system based on administrative data that would combine financing and delivery data. Ideally, in such a system, an electronic medical record would be linked into a practice management system in a provider’s office, and with the press of a button, a claim is sent and a medical record is created. Other routinely collected data would be incorporated into the system, with surveys (e.g., the Consumer Assessment of Health Plans and the Health of Seniors), disease management, contracts databases, and support databases adding important information. Mining the existing data for all relevant information would be a good cost-efficient procedure. An important step of this process would be the one in which the data stakeholders convene “to define the rules of the road” (i.e., who can and cannot have access) and to explore and map linkages to data resources. However, Peterson emphasized that before any of these goals and strategies are discussed, the stakeholders would need to define the products to be produced. Once these steps are taken, Peterson said that it would be necessary to demonstrate the capabilities of the system through monitoring and surveillance to assure there is a quick turn-around of data to inform policy and to demonstrate that a full-scale research project can be undertaken. An evaluation of the opportunity costs—both monetary and nonmonetary, such as the improvements in health—would be essential to determine the “return on capital” to consumers and the health industry. Although integrating such a system with the public-sector systems would bring about many challenges, Peterson reported that new technologies present an exciting opportunity to do just that. Dorothy Rice echoed this sentiment when she said that the private sector should be an important contributor to future health information systems. Jacqueline Kosecoff stated that it is not necessarily optimal to have all the data that a particular hospital or health care provider has collected. Instead, it is important to be able to track all care “delivered by a cohort of providers.” Kenneth Thorpe, along with several others, suggested that the federal government, more specifically the executive branch, should take the lead in coordinating such a system. This is the case in part, according to Robert
Murphy from Westat, because the federal government has a more adequate infrastructure than that available at the state and local levels. This sentiment was echoed by Miron Straf from the National Research Council, who spoke of a vision in which local and state public health communities would take advantage of the infrastructure of NCHS. David Fleming, from the Oregon Health Division, and others questioned whether federal agencies such as NCHS can, in fact, provide the necessary leadership to state and local agencies.
In summary, a number of countries have strong health information systems. Canada, with several collaborations among local and national organizations, Australia, Finland, France, and several others, have central coordinating bodies for their health information systems. Researchers in these countries believe they are able to successfully obtain data from a broad range of sources and across a wide variety of variables, yet are still able to maintain a level of privacy and confidentiality that has helped to ensure trust among their public. Several workshop participants praised the efforts of these national systems and asked if it was possible to build such a system in the United States. The question was raised whether a government or nongovernment entity should act as the coordinator if the United States were to build such a system. Jacqueline Kosecoff suggested that whichever organization could make data available cheaply and efficiently should take the lead regardless of whether it is a public- or private-sector organization. She continued by saying that researchers should stop arguing over who will house the data sources and worry more about getting a system in place. Daniel Friedman, from the Massachusetts Department of Public Health, echoed the comments of several at the workshop when he said that the United States can achieve what Canada has done and that the societal differences between the countries should not be seen as an insurmountable road block. He suggested that the health information community needs to start thinking that the United States can succeed in creating a comprehensive and effective health information system and that it is time to decide how to get it done.
FINANCING A HEALTH INFORMATION SYSTEM
Dorothy Rice reported that federal spending for health and human services statistics had reached $804.1 million in 1999. Despite the size of this investment, several workshop participants either suggested that more money is needed in U.S. data systems or wondered how a new and innova-
tive health information system could be financed in the present political climate (the fall of 1999). Rice commented that states need help and that the federal government needs to do more to take a leading role. The central governments in countries with successful health information systems appear to have provided greater financial support to these systems. Jennifer Zelmer reported, for instance, that the government in the United Kingdom has promised to contribute £1 billion of new money to their health information system over a seven-year period, while the Canadian government has estimated that they will spend over $1.5 billion on information technology for the health field in the year 2000, with the majority of the money going to support the infrastructure at the provincial, territorial, and local levels.
An issue of financial importance to the private sector is the appropriate compensation of medical care personnel for taking the time and resources to supply agencies and organizations with patient data. Elliot Stone wondered if the Health Care Financing Administration reimbursement would be the answer for those who follow national standards of data collection. Jacqueline Kosecoff stated that she would not want to have an agency, such as a federal body, tell her what and how to collect data unless she was compensated for that work, further noting, however, that she would rather see a system of tax credits than a system of reimbursement. There was a sentiment among participants that more efficient spending of available funds could be at least a partial answer to financing a health information system. Kenneth Thorpe, for example, noted that the federal government is spending hundreds of millions of dollars on health data and that private foundations are doing the same thing, but with much overlap among disparate surveys. Consolidation and integration might be a way to defragment the data collection process.
REFERENCES
Black, C., N.Roos, and L.Roos 1999 From Health Statistics to Health Information Systems: A New Path for the 21st Century. Paper commissioned by the National Committee on Vital and Health Statistics and presented at the Committee on National Statistics Workshop, Toward a Health Statistics System for the 21st Century, November 4, Washington, DC. Available: <http://www.ncvhs.hhs.gov/hsvision/visiondocuments.html> [July 12, 2001].
Evans, R.G., and G.L.Stoddard 1990 Producing health, consuming health care. Social Science and Medicine 31:1347– 1363.
Miller, R.H., and H.S.Luft 1997 Does Managed Care Lead to Better or Worse Quality of Care? Health Affairs 16:7–25.
National Research Council 2000 Improving Access to and Confidentiality of Research Data: Report of a Workshop. Committee on National Statistics, Christopher Mackie and Norman Bradburn, eds. Washington, DC: National Academy Press.
U.S. Department of Health and Human Services 1998 Leading Indicators for Healthy People 2010. A Report from the Working Group on Sentinel Objectives. Office of Disease Prevention and Health Promotion, U.S. Department of Health and Human Services. Available <http://odphp.osophs.dhhs.gov/pubs/LeadingIndicators/ldgindtoc.html> [July 12, 2001].






























