
2
Enabling Technologies
To understand the forces shaping networked systems of embedded computers it is useful to look at some of their underlying technologies—the devices used to compute, communicate, measure, and manipulate the physical world. The trends in these devices are what make EmNets such a compelling and interesting research question at this time. The current components are making large EmNets feasible now, and as these components continue to evolve, EmNets will soon become essential, even dominant, parts of both the national and global infrastructure.
Through the economics of silicon scaling, computation and communication are becoming inexpensive enough that if there is any value to be derived from including them in a product, that inclusion will probably happen. Unfortunately, while these “standard” components will enable and drive EmNets into the market, without careful research the characteristics that emerge from these collections of components may not always be desirable. EmNets present many new issues at both the component and system level that do not need to be (and have not been) addressed in other contexts.
This chapter provides a brief overview of the core technologies that EmNets use, the trends that are driving these technologies, and what new research areas would greatly accelerate the creation of EmNet-tailored components. Because the scaling of silicon technology is a major driver of computing and communication, this chapter starts by reviewing silicon scaling and then looks at how computing and communication devices
take advantage of scaled technologies. In communications technology, attention is focused on wireless communications technology since this will be an essential part of many EmNets and on wireless geolocation technology since geographic location is a factor in many EmNets. The remaining sections review other components critical to EmNets, namely, the software systems that make EmNets work and MEMS, the new way to build low-cost sensors and actuators. Scattered throughout the chapter are boxes that provide more details on many of the technologies discussed. Readers who are already well versed in these subject areas or who are more interested in understanding the systems-level issues that arise in EmNets should move on to Chapter 3.
SILICON SCALING
Much of the driving force for the technological changes seen in recent years comes from the invention of integrated circuit technology. Using this technology, electronic components are “printed” on a piece of silicon, and over the years this process has been improved so that the printed components have become smaller and smaller. The ability to “scale” the technology simultaneously improves the performance of the components and decreases their cost, both at an exponential rate. This scaling has been taking place for over 40 years, giving rise to eight orders of magnitude change in the size and cost of a simple logic element, from chips with two transistors in the 1960s, to chips with 100 million transistors in 2001. Scaling not only decreases the cost of the devices, it also improves the performance of each device, with respect to both delay and the energy needed to switch the device. During this same 40 years, gates1 have become 1000 times faster, and the power required per gate has dropped more than 10,000-fold. This scaling is predicted to continue for at least another 10 to 20 years before it eventually reaches some fundamental technical and economic limit (Borkar, 1999).
Silicon scaling continues to reduce the size, cost, and power and to improve the performance of electronic components. Reliability of the basic electronics has also improved significantly. Vacuum-tube electronics were limited by the poor reliability of the tubes themselves—filaments burned out regularly and interconnections were generally made by hand-soldering wires to sockets. Transistors were much more reliable due to cooler operation temperatures and the absence of filaments, but there were still huge numbers of soldered interconnects. As integrated circuits
have subsumed more and more functionality, they have also subsumed huge amounts of interconnections that are generally much more reliable than soldered pins on a printed circuit board.
Coupling this manufacturing process to the notion of a computer has driven a huge industry. For example, mainframe computers that occupied rooms in the 1980s now can fit on a single chip and can operate faster and at much lower power than the older systems. The scaling of technology has not only enabled the building of smaller, faster computers, it has made computing so cheap that it is economical to embed computing inside devices that are not thought of as computers to increase their functionality. It is this rapidly decreasing cost curve that created and continues to expand a huge market for embedded computing, and as this same technology makes communication cheaper, it will allow the embedded computers to talk with each other and the outside world, driving the creation of EmNets. Just as electronic locks seem natural now (and soon it will be hard to imagine a world without them), it will soon seem natural for embedded systems inside devices that are not typically thought of as computers to communicate with each other.
COMPUTING
The ability to manufacture chips of increasing complexity creates a problem of its own: design cost. While design tools continue to improve, both the number of engineers needed to design a state-of-the-art chip and the cost of said chip continue to grow, although more slowly than chip complexity. These costs add to the growing expense of the initial tooling to produce a chip, mainly the cost of the masks (“negatives”) for the circuits to be printed—such masks now cost several hundred thousand dollars. Thus, chips are inexpensive only if they are produced in volumes large enough to amortize such large design costs. The need for large volumes poses an interesting dilemma for chip designers, since generally as a device becomes more complex, it also becomes more specialized. The most successful chips are those that, while complex, can still serve a large market. This conflict is not a new one and was of great concern at the dawn of the large-scale integration (LSI) era in the 1970s. The solution then was to create a very small computer, or microprocessor, and use it with memory to handle many tasks in software that had previously required custom integrated circuits. This approach really created embedded computing, since it provided the needed components for these systems. Over the years the microprocessor was an essential abstraction for the integrated circuit industry, allowing it to build increasingly complex components (processors and memory) that could be used for a wide variety of tasks. Over time, these processors have become faster, and they are
now the key component in all computers, from Internet-enabled cell phones to mainframe servers.
The evolution of microprocessors over the past three decades has been unprecedented in the history of technology. While maintaining roughly the same user model of executing a sequential stream of instructions, these machines have absorbed virtually all of the extra complexity that process scaling provided them and converted it to increased performance. The first microprocessor was the Intel 4004, developed in 1971; it had 2300 transistors and ran at 200 kHz. A mere 30 years later, the Pentium 4 processor has almost 42 million transistors and runs at 1.7 GHz. Computer architects have leveraged the increased number of transistors into increased performance, increasing processor performance by over four orders of magnitude (see Box 2.1).
Growing Complexity
Increasing processor performance has come at a cost, in terms of both the design complexity of the machines and the power required by the current designs (on the order of 10 to 100 W). The growing complexity is troubling. When does the accumulating logical complexity being placed on modern integrated circuits cause enough errors in design to begin to drive overall system reliability back down? This is not a trivial concern in an era where volumes may be in the tens or hundreds of millions and failures may be life threatening. Another problem with the growing complexity is the growing cost to design these machines. New microarchitectures such as that for Intel’s Pentium 4 processor require a design team of several hundred people for several years, an up-front investment of hundreds of millions of dollars.
Also of growing concern is the fact that continuing to scale processor performance has become increasingly difficult with time. It seems unlikely that it will be possible to continue to extract substantially more parallelism at the instruction level: The easy-to-reach parallelism has now been exploited (evidence of this can be seen in Figure 2.1), and the costs in hardware resources and implementation complexity are growing out of all proportion to additional performance gains. This means that the improvement in instructions per clock cycle will slow. Adding to that concern, it also seems unlikely that clock frequency will continue to scale at the current rate. Unless a breakthrough occurs in circuit design, it will become very difficult to decrease clock cycle times beyond basic gate speed improvements. Overall microprocessor performance will continue to grow, but the rate of improvement will decrease significantly in the near future.
|
BOX 2.1 The dominant technology used to build integrated circuits is complementary metal-oxide semiconductor (CMOS) technology. As the integrated circuit shrinks in size, the characteristics of the basic transistors improve—they speed up. Historically the speed of a basic CMOS gate has been roughly proportional to its size. This performance increase will continue, although various problems might slow the rate of improvement in the future (SIA, 1999). In addition to gates, the other key component on an integrated circuit is the wire that connects the gates. The scaling of wires is more complex than that of the gates and has led to some confusion about how the performance of circuits will scale in the future. As technology scales, the delay of a wire (the length of time it takes for a signal to propagate across the wire) of constant length will almost certainly increase. At first glance this seems like a huge problem, since gate delays and wire delays are moving in opposite directions. This divergence has led a number of people to speak of wire-limited performance. The key point is, as technology scales, a wire of a given length spans a larger number of gates than the wire in an older technology, since all the gates are smaller. A circuit that was simply scaled to the new technology would also shrink in length, since everything has shrunk in size. The amount of delay attributable to this scaled wire is actually less than that of the original wire, so wire delay decreases just as a gate does. While the wire delay does not scale down quite as fast as the gate, the difference is modest and should not be a large problem for designers. One way of viewing the wire delay is to realize that in any given technology the delay of a wire that spans more gates is larger than the delay of a wire that span fewer gates. Communicating across larger designs (that is, designs with more gates per unit area) is more expensive than communicating across smaller designs. Technology scaling enables larger designs to be built but does not remove the communication cost for these complex designs. So, scaling does not make wire performance proportionally worse per se; rather it enables a designer to build a more complex system on a chip. The large communication delays associated with systems are starting to appear on chips. These growing communication costs of today’s large complex chips are causing people to think about smaller, more partitioned designs, and they are one driver of simpler embedded computing systems. |
Simpler Processors
Up to this point the focus has been on the highest performance processors, but technology scaling has also enabled much simpler processors to have more than sufficient performance.2 Rather than adding complex-
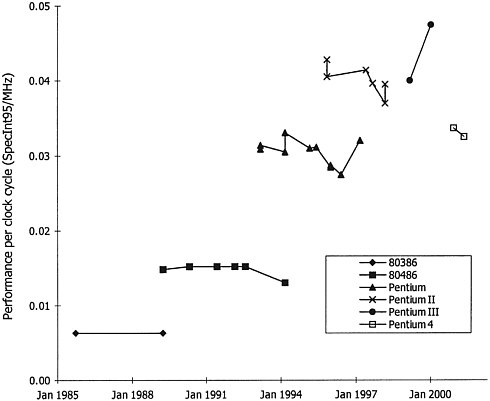
FIGURE 2.1 Instructions executed per cycle.
ity in order to wrest better performance from the chip, it is possible to use the added transistors for other functions, or not use them at all, making the chip smaller and cheaper and, as will be seen in the next section, less power consuming. It is these “simpler” processors that are used in most embedded systems, since they often do not need the highest performance. For many applications, the extra complexity can be and is used to interface to the outside world and to reduce the amount of off-chip memory that is needed to reduce the system cost.
As technology scales, these simpler processors have gotten faster, even if the design does not use more transistors, simply because the gates have become faster. Often a slightly more complex architecture is used, since it is now cheap enough. This scaling trend in the embedded proces-
|
|
CISC) debates of the 1980s. They refer to the complexity of a computer’s microarchitecture and implementation, not its instruction set. |
sor space has dramatically increased the performance of the processors being deployed and will continue to do so (see Box 2.2). The fastest embedded processors have a processing power that is within a factor of four of today’s desktop processors (e.g., an 800-MHz StrongArm processor compared with a 1.5-GHz Pentium 4), but most embedded processors have performance that is an order of magnitude worse. With increased processing power comes the ability to build more sophisticated software systems with enough cycles to support various communication protocols. The existence of very cheap cycles that can support richer environments is another factor pushing EmNets into existence.
Power Dissipation
Power dissipation in general-purpose central processing units (CPUs) is a first-order constraint, requiring more expensive power supplies and more expensive cooling systems, making CPU packages more expensive; it may even affect the final form factor of the computer system.3 Power has always been constrained in embedded systems, because such systems typically cannot afford any of the remedies mentioned above. For example, the controller in a VCR cannot require a large power supply, cannot have a fan for cooling, and cannot make the VCR be taller than such products would otherwise be.
There are two major strategies for taking advantage of the benefits of new processor technology: maximize performance or minimize power. For each new technology, the power needed to supply the same computation rate drops by a factor of three (see Box 2.3). The reason that general-purpose microprocessor power increases with each new generation is that performance is currently valued more than cost or power savings, so increased performance is preferred in the design process over decreased power requirements.
As power has become more important in complementary metal-oxide semiconductor (CMOS) designs, designers have developed a number of techniques and tools to help them reduce the power required. Since in CMOS much of the power is used to transition the value on a wire, many of the techniques try hard to ensure a signal is not changed unless it really should be and to prevent other ways of wasting power. The power saving ranges from simply turning off the processor/system when the ma-
|
BOX 2.2 While scaling technology allows the building of faster gates, it primarily allows the construction of designs that contain many more gates than in previous iterations. Processor designers have been able to convert larger transistor budgets into increased program performance. Early processors had so few transistors that function units were reused for many parts of the instruction execution.1 As a result it took multiple cycles for each instruction execution. As more transistors became available, it became possible to duplicate some key functional units, so each unit could be used for only one stage in the instruction execution. This allowed pipelining the machine and starting the next instruction execution before the previous one was finished. Even though each instruction took a number of cycles to complete execution, a new instruction could be started every cycle. (This sort of pipelining is analogous to a car wash. It is not necessary to wait until the car ahead exits the car wash before introducing a new car; it is only necessary to wait until it has cleared the initial rinse stage.) As scaling provided more transistors, even more functional units were added so machines could start executing two instructions in parallel. These machines were called superscalar to indicate that their microarchitectures were organized as multiple concurrent scalar pipelines. The problem with a superscalar machine is that it runs fast as long as the memory system can provide the data needed in a timely fashion and there are enough independent instructions to execute. In many programs neither of these requirements holds. To build a fast memory system, computer designers use caches2 to decrease the time to access frequently used data. While caches work well, some data will not be in the cache, and when that happens the machine must stall, waiting for the data to be accessed. A so-called out-of-order machine reduces this delay by tracking the actual data-flow dependency between instructions and allowing the instructions to execute out of program order. In other words, the |
chine is inactive, a technique that is used in almost all portable systems, to careful power control of individual components on the chip. In addition, power is very strongly related to the performance of the circuit. A circuit can almost always be designed to require less energy to complete a task if given more time to complete it. This recently led to a set of techniques to dynamically control the performance as little as necessary to minimize the power used.4 Two recent examples of this are the Transmeta Crusoe processor (Geppert and Perry, 2000) and the Intel Xscale processor (Clark et al., 2001).
|
4 |
See DARPA’s Power Aware Computing/Communication Program for more information on work related to this problem. Available at <http://www.darpa.mil/ito/research/pacc/>. |
|
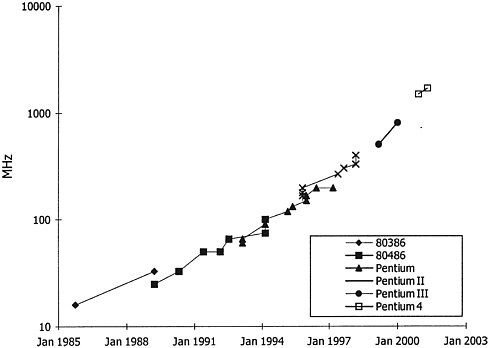
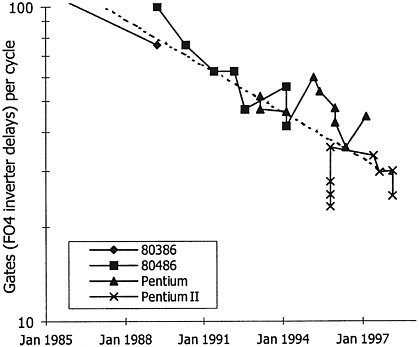
machine finds other work to do while waiting for slow memory elements. While much more complex than a simple superscalar machine, out-of-order processing does expose more parallelism and improves the performance of the processor. Each architectural step—pipelining, superscaling, out-of-order execution—improves the machine performance roughly 1.4-fold, part of the overall threefold performance improvement. Figure 2.1 plots a number proportional to the number of instructions executed each cycle for six generations of Intel processors. The data clearly show that increasing processor complexity has improved performance. Figure 2.2 gives the clock rate of these same processors; it shows a roughly two-fold increase in frequency for each generation. Since a scaled technology comes out roughly every 3 years, 1.4 of the overall performance increase comes from this improvement in speed. The remaining factor of 1.4, which comes from improvements in the circuit design and microarchitecture of the machine, is illustrated in Figure 2.3. This shows how many gates one can fit in each cycle and how this number has been falling exponentially, from over 100 in the early 1980s to around 16 in the year 2000. The decrease has been driven by using more transistors to build faster function units and by building more deeply pipelined machines. Multiplying these three factors of 1.4 together yields the threefold processor performance improvement observed. It should be noted that recent designs, such as the Pentium III and Pentium 4 chips, have not been able to achieve the increases in parallelism (instructions per cycle) that contributed to the threefold increase. This provides some concrete evidence that uniprocessor performance scaling is starting to slow down. |
The drive for low power causes a dilemma. (See Box 2.4 for a discussion of micropower sources for small devices.) While processor-based solutions provide the greatest flexibility for application development, custom hardware is generally much more power efficient. Early work in low-power design by Brodersen et al. (1992) and others showed that for many applications, custom solutions could be orders of magnitude lower in power requirements than a general-purpose processor. This is unfortunate, since the economics of chip production, as described earlier, make it unlikely that most applications could afford to design custom chips unless the design process becomes much cheaper. There are a couple of clear reasons why custom chips need less power. Their main advantage is that they are able to exploit the parallelism in the application. While exploiting parallelism is usually considered a way to increase perfor-
mance, since performance and power are related, one can take higher-performance systems and make them lower power. In addition to parallelism, custom solutions have lower overheads in executing each function they perform. Since the function is often hard wired, there is no need to spend energy to specify the function. This is in contrast to a processor that spends a large amount of its power figuring out what function to perform—that is, determining what instructions to fetch and fetching them (see Gonzalez and Horowitz, 1996).
As mentioned earlier, the downside of these custom solutions is their complexity and the cost of providing a new solution for each application. This conflict between good power-efficiency and flexibility leads to a number of interesting research questions about how to build the more general, power-efficient hardware that will be needed for EmNets. Some researchers are trying to generalize a custom approach,5 while others are trying to make a general-purpose parallel solution more power efficient.6 The best way to approach this problem is still an open question.
COMMUNICATION
As discussed earlier, it is very clear that silicon scaling has made computation very cheap. These changes in technology have also driven the cost of communication down for both wireline and wireless systems. The continued scaling of CMOS technology enables cheap signal processing and low-cost radio frequency circuits. This has been evident in the past several years with the rapid expansion of wireless networking technology, first into the workplace and now into the home (e.g., wireless Ethernet and Apple Airport), which permits laptops and tablets to have a locally mobile high-speed network connection. As the technology improves, more sophisticated coding and detection algorithms can be used, which either decrease the power or increase the bandwidth of the communication. Soon it will be possible to place a low-cost wireless transceiver on every system built, a development that would seem to make it inevitable that these embedded systems will be networked. One constraint is that while bandwidth is increasing and cost is decreasing, the power demands are not becoming significantly lower. Communication
|
5 |
See, for example, the work being done at the Berkeley Wireless Research Center, available at <http://bwrc.eecs.berkeley.edu/> or at the company Tensilica, <http://tensilica.com/>. |
|
6 |
See, for example, the work being done at the Stanford Smart Memories Project, available at <http://www-vlsi.stanford.edu/smart_memories/> or at the company ARC, <http://www.arccores.com/>. |
|
BOX 2.3 In CMOS circuits, power is dissipated by two different mechanisms: static, resulting from current flow through resistive paths from the power supply to ground, and dynamic, resulting from current needed to change the value of a signal on a wire. Dynamic power is frequency dependent, since no power is dissipated if the node values do not change, while static power is independent of frequency and exists whenever the chip is powered on. In modern CMOS chips, the explicit static power is usually very small, and dynamic power dominates. The static power is never zero, since some leakage current flows when the transistors are nominally off. Today there is a trade-off between leakage current and dynamic power, so in some high-power chips the leakage current can be quite large. This trade-off is described in more detail at the end of this box. The physical cause of dynamic power is the charging and discharging of the capacitance associated with the wire. Capacitance is a characteristic associated with all physical objects and depends on the shape of the wire. Roughly, the capacitance of a wire is proportional to its length. The dynamic power of a chip is just the sum of the dynamic power of each node on the chip, which in turn is just the energy used per cycle multiplied by the average number of cycles per second. The energy used to change the value of a capacitor is proportional to the value of the capacitance, C, and the square of the power supply voltage, V, used to power the chip. This leads to the common CV2F formulation for power in CMOS chips, where F is the frequency of the chip (the number of cycles per second). If an existing design is scaled to a new technology, all of the transistors |
mechanisms, which are critical for EmNets—they are what make up the networking aspects—are described in this section.
Wireline Communications
The wireline infrastructure is important both because some EmNets will connect to it directly and because those using wireless may generate communications flows with it. The evolution of the wireline infrastructure reflects both a historic emphasis on telephony as the principal application and the rise in data communications applications over the past few decades, a trend accelerated by the commercialization of the Internet in the 1990s. Advances in technology and the entry of new providers of wireline services in competition with traditional telephone companies have combined to lower costs and prices of data communication, in turn stimulating yet more demand for it.
The wireline infrastructure can be divided into segments that involve
|
become smaller by Δ, and the wires become shorter by Δ. This means that all the capacitances scale by Δ too. Additionally, the power supply is generally scaled by Δ as well, so the energy needed to switch a gate changes by the scaling factor cubed (Δ3). If this chip is run at the same frequency, it will take about three times less power for a 1.4-fold scaling of the technology. With this scaling, the gates will run about 1.4 times faster, so the machine could run at 1.4 times the frequency and still cut power consumption in half. The power dissipation of high-end microprocessors increases with scaling, since the additional transistors are spent on making a more complex chip (with concomitantly higher capacitance) that runs at twice the frequency rather than the nominal 1.4 times. This overwhelms the gain by scaling, and the power of the resulting processor increases. To continue to reduce the chip power with scaling, it is very important that the power supply voltage be scaled down. As the supply voltages scale down, another problem occurs. There is a transistor parameter, its threshold voltage, that affects both the transistor leakage current and the gate speed. It is the voltage where the transistor turns on. To maintain gate performance, it would be ideal for the voltage at which a transistor turns on to scale down at the same rate as the power supply voltage scales down. Unfortunately, the leakage current through an off transistor is also set by this parameter and increases rapidly as the threshold voltage approaches 0 V. One needs a threshold voltage of around 0.4 V for low leakage. In some high-performance systems it makes sense to use a lower threshold and deal with higher leakage currents, since the leakage power is still a small percent of the total power. In low-power systems, it is often decided to take the decrease in performance rather than increase the leakage. How to get around this interaction is an open research question. |
different technologies and different capacities for communications. Differential improvement of these segments affects the infrastructure’s ability to support the increase in communications anticipated from EmNets. Optical fiber has become prominent in the network backbones, and its capacity has been multiplied by the advent of wavelength-division multiplexing, which exploits the ability to communicate through different colors in the optical spectrum and which was enabled by all-optical-fiber amplifiers. Together, these and other advances have lowered the cost per bit of transmission in the backbone and for the wireline infrastructure generally, although the connection from end users (especially residential or small business users) to the backbone remains something of a bottleneck. Digital subscriber line (DSL) and cable modems increase the bandwidth to the end user, but they are unevenly deployed and will probably remain so through at least 2010.
Advances in silicon technology have also improved networking speed inside offices and homes. For structures with good quality wiring,
|
BOX 2.4 The power requirements of EmNets, like those of embedded and mobile computing environments, present difficult challenges. Some EmNets can, of course, be built with all mains-powered nodes. Others will require portable power, but current batteries will suffice (electronic watches, for example, require little enough power that batteries last for many years). Technology such as lithium polymer batteries already allows one to create energy sources in a wide variety of form factors. However, EmNets will stress power sources because of their need for long operating lifetimes and higher energy density. One can envision EmNets (as described elsewhere in this report) as consisting of large numbers of very small networked and often wireless components. The low data rates and activity factors will make clever on-chip power-management schemes and low operating voltage essential, but such approaches will not be sufficient to address the energy problem. For some applications that have very low average energy, it might be possible to extend lifetimes by extracting energy from the environment (light, vibration, RF), but further work is needed in this area. Some work in this area has been funded by the Defense Advanced Research Projects Agency (DARPA) and the Jet Propulsion Laboratory (JPL). Other systems simply need higher energy densities than current batteries provide. While battery technology continues to improve, energy density changes slowly. To obtain much higher densities generally means storing a fuel and supporting a chemical reaction to generate energy. The problem with these chemical solutions is that they generally become more efficient when made larger—building efficient small generators is hard. Fuel cells are an interesting option; however, more work is needed to devise small fuel cells that are superior to batteries and adequate for mobile platforms. A more ambitious approach is to miniaturize a combustion engine/electrical generator. MIT’s Micro Gas Turbine Generator Project1 is looking at the technology needed to create a miniature turbine 0.5 inch in diameter to create 50 W of electrical power. While there are many difficult problems with these combustion solutions, they would provide the best energy density if successful and should be part of the EmNets research program.
|
Ethernet speeds have been improved from 10 to 100 Mbps and will continue to improve with new gigabit systems. Even in homes without any new wires, signal processing has allowed people to create a network on top of the old phone line infrastructure. One good example of this effort is the Home Phoneline Networking Alliance.7 Other contexts that may
|
7 |
For more information, see <http://www.homepna.org/>. |
use wireline infrastructure for EmNets include vehicles and smart spaces; all contexts may eventually use a mix of wireline and wireless communications.
These technologies and infrastructure segments have been developing based on demand associated with conventional computers and telephones. Planning has been informed by speculation about other kinds of networked devices, and there has been some experience with television video being carried on these networks. Because the backbone economics most clearly supports optical systems, the potential for growth in capacity seems greatest there; the in-home network market is developing in part based on speculation about embedded systems in conjunction with computers and phones; broadband access to the home, the so-called last mile, continues to be problematic, however.8
Wireless Communications
EmNets will often involve wireless communications, in part because of the ease with which wireless networks can be deployed and connected, and in part because of the wide array of environments in which EmNets will operate. Wireless has been proven inasmuch as cellular telephony and paging networks have proliferated and grown in scale and coverage, both nationally and internationally. Movement beyond conventional telephony and paging to data applications, through personal digital assistants (PDAs) and advanced phones providing e-mail and Web access, has been reinforced by the rise of third-generation technology and standards. However, the new applications and services are limited in their data communications capabilities compared with wireline Internet capabilities. Beyond these larger area networks, where there are large, powerful, energy-rich base stations with large antennas and relatively capable units, much work is being done in short-range wireless systems. There are a multitude of new wireless technologies and accompanying standards that fill this space. For 10 to 30+ Mbps wireless communications, the 802.11b and 802.11a (sometimes known as wireless Ethernet) standards exist in the United States; the corresponding standards outside the United States are HiperLAN29 in Europe and Multimedia Mobile Access Communication (MMAC) in Japan. For wireless personal area network (PAN) systems such as Bluetooth (which was initially envisioned as a small form factor, low-cost, cable replacement technology for devices such as cell
|
8 |
See CSTB’s forthcoming examination of broadband issues, expected in 2001. |
|
9 |
HiperLAN2 was created to be a global standard with complete interoperability of high-speed wireless LAN products. See <http://www.hiperlan2.com/>. |
phones, laptops, and headphones), IEEE 802.15 is defining new generations of these systems.
Although wireless communication seems to be flourishing, the reality is that it involves overcoming many problems inherent in over-the-air communication.10 The radio-frequency spectrum is a scarce resource and will need to be shared among a multitude of highly heterogeneous devices with drastically different requirements for bandwidth and communication range. Sharing of the spectrum can occur in time, space, and frequency. Already, conflicts over frequency are arising between emerging technologies that make use of unregulated bands (e.g., at 2.4 GHz, 802.11 wireless Ethernet conflicts with many new cordless telephones, and both are now being widely deployed.) Low-cost radio transceivers are being developed that have very limited range, which isolates them in the space dimension. This has the beneficial effect of dramatically lowering the power consumption for communication but complicates communication by potentially requiring multiple hops when communicating with more distant nodes (and thus requiring intermediate nodes to expend their own power to route packets). An advantage of multihop, however, is that it provides the opportunity to do data aggregation and collaborative processing at an intermediate node. Many portable devices are also separating their communication in time to avoid interference, by having low-duty cycles of transmission. These devices are also trying to avoid interference by spreading themselves out in the frequency spectrum using spread spectrum techniques. Box 2.5 discusses Bluetooth as it relates to the need to share the available spectrum.
Two fundamental concerns for EmNets are scaling and heterogeneity. In wireless communication, scaling means maintaining adequate bandwidth per volume by decreasing the range, dividing up the spectrum, and taking turns using it. Which devices are brought into proximity can have important consequences if they can interfere with each other’s communication or have cumulative bandwidth needs that cannot be met. An important issue arises with long-lived EmNets: They will occupy a portion of the spectrum for their lifetime, impacting any other devices that come within range.11 It may very well be necessary to consider not
|
BOX 2.5 Bluetooth exemplifies an attempted solution to the need to share available spectrum. It was originally developed by cellular telephone manufacturers to simplify and thus increase the use of the cellular phone for long-range communication by a variety of consumer devices. The concept is simple: provide a replacement for cables that are used to connect laptops, MP3 players, etc., to network services. Bluetooth is short range—approximately 30 m—so that many users can interconnect the same devices within a small geographic area. The idea is to have high bandwidth per unit volume by providing smaller cells packed more closely together. Bandwidth density is just as important as bandwidth—as anyone can attest who has unsuccessfully tried to use a cellular phone in a crowd where hundreds of others were trying to do the same. By having a short range, it is possible for Bluetooth transceivers (now at power consumptions of less than 50 mW) to be included in a wide range of battery-powered devices with minimal impact. Bluetooth uses frequency hopping to further isolate users. Conversely, devices that do want to communicate must synchronize precisely so that they hop frequencies in unison (the Bluetooth specification includes a discovery procedure for this purpose). Synchronization inherently limits the number of devices that can communicate at any one time. As long as only a handful of devices are being used at one time, this is not an issue. The active devices synchronize, while the others park and conserve power. However, for many of the EmNets envisioned in this report, large numbers of devices will be actively communicating. Bluetooth does not adequately support these needs because it synchronizes devices into small clusters. Although devices can be part of more than one cluster, they and their entire cluster pay a considerable performance penalty in switching between clusters. An important open question for technologies such as Bluetooth is, How will a given device know (or be told) with which other devices it is to communicate? If multiple other devices are in range, how are the important ones for an application identified? Ownership may be important when users want to connect their personal laptop to their personal phone, but this may make it difficult to use a different phone. This problem is much more difficult when what is at issue are embedded elements of EmNets that are deployed as part of an active environment. Moving beyond phones, PDAs, and laptops to applications such as wireless sensor networks and other EmNets, Bluetooth and its ilk may have a role to play. However, significant additional development will be needed. |
only principled ways to claim a portion of the spectrum but also how to reclaim it when needs change. Heterogeneity means that large EmNets will require multihop networks that will forward data packets between devices that have to exist in different parts of the spectrum (possibly as far apart as radio frequency (RF) and infrared (IR)) or that are limited in range.
Boxes 2.6 and 2.7 describe two areas where EmNets stress wireless communications in new ways. Both focus on short-range, low-power issues, in which there is more uncertainty and need for work than in the other more mature technologies. The first looks at constraints on the circuits used, and the second examines the networking issues.
|
BOX 2.6 The constraints on communications for low-power, short-range wireless systems stem from environmental effects on radio frequency propagation. These effects, such as spatial separation of the nodes along with antenna gain, multipath propagation, and shadowing, arise from attenuation due to ground scattering effects. The spatial separation issue has both positives and negatives. Spatial, time, or frequency diversity can help with the issue of multipath propagation, and a multihop network can be employed to deal with path loss and shadowing. Each of these is discussed in more detail below. Spatial separation is an important factor in the construction of wireless communication networks. For low-lying antennas, intensity can drop as much as the fourth power of distance (Rappaport, 1996; Sohrabi et al., 1999b; Sommerfeld, 1949; Wait, 1998; Chew, 1990).1 This presents a problem when attempting to communicate along the ground. Surface roughness, the presence of reflecting and obstructing objects, and antenna elevation all have an impact on propagation. In general, power fall-off rarely approaches the free-space limit, and particularly in cluttered or near-ground environments a fourth power loss falloff is seen. The losses make long-range communication a power-hungry exercise; the combination of Maxwell’s laws (equations describing electromagnetic fields) and Shannon’s capacity theorem (describing the connection among error rates, transmission rates, and the capacity of the communications channel) together dictate that there is a limit on how many bits can be reliably conveyed given power and bandwidth restrictions. On the other hand, the strong decay of intensity with distance provides spatial isolation along the ground, allowing reuse of frequencies throughout a network. Multipath propagation (due to reflections off multiple objects) is also a very serious problem. It is possible to recover most of the loss generated thereby through diversity. Diversity can be obtained in any of the three domains of space, frequency, or time, since with sufficient separation the fade levels are independent. By spreading the information, the multiple versions will experience different fading, so that the result is more akin to the average, whereas if nothing is done it |
GEOLOCATION
In many electronic systems the geographic location of objects is not important; instead, it is the network topology, the relative position of objects within a network, that is important. Yet for many systems, geographic data can be very useful—for example, to find the nearest printer
|
is the worst-case conditions that dominate error probabilities. If the sensor nodes are not physically mobile and the terrain is static, the multipath losses will be invariant with respect to time. Likewise, spatial diversity is difficult to obtain, since multiple antennas are unlikely to be mounted on small platforms. Thus, diversity is most likely to be achieved in the frequency domain—for example, by employing some combination of frequency spread spectrum or hybrid spread/orthogonal frequency division multiplexing systems together with interleaving and channel coding. Networks of embedded computers that may be placed anywhere and that may grow in numbers and density with time will have a critical need for reliable communication; yet the interference among elements will grow proportionally, and frequency reuse may be of little or no value because of mobility and, possibly, uncertainty as to location. For such an application, spread spectrum and direct sequence guarantee a constant flat, wide spectrum for each user and are a good choice for maximizing both the capacity and the coverage of the network. It is not clear, however, whether the inherent inefficiencies will prove too complex and/or too costly. Measures that are effective against deliberate jamming are generally also effective against multipath fading and multiuser interference. Shadowing (wavefront obstruction and confinement) and path loss can be dealt with by employing a multihop network. If nodes are randomly placed in an environment, some links to near neighbors will be obstructed while others will present a clear line of sight. Given a sufficient density, the signals can in effect hop around obstacles. Multihop also presents opportunities for networking processing and reduction of data. Exploitation of these forms of diversity can lead to significant reductions in the energy required to transmit data from one location in the network to another; such exploitation becomes limited chiefly by the reception and retransmission energy costs of the radio transceivers for dense peer-to-peer networks. In wireless systems there is thus a close connection between the networking strategy and the physical layer. The connection is even stronger when considering the multiple access nature of the channel, since interference among users is often the limiting impairment. |
|
BOX 2.7 In contrast to conventional wireless networks, EmNets must potentially support large numbers of sensors in a local area with short range and low average bit rate communication (fewer than 1 to 100 kbps). The small separation between nodes can be exploited to provide multihop communication, with the power advantages outlined earlier. Since for short hops the transceiver power consumption for reception and listening is nearly equal to that for transmission, the protocol should be designed so that radios are off as much of the time as possible. This requires that the radios periodically exchange short messages to maintain local synchronization. It is not necessary for all nodes to have the same global clock, but the local variations from link to link should be small to enable cooperative signal processing functions. The messages can combine health-keeping information, maintenance of synchronization, and reservation requests for bandwidth for longer packets. The abundant bandwidth that results from the spatial reuse of frequencies and local processing ensures that relatively few conflicts will result in these requests, so simple mechanisms can be used. One such protocol suite that embodies these principles has been developed that includes boot-up, Media Access Control (MAC), energy-aware routing, and interaction with mobile units; see Sohrabi et al. (1999a). It indicates the feasibility of achieving distributed low-power operation in a flat multihop network. An alternative to a flat architecture is the use of clustering, possibly with clustering at many levels with respect to different network functions. This is particularly convenient if there are multiple classes of nodes, some with special capabilities such as long-range communications, or connections via gateway nodes to the Internet. Different approaches for performing network self-organization into clusters have been developed. Typically, clustering is implemented in ad hoc networks to reduce the number of instances of network reconfiguration in situations of high mobility relative to the messaging rate. It comes at the price of an increased energy burden to the cluster head and some inefficiency in multihop routing. The reduction in routing table updates and the relatively frequent role changes in situations of mobility take care of both concerns. In static networks, hierarchy may be imposed to simplify signal processing—for example, to avoid frequent leader election for processes that must be coordinated over large areas. This could occur even if routing takes place without clustering. A question that naturally arises is where processing and storage should take place. As indicated previously, communication, while becoming cheaper, costs a great deal compared with processing, so energy constraints dictate doing as much processing at the source as possible. Further, reducing the quantity of data to transmit significantly simplifies the network design and permits scaling to thousands of nodes per network gateway. |
in terms of meters, not network connections. In EmNets, this ability to determine one’s location in space is often critical—as a way to both name and identify objects and data and coordinate activity within an EmNet.12 For example, using location information in conjunction with static information about a building would allow the creation of logical location information, enabling an EmNet to determine which objects are in the same room or are cooled by the same air conditioner. Location information can also be used to determine when two (or more) nodes are in close geographical proximity to one another. This would be useful when trying to ensure redundant coverage of a particular area, but needing only one node in the area to be powered on at any given point. Boxes 2.8 and 2.9 provide details of techniques that can assist in determining the location of nodes and, consequently, the larger network geometry (encompassing geographic location, colocation, and proximity information). The first describes the Global Positioning System (GPS) and the second examines alternative geolocation techniques.
COMPUTING SOFTWARE—OPERATING SYSTEMS AND APPLICATIONS
Embedded systems have been around at least as long as the microprocessor. The software for these systems has been built, more or less successfully, using several different paradigms. Some systems are built from scratch by the manufacturer with all software being created specifically for the device in question. This software may be written in assembly language or may use a higher-level language. Other systems are made using existing software modules and wrapping an application around them. These preexisting modules might include an operating system, network protocols, control algorithms, drivers, and so on. Such modules are available from independent software vendors and in some cases as open source software. Finally, a very few systems are created using formal methods, high-level design tools, and rigorous design methodology.
|
BOX 2.8 By far the most common geolocation system in use today is the Global Positioning System (GPS), which was completed by the Department of Defense in 1994. Twenty-four satellites circle Earth in a pattern in which at least five satellites are visible from any location. These satellites contain very precise clocks, and their locations are known to a high degree of precision. They transmit a message that contains both the time on the satellite and the satellite’s position. The receipt of four signals provides enough information to solve for the location of the receiver and the time offset of the local clock.1 What makes GPS reception difficult is that radio frequency (RF) signals from the satellites are very weak. Special coding is used to allow receivers to detect these weak signals, but even with coding, GPS receivers generally work only if they have a direct line of sight to the satellites. Performance inside buildings or in an area covered by foliage is generally quite poor—a severe limitation for EmNets, which will often operate entirely inside buildings. A secondary issue is the large computation needed by current receivers to find the signals from the desired satellite quickly, which can consume considerable resources. Designing a geolocation system would be much easier if the receiver knew roughly where it was and what signals it should be looking for. This notion of an assisted geolocation system (assisted GPS) has recently been proposed to handle the need to locate a cell phone within a few tens of meters for emergency 911 calls. Assisted GPS leverages the following facts: (1) the nodes have a means to communicate with an outside server (that is, they don’t need to be completely self-contained, (2) the position of the nodes relative to the outside server is roughly known, and (3) it is possible (and inexpensive) to build high-quality GPS receivers to the outside servers to assist in determining the location of the nodes. Revisiting the GPS receiver’s task, the hard problem is finding the satellite’s signal in the background noise. Yet if the rough location of the node relative to the server is known, the server could calculate the signal that the receiver should see. With this added information, the receiver’s search space is much smaller, and the receiver can actually make intelligent guesses about where the signal is. This allows the receiver to integrate over longer sequences of data and improves its ability to find very small signals that are buried in noise. In the cell phone system |
These latter systems have been very small in number compared with the more ad hoc designs (Lee, 2000).
Today, as described elsewhere in this report, embedded systems are becoming highly networked and are changing in fundamental ways. This will necessitate important changes in the way the software for these systems is created. For most computers, the software running on a typical embedded system usually consists of an operating system, which is de-
|
example, the system roughly tracks the location of a phone using signal strength indications to switch between cells. The base station would know the visible satellites and their Doppler frequency shifts, which could be fed to the receivers to make it easier for them to find the needed signals. In many EmNets, the initial position estimate could be even better, which would improve the possibility of finding the weak satellite signals. Whether an assisted GPS can be made to work for EmNets is still an open research question and needs to be explored.2 In addition to the obvious issue of signal to noise for the GPS satellite broadcasts, a number of other issues need to be resolved. A critical requirement in these systems is that the time at the receivers be synchronized to the clocks at the server to better than the uncertainty of the signal delay; if it is not, the clock errors will decrease the gain achieved from the server station. This need for good time synchronization is a challenge for many EmNets since for power and cost reasons they may use low-duty-factor networks, which have large latency, and low-power, low-cost clocks, which have higher uncertainty. Another issue is the multipath problem that occurs in urban situations, where a reflected satellite signal can confuse the receiver. Still another concern with incorporating GPS location technology into EmNets is nontechnical: GPS is a creation of the United States Department of Defense, and it may be that many other countries would prefer not to have their positioning systems depend on it as such, notwithstanding the Defense Department’s position that it will not interfere with the accuracy of GPS.
|
signed to be useful for many systems with little change, and some application software. (See Box 2.10 for a discussion of requirements in traditional embedded systems.) In today’s EmNets, the line between application and operating system often blurs, with reusable components such as communications protocols sometimes considered an operating system and sometimes an application and virtual machines considered neither a true operating system nor an application but rather a sort of middleware.
|
BOX 2.9 The biggest disadvantage of GPS for a robust sensor network is the dependence on the external signal from each satellite and thus the sensitivity to multipath signals, signal absorption, jamming, and satellite loss. Implementing a non-satellite-based RF geolocation framework as part of a sensor network could provide a robust location algorithm and, ideally, would leverage the communication transceiver to limit system redundancy. The biggest hurdle to overcome for RF geolocation is the timing accuracy needed for useful submeter location capability. One-meter position accuracy requires discerning signal-timing differences of 3 ns. Clock accuracies may not need to be this fine if averaging and edge detection are used to compensate for clock error. However, multipath signals in cluttered environments also cause substantial errors in position accuracy to accumulate. Two-way measurements in which relative synchronization is not necessary are one way to get around synchronization problems (McCrady et al., 2000). However, much development remains to be done, as RF systems are still orders of magnitude in price, size, or accuracy from feasible integration in widely deployed EmNets. Ultrawideband (UWB) shows promise for delivering centimeter-accurate, multipath, integrated communications and position location capability. However, fully developed UWB-based systems with low-cost, compact clocks are not yet commercially available. In addition, the propagation characteristics of UWB signals have not been widely explored, and size, cost, and Federal Communications Commission (FCC) certification issues have not been finalized for developing UWB systems. A working group has been set up that describes some of these issues in more detail.1 As an alternative to using RF communication, acoustic signals could be used. Acoustic signals suffer from similar multipath, dispersion, and propagation problems in cluttered environments, but they require a much coarser time scale (six orders of magnitude coarser) for accurate positioning.2 While acoustic geoloca- |
Because in any case EmNets need to work as a whole, operating systems and application software are discussed together.
Traditional embedded systems are often networked, but generally in rather simple ways, or at least the connectivity roles of the embedded systems themselves are rather simple. However, with hardware power increasing rapidly and available bandwidth increasing even more rapidly, new modes of connectivity (both wired and wireless), richer user interfaces, and new standards such as Java, the functionality and resulting complexity are about to increase dramatically. These new EmNets change the rules of the game in a number of ways. They are still embedded systems, but they are also a part of an extremely complex, heterogeneous distributed system. They therefore retain the requirements of tra-
|
tion requires a separate acoustic transmitter, depending on an EmNet’s sensing requirements, the receiver may be integrated into existing sensing capability. Acoustic geolocation takes advantage of the relatively slow propagation of sound waves, but it requires development of an alternative subsystem and further exploration of the propagation issues involved before operational use with EmNets can be contemplated. The methods discussed above first measure distances between objects and then deduce their position; other approaches are possible. In some systems, precise location might not be needed. For example, a few beacons might be able to determine which side of a line an object is on; this might be enough for determining what is in a room but not exactly where. Extending this type of determination might enable the device (or the beacons) to estimate distance and angles between the object. These estimates again provide the basis for calculating geolocation. There are a number of ways to estimate angles and distance other than measuring time of flight. For example most cell phone systems track signal strength as a position estimate (for cell hand-off) and are starting to use antenna arrays to estimate the angle as well. Optical signals can also be used in this manner. For example, laser range finders use a laser and a camera to determine the location of different objects by changing the angle of the laser and measuring when it hits the object. Given the laser angle and the distance between the laser and the camera, one can estimate the distance to the object. These techniques are often much simpler than GPS and merit further research in the context of EmNets.
|
ditional embedded systems, as described above, but also have a number of new requirements. Several of these new requirements are discussed in detail elsewhere in this report: security, safety, reliability, usability, and privacy (Chapter 4); virtual machines and communication protocols (Chapter 3); complexity and analysis tools (Chapter 5); and service discovery (Chapter 3). Boxes 2.11, 2.12, and 2.13 expand upon upgradability, high availability, and the ability to work with new hardware as additional ways in which software will need to be refined to handle the requirements of EmNets.
An additional concern is the cost of correcting failures in EmNet software, which will often far exceed the corresponding cost in more traditional desktop and server environments. This is because the EmNets
|
BOX 2.10 Traditional, non-networked embedded software can be quite complex and have a number of requirements. These have implications both for the application and for the operating system. Several such requirements are the following:
|
will often be deployed in ways that make it difficult to deliver or test corrected software. Also, the costs of the failures themselves may be very high, since many EmNets will perform infrastructure-critical or even life-critical applications. The cost issue is complicated by the fact that the cost of updates and failures may be borne by the end user and not by the developer of the software, which may have no compelling economic rationale for developing reliable software and so may be tempted to cut corners at this critical juncture.
REAL-TIME AND PERFORMANCE-CRITICAL ASPECTS OF EMBEDDED OPERATING SYSTEMS
The new requirements listed above imply more complex, highly functional applications and services to support the systems. These services could be provided by specialized hardware but in most cases will probably be provided by an operating system. However, as mentioned, traditional embedded system requirements do not disappear. In particular, the requirement for real-time response is still critical for many products
and remains a challenge, as new functionality must be added without adversely affecting response.
A real-time operating system must enable applications to respond to stimuli in a deterministic amount of time, known as the latency. The actual amount of time is dependent on the application, but the determinism requirement is nonnegotiable. All design decisions in the operating system must therefore optimize system latency. This stands in contrast to most desktop and server operating systems, which are optimized for throughput and for protection of multiple processes, with latency far less important. Critical design decisions as basic as system data structures (queues, tables, etc.), memory protection and paging models, and calling semantics are driven by these very different optimization requirements, making it difficult or impossible to “add” real time to an operating system that was not designed from the beginning with that as a core requirement.
Like any modern operating system, most real-time embedded operating systems are multitasking. Unlike most desktop and server operating systems, however, embedded operating systems are split between those systems in which there are multiple processes, each residing in its own memory, and those in which all tasks live in the same memory map, with or without protection from one another. Furthermore, new systems are beginning to appear based on entirely different memory protection models, such as protection domains. Some of the issues that arise in embedded systems with respect to memory management, tasks, and scheduling are described in Box 2.14.
MICROELECTROMECHANICAL SYSTEMS
Microelectromechanical systems, or MEMS, had their start in a famous talk by the physicist Richard Feynman entitled “There’s Plenty of Room at the Bottom” (Feynman, 1960; Trimmer, 1997.) Feynman pointed out that tremendous improvements in speed and energy requirements, as well as in device quality and reliability, could be had if computing devices could be constructed at the atomic level. MEMS represent the first steps toward that vision, using the best implementation technology currently available: the same silicon fabrication that is used for integrated circuits.
MEMS devices generally attempt to use mechanical properties of the device, in conjunction with electronic sensing, processing, and control, to achieve real-world physical sensing and actuation. The accelerometers in modern cars with airbags are MEMS devices; they use tiny cantilever beams as the inertial elements and embody the extreme reliability required of such an application. Other MEMS devices take advantage of the wave nature of light, incorporating regular patterns of very fine comb
|
BOX 2.11 Traditionally, most embedded devices, once deployed, have rarely been upgraded, and then only very proactively and carefully, for instance by physically replacing read-only memory (ROM). In a world of networked embedded systems, and with rewritable, nonvolatile storage widely available, field upgrades will be more frequent and often far more invisible to end users of the systems.1 This will occur because EmNets may be in service for many years, and the environment to which they are connected and the functionality requirements for the device may change considerably over that time. In some cases, such upgrades are driven by a knowledgeable user, who purchases a new component of functionality and installs it, a nearly automatic procedure. In other cases, updates or upgrades may be invisible to the end user, such as when protocols or device addresses change. Devices like home gateways, automobiles, and appliances may be upgraded online without the consumer ever knowing about it and in ways well beyond the consumer’s understanding, raising the issue of usability and transparency to the user. Transparent software upgrade of deployed EmNets, while probably necessary and inevitable, presents a number of difficulties. The very fact that the upgrades are transparent to the end user raises troubling questions of who has control of the EmNet (the user or the upgrader?) and creates potential security and safety issues if such an upgrade is erroneous or malicious. What if the software is controllable or upgradable by parties that are not to be trusted? Further difficulty is caused by the heterogeneity of many EmNets. Many individual nodes may need to be upgraded, but those nodes may be based on different hardware and/or different operating systems. Deploying an upgrade that will work reliably across all these nodes and EmNets is a challenge closely related to the code mobility issues dis- |
structures, arranged to refract light in useful ways under mechanical control. A Texas Instruments MEMS device is the heart of a projector in which each pixel is the light bounced off one of millions of tiny mirrors, hinged such that the amounts of red, green, and blue light can be independently controlled.
Microfluidics is an emerging MEMS application in which the fluid capillaries and valves are all directly implemented on a silicon chip and controlled via onboard electronics. Still other MEMS devices implement a membrane with a tunneling current sensor for extremely precise measurements of pressure. The combination of MEMS sensing plus the computation horsepower of embedded processors opens the way to large networks of distributed sensing plus local processing, with communication back to central synthesis engines for decision making.
However, there are challenges to be overcome before MEMS can real-
|
cussed in Chapter 3. Finally, there may be simultaneity requirements—that is, all nodes in an EmNet, which may be widely dispersed geographically, may need to be upgraded at the same time. This requirement may need to be addressed by multistage commits, similar to those used in transaction processing. Online update is largely an application issue rather than an operating system issue. However, most system designers will expect the operating system to make the task easier and to handle some difficult problems like upgrade policy, verification, and security. Furthermore, in some cases the operating system itself may need to be field upgraded, a process that almost certainly requires operating system cooperation and that extends beyond the device being updated. A server infrastructure is required to set policies, supply the correct information to the correct devices, manage security of the information, and verify correctness. This infrastructure is likely to be supplied by a few providers, akin to Internet Service Providers (ISPs) or Application Service Providers (ASPs), rather than to be created anew for each individual deployed product. As of 2001, there is no consensus on how online field upgrade will work for the billions of networked embedded systems components that will be deployed, nor is there any significant move toward applicable standards. Field upgrade is likely to become an important focus of research and development work over the next several years as numerous systems are deployed that challenge the ability of simple solutions to scale up to adequate numbers and reliability. |
ize this promise. One is in the nature of real world sensing itself: It is an intrinsically messy business. A MEMS device that is attempting to detect certain gases in the atmosphere, for instance, will be exposed to many other gases and potential contaminants, perhaps over very long periods of time and with no maintenance. Such devices will have to be designed to be self-monitoring and, if possible, self-cleaning if they are to be used in very large numbers by nonexperts.
The aspects of silicon technology that yield the best electronics are not generally those that yield the best MEMS devices. As has been discussed, smaller is better for electronics. Below a certain size, however, MEMS devices will not work well: A cantilever beam used for sensing acceleration is not necessarily improved by making it smaller. Yet to meet the low cost needed for large numbers of sensing/computing/reporting devices, the MEMS aspects and electronics will have to be fabricated onto the
|
BOX 2.12 Many EmNets must work continuously, regardless of hardware faults (within defined limits) or ongoing hardware and software maintenance, such as hardware or software component replacement. Reliability in an unreliable and changeable environment is usually referred to as high availability and fault tolerance (HA/FT). HA/FT may require specialized hardware, such as redundant processors or storage. The operating system plays a key role in HA/FT, including fault detection, recovery, and management; checkpoint and fail-over mechanisms; and hot-swap capability for both hardware and software. Applications also need to be designed with HA/FT in mind. A layer between the application and the operating system that checks the health of the system and diagnoses what is wrong can be used to control the interaction between the two. HA/FT systems have not been widely used; instead, they tend to have niches in which they are needed, such as banking, electric power, and aircraft. Those who need them, often communications equipment manufacturers, have built them in a proprietary fashion, generally for a specific product. The first portable, commercial embedded HA/FT operating systems, as well as reusable components for fault management and recovery, are just starting to become available,1 but they have not yet been widely deployed in a general-purpose context. EmNets will very likely be used in a variety of contexts, and transferring HA/FT capabilities to EmNets is a challenge the community must meet.
|
same silicon. Much work remains to find useful MEMS sensors that can be economically realized on the same silicon as the electronics needed for control and communication.
SUMMARY
This chapter has provided a brief overview of the core technologies that EmNets will use, the trends that are driving these technologies, and the research areas that will accelerate the widespread implementation of EmNets. It has argued that silicon scaling, advances in computing hardware, software, and wireless communications, and new connections to the physical world such as geolocation and MEMS will be the technological building blocks of this new class of large-scale system.
Large systems will comprise thousands or even millions of sensing,
|
BOX 2.13 Software needs hardware, and the nature of hardware is changing. For decades, the relationship between hardware and software has been well defined. Computer architectures, whether microprocessor or mainframe, have changed slowly, on a time scale of many years. Software has resided in random access memory (RAM) or read-only memory (ROM) and has been executed on an arithmetic logic unit (ALU) on the processor in the computer. New developments in the hardware world will challenge some of the assumptions about this relationship. Multicore processors—multiple concurrent processing elements on a single chip—are becoming economical and common. They often include a single control processor and several simpler microengines specifically designed for a task such as networking or signal processing. Thus, a microprocessor is no longer a single computer but is becoming a heterogeneous multiprocessing system. Configurable processors, created with tools from companies such as ARC and Tensilica, make it very easy for a user to craft a custom microprocessor for a specific application. These tools can create real performance advantages for some applications. Programmable logic chips are growing larger, with millions of gates becoming available; they are also available in combination chips, which include a standard CPU core and a significant number of programmable gates. These make it possible to create multiple, concurrent processing elements and reconfigure continuously to optimize processing tasks. All of these advances hold great promise for performance, cost, and power efficiency, but all create real challenges for software. Applications and operating systems must be able to perform well in reconfigurable, multiprocessing environments. New frameworks will be required to make efficient use of reconfigurable processing elements. Interestingly, all of these advances put compilers and programming languages back in the forefront of software development.1
|
computing, and actuating nodes. The basic trends are clear: These large, inexpensive, highly capable systems are becoming feasible because of the cumulative effects of silicon scaling—as ever-smaller silicon feature sizes become commercially available, more and more transistors can be applied to a task ever more cheaply, thus bringing increasingly capable applications within economic range. There are also some countervailing trends, in the form of constraints: Communication is costly, both on-chip and between chips; there are problems looming in the areas of power
|
BOX 2.14 A multiprocess system uses virtual memory to create separate memory spaces in which processes may reside, protected from each other. A multitasking operating system usually implies that all tasks live in the same memory map, which comes with its own host of security implications. Since many embedded systems have no virtual memory map capability, these simpler systems are prevalent for many applications. A multitask system can also run much faster, since the operating system does not need to switch memory maps; this comes at the cost of less protection between running tasks, however. Those switches can make determinacy difficult, since all planning must take place around worst-case scenarios entailing significant swapping of page tables. A further concern is preemption. Preemption occurs when the system stops one task and starts another. The operating system must perform some housekeeping, including saving the preempted task’s state, restoring the new task’s states, and so on. The time it takes to move from one task to another is called the preemptive latency and is a critical real-time performance metric. Not all embedded operating systems are preemptive. Some are run-to-completion, which means that a task is never stopped by the operating system. This requires the tasks to cooperate, for instance by reaching a known stopping point and then determining whether other tasks need to run. Run-to-completion operating systems are very small, simple, and efficient, but because most of the scheduling and synchronization burden is pushed to the individual tasks, they are only applicable to very simple uses. Almost all embedded operating systems assign each task a priority, signifying its importance. In a preemptive system, the highest priority task that is ready is always running. These priorities may change for a number of reasons over time, either because a task changed a priority explicitly or because the operating system changes it implicitly in certain circumstances. The algorithms by which the operating system may change task priorities are critical to real-time performance, but they are beyond the scope of this study. Preemptive real-time embedded operating systems vary significantly in performance according to the various decisions made—both overt (multitask vs. multiprocess, number of priorities, and so on.) and covert (structure of the internal task queue, efficiency of the operating system’s code). Unfortunately, there are no standard benchmarks by which these systems are measured. Even commonly used metrics, such as preemptive latency, interrupt latency, or time to set a semaphore, can be very different because there is no universal agreement on precisely |
|
what those terms mean. When the application is added to the system, the resulting behavior is very complex and can be difficult to characterize. It may be very difficult to understand how settable parameters, such as task priority, are affecting system behavior. There are a number of methodologies, however, that can help with these problems. Other considerations beyond real-time execution and memory management emerge in EmNets. Numerous efforts address the real-time executive aspects, but current real-time operating systems do not meet the needs of EmNets. Many such systems have followed the performance growth of the wallet-size device. Traditional real-time embedded operating systems include VxWorks, WinCE, PalmOS, and many others. Table 2.1, taken from Hill et al. (2000), shows the characteristics for a handful of these systems. Many are based on microkernels that allow for capabilities to be added or removed based on system needs. They provide an execution environment that is similar to that of traditional desktop systems. They allow system programmers to reuse existing code and multiprogramming techniques. Some provide memory protection, as discussed above, given the appropriate hardware support. This becomes increasingly important as the size of the embedded applications grows. These systems are a popular choice for PDAs, cell phones, and television set-top boxes. However, they do not yet meet the requirements of EmNets; they are more suited to the world of embedded PCs, requiring a significant number of cycles for context switching and having a memory footprint on the order of hundreds of kilobytes.1 There is also a collection of smaller real-time systems, including Creem, pOSEK, and Ariel, which are minimal operating systems designed for deeply embedded systems, such as motor controllers or microwave ovens. While providing support for preemptive tasks, they have severely constrained execution and storage models. POSEK, for example, provides a task-based execution model that is statically configured to meet the requirements of a specific application. However, they tend to be control-centric—controlling access to hardware resources—as opposed to data-flow-centric. Berkeley’s TinyOS2 is focused on satisfying the needs of EmNets. Additional research and experimentation are needed to develop operating systems that fit the unique constraints of EmNets.
|
TABLE 2.1 Characteristics of Some Real-time Embedded Operating Systems
|
Name |
Preemption |
Protection |
ROM Size |
Configurability |
Targetsa |
|
POSEK |
Tasks |
No |
2K |
Static |
Microcontroller |
|
PSOSystem |
POSIX |
Optional |
|
Dynamic |
PII → ARM Thumb |
|
VxWorks |
POSIX |
Yes |
~286K |
Dynamic |
Pentium → Strong ARM |
|
QNX Neutrino |
POSIX |
Yes |
>100K |
Dynamic |
Pentium II → NEC chips |
|
QNX Real-time |
POSIX |
Yes |
100K |
Dynamic |
Pentium II → 386s |
|
OS-9 |
Process |
Yes |
|
Dynamic |
Pentium → SH4 |
|
Chorus OS |
POSIX |
Optional |
10K |
Dynamic |
Pentium → Strong ARM |
|
Ariel |
Tasks |
No |
19K |
Static |
SH2, ARM Thumb |
|
CREEM |
Data flow |
No |
560 bytes |
Static |
ATMEL 8051 |
|
aThe arrows in this column are used to indicate the range of capabilities of the targets. |
|||||
dissipation, battery life, and design complexity; and many of the areas known to be problematic for today’s systems are likely to be substantially more problematic with EmNets.
Networking solutions that work well enough for today’s systems are based on many assumptions that are inappropriate for EmNets. For instance, the potentially huge number of nodes, the ad hoc system extensions expected, the extended longevity, and the heavy reliance on wireless communications between nodes will collectively invalidate some basic assumptions built into today’s network solutions. Increased needs for system dependability will accompany the use of EmNets for real-time monitoring and actuating, but existing software creation and verification techniques will not easily or automatically apply. Other EmNet requirements, such as the need for software upgradability and fault tolerance,will also require great improvements in the state of the art.
Other technological enablers for EmNets will be MEMS and better power sources. MEMS devices show great promise for real-world sensing (temperature, pressure, chemicals, acoustical levels, light and radiation, etc.). They also may become important for real-world actuation.
EmNet nodes will be heterogeneous. Some will be as powerful as any server and will have more than sufficient power. But system nodes that are deployed into the real world will necessarily rely on very careful energy management for their power. Advances in power management will provide part of the solution; advances in the energy sources themselves will provide the other part. Improved batteries, better recharging techniques, fuel cells, microcombustion engines, and energy scavenging may all be important avenues.
Predicting the future of a field moving as rapidly as information technology is a very risky proposition. But within that field, certain trends are unmistakable: basic silicon scaling and the economics surrounding the semiconductor/microprocessor industry, power sources, and software. Some of these trends will seem almost inevitable, given the past 20 years of progress; others will require new work if they are not to impede the overall progress of this emerging technology.
REFERENCES
Borkar, S. 1999. “Design challenges of technology scaling.” IEEE Micro 19(4):23-29.
Brodersen, R.W., A.P. Chandrakasan, and S. Cheng. 1992. “Lowpower CMOS digital design.” IEEE Journal of Solid-State Circuits 27(4):473-484.
Chew, W.C. 1990. Waves and Fields in Inhomogeneous Media. New York, N.Y.: Van Nostrand Reinhold.
Clark, L., et al. 2001. “A scalable performance 32b microprocessor.” IEEE International Solid-State Circuits Conference Digest of Technical Papers, February.
Computer Science and Technology Board (CSTB). 1997. The Evolution of Untethered Communication. Washington, D.C.: National Academy Press.
Feynman, Richard P. 1960. “There’s plenty of room at the bottom: An invitation to enter a new field of physics.” Engineering and Science. California Institute of Technology: American Physical Society, February.
Geppert, L., and T.S. Perry. 2000. “Transmeta’s magic show.” IEEE Spectrum 37(5).
Gonzalez, R., and M. Horowitz. 1996. “Energy dissipation in general purpose microprocessors.” IEEE Journal of Solid-State Circuits (September):1277-1284.
Hill, J., et al. 2000. “System architecture directions for networked sensors.” Proceedings of the 9th International Conference on Architectural Support for Programming Languages and Operating Systems, Cambridge, Mass., November 12-15.
Lee, Edward A. 2000. “What’s ahead for embedded software?” IEEE Computer (September):18-26.
McCrady, D.D., L. Doyle, H. Forstrom, T. Dempsey, and M. Martorana. 2000. “Mobile ranging using low-accuracy clocks,” IEEE Transactions on MTT 48(6).
Parsons, David. 1992. The Mobile Radio Propagation Channel. New York: John Wiley & Sons.
Rappaport, T.S. 1996. Wireless Communications: Principles and Practice, Englewood Cliffs, N.J.: Prentice Hall.
Semiconductor Industry Association (SIA). 1999. Semi-Annual Report. San Jose, Calif.: SIA.
Sohrabi, K., J. Gao, V. Ailawadhi, and G. Pottie. 1999a. “Self-organizing sensor network.” Proceedings of the 37th Allerton Conference on Communications, Control, and Computing, Monticello, Ill., September.
Sohrabi, K., B. Manriquez, and G. Pottie. 1999b. “Near-ground wideband channel measurements.” Proceedings of the 49th Vehicular Technology Conference. New York: IEEE, pp. 571-574.
Sommerfeld, A. 1949. Partial Differential Equations in Physics, New York: Academic Press.
Trimmer, William. 1997. Micromechanics and Mems. New York: IEEE Press.
Van Trees, H. 1968. Detection, Estimation and Modulation Theory. New York: John Wiley & Sons.
Wait, J.R. 1998. “The ancient and modern history of EM ground-wave propagation,” IEEE Antennas and Propagation Magazine 40(5):7-24.
BIBLIOGRAPHY
Agre, J.R., L.P. Clare, G.J. Pottie, and N.P. Romanov. 1999. “Development platform for self organizing wireless sensor networks.” Presented at Aerosense’99, Orlando, Fla.
Asada, G., M. Dong, T.S. Lin, F. Newberg, G. Pottie, H.O. Marcy, and W.J. Kaiser. 1998. “Wireless integrated network sensors: Low power systems on a chip.” Proceedings of the 24th IEEE European Solid-State Circuits Conference.
Bult, K., A. Burstein, D. Chang, M. Dong, M. Fielding, E. Kruglick, J. Ho, F. Lin, T.-H. Lin, W.J. Kaiser, H. Marcy, R. Mukai, P. Nelson, F. Newberg, K.S.J. Pister, G. Pottie, H. Sanchez, O.M. Stafsudd, K.B. Tan, C.M. Ward, S. Xue, and J. Yao. 1996. “Low power systems for wireless microsensors.” Proceedings of the 1996 International Symposium on Low Power Electronics and Design, pp. 17-21.
Chatterjee, P.K., and R.R. Doering. 1998. “The future of microelectronics.” Proceedings of the IEEE 86(1):176-183.
Dong, M.J., G. Yung, and W.J. Kaiser. 1997. “Low power signal processing architectures for network microsensors.” Proceedings of the 1997 International Symposium on Low Power Electronics and Design, pp. 173-177.
Jones, Mike. 1997. “What really happened on Mars?” The Risks Digest: Forum on Risks to the Public in Computer and Related Systems 19(49), Available online at <http://catless.ncl.ac.uk/Risks/19.49.html#subj1>.
Lin, T.H., H. Sanchez, R. Rofougaran, and W.J. Kaiser. 1998. “CMOS front end components for micropower RF wireless systems.” Proceedings of the 1998 International Symposium on Low Power Electronics and Design.
Merrill, W.M. 2000. “Coax transition to annular ring for reduced input impedance at 2.4 GHz and 5.8 GHz.” Proceedings of the 2000 IEEE Antennas and Propagation Society International Symposium, Salt Lake City, Utah, July 16-21.
Merrill, W.M. 2000. “Short range communication near the earth at 2.4 GHz.” Proceedings of the 2000 USNC/URSI National Radio Science Meeting, Salt Lake City, Utah, July 16-21.
Pottie, G.J. 1999. “Wireless multiple access adaptive communication techniques.” In Encyclopedia of Telecommunications, Vol. 18. F. Froelich and A. Kent, eds. New York: Marcel Dekker Inc.
Proakis, J.G. 1995. Digital Communications, 3rd ed. Boston, Mass: WCB/McGraw-Hill, pp. 855-858.
Reed, J.H., K.J. Krizman, B.D. Woerner, and T.S. Rappaport. 1998. “An overview of the challenges and progress in meeting the E-911 requirement for location service,” IEEE Communications Magazine (April): 30-37.
Reeves, Glenn. “Re: What really happened on Mars?” The Risks Digest: Forum on Risks to the Public in Computer and Related Systems 19(49). Available online at <http://catless.ncl.ac.uk/Risks/19.54.html#subj6>.
Yao, K., R.E. Hudson, C.W. Reed, D. Chen, F. Lorenzelli. 1998. “Blind beamforming on a randomly distributed sensor array system.” IEEE Journal of Selected Areas in Communications 16(8):1555-1567.
Yu, T., D. Chen, G.J. Pottie, and K. Yao. 1999. “Blind decorrelation and deconvolution algorithm for multiple-input, multiple-output systems,” Proceedings of the SPIE, 3807.





































