
8
Imputations and Late Additions
We turn in this chapter to examine two groups of people whose census records were excluded from the 2000 Accuracy and Coverage Evaluation (A.C.E.) Program. The first group comprises people who required imputation to complete their census records (whole person imputations).1 They were excluded from the E-sample of census enumerations because they could not be matched to the independent P-sample, given incomplete reporting of data for them. The second group comprises people who are often referred to as “late additions.” Although they were in fact enumerated in a timely fashion, their records were deleted from the census file in summer 2000 as possibly duplicating other records. After further examination, they were reinstated in the census but too late to be included in the A.C.E. process. Collectively, these two groups are referred to as “people with insufficient information,” or IIs, in the formula for estimating the population from the A.C.E. with the method of dual-systems estimation (DSE—see Chapter 6).
Every census has people with insufficient information whose records are excluded from the coverage evaluation; however, the number of such people was considerably larger in 2000 than in 1990. The total number of IIs in 2000 was about 8.2 million people, 2.9 percent of the household population (excluding a small number of people reinstated in the census who also required imputation); the corresponding number in 1990 was about 2.2 million, 0.9 percent of the population. The people excluded from the A.C.E. break down into 5.8 million who required imputation and 2.4 million who were reinstated too late for A.C.E. processing.2 The people excluded from the Post-Enumeration Survey (PES) break down into 1.9 million who required imputation and 0.3 million who were enumerated in coverage improvement programs too late for PES processing. (There were no truly late enumerations in 2000 and no reinstated people in 1990.)
|
1 |
Another Census Bureau term for this group is “non-data defined,” meaning that their census records have reported information for only one short-form characteristic (name, age, sex, race, ethnic origin, or household relationship; see Chapter 7). |
|
2 |
Some people in group quarters also required imputation to complete their census records. Of the total population, including group quarters as well as household residents, 6 million people (2.1%) required imputation in 2000; corresponding figures for 1990 and 1980 are 2 million people (0.8%) and 3.5 million people (1.5%), respectively (Love and Dalzell, 2001:Table 1). |
In this chapter we first consider the role of IIs in explaining a puzzle from our initial analysis of the 2000 A.C.E. We then examine separately the characteristics of whole person imputations and people reinstated in the census too late to be included in the A.C.E. (Appendix A provides more detail on the material in this chapter.).
A PUZZLE
Our initial analysis of the 2000 A.C.E. and the 1990 PES led us to expect similar rates of net undercount for key population groups because of similarities in the estimates for each of two components of the DSE formula, namely, the match rate estimated from the P-sample and the correct enumeration rate estimated from the E-sample (see Tables 7-8 and 7-9 in Chapter 7). Yet the A.C.E. measured marked reductions in net undercount rates from 1990 levels for such groups as minorities, renters, and children and a consequent narrowing of differential undercount rates between historically less well-counted and better-counted groups.
Illuminating the Puzzle
Table 8-1 provides information from the 2000 A.C.E. and the 1990 PES that illustrates the puzzle and a large part of the solution. The first two columns of Table 8-1 show the coverage correction factors for 2000 and 1990. The coverage correction factor is the dual-systems estimate (DSE) of the population divided by the full census count, including people requiring imputation and people reinstated in the census too late for A.C.E. processing. The coverage correction factor minus one is similar to the net undercount rate (DSE minus the full census count divided by the DSE). The coverage correction factor would be used if the census data were to be adjusted for net undercount. The second two columns of Table 8-1 are the 2000 and 1990 correction ratios. The correction ratio is the estimated correct enumeration rate divided by the estimated match rate. If there were no people with insufficient information who had to be excluded from the E-sample, the correction ratio would equal the coverage correction factor. The third and last two columns of Table 8-1 are the 2000 and 1990 percentages of all people with insufficient information (IIs) in the census count, including people requiring imputation and people reinstated too late for A.C.E. processing. These people were not included in the E-sample but were added back to the census count when computing the coverage correction factors (see Chapter 6).
Looking at owners and renters for the non-Hispanic white and other races domain as an example, the correction ratios for 2000 are 1.022 for owners and 1.055 for renters, for a difference of 3.3 percentage points. For 1990, the correction ratios are 1.002 for owners and 1.045 for renters, for a difference of
TABLE 8-1 Coverage Correction Factors, Correction Ratios, and Percentage Insufficient Information People, by Race/Ethnicity Domain and Housing Tenure, 2000 A.C.E. and 1990 PES (weighted)
|
|
Coverage Correction Factor (DSE/Census) |
Correction Ratio (CE Rate/Match Rate) |
Percentage Insufficient Information People (IIs) |
|||
|
Domain and Tenure Group |
2000 |
1990a |
2000 |
1990a |
2000 |
1990a |
|
American Indian/Alaska Native on Reservation |
|
|||||
|
Owner |
1.053 |
1.139 |
1.120 |
1.172 |
6.00 |
3.16 |
|
Renter |
1.043 |
(Total) |
1.104 |
(Total) |
5.58 |
(Total) |
|
American Indian/Alaska Native off Reservation |
|
|||||
|
Owner |
1.016 |
N.A. |
1.048 |
N.A. |
3.51 |
N.A. |
|
Renter |
1.059 |
N.A. |
1.101 |
N.A. |
4.12 |
N.A. |
|
Hispanic Origin |
|
|||||
|
Owner |
1.013 |
1.019 |
1.060 |
1.030 |
4.61 |
1.03 |
|
Renter |
1.045 |
1.080 |
1.098 |
1.099 |
4.96 |
1.56 |
|
Black (Non-Hispanic) |
|
|||||
|
Owner |
1.007 |
1.023 |
1.046 |
1.036 |
3.81 |
1.20 |
|
Renter |
1.037 |
1.069 |
1.090 |
1.084 |
4.88 |
1.89 |
|
Native Hawaiian/Pacific Islander |
|
|||||
|
Owner |
1.028 |
N.A. |
1.074 |
N.A. |
4.49 |
N.A. |
|
Renter |
1.070 |
N.A. |
1,121 |
N.A. |
4.70 |
N.A. |
|
Asian (Non-Hispanic) |
|
|||||
|
Owner |
1.006 |
0.986 |
1.038 |
0.994 |
3.13 |
0.74 |
|
Renter |
1.016 |
1.075 |
1.059 |
1.093 |
4.10 |
1.71 |
|
White and Other Races (Non-Hispanic) |
|
|||||
|
Owner |
1.003 |
0.997 |
1.022 |
1.002 |
1.93 |
0.46 |
|
Renter |
1.019 |
1.032 |
1.055 |
1.045 |
3.47 |
1.44 |
|
Total |
1.012 |
1.016 |
1.040 |
1.022 |
2.93 |
0.90 |
|
NOTE: See text for discussion. aData for 1990 includes Pacific Islanders in the Asian (non-Hispanic) group. SOURCE: Davis (2001:Tables E-2, F-1, F-2). |
||||||
TABLE 8-2 Percentage Distribution of People Requiring Imputation and Late Additions to the Census in 2000, and Percentage Distribution of Total People with Insufficient Information in 1990, by Race/Ethnicity Domain and Housing Tenure
|
|
Percent of Household Population, 2000 |
|
||
|
Panel A Domain and Tenure Group |
People Requiring Imputation |
Late Additions |
Total with Insufficient Information |
Percent of Household Population with Insufficient Information, 1990a |
|
American Indian/Alaska Native on Reservation |
|
|||
|
Owner |
5.13 |
0.97 |
6.00 |
3.16 |
|
Renter |
4.74 |
0.94 |
5.58 |
(Total) |
|
American Indian/Alaska Native off Reservation |
|
|||
|
Owner |
2.36 |
1.20 |
3.51 |
N.A. |
|
Renter |
3.00 |
1.16 |
4.12 |
N.A. |
|
Hispanic Origin |
|
|||
|
Owner |
3.74 |
0.92 |
4.61 |
1.03 |
|
Renter |
3.99 |
1.00 |
4.96 |
1.56 |
|
Black (Non-Hispanic) |
|
|||
|
Owner |
2.84 |
1.00 |
3.81 |
1.20 |
|
Renter |
3.95 |
0.96 |
4.88 |
1.89 |
|
Native Hawaiian/Pacific Islander |
|
|||
|
Owner |
3.67 |
0.87 |
4.49 |
N.A. |
|
Renter |
3.83 |
0.92 |
4.70 |
N.A. |
|
Asian (Non-Hispanic) |
|
|||
|
Owner |
2.46 |
0.69 |
3.13 |
0.74 |
|
Renter |
3.35 |
0.77 |
4.10 |
1.71 |
|
White and Other Races (Non-Hispanic) |
|
|||
|
Owner |
1.24 |
0.71 |
1.93 |
0.46 |
|
Renter |
2.38 |
1.12 |
3.47 |
1.44 |
|
Total Owner |
1.66 |
0.75 |
2.39 |
0.56 |
|
Total Renter |
3.08 |
1.05 |
4.10 |
1.55 |
|
Panel B Age/Sex Group |
|
|||
|
Children Under Age 18 |
3.11 |
0.92 |
4.00 |
0.82 |
|
Men Aged 18–29 |
2.86 |
0.82 |
3.65 |
1.45 |
|
Women Aged 18–29 |
2.56 |
1.03 |
3.46 |
1.45 |
|
Men Aged 30–49 |
1.77 |
0.79 |
2.53 |
0.76 |
|
Women Aged 30–49 |
1.58 |
0.81 |
2.37 |
0.70 |
|
Men Aged 50 and Over |
1.25 |
0.81 |
2.04 |
0.69 |
|
Women Aged 50 and Over |
1.30 |
0.80 |
2.08 |
0.79 |
|
Total |
2.11 |
0.85 |
2.93 |
0.90 |
|
NOTE: The 2000 total with insufficient information is the unduplicated sum of people requiring imputation and late additions to the census; 1990 figures include small number of late additions to the census from coverage improvement operations. aData exclude American Indians living on reservations; the Asian (Non-Hispanic) data for 1990 include Pacific Islanders. SOURCE: Data for 2000 are from tabulations by panel staff of U.S. Census Bureau, Pre-Collapsed Post-Stratum Summary File (U.S.), February 16, 2001; data for 1990 are from Davis (2001:Tables F.1, F.2). |
||||
4.3 percentage points. If there were no people excluded from the E-sample because of insufficient information in the census, then the correction ratios would equal the coverage correction factors, with the result that the net undercount rate would be somewhat higher for white owners in 2000 than in 1990 and similar and quite high for white renters in both censuses. The differential net undercount between white owners and renters would be 3–4 percentage points. Yet the estimated coverage correction factors for 2000 are 1.003 for white owners and 1.019 for white renters, for a difference of only 1.6 percentage points; in comparison, the corresponding difference for 1990 is 3.5 percentage points. The reason for these results is that the 2000 census recorded larger percentages than did the 1990 census of white owners and renters—particularly renters—whose census records lacked sufficient information to be included in the E-sample: the percentage of IIs for white owners increased from 0.5 percent in 1990 to 1.9 percent in 2000; the percentage of IIs for white renters increased from 1.4 percent in 1990 to 3.5 percent in 2000.
The same patterns hold true for owners and renters in the Hispanic, non-Hispanic black, and non-Hispanic Asian domains, and for minorities, generally, compared with the non-Hispanic white and other races domain (see Table 8-1). The same patterns also hold true for children under age 18 (data not shown). The coverage correction factor for children was 1.016 in 2000 and 1.033 in 1990, indicating a reduction in their measured net undercount. However, their correction ratio was larger in 2000 than in 1990, 1.056 and 1.039, respectively. This change would have meant an increase in the net undercount for children were it not for a large increase in the number of children in the census with insufficient information who were not part of the E-sample—4.0 percent in 2000 and only 0.8 percent in 1990.
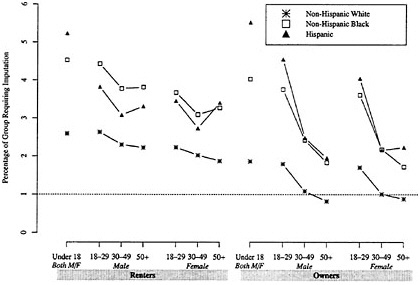
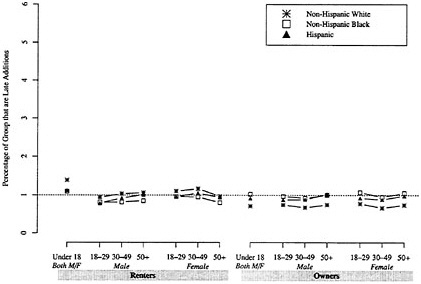
Thus, the increased percentages of people with insufficient information in the census largely appear to explain the reduction in measured net undercount from 2000 to 1990 for historically less well-counted groups. In particular, the increased percentages of people requiring imputation—as distinct from people reinstated too late for A.C.E. processing—contributed greatly to this result. As shown in Table 8-2 and Figures 8-1 and 8-2, people requiring imputation accounted for proportionally more of historically less well-counted groups, while the distribution of late additions to the census showed little variation by race/ethnicity, housing tenure, or age/sex categories.
For some groups, other factors also played a role in reducing their net undercount. For American Indians and Alaska Natives on reservations, there is not only an increase in people with insufficient information, but also a reduction in the correction ratio (see Table 8-1). It turns out that the P-sample had a smaller proportion of nonmatched cases in 2000 than in 1990 for this group, and the reduction in the nonmatch rate (or the increase in the match rate) was proportionally greater than the change in the correct enumeration rate (see Tables 7-8 and 7-9 in Chapter 7). The targeted extended search may have
been the principal cause for the increased match rate relative to the correct enumeration rate for this domain (see Navarro and Olson, 2001).
Role of IIs in the Census and the DSE
There are two important points about people with insufficient information, whether they are people requiring imputation or people reinstated in the census too late for A.C.E. processing. First, their exclusion from the dual-systems estimation does not likely affect to any significant degree the expected value of the DSE estimate of the population (although it does affect the variance of the DSE, as well as complicating the interpretation of the A.C.E. results—see Chapter 7). Second, they do not necessarily result in poor quality census data.
With regard to the first point, if all (or some) of the census records for people with insufficient information had, instead, not required imputation and been available in time for matching, the components of the DSE formula would have changed in ways that would be expected to result in about the same level of the DSE (see Hogan, 2001b).3 First, the base for computing the DSE—the census count minus people with insufficient information (C–II) —would be a higher number than that actually used in the DSE formula in 2000. Also, because more P-sample cases would have matched to the E-sample, the correction ratio would have decreased from the correction ratio that was actually estimated. The result of applying a lower correction ratio to a higher base (C–II) would have been about the same DSE as the actual estimate in which a higher correction ratio was applied to a lower base. A similar result obtains even if we assume that many of the people who were excluded from the A.C.E. were duplicates or other types of erroneous enumerations (see Box 8-1).
On the second point, people with “insufficient information” do not necessarily result in poor short-form information. Almost one-third of the total IIs in 2000 were people reinstated in the census, most of whom had complete information, although they may have included a higher-than-average proportion of duplicates. Also, imputations in many cases were carried out on the basis of knowing household size, as well as characteristics of the immediate neighborhood.
|
3 |
This can be seen by reexpressing the DSE formula as: the census count, C, minus IIs, times the correction ratio (the correct enumeration rate, CE/E, divided by the match rate, M/P). The usual expression equates the DSE to: (C–II) times the correct enumeration rate times the inverse of the match rate (see Eq. 1 in Chapter 6). |
|
BOX 8-1 Relationship of People with Insufficient Information (Imputations and Late Additions) to Dual-Systems Estimation: Illustrative Examples A. Suppose that a post-stratum has the following characteristics:
Then the correction ratio, CR (correct enumeration rate divided by match rate), is 1.0404, and the DSE is 1,019,600 from the following formula: DSE = (C–II)(CR) = 980,000(1.0404) = 1,019,600. The coverage correction factor, CCF, is 1,019,600 divided by 1 million (C) = 1.0196. The net undercount rate is (DSE—C)/DSE = 1.92 percent B. Now suppose that all of the IIs are, instead, able to be included in the A.C.E., i.e., they do not require imputation and they are available in time for A.C.E. processing. Assume that these 20,000 people contain 15,850 matches, 3,200 other correct enumerations, and 950 erroneous enumerations (similar to the A.C.E. E-sample). Then the P-sample match rate is [15,850 + (0.916)(1,000,000)]/1,000,000 = 93.185, which is a higher match rate than shown above. The recalculated E-sample correct enumeration rate is the same at 95.3. Now the correction ratio is 1.0227 and the DSE is: DSE = (C–II)(CR) = 1,000,000(1.0227) = 1,022,700, which only differs from the DSE for case A above by 3,100 people (or 0.3%). The coverage correction factor is 1,022,700 divided by 1 million (C) = 1.0227. The net undercount rate is (DSE–C)/DSE = 2.22 percent, which is essentially the same net undercount rate as 1.92 percent. C. Finally, suppose that all of the IIs are, instead, able to be included in the A.C.E., but that one-half of them (10,000) are erroneous enumerations and the rest are matches (8,200) and other correct enumerations (1,800). Then the P-sample match rate is (8,200 + 916,000)/1,000,000 = 92.42. The E-sample correct enumeration rate is [(10,000 + (0.953)(980,000)]/1,000,000 = 94.394. In this case, the P-sample match rate increases by a smaller amount than in case B above; the E-sample correct enumeration rate decreases. Now the correction ratio is 1.0214 and the DSE is: DSE = (C–II)(CR) = 1,000,000(1.0214) = 1,021,400, which only differs from the DSE for case A by 1,800 people (or less than 0.2%). The coverage correction factor is 1,021,400 divided by 1 million (C) = 1.0214. The net undercount rate is (DSE–C)/DSE = 2.10 percent. These examples illustrate the negligible effect that the IIs have on the value of the DSE. At the same time, they illustrate how the larger number of IIs in 2000 clouds the interpretation of the A.C.E. results in comparison with the 1990 PES. The correction ratio is considerably higher than the coverage correction factor for A.C.E. Also, estimates of duplicates and other kinds of erroneous enumerations are lower than they would otherwise be because so many more census records are excluded from A.C.E. processing. |
PEOPLE REQUIRING IMPUTATION
Situations Requiring Imputation
The Census Bureau distinguishes five situations in which imputation of person records is required (see Appendix A for the methods used for each situation):
-
Individual imputed person(s) in an enumerated household. An example in 2000 would be a household of seven members that had characteristics reported for six members, and the telephone follow-up failed to obtain information for the seventh person listed on the household roster. Individual persons requiring imputation comprised 0.9 percent of the total household population in 2000, 2.33 million people (Schindler, 2001), compared with 0.2 percent of the total population in 1990, 373,000 people (including some imputations for persons in group quarters; Love and Dalzell, 2001).
-
Person imputations in a household for which the number of residents was known (perhaps from a neighbor or landlord), but no characteristics were available for them. Whole households that required imputation included 0.8 percent of the household population in 2000, 2.27 million people, and 0.6 percent in 1990, 1.55 million people.
-
, (4), and (5) Persons imputed in a household or at an address for which there was no information on household size (category 3), or sometimes no information on occupancy status (category 4), or sometimes not even information on status as a housing unit (category 5). Together, these three categories comprised 0.4 percent of the household population counted in 2000, 1.17 million people, compared with only 0.02 percent of the household population counted in 1990, 54,000 people.
Information is available on each of the three categories, (3), (4), and (5), separately for 2000 (but not for 1990). Category (3) includes persons imputed in a household that was known with reasonable certainty to be occupied but the household size was not known. Members of such households were 0.2 percent of the household population (496,000 people). Category (4) includes persons imputed in a housing unit that was known to exist but for which its status as occupied or vacant was not certain. Members of households with occupied status, size, and person characteristics imputed were 0.1 percent of the household population in 2000 (260,000 people). Finally, category (5) includes people imputed at an address for which nothing was certain—not its existence as a housing unit, its occupancy status, its size, or household composition. Members of households in this category were 0.2 percent of the household population (415,000 people).
Distribution of Imputations Among Population Groups
Race/Ethnicity Domain and Housing Tenure
Table 8-3 shows the distribution of people requiring imputation in 2000 among race/ethnicity and housing tenure groups by type of imputation required. It also shows the total percentage of people requiring imputation for each group; note that the overall percentages are low.
Several patterns stand out. First, the proportion of imputations that involved filling in a data record for one (or possibly more) individuals missing in an enumerated household (type 1) is higher for owners (43%) than renters (37%), and this pattern holds for all race/ethnicity groups except American Indians and Alaska Natives. In contrast, the proportion of imputations that involved supplying data records for all people in a household for which the number of people, but not their characteristics, was known (type 2) is higher for renters (45%) than owners (34%), and this pattern holds uniformly for all race/ethnicity groups.
These differences could make sense in light of knowledge of different response propensities and other characteristics for owners and renters. Owners have higher mail return rates than renters, and average household size also tends to be larger for owner-occupied housing than renter-occupied housing.4 Consequently, it is at least plausible to assume that proportionately more owners than renters sent in questionnaires indicating a larger household size than the number of people for whom they reported characteristics. If telephone follow-up did not locate these households, then one or more of their members would require imputation. Conversely, one could conjecture that enumerators would more often have a hard time gleaning any information for a rented housing unit beyond the household size (and the fact it was rented) than would be true for owned units. Hence, more renter-occupied units would require imputation of all their members.
Another striking pattern in Table 8-3 is that American Indians and Alaska Natives on reservations have the highest proportions of imputations for status as a housing unit (type 5). This finding suggests that there may have been difficulties in developing the address list for reservations. American Indians and Alaska Natives on reservations also have the highest total proportion of people requiring imputation of any race/ethnicity group (5%).
|
4 |
Mail return rates in 2000 were about 77 percent for owners and 57 percent for renters (from tabulations by panel staff of U.S. Census Bureau, E-Sample Person Dual-System Estimation Output File, February 16, 2001; weighted using TESFINWT); see U.S. General Demographic Characteristics Quick Table for average household size by tenure at http://factfinder.census.gov/home/en/c2ss.html. |
TABLE 8-3 Distribution of People Requiring Imputation by Type of Imputation, by Race/Ethnicity Domain and Housing Tenure, 2000
|
|
Percent of People Requiring Imputation by Typea |
|
||||
|
|
Person |
Household |
Size |
Occupancy |
Housing Unit |
Percent of Total Household Population Requiring Imputation |
|
Domain and Tenure Group |
(1) |
(2) |
(3) |
(4) |
(5) |
|
|
American Indian/Alaska Native on Reservation |
|
|||||
|
Owner |
41.4 |
9.2 |
12.1 |
1.9 |
35.7 |
5.1 |
|
Renter |
42.9 |
10.1 |
14.5 |
1.2 |
31.2 |
4.7 |
|
American Indian/Alaska Native off Reservation |
|
|||||
|
Owner |
38.6 |
34.7 |
9.3 |
4.5 |
12.9 |
2.4 |
|
Renter |
40.5 |
40.5 |
7.8 |
3.7 |
7.5 |
3.0 |
|
Hispanic Origin |
|
|||||
|
Owner |
61.5 |
22.8 |
7.0 |
2.2 |
6.5 |
3.7 |
|
Renter |
54.3 |
32.0 |
7.2 |
2.3 |
4.2 |
4.0 |
|
Black (Non-Hispanic) |
|
|||||
|
Owner |
43.2 |
39.3 |
9.4 |
3.4 |
4.7 |
2.8 |
|
Renter |
34.1 |
49.1 |
10.4 |
3.2 |
3.3 |
4.0 |
|
Native Hawaiian and Pacific Islander |
|
|||||
|
Owner |
60.6 |
25.7 |
6.5 |
1.5 |
5.6 |
3.7 |
|
Renter |
49.3 |
36.3 |
7.6 |
1.7 |
5.1 |
3.8 |
|
Asian (Non-Hispanic) |
|
|||||
|
Owner |
62.1 |
25.6 |
5.2 |
2.4 |
4.8 |
2.5 |
|
Renter |
39.9 |
45.5 |
8.0 |
2.9 |
3.7 |
3.4 |
|
White and Other Races (Non-Hispanic) |
|
|||||
|
Owner |
35.3 |
38.1 |
8.8 |
7.0 |
10.9 |
1.2 |
|
Renter |
27.1 |
51.9 |
9.1 |
5.1 |
6.8 |
2.4 |
|
Total |
40.3 |
39.3 |
8.6 |
4.5 |
7.2 |
2.1 |
|
Owner |
43.2 |
34.3 |
8.4 |
5.2 |
8.9 |
1.7 |
|
Renter |
37.0 |
45.3 |
8.9 |
3.7 |
5.1 |
3.1 |
|
aSee text for definitions of imputation types. SOURCE: Tabulations by panel staff from U.S. Census Bureau, Census Imputations by Post-Stratum File, July 30, 2001 (see Schindler, 2001). |
||||||
Age/Sex Categories
For age/sex categories (data not shown in Table 8-3), the most striking finding is that children under 18 have not only the highest total proportion of people requiring imputation of any age group (3.1%), but also the highest share of imputations that occurred in otherwise enumerated households (60% were type 1 imputations). No other age/sex group has as high a share of person imputations; the next highest proportions of type 1 imputations are for men aged 18–29 (37.9%) and women aged 18–29 (35%). This finding is consistent with an assumption that imputation of individuals in large households that did not report (or lacked enough room to report) characteristics for all their members most often involved children.
It is true that type 1 imputations could occur not only in households with more than six members, but also in smaller households that did not report characteristics for all of their members. It is at least plausible to assume, however, that the decision to reduce the size of the questionnaire by limiting the number of persons for whom characteristics could be reported from seven in 1990 to six in 2000 was a primary cause of the large increase in type 1 imputations in 2000 compared with 1990 and the predominance of type 1 imputations among children.
Indirect evidence for this assumption comes from analysis by panel staff of matched P-sample and E-sample cases in the 2000 A.C.E. by household composition. The analysis finds that the percentage of E-sample households for which the P-sample found one or more people in the household who were missed, or possibly missed, in the census rises almost from about 3 percent of single-person and two-person households to about 17 percent of households with nine or more members. In the middle of the E-sample household size distribution, the percentages of households with one or more P-sample omissions are, respectively, 5.8 percent, 11.5 percent, 9.0 percent, and 12.1 percent for five-person, six-person, seven-person and eight-person households. This pattern, in which the percentage for six-person households does not fit the sequence, suggests that the telephone follow-up to fill in the characteristics of all persons in households with more than six persons did not work completely. Alternatively, some households with more than six members may have chosen to report only six to forestall follow-up.
Distribution of Imputations by State
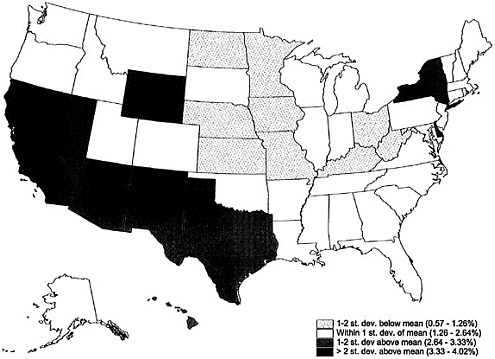
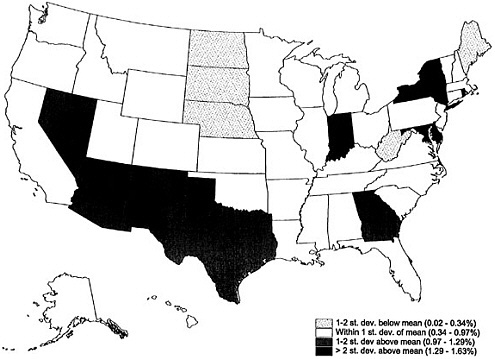
Figure 8-3 shows for each state the percentage of its population in 2000 that represented people requiring imputation. The percentage varied from 1 percent in Iowa and Nebraska to 3.74 percent in the District of Columbia. States with the highest proportions of people requiring imputation included a group in the Southwest: Arizona, California, Nevada, New Mexico, and Texas, plus
Delaware, the District of Columbia, Hawaii, New York, and Wyoming. States with the lowest proportions of people requiring imputation included a group of Midwest states: Iowa, Kansas, Minnesota, Missouri, Nebraska, and North Dakota, plus Kentucky, Ohio, and West Virginia.
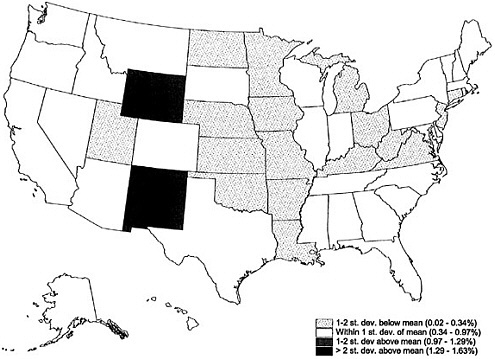
Figures 8-4 through 8-6 show the state variation in the three major types of imputation situations: category (1), partial household imputation, with some but not all members of the household fully enumerated (Figure 8-4); category (2), whole household imputation, with household size reported but not the characteristics of the members (Figure 8-5); and categories (3)–(5), housing status imputation, with household size and possibly occupancy status and housing unit status imputed first (Figure 8-6). Generally, they show similar patterns to those in Figure 8-3.5
Thus, several Southwest states, Alaska, Hawaii, and New York had higher-than-average proportions of people requiring partial household imputation (Figure 8-4), with California having the highest rate. This result is consonant with the finding that many California census tracts had marked increases in mail return rates in 2000 versus 1990 (see Appendix B), and so could have had relatively high proportions of mailed-back returns that did not (or could not) provide characteristics for all household members.
There is a wider range among states of proportions of people requiring whole household imputation than of people requiring only partial household imputation. Delaware, Maryland, and New York had the highest rates of people requiring whole household imputation, and Maine, Nebraska, North and South Dakota, and West Virginia had the lowest rates (Figure 8-5). Proportions of people requiring housing status imputation are the lowest and the most evenly distributed across states (Figure 8-6). Relatively high rates of housing status imputations for New Mexico and Wyoming may be associated with larger numbers of American Indians living on reservations. Data are not yet available with which to analyze distributions of people requiring imputation for smaller geographic areas.
|
5 |
The same four groupings are used in Figures 8-4 through 8-6: from 1 to 2 standard deviations below the mean to greater than 2 standard deviations above the mean. The distribution from which the groupings derive includes 153 state percentages—those for partial household imputations, whole household imputations, and housing status imputations for each state and the District of Columbia. |
LATE ADDITIONS
Of 6 million people whose census records were removed from processing in summer 2000 because they were thought to duplicate enumerations for other households, 2.4 million were reinstated in the census but too late for A.C.E. processing. As noted above, there was little variation in the distribution of people reinstated in the census by race/ethnicity group, housing tenure, or age/sex categories. In this section we look at their distribution by geographic area. We also consider the possibility that people reinstated in the census still contain a high proportion of duplicates and what the A.C.E. can explain about duplicates in the census.
Geographic Variation
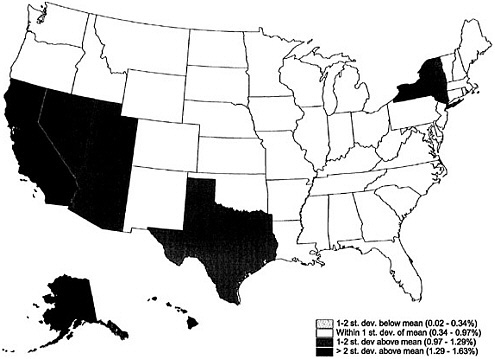
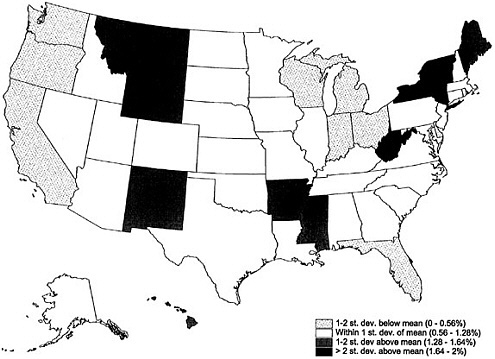
Figure 8-7 shows for each state the percentage of its census count that represented people reinstated in the census at the conclusion of the summer 2000 program that identified duplicates in the Master Address File (MAF). The percentage of people reinstated in the census varied relatively little among states—from 0.1 percent in the District of Columbia and 0.4 percent in Delaware to 1.7 percent in New York and Vermont, compared with a national average of 0.9 percent. States with the largest proportions of people reinstated in the census included Arkansas, Hawaii, Maine, Mississippi, Montana, New Mexico, New York, Vermont, West Virginia, and Wyoming. States with the lowest proportions of late additions included California, Delaware, District of Columbia, Florida, Indiana, Michigan, Ohio, Oregon, Washington, and Wisconsin.
There is probably more variation in percentages of people reinstated in the census at smaller levels of geographic aggregation than at the state level. The Census Bureau indicated that the decision to reinstate people who were originally identified as duplicates was most often made in rural areas with nonstandard addressing styles and in apartment buildings in cities, for which individual apartment addresses were not clear (Miskura, 2000b). In other words, when there was cause for doubt about a duplication because the addresses could not clearly be compared, the person record was often reinstated.
Percentages of people reinstated in the census for certain A.C.E. post-strata categorized by region show several patterns (Farber, 2001b:Table 3-1). The highest percentages of people reinstated in the census (2–4%) are most often found in strata for either rural areas or large cities, specifically in strata for:
-
mailout/mailback areas with low mail return rates in the largest cities of the Northeast for non-Hispanic white owners, black owners, and Hispanic owners;
-
non-mailout/mailback (i.e., update/leave and list/enumerate) areas in all regions of the country for non-Hispanic white renters; and
-
non-mailout/mailback areas with low mail return rates (update/leave areas) in all regions of the country for non-Hispanic white owners and in the South and West for Hispanic renters.
Of course, no census can be conducted completely uniformly for all geographic areas. However, the concern is that sizable geographic variation in the completeness of the census count could affect uses of the census that are based on population shares. Moreover, adjustment of the census counts in the presence of substantial local variations could be problematic: a disproportionately well-counted area would receive an adjustment that is likely too great and the reverse would be true for a disproportionately less well-counted area.
Further research is needed on geographic variations in the completeness of the census due not only to people reinstated in the census, but also to people requiring imputation. Such research needs to be at a finer geographic level than states and needs to trace variations to their sources in the MAF.
Duplication
An often-voiced worry about the 2000 census was that changes in the method used to construct the MAF and additional opportunities for enumeration would lead to an increase in erroneous enumerations, particularly duplicates. Construction of the MAF encouraged acceptance of addresses from multiple sources. Enumeration opportunities included mail, telephone, Internet, the “Be Counted” forms that were widely distributed just prior to Census Day, and various follow-up operations.
In fact, duplicates from additional opportunities for enumeration in 2000 appeared relatively low (see Appendix A). However, extensive unduplication operations had to be undertaken for the MAF, including the special unduplication effort in summer 2000.
It is likely that the Bureau’s efforts to remove duplications from the MAF were not completely successful. In particular, the people reinstated in the census at the conclusion of the special unduplication operation may have contained a larger-than-average proportion of duplicates and other erroneous enumerations. Also, some of the people requiring imputation, particularly those at addresses for which the housing unit status had to be imputed first, may have been duplicates or other types of erroneous enumerations.
The reason for concern about duplications is that they may not simply offset people with the same characteristics who were omitted from the census. Research from previous censuses (see Ericksen et al, 1991; see also Appendix B) suggests that not only omissions, but also duplicate and other erroneous enumerations are more likely to occur among historically less well-counted groups. However, the relationship is not as strong for duplicates as it is for
omissions, so that duplication can increase, not reduce, differences in net undercount rates between less well-counted and better-counted groups.
Because net undercount rates in 2000 declined proportionally more from 1990 rates for historically less well-counted groups than for others, it does not appear that duplication had a serious effect on differential coverage of population groups in 2000. In fact, it may have helped reduce differential coverage. However, duplication could well have varied across geographic areas.
Measurement of Duplication in the A.C.E.
The A.C.E. estimated duplicates in the E-sample universe, and it found many fewer than the number estimated by the 1990 PES. In addition, the estimated number of duplicates in both the A.C.E. and the PES, but particularly the A.C.E., seems too low in relation to the total number of erroneous enumerations of all types (see Table 7-10 in Chapter 7). These results are not entirely unexpected for at least three reasons.
First, neither the A.C.E. nor the PES is well designed to measure duplicates as distinct from other kinds of erroneous enumerations. They will not, for example, identify enumerations of snowbirds at both their winter and their summer residences as duplicates because the search area is limited to a block cluster or a ring of surrounding blocks (the A.C.E. used a targeted extended search—see Chapter 6). For the same reason, they will not identify enumerations for children of divorced or separated parents who spend time with each parent or enumerations for college students who were counted at home and at college as duplicates.6
Second, the A.C.E., as distinct from the PES, likely underestimated duplicate enumerations because it was not designed to measure duplicates (or omissions) that occurred within the group quarters population (the PES included group quarters residents not in institutions). Third, the A.C.E. could not measure the extent to which people not part of the E-sample universe (those requiring imputation or reinstated in the census too late for A.C.E. processing) contained duplicates, and there were many more such cases in 2000 than in 1990. Also, if the special operation to unduplicate addresses in the MAF had not permanently deleted 3.6 million people of the 6 million originally set aside for examination, then the A.C.E. would have measured more duplicate enumerations. For all these reasons, the A.C.E. estimates of duplicate census enumerations should be viewed as a lower bound.
CONCLUSIONS
We have devoted considerable attention to people requiring imputation and people whose census records were reinstated too late for A.C.E. processing, even though the numbers involved are small relative to the total population. We have done so because of the small size of the estimated net undercount, which means that relatively small changes in the enumeration of population groups can affect their net undercount rates. We conclude that the exclusion from the A.C.E. of people requiring imputation and people reinstated in the census did not likely affect the DSE to any appreciable degree (as explained in Hogan, 2001b; see also Box 8-1). We find that the larger numbers of imputed and reinstated people lead mathematically to a reduction in the overall net undercount rate; specifically, the larger numbers of people requiring imputation contributed to reducing net undercount rates for historically less well-counted groups. However, the larger numbers of imputed and reinstated people also made the results from the A.C.E. less easy to interpret and less useful as a guide to gross errors in the census. It is not yet known whether the imputed and reinstated people resulted in more variation in population coverage across geographic areas.
While there will always be people who require imputation to complete their census records and other people who are enumerated too late for inclusion in coverage evaluation, it seems clearly desirable to reduce their numbers from 2000 levels. Direct information from respondents—collected in time to support normal census and coverage evaluation procedures—is always preferable to imputed and reinstated responses. For planning the 2010 census, considerable research is needed on the sources of addresses for which people were imputed or reinstated in 2000; features of census operations that may have increased the number of people requiring imputation; and methods and their associated costs and benefits for reducing the number of people requiring imputation and minimizing the number of late or reinstated enumerations. For purposes of evaluating the 2000 census data, research is also needed on the exact nature and quality of the imputation and reinstatement procedures used in the 2000 census.
People Requiring Imputation
It is important to keep in mind that many cases of whole person imputations are based on definite knowledge that one or more individuals should be counted at an address. Indeed, the largest group of people requiring imputation in 2000 were individual members of an enumerated household, not the
entire household (type 1). These cases were genuine household enumerations for which the computer was used to supply characteristics of the missing members on the basis of knowing a great deal about the household. Further analysis is needed of type 1 imputations, which contributed to reducing the net undercount of children in 2000: Were most such imputations among households with more than six members? On mailed-back returns rather than enumerator-obtained returns? On returns that lacked a telephone number, which is a reason that the coverage edit and telephone follow-up operation could have missed them? Did the imputations produce a reasonable distribution of households by size?
Most important, can it be established that the reduced size of the questionnaire in 2000 encouraged mail returns from large households that might otherwise have failed to respond or have been poorly enumerated in follow-up? If so, then there is an argument for continuing to use a shorter questionnaire in 2010, even though more people may require type 1 imputations as a consequence. In that regard, a thorough evaluation is needed of the performance of the coverage edit and telephone follow-up operation, which was intended to complete the census records for partially enumerated households. If many of the households in the telephone follow-up workload did not provide telephone numbers or could not be reached despite repeated calls, then there is an argument for considering the benefits and costs of field follow-up of partially enumerated households as a supplement to telephone follow-up in 2010.
Looking at the numbers of people requiring imputation in a household for which occupancy status and size were known, but not characteristics (type 2), they are similar to 1990. There apparently will always be some households that are reported to be occupied and for which a household size can be obtained but not other characteristics. We believe it makes sense to include people for these households in the census by using information for other households in the immediate neighborhood rather than drop the addresses. Imputations for these kinds of households were proportionately greater among renter households than owner households in 2000, which helps explain the narrowing of the difference in net undercount rates between owners and renters from the 1990 levels.
Looking at categories (3)–(5), it is difficult to explain the much larger number of people in 2000 than in 1990 (1.17 million and 54,000) who required imputation when characteristics of the housing unit had to be imputed first.7 It
is possible that some of these cases—perhaps a large proportion—were erroneous or duplicates (type 2 situations could also include duplicates). Research is needed on the geographic distribution of housing status imputations, the sources of addresses for them in the MAF, and the extent to which features of the 2000 nonresponse and coverage improvement follow-up operations (e.g., instructions to enumerators) may have contributed to the larger number of such cases. Research is also needed on the quality of the housing status imputation process, which was refined somewhat from the 1990 procedure (see Appendix A). Although it may result that the housing status imputations in the 2000 census appear reasonable, it is clearly desirable to minimize the number of census enumerations for which so little is known. Hence, research on the sources of these enumerations is important to carry out for planning the 2010 census.
Late Additions
Research is needed on the sources and geographic distribution of the MAF addresses that necessitated the special unduplication operation in summer 2000. This operation was unprecedented. Not only did it pose a risk for census data processing, but it also meant that the A.C.E. was less informative about erroneous enumerations than if the records that were reinstated at the conclusion of the special operation had been available to include in the A.C.E. It seems desirable to preclude the necessity for any such late-occurring address clean-up operation in future censuses, which means that the Census Bureau’s plans for reengineering the MAF development process for the 2010 census are critically important (see Chapter 4).
Research is also needed on the quality of the reinstated records in 2000. Field work may be needed to estimate the extent of duplication among the reinstated records (and among some types of imputations). In addition, research is needed on the extent of duplication of people with more than one residence. A possible way to study the issue would be to use the American Community Survey to ask about multiple residences at the time of the census and then to check the census records to determine how such cases were enumerated.
























