
Page 79
Chapter 7
Design of Automated Authoring Systems for Tests
Eva L. Baker
The Center for the Study of Evaluation University of California, Los Angeles
INTRODUCTION AND BACKGROUND
This paper will address the goals and requirements of computer-based tools and systems to support the design of assessment tasks. 1 This is not a new idea, but one with a conceptual history (Baker, 1996; Bunderson, Inouye, & Olsen, 1989; O'Neil & Baker, 1997) and early work in item generation (Millman & Greene, 1993; Roid & Haladyna, 1982). The rationale for an increased investment in R&D in this area resides in the improved availability of software tools, modern understanding of assessment and validity, present practice, and unresolved difficulties in assessment design and use. There are five underlying claims that should affect any R&D on assessment design and development:
-
Achievement test design needs improvement in order to meet the challenges of measuring complex learning, within cost and time constraints, and with adequate validity evidence.
-
The theory of action underlying accountabilityfocused testing requires that single tests or assessments be employed for a set of multiple, interacting purposes: diagnosis, instructional improvement, certification, program evaluation, and accountability (Baker & Linn, in press).
-
For the most part, tests developed for one purpose are applied on faith to meet other educational purposes. There is almost no validity evidence supporting these multiple purposes in widely used achievement tests. Such evidence is needed (American Educational Research Association [AERA], American Psychological Association, & National Council on Measurement in Education, 1999)
-
An integral part of improved learning is the idea that assessments that occur during instruction (whether computer or teacherdelivered) need to provide relevant information about performance in the target domain of competence. Alignment of these tests is essential, and teachers are an essential target for test development assistance (Baker & Niemi, 2001).
-
Performance assessments provide one source of practical knowledge for improvement, but sustained systematic strategies for their development, validation, and implementation have been neither clearly articulated nor widely accepted.
Page 80
A second set of assertions pertains to the present state of online assessment and authoring systems:
-
- Online assessments, using simulations, open-ended oral or verbal responses, other constructed responses, and automated approaches to development are relatively well in hand as proof of concept examples (Braun, 1994; Clauser, Margolis, Clyman, & Ross, 1997; Bennett, 2001).
-
- Authoring components to create integrated testing systems have been described by Frase and his colleagues (in press). Schema or template-based, multiple-choice development, and test management systems have made significant progress (Bejar, 1995; Bennett, in press; Chung, Baker, & Cheak, 2001; Chung, Klein, Herl, & Bewley, 2001; Gitomer, Steinberg, & Mislevy, 1995; Mislevy, Steinberg, & Almond, 1999).
-
- New assessment requirements, growing from federal statutes or from the expanded role of distance learning, will continue to propagate. Efficient means of online test design need to be built.
Much of the current effort has been devoted to improving computer-administered tests so that they provide more efficient administration, display, data entry, reporting, and accommodations. Ideally, computer administration will enhance measurement fidelity to desired tasks and the overall validity of inferences drawn from the results. A good summary of the promise of computerized tests has been prepared by Bennett (2001). Computerized scoring approaches for open-ended tasks have been developed. Present approaches to essay scoring depend, one way or another, on a set of human raters (Burstein, 2001; Burstein et al., 1998; Landauer, Foltz, & Laham, 1998; Landauer, Laham, Rehder, & Schreiner, 1997). Other approaches to scoring have used Bayesian statistical models (Koedinger & Anderson, 1995; Mislevy, Almond, Yan, & Steinberg, 2000) or expert models as the basis of performance scoring (Chung, Harmon, & Baker, in press; Lesgold, 1994). Let us assume that only propositional analyses of text remain to be done. These scoring approaches will apply ultimately to both written and oral responses.
DESIRABLE FEATURES OF AN AUTOMATED AUTHORING SYSTEM
If we argue that a significant R&D investment is needed to improve test design and, therefore, our confidence in test results, let us envision software tools that result in solving hard and persistent problems, as well as advancing our practice significantly beyond what present stage. What is on our wish list? The goals of one or more configurations of a system are identified below:
-
- improved achievement information for educational decision making;
-
- assessment tasks that measure challenging domains, present complex stimuli, and employ automated scoring and reporting options;
-
- assessment tasks that are useful for multiple assessment purposes;
-
- reduced development time and costs of high-quality tests;
-
- support for users with a range of assessment and content expertise, including teachers; and
-
- reduced timelines for assembling validity evidence.
Page 81
Let us consider four key categories for organizing the development effort for assessment tasks: cognitive requirements, content, validity, and utility.
Cognitive Requirements
First, we would like to design assessments that require significant intellectual activity for the examinees. We need the assessments to focus primarily on open-ended responses, constructed at one sitting or over time, developed individually or by more than one examinee partner. We want the assessments to reflect explicit cognitive domains, described as families of cognitive demands, with clearly described attributes and requirements. At CRESST (Center for Research on Evaluation, Standards, and Student Testing), we have used a top-level formulation that has guided work by many of our team (Baker, 1997). These cognitive families involve performance tasks with requirements illustrated in Figure 7-1.
Figure 7-1 Families of cognitive demands as starting points for authoring tasks. 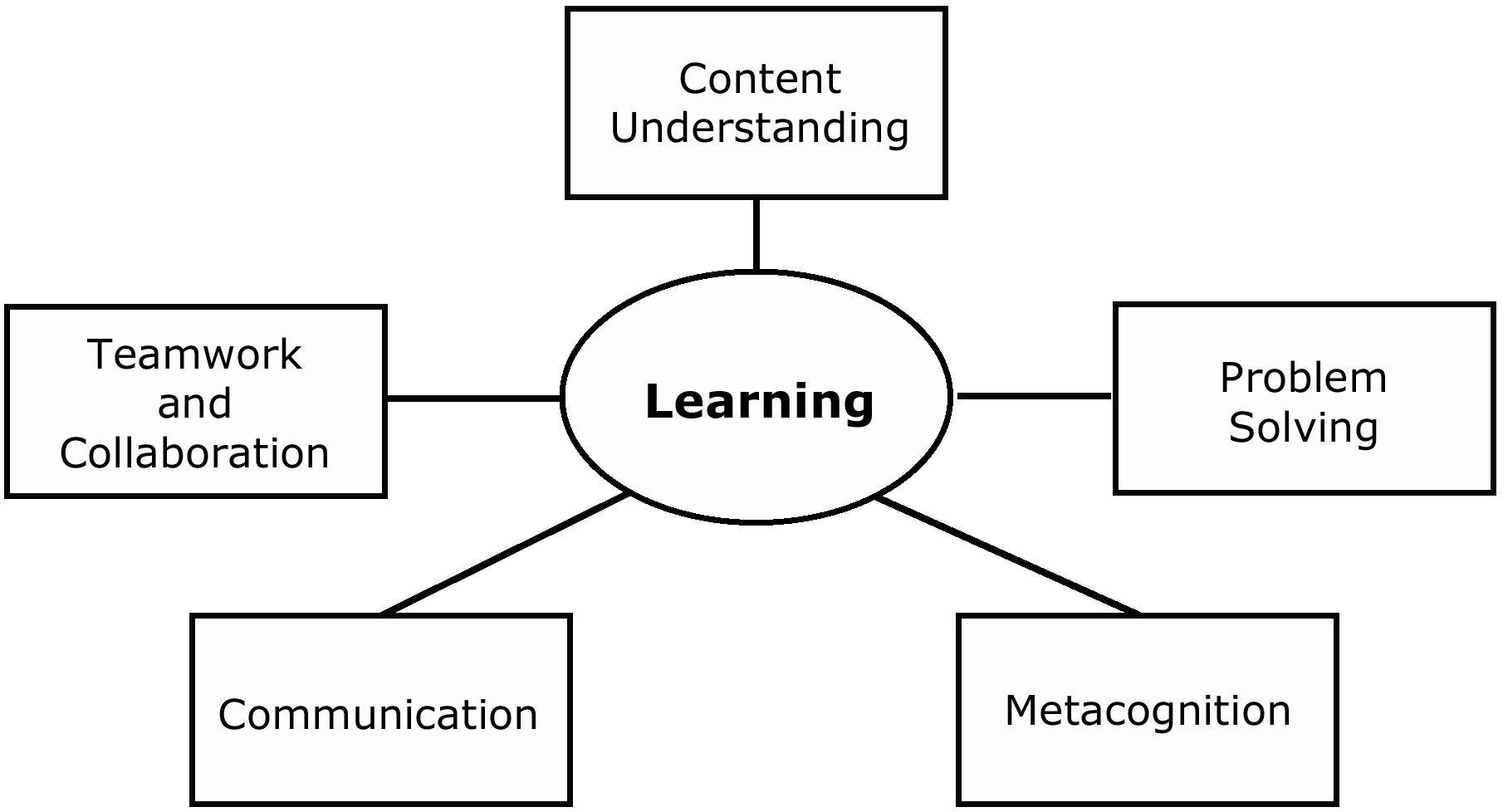
~ enlarge ~
We have been conducting research on these components since 1987 (Baker, Linn, & Herman, 2000; Baxter & Glaser, 1998; Chung, O'Neil, & Herl, 1999; Glaser, Raghavan, & Baxter, 1992; Niemi, 1995, 1996, 1997; O'Neil, Chung, & Brown, 1997; O'Neil, Wang, Chung, & Herl, 2000; Ruiz-Primo, Schultz, Li, & Shavelson, 2001; Ruiz-Primo & Shavelson, 1996; Ruiz-Primo, Shavelson, Li, & Schultz, 2001). These cognitive requirements will call out specific features of tasks and responses, as well as criteria for judging responses. Initially implemented as templates, these cognitive demands should be available in componential form to enable the recombination of sub-elements. To computerize the design of such assessments, the key components or elements would need to be analyzed. For example, in problem solving, we would definitely need to have a component that dealt with problem identification. In a template form of an authoring system, screens would be sequenced that would step the author through the task of deciding how many cues to include and how embedded in text or graphics the presentation of the problem will be. In object form (where object is defined as a subroutine of computer code that
Page 82
performs the same function), the author would be assisted in using appropriate language so that the problem would be well defined. It is key that the components of cognitive demands are used as the starting point, either in template or object form (Derry & Lesgold, 1996). These components, expressed as rules (or as operating software), are instantiated in subject matter by the author, much as linguistic rules for natural language understanding are instantiated in various content domains. Using cognitive demands as a point of departure, rather than subject matter analysis, will increase transfer of learning across topics and domains because similar frameworks or components will be used in different subject areas. Transfer occurs at the level of the learner, but an approach that starts with cognition may also have a higher payoff. It should enable more coherent instructional approaches for teachers in multiple-subject classrooms or interdisciplinary endeavors.
Content
In discipline-based achievement tests, it is what is learned that is of central importance. What is missing in most formulations of test authoring systems is computer-supported strategies to access content to be learned and measured. Some commercial authoring systems step people through the use of templates without providing any assistance on access and editing of content. The fact is that off-line test development has relatively simple approaches to content access. Visit a test development operation, and you may still find content examples and relevant questions stored on 3 x 5 index cards, ready to be sorted into the next tryout. The identification of relevant content, whether for problems, for text, or for examples, is clearly a major bottleneck in test design. Difficult conceptual work is required to identify the rules for inclusion of content in particular domains, a problem made harder and somewhat more arbitrary by the varying standards of clarity in top-level standards intended to be measured. Progress has been made in systems for organizing and searching content (Borgman, Hirsh, Walter, & Gallagher, 1995; Deerwester, Dumais, Furnas, Landauer, & Harshman, 1990; Leazer, 1997; Leazer & Furner, 1999; Lenart, 1995). One of the questions is whether search and organizational rules for document organization can be applied within documents to select candidate content for tests. Clearly, it is time for a merger of browser technology, digital library knowledge structures, and test design requirements. We propose an application of Latent Semantic Indexing (LSI) to the search and acquisition of content for automated design (Wolfe et al., 1998). Procedures to search and import candidate content for use in assessments, as explicit domains of content to be sampled, are needed immediately.
The difficulty of first creating credible, operable templates and then moving to objects (or computer subroutines) cannot be ignored. The problem is technical on two levels. By far the harder part is to identify and regularize the components of tasks, using one or another framework of cognitive demands as the point of departure. To accomplish these tasks, there would need to be agreement on components of key value, e.g., those in problem solving or content understanding. The next phase is to determine the order or orders in which such authoring would occur, including revision loops. Such functional specifications would need to be translated into supportive computer code and embedded in a system with user interfaces to accommodate the potential range of authors, from military trainers to K-12 test developers. Finally, there would need to be a set of activities that demonstrate that components resulted in comparable tasks, first within topics and disciplines and then between them.
Page 83
The conditions required for the use of browser technology to search and acquire candidate software may be available, but this technology may also require a level of internal coding of content that so far has not been standard in the development of instructional materials. This internal coding would need a proof of concept implementation, so that the additional costs required could be underwritten. Neither of these tasks is easily accomplished, and both require intellectual and financial investment. They are provided as a part of the wish list that describes where we need to be if testing is to be a high-quality practice based on the best we know about human development and technological support. Start-up costs for each project should run around $5 million for about three years.
Validity
The best authoring system would allow users to generate assessments with high technical quality (AERA et al., 1999). The created assessments would provide an adequate degree of accuracy and validity arguments drawn from their subsequent empirical data to document their quality. Assessments intended to meet multiple purposes would require additional technical attributes and relevant evidence supporting their applicability for various uses: making individual, group, or program decisions or supporting prescriptions offered to ameliorate unsatisfactory results.
Acquisition of validity evidence is a second major bottleneck for high-quality tests, apparent because of the lack of evidence relevant for many current test uses. Because such magic is not available, can assessments be designed so that their a priori characteristics predict technical quality? There are at least three approaches to consider. One is to use automated review criteria to reduce likely validity problems. Consider an obvious example. There is a great deal of evidence that linguistic barriers (semantic, syntactic, and discourse levels) create construct-irrelevant variance in test performance (Butler & Stevens, 1997; Abedi, 2001). Parsers that identify and highlight such barriers could easily improve the probabilities of reducing this source of error. A second approach is to address characteristics that are known to support particular test purposes. For example, the diagnostic value of an assessment will depend upon the relationship of subtasks to criterion task performance, and the degree of diagnostic confidence is related to the number of items or breadth of contexts used in the assessment task. Another example of qualitative analysis relates to the idea of “objects” in design (Derry & Lesgold, 1996). We would want to assure that assessment tasks, intended to provide a reasonably equivalent level of difficulty in a particular domain, would be descriptively analyzed to be certain that critical features were shared by all tasks in the alleged domain. A third approach is to experiment carefully with features of examinations, and then generate comparable tasks and examine the extent to which they perform as intended, for example, whether they show sensitivity to different instructional interventions.
Perhaps the most challenging issue in the validity/technical quality area is finding ways to reduce the time it takes to assess the validity and accuracy of the test for its various purposes. Authoring systems that incorporate simulation and modeling, rather than relying on laboriously accumulated norming or tryout groups or year-long data collection efforts, are essential if the testing industry is to keep up with policy makers' desires. We believe such simulations are
Page 84
possible if very small, carefully selected pilot data are used. Obviously, this claim would need to be verified.
Utility
For an authoring system to be useful, it will need to be adapted to the range of users who may be required to design (or interpret) tests. Thus, interfaces and technical expertise are required to make components or entire test design systems operate successfully. User groups with different levels of expertise will need systems to adapt to, and compensate for, limits in their expertise, interest, or time. These groups include teachers (who need to create assessments that map legitimately to standards and external tests), local school district and state assessment developers, the business community, and commercial developers. Not everyone intends to create full-service tests. For example, school district, state, and military personnel may use such an authoring system to design prototypes of tasks in order to communicate their intentions for assessment systems to potential contractors. A diverse audience will mean a range of expertise in the background knowledge required for the system. The range will include knowledge about testing, subject matter, and learning. Embedded tutorials, explaining default conditions and advising users on why decisions they make may be inappropriate, will need to be built and verified.
Although it may be obvious, it is still worth saying that exposure to such a system should result in positive payoff for instructional design and teaching. It is possible that analytical and creative thinking inspired by such authoring environments will spill over to teaching design as well.
Common standards for design, communication, and data reporting are also required of authoring systems. At the present time, the tension between proprietary test design and quality is clear, and far too often algorithms and procedures are cloaked by the shadow of commercial endeavor, a reality that makes choices among measures rely on preference for surface features of tests. A system like SCORM (Shareable Content Object Reference Model) would be ideal. SCORM, which is used by the U.S. Department of Defense for its training procurements, describes standards guiding the interoperability of components and content.
Design Phases
Competing complete systems should be designed and applied to high-priority areas. These will probably remain in the template mode in the short run. Generalizability of their utility for different content, tasks, cognitive demands, and examinees can be assessed. Simultaneous efforts should be made to create reusable components (objects) to improve aspects of the design process, including specifications and simulation authoring systems (see, for example, RIDES [Munro et al., 1997] and VIVIDS [Munro & Pizzini, 1998]). In addition, funding should be available for competing analyses of the objects or modules needed to develop fully object-oriented assessment design environments. Competing designs will differ on the level of granularity and on the degree to which they can be easily recombined to generate new assessment prototypes. Finally, we need a fundamental analysis of the components of performance, including task, content, and cognitive and linguistic demands. Using the metaphor
Page 85
of the genome, we speak of the Learnome (Baker, 2000). Investment in the Learnome and its resulting primitives could greatly improve our understanding of the components of performance, assessment, and instruction.
RECOMMENDATIONS FOR RESEARCH PRIORITIES
-
Fund competing, publicly available authoring components, requiring proof-of-concept to include validity evidence in at least three different task areas.
-
Fund competing template-focused systems designed for users with different levels of expertise.
-
Fund competing total object-oriented systems, requiring common interoperability standards, addressing different ages of learners and different task complexity.
-
Specifically fund approaches that import candidate content for use in assessment design and development.
-
Fund fundamental descriptive domain and performance analyses intended to result in primitives for use in future object-oriented systems.
-
Fund research intended to model and speed up validity evidence for the development of new measures.
REFERENCES
( 2001 ). Standardized achievement tests and English language learners: Psychometrics and linguistics issues (Technical Report). Los Angeles: University of California, National Center for Research on Evaluation, Standards, and Student Testing.
. ( 1999 ). Standards for educational and psychological testing . Washington, DC : American Educational Research Association .
( 1997 ). Model-based performance assessment. Theory Into Practice , 36(4), 247-254 .
( 1996 ). Readying NAEP to meet the future. In G. Bohrnstedt (Ed.), Evaluation report on the 1994 NAEP trial state assessment . Palo Alto, CA : National Academy of Education .
( 2000, November ). Understanding educational quality: Where validity meets technology . William H. Angoff Memorial Lecture Series. Princeton, NJ : EducationalTesting Service .
, & (in press). Validity issues for accountability systems. In R. Elmore & S. Fuhrman (Eds.), Redesigning accountability .
, , & ( 2000 ). Continuation proposal (submitted to the Office of Educational Research and Improvement, U.S. Department of Education). Los Angeles: University of California, National Center for Research on Evaluation, Standards, and Student Testing.
Page 86
, & ( 2001 ). Assessments to support the transition to complex learning in science (Proposal to the National Science Foundation). Los Angeles: University of California, National Center for Research on Evaluation, Standards, and Student Testing.
, & ( 1998 ). The cognitive complexity of science performance assessments. Educational Measurement: Issues and Practice , 17(3), 37-45 .
( 1995 ). From adaptive testing to automated scoring of architectural simulations. In E.L. Mancall & P.G. Bashook (Eds.), Assessing clinical reasoning: The oral examination and alternative methods ( pp. 115-130 ). Evanston, IL: The American Board of Medical Specialties.
(in press). An electronic infrastructure for a future generation of tests. In H.F. O'Neil, Jr. & R. Perez (Eds.), Technology applications in education: A learning view . Mahwah, NJ : Erlbaum .
( 2001 ). How the internet will help large-scale assessment reinvent itself. Education Policy Analysis Archives , 9(5), 1-26 .
, , , & ( 1995 ). Children's searching behavior on browsing and keyword online catalogues: The science library catalogue project. Journal of the American Society for Information Science , 46 , 663-684 .
( 1994 ). Assessing technology in assessment. In E.L. Baker & H.F. O'Neil, Jr. (Eds.), Technology assessment in education and training ( pp. 231-246 ). Hillsdale, NJ : Erlbaum .
, , & ( 1989 ). The four generations of computerized educational measurement. In R. Linn (Ed.), Educational measurement ( 3rd ed., pp. 367-408 ). New York : Macmillan .
( 2001, April ). Automated essay evaluation with natural language processing . Paper presented at the annual meeting of the National Council on Measurement in Education, Seattle, WA.
, , , , , , , , , & ( 1998 ). Computer analysis of essay content for automatic score prediction: A prototype automated scoring system for GMAT analytical writing assessment (ETS Rep. RR-98-15). Princeton, NJ : Educational Testing Service .
, & ( 1997 ). Accommodation strategies for English language learners on large-scale assessments: Student characteristics and other considerations (CSE Tech. Rep. No. 448). Los Angeles : University of California, National Center for Research on Evaluation, Standards, and Student Testing .
, , & ( 2001 ). Knowledge mapper authoring system prototype . (Final deliverable to OERI). Los Angeles : University of California, National Center for Research on Evaluation, Standards, and Student Testing .
, , & (in press). The impact of a simulation-based learning design project on student learning. IEEE Transactions on Education .
, , , & ( 2001 ). Requirements Specification for a knowledge mapping authoring system . (Final deliverable to OERI). Los
Page 87
Angeles: University of California, National Center for Research on Evaluation, Standards, and Student Testing .
, O' , & ( 1999 ). The use of computer-based collaborative knowledge mapping to measure team processes and team outcomes. Computers in Human Behavior , 15 , 463-494 .
, , , & ( 1997 ). Development of automated scoring algorithms for complex performance assessments: A comparison of two approaches. Journal of Educational Measurement , 34(2), 141-161 .
, , , , & ( 1990 ). Indexing by latent semantic analysis. Journal of the American Society for Information Science , 41 , 391-407 .
, & ( 1996 ). Toward a situated social practice model for instructional design. In D.C. Berliner & R.C. Calfee (Eds.), Handbook of educational psychology ( pp. 787-806 ). New York : Macmillan .
, , , , , , , , & (in press). Technology and assessment. In H.F. O'Neil, Jr. & R. Perez (Eds.), Technology applications in education: A learning view . Mahwah, NJ : Erlbaum .
, , & ( 1995 ). Diagnostic assessment of trouble-shooting skill in an intelligent tutoring system. In P.D. Nichols, S.F. Chipman, & R.L. Brennan (Eds.), Cognitively diagnostic assessment ( pp. 73-101 ). Hillsdale, NJ : Erlbaum .
, , & ( 1992 ). Cognitive theory as the basis for design of innovative assessment: Design characteristics of science assessments (CSE Tech. Rep. No. 349). Los Angeles : University of California, National Center for Research on Evaluation, Standards, and Student Testing .
, & ( 1995 ). Intelligent tutoring goes to school in the big city. International Journal of Artificial Intelligence in Education , 8 , 30-43 .
, , & ( 1998 ). An introduction to latent semantic analysis. Discourse Processes , 25 , 259-284 .
, , , & ( 1997 ). How well can passage meaning be derived without using word order? A comparison of latent semantic analysis and humans. In M.F. Shafto & P. Langley (Eds.), Proceedings of the 19 th annual meeting of the Cognitive Science Society ( pp. 412-417 ). Mahwah, NJ : Erlbaum .
( 1997 ). Examining textual associations using network analysis . Paper presented at the International Association for Social Network Analysis (Sunbelt), San Diego, CA.
, & ( 1999 ). Topological indices of textual identity networks. Knowledge: Creation, Organization and Use: Proceedings of the 62 nd ASIS Annual Meeting , 36 , 345-358 .
( 1995 ). CYC: A large-scale investment in knowledge infrastructure. Communications of the ACM , 38(11), 32-38 .
Page 88
( 1994 ). Assessment of intelligent training technology. In E.L. Baker & H.F. O'Neil, Jr. (Eds.), Technology assessment in education and training ( pp. 97-116 ). Hillsdale, NJ : Erlbaum .
, & ( 1993 ). The specification and development of tests of achievement and ability. In R.L. Linn (Ed.), Educational measurement ( 3rd ed., pp. 335-366 ). New York : Macmillan .
, , , & ( 2000 ). Bayes nets in educational assessment: Where do the numbers come from? (CSE Tech. Rep. No. 518). Los Angeles : University of California, National Center for Research on Evaluation, Standards, and Student Testing .
, , & ( 1999 ). Evidence-centered assessment design . Princeton, NJ : Educational Testing Service .
, , , , , & ( 1997 ). Authoring simulation-centered tutors with RIDES. International Journal of Artificial Intelligence in Education , 8 , 284-316 .
, & ( 1998 ). VIVIDS reference manual . Los Angeles : University of Southern California, Behavioral Technology Laboratories .
( 1996 ). Assessing conceptual understanding in mathematics: Representation, problem solutions, justifications, and explanations. Journal of Educational Research , 89 , 351-363 .
( 1997 ). Cognitive science, expert-novice research, and performance assessment. Theory into Practice , 36(4), 239-246 .
( 1995 ). Instructional influences on content area explanations and representational knowledge: Evidence for the construct validity of measures of principled understanding— mathematics (CSE Tech., Rep. No. 403). Los Angeles : University of California, National Center for Research on Evaluation, Standards, and Student Testing .
, & ( 1997 ). A technology-based authoring system for assessment. In S. Dijkstra, N.M. Seel, F. Schott, & (Eds.), Instructional design: International perspectives . Vol. II: Solving instructional design problems ( pp. 113-133 ). Mahwah, NJ : Erlbaum .
, , & ( 1997 ). Use of networked simulations as a context to measure team competencies. In H.F. O'Neil, Jr. (Ed.), Workforce readiness: Competencies and assessment ( pp. 411-452 ). Mahwah, NJ : Erlbaum .
, , , & ( 2000 ). Assessment of teamwork skills using computer-based teamwork simulations. In H.F. O'Neil, Jr. & D.H. Andrews (Eds.), Aircrew training and assessment ( pp. 245-276 ). Mahwah, NJ : Erlbaum . , & ( 1982 ). A technology for test-item writing . New York : Academic Press .
, , , & ( 2001 ). Comparison of the reliability and validity of scores from two concept-mapping techniques. Journal of Research in Science Teaching , 38(2), 260-278 .
Page 89
, & ( 1996 ). Problems and issues in the use of concept maps in science assessment. Journal of Research in Science Teaching , 33(6), 569-600 .
, , , & ( 2001 ). On the validity of cognitive interpretations of scores from alternative concept-mapping techniques. Educational Assessment , 7(2), 99-141 .
, , , , , , & ( 1998 ). Learning from text: Matching readers and texts by latent semantic analysis. Discourse Processes , 25(2-3), 309-336 .











