
5
Evidence from Polygraph Research: Quantitative Assessment
This chapter presents our detailed analysis of the empirical research evidence on polygraph test performance. We first summarize the quantitative evidence on the accuracy of polygraph tests conducted on populations of naïve examinees untrained in countermeasures. Although our main focus is polygraph screening, the vast majority of the evidence comes from specific-incident testing in the laboratory or in the field. We then address the limited evidence from studies of actual or simulated polygraph screening. Finally, we address several factors that might affect the accuracy of polygraph testing, at least with some examinees or under some conditions, including individual differences in physiology and personality, drug use, and countermeasures.
SPECIFIC-INCIDENT POLYGRAPH TESTING
Laboratory Studies
For our analysis, we extracted datasets from 52 sets of subjects in the 50 research reports of studies conducted in a controlled laboratory testing environment that met our criteria for inclusion in the quantitative analysis (see Appendix G). These studies include 3,099 polygraph examinations. For the most part, examinees in these studies were drawn by convenience from a limited number of sources that tend to be most readily available in polygraph research environments: university undergradu-
ates (usually but not always psychology students); military trainees; other workplace volunteers; and research subjects recruited through employment agencies. Although samples drawn from these sources are not demographically representative of any population on which polygraph testing is routinely performed, neither is there a specific reason to believe such collections of examinees would be either especially susceptible or refractory to polygraph testing. Since the examinees thus selected usually lack experience with polygraph testing, we will loosely refer to the subjects from these studies as “naïve examinees, untrained in countermeasures.” The degree of correspondence between polygraph responsiveness of these examinees and the special populations of national security employees for whom polygraph screening is targeted is unknown.
Many of the studies collected data and performed comparative statistical analyses on the chart scores or other quantitative measures taken from the polygraph tracings; however, they almost invariably reported individual test results in only two or three decision classes. Thus, 34 studies reported data in three categories (deception indicated, inconclusive, and no deception indicated, or comparable classifications), yielding two possible combinations of true positive (sensitivity) and false positive rates, depending on the treatment of the intermediate category. One study reported polygraph chart scores in 11 ranges, allowing extraction of 10 such combinations to be used to plot an empirical receiver operating characteristic (ROC) curve. The remaining 17 used a single cutoff point to categorize subjects relative to deception, with no inconclusive findings allowed. The median sample size of the 52 datasets from laboratory studies was 48, with only one study having fewer than 20 and only five studies having as many as 100 subjects.
Figure 5-1 plots the 95 combinations of observed sensitivity (percent of deceptive individuals judged deceptive) and false positive rate (percent of truthful people erroneously judged deceptive), with straight lines connecting points deriving from the same data set. The results are spread out across the approximately 30 percent of the area to the upper left. Figure 5-2 summarizes the distribution of accuracy indexes (A) that we calculated from the datasets represented in Figure 5-1. As Figure 5-2 shows, the interquartile range of values of A reported for these data sets is from 0.81 to 0.91. The median accuracy index in these data sets is 0.86. The two curves shown in the Figure 5-1 are ROC curves with values of the accuracy index (A) of 0.81 and 0.91.1
Three conclusions are clearly illustrated by the figures. First, the data (and their errors of estimate; see Appendix H, Figure H-3) clearly fall above the diagonal line, which represents chance accuracy. Thus, we conclude that features of polygraph charts and the judgments made from them are correlated with deception in a variety of controlled situations
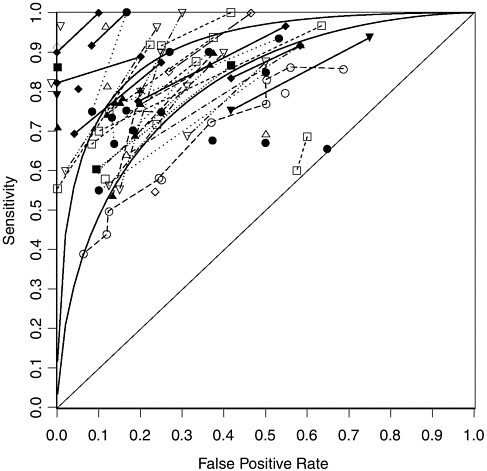
FIGURE 5-1 Sensitivity and false positive rates in 52 laboratory datasets on polygraph validity.
NOTES: Points connected by lines come from the same dataset. The two curves are symmetrical receiver operating characteristic (ROC) curves with accuracy index (A) values of 0.81 and 0.91.
involving naïve examinees untrained in countermeasures: for such examinees and test contexts, the polygraph has an accuracy greater than chance. Random variation and biases in study design are highly implausible explanations for these results, and no formal integrative hypothesis test seems necessary to demonstrate this point.
Second, with few exceptions, the points fall well below the upper left-hand corner of the figure indicative of perfect accuracy. No formal hypothesis test is needed or appropriate to demonstrate that errors are not infrequent in polygraph testing.
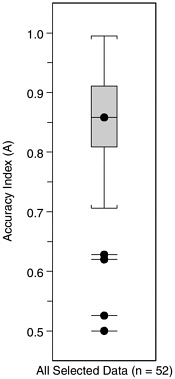
FIGURE 5-2 Accuracy index (A) values from 52 datasets from laboratory polygraph validation studies. The central box contains the middle half of the values of accuracy (A), with the median value marked by a dot and horizontal line. “Whiskers” extend to the largest and smallest values within 1.5 interquartile ranges on either side of the box. Values farther out are marked by detached dots and horizontal lines.
Third, variability of accuracy across studies is high. This variation is likely due to a combination of several factors: “sampling variation,” that is, random fluctuation due to small sample sizes; differences in polygraph performance across testing conditions and populations of subjects; and the varying methodological strengths and weaknesses of these diverse studies. The degree of variation in results is striking. For example, in different studies, when a cutoff is used that yields a false positive rate of roughly 10 percent, the sensitivity—the proportion of guilty examinees correctly identified—ranges from 43 to 100 percent. This range is only moderately narrower, roughly 64 to 100 percent, in studies reporting a cutoff that resulted in 30 percent of truthful examinees being judged deceptive. The errors of estimate for many of the studies fail to overlap with those of many other studies, suggesting that the differences between study results are due to more than sampling variation.
We looked for explanations of this variability as a function of a variety of factors, with little success. One factor on which there has been much contention in the research is test format, specifically, comparison question versus concealed information test formats. Proponents of concealed information tests claim that this format has a different, scientifically stronger rationale than comparison question tests in those limited
situations for which both types of tests are applicable. Indeed, the concealed information tests we examined did exhibit higher median accuracy than the comparison question tests, though the observed difference did not attain conventional statistical significance. Specifically, the median accuracy index among 13 concealed information tests was 0.88, with an interquartile range from 0.85 to 0.96, while the corresponding median for 37 comparison question tests was 0.85, with an interquartile range from 0.83 to 0.90. (Two research reports did not fit either of these two test formats.) The arithmetic mean accuracies, and means weighted by sample size or inverse variance, were more similar than the reported medians. We regard the overall evidence regarding comparative accuracy of control question and concealed knowledge test formats as thus suggestive but far from conclusive.
Our data do not suggest that accuracy is associated with the size of the study samples, our ratings of the studies’ internal validity and their salience to the field, or the source of funding.2 We also examined the dates of the studies to see if research progress had tended to lead to improvements in accuracy. If anything, the trend ran against this hypothesis. (Appendix H presents figures summarizing the data on accuracy as a function of several of these other factors.)
It is important to emphasize that these data and their descriptive statistics represent the accuracy of polygraph tests under controlled laboratory conditions with naïve examinees untrained in countermeasures, when the consequences of being judged deceptive are not serious. We discuss below what accuracy might be under more realistic conditions.
Field Studies
Only seven polygraph field studies passed our minimal criteria for review. All involved examination of polygraph charts from law enforcement agencies’ or polygraph examiners’ case files in relation to the truth as determined by relatively reliable but nevertheless imperfect criteria, including confession by the subject or another party or apparently definitive evidence. The seven datasets include between 25 and 122 polygraph tests, with a median of 100 and a total of 582 tests. Figure 5-3 displays results in the same manner as in Figure 5-1. The accuracy index values (A) range from 0.711 to 0.999, with a median value of 0.89, which, given sampling and other variability, is statistically indistinguishable from the median of 0.86 for the 52 datasets from laboratory studies. There were no obvious relationships between values of A and characteristics of the studies. (Further discussion of these data appears in Appendix H.)
These results suggest that the average accuracy of polygraph tests examined in field research involving specific incident investigations is
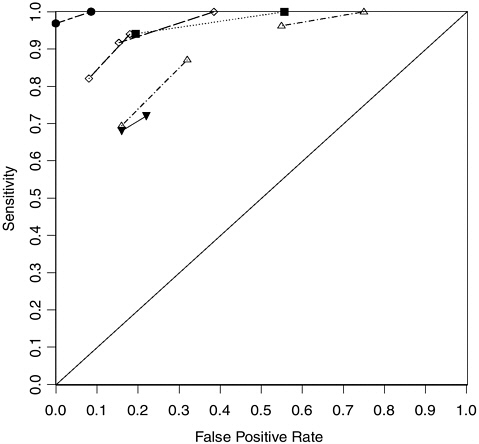
FIGURE 5-3 Sensitivity and false positive rate in seven field datasets on polygraph validity.
NOTE: Points connected by lines come from the same dataset.
similar to and may be slightly higher than that found from polygraph validity studies using laboratory models. (The interquartile range of accuracy indexes for all 59 datasets, laboratory and field, was from 0.81 to 0.91, the same range as for the laboratory studies alone.) In the next section, we discuss what these data suggest for the accuracy of the full population of polygraph tests in the field.
From Research to Reality
Decision makers are concerned with whether the levels of accuracy achieved in research studies correspond to what can be expected in field polygraph use. In experimental research, extrapolation of laboratory re-
sults to the field context is an issue of “external validity” of the laboratory studies, that is, of the extent to which the study design, combined with any external knowledge that can be brought to bear, support the relevance of the findings to circumstances other than those of the laboratory study. For example, an externally valid polygraph study would suggest that the accuracy observed in it would also be expected for different types of examinees, e.g., criminals or spies instead of psychology students or respondents to newspaper advertising; interviews of different format or subject matter, e.g., comparison question tests for espionage screening instead of for investigations of a mock theft; examiners with differing backgrounds, e.g., police interrogators rather than full-time federally trained examiners; and in field situations as well as in the laboratory context.
If, as we believe, the polygraph is closely analogous to a clinical diagnostic test, then both psychophysiological theories of polygraph testing and experiences with other clinical diagnostic tests offer useful insights regarding the external validity of laboratory polygraph accuracy for field contexts. Each perspective raises serious concerns about the external validity of results from laboratory testing in the field context.
Higher Stakes. The theory of question construction in the comparison question polygraph technique relies at its core on the hypothesis that emotional or arousal responses under polygraph questioning increase the more concerned examinees are about being deceptive. Thus, innocent examinees are expected to show stronger responses to comparison than to relevant questions. This hypothesis suggests that factors that increase this concern, such as the costs of being judged deceptive, would increase emotional or arousal response and amplify the differences seen between physiological responses to relevant and comparison questions. On the basis of this hypothesis, one might expect polygraph accuracy in laboratory models to be on average somewhat below true accuracy in field practice, where the stakes are higher. There is a plausible contrary hypothesis, however, in which examinees who fear being falsely accused have strong emotional responses that mimic those of the truly deceptive. Under this hypothesis, field conditions might have more false-positive errors than are observed in the laboratory and less accuracy.
Under orienting theory, which provides the rationale for concealed information polygraph testing, it is the recognition of a novel or significant stimulus that is presumed to cause the autonomic response. Increasing the stakes might increase the significance of the relevant item and thus the strength of the orienting response for examinees who have concealed information, with the result that the test will do better at detecting such information as the stakes increase. However, as with arousal-based
theories, various hypotheses can be offered about the effect of increased stakes on detection accuracy that are consistent with orienting theory (Ben-Shakhar and Elaad, 2002). Thus, theory and basic research give no clear guidance about whether laboratory conditions underestimate or overestimate the accuracy that can be expected in realistic settings.
Available data are inadequate to test these hypotheses. Two meta-analyses suggest that strength of motivation is positively associated with polygraph accuracy in comparison question (Kircher et al., 1988) and concealed information (Ben-Shakhar and Elaad, 2003) tests, but there are limitations to both analyses that preclude drawing any definite conclusions.3 In the papers we reviewed, only one of the laboratory models under which specific-incident polygraph testing was evaluated included stakes that were significant to the subjects’ future outside the polygraph room and so similar to those in field applications (Ginton et al., 1982). Unfortunately, that study was too small to be useful in evaluating polygraph accuracy.
Evidence from Medical Diagnostic Testing. Substantial experience with clinical diagnostic and screening tests suggests that laboratory models, as well as observational field studies of the type found in the polygraph literature, are likely to overstate true polygraph accuracy. Much information has been obtained by comparing observed accuracy when clinical medical tests are evaluated during development with subsequent accuracy when they become accepted and are widely applied in the field. An important lesson is that medical tests seldom perform as well in general field use as their performance in initial evaluations seems to promise (Ransohoff and Feinstein, 1978; Nierenberg and Feinstein, 1988; Reid, Lachs, and Feinstein, 1995; Fletcher, Fletcher, and Wagner, 1996; Lijmer et al., 1999).
The reasons for the falloff from laboratory and field research settings to performance in general field use are fairly well understood. Initial evaluations are typically conducted on examinees whose true disease status is definitive and uncomplicated by other conditions that might interfere with test accuracy. Samples are drawn, tests conducted, and results analyzed under optimal conditions, including adherence to optimal procedures of sample collection and preservation, use of fresh reagents, and evaluation by expert technicians in laboratories that participated in test development. In contrast, in general field use the test is used in a wide variety of patients, often with many concomitant disease conditions, possibly taking interfering medications, and often with earlier or milder cases of a disease than was the case for the patients during developmental testing. Sample handling, processing, and interpretation are also more variable.
Evaluation of a diagnostic test on general patient samples is often done within the context of ongoing clinical care. This may be problematic if the test is incorporated into the diagnostic process for these patients. Unless special care is taken, other diagnostic findings (e.g., an image) may then influence the interpretation of the test results, or the test result itself may stimulate further investigation that uncovers the final diagnosis against which the test is then evaluated. These types of “contamination” have been extensively studied in relation to what is termed “verification bias” (see Begg and Greenes, 1983). They artificially increase the correlation between a test result and its diagnostic reference, also exaggerating the accuracy of the test relative to what would be seen in field application.
Manifestations of these issues in evaluations of polygraph testing are apparent. Laboratory researchers have the capacity to exercise good control over contamination threats to internal validity. But such research typically uses subjects who are not representative of those examined in the field and are under artificial, uniform, and extremely clear-cut conditions. Polygraph instrumentation and maintenance and examiner training and proficiency are typically well above field situations. Testing is undertaken concurrent with or immediately after the event of interest, so that no period of potential memory loss or emotional distancing intervenes.
Thus, laboratory evaluations that correctly mirror laboratory performance are apt to overestimate field performance. But field evaluations are also apt to overestimate field performance for several reasons. The polygraph counterpart to contamination of the diagnostic process by the test result has been discussed in Chapter 4. So has the counterpart to evaluating only those cases for which the true condition is definitively known. In addition, expectancies, particularly those of examiners, are readily contaminated in both field applications and evaluations of field performance. Polygraph examiners typically enter the examination with information that shapes their expectations about the likelihood that the examinee is guilty. That information can plausibly influence the conduct of the examination in ways that make the test act somewhat as a self-fulfilling prophecy, thus increasing the apparent correspondence between the test result and indicators of truth and giving an overly optimistic assessment of the actual criterion validity of the test procedure.
In view of the above issues, we believe that the range of accuracy indexes (A) estimated from the scientifically acceptable laboratory and field studies, with a midrange between 0.81 and 0.91, most likely over-states true polygraph accuracy in field settings involving specific-incident investigations. We remind the reader that these values of the accuracy index do not translate to percent correct: for any level of accuracy, per-
cent correct depends on the threshold used for making a judgment of deceptiveness and on the base rate of examinees who are being deceptive.
SCREENING STUDIES
The large majority of the studies we reviewed involve specific-issue examinations, in which relevant questions are tightly focused on specific acts. Such studies have little direct relevance for the usual employee screening situation, for three reasons. First, in screening, the test is not focused on a single specific act, so the examiner can only ask questions that are general in nature (e.g., have you had any unauthorized foreign contacts?). These relevant questions are arguably more similar to comparison questions, which also ask about generic past actions, than is the case in specific-incident testing. It is plausible that it will be harder to discriminate lying from truth-telling when the relevant and comparison questions are similar in this respect.
Second, because general questions can refer to a very wide range of behaviors, some of which are not the main targets of interest to the agencies involved (e.g., failure to use a secure screen saver on a classified computer while leaving your office to go to the bathroom), the examinee may be uncertain about his or her own “guilt.” Examinees may need to make a series of complex decisions before arriving at a conclusion about what answer would be truthful before deciding whether to tell the truth (so defined) or fail to disclose this truthful answer. Instructions given by examiners may alleviate this problem somewhat, but they are not likely to do so completely unless the examinee reveals the relevant concerns.
Third, the base rate of guilt is usually very low in screening situations, in contrast with specific-incident studies, in which the percentage of examinees who are guilty is often around 50 percent and almost always above 20 percent. Examiners’ expectations and the examiner-examinee interaction may both be quite different when the base rates are so different. In addition, the implications of judging an examinee deceptive or truthful are quite different depending on the base rate, as we discuss in detail in Chapter 7.
A small number of studies we reviewed did specifically attempt to estimate the accuracy of the polygraph for screening purposes. Given the centrality of screening to our charge, we offer detailed comments on the four studies that met our minimal quality standards as well as three others that did not. Four of these seven studies (Barland, Honts, and Barger, 1989; U.S. Department of Defense Polygraph Institute, 1995a, 1995b; Reed, no date) featured general questions used in examinations of subjects, some of whom had committed specific programmed transgressions. While this “mock screening situation,” as it was termed by Reed (no date), is an
incomplete model for actual polygraph screening, the resulting data seem reasonably relevant. An important screening-related question that can be addressed by such studies is whether polygraph-based judgments that an examinee was deceptive on the test are attributable to polygraph readings indicating deception on questions that the examinee actually answered deceptively or to false positive readings on other questions that were answered truthfully. While simply identifying that an examinee was deceptive may be sufficient for many practical purposes, scientific validity requires that polygraph charts show deception only when deception was actually attempted.
Barland, Honts, and Barger (1989) report the results of three experiments. In their first study, the questions and examination methods differed across examiners, and the false negative rate was extremely high (66 percent of the guilty examinees are not identified as deceptive). There was also wide variation in the formats and the standards used to review examinations. In their second study, the authors compared multiple-issue examinations with multiple single-issue examinations. While this study achieved higher overall sensitivity, there was little success in determining which guilty examinees committed which among a number of crimes or offenses. Their third study retested a number of subjects from the first study, and its results are hence confounded. Collectively, results of these three studies do not provide convincing evidence that the polygraph is highly accurate for screening.
Three U.S. Department of Defense Polygraph Institute (DoDPI) studies designed to validate and extend the Test of Espionage and Sabotage (TES) (U.S. Department of Defense Polygraph Institute, 1995a, 1995b; Reed, no date) showed overall results above chance levels of detection but far from perfect accuracy. One of these studies passed our screening (Reed, no date), and it reported data indicating an accuracy (A) of 0.90, corresponding to a sensitivity of approximately 85 percent and a specificity of approximately 78 percent. All three studies share biases that make their results less convincing than those statistics indicate. Deceptive examinees were instructed to confess immediately after being confronted, but nondeceptive examinees whose polygraph tests indicated deception were questioned further, in part to determine whether the examiner could find explanations other than deception for their elevated physiological responses. Such explanations led to removal of some subjects from the studies. Thus, an examiner classifying an examinee as deceptive received immediate feedback on the accuracy of his or her decision, and then had opportunity and incentive, if the result was a false positive error, to find an explanation that would justify removing the examinee from the study. No comparable search was conducted among true positives. This process biases downwards the false positive rate observed in association with any
observed sensitivity of the test and therefore biases upwards estimates of accuracy.
The other two studies that passed our screening (Raskin and Kircher, 1990; Honts and Amato, 1999) dealt with deception on preemployment screening tests. They both were pilot studies, had small sample sizes, allocated subjects to other treatment categories than just deceptive/innocent, and had a variety of other methodological problems. The results we could extract that pertained to accuracy were unimpressive, in the bottom 25 percent of the studies from which we extracted data.
One study deserves special attention because, although it did not meet our minimal screening criteria, it is the only available study that reports results from a real screening situation. Brownlie, Johnson, and Knill (1998) reported a study of 769 relevant-irrelevant polygraph tests of applicants for security positions at Atlanta International Airport between 1995 and 1997. The tests included four relevant questions, on past convictions for traffic violations or felonies, past bankruptcies, and use of marijuana during the past 30 days. As is typical with relevant-irrelevant testing, scoring was done by examiners’ impressions rather than any standardized method, a fact that makes generalization to other examiners very risky. The study reported results that correspond to an accuracy index of 0.81, a value well above chance, but still in the bottom 25 percent of the studies from which we extracted data.4
A desirable feature found in some screening studies is that examiners know neither which examinees are deceptive nor which of several questions a deceptive examinee will answer untruthfully (e.g., Barland, 1981; Correa and Adams, 1981; Honts and Amato, 1999; Raskin and Kircher, 1990; Timm, 1991). These studies mimic one aspect of true screening: the examiner is not certain which item is “relevant.” But in other respects these studies they are still a far cry from normal screening, in which the examinee has not been instructed specifically to lie, the list of possible deceptive answers is effectively infinite, and examinees may be deceptive about multiple items. In mock screening experiments, the mock transgression is highly salient, at least to all “programmed guilty” examinees, and everyone involved in the situation knows that the critical event is a specific staged transgression (even if they do not know the precise one). In typical real-life screening applications, there are a wide range of behaviors that might lead examinees either to admit minor infractions or to deny them, based on their individual perceptions of what the examiner “really” wants to know. Thus, examinees in actual polygraph screening may not know or may not agree about precisely what constitutes an honest and complete answer to some questions. In contrast, mock screening studies include a narrow range of issues that might be the target for deception, and subjects are assigned to deceptive or nondeceptive roles,
thus removing any internal sense of doubt about whether or not their responses are in fact deceptive. These differences between mock screening studies and real screening applications limit the external validity of the mock screening studies. The likely result is decreased random variation in physiological responses, and therefore higher accuracy, in mock screening studies than in actual screening settings.
Nevertheless, the results of these studies do shed some light on the possible accuracy of screening polygraphs. These studies do not provide strong evidence for the validity or utility of polygraph screening. First, the level of accuracy in distinguishing deceptive from nondeceptive examinees in these studies was generally lower than that achieved in comparison question test and concealed information test studies focused on specific-incident investigation. This finding, though not strongly supported because of the limitations of the evidence, is not surprising. It has been widely remarked that the psychological difference between relevant and comparison questions is probably smaller when both questions are generic than when the relevant questions address specific acts. This similarity would make it harder to distinguish the physiological concomitants of truthfulness from those of deception in screening tests than in specific-incident tests.
Second, these studies do not show consistent accuracy in identifying the specific questions that were answered deceptively (negative results are reported by Barland, Honts, and Barger [1989] and U.S. Department of Defense Polygraph Institute [1995a, 1995b]; positive results are reported by Brownlie et al. [1998] and Kircher et al. [1998]). The finding in several studies that examiners cannot reliably distinguish truthful from deceptive responses (even if they can distinguish truthful from deceptive examinees) directly contradicts the most basic assumptions that guide polygraph use. It also has practical implications. If examiners obtain evidence of a deceptive response and follow up by focusing on the question that triggered their judgment, they are no more likely to be focusing on the correct question than if their follow-up was guided by the flip of a coin. Thus, if an examinee is in fact guilty of deception with regard to a specific serious security violation, and the examiner concludes that deception is indicated, the follow-up interrogation may often be based on the wrong question. The examinee might well confess to some mild transgression in the area targeted by that question and subsequently satisfy the examiner that the problem is not serious, even though there may be a more serious problem in another area. We have been given conflicting reports from various agencies concerning the degree to which examiners focus on target questions in follow-up interrogation. The evidence from the existing screening studies makes it clear that it is wise to train examiners to treat a
positive response as a possible indication of deception to any question, not necessarily the specific one for which deception was indicated.
We have also examined preliminary and as yet unfinished reports on two subsequent DoDPI “screening” studies, carried out in 1997 and in 2001. These studies share many characteristics of the earlier DoDPI research, and their results do little to assuage our concerns regarding the limited scientific support for the validity of the Test for Espionage and Sabotage (TES) as a screening instrument.
SPECIAL POPULATIONS AND CONDITIONS
This section summarizes the evidence on accuracy related to particular issues. Because the quantitative data are so sparse for many important issues, each section also includes qualitative judgments about the likely meaning of what we know for polygraph interpretation (e.g., judgments about the robustness of polygraph evidence across examinee populations).
Individual Differences in Physiology
Individual differences in psychophysiological measures are common. Such differences have been reported in measures of many response systems, including the electrodermal, cardiovascular, endocrine, and central nervous systems. A growing body of research indicates that such differences in adults are moderately stable over time and are associated with a wide range of theoretically meaningful behavioral measures (see Kosslyn et al., 2002, for a review).
One of the earliest reported individual differences in a psychophysiological measure that was meaningfully associated with behavior is in electrodermal lability (Crider and Lunn, 1971). This is defined as the frequency of “nonspecific” electrodermal responses—responses that are observed in the absence of any external eliciting stimulus. A few studies have investigated whether this individual difference variable affects the accuracy of the polygraph, with inconsistent results. In two studies, Waid and Orne (1980) found that electrodermally stabile subjects (those exhibiting relatively few spontaneous responses) were less frequently detected in a concealed information task in comparison with electrodermally labile subjects. The number of items detected on the concealed information test was positively correlated with the frequency of nonspecific electrodermal responses. In addition, among innocent subjects, those with higher levels of electrodermal lability were more frequently falsely identified as deceptive. These studies only analyzed electrodermal activity; consequently, is not clear how much the accuracy of a full polygraph would have been
affected by individual differences in electrodermal lability in these examinees.
A subsequent DoDPI-sponsored study using a comparison question test (Ingram, 1994) found no relationship between electrodermal lability and the detection of deception by blind scorers. This study also found, however, that the proportion of the subject sample accurately detected as deceptive using skin conductance amplitudes was not significantly above chance. These are the only reports of such associations we were able to find, other than two doctoral dissertations that had other methodological problems and were never published.
We have found no studies of how any other individual differences in psychophysiological responsiveness may affect the accuracy of polygraph tests. In sum, investigation of whether individual differences in physiological responsiveness is associated with the accuracy of polygraph detection of deception has barely begun.5
Individual Differences in Personality
A small body of research addresses the question of whether the accuracy of polygraph testing is affected by the personality traits and characteristics of examinees. The research has addressed some personality traits characteristic of psychologically “normal” individuals and some characteristics of psychologically “abnormal” individuals. Various theoretical rationales have been offered for expecting that the investigated traits might affect physiological responses during polygraph testing.
Studies have been conducted comparing individuals in normal populations who are “high” and “low” on personality dimensions, such as trait anxiety (Giesen and Rollison, 1980), Machiavellianism (Bradley and Klohn, 1987), and self-monitoring (Bradley and Rettinger, 1992). Studies on abnormal individuals have been confined primarily to personality disorders (Gudjonsson, 1982) and psychopathy (e.g., Hammond, 1980; Patrick and Iacono, 1989; Raskin and Hare, 1978). These studies vary substantially in their internal and external validity. All of them were based on specific-incident scenarios, not screening scenarios.
Two studies found that “normal” personality traits moderated physiological indexes of deception. Giesen and Rollison (1980) found that the self-reported trait of anxiety affected skin conductance responsivity during a concealed information test such that subjects with high trait anxiety who were “guilty” of a mock crime responded more strongly than subjects low on trait anxiety. Subjects with low anxiety showed little skin conductance responsivity, regardless of whether they were innocent or guilty. Bradley and Klohn (1987:747) found that subjects high in Machiavellianism (i.e., those “able to focus more directly on the relevant
aspects of the situation”) were more physiologically responsive when “guilty” than when “innocent.”
Other studies have failed to find effects of normal personality variation on polygraph accuracy. For example, Bradley and Rettinger (1992) found no differences with respect to polygraph detection of deception between subjects high and low in their propensity to monitor their own social demeanor. Gudjonsson (1982) found no consistent overall relationships between personality traits assessed by a battery of personality inventories (i.e., Eysenck Personality Inventory, Gough Socialization Scale, and the Arrow-Dot Test) and detection of deception using a concealed information test for normal or personality-disordered individuals.
Regarding psychopathy, Hammond (1980) found no differences in the detectability of deception using a mock crime scenario among normal individuals, alcoholics, and psychopaths. Similarly, neither Raskin and Hare (1978) nor Patrick and Iacono (1989) found any differences in the detectability of deception between psychopathic and nonpsychopathic prison inmates.
Although consistent personality effects on polygraph accuracy have not been found, it would be premature to conclude that personality traits in general have little effect: two studies did find such relationships, there is a paucity of relevant high-quality research, and the statistical power of the studies to find moderating effects if they exist is quite limited.
Sociocultural Group Identity
In Chapter 3 we discuss empirically supported theories relating physiological responses, including responses measured by the polygraph, to the interpersonal context. These theories have existed in the basic social psychological and sociological literature for some time (e.g., Goffman, 1963; Blascovich et al., 2000). The theories and associated research (Blascovich et al., 2001a) suggest that apparent stigmatizing qualities (e.g., race, age, gender, physical abnormalities, socioeconomic status) of the participants in situations like polygraph examinations might affect polygraph test results. However, relatively little work has been done to test these theories in the context of polygraph examiner-examinee interactions. There is some polygraph research bearing on the effects of sociocultural group identity, however. Some studies have reported polygraph accuracy as a function of the gender of examinees, fewer have reported on the race of examinees, and almost none on ethnicity. Only a few studies have data bearing on gender and race in combination, and only two have considered examiner and examinee characteristics in combination. As with the research on personality differences, the studies vary substantially in their internal and external validity.
Generally, the research on gender has failed to find effects, with most studies indicating no statistically reliable differences in detection of deception between males and females. Two studies (Bradley and Cullen, 1993; Matte and Reuss, 1992) found gender differences in specific physiological responses during polygraph tests, but the differences were not consistent across studies. The effect sizes in these gender studies are rarely calculable.
We found only two studies that compared polygraph accuracy by race of examinees (Reed, 1993; Buckley and Senese, 1991). Neither reported significant effects of examiner’s race, examinee’s race, or their interaction on polygraphic detection of deception. One of the studies, however (Buckley and Senese, 1991), reported only on blind rescoring of polygraph charts, so it is only partially relevant to the question of whether racial variables in the social interaction of the polygraph examination affect test results. The sample size is not large enough (40 polygraph records in all) to support any firm conclusions. Reed (1993) reported on a larger sample of 375 polygraph tests given by trainees at DoDPI and found no statistically reliable differences in accuracy between tests given to Caucasian and African American examinees. Reed also mentions an earlier dataset of 1,141 examinations, also given in DoDPI training classes, in which false positive results were significantly more common among the 81 nondeceptive African American examinees than among the 320 nondeceptive Caucasian examinees, as might be expected from the theoretical arguments presented in Chapter 3. However, there is no research report available on this dataset. We found only one study on ethnicity, conducted on different Bedouin groups in Israel; this study was so poorly reported that no objective interpretation can be made.
In our view, the effects of sociocultural group identity of examiners and examinees on the polygraphic detection of deception have been investigated only minimally, with little methodological sophistication, and with no attention to theoretically significant variables or mechanisms. In the reported research, effect sizes are rarely calculable. That some studies have found gender differences on intensity of physiological responses of one sort or another appears to have been ignored in the rest of the research literature (and the practice of polygraph testing). Finally, the preponderance of white male examiners has made it extremely difficult to develop and implement research studies that would examine interactions between examiner and examinee race with sufficient statistical power to draw conclusions. For the most part, the concerns about the possible decrement in accuracy in polygraph tests on stigmatized groups that were raised in Chapter 3 on the basis of basic research in social psychophysiology have not been addressed by polygraph research.
Expectancy Effects
Given the operation of expectancy effects in many social interactions (see discussion in Chapter 3), one might expect that examiner expectancies of examinee guilt might influence not only examiners’ judgments of charts, but also examinees’ physiological responses during polygraph tests. However, we could find very little research on these issues. In one study, expectancies affected examiners’ scoring of charts that had previously been judged inconclusive, but not of charts with conclusive results (Elaad, Ginton, and Ben-Shakhar, 1994). We found only one small study (28 polygraph examinations) that considered the effects of examiners’ expectancies that were induced in advance of the polygraph examination (Elaad, Ginton, and Ben-Shakhar, 1998): The expectancy manipulation produced no discernible effect on test results. This evidence is too limited to draw any strong conclusions about whether examiners’ expectancies affect polygraph test accuracy.
There is a small body of research on the effects of examinees’ expectancies, conducted in part to test the hypothesis that so-called stimulation tests, which are intended to convince examinees of the polygraph’s ability to detect deception, improve detection accuracy. Although the results are mixed, the research provides some support for the hypothesis (e.g., Bradley and Janisse, 1981; Kircher et al., 2001).
Drug Effects
The potential effect of drugs on polygraph outcomes has received scant attention in the experimental literature. An early report examined the possible effect of the anxiolytic meprobamate (sometimes prescribed under brand names including Equanil and Miltown) on a concealed information task (Waid et al., 1981). This experiment was performed on a small sample of undergraduates and found that meprobamate in doses that were not detectable by the examiner significantly impaired the detection of deception in a concealed information analogue task. In a replication and extension of this study, Iacono and colleagues (Iacono et al., 1992) compared the effects of meprobamate, diazepam (a benzodiazepine) and propranolol (a beta-blocker) on detection of guilt with a concealed information task. Contrary to the findings of Waid et al. (1981), this study found that none of the drugs evaluated had a significant effect on the detection of deception, nor was there even a trend in the direction reported by Waid et al. The nature of the mock crimes was different in these studies, though drug dose was identical. Using diazepam and methylphenidate, a stimulant, in separate groups of subjects, Iacono, Boisvenu, and Fleming (1984) evaluated the effect of these drugs and a
placebo on the electrodermal detection of deception, using a concealed information task with examiners blind to drug condition. The results indicated that the drugs had no effect. O’Toole et al. (1994) studied the effect of alcohol intoxication at the time of the mock crime on the detection of deception in a concealed information task. Intoxication at the time of the mock crime had no significant effect on the detection of deception though it did affect memory for crime details. Bradley and Ainsworth (1984), however, found that alcohol intoxication at the time of a mock crime reduced the accuracy of detection.
Overall, there has been little research on the effect of drugs on the detection of deception. The subjects tested have been exclusively undergraduates, dose-response effects have not been evaluated, and the mock crimes have been highly artificial with no consequence for detection. The weight of the published evidence suggests little or no drug effects on the detection of deception using the concealed information test, but given the few studies performed, the few drugs tested, and the analogue nature of the evidence, a conclusion that drugs do not affect polygraph validity would be premature.
COUNTERMEASURES
Perhaps the most serious potential problem with the practical use of the polygraph is the possibility that examinees—particularly deceptive ones—might be able to decrease the test’s accuracy by engaging in certain behaviors, countermeasures, designed to produce nondeceptive test results. A wide range of potential countermeasures has been suggested (Krapohl, 1995, presents a taxonomy), and the effectiveness of some of these countermeasures has been examined in the empirical literature. Major classes of countermeasures include using drugs and alcohol to dampen polygraph responses (Cail-Sirota and Lieberman, 1995), mental countermeasures (e.g., relaxation, production of emotional imagery, mental disassociation, counting backwards, hypnotic suggestion, and attention-focusing techniques), and physical countermeasures (e.g., breath control, behaviors that produce pain before or during questioning, such as biting one’s tongue, or behaviors that produce muscle tension before or during questioning, such as pressing one’s toe to the floor or contracting a variety of muscles in the body). Advice about how to use countermeasures to “beat” the polygraph is readily available (e.g., Maschke and Scalabrini, no date; Williams, 1996) and there is anecdotal evidence of increasing levels of countermeasure use in federal security screening programs.
Countermeasures have long been recognized as a distinct threat to the validity and utility of the polygraph (U.S. Office of Technology As-
sessment, 1983). Guilty examinees have incentives to try to influence the examination in ways that reduce the likelihood that their deception will be detected. Some examinees who have not committed crimes, security breaches, or related offenses, or who have little to hide, might nevertheless engage in countermeasures with the intent to minimize their chances of false positive test results (Maschke and Scalabrini, no date). This strategy is not risk-free for innocent examinees. There is evidence that some countermeasures used by innocent examinees can in fact increase their chances of appearing deceptive (Dawson, 1980; Honts, Amato, and Gordon, 2001). Also, several agencies that use the polygraph in screening job applicants or current employees have indicated that examinees who are judged to be using countermeasures may, on these grounds alone, be subject to the same personnel actions that would result from a test that indicated deception. Because countermeasures might influence test outcomes and personnel actions, and because the effects of countermeasures on test validity and utility might depend on the examiner’s ability to detect these behaviors, it is important to examine the empirical research on the effects and the detectability of physical and mental countermeasures.
Rationale
Most methods of polygraph examination rely on comparisons between physiological responses to relevant and comparison questions. Examinees who consistently show more pronounced reactions to relevant questions than to comparison or irrelevant questions are most likely to be judged deceptive. Maschke and Scalabrini (no date:68), referring to the comparison (control) question test format suggest that “. . . the key to passing a polygraph test . . . is to produce stronger physiological responses when answering control questions than when answering the relevant questions.” They advise examinees that they can beat the comparison question test by identifying comparison questions and producing stronger-than-normal reactions to these questions.6
Most of the physical countermeasures described in the literature appear to be designed to strengthen responses to comparison questions. For example, there are a number of ways of inducing mild pain when responding to comparison questions (e.g., biting one’s tongue, stepping on a hidden tack in one’s shoe), and it is possible that the heightened physiological responses that accompany pain can mimic the responses polygraph examiners take as indicators of deception when they appear after relevant questions. Muscle contraction might produce similar reactions and might be difficult to detect, depending on the amount of training and the muscle groups involved (Honts, 1986). Mental countermeasures have
also been suggested as a method for enhancing responses to comparison questions. For example, Honts (1986) and Maschke and Scalabrini (no date) suggest that the use of exciting or arousing mental imagery during comparison questions might lead to stronger physiological responses. A second strategy for reducing differences between responses to relevant and to comparison questions is to dampen responses to relevant questions. The mental countermeasures described in the literature (e.g., mental imagery, attention focusing) might be used for this purpose. It is widely believed that physical and mental countermeasures are ineffective for reducing physiological responses to relevant questions in polygraph examinations, but investigations of this strategy have not been reported.
Our review of basic theory and research in physiological psychology (see Chapter 3) makes it clear that a wide range of physiological responses can be brought under some level of conscious control. Countermeasure research has examined a limited set of strategies for influencing the readings obtained by the polygraph (e.g., muscle tensing, self-inflicted pain), but many other possibilities remain, including the use of biofeedback and conditioning paradigms. It is entirely plausible, from a scientific viewpoint, to develop a range of countermeasures that might effectively mimic specific physiological response patterns that are usually the focus of a polygraph test. It is not clear whether there would be individual differences in physiological response patterns with particular countermeasures or in the ease with which specific countermeasures are mastered. Nor is it clear whether examinees can learn to replicate faithfully their responses to comparison questions when answering relevant questions: systematic differences between comparison and relevant responses, even those that are not part of the standard scoring criteria for evaluating polygraph charts, might make it possible to detect countermeasures.
Most studies of countermeasures have focused on the effects of these measures on test outcomes and on the accuracy of polygraph tests, without directly examining whether these measures in fact produced their desired physiological effects. For example, Honts, Hodes, and Raskin (1985) and Honts, Raskin, and Kircher (1987) focus on the overall effects of countermeasures use without determining whether specific countermeasures (e.g., self-induced pain) lead to increased reactions to comparison questions. Some studies, however (e.g., Honts, 1986), have looked at the physiological responses to specific questions when countermeasures have or have not been attempted and provide some evidence that it is possible to produce more pronounced reactions to comparison questions with countermeasures. Some studies (e.g., Kubis, 1962) have examined the effects of particular countermeasures on accuracy of detection through specific physiological channels, as well as when all channels are examined.
The empirical research on countermeasures has not provided enough information to determine whether specific countermeasures have the specific physiological effects that would lead a polygraph examiner to judge an examinee as nondeceptive. Consequently, it is difficult to determine why specific countermeasure strategies might or might not work. We would not expect specific countermeasures (e.g., biting one’s tongue) to have uniform effects on all of the chart readings obtained during a polygraph test, and studies that focus exclusively on the effects of countermeasures on accuracy do not allow one to determine why specific approaches might work or fail to work in different contexts.
Effects
Drugs
Studies of the effects of countermeasures on the outcomes of polygraph examinations have yielded mixed outcomes. Studies on the effects of drugs, already discussed, are a good example. An early study by Waid et al. (1981) suggested that the use of the drug meprobamate reduced the accuracy of polygraph examinations, but subsequent studies (Iacono, Boisvenu, and Fleming, 1984; Iacono et al., 1992) suggest that similar drugs, such as diazepam (Valium) and methlyphenidate (Ritalin), have little effect on the outcomes of polygraph examinations.
It is difficult to draw firm conclusions from research on the effects of drugs and alcohol on polygraph examinations for two reasons: there are relatively few studies that provide data, and these studies share a central weakness that is endemic in most of the polygraph research we have reviewed—a failure to articulate and test specific theories or hypotheses about how and why drugs might influence polygraph outcomes. These studies have rarely stated or tested predictions about the effects of specific classes of drugs on specific physiological readings obtained using the polygraph, on the examiner’s interpretations of those readings, or of other behaviors observed during a polygraph examination. Different classes of drugs are likely to affect different physiological responses, and the effects of one class of drugs (e.g., benzodiazepines used to treat anxiety) might be qualitatively different from the effects of alcohol or some other drug. Research on drug and alcohol effects has not yet examined the processes by which these substances might influence polygraph outcomes, making it difficult to interpret any studies showing that particular drug-based countermeasures either work or fail to work.
Mental and Physical Strategies
Studies of mental countermeasures have also produced inconsistent findings. Kubis (1962) and Wakamatsu (1987) presented data suggesting that some mental countermeasures reduce the accuracy of polygraph tests. Elaad and Ben-Shakhar (1991) present evidence that certain mental countermeasures have relatively weak effects, findings that are confirmed by Ben-Shakhar and Dolev (1996). Timm (1991) found that the use of posthypnotic suggestion as a countermeasure was ineffective. As with the research reviewed above, studies of the effects of mental countermeasures have failed to develop or test specific hypotheses about why specific countermeasures might work or under which conditions they are most likely to work. There is evidence, however, that their effects operate particularly through the electrodermal channel (Ben-Shakhar and Dolev, 1996; Elaad and Ben-Shakhar, 1991; Kubis, 1962).
A series of studies by Honts and his colleagues suggests that training subjects in physical countermeasures or in a combination of physical and mental countermeasures can substantially decrease the likelihood that deceptive subjects will be detected by the polygraph (Honts, 1986; Honts et al., 1996; Honts, Hodes and Raskin, 1985; Honts, Raskin, and Kircher, 1987, 1994; Raskin and Kircher, 1990). In general, these studies suggest that physical countermeasures are more effective than mental ones and that a combination of physical and mental countermeasures is probably most effective. These studies have involved very short periods of training and suggest that countermeasures are effective in both comparison question and concealed information test formats.
Limitations of the Research
Several important limitations to the research on countermeasures are worth noting. First, all of the studies have involved mock crimes and most use experimenters or research assistants as polygraph examiners. The generalizability of these results to real polygraph examinations— where both the examiner and the examinee are highly motivated to achieve their goals (i.e., to escape detection and to detect deception, respectively), where the examiners are skilled and experienced interrogators, where admissions and confessions are a strong factor in the outcome of the examination, and where there are important consequences attached to the polygraph examination—is doubtful. It is possible that the effects of countermeasures are even larger in real-life polygraph examinations than in laboratory experiments, but it is also possible that those experiments overestimate the effectiveness of the measures. There are so many
important differences between mock-crime laboratory studies and field applications of the polygraph that the external validity of this body of research is as much in doubt as the external validity of other laboratory studies of polygraph test accuracy.
Second, the bulk of the published research lending empirical support to the claim that countermeasures substantially affect the validity and utility of the polygraph is the product of the work of Honts and his colleagues. It is therefore important to obtain further, independent confirmation of these findings from multiple laboratories, using a range of research methods to determine the extent to which the results are generalizable or limited to the particular methods and measures commonly used in one laboratory.
There are also important omissions in the research on countermeasures. One, as noted above, is that none of the studies we reviewed adequately investigated the processes by which countermeasures might affect the deception of deception. Countermeasures are invariably based on assumptions about the physiological effects of particular mental or physical activities and their implications for the outcomes of polygraph tests. The first step in evaluating countermeasures should be a determination of whether they have their intended effects on the responses measured by the polygraph, followed by a determination of whether these specific changes in physiological responses affect the outcomes of a polygraph test. Countermeasure studies usually omit the step of determining whether countermeasures have their intended physiological effects, making any relationships between countermeasures and polygraph test outcomes difficult to evaluate.
Another omission is the apparent absence of attempts to identify the physiological signatures associated with different countermeasures. It is very likely that specific countermeasures (e.g., inducing pain, thinking exciting thoughts) produce specific patterns of physiological responses (not necessarily limited to those measured by the polygraph) that could be reliably distinguished from each other and from patterns indicating deceptive responses. Polygraph practitioners claim that they can detect countermeasures; this claim would be much more credible if there were known physiological indicators of countermeasure use.
A third omission, and perhaps the most important, is the apparent absence of research on the use of countermeasures by individuals who are highly motivated and extensively trained in using countermeasures. It is possible that classified research on this topic exists, but the research we reviewed does not provide an answer to the question that might be of most concern to the agencies that rely on the polygraph—i.e., whether agents or others who are motivated and trained can “beat” the polygraph.
Detection
Polygraph examiners commonly claim to be able to detect the use of countermeasures, both through their observations of the examinee’s behavior and through an assessment of the recorded polygraph chart. Some countermeasures, such as the use of psychoactive drugs (e.g., diazepam, commonly known as Valium), have broad behavioral consequences and should be relatively easy to detect (Iacono, Boisvenu, and Fleming, 1984). Whether polygraph examiners can detect more subtle countermeasures or, more importantly, can be trained to detect them, remains an open question.
Early empirical work in this area by Honts, Raskin, and Kircher (1987) suggested that countermeasures could be detected, but later work by Honts and his colleagues suggests that polygraph examiners do a poor job in detecting countermeasures (Honts, 1986; Honts, Amato, and Gordon, 2001; Honts and Hodes, 1983; Honts, Hodes, and Raskin, 1985; Honts, Raskin, and Kircher, 1994). Unfortunately, this work shares the same limitations as the work suggesting that countermeasures have a substantial effect and is based on many of the same studies. There have been reports of the use of mechanisms to detect countermeasure in polygraph tests, notably, reports of use of motion sensors in some polygraph equipment to detect muscle tensing (Maschke and Scalabrini, no date). Raskin and Kircher (1990) present some evidence that these sorts of detectors can be effective in detecting specific types of countermeasures, but their general validity and utility remain a matter for conjecture. There is no evidence that mental countermeasures are detectable by examiners. The available research does not address the issue of training examiners to detect countermeasures.
Incentives for Use
Honts and Amato (2002) suggest that the proportion of subjects who attempt to use countermeasures could be substantial (see also Honts, Amato, and Gordon, 2001). In particular, they report that many “innocent” examinees in their studies claim to use countermeasures in an effort to produce a favorable outcome in their examinations (the studies are based on self-reports). Even if these self-reports accurately represent the frequency of countermeasure use in the laboratory, it is unwise to conclude that countermeasures are equally prevalent in high-stakes field situations.
Because it is possible that countermeasures can increase “failure” rates among nondeceptive examinees and because a judgment that an examinee is using countermeasures can have the same practical effect as the
judgment that the test indicates deception, their use by innocent individuals may be misguided. Yet, it is certainly not irrational. Examinees who are highly motivated to “pass” their polygraph tests might engage in a variety of behaviors they believe will improve their chances, including the use of countermeasures. It is therefore reasonable to expect that the people who engage in countermeasures include, in addition to the critical few who want to avoid being caught in major security violations, people who are concerned that their emotions or anxieties (perhaps about real peccadilloes) might lead to a false positive polygraph result, and people who simply do not want to stake their careers on the results of an imperfect test. Unfortunately, there is no evidence to suggest how many of the people who use countermeasures fall in the latter categories. The proportion may well have increased, though, in the face of widespread claims that countermeasures are effective and undetectable.
Of course, the most serious concern about countermeasures is that guilty individuals may use them effectively to cover their guilt. The studies we reviewed provide little useful evidence on this critical question because the incentives to “beat the polygraph” in the experiments are relatively small ones and the “guilt” is nominal at best. The most troubling possibility is that with a serious investment of time and effort, it might be possible to train a deceptive individual to appear truthful on a polygraph examination by using countermeasures that are very difficult to detect. Given the widespread use of the polygraph in screening for security-sensitive jobs, it is reasonable to expect that foreign intelligence services will attempt to devise and implement methods of assuring that their agents will “pass” the polygraph. It is impossible to tell from the little research that has been done whether training in countermeasures has a good possibility of success or how long such training would take. The available research does not engender confidence that polygraph test results will be unaffected by the use of countermeasures by people who pose major security threats.
In screening employees and applicants for positions in security-related agencies, because the prevalence of spies and saboteurs is so low, almost all the people using countermeasures will not be spies, particularly if, as we have heard from some agency officials, the incidence of the use of countermeasures is increasing. To the extent that examiners can accurately identify the use of countermeasures, people using them will be detected and will have to be dealt with. Policies for doing so will be complicated by the likelihood that most of those judged to be using countermeasures will in fact be innocent of major security infractions. They will include both individuals who are using countermeasures to avoid being falsely suspected of such infractions and individuals falsely suspected of using countermeasures.
Research Questions
If the U.S. government established a major research program that addressed techniques for detection of deception, such a program would have to include applied research on countermeasures, addressed to at least three questions: (1) Are there particular countermeasures that are effective against all or some polygraph testing formats and scoring systems? (2) If so, how and why do they work? (3) Can they be detected and, if so, how?
The research would aim to come as close as possible to the intended settings and contexts in which the polygraph might be used. Countermeasures that work in low-stakes laboratory studies might not work, or might work better, in more realistic polygraph settings. Also, different countermeasure strategies might be effective, for example, in defeating screening polygraphs (where the distinction between relevant and comparison questions might not always be obvious) and in defeating the polygraph when used in specific-incident investigations. Studies might also investigate how specific countermeasures relate to question types and to particular physiological indicators, and whether specific countermeasures have reliable effects.
Countermeasures training would also be a worthy subject for study. Authors such as Maschke and Williams suggest that effective countermeasure strategies can be easily learned and that a small amount of practice is enough to give examinees an excellent chance of “beating” the polygraph. Because the effective application of mental or physical countermeasures on the part of examinees would require skill in distinguishing between relevant and comparison questions, skill in regulating physiological response, and skill in concealing countermeasures from trained examiners, claims that it is easy to train examinees to “beat” both the polygraph and trained examiners require scientific supporting evidence to be credible. However, we are not aware of any such research. Additional questions for research include whether there are individual differences in learning and retaining countermeasure skills, whether different strategies for countermeasure training have different effects, and whether some strategies work better for some examinees than for others.
Research could also address methods of detecting countermeasures. The available research suggests that detection is difficult, especially for mental countermeasures, but the studies are weak in external validity (e.g., low stakes for examiners and examinees), and they have rarely systematically examined specific strategies for detecting physical or mental countermeasures.
Research on countermeasures and their detection has potentially serious implications for security, especially for agencies that rely on the poly-
graph, and it is likely that some of this research would be classified. Elsewhere, we advocate open public research on the polygraph. In areas for which classified research is necessary, it is reasonable to expect that the quality and reliability of this research, even if conducted by the best available research teams, will necessarily be lower than that of unclassified research, because classified research projects do not have access to the self-correcting mechanisms (e.g., peer review, free collaboration, data sharing, publication, and rebuttal) that are such an integral part of open scientific research.
CONCLUSIONS
Overall Accuracy
Theoretical considerations and data suggest that any single-value estimate of polygraph accuracy in general use would likely be misleading. A major reason is that accuracy varies markedly across studies. This variability is due in part to sampling factors (small sample sizes and different methods of sampling); however, undetermined systematic differences between the studies undoubtedly also contribute to variability.
The accuracy index of the laboratory studies of specific-incident polygraph testing that we found that had at least minimal scientific quality and that presented data in a form amenable to quantitative estimation of criterion validity was between 0.81 and 0.91 for the middle 26 of the values from 52 datasets. Field studies suggest a similar, or perhaps slightly higher, level of accuracy. These numerical estimates should be interpreted with great care and should not be used as general measures of polygraph accuracy, particularly for screening applications. First, none of the studies we used to produce these numbers is a true study of polygraph screening. For the reasons discussed in this chapter, we expect that the accuracy index values that would be estimated from such studies would be lower than those in the studies we have reviewed.7
Second, these index values do not represent the percentage of correct polygraph judgments except under particular, very unusual circumstances. Their meaning in terms of percent correct depends on other factors, particularly the threshold that is set for declaring a test result positive and the base rate of deceptive individuals tested. In screening populations with very low base rates of deceptive individuals, even an extremely high percentage of correct classifications can give very unsatisfactory results. This point is illustrated in Table 2-1 (in Chapter 2), which presents an example of a test with an accuracy index of 0.90 that makes 99.5 percent correct classifications in a hypothetical security screening situation, yet lets 8 of 10 spies pass the screen.
Third, these estimates are based only on examinations of certain populations of polygraph-naïve examinees untrained in countermeasures and so may not apply to other populations of examinees, across testing situations, or to serious security violators who are highly motivated to “beat” the test. Fourth, even for naïve populations, the accuracy index most likely overestimates performance in realistic field situations due to technical biases in field research designs, the increased variability created by the lack of control of test administration and interpretation in the field, the artificiality of laboratory settings, and possible publication bias.
Thus, the range of accuracy indexes, from 0.81 to 0.91, that covers the bulk of polygraph research studies, is in our judgment an overestimate of likely accuracy in field application, even when highly trained examiners and reasonably well standardized testing procedures are used. It is impossible, however, to quantify how much of an overestimate these numbers represent because of limitations in the data. In our judgment, however, reliance on polygraph testing to perform in practical applications at a level at or above A = 0.90 is not warranted on the basis of either scientific theory or empirical data. Many committee members would place this upper bound considerably lower.
Despite these caveats, the empirical data clearly indicate that for several populations of naïve examinees not trained in countermeasures, polygraph tests for event-specific investigation detect deception at rates well above those expected from random guessing. Test performance is far below perfection and highly variable across situations. The studies report accuracy levels comparable to various diagnostic tests used in medicine. We note, however, that the performance of medical diagnostic tests in widespread field applications generally degrades relative to their performance in validation studies, and this result can also be expected for polygraph testing. Existing polygraph field studies have used research designs highly vulnerable to biases, most of which exaggerate polygraph accuracy. We also note that the advisability of using medical diagnostic tests in specific applications depends on issues beyond accuracy, particularly including the base rate of the condition being diagnosed in the population being tested and the availability of follow-up diagnostic tests; these issues also pertain to the use of the polygraph.
Screening
The great bulk of validation research on the polygraph has investigated deception associated with crimes or other specific events. We have found only one true screening study; the few other studies that are described as screening studies are in fact studies focused on specific incidents that use relatively broad “relevant” questions. No study to date
addresses the implications of observed accuracy for large security screening programs with very low base rates of the target transgressions, such as those now being conducted by major government agencies.
The so-called screening studies in the literature report accuracy levels that are better than chance for detecting deceptive examinees, but they show inconsistent results with regard to the ability of the test to detect the specific issue on which the examinee is attempting to deceive. These results indicate the need for caution in adopting screening protocols that encourage investigators to follow up on some issues and ignore others on the basis of physiological responses to specific questions on polygraph charts.
There are no studies that provide even indirect evidence of the validity of the polygraph for making judgments of future undesirable behavior from preemployment screening tests. The theory and logic of the polygraph, which emphasizes the detection of deception about past acts, is not consistent with the typical process by which forecasts of future security-related performance are made.
Variability in Accuracy Estimates
The variability in empirical estimates of polygraph accuracy is greater than can be explained by random processes. However, we have mainly been unable to determine the sources of systematic variability from examination of the data. Polygraph test performance in the data we reviewed did not vary markedly with several objective and subjective features coded by the reviewers: setting (field, laboratory); type of test (comparison question, concealed information); funding source; date of publication of the research; or our ratings of the quality of the data analysis, the internal validity of the research, or the overall salience of the study to the field. Other reviews suggest that, in laboratory settings, accuracy may be higher in situations involving incentives than in ones without incentives, but the evidence is not definitive and its relevance to field practice is uncertain.
The available research provides little information on the possibility that accuracy is dependent on individual differences among examinees in physiology or personality, examinees’ sociocultural group identity, social interaction variables in the polygraph examination, or drug use by the examinee. There is evidence in basic psychophysiology to support an expectation that some of these factors, including social stigmas attached to examiners or examinees and expectancies, may affect polygraph accuracy. Although the available research does not convincingly demonstrate any such effects, replications are very few and the studies lack sufficient statistical power to support negative conclusions.
Countermeasures
Any effectiveness of countermeasures would reduce the accuracy of polygraph tests. There are studies that provide empirical support for the hypothesis that some countermeasures that can be learned fairly easily can enable a deceptive individual to appear nondeceptive and avoid detection by the examiners. However, we do not know of scientific studies examining the effectiveness of countermeasures in contexts where systematic efforts are made to detect and deter them.
There is also evidence that innocent examinees using some countermeasures in an effort to increase the probability that they will “pass” the exam produce physiological reactions that have the opposite effect, either because their countermeasures are detected or because their responses appear more rather than less deceptive. The available evidence does not allow us to determine whether innocent examinees can increase their chances of achieving nondeceptive outcomes by using countermeasures.
The most serious threat of countermeasures, of course, concerns individuals who are major security threats and want to conceal their activities. Such individuals and the organizations they represent have a strong incentive to perfect and use countermeasures. If these measures are effective, they could seriously undermine any value of polygraph security screening. Basic physiological theory suggests that training methods might allow individuals to succeed in employing effective countermeasures. Moreover, the empirical research literature suggests that polygraph test results can be affected by the use of countermeasures. Given the potential importance of countermeasures to intelligence agencies, it is likely that classified information on these topics exists. In open communications and in a classified briefing for some of the committee, we have not been told of any such research, so we cannot verify its existence or relevance.
NOTES
|
1. |
Appendix H explains how we estimated the ROC curves and values of A. It also presents additional descriptive statistics on these A values. |
|
2. |
Two published meta-analyses claim to find associations between accuracy and characteristics of the studies, and therefore deserve discussion. In one, Kircher and colleagues (1988) reported that polygraph accuracy (measured as Pearson’s r between test results and actual truthfulness or deception) was correlated with three study characteristics across 14 polygraph studies of comparison question tests. The characteristics were examinee population (college students or others), incentive strength (the presence or absence of a tangible consequence of being judged deceptive, for both innocent and guilty examinees), and whether or not the study used field testing techniques that allowed examiners to conduct three or more charts in order to get a conclusive result. Because these characteristics were highly correlated with each other in the 14 studies, and with whether or not the studies were conducted in the authors’ laboratory, it is difficult to attribute the observed associations to any specific characteristic. We do not place much confidence in the reliability of the correlations because of the instability of the estimates for such a small number of studies and because of the inherent limits of Pearson’s r as an index of polygraph accuracy. Moreover, our examination of one of these variables (strength of incentive) failed to reveal an association with test accuracy in our sample of studies, which is larger and covers a broader range of incentives. Kircher and colleagues coded incentive strength as high for studies that offered as little as a $5 bonus to examinees for producing a nondeceptive result; only one study in the Kircher meta-analysis involved an incentive stronger than a $20 bonus. In the other meta-analysis, Ben-Shakhar and Elaad (2002b) examined 169 experimental conditions from 80 laboratory studies of concealed information tests. The study included a large number of studies that did not meet our quality criteria or that we did not use to estimate accuracy because they did not include a comparison group that lacked any concealed information. Its overall results were generally consistent with ours, but it did find positive associations of accuracy with three moderator variables: number of sets of relevant and comparison questions, the presence of motivational instructions or monetary incentives, and the presence of the requirement that deceptive examinees make a deceptive answer (rather than a nonresponse). We cannot compare their results directly with ours because of the large number of studies that support their analysis of moderator variables that are not in our dataset. For example, all but one of the studies covered in this meta-analysis that are also in our dataset were coded by Ben-Shakhar and Elaad as positive for the motivation variable. These meta-analyses cover only laboratory studies, so their relevance to field practice is uncertain. |
|
3. |
As stated in Note 2, Kircher et al. (1988) evaluated only 14 studies and considered bonuses of $5 to $20 as strong motivations. Ben-Shakhar and Elaad (2002) included a considerable number of studies in their analysis that did not meet our basic quality criteria or that we excluded from our analysis because they lacked a comparison group of examinees who had no concealed information. We consider their evidence suggestive of a motivation effect but not definitive. |
|
4. |
This study shares important features with true screening studies and with specific-incident studies. The questions are broader in scope than in a traditional specific-incident study, but still deal with specific, discrete, and potentially verifiable events. For example, one relevant question in this study was “Have you been convicted of a felony in the state of Georgia?” There is little room for ambiguity in interpreting the question or the answer, in contrast with typical screening questions, which are more |

































