
For over 100 years, the evolution of modern survey methodology— using the theory of representative sampling to make inferences from a part of the population to the whole—has been paralleled by a drive toward automation, harnessing technology and computerization to make parts of the survey process easier, faster, or better. Early steps toward survey automation include the use of punch (Hollerith) cards in tabulating the 1890 decennial census. The collaboration of surveys and technology continued with the use of UNIVAC I to assist in processing the 1950 census and the use of computers to assist in imputation for nonresponse, among other developments. Beginning in the 1970s, computer-assisted interviewing (CAI) methods emerged as a particularly beneficial technological development in the survey world. Computer-assisted telephone interviewing (CATI) allows interviewers to administer a survey instrument via telephone and capture responses electronically. The availability of portable computers in the late 1980s ushered in computer-assisted personal interviewing (CAPI), in which interviewers administer a survey instrument to respondents using a computerized version of the questionnaire on a portable laptop computer.
CAI methods have proven to be extremely useful and beneficial in survey administration. However, as survey designers have come to depend on software-based questionnaires, some problems have become evident. Among these is the challenge of effectively documenting an electronic questionnaire: creating an understandable representation of the survey instrument so that users and survey analysts alike can follow the flow through a questionnaire’s items and understand what information is being collected. Testing electronic questionnaires is also a major challenge, not only in the software sense of testing (e.g., ensuring that all possible paths through the questionnaire work correctly) but also in terms of such factors as usability, screen design, and wording. The problems of documentation and testing survey questionnaires are particularly acute for large and complicated instruments, such as those utilized in major federal surveys; for such large surveys, even relatively minor challenges in a questionnaire can produce lengthy delays in the fielding of surveys. The practical problems encountered in documentation and testing of CAI instruments suggest that this is an opportune time to reexamine not only the process of developing CAI instruments but also the future directions of survey automation writ large—for example, to see whether strategies for resolving current CAI problems provide guidance on how best to develop stand-alone surveys for administration via the Internet.
Accordingly, the Committee on National Statistics (CNSTAT) of the National Academies convened a Workshop on Survey Automation on April 15–16, 2002, with funding from the U.S. Census Bureau (by way
of the National Science Foundation). The Workshop on Survey Automation brought together representatives from the survey research, computer science, and statistical communities. Presentations were designed so that survey researchers and methodologists could be shown directions for possible remedies to the problems of documentation and testing, and so that computer scientists could be introduced to the unique demands of survey research. The second day of the workshop suggested emerging technologies in survey research, each of which is an area in which further collaboration between survey researchers and methodologists and computer scientists could be fruitful.
The proceedings of the workshop—an edited transcript of the workshop presentations—are contained in this volume. In this short summary report, we draw from the proceedings and outline the major findings and themes that emerged from the workshop, among them:
-
the need to retool survey management processes in order to facilitate incremental development and testing and to emphasize the use of development teams;
-
the need to better integrate questionnaire documentation—and, more generally, the measure of complexity—into the instrument design process, making documentation a vital part throughout the development process rather than a post-production chore; and
-
the need for the survey research community to reach beyond its walls for further expertise in computer science and related disciplines.
The issues and hence our comments in this report pertain to the entire computer-assisted survey research community—the collection of federal statistical agencies, independent survey organizations, software providers, and interested stakeholders engaged in modern survey methods. Understanding the challenges and crafting solutions will necessarily take communication and collaboration among government, industry, and academia.
At the outset, it is important for us to reiterate that the basis of this report is a one and one-half day workshop. The time limitation of a workshop affects the scope of material that can be covered. In structuring the workshop, we focused principally on CAPI issues and their implementation in large surveys, drawing on Census Bureau experience with CAPI in particular. In this context, documentation and testing problems—and the need for solutions—are likely to be acute. Although this report refers primarily to CAPI, a great deal of the discussion is applicable to computer-assisted interviewing in general. That said, this
report of a workshop is necessarily more limited in scope than a complete study of automation in surveys would be.1 Moreover, no single, short workshop presentation is sufficient to support strong recommendations in favor of any particular methodology or software package, and no such endorsement should be inferred from these remarks. As we discuss in greater detail later, more concrete guidance on specific approaches would require further collaboration—making survey researchers and computer scientists familiar with each other’s work—of a scope beyond that of a single-shot overview workshop. Accordingly, we hope that the comments in this report are interpreted as suggestive rather than strictly prescriptive.
INTRODUCTION
Since the late 1980s, the advent of portable laptop computers has offered survey practitioners newfound opportunities and challenges. The new practice of computer-assisted personal interviewing (CAPI) inherited some features from the existing technology of computer-assisted telephone interviewing (CATI) but differed principally in the manner of administration. CATI interviewers typically operate out of fixed centers and are under more direct supervisory control. In contrast, CAPI interviewers are deployed in the field, thus enabling direct face-to-face contact between interviewer and respondent; the field nature of CAPI work also promised to give CAPI interviewers a greater measure of autonomy than their CATI counterparts. Furthermore, face-to-face CAPI questionnaires are often longer and more extensive than telephone surveys.
The great promise of computer-assisted interviewing (CAI) has always been its infinite potential for customization. By virtue of its electronic form, a CAI questionnaire can be tailor-fit to each respondent; skip sequences can be constructed to route respondents through only those questions that are applicable to them, based on their preceding answers. Drawing on previously entered data, the very wording of questions that appear on the laptop screen can be altered to reduce burden on the interviewer and to best fit the respondent. Such custom wordings may include references to “his” or “her” (based on an earlier answer to gender) rather than generic labels, or automatically computed reference periods based on the current date.
For example, Figure I-1 shows an excerpt from a paper version of the National Crime Victimization Survey. This excerpt is not meant as an
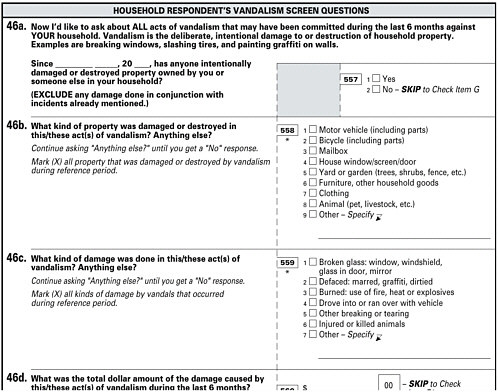
Figure I-1 Example of paper-and-pencil-style questionnaire, as seen by an interviewer.
NOTE: This an excerpt from a version of the National Crime Victimization Survey (NCVS), as it would be seen by an interviewer administering the questionnaire to a respondent (the NCVS is partially conducted by CATI).
exemplar of paper questionnaires; indeed, the particular layout used here may be considered old style, and cognitive research has suggested better ways to structure paper questions in order to guide flow. But the excerpt suggests the basic structure of a paper questionnaire. Here, a question asks the respondent if he or she has recently been the victim of vandalism; if not, questioning is supposed to jump to an entirely different set of questions. But if they have, questioning continues within the set of vandalism questions, asking what kind of property was damaged.
Figure I-2 illustrates how this brief questionnaire segment might be handled in a computerized survey instrument. The specific pieces of logic in Figure I-2 are drawn from an instrument document (IDOC); it differs from the actual CAI code in that it has been post-processed and the pointers to and from immediate next steps have been cleaned and

Figure I-2 Example of questionnaire item flow patterns in a CAI instrument.
NOTE: These excerpts parallel Figure I-1 in that they derive from the same portion of the National Crime Victimization Survey. However, the views shown here are those would be visible to a survey analyst, not an interviewer or a respondent; further, these are not portions of the raw computer code of the computerized questionnaire. These segments are excerpted from an instrument document (IDOC), the output of a specific automated documentation program on a CASES-coded version of the survey instrument.
formatted. Items referenced as [fill …] are automatic fills, such as the reference date, and are filled in by the computer during the administration. The arrows and the “How to Get to This Item” boxes give a quick glimpse at the basic skip sequence governing this section of the questionnaire; the “Yes”/1 answer in the first question causes the jump to the second question on property type; and a response to that question causes a jump to a logical decision point (the lowermost box in Figure I-2), which will suggest a different path if the answer is “Other” than if the respondent gives one of the eight defined property types.
The use of CAPI also brought with it the promise of more accurate survey data. Errors caused by interviewers mistakenly skipping portions of paper questionnaires or by respondents being asked questions not applicable to their particular circumstances could be curbed by effective routing through the instrument. Computerization enables in-line editing and error checking; input values can be checked for accuracy and consistency (e.g., by asking for both age and birthdate and comparing the results); and flags can be raised, prompting the interviewer to solicit corrective information. Moreover, computerized questionnaires can facilitate easier “dependent interviewing” in longitudinal panel surveys, a practice in which answers from a respondent’s questionnaire in a previous administration are used to frame questions on a current survey. Dependent interviewing can jog the memories of respondents in longitudinal surveys and provide for consistency in answers from wave to wave. Finally, data capture in CAPI surveys is automatic; answers need not be transcribed from paper forms or input using technologies like optical scanning.
The benefits of CAPI implementation—along with the experience of many successful conversions to CAPI—have led survey developers to pursue more extensive and complicated computerized questionnaires. The success of CAPI has brought with it a need and desire for added complexity. But the problem with an infinitely customizable instrument is that all the logical components therein—all of the potentially millions of logical paths through an instrument—must flow smoothly, because it is impossible to know ahead of time what specific path a particular respondent’s answers may follow. All behind-the-scenes fills and calculations must operate properly to make sure that the questions are displayed on the screen correctly; all data input by the interviewer must be processed and coded correctly on the data output file to be of any utility. Thus, every computerized survey instrument must be a correctly functioning, error-free piece of software—a goal that is difficult enough for small surveys but greatly compounded by the sheer size and complexity of some of the federal surveys for which CAPI has been implemented.








