
requirements; the real joke is that the requirements end up being what the source code does. [laughter] And there’s a certain pathological truth to that, but that’s the way you end up. And then you re-engineer your way back out. And the other thing that happens all the time in software is that the first thing that goes is documentation. And right with it goes testing. And documentation winds up being what you can get out after the fact, and the testing—unfortunately—has been very ad hoc, at incredible expense. Now, one of the things you’re going to see in the handout is that we developed some technology that said when you think about your architecture early, there’s a way to figure out your integration test before you build the system. In other words, you can take the way you are thinking about the system and build the high-level test before. And that’s the only time you get the leverage, because once you start building it there’s such a panic to get it out that you can’t [get] in the middle of that. So the real psychology is: how do I develop my test before the fact? And there it’s clean intellectually as well because you know ahead of time what it should be doing. It’s not that you follow what it’s doing as the requirement.
So I want to thank you. I’ve kind of enjoyed this because this probably sets for me the record of not being a bird of a feather, if you know what I mean. [laughter] Because I have no idea in the world, and I promised myself when I got here not to study it because I wanted to come out of the box clean [laughter] with no preconceived issues. But it has stuck me that the issues I think are very, very similar. So thank you.
CORK: We will take a fifteen minute break. In keeping with the NRC policy of constant feeding [laughter], there are cookies and such in the back. We’re about a half-hour off schedule so hopefully we’ll make up a little bit of time. But we’re doing okay.
MODEL-BASED TESTING IN SURVEY AUTOMATION
Harry Robinson
CORK: If everyone could settle down, we have a last little stretch here, but we are in the home stretch—the last segment for the day. The last segment that we’re going to do today is focused on the problem of testing of instruments. In particular, it’s going to be centered around the idea of model-based testing, a computer science approach that seemed sort of immediately applicable to some of these problems. And, to give a general idea of what model-based testing is, we have one of the best practitioners of it here, Harry Robinson from Microsoft.
ROBINSON: Thank you, Dan. Can everyone hear? Okay.
So, yes, like my confreres from the software world, I know nothing about surveys. So let’s just get that out right away. But what I do know about is testing, and from what I see you folks are leaving the world of surveys to some degree and moving to software, and so expertise on software testing may inform your efforts to test your questionnaires.
So I work for Microsoft; I’m currently with the Six Sigma Productivity Team. I’m in charge of test productivity initiatives and, before Microsoft, I was with HP for three years and before that with Bell Labs for ten.
OK—the theme. I test software, you test surveys. But your surveys are becoming software. And there [are] actually models that underlie them both. And what’s been fascinating to me is that even though I have nothing to do with surveys during my normal life the number of things that people have said about how you do surveys keep resonating with me and how we do software testing.
Once you left the world of paper, you entered the software world. And in much the same way that we are very feature-driven in the industry, you folks sound like you’re feature-driven because you can do it. And so what you’re ending up with is the same kind of tension we have between features that you’d really like to get in and your ability to validate that you haven’t introduced bugs into your system along the way. Lots of bugs, evidently, from survey instruments; it sounds like a lot to me.
Just in terms of the cost of bugs, just for a second, in keeping with the trend, $300—I mean, 300 times—is a low estimate. [laughter] Because if you find a bug in the field—which is part of the reason why Microsoft really doesn’t need the reputation of releasing things to have people test, because once you’ve released it, by the time you get it back you have to regression test it through all those systems. And then you have to redeploy. Oh, it’s terrible. So let’s use 300 as a low estimate.
And another thing is that I’m fascinated to hear the work on complexity. I know of a project before my time at Microsoft where—if you’re familiar with software bug trends—usually the bug trend towards the early part of a project starts up here and then comes down here, and you kind of say, here’s where we’re going to release. There was a project where it was essentially a big bowl of mud and every time you fixed something you broke more things. So what they actually had—so, this is basically a zero-defect type approach … what they actually had was an infinite-defect approach. [laughter] Every time they fixed it they broke more stuff, and they did what was really the sensible thing—they shipped. [laughter]
Software testing problems—[first,] time is limited. You have some time—in between when there is something to test and when you actually have to give it to somebody—[in which] you need to be able to find as many bugs as you can. And what you need to do is address your efforts
all along those areas of time to be doing the best things at the best times. Applications are complex, and getting more so. Used to be that you had your spreadsheet, you had your database. Now your spreadsheet talks to their database and in fact is callable from within their database. Requirements are fluid. “Fluid” is essentially a euphemistic term here, although I love that clip art here because it looks like they’re swimming upstream.
So, some ways that we’ve tended to handle software testing in the industry … Manual testing is kind of the first thing everybody thinks about, OK? You sit down and you actually try it out. Then you sit down and try it out a slightly different way. And you do it again a different way, and you find some bugs—this is good. You give those bugs to [Development], Dev fixes those bugs, they give ’em back to you. You try it out this way, you try it out that way. After about ten iterations you are glassy-eyed and just banging at keyboards and couldn’t see a bug if it bit you. It’s very labor-intensive and it’s not very useful; actually, it has a very short half-life. You find a lot of superficial bugs but that’s about it.
Scripted automation—now this is what we were talking about. This is where you take a path through your questionnaire and then you save that, so that you can re-play it later on. [I’m referring to it as] scripted automation; it’s also called something like capture-replay. It sounds like it’s good, but actually it is a bit of fool’s gold to you, because what it does is—you are doing scripted automation, picking your way through the questionnaire. You’re actually looking for bugs, but by the time you get that automation path working, that automation path has pretty much found all the bugs you’re going to find. So you are not getting the benefit from that. What you’re actually finding are regression bugs, but you’re not going to find regression bugs in that path because, if you change that path, then your script doesn’t work any more. So what you’re actually doing is finding bugs somewhere else in your process. So scripted automation has its place, but not to the degree that it gets relied on.
So let’s look at models. And my definition of a model is very general. A model is a description of how the system behaves, on some level. So think about what people were saying earlier in this; you know, “we lost the point where we could get our head around it.” Well, models are all about keeping your head around it. I have a model of the way my car works; I know nothing from under the hood. But I know that you turn the key and it goes, “Vrooom,” and that’s good. You turn the key and it goes, “Vrunk,” and that’s bad. And sometimes I have to go find someone who has a better model of what’s inside my car [laughter]. But the thing is that I could actually test my car, because as long as somebody knows
the difference between “Vrooom” and “Vrunk,” I’m there. To the same extent, if you can explain to your computer something about how your system is supposed to behave, you can use the computer to generate the tests. And for companies in the industry this makes lots of sense because computers will work even longer than new hires [laughter]; you don’t have to pay them, and you don’t have to give them stock options. So to the extent that you can push your work over on to computers, it’s good.
I love the fact that everybody seems to know what a “graph” is. [Usually,] I have to say that it has nothing to do with x [and] y axes. [The “graphs” we talk about have [a] start node, end node; an arc is how you get between—also called an edge. So, typical kind of graph, OK? Nodes, edges. And these are unidirectional, too, by the way, so there are little arrows saying that you go from here to there.
You can model survey routing as a graph. Now, there are other ways you can use models in testing, in testing the questionnaire. You could use models, for instance, in testing data validation on the various questions. But what I’ll deal with here, really, is using models to test the routing.
So, here’s that same one but now we’ve given some names and meanings to what’s going on. So here’s my questionnaire. [SeeFigure II-22.] I start my questionnaire; first thing I ask is age. If the age is less than 17, I’m done. If the age is more than 16 I go to marital status. At marital status I ask, you know, single, married, divorced, separated. Single, I’m done. Otherwise, I go here. Once I finish that I ask spouse age. And so this is very simple but I think it’s not … I read Jelke Bethlehem’s thing, and reproduced it, and actually got part of it wrong. [laughter] Why I’d want to know the spouse’s age when I’m divorced, I don’t know.
So here’s how you would tend to think about testing this, a walk through the graph. {Start}, {less than 17}: that’s one test case. {More than 16} and {single}, another test case.{More than 16} and {married } … well, now I’d like to know your spouse’s age. {More than 16}, {divorced}, {spouse age}. {More then 16}, {separated}, {spouse age}. So I’ve tested every possibility there. So that’s what my test cases look like, that I’m now going to stick somewhere.
Now let’s do something that I know a little bit about—the clock.40 You know, it no longer even ships, which is sad. But the clock—everybody knows basically what the clock application does. It’s pretty simple. It’s actually kind of complex in some ways; it’s got some intriguing bugs. And it’s actually kind of hard to test because, for instance, it’s hard to tell what time it is for your automation.
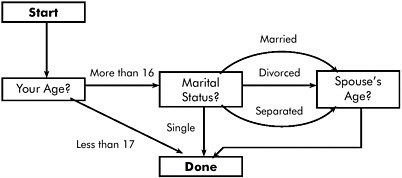
Figure II-22 Simple survey example.
SOURCE: Workshop presentation by Harry Robinson.
The clock is a graph. [SeeFigure II-23.] I could talk about an application about having states as well, just as you can talk about being on a particular question. I can talk about, well, now, I’m sitting here [at {clock not working}]. I {start} it and now I’m running it and I’ve got the {analog}, which has the hands. If I switch to {digital}, now I’m over here. If I turn it off, I’m actually not running, but I’m now not running in digital mode. Because if I start it again, I’m here. If I go {analog} again, I’m back. Interestingly, if I go from {digita} to {digital}, I’m back to {digital}. I don’t know why that’s enabled as a possibility, but it’s there. But what you might think of this … well, I’ll get to it.
If I were going to test the clock, here [are] my test cases. First test, I {start} it and I {stop} it. I check that into my test case manager. I {start } it, and I make sure that it goes back and forth between display modes [(from {analog} to {digital} and vice versa)]. I check that that bit about being stopped and coming back in digital works. And then I check one that actually runs and picks up those little self-loops. Now that is my test case group.
The problem with it is that it is a bunch of separate paths that I am saving, OK? They’re hard-coded, and I’m going to have lots of them. It’s not unusual for people to have 10,000 test cases like this. And it only does what I specifically made it do. I took it through it by hand and now it’s going to repeat that. But this is what, in testing, is called the “minefield fallacy.” The best way to avoid stepping on a mine in a minefield is to follow somebody’s footsteps who made it all the way across. The best way not to find bugs in a software program is to run things that you’ve already run. OK, so now you’re maintaining this, and everybody
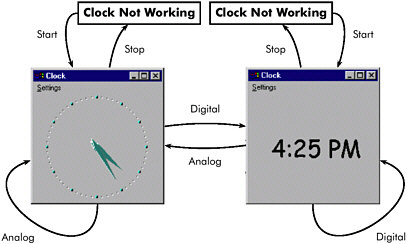
Figure II-23 Operational states of Windows clock application, viewed as a flow graph and a model.
SOURCE: Workshop presentation by Harry Robinson.
is usually proud of having a big test case database. The problem is: now, they’re wearing out and, worst of all, somebody changes this functionality. Now you have to go back and re-record maybe hundreds, maybe thousands, of tests. But wait a minute—that is exactly what you are doing here with the questionnaire. Same sort of a problem. I don’t know how many automated test cases you have, but if you have automation you probably have a lot.
OK, Twinkies.41 I have no idea what the shelf-life of a Twinkie is. But I can tell you that the half-life of an automated test is probably a few minutes. By the time you’ve checked it in to your test case manager, it is not of much use to you anymore. And it’s even worse because once you’ve started migrating over to different systems, different test environments, then you’re porting code that isn’t much use to you anymore.
So, go back to the model; go back to the description of what the system does. And let that model generate tests for you. So, this is why I’m fascinated that this workshop is about documentation and testing, because what you’ll see out of this—hopefully—is that documentation and testing both have a lot to do with each other. One thing models are about is about being executable specs; they are documentation that you can actually use to test the system.
OK, so here we are with this—don’t worry about how you would actually represent that. There are tools that allow you, in a simple way, to represent state graphs. Big state graphs, sometimes.
You can do a random walk. Now, the nice thing about a random walk is that it will give you unusual things that you might not have thought of to try. OK, so, maybe there’s a bug [you are unaware of; for instance,] if you hit {analog} three times in a row. [If] there is, the monkey [might pick it up.] This, in Microsoft terms, is partly called a “monkey” Because it’s like [the adage that] if you put enough monkeys to typing that eventually they could produce Shakespeare. This is better than a monkey, though, because what it does—monkeys actually just hit the keyboard and wait for something to crash. What this does is, as it’s running, it can say that I know I’m in {clock not running} mode. I do a {start}; now I know that I should be in {analog}mode and I should be running. And you can write your automation to verify that. And then what can you do now? I could do {analog}, I could do {digital}, or I could {stop }. You do it; once you’ve done it, you can verify the answer again. So it ends up being a very powerful test for you. Stop me if there are questions, by the way.
Testing every action … in graph theory this is called a “postman walk.” Because it’s like what a postman does delivering the mail. If you think about these as being streets, the postman has to visit every street. It may be that a postman has to walk down a street he’s already walked down, and that you try to keep to a minimum. But what you want to be able to do is to exercise, here, all of the actions in that state graph. So, you’re executing all the actions. And at the end of all of those executions, you’re verifying that it came out right.
You can say, I don’t really care about little loops; what I really care about is where I think the bugs are, and I think bugs come about when I change state. These aren’t changing my state, so I’ll save them for later. This is a big thing in models, when you’re using them to generate your tests. You can use them to generate millions, billions of tests. What you want to do, first, is generate those that you think are going to find your bugs.
Here’s another one. Find me, starting at {clock not running}, [every] path through this graph that has length 4 or less. And execute it. OK? Now, this, we had somebody who was doing an [Application Programming Interface (API)], a function, and actually a cluster of functions.42
And her management felt—actually, her word was “cringey” about the fact that they were just doing to do random walks through this API. So what we did was to sit down and figure out an easy way to implement this algorithm on this API. And what were able to do was to get every path through the states of that API of—I think it was 12, 12 steps or less. That’s a whole lot of coverage. It took a lot of machines, but they had a lot of machines; it took some time, but they had a week. [laughter] I’ll demo it at the end, if the demo deities are smiling on me.
OK, back to surveys—here’s that survey model again. Maybe what I’d like to do is random walk through the survey. I [add] in a pseudo-transition here that’s a dotted that line that says, “when I’m done, go back to the start.” So now I could have somebody, I could set this off to run and it would say, “OK, now I’m going to start the survey and now I’monquestion {your age}.” OK? From question {your age} I can verify whatever I can about your state. Then, because I’m the one driving the test, I can say, “I know, from my description of the system that if I give an age of more than 16 it should go one way; if it goes less than 17 it goes the other way.” I put either one of those in, and then I can verify that I did get to the state that I want. The problem with a random walk is that, again, it’s going to do things like, for instance, here, it’s going to go through the same path twice in a row. If you don’t have an incredibly large space, though, this will eventually hit everything. The problem is that it may take a while to hit everything. Yeah?
BANKS: [Very] often, things will go wrong [in areas where] they ask for your age and somebody will say “twelve to sixteen.” Or they will give it in months, or they will say “16 and a half,” and it’s not clear to me that this structure you’ve laid out captures that.
ROBINSON: So, what do you do, how do you handle error cases, essentially? Right? Where somebody gives you an alphabetic input on {your age}? In this module, you could actually—in the same way that {analog} curves back onto itself—you can say, “if I have an invalid input, then I will process the invalid input and come right back to the question.” So you would end up having little loops along there.
One thing there that I thought you were going to ask is what if they were something like, “OK, I’m on {marital status}—oh, wait, I forgot, I’m less than 17.” Well, this whole thing of backing up—that would be awful to do, trying to get coverage in scripted automation. But models could handle that fairly well.
What’s interesting, then, is that models make you think out your questionnaire. So, for instance, one thing you can do in models is to check for internal consistency. For instance, say that I am less than 17; then I will expect not to see a marital status just given this. You know, it
will be a “doesn’t apply.” But that changes if I allow going back. Because now somebody can come along and say, “start, more than 16, divorced, back, back, 15 years old.” So what it does is say to you that you could put a “back” in there, [and] this is what’s going to happen. And there are ways that you can now help out—from the testing side—even before there’s code or even before there’s a questionnaire. Because you know these are the ramifications of what’s going to happen.
OK, now here’s a Chinese postman walk—check every answer. Now this is particularly bushy here because we had to pick up all of those. Now, with a bigger questionnaire you could actually get in a lot of overlap. So, for instance, I’d be interested in the correspondence between a postman walk and the basis paths; it seems like a there’s a strict correlation going on. What if you just delivered a questionnaire to me and we need a really fast thing that just says: are the questions right? Did the questions come up correctly? I don’t really care about the answers yet. Here’s something that will take me through all the questions, so this is actually a travelling salesman’s walk. So I might want to run this before I run the one that checks every question plus every answer.
How many paths are there that are less than some number of questions? So, for instance, my kids are about this big now. So we were throwing some stuff out, and I came across “Chutes and Ladders.” And if you remember “Chutes and Ladders,” it’s where you count up and go up ladders and go down slides … so I modelled it. Do you know how many, what the fewest number of moves is for getting through “Chutes and Ladders”? I may be the only one … [laughter] It’s seven. Do you know how many ways you can get through “Chutes and Ladders” in seven moves? [inaudible reply] Wrong; 438. OK, so if you had to test “Chutes and Ladders”—which is kind of like a questionnaire—you know, you go here and then you’re there—yeah, you could actually say to it, here’s what it should look like. You have thrown a six, and now you’re here and you should end up down there.
Here’s for the Markovians in the family. If you know the likelihood of answers—[for] instance, you know where people are most likely to go in and give you various answers … [Suppose you take a guess or use previous data, and] you’ve assigned a probability to all of those links. [Referring back toFigure II-22, the hypothetical probabilities on the presentation slide are: .7 for age less than 17 and .3 for age greater than 16; and .3 for married, .15 for divorced, .05 for separated, and .5 for single.] That means that every path from start to done now has a probability associated with it. You can figure out the path probabilities and sort them, and you can sort them so you hit the most common paths first. So, for instance, 70 percent—you pick up 70 percent, 30, here’s another 15 percent, and 30,
30, another nine percent.43
[An advantage of this kind of testing is that it can reduce the number of steps to reproduce a bug. For a particular path,] if it does repro the bug, then I have a new shortest path for repro-ing. For instance, here’s the bug. Let’s say I chose “clock not running” and “digital but running”—that’s the shortest path, since the path would now go “start, digital, digital, stop,” and it would hit the bug, so that’s my new shortest path. Do it again, and that’s my new shortest path. Yeah?
PARTICIPANT: Tell me—when you’re using these models, who’s doing the actual testing?
ROBINSON: Who’s doing the actual testing? You’d have to rephrase the question to, “Who is actually executing the tests?”?
PARTICIPANT: Let me give an example. Suppose that I am the questionnaire designer and I didn’t want to ask the spouse’s age if the person was divorced, but the programmer programmed it to do that and they thought it was supposed to do that. So, if I was the person who was actually running the questionnaire, looking at the output I would not want to see an age and a spouse’s age if marital status shows divorced. I would know something was wrong, but the programmer wouldn’t.
ROBINSON: Right, so what—there’s a couple of things you could do there, and that’s why I asked what you meant by “testing.” Because there’s testing that a tester does to understand how to put together the model but the actual execution is done by computers without people being hands-on. People can be hands-on for other stuff. So, for instance, if you know that you don’t want a spouse to have an age—excuse me, divorced spouse—if you don’t want a divorced spouse to have an age, you could actually put into your model checker something that says, “if I have divorce and an age, then something has gone wrong; I’ve gone down a wrong path to an invalid statement. I shouldn’t have gone that way.” It gets more complicated when you allow people to back up because now they could have gone down and said, “yes, I’m married, here’s my spouse’s age, back up, back up, divorced.” And somehow worked it in there. So you’d have to be tricky about that. But part of it is the tiein with documentation, OK? If the spec says that you shouldn’t have a divorced spouse with an age, then that actually becomes part of the model. And if I say “divorced” and it comes and gives me a spouse’s age, the model is going to expect not to get a spouse’s age but to be done. And so it will say, “I’m on the wrong question.”
PARTICIPANT: Yeah, yeah—I understand what you’re saying. But what I’m saying is that it’s not the same person. Is it the programmer or the person who understands the questionnaire? And, just like the person who’s programming the clock, is it the person who understands the clock or the person who’s been given the spec?
ROBINSON: The person who’s been given the spec—this is black box test, so it’s independent of how it could have been implemented. So, for instance, I don’t know whether you’ve implemented your clock in C or C++ or COBOL—all I know is the external behavior that I expect from it. And then I can test to that.
DOYLE: In that sense, are you suggesting that we basically write the instrument twice? Once, say, in spec mode, and once to test the logic? I mean, is that what happens here?
ROBINSON: So, the question is: are we actually writing the instrument twice? And, in a sense, the answer is: yeah. In the same way, though, that I am creating a model of the clock that doesn’t actually have any moving parts. They have written the clock in C or whatever; I have written the clock as a small, finite state machine—a small graph that’s moving around. So what I’ve done is created a model that’s much simpler than the actual clock. OK, say, for instance, for doing the data on the questionnaire, you might have a whole bunch of database operations that you have to go through and all this. You need not model it that way, though; you can model it as a finite state machine. It would be a big one, but you are doing a different sort of implementation than they are …
DOYLE: And what sort of language are you implementing this alternative version in?
ROBINSON: Well, these can be implemented in anything. Some of my models are done in Visual Test; there are some tools on the market that allow you to specify. I would guess—and I don’t know—but I would guess that the questionnaire definition language could be used, because it is a model of what’s going on. Because by reading that XML …
DOYLE: So, for instance, the current document …
ROBINSON: No—for instance, about the …
DOYLE: TADEQ?
ROBINSON: Yes, the TADEQ thing …
DOYLE: But that’s what’s coming out of the code that’s been written …
ROBINSON: OK, but what you are doing as you are going through … you are saying that if you are generating data that is, oh, not for this one, but more than 18 years old, then I should know what it is that is going to happen. So you are doing what is equivalent to, basically, two-version programming. But the trade-off in performance that you do
and what actually has to happen is much deeper than what the model is going to do.
DOYLE: Is the level of effort required to write the second version— equal, half, one-third of the effort needed to write the original?
ROBINSON: OK, so what’s the comparison of the effort levels? I have a quote on this; it’s about 10 percent, because what you’re doing is modelling the fairly straightforward parts, and you’re not doing stuff like database accesses, and you’re not doing communications.
PIAZZA: Could you do some of this evaluation after the fact? [Particularly] thinking of these big questionnaires … for each of these possible questions you could choose one [answer] at random, and how bad is that answer, and follow where that takes you. Answer that at random, and so forth …
DOYLE: That’s the random walk model?
ROBINSON: Yes, that’s the random walk. But the difference is that when you do these sorts of random walks, it may look random to the questionnaire but you know what you’re choosing.
PIAZZA: Right, yes, but that’s the hard part! I’m kind of raising, or promoting, at least the possibility of generating datasets—the results of random responses to the questions, and you could get 50 or 100 thousand of these. Produce the dataset and then start looking, I suppose, for the sorts of anomalies you’re talking about—somebody who’s not married but has a spouse’s education listed. I think that what you’re talking about is doable, but I’m asking whether this approach might be more efficient than programming a parallel instrument, where you’re evaluating at every corner whether it’s doing the right thing.
ROBINSON: So you wouldn’t need, necessarily, to evaluate at every corner; it works out nicely, for applications, because applications don’t necessarily have an end. I mean, you could keep coming out with iterations on the clock all the time. It may be that you have some notion of what you want the answer to be; then you could check it at the end.
OK, this is a—I can do this at the end, if we have time. I don’t actually own a watch, so I don’t know how we’re doing on time …
CORK: About ten minutes …
ROBINSON: Ten minutes, OK. This is a bug in the clock. It’s actually Y2K-compatible—it didn’t work before year 2000, and it still doesn’t. [laughter] What actually happens is that you go through a particular sequence and the year goes away. And what you can actually do is, in the demo, there’s an 84-step sequence that does this. You can just start this automatically going and it cuts it down to, I can’t remember, six or seven steps. And it’s all purely automatic. This, to us, is a big time-saver, because we have plenty of machines that can bang away at shortening repro sequences. What we don’t have is a lot of people.
OK, so for instance, the random walk you could do much the same. And it would just be easier to find out: where exactly did we go wrong? Regression testing—part of the problem with regression testing is that you don’t—you know when you give a bug to a developer with a repro sequence, when you get it back you know that the one thing that the developer checked is the repro sequence. OK, so it’s almost useless to test that; what you’d really like to do is to test things kind of in that same neighborhood.
So, for instance, what you could do is to take your graph and assign weights to the links. This is sort of a poor man’s Markov chain. Make the weights along this chain much less, and say: find me paths through the system that have as low a weight as possible. What you’re going to end up with are paths that kind of stick here but that do go up and down, and around. So you begin to evolve—for instance, if you have 5 on the thin ones and 1 on the thick blue ones, that would weight 4. That would weight 18, another 18, 20, 20, and so what you end up doing is kind of generating this cocoon of regression tests around the area where you found the bug. This is actually more useful to you because you care about things in the periphery and not exactly where the bug was found.
So, for instance, if you found a survey bug there, you would probably test that one. But what you want to do is look around that one and say, give me the other things that go through somewhat similar paths; that’s what I’d really like.
OK, so here’s that quote: 10 percent of the program code is specific to the application. And that’s usually the easiest 10 percent. So you’re dealing with a much simpler problem. And, for instance, for here, what we run into is: you have to get a response back to a user in half a second, two seconds, something. And so as you’re moving along here to get faster and faster with speed, you’re choosing more and more complex algorithms to use because they’re faster. For the testing, we don’t care that much about the speed; we don’t have to go through something that quickly because we don’t care that much and because we have control over the data, we don’t need all that complexity. So where the testing comes in handy for us is, we are doing these two implementations but there’s a differential here. We’re trading something we don’t care about—which is the speed at which something runs—for something that we do. We have a better chance of getting this model right than we do of actually getting the system under test right. But they should get the same answer, and we can run them against each other.
Early bugs—you find a lot of bugs in just the spec, just sitting down and saying, what happens here? What happens there? We go completely opposite—somebody earlier said that you shouldn’t automate, things aren’t stable enough in version 1, or something. We actually automate
as soon as there’s a feature, something into place, and then we incrementally grow it. So there’s something like the “turn clock on-and-off” sequence in there because you can continue to grow later functionality from there.
Easy to maintain, lots of tests—tests of what you expect and what you don’t. You can put in enough oracles, test oracles, things that will tell you when things are going right or going wrong so that you can find bugs that you wouldn’t necessarily be testing for directly.
PARTICIPANT: [Inaudible]
ROBINSON: Oh, I’m sorry … “pesticide paradox” is the thing about a test wearing out, when you have a field full of bugs you spray it with some pesticide, you kill 98 percent of the bugs. But the remaining 2 percent are resistant, and you’re not going to get them no matter how many times you apply that pesticide.
This is not test automation that’s common in the industry yet. It’s a difficult sell—let’s say it that way—because it’s much less obvious that you can get benefit from it. It benefits largely from things that you are going to do over some amount of time. So it doesn’t have the flash that a capture-replay has. So what happens is that you end up with testers who have learned the other way and are uncomfortable with this or for whom this is outside their skill set. We have lots of testers, for instance, who are liberal arts majors and don’t program at all. This can make them uncomfortable. You need testers who can design, who can understand what the thing is supposed to do.
It can be a significant up-front investment, finding out in advance what’s going to happen. The notion we go with is that it is an investment, though, and what we tend to do is to start small and let the models pay for themselves along the way, because they keep the product very stable. It will not catch all the bugs; I was helping the people on Xbox do some modelling for their stuff, and somebody said, “you know, we have this problem where the elves sink into the floor.” [laughter] I don’t know a model that can keep your elves from sinking into the floor; what it can do for you is to verify that you’re navigating through the game, or whatever, correctly.
Metrics, they had metrics—bug counts. Bug counts were always abad metric. You know, “we found 10,000 bugs.” Is that good, is that bad? Because nobody cares how many bugs you found; they want to know how many bugs you didn’t and left in. Number of test cases—if you can generate test cases, then the number of test cases gets a little bit iffy. You can say how much water there is in your bucket, but how much is there in your faucet? Better metrics—coverage. Have you covered the spec, the requirements? In the code? Have you covered the model? So
things where you can say, “this is where we are; we’ve covered this much. Here’s the amount that we don’t currently know.”
PARTICIPANT: So what type of testing do you use, to supplement the model-based testing, since that doesn’t catch all the bugs?
ROBINSON: We use some scripts, because scripts are very good for doing build verification tests, tests where you’ve just got to know if this particular part runs. Sometimes, though, we generate those with models, because there’s just something that you want to get going, get running. What this does, though, is it frees up people to do the kind of testing that people are better at—people are better for judging that something looks right, that it’s got a good feel to it, that it’s easy to use. What this does is it takes people out of being the automation engines and lets things create themselves.
OK. I host the model-based testing Web page.44 It is a very shoe-string operation; it’s actually redirected to my Geocities account. So we’re not exactly a mover-and-shaker. But what it does is point to a lot of resources on different kinds of models. State models are one kind, grammar models, monkey models—there [are] several different varieties. Questions?
PARTICIPANT: It sounds like the model-based testing has been a career move, a change of careers. For example, in my case, am I better off being an author or an exterminator? [laughter, then inaudible follow-up]
ROBINSON: I don’t know; I started up as a developer but found that I enjoy finding bugs more. You know, so it may be …
PARTICIPANT: [inaudible]
ROBINSON: So part of it is: would you rather be a writer or an editor? Because, you know, the editor goes through and tells the writer, maybe you can do this, maybe you can do that.
PARTICIPANT: Can you tell me that being a model-based tester is any better than … [inaudible]
ROBINSON: I wish I could. One of the reasons I ended up in the position I’m in is partly because more people need to hear about this kind of testing. Right now, what they’re doing is pulling in people from the street to test, and those aren’t the people we need. We need people who understand graphs, who understand combinatorics, who can say, “I know how to actually put together a test system.” And make sure that there’s a distinction between activity—which anybody can do—and productivity—which is what somebody cares about.
DOYLE: One of the things that we’re not talking about is the matter of testing on all variations of a questionnaire … We have all of these design tools, and whether we have five questions in sequence with skip
patterns or one question with five variations on wording, depending on the characteristics of the response—it could go either way. One of those is connected to this type of testing, the other is one that takes a lot of time. Would you recommend that we choose the five-question version in order to adapt your type of model-based testing? Or would you …
ROBINSON: Well, I think that they both can be modelled. What you would end up doing is …
DOYLE: Having to model all the many variations?
ROBINSON: … The variation on the verbiage; can you give me an example?
DOYLE: There was a question, if you remember, on the thing Tom Piazza put out that if TCOUNT=1 you get asked this question and if greater than 1 you get asked that question? And on the screen it has the same name so it’s technically the same question but the words that appear on the page are going to be different depending on whether there’s an actual TCOUNT.
ROBINSON: Yes, those both sound very modelable. What you could do is choose one. And then if later on you decide to change it it is very easy to change the model to adapt. Because what you do is change that part and run it all, just as—I’m a tester congenitally here—somebody before gave a choice that said is your income between 500 and 1000 or between 1000 and 2000, or something …
DOYLE: And missing something in between …
ROBINSON: Yeah, where does 1000 go? No tester would have let you go on that...
DOYLE: Cognitive psychologists would put that there …
PARTICIPANT: I think this is a very important question about the demographics . . .
ROBINSON: Oh, my God! I wasn’t even here! [laughter]
PARTICIPANT: What do you do with your English majors?
ROBINSON: What do I do with the English majors? I’m a religion major.
PARTICIPANT: Do you rephrase it?
ROBINSON: No; what I’m doing is putting together a talk about how liberal arts majors make the best testers . . .
PARTICIPANT: … because they’re logical?
ROBINSON: They’re logical, and they delve. Remember when you used to sign up for a course because, you know, we’re going to delve into Shakespeare or something. That’s what you need—somebody who will get in there and say, “what are we actually doing?” Those are the right questions, and the right questions asked early enough can save a lot of trouble downstream.
















