
Building from this theme, other conclusions from the workshop fall into three basic categories:
-
Reconciling survey design with software engineering. Best practices in software engineering suggest the critical importance of building testing into the design process and of sequencing work on parts of a larger product. In software engineering terms, the objective is to think of computerized survey design as a product development project and consequently to select an appropriate life-cycle model for the questionnaire and software development process. The workshop presentations suggested specific techniques and organizational styles that may be useful in a retooled survey design system.
-
Measuring and dealing with complexity. The workshop offered a glimpse at strategies for assessing the complexity of computer code—mathematical measures based on graph theory that identify the number of basis paths through computer code and the degree to which code is logically structured into coherent, separable sub-sections. Such strategies may be used to go beyond the traditional concept of documentation in the survey automation context and underscore the bedrock importance of documentation in the survey design cycle. Attention to the mathematical complexity of CAI code may also be the impetus for much-needed discussion of the complexity of the surveys themselves—that is, the extent to which extensive use of CAI features like fills and backtracking adds value and functionality to the final code and offsets the programming costs those features incur.
-
Reducing the insularity of the survey community. The human communication interface and other features specific to surveys make the challenges of survey automation unique, but not so unique that experiences and practices outside the survey world are irrelevant. The survey industry should work to foster continuing ties with other areas of expertise in order to get necessary help.
These three categories are used to structure the remainder of this report.
CHANGING SURVEY MANAGEMENT PROCESSES TO SUIT SOFTWARE DESIGN
Computer science–oriented presentations at the workshop ranged from a discussion of high-level software engineering principles to a detailed outline of a newly emerging model for structuring labor and assignments in a large software project. The presentations are suggestive
of some general directions that may be useful, particularly in terms of rethinking the broad outline of the CAPI survey design process.
Establish an Architecture and Standards
In his remarks, Jesse Poore emphasized the importance of a “product line architecture” in structuring large, ongoing software projects. A product line architecture is a product development strategy, a plan under which the major elements of a larger product are identified. Some elements are cross-cutting across various parts of the design process, while others are more limited in scope. This architecture then becomes a living document; it can be reviewed over the years and altered as necessary, but it endures as an organizational guide.
The major benefits of thinking in terms of an overarching product line architecture are twofold. First, it begins to scale back the overall difficulty of the task by emphasizing its modular nature. By dividing a large and complex task into more easily approachable pieces, implementing changes in parts of the process can be eased. Second, it emphasizes standards and the common features of product releases. A product line architecture defines elements that are common to all product releases as well as permissible points of variation. Having resolved the task of producing a product (e.g., a cellular phone) into modular (and to some extent common) pieces, the task of constructing a new version of the product is one of making selected changes in some parts—but not necessarily all parts, nor all at once. Hence, a new cellular phone will build from a substantial base of established work, and development of new features will have been fairly contained and manageable.
Poore provides a prototype product line architecture for the production of a CAPI instrument; it is shown in Figure I-3. What this architecture illustrates is, for instance, that security is a concern that cross-cuts all the stages of instrument development but that should be separable, in the sense that security protocols could be a common feature to multiple surveys. Accordingly, security mechanisms could be developed separately (allowing, of course, for inputs and outputs in each stage of instrument development) and need not be reinvented for each questionnaire development project. Likewise, the mechanics of statistical operations embedded in survey code could be considered another cross-cutting yet separable layer. This hypothetical product line architecture is, as Poore notes, purely illustrative, and the degree to which it is correct or needs refinement awaits future work. But the idea of developing a product line architecture in the survey context has definite merit, chiefly because it would stimulate development of standards within individual survey organizations and across the survey community as a whole.
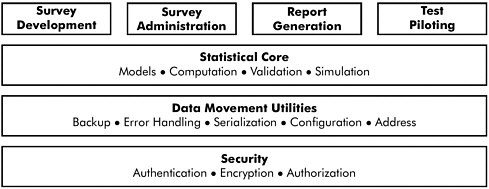
Figure I-3 Prototype product line architecture for a CAPI process.
NOTE: This figure is repeated later in the proceedings, in line with Jesse Poore’s presentation.
SOURCE: Workshop presentation by Jesse Poore.
Although individual surveys vary in the specific content they cover, there is a similarity in functionality and structure—between different versions of the same survey and between different surveys entirely— that is not fully exploited in current CAPI implementation. To be clear, it is not survey measurement itself that we suggest needs standardization; individual organizations and researchers should always have wide latitude to define the information they hope to solicit from respondents and to craft questions accordingly. Instead, the need for standards arises because individual organizations find themselves reinventing even the most basic of structures—automatic fills of “his” or “her” based on an answer to gender, rosters in which names of household members can be stored and retrieved, questions of “yes/no” or “yes/no/other” types, for example. These mechanical structures are common across surveys within organizations as well as across entire survey organizations; they are instances in which industry standards or an archive of reusable code could ease programmers’ burden and reduce errors.
Adopt Incremental Development and Testing and the Early Detection of Errors
During the first day of the workshop, a recurring topic was the difference in cost of software errors detected at the early stages of design and those found in later stages or after the software has been fielded. And although the bidding war that ensued throughout the day as to the exact magnitude of the multiplier on the cost of field-detected errors versus
early detected errors—ranging from 32 to “astronomical”—added some levity to the day’s proceedings, the underlying point is quite serious.
The formulation of a product line architecture is a first step used in contemporary computer science to try to detect errors early—to try to simplify the development process to reduce the opportunity for errors. A next step is to refine steps further and to develop work plans that are incremental in nature; this, too, is an organizational and behavioral change that could be useful in the survey context.
Incremental development is, as the name implies, a basic concept: resolve the large software/survey design task into modules or smaller pieces. These pieces can then be worked on separately and integrated one by one over time into the larger system under development. To borrow Poore’s evocative phrasing, milestones (long-term deadlines and deliverable schedules) are always important to keep in mind, but it is also important to manage to what might be called “inch pebbles”—the parts of the project that will be done within a shorter time frame.
Testing is carried out during each stage of the integration process, rather than waiting until a large number of modules are simultaneously connected together at the final stage of development—the kind of en masse, last-minute, and depleted-budget activity that is unlikely to shed real light on the reliability of the finished product. Incremental tests or software inspections may also serve as a valuable feedback mechanism by pointing out defects in the specifications and design documents that are developed even before coding begins.
As Poore notes, an additional benefit of an incremental development strategy—beyond its integration of testing into the design process—is that it can help create an environment of success in the project team. Because of the difficulties of managing a complicated system as a whole, large projects can often founder; they can remain grounded at 70 or 80 percent complete for long periods of time when problems in one part bring the whole project to a standstill. In incremental development, there can be a greater sense of accomplishment; a particular module may be only a small part of the larger system, but there is value in being confident that this small piece is internally complete and ready for integration with the rest of the system (as well as further testing).
Together, an overarching product line architecture and incremental development may be particularly useful strategies in dealing with what was portrayed as a major problem in current survey work: requirements and specifications that are not well specified at the outset and that shift over time. This is particularly the case with surveys conducted by federal statistical agencies, for which new legislation or policy needs can suddenly shift the focus of an individual survey. The trick in rethinking the process is to construct an environment in which forward motion can
always be made by proceeding with what is known and what is specified, and smaller parts of the project can be completed without being derailed by sudden changes elsewhere in the survey.
We certainly recognize that revising current survey practice to reflect these principles is no easy task. But identifying the set of problems currently experienced in CAI implementation and matching them to proposed solutions—whether through incorporation of best practices from software engineering or through industry-wide work on standardized solutions for the design of some CAI items—are important tasks, and ones that ought to be of considerable intellectual and professional excitement as well. It is, in short, a call for the survey industry as a whole to start a dialogue on standards and principles that have been lacking in the past.
On the topic of errors, a final practical point emerged at various times during the workshop. Although the aim is certainly to detect and fix errors early, there is no way to avoid errors entirely. Consequently, it is important for survey organizations to develop effective error tracking systems wherein errors at all stages of development—including those found in the field—can be logged and act as a feedback mechanism for designing the next iteration of a survey. It is possible that such an error tracking system could include building a “state capture” facility into CAI software, logging system events continuously through interviews and recording failure conditions when they occur. The log thus generated could then be very helpful in efficiently reproducing—and fixing—errors that caused the failure. It would also be beneficial to build error tracking tools in such a way that errors could be evaluated and classified by severity, considering both the cost of fixing them and the consequences for data quality of not fixing them. Defect tracking systems are common in software engineering usage, and hence discussion of the form of such a system for CAI implementations is an activity for which collaboration between the survey and software communities could be fruitful in the near term. Similarly, systems used in software engineering operations to configure and track design specifications could also be a useful short-term collaboration opportunity.
Employ Development Teams, Not Chains
Lawrence Markosian’s presentation outlined one emerging framework—known as “extreme programming” (XP)—that is finding acceptance among software developers and takes incremental development as a basic principle. Intended to be applicable to high-risk systems in which specifications are often fluid, XP puts high emphasis on programming individual parts of code in pairs and frequent team meetings, emphasizing progress made on incremental parts of the project. Similar specific
practices were also described during the course of the workshop: Poore advocated internal peer review of code and other work products, and Robert Smith’s presentation described the general strategies used by the Computer Curriculum Corporation in structuring its software-building tasks.
As Smith commented in his remarks, it would be a mistake for the survey community to seize on any particular style for organizing software development and programming work—such as XP—and follow that style blindly. Instead, survey research organizations should be encouraged to research existing organizational styles and to experiment with them to the extent possible, ultimately forging a hybrid organizational strategy best suited to survey problems and context. Whether the specific mix of meetings and labor assignments in extreme programming is useful or even applicable in existing survey organizations—particularly the statistical agencies—is an open question, but such systems do revolve around central features that would be useful to consider.
The presentation of current survey practice at the workshop drew extensively from the Census Bureau’s experience and, accordingly, descriptions of the labor organization in the survey process had a distinctly bureaucratic feel. Analysts (content matter specialists), designers, managers, programmers, cognitive testers—these and other roles in the survey design process were portrayed as being independent of each other and carrying out their jobs largely in isolation. The resulting structure seems to portray the survey-building process at the Census Bureau as strongly hierarchical and linear; the style seems to be unit-based, with responsibility for the entire survey being passed in turn from group to group and problems noted at one stage forcing the entire project to backtrack in the development process. Of course, other survey organizations—particularly nongovernmental entities—may structure the labor of questionnaire development differently. However, all organizational systems face important questions about responsibility for such cross-cutting concerns as documentation and testing: to what extent are survey managers, content matter specialists, or programmers responsible for instrument testing—responsible not only in terms of completing and evaluating the work but also budgeting time and resources for it to be done?
The concepts of extreme programming and peer review—as well as that of a product line architecture—suggest that it is desirable to consider task- or team-based structures. It may be best to have more input from programmers and field representatives early in the design process, and there may be benefits from investigating structures in which cognitive specialists are more members of the design team and perceived less as a level of oversight. Successful software engineering projects involve re-
solving the tasks into modular, addressable pieces and moving incremental pieces completely through the development cycle, rather than passing the entire project between task groups. It remains to structure the organization’s labor strategy to work optimally under that framework, and survey organizations like the Census Bureau should be strongly encouraged to experiment with team-based programming styles.
Enable Automated Testing
In our view, attention to the general instrument development process could do much to correct some of the problems experienced in the CAPI implementation of large survey instruments. The extensive time delays that currently arise from very small changes in questions could be contained through a modular structure; attention to documentation and testing—including implementation of systems to achieve traceability and management of specifications throughout the development process— could dramatically improve the information available to developers and end users alike. Moreover, testing based on modular, incremental pieces of the project rather than a single end-of-project crunch should build confidence in much of the CAPI code. However, a basic truth remains that manual testing and hand input of selected scenarios are not adequate to certify that all of the myriad paths through a questionnaire will function properly.
As mentioned at the workshop, some facility has been developed to generate scripts that automate the steps of entering a test scenario for an instrument coded in Blaise. This manner of scripted testing is at the middle level of the trichotomy of test strategies suggested in Harry Robinson’s presentation, the first level being manual testing. Developing capacity for these set preprogrammed scripts is an achievement but, as Robinson noted, automated test scripts are of quite limited use. As he put it, their shelf life is extremely short; virtually from the time they are developed they are out of date, since any change—particularly any change arising from a run-through of that selected script—can make the script useless. Scripts may make it possible to run more scenarios than would be possible under manual testing, but this still means that bugs can be detected only along the paths envisioned by the script and not elsewhere in the instrument.
The next tier of testing is automated testing, under which the computer makes random or probabilistically generated walks through the computer code. In the CAPI context, a simplified vision for how automated testing would work would be to put a range of possible answers on all the various questions, perhaps randomly drawn or perhaps based on previous survey administrations. An automated test routine would then
step through the questionnaire, generating answers at each step along the way; by monitoring the progress, developers could find parts where the code breaks down. Moreover, automated testing could be used to assess the entire survey data collection process; the output dataset that emerges from some large number of tests could itself be analyzed to determine whether responses appear to be coded correctly. The practice of automated testing, of course, is harder than simplified visions allow, one in which active computer science research continues. Accordingly, automated testing is an area in which the survey community should monitor ongoing research to find techniques that suit their needs; the community then needs to work with their CAPI software providers to achieve the capability to implement those methods.
In his remarks, Robinson advocated one method for testing software systems that is growing in acceptance. The idea behind this method— called model-based testing—is to represent the functioning of a software system as various tours through a graph. The graph that is created for this purpose uses nodes to represent observable, user-relevant states (e.g., the performance of a computation, the opening of a file), and the arcs between a set of nodes represent the result of user-supplied actions or inputs (e.g., user-supplied answers to multiple-choice questions) that correspond to the functioning of the software in proceeding from one state of use to another. (A side benefit of developing a graphical model of the functioning of a software system is that it helps to identify ambiguities in the specifications.) The graphical representation of the software can be accomplished at varying levels of detail to focus attention on components of the system that are in need of more (or less) intensive testing. These graphical models are constructed at a very early stage in system development and are further developed in parallel with the system. Many users have found that the development of the graphical model is a useful source of documentation of the system and provides a helpful summary of its features.
Equipped with this model, automated tests can be set in motion. One could consider testing every path through the graph, but this would be prohibitively time-consuming for all but the simplest graphical models. Other strategies for which model-based testing algorithms have been applied include choosing test inputs in such a way that every arc between nodes in the graphical model is traversed at least once. Still other strategies include testing every path of less than n steps (for some integer n)or to conduct a purely random walk through the graph. Random walks are easy to implement and often useful, but they can be inefficient in terms of time because they may not cover a large graph quickly.
Markov chain usage models build on the graphical representation of a software program used in model-based testing. In this technique,








