
may be time to realize that the instrument itself is becoming part of the design border …
DOYLE: It’s become what?
PARTICIPANT: Part of the design border, the design desk for survey researchers. And that they cannot fully think about the specification and design of the instrument almost until the thing’s half-programmed. And while we don’t like that from the programming side, it may be really inevitable. And we need to start thinking about these specification database systems that are starting to roll out as somehow being a reasonable workspace for a non-programmer, for a survey researcher, and actually some creative work can be done inside them.
DOYLE: Yes, excellent.
PARTICIPANT: And just finally accept that it’s going to be iterative throughout the whole process.
DOYLE: Yes … can we keep going? CORK: Actually, we’ve got a lot to get through, and I want to keep as much on-track as we can. I hate cutting off discussion, but let’s take a short break and then we’ll start up again at 10:40.
[A short break was held.]
SOFTWARE ENGINEERING—THE WAY TO BE
Jesse Poore
CORK: This morning, we had an overview of current practices as laid out by the Census Bureau. We’re now going to turn toward the computer science perspective, and introduce Jesse Poore, who is a professor of computer science at the University of Tennessee.
POORE: You’re probably wondering what a person like me is doing at a place, a meeting like this. I don’t know the answer either, but I have some data. I was giving a speech at a defense workshop a few months ago and described myself as a drab and humorless person. And immediately after that Mike Cohen ran up and invited me to speak here! [laughter] So, I don’t know if there’s a connection or not.
I want to say just a few words about what I understand your mission to be, and a few words about what I understand your situation to be with respect to software. I’m here to talk about software. I want to remind you about Moore’s Law, which addresses the change in technology. And then I’ll talk about software engineering, which is the primary reason I’m here.
I know that what you do is extremely important. You are responsible, probably, for the data that’s behind [Alan] Greenspan’s most exciting speeches. And I know we have redistricting every ten years which is
really exciting. And there are housing starts. I built a house once, and I always wonder when I hear about the housing starts if they’re going to finish any of them. [laughter] The punch list is always pretty long.
Seriously, I know you’re supporting a lot of public policy decisions in all branches of government, and the Bureau of Labor Statistics, the Bureau of the Census, and others have a very distinguished history. And in fact they can be credited with a lot of the early progress in computing and data processing. But the question is really: what about the future? And when I think about the future of the business you’re in, it seems to me that the public interest groups, the news groups, the special interest groups are really encroaching on your turf. I think they’re moving in on you. And I was thinking about how can you win in this business, and I think the way to win is to be first with the right information. The other guys don’t have to have the right information; they just have to be first. But you have to be first with the right information. And you have to have trust associated with your data.
So I look at the problem as how do you move fast—how do you move really fast, so that the decision-makers will turn to you for information instead of turning to the person who’s handiest? And how are you first with the right information, that’s statistically correct, secure, and trusted?
So I don’t think of your job so much as the design of surveys and all the problems associated with survey design, as we were just talking about. I look at it more from the point of view of the business you’re in: who your competitors or threats might be and what you have to do to win. And the role that software might play in that.
I spent some time looking at your software situation—not a lot of time, less than a day.14 And my conclusion is that there’s nothing unique there or overly complex; I just don’t see any hard software problems. Now, I’m beginning to think based on the earlier discussion that there’s some merging of software issues with survey issues. And so maybe what I’m looking at is just the software problem, and really it’s the problem of the survey designs being munged together with some of the software problems. So, to the extent that that’s the case, just keep in mind as I’m talking that I’m thinking mostly of the software problem, and you might want to put the survey design problem on a separate plane. And it might be very similar; it might be an analogous problem. But it would be important to keep the two separated.
But, even though I don’t see anything unique or overly complex, it’s complex enough—it’s not an easy, casual problem. So you have to take
a very structured approach to the software engineering, and I think you have to pay special attention to the role of the technology in what you’re doing.
Moore’s Law says that basically you get a doubling in the bang-for-the-buck every 18 months.15 And it seems to me that this is extremely important for you, that you have to operate from the point of view that you’re going to be using very modern technology all the time. And I’ve heard DOS mentioned once here today, and I’ve heard other things mentioned that seem to be throwbacks to an earlier data processing era. And I think you have to be more modern; you have to be very modern all the time.
One thing that Moore’s Law doesn’t really cover directly—but is implied from it—is the fact that you get new dimensions in this technology. The fact that things get faster-faster-faster, cheaper-cheaper-cheaper, smaller-smaller-smaller means that you can get new technology that you didn’t get before. Things that you can carry in a laptop that once would have filled a room—the wireless technologies and all of the multimedia. Like I said, I think that the news groups and special interest groups are in some sense your competitors. And they’re out there using the media in various ways—wireless, broadcast, and so on—probably even having their samples drawn before they know what the survey will be.
So I think you take into account all of these technologies that might be available to you. And in order to reap the benefit of Moore’s Law, you have to stay in the mainstream of software. This is easier said than done, but if you end up in some backwater and new hardware comes along, new software comes along, new operating systems, new applications, and you can’t get out of the hole you’re in, that’s an especially hard problem.
There are two sides to this. Unfortunately, it isn’t always the case that the first technology to the market becomes the standard. Sometimes it’s the second one, or the third one. So you’ve got to be very modern, but you don’t necessarily want to be the first to jump—you want to be the second to jump. Just hold back a respectable distance there, but stay very, very, very modern.
Now, one idea I want you to think about is product line architecture. This [slide] is not an architecture for your product line [SeeFigure II-2]; this is a picture to let me talk about product line architectures, because I don’t know enough about your business to even pretend to give you

Figure II-2 General structure of a product line architecture.
SOURCE: Workshop presentation by Jesse Poore.
an architecture either for your software or for your survey development. But the concept is this. Product line architectures exist for companies like Hewlett-Packard, which makes laser printers. And they roll out new laser printers every 12, 18 months, something like that—each one of them is a variation on a theme. Each one contains some new content, but a lot of existing content. Nokia makes telephones—they roll out one telephone after the other. Each telephone has something new about it, but contains a lot of old content. And so you might think of your own software systems or your own surveys as being part of a product line, where each one that comes out is a variation on the theme—it’s got something new, but hopefully it’s about 80 percent old, familiar, working stuff.
So the concept of the product line architecture is to separate various concerns. In your case, I was thinking security might be one of them. You would want to separate out all aspects of security from every laptop you’re using, from every desktop machine in your organization—all the way through your big data centers that process a lot of information. You would like to have security cut across all of that, so that when you change security in one piece you can update it throughout the systems. Mean-while, you want data movement to be totally separate from the security issue, but likewise data movement should be a matter that’s comprehensive across all the platforms, all the laptops right on into the data center. The statistical analysis core of your systems shouldn’t in any way be intertwined with your data movement utilities. When I hear comments like, “When I make a change over here it breaks something over there,” it makes me think that you don’t have an architecture in place, and that
there’s not a sufficient isolation—separation—of concerns in the design.
So the concept is to have this overarching architecture that helps you to separate concerns and make everything that you do more modular and more easily dealt with a piece at a time. You don’t ever want to have to change your whole scheme; you only want to change a piece at a time.
The other thing is to consider an incremental development strategy where—with this architecture—you would have some multi-year series of increments. You’ve got to be planning and anticipating the technology— you may be wrong but you should always have a working hypothesis of where it is and where it’s going. And you update that all of the time. So you have a rationale for this series of increments—what you’re going to change, when you’re going to change it, and why you’re going to change it. You should constantly reinforce this architecture or—if you find that the architecture isn’t supporting something you need—you should change the architecture. You want to work in the smallest natural increments; you want to get away from taking on these huge challenges. I once was working with Ericsson—I do a lot of work with companies, so even though I’m the pointy-headed academic, most of what I’m saying is in use in a lot of companies. Someone in Ericsson was planning a project that was being pitched to a vice-president in Montreal, and they came up with something like one-half million staff hours, a half million labor hours for the project. And the guy says, “We’ve never had—in the history of Ericsson—a project that was bigger than about 200,000 staff hours that ever succeeded. So, no, I don’t approve of this project.” [laughter]
Even that’s pretty big; everything’s relative. In my research group, my small laboratory group, we look at everything in terms of three or four people working on something for three or four months, and we want an end result. We want to be in and out with a finished product in a short amount of time, relatively small number of people. I think that’s extremely important, and my idea of a small increment—the smallest natural increment—is probably a lot smaller than you would think about. Everything has to be properly staffed and scheduled, and you want to meet these schedules and budgets with quality.
The idea of incremental development is that you don’t take on a project—a big project—that’s going to be, you know, 20 percent complete, then 40 percent complete, then 60 percent complete, then 80 percent complete, and 80 percent complete, and 80 percent complete. [laughter] You don’t want to do that. You want to have a piece of the job where you can say, “This 20 percent of the job is 100 percent complete; it works, I can demonstrate it to the end user, to the customer. It may not do much, but it’s 100 percent complete.” And then you do the next piece, and you add on to that. And, of course, planning the increments
is critical because you want to do the most important things first. And then your 40 percent of the project is 100 percent complete. Absolutely done, in every respect—documented, tested, ready to ship, if it’s worth shipping. And then you move on through until finally you ship the final product. This creates a much better work environment than taking on the whole big project and farming out the pieces, and then trying to get them to come together in an “integration crunch,” as it’s called. If you do incremental development, every cycle—every increment—is really an integration test, an integration of the product up to that stage. It works very, very well.
You want to create an environment of success. There are too many data processing organizations that are just living year after year in failure. They never do anything on time, on schedule, with the quality. It’s just failure, a constant life of failure. That’s no fun. So it’s much, much better to create an environment of success. And to do that you want to have all your standards, conventions, and styles documented, carefully selected, carefully reasoned. I’m not advocating any particular standards, conventions, or styles—I’m just saying you should have them. And that they should be well documented, well followed.
There [are] lots and lots of basic tools out there to support standards, everything from project planning to configuration management and so on. I also advocate that you work in teams with peer review, so that no work product no matter what it is—specification, code, test plan, anything—every work product is only done when three smart people think it’s right. So that everything is visible, all the plans are visible, all assignments, all the progress, all the problems are visible—they’re out there, and everyone’s talking about it. Which means that you manage to what I call “inch pebbles” rather than milestones. The milestones are great, but I want to know what’s going to get done today—what’s going to get done this week. Don’t tell me about three months from now—I want to know about this week, maybe today, maybe tomorrow, what’s going to get done.
You want to avoid this game software developers play, called “schedule chicken.” [laughter] The way “schedule chicken” works is that you have, say, two groups in an organization—they’re both behind. But each one of them thinks, “I’m better off than the other guy.” And each one of them thinks, “The other guy is going to feel the pressure first. That guy will break. I’m tough, and I’m going to manage it through.” So they both keep lying about their progress, at every review, at every meeting— hoping the other guy will break because I know if the other guy breaks and gets some more time in his schedule, then I’ll announce that, “Hey, since there’s a little more time I can do a little extra here and catch up.” And that’s the way you wind up with these projects that are 80 percent
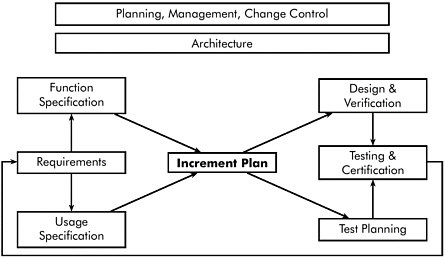
Figure II-3 Schematic model of a successful software environment.
SOURCE: Workshop presentation by Jesse Poore.
done, 80 percent done, 80 percent done, is with “schedule chicken.” So we don’t want to allow that. So the inch pebbles will help solve that problem.
So the picture might look something like this. [SeeFigure II-3.] Planning, management, change control—all of that is ever-present throughout the project. It requires eternal vigilance. It should never go away, it should never become slack—it’s always there, and you talk about it every day. The architecture is something that should be fairly stable. Again, it’s always present—it might change, but it’s changing less rapidly than other things. Then you go into the development activities where you have your requirements. And I like to think of the requirements in two ways—work with them first as a functional specification, and then also work with them as a usage specification. So you’re talking about not only what’s going to be there and what it’s going to do: you talk about how it’s going to be used. And how the thing’s going to be used should always be right up front and ever-present. I looked at a new system that was going into the Water Management District of Southern California, which could also be called the Los Angeles Water Company. And they were putting in a big new system to replace this mainframe with slave terminals attached to it—a pretty efficient scheme. So they asked me to take a look at it and see whether it was going to come up on schedule, work on time. The first thing I said was, “Well, let’s see this person who
works at this counter log in and use the system.” It took 27 steps to log in. And I said I didn’t think it would work. [laughter] If every worker in the whole water company has to go through 27 steps just to log in, when the old system had three, then someone hasn’t been paying very much attention to the usage requirements.
Well, anyway, you look at the functional activity, the usage activity; think about the increment plan, the smallest natural increments. Then you branch and go into design and verification of the code on one hand, test planning on the other hand. When the code’s done, the test planning’s ready, you put them together and do the testing and certification. And these little layers are to indicate multiple increments, and you cycle back—reconsider the requirements and see if everything is still the way it’s supposed to be. If it is, go forward; if it’s not, you make the changes and you go through the next increment. So you operate in that sort of software development cycle within the framework of the architecture, in the context of the architecture and the ongoing management, planning, and change control.
I guess I don’t mean the same thing by “documentation” as was discussed earlier—maybe, maybe not—but I do have that attitude that if documentation is important at all, then do it first. If it’s not important, then don’t do it at all, I guess is the answer. But here I’m talking about documentation in terms of software development, software engineering. And so we want to maintain written requirements. You want to convert those requirements to precise specifications—that’s probably the most important work in the entire activity of software development, getting those loose English statements in various memos, documents, sometimes a booklet if you’re lucky, but those statements of what’s presumed to be wanted—convert it into precise specifications. Something that’s tight enough that programmers can do their job without having to invent or to make up information about what was wanted. The programmers should not have to make any decisions about what the end user wanted. And so you try to get those into the specifications first.
In doing the process of doing that, you will invariably find conflicting information; you’ll find missing information. Things are inconsistent and you have to make decisions. You tag and trace all those decisions so that later on when you find that a statistical algorithm was changed, it was changed because a statistician told you to change it—not because, say, a field interviewer told you to change it.
Prepare the user guides while you’re writing the specs; prepare the test plans while you’re writing the specs. The hope is that you will not design an untestable system. There’s no reason to design untestable systems. You’d like to always know how you’re going to test the system, that you’re going to be able to test it in a satisfactory way given the time
and money available. Then you produce these complete, consistent, and traceably-correct specifications—that’s what I mean by documentation. All of that is documented from the top down, and then the programmers can take over and write some really good code. Yes?
BANKS: In the software world, when you try to lay out your requirements, it’s pretty well understood that you want the software to do particular things.
POORE: Sometimes.
BANKS: Well, OK. But my sense is that we have a less clear understanding of what specific legislative decisions, or judicial decisions, or executive decisions may be driven by the results of the survey.
POORE: That may well be, but I would have to ask: how big a factor is that? Is that 50 percent of everything that’s going on, or is it 1 percent? And, if it’s 1 percent of the trouble, I’m willing to let you have 1 percent of the slack for that. But I won’t give you 50 percent of the slack if it’s 1 percent of the problem, right? So those things happen.
I’ve been trying to think of an application that I’ve done that’s similar to survey data—just looking at my own experience for things—and I can’t come up with anything that’s right on. But the closest I’ve come up with is this: the Oak Ridge National Laboratory tracks a lot of toxic, hazardous waste material, everything from five-gallon buckets, to drums and barrels. Some of it is liquid, some powder, and so on. Every container of it has to be tracked—it’s put on tracks, it’s put in storage, it’s put on railcars, it’s moved here, it’s moved there. And the whole idea is that none of it ends up in a public school cafeteria. [laughter]Sothatwould be bad. So they had these survey forms; they had these laptops. They go to the people who are containerizing it at the source and putting it on shipments. They’ll go interview people who are receiving stuff and see what they received. And they’ll cross-check what was shipped with what was received. They’ll ask the truck driver who did so-and-so, you know, “You went here … No, you didn’t go up and dump anything in that lake?” It’s just all these different sources asking question after question after question, and cross-checking and correlating everything to look out for a problem. When I first looked at this, I did some estimates of how many paths there would be. And I said that it’s untestable—you don’t have enough time or money to test it. And they said, “Fine, so what do we do about it?” And I said, “Well, you reduce options. You cut out gratuitous complexity. You get rid of questions that really don’t matter, and you narrow the thing down to the things that are absolutely important, and you control everything. And so we were able to get a system that was testable, to test it and get it into use.
I was talking with Daryl [Pregibon] earlier about the statistical analysis that follows from some of these activities, and I don’t understand
how the analysis at the other end can make use of a lot of the detail that it sounds like is going into these questions. But I’m way off track.
Anyway, you don’t have 100 percent control. But you control absolutely everything you can control, and isolate that other part—it makes a big difference.
Well, you’re going to hear a lot about model-based testing, so I won’t talk too much about that. I do think it’s important. Well, your quality goals and requirements are going to be part of the architecture. There are ways to meet those quality goals, and I think that model-based testing is a good approach. With the kind of complexity I’m hearing about here, I’m convinced that you will have to automate that. If you don’t automate your testing, it’s unlikely that you will do enough testing of sufficient variety in a short enough time at a low enough cost to satisfy you. So you should look into automated testing.
I would say you develop the code last—the coding is the easiest part, particularly when you have good specifications. Coding is very, very important because you want it to be done right, you want it to be as simple as possible, clear, transparent, easy-to-read, no tricks, and to exactly what the specification says it should do and nothing more. And the way we like to work is that when code is written we verify it with the specs and all the standards and all the interfaces; that’s a labor-intensive process that involves at least three people. We check every line of code in detail against, again, all the standards and all the specs. It turns out to be very economical in the long run because it eliminates so much re-work that you more than pay for it.
Now, it sounds like you’re doing a similar thing with the survey development, and I think that’s probably the right thing to do. I think you’ll do more good with peer review of your surveys than you will in testing your surveys, particularly if you develop some nice modular structure for putting them together.
When you were talking about all the paths through your surveys, I was thinking, “Well, there are paths through code.” And, sure, there’s an infinite number of paths. But you don’t deal with that. When you’re dealing with code you deal with a finite set of structures—a finite set of units—and you argue with respect to the finite set of units and not the infinite set of paths. And a similar thing should be possible with surveys, I would think.
I was asked to talk about testing, more so than other aspects. And I will continue to talk about that some. However, my view is that you’ve got a testing problem secondary to having a specification problem. So my view is that you should really focus on your requirements and specifications first, and that your testing problem will get a lot easier, a lot better.
We build models for software testing, and when we build these models we perform what we call the “crafted” tests first. Those are the ones required by contract or law or industry standards—things that you specifically want to test. We record all the information from the tests when we’re running the tests; we monitor the progress, monitor stopping criteria. The people I work with are generally testing in order to establish or assert a certain reliability to the code, so they’re monitoring the progress and stopping conditions to see when they’ve collected enough empirical data to make those sorts of claims. If the progress is good, we keep going; if the progress is bad, we can see that the code isn’t going to pass and you return it to development. If you’re meeting your goals, you can move forward. Yes?
PARTICIPANT: Is it typical for the testing group to be independent, i.e., be independent of the group that’s writing the specification or authoring the instrument or doing the programming, so that they have their own workload? Rather than adding that onto the responsibility that they already have and having specification writers coming back after it’s been authored and doing re-testing? Is it typical for a testing group to have that separate focus?
POORE: Well, you can find most any organization imaginable, so there [are] lots of different ways of doing things. I would say the more mature organizations tend to have a separate testing and quality control group from the development group. The people I work with tend to get those groups together at the early stages to talk about the product and what they’re developing and how they’re developing it. And then the coders—the programmers—go off with the specification in one direction, the testers go off with the specification in the other direction, and they work independently until the two come together.
But I certainly know of organizations that just aren’t big enough to do that, so the developers also do the testing. And in those cases we try to build some independence, state the criteria up front as to how the product will be tested and hold to that statement.
After the products are released, I would recommend that you track all field-reported failures and understand why those failures happened, look at all the factors of production. I mean, when you do [this] kind of work, you’re doing it in an environment where the failures are relatively few. If you’re working in an environment where you’re just overwhelmed with failures it doesn’t make sense to do a lot of these things. You do a root-cause analysis on each and every problem and find that it’s the same thing—that people didn’t know what they were working on, or didn’t understand the programming language they were writing in. And you should find that maybe once—not a dozen times or a thousand times. And when you track field-reported errors in an environment of

Figure II-4 Conjectured multipliers on cost of correcting errors at different phases of a software design project.
SOURCE: Workshop presentation by Jesse Poore.
success—in an organization that is typically doing good work, meeting schedules, budgets, and quality—then you’re doing this from the standpoint of finding out what needs to be revised about the architecture or the planning or your process or your technology or the staff, in order to do better and not to repeat those kinds of problems.
The data look sort of like this. [SeeFigure II-4.] You may not be able to read that, but number one back there is requirements analysis, number two is preliminary design. One of the groups I work with a lot—Raytheon—uses this terminology: requirements analysis, preliminary design, detailed design, code and test, and so on. And their data is not exactly a doubling; it’s close. In some of the phases it’s a doubling, in some others it’s just a little bit below that, as to what it costs to correct an error. If you find and correct an error in requirements analysis, then it is unit cost. If that error escapes from requirements analysis and doesn’t get caught until preliminary design, then it’ll cost you twice as much. If you don’t even catch it there and it escapes all the way to detail design, you’re now four times as much as it would have been before. And if you look at some mature products in good organizations … fixing field-reported errors can be about 32 times the cost of fixing an error at the outset. So fixing an error might cost ten or twelve thousand dollars. And they’re getting two or three hundred a month. And that’s steady-state. Do a little bit of multiplication there, and you come up with some big numbers. That’s the cost of field-reported errors. And so you can see the motivation is very strong to prevent those. Yes, sir?
PARTICIPANT: I love your slide, I love your point. My experience has been that the steepness of the curve is much stronger than that, and that the cost of an error in the field is much more than 32 times.
POORE: Right. I’m emphasizing again that we’re talking about what you might call CMM Level 4 organizations, who have methods in place for doing all of these things.16 If you’re less mature as an organization, then I guess it would be much more costly.
At any rate, my point is that a lot can be denied in the software development world; the one thing that can not be denied is a field-reported failure. You just can not sidestep that. So, even though everything we know from theoretical considerations and experience and so on says build the quality in early, do the right thing at the very first stage—there’s no way to get a handle on that within a software development organization. It’s very difficult to jump into the middle of detailed design and say, “You guys are not doing a good enough job, and you’re going to mess things up at the next phase.” That’s hard to do. That’s why we’re always finding ourselves starting at the bottom of the food chain; you can not deny the field-reported error, or its cost, and you start moving upstream. And you say, well, we can’t blame all this on integration and test. You can’t say that they should have caught it. That’s just an oversimplification. Maybe they should have caught something; you fix whatever they should have caught. But then the next problem is what to do with the things that they had no way of catching, they should not have caught, that [are] unreasonable for them to catch. Well, “they should have been caught earlier.” And so it goes—it’s sort of like a little proof-by-induction or something, as you go all the way back to the base. And the extent [to which] you get it right in requirements analysis and preliminary design will determine everything about your success in terms of schedule and budget from there on out. Yes?
DOYLE: What do you do if you’re in a circumstance where you need to get to started but you really don’t have the scope laid out to the point where you can do a complete requirements analysis?
POORE: Well, I don’t accept those terms. [laughter] I don’t accept thoseterms. Whydoyouhavetogetstarted? Whatisitthatyou’re getting started to do? I mean, how are you getting motivated to get started if you don’t know what the job is yet?
DOYLE: Well, what if you know one-third of the job, pieces here and there?
POORE: Ah, OK—then you have to have this architecture that will let you do productive work on what you know is available to do, and stop there, so that you won’t do more work than you can keep. You
don’t want to do work that you throw away; you don’t want to do rework.
DOYLE: But what if the parts that we know don’t follow good, sensible, modular design at all?
POORE: Then the chances of you doing any productive work on it that you get to keep are nil. So work on something you do know. You can’t have it both ways, is my point [laughter]. You either have to have an …
DOYLE: Our situation is that you can’t wait because you’d run out of time, waiting for every “i” to be dotted and “t” to be crossed.
POORE: But I’d say you just can’t have it both ways. You either have to have a structure, an architecture, an environment where you can do work and not lose it, or there’s no point in doing it. If it’s going to result in re-work, if it’s going to be thrown away, then … Let me give you the best example. I never succeed in convincing people of this until after they’ve tried it; can’t win it on argument. Unit testing—it’s a big waste. Because by definition when you do unit testing and then you try to integrate and things don’t work, you have to go back and make changes. And when you make those changes you’re undoing a lot of the unit testing that you were doing. So that’s an activity that’s very, very common in software development, awfully hard to change. But when you get any organization to get onto an incremental development instead of a unit separate, unit test, and integrate—they’ll never go back to it, and they’ll cut out that wasteful step. But it’s a hard argument to make.
TUCKER: From your earlier description about dividing into small increments, you put a heavy emphasis on project management.
POORE: Yes.
TUCKER: And I think we have a real problem in trying to have enough of that talent to do the instrument. What you’re talking about is day-to-day, week-to-week intensive …
POORE: Well, there’s a little bit more to it than that. The management is important, but incremental development forces a different ordering of events.
For example, I worked with the IBM Storage Systems Division in Tucson. They make tape drives, disk drives, disk storage units, and things like that. The first time we did incremental development there— incremental development says that you’ve always got to have something useable, deliverable to the customer, from the user point of view. And so that would mean that the first thing you’d have to do is the power-on reset. You know, turn the tape drive on and turn it off. And they said that we always do that last—there’s nothing interesting or hard about that, so we do that last. So I said, “Well, we can’t do our increment test
unless you can turn the thing on and off.” So, OK, they were going to try the method our way, and they said we’ll do it. They normally would have done it last, and they did it first. So the first increment, you could turn the tape drive on, it would go through its internal test, come up ready to work, and you turn it off, and that’s all it would do. But if anyone wanted that tape drive we could ship it; it would work.
PARTICIPANT: I don’t want it!
POORE: Oh, you’ve got one of those! [laughter] The next increment we put in the fundamental commands to move the tape forward and backward. Turn it on, move the tape, turn it off— that’s what it would do. The next increment we put in the basic read-and-write commands, and we could read and write data. At that point, the thing was actually useable. The next level, we implemented more of the SCSI protocol for that tape drive, and at that point it was useable and could have been shipped. And in the final increment we put in the final bells and whistles of the SCSI protocol, which are probably rarely if ever used. So that at any point along the line you could quit.
So for your survey instruments, I would like to think that each one is a variation on a previous theme, that you could find one out there that’s very similar to the one you’re doing. OK, you say no. Now, let me ask you this: is the question you’re answering—is the purpose you’re serving—is the reason for doing this survey in any way related to any other job you’ve been given before? I mean, is it similar?
DOYLE: Well, we often have a data series where we do some repetitions. And so in that case we have some similarities. But we have a lot of one-time surveys that are unique for a particular compilation.
POORE: But aren’t the one-time surveys, in some way, similar to each other?
DOYLE: They’re always very unique in the questions that they pose.
POORE: But … I keep wanting to find a framework, to say that you could adopt this framework and go in and work with the details.
ONETO: Well, I think that in the survey world we really did embark on an incremental development strategy …
DOYLE: Oh, yeah …
ONETO: … ten years ago, but we just didn’t know it. And the increments have been expensive, because the increments are each time we’ve fielded a survey. And I think that there has been a building of knowledge and a building of expertise. And, according to what you’ve presented here, I think most of our maturity perhaps has been at the requirements and specifications development stage.
Prior to automation our biggest time constraint was getting OMB’s clearance at the time we were getting ready to go into the field. But now















