
Appendix A
A Freight Data Business Plan
Rick Donnelly, PBConsult, Inc.1
The goal of a national freight data program is to make the freight transportation system as efficient, safe, and secure as possible through informed planning and investment decisions. These goals cannot be reached without information about the magnitude and economic importance of freight flows at the national, regional, and urban levels. However, this information is not readily available. In this appendix, a national freight data program that will meet the needs of transportation planners and decision makers at the local, state, and federal levels is outlined.
PROBLEM
The safe and efficient movement of freight has become a significant transportation policy issue. The contribution of freight to a regional
economy and the role it plays in the nation’s economic competitiveness have become important topics at all levels of government. Productivity gains realized by industries over the last 15 years are in part a result of improvements in transportation infrastructure, deregulation, technology, and business process improvements such as supply chain logistics. Improving the efficiency of freight movements will be necessary to permit further increases in productivity.
Congestion in urban areas is now seen as an impediment to economic competitiveness. For this reason, analysts are increasingly called upon to document the economic contribution of freight and the costs and benefits associated with public–private partnerships and infrastructure investment. However, the factors, agents, and dynamics associated with freight movements are complex and often affected by labor, pricing, and regulatory mechanisms. For example, although most of the nation’s freight transportation assets are privately held, freight often moves upon or through publicly provided infrastructure.
Most communities lack information on freight flows or an appreciation of the impact of freight movement on their local economy and transportation system. The regional nature of freight flows and the connections of these flows between metropolitan areas are often not understood. Data from the national level cannot inform local policy making, both because of the data’s focus on the state level and lack of integration across various modal and industry sources. Thus, transportation planners currently lack the information necessary to inform decision making, with the result that the utilization of funds and resources is often inefficient and uncoordinated.
POTENTIAL CLIENT BASE
For the purposes of this business plan for a national freight data program, the primary clients are public-sector transportation planners and policy makers at the local, state, and federal levels. These clients include planners seeking to understand and forecast freight flows and their economic significance, as well as officials concerned with state and federal taxation, regulation, and monitoring. The data must also be useful to policy researchers in universities. Other clients include the private sector, which has many of the same information needs as government and would be well
served by data programs that enable companies to identify underserved or emerging markets and clientele. The needs of this sector should be taken into account in the design of a freight data program. Information that helps private enterprise make more profitable investments would contribute to making the entire transportation system more efficient and competitive. In the longer term, such a national freight data program would foster better joint decision making and public–private financing.
ASSESSMENT OF THE COMPETITION
There are several sources of freight transportation data in the public and private arenas. Most of them focus on intercity and international movements by rail and marine modes of transport, although they vary widely in purpose, scope, extent, and level of detail. Public-sector sources include the Commodity Flow Survey (CFS), the Vehicle Inventory and Use Survey (VIUS), rail waybill statistics, foreign trade data, and traffic monitoring data. Private-sector sources include the Port Import Export Reporting Service (PIERS) from the Journal of Commerce and the Transearch data from Reebie Associates. These sources are adequate to meet the needs for which their data are collected, but users face difficulties in combining and comparing data from the different sources because of incompatible metrics and definitions.
Only two sources of data on domestic freight transportation—the public CFS and the private Transearch database—attempt to depict a picture of freight movements by all modes of transportation at the national and state levels. Both have the potential to illuminate trucking, intermodal, and container flows. Therefore, to be considered viable, alternatives to these sources should add significant value to what CFS and Transearch already provide.
The CFS is conducted as part of the Economic Census. It is jointly funded by the Census Bureau of the U.S. Department of Commerce and the Bureau of Transportation Statistics (BTS) of the U.S. Department of Transportation (USDOT). In its current form, the CFS was conducted in 1993 and 1997. The 2002 survey is in the field, and results are expected to become available in 2004. The CFS surveys shippers from selected mining, manufacturing, and wholesale firms. As such, it can
capture only a part of total freight movements. Moreover, available evidence suggests that it significantly underreports international trade movements.
The high cost of the CFS, coupled with a sense of dissatisfaction among users with several of its aspects, has prompted BTS to examine alternatives. In November 2000, the bureau sponsored a Freight Data Round Table in Washington, D.C., to solicit input on the program’s future. The CFS was widely viewed as very important to the participants, who represented a broad spectrum of users. They reported that the data were essential for a number of transportation planning, regulatory, and research activities at the local, state, and federal levels. However, dissatisfaction with several aspects of the CFS emerged. The timeliness of the data’s availability, the geographic scale of reporting, and the imperfect coverage of the shipper industry were cited as key limitations of the data. Many of these same issues were raised a year later in Saratoga Springs, New York, at the conference “Data Needs in the Changing World of Logistics and Freight Transportation.”2 Participants in both meetings underscored the importance of consistent and comprehensive freight data. These information needs and the growing dissatisfaction with the content and coverage of CFS data have prompted BTS to reconsider how freight data are collected, summarized, and disseminated to its customers.
The Transearch database is maintained and distributed by Reebie Associates. Data are available for purchase at many different levels of modal, geographic, and commodity detail. Historically, these data have been available only at the state level, probably owing to their basis in the CFS and other public sources. Data at the county level have become available more recently. The limitation of these data has more to do with what is not known about them. The vendor fuses public data sources and augments them with information it collects from carriers and shippers. However, little more is known about how the database is constructed. The Transearch data appear to offer little insight into container traffic and only limited information on intermodal movements. Despite these limitations, the product is widely used by transportation planners at all levels
|
2 |
Meyburg, A. H., and J. R. Mbwana (eds.). 2002. Conference Synthesis: Data Needs in the Changing World of Logistics and Freight Transportation. New York State Department of Transportation, Albany. www.dot.state.ny.us/ttss/conference/synthesis/pdf. |
of government. Reebie Associates is the market leader in providing such data to the public sector and presumably to the private sector as well. The Transearch data are the yardstick by which any alternative initiative should be measured.
THE INFORMATION GAP
At present, holistic data on freight flows at the local level are virtually nonexistent. State and metropolitan agencies rarely collect data on freight movements, and fewer still use forecasting or operational models to assess their area’s needs. Thus, there is a major unfilled need for data on freight movements by all modes of transportation in greater geographic detail than is provided by most national data sets. Such data would illuminate flows in urban areas as well as between them.
A further problem is the lack of comprehensive freight data covering all modes. In particular, the largest and fastest-growing segments of the transportation market by almost any measure—motor carrier flows, truck–rail combinations, and containerization—are not well covered by any existing efforts. Furthermore, all competing data sources are beset with incompatibilities, ranging from how commodities are classified to modal definitions to how the data are reported. The lack of integration of data frustrates users who are trying to combine data to summarize total freight demand by all modes. An obvious solution would be to work with the vendors to standardize definitions. However, preliminary contact with many vendors revealed that most seem content with the current structure of their products and are, at best, indifferent to the idea of harmonized modal, commodity, and flow metrics. A product capable of incorporating information from these third-party sources would be a significant advance that none of the products alone could match.
All available freight data are affected by a fundamental conflict between confidentiality and utility. Almost all users of the data are frustrated by the data’s coarse spatial resolution, which makes the data incapable of usefully informing analyses at the scale of most appraisals. However, the data’s level of abstraction is not arbitrary. Most data are provided by private firms with a legitimate business need to protect the confidentiality of their customers. Access is closed to the raw data that would otherwise provide public-sector planners with data at the scale
they seek. A product capable of resolving this conflict would have tremendous utility.
As a result of the deficiencies outlined above, decision makers in the public and private sectors lack important and relevant information on freight flows. Meeting the information needs of the entire spectrum of users is well beyond the capability of any single data provider. However, there are basic elements of information that are useful to almost all users and investors. These include the origin, destination, intermediate stops, weight, frequency, commodity classification, modes of transport and interconnectivity, and value of the shipment. Additional data that reveal differences between long- and short-haul shipments are important, as are data about routing. These data will usefully inform public-sector planning and policy making, while providing limited and potentially less useful information to the private sector.
PRODUCT DEFINITION
This plan for a national freight data program builds upon innovative ideas from both the BTS-sponsored Freight Data Round Table and the Saratoga Springs conference (see above). It outlines the program’s essential elements and adds several components that have not previously been considered. The magnitude of the freight data problem hinders attempts to create a single data source or program capable of addressing all needs. Indeed, there is a readily apparent need to create an architecture3 or high-level context within which to place a candidate freight data program. A high-level view of the proposed architecture for a national freight data program is shown in Figure A-1. An advisory committee will oversee the detailed design of a multifaceted survey program. The survey programs would be supplemented with data from other sources and data derived by synthetic techniques. The resulting databases would be made widely available to the user community, whose comments and feedback would help inform the evolution of all parts of the architecture.
The goal of such a freight data program will be to provide a timely, comprehensive, and consistent database of multimodal freight flows in
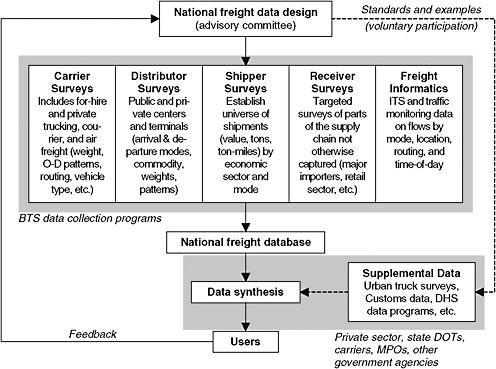
Figure A-1 Proposed architecture of a national freight data program. (BTS = Bureau of Transportation Statistics; O-D = origin–destination; DHS =Department of Homeland Security; MPO =metropolitan planning organization; state DOT = state department of transportation.)
North America. The data will include domestic as well as international flows. It must be capable of providing data at varying levels of geography. The program will be developed over time; the program design and quick implementation of carrier surveys will be undertaken first. The design of more complex components, such as establishment surveys, will be carried out in later years.
Several components of the system will be necessary for meeting these goals.
National Freight Data Architecture
An ideal data program will encompass several surveys and establish linkages to other databases. Careful design of an overall architecture that will
facilitate the access to and fusion, reporting, and maintenance of these data will be essential. The architecture will also specify future directions for the program. It is anticipated that the eventual program goal will be to depict the movement of goods through the entire supply chain, although the initial work may only capture many of the same segments of freight flow as do current surveys. An important part of the data architecture will be the description of supply chain linkages and the data required to understand them.
An Integrated Program of Freight Surveys
This program will replace the CFS and the survey’s singular emphasis on shipments from selected industries. It will attempt to capture a wider range of freight movements by expanding its sampling frame to include receivers as well as shippers and samples from all sectors of the economy. Moreover, it is recommended that this program be conducted continually. Despite the intuitive appeal of panel surveys, it is suggested that the freight surveys be structured as a rolling series of cross-sectional surveys rather than a time series of selected establishments. The resulting data will be summarized at the state and metropolitan area levels, as is currently done for the CFS. Other survey programs, such as the American Community Survey, have successfully transitioned to rolling sampling, and this experience could be useful in implementation of continuous surveying by a national freight data program.
An important departure from the current CFS will be the availability of microdata for planners and researchers with sensible but sufficient safeguards to protect the privacy of the parties involved in the surveyed transactions.
It is envisioned that the program will initially be capable of collecting a sample as large as that of the current CFS. This will probably be adequate for reporting the universe of freight movements in North America, but only at the state or regional level. The sampling frame necessary to capture comparable data at the county or subcounty level, even for a few states, would far exceed the resources likely to be made available for such a program. This major limitation will be overcome in two important ways, which are discussed next.
Freight Data Synthesis
It is impractical to design a survey program capable of meeting the needs of all transportation planners across the country. A synthetic process of generating these data—especially in the short term before all of the different but complementary surveys become fully operational— offers a tractable compromise. A variety of simulation techniques can be employed that provide flexibility to accommodate data needs on an individual case basis, permitting the use of all available local data as well as relevant third-party sources. A port city, for example, might place particular emphasis on intermodal accessibility and the clustering of transportation firms near it, as the cities of Portland and Los Angeles have recently done.
Data synthesis would provide the same type of information available from the different surveys but at the local or subregional level. Constraints can be imposed to match urban cordon counts, Highway Performance Monitoring System data, or just about any other source of information. A likely scenario would involve the use of economic input– output tables to help allocate flows by commodities to the appropriate producing and consuming industries in an urban area. Other information sources, such as the VIUS, might provide marginal distributions to help condition each simulation.
Synthetic data will also be capable of illuminating gaps in the coverage and content of the different freight surveys. This will allow adjustments in the survey instrument, methodology, and sampling frame. The ongoing nature of the national freight data program will allow these changes to be made quickly. For example, the data collection process in urban areas might be augmented with data on the local economy. Changes in the local economy would trigger adjustments in both survey methodology and synthesis.
Freight Informatics Initiative
Electronic data interchange and automated data collection methods have the potential to greatly reduce the cost and respondent burden associated with data collection. However, currently operational systems are tailored to individual firms and lack linkages to the type of information
typically used by planners, such as origin, destination, mode and intermodal connections, and commodity classification. Moreover, these systems are currently deployed more often by carriers, who may have only incomplete information on commodity classification or no knowledge of the shipment’s place in the overall supply chain.
The freight informatics initiative would examine the institutional and technical issues surrounding electronic data collection and its potential for use in freight data collection. It is envisioned that a prototype system will be designed and placed into limited field testing. Linkages with intelligent transportation system (ITS) efforts at USDOT and other agencies will permit the program to benefit from the considerable progress that has already been made in commercial vehicle operations and electronic data interchange initiatives.
Standard Survey Methodologies
The freight data programs suggested here and other federal initiatives will improve the quality of data and information available. However, they are unlikely to meet all the data needs of local users, particularly those states and urban areas that want to construct freight travel models or conduct detailed corridor or facility studies. Many of these agencies have little or no experience in designing and conducting freight surveys.
A standard survey practice would enable states and urban areas to expand the freight survey samples in their jurisdiction so they can gain additional local information to complement the national survey. A similar approach has been successfully adopted for the National Household Travel Survey. This task will involve the development of standard prototype survey instruments and methods for urban areas. The consistent data that can be harvested as a result will be useful at both the local and the national levels and will facilitate improvement of both the national freight database and data synthesis procedures.
Summary
The interactions among these parts of the national freight data program are shown in Figure A-1. The national freight data design defines the
Table A-1 Timing of Business Plan Implementation
|
Immediate Actions (this fiscal year) |
Short-Term Actions (1–4 years) |
Long-Term Actions (5 years and beyond) |
|
Development of the national freight data design Begin mining and publishing existing ITS data |
Refinement of the national freight data design Design and begin carrier survey program Design and begin distributor survey program Design and pilot test freight informatics Begin data synthesis |
Continued refinement of the national data design Continued refinement and conduct of carrier and establishment surveys Full implementation of freight informatics initiative Design and implement shipper and receiver surveys Refine and continue data synthesis |
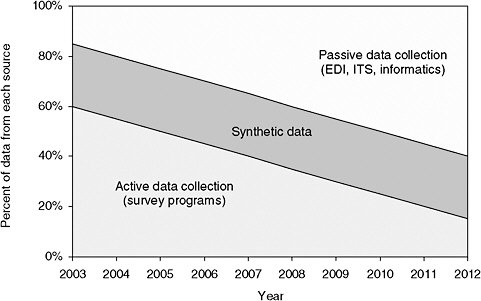
Figure A-2 Schematic representation of the roles of various data sources over time.
various components of the survey program, some of which may be developed sooner than others. A notional view of the timing of each part of the architecture is shown in Table A-1. The resulting database will evolve over time. For reasons of constraints on cost and knowledge, there will always be a role for data synthesis in the process. This will be especially true in the program’s early years, before enough survey data can be acquired to portray a statistically valid picture of freight movements, especially at the metropolitan level or between urban areas. This process is illustrated in Figure A-2. As electronic data collection and the mining of real-time transaction data become more commonplace, the importance of traditional surveys and data synthesis can be expected to diminish. The former will still be the most efficient means of gathering data in some instances, while the latter will always have a place in generating data that cannot be measured in society.
BTS can play an important role in a national freight data program. With its mission and resources, it has the capability of defining an agenda for freight data collection and dissemination and the means of implementing it.
BENEFITS
A national freight data program will provide better-quality and more complete information than is currently available through any existing data source. It will address needs that cannot be met through any combination of currently available freight transportation data, whether provided publicly or privately. The data synthesis element of the program will focus on providing the timely data needed to inform planning and investment decisions at urban and local levels. When analytical requirements dictate higher levels of accuracy and precision, these synthetic data will offer insights that can then be supplemented with locally collected data.












