
SUMMARY OF DISCUSSION
THE DISCUSSION of Area 6 opened with a presentation by the Chairman, Dr. John W.Tukey, of a consensus of panelists’ views concerning the papers, which was clarified and made more explicit in later discussion. The papers generally introduced mathematical structure, but this was used for linguistic description rather than as a basis for applying known theorems. Panel members saw considerable usefulness in putting matters in a formal language, even though there may have been nothing new said. (It was emphasized in discussion that, for example, the clarity of statement of Mooers’ paper, as illustrated by the separation of prescription and delineation spaces, was likely to be very valuable.)
Members of the panel emphasized that additional formal structures are likely to be required for any adequate theory. As mathematics should be shaped to the needs of the use to which it is put, no single mathematical technique available today, such as partial order or lattice theory, is likely of itself to carry us far in a field with such broad ramifications as that of information retrieval. After the problems of information retrieval has been carefully studied for a long time, there may be a mathematical technique appropriate to the field. But if so, it probably will not be one of the techniques known today. The panelists found the discussion of relationships among terms or descriptors good so far as it went, but pointed out that adequate accounts will have to treat more diverse and complex relations. (There was some discussion of the extent to which interfixes are analogous to, but somewhat more flexible than, Dr. Vickery’s interlocking relations.)
The paper in Area 2, by Lykoudis, Liley, and Touloukian, was cited as an example of a successful combination of formulation, mathematical development, and experimental verification on a modest scale.
Information retrieval potentially involves very large systems, and analogies with other large systems might be helpful. Mechanization and automation of such systems has not necessarily reduced the complexity of functional separations that existed in the manual system. Thus, it was pointed out that the U.S. telephone system has been called the largest computer in the world, yet mechanization has not eliminated local central offices, toll-tandem offices, and the like. Instead, the long-distance call of tomorrow, like that of today, might go through a half-dozen or more exchanges. Information retrieval today is a multistage process. One should not expect machines to change this.
Diagramming the Functions Occurring in Retrieval
Three diagrams were then introduced to illustrate the multistage process in information retrieval. First, a description of the conventional index-abstract-document search was used as an example of a three-stage system. The structure of an information token was displayed as consisting of three parts: the index, that by which the token can be selected; the brief, that which is a guide to whether the next most detailed token should be examined; and the outdex, that which guides the retrieval of the next more detailed token. Classical examples include a subject index to abstracts, where the subject heading serves as index, the author’s name and short title of the paper serve as brief, and the page or abstract number of identification serves as outdex.
The second diagram, reproduced here as Fig. 1, attempts to set out a pattern within which the first stage of a multistage information retrieval system, whether manual or mechanized, can be fitted. The querist appears both at the top and at the bottom. At the top he generates an initial vague query, probably phrased in common or vulgar language, and a query formalizer (whether librarian or future machine), then engages in an exchange with the querist in order to come up with a proper, formal query. The suggested formalization goes back to the querist in a language which he can understand—an external
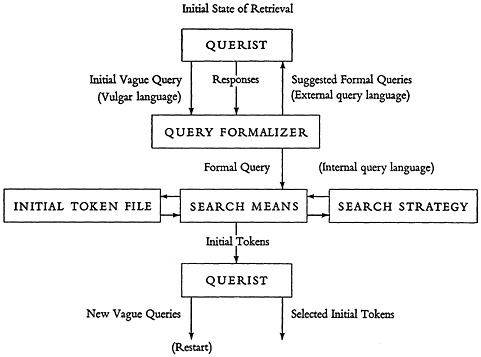
FIGURE 1.
query language. As an approved formal query goes forward into the next stage, however, it may be expressed in an internal query language, which is different both in structure and expression.
At the next level (Fig. 1) are shown a search means, a search strategy, and the file of initial information tokens. Selected initial tokens are referred to the querist who may pose new vague queries, or who may decide to examine indicated tokens of the next more detailed level, or both.
The third diagram provided for the generalized pattern of any later stage of retrieval, in which tokens of one stage are selected by the querist and are then used in a retrieval operation to select tokens of the next stage.
Discussion of this material led to apparent agreement: (1) that in this field, of information retrieval, theory is often still trying to describe library practice (Mooers); (2) that in presenting the graphical material the panelists were concerned with pedagogy and not with announcing brave new insights (Fairthorne, Tukey) but that explicit statement is useful (Touloukian); and (3) that the diagrams did not give enough attention to modification of both querist and search strategy during a search (Hayes, Mooers, Shaw).
Some Matters of Theory
The Chairman next raised the question of how general a retrieval theory ought to be this year and next. He suggested, first, that the broad structure in which a general theory should operate should encompass all present systems, whether manual or mechanized, as well as those that appear reasonably possible in the future. Secondly, the broad structure should try to establish clear functional parts where appropriate. Detailed theories of such functional parts should then be sought. Finally, it will be important to learn by experiment how, in functional terms, classical retrieval is carried out.
He suggested that another important analogy could be drawn between the telephone system and information retrieval, namely, that information theory has not taught us how to build telephone systems nor what restraints we must suffer in such building. It has only taught us how well we can use a transmission channel, which is an important functional part of a telephone system. Information and communication theory could tell us how to pack (code) information that is of an anticipated nature. Information theory therefore could be expected to apply to the expression, but not the structure, of the internal query-language; to the organization of the search means and the initial token file and of their intercommunication; and to the organization of retrieval means, of kth token files, and of their intercommunication; but not to information retrieval as a whole.
Application of information theory did not seem at all likely for more difficult problems such as the structure of the internal query language, the nature and mode of application of the search strategy, or the structure and expression of the external query language. It is therefore in such areas that the hardest and most creative thought is needed.
As a final point, Dr. Tukey stressed that any sound retrieval system must learn, must modify itself steadily. It must do this, not only during the course of a difficult search but over longer periods. To this end, it must be concerned, for example, with what is asked for together, with what users finally accept together, with what users state to be related, and with what new concepts of importance are arising. As the bulk and diversity of the information to be handled continue to increase, the learning ability of retrieval systems seems likely to become one of their most important features.
Discussion emphasized convergence on two points: that the engineering of the retrieval process itself, including the organization of the file, is both of vital importance and a major intellectual challenge (Taube, Hayes, Bar-Hillel); and that organization of the tokens before transmission to the querist is often crucial (Farradane, Hayes, Fairthorne).
PRESENTATION BY PANEL MEMBERS
Mr. Russell A.Kirsch began by relating two of the Area 6 papers to the second of the three fields—indexing, coding, and machines—into which Dr. Jonker had just proposed dividing the over-all field of storage and retrieval. The Mooers paper attempted to relate three apparently quite different systems for encoding indexed information to one common formal structure. The Fairthorne paper approached the problem in a different way. In coding indexed items, one of the things that significantly affected the list of mechanisms that can manipulate the information is the language in which the information is expressed. Mr. Fairthorne appeared to be concerned with the introduction of a formalism which would enable us to handle the different coding techniques that are used in a retrieval system. Mr. Kirsch remarked that, contrary to the remarks of Professor Oettinger in the Area 5 discussions, he felt that the introduction by Harris, of the mathematical structure of groups of transformations, in his paper on linguistic transformations, was appropriate and wise, as it opened up the possibility of putting much formal knowledge to work.
Mr. Kirsch remarked concerning the apparent relative neglect, both in the papers and in the discussions, of three problems of considerable importance and difficulty. First is the formidable problem of indexing—the problem of producing from documents some type of surrogates that can be used for subsequent manipulation. A second critical problem area is that of attempting to
handle natural language in a machine. Noting that there are only the two papers on this subject, one by Harris and one by Yngve, he suggested that the distribution of effort in this area is out of balance with the importance of the problem. The third problem is that of handling graphical configurations—printed characters, pictures, and diagrams.
Mr. Kirsch suggested that a principal basis for the difficulties encountered in handling parts of the retrieval problem is the tremendously diverse nature of the information. One of the reasons that we are looking for a theory is simply the matter of economy. If a theory can be developed, this would result in a considerable simplification of the problem. He called attention to the last sentence of Mr. Fairthorne’s paper in Area 6: “Systems founded on neat and economical theory are neat and economical in other ways.”
Dr. Marvin L.Minsky emphasized that a modern computer can perform tasks far beyond the scope suggested to us by the nature of the individual operations, the ability to be programmed to alter its own program. Dr. Minsky began by stressing the difference between what a machine can do and what a program can do, and stating that the only limit to the latter was the cleverness of the programmer. (Once the principles and general structure of a program are worked out, they can be implemented on any general purpose computer with access to sufficient memory.)
He went on to discuss some recent developments in heuristic programming, especially as applied to programs for playing chess and checkers, and for proving theorems. In such programs, the machine is instructed what to try first, and how to use results of the trials to modify further action. The programmer himself may not know what trials will work, nor how to find them explicitly. Dr. Minsky estimated that in a few years a large fraction of computer time would be spent in executing such programs.
The complexity of programs built up by the action of other programs, and the inability to tell in advance what details of a heuristic program would be executed in a specific application, make the development of a detailed theory of the behavior of such programs almost impossible. Indeed, nothing so complicated has ever been successfully treated in detail by mathematics. There must be a theory of building systems without a detailed theory. This will be particularly true for a retrieval system that is to grow in sophistication.
Dr. Minsky said that an art of constructing these dreadfully complicated programs is being developed so that they can be modified without understanding them over again. We are trying to gain an understanding, perhaps sometimes even a theory, of how systems can be built which are so stable, or so resilient, that they can be modified or improved without having to be redesigned or reanalyzed as wholes.
Potential applicability to the multistage retrieval process is obvious. The
programmer does not know in advance what path his program will take as it goes through a particular search. It is not known in advance whether the results of the search to a certain point may require beginning again with a modified search strategy. For example, a particular type of information token might be used, one which, if selected, would indicate not that a particular piece of information would be available for retrieval but rather that a poor search prescription had been used. It is possible to give advice to a “machine” that is able to accept such tokens. Thus, the possibility of designing really flexible systems is promised.
Dr. Minsky said that the best collection of papers on artificial intelligence and on programs to solve problems for which ways of solution were unknown would be the papers of the conference on Mechanization of Thought Processes, to be held at Teddington, England (November 25, 1958).
In later discussion, Dr. Minsky went on to say that the proper language to describe processes that involve so much returning and self-modification is not the language of classical mathematics but the language of programming. This is not the language of the 100 or so relatively trivial basic machine instructions, but rather the language embracing the far more profound operations used in automatic compilers and the like. This is a language that psychology, sociology, engineering, and retrieval have lacked. It has a further great advantage; in order to see what may happen in a complex process, one need only load the machine and press the start button.
Mr. Kirsch remarked that flow charts for a retrieval problem for the Patent Office were fantastically complicated, and that the ability to make systems without the need of detailed systems design seemed essential to him also.
Dr. Benoit Mandelbrot urged that the study of taxonomic trees, especially those developed in botany and zoology, is pertinent to the analysis of the information retrieval problem. He stressed that taxonomy is the original classification procedure where there are a large number of items having a large number of properties, only some of which are used for classificatory purposes. Taxonomy has been marked by the use of intermediate categories whereby individual species were not necessarily described directly but were grouped into families and genera that could be defined more systemically.
This fact suggested the possibility of experimentally determining how the procedures that have been followed by taxonomists would compare with the procedures which a classification specialist of today would follow if he were presented the same problem without a prior background of knowledge. Would different persons starting from different principles of classification in fact arrive at similar results?
An important reason for concern about classification is the very rapid
exponential increase both in the number of items and in the number of categories that must be dealt with in a classificatory operation. Exactly such an exponential increase is encountered in the models that biologists have proposed to explain the existing taxonomies. Under circumstances of such increase, preconceived ideas of an optimal basis for classification soon collapse into disordered systems, or into something quite different from the original criteria. For example, when taxonomies of families of animals or vegetables are examined, we find that some of the statistical properties are the same in all cases and that the schemes are very far from being optimum from the standpoint of even the least sophisticated coding theory. Yet these schemes have properties perhaps even more systematic than that of dividing each sub-set into two equally probable sub-sub-sets. Thus, investigation of the growth of existing taxonomies whose branches were split apparently randomly might lead to better understanding of methods adaptable to situations of continuing growth, than might investigation of classificatory procedures constructed by splitting into equal, and equiprobable, parts as might be suggested by communication theory.
Dr. W.J.Turanski discussed three functions of a theory: it should indicate its own scope, it should describe usefully, and it should help with engineering. Just as mathematics is what mathematicians, who are identified by an attitude and habit of mind, do, so information retrieval is the retrieval, as opposed to the resynthesis, of information. Storage of basic elements alone, rather than information, would not be information retrieval. Thus, the storage of axioms, rules of procedure, and heuristics, and producing a source of theorems, would not be information retrieval.
One of the dangers of various branches of mathematics is the power of their expressive vocabulary, which is so great as to be able to describe almost anything. Not all such descriptions are interesting. Finding good modes of description which present this essential feature of interest will be important for a theory of information retrieval. It will be important to recall “Fairthorne’s principle” as stated in his paper in Area 6, “…the properties of the way in which we talk about things can distort or obscure the properties of the things talked about.”
A theory can help solve engineering problems. These are problems of getting things done subject to such constraints as limitations of time, money, and equipment. In this connection the facts that the population of requests may often be segregated into subpopulations and that these subpopulations change with time are often important. The latter makes inflexibility serious; the former makes retrieval networks (where the basically straight-line path of Fig. 1 is replaced by interweaving alternatives) attractive.
The discussion at this point was diverse. Miss Margaret Masterman felt that it was important to go far further into the absolutely fundamental question of what it was like for mathematics to be applied to a theory of this sort, and how one may know that he is proceeding properly in making an application. Dr. Minsky replied to the effect that just because some of the panel members are mathematicians it was not their job to say that a theory of retrieval is identical with applying mathematical theories to retrieval. Dr. Gilbert W.King urged the importance of the “breeding” of ideas and their cross-indexing in a lattice. Dr. Don Swanson raised the question of the importance of consistency from human to human in the execution of a task, as a guide to its mechanizability. Dr. Minsky stated that, since human consistencies can be due to common error or superstition, and human inconsistencies can be due to differences in background, he felt that observable consistency is not a useful criterion for mechanizability.
FURTHER PANEL PRESENTATIONS
Dr. Yehoshua Bar-Hillel opened the discussion of organization by discussing concepts of “relatedness” and “degree of relevance” which needed to be carefully distinguished. Much of his discussion was formulated in terms of documents, queries, and index terms. The elementary approach of matching the set of terms for a document against the set of terms for a query runs into many difficulties. The introduction of interfixes and other relations was made necessary by some of these difficulties. The nature of other difficulties was such as to force any theory into probabilistic terms, thus greatly complicating its structure. He felt that the best that can be done with such techniques is probably a compromise, recomplicating a simple descriptor system in the direction of a subject-heading system.
He then went on to discuss notions of relatedness of the form “A is related to B if and only if A and B occur together in some C,” and those which derive from these when chains of such relatedness of some fixed length are considered as defining a weaker notion of relatedness. The notion of relatedness of documents when they have an index term in common, and the notion of relatedness of terms when they apply together to at least one document, belong to this class. They have been tried; a formal theory exists which can be directly applied; Dr. Bar-Hillel’s strong hunch was that this would not lead to any interesting results. Another notion is that of considering documents as related when requested together. If applied vigorously this would be most dangerous because it would canalize research. The notion of relatedness of indexes that appear in the same query also belongs to the same group.
The relatedness of topics and concepts is an infinitely more difficult problem than those just discussed. Dr. Bar-Hillel believed that any simple-minded approach to this problem is sure to fail. Merely going back to the indexes as such would fail. Although machines deal with terms, not with topics or concepts, the problem of relatedness of topics and concepts is basic to all these problems of relatedness.
Dr. Julian Bigelow commented on the need for explicit interpretations in describing models and the need for growing theory from the basis of a real knowledge of present-day practice. He felt that the six papers in this Area are excellent examples of model studies, and that more work along such lines would be a great contribution. In theoretical papers giving mathematical models it is most desirable to attach an appendix which gives as clear interpretations of the mathematical entities as possible. Thus he found the use of “spaces,” without an indication of whether or not ideas of “neighborhood” (and which, if any) were to be used, likely to lead to misapprehension. Neighborhoods in retrieval spaces were likely to be inhomogeneous and very peculiar.
He felt an enormous need for understanding what the empirical process is as people do it (and not as they say they do it). This would require detailed recording, in an impartial way, of many steps of communication during many inquiries. To continue adjustment of understanding and theory, such recording would need to continue through the stages of mechanization. In particular, persons entering the system should begin by describing themselves and their motivation as well as stating their formal query. He also felt that such description might be important for fully mechanized systems.
The understanding gained from full recording could serve several purposes. Near-future mechanized systems must work with people with today’s habits. Adequate schemes of relatedness need guidance and validation in terms of human practice. The most profitable and powerful way to develop theory-would be to build up slowly on an empirical foundation.
Dr. Donald M.MacKay felt that problems of meaning should not be avoided. Information theory had avoided them by presupposing an extent of statistical knowledge impractical in information retrieval. Meaning for retrieved information might be definable through the needs it meets, by its selective effects on the actions or states of readiness for action of the recipients. A classification scheme for needs or states of demand for the selective function of information then would be required. Such a scheme would allow Dr. Bigelow’s inquirers to describe themselves in effective terms.
He felt that the possible symmetry between the information and queries deserves further exploitation. Documents could be made active to scan need
lists, at the same time that need lists are scanning documents. Syndicating together blocks of related needs could serve efficiency, just as does syndicating together blocks of related documents. The degree to which departure is made from symmetry of activity, in one direction or the other, should depend on the statistics of the situation. Infrequently used documents should scan; frequently used documents should be scanned.
Dr. I.J.Good spoke about the problems of definition and the possibility of useful definitions of clumps. The description of required information is analogous to the definition of a word. John Wisdom (The London School of Economics and Political Science, University of London) has considered the definition of a cow, which typically has many properties, no one of which is essential to its cowness. Formulation of any definition in terms of a function of qualities or of probabilities of having qualities leads to dependence on such things as time and context, and these in turn depend on others. To produce accurate definitions is very difficult.
Dr. Good went on to consider networks connecting vertices, which might represent documents, or propositions, or described customers, each connected by paths characterized by two impedances, one in each direction. Each impedance could be taken to be the reciprocal of the relevance of one point to the other. Once these relevances are numerically given one can try various rules for identifying clumps of points, clumps of clumps, clumps of clumps of clumps, and so on. These would form tree-like structures intersecting one another, and seem likely to lead to more general structures than lattices. Dr. Good did not wish to bore the audience with discussion of trials of detailed rules for identifying clumps. He did discuss the possibility of using functions of relative frequencies of words as measures of relevance. Dr. Bar-Hillel commented on the advantages of using ratios of relative frequencies to relative frequencies in “general English.” Dr. Good pointed out the advantages of ratios to relative frequencies for a larger context which was still not as broad as “general English.”
INFORMAL DISCUSSION
Area 6 discussion was resumed on an informal basis in the afternoon, and began with a discussion of Dr. Jonker’s paper. After some misconceptions of the morning discussion had been clarified, Dr. Bar-Hillel stated that the term “continuum” was misleading (because of its implication of connectedness) and that it was probable that Dr. Jonker meant “linear order.” But Dr. Bar-Hillel felt that it was “clearly wrong” that all indexing systems can be arranged in a linear order; that Dr. Jonker had not tried to demonstrate, rather than
state, this; that even if linear ordering were possible it would be amazing if “length of terms” provided a reasonable order; and that length of term depended very much upon the size of an alphabet, vocabulary, and so forth, chosen as a basis for counting. Dr. Minsky said that no one could believe that Dr. Bar-Hillel meant that it doesn’t matter in practice how many bits it takes to specify a symbol which must be stored. He went on to say that he had difficulty in Dr. Jonker’s paper in understanding whether “length of individual term” or “length of average retrieval prescription” was arranged along the “continuum.”
The discussion of these points continued without adequate distinction between a number of alternative thoughts: (1) that one important way in which index systems vary is roughly as described by Dr. Jonker, although precise comparisons are difficult or impossible; (2) that a precise definition could be given of a characteristic or coordinate of indexing systems which would establish the kind of order considered by Dr. Jonker without completely determining all the important characteristics of such systems; (3) that a precise definition could be given, so that systems near to one another on this coordinate would be near to one another in all relevant characters. Apparently Dr. Jonker felt that (1) was almost as good as (2), while Dr. Bar-Hillel thought that (2) without (3) was of little use.
The subject of the treatment of interfixes and relations according to Dr. Jonker was brought up. He apparently proposed to deal with them by treating clauses as large as might be necessary as single terms.
Mr. Farradane then restressed the need for the ultimate general theory of storage and information to cover all stages, particularly including the initial problem of indexing and the final problem of synthesizing the output information into a coherent whole. Both of these areas require analysis in terms of human thought, and it is here that his interest lies.
Diseases of Cats
During the morning session, Dr. Bar-Hillel had posed the question, “Which is logically more closely related to a query on ‘diseases of cats’: diseases of animals, diseases of siamese cats, diseases of ducks, life cycle of cats?” He expressed his feeling that no theory could answer this question. In the afternoon discussion, Dr. Wall stated that he believes the thesaurus approach would work if unit concepts were employed. Dr. Bar-Hillel said that he did not have the slightest idea whether “animals” is more closely related to “cats” than is “dogs.” Mr. Farradane felt that in dealing with things related to “diseases of cats” one could assess relatedness to “diseases” and to “cats” separately,
and then combine the results. Dr. Good pointed out that if words were among the vertices of a network, then adding a word automatically increases clumpiness near the word, and the existence of a machine-recognized clump suggests the need for an associated word. Mr. Farradane went on to say that the probable faults of choice of the inquirer are important in dealing with the relatedness difficulties brought out by Dr. Bar-Hillel in connection with “diseases of cats.”
Questioning by Dr. Wall brought out the fact that Dr. Bar-Hillel did not mean that a librarian who understood the meanings of the words (and who could talk to the inquirer) could not deal with the “diseases of cats,” but only that there was no automatic logical relationship to select a related topic (and he doubted the existence of a practical and mechanical rule).
Mr. Vickery then made a number of points about assessing relevance from relations of sets of documents and query terms. A one-to-one match of all terms would equate query and document. Both auto-abstracting and ranking by the querist of nearby sets of terms offer promise. What is attempted in libraries is to rank the documents in a scale of relevance based on the observations of previous use and satisfied users. This is what any classification or thesaurus structure does. The scale of relevance changes from time to time and from one questioner to another. The job is to find ways of making systems more sensitive to this changing relevance; not to worry that the “relevance” is only very, very probable.
Mr. Fairthorne pointed out that the relevance of a document and the description of its “contents” are not the same. He went on to say that one reason why biological types of classification, as suggested by Dr. Mandelbrot, are not used by librarians is that they serve to pull out extinct animals; librarians are not concerned with pulling out extinct books. He emphasized that a pair of documents once irrelevant can become relevant, but not vice versa. As a consequence there was trouble with the denial of the “excluded middle.” Such strong symmetric algebras as lattice theory seemed to him inappropriate. He concluded by emphasizing the need for two algebras, one for retrieval of “all but not only” and the other for the retrieval of “only but not all.” (See American Documentation, July 1958, pages 159–164, for further detail.) The “backlash” between these two algebras is important.
Dr. Taube then pointed out past carelessness about the distinction between plans (or dreams) and actual operating machines, alluding to the previous day’s discussion of the Perceptron. He then challenged the existence of machines that can act heuristically. Dr. Minsky pointed out that there are machines that play chess and checkers (checkers well enough to beat good amateurs, chess poorly); that there are machines which can, and do, prove theorems in the propositional calculus; and that there are at least four or five
separate instances of general purpose computers being used for character recognition.
Fano’s Dream
Dr. Robert M.Fano presented his dream of a library service. He said that he would be unwilling to phrase his questions in any prescribed words (descriptors, classifications, or others); his thoughts did not fit in such paths; he was individualistic in that matter. He would be prepared to list documents which were “like” what he requested, and to list others which were “unlike.” (This type of query language had already been brought up during Dr. Bigelow’s presentation.)
Dr. Fano envisioned such a retrieval technique embedded in a library system with a closed-circuit TV and keyboard in his office, so that he could request from his chair, and either read what was retrieved on the screen or have copies sent to him. (The screen would also serve for verbal messages from the retrieval computer as the search progressed.)
How could such service be accomplished? He felt that storage of one number for each pair of related documents would suffice. He preferred not to think of these numbers as measures of relevance (as in Dr. Good’s presentation) but as experimentally obtained measures of association, with useful operational properties. The basic problem in using them was to obtain the effect of searching through the library of documents without performing a correspondingly large number of operations. He had some definite ideas as to how this might be done, but this discussion session was neither the place nor the time to give details. In any case, such ideas could be only a starting point for an experimental investigation of the problem.
Dr. Fano felt that such a library system would be a very large system that could not be designed a priori, but only developed in successive steps through experimentation. Its operation could not be tried out with pencil and paper or on a small library. He made the point very strongly that extrapolating results from a small system to a large one is a very dangerous business. The major technical difficulty would not be the availability of suitable digital computers in view of the fantastic progress in the development of micro-components. The bottleneck would be in programming the computer. He agreed with Dr. Minsky that quite a bit of progress is being made, and that the problems are very tough but not unsolvable.
How could suitable measures of association be developed? He thought that citations of one document by another would be a web strong enough to establish a beginning. Progress (he did not like to say learning) could then be pro-
grammed by calling for the modifying of associations in terms of such observations as frequency of co-use of two documents by one requester.
Costs of the final system would not be prohibitive, although large. Development would be expensive, as it always is. He stressed that the whole field needs much more experimental research (not to be confused with development of hardware) and that funds for such a costly resaerch have been lacking.
Discussion of Fano’s dream began with comments from the chair that (1) associative systems have the advantage of no classifications to wear out and (2) are likely to take as unit documents portions of present day documents. Mr. Taffee Tanimoto (IBM) and Mr. Williams (duPont) stated that they had programmed (independently) and used at least the first phases of the associative access system dreamed by Dr. Fano. Mr. Tanimoto’s system was concerned with the classification of plants. Mr. Williams emphasized that the approximation in indexing what was written was only added to the approximation of what was written to the writer’s thoughts. Dr. Bar-Hillel pointed out that Dr. Fano’s dream was dreamed by a Russian Academician between 1947 and 1951.
Dr. Bar-Hillel went on to state that while Dr. Fano’s dream could be realized, the question is whether it should be. Large amounts of money would be required, and one should be sure that this would be a good way to spend it. There are many schemes that could be tried out, but only those for which strong plausibility arguments could be given deserve trial.
Dr. Bar-Hillel was sorry that Dr. Fano had not had time to be explicit about his suggested measures of relatedness. Dr. Bar-Hillel would be ready, within an hour after being given a measure, to present another measure which is better in a well defined sense. He felt, for instance, that being co-quoted, which is based on knowledge, is better than being co-requested, which is based on ignorance. But this, too, could be improved on.
The Chairman suggested that Dr. Bar-Hillel be hired for 200 hours to make 100 successive improvements. Dr. Fano suggested that it would be better for those interested to get together and “improve” measures jointly. Dr. Fano went on to emphasize the inadequacy of persuasive reasons without experiment. It takes the combination to produce a rapid and natural evolution of concepts and knowledge. Mr. Moorers took Dr. Fano’s dream quite seriously. Just as computers had buffer units, to mediate between machines, the dream needed a duffer unit, a simple and fool-proof mechanism with keyboard and printout, to mediate between people and machines. Mr. Norman Ball (National Science Foundation) called Dr. Fano’s attention to a very large-scale operating manual (non-mechanical) model of his dream called the Patent
Office Search Room. Dr. Fano confessed that his dream represents the ultimization of what he believes goes on in any library. Mr. Hayes emphasized the problem of storage and pulling out in a large library, and argued that the purpose of classification is more fundamentally that of easy access than that of determining which document is wanted. Dr. Baumann (M.I.T.) asked the audience to think about the “human being,” with the capability to read all the books in all the libraries, to retain what he had read, and to interpret what he had retained. This would be a long step toward Dr. Fano’s dream. If this capability were ever to be realized by an intelligent machine, there might be need for care that the machine did not become super-intelligent and do our thinking for us.
A librarians comment was made by Mr. Cleverdon. From the discussion which had gone on all day, it was quite obvious to him that the mathematicians are trying to find a mathematical statement of what librarians have been doing for a long time. This has tended to cause the librarians a bit of heat, because they did not realize why this was suddenly the case. Mr. Fairthorne’s 1947 paper on mathematics of classification was an attempt to help librarians with their work. Today’s activities are different, probably because of the possibility of putting some library operations onto machines. If the librarians’ activities are to be mechanized, someone must find exactly how and why librarians do everything they do. And to find out “why” librarians do what they do, experiments are needed. He had one in progress, but others are needed. A moderate percentage of the total investment in information retrieval should be used for experiments; all of it should not be used for machines.
JOHN W.TUKEY, Rapporteur and Discussion Panel Chairman
LAWRENCE F.BUCKLAND, Area Program Chairman
















