
Appendix H
2000 Census Long-Form-Sample Data Processing
Similar to the companion Appendix G on basic data processing, this appendix describes the processing of the items that were asked of the long-form sample in the 2000 census (see Appendix B for a listing of the long-form-sample items). It covers data capture, weighting, and imputation, assignment, and editing of items for missing and inconsistent responses. About 1 in 6 households received the long form in 2000. Sampling rates were 1 in 2 for governmental areas (counties, towns, townships, and school districts) with fewer than 800 occupied housing units (fewer than about 2,100 people); 1 in 4 for governmental areas with 800–1,200 occupied housing units (about 2,100–3,100 people); 1 in 6 for census tracts with fewer than 2,000 occupied housing units (fewer than about 5,200 people); and 1 in 8 for larger census tracts. (Estimates of occupied housing units were those developed by the Population Division as part of the intercensal estimates program.) The 1990 census long-form sampling scheme was similar, except that there was no 1 in 4 sampling rate and school districts were not among the governmental areas that were eligible to be oversampled.
H.1 DATA CAPTURE
For the 2000 census, data capture of information on questionnaires was performed by scanning short-form and long-form returns into computer files and using optical mark and optical character recognition (OMR/OCR) to record the information. Clerks keyed data items from images when the automated technology could not read the responses. Keying of long-form-sample information was carried out in a second, separate process in order to permit the fastest possible completion of data capture for the basic items on all returns.
After data capture, long-form-sample records for households and their members could fall into one of two categories:
-
Long-Form Data-Defined At least one member of a household in the long-form sample was “long-form data-defined;” that is, at least one member had at least two long-form data items reported. All records for long-form data-defined households were retained in the sample. Any long-form housing or person items not reported, or reported inconsistently, had missing or consistent values supplied through item imputation, assignment, and editing. Imputations for any missing complete-count items that were performed during the basic data processing were retained (i.e., they were not reimputed during the long-form-sample processing).
-
Whole-Household Nonresponse Households that lacked any long-form data-defined persons were dropped from the sample. Weights were developed for long-form data-defined households and their members so that long-form-sample estimates agreed with complete-count totals on basic items. The weighting effectively adjusted for whole-household nonresponse.
H.2 WEIGHTING
H.2.a Initial Weighting Areas
In a procedure similar to that used in 1990, 2000 long-form-sample weights were developed to produce estimates for specified groups and geographic areas that agreed with estimates from the basic (complete-count) data records. A goal of the weighting was to
minimize the variation in weights, which, in turn, would minimize the variation in estimated sampling error across population groups and geographic areas. Adjusting the weights to match complete-count controls would also reduce the variance in estimates.1 The weighting was specified by the Decennial Statistical Studies Division (see Hefter, 2000; see also U.S. Census Bureau, 2003d:Ch.8).
Initial weighting steps included defining initial weighting areas and computing for each the ratio of basic records (complete-count data-defined people and whole-person and whole-household imputations) to long-form data-defined records. The purpose for the ratios was to determine if data augmentation would be needed before proceeding to calculate final weights.
Initial weighting areas (IWAs) were defined within counties. They comprised all of the records in a tabulation block group with thesameexpectedsamplingrate(1/2, 1/4, 1/6, or 1/8). Ratios were calculated of long-form data-defined records to the total records in each IWA separately for housing units, persons in group quarters, and persons counted in service-based enumeration.
H.2.b Data Augmentation
In order to achieve the target IWA ratios of sample to total records for housing units, group quarters enumerations, and service-based enumerations so that weights would not be too large, an appropriate number of records that were not previously long-form data-defined were selected to be augmented—that is, have values for their long-form data items supplied through editing, assignment, and imputation. After this first round of augmentation, IWAs were combined into final weighting areas (FWAs), and a second round of augmentation was performed as needed.
As it turned out, augmentation was rarely required in 2000: only 1,477 occupied housing units were selected for augmentation out of 16.4 million occupied units in the long-form sample (2,412 vacant housing units were also selected for augmentation). Less than 0.001 percent of long-form-sample household member records (unweighted) were augmented people (4,090 of 42.6 million records);
however, 4.2 percent of group quarters long-form-sample records were augmented people. On a weighted basis, augmented household members represented only 0.002 percent of the household population estimated from the long-form sample, while augmented group quarters residents represented 11.9 percent of the group quarters population estimated from the long-form-sample. This percentage is disturbingly high. It would be useful to know how it varied by type of group quarters (e.g., college dormitory or prison).
H.2.c Final Weighting Areas
The specifications for combining IWAs into FWAs called for no FWA to have fewer than 400 long-form data-defined persons, while also observing the constraint that IWAs were never combined across counties. If an IWA had more sample persons than the threshold, it was an FWA on its own. If it had fewer sample persons, then it was combined with one or more IWAs in the same tabulation block group, or in the same census tract if necessary, or in the same county if necessary, to reach the threshold. When possible, IWAs werecombinedthathadthesameexpectedsamplingrate.
H.2.d Construction of Weights
Initial weights were calculated separately for five groups: persons in households, group quarters residents, service-based enumerations, occupied housing units, and vacant housing units. These weights were the ratio of the complete count to the long-form-sample count for each group in an IWA.
Final Person Weights
Next, person weighting matrixes were computed for each FWA. The matrix for household members included the complete count, unweighted sample count, and weighted count (based on the initial person weights) for each cell of a 4-dimensional matrix (39,312 cells). Marginal counts (complete count, unweighted, initially weighted) were also produced for each cell of each dimension separately.
The four dimensions for household members were as follows (there were simpler matrices for group quarters residents and service-based enumerations):
-
three categories of household type by seven categories of household size (21 cells);
-
three categories of sampling type (1 in 2, 1 in 4, 1 in 6, or 1 in 8) (3 cells);
-
two categories of householder status (householder or not) (2 cells); and
-
two categories of Hispanic origin, by six categories of race (American Indian or Alaska Native, Black, Asian, Native Hawaiian or Other Pacific Islander, White, Other, with multiple-race persons assigned to the largest nonwhite single-race category in the FWA), by 13 categories of age, by two categories of sex (312 cells).
Type of return (mail, enumerator) was not included as a dimension in the weighting matrix, although almost all non-sample-data-defined records (whole-household nonrespondents) were enumerator returns and not mail returns. Thus, members of non-sample-data-defined occupied housing units were 17.7 percent of total enumerator long-form household member records, compared with only 0.5 percent of total mail long-form household member records (from tabulations by Census Bureau staff provided to the panel spring 2003).
The cells of the household member weighting matrix were collapsed as necessary. The entire matrix was collapsed to a single cell if the complete person count in the FWA was more than 40 times the uninflated sample count. One or more cells in a single dimension were collapsed, following the process below (see Hefter, 2000:Section V.I, for the rules for combining categories within a dimension):
-
first, determine if one or more categories of the household type/size dimension needed to be collapsed (each category must have at least 10 sample persons and a ratio of complete-count persons to initially inflated sample persons of less than 3.5);
-
next, determine if the Hispanic origin classification failed (both the Hispanic and non-Hispanic categories must have at least 150 complete-count persons in addition to the criteria above for household type/size);
-
next, determine if the race categories (within Hispanic origin, if still present) required collapsing (each category must meet the criteria specified for Hispanic/non-Hispanic);
-
next, determine if the age/sex classifications within Hispanic/race categories must be collapsed (each category must have at least 10 sample persons and a ratio of complete-count persons to initially inflated sample persons of less than 4);
-
next, determine if the householder/nonhouseholder dimension failed (each category must have at least 10 sample persons and a ratio of complete-count persons to initially inflated sample persons of less than 3.5);
-
finally, determine if the sampling type categories required collapsing (each must have at least 10 sample persons and a ratio of complete-count persons to initially inflated sample persons of less than 3.5).
After the final person matrix was determined for an FWA, then an iterative proportional fitting (raking) procedure was conducted, in which the initially inflated sample counts in each cell were adjusted so that the marginal cell totals for each dimension were practically equal between the complete counts and the inflated sample counts. This result was accomplished by first adjusting the initially inflated cell counts to equal the complete-count marginals for one dimension, then a second dimension, and, sequentially, through all the dimensions, followed by additional iterations as needed until a specified stopping point was reached. (See National Research Council, 1985:App.3.2, for a general description of iterative proportional fitting, which has been used in every census since 1970.)
The last step in constructing person weights was to use a controlled rounding procedure in order to produce integer weights within each state. Before approving these weights, they were tested to be sure they did not exceed specified size criteria. If they did, then a procedure was used to force additional collapsing of the person-weighting matrix, by successively lowering the maximum ratio of complete-count persons to initially inflated sample persons that was permitted.
The distribution of final long-form-sample person weights for 2000 is concentrated in the range of 3–30, with a longer upper tail for
group quarters residents compared with all people, as seen below. It would be useful to analyze weight distributions and average weights for small geographic areas.
|
Cumulative Percent |
||
|
Weight Value |
All Persons |
Group Quarters |
|
1 |
0.45 |
0.02 |
|
2 |
4.33 |
0.12 |
|
3 |
7.34 |
0.44 |
|
4–10 |
70.58 |
56.76 |
|
11–20 |
98.06 |
80.23 |
|
21–30 |
99.60 |
91.70 |
|
31–40 |
99.91 |
97.89 |
|
41–50 |
99.97 |
99.22 |
|
51–max. |
100.00 |
100.00 |
|
(Max =) |
(320) |
(180) |
|
SOURCE: Tabulated by panel staff from U.S. Census Bureau, Edit Tallies for Long-Form Population Records (variable WT; see Philipp, 2001). |
||
Final Occupied Household Weights
The procedure for developing occupied household weights was similar to that for persons. The only difference was in the definition of the weighting matrixes and the criteria for collapsing.
The occupied household weighting matrix consisted of three dimensions (1,512 cells):
-
three categories of household type by seven categories of household size (21 cells);
-
three categories of sampling type (3 cells);
-
two categories of tenure by two categories of Hispanic/non-Hispanic origin of householder by six categories of race of householder (as defined for the person weighting) (24 cells).
The entire matrix was collapsed to a single cell if the ratio of the complete count to the unweighted sample count was more than 40 to 1 for an FWA. One or more categories of a dimension were collapsed if the marginal unweighted sample count was less than 5 or the ratio of complete-count persons to initially inflated sample persons was greater than 3.5 (for tenure, Hispanic origin, and race, collapsing also occurred if there were fewer than 50 sample cases in a
cell). The collapsing proceeded by testing, sequentially, household type/size categories, tenure categories, Hispanic origin categories within tenure, race categories within tenure/Hispanic origin, and sampling type categories.
Final Vacant Housing Unit Weights
The process for developing vacant housing unit weights was not iterative. Vacant units were classified into three categories: vacant for rent, vacant for sale, other vacant. These categories were collapsed as necessary, and weights were calculated for the vacant units in each category in an FWA by inflating the initially inflated sample counts to equal the complete counts.
H.3 ITEM IMPUTATION
Imputation (using reported values from another person or household in a hot-deck procedure), assignment (using reported values for the same person or household), and editing (changing values according to specified rules for consistency) were used in 2000 for all instances of missing and inconsistent values for members of long-form-sample data-defined households (whether or not the person record was sample data-defined). These procedures were also used for all long-form-sample data-defined group quarters residents. The imputations made during the complete-count processing of basic items were retained and not reimputed in the long-form-sample data processing. The hot-deck imputation procedure is described in broad outline in Appendix G.1; the Census Bureau uses the term “allocation” for item imputation.
The edit and imputation specifications for the long-form were quite complex. Generally, related variables (e.g., the set on education, see below) were imputed sequentially so that responses to a specific question would be consistent with responses to a logically preceding question. In the case of income and employment variables, there was a “joint economic edit,” which was the most complex procedure of all (see U.S. Census Bureau, 2002b). It was carried out after all other editing and imputation had been performed and applied to year last worked, industry, occupation, class of worker, work experience in 1999, earnings, and all other income
types. For yet another example of long-form-sample imputation and edit specifications, see Appendix G.2.b which describes procedures for editing and imputing housing tenure. The long-form procedures were much more complex than the short-form procedures because of the availability of related variables on the long form, such as mortgage payment and rent. For most long-form person variables, there were somewhat different procedures for household members and group quarters residents.
H.3.a Example of Edit and Imputation Specifications: Education Variables
The three education variables—school enrollment, grade attending, and educational attainment—were edited jointly (see U.S. Census Bureau, 2001a). Variables that were used for the education edits and imputations included age, race, ethnicity, whether worked last week or was on layoff or temporarily absent from work, occupation, and employment status recode. Starting (“cold-deck”) values were specified for 17 different matrices, although these values were superceded by the “warm deck,” and then were continuously updated through the “hot-deck” process (see Appendix G.1).
The first steps involved a large number of edits based on age. For example, all three education variables were set to zero (not in universe) if age (which may have been imputed in the complete-count processing) was less than 3 years. One or more of the education variables were also set to zero if the reported or imputed age was not consistent with the educational data (e.g., if age was 18 or more and school enrollment was no, then any reported value for grade attending was set to zero). These edits assumed that age reporting and imputation were reliable.
Next were edits to make educational attainment consistent with reported grade attending. For example, if grade attending was grade 1 to grade 4 and age was 8–10, but educational attainment was greater than grade 4, then educational attainment was blanked and imputed at a later step. Sometimes, it was grade attending that was blanked depending on age and reported educational attainment.
After the edits were completed, then blank values because of nonresponse or editing were imputed using the specified imputation matrix. Some matrices were simple; for example, when educational
attainment was missing but school enrollment and grade attending were reported, then the imputed value for educational attainment was the hot-deck value in the appropriate cell of a matrix of categories of age by grade attending. More complex matrices handled situations when all three education variables were missing: matrix 7A imputed all three education variables for unemployed people according to the hot-deck values in the appropriate cell formed by age and race/ethnicity; matrix 7B imputed all three education variables for employed people according to the hot-deck values in the appropriate cell formed by age and occupation group.
H.3.b Analysis
Chapter 7 analyzes imputation rates for the 2000 and 1990 census long-form samples and the Census 2000 Supplementary Survey. Eight tables supplement those provided in Chapter 7. Tables H.1 through H.7 are for the household population (see National Research Council, 1995b:App.L, for similar tables for 1990): imputation rates for selected population and housing items by self versus enumerator form for 2000 and 1990 (Table H.1); imputation rates for selected population and housing items for 2000 by race and Hispanic origin of the reference person or householder (Table H.2); imputation rates for the worst 10 percent census tracts for selected population and housing items for 2000 by race and Hispanic origin of the reference person (Table H.3); imputation rates for selected population and housing items for 2000 by geographic aggregations (Table H.4); imputation rates for the worst 10 percent census tracts for selected population and housing items for 2000 by geographic aggregations (Table H.5); 2000 imputation rates, 2000 imputation and assignment rates (1990-comparable), and 1990 imputation rates for population items (Table H.6); and 2000 imputation rates, 2000 imputation and assignment rates (1990-comparable), and 1990 imputation rates for housing items (Table H.7). Table H.8 provides 2000 imputation and assignment rates and 1990 imputation rates for population items for group quarters residents by type of group quarters.
Figure H.1 graphs comparable imputation rates for 2000 and 1990 for housing items. It shows (as would a similar graph for population items) that 2000 imputation rates are higher than 1990 rates for most items. One reason relates to the fact that the percentage of long
forms included in sample processing was 2 percentage points higher in 2000 than in 1990 (93.2 percent and 91.2 percent, respectively). It was easier for a household to be sample data-defined in 2000 because of the layout of the questionnaire (see discussion in Chapter 7), but, as a consequence, a larger proportion of sample data-defined forms in 2000 were only minimally completed, which produced higher imputation rates. Another and more important reason for higher imputation rates in 2000 is that the design, in contrast with 1990, precluded telephone and field follow-up for missing content (see discussion in Chapter 4). Users should examine both weighting factors and imputation rates to assess the effects of nonresponse on the variability and possible bias of estimates from the 2000 and 1990 long-form samples.
Table H.1 Imputation/Assignment Rates for Selected Population and Housing Items, 2000 and 1990 Census Long-Form Sample, Household Members, by Type of Response: Household Respondent (Self) vs. Enumerator-Filled (Enum) (weighted)
Table H.2 Imputation Rates for Selected Population and Housing Items, 2000 Census Long-Form Sample, Household Members, by Race and Hispanic Origin of Household Reference Person (weighted)
Table H.3 Imputation Rates for Selected Population and Housing Items, 2000 Census Long-Form Sample, Household Members, 10% Worst Census Tracts, by Race and Hispanic Origin of Reference Person (weighted)
Table H.4 Imputation Rates for Selected Population and Housing Items, 2000 Census Long-Form Sample, Household Members, by Geographic Aggregations (weighted)
Table H.5 Imputation Rates for Selected Population and Housing Items, 2000 Census Long-Form Sample, Household Members, Worst 10% Census Tracts, by Geographic Aggregations (weighted)
Table H.6 Imputation Rates for Population Items, 2000 and 1990 Census Long-Form Sample, Household Members (weighted)
Table H.7 Imputation Rates for Housing Items, 2000 and 1990 Census Long-Form Sample, Household Members (weighted)
Table H.8 Imputation/Assignment Rates (percents) for Selected Population Items for Group Quarters Residents, 2000 and 1990 Long-Form Samples, by Type of Group Quarters (weighted)
|
Type of Group Quarters and Year |
Sex |
Age |
Hispanic Origin |
Race |
Marital Status |
Attend School |
Grade Attend |
Highest Grade |
|
Total |
|
|||||||
|
2000 |
3.0 |
3.8 |
8.0 |
4.5 |
18.0 |
31.9 |
30.0 |
39.3 |
|
1990 |
0.6 |
1.5 |
7.6 |
1.8 |
4.2 |
15.3 |
— |
17.9 |
|
Prisons |
|
|||||||
|
2000 |
2.7 |
5.5 |
11.8 |
5.4 |
30.9 |
47.7 |
70.1 |
53.8 |
|
1990 |
1.1 |
2.1 |
16.8 |
2.7 |
11.1 |
28.9 |
— |
24.6 |
|
Juvenile Institutions |
|
|||||||
|
2000 |
2.9 |
3.7 |
8.2 |
5.2 |
21.4 |
37.4 |
38.3 |
43.6 |
|
1990 |
0.6 |
3.3 |
5.0 |
2.0 |
2.6 |
12.6 |
— |
13.7 |
|
Nursing Homes |
|
|||||||
|
2000 |
3.4 |
1.8 |
5.1 |
1.5 |
17.7 |
33.1 |
89.1 |
51.7 |
|
1990 |
0.3 |
0.8 |
4.7 |
1.0 |
2.8 |
20.0 |
— |
32.6 |
|
Hospitals and Schools for Handicapped |
|
|||||||
|
2000 |
4.6 |
10.9 |
8.8 |
4.8 |
21.9 |
39.8 |
65.4 |
52.8 |
|
1990 |
0.6 |
1.2 |
9.4 |
2.1 |
4.6 |
25.8 |
— |
30.7 |
|
College Dormitories |
|
|||||||
|
2000 |
1.9 |
3.4 |
7.1 |
5.4 |
8.1 |
20.7 |
20.2 |
19.2 |
|
1990 |
0.2 |
1.3 |
3.4 |
1.4 |
1.2 |
3.2 |
— |
2.8 |
|
Military Quarters |
|
|||||||
|
2000 |
1.7 |
1.7 |
4.2 |
4.9 |
2.9 |
4.6 |
99.8 |
3.8 |
|
1990 |
0.5 |
0.9 |
7.1 |
1.4 |
1.5 |
6.4 |
— |
5.4 |
|
Shelters |
|
|||||||
|
2000 |
5.1 |
4.7 |
15.5 |
9.2 |
14.1 |
24.7 |
40.9 |
28.2 |
|
1990 |
2.1 |
3.3 |
20.3 |
5.6 |
13.3 |
23.1 |
— |
20.6 |
|
Group Homes |
|
|||||||
|
2000 |
4.1 |
2.9 |
6.7 |
3.5 |
17.6 |
30.1 |
49.8 |
42.2 |
|
1990 |
1.3 |
1.7 |
7.8 |
2.2 |
3.9 |
18.3 |
— |
21.2 |
|
Other Group Quarters |
|
|||||||
|
2000 |
4.4 |
3.7 |
6.6 |
4.5 |
19.4 |
32.0 |
47.6 |
42.9 |
|
1990 |
1.3 |
2.6 |
7.1 |
3.4 |
5.0 |
16.9 |
— |
17.2 |
|
Type of Group Quarters and Year |
Speak Another Lang. |
Language Spoken |
English Speaking Ability |
Place of Birth |
Citizenship |
Year Entered U.S. |
Where Lived 5 Years Ago |
State 5 Yrs. Ago |
|
Total |
|
|||||||
|
2000 |
39.2 |
38.3 |
33.9 |
40.2 |
36.5 |
29.8 |
44.9 |
42.8 |
|
1990 |
18.2 |
27.7 |
22.1 |
19.2 |
14.0 |
30.1 |
18.1 |
19.3 |
|
Prisons |
|
|||||||
|
2000 |
58.3 |
59.2 |
56.8 |
54.0 |
53.0 |
50.4 |
70.6 |
66.7 |
|
1990 |
29.8 |
35.7 |
29.8 |
31.7 |
24.7 |
38.0 |
33.5 |
32.8 |
|
Juvenile Institutions |
|
|||||||
|
2000 |
44.4 |
38.0 |
34.1 |
46.2 |
42.1 |
37.9 |
49.9 |
51.5 |
|
1990 |
16.2 |
25.6 |
18.6 |
18.4 |
12.1 |
25.2 |
16.2 |
21.9 |
|
Nursing Homes |
|
|||||||
|
2000 |
46.6 |
46.0 |
36.8 |
49.2 |
42.4 |
49.1 |
47.4 |
50.7 |
|
1990 |
25.5 |
34.8 |
26.8 |
25.5 |
18.8 |
46.2 |
23.9 |
29.2 |
|
Hospitals and Schools for Handicapped |
|
|||||||
|
2000 |
50.7 |
47.5 |
40.2 |
54.3 |
47.4 |
41.1 |
53.7 |
59.7 |
|
1990 |
30.3 |
43.4 |
34.0 |
32.4 |
24.2 |
46.0 |
28.7 |
38.7 |
|
College Dormitories |
|
|||||||
|
2000 |
20.6 |
19.0 |
16.3 |
22.2 |
19.9 |
11.3 |
23.7 |
23.9 |
|
1990 |
5.8 |
14.2 |
11.0 |
6.7 |
3.9 |
11.7 |
4.7 |
6.5 |
|
Military Quarters |
|
|||||||
|
2000 |
4.1 |
7.7 |
4.1 |
5.4 |
3.8 |
10.6 |
12.8 |
6.3 |
|
1990 |
7.1 |
12.5 |
8.1 |
6.8 |
5.5 |
12.2 |
7.0 |
7.4 |
|
Shelters |
|
|||||||
|
2000 |
28.0 |
31.4 |
24.2 |
35.2 |
32.9 |
27.1 |
45.0 |
34.1 |
|
1990 |
24.0 |
40.1 |
32.0 |
29.3 |
19.8 |
42.1 |
26.5 |
29.6 |
|
Group Homes |
|
|||||||
|
2000 |
38.3 |
43.0 |
35.3 |
45.3 |
36.4 |
33.0 |
42.3 |
46.4 |
|
1990 |
20.4 |
31.3 |
22.1 |
24.2 |
15.7 |
35.1 |
21.0 |
24.4 |
|
Other Group Quarters |
|
|||||||
|
2000 |
39.4 |
34.2 |
29.7 |
43.8 |
38.1 |
21.6 |
43.7 |
47.2 |
|
1990 |
18.3 |
22.9 |
20.5 |
18.7 |
14.5 |
26.2 |
18.9 |
23.3 |
|
|
Disability |
Grandchildren |
||||||
|
Type of Group Quarters and Year |
Senses |
Physical Activity |
Mental |
Self Care |
Mobility |
Work |
In Home |
Responsible for |
|
Total |
|
|||||||
|
2000 |
44.2 |
45.4 |
45.1 |
45.6 |
46.9 |
47.7 |
30.0 |
25.2 |
|
1990 |
— |
— |
— |
17.3 |
16.7 |
18.1 |
— |
— |
|
Prisons |
|
|||||||
|
2000 |
58.2 |
63.5 |
63.7 |
64.8 |
66.2 |
66.7 |
36.5 |
18.7 |
|
1990 |
— |
— |
— |
33.1 |
31.5 |
34.2 |
— |
— |
|
Juvenile Institutions |
|
|||||||
|
2000 |
43.3 |
45.1 |
45.9 |
46.2 |
47.9 |
48.4 |
— |
— |
|
1990 |
— |
— |
— |
19.8 |
18.7 |
18.2 |
— |
— |
|
Nursing Homes |
|
|||||||
|
2000 |
46.9 |
45.4 |
45.3 |
45.2 |
47.4 |
49.0 |
44.0 |
48.6 |
|
1990 |
— |
— |
— |
21.6 |
21.2 |
23.0 |
— |
— |
|
Hospitals and Schools for Handicapped |
|
|||||||
|
2000 |
56.0 |
55.3 |
54.6 |
55.1 |
56.2 |
57.3 |
47.4 |
25.3 |
|
1990 |
— |
— |
— |
28.1 |
27.3 |
27.7 |
— |
— |
|
College Dormitories |
|
|||||||
|
2000 |
21.8 |
22.1 |
21.9 |
22.1 |
22.3 |
22.7 |
0.5 |
15.7 |
|
1990 |
— |
— |
— |
6.6 |
6.3 |
6.0 |
— |
— |
|
Military Quarters |
|
|||||||
|
2000 |
— |
— |
— |
— |
— |
— |
83.3 |
14.8 |
|
1990 |
— |
— |
— |
— |
— |
— |
— |
— |
|
Shelters |
|
|||||||
|
2000 |
30.5 |
32.1 |
29.7 |
30.8 |
32.2 |
33.3 |
39.3 |
14.9 |
|
1990 |
— |
— |
— |
26.5 |
25.1 |
32.8 |
— |
— |
|
Group Homes |
|
|||||||
|
2000 |
38.8 |
38.7 |
37.4 |
38.3 |
39.1 |
40.1 |
31.2 |
28.5 |
|
1990 |
— |
— |
— |
20.0 |
19.2 |
25.8 |
— |
— |
|
Other Group Quarters |
|
|||||||
|
2000 |
40.8 |
41.3 |
40.3 |
40.8 |
42.5 |
43.8 |
33.2 |
23.9 |
|
1990 |
— |
— |
— |
18.2 |
17.4 |
21.2 |
— |
— |
|
Type of Group Quarters and Year |
Veteran Status |
Years Served |
Employment Recode |
Place of Work (State) |
How Get to Work |
Use Carpool? |
Time Leave for Work |
When Last Worked |
|
Total |
|
|||||||
|
2000 |
39.6 |
35.7 |
5.5 |
11.4 |
12.0 |
14.4 |
20.0 |
45.8 |
|
1990 |
18.0 |
32.1 |
5.1 |
14.1 |
12.1 |
14.6 |
21.9 |
30.1 |
|
Prisons |
|
|||||||
|
2000 |
57.5 |
54.5 |
— |
— |
— |
— |
— |
70.2 |
|
1990 |
29.2 |
37.4 |
4.7 |
73.7 |
84.6 |
86.7 |
85.8 |
60.7 |
|
Juvenile Institutions |
|
|||||||
|
2000 |
41.6 |
62.7 |
— |
— |
— |
— |
— |
51.9 |
|
1990 |
16.0 |
59.3 |
0.2 |
14.3 |
14.2 |
50.9 |
41.1 |
44.5 |
|
Nursing Homes |
|
|||||||
|
2000 |
48.6 |
52.7 |
— |
— |
— |
— |
— |
50.1 |
|
1990 |
27.1 |
46.5 |
0.1 |
17.0 |
17.8 |
17.7 |
23.0 |
38.8 |
|
Hospitals and Schools for Handicapped |
|
|||||||
|
2000 |
50.5 |
39.0 |
— |
— |
— |
— |
— |
54.5 |
|
1990 |
27.9 |
43.6 |
— |
21.7 |
28.0 |
71.4 |
44.6 |
47.8 |
|
College Dormitories |
|
|||||||
|
2000 |
21.6 |
30.1 |
9.3 |
9.6 |
10.3 |
13.0 |
18.0 |
24.8 |
|
1990 |
5.7 |
20.8 |
6.6 |
10.2 |
7.7 |
8.3 |
17.8 |
9.7 |
|
Military Quarters |
|
|||||||
|
2000 |
1.8 |
9.4 |
3.8 |
9.0 |
8.7 |
10.0 |
18.0 |
15.1 |
|
1990 |
2.5 |
26.3 |
— |
10.0 |
8.4 |
11.3 |
18.1 |
4.1 |
|
Shelters |
|
|||||||
|
2000 |
31.1 |
30.5 |
20.5 |
21.3 |
20.5 |
22.2 |
29.1 |
35.6 |
|
1990 |
25.8 |
32.9 |
27.6 |
36.0 |
30.9 |
33.6 |
44.2 |
35.1 |
|
Group Homes |
|
|||||||
|
2000 |
38.3 |
43.6 |
10.8 |
12.5 |
13.8 |
15.0 |
20.5 |
43.4 |
|
1990 |
20.1 |
28.2 |
14.1 |
27.3 |
24.7 |
26.6 |
32.0 |
33.9 |
|
Other Group Quarters |
|
|||||||
|
2000 |
40.2 |
49.7 |
22.1 |
24.9 |
28.5 |
33.9 |
36.3 |
46.2 |
|
1990 |
18.7 |
42.9 |
20.6 |
24.2 |
23.1 |
26.7 |
33.6 |
23.5 |
|
Type of Group Quarters and Year |
Industry |
Occupation |
Class of Worker |
Work Last Year |
Number Weeks Worked |
Usual Hours Worked |
Wage/Salary Income |
Self-Employ. Income |
|
Total |
|
|||||||
|
2000 |
46.2 |
46.9 |
54.4 |
47.7 |
42.8 |
41.3 |
50.1 |
42.7 |
|
1990 |
20.9 |
21.3 |
22.5 |
26.9 |
21.4 |
20.6 |
27.4 |
23.2 |
|
Prisons |
|
|||||||
|
2000 |
75.2 |
75.4 |
78.3 |
70.6 |
72.5 |
71.2 |
74.3 |
67.4 |
|
1990 |
46.4 |
44.2 |
46.6 |
43.3 |
40.2 |
38.6 |
49.7 |
42.6 |
|
Juvenile Institutions |
|
|||||||
|
2000 |
54.9 |
55.6 |
58.1 |
55.1 |
50.7 |
49.6 |
43.7 |
38.1 |
|
1990 |
25.2 |
25.1 |
25.8 |
26.0 |
23.2 |
23.2 |
21.6 |
18.5 |
|
Nursing Homes |
|
|||||||
|
2000 |
78.6 |
78.2 |
80.4 |
52.6 |
69.9 |
69.5 |
48.2 |
47.7 |
|
1990 |
35.6 |
32.0 |
35.6 |
32.2 |
23.3 |
22.5 |
27.3 |
26.9 |
|
Hospitals and Schools for Handicapped |
|
|||||||
|
2000 |
51.5 |
52.0 |
65.5 |
57.3 |
43.5 |
42.6 |
56.1 |
51.0 |
|
1990 |
36.9 |
35.9 |
37.1 |
37.8 |
33.9 |
32.5 |
36.6 |
32.5 |
|
College Dormitories |
|
|||||||
|
2000 |
29.3 |
30.7 |
32.4 |
26.8 |
29.1 |
27.4 |
34.7 |
23.4 |
|
1990 |
9.9 |
11.1 |
11.5 |
11.2 |
13.2 |
12.7 |
15.0 |
10.1 |
|
Military Quarters |
|
|||||||
|
2000 |
5.7 |
5.9 |
80.4 |
16.4 |
20.3 |
18.6 |
17.4 |
3.1 |
|
1990 |
1.1 |
5.7 |
7.8 |
21.3 |
17.5 |
17.2 |
15.8 |
9.6 |
|
Shelters |
|
|||||||
|
2000 |
38.9 |
38.6 |
42.1 |
38.8 |
40.9 |
38.5 |
41.2 |
32.1 |
|
1990 |
38.2 |
36.4 |
37.2 |
36.6 |
39.0 |
38.1 |
37.1 |
33.3 |
|
Group Homes |
|
|||||||
|
2000 |
42.8 |
43.8 |
44.9 |
46.1 |
46.1 |
44.6 |
50.5 |
39.9 |
|
1990 |
30.6 |
29.5 |
30.3 |
29.5 |
31.9 |
31.1 |
32.4 |
25.8 |
|
Other Group Quarters |
|
|||||||
|
2000 |
43.3 |
43.5 |
46.3 |
49.0 |
51.3 |
50.4 |
49.8 |
41.4 |
|
1990 |
30.6 |
29.0 |
29.3 |
29.3 |
33.1 |
32.3 |
30.4 |
24.1 |
|
Type of Group Quarters and Year |
Interest Income |
Social Security |
SSI Income |
Public Assist. |
RetireMent |
Other Income |
All Income Imputed |
Some/All Income Imputed |
|
Total |
|
|||||||
|
2000 |
54.5 |
57.4 |
55.5 |
55.2 |
55.5 |
54.5 |
59.9 |
63.1 |
|
1990 |
29.9 |
30.7 |
— |
29.0 |
29.1 |
29.6 |
35.4 |
37.5 |
|
Prisons |
|
|||||||
|
2000 |
74.1 |
74.1 |
74.1 |
74.2 |
74.2 |
73.8 |
78.3 |
79.7 |
|
1990 |
46.8 |
46.7 |
— |
46.5 |
46.7 |
46.7 |
54.4 |
56.1 |
|
Juvenile Institutions |
|
|||||||
|
2000 |
61.0 |
61.2 |
61.4 |
61.4 |
61.2 |
60.7 |
65.0 |
66.1 |
|
1990 |
29.1 |
29.1 |
— |
29.0 |
28.9 |
28.9 |
32.4 |
33.4 |
|
Nursing Homes |
|
|||||||
|
2000 |
68.1 |
75.9 |
68.7 |
68.3 |
69.4 |
67.1 |
76.9 |
79.0 |
|
1990 |
44.9 |
50.8 |
— |
45.3 |
45.5 |
44.2 |
51.8 |
53.4 |
|
Hospitals and Schools for Handicapped |
|
|||||||
|
2000 |
61.5 |
64.8 |
63.9 |
63.3 |
62.9 |
61.9 |
65.9 |
70.5 |
|
1990 |
38.8 |
40.0 |
— |
39.2 |
39.0 |
38.8 |
41.3 |
46.6 |
|
College Dormitories |
|
|||||||
|
2000 |
31.8 |
31.2 |
31.2 |
31.1 |
31.2 |
30.8 |
35.7 |
38.2 |
|
1990 |
11.1 |
10.8 |
— |
10.6 |
10.6 |
10.7 |
14.9 |
16.5 |
|
Military Quarters |
|
|||||||
|
2000 |
15.8 |
31.1 |
31.1 |
31.1 |
31.1 |
30.5 |
18.7 |
32.9 |
|
1990 |
10.3 |
0.6 |
— |
0.6 |
0.6 |
10.2 |
15.3 |
17.2 |
|
Shelters |
|
|||||||
|
2000 |
41.1 |
41.0 |
41.1 |
41.2 |
40.9 |
39.7 |
44.9 |
51.3 |
|
1990 |
37.5 |
37.7 |
— |
37.1 |
37.5 |
37.3 |
40.9 |
44.0 |
|
Group Homes |
|
|||||||
|
2000 |
51.6 |
55.1 |
54.9 |
53.0 |
52.6 |
51.1 |
58.3 |
66.0 |
|
1990 |
30.8 |
32.2 |
— |
31.9 |
31.1 |
31.1 |
35.2 |
41.2 |
|
Other Group Quarters |
|
|||||||
|
2000 |
56.6 |
59.8 |
57.4 |
55.9 |
57.0 |
55.3 |
63.1 |
67.0 |
|
1990 |
28.0 |
28.7 |
— |
27.7 |
27.8 |
27.8 |
34.2 |
36.9 |
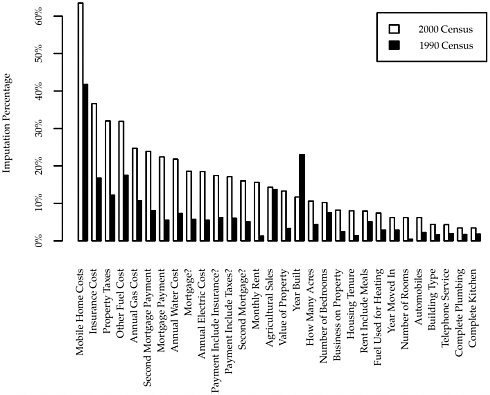
Figure H.1 Imputation/Assignment Rates for Housing Items, 2000 and 1990 Census, Persons Receiving the Long Form (weighted)
NOTES: 2000 rates include imputations and assignments (comparable to 1990), and are the “2000b” figures reported in Table H.7.
SOURCE: Tabulations by U.S. Census Bureau staff from the 2000 Sample Census Edited File (SCEF) and the 1990 Sample Edited Data File (SEDF), provided to the panel spring 2003.


























