
5
Today’s Supercomputing Technology
The preceding chapter summarized some of the application areas in which supercomputing is important. Supercomputers are used to reduce overall time to solution—the time between initiating the use of computing and producing answers. An important aspect of their use is the cost of solution—including the (incremental) costs of owning the computer. Usually, the more the time to solution is reduced (e.g., by using more powerful supercomputers) the more the cost of solution is increased. Solutions have a higher utility if provided earlier: A weather forecast is much less valuable after the storm starts. The aggressiveness of the effort to advance supercomputing technology depends on how much added utility and how much added cost come from solving the problem faster. The utility and cost of a solution may depend on factors other than time taken—for instance, on accuracy or trustworthiness. Determining the trade-off among these factors is a critical task. The calculation depends on many things—the algorithms that are used, the hardware and software platforms, the software that realizes the application and that communicates the results to users, the availability of sufficient computing in a timely fashion, and the available human expertise. The design of the algorithms, the computing platform, and the software environment governs performance and sometimes the feasibility of getting a solution. The committee discusses these technologies and metrics for evaluating their performance in this chapter. Other aspects of time to solution are discussed later.
SUPERCOMPUTER ARCHITECTURE
A supercomputer is composed of processors, memory, I/O system, and an interconnect. The processors fetch and execute program instructions. This execution involves performing arithmetic and logical calculations, initiating memory accesses, and controlling the flow of program execution. The memory system stores the current state of a computation. A processor or a group of processors (an SMP) and a block of memory are typically packaged together as a node of a computer. A modern supercomputer has hundreds to tens of thousands of nodes. The interconnect provides communication among the nodes of the computer, enabling these nodes to collaborate on the solution of a single large problem. The interconnect also connects the nodes to I/O devices, including disk storage and network interfaces. The I/O system supports the peripheral subsystem, which includes tape, disk, and networking. All of these subsystems are needed to provide the overall system. Another aspect of providing an overall system is power consumption. Contemporary supercomputer systems, especially those in the top 10 of the TOP500, consume in excess of 5 megawatts. This necessitates the construction of a new generation of supercomputer facilities (e.g., for the Japanese Earth Simulator, the Los Alamos National Laboratory, and the Lawrence Livermore National Laboratory). Next-generation petaflops systems must consider power consumption in the overall design.
Scaling of Technology
As semiconductor and packaging technology improves, different aspects of a supercomputer (or of any computer system) improve at different rates. In particular, the arithmetic performance increases much faster than the local and global bandwidth of the system. Latency to local memory or to a remote node is decreasing only very slowly. When expressed in terms of instructions executed in the time it takes to communicate to local memory or to a remote node, this latency is increasing rapidly. This nonuniform scaling of technology poses a number of challenges for supercomputer architecture, particularly for those applications that demand high local or global bandwidth.
Figure 5.1 shows how floating-point performance of commodity microprocessors, as measured by the SPECfp benchmark suite, has scaled over time.1 The trend line shows that the floating-point performance of
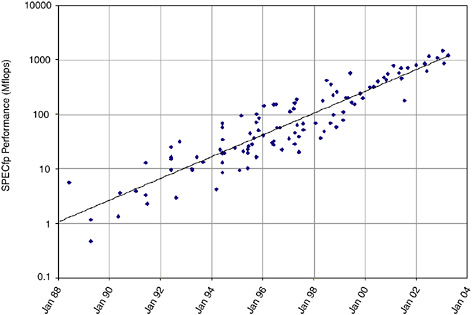
FIGURE 5.1 Processor performance (SPECfp Mflops) vs. calendar year of introduction.
microprocessors improved by 59 percent per year over the 16-year period from 1988 to 2004. The overall improvement is roughly 1,000-fold, from about 1 Mflops in 1988 to more than 1 Gflops in 2004.
This trend in processor performance is expected to continue, but at a reduced rate. The increase in performance is the product of three factors: circuit speed (picoseconds per gate), pipeline depth (gates per clock cycle), and instruction-level parallelism (ILP) (clock cycles per instruction). Each of these factors has been improving exponentially over time.2 However, increases in pipeline depth and ILP cannot be expected to be the source of further performance improvement, leaving circuit speed as the driver of much of future performance increases. Manufacturers are expected to compensate for this drop in the scaling of single-processor performance by placing several processors on a single chip. The aggregate performance of such chip multiprocessors is expected to scale at least as rapidly as the curve shown in Figure 5.1.
Figure 5.2 shows that memory bandwidth has been increasing at a
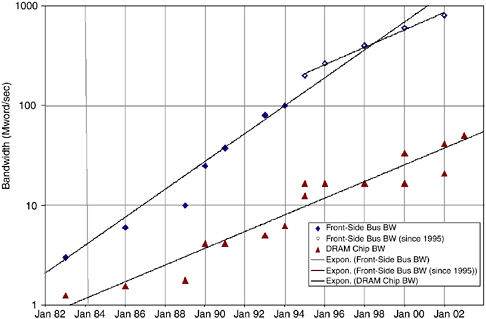
FIGURE 5.2 Bandwidth (Mword/sec) of commodity microprocessor memory interfaces and DRAM chips per calendar year.
much slower rate than processor performance. Over the entire period from 1982 to 2004, the bandwidth of commodity microprocessor memory systems (often called the front-side bus bandwidth) increased 38 percent per year. However, since 1995, the rate has slowed to only 23 percent per year. This slowing of memory bandwidth growth is caused by the processors becoming limited by the memory bandwidth of the DRAM chips. The lower line in Figure 5.2 shows that the bandwidth of a single commodity DRAM chip increased 25 percent per year from 1982 to 2004. Commodity processor memory system bandwidth increased at 38 percent per year until it reached about 16 times the DRAM chip bandwidth and has been scaling at approximately the same rate as DRAM chip bandwidth since that point. The figure gives bandwidth in megawords per second, where a word is 64 bits.
We are far from reaching any fundamental limit on the bandwidth of either the commodity microprocessor or the commodity DRAM chip. In 2001, chips were fabricated with over 1 Tbit/sec of pin bandwidth, over 26 times the 38 Gbit/sec of bandwidth for a microprocessor of the same year. Similarly, DRAM chips also could be manufactured with substantially higher pin bandwidth. (In fact, special GDDR DRAMs made for graphics systems have several times the bandwidth of the commodity
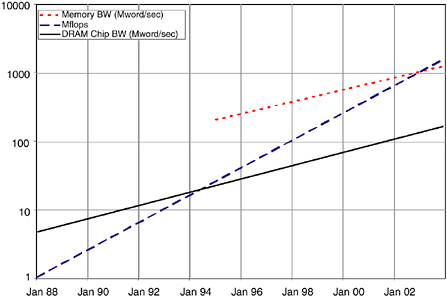
FIGURE 5.3 Arithmetic performance (Mflops), memory bandwidth, and DRAM chip bandwidth per calendar year.
chips shown here.) The trends seen here reflect not fundamental limits but market forces. These bandwidths are set to optimize cost/performance for the high-volume personal computer and enterprise server markets. Building a DRAM chip with much higher bandwidth is feasible technically but would be prohibitively expensive without a volume market to drive costs down.
The divergence of about 30 percent per year between processor performance and memory bandwidth, illustrated in Figure 5.3, poses a major challenge for computer architects. As processor performance increases, increasing memory bandwidth to maintain a constant ratio would require a prohibitively expensive number of memory chips. While this approach is taken by some high-bandwidth machines, a more common approach is to reduce the demand on memory bandwidth by adding larger, and often multilevel, cache memory systems. This approach works well for applications that exhibit large amounts of spatial and temporal locality. However, it makes application performance extremely sensitive to this locality. Applications that are unable to take advantage of the cache will scale in performance at the memory bandwidth rate, not the processor performance rate. As the gap between processor and memory performance continues to grow, more applications that now make good use of a cache will become limited by memory bandwidth.
The evolution of DRAM row access latency (total memory latency
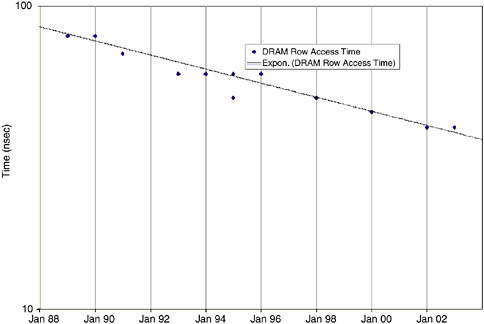
FIGURE 5.4 Decrease in memory latency (in nanoseconds) per calendar year.
is typically about twice this amount) is shown in Figure 5.4. Compared with processor performance (59 percent per year) or even DRAM chip bandwidth (25 percent per year), DRAM latency is improving quite slowly, decreasing by only 5.5 percent per year. This disparity results in a relative increase in DRAM latency when expressed in terms of instructions processed while waiting for a DRAM access or in terms of DRAM words accessed while waiting for a DRAM access.
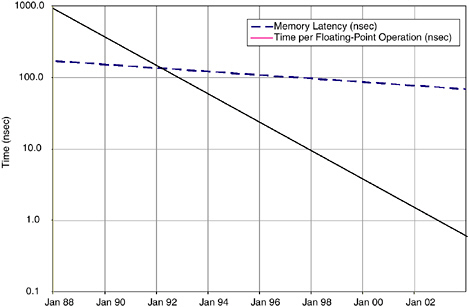
The slow scaling of memory latency results in an increase in memory latency when measured in floating-point operations, as shown in Figure 5.5. In 1988, a single floating-point operation took six times as long as the memory latency. In 2004, by contrast, over 100 floating-point operations can be performed in the time required to access memory.
There is also an increase in memory latency when measured in memory bandwidth, as shown in Figure 5.6. This graph plots the front-side bus bandwidth of Figure 5.2 multiplied by the memory latency of Figure 5.4. The result is the number of memory words (64-bit) that must simultaneously be in process in the memory system to sustain the front-side bus bandwidth, according to Little’s law.3Figure 5.6 highlights the
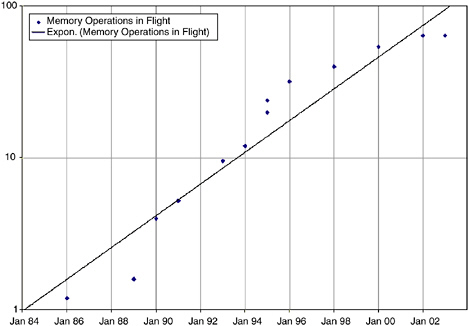
need for latency tolerance. To sustain close to peak bandwidth on a modern commodity machine, over 100 64-bit words must be in transfer simultaneously. For a custom processor that may have 5 to 10 times the bandwidth of a commodity machine, the number of simultaneous operations needed to sustain close to peak bandwidth approaches 1,000.
Types of Supercomputers
Supercomputers can be classified by the degree to which they use custom components that are specialized for high-performance scientific computing as opposed to commodity components that are built for higher-volume computing applications. The committee considers three classifications—commodity, custom, and hybrid:
-
A commodity supercomputer is built using off-the-shelf processors developed for workstations or commercial servers connected by an off-the-shelf network using the I/O interface of the processor. Such machines are often referred to as “clusters” because they are constructed by clustering workstations or servers. The Big Mac machine constructed at Virginia Tech is an example of a commodity (cluster) supercomputer. Commodity processors are manufactured in high volume and hence benefit from economies of scale. The high volume also justifies sophisticated engineering—for example, the full-custom circuits used to achieve clock rates of many gigahertz. However, because commodity processors are optimized for applications with memory access patterns different from those found in many scientific applications, they realize a small fraction of their nominal performance on scientific applications. Many of these scientific applications are important for national security. Also, the commodity I/O-connected network usually provides poor global bandwidth and high latency (compared with custom solutions). Bandwidth and latency issues are discussed in more detail below.
-
A custom supercomputer uses processors that have been specialized for scientific computing. The interconnect is also specialized and typically provides high bandwidth via the processor-memory interface. The Cray X1 and the NEC Earth Simulator (SX-6) are examples of custom supercomputers. Custom supercomputers typically provide much higher bandwidth both to a processor’s local memory (on the same node) and between nodes than do commodity machines. To prevent latency from idling this bandwidth, such processors almost always employ latency-hiding mechanisms. Because they are manufactured in low volumes, custom processors are expensive and use less advanced semiconductor technology than commodity processors (for example, they employ standard-cell design and static CMOS circuits rather than full-custom de-
-
sign and dynamic domino circuits). Consequently, they now achieve clock rates and sequential (scalar) performance only one quarter that of commodity processors implemented in comparable semiconductor technology.
-
A hybrid supercomputer combines commodity processors with a custom high-bandwidth interconnect—often connected to the processor-memory interface rather than the I/O interface. Hybrid supercomputers often include custom components between the processor and the memory system to provide latency tolerance and improve memory bandwidth. Examples of hybrid machines include the Cray T3E and ASC Red Storm. Such machines offer a compromise between commodity and custom machines. They take advantage of the efficiency (cost/performance) of commodity processors while taking advantage of custom interconnect (and possibly a custom processor-memory interface) to overcome the global (and local) bandwidth problems of commodity supercomputers.
Custom interconnects have also traditionally supported more advanced communication mechanisms, such as direct access to remote memory with no involvement of a remote processor. Such mechanisms lead to lower communication latencies and provide better support for a global address space. However, with the advent of standard interconnects such as Infiniband4 the “semantic gap” between custom interconnects and commodity interconnects has shrunk. Still, direct connection to a memory interface rather than an I/O bus can significantly enhance bandwidth and reduce latency.
The recently announced IBM Blue Gene/Light (BG/L) computer system is a hybrid supercomputer that reduces the cost and power per node by employing embedded systems technology and reducing the per-node memory. BG/L has a highly integrated node design that combines two embedded (IBM 440) PowerPC microprocessor cores, two floating-point units, a large cache, a memory controller, and network routers on a single chip. This BG/L chip, along with just 256 Mbyte of memory, forms a single processing node. (Future BG/L configurations may have more memory per node; the architecture is designed to support up to 2 Gbyte, although no currently planned system has proposed more than 512 Mbyte.) The node is compact, enabling 1,024 nodes to be packaged in a single cabinet (in comparison with 32 or 64 for a conventional cluster machine).
BG/L is a unique machine for two reasons. First, while it employs a commodity processor (the IBM 440), it does not use a commodity processor chip but rather integrates this processor as part of a system on a chip. The processor used is almost three times less powerful than with single-chip commodity processors5 (because it operates at a much lower clock rate and with little instruction-level parallelism), but it is very efficient in terms of chip area and power efficiency. By backing off on absolute single-thread processor performance, BG/L gains in efficiency. Second, by changing the ratio of memory to processor, BG/L is able to realize a compact and inexpensive node, enabling a much higher node count for a given cost. While custom supercomputers aim at achieving a given level of performance with the fewest processors, so as to be able to perform well on problems with modest amounts of parallelism, BG/L targets applications with massive amounts of parallelism and aims to achieve a given level of performance at the lowest power and area budget.
Performance Issues
The rate at which operands can be brought to the processor is the primary performance bottleneck for many scientific computing codes.6,7 The three types of supercomputers differ primarily in the effective local and global memory bandwidth that they provide on different access patterns. Whether a machine has a vector processor, a scalar processor, or a multithreaded processor is a secondary issue. The main issue is whether it has high local and global memory bandwidth and the ability to hide memory latency so as to sustain this bandwidth. Vector processors typically have high memory bandwidth, and the vectors themselves provide a latency hiding mechanism. It is this ability to sustain high memory bandwidth that makes the more expensive vector processors perform better for many scientific computations.
A commodity processor includes much of its memory system (but little of its memory capacity) on the processor chip, and this memory system is adapted for applications with high spatial and temporal locality. A typical commodity processor chip includes the level 1 and level 2 caches
on the chip and an external memory interface that limits sustained local memory bandwidth and requires local memory accesses to be performed in units of cache lines (typically 64 to 128 bytes in length8). Scientific applications that have high spatial and temporal locality, and hence make most of their accesses from the cache, perform extremely well on commodity processors, and commodity cluster machines represent the most cost-effective platforms for such applications.
Scientific applications that make a substantial number of irregular accesses (owing, for instance, to sparse memory data organization that requires random access to noncontiguous memory words) and that have little data reuse are said to be scatter-gather codes. They perform poorly on commodity microprocessors, sustaining a small fraction of peak performance, for three reasons. First, commodity processors simply do not have sufficient memory bandwidth if operands are not in cache. For example, a 3.4-GHz Intel Xeon processor has a peak memory bandwidth of 6.4 Gbyte/sec, or 0.11 words per flops; in comparison, an 800-MHz Cray X1 processor has a peak memory bandwidth of 34.1 Gbyte/sec per processor, or 0.33 words per flops; and a 500-MHz NEC SX-6 has a peak memory bandwidth of 32 Gbyte/sec, or 0.5 words per flops. Second, fetching an entire cache line for each word requested from memory may waste 15/16 of the available memory bandwidth if no other word in that cache line is used—sixteen 8-byte words are fetched when only one is needed. Finally, such processors idle the memory system while waiting on long memory latencies because they lack latency-hiding mechanisms. Even though these processors execute instructions out of order, they are unable to find enough independent instructions to execute to keep busy while waiting hundreds of cycles for main memory to respond to a request. Note that low data reuse is the main impediment to performance on commodity processors: If data reuse is high, then the idle time due to cache misses can be tolerated, and scatter-gather can be performed in software, with acceptable overhead.
There are several known techniques that can in part overcome these three limitations of commodity memory systems. However, they are not employed on commodity processors because they do not improve cost/ performance on the commercial applications for which these processors are optimized. For example, it is straightforward to build a wider interface to memory, increasing the total bandwidth, and to provide a short or sectored cache line, eliminating the cache line overhead for irregular accesses.
A latency-hiding mechanism is required to sustain high memory bandwidth, and hence high performance, on irregular applications. Such a mechanism allows the processor to initiate many memory references before the response to the first reference is received. In short, it allows the processor to fill the memory system pipeline. Without a latency-hiding mechanism, the processor idles waiting for a response from memory, and memory bandwidth is wasted, since no new requests are initiated during the idle period.
Common approaches to latency hiding, including multithreading and vectors (or streams), use parallelism to hide latency. A multithreaded processor uses thread-level parallelism to hide latency. When one thread needs to wait for a response from memory, the processor switches to another thread. While some commodity processors provide limited multithreading, they fall short of the tens to hundreds of threads needed to hide main memory latency—currently hundreds of cycles and growing. Vectors or streams use data parallelism9 to hide latency. Each vector load instruction loads a vector (e.g., up to 64 words on the Cray X1), allowing a small number of instructions to initiate a large number of memory references, filling the memory pipeline.
Architectural organizations that enhance locality reduce bandwidth demand, complementing a high-bandwidth memory system. Two such organizations are currently being actively studied: processor-in-memory (PIM) and stream processing. A PIM machine integrates processors near or on the memory chips, allowing data to be operated on locally in memory. This approach is advantageous if there are large amounts of spatial locality—data can be operated on in place rather than having to be moved to and from a remote processor, reducing demand on bandwidth. Current research is focused on developing compilation techniques to exploit this type of spatial locality and on quantifying this locality advantage for programs of interest.
Stream processors exploit temporal locality by providing a large (100 kbyte or more) software-managed memory, the stream register file, and reordering programs so that intermediate results are stored in the stream register file and then immediately consumed without ever being written to memory. Short-circuiting intermediate results through this large register file greatly reduces demand on the memory system. There is some current software research on compilation techniques to take advantage of
explicit data staging and on organizations to integrate software-managed memory with hardware-managed caches.
Global bandwidth issues are similar to local bandwidth issues but also involve the interconnection network and network interface. Because the cost of bandwidth increases with distance it is prohibitively expensive to provide flat memory bandwidth across a supercomputer. Even the best custom machines have a bandwidth taper with a local to global bandwidth ratio of about 10:1. Similarly, latency increases across a machine. In the past, well-designed custom machines exhibited global latencies that were only a few times local latency (e.g., 600 cycles to access global memory and 200 cycles to access local memory). Similar ratios will become harder to support in the future as the physical size of current systems increases and the absolute speed of light bounds global latency to be at least a few hundreds of nanoseconds.
Most commodity cluster machines employ off-the-shelf interconnect (such as Gigabit Ethernet) that is connected to the I/O buses of the processing nodes. This results in very low global bandwidth and high global latency (for instance, 10,000 cycles is not unusual). Moreover, software libraries are used to initiate message passing data transfers between processing nodes. The overhead of executing these library calls is sufficiently high that transfers must be aggregated into large units, often thousands of bytes, to amortize the overhead. This aggregation complicates the programming of these machines for programs where the natural transfer size is a few words.
As with local bandwidth, there are several known techniques to address global bandwidth and latency. These techniques are not typically employed in commodity interconnects but can be used in hybrid machines. Such machines cannot widen the memory interface of a commodity microprocessor. However, they can provide an external memory interface that has a wide path to the actual memory chips, supports efficient single-word access, and hides latency by allowing many remote accesses to be initiated in parallel (as with T3E E-registers). It is quite straightforward to interface the interconnection network to the processor-memory interface. The network interface can generate automatically a network request message for each memory access request to a remote address (global address space); it can process arriving requests and generate reply messages with no involvement from the main processor.
A wealth of technologies exists for building fast interconnection networks. High-speed electrical and optical signaling technology enables high raw bandwidth to be provided at reasonable cost. High-radix routers enable tens of thousands of nodes to be connected with just a few hops, resulting in both low cost and low latency. However, the software-driven, I/O-bus-connected interfaces of commodity cluster machines are
unable to take advantage of the bandwidth and latency that can be provided by state-of-the-art networks.
The local and global memory bandwidth bottleneck is expected to become a more serious problem in the future due to the nonuniform scaling of technology, as explained in the preceding section. Memory latency hiding is becoming increasingly important as processor speed increases faster than memory access time. Global latency hiding is becoming increasingly important as global latency becomes constrained by the speed of light (see Table 5.1), while processor speeds continue to increase. The cost and power of providing bandwidth between chips, boards, and cabinets is decreasing more slowly than the cost and power of providing logic on chips, making the cost of systems bandwidth dominated by the cost of global bandwidth.
Another trend is the increased complexity of supercomputers and the increased variety of supercomputing platforms. A vector supercomputer will have at least three levels of parallelism: vector parallelism within a processor, thread parallelism across processors within an SMP, and internode parallelism. The synchronization and communication mechanisms will have very different performance and semantics at each level. Performance of commodity processors is affected by their cache hierarchy, which often includes three levels of caches, each with a different structure, as well as a translation lookaside buffer to cache page table entries. The processor performance is also affected by the performance of mechanisms such as branch prediction or cache prefetching, which attempt to hide various latencies. Many supercomputing applications stretch the capabilities of the underlying hardware, and bottlenecks may occur in many different parts of the system. As a result, small changes in the application
TABLE 5.1 Parallel Hardware Trends
|
|
Annual change (%) |
Typical value in 2004 |
Typical value in 2010 |
Typical value in 2020 |
|
No. of processors |
20 |
4,000 |
12,000 |
74,000 |
|
General bandwidth (Mword/sec) |
26 |
65 (= 0.03 word/flops) |
260 (= 0.008 word/flops) |
2,600 (= 0.0008 word/flops) |
|
General latency (nsec) |
(28) |
2,000 (= 4,000 flops) |
280 (= 9,000 flops) |
200 (= 670,000 flops) |
|
MPI bandwidth (Mword/sec) |
26 |
65 |
260 |
2,600 |
|
MPI latency (nsec) |
(28) |
3,000 |
420 |
300 |
code can result in large changes in performance. Similarly, the same application code may exhibit a very different behavior on two fairly similar hardware platforms.
The largest supercomputers today include many thousands of processors, and systems with close to 100,000 processors are being built. Commodity processors are often designed to have a mean time to failure (MTTF) of a few years—there is no incentive to have the MTTF much longer than the average lifetime of a processor. Systems consisting of thousands of such processors have an MTTF that is measured in hours, so that long-running applications have to survive multiple failures of the underlying hardware. As hundreds of thousands of such processors are assembled in one supercomputer, there is a risk that the MTTF of a large supercomputer will be measured in minutes, creating a significant problem for a commodity supercomputer. Hardware mechanisms can be used to provide transparent recovery from such failures in custom supercomputers and, to a lesser extent, in hybrid supercomputers.
Trade-offs
It is important to understand the trade-offs among various supercomputer architectures. The use of custom processors with higher memory bandwidth and effective latency-hiding mechanisms leads to higher processor performance for the many scientific codes that have poor temporal and spatial locality. One can compensate for lower node performance in commodity systems by using more nodes. But the amount of parallelism available in a problem of a given size is limited; for example, in an iterative mesh algorithm, the level of parallelism is bounded by the number of points in the mesh. Furthermore, the parallel efficiency of computations decreases as one increases the number of processors used (each additional processor contributes slightly less).
One reason for decreasing returns from larger amounts of parallelism is Amdahl’s law, which states that if a fraction s of a program’s execution time is serial, then the maximum potential speedup is 1/s. For example, if 1 percent of the code is serial, then there is very little gain from using more than 100 processors.
Another reason is that the relative overhead for communication between processors increases as more processors are used. Many computations proceed in alternating computation and communication phases; processors compute independently during the computation phase and synchronize and exchange data during the communication phase. As the number of processors is increased, the amount of computation done by each processor during a computation phase decreases, and the synchronization overhead becomes a higher fraction of the total execution time.
Many computations exhibit a surface-to-volume behavior that leads to relatively more data being exchanged when the computation is split among a larger number of processors. Thus, an iterative algorithm on a three-dimensional Cartesian mesh is parallelized by allocating to each processor a subcube; communication involves exchanges between grid points at the boundary of the subcubes. The number of points per subcube, hence the number of operations performed in a computation phase, decreases in proportion to the number p of processors used. But the surface of the subcubes, hence the amount of data exchanged between subcubes, decreases in proportion to p2/3.
Load balance becomes more of an issue as the number of nodes is increased. As fewer data points are processed per node, the variance in execution time across nodes increases. This variance causes many nodes to idle while waiting for the most heavily loaded nodes to complete execution.
Other factors reduce the relative performance or increase the relative cost of very large clusters. Having more nodes often results in higher failure rates. To compensate, one needs more frequent checkpoints, which take time. More frequent checkpoints and restarts increase the relative overhead for error tolerance. The cost of some components of the system (in particular, the interconnect) increases faster than linearly with the number of nodes. The performance of various system services and tools may decrease: For example, it may take longer to load and start a job; debuggers and performance tools may not scale. Total power consumption may be higher, and the need for more floor space may be a practical obstacle.
Custom supercomputers are a good way to achieve lower time-to-solution performance for applications that have poor temporal and spatial locality and for applications that have limited amounts of parallelism or fast-decreasing parallel efficiency. Because of their limited volumes, custom processors are significantly more expensive than commodity processors. Thus, in many cases, the reduction in execution time is achieved at the expense of an increase in cost per solution.
The use of fewer, more powerful processors also typically reduces programming effort. Consider, for example, a weather code that simulates the atmosphere by discretizing the simulated atmosphere into cubic cells. If more processors are used, then each processor is allocated fewer cells. A code that partitions the cells in one dimension (longitude) is simpler than a code that partitions them in two dimensions (longitude and latitude), and such a code is simpler than a code that partitions cells in three dimensions (longitude, latitude, and altitude). If finer partitioning is needed, partitioning along more dimensions will be required. If it is acceptable to run the code only on a custom supercomputer, or to use a
custom supercomputer for the more performance-demanding runs, then the programming time is reduced. (Weather codes are now adapted to run on each type of supercomputer platform; however, many codes run by intelligence agencies are customized to one platform.)
The advantages of a custom interconnect and custom interconnect interface can be understood in a similar way. If the interconnect has higher effective bandwidth and lower latency, then the synchronization and communication overheads are smaller, parallel efficiency increases, and it becomes possible to apply efficiently a greater number of processors on a problem of a given size in situations where performance does not scale well because of communication costs. One can more easily dynamically load balance a computation by allowing idle processors to process data points stored on other nodes. In addition, a custom interconnect simplifies programming because one need not aggregate communications into large messages: A custom interconnect and custom interface will typically provide better support for shared name space programming models, which are generally accepted to reduce programming overheads. (Here again, the reduction is most significant for codes that will only run on machines with custom interconnects.)
In summary,
-
Commodity supercomputers have a cost advantage for many scientific computing applications; the advantage weakens or disappears for applications with poor temporal and spatial locality or for applications with stringent time-to-solution requirements, where custom supercomputers do better by reducing both programming time and execution time. As the memory gap continues to increase, the relative performance of commodity supercomputers will further erode.
-
Many applications will scale up with better efficiency on hybrid supercomputers than on commodity supercomputers; hybrid supercomputers can also support a more convenient programming model.
The preceding discussion was processor-centric. A slightly different perspective is achieved by a memory-centric view of parallel computations. For codes where data caches are not effective, performance is determined by the rate at which operands are brought from memory. The main memory of custom processors has similar latency to the main memory of commodity processors; in order to achieve a given level of performance, both need to sustain the same number of concurrent memory accesses. From the memory perspective, custom architectures do not reduce the amount of parallelism needed to support a given level of performance but enable more memory parallelism per processor; interprocessor parallelism is replaced by intraprocessor parallelism, where one processor sup-
ports a larger number of concurrent memory operations. An important advantage is that synchronization and communication among operations executed on the same processor are much faster than synchronization and communication across processors. The faster synchronization and communication also enable finer-grained parallelism to be efficiently exploited, in effect exposing more parallelism than is available internode. Thus, the shift to custom processors can help speed up computations that have enough intrinsic parallelism (significantly more than the number of custom processors used) and that exhibit a surface-to-volume behavior so that most communications and synchronization are intranode. Another advantage is better utilization of the processor and memory bus on applications with low cache reuse.
The memory-centric discussion does not change the basic conclusions reached on the relative advantages of custom or hybrid supercomputers, but it introduces some caveats: To take advantage of custom supercomputers, one needs problems where the level of intrinsic parallelism available is much higher than the number of processors and where most communications are local. One often needs a multilevel problem decomposition and different mechanisms for extracting intranode and internode parallelism. Furthermore, vector processors support only a restricted form of intranode parallelism—namely, data parallelism where the same operation is applied to all the components of a vector. Codes need to be amenable to this form of parallelism in order to take advantage of intranode parallelism.
Trends in Supercomputer Architecture
Supercomputer evolution is driven by many forces.10 Moore’s law provides semiconductor components with exponentially increasing numbers of devices. As semiconductor technology evolves, commodity microprocessors improve in performance. The different scaling rates of components (e.g., processors improving faster than memory and interconnect bandwidth) create a need for novel architectures and software to compensate for the gap. At the same time, new applications drive demands for processing, global and local bandwidth, and I/O bandwidth.
Some evolution is parametric—that is, just a scaling of existing architecture and software. Replacing the processors in a machine with a new
TABLE 5.2 Hardware Trends
|
|
Annual change (%) |
Typical value in 2004 |
Typical value in 2010 |
Typical value in 2020 |
|
Single-chip floatingpoint performance (Gflops) |
59 |
2 |
32 |
3,300 |
|
Front-side bus bandwidth (Gword/sec) |
23 |
1 (= 0.5 word/flops) |
3.5 (= 0.11 word/flops) |
27 (= 0.008 word/flops) |
|
DRAM bandwidth (Mword/sec) |
25 |
100 (= 0.05 word/flops) |
380 (= 0.012 word/flops) |
3,600 (= 0.0011 word/flops) |
|
DRAM latency (nsec) |
(5.5) |
70 (= 140 flops or 70 loads) |
50 (= 1,600 flops or 170 loads) |
28 (= 94,000 flops or 780 loads) |
generation of faster processors and the memories with a new generation of larger memories is an example of parametric evolution. This evolution is relatively simple (all that is required is integration), no new hardware or software technology needs to be developed, and old software runs with, at most, minor changes.
As different parts of the system scale at different rates, new bottlenecks appear. For example, if processor speed increases but the interconnect is not improved, then global communication may become a bottleneck. At some point, parametric evolution breaks down and qualitative changes to hardware and software are needed. For example, as memory latency (measured in processor cycles) increases, at some point a latency-hiding mechanism is needed to sustain reasonable performance on nonlocal applications. At this point, vectors, multithreading, or some other mechanism is added to the architecture. Such a change is complex, requiring a change in software, usually in both systems software (including compilers) and applications software. Similarly, increased latency may necessitate different software mechanisms, such as dynamic load balancing.
Table 5.2 shows expected parametric evolution of commodity components used in supercomputers—summarizing the trends shown earlier in Figure 5.1 through Figure 5.6.11 As explained previously, the annual 59 percent improvement in single processor speed is expected to decrease in
the future. However, the committee expects that processor chips will compensate for that by putting several processors on each chip to continue to scale the performance per chip at 59 percent annually. The numbers in Table 5.2 for 2010 and 2020 reflect this scaling of chip multiprocessors.
Table 5.2 highlights the divergence of memory speeds and computation speeds that will ultimately force an innovation in architecture. By 2010, 170 loads (memory reads) will need to be executed concurrently to keep memory bandwidth busy while waiting for memory latency, and 1,600 floating-point arithmetic operations can be performed during this time. By 2020, 780 loads must be in flight, and 94,000 arithmetic operations can be performed while waiting on memory. These numbers are not sustainable. It is clear that systems derived using simple parametric evolution are already greatly strained and will break down completely by 2020. Changes in architecture and/or programming systems are required either to enhance the locality of computations or to hide large amounts of latency with parallelism, or both.
It is not clear if commodity processors will provide the required innovations to overcome this “memory wall.” While the PC and server applications for which commodity processors are tuned also suffer from the increased gap between arithmetic and memory performance, they exhibit sufficient spatial and temporal locality so that aggressive cache memory systems are largely sufficient to solve the problem. If commodity processors do not offer latency-hiding and/or locality-enhancing mechanisms, it is likely that a smaller fraction of scientific applications will be adequately addressed by these processors as the processor-memory performance gap grows.
Figure 5.7 shows the increase in the number of processors for high-end systems. At the high end, the number of processors is increasing approximately 20 percent per year. The committee sees no technology limits that would cause this trend to change. Extrapolating this trend to 2020 indicates a number of processors in the 100,000 range; since each of them will have significant amounts of concurrency for latency hiding, systems will run tens of millions of concurrent operations.
Figures 5.8 and 5.9 show measured latency (in microseconds) and bandwidth (in megabytes per second) for MPI programs between two nodes in a variety of commodity and hybrid supercomputer systems.12
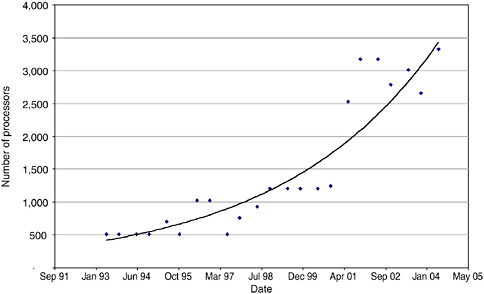
FIGURE 5.7 Median number of processors of the 10 leading TOP500 systems.
(The committee considers MPI measurements because the algorithmic models below are based on message passing programs.) Least-squares fits to the data show an annual improvement of 28 percent in latency and 29 percent in bandwidth, albeit with substantial variation. (R2 values for the formulas are 0.83 and 0.54, respectively.) The improvement rates for lower-level communication systems (e.g., SHMEM on the Cray T3E) are similar—28 percent for latency and 26 percent for bandwidth.
The committee summarized the expected evolution of parallel systems in Table 5.1. A later section will discuss these extrapolations in more detail. For now, the committee simply points out that even if the individual components continue to improve parametrically, the overall system will see radical changes in how they are balanced. Parametric evolution of the system as a whole is unsustainable, and current machines arguably have already moved into a problematic region of the design space.
The numbers in Table 5.1 should be taken with a grain of salt, as they integrate factors such as software overheads and transmission delays that evolve at different rates. Furthermore, light traverses 60 m in 200 nsec, less than the diameter of the largest supercomputer installations; the decrease in general latency will slow down as one approaches this limit. However, even the numbers are grossly inaccurate; they clearly show that a parametric evolution of current communication architectures is not sustainable.
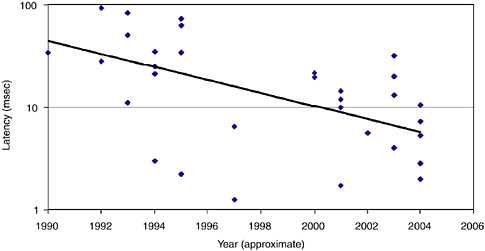
FIGURE 5.8 Latency.
FIGURE 5.9 Bandwidth.
SUPERCOMPUTING ALGORITHMS
An algorithm is the sequence of basic operations (arithmetic, logic, branches, and memory accesses) that must be performed to solve the user’s task. To be useful, an algorithm must solve the user’s problem with sufficient accuracy and without using too much time or memory (exactly how much accuracy, time, or memory is enough depends on the applica-
tion). Improvements in algorithms can sometimes improve performance as much as or more than improvements in hardware and software do. For example, algorithms for solving the ubiquitous linear system arising from the Poisson equation13on a regular three-dimensional grid with n grid points have improved over time from needing O(n7/3) to O(n) arithmetic operations.14 Such algorithmic improvements can contribute as much to increased supercomputer performance as decades of hardware evolution,15 even when the O(n) algorithms run at a much lower fraction of peak machine speed than the older O(n7/3) algorithms. While such dramatic breakthroughs are hard to predict, the rewards can be significant. Further research can lead to such breakthroughs in the many complicated domains to which supercomputers are applied.
There was considerable discussion of algorithms at the committee’s applications workshop, as well as at site visits and in the recent reports of other study groups.16 The presenters and reports concur that, although much is known about algorithms for solving scientific problems using supercomputing, a great deal more knowledge is needed. For some fields, the algorithms now in use will not solve the most challenging problems, even if they are run on the most capable systems expected to be available in a foreseeable future. For other fields, satisfactory algorithms of any kind remain to be developed. While these algorithmic needs arise from quite different application areas, they often have much in common.
The committee first describes the nature of the algorithms in common use, including their demands on the underlying hardware, and then summarizes some of their shortcomings and future challenges.
Solving Partial and Ordinary Differential Equations
Differential equations are the fundamental equations for many problems governed by the basic laws of physics and chemistry. Traditionally,
much algorithmic research has been devoted to methods for their solution. These continuous equations are typically discretized by replacing them by algebraic equations for a (large) set of discrete variables corresponding to points or regions on a mesh approximating the physical and/ or time domain of the continuous equations. (Alternatively, the solution could be represented by a collection of particles, vortices, or other discrete objects.) These equations arise, for example, in fusion, accelerator design, nuclear physics, weapons design, global climate change, reactive chemistry, astrophysics, nanotechnology, contaminant transport, material science, drug design, and related fields. A more recent variation on this theme is stochastic differential equations, where one or more of the terms represent a random process of some kind, like diffusion. In this case the goal is to compute certain statistics about the set of possible solutions. Included in this category of algorithms is work on new ways to discretize the equations and work on fast solution methods, such as multigrid and other multilevel methods, which use a hierarchy of meshes.
The demands these algorithms place on hardware depend both on the method and on the differential equation. Elliptic partial differential equations (PDEs), of which the aforementioned Poisson equation is the canonical example, have the property that the solution at every mesh point depends on data at every other mesh point, which in turn places demands on memory and network bandwidth. Their discretizations often use so-called “implicit difference schemes,” which lead to large sparse systems of equations to be solved. On the other hand, the data at distant mesh points can often be compressed significantly without losing much accuracy, ameliorating bandwidth needs (a property exploited both by multigrid methods and by some of the fast transforms discussed below). In contrast to elliptic equations, time-dependent equations may (e.g., parabolic PDEs arising in diffusion or heat flow or their approximations by systems of ordinary differential equations [ODEs]) or may not (e.g., hyperbolic PDEs arising in electromagnetics or, again, some ODEs) have the same global dependence at every time step and corresponding bandwidth need. In the case without global dependence, often discretized using so-called “explicit difference schemes,” communication only occurs between mesh points at processor boundaries, so that a surface-to-volume effect determines bandwidth needs. Some time-dependent equations (e.g., “stiff” ODEs) must be solved using communication-intensive implicit methods in order to avoid extremely small time steps. Even without global dependence, a time-dependent equation with a rapidly changing solution solved with a mesh that adapts to the solution may again have high bandwidth demands in order to support load balancing (see below). Finally, if the equation has a lot of “local physics” (e.g., as would a nuclear weapons simulation requiring the solution of complicated equa-
tions of state at each mesh point), then the correspondingly higher ratio of floating-point operations to memory operations makes performance less sensitive to bandwidth. This variety of behaviors can be found in many of the ASC codes.17
Long-standing open problems include overcoming the need for tiny (femtosecond) time steps in molecular dynamics simulations18 and finding better anisotropic radiation transport algorithms than flux-limited diffusion, discrete ordinates (Sn), or Monte Carlo,19 among many others. The desire to solve larger systems of equations describing more complicated phenomena (not all of which may be represented or discretized the same way) on more complicated domains spurs ongoing innovation in this area.
Mesh Generation
The committee considered both generating the above-mentioned initial mesh and adapting it during the solution phase. As for time to solution, it is often the process of generating the initial mesh that takes the most time. This is because it often requires a great deal of human intervention to create a suitable geometric model of a complicated physical system or object. Even when those models are available (as in the case of NASA’s space shuttle), creating a mesh suitable for simulation may take months using traditional methods. The shuttle in particular has benefited from recent breakthroughs in mesh generation,20 but many problems remain in producing three-dimensional meshes with guaranteed geometric and mathematical properties and in doing so efficiently in parallel or when memory is limited.
In addition to generating the initial mesh, hierarchies of meshes are needed for multigrid and multilevel methods, and producing these hierarchies in an automatic fashion so as to appropriately approximate the solution at each level of resolution is challenging. When the mesh represents a deforming material, algorithms are needed to deform the mesh as
|
17 |
Based on excerpts from the white paper “Computational Challenges in Nuclear Weapons Simulation,” by Charles F. McMillan et al., LLNL, prepared for the committee’s Santa Fe, N.M., applications workshop, September 2003. |
|
18 |
Molecular dynamic simulations use time steps of a few femtoseconds; some phenomena, such as protein folding, take many milliseconds. |
|
19 |
Expert Group on 3D Radiation Transport Benchmarks, Nuclear Energy Agency of the Organisation for Economic Cooperation and Development (OECD), <http://www.nea.fr/html/science/eg3drtb>. |
|
20 |
NASA, Office of Aerospace Technology Commercial Technology Division. 2003. “Faster Aerodynamic Simulation with Cart3D.” Spinoff 2003, p. 56. |
well. Meshes are also sometimes adapted during the solution process to have higher resolution (more points) in regions where the solution is complicated and fewer points in simple regions. The complicated region can move during solution; an example is the intricate flame front between burnt and unburnt gas in an internal combustion engine.21 Using a static mesh fine enough everywhere to resolve the solution would take orders of magnitude more work than using it only in complicated regions. Effective use of large numbers of parallel processors in these algorithms is an ongoing challenge, because the workload and load (im)balance changes unpredictably with the position of the complicated region.
Dense Linear Algebra
This class of algorithms for solving linear systems of equations, least squares problems, and eigenvalue problems in which all equations involve all or most variables, is epitomized by the Linpack benchmark discussed elsewhere in this report. These algorithms are among the least sensitive to memory and network bandwidth of any discussed here, provided the problems are large enough. Dense linear algebra still forms a significant fraction (but not majority) of the workload at some supercomputer centers. For example, NERSC reports that materials science applications representing 15 percent of their total cycles spend 90 percent of their time in dense linear algebra routines today.22 Recent research has focused on exploiting structure, in effect finding and using sparse representations “hidden” inside certain dense problems. It is worth noting that even in this relatively mature field, only a relatively small fraction of the algorithms with good sequential software implementations have good parallel software implementations.
Sparse Linear Algebra
The discrete equations on a mesh arising in a discretized differential equation are typically sparse (i.e., most equations involve just a few variables). It is critical to exploit this mathematical structure to reduce memory and arithmetic operations, rather than using dense linear algebra. Ideal algorithms scale linearly—that is, they take time proportional to nnz/p,
where nnz (“number of nonzeros”) is the total number of appearances of variables in all equations and p is the number of processors. In other words, an ideal algorithm performs just a constant amount of work per nonzero and communicates very little. Whether in fact a reasonably efficient (let alone ideal) algorithm can be found depends strongly on the structure of the equations (namely, which variables appear and with what coefficients), so there is a large set of existing algorithms corresponding to the large variety of problem structures.23 These algorithms are generally limited by memory and network bandwidth and are the bottlenecks in PDE solvers mentioned earlier, for PDEs where the solution at each point depends on data at all mesh points. General solution techniques (e.g., sparse Gaussian elimination) have been parallelized, but they are limited in scalability, especially for linear systems arising from three-dimensional PDEs. However, they remain in widespread use because of their reliability and ease of use. Iterative methods, which typically rely on the more scalable operation of matrix vector multiplication, can be much faster but often require careful problem-dependent design to converge in a reasonable number of iterations. As new exploitable problem structures arise and computer architectures change, algorithmic innovation is ongoing.
Discrete Algorithms
Discrete algorithms are distinguished from others in this summary by having few, if any, floating-point numbers required to define the inputs or outputs to the problem. Discrete algorithms can involve a wide array of combinatorial optimization problems arising in computational biology (for instance, looking for nearly matching sequences), the analysis of large data sets (finding clusters or other patterns in high-dimensional data sets), or even other parallel computing algorithms (balancing the workload or partitioning a sparse matrix among different parallel processors). Many of these problems are NP-hard (non-deterministic polynomial-time hard), meaning that an optimal solution would take impractically long to compute on any foreseeable computer, so that heuristic approximations are required. Again, the diversity of problems leads to a diversity of algorithms (perhaps involving floating point) and an ongoing potential for innovation.
Other discrete algorithms involve number theory (arising in cryptanalysis), symbolic algorithms for exact solutions to algebraic equations (arising in the intelligence community and elsewhere), and discrete event simulation and agent-based modeling (arising in traffic, epidemiology, and related simulations). It appears that relatively little work (at least work that has been made public) has been done to parallelize symbolic algorithms.
Fast Transforms
There are a variety of widely used fast transform methods—such as the fast Fourier transform (FFT), wavelets, the fast multipole method, kernels arising in quantum chemistry, and their numerous variations—where a clever reformulation changes, for example, an O(n2) algorithm into an O(n log n) algorithm. These reformulations exploit the underlying mathematical or physical structure of the problem to represent intermediate results in compressed forms that are faster to compute and communicate. A recent big advance is O(n) methods in electronic structures calculations. It is an ongoing challenge to adapt these methods to new problem structures and new computer architectures. Some of these algorithms (e.g., the fast multipole method) limit their bandwidth requirements by compressing and approximating distant data before sending them, whereas others (e.g., the FFT) need to communicate more intensively and so require more bandwidth to scale adequately. Fastest Fourier transform in the West (FFTW)24 is a successful example of a system for automatically adapting an FFT algorithm to perform well on a particular problem size and a particular computer.
New Algorithmic Demands Arising from Supercomputing
In addition to opportunities to improve algorithms (as described above in the categories of differential equations, mesh generation, linear algebra, discrete algorithms, and fast transforms), there are new, cross-cutting algorithmic needs driven by supercomputing that are common to many application areas.
Disciplinary Needs
One reason for needing increased supercomputer performance is that many applications cannot be run using realistic parameter ranges of spa-
|
24 |
See <http://www.fftw.org>. |
tial resolution and time integration. For many such applications, applying more computer power with substantially the same algorithms can significantly increase simulation quality. For example, mesh resolution can be increased. But the need for higher-resolution analyses may also lead to the need for faster algorithms. For example, solving a problem 10 times larger than currently possible would require 10 times as powerful a machine using an algorithm with complexity O(n) but 100 times as powerful a machine using an algorithm with complexity O(n2). It is sometimes possible to use physics-based algorithms (like the fast multipole method) or physics-based preconditioners that exploit particular properties of the equations being solved. One important area needing research is scalable adaptive methods, where the computational work adapts depending on the complexity of the physical solution, making load balancing difficult as the solution changes over time. But in other applications, increased mesh resolution may require the development of new physics or algorithms to resolve or approximate phenomena at tiny scales. In some cases, submodels of detailed processes may be required within a coarser mesh (e.g., cloud-resolving submodels embedded within a larger climate model grid). Sometimes completely different physical models may be required (e.g., particle models instead of continuum models), which in turn require different algorithms. In some problems (such as turbulence), physically unresolved processes at small length or time scales may have large effects on macroscopic phenomena, requiring approximations that differ from those for the resolved processes. A similar example arises in molecular dynamics, where the molecular motions at the shortest time scales must currently be computed at intervals of 10–15 seconds to resolve reactions that may take a second or more; a new algorithm is needed to avoid the current bottleneck of 1015 sequential steps.
Interdisciplinary Needs
Many real-world phenomena involve two or more coupled physical processes for which individual models and algorithms may be known (clouds, winds, ocean currents, heat flow inside and between the atmosphere and the ocean, atmospheric chemistry, and so on) but where the coupled system must be solved. Vastly differing time and length scales of the different disciplinary models frequently makes this coupled model much harder to solve. Emerging application areas also drive the need for new algorithms and applications. Bioinformatics, for example, is driving the need to couple equation-driven numerical computing with probabilistic and constraint-driven computing.
Synthesis, Sensitivity Analysis, and Optimization Replacing Analysis
After one has a model that can be used to analyze (predict) the behavior of a physical system (such as an aircraft or weapons system), it is often desirable to use that model to try to synthesize or optimize a system so that it has certain desired properties, or to discover how sensitive the behavior is to parameter changes. Such a problem can be much more challenging than analysis alone. As an example, a typical analysis computes, from the shape of an airplane wing, the lift resulting from airflow over the wing by solving a differential equation. The related optimization problem is to choose the wing shape that maximizes lift, incorporating the constraints that ensure that the wing can be manufactured. Solving that problem requires determining the direction of change in wing shape that causes the lift to increase, either by repeating the analysis as changes to shape are tried or by analytically computing the appropriate change in shape. Similar optimization problems can arise in any manufacturing process, as can parameter identification problems (e.g., reconstructing biological images or Earth’s structure from measurements of scattered waves), finding stable molecular configurations, and optimizing control. This transition to synthesis, sensitivity analysis, and optimization requires improved algorithms in nonlinear solvers, mathematical optimization techniques, and methods for quantifying uncertainty.
Huge Data Sets
Many fields (e.g., biology) that previously had relatively few quantitative data to analyze now have very large amounts, often of varying type, meaning, and uncertainty. These data may be represented by a diversity of data structures, including tables of numbers, irregular graphs, adaptive meshes, relational databases, two- or three-dimensional images, text, or various combined representations. Extracting scientific meaning from these data requires coupling numerical, statistical, and logical modeling techniques in ways that are unique to each discipline.
Changing Machine Models
A machine model is the set of operations and their costs presented to the programmer by the underlying hardware and software. Algorithmic research has traditionally sought to minimize the number of arithmetic (or logical) operations. However, the most expensive operation on a machine is not arithmetic but, rather, fetching data from memory, especially remote memory. Furthermore, the relative costs of arithmetic and fetching data can change dramatically between machines and over time. This
has profound implications for algorithm design. Sometimes this means that the fastest algorithm must compress data that are needed far away before communicating them; this compression often involves approximations (which one must carefully bound) that rely on the detailed physics or other mathematical structure of the problem. The fast multipole method and multigrid algorithms are celebrated and widely used examples of this technique. In these examples, reducing arithmetic and reducing data fetching go hand in hand. But there are yet other examples (e.g., certain sparse matrix algorithms) where one must increase the amount of arithmetic substantially from the obvious algorithm in order to reduce memory fetches and so speed up the algorithm.25 As the machine model changes between technology generations or among contemporaneous platforms, an algorithm will probably have to be changed to maintain performance and scalability. This optimization process could involve adjusting a few parameters in the algorithm describing data layouts, running a combinatorial optimization scheme to rebalance the load, or using a completely different algorithm that trades off computation and communication in different ways. Successful tuning by hand is typically a tedious process requiring familiarity with everything from algorithms to compilers to hardware. Some success has been achieved in automating this process, but only for a few important algorithmic kernels, such as ATLAS26 for matrix-matrix multiplication or FFTW for fast Fourier transforms. Work is needed on these adaptive algorithms to make them more broadly applicable and available to more users.
SUPERCOMPUTING SOFTWARE
The software used for computing in general and supercomputing in particular has multiple purposes. The system software—the operating system, the scheduler, the accounting system, for example—provide the infrastructure for using the machine, independently of the particular applications for which it is used. The programming languages and tools help the user in writing and debugging applications and in understanding their performance. The applications codes directly implement the application. The software system is sometimes described as a stack of abstractions, in the sense that the operating system is the lowest level, programming lan-
guages and tools sit on top of the operating system, and the applications form the top layer. Each of the conceptual layers is important in the overall system, and each layer in a supercomputer system has special characteristics that distinguish it from the layers in other kinds of computing systems.
Supercomputing software has many requirements in common with software for other computing systems. Layered abstractions provide higher-level operations for most users, allowing them to reuse complex operations without needing the deep knowledge of the specialists writing the lower levels. Portability is essential, since many programs outlast their original platforms. In the supercomputing arena, a computer has a typical useful lifetime of 5 years, while many-decades-old applications codes are still in daily use. Execution efficiency is important in all areas, particularly for supercomputers, because of the high cost of the systems and the heavy demands of the applications. Ensuring correct results, a problem on all computers, is of course especially difficult on a large, complex system like a supercomputer.
Other issues are unique to supercomputer software. Foremost among these is the requirement for excellent scalability at all levels of the software. To benefit from parallel hardware, the software must provide enough concurrent operations to use all the hardware. For example, a supercomputer with a thousand processors needs many thousands of operations available for execution at all times—or many tens of thousands if custom processors are used. Today’s largest systems typically have on the order of 10,000 processors to keep busy concurrently. Future systems may push this degree of concurrency to 100,000 or 1 million processors and beyond, and the concurrency level within each processor will need to increase in order to hide the larger memory latency. In addition to having a high level of concurrency, scalable software needs to avoid sequential bottlenecks so as not to suffer from the consequences of Amdahl’s law, and it needs to manage the global communication and synchronization efficiently in order to reduce communication overheads.
Operating Systems and Management Software
Operating systems manage the basic resources of the system, such as the memory, the network interfaces, the processors, and the I/O devices. They provide services such as memory and process management to enable multiple executing programs to share the system and abstractions such as interfaces and file systems that both facilitate the programming layers above and reduce hardware dependence. Other key services they provide are security and protection, logging, and fault tolerance. Closely associated with those operating system roles is the management software
that provides interfaces for servicing users. Key components include user accounts, queuing systems, system monitors, and configuration management.
In the operating system arena, virtually all supercomputers today use some variant of UNIX, including such systems as AIX (from IBM), IRIX (SGI), Linux (open source), SUPER-UX (NEC), Tru64 (Hewlett-Packard), UNICOS (Cray), and MacOS X (Apple). A few projects have created supercomputer-class clusters running versions of Microsoft Windows; a prominent example of such a system is at the Cornell Theory Center, 146th on the June 2004 TOP500 list.
Management software for supercomputing is quite varied. For example, just within the top 10 machines on the TOP500 list are found at least four batch job submission systems (LSF, Batch Priority Scheduler, Distributed Production Control System, and LoadLeveler). Even among sites that use the same management tools, the configurations—for instance, the number of queues and the policies that control them—differ substantially. Although there are open source versions of some of these tools, most production sites use proprietary management software even if they use open source software such as Linux for other software components. This is probably due to limitations of the open source tools. For example, Portable Batch System (OpenPBS) supports up to 32 processors, not nearly enough for supercomputing use. Management software for supercomputing typically uses straightforward extensions or improvements to software for smaller systems, together with policies tailored to their user community.
It is challenging to scale an operating system to a large number of processors. A modern operating system is a complex multithreaded application with asynchronous, event-driven logic, many sequential bottlenecks, and little data locality. It is hard to scale such an application, and even harder to do so while maintaining full compatibility with a broadly used commercial operating system such as Linux or Windows. Many of the operating system services (and the programming tools) need to scale as the number of concurrent threads that are created. Thus, custom systems that achieve a given level of performance with fewer concurrent threads facilitate the scaling of these subsystems.
Large supercomputers are typically managed by multiple operating system images, each controlling one node. A single-system image (common file space, single login, single administrative point of control, etc.) is provided by a set of distributed services that coordinate and integrate the multiple kernels into one system in a way that provides scalability and fault tolerance. This approach creates a fundamental mismatch between the virtual machine provided by the operating system, which is loosely
coupled, and the application running atop this virtual machine, which is tightly coupled.
A key manifestation of this mismatch is the lack of concurrent scheduling. Most existing parallel programming models implicitly assume that the application controls a dedicated set of processors executing at the same speed. Thus, many parallel codes consist of an alternation of compute phases, where an equal amount of computation work is performed by each process and by global communication and synchronization phases. But a computation that frequently uses global synchronizations cannot tolerate nonsynchronized variations in computation speed that are due, for example, to asynchronous system activities (daemons, page misses, and so on). For example, suppose that each node spends 1 percent of its time handling system events and each event requires five times as long as it takes to execute a barrier (a synchronization of all active processes). If these system events occur simultaneously at all nodes, then the global loss of performance is 1 percent (as one might expect). However, if they occur at random times in a 100-node computation, then each barrier is statistically expected to be preceded by a system event, effectively raising the synchronization cost 500 percent. The effect is smaller on smaller systems, but still significant; for example, a 50-node system in the same circumstances would see a 250 percent synchronization cost increase. A programmer without detailed knowledge of the underlying operating system would be unable to design an appropriate program to compensate for this variation. Most supercomputer manufacturers (IBM, Hewlett-Packard, Cray) were surprised to encounter this problem on their systems, and most resolved it by various ad hoc means.
Some supercomputers run a microkernel on the compute nodes that reroutes many system functions to a service node running the full-function operating system. This approach reduces asynchronous system events on the compute nodes and also reduces the frequency of software failures. The implicit assumption in this approach is that page faults can be virtually eliminated.
The “crystalline” model of a parallel computer, where all processes execute the same quantity of work at the same speed, is harder and harder to maintain as the number of processors increases and low-probability events (in particular, recoverable failures) are more likely to disturb the smooth progress of individual processes. The model is increasingly inappropriate for complex, dynamic, heterogeneous applications. Changes in operating system structures to reduce asynchrony or in programming models to tolerate asynchrony (or, likely, both) will be required. Indeed, the more recent programming languages described in the next section tend to allow looser synchronization. However, it remains for applica-
tions and algorithms to utilize this freedom to improve their real-world performance.
Programming Models, Programming Languages, and Tools
A programming model is an abstract conceptual view of the structure and operation of a computing system. For example, a uniform shared memory (or a global addressing) model supports the abstraction that there is one uniformly addressable storage (even though there may be multiple physical memories being used). The use of a given programming model requires that the operating system, the programming languages, and the software tools provide the services that support that abstraction. In the context of this discussion, the programming languages at issue are the ones in which applications are written, not the ones in which the systems software is written (although the tools that support the applications programming language must provide appropriate interfacing with systems software). Programming tools provide a means to create and run programs. Key tools include compilers, interpreters, debuggers, and performance monitors.
The programming languages and tools for supercomputing are diverse. Many applications, in fact, use components written in more than one language. A useful taxonomy of languages might be based on the parts of the supercomputer under the control of language operations. Sequential imperative languages, such as C and Fortran, are commonly used to program individual processing elements (which may be single-processor nodes or threads in multithreaded systems). Nodes consisting of several processors with a shared memory are typically programmed using modest extensions to these languages, such as the OpenMP27 extensions, which have bindings for C and Fortran. Collections of nodes (or processors) that do not share memory are programmed using calls to run-time system libraries for message passing, such as MPI, or other communications paradigms (for instance, one-sided communication). There has been some progress in the use of better-integrated parallel languages. As their names suggest, High-Performance Fortran (HPF)28 and Co-Array Fortran29 are parallel dialects of Fortran, and UPC30 is a parallel version of C. There are also research languages based on Java, such as Titanium.31
|
27 |
See <http://www.openmp.org>. |
|
28 |
|
|
29 |
See <http://www.co-array.org/>. |
|
30 |
See <http://upc.gwu.edu/>. |
|
31 |
These languages support a shared memory model, in the sense that a single partitioned global name space allows all executing threads to access large shared data stored in shared (but distributed) arrays. At the full-system level, scripting languages (e.g., Python and Perl) are often used to link components written in all of the languages mentioned above. Object-oriented languages such as C++ and component frameworks such as Common Component Architecture (CCA)32 and Cactus33 are also used to provide a layer of abstraction on components written in lower-level languages. Of course, each language requires its own compiler and development tools. Some sharing of tools is possible in principle but less common in practice. One exception is the TotalView debugger,34 which supports Fortran, C, OpenMP, and MPI.
Parallel programming languages and parallel programming models are necessarily compromises between conflicting requirements. Although many of the current compromises are deemed to be inadequate, it is not clear what a better solution should be. The use of dialects of Fortran and C stems, in part, from a desire to migrate legacy software and tools and to exploit existing user expertise. The ecosystem complexity described in Chapter 6 makes it difficult to experiment with new approaches.
To improve programmer productivity it would be desirable to have languages with a higher level of abstraction. A higher level of abstraction and/or a more restricted model of parallelism are essential in order to be able to comprehend the behavior of a large parallel code, debug it, and tune it. It is not possible to understand the behavior of 10,000 concurrent threads that may interact in unexpected ways. Although many bugs can be found on smaller runs, some problems only manifest themselves at large scales; therefore, the ASC program since at least 1998 has listed support for thousands of processors as one of its top requirements for parallel debuggers.35 However, controlling concurrency and communication are essential activities in parallel algorithm design; a language that does not express parallelism and communication explicitly forces the programmer to reverse-engineer the implementation strategy used, so as to guess how much concurrency or how much communication will be generated by a given program. For example, a compiler for a sequential language that generates code for a vector machine may be very sensitive to exactly how the program is written, whereas a language with vector operations makes that form of parallelism explicit. Even if the compiler determines that a
|
32 |
See <http://www.cca-forum.org/>. |
|
33 |
See <http://www.cactuscode.org/>. |
|
34 |
See <http://www.etnus.com/>. |
|
35 |
See <http://www.lanl.gov/projects/asci/PSE/ASCIdebug.html/>. |
particular vector operation is not profitable (e.g., owing to short vector length), the notation may still help optimization (e.g., by improving the program analysis information available).
It is desirable to have portability across platforms. Portability is needed both to leverage the variety of platforms that a community may have access to at a given point in time and to handle hardware evolution. Supercomputer applications often outlive the hardware they were designed for: A typical application may be used for 20 years, while the useful life of a supercomputer is more often 5 years. (Currently, the oldest machine on the June 2004 TOP500 list is 7 years old.) By the same token, one wants good performance on each platform. Parallel platforms are distinguished not only by low-level details such as the precise instruction set of processors; they also may have very different performance characteristics, with numbers of processors ranging from just a few to 100,000, with global latency ranging from hundreds of cycles to more than 10,000 cycles, and so on. In some cases, different algorithms are needed to accommodate such large differences. In general, the more disparate the set of target platforms, the harder it is for a single computer program to be mapped efficiently onto all target platforms by compiler and run time; some user help is needed. In practice, supercomputer codes written to port to a multiplicity of platforms contain multiple versions tuned for different platforms. It is not clear how one improves this situation in general. Some research projects have attempted this in specific cases, including packages that generate tuned versions of library codes such as ATLAS36 and FFTW,37 domain-specific program generators such as the Tensor Contraction Engine38 and Spiral,39 and dynamic code generators such as tcc.40
Supercomputer platforms differ not only in the relative performance of their interconnects but also in the communication mechanisms sup-
|
36 |
R. Clint Whaley, Antoine Petitet, and Jack Dongarra. 2001. “Automated Empirical Optimization of Software and the ATLAS Project.” Parallel Computing 27(1-2):3-35. |
|
37 |
See <http://www.fftw.org/>. |
|
38 |
G. Baumgartner, A. Auer, D.E. Bernholdt, A. Bibireata, V. Choppella, D. Cociorva, X. Gao, R.J. Harrison, S. Hirata, S. Krishnamoorthy, S. Krishnan, C. Lam, M. Nooijen, R.M. Pitzer, J. Ramanujam, P. Sadayappan, and A. Sibiryakov. In press. “Synthesis of High-Performance Parallel Programs for a Class of Ab Initio Quantum Chemistry Models.” Proceedings of the IEEE. |
|
39 |
Markus Püschel, Bryan Singer, Jianxin Xiong, José Moura, Jeremy Johnson, David Padua, Manuela Veloso, and Robert W. Johnson. 2004. “SPIRAL: A Generator for Platform-Adapted Libraries of Signal Processing Algorithms.” Journal of High Performance Computing and Applications 18(1):21-45. |
|
40 |
Massimiliano Poletto, Wilson C. Hsieh, Dawson R. Engler, and M. Frans Kaashoek. 1999. “C and tcc: A Language and Compiler for Dynamic Code Generation.” ACM Transactions on Programming Languages and Systems 21(2):324-369. |
ported by their hardware. Clusters may not support direct access to remote memories; with no such hardware support, it is challenging to provide efficient support for a shared memory programming model. If support for shared memory is deemed important for good software productivity, then it may be necessary to forsake porting to clusters that use LAN interconnects.41
Different forms of parallelism operate not only on different supercomputers but at different levels within one supercomputer. For instance, the Earth Simulator uses vector parallelism on one processor, shared memory parallelism within one node, and message passing parallelism across nodes.42 If each hardware mechanism is directly reflected by a similar software mechanism, then the user has to manage three different parallel programming models within one application and manage the interaction among these models, a difficult task. If, on the other hand, a common abstraction such as multithreading is used at all levels, then the mapping from user code to hardware may be less efficient. Two-level (or multilevel) problem decomposition is probably unavoidable, since on-chip parallelism will increasingly be the norm and on-chip communication will continue to be much faster than off-chip communication. Mechanisms for combining different programming models are not well understood and are a topic for research.
To the extent that on-chip or intrachip parallelism can be handled automatically by compilers, the need for distinct programming models can be reduced. Compilers have been fairly successful with automatic vectorization of code and reasonably successful with automatic parallelization in situations where there are relatively few implementation threads, where communication among implementation threads is very efficient, and where the application’s dependences can be automatically analyzed (for instance, data parallelism, where the same operation is applied to multiple data items). Compilers have been less successful with automatic parallelization, where communication and synchronization among threads is relatively expensive or where data access is more irregular. Automatic parallelization is seldom, if ever, used to map sequential codes onto large supercomputers. It is still very much a research issue to find out the best division of labor between programmer, programming environment, and run time in managing parallelism at the different levels of a complex modern supercomputer.
|
41 |
New emerging SAN interconnects, such as Infiniband, do support remote memory access (see, for example, the Infiniband Trade Association Web site at <http://www.infinibandta.org/specs>). However, it is not clear that they will do so with the low latency necessary for the efficient support of shared memory programming models. |
|
42 |
The design of the Earth Simulator system is summarized in Chapter 7. |
Libraries
Since the earliest days of computing, software libraries have been developed to provide commonly used components in a convenient form to facilitate reuse by many programs. Indeed mathematical software libraries are a standard example of successful software reuse. Key examples used for supercomputing include mathematical libraries such as LAPACK43 for linear algebra, templates such as C++ Standard Template Library,44 run-time support such as MPI for message passing, and visualization packages such as the Visualization Tool Kit (VTK).45
The libraries of most interest to supercomputing involve mathematical functions, including linear algebra (e.g., LAPACK and its kin), Fourier transforms (e.g., FFTW and other packages), and basic functions. Owing to the needs of modern scientific software, advanced data structures (e.g., the C++ Standard Template Library), data management (e.g., HDF),46 and visualization (e.g., VTK) are all vital for full application development as well. Both the mathematical and computer science libraries are typically required in both sequential and parallel form; sequential forms solve subproblems on a single processor, while the parallel variants are used for the global computation.
Applications Software
Applications software provides solutions to specific science and engineering problems. Such software is necessarily domain- or problem-specific and ranges from small codes maintained by a single researcher (for instance, a student’s dissertation work) through large community codes serving a broad topic (for instance, MM5 for atmospheric research47) to commercial codes such as the NASTRAN structural engineering package.48
Large community codes can have hundreds of thousands of source lines; commercial packages can have many millions of lines, written over decades. Such codes are hard to port to new hardware platforms or new programming languages because of their size, the possible lack of struc-
|
43 |
|
|
44 |
David R. Musser, Gillmer J. Derge, and Atul Saini. 2001. STL Tutorial and Reference Guide, 2nd ed.: C++ Programming with the Standard Template Library. Boston, Mass.: Addison-Wesley. |
|
45 |
|
|
46 |
See <http://hdf.ncsa.uiuc.edu/>. |
|
47 |
See <http://www.mmm.ucar.edu/mm5/>. |
|
48 |
See <http://www.mscsoftware.com/products/products_detail.cfm?PI=7>. |
ture due to repeated accretions, and the difficulty of verifying major changes. In the case of important codes such as NASTRAN, it is the platform that has to adapt to the application, not vice versa; compilers have to continue supporting obsolete language features, and obsolete architectures may continue having a market due to their support of important packages.49 Thus, while the accelerated evolution of supercomputer architectures and programming environments satisfies important mission requirements of agencies and may accelerate scientific discovery, it also accelerates the obsolescence of important packages that cannot take advantage of the larger scale and improved cost/performance of new supercomputers.
Scalability of applications is a major challenge. One issue already discussed is that of appropriate programming languages and programming models for the development of supercomputing applications. Most application developers would like to focus their attention on the domain aspects of their applications. Although their understanding of the problem will help them in finding potential sources of concurrency, managing that concurrency in more detail is difficult and error prone. The problem is further compounded by the small size of the supercomputer market, the cost of large supercomputers, and the large variety of supercomputer applications and usage models. Because of the small size of the supercomputer market, commercial software vendors are unlikely to invest in state-of-the-art application development environments (ADEs) for parallel computing. Indeed, supercomputer users have to use ADEs that are less well integrated and less advanced than those used by commercial programmers. The high cost of supercomputers implies that achieving close to the best possible hardware performance is often paramount. Even on sequential processors one can often get a fivefold or better improvement in performance by playing close attention to hardware and system parameters (cache sizes, cache line sizes, page size, and so on) and tuning code for these parameters. The reward for platform-specific tuning on supercomputers can be much larger. But such code tuning is very laborious and not well supported by current ADEs. The variety of supercomputing applications implies that it is not sufficient to tune a few key subsystems and libraries: Most supercomputer programmers have to deal with performance issues. Finally, supercomputer applications range from codes with a few thousands of lines of source code that are developed in days by one person and run once, to codes with millions of
lines that are developed over many years by teams with tens of programmers and used over decades; it is not clear that the same programming languages and models can fit these very different situations.
Fortunately, software abstractions simplify these tasks and in some cases automate them. Data-parallel languages like HPF provide the ability to do the same (or very similar) operations on all (or many) elements of a data structure, with implicit synchronizations between these array operations. Other abstractions make the concurrency explicit but simplify and standardize the synchronization and communications. Languages with a loosely synchronous model of computation proceed in alternating, logically synchronized computation and communication steps. Most MPI programs follow this paradigm, although MPI does not require it. Similarly, many operating system operations encapsulate resources to avoid inappropriate concurrent operations.
All of these abstractions, however, represent trade-offs. For example, the global synchronizations used in a loosely synchronous model can cause onerous overheads. Alternatively, programs may allow more asynchrony between concurrent threads, but then the user has to understand the effect of arbitrary interleaved executions of interacting threads and use proper synchronization and communication, which is often complex. Compilers for data-parallel languages have had difficulty achieving good parallel efficiency owing to the difficulty of minimizing synchronization and communication from fine-grain operations. Successfully using any of these approaches on a large machine is a difficult intellectual exercise. Worse yet, the exercise must often be repeated on new machines, which often have radically different costs for the same operations or do not support some abstractions at all. Perhaps worst of all, even apparently minor inefficiencies in software implementation can have a devastating effect on scalability; hence, effectively programming these systems in a way that allows for software reuse is a key challenge.
Finally, implementation effort is a major consideration given the limited resources available for HPC software. One important reason that MPI is so successful is that simple MPI implementations can be created quickly by supplying device drivers for a public-domain MPI implementation like MPICH.50 Moreover, that MPI implementation can be improved incrementally by improving those drivers and by tuning higher-level routines for the particular architecture. On the other hand, an efficient implementation of a full language like HPF may require many tens, if not hundreds,
of person years. Development teams for HPF at various companies have been significantly larger than development teams for MPI; yet HPF implementations are not as mature as MPI implementations. Implementation cost and, hence, quality of implementation is also a big problem for tools and libraries: today’s supercomputing tools frequently do not address the problems of interest to application programmers, do not function as advertised, and/or do not deliver a significant fraction of the performance available from the computer.
Reliability and Fault Tolerance
Another area where there is a complex interplay between hardware and software is reliability and fault tolerance. As systems become larger, the error rate increases and the mean time between failures (MTBF) decreases. This is true both of hardware failures and software failures. Hardware failures on some large ASC supercomputers are sufficiently frequent so as to cause 1,000 node computations to suffer about two unrecoverable failures a day. (This corresponds to an MTBF of about 3 years per node.) This problem is overcome by frequently checkpointing parallel applications and restarting from the last checkpoint after a failure occurred. At current failure rates, the fraction of performance loss due to checkpoints and restarts is modest. But, extrapolating today’s failure rates to a machine with 100,000 processors suggests that such a machine will spend most of its time checkpointing and restarting. Worse yet, since many failures are heat related, the rates are likely to increase as processors consume more power. This will require new processor technologies to enable cooler-running chips, or even more support for fault tolerance.
There is little incentive to reduce failure rates of commodity processors to less than one error per few years of operations. Failure rates can be reduced using suitable fault-tolerant hardware in a custom processor or by using triplicated processors in hybrid supercomputers.
In many supercomputers the majority of failures are due to system software. Again, there is little incentive for commercial operating system producers to reduce failure rates to the level where a system with 100,000 copies of Linux or Windows will fail only once or twice a day. Failures can be reduced by using a specially designed operating system and, in particular, by using a reduced-function microkernel at the compute nodes.
Alternatively, higher error rates can be tolerated with better software that supports local rather than global fault recovery. This, however, may require more programmer effort and may require a shift in programming models—again toward a programming model that is more tolerant of asynchrony.
PERFORMANCE ESTIMATION
Most assertions about the performance of a supercomputer system or the performance of a particular implementation of an application are based on metrics—either measurements that are taken on an existing system or models that predict what those measurements would yield. Supercomputing metrics are used to evaluate existing systems for procurement or use, to discover opportunities for improvement of software at any level of the software stack, and to make projections about future sources of difficulty and thereby to guide investments. System measurement is typically done through the use of benchmark problems that provide a basis for comparison. The metrics used to evaluate systems are considerably less detailed than those used to find the performance bottlenecks in a particular application.
Ideally, the metrics used to evaluate systems would extend beyond performance metrics to consider such aspects of time to solution as program preparation and setup time (including algorithm design effort, debugging, and mesh generation), programming and debugging effort, system overheads (including time spent in batch queues, I/O time, time lost due to job scheduling inefficiencies, downtime and handling system back-ground interrupts), and job postprocessing (including visualization and data analysis). The ability to estimate activities involving human effort, whether for supercomputing or for other software development tasks, is primitive at best. Metrics for system overhead can easily be determined retrospectively, but prediction is more difficult.
Performance Benchmarks
Performance benchmarks are used to measure performance on a given system, as an estimate of the time to solution (or its reciprocal, speed) of real applications. The limitations of current benchmarking approaches—for instance, the degree to which they are accurate representatives, the possibilities for tuning performance to the benchmarks, and so forth—are well recognized. The DARPA-funded High Productivity Computing Systems (HPCS) program is one current effort to improve the benchmarks in common use.
Industry performance benchmarks include Linpack, SPEC, NAS, and Stream, among many others.51 By their nature they can only measure lim-
|
51 |
See <http://www.netlib.org/benchweb>. Other industrial benchmark efforts include Real Applications on Parallel Systems (RAPS) (see <http://www.cnrm.meteo.fr/aladin/meetings/RAPS.html>) and MM5 (see <http://www.mmm.ucar.edu/mm5/mpp/helpdesk/20030923.html>). |
ited aspects of system performance and cannot necessarily predict performance on rather different applications. For example, LAPACK, an implementation of the Linpack benchmark, produces a measure (Rmax) that is relatively insensitive to memory and network bandwidth and so cannot accurately predict the performance of more irregular or sparse algorithms. Stream measures peak memory bandwidth, but slight changes in the memory access pattern might result in a far lower attained bandwidth in a particular application due to poor spatial locality. In addition to not predicting the behavior of different applications, benchmarks are limited in their ability to predict performance on variant systems—they can at best predict the performance of slightly different computer systems or perhaps of somewhat larger versions of the one being used, but not of significantly different or larger future systems. There is an effort to develop a new benchmark, called the HPC Challenge benchmark, which will address some of these limitations.52
As an alternative to standard benchmarks, a set of application-specific codes is sometimes prepared and optimized for a particular system, particularly when making procurement decisions. The codes can range from full-scale applications that test end-to-end performance, including I/O and scheduling, to kernels that are small parts of the full application but take a large fraction of the run time. The level of effort required for this technique can be much larger than the effort needed to use industry standard benchmarking, requiring (at a minimum) porting of a large code, detailed tuning, rerunning and retuning to improve performance, and re-writing certain kernels, perhaps using different algorithms more suited to the particular architecture. Some work has been done in benchmarking system-level efficiency in order to measure features like the job scheduler, job launch times, and effectiveness of rebooting.53 The DARPA HPCS program is attempting to develop metrics and benchmarks to measure aspects such as ease of programming. Decisions on platform acquisition
|
52 |
The HPC Challenge benchmark consists of seven benchmarks: Linpack, Matrix Multiply, Stream, RandomAccess, PTRANS, Latency/Bandwidth, and FFT. The Linpack and Matrix Multiply tests stress the floating-point performance of a system. Stream is a benchmark that measures sustainable memory bandwidth (in Gbytes/sec), RandomAccess measures the rate of random updates of memory. PTRANS measures the rate of transfer for large arrays of data from the multiprocessor’s memory. Latency/Bandwidth measures (as the name suggests) latency and bandwidth of communication patterns of increasing complexity between as many nodes as is timewise feasible. FFTs stress low spatial and high temporal locality. See <http://icl.cs.utk.edu/hpcc> for more information. |
|
53 |
Adrian T. Wong, Leonid Oliker, William T.C. Kramer, Teresa L. Kaltz and David H. Bailey. 2000. “ESP: A System Utilization Benchmark.” Proceedings of the ACM/IEEE SC2000. November 4-10. |
have to balance the productivity achieved by a platform against the total cost of ownership for that platform. Both are hard to estimate.54
Performance Monitoring
The execution time of a large application depends on complicated interactions among the processors, memory systems, and interconnection network, making it challenging to identify and fix performance bottlenecks. To aid this process, a number of hardware and software tools have been developed. Many manufacturers supply hardware performance monitors that automatically measure critical events like the number of floating-point operations, hits and misses at different levels in the memory hierarchy, and so on. Hardware support for this kind of instrumentation is critical because for many of these events there is no way (short of very careful and slow simulation, discussed below) to measure them without possibly changing them entirely (a Heisenberg effect). In addition, some software tools exist to help collect and analyze the possibly large amount of data produced, but those tools require ongoing maintenance and development. One example of such a tool is PAPI.55 Other software tools have been developed to collect and visualize interprocessor communication and synchronization data, but they need to be made easier to use to have the desired impact.
The limitation of these tools is that they provide low-level, system-specific information. It is sometimes difficult for the application programmer to relate the results to source code and to understand how to use the monitoring information to improve performance.
Performance Modeling and Simulation
There has been a great deal of interest recently in mathematically modeling the performance of an application with enough accuracy to predict its behavior either on a rather different problem size or a rather different computer system, typically much larger than now available. Performance modeling is a mixture of the empirical (measuring the performance of certain kernels for different problem sizes and using curve fitting to predict performance for other problem sizes) and the analytical
(developing formulas that characterize performance as a function of system and application parameters). The intent is that once the characteristics of a system have been specified, a detailed enough model can be used to identify performance bottlenecks, either in a current application or a future one, and so suggest either alternative solutions or the need for research to create them.
Among the significant activities in this area are the performance models that have been developed for several full applications from the ASC workload56,57,58 and a similar model that was used in the procurement process for the ASC Purple system, predicting the performance of the SAGE code on several of the systems in a recent competition.59 Alternative modeling strategies have been used to model the NAS parallel benchmarks, several small PETSc applications, and the applications Parallel Ocean Program, Navy Layered Ocean Model, and Cobal60, across multiple compute platforms (IBM Power 3 and Power 4 systems, a Compaq Alpha server, and a Cray T3E-600).60,61 These models are very accurate across a range of processors (from 2 to 128), with errors ranging from 1 percent to 16 percent.
Performance modeling holds out of the hope of making a performance prediction of a system before it is procured, but currently modeling has only been done for a few codes by experts who have devoted a great deal of effort to understanding the code. To have a wider impact on the procurement process it will be necessary to simplify and automate the modeling process to make it accessible to nonexperts to use on more codes.
Ultimately, performance modeling should become an integrative part of verification and validation for high-performance applications.
Supercomputers are used to simulate large physical, biological, or even social systems whose behavior is too hard to otherwise understand or predict. A supercomputer itself is one of these hard-to-understand systems. Some simulation tools, in particular for the performance of proposed network designs, have been developed,62 and computer vendors have shown significant interest.
Measuring performance on existing systems can certainly identify current bottlenecks, but it not adequate to guide investments to solve future problems. For example, current hardware trends are for processor speeds to increasingly outstrip local memory bandwidth (the memory wall63), which in turn will increasingly outstrip network bandwidth. Therefore, an application that runs efficiently on today’s machines may develop a serious bottleneck in a few years either because of memory bandwidth or because of network performance. Performance modeling, perhaps combined with simulation, holds the most promise of identifying these future bottlenecks, because an application (or its model) can be combined with the hardware specifications of a future system. Fixing these bottlenecks could require investments in hardware, software, or algorithms. However, neither performance modeling nor simulation are yet robust enough and widely enough used to serve this purpose, and both need further development. The same comments apply to software engineering, where it is even more difficult to predict the impact on software productivity of new languages and tools. But since software makes up such a large fraction of total system cost, it is important to develop more precise metrics and to use them to guide investments.
Performance Estimation and the Procurement Process
The outcome of a performance estimation process on a set of current and/or future platforms is a set of alternative solution approaches, each with an associated speed and cost. Cost may include not just the cost of the machine but the total cost of ownership, including programming, floor space, power, maintenance, staffing, and so on.64 At any given time, there
|
62 |
See <http://simos.stanford.edu>. |
|
63 |
Wm. A. Wulf and S.A. McKee. 1995. “Hitting the Wall: Implications of the Obvious.” Computer Architecture News 23(1):20-24. |
|
64 |
National Coordination Office for Information Technology Research and Development. 2004. Federal Plan for High-End Computing: Report of the High-End Computing Revitalization Task Force (HECRTF). May. |
will be a variety of low-cost, low-speed approaches based on COTS architectures and software, as well as high-cost, high-speed solutions based on custom architectures and software. In principle, one could then apply principles of operations research to select the optimal system—for example, the cheapest solution that computed a solution within a hard deadline in the case of intelligence processing, or the solution that computed the most solutions per dollar for a less time-critical industrial application, or the number of satisfied users per dollar, or any other utility function.65
The most significant advantage of commodity supercomputers is their purchase cost; less significant is their total cost of ownership, because of the higher programming and maintenance costs associated with commodity supercomputers. Lower purchase cost may bias the supercomputing market toward commodity supercomputers if organizations do not account properly for the total cost of ownership and are more sensitive to hardware cost.
THE IMPERATIVE TO INNOVATE AND BARRIERS TO INNOVATION
Systems Issues
The committee summarizes trends in parallel hardware in Table 5.1. The table uses historical data to project future trends showing that innovation will be needed. First, for the median number of processor chips to reach 13,000 in 2010 and 86,000 in 2020, significant advances will be required in both software scalability and reliability. The scalability problem is complicated by the fact that by 2010 each processor chip is likely to be a chip multiprocessor (CMP) with four to eight processors, and each of these processors is likely to be 2- to 16-way multithreaded. (By 2020 these numbers will be significantly higher: 64 to 128 processors per chip, each 16- to 128-way multithreaded.) Hence, many more parallel threads will need to be employed to sustain performance on these machines. Increasing the number of threads by this magnitude will require innovation in architecture, programming systems, and applications.
A machine of the scale forecast for 2010 is expected to have a raw failure rate of several failures per hour. By 2020 the rate would be several failures per minute. The problem is complicated because there are both more processors to fail and because the failure rate per processor is expected to increase as integrated circuit dimensions decrease, making cir-
cuitry more vulnerable to energetic particle strikes. In the near future, soft errors will occur not just in memory but also in logic circuits. Such failure rates require innovation in both fault detection and fault handling to give the user the illusion of a fault-free machine.
The growing gap between processor performance and global bandwidth and latency is also expected to force innovation. By 2010 global bandwidth would fall to 0.008 words/flops, and a processor would need to execute 8,700 flops in the time it takes for one communication to occur. These numbers are problematic for all but the most local of applications. To overcome this global communication gap requires innovation in architecture to provide more bandwidth and lower latency and in programming systems and applications to improve locality.
Both locally (within a single processor chip) and globally (across a machine), innovation is required to overcome the gaps generated by nonuniform scaling of arithmetic local bandwidth and latency, and global bandwidth and latency. Significant investments in both basic and applied research are needed now to lay the groundwork for the innovations that will be required over the next 15 years to ensure the viability of high-end systems. Low-end systems will be able, for a while, to exploit on-chip parallelism and tolerate increasing relative latencies by leveraging techniques currently used on high-end systems, but they, too, will eventually run out of steam without such investments.
Innovations, or nonparametric evolution, of architecture, programming systems, and applications take a very long time to mature. This is due to the systems nature of the changes being made and the long time required for software to mature. The introduction of vector processing is a good example. Vectors were introduced in the early 1970s in the Texas Instruments ASC and CDC Star. However, it took until 1977 for a commercially successful vector machine, the Cray-1, to be developed. The lagging balance between scalar performance and memory performance prevented the earlier machines from seeing widespread use. One could even argue that the systems issues were not completely solved until the introduction of gather-and-scatter instructions on the Cray XMP and the Convex and Alliant mini-supercomputers in the 1980s. Even after the systems issues were solved, it took additional years for the software to mature. Vectorizing compilers with advanced dependence analysis did not emerge until the mid 1980s. Several compilers, including the Convex and the Fujitsu Fortran Compilers, permitted applications that were written in standard Fortran 77 to be vectorized. Applications software took a similar amount of time to be adapted to vector machines (for example, by restructuring loops and adding directives to facilitate automatic vectorization of the code by the compiler).
A major change in architecture or programming has far-reaching ef-
fects and usually requires a number of technologies to be successful. Introducing vectors, for example, required the development of vectorizing compilers; pipelined, banked memory systems; and masked operations. Without the supporting technologies, the main new technology (in this case, vectors) is not useful. The main and supporting technologies are typically developed via research projects in advance of a first full-scale system deployment. Full-scale systems integrate technologies but rarely pioneer them. The parallel computers of the early 1990s, for example, drew on research dating back to the 1960s on parallel architecture, programming systems, compilers, and interconnection networks. Chapter 6 discusses the need for coupled development in more detail.
Issues for Algorithms
A common feature of algorithms research is that progress is tied to exploiting the mathematical or physical structure of the application. General-purpose solution methods are often too inefficient to use. Thus, progress often depends on forming interdisciplinary teams of applications scientists, mathematicians, and computer scientists to identify and exploit this structure. Part of the technology challenge is to facilitate the ability of these teams to address simultaneously the requirements imposed by the applications and the requirements imposed by the supercomputer system.
A fundamental difficulty is the intrinsic complexity of understanding and describing the algorithm. From the application perspective, a concise high-level description in which the mathematical structure is apparent is important. Many applications scientists use Matlab66 and frameworks such as PETSc67 to rapidly prototype and communicate complicated algorithms. Yet while parallelism and communication are essential issues in the design of parallel algorithms, they find no expression in a high-level language such as Matlab. At present, there is no high-level programming model that exposes essential performance characteristics of parallel algorithms. Consequently, much of the transfer of such knowledge is done by personal relationships, a mechanism that does not scale and that cannot reach a large enough user community. There is a need to bridge this gap so that parallel algorithms can be described at a high level.
It is both infeasible and inappropriate to use the full generality of a complex application in the process of designing algorithms for a portion of the overall solution. Consequently the cycle of prototyping, evaluating,
and revising an algorithm is best done initially by using benchmark problems. It is critical to have a suitable set of test problems easily available to stimulate algorithms research. For example, the collection of sparse matrices arising in real applications and made available by Harwell and Boeing many years ago spawned a generation of research in sparse matrix algorithms. Yet often there is a dearth of good benchmarks with which to work.68 Such test sets are rare and must be constantly updated as problem sizes grow.
An Example from Computational Fluid Dynamics
As part of the committee’s applications workshop, Phillip Colella explained some of the challenges in making algorithmic progress. He wrote as follows:69
Success in computational fluid dynamics [CFD] has been the result of a combination of mathematical algorithm design, physical reasoning, and numerical experimentation. The continued success of this methodology is at risk in the present supercomputing environment, due to the vastly increased complexity of the undertaking. The number of lines of code required to implement the modern CFD methods such as those described above is far greater than that required to implement typical CFD software used twenty years ago. This is a consequence of the increased complexity of both the models, the algorithms, and the high-performance computers. While the advent of languages such as C++ and Java with more powerful abstraction mechanisms has permitted us to manage software complexity somewhat more easily, it has not provided a complete solution. Low-level programming constructs such as MPI for parallel communication and callbacks to Fortran kernels to obtain serial performance lead to code that is difficult to understand and modify. The net result is the stifling of innovation. The development of state-of-the-art high-performance CFD codes can be done only by large groups. Even in that case, the development cycle of design-implement-test is much more unwieldy and can be performed less often. This leads to a conservatism on the part of developers of CFD simulation codes: they will make do with less-than-optimal methods, simply because the cost of trying out improved algorithms is too high. In order to change this state of affairs, a combination of technical innovations and institutional changes are needed.
As Dr. Colella’s discussion suggests, in addition to the technical challenges, there are a variety of nontechnical barriers to progress in algorithms. These topics are discussed in subsequent chapters.
Software Issues
In extrapolating technology trends, it is easy to forget that the primary purpose of improved supercomputers is to solve important problems better. That is, the goal is to improve the productivity of users, including scientists, engineers, and other nonspecialists in supercomputing. To this end, supercomputing software development should emphasize time to solution, the major metric of value to high-end computing users. Time to solution includes time to cast the physical problem into algorithms suitable for high-end computing; time to write and debug the computer code that expresses those algorithms; time to optimize the code for the computer platforms being used; time to compute the desired results; time to analyze those results; and time to refine the analysis into an improved understanding of the original problem that will enable scientific or engineering advances. There are good reasons to believe that lack of adequate software is today a major impediment to reducing time to solution and that more emphasis on investments in software research and development (as recommended by previous committees, in particular, PITAC) is justified. The main expense in large supercomputing programs such as ASC is software related: In FY 2004, 40 percent of the ASC budget was allocated for application development; in addition, a significant fraction of the acquisition budget also goes, directly or indirectly, to software purchase.70 A significant fraction of the time to solution is spent developing, tuning, verifying, and validating codes. This is especially true in the NSA environment, where new, relatively short HPC codes are frequently developed to solve new emerging problems and are run once. As computing platforms become more complex, and as codes become much larger and more complex, the difficulty of delivering efficient and robust codes in a timely fashion increases. For example, several large ASC code projects, each involving tens of programmers, hundreds of thousands of lines of code, and investments from $50 million to $100 million had early milestones that proved to be too aggressive.71 Many supercomputer users feel
that they are hampered by the difficulty of developing new HPC software. The programming languages, libraries, and application development environments used in HPC are generally less advanced than those used by the broad software industry, even though the problems are much harder. A software engineering discipline geared to the unique needs of technical computing and high-performance computing is yet to emerge. In addition, a common software environment for scientific computation encompassing desktop to high-end systems will enhance productivity gains by promoting ease of use and manageability of systems.
Extrapolating current trends in supercomputer software, it is hard to see whether there will be any major changes in the software stack used for supercomputers in the coming years. Languages such as UPC, CAF, and Titanium are likely to be increasingly used. However, UPC and CAF do not support object orientation well, and all three languages have a static view of parallelism (the crystalline model) and give good support to only some application paradigms. The DARPA HPCS effort emphasizes software productivity, but it is vendor driven and hardware focused and has not generated a broad, coordinated community effort for new programming models. Meanwhile, larger and more complex hardware systems continue to be put in production, and larger and more complex application packages are developed. In short, there is an oncoming crisis in HPC software created by barely adequate current capabilities, increasing requirements, and limited investment in solutions.
In addition to the need for software research, there is a need for software development. Enhanced mechanisms are needed to turn prototype tools into well-developed tools with a broad user base. The core set of tools available on supercomputers—operating systems, compilers, debuggers, performance analysis tools—is not up to the standards of robustness and performance expected for commercial computers. Tools are nonexistent or, even worse, do not work. Parallel debuggers are an oftencited example. Parallel math libraries are thought to be almost as bad, although math libraries are essential for building a mature application software base for parallel computing. Third-party commercial and public domain sources have tried to fill the gaps left by the computer vendors but have had varying levels of success. Many active research projects are also producing potentially useful tools, but the tools are available only in prototype form or are fragmented and buried inside various application efforts. The supercomputer user community desperately needs better means to develop these technologies into effective tools.
Although the foregoing discussion addresses the need for technical innovation and the technical barriers to progress, there are significant policy issues that are essential to achieving that progress. These topics are taken up in subsequent chapters.





















































