
9
Stewardship and Funding of Supercomputing
Chapters 1 through 8 of this report described in some detail the current state of supercomputing and provided some context based on history, policy considerations, and institutions. The situation we find ourselves in at the present time can be summarized as follows:
-
In the United States, the government is the primary user of supercomputing (directly or indirectly). Supercomputing is used for many public goods, including national defense, pollution remediation, improved transportation, and improved health care. It is used for government-sponsored basic research in many areas of science and engineering. Although U.S. industry uses supercomputing as well, companies report that there are major inhibitors to greater use.1
-
Many of the most computationally demanding applications have great societal benefit. Health care, defense, climate and earthquake modeling, clean air, and fuel efficiency are examples of public goods that are facilitated by the applications discussed earlier.
-
U.S. leadership in supercomputing is essential. Supercomputing plays a major role in stockpile stewardship, in intelligence collection and analysis, and in many areas of national defense. For those applications, the government cannot rely on external sources of technology and expertise. More broadly, leadership in science and engineering is a national
-
priority.2 Leadership in supercomputing is an important component of overall leadership in science and engineering.
-
By its very nature, supercomputing has always been characterized by higher performance than mainstream computing. However, as the price of computing has dropped, the cost/performance gap between mainstream computers and top-priced supercomputers has increased. The computer market has grown most vigorously at the bottom end (cheap PCs and low-end servers). The share of that market devoted to supercomputing has diminished, and its importance in economic terms to hardware and software vendors has decreased. Even within supercomputing, the relative weight of the most challenging systems, those based on custom components, has decreased as an increasing number of supercomputer users are having their needs met by high-end commodity systems. Yet some essential needs can only be met by custom components. Consequently, market forces are less and less natural drivers of advances in supercomputing-specific technologies.
-
Supercomputer systems are highly complex. Supercomputing is, almost exclusively, parallel computing, in which parallelism is available at all hardware and software levels of the system and in all dimensions of the system. The coordination and exploitation of those aspects of parallelism is challenging; achieving balance among the aspects is even more challenging.
-
Ecosystem creation is both long term and expensive. The amalgam of expertise, technology, artifacts, and infrastructure that constitutes a supercomputing ecosystem is developed over a significant period of time. To get all the necessary components in place, a lot of effort is required. The nurturing of human talent, the invention of new ideas and approaches, and the use of those ideas and approaches in hardware and software artifacts all require significant investment. Given the lead time needed, and the fact that a given ecosystem has a bounded lifetime, investment in future ecosystems is needed to sustain leadership.
Given that leadership in supercomputing is essential to the government, that supercomputing is expensive, and that market forces alone will not drive progress in supercomputing-directed technologies, it is the role of the government to ensure that supercomputing appropriate to our needs is available both now and in the future. That entails both having the necessary activities in place in an ongoing fashion and providing the funding to support those activities.
The government needs to be concerned with both the producers of supercomputing—the researchers who create new technology, the hardware and software designers, the manufacturers and service organizations—and the consumers of supercomputing—the academic, government, and industrial users.
SATISFYING CURRENT SUPERCOMPUTING NEEDS
Virtually every group consulted by the committee had concerns about access to supercomputing. Supercomputer center directors in academic settings and in both unclassified and classified mission-oriented centers were concerned about two things: (1) the large amount of time and effort required for procurement decisions and (2) the long time (up to 3 years) between the initial decision to acquire a new system and its actual installation. The recent report by the JASONs3 noted the need for increased capacity computing for the DOE/NNSA Stockpile Stewardship Program. (As pointed out previously, users of capability computing are also users of capacity computing.) Demand for time on NSF supercomputing center resources greatly exceeds supply;4 at the same time, the performance gap between those resources and the highest capability systems is increasing.5 Academic access to DOE/DoD mission-oriented centers is limited by the priority assigned to the mission and, in some cases, by the constraints on access by noncitizens.
At the same time, many users complained about the difficulties in using supercomputer systems to full advantage, the problems caused by moving to a new system, and the absence of supercomputing systems of sufficiently high performance to solve their problems. Those communities able to draw on hero programmers worry that the supply of such individuals is too small.
Some of these immediate needs can be satisfied by additional funding. Capacity computing is a commodity that can be purchased. Additional staffing could help with migration to new systems—higher salaries might help increase the supply of such staff. However, the difficulties of using current systems and the absence of more powerful systems are not fixed so quickly.
|
3 |
JASON Program Office. 2003. Requirements for ASCI. July. |
|
4 |
The National Resource Allocations Committee (NRAC) awards access to the computational resources in the NSF PACI program. Information is available at <http://www.npaci.edu/Allocations/alloc_txt.html>. |
|
5 |
See TOP500 rankings. |
ENSURING FUTURE SUPERCOMPUTING LEADERSHIP
The Need for Hardware and Software Producers
The need for the government to ensure that there are suppliers to meet national needs is not unique to supercomputing. The committee’s earlier discussion suggests some possible modes of government intervention. In the case of supercomputing, the discussion of ecosystems has illustrated the interdependency of hardware, system software, and applications software. Nevertheless, different forms of intervention might be possible in different cases.
In the committee’s view, it is necessary that there be multiple suppliers of both hardware and software. As it discussed previously, different applications (and different problems within those applications) have different computational needs. There is no single architecture or architectural family that will satisfy all needs. In the foreseeable future, some of the needed architectures will come from systems built from custom processors. Among the possible hardware suppliers are vertically integrated supercomputer vendors, such as Cray used to be,6 vertically integrated supercomputer product lines within larger companies such as IBM or Hewlett-Packard, and systems created from products of horizontal vendors that produce components (e.g., commodity microprocessors from Intel, AMD, and Apple/IBM and switches from LAN vendors, Myricom or Quadrics).
Vertically integrated companies usually provide system software as well as hardware. However, the committee also believes it is possible to have nonprofit software organizations that develop and maintain community codes, software tools, or system software. These organizations might have a single physical location, or they might be geographically distributed. Their products might be open source, or they might have other licensing agreements. They would likely draw on contributions from the larger research and development community, much as Linux efforts do today. They might be broad in scope or more narrowly specialized. Historically, supercomputing software has also been supplied by ISVs. However, participants in many such companies say that there is no longer a successful profit-making business model, in part because highly skilled software professionals are so attractive to larger companies. For example, many companies that were developing compilers, libraries, and tools for high-performance computing went out of business, were bought, or no
longer focus on high-performance computing (e.g., KAI, PGI, Pallas, APR, and Parasoft). No new companies have entered this field to replace those that left.
In all of these possible modes of intervention, one thing is clear. Success in creating the suppliers depends on long-term, stable, predictable acquisitions and on the fruits of long-term, government-funded R&D.
The Need for Stability
The committee heard repeatedly from people with whom members spoke about the difficulties and the disincentives caused by the lack of long-term planning and the lack of stability in government programs. In order to undertake ambitious projects, retain highly skilled people, achieve challenging goals, and create and maintain complex ecosystems, organizations of all kinds need to be able to depend on predictable government commitments—both to programs and to ongoing funding for those programs.7 If that stability is absent, companies will go out of business or move in other directions, researchers will shift to other topics, new professionals will specialize in other skills, corporate memory is lost, and progress on hard problems slows or stops. Once interruptions occur, it may be difficult and expensive, or even impossible, to recover from lost opportunities or discarded activities.8
Ongoing commitments are not entitlements; the government should demand accountability and performance. However, priorities and long-term objectives need to be sufficiently clear that when funded efforts are performing well, they have stability.
The committee heard of many areas where stability has been lost. Following are a few examples.
|
7 |
For example, approximately 80 percent of Cray’s sales in 2003 were to the U.S. government. Cray’s revenue dropped from over $100 million in 2003 to less than $20 million in 2004 due to a drop in a defense appropriation and a delay in DOE’s Oak Ridge National Laboratory project (see Lawrence Carrel, 2004, “Crunch Time at Cray,” available online at <http://yahoo.smartmoney.com/onedaywonder/index.cfm?story=20040727>). |
|
8 |
The same issue has been studied for other long-term government procurements. For example, a RAND study examined in 1993 the costs and benefits of postponing submarine production; even though no new submarines were needed until 2006, the cost of the lost of expertise was believed to outweigh the savings from postponing production by 10 years (J.L. Birkler, J. Schank, Giles K. Smith, F.S. Timson, James R. Chiesa, Marc D. Goldberg, Michael G. Mattock, and Malcolm Mackinnon, 1994, “The U.S. Submarine Production Base: An Analysis of Cost, Schedule, and Risk for Selected Force Structures,” RAND document MR-456-OSD; summary at <http://www.rand.org/publications/RB/RB7102/>). |
-
Architecture. DARPA built up an impressive body of national expertise in supercomputer architecture in the 1980s and 1990s, which was then allowed to languish and atrophy. DOE sponsored the acquisition and evaluation of experimental architectures in the 1980s, but such experimentation has largely disappeared.
-
Software. NASA actively supported the development and maintenance of libraries, benchmarks, and applications software, but support for many projects and organizations that would have continuing value has disappeared.
-
Collaborations. The NSF Grand Challenge program of the early 1990s produced some strong collaborative interdisciplinary teams that had no follow-on program in which to continue. More recently, the NSF ITR program has again led to the creation of successful collaborations, but their expertise seems destined to be lost.
It is difficult to achieve stability in the face of local decisions that have an unpredictable collective effect. Each of the inauspicious outcomes mentioned above has an explanation. Some outcomes stem from the turnover of government personnel and concomitant shifts in budget priorities. Others come from the near-universal desire to start something new without, however, waiting to extract the best aspects of the previous programs. Still others ensue when agencies decide to stop sponsoring an important activity without finding other sponsorship. The net effect is that U.S. leadership in supercomputing suffers.
The Need for a Continuum from Research to Production
As the discussion in Chapter 5 makes clear, research in supercomputing has to overcome many hard, fundamental problems in order for supercomputing to continue to progress. The dislocations caused by increasing local and remote memory latencies will require fundamental changes in supercomputer architecture; the challenge of running computations with many millions of independent operations will require fundamental changes in programming models; the size of the machines and the potential increase in error rates will require new approaches to fault-tolerance; and the increased complexity of supercomputing platforms and the increased complexity of supercomputing applications will require new approaches to the process of mapping an application to a platform and new paradigms for programming languages, compilers, run-time systems, and operating systems. Restoring a vigorous, effective research program is imperative to address these challenges.
Research and development in an area such as supercomputing requires the interactions of many organizations and many modes of activity
(see Box 9.1 and Figure 9.1). It also requires its own instrumentation. Research in applications requires stable production platforms. In contrast, research in technologies requires experimental platforms that are not used for production. While production platforms for applications research are in short supply today, experimental platforms are largely absent.
To ensure that there will be new technologies to form the basis for supercomputing in the 5- to 15-year time frame (a typical interval between
|
BOX 9.1 Basic research is generally done in small projects where many different ideas can be explored. The research can be integrated with graduate education if conducted in academia, thus ensuring a steady supply of professionals. Experimental systems research and applied research projects can further validate ideas emerging from basic research and will often (but not always) involve larger groups, whether in academia or in national or corporate research laboratories. Before a fundamentally new design can become a product, it is often necessary to develop a large “vertical” prototype that integrates multiple technologies (e.g., new architecture, a new operating system, new compilers) and validates the design by showing the interplay of these technologies. Such a prototype can lead to a vertical product, where one vendor develops and provides much of the hardware and software stack of a system. However, part of the supercomputing market is served by horizontal vendors that provide one layer of the system stack for many different systems—for example, companies such Myricom or Etnus produce, respectively, switches and debuggers for many platforms. To the same extent, some large applied research or prototyping efforts are best organized horizontally—for example, an effort where a group develops a new library to be widely available on many supercomputer platforms. The technology developed by such a group may migrate to a horizontal vendor or be adapted and turned into a product for a specific platform by a vertical vendor. The free dissemination of ideas and technologies is essential for this research enterprise to succeed, because a relatively small group of people have to ensure rapid progress of complex technologies that have complex interactions. The model is not a simple pipeline or funnel model, where many ideas flourish at the basic research level, to be downselected into a few prototypes and one or two winning products. Rather, it is a spiral evolution with complex interactions whereby projects inspire one another; whereby ideas can sometimes migrate quickly from basic research to products and may sometimes require multiple iterations of applied research; and whereby failures are as important as successes in motivating new basic research and new products. |
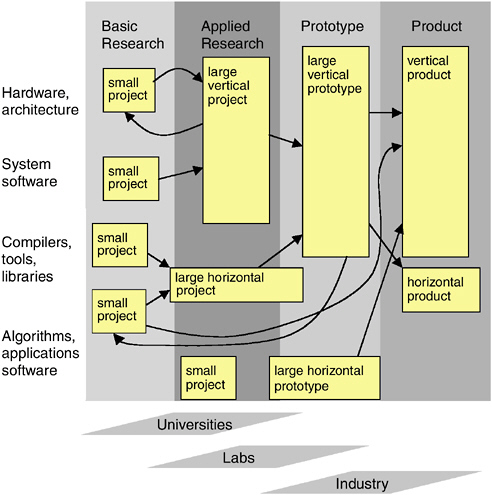
FIGURE 9.1 The research-to-production continuum.
research innovation and commercial deployment in the computer industry), a significant and continuous investment in basic research (hardware architecture, software, and numerical methods) is required. Historically, such an investment in basic research has returned large dividends in the form of new technology. The need for basic research in supercomputing is particularly acute. Although there has been basic research in general-purpose computing technologies with broad markets, and there has been significant expenditure in advanced development efforts such as the ASC program and the TeraGrid, there has been relatively little investment in basic research in supercomputing architecture and software over the past
decade, resulting in few innovations to be incorporated into today’s supercomputer systems.
Our country has arrived at this point by a series of investment decisions. In the 1990s, HPCCI supported the development of several new computer systems. In retrospect, we did not recognize the critical importance of long-term, balanced investment in all of hardware, software, algorithms, and applications for achieving high performance on complex scientific applications. Instead, mission-oriented government agencies (including non-computer-science directorates of NSF) focused their investments on their mission applications and algorithms tailored for them rather than on broad-based improvements. This was noted in a 1999 PITAC report9 and, more obliquely, in PITAC’s review of the FY 2000 Information Technology for the 21st Century (IT2) budget initiative.10 A recent report card on the PITAC implementation11 listed “HPC software still not getting enough attention” as one of three top-level concerns.
Research in supercomputer architecture, systems software, programming models, algorithms, tools, mathematical methods, and so forth is not the same as research in using supercomputing to address challenging applications. Both kinds of research are important, but they require different kinds of expertise; they are, in general, done by different people, and it is a mistake to confuse them and to fail to support both.
Basic long-range research is the exploration of ideas. It is not the same as advanced development, although such development often ensues. Basic research projects should not be required to produce products or deliverables other than exposition, demonstration, and evaluation. A valuable benefit of basic research is that it can combine research and education—helping to create the next generation of supercomputing professionals. The benefits of that education outweigh the occasional delays in progress stemming from inexperience. An important attribute of well-run research projects is that they make room for serendipity. Many important discoveries arise from satisfying needs along the way to the main goal—an often-cited example is the NCSA Mosaic browser, which was an unintended consequence of NCSA’s interest in Web access to scientific data. Performance tools are another example.
As the discussion in Chapter 5 made clear, supercomputing is headed
|
9 |
President’s Information Technology Advisory Committee (PITAC). 1999. Information Technology Research: Investing in Our Future. Report to the President. February. Available at <http://www.hpcc.gov/pitac/report/>. |
|
10 |
Available at <http://www.hpcc.gov/pitac/pitac_it2_review.pdf>. |
|
11 |
Ken Kennedy. 2004. “PITAC Recommendations: A Report Card.” Presentation to the President’s Information Technology Advisory Committee. June 17. Available at <http://www.hpcc.gov/pitac/meetings/2004/20040617/20040617_kennedy.pdf>. |
for major problems as systems continue to scale up; it is not clear that incremental research will solve these problems. While incremental research has to be pursued so as to continue the flow of improvements in current platforms, there must also be room for outside-the-box thinking—that is, for projects that propose to solve the problems of supercomputing in an unorthodox manner.
An important stage in the transfer of research results to deployment and products is the creation and evaluation of prototypes. Not all basic research leads to prototypes, but prototypes are essential to migrating research results into practice. Prototyping provides an essential opportunity to explore the usefulness and the usability of approaches before committing to product development. For example, prototype systems serve to identify research issues associated with the integration of hardware and software and to address system-level problems such as system scalability and I/O performance in high-performance computing.
Ultimately, the purpose of the technology research is to facilitate the use of supercomputing. Prototyping is an appropriate stage at which to support technology and applications partnerships, in which applications researchers become early adopters of prototypes and evaluate them against their applications. Successful partnerships are those from which both the technology researchers and the applications researchers benefit—the technology researchers by getting feedback about the quality and utility of their results; the applications researchers by advancing their application solutions. As part of the transfer of research to production, prototyping activities should normally include industrial partners and partners from government national laboratories. The building of prototypes and hardening of software require the participation of professional staff—they cannot be done solely by researchers.
Prototypes may range from experimental research systems to more mature advanced development systems to early examples of potential products. Because both industry representatives and professional staff are involved, there is often considerable pressure for prototyping projects to yield products. That is not their purpose—the primary purpose is experience and evaluation. However, organizations sometimes find it difficult to take that view when there is strong pressure for short-term delivery of products or deliverables from users. Government investment to support prototyping is needed in all contributing sectors, including universities, national laboratories, and vendors.
Mechanisms are needed to create productive partnerships of this kind and to sustain them. Both the NSF Grand Challenge program and the NSF PACI program have stimulated such partnerships. The most successful partnerships are those organized around research problems, not around funding opportunities.
The Need for Money
Progress in supercomputing depends crucially on a sustained investment by the government in basic research, in prototype development, in procurement, and in ensuring the economic viability of suppliers. Erratic or insufficient funding stifles the flow of new ideas and cuts off technology transfer, inevitably increasing aggregate costs.
Basic research support requires a mix of small science projects and larger efforts that create significant experimental prototypes. Large numbers of small individual projects are often the best way of exploring new concepts. A smaller number of technology demonstration systems can draw on the successes of basic research in architecture, software, and applications concepts, demonstrate their interplay, and validate concepts ahead of their use in preproduction or production systems. These would typically be the sorts of projects centered at universities or research laboratories.
It is difficult to determine the U.S. government investment in supercomputing research at the present time, in terms of either money or the number of projects. The current Blue Book12 has a category called High-End Computing Research and Development. (This annual publication is a supplement to the President’s budget submitted to Congress that tracks coordinated IT research and development, including HPC, across the federal government.13) From the description of the programs in various agencies, one sees that the category includes efforts that are in development and research efforts, as well as research in topics outside the scope of this discussion (such as quantum computing or astronaut health monitoring). The recent HECRTF report14 estimates 2004 funding for basic and applied research in high-end computing to be $42 million.
A search of the number of funded NSF projects with the word “parallel” in the title or abstract (admittedly an imperfect measure) shows that there were an average of 75 projects per year in the 1990s, but only 25 from 2000 to 2003.15 The committee does not have numbers for other agencies, but its experience suggests that there were decreases at least as
|
12 |
National Coordination Office for Information Technology Research and Development. 2004. Advanced Foundations for American Innovation: Supplement to the President’s Budget. Available online at <http://www.hpcc.gov/pubs/blue04/>. |
|
13 |
An archive of these documents is at <http://www.hpcc.gov/pubs/bb.html>. |
|
14 |
NITRD High End Computing Revitalization Task Force (HECRTF). 2003. Report of the Workshop on the Roadmap for the Revitalization of High-End Computing. Daniel A. Reed, ed. June 16-20, Washington, D.C. |
|
15 |
These projects include some that entail only equipment or workshop sponsorship and a few that have nothing to do with supercomputing. On the other hand, there are undoubtedly supercomputing projects that have not been described using the word “parallel.” |
great at other agencies. Decreases in Ph.D. production and publication of supercomputing research papers are consistent with this falloff in support.
The committee estimates the necessary investment in these projects at approximately $140 million per year, with approximately 35 to 45 projects of 3- to 5-year duration initiated each year and funded at $300,000 to $600,000 per year and three or four technology demonstration projects averaging 5 years in length initiated each year, each at between $3 million and $5 million per year. Even the smaller projects need professional staff, which becomes more expensive as the number of staff members increases. The demonstration projects will likely involve larger, multidisciplinary teams and may require the manufacture of expensive hardware and the development of large, complex software systems. Both small and large projects will often require more expensive infrastructure and more extensive and expensive personnel than similar NSF-supported projects in computer science and computer engineering; the underlying platforms are large, complex, and expensive, and most of the difficult problems are at the integration level. The limited supercomputing industrial base precludes the industrial support—in particular, equipment donations—that often supplements federal research funding in other areas in computer science and computer engineering.
That estimate does not include support for applications research that uses supercomputing—it includes only support for research that directly enables advances in supercomputers themselves. Also, it does not include advanced development, testbeds, and prototyping activities that are closer to product creation (such as DARPA’s HPCS program). The estimate is necessarily approximate but would bring us part of the way back to the level of effort in the 1990s. As one data point, to increase the number of Ph.D.’s to 50 a year would require approximately $15 million a year just for their direct support (assuming an average of $60,000 per year and 5 years per student), and that education would come only in the context of projects on which they worked. Not all projects are conducted in academia, and not all projects produce Ph.D. students in any given year.
Prototypes closer to production would normally be produced not by research groups but by companies and advanced development organizations (usually with research collaborators). The first two phases of the DARPA HPCS program are sponsoring activities of that kind, at a level of about $60 million per year. This level for the three projects seems reasonable.
By way of comparison, the Atkins report16 (Chapter 6) proposes a
yearly budget of $60 million for fundamental and applied research to advance cyberinfrastructure and a yearly budget of $100 million for “research into applications of information technology to advance science and engineering research.” Taking into account the fact that cyberinfrastructure includes more than supercomputing and that the categories are different, the Atkins committee’s estimate is similar to this committee’s.
The sustained cost of providing a supply of production-quality software depends in part on the funding model that is assumed. The cost of a nonprofit software organization of the kind described earlier would be $10 million to $15 million per year, but such an organization would provide only a fraction of the needed software. A vertically integrated supercomputer vendor would provide some system software as part of the delivered system. The development cost for such a supplier is on the order of $70 million per year, some of which would come from the purchase of systems and some from direct investment in R&D.
These estimates do not include the cost of procuring capability supercomputers to satisfy government missions (except indirectly as customers of vendors). Assuming a cost of between $100 million and $150 million per procurement and six or seven procurements per year by organizations such as DOE (the National Nuclear Security Administration and the Office of Science), DoD (including NSA), NSF, NIH, NOAA, and NASA, the procurement cost for capability supercomputers would be approximately $800 million per year. This estimate does not include the cost of meeting capacity computing needs.
The Need for People
The report presented in Chapter 6 some results from the most recent Taulbee Survey, which showed that only 35 people earned Ph.D.’s in scientific computing in 2002. This is not an anomaly, as the chart in Figure 9.2 shows.17 The average yearly number of Ph.D.’s awarded in scientific computing in the last 10 years was 36; on average, government laboratories hire only three of them a year. These numbers are extremely low.
While it is hard to collect accurate statistics, the same situation seems to hold for other areas of supercomputing. For example, few students study supercomputer architecture. Increased and stable research funding is needed not only to ensure a steady flow of new ideas into supercomputing but also, and perhaps more importantly, to ensure a steady flow of new people into supercomputing.
|
17 |
Taulbee Survey data are available at <http://www.cra.org/statistics/>. |
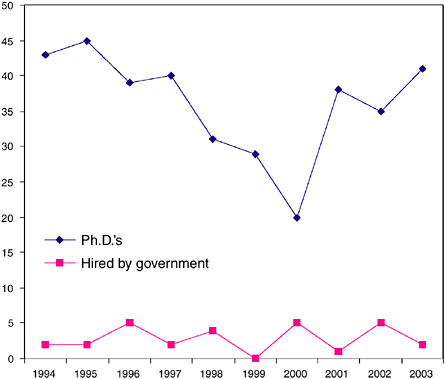
FIGURE 9.2 Number of Ph.D.’s in scientific computing and number hired by government laboratories.
The Need for Planning and Coordination
Given the long lead time that is needed to create an ecosystem, it seems obvious that planning for technological progress would be advisable. Given that there are commonalities in supercomputing systems used for many different purposes, it is equally obvious that coordination among government agencies, as well as within government agencies, would be a good thing. Not surprisingly, many previous studies have noted the benefits of planning and coordination and have made recommendations along those lines. There has also been legislation for that purpose. For instance, Finding 5 of the High-Performance Computing Act of 1991 stated as follows: “Several Federal agencies have ongoing high performance computing programs, but improved long-term interagency coordination, cooperation, and planning would enhance the effectiveness of these programs.”18 Among its provisions, the Act directed the President to “imple-
ment a National High-Performance Computing Program, which shall (A) establish the goals and priorities for Federal high-performance computing research, development, networking, and other activities; and (B) provide for interagency coordination of Federal high-performance computing research, development, networking, and other activities undertaken pursuant to the Program.”
Yet the need for planning and coordination remains. The committee gave particular attention to two aspects of planning and coordination: What needs to be done? Who needs to take responsibility for it? A coordinated way to figure out what needs to be done would be to create and maintain a supercomputing roadmap. The issue of responsibility must satisfy the identified needs of hardware and software producers for stability over time, for a research-to-production continuum, and for the continuing allocation of adequate funding.
A Supercomputing Roadmap
Roadmaps are one kind of planning mechanism. A roadmap starts with a set of quantitative goals, such as the target time to solution for certain weapons simulations or the target cost per solution for certain climate simulations. It identifies the components required to achieve these goals, along with their quantitative properties, and describes how they will enable achievement of the final quantitative goals. For example, certain classes of technologies might enable certain processor and memory speeds. In order to evaluate progress, conduct rational short- and medium-term planning, and accommodate increasing scientific demands, the roadmap should specify not just a single performance goal (like petaflops) at a distant point in time but a sequence of intermediate milestones as well. The roadmap also identifies the activities (for instance, work on higher bandwidth networks or work on higher performance optimization tools) and the resources (such as widgets, money, or people) needed for each goal. A roadmap is periodically updated to reflect current progress and needs. The roadmap needs to be quantitative to allow rational investment decisions and instill confidence that the ultimate goal will be reached.
One well-known roadmap activity is that by the semiconductor industry,19 which spends approximately $1 million per year on the effort.
Many recent supercomputing-related reports identify the need for roadmaps and attempt to provide them.20 However, these reports only partially quantify their goals: They do not identify all the necessary components and almost universally do not quantitatively explain how the components will enable reaching the final goal. For this reason, they cannot yet be used for rational investment decisions.
In the case of the semiconductor industry roadmap, because the participants all share common economic goals and motivations, they are strongly motivated to cooperate. This is not the case in supercomputing, where the participants include (at least) the national security establishment, academic scientists, industrial users, and the computer industry. The computer industry’s commercial goals of building cost-effective computers for popular commercial applications and the national security establishment’s goal of weapons simulation may or may not be well aligned. The goals of climate modeling, weapons simulation, cryptography, and the like may all require somewhat different supercomputer systems for their attainment. But they will all share certain components, like scalable debuggers. So a supercomputing roadmap will necessarily be somewhat different from the semiconductor industry roadmap.
In particular, some components of the roadmap will be inputs from the computer industry, basically a set of different technology curves (such as for commercial processors and for custom interconnects) with associated performances and costs as functions of time. Other components will be application codes, along with benchmarks, performance models, and performance simulations that measure progress toward the final goals. Activities will include better software tools and algorithms, whose contribution is notoriously hard to quantify because of the difficulties of software engineering metrics and the unpredictability of algorithm breakthroughs but whose availability is nonetheless essential.
For each application, the roadmap will investigate a set of technological solutions (combinations of algorithms, hardware, and software) and for each one estimate as carefully as possible both the time to solution (or its reciprocal, speed) and the total cost of ownership. (These were both discussed in more detail in the section on metrics in Chapter 5.) Finally, given a utility function, which could be the cheapest solution that meets a certain hard deadline, or the maximum number of solutions per dollar, or whatever criteria are appropriate, it might be possible to choose the optimal technological solution.
The above process is a typical rational industrial planning process. A unique feature of supercomputing that makes it difficult is the technical challenge of estimating the time to solution of a complicated problem on a future hardware and software platform that is only partially defined. Here are some possible outcomes of this roadmap process:
-
Performance models will show that some applications scale on commodity-cluster technology curves to achieve their goals. For these applications, no special government intervention is needed.
-
For other applications, it may be the case that the algorithms used in the application will not scale on commodity-cluster technology curves but that known alternative algorithms will scale. Supporting these applications may require investment in algorithms and software but not hardware.
-
For yet other applications, commodity processors will be adequate, but only with custom interconnects. In this case, government investment in supercomputer interconnection network technology will be required, in addition to the investment in associated software and related costs.
-
For some applications, only full-custom solutions will work. In this case long-term technology R&D and “submarine”-style procurement will be required.
It is likely that this roadmap process will identify certain common technologies that different applications can use, such as software tools, and it will be fortunate if this turns out to be so. Indeed, in order to leverage government investment, the roadmap process must be coordinated at the top in order to identify as many common solutions as possible.
Responsibility and Oversight
In response to the High-Performance Computing Act of 1991, the National Coordination Office for High Performance Computing and Communications (NCO/HPCC) was established in September 1992. (It has had several name changes subsequently.) That office has done an excellent job over the years of fostering information exchange among agencies, facilitating interagency working groups, and increasing human communication within the government concerning high-end computing. However, its role has been coordination, not long-range planning.
The High-Performance Computing Act of 1991 also directed the President to establish an advisory committee on high-performance computing. That committee, the President’s Information Technology Advisory Committee (PITAC), which was not established until 1997 under a somewhat
broader mandate, issued a report in February 1999, in which it recommended that a senior policy official be appointed and that a senior-level policy and coordination committee be established for strategic planning for information technology R&D.21 Neither recommendation has been followed.
In May 2004, an interagency High End Computing Revitalization Task Force (HECRTF) report again recommended an interagency governance and management structure. The report suggests some forms that such a structure might take.22 Legislation has been proposed to implement that recommendation.
The NSF is a primary sponsor of basic research in science and engineering and thus has the responsibility to support both the engineering research needed to drive progress in supercomputing as well as the infrastructure needs of those using supercomputing for their scientific research. However, a study of research grants in areas such as computer architecture shows a steady decrease in research focused on high-performance computing in the last decade: NSF has essentially ceased to support new HPC-motivated research in areas such as computer architecture or operating systems. In computational sciences, reduced NSF support for long-term basic research is not compensated for by an increase in DOE support through the SciDAC program, because the latter’s 5-year project goals are relatively near term. The significant DARPA investment in the HPCS program has not extended to the support of basic research. There is at present a gap in basic research in key supercomputing technologies.
NSF supported supercomputing infrastructure through the PACI program, which ended in September 2004. There is some uncertainty about follow-on programs. Supercomputing infrastructure at NSF is the responsibility of the Division of Shared Cyberinfrastructure (SCI) within the Directorate for Computer and Information Science and Engineering (CISE); most of the users of this infrastructure are supported by other disciplinary directorates in NSF, or by NIH. The role of supercomputing in the larger cyberinfrastructure is not yet clear. This uncertainty continues to hurt supercomputing centers: It leads to a loss of talent as the more creative and entrepreneurial scientists move to areas that seem to offer more promising opportunities, and it leads to a conservative strategy of diversifying into many different directions and small projects to reduce risk,
rather than placing a few large bets on projects that could have an important impact.
This chapter has focused on the tangible aspects of supercomputing and the actions needed to improve them. However, one should not neglect the intangible assets of the supercomputing enterprise. Supercomputing has attracted the brightest minds and drawn broad support because of the reality as well as the perception that it is a cutting-edge, world-changing endeavor. The reality has not changed. There are difficult fundamental computer science and engineering problems that need to be solved in order to continue pushing the performance of supercomputers at the current rate. Clearly, fundamental changes will be needed in the way supercomputers are built and programmed, to overcome these problems. Supercomputers are becoming essential to research in an ever-growing range of areas; they are solving fundamental scientific problems and are key to progress on an increasing range of societal issues. Computational science is becoming an increasingly challenging intellectual pursuit as the ad hoc use of numerical recipes is replaced by a deeper understanding of the relation between the physical world and its discrete representation. The reality is there, but, arguably, the perception has dimmed. As some uses of high-performance computing become easier and more common, it becomes easier to forget the incredibly difficult and immensely important challenges of supercomputing.
Initiatives to buttress the research on supercomputing technologies and the use of supercomputers in science and engineering should address the perception as well as the reality. It is important that research programs be perceived as addressing grand challenges: The grand engineering challenge of building systems of incredible complexity that are at the forefront of computer technology and the grand scientific challenges addressed by these supercomputers. It is also important that government agencies, supercomputing centers, and the broad supercomputing community do not neglect cultivating an image they may take too much for granted.



















