
Identifying Microbial and Chemical Contaminants for Regulatory Purposes: Lessons Learned in the United States
Rebecca T. Parkin
SUMMARY
Identification of potentially hazardous contaminants is the first step in risk management paradigms and in complying with regulatory mandates. While efficient identification is a key to the development of the United States Environmental Protection Agency’s Contaminant Candidate List for drinking water regulation, there is a growing interest in proactive identification schemes outside of regulatory frameworks. This interest is resulting in the development and application of methods previously not used for hazard identification. The purposes of this paper are to describe the methods used in the United States to identify drinking water contaminants for regulatory purposes, evaluate the strengths and weaknesses of those methods, list the lessons learned, describe newly proposed methods that are currently being developed for evaluation, and propose potential international collaboration.
INTRODUCTION
The vision of a world with healthy water for all has been an elusive but continuously important ideal for many centuries. An international coalition declared “all water users must be supplied with water that will protect them from any health risk” (Bourbigot, 2000). Despite significant advances in the twentieth century, many challenges remain before the world can achieve this ambitious goal. The World Health Organization’s work plan for water sanitation includes numerous activities designed to protect human health through improved water management (WHO, 2002). Ways to identify and respond to drinking water
contaminants must become more proactive so that a broader range of feasible response options can be developed.
In the United States, regulation of drinking water contaminants has increased rapidly in the past decade since 1990. However, enforceable regulations were first instituted in 1914 to reduce the spread of disease across state lines. Under the Interstate Quarantine Act of 1893, municipalities that used their water in interstate carriers (e.g., buses, ships, and trains) were required to meet a federal regulation for fecal coliform bacteria. In 1925, 1942, 1946, and 1962, the federal Public Health Service added more contaminants to this regulation. Evidence from the late 1960s and early 1970s indicated that many previously undetected contaminants were in public water supplies and posed potential human health effects. Following the publication of these environmental data and Silent Spring (Carson, 1962), public awareness and concerns increased. Although most states adopted the earlier federal standards for the regulation of local water supplies, federally mandated regulations for large-scale water supplies did not exist until 1974.
Before the Safe Drinking Water Act (SDWA) was passed in 1974, most drinking water contaminants were controlled through guidelines and non-enforceable mechanisms. A major goal of the SDWA was to protect public health by ensuring that contaminants in public water systems met national standards. Environmental surveys following passage of the SDWA revealed the presence of additional contaminants. As a result, in 1986 Congress required that 25 more substances (chemicals and pathogens) be regulated every three years. This requirement proved to be unachievable, especially without new resources. The lessons learned from the efforts to meet these requirements led to a Congressional mandate to regulate contaminants on the basis of occurrence in water, level of risk posed, and the probability of adverse health effects (NRC, 1997).
For most of the twentieth century, the United States identified hazardous substances and microbial pathogens in drinking water through investigations of disease outbreaks. Although this approach has been recognized as limited (Balbus and Embrey, 2002), it has been the traditional method used by epidemiologists. In 1970, the U.S. Environmental Protection Agency (EPA) was charged with controlling hazardous substances in drinking water and other media (United States Code Annotated, 1970). In response, the agency began developing procedures to identify and prioritize chemical contaminants. A standardized chemical risk assessment framework published in 1983 was used on a substance-specific basis (NRC, 1983). However, this process proved to be too resource intensive and time-consuming to prioritize the increasing number of contaminants needed for research and regulatory purposes.
In the mid-1980s, EPA reported that the classification of substances into categories based on the weight of scientific evidence was an important part of the process of setting public health priorities and began developing more efficient ways to do so (EPA, 1987). In 1996, Congress directed the EPA to develop
a list of unregulated contaminants, known as the Contaminant Candidate List (CCL), every five years and to evaluate at least five contaminants every five years for potential regulation (SDWA, 1996). As evidenced by the process used to develop and publish the first CCL (CCL1) in 1998, this requirement proved to be very difficult to meet (NRC, 2001). Although EPA developed a risk-based conceptual model, the agency’s planned process, including the publication of a Contaminant Identification Method incorporating public input, could not be implemented in time to meet the legislative deadline. Consequently, EPA staff compiled existing lists of contaminants from the Agency’s programs (e.g., water, hazardous waste sites), obtained some external input, pared the list based on drinking water occurrence, and finalized the list with 50 chemicals and 10 microorganisms. One of the problems with this approach was that available occurrence data became the critical criterion for selection; potential health effects became secondary and were not considered for any substance deleted from the proposed CCL. This truncated process did not satisfy many in Congress, the public, or the Agency. As a result, EPA requested the assistance of the National Research Council (NRC) to design a better identification and prioritization process for the second CCL (CCL2).
The NRC convened an interdisciplinary committee that examined the strengths and weaknesses of the EPA’s CCL1 process and also reviewed types of decision-making processes that could be considered for the CCL2. In a series of reports, the committee proposed a two-step process and specific methods for identifying and classifying potential drinking water hazards more efficiently (NRC, 1999a; NRC, 1999b; NRC, 2001).
This paper reviews the three major types of identification methods, lessons learned from these methods, and the NRC’s rationale for its recommended process and technique. A new approach that builds on the NRC’s recommendation (Parkin et al., 2002) and potential international collaborative efforts are also presented.
IDENTIFICATION AND PRIORITIZATION METHODS
When individual chemical or microbial agents are examined for risk management processes, clarification of the risk problem (usually called problem definition or initiation) is followed by a preliminary evaluative step. This first review is known as hazard identification for chemicals (NRC, 1983) and problem formulation for microbial pathogens (ILSI, 2000). The purpose of this step is to determine from existing information whether the chemical or microbial agent of concern is potentially harmful to humans and whether a more detailed risk assessment is required. This decision does not involve an intensive assessment, but often is a qualitative or semi-quantitative evaluation.
When numerous potentially hazardous substances and organisms must be evaluated and ranked for regulatory processes, risk assessment procedures for
each contaminant are not feasible because of the extensive data and time required for implementation. Increasingly, regulatory programs in the United States must produce fairly rapid prioritizations of a large number of hazards, so that the greatest public health harms can be minimized and the risk reduction benefits can be achieved in a timely manner. Until the 1990s, the methods most often used were based predominantly on experts’ judgments. From the 1980s, more routinized processes known as rule-based methods have been used. These methods incorporate preset scoring, weighting, and combining algorithms. However, rule-based methods have required more time than expected and have not necessarily resulted in efficient or effective prioritization processes. The NRC noted that prototype classification methods might be appropriate to consider for future prioritization tasks (NRC, 2001). This section describes and evaluates the three major approaches that may be used to identify and prioritize drinking water contaminants.
Expert Judgment Processes
The approach most often used in the United States is a set of methods known as expert judgment processes. This approach relies on techniques that combine the input of many experts using formal or informal procedures. Experts have relevant academic or technical knowledge, but typically must also have had substantial experience with drinking water issues. Participants in drinking water-related processes typically come from academic institutions, water utilities, and professional associations related to the disciplines or the public water supply industry.
The more informal methods used to combine experts’ knowledge and experience involve sharing of knowledge and opinions in group meetings, technical workshops, conference calls, analyses, and/or draft documents. Examples of expert judgment approaches include the following:
-
agencies’ standing science advisory boards and related committees of experts (e.g., EPA’s Science Advisory Board);
-
time-limited and issue-specific expert committees (e.g., NRC’s Committee on Drinking Water Contaminants);
-
peer review panels (e.g., specially convened groups to review journal submissions or grant applications, or to oversee specific site or research projects); and
-
consensus conferences (e.g., to develop better methods to track waterborne diseases).
Many times experts are convened at least once to debate their views and develop consensus. Often documents are read in advance of the debate and a group report is generated after common views have been identified. Less often, when com-
mon ground has not become readily apparent, formal methods such as the Delphi process (reviewed in NRC, 2001) have been used to finalize the group’s decisions. Of the three types of identification and prioritization methods, expert judgment techniques are often the easiest to implement. They are the most familiar to experts, require few or no technical or analytical tools to support the group’s process, and are relatively inexpensive. However, the outcomes of these methods have notable limitations. They may not be transparent or easy to explain to people who were not involved in the process. Additionally, the results may not be readily reproduced by a separate but similar set of experts. The decisions from this approach are highly dependent on the knowledge and views of the experts selected for the process, the group’s specific scope and agenda, the dynamics that evolve within the group, and the influence of participating or contributing agency personnel. Frequently, little or no input is obtained from non-experts, leading to controversies when the experts’ decisions are announced. Expert judgment processes have tended to be decide-announce-defend approaches that have often conflicted with the U.S. public’s expectations.
Although still often implemented because of their simplicity and familiarity, these methods are increasingly being seen as over-used. Many times they are not the best suited for policy purposes, particularly when non-expert input needs to be integrated with expert knowledge and views or when public support and cooperation will be needed to implement the final decisions. Expert judgment processes may neither be particularly efficient nor produce the most effective and meaningful results for public policy or regulatory purposes. There is growing recognition that the disadvantages of these methods need to be more seriously considered before they are selected as the method of choice for contaminant identification and prioritization tasks.
Rule-Based Methods
These classification approaches score and then combine characteristics of contaminants in weighted algorithms to produce prioritized lists. The algorithms may be quantitative, qualitative, or semi-quantitative and result in either unique ranks for specific contaminants or broad categories for similar contaminants. Multiplicative methods are used more often than additive strategies to combine attribute values in an overall score or rank. Rule-based approaches are fairly rigid structures intended to remove subjectivity while enhancing transparency and consistency of results.
The NRC Committee on Drinking Water Contaminants reviewed 10 rule-based methods designed to prioritize hazardous contaminants (NRC, 1999a). The committee found that the results of the methods depended on the systems’ purposes, the contaminants selected for ranking, the ranking criteria and weighting algorithm, and the databases chosen to determine the input information. Nearly all of the 10 methods reviewed used data on both exposure and toxicity,
but none considered the impacts of the degradation byproducts of the input toxicants. All involved subjective, expert judgments, but all were less subjective than expert judgment methods. The committee determined that the rule-based processes reviewed were seen as more objective and consistent than expert judgment methods. The committee concluded that rule-based methods could provide useful preliminary screenings of a larger number of substances than can be handled using expert processes. The information needed to evaluate substances in rule-based methods may require extensive extraction of data from many sources of information. An important disadvantage of these methods is that the weights and combining methods to be used in the algorithm must be determined a priori; that is, before the method is applied to any contaminants. As a result, many regulatory processes that have relied on rule-based approaches have become quite long and controversial as experts, and sometimes stakeholders, have become engaged in intense debates about the exact weights and procedures to be used. These conflicts may occur even when the participants begin with mutually agreed-upon goals and agendas, because they begin to realize the potential consequences of the proposed weights and formulas. Similarly, the points of science policy interface in these methods may not be clear, providing more opportunities for contentious disputes to arise and stall completion of the design process. While these issues may extend the time to develop the tool considerably, the time required to implement these methods could also be lengthy. Delays and inconsistencies have often occurred, especially when the documentation for the process has lacked clear instructions about the handling of missing or imprecise data.
Many rule-based tools were developed to improve on expert judgment approaches, but have been found to have fewer advantages than expected. They are appealing because they tend to provide more rapid and useful preliminary analyses of larger sets of contaminants than do expert judgment methods. Although the implementation of rule-based ranking processes tends to be more objective and consistent than expert judgments, there may be substantial but not apparent subjectivity imbedded in them. When stakeholders discover the impacts of such hidden decisions, their trust in the regulatory ranking process may plummet, undermining the program’s abilities to proceed to actions.
Prototype Classification Approaches
There are several features that set these methods apart from the other two types of approaches. Although human beings are especially adept at prototyping tasks, when they use their mental processes alone they typically cannot process a large amount of information to make decisions efficiently and consistently over time. As a result, classifications of complex entities determined through human cognition alone tend to be slow and labor-intensive. An example of prototyping can be seen in medical practice. Physicians make decisions about how to treat patients who have similar clinical diagnoses, but their treatment decisions differ
from one patient to another. The doctors may not always be able to state explicitly the specific criteria they used to make those decisions, but know that experience indicates that some treatment strategies will work more effectively with some patients as opposed to others. Physicians’ decision processes may be very systematic and highly effective but largely subconscious because of the large number of factors that contribute to their final treatment selections.
Prototype classification methods mimic human prototyping processes by providing a systematic, experience-based tool but have the advantage of permitting efficient analysis of a very large amount of information. This asset is often realized through the application of computerized models. These methods begin with known classifications of prototypes (obtained from historical data) that embody the kinds of outcomes one wishes to achieve. They do not rely on a classification scheme fixed a priori, but build on characteristics of past experiences by using input and outcome data from decisions already made. Just as humans do not typically discard or ignore past experience when they classify new but similar entities, these methods require acceptance of past decisions as suitable for future ones. Although prototype classification methods have been available for several decades, lack of access to high-speed computing capacity and well-accepted, standardized software limited the range of their practical applications until the 1990s.
This approach processes input variable values to construct a computerized network that discerns an algorithm, and thereby reliably maps the inputs into classification outcomes. Using data from past experiences, the network develops weights and methods to combine the variables a posteriori, removing much of the subjectivity and time involved with expert judgment and rule-based methods. The model is trained using input and output values from past experiences and is tested by using different sets of known values. Sensitivity analyses are conducted to obtain the most accurate form of the model before putting it into high-throughput use.
These methods require compilation and organization of existing information on input and output characteristics for a set of substances that is large enough to both train and test the model. Expert decisions are involved in the design but not implementation of the model, thus removing many of the negative impacts of subjectivity found in the expert judgment and rule-based methods. The design decisions involve identification of substances for which decisions similar to the ones of interest have been made, choice of data sets with information on potential input and output variables for those substances, selection of the types and nature of input and output variables to be used in the model, and choice of initial model architecture (e.g., linear, sigmoidal, or other forms of relationships between the input variables). The major activities required to obtain a stable computerized algorithm are development of the list of attributes for the model, construction of the input database, and analysis of the training set outputs to determine the most effective “cut points” between the outcome classifications.
Expert judgment and rule-based methods suffer from the problems of developing consensus for decision criteria and processes, with the latter often getting bogged down in debates about weights and formulas for combining weights. The advantages of the prototype classification approach are that it minimizes the impacts of expert judgment, does not require a priori decision-making about the weights and formulas, produces scientifically based outcomes that are reproducible, processes all input information in a non-sequential manner so that no one factor serves as a “gate keeper,” allows for more than two outcome categories, and permits processing of a very large number of substances in a limited amount of time. Additionally, by using only fundamental characteristics of substances as input variables, proactive identification of hazards well beyond substances related to already known or suspected risks becomes possible. The primary advantage of prototype classification methods that distinguishes them from rule-based methods is the a posteriori determination of weights on the basis of past experience.
The disadvantages of prototyping methods are that they may require a lot of data for many substances; involve some assumptions and judgments to design the model; may result in an over-designed tool (i.e., a model that is more complex than necessary to make the desired decision); and may not be readily understood by people who have not been involved in the design decisions. However, expert judgment and rule-based methods also involve many aspects that are not transparent, not documented, and may not even be recognized by the persons who construct the processes and outputs. Specifically, the determination of weights and consequences of design decisions may only be superficially transparent.
When using prototype classification schemes, the goal should be to develop the simplest, most robust model that produces the type of decision required; e.g., the identification of drinking water contaminants that should be considered further for regulation. The accomplishment of this goal through simple models not only enhances the ability to explain the input-output relationships, but also reduces the amount and complexity of data and documentation needed to replicate the results.
The major forms of prototype classification schemes are machine learning classification systems, clustering algorithms, neural network models, and hybrids of these three. Only neural network modeling will be discussed further here, because this is the set of models that have recently been pilot tested (NRC, 2001) and are being developed (Parkin et al., 2002) for the proactive identification of drinking water contaminants. Although this method has been used widely for other purposes (e.g., clinical and financial decisions), it has not been previously used for environmental hazard prioritization processes.
NEURAL NETWORK MODELS
This method typically involves several to many input variables processed in a forward configuration to generate a fairly small number of outcome classifica-
tions. To use neural network models the designer chooses the model’s architecture; that is, determines the input variables and scoring systems to be considered, the number of neurons (or decision points), the organization of the model, the transfer functions that operate at each node, and the methods to analyze the sensitivity and set the “cut points” between the outcome categories. The method provides the capacity to capture linear and non-linear dependencies and constructs multiple, complex relationships that are not readily apparent in human prototyping activities (Garson, 1998). The method can produce simple, single-node models or highly complex models, such as are used to predict credit-worthiness in financial settings. However, the simplest model that effectively produces reliable outcomes is preferable.
The NRC committee recommended neural network models to the EPA for more rapid identification of the set of substances that should be considered for regulatory purposes. This recommendation was based on several important observations and decisions. The committee recognized that EPA’s past reliance on expert judgment and rule-based methods has not produced results in an efficient, open, or reliable manner. The time and staff resources available to EPA to prepare the CCL2 were important factors that led the committee to design the simplest process that would achieve a credible set of outcomes. The committee agreed that the process had to be science-based, systematic, defensible, and transparent. Finally, the group recognized that past prioritization processes used by EPA had evaluated chemicals and microbial pathogens separately, but felt that these two sets of contaminants needed to be integrated in one streamlined process. Thus, the committee decided to design a tool that would have the ability to evaluate both chemicals and microbial pathogens with the same input variables. As a result, programmatic priorities could be set across, and not just within, broad or superficial contaminant categories (NRC, 2001).
The committee developed and recommended a two-stage identification process: going from a “universe” to a shorter initial list before screening again to obtain the final list of substances for regulatory consideration. From all existing chemicals, microorganisms, radiological and other substances (hundreds of thousands of substances), there is a smaller subset (tens of thousands of substances) that constitutes the universe of substances that may be found in drinking water. This universe was the committee’s starting point for the recommended two-step process (Figure 1).
First, the universe would be screened to create a Preliminary Contaminant Candidate List (PCCL) containing no more than a few thousand substances. The winnowing required for this step may be accomplished through the use of simple screening criteria and limited expert judgment. For example, the data needed to implement this screening step for chemicals would include information on their use, location, and physical characteristics. Substances on the PCCL would be those that are known to occur or potentially occur in drinking water and those that are known or suspected to cause adverse health effects. The combination of
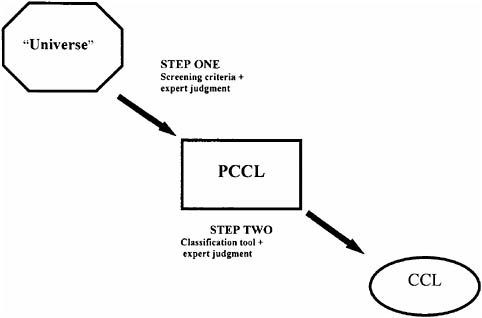
FIGURE 1 Recommended two-step process for identification of contaminants for regulatory consideration (As adapted from NRC, 2001). PCCL is the Preliminary Contaminant Candidate List, and CCL is the Contaminant Candidate List.
these two criteria would result in four categories of substances that would be placed on the PCCL but treated equivalently from that point (Figure 2).
In the second step, the PCCL would be assessed to determine which substances (potentially about one hundred) should be placed on the CCL and therefore be considered further for regulatory purposes. The committee recommended the use of neural network models for narrowing the PCCL to the CCL (NRC, 2001). The committee found the development of the model fairly simple and time-efficient. It required committee consensus on the few input variables that would be used, the scoring schemes for each variable, and the datasets that would be used to score the substances’ attributes. A few committee members individually conducted the additional model development and implementation activities.
Consensus on the variables to be used as inputs, describing the potential occurrence and health effects of substances, was obtained very rapidly. There were five input variables: three for occurrence (prevalence, magnitude, and persistence-mobility) and two for health effects (severity and potency). Upon initial review of the original six attributes selected by the committee, persistence and mobility were found to be so highly correlated that only one score for these
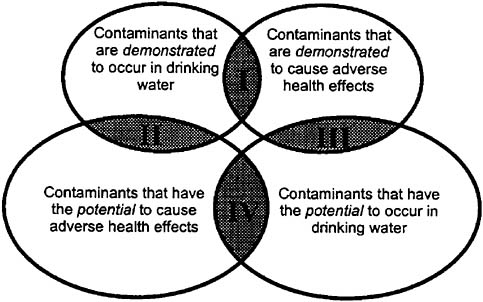
FIGURE 2 Conceptual approach to identifying contaminants for inclusion in a Preliminary Contaminant Candidate List (PCCL) (NRC, 1999a).
two attributes was necessary in the model. Relevant information about chemicals was known to exist in well-recognized, peer reviewed databases and could be readily accessed for the scoring task (NRC, 2001).
The committee then broke into subcommittees to develop scoring frameworks for microorganisms, occurrence, and health effects. Microorganisms were evaluated separately, because existing databases did not include them, and fundamental decisions were needed to determine whether pathogens could be included in our modeling exercise. Ultimately, a separate chapter was written about microorganisms proposing a new approach to obtain the data necessary to score them simultaneously with chemicals. The final frameworks for scoring occurrence and health effects were based on a number of scientific issues. The scores for the five attributes ranged from zero or one through ten (NRC, 2001).
A list of 85 contaminants (chemicals and microorganisms) that do or could occur in drinking water was prepared based on past regulatory decisions. Using the subcommittees’ draft scoring systems and existing databases (developed by EPA, the U.S. Food and Drug Administration, and the National Library of Medicine) with the necessary information for the substances, the input database was created in about two weeks by a toxicologist, with limited input from a few other committee members who had more detailed knowledge of complex chemicals or the design of the databases. Only one draft scoring scheme (that for
severity) had to be revised after the first few attempts to use it.1 Another committee member selected the modeling software (Matlab and Matlab Neural Network Toolbox of Mathworks, Inc., in Natick, Massachusetts), chose the training algorithm (conjugate gradient method), and used the substances’ input scores to train and test the neural network model. A sensitivity analysis of the initial training set results showed that there had been limited misclassification of past regulatory decisions. The cut point for the outcome variable (“consider further for regulation” or “do not consider further”) was revised based on the committee’s review and discussion of these findings. The revised cut point produced highly accurate and reliable results in the model rerun. Data for 63 regulated and 17 unregulated substances were used to train the model, and information on five substances was used to test it.
The final model had two layers connected in a feed-forward configuration (Figure 3). The first layer was hidden and included two nodes, each of which involved a sigmoidal (simple, non-linear) transfer function. The second layer was a linear function that produced the two outcome categories (consider further or not). Although more complex models could have been constructed, a comparison of this model’s outputs with those of a strictly linear model revealed that the neural network model yielded superior results with a minimum of additional complexity. The two-layer model met the goal of achieving effective outputs with the least complex model, so the committee recommended this simple neural network model form for the PCCL-CCL screening step.
Time and resources, however, severely limited the committee’s ability to develop the model to the extent needed for regulatory purposes. Recognizing this, the NRC advised EPA to review the committee’s fundamental decisions, determine what would be needed to support a public process to implement the neural network model approach, and test the model with several datasets before using it for obtaining the CCL2 (NRC, 2001).
Following EPA’s acceptance and review of the NRC committee’s report, several committee members oriented EPA staff to the details of the neural network model development process. From winter 2002, staff members began making the fundamental decisions necessary to design EPA’s version of a PCCL-CCL neural network model. They also began compiling the necessary input databases so that the model could be developed and CCL2 published by the mandated deadline of February 2003. However, by fall 2002 the agency determined that additional time was needed to implement means not only to develop a model but also to establish an effective stakeholder process. The NRC committee pointed out the importance of this input and urged the EPA to include as much public comment
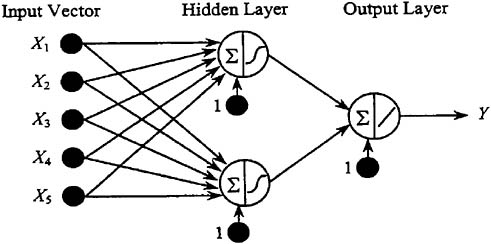
FIGURE 3 Multi-layer neural network model used for contaminant classification (NRC, 2001).
as possible. However, with the time available, EPA was not able to fully meet the participatory ideals described by the committee (NRC, 2001). EPA is now targeting the 2007 regulatory timeframe for the modeling and stakeholder processes.
LESSONS LEARNED
Although they have been extensively used, expert judgment and rule-based processes do not have the capacity to screen large numbers of potentially hazardous substances to protect public health in a timely, efficient, and consistent manner. Concerns about the possibly high impacts and low transparency of subjective decisions in these two approaches have reduced their value for regulatory processes. As a result, prototype classification schemes, particularly neural network modeling, are now being developed and tested to determine their advantages and disadvantages for identifying and prioritizing contaminants. Already important lessons have been learned about this approach for drinking water contaminants.
Prototyping may reduce the time and number of controversies involved in developing consensus on the key attributes of substances and the sources of data to score those attributes. Scoring schemes may require some consensus building, but are unlikely to entail extensive decision processes. For example, although the NRC committee’s draft severity scale was too limited to distinguish substances’ health impacts effectively, the scaling problem became apparent in scoring only a few substances and was readily improved and reapplied successfully. Fairly
general attribute data appear to be sufficient to sort substances into those that merit further regulatory consideration and those that do not. An important part of developing a neural network model is examining the potential correlations and culling out highly correlated attributes so that the final set of attributes used in the model only includes those that are necessary to produce reliable outcome values.
Data sufficient to score attributes is readily available and does not require highly technical or time-consuming evaluations to determine appropriate scores. The choice of databases to be used in the scoring step should relate to the quality and relevance of the information to the attributes to be included in the model. For example, in a model focused on protecting public health, data such as ambient water information has less immediate relevance than tap water data for scoring occurrence. One important limitation is the lack of appropriate attribute data in a centralized database for microorganisms. The necessary data may become available in the next few years, but were not ready to any significant extent for the CCL2.
A sufficient number of substances need to be scored and used to ensure a robust neural network model. Five times the number of attributes to be used is the minimum number of substances that should be used to train the model. A small number of substances can be processed to test the model, but several data sets should be used to conduct repeated tests and thereby ensure the model’s stability before broad application.
The importance of proactively identifying substances for regulatory purposes cannot be understated. Not only will more efficient and comprehensive screening processes produce greater public health protection, but they will also provide more time for new risk management strategies and technologies to be developed.
A NEW DIRECTION
Drinking water utilities not only attempt to anticipate regulatory requirements, but also must address public concerns about actual or potential drinking water contaminants. In an effort to develop a tool so that emerging contaminant concerns can be foreseen more readily, the American Water Works Association Research Foundation (AWWARF) funded a project to identify contaminants proactively (Parkin et al., 2002).
This project is focused on combining scientific data (as in the NRC model) and public concerns in a neural network model that will provide early indication of substances that may require more detailed attention and review. It is based on the premise that substances may emerge as public concerns from the public’s perceptions of substances rather than from scientific knowledge alone. The conceptual foundation for this project is several decades of scientific investigations into the formation of expert and non-expert risk perceptions (Fischhoff et al., 1997). It is well known that the factors that influence the perceptions of these two groups differ in important ways (e.g., Morgan et al., 2002).
The investigators are determining the input attributes (and appropriate data sources) that will result in four distinct outcome categories: 1) substances that are of both scientific and public concern, 2) substances that are of neither scientific nor public concern, 3) substances that are of scientific but not public concern, and 4) substances that are of public but not scientific concern (Figure 4). Although the work on this project is in initial stages, evaluation of the sources and types of information available to evaluate public concerns has revealed some themes and directions that will shape the final model. The results of the project will be reported in late 2003 and are expected to be of interest to utilities and regulatory agencies.
PROPOSED COLLABORATIONS
At this early stage of neural network model development for drinking water contaminant identification, the opportunities to test the method in a range of regulatory and practice settings have not been adequately considered. As more organizations attempt to design and use neural network (or other prototype classification) models to protect public health, it will become possible to evaluate the impacts of differing designs, decision-making processes, and societal
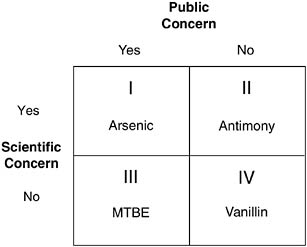
FIGURE 4 Proposed outcomes for a neural network model with examples of substances in each category (Parkin et al., 2002).
I. Scientific and public concern
II. Scientific concern, but no public concern
III Public concern, but no scientific concern
IV. No scientific or public concern
contexts. The lessons learned from these efforts need to be reported in the peer-reviewed literature so comparisons can be made. Ideally, studies should be designed so that the impacts of differing model development processes and decisions can be evaluated systematically, and scientifically derived lessons can be obtained.
Collaboration among experts with differing but complementary backgrounds has taken place in the NRC’s committee and is now occurring at the EPA and in the AWWARF project based at The George Washington University in Washington, DC (Parkin et al., 2002). Because of the range of knowledge, data sources, and techniques that these teams bring to the model development activities, their efforts are likely to result in a broader range of insights and more robust neural network models. Similarly, collaboration of experts from different regulatory settings would provide new opportunities to understand when and how neural network models may be most useful as decision support tools for regulatory purposes.
A range of prototyping techniques should be considered, developed, and tested in a variety of contexts. Formal collaborations among experts from different settings would advance capabilities and insights about the tools’ value for contaminant identification tasks designed to meet a variety of goals. Diverse settings would offer an opportunity to design a scientifically based social research initiative in which the impacts of differing decision-making processes and modeling choices on the techniques and the regulatory goals can be examined and reported in a more rigorous and credible manner.
CONCLUSIONS
In conclusion, expert and rule-based methods have been found to be too limited for efficient, proactive drinking water contaminant identification and prioritization processes for regulatory programs. During the 1990s, new computing and software capabilities became available and have produced stable prototyping classification methods that can be more widely used to address drinking water issues. These methods may improve both the speed and effectiveness of contaminant assessment, but many lessons need to be learned about the tool’s utility in a variety of settings. Experts’ knowledge about the strengths and weaknesses of the approach will grow more quickly and advances will be made as experience is gained in diverse settings. With deeper understanding of prototyping methods and their practical value, regulatory program managers will be able to make better decisions about how to identify and rank hazardous substances. The large number of new chemicals being made and microorganisms evolving makes proactive public health protection more urgent, and innovative decision-making tools and methods more critical. Prototyping classification techniques offer regulators a new, efficient and reproducible way to achieve this goal, possibly with fewer controversies. The lessons learned in the next decade about this
set of techniques are expected to open up opportunities for more rapid and appropriately focused public health initiatives.
ACKNOWLEDGEMENTS
The author acknowledges the contributions made by her colleagues on the NRC Committee on Drinking Water Contaminants that serve as the partial basis for one of her current research projects, the American Water Works Association Research Foundation Project #2776. She also gratefully recognizes the technical assistance of Lisa Ragain and Martha Embrey, research staff of the Center for Risk Science and Public Health, School of Public Health and Health Services, The George Washington University, Washington, DC.
SELECTED BIBLIOGRAPHY
Balbus, J.M. and M.A. Embrey. 2002. Risk factors for waterborne enteric infections. Current Opinion in Gastroenterology 18(l): 46-50.
Bourbigot, Marie-Marguerite. 2000. Access to healthy water and an efficient wastewater treatment system. World Conference on Science. Science for the Twenty-First Century: A New Commitment. Paris: United Nations Educational, Scientific, and Cultural Organization. Available at http://unesdoc.unesco.org/images/0012/001207/120706e.pdf.
Canadian Standards Association (CSA). 1997. Q850 Risk Management: Guideline for Decision-Makers. Toronto.
Carson, R. 1962. Silent Spring. Greenwich, Connecticut: Fawcett.
Fischhoff, B., A. Bostrom, and M.J. Quadrel. 1997. Risk perception and communication. Pp. 987-1002 in Detels, R., W. Holland, J. McEwen, and G. Omerm, eds. Oxford Textbook of Public Health. London: Oxford University Press.
Garson, G.D. 1998. Neural Networks: An Introductory Guide for Social Scientists. Thousand Oaks, CA: SAGE Publications.
International Life Sciences Institute (ILSI). 2000. Revised Framework for Microbial Risk Assessment. Washington, DC: ILSI, Risk Science Institute.
Morgan, G., B. Fischhoff, A. Bostrom, and C.J. Atman. 2002. Risk Communication: A Mental Models Approach. Cambridge: Cambridge University Press.
National Research Council (NRC). 1983. Risk Assessment in the Federal Government: Managing the Process. Washington, DC: National Academy Press.
National Research Council (NRC). 1997. Safe Water from Every Tap. Washington, DC: National Academy Press.
National Research Council (NRC). 1999a. Setting Priorities for Drinking Water Contaminants. Washington, DC: National Academy Press.
National Research Council (NRC). 1999b. Identifying Future Drinking Water Contaminants. Washington, DC: National Academy Press.
National Research Council (NRC). 2001. Committee on Drinking Water Contaminants, Classifying Drinking Water Contaminants for Regulatory Consideration. Washington, DC: National Academy Press.
Parkin, R. 2002. Strategies for identifying emerging drinking water contaminants and communicating to address public concerns. American Water Works Association Research Foundation (AWWARF) Research Project 2776. Denver, CO: AWWARF. Available at http://www.awwarf.com/research/.
Presidential/Congressional Commission on Risk Assessment and Management. 1997. Risk Assessment and Risk Management in Regulatory Decision-Making: Final Report, Volume 2. Washington, DC.
Safe Drinking Water Act (SDWA) Amendments of 1996, 42 U.S.C. 300 (1974).
United States Environmental Protection Agency (EPA). 1987. Risk Assessment Guidelines of 1986. EPA-600/8-87/045. Washington, DC.
United States Code Annotated. Reorganization Plan No. 3 of 1970. 91st Congress, Second Session, Vol. 3.
World Health Organization (WHO). 2002. 2000-2001 Work Plan. Available at http://www.who.int/docstore/water_sanitation_health/General/workplan.htm.


















