
2
The Domain Name System: Emergence and Evolution
The Domain Name System (DNS) was designed and deployed in the 1980s to overcome technical and operational constraints of its predecessor, the HOSTS.TXT system. Some of the initial design decisions have proven to be extraordinarily flexible in accommodating major changes in the scale and scope of the DNS. Other initial design decisions constrain technical and policy choices to the present day. Thus, an understanding of the system architecture and the rationale for the design characteristics of the DNS provides the base for understanding how the DNS has evolved to the present and for evaluating possibilities for its future. This chapter outlines the origin and development of the DNS and describes its key design characteristics, which include both technological and organizational aspects.1
2.1 ORIGIN OF THE DOMAIN NAME SYSTEM
For the first decade or so of the ARPANET,2 the host3 table file (HOSTS.TXT) served as its directory. HOSTS.TXT provided the network
|
1 |
A general presentation of the history of the Internet is beyond the scope of this report. One source of documentation on the Internet’s history is available at <http://www.isoc.org/internet/history/>. |
|
2 |
The Internet grew out of the ARPANET project (funded by the Defense Advanced Research Projects Agency (DARPA), which was known as ARPA for a period of its history); for many years the ARPANET served as the core of the Internet. |
|
3 |
A host is the primary or controlling computer in a network. |
address for each host on the ARPANET,4 which could be looked up by using the host’s one-word English language name, acronym, or abbreviation. The Network Information Center (NIC) at the Stanford Research Institute5 managed the registration of hosts and the distribution of the information needed to keep the HOSTS.TXT file current. The list of host names and their mapping to and from network addresses was maintained in the frequently updated HOSTS.TXT file, which was copied to and stored in each computer connected to the ARPANET. Thus, HOSTS.TXT6 was introduced to:
-
Simplify the identification of computers on the ARPANET. Simple and familiar names are much easier for humans to remember than lengthy (12-digit) numeric strings; and
-
Provide stability when addresses changed. Since addresses in the ARPANET were a function of network topology and routing,7 they often had to be changed when topology or routing changed. Names in the host table could remain unchanged even as addresses changed.
The HOSTS.TXT file had a very simple format. Each line in HOSTS.TXT included information about a single host, such as the network address, and when provided, system manufacturer and model number, operating system, and a listing of the protocols that were supported.
Because a copy of the host table was stored in every computer on the ARPANET, each time a new computer was added to the network, or an-
|
4 |
These network addresses could be represented using the Internet Protocol (IP) format or in the equivalent (now unused) ARPANET Network Control Protocol (NCP) format. The most widely used version (v4) of IP represents addresses using 32 bits, usually expressed as four integers in the range from 0 to 255, separated by dots. An example of an IP address is 144.171.1.26. |
|
5 |
Stanford Research Institute became known as SRI International in 1977. |
|
6 |
For further discussion, see L. Peter Deutsch, “Host Names On-line,” Request for Comments (RFC) 606, December 1973; Ken Harrenstien, Vic White, and Elizabeth Feinler, “Hostnames Server,” RFC 811, March 1982; and Ken Harrenstien, M. Stahl, and Elizabeth Feinler, “DOD Internet Host Table Specification,” RFC 952, October 1985, all available at <http://www.rfc-editor.org>. RFCs are created to document technical and organizational aspects of the Internet. The Internet Engineering Task Force (IETF) manages the process for discussing, evaluating, and approving RFCs. See Box 3.3. For a discussion of the role of the DNS more generally, see John C. Klensin, “Role of the Domain Name System,” RFC 3467, February 2003. |
|
7 |
Routing refers to the way data flowed on the ARPANET. Data transmitted from point A to point B might have traversed many different paths, or routes, on the ARPANET. Note that the ARPANET, as the original network to employ the Internet Protocol (IP), was often referred to as “the Internet,” although the term later formally encompassed the aggregate of interconnected IP-based networks. |
other update was made, the entire table had to be sent to every computer on the network for the change to be recognized.8 As increasing numbers of computers joined the ARPANET, the updating task became more and more burdensome and subject to error and failure, and, as a consequence, several major problems developed from the use of the HOSTS.TXT file:
-
Failure to scale. As the ARPANET started to grow rapidly, it became clear that the centralized HOSTS.TXT file failed to scale in two ways. First, the volume of updates threatened to overwhelm the NIC staff maintaining HOSTS.TXT. Second, because every system needed to have an up-to-date copy of HOSTS.TXT, announcement of a new copy of HOSTS.TXT meant that the NIC server where the current version of HOSTS.TXT was stored was inundated with attempts to download the file. Moreover, the download problem was aggravated because HOSTS.TXT kept getting bigger. In short, more hosts on the network meant more updates, more hosts trying to download, and more data to download.
-
Inadequate timeliness. It often took several days to get a new host listed in HOSTS.TXT while the NIC staff processed the request to add the host entry. Until it was listed and communicated, the host was effectively invisible to the rest of the ARPANET. In a community already becoming accustomed to getting data instantly over the network, this delay was a source of frustration. Similarly, correcting an error often took a few days, because fixes to any errors were not generally available until the next HOSTS.TXT file was released—which caused further frustration. The maintainers of some hosts also did not update their copies of the table at very frequent intervals, resulting in those hosts having obsolete or incomplete information even when the master copy of the table was up-to-date.
-
Susceptibility to failure. The system had multiple ways to fail. Probably the most famous outage occurred when the NIC released a version of HOSTS.TXT that omitted the entry for the system where the HOSTS.TXT file was stored. When the subsequent HOSTS.TXT file was released, most systems could not download it, because they could not look up the relevant host name! There were also cases where partial tables were inadvertently released. Furthermore, seemingly innocuous additions to HOSTS.TXT could cause the programs that converted HOSTS.TXT into local formats to fail.
-
Name conflicts. The HOSTS.TXT name space was flat, which meant that host names had to be unique. Popular host names such as Frodo were selected first, and so some people had to invent alternate names for their systems.
The emergence of these problems caused technologists to develop a new, distributed, method for managing the mapping of names and addresses.
2.2 DESIGNING THE DOMAIN NAME SYSTEM
In the early 1980s, research on naming systems—systems for associating names with addresses—was underway and a few prototype naming systems had just been developed, most notably the Grapevine and Clearinghouse systems at the Xerox Palo Alto Research Center (PARC).9 Also in progress at this time was preliminary work on other computer network addressing standards such as X.400.10 Because of the uncertainty as to whether these research and development efforts would yield in the near term an operational system with the required functionality and needed scale, Internet researchers elected to develop their own protocols.
In August 1982, Zaw-Sing Su and Jon Postel authored “The Domain Naming Convention for Internet User Applications,” Request for Comments (RFC) 819, which described how Internet naming should be changed to facilitate a distributed name system. As envisioned in this document, Internet names would be organized into logical hierarchies, represented by text components separated by a period (“.”) (thus the existing host “ISIF”—host computer “F” at the Information Sciences Institute (ISI)—would become F.ISI), and the various parts of the name as assigned (i.e., the parts delimited with periods) would be managed by different network servers. RFC 819 specified only how names would be represented—the details of how the management of various parts of assigned names would take place operationally by the different network servers remained to be determined.
In November 1983, Paul Mockapetris authored “Domain Names—Concepts and Facilities” (RFC 882) and “Domain Names—Implementation and Specification” (RFC 883), which specified a set of protocols, called the Domain Name System, that implemented the hierarchical name space proposed by Su and Postel. Reflecting the discussions of the previous several months on the electronic mail list Namedroppers, the proposed DNS
supported more sophisticated services and features than simply converting host names to addresses (e.g., the proposed system would provide a way to map a name to different addresses, depending on the purpose for which an inquiry was being made). With some modest changes, the proposed protocols are exactly those in use two decades later.
Conceptually, the DNS is implemented through a distributed and hierarchical series of tables, linked like the branches of an inverted tree springing from a single, common root. When an address is sought, the search proceeds successively from the table at the root (or top) of the tree to successive branches and leaves, or lower tables, until the table that holds the desired address is found. For a particular query, only the last table in the search serves as a white pages directory. All of the other tables serve as directories of directories, each one pointing to lower-level directories on a path to the one holding the desired address. Thus, the entries in a table at any given level of the tree can include pointers to lower-level tables as well as final network addresses. See Figure 2.1.
When a change is made in the network, only the table directly affected by that change must be updated and only the local organization (e.g., the system administration function in a university or corporation) responsible for that table needs to make the update. As a result, the work of registering changes is distributed among many organizations, thus reducing the burden each must carry.
The DNS naming syntax corresponds to the levels in the hierarchical tree. Each node in the tree has a name that identifies it relative to the node
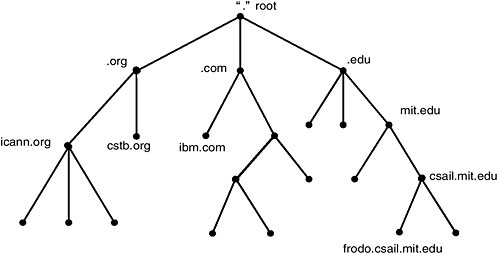
FIGURE 2.1 The hierarchical Domain Name System inverted tree structure.
above it. The highest level, the “root node,” has the null name. In text it is written as a single dot (“.”) or simply implied (and thus not shown at all). Each node below the root is the root of another subtree, a domain, that can in turn be further divided into additional subtrees, called subdomains. Each subdomain is written in text to include its name and the subdomains above it in the applicable hierarchy. In Figure 2.1, .com, .org, and .edu are top-level domains (TLDs) and cstb.org, mit.edu, and ibm.com are subdomains of the TLDs, often called second-level domains. The third-level domain, csail.mit.edu, is a subdomain within the mit.edu second-level domain.
The DNS name of a computer is the name of its node or end point in the Domain Name System. Thus, frodo.csail.mit.edu would be the computer (or device) named “frodo” that is located within the csail.mit.edu subdomain of the mit.edu second-level domain within the .edu TLD. On the other hand, myownpersonalcomputer.com (without any further subdomains) could point directly to a particular computer.
Applications, such as Web browsers and e-mail software, use domain names as part of the Uniform Resource Identifiers (URIs; see Box 6.2) or other references that incorporate information about the protocols required for communication with the desired information source. Examples of URIs are http://www.national-academies.org and mailto:someperson@example.com. In the first example, “http” refers to the Hypertext Transfer Protocol (HTTP) used for communication with sites on the World Wide Web. In the second example, a particular user at the host identified by “example.com” is identified as the addressee for electronic mail.
In terms of information technology, the Domain Name System is implemented through a series of name servers that are located at each of the nodes in the hierarchy. Each name server contains a table that indicates the locations of the name servers immediately below it in the hierarchy and the portion of the hierarchy for which it contains the final (authoritative) network addresses. Thus, the root name servers (at the top of the hierarchy) contain the locations of each of the name servers for the top-level domains.11 At any given node, such as .com or ibm.com, there are expected to be multiple (physical) name servers at different Internet Protocol (IP) addresses, each with identical information; the purpose of this redundancy is to share the workload to ensure adequate system performance.
When a user wants to reach www.national-academies.org, his or her computer usually sends a message to a nearby name server (usually local or operated by the user’s Internet service provider), where software (called
|
11 |
Each of these root name servers contains identical information; the purpose of having multiple root name servers is to distribute the query workload and ensure reliable operation. Specifics concerning the root name servers are discussed in Chapter 3. |
a resolver), in conjunction with other name servers and resolvers, performs a series of queries to find the name server that is authoritative for www.national-academies.org. That server is then queried for the corresponding IP address(es) and returns the resulting address(es) to the user’s computer.12
2.2.1 Simple, Mnemonic, and Deeply Hierarchical Names
As indicated above, domain names were intended to enable a more convenient and efficient way of referring to IP addresses and other information, using a simple taxonomy. The early DNS included eight generic top-level domains (gTLDs): .edu (institutions of higher education—most of which were based in the United States), .gov (U.S. government), .mil (U.S. military), .com (commerce), .net (network resources), .org (other organizations and persons13), .int (international treaty organizations), and .arpa (network infrastructure).14 In addition, country-code top-level domains (ccTLDs) were created based on the two-letter code set (e.g., .gh for Ghana or .au for Australia) in the ISO 3166-1 standard.15
Despite the ability of the protocols and data structures themselves to accommodate any binary representation, DNS names were historically restricted to a subset of the ASCII character set.16 Selection of that subset was driven in part by human factors considerations, including a desire to eliminate possible ambiguities in an international context. Hence, character codes that had international variations in interpretation were excluded; the underscore character (too much like a hyphen) and case distinctions (upper versus lower) were eliminated as being confusing when written or read by people; and so on. These considerations appear to be very similar to those that resulted in similarly restricted character sets being used as protocol elements in many International Telecommunication Union (ITU) and International Organization for Standardization (ISO) protocols.
|
12 |
The summary provided in this paragraph is quite simplified; there are many discrete technical processes that are not articulated here. See Chapter 3 for a more detailed explanation. |
|
13 |
Initially, the .org TLD was intended as the category for organizations and individuals that did not fall into any of the other categories. Through time, many individuals increasingly viewed .org as representing the domain name space for non-profit organizations. |
|
14 |
These definitions of the gTLDs were generally followed, although a number of exceptions existed. |
|
15 |
Thus, the determination of what constitutes a country did not need to be addressed by those who administer the DNS. See <http://www.iso.org/iso/en/prodsservices/iso3166ma/index.html>. |
|
16 |
This subset, which derives primarily from the original HOSTS.TXT naming rules, includes the 10 Arabic digits, the 26 letters of the English alphabet, and the hyphen. |
Another initial assumption behind the design of the DNS was that there would be relatively many physical hosts for each second-level domain name and, more generally, that the system would be deeply hierarchical, with most systems (and names) at the third level or below. Some domains—those of most universities and some large corporations and the country code for the United States (.us)—follow this model, at least in its original design, but most do not17 (see Chapter 3 for discussion). However, experience through mid-year 2005 has shown that the DNS is robust enough—given contemporary machines as servers and current bandwidth norms—to operate reasonably well even though the design assumption of a deep hierarchy is not satisfied. Nonetheless, it is still useful to remember that the system could have been designed to work with a flat structure (e.g., the huge, flat structure under .com comprising tens of millions of names) rather than a deeply hierarchical one. For example, based on an assumption of a flat structure at the TLD level, one would probably not wish to assign specific operational responsibility by TLD (as is the case currently). Instead, it might have made more sense to design the system as one database that is replicated on a limited number of servers (to share the workload and coordinate updates in a manageable way).
2.2.2 Experimental Features
The DNS specification included a number of experimental features, intended to enhance the services that the DNS could provide beyond simple name-to-address lookup. Several of these features were intended to facilitate improved support of electronic mail. Several resource records18 were intended to improve e-mail routing, helping to ensure that e-mail sent to a particular host took a reliable route to that host. The DNS also included features intended to support e-mail lists and aliases. The idea was to make it easier to maintain mailing lists and to forward mail when someone’s e-mail address changed. In addition, the DNS contained a feature to track “well-known services.” The purpose of this feature was to provide a list of services (e-mail, File Transfer Protocol, Web) that are
|
17 |
The .us country code TLD was designed originally to use geographical and political jurisdictions as subdomains. As one moves to the left, each subdomain represents a subset of the area represented by the immediately preceding name. For example, in the name “www.cnri.reston.va.us,” “va” represents the state of Virginia within the United States, “reston” represents a city within Virginia, and “cnri” represents an organization in the city of Reston. |
|
18 |
Each table within the domain name tree hierarchy contains resource records, which are composed of fields such as the type (i.e., does this record correspond to a host address, an authoritative name server, or something else) and time to live (i.e., for what period of time may this record be cached before the source of the information should be consulted again?). See Box 3.2 for a detailed discussion of resource records. |
available from a host. Most of the experimental features have not been adopted for general use. Indeed, the original set of e-mail-related record types were deprecated in favor of a newer model (see Section 2.3.3) and the “well-known services” record was determined to be unworkable.
2.3 DEPLOYING THE DOMAIN NAME SYSTEM
Whereas the design of the DNS looked reasonable on paper, several limitations of the new system, as with any new system, did not become apparent until initial deployment began. Addressing these limitations caused a delay in the full implementation of the DNS. The plan called for a switchover to the DNS in September 1984, but full conversion did not take place until 1987. Some of the delay was attributable to reconciling naming conflicts.19 A large part of the delay derived from a far longer than expected period to implement and debug the DNS, of which a significant portion derived from simple procrastination—just not getting around to installing and implementing the DNS. Another delay included the difficulty of retrofitting the DNS into old operating systems that were no longer actively maintained.
2.3.1 Caching
The design of the DNS allows for the existence of caches. These are local data storage or memory that can significantly reduce the amount of network traffic associated with repeated successful queries for the same data by providing access to the data in servers closer to the end user than the authoritative name server.20 The data in these caches need to be refreshed at regular intervals21 to ensure that the cached data are valid. In the initial version of the DNS specification, several timing parameters had time-to-live limits of approximately 18 hours. It quickly became apparent, however, that in many cases data changed slowly, and so updating caches every 18 hours or so was unnecessary. As a consequence, the protocol specification was changed to increase the allowed range of these timing parameters; several other protocol parameters were also given expanded ranges, based on the theory that one incompatible protocol change early on would be better than a series of such changes. This happened early
|
19 |
Most or all of these conflicts were internal ones—for example, subunits of a university trying to obtain the same domain name as the university. |
|
20 |
An additional potential benefit from the use of caches is an improvement in user response time. |
|
21 |
As defined in the time-to-live field in the resource records. See Chapter 3. |
enough that there was no serious difficulty in deploying upgraded software.
In its original design, the DNS did not have a corresponding mechanism for reducing the network traffic associated with repeated unsuccessful queries (i.e., queries for which no entry in the relevant authoritative table is found). Within a few years of the initial implementation of the DNS, it became apparent that such a mechanism would be beneficial, given the number of identical queries that are unsuccessful. A proposed mechanism for negative response caching was developed, and the data necessary to support it were added to the protocol in a way that did not affect software based on earlier versions of the protocol, but the full deployment of the new mechanism was slow. The name server side of the new mechanism was very simple and was deployed fairly quickly, but initial support for the client (user) side of the negative caching mechanism was limited to a few implementations and was not adopted more generally until much later. The lack of widespread and correct client-side support for negative caching is a problem that still persists.22
2.3.2 Lookup Timeouts
The biggest single difficulty in the transition from HOSTS.TXT to the DNS, however, was not due to any specific shortcoming of the DNS. Rather, it was attributable to the fundamental change in the nature of the lookup mechanism. In the HOSTS.TXT world, any particular host lookup operation would either succeed or fail immediately—the HOSTS.TXT file is located on the user’s system; it is not dependent on Internet connectivity at the moment of lookup. The DNS added a third possible outcome to any lookup operation: a timeout attributable to any of a number of possible temporary failure conditions (e.g., the required name server is down, so one does not know whether the particular name is indeed in the table or not). The occurrence of a timeout indicates neither success nor failure; it is the equivalent of asking a yes or no question and being told “ask again later.” Many of the network programs that predated the DNS simply could not handle this third possibility and had to be rewritten. While
this was something of a problem for programs intended to be run directly by a user (e.g., one then-popular e-mail client checked the host name of every recipient during composition), it was a far more serious problem for programs that ran unattended, such as mail transfer agents. These programs had to be rewritten to handle DNS timeout errors in the same way as they would handle any other form of connection failure. Conceptually, this was simple enough, but it took several years to actually track down and fix all the places in all the programs that made implicit assumptions about the host lookup mechanism. Toward the end of this period, the Internet had entered an era of periodic “congestion collapses” that eventually led to a fundamental improvement in certain algorithms used in the Internet infrastructure. During each of these congestion collapses, DNS lookups (along with all other forms of Internet traffic) frequently timed out, which made it much more obvious which applications still needed to be converted to handle timeouts properly. To this day, however, correct handling of the possibility of timeouts during a DNS lookup represents an issue in application design.
2.3.3 Convergence in Electronic Mail Systems
In the mid-1980s, the Internet was one of the major data networks.23 Although data could not move from one network to the next, e-mail was able to flow—through carefully designed e-mail gateways—between the networks. Some of the busiest computers on each network were the machines whose job it was to relay e-mail from one network to the next.24 Unfortunately, the system of gateways required users to route their e-mail by explicitly using the e-mail address. For instance, to send e-mail over the Internet to a colleague at Hewlett Packard Laboratories on the Computer Science Network (CSNET), one had to address the e-mail to colleague%hplabs.csnet@relay.cs.net. This complex syntax says that the Internet should deliver the e-mail to relay.cs.net and then send the message on to the appropriate address on cs.net.25 Thus, some people had
|
23 |
These major data networks included BITNET, Internet, CSNET, UUCP, and Fidonet. See John S. Quarterman, The Matrix: Computer Networks and Conferencing Systems Worldwide, Digital Press, Bedford, Mass., 1990; and Donnalyn Frey, Buck Adams, and Rick Adams, !%@: A Directory of Electronic Mail Addressing and Networks, O’Reilly and Associates, Sebastopol, Calif., 1991. |
|
24 |
For instance, relay.cs.net and seismo.css.gov, the e-mail gateways between the Internet and the Computer Science Network, and an important one of those between the Internet and the Unix-to-Unix network, respectively, were typically the top two hosts (in terms of traffic sent or received) on the ARPANET in the mid-1980s. |
|
25 |
In some instances, the messages were even messier; someone on the Unix-to-Unix network (UUCP) might have to write an address such as <ihnp4!seismo!colleague%hplabs.csnet@relay.cs.net> to send an e-mail. |
one e-mail box yet had business cards listing three or four different ways to send e-mail to them. There were ample opportunities for confusion and mis-routed e-mail.26
The original DNS specification tried to address this problem by making it possible to send e-mail to names that were not connected to the Internet. For instance, if the Example Company was on the UUCP network, but wanted to exchange e-mail over the Internet, it could register Example.com and place an entry in the DNS directing that all e-mail to names ending Example.com should be forwarded to the UUCP e-mail gateway, which would know to forward the e-mail to the Example Company’s e-mail hub.
Unfortunately, the original DNS scheme for e-mail routing was not up to the task. It did not handle certain types of e-mail routing well, and, worse, it could cause e-mail errors that resulted in lost e-mail.
The result was a new scheme using Mail eXchangers (MXs) so that, for any domain name, the DNS would store a preferentially ordered list of hosts that would handle e-mail for that name. The rule is to start with the most preferred host in the list and work down the list until a host is found that will accept the e-mail.27 This simple rule could be combined with the DNS facility for wildcarding (following rules that state that all names ending in a particular domain, or that a particular subset of names ending in a name, should all get the same response)28 to create e-mail routing for almost any desirable situation. In particular, it was possible to address e-
|
26 |
For instance, at Princeton University there was a weekly tape swap between the operators of princeton.bitnet and princeton.csnet—two machines on different networks that routinely got e-mail accidentally intended for the other. |
|
27 |
See Craig Partridge, “Mail Routing and the Domain Name System,” RFC 974, January 1986, available at <http://www.rfc-editor.org>. |
|
28 |
For example, in the early days of e-mail connectivity to much of Africa, e-mail hubs were set up inside the countries, serving all users there. These hubs did not have direct Internet connectivity to the rest of the world but were typically served through occasional dial-up connections that, in turn, usually used non-TCP/IP connections. To facilitate this arrangement, the DNS was set up so that all traffic for, say, South Africa (the .za ccTLD), regardless of the full domain name, would be routed to a mail-receiving system in the United States. That system would then open an international dial-up connection at regular intervals and transfer the accumulated e-mail over it. The e-mail hub in South Africa would then distribute the e-mail to other hubs within the country, often using the originally specified domain as an indication of the appropriate domestic server. This model had the added advantage that, when permanent connectivity became available, user and institutional e-mail addresses and domain names did not have to change—users just saw a dramatic improvement in service and turnaround time. More information on the history of this strategy may be found at <http://www.nsrc.org/> and in John C. Klensin and Randy Bush, “Expanding International E-mail Connectivity: Another Look,” Connexions—The Interoperability Report 7(8):25-29, 1993, available at <http://www.nsrc.org/articles/930600.connexions>. |
mail to domains that were off the Internet, or domains that were partly on and partly off the Internet.
The development of a dependable and highly flexible mechanism for routing Internet e-mail had two almost immediate consequences. First, all the other major e-mail networks converted to using domain names or names that looked like domain names.29 These other networks all had non-hierarchical (i.e., flat) name spaces, with many of the same scaling problems that were experienced with HOSTS.TXT, and were looking for a workable hierarchical name space. Once it was shown that the DNS would work for e-mail, it was simpler for companies to adopt domain names and, in some cases, adapt the DNS to run on their networks rather than to devise their own naming scheme. Thus, within a matter of 18 months to 2 years, the Babel of e-mail addresses was simplified almost everywhere in the world to user@domain-name. A second effect was that companies could now change networks without changing their host names and e-mail addresses, providing incentives for some companies to make the switch to the Internet. Indeed, by 1990, almost all the networks that had offered services comparable to the Internet were either gone or going out of business.30 Around the same time, companies began to encourage their employees to put e-mail addresses on business cards (it had often been discouraged because, as previously noted, e-mail addresses were so complicated). Domain names thereafter became a (small) part of everyday business.
There were also some longer-term effects. First, it was very clear that the DNS could provide names for things that were not hosts. For instance, almost every organization soon made it possible to send e-mail to someperson@example.com, even though there was no actual machine named example.com, but rather a collection of servers (e.g., mailserver1.example.com, mailserver2.example.com, and so on) that handled e-mail for the example.com domain. The DNS began to be viewed as a general naming system. Second, because almost all naming
|
29 |
For convenience and as a transition strategy, many sites chose to treat, for example, “BITNET” and “UUCP” as if they were top-level domain names, mapping those names through the DNS or other facilities into gateway paths. So a generation of users believed that, for example, smith@mitvmb.bitnet was an Internet domain name when, in fact, it was mapped to smith%mitvmb.bitnet@mitvma.mit.edu, where the latter was a gateway between the Internet and BITNET. The full use of MX records, so that the same user could be addressed as smith@mitvmb.mit.edu, came along only somewhat later. |
|
30 |
In economics, network effects (or, alternatively, positive network externalities) explain the rationale for the convergence to Internet-based e-mail: The value of a network to a user increases as more users join the same network, or other networks that are compatible with it. See, for example, Jean Tirole, The Theory of Industrial Organization, MIT Press, Cambridge, Mass., and London, 1988, pp. 404-409. |
systems had been designed primarily to support e-mail, and domain names had won the battle for how e-mail was done, the other naming systems diminished in importance and use, leaving the DNS as the only widely available naming system. The result was that the DNS was viewed as a general service, albeit an imperfect one: but even if imperfect, it was the only naming system that was widely available, and thus it became the one of choice.
2.3.4 The Whois Database
The Whois database was developed in the 1970s to track authorized ARPANET users and, in particular, those users that could request addresses on the network. For each host or domain name, the information in the Whois database was supposed to include the contact information (such as the contact person’s name, organization, street address, electronic mail address, and phone number) of those with responsibility for the host or domain name; additional information could also be stored and accessed. From a technical design and operational viewpoint, the Whois database is independent of either the HOSTS.TXT file or the DNS.31 For a while, the Whois database, maintained by the Network Information Center (NIC), served as a de facto white pages directory of ARPANET users. Beyond the online database, the NIC printed a phone book of everyone listed in the Whois database about once a year until 1982.
Around the time of the last NIC phone book, the Whois database was rapidly losing its value as a white pages directory because many new Internet users were not being included in the database. However, at the same time, the Whois database was becoming increasingly important for network operations because the NIC (which at the time also managed the allocation of IP addresses) would not give out an IP address, a host name, or a domain name to anyone who did not have a Whois entry. Furthermore, the NIC put all address and name registrations into the Whois database. So, given a host name or address, any user on the network could query the database to learn who had control of that host name or address. Thus, if a network operator noticed (or had a user complain) that a domain name suddenly could not be looked up, or that a particular network appeared to be unreachable, the operator could query the Whois database and find out whom to call about the issue.
By the late 1980s, problems began to develop with the Whois database. The first problem, which proved easy to solve, was that in many cases the formal institutional contact for the name or address was a corporate or university officer or administrator and was not the network operations person who actually managed the network or domain name server. The NIC resolved this problem by updating the database to keep track of both the administrative and operational contact for each address and domain. The second problem, which was not so easy to solve, was trying to keep the Whois data current—a problem that existed even before the explosive growth of the Internet and demands on the DNS in the 1990s.32
2.3.5 The DNS as a Production System
By 1990, the DNS was a production system and deeply ingrained in the Internet and its culture.33 The use of HOSTS.TXT was declining rapidly. But the move to a production system was not easy: Deploying the DNS in the 1980s required several years of debugging and resolving various issues. Timeouts and negative caching remain, to some extent, open issues in 2005.
Several lessons are apparent from the process of developing and deploying the DNS. A good new design that solves important problems can catch on, but it will take time for solid implementations to be developed. And even if a new design offers significant advantages, adoption will take time. Even when the Internet was comparatively small, switches from HOSTS.TXT to DNS or from e-mail Babel to uniform naming took a significant amount of time. Given the decentralized nature of the Internet, network service providers, hardware and software vendors, end users, or others can inhibit worthwhile technical advances from being implemented through mere procrastination or a deliberate decision that the implementation of a particular software upgrade is simply not sufficiently beneficial to them. Given the much larger scale and scope of the DNS and the embedded base of software two decades later, successful implementation of any proposed new system or major changes to the existing DNS may prove difficult.34
|
32 |
The history of the Whois database through the 1990s can be found in Section 2.5.3. |
|
33 |
By the late 1980s, the Internet was in fact an operational network and not only a subject of research and, as such, increasingly fell outside DARPA’s research mission. At this time, DARPA was working with other federal agencies, notably the National Science Foundation, to hand off the infrastructure it had created. |
|
34 |
See Tirole, The Theory of Industrial Organization, 1988, pp. 406-409, for a brief discussion of the kinds of coordination and strategic issues that can arise in a network like the DNS. |
2.4 CONTINUING GROWTH AND EVOLUTION OF THE INTERNET AS A TECHNICAL INFRASTRUCTURE
The increasing popularity of personal computers changed the basic model of computing in most organizations from a model based on central computing using mainframes or minicomputers with terminals to one based on personal computers connected in local area networks, which in turn were connected to central resources (i.e., the client/server model of computing). The adoption of the personal computer by consumers (which is correlated with the improving price/performance of computers and, in particular, increasing modem speeds at affordable prices) provided the household infrastructure for supporting widespread dial-in access to the Internet by the mid-1990s in the United States.35
To function on the Internet, a computer needs to have some basic information, such as its IP address, the IP address of at least one router,36 and the IP addresses of a few critical services.37 In the world of a relatively small number of large mainframes or minicomputers, such information was entered manually on each new computer when installed and, once configured, rarely changed. In such a world, IP addresses functioned as de facto stable identifiers, with the DNS (or its HOSTS.TXT predecessor) representing a convenience, not a necessity.38
However, as the number of computers increased sharply, such a custom approach became increasingly impractical. Thus, a mechanism to
|
35 |
According to the Current Population Survey (conducted by the U.S. Census Bureau), personal computer adoption in the United States continued to increase throughout the 1990s and demonstrated a 5-fold increase from 1984, the first year data was collected on computer ownership to the year 2000. By the year 2000, 51 percent, or 54 million households, had access to at least one computer at home, up from 36.6 percent in 1997. The percentage of households with Internet access more than doubled between these years, from 18 percent in 1997 to 41.5 percent, or 42 million households, by the year 2000. Computer access and Internet access were becoming synonymous: more than four in five households with computer access also had Internet access. For the full report, see Eric C. Newburger, “Home Computers and Internet Use in the United States: August 2000,” Current Population Reports, U.S. Department of Commerce, U.S. Census Bureau, Washington, D.C., September 2001, available at <http://www.census.gov/prod/2001pubs/p23-207.pdf>. |
|
36 |
A router is a device that determines the next Internet Protocol (IP) network point to which a data packet should be forwarded toward its destination. The router is connected to at least two networks and determines which way to send each packet based on its current understanding of the state of the networks to which it is connected. Routers create or maintain a table of the available routes and use this information to determine the best route for a given data packet. |
|
37 |
Examples include the address of an e-mail server (because most computers do not operate their own mail server) and the address of a DNS resolver (explained in Chapter 3). |
|
38 |
Indeed, the IP addresses of certain important servers were well known to system administrators. |
automate this startup process was developed. One approach is contained within the Bootstrap Protocol (BOOTP), a very simple protocol that enabled a computer to ask a local central server for and receive a number of critical parameters. BOOTP and other protocols of a similar type shared one important characteristic: Each protocol had a mechanism to allocate IP addresses to computers, but did not have any mechanism to reclaim IP addresses when they were no longer needed. In the 1980s, this was not a problem because IP addresses were plentiful. However, by the early 1990s IP addresses, which had once seemed to be a nearly inexhaustible resource, were starting to look like a scarce resource that required conservation, a consequence of the tremendous growth of the Internet. Protocols to support the “leasing” or temporary assignment of IP addresses were developed,39 such as the Dynamic Host Configuration Protocol (DHCP)—a direct successor of BOOTP—or the Point-to-Point Protocol (PPP).40 An important reason for the development of these protocols was to support system and local area network (LAN) management and auto-configuration, but the timing was fortuitous inasmuch as these protocols could also help with the conservation of IP addresses.
The spread of network address translators (NATs)—in part, a response to the increased difficulty of obtaining large blocks of IP addresses in the latter half of the 1990s—further degraded the usability of IP addresses as stable identifiers. The basic function of a NAT is to rewrite IP addresses in the data that it forwards. NATs map the set of IP addresses for external traffic (i.e., the IP addresses that are visible to the world) to a set of IP addresses for internal traffic (e.g., an organization’s LAN); thus, an organization can have many more internal IP addresses than external ones. The use of NATs distorts the one-to-one mapping between Internet hosts and IP addresses that many applications assumed in their design—thus, any application that depends on IP addresses is at risk when its traffic goes through a NAT.41
As a result of these changes, IP addresses have become much less useful as stable identifiers than they once were. In the case of most appli-
cation protocols, the “obvious” answer has been to replace the use of IP addresses with DNS names wherever possible. Thus, over the last decade, applications have come to rely on DNS names very heavily as stable identifiers in place of IP addresses.
Another departure from transparent architecture42 came with the introduction of packet-filtering routers, one of the simplest kinds of firewalls.43 A number of organizations introduced such firewalls beginning in the late 1980s with the intent to defend their sites against various real and perceived threats. The much-publicized Morris worm44 further raised the profile of network security and provided network administrators with an additional motivation to install firewalls (thereby further inhibiting transparency in the network architecture).45
As network security attracted increasing attention, some focus was directed to the DNS itself. DNS security emerged as an issue in the form of a proposed addition of a cryptographic signature mechanism to the DNS data.46 Such a mechanism would help ensure the integrity of the DNS data communicated to the end user. The original DNS design did not include a mechanism to ensure that a name lookup was an accurate representation of the information provided by the entity responsible for the information. DNS information was assumed to be accurate as the result of general notions of network cooperation and interoperation (i.e., based on the presumption that nobody would deliberately attempt to
|
42 |
In this context, a transparent network is one that does not interfere with arbitrary communication between end points. |
|
43 |
Packet-filtering routers attempt to block certain types of data from entering or leaving a network. |
|
44 |
In 1988, a student at Cornell University, Robert T. Morris, wrote a program that would connect to another computer, find and use one of several vulnerabilities to copy itself to that second computer, and begin to run the copy of itself at the new location. Both the original code and the copy would then repeat these actions in a theoretically infinite loop to other computers on the ARPANET. The worm used so many system resources that the attacked computers could no longer function, and, as a result, 10 percent of the U.S. computers connected to the ARPANET effectively stopped at about the same time. From “Security of the Internet,” available at <http://www.cert.org/encyc_article/tocencyc.html>. Also published in The Froehlich/Kent Encyclopedia of Telecommunications, Vol. 15, Marcel Dekker, New York, 1997, pp. 231-255. |
|
45 |
The relative value of firewalls in advancing network security can be debated, and such discussions can be found elsewhere; see, for example, Fred B. Schneider, editor, Computer Science and Telecommunications Board, National Research Council, Trust in Cyberspace, National Academy Press, Washington, D.C., 1999. |
|
46 |
Digital signatures do not provide foolproof security, but they can demonstrate that the holder of the corresponding private cryptographic key (i.e., a secret password) produced the data of interest. This is more or less like trusting a document that bears a particular seal—one must independently make a determination that an authorized person had possession of the seal when it was used and that the seal is legitimate but, if both of those conditions are met, it provides some assurance of the authenticity of the document. |
tamper with DNS information). Work on DNS Security Extensions (DNSSEC) started in the early 1990s and continues more than a decade later.47 See Chapter 4 for further discussion of DNSSEC and DNS security in general.
2.5 ECONOMIC AND SOCIAL VALUE OF DOMAIN NAMES
The nature of the growth in the Internet during the 1990s was qualitatively different from the growth in the 1980s. Most of the new Internet users in the 1990s were non-technical people who were not associated with academic institutions or the computer and communications industry. Instead, these new users represented a cross section of society that typically accessed the Internet from their places of employment, through dial-up connections from their homes, and by gaining access through libraries, schools, and community organizations.
These new users and the organizations that supported them (such as Internet service providers, electronic commerce companies, non-profit information services, and so on.) were primarily interested in how the Internet in general, and Internet navigation and the Domain Name System in particular (especially using the World Wide Web and e-mail), could advance and support personal and business goals—that is, they were not very interested in the technology per se. Consequently, increasing effort was directed to support these non-technical goals, and thus, it is not surprising that economic value, social value, and globalization emerged as major forces influencing the DNS and Internet navigation in the 1990s.
2.5.1 Demand for Domain Names and Emergence of a Market48
The rapid growth of the World Wide Web stimulated interest in and the demand for domain names because Web addresses (Uniform Resource Locators; URLs [see Box 6.2])49 incorporate domain names at the top of their naming hierarchy. One of the early major uses of the Web that appealed to a wide range of the new users—and helped to continue attracting additional new users to the Web—was electronic commerce. The .com generic top-level domain (gTLD) became a kind of directory service for companies and their products and services. If a consumer wanted to find
|
47 |
For further information on the historical progression of DNSSEC, see Miek Gieben, “A Short History of DNSSEC,” April 19, 2004, available at <http://www.nlnetlabs.nl/dnssec/history.html>. |
|
48 |
A significant portion of this subsection was derived from Milton L. Mueller, Ruling the Root: Internet Governance and the Taming of Cyberspace, MIT Press, Cambridge, Mass., and London, 2002. |
|
49 |
Examples of URLs include <http://www.whitehouse.gov> or <http://www.un.org>. |
the Web site for a company, the consumer would often be able to guess the URL by entering part or all of the company’s name followed by .com in the browser command line; often, the desired site would be located. This practice was further encouraged by the use of second-level domain names in advertisements and by the naming of companies by their second-level domain name (e.g., priceline.com). Even if the user’s initial guess(es) did not work, users would often then try the company’s name followed by .net or .org, or variations of the company’s name in combination with one of these gTLDs, such as ibmcomputers.net.50
It did not take users long to discover that shorter, shallower, URLs were easier to guess, use, remember, and advertise than longer ones. The shortest URL of all was based solely on a domain name. Thus, if one wanted to post a distinct set of resources on the Web, or create an identity for an organization, product, or idea, it often made sense to register a separate domain name for it rather than create a new directory under a single domain name. Hypothesizing that customers would look for products and services by guessing at a similar domain name, companies like the Procter & Gamble Company, for example, registered pampers.com and used that as a URL (namely, <http://www.pampers.com>), which also had the advantage of being much easier to communicate to users, and for users to remember, than, say, <http://www.pampers.procterandgamble.com>. These different domain names would be used even if all the information resided on a single computer. In short, domain names began to refer to products or services rather than just network resources (e.g., host names).51
Before the rise of the Web, the largest concentration of domain name registrations was under the .edu TLD (as of March 1993). The Internet’s rapid growth after 1993, however, radically altered the distribution of domain names across TLDs; until at least 1997, .com attracted the large majority of new domain name registrations.52 Most of the users rushing to take
|
50 |
Sometime in 1996 or 1997, browser manufacturers made .com the default value for any names typed directly into the browser command line. That is, whenever a user typed <name> without a top-level domain into the command line, the browser automatically directed the user to www.<name>.com. Making .com the default value for all browser entries reinforced the value of .com registrations relative to other TLDs. In effect, a .com domain name functioned as a global keyword, and the possession of a common, simple word in the .com space was sure to generate significant traffic from Web browsers. This explains, to some degree, why some domain names sold for hundreds of thousands or even millions of dollars. As noted in Section 1.2, footnote 9, browsers no longer operate in this way. |
|
51 |
Generic words were also registered (e.g., cough.com was registered by Vicks). |
|
52 |
See <http://web.archive.org/web/20020816085435/www.wia.org/pub/timeline.txt >. Initiatives to use the Internet for commercial purposes (including R&D within companies) before the rise of the Web led to an increase in .com registrations. And with wide use of the Web came registrations of multiple domain names to single companies, a practice that had been discouraged in the past. |
advantage of the Web were businesses, and .com was the only explicitly commercial top-level domain. Furthermore, the U.S.-based InterNIC operated the only unrestricted, large-scale registry (supporting .com and other gTLDs). Most country-code registries at this time were slow, or expensive, or followed restrictive policies and considered a domain name a privilege rather than a commercial service.53 Indeed, in some of the countries with restrictive country-code registries, such as Japan and France, more businesses registered in .com than under their own ccTLD. The available statistics provide the basis for estimating that roughly 75 percent of the world’s domain name registrations resided in .com at the end of 1996.54 Thus, the .com TLD became the dominant place for domain name registration worldwide in the mid-1990s, which by the late 1990s became reflected in popular culture through phrases such as a “dot-com company” (or simply a “dotcom”) or “dot-com economy.”
Interest in domain names extended beyond the for-profit sector. The visibility of governmental entities and non-profit organizations also became increasingly tied to domain names as the Web became a key mechanism for providing information and services to the public and their constituencies. Moreover, individuals also wanted their own domain name as the identifier for their personal information posted on the Web or for a myriad of other purposes (e.g., establishing fan sites55). Opportunistic companies capitalized on (and perhaps helped to create) this demand by developing services so that users could register a domain name and obtain support for establishing and maintaining a Web page as an integrated service for a monthly or annual fee.
Domain names also became involved in electoral politics and social commentary. Political campaigns established Web sites with descriptive domain names in the URLs such as <http://www.algore2000.com> or <http://www.georgewbush.com>56 to provide access to information
|
53 |
In February 1996, when the InterNIC had about a quarter of a million second-level registrations, Germany (.de) had only 9000 total registrations, and Great Britain (.uk) had only 4000. Japan, Canada, Australia, and other major leading participants in the Internet had numbers comparable to the United Kingdom’s. However, some countries (e.g., the United Kingdom) have restrictive policies with respect to registering in the second-level domain so that most entities actually have to register in the third-level domain (e.g., sothebys.co.uk) that would instead be a second-level domain registration in other TLDs (e.g., sothebys.com). |
|
54 |
InterNIC gTLD registrations accounted for an estimated 85 percent of all domain name registrations worldwide, and .com accounted for 88.6 percent of all InterNIC gTLD registrations. (About 62 percent of all registered domains worldwide resided in .com in 2002.) |
|
55 |
See, for example, <http://www.juliaroberts.de>, a fan site and tribute to the actress Julia Roberts that is based in Germany; accessed on April 16, 2005. |
|
56 |
Note that campaign information was not available at the Al Gore site as of April 16, 2005. |
about their respective candidates, to organize volunteers, and to solicit contributions. Web sites were also created to critique or parody virtually anything, from the practices of certain companies or their products or services to various social and political causes. A common practice was to register a domain name that included the name of interest followed by “sucks,” or something similar, and to associate that domain name with a Web site that criticized the entity in question. In addition to motivating legal actions to try to prevent the use of domain names in this fashion, this practice caused many companies to pre-emptively register these types of domain names for themselves.57
Therefore, for various reasons, the demand for domain names increased tremendously during the 1990s.58 Further fueling the demand was aggressive marketing by companies that register domain names and provide related services, efforts by IT companies more generally that played up domain names (especially .com names) in their larger marketing campaigns, and the popular and technical press, which devoted a lot of attention to anything related to domain names.
The increasing demand for domain names was attributed to interest in facilitating Internet navigation as well as to the value of domain names irrespective of their functional utility on the Internet (e.g., placing a domain name on posters in a subway station as a part of a marketing campaign). Thus, the real value of certain domain names in the rapidly growing and commercializing Web and Internet was far greater than the price of setting up a domain name (which was on the order of $50 at the retail level).59 The predictable consequence was the development of an aftermarket for certain domain names. In 1996, tv.com sold for $15,000 and in 1997, business.com changed hands for $150,000.60 Not surprisingly, speculation in the registration of domain names took place: An individual or firm would register domain names (often very many) with the intent of reselling them to others for a premium. Such speculators would not only register generic or descriptive names (e.g., “business,” “fever,” and so on) with the hope of appealing to multiple pro-
|
57 |
However, this was a difficult proposition, considering the nearly limitless variations of less-flattering names that can be devised. See further discussion in the next section. |
|
58 |
The growth in the registration of domain names was phenomenal. For example, in September 1995, there were approximately 120,000 registered domain names. By May 1998, 2 million domain names were registered. See “Fact Sheet: NSF and Domain Names,” National Science Foundation, Arlington, Va. |
|
59 |
Domain names are registered through and maintained by registrars; see Chapter 3 for an extended discussion. |
|
60 |
Business.com was resold for $7.5 million in 1999. With some irony, the committee observes that www.business.com links to “The Business Search Engine” (as of March 27, 2004), a “comprehensive business directory.” |
spective purchasers, but would also register domain names incorporating the trademarks of third parties with the hope that the corresponding trademark owner would purchase the domain name from the speculator as well. See Box 2.1 for further discussion on the value of domain names.
An industry emerged to provide services related to the transfer and assignment of domain names and related services.61 The pressure for new TLDs led to the conversion of some country codes to quasi-generic TLDs. For example, the marketing of .cc (a country-code TLD created to represent the Cocos Islands but later marketed as a de facto gTLD) further increased the variety and value of certain domain names. However, true additional gTLDs did not materialize in the 1990s (despite the intense arguments and efforts made by some individuals and organizations), which helped to solidify the dominance of the then-extant TLDs, especially of .com.62
2.5.2 The Rise of Conflicts Over Domain Names
As the number of domain name registrations exploded, conflicts developed over the right to register particular names at the second level of many of the TLDs.63 The basis for most of these conflicts derived from the unique naming associated with the DNS. The DNS does not have the capability to incorporate context into domain names, so each domain name must be unique worldwide and then in turn, a Web site at that domain name can then be accessed throughout the world.64 The consequence is that it is significantly harder to pick a domain name that is both unused and memorable.
Claims to rights to domain names can be based on a number of different legal, political, economic, ethical, or cultural criteria. A common prob-
|
61 |
Registrars, and the industry surrounding registrars and allied services, are discussed in detail in Chapters 3 and 4. |
|
62 |
Discussion of the gTLDs added in the early 2000s (e.g., .info) and general discussion of the issues involved with adding new gTLDs can be found in Chapters 3 and 4. |
|
63 |
“Rights to names” refers to claims to exclusive or privileged use of an identifier based on the meaning or economic value of the name. |
|
64 |
The mythical (or perhaps real) Joe’s Pizza illustrates the point. The DNS can support only one www.joespizza.com worldwide, but in the physical world, people can usually distinguish among the (presumably) multiple Joe’s Pizza restaurants around the world. If a person is located in the center of a city and asks a taxi driver to take her to Joe’s Pizza, it is presumed that she wishes to travel to a restaurant within a few miles, not a Joe’s Pizza located in a city 2000 miles away. Although the requestor does not state this context explicitly, it is assumed in the conversation. As of February 4, 2005, joespizza.com was registered by BuyDomains.com and offered for resale at a minimum price of $1488. |
|
BOX 2.1 Semantic Value Economic value often arises when names have some semantic distinction—a meaning—and are visible in a public arena. The value of meaningful names will differ from nil to very high depending on the meaning and the potential application. Examples include sex.com and gardentips.com. Mnemonic Value In many contexts, it can be important for a name or identifier to be easily remembered. If users cannot remember the name, or it is too long or complicated to reproduce, the object will not be found. Memorability, and in some cases guessability, facilitates more incoming traffic and more business and, therefore, gives rise to economic value. One example is gm.com (i.e., a second-level domain name for the General Motors Corporation). Personal Value Even when there is no apparent commercial consequence, the human desire to make a statement and assert an identity can give economic value to identifiers in a public name. Someone with a high regard for himself might want the domain name i-am-the-best.com.1 Stability Value Users can accumulate equity in a particular identifier, which becomes closely associated with them and expensive to change. Changing a telephone number or e-mail address that has been used for many years can be burdensome because of the large number of personal contacts and records that contain the number. Thus, equity in an identifier raises switching costs for consumers, making them more likely to stay with the provider of that identifier. Pure Scarcity Value Meaningless identifiers, such as bank account numbers, function economically as an undifferentiated resource pool. They may possess economic value by virtue of their scarcity, but no one cares which particular identifier he or she gets. In the DNS, there are plenty of possible names (accepting that random strings of letters and digits can produce domain names (e.g., akwoeics8320dsdfa0867sdfad02c.org); there is scarcity of some desired names, with desirability defined by one of the reasons above (e.g., only a small subset of all possible domain names have semantic value). |
lem raised by all such claims is that any reasonable attempt at resolution must balance the value of avoiding confusion or preventing illegal or otherwise undesired appropriation of identity against the value of free expression, open communication, and fair use. Whenever semantics and economics enter the picture, however, society and all of its conflicts come along with them. The resultant conflicts over who has rights to use particular domain names has enmeshed and continues to enmesh apparently technical naming processes in economic, public policy, and legal issues.65
Trademark Conflicts
In the commercial world, trademark law provides one of the oldest, most widely recognized and well-developed regimes for recognizing and protecting exclusivities in the use of source identifiers of goods or services within specific fields and territories. Trademark laws developed, in part, to protect consumers against various forms of fraud, deception, or confusion that might result from the ways in which products and services are identified. By giving producers an exclusive right in an identifier, trademarks reduce consumer search costs and channel the benefits of developing a good reputation to the producer responsible for the reputation. Trademark protection is not, however, intended to give firms ownership of common words alone, to prevent non-commercial or fair use, or to inhibit public discussion of companies, products, and services involving direct references to the mark.
The great emphasis placed on second-level domain names created a problem for some trademark holders, especially for those that held trademarks that were well known in the United States or worldwide. Trademark rights (which are traditionally accorded on a country by country basis) generally arise through use of a trademarkable name, logo, color, sound, or other feature, in association with the marketing and sale of particular types or classes of goods and services in commerce. Some coun-
|
65 |
In his paper “External Issues in DNS Scalability,” Paul Vixie argues for eliminating the disputes associated with domain names by eliminating all meaningful top-level domains and replacing them with meaningless alphanumeric identifiers. See conference paper, November 11, 1995, available at <http://www.ksg.harvard.edu/iip/GIIconf/vixie.html>. Whereas the number of conflicts would surely decline, so, too, would the benefits to those who prefer specific domain names that have meaning or some other characteristic. As with phone numbers, however, competition for certain numbers will ensue unless they are assigned randomly and a secondary market (in either names or entities that control names) is prohibited. |
tries will allow someone to reserve or even register a trademark without using it, but most countries (including the United States) require use to claim protection under trademark law.66 Similar to trademarks, domain names can act as source-identifiers suggesting the identity, quality, or source of a good or service. Accordingly, domain names may conflict with trademarks because of their similarity in function.
If a trademark holder allows someone else to use the trademark or mark either in the same class of goods/services or in some other way that could create confusion in the marketplace, the other party may begin to acquire rights as a result of that use, and those rights reduce the value of the mark to its original owner. Within the United States, the problem is further complicated by the existence of federal and state antidilution laws that permit owners of famous marks to enjoin others from commercial uses of such marks, even where such commercial uses are in classes of goods or services different from that of the famous mark.67 Designed to prevent the whittling away of the identification value of the plaintiff’s mark, antidilution laws differ from more traditional trademark laws, which are designed to prevent consumer confusion within the same class of goods or services.68 In order to determine whether a mark is subject to federal antidilution protection (i.e., whether it is considered to be a famous mark), the law provides several non-exclusive factors that may be considered.69 Some states within the United States have more generous definitions of “famous marks,” while other countries have similar or different definitions or do not recognize the concept at all. Another one of the factors to be used in this determination under U.S. law is “the nature and extent of use of the same or similar marks by third parties.” This factor demonstrates that a potentially famous mark owner’s antidilution rights, like rights against infringement, can be lessened or lost by its failure to police its mark.
Thus, trademark holders became quite concerned about the activities of parties that had registered domain names that either were confusingly similar to their trademarks or diluted their famous marks. Generally, to cause a likelihood of confusion under trademark law,70 a domain name must be used in connection with an offering of goods and services or it must be used commercially for antidilution laws to apply, but cybersquatters raised a slightly different problem. Cybersquatters are generally defined as domain name speculators who register a domain name that incorporates a trademark owned by another party, not in order to use the domain name, but with the intent of reselling the registered domain name to that party for an amount that far exceeded the cybersquatter’s registration cost. The most contentious examples of cybersquatting were those in which domain names incorporating trademarks (or phonetic or typographical variants of them) were associated with Web sites that included pornographic content or other information that would confuse or offend users who reached that Web site by mistake or assumed that the trademark holder had registered the domain name and that the Web site associated with it belonged to the trademark holder. The cybersquatter would then offer to sell the domain name to the trademark owner for a substantial sum, which some companies agreed to pay, if for no other reason than to stop the offending use. Such actions, of course, only fueled more cybersquatting activities. Cybersquatters also figured out that users were trying alternative domain names (e.g., ibm-computers.com instead of ibm.com) and began to register many different combinations, such as ibmcomputers.com and ibmcomputer.com. Partially in response to these actions, many companies began to register various combinations them-selves—so-called pre-emptive registrations71—and to seek remedies through the courts, various dispute resolution processes, and legislative action.72
At least one court has held that a cybersquatter’s registration of a domain name that incorporated a plaintiff’s famous mark, without the sale of any goods or services via the Web site associated with that domain name, was a violation of the federal antidilution statute because the defendant made “commercial use” of the trademark when he attempted to
sell the domain name back to the owner of the famous mark.73 Another court has found the attempted sale or licensing of domain names containing trademarks to be trademark infringement, similarly concluding that the sale of these domain names was a commercial use of the marks.74 Additionally, the Anticybersquatting Consumer Protection Act (ACPA), enacted in 1999,75 provides additional rights to trademark owners against those who register, traffic in, or use, with the bad-faith intent to profit, a domain name that is identical or confusingly similar to a registered or unregistered mark that was distinctive or dilutive of a famous mark when the domain name was registered. Despite the creation of ACPA and other domain name dispute resolution mechanisms,76 the costs involved with pre-emptive registrations and the enforcement of trademarks ultimately led many representatives of trademark holder interests to resist efforts to create new TLDs, fearing that these costs would continue to increase substantially if new additional TLDs were created.
In contrast, the protective efforts by trademark holders in some instances have also raised conflicts with other legally equivalent rights held by the individuals using the domain names. For example, suppose a group critical of a corporation wants to create a public space for discussion and register a domain name associated with that corporation (e.g., companyname.org). Does such a registration constitute an infringement of the corporation’s trademark because it creates consumer confusion or is it dilutive because it tarnishes the reputation of the corporation, or rather is it an exercise of a protected right, such as freedom of speech under the First Amendment of the U.S. Constitution? Discussions related to domain names, trademark concerns, and public policy issues will continue into the 21st century.77
Other conflicts involving trademarks arose for reasons that had nothing to do with the above-described conflicts between trademark holders and their cybersquatting antagonists. For example, Chris Van Allen, then 12 years old, registered the second-level domain name pokey.org because Pokey was his nickname, and was subsequently ensnarled in a trademark dispute with Prema Toy Company, owner of the trademarks on the claymation character Gumby and his horse Pokey, which wanted control
|
73 |
See Intermatic, Inc. v. Toeppen, 947 F. Supp. 1227 (N.D. Ill. 1996). |
|
74 |
See Toys “R” Us, Inc. v. Abir, 45 U.S.P.Q.2d 1944 (S.D.N.Y. 1997). |
|
75 |
See 15 U.S.C. § 1125(d). |
|
76 |
See Section 3.5 for an extended treatment. |
|
77 |
The state of understanding continues to evolve. See, for example, The Taubman Company v. Webfeats, et al., Nos. 01-2648/2725 (6th Circuit, February 7, 2003). |
over the domain name.78 Ultimately, Prema Toy Company withdrew its complaint.79 In other cases, disputes arose between different entities with equally valid rights to the same second-level domain name, such as “bob.com,” which might have been coveted by many men named Robert, and “avon.com,” which might have been coveted by a variety of different companies around the world that have legitimate rights to the trademark Avon for different products or services in different countries.
This latter example presents a particularly difficult point that cannot be easily resolved by simply granting the second-level domain name to the entity with the legal right to use it as a trademark, since multiple entities can have such legitimate rights. Under most countries’ trademark laws, multiple entities can use the same trademark in the same country, provided each entity uses the trademark for different categories (called classes) of goods or services, as long as there is no possibility of confusing consumers as a result, and each trademark has to be registered within each country in which it is used in order to be fully protected. Hence it is entirely possible to have one company legitimately use the trademark “avon” for automotive tires in the United States, and a second company to use the same trademark for cosmetics. Unfortunately, however, there can be only one avon.com, and so the first entity to register that domain name has often been able to use it to the exclusion of all other legitimate users worldwide.80
Beyond Trademark Conflicts
Trademark issues dominated domain name conflicts in the late 1990s and into the beginning of the 21st century, but other conflicts also demanded attention. For example, some governments asserted rights to control the assignment of country-code TLDs and country names and the registration of those names, even beyond the second level.81 Some governments assert that this is an extension of national sovereignty. Similar claims may be asserted by ethnic groups and indigenous tribes that have
|
78 |
See Courtney Macavinta, “Short Take: Pokey Causes Net Trademark Uproar,” News.com, March 23, 1998, available at <http://news.com.com/2110-1023-209417.html?legacy=cnet>. The dispute also involved Pokey’s Network Consulting, which registered pokey.com. |
|
79 |
See Heather McCabe, “Pokey Wins His Domain Name,” Wired News, April 22, 1998, available at <http://www.wired.com/news/business/0,1367,11846,00.html>. |
|
80 |
See Chapters 3 and 5 for a discussion of how trademark conflicts over domain names can be (and should be) managed. |
|
81 |
See the principles for delegation and administration of ccTLDs presented by the ICANN Government Advisory Committee, February 23, 2000, available at <http://www.icann.org/committees/gac/gac-cctldprinciples-23feb00.htm>. |
not achieved the political status of sovereigns, but that nevertheless wish to protect or control the use of their collective name. In some jurisdictions, the subunits of national governments, such as city administrations or port authorities, have claimed exclusive rights to the use of their name in the DNS.82 In a similar vein, some international organizations have asserted a right to prevent others from registering domain names identical to their acronyms or names.83 These claims have more to do with the imputed legitimacy of the association than with commercial confusion. Here, too, issues arise regarding the balance struck between the use of the name as an identifier and its legitimate use as a reference to the identified entity. These claims also raise questions about who in the affected society has the right to control the name. Also, some legal regimes, which are analogous to trademark law because they are related to reputation in commerce, attempt to vest regions or localities, rather than specific firms or products, with exclusive rights to a name for a certain use. These regimes of “controlled appellations of origin” might be applied, for example, to wines or other agricultural products.84
In addition to nations, regions, and international organizations, many people feel that they have some ownership right over their personal name and other aspects of their persona. National systems of law often recognize “rights of personality” when defined as the ability of a person “to control the commercial use of his or her identity.”85 In the United States, there currently is no federal right of publicity or privacy; rather, the promulgation of such laws has been left to the states. About half of the states have recognized the right of publicity, either through common law or statute.86 Other states provide similar protections as a part of the right of
|
82 |
See, for example, Excelentisimo Ayuntamiento de Barcelona v. Barcelona.com Inc., WIPO Case No. D2000-0505, available at <http://arbiter.wipo.int/domains/decisions/html/2000/d2000-0505.html>; and Salinas, California, National Arbitration Forum, City of Salinas v. Brian Baughn, WIPO Case No. FA0104000097076, available at <http://www.arbitrationforum.com/domains/decisions/97076.htm>. |
|
83 |
For example, international organizations such as the International Monetary Fund (IMF) or the World Health Organization (WHO). See The Recognition of Rights and the Use of Names in the Internet Domain Name System, Report of the Second WIPO Internet Domain Name Process, September 3, 2001, available at <http://wipo2.wipo.int/process2/report/pdf/report.pdf>. |
|
84 |
For further discussion see, “Geographic Identifiers,” in The Recognition of Rights and the Use of Names in the Internet Domain Name System, 2001. |
|
85 |
See McCarthy, McCarthy on Trademarks and Unfair Competition, 4th ed., 1992. |
|
86 |
See, for example, Carson v. Nat’l Bank of Commerce, 501 F.2d 1082, 1084 (8th Cir. 1974) (recognizing a common-law right of publicity in Nebraska); and FLA. STAT. ANN. §540.08 (West 2002) (providing for a statutory right of publicity in Florida). |
privacy.87 Under the Restatement (Second) of Torts §§ 652A - 652C (1979), invading an individual’s right of publicity is similar to invading her privacy through unauthorized appropriation of her name or likeness.88
One of the primary motives behind passage of the Anticybersquatting Consumer Protection Act in the United States, for example, was the widespread registration of the names of U.S. politicians as domain names and their linkage to Web sites that were satirical or critical.89
Communications technology can create new arenas for disputes over rights to names. In particular, the process of entering an identifier into a network creates numerous opportunities for conflicts over the boundary of a name right. Of course, many of the underlying issues—confusion, fraud, competition, fair use, freedom of expression—are familiar from other contexts.
A good part of the advertising economy of the Internet is based on paying for “hits” (i.e., the exposure of the content of a Web site to a distinct user).90 Thus, the practice of “typosquatting” developed, wherein entrepreneurs registered domain names that were only a keystroke or two
|
87 |
See, for example, Allison v. Vintage Sports Plaques, 136 F.3d 1443 (11th Cir. 1998) (describing the appropriation of plaintiff’s personality for a commercial use as an invasion of privacy tort in Alabama). |
|
88 |
In 1953 in the case of Haelan Labs. v. Topps Chewing Gum, the right of publicity was first explicitly recognized as a right independent of the right of privacy and as an individual’s right to the publicity value of his photograph. The court distinguished the right of publicity from the right of privacy because “many prominent persons … far from having their feelings bruised through public exposure of their likeness, would feel sorely deprived if they no longer received money for authorizing advertisements [or] popularizing their countenances.” See Haelan Labs. v. Topps Chewing Gum, 202 F.2d 866, 868 (2d Cir. 1953). Thus, the right of publicity has developed into a body of law distinct from, but related to, copyright law, privacy rights, and the law of unfair competition. While certain states encode publicity rights within their right of privacy statutes, prominent case law and jurisprudence acknowledge the development of the right of publicity as an independent body of law. See, for example, Carson v. Here’s Johnny Portable Toilets, 698 F.2d 831, 834 (6th Cir. 1983) (stating, “[T]he right of privacy and the right of publicity protect fundamentally different interests and must be analyzed separately.”). When commercial exploitation of names is involved, personality rights often overlap with, or are informed by a logic that parallels, trademark rights. Indeed, a person’s name is often registered as a trademark or used to brand products or services (e.g., Michael Jordan). But rights of personality are often asserted even when commerce is not directly involved. |
|
89 |
U.S. Patent and Trademark Office, “Report to Congress: the Anticybersquatting Consumer Protection Act of 1999,” January 2000. A law passed by the state of California makes it illegal to register someone else’s name as a domain name “without regard to the goods and services of the parties.” See Section 17525 of the California Business and Professions Code, at <http://www.leginfo.ca.gov/cgi-bin/displaycode?section=bpc&group=17001-18000&file=17525-17528.5>. |
|
90 |
See Section 7.2.2 for an extended discussion. |
apart from popular domains. These “typo” domains would then be linked to advertisements in order to collect pay-per-hit revenue from people who mistyped the locator into the browser. The cybersquatter John Zuccarini refined the practice of “typosquatting” to an art, registering hundreds of close misspellings of popular domain names and trapping users into a parade of cascading Web pages, some of them pornographic.91
There are even fuzzier boundaries to consider. There are businesses that register large collections of expired domain names in order to collect advertising hits from people who are looking for the old Web site.92 Is this an abusive practice or one as innocent as putting up a billboard on a choice spot on a busy highway?
Beyond Second-Level Domain Names
Thus far, the discussion has focused on second-level domain names. Although less common, there are disputes involving third-, fourth- and higher-level domain names, as well as involving directory and file descriptors. For example, in Bally Total Fitness Holding Corp. v. Faber, 29 F. Supp. 2d 1161 (C.D. Cal. 1998), an infringement suit was brought against a defendant who used the URL <http://www.compupix.com/ballysucks> to post critical comments regarding the plaintiff. The court held that “no reasonable consumer” was likely to confuse the defendant’s domain name with the plaintiff’s marks BALLY, BALLY TOTAL FITNESS, and BALLY’S TOTAL FITNESS, because, among other things, the defen-
|
91 |
See, for example, Joanna Glasner, “Typo-Loving Squatter Squashed,” Wired, October 31, 2000, available at <http://www.wired.com/news/business/0,1367,39888,00.html>. In 2004, Zuccarini was sentenced to 30 months in prison for using misleading domain names to trick children into visiting pornographic Web sites in violation of the federal Truth in Domain Names Act. See “U.S. Man Jailed for Luring Children to Porn Sites,” Reuters, February 26, 2004. |
|
92 |
Other cases include attempts to protect the “nonproprietary” status of a name by excluding it from a name space. The World Health Organization and the World Intellectual Property Organization (WIPO) proposed to do this with respect to International Nonproprietary Names (INNs), a list of over 3000 names of pharmaceutical substances. See “International Nonproprietary Names (INNs) for Pharmaceutical Substances,” in The Recognition of Rights and the Use of Names in the Internet Domain Name System, Report of the Second WIPO Internet Domain Name Process, September 3, 2001, available at <http://wipo2.wipo.int/process2/report/pdf/report.pdf>. This proposal is particularly problematic because the list of INNs not only is long, but also expands over time. Religion is another potential source of rights claims. Certain religions recognize words as sacred and attempt to protect or restrict their use. |
dant did not use the plaintiff’s mark in his domain name.93 Based on the facts of the case, the court stated that the result would have been the same even if the defendant’s domain name was ballysucks.com.94 The court also contrasted the defendant’s domain name and the hypothetical second-level ballysucks.com domain name with other cases where likelihood of confusion was found when the plaintiff’s mark was the only mark (e.g., panaflex.com) used in the defendant’s second-level domain.95
In another example, the Usenet newsgroup name space contains numerous descriptors that use a variety of names to describe the space, including, for instance, the name Disney (e.g., alt.disney.disneyland or rec.arts.disney.parks). These newsgroups (which are visible to most Internet users) are not run by the Disney Corporation, and the content and administration of the group may or may not have the corporation’s approval. In the even more freewheeling world of AOL screen names, any user can appropriate the name of his or her favorite Disney character (even in less than flattering variations) and use it as his or her screen name and e-mail address. While it is clear that no exemption exists for Usenet groups and AOL screen-name aliases, it does appear that trademark holders have chosen not to pursue many of these uses in these naming spaces.96
Yet current law and policy regarding domain names erect major distinctions between the various parts of the domain name used in a URL. Within the generic and most country-code top-level domains, all (or at least most) of the political and legal conflict over rights to names takes place over the second-level domain name. The third-level domain and all identifiers to the right of the domain name are generally outside the scope of challenge through dispute resolution processes.97 Current law and policy therefore regard the top-level domain as a fixed set of generic cat-
|
93 |
See The Recognition of Rights and the Use of Names in the Internet Domain Name System, 2001, pp. 1163-1165. |
|
94 |
See The Recognition of Rights and the Use of Names in the Internet Domain Name System, 2001, p. 1165. |
|
95 |
See The Recognition of Rights and the Use of Names in the Internet Domain Name System, 2001, p. 1165. |
|
96 |
Many trademark holders have not done anything regarding many newsgroup names, in part because it is difficult to police such activities as well as prove that trademark infringement or dilution has occurred. Indeed, as soon as a name was removed or changed in this space, another of the millions of users could create a new one. |
|
97 |
There are some important exceptions, such as the case of .uk, for which most entities register at the third level (e.g., Disney.co.uk) rather than at the second level. For these exceptions, it is the fourth level and beyond that are outside the purview of dispute resolution processes. Dispute resolution processes are further described in Chapters 3 and 5. |
egories or country codes, the second-level domain as the identifier of an organization, product, or Web site, and the third-level domain as part of a “private” naming system, wherein assignments can generally be left to the discretion of whoever holds the second-level name.
To further illustrate this point, Yahoo! Inc. has been an active defender of its brand name in cyberspace. It has challenged the registration of hundreds of second-level domains, including some rather remote misspellings, such as “jahu” or “yhuu,” whenever they appear in the second level of a domain name. But under current legal precedent, it would likely take no action against a name such as yahoo.blatant.cybersquatter.com. In all likelihood, however, Yahoo’s decision not to pursue claims for trademark infringement or dilution for alternative uses of its brand name and mark is less influenced by current precedent than it is by Yahoo’s likelihood of success on the merits, especially in view of decisions such as that in the above noted Bally Total Fitness Holding Corp. v. Faber case.
By contrast, second-level domain names are ripe for generating conflicts over rights to names. They are meaningful, they are perceived as being economically valuable, and they are part of a global, public naming system administered via collective action. And perhaps most importantly, they are susceptible to centralized control because of the existence of a single, central point of coordination, the relevant registry. See Box 2.2.
2.5.3 Whois
In concert with the rise in the interest in and demand for domain names was a corresponding increase in the value of contact information associated with domain names. Hence, interest in the Whois database continued to rise in the 1990s.
Some of the targeted uses of the Whois data were for old-fashioned marketing purposes—for example, to send sales brochures and to make telephone solicitations to network operators and domain name registrants. As domain names became economically valuable after 1995, accessing Whois data also became a popular way to find out which domain names were taken, who had registered them, and the creation and expiration date of the registration. The Whois database also became an investigation and monitoring tool for intellectual property rights holders. When a trademark holder discovered a potentially infringing domain name, the trademark holder could use the Whois database to identify, investigate, and contact the registrant of the domain name. At that time, the Whois database could also be used to determine if the same registrant had registered any similar domain names that the trademark holder did not know about or to search for further evidence of cybersquatting by the registrant. Trademark holders also discovered that they could use the database proactively
|
BOX 2.2 For the most part, the initial dominance of .com among the TLDs was a historical accident, a product of the chance conjunction of the commercialization of the Internet, the rise of the Web, the openness of the InterNIC registry relative to the ccTLD registries, and the lack of any other commercially oriented TLD in the original set of gTLDs. Once .com became established as the most desired TLD for many registrants, other forces contributed to the solidification of .com’s increasing dominance. As discussed elsewhere in this section, “Beyond Second-Level Domain Names,” the rise in value of .com names (whether for navigation or marketing functions) led to the registration of some domain names for speculative, abusive, or preemptive purposes. Based on a desire to avoid further registration of domain names for these same purposes in new TLDs, some resistance developed to the creation of new TLDs, thereby reinforcing the focus on extant TLDs (with disproportionate advantage to .com, given its dominant market position). Whether the historical dominance of .com from the mid-1990s will continue in the future of the DNS is discussed in Section 5.4. |
to perform searches for character strings that matched trademarks, and retrieve many of the domain name registrations in the generic top-level domains that matched or contained a trademark. This automated searching function proved to be so valuable that trademark interests began to demand that the Whois functions be institutionalized, expanded, and subsidized, including the right to purchase the complete list and contact data for all of a registrar’s customers. The first World Intellectual Property Organization (WIPO) domain name process, initiated in 1998 in response to a U.S. government request, as detailed by a U.S. Commerce Department white paper,98 recommended that the contact details in a Whois record be contractually required to be complete, accurate, and up to date, on penalty of forfeiture of the domain name.99
2.6 GLOBALIZATION
Worldwide interest in the DNS developed during the 1990s along with increasing concern about U.S. dominance of a critical element of global communication and a commercial resource on which other nations fore-
|
98 |
For the text of the white paper, see <http://www.ntia.doc.gov/ntiahome/domainname/6_5_98dns.htm>. |
|
99 |
See paragraph 73 of The Management of Internet Names and Addresses: Intellectual Property Issues. Final Report of the WIPO Internet Domain Process, April 30, 1999, available at <http://wipo2.wipo.int/process1/report/finalreport.html#49>. |
saw their economies and societies becoming ever more dependent. With increasing recognition of this value came a growing desire to participate in the management and policy decision making with respect to domain names.
An issue of particular interest in many countries is access to the Internet and the DNS using home-country languages other than English. As the number of users whose first language is not based on Roman characters grew dramatically during the 1990s, interest developed in domain names based on non-Roman scripts (e.g., Chinese, Hebrew, Arabic, and so on). Several major efforts have been undertaken to accommodate internationalized domain names (IDNs) within the Internet infrastructure.100
The design of the DNS, however, presents formidable technical challenges for the accommodation of languages that use non-Roman characters. As a lookup system, the DNS must be able to determine unambiguously whether or not there is a match with a query. Comparing strings is much more difficult than most people realize, because the definition of what is “equal” is often not deterministic. For the French language in Canada and in France, for example, there are different rules as to whether an accent stays over a character when it is converted from lower to upper case. And some languages (e.g., Chinese) cannot be reduced to a relatively small number of standardized characters (e.g., the character set for English). See Section 4.3 for further discussion of the IDN issue and the increasing interest and involvement by parties outside the United States in matters related to the DNS.
2.7 ADMINISTRATION OF DOMAIN NAMES
In the 1980s, the Network Information Center managed the registration of domain names, operating under the auspices of SRI International and funded by the Department of Defense (DOD), by DARPA and the Defense Information Systems Agency (DISA).101 Jon Postel and other researchers at the Information Sciences Institute at the University of Southern California had been given the authority to establish procedures for assigning and keeping track of protocol and network numbers and controlled the definition of TLDs.102 Overall, the administration and policy oversight for domain names was relatively straightforward.
|
100 |
See discussion in Section 4.3. |
|
101 |
Formally, the NIC was the Defense Data Network-Network Information Center (DDN-NIC). |
|
102 |
Jon Postel had a central role in the DNS from the beginning as co-author of “The Domain Naming Convention for Internet User Applications,” RFC 819. Postel “held leadership positions in several Internet infrastructure activities. He was founder and head of the Internet Assigned Numbers Authority, RFC editor, and chief administrator |
In the mid-1980s, the National Science Foundation (NSF) created NSFNet to provide data communication services to researchers and educators. It selected the Transmission Control Protocol/Internet Protocol (TCP/IP) as its transport protocol and worked closely with the Department of Energy, the National Aeronautics and Space Administration, and DARPA to share facilities to extend this infrastructure in the United States and worldwide. NSF encouraged campus network investment by focusing its efforts on high-speed and high-capacity long-haul “backbone”103 and regional networks to connect the campuses. Thus, the responsibility for the civilian network gradually shifted from the DOD to NSF. (See Box 2.3 for a timeline of the shifting administration of domain names.) In the early 1990s, NSF made another important decision—to withdraw as the primary financial benefactor for the backbone of the Internet and to encourage a commercial market for support of transport facilities.
Continuing on this path, in 1993 NSF replaced DOD as the funding agency for domain name management. As the workload increased, NSF contracted with Network Solutions, Inc. (NSI) to manage the registration for most of the gTLDs (.com, .net, .org, .edu, and .gov), through InterNIC. At this time, NSF, preserving the practice that the registration of domain names would be free to registrants, subsidized the costs associated with domain name registration. See Box 2.3.
Increasing scale was not the only impetus for administrative evolution. The increasing economic and social value of domain names caused new players to become interested in the realm of domain names. As discussed earlier, holders of highly visible and valuable trademarks developed an active interest in domain names. Many other entities, from national governments and public interest groups to the firms in the emerging domain name industry, also developed a keen interest in all things related to domain names. Thus, the 1990s saw the domain name community expand radically, both in scale and, especially important to understand, in the scope of the interests and backgrounds of participants.104
|
|
of the .us domain. He was expected to play a crucial role in the future of Internet administration, which [was] in the process of being transferred to the private sector [the Internet Corporation for Assigned Names and Numbers (ICANN)].” See “In Memoriam, Dr. Jonathan B. Postel, August 3, 1943 – October 16, 1998,” The Domain Name Handbook, available at <http://www.domainhandbook.com/postel.html>, accessed March 31, 2004. |
|
BOX 2.3 1991 Responsibility for much of the Network Information Center (NIC) was transferred from SRI International (operating on the behalf of the Department of Defense; DOD) to Government Systems, Inc., which then subcontracted the entire operation to Network Solutions, Inc. (NSI). NSI started operating the NIC in 1992. 1993 The National Science Foundation (NSF) replaced DOD as the funding source for the NIC. NSF completed a service contract with InterNIC, the umbrella organization for the participating contractors AT&T (directory and database services), NSI (registration services), and General Atomics/ CERFnet (information services). Thus, NSF engaged NSI to take over domain name registration services for most of the generic top-level domains (gTLDs) through a 5-year cooperative agreement. 1994 “Domain Name System Structure and Delegation” (RFC 1591), written by Jon Postel, was published and gained general acceptance.1 1995 NSF and NSI amended their cooperative agreement, imposing a $100 fee for 2 years of domain name registration. 1997 The International Ad Hoc Committee (IAHC), a coalition of individuals representing various constituencies established in 1996, released a proposal for the administration and management of gTLDs that included a framework for a governance structure, captured in a document known as the Generic Top Level Domain Memorandum of Understanding (gTLD-MoU).2 The U.S. government created an interagency group to address the domain name issue and assigned lead responsibility to the National Telecommunications and Information Administration (NTIA), Department of Commerce. This interagency group reviewed the IAHC proposal and solicited public comment. As a part of the Clinton Administration’s “Framework for Global Electronic Commerce,”3 the Department of Commerce was directed to privatize the |
|
Domain Name System in a manner that would increase competition and facilitate international participation in its management. The department issued a call for public input relating to the overall framework of the DNS. 1998 The NTIA released “A Proposal to Improve Technical Management of Internet Names and Addresses,” also known as the Green Paper. This proposal called for a private, non-profit corporation, headquartered in the United States, to manage domain names and IP addresses, and for “the addition of up to five new registries.”4 A final statement of policy, the “Management of Internet Names and Addresses,” also known as the White Paper, was issued by NTIA. The White Paper reaffirmed the goals of the Green Paper, while having the U.S. government take a more hands-off approach, and urged the creation of a new not-for-profit corporation to oversee the management and assignment of domain names and IP addresses. Goals for the new corporation included ensuring stability, competition, private and bottom-up coordination, and fair representation of the Internet community.5 NSF transferred authority to the U.S. Department of Commerce to administer the cooperative agreement under which domain name registration services are provided.6 Internet constituencies (e.g., those that attended the workshops held under the auspices of the International Forum on the White Paper) discussed how the new entity (the New Corporation, or “NewCo”) might be constituted and structured. A group led by Jon Postel (and under his name) proposed a set of bylaws and articles for the incorporation of NewCo. The final version of NewCo’s (then named as the Internet Corporation for Assigned Names and Numbers; ICANN) bylaws and articles of incorporation were submitted to NTIA in October. On November 25, NTIA and ICANN signed an official memorandum of understanding (MoU), with an initial termination date of September 30, 2000. In October, NTIA and NSI extended their cooperative agreement through September 2000. NSI committed to a timetable for the development of a shared registration system (SRS) that permitted multiple registrars to provide registration services within the .com, .net, and .org gTLDs. Also, NSI agreed to separate its registrar and registry operations into separate divisions, to recognize NewCo, and to make no changes to the root without written approval from the U.S. government.
|
By 1996, the belief by some (e.g., Jon Postel) that additional TLDs were needed led to the establishment of the International Ad Hoc Committee (IAHC) to develop a framework for the administration of domain names, which became known as the Generic Top Level Domain Memorandum of Understanding (gTLD-MoU). The IAHC’s proposal for an institutional framework prompted a strong reaction from a few key constituencies and “sent ripples through the international system,” as characterized by Milton Mueller.105 Although the gTLD-MoU was not implemented, its creation did motivate the discussions leading to the development of the Green and White Papers (see Box 2.3) and the eventual creation of the Internet Corporation for Assigned Names and Numbers (ICANN) in late 1998.
NSI exclusively operated the .com, .net, and .org TLDs through 1998. The registry operations (associated with the management of the TLD databases themselves) and registrar operations (associated with the retail functions of dealing with customers) were integrated. NTIA’s agreement with NSI in late 1998 required NSI to separate its registry and registrar functions so that other registrars could enter the market. To facilitate the entry of other firms, NSI also agreed to establish a shared registration system to enable all registrars (including NSI’s registrar unit) to interact with the registry database. The vibrant market for domain name registration services in the .com TLD that developed in the late 1990s also spurred interest in the creation of new TLDs.
Thus, the DNS has experienced an extraordinary evolution since its birth in the early 1980s. Initially intended to address specific technical and operational problems of concern to a small, relatively homogeneous group of computer scientists and engineers, the DNS came to involve individuals from many different sectors such as law, business, government, and the public interest. The issues surrounding the DNS became increasingly non-technical in nature and increasingly complex and controversial, and so the founding of ICANN did not end the conflict among constituents, but rather provided the forum for their often intense discussion. Chapters 3 and 5 further explore these conflicts and the alternatives for their possible resolution.








































