
3
The Domain Name System: Current State
The Domain Name System (DNS) in 2005 serves aglobal Internet far larger and more diverse, in users and in uses, than the relatively small homogeneous network for which it was first deployed in the early 1980s. To meet the needs of this expanded and enhanced Internet, the DNS has developed into a complex socio-technical-economic system comprising distributed name servers embedded in a multilayered institutional framework. This chapter describes the DNS as it exists in 2005 to establish a base for consideration of the future of the DNS and of navigation on the Internet.
The chapter begins with an explanation of how the DNS responds to queries, illustrating the process with a query about the Internet Protocol (IP) address that corresponds to a particular domain name. It then describes the basic architecture of the DNS: its domain name space, its hierarchical structure, its basic programs, and its key standards and protocols. The core of the chapter is a description of the implementation of this architecture at three levels of the DNS hierarchy: the root, the top-level domains, and the second- and third-level domains. The distinctive characteristics of each level are examined first, followed by descriptions of the technical system and its institutional framework. The committee’s conclusions about the current performance of the DNS architecture and the implementation of each level are presented at the end of each section. Open issues affecting the future of the DNS are collected and analyzed in Chapters 4 and 5.
Many of the contentious issues that arise in the context of the DNS concern domain names themselves—in particular, the definition of permissible names and the rights to their use. Some of those issues are introduced and discussed in Chapter 2.
3.1 OPERATION OF THE DOMAIN NAME SYSTEM1
Many things happen when a query to the DNS is initiated. If the DNS were a centralized database, such as HOSTS.TXT,2 every query would go directly to a central file where the answer would be found (or its absence noted). However, because the DNS is a hierarchical, distributed database, a search in response to a query generally requires several steps. If necessary, it can begin at the root and traverse a course through the tree of files to the one in which the sought-for answer resides. However, frequently the search can begin further down the tree because previous answers are stored and reused by the querying client. The design of the DNS ensures that the path down the tree will be followed without detours or false starts, leading directly to the desired file because the structure of the domain name spells out the route. This process may best be understood through an example, shown in Figure 3.1, which illustrates the use of the DNS to find the IP address corresponding to the hypothetical domain name indns.cstb.nas.edu.3
This is what would happen if, for example, the user wanted to access a Web site at that name, in which case the requesting application would be a browser. However, the same process would be followed for, say, an e-mail application or any other application supported by a host4 on the Internet.
Two versions of the process are described below: first, the version shown in Figure 3.1, which would be followed if this were a new query from a computer that was not on the same DNS subtree as the cstb.nas.edu server; and then a version shortened by taking advantage of additional information from shared servers or previous queries.
|
1 |
This section elaborates on the high-level explanation in Chapter 2. It draws extensively on material in Paul Albitz and Cricket Liu, DNS and BIND, O’Reilly & Associates, Sebastopol, Calif., 2001. |
|
2 |
HOSTS.TXT is the predecessor of the DNS and is described in Section 2.1. |
|
3 |
The process shown in Figure 3.1 assumes that the querying client has stored no relevant previous answers. |
|
4 |
A “host” is a network computer on which applications run providing services, such as computation or database access, to end users on the network. |
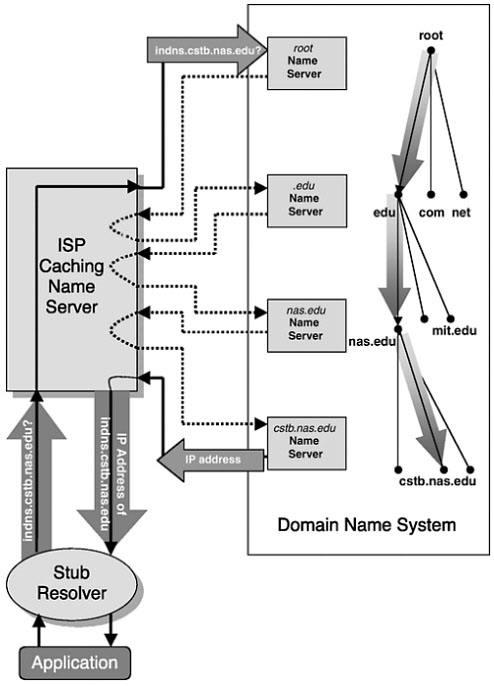
3.1.1 A New, Remote Query
When a domain name is used in a Web browser, e-mail program, or otherwise, the applications program forms a request—a query. The example query, “What is the IP address corresponding to the domain name indns.cstb.nas.edu?,” goes first to a piece of software called a resolver. Resolver software is ordinarily incorporated as part of other software resident on the user’s computer5 or in a host to which it is linked. There are two kinds of resolvers: stub resolvers and iterative resolvers. Both types of resolver send queries to name servers (see below), but they differ in how the resolver selects the name servers to which it sends the query and how much of the work of answering the query is performed by the resolver. A name server is a computer running one of a small number of name-serving programs, the most common of which is the Berkeley Internet Name Domain (BIND) software.6 A stub resolver simply forwards the query to a local name server and awaits a reply. It places on the name server the burden of searching the DNS for the answer. An iterative resolver, in contrast, retains control of the search by using the answer from each successive name server to guide its search. This example assumes that the query comes from a stub resolver.
Name servers are located throughout the Internet: at the root and the top-level domain registries, in organizations’ intranet infrastructures, and at Internet service providers (ISPs). Name servers can perform two important functions:
-
First, they are designed to reply directly to queries concerning the portion of the domain name space for which they have complete information, which is called their zone and for which they are said to be authoritative (see Section 3.1.2).
-
Second, they can, by incorporating an iterative resolver, reply to queries concerning zones for which they are not authoritative, obtaining information from other name servers in the DNS (described in this section). The incorporated iterative resolver will in almost all cases also contain a file or cache of answers obtained as a result of processing previous queries (see Section 3.1.3). In this case, the combination of name server and iterative resolver is said to be a caching or recursive name server.
|
5 |
For example, this is part of the Transmission Control Protocol/Internet Protocol (TCP/IP) stack in Microsoft Windows software, but some applications incorporate their own resolvers. Consequently, a computer may contain more than one resolver. |
|
6 |
This name server program was originally written in 1983-1984 by a group of graduate students at the University of California, Berkeley, with funding from the Defense Advanced Research Projects Agency. Name servers are discussed further in Section 3.2.3. |
In practice, name servers with a heavy query demand or at the top levels of the DNS hierarchy are often configured to be authoritative only and not to offer caching/recursive services, except through a separate server. The name servers at ISPs, however, will offer caching/recursive services to their customers’ stub resolvers, but may not be authoritative for any domain.
In Figure 3.1, the query is shown as going first to a name server offering recursive services located at the user’s ISP.7 Since in this example the iterative resolver incorporated into the ISP’s name server has not recently seen this query or any portion of it and the name server is not authoritative for any portion of the query, it sends the query on to the DNS root. It is able to find the root because the IP addresses of the name servers for the root, called the root hints data, were manually entered into a file on the computer, the hints file. Some systems automatically detect changes to the list of root name servers and make use of them, but the software never changes the file because to do so might eliminate the fallback in case of an attack that maliciously delivered an incorrect list.
There are 13 root name servers (and many satellite copies of them)8 distributed around the world, and the querying name server will go to one chosen by an algorithm that, although differing among name server implementations, usually takes the shortest response time into account. The multiple computer copies of some of the 13 name servers employ a technology called “anycast” addressing (see Box 3.1). Although geographically distributed, each satellite is capable of responding to queries to the same IP address.
If, for some reason, one root name server (or its closest satellite) does not respond, the iterative resolver will continue to try other servers according to its selection algorithm, and so on, until it receives a response. Similar behavior is common to all iterative resolvers at whatever level in the DNS hierarchy they are searching.
The response of a root name server, which is configured to be authoritative only, takes the form: “The address of indns.cstb.nas.edu is not in my zone’s name file, but here are the names or addresses of name servers that are authoritative for .edu.” The ISP’s iterative resolver then sends the same query to one of the .edu name servers, which responds: “The address of indns.cstb.nas.edu is not in my zone’s name file, but here are the names or addresses of the name servers that are authoritative for nas.edu.”
|
7 |
Where a query goes first is a consequence of an explicit configuration choice made by the user, an ISP, an enterprise IT department, or by a dynamic configuration protocol whose values are supplied by one of those sources. |
|
8 |
See Table 3.1 for a listing of the 13 root name servers and their base and satellite locations. See Box 3.1 for a description of satellite servers. |
|
BOX 3.1 Anycast addresses, a special type of Internet Protocol (IP) address, were invented in the early 1990s to simplify the process of finding replicated services (i.e., services that are provided by multiple and identical servers).1 Some of the operators of root name servers have implemented anycast addressing as a way to facilitate load sharing, to improve service, and to reduce vulnerability to attacks. The use of anycast addresses allows a root name server operator to install copies of the root zone file at different servers (in this report, those servers that replicate the root zone file are called satellites). Properly configured and located, each of the satellites will get a share of the traffic for the root name server. Although the shares will, in most cases, not be equal, the load of queries will be distributed and thus relieve the load burden on the root name server. Satellites that are located at the same physical site are using local anycast addressing, also known as load balancing, which is widely deployed among the root name server operators. From the user’s perspective, the great advantage derived from the adoption of anycast addressing is improved service. The satellites are typically placed at topologically diverse locations in the Internet. Queries can therefore be answered more swiftly. An additional benefit is that the DNS queries use, in the aggregate, fewer network resources, because servers will tend to be “closer” on the network to the sources of the queries. The use of anycast addressing can sharply reduce the impact of an attack on a root name server: In the short run, physically disabling a root name server does not affect the operation of its satellites, and physically disabling a satellite disables only that satellite. In the long run, there is the question of how satellites would obtain updated root zone information. It is also much harder to mount an effective electronic attack—because queries are routed to the closest satellite (or the root name server itself, if it is the closest). An attacker would need to place (or acquire) machines close to |
The ISP’s resolver then queries one of the nas.edu name servers, which refers it to a cstb.nas.edu name server, which is authoritative for the requested domain name and replies with the corresponding IP address.
3.1.2 Local Query
A name server can answer many queries quickly when these queries request the address of a domain name for which the name server is authoritative. This is often the case, for example, for name servers on organizational intranets, where most of the requests are for IP addresses of other computers on the intranet. In such a case, the name server can respond to the query without going to the larger DNS, simply by looking up the an-
|
each of the satellites and the root name server if the attacker wished to disable all access to the service.2 A single attacking machine might disable the closest server—whether a satellite or the root name server itself. The other servers would be affected only in a minimal way, through a slightly increased load if one server were rendered inoperative. Therefore, the adoption of anycast addressing by the root name server operators is a positive development. However, more general use of anycast addressing is problematic because current methods for deploying these addresses waste a number of IP addresses.3 Given the importance of a robust DNS, this wastage is acceptable for the operation of the root name servers, but not necessarily for other domain name servers. Monitoring the performance of satellites presents root name server operators with a difficult problem. Such monitoring involves the placement of monitoring devices within the part of the Internet that each satellite serves and can represent a significant logistical challenge because the satellites may be widely dispersed.
|
swer in its local database. For example, if the local name server in the previous example was authoritative for cstb.nas.edu, it could provide the response directly.
3.1.3 Repeat Query
A caching name server can answer many other queries quickly when it has responded previously to queries that were identical or matched at a higher level of the tree. (For example, in 2005 virtually every caching name server is highly likely to have cached the IP address for www.google.com.) It maintains those answers in a cache of information containing the addresses of name servers (and other data) it has previ-
ously obtained. Before going to the root, it searches its cache to find the known name servers closest (in the DNS hierarchy) to the domain being sought.
For example, if the ISP’s caching name server in the previous example were to receive a query for the address of tdd.cstb.nas.edu, it would check to see if it already knew the address of the name server authoritative for cstb.nas.edu. If it did, its iterative resolver would send the query directly to that server, shortening the path that must be taken to obtain an authoritative response. If it did not, it would then check to see if it had the address of the name server authoritative for nas.edu, and finally .edu. Only if it had none of those addresses would it go to the root.
This property of caching—that it limits the number of queries that are sent to the root name server—has been crucial to the manageability of the growth in the query load on the root system. If all DNS queries were to start at a root name server, the capacity of the root system (as a whole) would have to be of an entirely different magnitude, posing more formidable technical and economic challenges as a consequence.
The Internet and the many services on it are subject to constant, sometimes rapid change. As a result, cached information can become outdated. To reduce that problem, the administrator of each zone assigns a time to live (TTL) to each datum that it sends out in reply to a query. After the corresponding amount of time has passed, the name server is expected to eliminate the datum from its cache.
Often a name server will receive information that a domain name being sought does not exist. That can happen because the query is ill formed, contains a typographical error, is based on a user’s incorrect guess about a desired domain name, refers to a name that does not exist or no longer exists, or refers to a domain name on a private network that is not on the public DNS.9 Since such inquiries do not correspond to a cached address, even the caching name server system will not normally relieve the load on the root name servers related to such requests. To minimize the load on the network and improve response time, however, it is desirable that name servers store information about such non-existent domains. That practice is referred to as negative caching (as introduced in Section 2.3.1). The need to assign a TTL also applies to negative caching, since a previously non-existent domain may come into existence and would be missed if the negative cache did not eliminate responses regularly.
|
9 |
A significant portion of queries to the root name servers are ill formed or in error according to studies by researchers. See, for example, Duane Wessels and Marina Fomenkov, “Wow, That’s a Lot of Packets,” Proceedings of Passive and Active Measurement Workshop, 2003, available at <http://www.caida.org/outreach/papers/2003/dnspackets/>. |
3.2 ARCHITECTURE OF THE DOMAIN NAME SYSTEM
The architecture of the DNS—its conceptual design—comprises its name space, its hierarchical structure, and the software that specifies operations within that name space and structure.10 The software comprises two components: programs, which implement the resolver and name server functions on various computers; and technical standards, which define the formats of the communication between the programs, as well as the logical structure11 of the files in a name server.
3.2.1 Name Space
The name space for domain names is the set of all symbol strings that adhere to the rules for forming domain names specified in the design of the DNS. Those rules define a standard format that imposes a tree structure on the name space. Each node on the tree has a label, which consists of 1 to 63 characters drawn from a restricted subset of ASCII12 comprising the 26 letters of the Roman alphabet, the 10 numerals from 0 to 9, and the hyphen. Labels may not begin or end with a hyphen.13 The fully qualified domain name of a node is the list of the labels on the path from the node to the root of the tree written with the deepest node on the left and with those to the right getting successively closer to the root. In external presentation form, the labels are separated by dots (.). By convention, the root label has null length and is written as a dot (.), but its presence is optional. Thus, “www.nas.edu.” (with a trailing dot) and “www.nas.edu” (without a trailing a dot) are equivalent domain names. The total length of a domain name must be less than 256 characters. Each node on the tree (including the leaves) corresponds to a collection of data, which may be empty at the internal nodes, unless they constitute a delegation point. The data are represented by resource records, which are described in Box 3.2 in Section 3.2.4.
3.2.2 Hierarchical Structure
The hierarchical, tree structure of the DNS facilitates both an efficient response to queries and the effective decentralization of responsibility for
|
10 |
The evolution of the DNS is described in Chapter 2. |
|
11 |
They will be stored in whatever data structures the local database software requires. |
|
12 |
American National Standards Institute, “USA Code for Information Interchange,” X3.4, 1968. |
|
13 |
The limitation to the 37 ASCII characters is not a strict requirement of domain names but results from the constraints placed on domain names by other protocols. |
its maintenance and operation. That is accomplished through the division of a domain into subdomains, which taken together need not directly include all of the hosts in the domain. The responsibilities for maintaining the name files for some or all of the subdomains can then be delegated to different organizations. They, in turn, can further divide and delegate, a process that can be repeated as often as necessary. The parent domain need only retain pointers to the subdomains so that it can refer queries appropriately.
The hierarchical delegation of responsibility is one of the great strengths of the DNS architecture. It is up to the organization responsible for a zone to maintain the corresponding zone file (thus, the organization has considerable motivation to provide satisfactory maintenance)—the data file in the zone’s name servers that contains pointers to hosts in the zone and to the name servers for delegated zones (see “DNS Zone Data File” in Section 3.2.4). The work of keeping the DNS current is, thereby, distributed to organizations throughout the entire DNS tree, down to the lowest leaves. Instead of a central organization being responsible for keeping the DNS data current and accurate, which would have been an impossible task, there are millions of organizations and individuals across the globe doing the work.
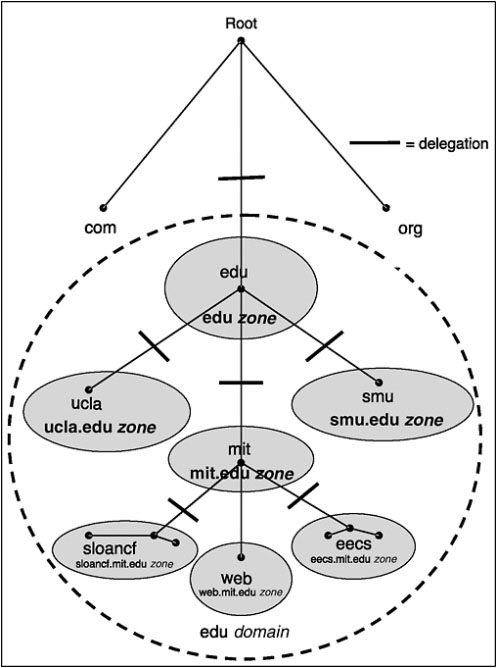
Figure 3.2 illustrates the delegation of responsibility from the root to the .edu domain, whose name servers are said to be authoritative for the .edu zone. The .edu domain in turn delegates responsibility, in this limited illustration, for the subdomains to three universities—the University of California at Los Angeles (UCLA), Southern Methodist University (SMU), and the Massachusetts Institute of Technology (MIT), whose name servers are authoritative for their corresponding zones—ucla.edu, smu.edu, and mit.edu. In Figure 3.2 the MIT subdomain is further delegated to two departments for illustrative purposes—Sloan School and Electrical Engineering and Computer Science, whose name servers are authoritative for their zones—sloancf.mit.edu and eecs.mit.edu. Note that in the example, the mit.edu zone includes a pointer directly to a host—web.mit.edu—in addition to pointers to the delegated zones.
This distribution of responsibility, combined with the distributed handling of tasks by the technology, is why the DNS scales, or handles growth so well.
3.2.3 Programs: BIND and Others
The DNS requires only two types of programs to operate within the context of the existing Internet.
First, there must be resolver software. The resolver, recall from Section 3.1, is a client that accepts a query, passes the query to a name server, interprets the response, and returns the response to the source of the query. Generally, resolvers are just a set of library routines within a name server, a browser, or an operating system.
Second, there must be name server software that performs the functions described in Section 3.1. As noted above, the most common name server software is BIND,14 which is used on the majority of name servers on the Internet.15 There have been many versions of BIND produced since it was originally written in the early 1980s. The most recent releases (as of March 2005) are BIND 8.4.6, which extends and enhances prior versions, and BIND 9.3.1 and 9.2.5, which are the latest releases of a major rewrite of the underlying architecture undertaken in response to anticipated demands resulting from the rapid growth of the Internet. Although originally written for Unix operating systems, BIND has been programmed for other operating systems, including Windows NT and Windows 2000.16 It has also been used as the basis for many vendor name servers.17
The rest of this section uses BIND as an example because it is widely deployed. However, other name server software may behave differently in some respects and still conform to the domain name server standards.
A name server running BIND, or a comparable program, has complete information and authority over the zones for which it is authoritative. It contains all domain names from the top of its zone down to its leaves, except for those that are delegated to zones within it. See Figure 3.2.
Each zone must have a primary master (or primary) server that receives the contents of the zone data file from some manually prepared local file. The primary server is the ultimate source of information about the corresponding domain. Generally, there is at least 1 and possibly as many as 12 secondary servers, which obtain copies of the zone data file from the primary or another secondary.
BIND has not traditionally made severe computational or storage demands on the computers that run it. It has often been implemented on old machines that have been taken out of front-line service. However, BIND 9 incorporates security and other features that impose more severe computational loads. In general, the computational requirements on a name server depend on the number of queries per second and the relative distribution of the types of queries (because some types of queries impose greater computational demands than others), as well as the extent of change of the zone files. The memory requirements are determined by the
|
14 |
BIND also contains a resolver library. |
|
15 |
According to a survey by Internet Systems Consortium, Inc., in January 2004 it was used by almost 75,000 servers; the second most popular name server software was provided by Microsoft for almost 15,000 servers. For more information about the survey and BIND, see “ISC Internet Domain Survey,” March 10, 2004, available at <http://www.isc.org>. |
|
16 |
See “DNS Server Software” at <http://www.dns.net/dnsrd/servers/> for a survey of DNS servers available on various operating systems. |
|
17 |
A current list is posted at <http://www.isc.org/>. |
size of its cache and zone files. In the latest versions of BIND, the cache size can be controlled. In general, the cache size for a new name server is determined by observation of the name server’s operation over a few weeks to determine how much memory is required to respond to the query demand at its installation.
3.2.4 Standards
The queries and responses that flow between name servers must be in a protocol that is readily interpretable by any name server, no matter which software and hardware it uses. To that end, the data in the queries and responses are, like the zone data, represented as resource records (Box 3.2).
|
BOX 3.2 Resource records are used in every DNS zone data file and every DNS message.1 Resource records begin with a domain name (NAME), which is followed by the type (TYPE) and class (CLASS) fields. Those fields are followed by the time to live (TTL) and a data field (RDATA), appropriate to the type and class. Domain names and IP addresses make up a large portion of the data in a typical zone data file. NAME: The domain to which the record refers. TYPE: The type of data in the resource record. The list of possible types is open-ended; each is associated with a type code. There were more than 50 in June 2005, of which no more than 20 are used to any extent. Examples: A = host IP address; NS = an authoritative name server; MX = mail exchange.2 CLASS: Only one class, IN for Internet, is widely used. Four classes have been defined to date, one of which is obsolete. TTL: Specifies the time interval (in seconds) that the resource record may be cached before the source of the information should again be consulted. Example: 86400 (equivalent to one day). RDATA: Describes the resource in question. Example: If the class = IN and the type = A, this field is an IP address.3 If the class = IN and the type = NS, this field is a domain name.
|
DNS Zone Data File
Each DNS zone has a zone data file (also called the master file) that contains both resource records describing the zone and actual data records for the zone. The former group specifies:
-
The domain name of the primary name server and the e-mail address of the responsible person, as well as times associated with updating the secondary name servers;
-
All the name servers that are authoritative for the zone; and
-
The IP addresses of the name servers (name-to-address mappings) that are in the zone.
There can also be data files that contain reverse mappings (i.e., tables for conversion from IP addresses back to computer names). The domain names in these files look like IP addresses turned back to front, and they all end in in-addr.arpa.18
The zone data file may contain some additional types of resource records. The specification of resource records allows additional types of data to be added in the future, as required.
DNS Message Format
The DNS message format comprises five sections, some of which may be empty:
-
Header,
-
Question: the question for the name server (includes domain name),
-
Answer: resource records answering the question,
-
Authority: resource records pointing toward an authority, and
-
Additional: resource records holding additional information.
The lengths of the four sections that follow it are specified in the header section.
The practical limitation on the number of root name servers to 13 is a consequence of the DNS message format and the design decision to use datagrams employing a minimal protocol—the User Datagram Protocol (UDP)19—to send DNS queries and responses so as to achieve high per-
|
18 |
Addresses are converted to names in the .arpa domain for DNS lookup. The in-addr.arpa zone contains the hosts associated with all registered IPv4 addresses. |
|
19 |
For more information on the User Datagram Protocol, see Jon Postel, “User Datagram Protocol,” RFC 768, August 28, 1980, available at <http://www.rfc-editor.org>. |
formance. Because in current practice there must be room within the datagram answer section for a list of all root servers—in order to update the list of root servers20 in every iterative resolver—the number of root servers is constrained by the maximum length of that section.21 To maximize the number of root servers, their names were shortened and standardized for more efficient compression, increasing to 13 the maximum number that could fit in the space available.
3.2.5 Functions and Institutions
There are two critical functions that the DNS institutional framework performs in support of the standards and the programs that define the DNS. The first is maintenance of the DNS standards, and the second is ensuring the availability of DNS name server software. DNS client software, primarily stub resolvers, is widely available in standard software—operating systems, Web browsers—and the specifics of their provision are not further considered here.
Maintenance of the DNS Standards—The Internet Engineering Task Force
The definition and maintenance of the basic standards for the DNS are the responsibility of one informal organization—the Internet Engineering Task Force (IETF) (see Box 3.3). The IETF has attracted experienced and knowledgeable technical talent, who volunteer considerable time to its activities. The requests for comments (RFCs) process has provided a means for this diffuse technical community to build a freely available, peer-reviewed store of knowledge and the successful standards and protocols that enable the Internet and the DNS to function reliably and to adapt smoothly to the additional requirements imposed by increased scale, new applications, and new classes of users. Although the IETF’s standards and protocols underpin the worldwide Internet and the DNS, it does not have the authority, the political or economic power, or the interest to force their adoption or validate their implementation. Rather, their universal use has been the result of the practical benefit of having freely
|
BOX 3.3 The Internet Engineering Task Force (IETF)1 is a voluntary, non-commercial organization comprising individuals concerned with the evolution of the architecture and operation of the Internet. It is open to anyone who wishes to participate and draws from a large international community. However, almost all its participants are technologists from universities, network infrastructure operators, and firms in related industries. Although the IETF holds three meetings each year at locations around the world, much of its work is conducted through the circulation of e-mail to electronic mailing lists. The IETF divides its activities among working groups, organized into areas that are managed by area directors (ADs). The ADs, in turn, are members of the Internet Engineering Steering Group (IESG). The Internet Architecture Board (IAB) provides general oversight on Internet architecture issues and adjudicates appeals that are unresolved by the IESG, but it is not actively involved in standards development or implementation. The Internet Society (ISOC) charters the IAB and IESG.2 Requests for comments (RFCs) were established in 1969 to document technical and organizational aspects of the Internet (originally the ARPANET). RFC memos discuss protocols, procedures, programs, concepts, and various other aspects of the Internet. The IETF defines the official specification documents of the Internet Protocol suite that are published as “standards-track” RFCs. RFCs must first be published as Internet-Drafts—a mechanism to provide authors with the ability to distribute and solicit comments on documents that may ultimately become RFCs. An Internet-Draft, which can be published by anyone, has a maximum life of 6 months, unless updated and assigned a new version number. The Internet-Drafts that are intended for progression onto the standards track, and some other documents at IESG discretion, are “last called,” which involves an announcement being sent out to the Internet community that the IESG wants input on the document. The Last Call is usually of a few weeks’ duration. Using input from it, the IESG makes a decision on further processing of the Internet-Draft. Such decisions might include rejection of the draft, publishing it as a standards-track document, or handling it in some other way. Documents that are considered valuable and permanent, including all standards-track documents, are then submitted to the RFC editor for publication as RFCs.3
|
available high-quality standards that all can share, and that give no organization proprietary advantage. As a volunteer collaborating body, the IETF periodically restructures its processes. In 2003, the IETF identified a number of problems, both routine and structural, in its operations and initiated a process of problem resolution.22 As is typical, it did so publicly via the RFC process.
Providing Root Name Server Software—Internet Software Consortium, Inc., and Other Software Providers
Internet Systems Consortium, Inc. (ISC), a not-for-profit organization formerly called the Internet Software Consortium, has assumed responsibility for continuing maintenance and development of BIND.23 Although ISC’s scope is considerably more focused than the IETF’s, it, too, has played a key role in the smooth development and operation of the Internet and the DNS. By continuing to evolve BIND and making it readily available worldwide, free of charge, ISC has provided a widely adopted implementation of the DNS standards promulgated by the IETF.
Implementations of BIND and other DNS server software are also available from Microsoft and other software companies as well as from various providers in the form of freeware and shareware.
3.2.6 Assessment
Conclusion: The architecture of the Domain Name System has demonstrated the ability to scale to support the Internet’s rapid growth, never holding up its development because of an inability to meet the challenges of vast increases in the number of domain names, users, and queries. Furthermore, it has demonstrated robustness, operating reliably despite malicious attacks and a very high volume of erroneous requests. What failures there have been have occurred in subzones of the system and have been insulated from the rest of the DNS by its hierarchical, distributed structure.
The hierarchical architecture and caching have been critical to the ability of the DNS to scale smoothly. First, they ensure that many queries are
|
22 |
The problem statement and the history of the response are described in E. Davies, ed., “IETF Problem Statement,” RFC 3774, May 2004, available at <http://www.rfceditor.org>; and E. Davies and J. Hoffman, eds., “IETF Problem Resolution Process,” RFC 3844, August 2004, available at <http://www.rfc-editor.org>. |
|
23 |
Information about ISC is available at <http://www.isc.org>. |
resolved locally, never reaching the higher levels of the DNS. Second, even queries that do reach higher levels of the DNS do so only the first time they are made by a specific name server in a given period (the TTL), with all subsequent queries from the same name server during that period being answered locally.
These benefits are amplified by the ability of large ISPs, such as MCI and Verio, to maintain very large caches and, thereby, to handle a substantial portion of the queries originating from their customers without ever passing them along to the DNS.
Conclusion: Through its RFC process, the IETF has created a store of knowledge and a body of standards and protocols that have, thus far, enabled the Internet and the DNS to function reliably and to adapt smoothly to the additional requirements imposed by increased scale, new applications, and new classes of users. Though ISC’s scope is much more focused than the IETF’s and its participation and decision-making processes are far less open and public, by continuing the evolution of BIND and making it readily available ISC has brought most of the IETF DNS standards24 into practical effect.
However, the continued growth of the Internet is posing new challenges and placing new demands on the DNS architecture. The issues of future security and robustness, internationalized domain names, and the intersection of the DNS with the telephone system are addressed in Chapter 4.
3.3 IMPLEMENTATION—THE DOMAIN NAME SYSTEM ROOT ZONE
The top of the DNS inverted tree is its root, or more properly, the root zone (see Section 3.1.1). The root zone name file (or, simply, root zone file) is stored in 13 root name servers, which use it to respond to queries to the root. As shown in Section 3.1, while queries can enter lower on the tree if their resolvers have current cached information, or if the query lies within the zone of the local name server, the root serves as the assured point of entry to the DNS for any other query.
3.3.1 Characteristics of the Root Zone
Defining Characteristics
The root zone file defines the DNS. For all practical purposes, a top-level domain (and, therefore, all of its lower-level domains) is in the DNS if and only if it is listed in the root zone file. Therefore, presence in the root determines which DNS domains are available on the Internet.25 As Internet use has grown, especially with the explosive growth of the Web and its reliance on domain names as key parts of Web site addresses, entry of a top-level domain into the root zone file has become a subject of substantial economic and social importance. Consequently, who controls entry into the root, and by what means, have become controversial subjects. The current process for resolving these issues is described in Section 3.3.3.
Critical Characteristics
The root zone and the root name servers are critical to the operation of the DNS. The effective and reliable operation of the DNS, and of the Internet, is entirely dependent on the accuracy and integrity of the root zone file (and its copies) and the security, reliability, and efficiency of the root name servers. Fortunately, the root zone has proven highly resilient and resistant to errors or disruptions.
One possible source of error is an incorrect entry—a mistyped domain name or an erroneous IP address—in the root zone file. A consequence could be misdirection of queries seeking a particular top-level domain (TLD) name server, say .net. That could prevent users searching for the address of any domain name within that name server’s TLD, say any address in .net, from reaching it through the specific root name server containing the incorrect entry. If the error were updated in all copies of the root zone file, access would effectively be denied to all domain names in that TLD, except from name servers that had previously cached the correct address.26 However, relatively simple error detection and correction procedures can quickly prevent such errors. (For example, most large top-level domains are programmed to regularly query the root to ensure that it is properly routing queries seeking that TLD.)
A possibly disruptive event would involve one or more of the root name servers being non-operational for hours or more. This might happen because of the unexpected failure of a computer or communication link (accidental or purposeful) or because of regular maintenance. However, since the capacity of each name server is many times greater than its average load, and iterative resolvers can use any of the root name servers, other name servers can take up the load without degradation in the system’s performance that is perceptible to users. Moreover, in recent years such outages have been very rare.27
Although, as noted, there have been instances in the past of errors in the root zone file that have had significant effects on the reliable operation of the DNS, there have been none in recent times. At least for the current rates of queries and of changes in the root zone file, the systems of error checking and correction and of capacity sharing appear to be working successfully.
Unique Characteristics
The design of the DNS is predicated on the existence of a single authoritative root that ensures that there is one and only one set of top-level domains. However, some of those who object to the pace at which new generic TLDs have been added to the root, or to the process by which they have been selected, have sought a solution through the addition of one or more roots. They have been joined by some who believe in the principle that having competition in the delivery of root services would benefit Internet users.
On the other side are those who argue that additional roots would compromise the reliable operation of the Internet by, among other things, opening the possibility of multiple addresses, associated with different entities, being assigned the same domain name.28 Most experienced technologists view the idea of introducing multiple roots for the DNS as threatening the stable operation of the DNS.
|
27 |
For example, in 2000, 4 of the 13 root servers failed for a brief period because of a technical mistake. In 1997, a more serious problem involving the transfer of an incorrect directory list to seven root servers caused much of the traffic on the Internet to come to a stop. As reported in “ISC Sets Up Crisis Centre to Protect Domain Name System,” Sydney Morning Herald, October 21, 2003, available at <http://www.smh.com.au/articles/2003/10/21/1066631394527.html>. |
|
28 |
See, for example, M. Stuart Lynn, “ICP-3, a Unique, Authoritative Root for the DNS,” ICANN, July 2001, available at <http://www.icann.org/icp/icp-3.htm>; also, Internet Architecture Board, “IAB Technical Comment on the Unique DNS Root,” RFC 2826, May 2000, available at <http://www.rfc-editor.org>. |
Moreover, since which domains are accessible to a user would depend on which of the multiple roots were used, these technologists see a multiple-root DNS as balkanizing the Internet. Although there may be some benefits from having competing roots, the presence of network externalities29 encourages ISPs and name servers to converge on a single root that provides global compatibility. Consequently, many technologists and economists believe it is unlikely that an alternative root would achieve widespread success.30 In their view, while competition may serve a valuable purpose in the short term, the task of maintaining the root zone file will equilibrate on a single, dominant root zone file, albeit an equilibrium in which operational control is shared among a number of (non-competing) entities.31
There have been several attempts to create alternate roots that have data about the TLDs that are recognized by the current root servers plus some additional TLDs that the operator of the alternate root is trying to promote. However, these attempts have generally been unsuccessful, in large measure because of the lack of global compatibility among the domain names recognized only by alternative roots, which has made users unwilling to use them. However, one company—New.net—claims to have reached financial profitability, to have registered over 100,000 domain names, and to be potentially accessible to 175 million Internet users through allied ISPs and browser plug-in software. It offers 12 additional TLDs in English as well as in each of Spanish, French, Portuguese, Italian, and German.32 Although the continued existence of New.net can be seen as a challenge to the DNS and ICANN’s management of the root zone file, it has not thus far appeared to have had any significant effect on either. Furthermore, in September 2004, New.net was acquired by the Vendare Group, an online media and marketing company, as the basis for a division offering search services, while continuing to offer domain name registration.33
|
29 |
Network externalities are the increased benefits received by one user of a system as the number of users of the system increases. |
|
30 |
Milton L. Mueller, “Competing DNS Roots: Creative Destruction or Just Plain Destruction?” Journal of Network Industries 3(3):313-334, 2002. |
|
31 |
If an alternate root attracts a sufficient number of registrations, it raises the possibility that TLDs in the alternate root and registrations within these TLDs could be created for speculative purposes. If ICANN creates a TLD that already exists in an alternate root, the organization that controls the corresponding TLD in the alternate root could be willing to transfer the registered names to the ICANN TLD—for a price. |
|
32 |
This information was obtained from <http://www.new.net/> in February 2004. |
|
33 |
The Vendare Group, “The Vendare Group, Online Media and Marketing Company, Acquires Search-Services Provider New.net,” press release, September 17, 2004, available at <http://www.new.net/id_9172004.tp>. |
3.3.2 Technical System of the Root Zone
The Root Zone File
The root zone file contains resource records for all the TLDs as well as for the root. In February 2005, there were 258 sets of entries. Of those, 243 were country code TLDs (ccTLDs) and 15 were generic TLDs (gTLDs). (One of the gTLDs was the domain .arpa that is used for infrastructural purposes, which is sometimes considered a separate category.) Because there are multiple records in the root zone file for each of the subdomains, there were a total of 2143 records in the root zone, which translates to about 78 kilobytes of storage. Moreover, although, as noted earlier, all the root name servers together execute, in total, 8 billion searches a day on this file,34 this is well within their computational capability because of the substantial overprovisioning of the system.
The Root Name Servers
Like other zone files, the root zone initially had a primary or master server accessible from the DNS and several—in this case, 12—secondary or slave servers. That primary zone file was the most current of the files, and all updates and changes were made to it; it served as the reference source for the root zone. The secondary files were updated from it on a regular basis, at least twice daily. Starting in 1996 and achieving adoption by all secondaries by the end of 2001, the role of the primary was transferred to a “hidden primary,” which is a server that is used to update the secondaries but is not itself accessible from the DNS. VeriSign operates this hidden primary. All 13 of the public root name servers are now secondaries, including the former primary. Digital signatures, error checking, and correction processes are in place to minimize the chance of introducing errors or being successfully attacked during updates.
The December 2004 status of the group of 13 named root name servers is shown in Table 3.1.35 They are designated by the letters A through M. The A-root server, a.root-server.net, was until recently the primary but, as noted above, has been replaced by a hidden primary. See Box 3.4.
|
34 |
The F-root server (which includes its satellites), one of 13 root servers, answered more than 272 million queries per day according to the Internet Systems Consortium in January 2004. See <http://www.isc.org>. |
|
35 |
For the current version of this table, see <http://www.root-servers.org>. That Web site also contains links to the root name server operators and to other relevant information.. |
Although the home locations of some of the root servers are the result of historical accident, they were originally determined by analysis of network traffic flows and loads, seeking to have at least one server “close” in terms of message communication time to every location on the network. It is important to have root servers distributed so that they provide a uniform level of service across the network.36 Having a root server in a well-connected area is fairly unimportant to that area, since users there are likely to be able to reach several servers. By contrast, if an area is fairly isolated from most of the network, it is important that the ISPs that serve it acquire sufficient connectivity to enable the area’s users to access one or more root servers at all times.
Considerations of this type are both complex and important but were not sufficient to determine a unique set of locations for the home sites of the 13 root servers. However, as the Internet has evolved, these original locations became less satisfactory, which has been one of the reasons for the proliferation by some operators—notably C, F, I, J, K, and M in Table 3.1—of satellite sites at different locations. These satellite sites use anycast addressing (see Box 3.1), which enables servers with the same IP address to be located at different points on the Internet. Copies of the F-root server, for example, can be placed at multiple locations around the world. The widespread distribution of anycast satellites of the 13 root servers has improved the level of service provided to many previously less well served locations.
Some have believed that 13 root name servers are too few to meet requirements for reliability and robustness, which requires sufficient capacity distributed widely enough to protect against system or network failures and attacks. Others have believed that more root servers are needed to satisfy institutional requirements. Their concern arose from the belief that to be a full participant in the Internet, a nation or region must have its own root name server. While technical reasons37 make it difficult to increase the number of root name server IP addresses beyond 13, the rapidly increasing use of anycast addressing has enabled the root name server system to respond to both the technical and institutional requirements through the addition of multiple geographically distributed anycast root server satellites. Even so, since it addresses the distribution only of
|
36 |
See Tony Lee, Brad Huffaker, Marina Fomenkov, and kc klaffy, “On the Problem of Optimization of DNS Root Servers Placement,” Passive Measurement and Analysis Workshop, 2003, available at <http://www.caida.org/outreach/papers/2003/dnsplacement/>. |
|
37 |
See “DNS Message Format” in Section 3.2.4 for an explanation of the technical limitations. |
TABLE 3.1 The 13 Root Name Servers and Their Anycast Satellites as of December 2004
|
Name |
Operator |
|
A |
VeriSign Naming and Directory Services |
|
B |
Information Sciences Institute, University of Southern California |
|
C |
Cogent Communications |
|
D |
University of Maryland |
|
E |
NASA, Ames Research Center |
|
F |
Internet Systems Consortium, Inc. |
|
G |
U.S. DOD Network Information Center |
|
H |
U.S. Army Research Laboratory |
|
I |
Autonomica/NordUNet |
|
J |
VeriSign Naming and Directory Services |
|
K |
Réseaux IP Européens—Network Coordination Centre |
|
L |
ICANN |
|
M |
WIDE Project |
|
SOURCE: This table derives directly from information provided at <http://www.root-servers.org> as accessed on February 13, 2005. |
|
servers and not of the operating institutions, the location issue is likely to continue to add some political acrimony to any selection process that might follow from the withdrawal of one of the current operators. (See Section 5.3.)
There is no standard hardware and software implementation of the root name servers. Each of the responsible organizations uses its preferred equipment and operating and file systems, although most of them run
|
Locations |
Country |
|
Dulles, VA |
USA |
|
Marina del Rey, CA |
USA |
|
Herndon, VA; New York City; Chicago; Los Angeles |
USA |
|
College Park, MD |
USA |
|
Mountain View, CA |
USA |
|
Palo Alto, CA; San Jose, CA; New York City; San Francisco; Ottawa; Madrid; Hong Kong; Los Angeles; Rome; Auckland; São Paulo; Beijing; Seoul; Moscow; Taipei; Dubai; Paris; Singapore; Brisbane; Toronto; Monterrey; Lisbon; Johannesburg; Tel Aviv; Jakarta; Munich; Osaka; Prague |
USA |
|
Vienna, VA |
USA |
|
Aberdeen, MD |
USA |
|
Stockholm; Helsinki; Milan; London; Geneva; Amsterdam; Oslo; Bangkok; Hong Kong; Brussels; Frankfurt; Ankara; Bucharest; Chicago; Washington, DC; Tokyo; Kuala Lumpur |
Sweden |
|
Dulles, VA (2 locations); Mountain View, CA; Sterling, VA (2 locations); Seattle, WA; Amsterdam; Atlanta, GA; Los Angeles; Miami; Stockholm; London; Tokyo; Seoul; Singapore |
USA |
|
London, Amsterdam, Frankfurt, Athens, Doha, Milan, Reykjavik, Helsinki, Geneva, Poznan, Budapest |
NL |
|
Los Angeles |
USA |
|
Tokyo, Seoul, Paris |
Japan |
some version of the BIND name server software.38 Although there might be some operational advantages to having standard implementations,
|
BOX 3.4 VeriSign, Inc., founded in 1995, describes itself as providing “intelligent infrastructure services that support the digital economy.” Its acquisition in 2000 of Network Solutions, Inc. made it the registry for three gTLDs: .com, .net, and .org and the operator of the A-root and the J-root name servers. It currently operates the A-root and J-root name servers, the hidden root primary, and the name servers for the .com, and .net TLDs. At the end of 2004, its Naming and Directory Services unit managed a database of over 38 million names in the .com and .net gTLDs; owned and maintained 13 gTLD name server sites around the globe that handled the more than 14 billion transactions per day for those two gTLDs; and provided access to the .com and .net gTLD registries for more than 150 ICANN-accredited registrars that submit over 100 million domain name transactions daily to its Shared Registration System. As a registrar—through a subsidiary renamed Network Solutions, Inc. in 2003—it registered more than 500,000 new domain names during the second quarter of 2002, and an additional 700,000 names were renewed or extended. More than 8.7 million active domain names in .com and .net were under management by VeriSign’s registrar. However, in October 2003, it sold Network Solutions to a private equity firm for $100 million.1
|
most Internet technologists believe that variation in the underlying hardware and software of the root name server system is highly desirable, since it ensures that an error in a particular piece of hardware or software will not lead to the simultaneous failure of all of the root servers.
As the number and rate of queries to the root name servers have increased, hardware and software upgrades have enabled the servers to keep up.39 However, the pace of inquiries is likely to continue to grow and it is conceivable that it could, in principle, exceed the capacity of a system comprising even the most powerful single computers. Because of anycasting and multiprocessing, through which a root server can comprise multiple processors, the number of computers at each root-server address is effectively unrestricted. Moreover, it is plausible to expect continued improvements in computing and communications performance. Consequently, it is
unlikely that the query load will ever be able to outrun the computing capacity of the 13 named root name servers and their satellites.
3.3.3 Institutional Framework of the Root Zone
Because the root is central and critical to the operation of the DNS, decisions about the root zone and the root name servers are of substantial importance, and the institutions that bear responsibility for them take on an important role as stewards of the DNS.
Those institutions carry out four critical functions:
-
Deciding what new or revised entries will be permitted in the root zone file;
-
Creating the root zone file, keeping it current, and distributing it to all the root name servers;
-
Selecting the locations and the operators of the root name servers; and
-
Establishing and continually and reliably operating the root name servers.
The diverse collection of institutions that performs these functions includes a not-for-profit corporation—ICANN; a U.S. government agency—the Department of Commerce; a corporation—VeriSign; and an informal group consisting of the commercial, non-commercial, and governmental root name server operators.
Approving the Root Zone File—U.S. Department of Commerce and ICANN
The fundamental importance of the root zone file to the operation of the DNS and, therefore, of the Internet means that special attention is paid to the process by which new or revised entries to the file are authorized. Some process must be in place to decide whether a change is legitimate; otherwise, persons or organizations with malicious motives or inadequate capabilities could make or revise entries. Currently the authority to make changes lies with the U.S. Department of Commerce (DOC).40 However, the day-to-day operational responsibility is at VeriSign. As part of the DOC’s delegation of responsibility to ICANN (see Box 3.5), the process of authorization for new or modified entries in the root zone was changed.
|
40 |
See Section 2.7 for a history of that authority. |
|
BOX 3.5 As described in Chapter 2, the Internet Corporation for Assigned Names and Numbers (ICANN) is a not-for-profit corporation founded in October 1998 in California by a group of individuals interested in the Internet. It was sponsored by the U.S. Department of Commerce (DOC) to serve as a technical coordination body for the Internet. Consequently, ICANN has assumed responsibility (under a memorandum of understanding—and its six amendments—with the DOC) for a set of technical functions previously performed under U.S. government contract by the Internet Assigned Numbers Authority (IANA) and other groups. However, in practice, many of its most important and controversial activities have been as a policy-setting, rather than as a technical coordination, body. IANA continues as a function of ICANN with overall administrative responsibility for the assignment of IP addresses, autonomous system numbers, top-level domains, and other unique parameters of the Internet. In addition, ICANN is charged with coordinating the stable operation of the Internet’s root server system. ICANN’s primary governing body is its board of directors, which now comprises 15 voting members and the president, ex officio. Dissatisfaction with the composition of the board and with the nature of the selection process inspired a reform effort that resulted in new bylaws that guided the selection of a new board in 2003. (See Section 5.2.4, Alternative F, for a description of this reform.) ICANN has three supporting organizations: the Address Supporting Organization (ASO), which deals with the system of IP addresses; the Country-Code Names Supporting Organization (ccNSO), which focuses on issues related to the country-code top-level domains; and the Generic Names Supporting Organization (GNSO), which handles issues related to the generic top-level domains. In addition, it has four advisory committees: the At-Large Advisory Committee (ALAC) for the Internet community at-large; the DNS Root Server System Advisory Committee (RSSAC) for root server |
All such requests go first to the Internet Assigned Numbers Authority (IANA) (now a function of ICANN) and then to the DOC for final approval. Once the addition or change is approved, the DOC notifies IANA and VeriSign. VeriSign Naming and Directory Services then makes the change in the hidden primary, which distributes the changed root zone file to the other root name servers (see “Operating the Root Name Servers” in Section 3.3.3).
There are three kinds of changes to the root zone file. The first kind of change is a modification of the data associated with an existing resource record. This might entail a change in the IP address of one or more of the
|
operators; the Governmental Advisory Committee (GAC) for governments; and the Security and Stability Advisory Committee (SSAC) for security. There is also the Technical Liaison Group (TLG) for standards-setting organizations and an Internet Engineering Task Force liaison who provides technical advice to ICANN. The supporting organizations and advisory committees together represent a broad cross section of the Internet’s commercial, technical, academic, non-commercial, and user communities and advise the board on matters lying within their areas of expertise and interest. As part of the reform effort, ICANN adopted a new mission statement: The mission of ICANN is to coordinate the stable operation of the Internet’s unique identifier systems. In particular, ICANN:
ICANN is open to the participation of any interested Internet user, business, or organization. It holds several meetings a year at locations around the world.1 ICANN has been the subject of many controversies regarding its governance, its processes, and its decisions since its founding. The primary issues are discussed in Section 5.2. A good sense of the full range of controversies that have surrounded ICANN can be obtained from <http://www.icannwatch.org>, CircleID (<http://circleid.com>), and ICANNFocus (<http://www.icannfocus.org>), through the resources that can be linked to from these sites, and from innumerable articles written about ICANN.
|
name servers resulting, for example, from a change in the network service provider. The data entry process is straightforward, and so such changes should be routine and rapid. However, they do require a stage of verification to ensure that the request is legitimate and not, for example, an effort by a third party to capture a top-level domain. Nevertheless, such requests should be processed in a few hours or days.
The second kind of change is a shift in the responsibility for a TLD, typically a ccTLD. In such redelegation cases, the questions that must be resolved may be more difficult and time-consuming. (See “Selecting the Organizations Responsibile for the TLDs” in Section 3.4.3 for a discussion
of the issues.) In particular, they may entail judging which organization has the “right” to operate the registry for a ccTLD, which can become embroiled in national politics. These changes will generally take longer but should proceed according to a formal and transparent process.
The third kind of change is the addition of data about a new TLD to the root zone file (see “Selecting the Organizations Responsible for the TLDs” in Section 3.4.3). This is a single process for new gTLDs. An ICANN selection process recommends both the domain name that shall be added and who shall operate it. It is a two-step process for new ccTLDs. Who will be responsible for operations is a separate recommendation from the decision to add a ccTLD name to the list of ccTLDs. Such changes should take place within a few days after the appropriate decisions have been made.
Maintaining the Root Zone File—VeriSign
VeriSign, as the operator of the hidden primary root zone server, is responsible for maintaining the root zone file and for distributing it to the secondary servers. It performs this function under the terms of a memorandum of understanding (MoU) with the DOC.
Since any errors in the root zone file can affect large numbers of sites and users, accurate and error-free preparation and distribution of the file are essential. In the first instance, this is a human function. Someone must enter additions and updates into the database, create a new zone file, and check it for errors. Individuals at the secondary sites must check to ensure that the file has not been corrupted during its distribution. However, computer techniques and aids can be used to support this process and reduce the demands on humans. Furthermore, regular queries of the root by each of the TLD operators can be used to test the entries corresponding to their TLDs and provide further assurance that no undetected errors are present in the file.
Selecting the Root Name Server Operators—Self-Selection
The current root name server operators were not selected through a formal evaluation and qualification process, although they play a fundamental role in ensuring the availability and reliability of the root. Rather, the group is the cumulative result of a sequence of separate decisions taken over the years since the establishment of the DNS. It is a loosely organized collection of autonomous institutions whose names are given in Table 3.1. Ten of them are based in the United States. Of those, three are associated with the U.S. government (National Aeronautics and Space Administration (NASA), Department of Defense (DOD), and the U.S. Army), two are universities (University of Maryland and University of
Southern California), two are corporations (VeriSign and Cogent Communications), and two are not-for-profits (ISC, Inc. and ICANN). Three are based outside the United States: one in Sweden, one in the Netherlands, and one in Japan.
One of the responsibilities that ICANN assumed under its agreement with the DOC is coordinating the stable operation of the root server system. To do so, it established the DNS Root Server System Advisory Committee, whose responsibilities were spelled out in ICANN’s bylaws (Article VII, Section 3(b)).
The responsibility of the Root Server System Advisory Committee shall be to advise the Board (of ICANN) about the operation of the root name servers of the domain name system. The Root Server System Advisory Committee should consider and provide advice on the operational requirements of root name servers, including host hardware capacities, operating systems and name server software versions, network connectivity and physical environment … should examine and advise on the security aspects of the root name server system … [and] should review the number, location, and distribution of root name servers considering the total system performance, robustness, and reliability.
The parties will collaborate on a study and process for making the management of the Internet (DNS) root server system more robust and secure.
ICANN’s intent is to enter into an MoU41 with each server operator that will spell out the root name server performance requirements, such as service levels, reliability, and security. However, as of February 2005, no MoUs had yet been signed.
In the absence of an agreed oversight role for ICANN, there is, at present, no formal process for selecting a new root name server operator if one of the incumbents should withdraw, although it is clear that the set of remaining operators could, and probably would, work together to make the selection. (See Section 5.3 for a discussion of this issue.)
Operating the Root Name Servers—The Root Name Server Operators
The role of the operators of the 13 root name servers is to maintain reliable, secure, and accurate operation of the servers containing the current root zone on a 24-hour-a-day, 365 days-per-year-basis. Each server is expected to have the capacity to respond to many times the rate of queries it receives and must increase its capacity at least as fast as the query rate
|
41 |
The DNS Root Server System Advisory Committee has drafted a model memorandum of understanding, available at <http://www.icann.org/committees/dns-root/modelroot-server-mou-21jan02.htm>. |
increases. An attempt to define the responsibilities of the root name server operators was made in RFC 2870, issued in June 2000,42 but the ideal that it describes has not been achieved.
Historically, the operators of the root servers have not charged fees for resolving Internet address queries, instead obtaining support in other ways for the substantial costs they incur in providing the service. These operators choose to do so either because (1) they believe that operating a root server is a public service (and sufficiently inexpensive that they can afford the cost) or (2) they believe that operating a root server conveys a business, or other, advantage to them. Nevertheless, it is a valuable service, whose provision is a little-known and little-appreciated gift in kind to all users of the Internet.
3.3.4 Assessment
Conclusion: The system of DNS root name servers currently responds to more than 8 billion queries per day43 and does so reliably and accurately as shown by its virtually uninterrupted availability and the very low occurrence of root-caused misdirections. Because the majority of queries are served from cached answers lower in the hierarchy, the entire DNS responds to many times that number each day with correspondingly good results. However, the robust operation of the root name servers is potentially vulnerable to an excessive query load, either inadvertent or malicious, that might slow down their responses or cause them to fail to respond.
Data collected about root name server operation has revealed that a substantial fraction—between 75 percent and 97 percent—of the load on those servers may be the result of erroneous queries.44 These errors fall into three categories: stupid—for example, asking for the IP address of an IP address; invalid—for example, asking for the IP address of a nonexistent domain; and repetitive—for example, continuing to send an incorrect query even after receiving a negative response. Analysis has revealed that the sources of many of these errors lie in faulty resolver or name server software and faulty system management that misconfigures name servers
|
42 |
See Randy Bush, Daniel Karrenberg, Mark Kosters, and Raymond Plzak, “Root Name Server Operational Requirements,” RFC 2870, June 2000, available at <http://www.rfc-editor.org>. |
|
43 |
The monthly average load on all root name servers in December 2004 was around 90,000 queries per second according to the Internet Society’s Member Briefing No. 20, “DNS Root Name Servers—Frequently Asked Questions,” January 2005, available at <http://www.isoc.org/briefings/020/>. |
|
44 |
The 97 percent figure is from Wessels and Fomenkov, “Wow, That’s a Lot of Packets,” 2003. However, according to an anonymous reviewer, VeriSign’s experience on its two servers is closer to 75 percent. |
or resolvers and does not monitor performance closely enough to catch errors. The latter is not purely a technical issue but poses an institutional issue.45 Software developers, system administrators, and users generally have few incentives to make an effort to prevent the occurrence of this extra load.
In addition, the system of root name servers may be vulnerable to malicious attempts to overload it. In October 2002, the root name server system was subjected to such a denial-of-service attack that sought to swamp the system with queries.46 Eight of the 13 servers were inaccessible from some places on the Internet for an hour or more, but the remaining 5 served the Internet without observable degradation. Although the system successfully resisted this attack, which lasted only an hour and a half, it should serve as a warning about the potential for longer and more sophisticated attacks in the future.
Conclusion: The root name servers receive far too many incorrect or repetitive queries, increasing the load that they must serve. This unnecessary load arrives at the root name servers because many sites on the Internet employ faulty software, misconfigure their resolvers or name servers, or do not manage their systems adequately. The root name server operators, however, lack the means to discipline the sites at fault.
Conclusion: The root name servers are subject to malicious attack, but through overprovisioning and the addition of anycast satellites have substantially reduced their vulnerability to denial-of-service attacks. Furthermore, the widespread caching of the root zone file and its long time to live mean that the DNS could continue to operate even during a relatively long outage of most or all of the root name servers and their satellites.
Recommendation: To be able to continue to meet the increasing query load, both benign and malign, the root name server operators should continue to implement both local and global load balancing through the deployment of anycast satellites.
|
45 |
These analyses have been sponsored by the Cooperative Association for Internet Data Analysis (CAIDA) and have been reported in many publications. In addition to the Wessels and Fomenkov study, see, for example, Nevil Brownlee, kc claffy, and Evi Nemeth, “DNS Measurements at a Root Server,” Proceedings of IEEE Globecom, CAIDA, San Antonio, Tex., November 2001, pp. 1672-1676. Also see <http://caida.org/outreach/papers/2001/DNSmeasroot/>. |
|
46 |
See, for example, David McGuire and Brian Krebs, “Attack on Internet Called Largest Ever,” Washington Post, October 22, 2002. Three root server operators coauthored an authoritative report about the attack. It can be found at <http://d.rootservers.org/october21.txt>. |
Conclusion: Notwithstanding the deployment of anycast servers and installation of backup servers at remote locations, the concentration of root name server facilities and personnel in the Washington, D.C., area and, to a lesser extent, in the Los Angeles area is a potential vulnerability.
Recommendation: The need for further diversification of the location of root name server facilities and personnel should be carefully analyzed in the light of possible dangers, both natural and human in origin.
Conclusion: The system of root name servers lacks formal management oversight, although the operators do communicate and cooperate. Not everyone would agree that formal oversight is desirable. Should one or more of the current root name server operators withdraw from that responsibility, or fail to exercise it reliably, effectively, or securely, there would be no responsible organization or formal process for removing the failed operator or for recruiting and selecting a replacement. In their absence, the informal, collegial processes that led to the current group of operators would likely continue to be used.
Conclusion: The root name server operators have provided effective and reliable service to the community of Internet users without any form of direct compensation for that service from the users. With the growth in the scale and economic importance of the Internet, and with the expense of ensuring secure operation, the root name server operators face increasing costs and potential liabilities that some, at least, may find too great to meet without compensation.47 Indeed, the current system for maintaining root servers may well face additional economic pressures, as well as technical ones, as the volume of Internet traffic increases, especially if the number of TLDs were to be expanded.
The root zone must be kept secure and robust in the face of possible future threats. Moreover, the continued stable management and financing of root zone operations must be ensured for the DNS to function. These challenges and approaches to meeting them are discussed in Section 5.3.
|
47 |
As noted in President’s Report: ICANN—The Case for Reform, February 24, 2002, “… some organizations that sponsor a root name server operator have little motivation to sign formal agreements [with ICANN], even in the form of the MOU that is now contemplated. What do they gain in return, except perhaps unwanted visibility and the attendant possibility of nuisance litigation? They receive no funding for their efforts, so why should they take on any contractual commitments, however loose?” The same logic raises questions about their incentives to continue to operate the root name servers. See <http://www.icann.org/general/lynn-reform-proposal-24feb02.htm>. |
3.4 IMPLEMENTATION—THE TOP-LEVEL DOMAINS
The portion of the DNS hierarchy that has captured the most public attention and attracted the greatest controversy is the level just below the root, the top-level domains. As noted above, in February 2005 there were 258 such domains in the two major categories defined in the early days of the DNS (see Section 2.2.1): 243 country code top-level domains (ccTLDs) and 15 generic top-level domains (gTLDs). These TLDs are, in turn, the top of a hierarchy of second-level domain names. Typically, the commercial gTLDs have very flat structures with many second-level names, but the others vary widely, some having very deep structures. The ccTLDs also have a wide range of structures, some having several levels of hierarchy, which may be structured geographically or generically.
3.4.1 Characteristics of the TLDs
ccTLDs
The 243 ccTLDs are each associated with a nation or region or external territory and designated by the two-letter abbreviation for that entity assigned by the International Organization for Standardization in ISO 3166-1.48 Examples of ccTLDs are .ke for Kenya, .jp for Japan, and .de for Germany.49 The expectation was that a ccTLD would signify a location and would be supervised and administered by an organization in the corresponding location, and be limited to registrants with a presence there; however, these criteria are not effectively enforced. Moreover, a number of small nations and territories have licensed administration of their domains—for example, .tv for Tuvalu and .cc for the Cocos Islands—to commercial bodies that register anyone who wishes to use that ccTLD’s two-letter domain. Such ccTLDs are for all practical purposes equivalent to commercial gTLDs. This equivalence is further explored in “Recharacterizing TLDs” in Section 3.4.1.
The largest ccTLDs are listed in Table 3.2, as are most of those ccTLDs, shown in boldface, that have contracted for commercial use of their domains. The .us domain, which had been limited to third- and fourth-level registrations in a locality-based hierarchy, is shown in italics. In April 2002, registration at the second level in .us was opened with
|
48 |
See <http://www.iso.org/iso/en/prods-services/iso3166ma/index.html> for a list of the abbreviations. |
|
49 |
There are a few exceptions to the use of ISO 3166-1 two-letter abbreviations. For example, the United Kingdom is assigned .uk rather than .gb (for Great Britain). ICANN has also assigned ccTLD two-letter codes to each of the Channel Islands and to Ascension Island, which are not in ISO 3166-1, because it was anticipated that they would be added to the list. |
the intent that any U.S. citizen or resident and any business or organization with a bona fide presence in the United States could register a domain name in .us.50
Table 3.2 shows the number of domains registered at the first available level under each top-level domain in February 2003. The total at that time was just over 19 million. By December 2003, almost 24 million domains had been registered in ccTLDs, and by November 2004 it had reached 25.6 million. As noted above, some country code TLDs have further generic or geographic substructures. In those cases, the count of domains is the sum of those registered under each second- or third-level domain, depending on the highest level at which registration by the general public is permitted.
gTLDs
There are 15 gTLDs, 8 that date from the early years of the DNS—.net, .com, .org, .edu, .gov, .mil, .int, and .arpa—and 7 that were authorized by ICANN in November 2000. As their designations suggest, the expectation was that registration in the original gTLDs would be by types of organizations. Commercial organizations were expected to register in .com, accredited educational organizations in .edu, network infrastructure organizations in .net, U.S. government organizations in .gov and .mil, and international treaty organizations in .int. The .org TLD was created for organizations that did not fit into one of the other gTLDs. The designation .arpa was assigned for network infrastructural use.
In announcing the authorization of the seven new gTLDs—.biz, .info, .name, .aero, .museum, .coop, and .pro, ICANN distinguished between sponsored and unsponsored TLDs. Those that are sponsored have a not-for-profit organization representing the community of potential registrants. The charters of the sponsored TLDs specify that registrants are restricted to those satisfying criteria appropriate to that community. Thus, .aero is restricted to people, entities, and government agencies that (1) provide for and support the efficient, safe, and secure transport of people and cargo by air and (2) facilitate or perform the necessary transactions to transport people and cargo by air. Registrations in .museum are restricted to entities that are recognized by the International Council of Museums as museums, professional associations of museums, or individuals who are professional museum workers. And registrations in .coop are restricted to members of the international cooperative movement, which is further defined by mem-
TABLE 3.2 Some Large Country-Code Top-Level Domains
|
ccTLD |
Country or Territory |
Registered Domain Namesa |
|
.de |
Germany |
6,117,000 |
|
.uk |
United Kingdom |
4,168,000 |
|
.nl |
Netherlands |
827,000 |
|
.it |
Italy |
767,000 |
|
.ar |
Argentina |
627,000 |
|
.jp |
Japan |
568,000 |
|
.us |
United States |
529,000 |
|
.kr |
Republic of Korea |
507,000 |
|
.cc |
Cocos (Keeling) Islands |
500,000 |
|
.ch |
Switzerland |
500,000 |
|
.dk |
Denmark |
428,000 |
|
.br |
Brazil |
427,000 |
|
.au |
Australia |
343,000 |
|
.ca |
Canada |
310,000 |
|
.at |
Austria |
272,000 |
|
.tv |
Tuvalu |
262,000 |
|
.be |
Belgium |
238,000 |
|
.ws |
Western Samoa |
183,000 |
|
.cn |
China |
179,000 |
|
.pl |
Poland |
175,000 |
|
.fr |
France |
163,000 |
|
.ru |
Russian Federation |
156,000 |
|
.za |
South Africa |
134,000 |
|
.tw |
Taiwan |
123,000 |
|
.nu |
Niue |
112,000 |
|
.to |
Tonga |
97,000 |
|
Total (including ccTLDs not listed above) |
25,637,000 |
|
|
NOTE: Individual domain data is for February 2003; the total is for November 2004. aSOURCE: ICANN’s Budget for Fiscal Year 2003-2004. See <http://www.icann.org/financials/revised-proposed-budget-24jun03.htm>. Domain name counts where not available are estimated from the average of all other ccTLDs for which data is available (from Web sites or other direct information). These estimated counts represent about 16 percent of all ccTLD domain names. The total (for November 2004) was provided by Matthew Zook, Department of Geography, University of Kentucky. |
||
bership in one or more of eight specific classes. ICANN allows unsponsored TLDs to be either restricted or unrestricted. Thus, .info is unrestricted—anyone can register a name in .info, whereas .name is restricted to individuals and .biz is restricted to bona fide business or commercial uses. Determination of who is eligible to register is up to the domain operator operating under the terms of its agreement with ICANN.
TABLE 3.3 Generic Top-Level Domains in 2004
|
gTLD |
Type |
Current Purpose |
|
.com |
Unsponsored |
Unrestricted |
|
.net |
Unsponsored |
Unrestricted |
|
.org |
Unsponsored |
Unrestricted |
|
.edu |
Sponsored |
U.S. accredited higher educational institutions |
|
.mil |
Sponsored |
U.S. military |
|
.gov |
Sponsored |
U.S. governments |
|
.arpa |
Sponsored |
Internet infrastructure |
|
.int |
Unsponsored |
International treaty organizations |
|
.info |
Unsponsored |
Unrestricted |
|
.biz |
Unsponsored |
Businesses |
|
.name |
Unsponsored |
Individuals |
|
.pro |
Unsponsored |
Professionals |
|
.museum |
Sponsored |
Museums |
|
.aero |
Sponsored |
Air-transport industry |
|
.coop |
Sponsored |
Cooperatives |
|
aSOURCE: ICANN’s Budget for Fiscal Year 2003-2004. See <http://www.icann.org/financials/revised-proposed-budget-24jun03.htm>. Domain count data provided courtesy of Matthew Zook, Department of Geography, University of Kentucky. Ongoing data series are available at his Web site <http://www.zooknic.com/>. bNeulevel is a joint venture of Neustar, Inc., and Australia-based Melbourne IT, Ltd. c.pro started accepting registrations in the United States on June 1, 2004, from licensed MDs, lawyers, and CPAs; added Canadian and U.K. professionals in September 2004; and added engineers in February 2005. |
||
The 15 generic TLDs are shown in Table 3.3 together with, for each, its type and purpose, the organization responsible for its operation, and the number of second-level domains that are registered in it. Note, however, that in many domains there are far more registrants at the third and lower levels.
Recharacterizing TLDs
Although a distinction between generic TLDs and national or country code TLDs is widely accepted and used in policy discussions, the reality of practice is that the distinctions have been significantly eroded.
|
Organization |
Domainsa |
|
VeriSign GRS |
33,352,000c |
|
VeriSign GRS |
5,324,000c |
|
Public Interest Registry (PIR) as of January 1, 2003 |
3,307,000c |
|
Educause |
7,400c |
|
U.S. DOD Network Information Center |
?c |
|
U.S. General Services Administration (GSA) |
1,100c |
|
Internet Architecture Board/Internet Assigned Numbers Authority (IANA) |
?c |
|
IANA |
88c |
|
Aflilias, LLC |
3,334,000c |
|
Neulevelb |
1,088,000c |
|
Global Name Registry |
87,000c |
|
Registry.pro |
—c |
|
MuseDoma |
658d |
|
SITA |
4,000+e |
|
DotCooperation, LLC |
7,992f |
|
Total |
46,412,000g |
|
dData provided by Cary Karp, president and CEO, MuseDoma, personal communication, February 20, 2004. eAs listed on the .aero Web site in February 2005. See <http://www.information.aero/users.php>. fAs of February 2004. Carolyn Cooper, dot Coop Operations Center, personal communication, March 17, 2004. gTotal reported on the Zooknic Web site at <http://www.zooknic.com>, February 2005. |
|
Among the generic gTLDs, three—.edu,51 .mil, and .gov—are currently restricted to new registrations by U.S. organizations and, in principle, could have been established as second-level domains under the .us ccTLD.
As noted above, among the ccTLDs, a number—including .cc, .tv, .bz, .ws, .nu, and .to—actively seek global registrants and function as though they were gTLDs.
Moreover, the registrants in some gTLDs have not been limited to those originally expected. In practice, .com, .net, or .org have all been operating as unrestricted TLDs—any person or organization can register in them.
Since many policy issues concern the desirable number and type of TLDs, it is useful to introduce a characterization of TLDs that better captures the reality of their current state.
In Table 3.4, the TLDs are recharacterized into eight types, designated by the numbers 1 to 8, which are given in the first column. The second column, “TLD,” indicates whether the domain is currently considered a gTLD or a ccTLD.
The “Scope” column shows whether the TLD is open to registrants from anywhere on the globe—global—or is primarily for those who are located within the national boundaries of the country—national. (Many ccTLDs that are primarily national will accept some non-national registrants, but usually they must have an association with the country.) In addition, the .arpa TLD is open only to register elements of the infrastructure of the Internet, so its scope is designated as infrastructural.
The “Restriction” column in Table 3.4 indicates whether the generic TLD or, within national boundaries, the ccTLD has second- or third-level domains that are intended to be restricted to members of specific communities (however, the enforcement of these restrictions varies widely). Most ccTLDs have no restrictions on registrations at the second level, but some, such as .ar (Argentina) and .au (Australia), and the .us (United States) until recently, register only at the third level under a limited number of restricted second-level domains, such as com.ar and com.au for commercial organizations. However, Great Britain, .uk, has some second-level domains that are restricted, such as ltd.uk and plc.uk, and others, such as co.uk, that are not. As with other aspects of the DNS, restriction within ccTLDs is not really “yes” or “no,” but more accurately “yes,” “no,” or “some.” That situation is reflected in Table 3.4 by treating second-level domains of such ccTLDs as though they were “separate” TLDs—see the examples in 7 and 8.
The “Sponsor” column indicates whether an organization representative of a community has responsibility for managing a gTLD and for enforcing registration restrictions, if any. The concept of sponsor for a ccTLD is less clear. To some degree, for example, the governments of the United States and of France, for example, can be viewed as the sponsors of their ccTLDs. The corresponding entries are left blank.
Thus, among the 15 current gTLDs, 4 are of Type 1—.com, .net, .org, and .info. Type 2 includes three TLDs–.museum, .aero, and .coop. There are four in Type 3: .name, .biz, .pro, and .int. That leaves three in Type
TABLE 3.4 Types of Top-Level Domains
|
Type |
TLD |
Scope |
Intended Restriction |
Sponsor |
Examples |
|
1 |
gTLD |
Global |
No |
No |
.com, .net, .info, .org |
|
2 |
gTLD |
Global |
Yes |
Yes |
.aero, .museum, .coop |
|
3 |
gTLD |
Global |
Yes |
No |
.biz, .name, .pro, .int |
|
4 |
gTLD |
National |
Yes |
Yes |
.mil, .gov, .edu |
|
5 |
ccTLD |
Global |
No |
– |
.cc, .tv, .bz |
|
6 |
ccTLD |
National |
No |
– |
.jp, .fr, .us, .co.uk |
|
7 |
ccTLD |
National |
Yes |
– |
com.au, id.au, .ltd.uk |
|
8 |
gTLD |
Infrastructural |
Yes |
Yes |
.arpa |
4—.edu, .mil, and .gov, which are discussed below as ccTLDs—and one in Type 8, .arpa.
It has not been possible to assign a type to each of the 243 ccTLDs, but examples of each of the four types have been identified in Table 3.4.
Type 5 comprises many ccTLDs that function as generic TLDs. As noted above, they are generally small countries that have recognized, or been shown, that their two-letter designation can be marketed globally to companies and individuals who would find it commercially or personally valuable. Thus, the lease of the domain name of Tuvalu (population: 11,000) could provide that Pacific Island nation with $50 million in royalties over the next dozen years. The .TV Corporation, a subsidiary of VeriSign, in June 2005 listed on its site such “premium registrations” as business.tv, which is available for $1 million, and weather.tv, which would cost the registrant $250,000. The administrator of this TLD is the Ministry of Finance and Tourism of Tuvalu, although in fact, the ministry appears to have delegated all of its decision-making authority to the .TV Corporation as a part of the lease. Other nations are managing their globally available domains themselves. Western Samoa (population: 178,000), another Pacific island nation, markets .ws directly and handles the registration locally. Western Samoa had two ISPs and 3000 Internet users in 2002.52
|
52 |
See CIA, The World Factbook, 2004, available at <http://www.odci.gov/cia/publications/factbook/fields/2028.html>. |
While some ccTLDs function as gTLDs, Type 4 comprises the three gTLDs that function like ccTLDs—.edu, .gov, .mil. All three are limited to registrants in the United States that are, in turn, restricted to specific communities—primarily accredited higher educational institutions,53 civilian government54 agencies, and federal military agencies.
The remaining two types distinguish between restricted and non-restricted ccTLDs. Almost all ccTLDs are unrestricted at the second and third levels and fall into Type 6, but some, such as Australia, Argentina, and Austria, have introduced categories resembling the gTLD categories as their second levels. They belong to Type 7. Thus, Australians cannot register directly in the .au domain but must instead use the category appropriate to their status: com.au for commercial organizations, asn.au for associations, id.au for individuals, and so on.
Thus, the apparently simple distinction between gTLDs and ccTLDs is really more complex. The differences among TLDs lie in the differences in the policies that they operate under, not in whether they were originally associated with a country code or a generic category.
3.4.2 Technical System of the TLDs
Every TLD has an associated zone file, which is stored in name servers whose addresses are recorded in the root zone file. ICANN requires that there be at least two name servers for each ccTLD and at least five for each gTLD with which it has agreements. Some TLDs have as many as 13 name servers, depending on the query load, the need for security against attack, and their desire to improve access by their users. Each name server is implemented on one or more computers, most of which run a version of BIND.55
The zone files on all TLDs are larger, generally very much larger, than the root zone file. At the extreme, .com contains more than 33 million second-level domains, but even Greenland has more than 1200 domains registered. Moreover, because of the hierarchical nature of DNS search,
the ease of caching the labels and associated resource record sets in the small root zone file, and the long TTLs within that file, the TLD name servers receive a greater number of queries than the root name servers. For example, according to VeriSign .com and .net alone receive over 14 billion queries per day, while the root receives about 8 billion queries per day.
TLD name servers face specific unique technical issues distinct from those that involve the roots. One issue is increased traffic resulting from low TTLs on second-level zone records. A popular second-level zone can increase traffic to its parent TLD name servers by lowering its TTL, effectively defeating the DNS’s caching mechanism. (The root name servers do not suffer from this potential problem to the same extent, since TLD name servers give out mostly referrals. As a result, name server caches throughout the Internet retain the copy of the TLD records from the root zone with their 48-hour TTLs.56)
TLDs probably receive some bogus queries, but perhaps not as many as the root, since at least a portion of the query must be correct—the TLD name. Their name servers face the same vulnerabilities that are faced by the root name servers. However, although the effect would be significant if the operations of large TLDs such as .com or .uk were to be interrupted, the consequence of a short interruption of most TLDs, individually, would not be significant for the overall Internet. An attack that could take out a substantial number of TLD servers would be significant but difficult to sustain because of the number of distinct targets that would be involved.
3.4.3 Institutional Framework of the TLDs
The effective operation of the top-level domains requires that an institutional framework perform four functions:
-
Deciding which new TLDs will enter the root zone file,
-
Determining the organization to be responsible for a TLD,
-
Determining the organization to operate a TLD’s name server, and
-
Operating the TLD registry.
Many different organizations, international and national, governmental and private, for-profit and not-for-profit, including ICANN, VeriSign, and the DOC, are engaged in these activities. Their processes and interactions are complex and, often, controversial.
Selecting New TLDs
The original DNS design assumed a single, unified, name space (in which the set of names that one user is able to look up is the same set of names that any other user is able to look up).57 Unless uncoordinated entry into the root zone file is permitted, which would require that the operators of the root servers recognize any TLD that chooses to operate, some entity must decide how many and which TLDs there will be and who will operate them. “Selecting new TLDs” means deciding which new TLDs will enter the root zone file. As described above, that decision is made by the U.S. Department of Commerce upon the recommendation of ICANN. Therefore, it is in the first instance a decision for ICANN. The decision process that is employed differs between ccTLDs and gTLDs.
ccTLDs
There is generally no need for a complex decision process for entry of ccTLDs since, as noted earlier, they are available to countries and external territories represented by country codes in ISO 3166-1. This list has been used as the authoritative source for country codes because, as was stated in RFC 1591, “the IANA is not in the business of deciding what is and what is not a country.”58 When new entities are assigned a two-letter identifier by the ISO, that entity is automatically entitled to have a ccTLD. However, two situations have arisen that cannot be resolved solely by this rule. The first occurs when a country is removed from the ISO list. The two-letter code for the Soviet Union, SU, was removed from the list in September 1992 and placed in “transitional reserved status,” which means that its use should be stopped as soon as possible. But, although this issue is on ICANN’s agenda, it has not yet addressed the complicated issues that arise when a country is removed from the ISO 3166-1 list. Indeed, it is still possible to register in the .su domain, and this domain remains in the root.
The second situation occurs when an international entity requests a ccTLD that is not on the ISO 3166-1 list. In July 2000, the European Commission wrote to ICANN requesting the inclusion of the .eu domain in
|
57 |
It is this assumption that alternative or multiple roots violate. This discussion assumes a single root. |
|
58 |
Jon Postel, “Domain Name System Structure and Delegation,” RFC 1591, March 1994, p. 6, available at <http://www.rfc-editor.org>. |
the DNS root.59 Its request noted that the ISO had agreed to use of the two-letter code EU as a TLD. (The code, although not in ISO 3166-1, had “exceptional reserved status” enabling its use for specific ISO-approved purposes.) At its September 25, 2000, meeting, the ICANN board passed a resolution that approved for delegation as ccTLDs those codes from the ISO’s exceptional reserved list for which the reservation permits any application requiring a coded representation of the entity.60 In March 2005, ICANN authorized the creation of the .eu TLD, which is expected to begin operation in early 2006.61 It will be open to any person living in the EU, as well as businesses with their headquarters, central administration, or main base in the EU.62 The exceptional reserved list is no longer published, and a policy has been implemented to prohibit the creation or reservation of an unrestricted name that is not on the ISO 3166-1 list.
The process of deciding who will be delegated responsibility for operating a ccTLD upon its first entry into the root, or for redelegating responsibility subsequently, can become very complex. This process is discussed in the next section and in Section 5.5.
gTLDs
The gTLDs are a different matter. They fall into two groups: the first eight, which were selected at the time of initiation of the DNS—the legacy gTLDs; and the seven that were selected by ICANN in 2000 for addition to the root—the new gTLDs. (An additional 4 to 10 are being added during 2005 as the result of an ICANN selection process initiated in 2004. See Alternative A under “What Selection Process Should Be Used” in Section 5.4.2.)
The legacy gTLDs were selected by the developers of the DNS and a group of network and information center operators. Jon Postel, writing
|
59 |
Letter from Erkki Liikanen, member of the European Commission, to Mike Roberts, (then) CEO and president of ICANN, dated July 6, 2000, available at <http://europa.eu.int/ISPO/eif/InternetPoliciesSite/DotEU/LetterLiikanenRoberts.html>. |
|
60 |
ICANN, “Preliminary Report. Special Meeting of the Board,” September 25, 2000, available at <http://www.icann.org/minutes/prelim-report-25sep00.htm#00.74>. |
|
61 |
See Ellen Dumout, “ICANN Approves .eu Net Domain,” c/net news.com, March 24, 2005, available at <http://news.com.com/2100-1038_3-5634121.html>. |
|
62 |
See the October 2004 EU Fact Sheet, “Open for Business in 2005: yourname.eu.,” available at <http://europa.eu.int/information_society/doc/factsheets/017-doteunovember04.pdf>. There is a more complex story behind the .eu TLD, but it is beyond the scope of this chapter. |
almost 10 years later, still maintained a policy that he expressed as: “It is extremely unlikely that any other TLDs will be created.”63 However, by the following year, Postel had changed his mind and recommended the creation of new TLDs to compete with NSI, which had a monopoly in commercial gTLD registrations, and in 1996 he recommended the creation of 150 or 300 new TLDs. At the same time, the rapid growth in size and scope of the Internet, driven by the introduction of the World Wide Web, created a heavy demand for second-level domain names in the gTLDs, especially in .com. (See Section 2.5.1.) That, in turn, led to a public demand for additional gTLDs. In response to that demand (some would argue it was a belated response), ICANN created a process, which it used during the year 2000 to select the new gTLDs. ICANN treated the addition of gTLDs as an experiment in order to seek compromises that would satisfy the contending interest groups, although that did not prevent the additions from becoming controversial. Since that process also entailed selecting the organizations responsible for the TLDs and the TLD name server operators, its description is deferred to “Selecting the TLD Registry Operators” below.
To at least some degree, TLDs compete with one another for the patronage of those entities that wish to register domain names, although the maximum prices that ICANN has negotiated with the gTLDs limit the extent of this competition. This competition might be more intense—both with respect to the prices charged and the services offered—the larger the number of competitors, although beyond some point the effect of additional entry is likely to be small and the costs of switching from one domain to another are likely to give incumbents a strong advantage. In any event, even when firms wish to operate TLDs, either because they observe incumbents earning large profits or because they believe they can offer better or cheaper services, entry is constrained by their need to obtain approval from ICANN for inclusion in the root file.64
Over the past few years, the demand for registrations in the TLDs has gone through several changes. While the ccTLD registrations have grown continually throughout the period, those in the previously rapidly growing gTLDs declined in the aftermath of the dot-com bust and only began to grow again in mid-2002. According to ICANN writing in mid-2003: “The domain name counts for ccTLDs have jumped 22% over the numbers used last year [in the budget]. The count for gTLDs, however, has
declined 5%, largely due to a drop-off in .com whose statistics dominate the overall gTLD count because of its comparative size.”65 In fact, the name counts in all three of the largest gTLDs—.com, .net, and .org—declined from 2002 to 2003. Both .net and .org declined by 14 percent. However, by August 2003, another source reported that the total number of .com, .net, and .org domain names had returned to the high mark of 30.7 million reached in October 2001.66 Sustained growth had returned in July 2002, and over the next 13 months the total registrations in those three domains grew an average of 250,000 per month. As further confirmation of the renewed demand for those gTLDs, VeriSign reported67 that an average of 1.2 million new registrations for domain names ending in .com and .net were added each month in the third quarter of 2004—a 33 percent increase over the third quarter of 2003.”68
Selecting the Organizations Responsible for the TLDs
ICANN has been delegated authority by the DOC (and subject to the DOC’s approval) over entries in the root zone and, consequently, it can determine which organization is delegated responsibility for each ccTLD and gTLD. The delegated responsibility entails arranging for the establishment and operation of (1) name servers for the TLD satisfying Internet technical requirements and (2) a domain name registration process that meets the needs of the local or international Internet communities.
In the case of ccTLDs, the organizations with delegated responsibility are designated managers or sponsors, and they are designated the sponsors for sponsored gTLDs. Sponsors are primarily either government or not-for-profit organizations that provide their own funding, although profit-making organizations run the commercial gTLDs and some ccTLDs. In both groups of TLDs, the responsible organization need not operate the required name server and domain registration functions itself and generally contracts with a specialist organization, which may be a commercial service, to carry out those functions. In the case of the seven unsponsored
|
65 |
See ICANN’s Budget for Fiscal Year 2003-2004, available at <http://www.icann.org/financials/revised-proposed-budget-24jun03.htm>. |
|
66 |
Zooknic Internet Intelligence, “gTLD Domains Returning to 2001 Levels,” press release. August 25, 2003, available at <http://www.zooknic.com/pr_2003_08_25.html>. |
|
67 |
VeriSign, “VeriSign Issues Quarterly Domain Name Industry Brief; Overall Domain Name Registration Tops Past Record of 66.3 Million,” December 1, 2004, available at <http://www.verisign.com/verisign-inc/news-and-events/news-archive/us-news2004/page_019484.html>. |
|
68 |
See also Linda Rosencrance, “Domain Name Registrations Hit All-Time High,” Computerworld, June 8, 2004, available at <www.computerworld.com/developmenttopics/websitemgmt/story/0,10801,93716,00.html>. |
gTLDs (other than .int), the responsible organization and the operating organization are the same and had until recently all been commercial services. However, ICANN designated Public Interest Registry (PIR), a not-for-profit, to manage .org beginning in 2003. PIR has contracted with a Dublin-based company, Aflilias, to provide the registration services and Afilias has contracted, in turn, with a commercial provider of DNS services, UltraDNS, to run the name servers.
For the ccTLDs and the legacy gTLDs, ICANN must have a process for recognizing the organizations that will be responsible for the TLD when a new ccTLD is added or when a change of responsibility is desired for whatever reason. The processes used for the ccTLDs and the legacy gTLDs are different. They are described below. For the new gTLDs, the processes of selecting a manager and selecting an operator were combined since the prospective manager’s choice of operator was one factor in the manager selection decision. That combined process is described below in “Selecting the TLD Registry Operators.”
ccTLDs
IANA began delegating responsibility for ccTLDs shortly after the deployment of the DNS and most delegations predate the formation of ICANN. ICANN’s policy has been not to challenge these except in cases where a government seeks redelegation.69 In the early days of the DNS, responsibility for ccTLD management was usually assigned to the Internet pioneers who volunteered for the task. Generally, there was only one interested organization since, at the time, the commercial prospects were thought to be minimal. Even so, there was considerable due diligence on many applications to determine that other possible applicants had been identified and, if there were any, that they supported the active application. There were, however, some cases of multiple applications and post-delegation challenges by those who sought various other benefits such as prestige or the ability to leverage the role into sale of Internet services. The managers agreed to abide by a set of policies for the administration and delegation of ccTLDs that covered technical requirements and the circumstances under which IANA would make or change a delegation of responsibility.70 Often the corresponding governments did not know or did not care about the Internet or the applicable ccTLD.
|
69 |
This section draws extensively on material in ICANN, “Update on ccTLD Agreements.” September 20, 2001, available at <http://www.icann.org/montevideo/cctldupdate-topic.htm>. See also Jon Postel, RFC 1591, 1994. |
With the growth in the size and importance of the Internet and the formation of ICANN, that situation has changed. Governments increasingly want to participate in the selection and oversight of the manager of their ccTLDs.71 Furthermore, ICANN felt the need for more precisely described agreements spelling out the mutual obligations and responsibilities among governments, ICANN, and the delegated managers of ccTLDs. Consequently, the board of ICANN authorized the development of such agreements with the ccTLDs.
According to ICANN, it was soon realized that no single agreement or, even, structure of agreement would fit every ccTLD. However, after consideration of the wide variety of specific circumstances in the 243 ccTLDs, ICANN found that most would fit into one of two general situations that differ principally in the involvement of the local government or public authority. In the first, legacy situation, the government is not involved. In the second, triangular situation, it is, thus yielding three participants: a ccTLD, ICANN, and a local government. ICANN proposed two types of agreements, corresponding to these two situations.
According to the proposed agreement for the legacy situation, the ccTLD manager would operate under the oversight of ICANN only, subject of course to the laws of the country. ICANN would have the sole responsibility to ensure that the ccTLD manager operates as a trustee for both the local and the international Internet communities.
According to the proposed agreement for the triangular situation, ICANN would retain the responsibility to see that the ccTLD manager meets its responsibilities to the international Internet community and to any non-national registrants, while the local government would assume responsibility for ensuring that the interests of the local Internet community are served.
According to ICANN, the decision as to which arrangement to pursue would be reached by the government and the ccTLD manager (or candidate manager) in consultation with the local Internet community, with ICANN adopting “a neutral stance.”
In the legacy situation, ICANN would have the full authority to select and, when necessary, change the ccTLD manager. (Although they are not signatories to the agreements, governments are notified if one is in preparation in case they want to be involved.) In the triangular situation, the
|
70 |
The general responsibilities of the ccTLD managers are documented in RFC 1591 and in the ICANN publications ICP-1, Internet Domain Name System Structure and Delegation (ccTLD Administration and Delegation), May 1999, and ccTLD Constituency Best Practice Guidelines for ccTLD Managers, 4th Draft, March 10, 2001. However, neither of the ICANN documents appears to have achieved consensus among all the ccTLD managers. |
|
71 |
See discussion in Section 5.5.2. |
relevant government or public authority would communicate its designation of a ccTLD manager to ICANN, which would then decide whether or not to accept the designee and, assuming a positive decision, seek to negotiate an appropriate agreement with the manager.
The proposed agreements with the ccTLDs are intended to cover the following areas: (1) the delegation of responsibility to the ccTLD and description of the circumstances that would lead to its termination, (2) specification of the local and global policy responsibilities of the ccTLD, (3) characterization of the relationship with ICANN and their respective responsibilities, and (4) funding for ICANN.
Despite ICANN’s efforts to get ccTLDs to enter into agreements with it, by June 2005 it had completed only 12 of them. A number of ccTLDs object to accepting ICANN’s formal authority over their operations. This issue is discussed in detail in Section 5.5.
gTLDs
ICANN has acted to change the organization responsible for several of the eight legacy gTLDs. The most significant instance was its negotiation with VeriSign Global Registry Services, the legacy manager of .com, .net, and .org. Because those three gTLDs contain the registrations of the vast majority of the Internet’s gTLD second-level domains and, in particular, almost all of those on its unsponsored and unrestricted domains, VeriSign’s position as the profit-making sole supplier of those three was felt by many in the Internet community to be detrimental to the long-term health of the Internet. In May 2001, VeriSign, Inc., ICANN, and the DOC signed a revised agreement in which VeriSign agreed to give up its operation of .org at the end of 2002 while extending the term of its operation of .net to the beginning of 2006 and of .com to November 2007. Both of the latter agreements are renewable, although under different terms: under existing agreements, .net had to be put out for bid by ICANN by the end of 2005, while VeriSign has presumptive renewal rights for .com, unless it materially breaches the agreement. ICANN initiated an open bidding process for .net in March 2004 and in June 2005 selected VeriSign, Inc., to continue as the operator.72
To select a new manager for .org, ICANN issued a request for proposals (RFP) in May 2002. In response, it received 11 proposals from a variety of organizations, both commercial and not-for-profit. According to ICANN, those proposals were reviewed by three independent evaluation
|
72 |
See ICANN, “.NET Request for Proposals,” December 10, 2004, available at <http://www.icann.org/tlds/dotnet-reassignment/net-rfp-final-10dec04.pdf>. |
teams that were charged with looking at technical issues and at the ability of the proposals to meet the specific needs of .org. Comments were also received from the public and the applicants, which, according to ICANN, were used by the ICANN staff to prepare an evaluation report and recommendation. The ICANN board accepted the staff recommendation and ICANN contracted with the PIR, a wholly-owned subsidiary of the Internet Society, to become the manager of .org, effective January 1, 2003. A similar process was followed for .net.
Selecting the TLD Registry Operators
An organization that is responsible for reliably performing the functions of (1) operating the TLD name servers and (2) registering second-level domains in the TLD is called a registry.73 It may or may not be the same as the delegated manager for the TLD.
For example, VeriSign is the manager and operates the registry for .com and .net. PIR is the manager of .org, but, as noted above, it has subcontracted with Afilias to operate the TLD registry, which has contracted the name server function to UltraDNS. Afilias also operates the registry for .info, for which it also serves as the manager, and for .vc, the ccTLD for residents of St.Vincent and the Grenadines, which is managed by the Ministry of Communications and Works of St.Vincent and the Grenadines.
There is always one, and only one, registry for a given TLD, but, as noted above, an organization can be the registry operator for more than one TLD. While the majority of TLD managers are non-commercial organizations, some registry operators are commercial organizations that operate for profit; they register the vast majority of domain names.
ccTLDs
The manager of a ccTLD may also be the registry operator, or it may subcontract the registry services in whole or in part to other organizations. The process for selecting the registry services operator is entirely up to the ccTLD manager, subject only to whatever restrictions the national
government may impose. The situations differ widely among the 243 ccTLDs.
Since the growth of the World Wide Web has vastly extended the scope, scale, and importance of the Internet, two phenomena have worked to shape the operational arrangements of ccTLDs in a country. First, there has been a movement from the early informal arrangements, which often involved voluntary efforts by the computer science department of a university in the country, to more formal arrangements that provide legal protection and engage a wider national community in policy-setting roles. Second, there has been a tendency to contract the actual operations to commercial organizations more willing and able to undertake the responsibilities than academic institutions.
For example, in Austria, the current manager and registry is Nic.AT, which is a limited-liability company that since 2000 has been wholly owned by a charitable foundation, the Internet Private Foundation Austria. Nic.AT was established in 1998 by the Austrian ISP Association to take over responsibility for the ccTLD from the University of Vienna, which had managed it from its inception but was faced with an increasing number of registrations, legal questions, and name conflicts beyond its competence. While Nic.AT handles the name registration, it contracts with the University of Vienna computer center to run the .at name servers.
In contrast, the new registry and registry operator for the .us TLD is a commercial company, Neustar, which also is the registry and registry operator for the new gTLD .biz. In the .us case, the manager, the DOC, decided to change the operational model from a deeply hierarchical, mostly geographic, extensively delegated structure to one that would be exploited commercially at the second level. Unlike the Austrian case, there was no pressure for the change in strategy from the previous manager or operator, and no significant pressure from users/registrants in the domain—indeed, many of them argued against it. And the DOC RFP essentially required a commercial operator with commercial intentions.
Legacy gTLDs
The registries for the legacy gTLDs are the consequence of history. NSI had been operating the registries for .com, .org, and .net by agreement with the U.S. government when VeriSign purchased it and assumed the responsibility. As noted above, PIR, upon becoming manager of .org, contracted with Afilias to run the registry. The organizations shown in Table 3.3 for each of the other legacy gTLDs are the associated registries (and also sponsors).
New gTLDs
In July 2000, the ICANN board adopted a policy for the introduction of new gTLDs that called for the solicitation and submission of proposals to sponsor or operate them. In August 2000, the RFP was published. It specified the contents of the detailed multipart proposal, which was to be accompanied by extensive supporting documentation and a non-refundable $50,000 application fee. The deadline for applications was October 2000.
As explained by ICANN, two types of gTLDs were specified: sponsored and unsponsored. In the latter case, the application was to be submitted directly by the organization proposing to serve as the registry. In the former case, the application was to be submitted by the sponsoring organization but would include the proposal of an organization that had agreed to perform the registry functions for the sponsoring organization. Thus, the registries for the new TLDs were selected through the ICANN process whether ICANN made the decision directly or accepted the sponsoring organizations’ selections.
ICANN announced that the selection criteria would be the following:
-
The need to maintain the Internet’s stability;
-
The extent to which selection of the proposal would lead to an effective proof of concept concerning the introduction of top-level domains in the future;
-
The enhancement of competition for registration services;
-
The enhancement of the utility of the DNS;
-
The extent to which the proposal would meet previously unmet types of needs;
-
The extent to which the proposal would enhance the diversity of the DNS and of registration services generally;
-
The evaluation of delegation of policy-formulation functions for special-purpose TLDs to appropriate organizations;
-
Appropriate protections of rights of others in connection with the operation of the TLD; and
-
The completeness of the proposals submitted and the extent to which they demonstrate realistic business, financial, technical, and operational plans and sound analysis of market needs.
ICANN received 47 applications, of which 2 were returned for non-payment of the fee and 1 was withdrawn, leaving 44 to be evaluated. The ICANN staff carried out evaluation with the assistance of outside technical, financial/business, and legal advisors. ICANN’s goal was to select a “relatively small group of applications” that (1) were functionally diverse and (2) satisfied the selection criteria.
At its November 2000 meeting, the ICANN board acted on the staff evaluation and selected the seven new gTLDs—.biz, .info, .name, .pro, .museum, .aero, and .coop. Four were unsponsored—.biz, .info, .pro, and .name—and, therefore, amounted to the direct selection of a registry as well as the TLD. The other three were sponsored, and each included a designated registry chosen by the sponsor to operate its TLD.
The registries for .com, .net, .org and for the seven new gTLDs have agreed to pay certain fees and adhere to certain requirements as spelled out in ICANN’s sponsored and unsponsored TLD agreements. (The registries for .edu, .gov, and .mil operate under separate agreements with agencies of the U.S. government. ICANN is the registry for .int, and the Internet Architecture Board (IAB) manages .arpa. Therefore, they do not have agreements with ICANN.)
ICANN’s TLD agreement obligates the sponsor and the registry to (1) satisfy functional and performance specifications set by ICANN; (2) enter into agreements with any ICANN-accredited registrar (see “Selecting the Organizations to Register Domains” in Section 3.5.2) desiring such an agreement and accord the registrar fair treatment; (3) provide query and bulk access to registrant data—Whois information (see Box 3.6); (4) periodically deposit its registrant data into escrow with an ap-
|
BOX 3.6 Whois services provide contact information about the registries, registrars, or registrants in the DNS. (See Sections 2.3.4 and 2.5.3 for information on the development of the Whois service and background on the issues surrounding it.) ICANN-accredited registrars are contractually obligated to collect and provide access to information about the name being registered, the names and IP addresses of its name servers, the name of the registrar, the dates of initiation and expiration of the registration, the name and postal address of the registrant, and the name and postal, telephone, and e-mail addresses of the technical and administrative contacts for the registered name. These must be made available either directly by the registrar or, in some cases, by the registry. There are many separate Whois services on the Internet run by registrars, registries, and other organizations (often, as with universities, of their own second- or third-level domains). In addition, there are numerous Web sites that provide links to many of the Whois sites, such as Allwhois.com and Better-Whois.com. |
proved escrow operator; and (5) comply with consensus policies established by ICANN.
The ICANN process for adding gTLDs that was implemented in 2000 was quite controversial. Many participants and observers complained about the design and implementation of the process. The issue of whether and how to add new gTLDs is examined in detail in Section 5.4.
Operating the TLD Registries
Every TLD registry operator must perform two basic functions: register domain names requested by registrants and operate the name servers that will link those domain names with their IP addresses and other critical information. Even these basic responsibilities may be divided between organizations, some commercial and some non-commercial, as noted above in the cases of Austria and of .org. In contrast, a single commercial organization, VeriSign, is the manager, runs the registry, and runs the name servers for .com and .net.
The registration operation produces the entries to the zone file for that domain, the content of the Whois file, and records of billing and payment, where appropriate. When the TLD has restrictions on who may register either in the domain (such as restricting registrations to nationals or residents of a country or to professionals or museums) or in its generic subdomains (such as Australian businesses in com.au or British limited liability corporations in ltd.uk), each application for a domain name must be examined to ensure that those restrictions are satisfied.
The ICANN agreements with 12 gTLDs include functional and operational specifications that the registry operators are responsible for meeting, while the few agreements with ccTLDs specify only general requirements for Internet connectivity, operational capability, and adherence to key RFCs, as well as agreements to make financial contributions to ICANN. Ideally, all operators of TLD name servers should satisfy certain minimal technical conditions to ensure their compatibility with the Internet and that they are configured so as not to pose a danger to the stability of the Internet, although there is no mechanism for enforcing this for the TLDs not covered by ICANN agreements.
3.4.4 Assessment
Conclusion: The level of technical capability and competence varies widely across the 258 TLD registries. The gTLDs and the large ccTLDs generally operate at a high level of availability and responsiveness. Although there are no readily available measures of the performance of the majority of ccTLDs, they appear to provide adequate service.
Recommendation: Regular and systematic testing of the availability and operation of secondary servers should be adopted by top-level domain registry operators. Policies and procedures should be developed to clarify what to do when problems are identified and what measures can be taken when problems are not resolved within a reasonable period of time.
Conclusion: No single organization has the authority and the ability to oversee the operation of all the TLDs. ICANN’s formal authority extends only as far as the provisions of its agreements with 10 gTLDs and 12 or so ccTLDs and the authority it has to recommend changes in the root zone to accommodate new or reassigned TLDs.
Even where there is a contract, ICANN’s authority has been tested. VeriSign’s introduction in October 2003 of its Site Finder service raised fundamental issues of both a technical and an institutional nature and has been challenged in the courts.74
3.5 IMPLEMENTATION—THE SECOND- AND THIRD-LEVEL DOMAINS
The domain names in the DNS hierarchy that Internet users interact with most directly are those at the second level (or in those ccTLDs with fixed second-level domains, such as ltd.uk, those at the third level). They are generally the key identifiers in e-mail addresses (such as recipient@mailserver1.nas.edu) or a Web address (such as http://www.nas.edu). They are the names that businesses, individuals, government agencies, non-profit organizations, and various other groups acquire to identify themselves on the Internet—the names on their signposts in cyberspace. More than 70 million second-level (and, in some instances, third-level) domain names were registered during early 2005, with about two-thirds in the gTLDs (more than half in the two largest gTLDs—.com and .net) and about one-third in the ccTLDs.75
3.5.1 Technical System of the Second- and Third-Level Domains
Second- and third-level domains may have their own name servers to respond to queries to their zone files, as most large organizations do, but often the services are provided by ISPs or other Web site hosting organi-
zations that store the zone file on their name servers. This is the course taken by most small organizations and individuals, although there are many exceptions.
The zone file of a second- or third-level domain may be very small if it belongs, for example, to an individual, or it may be quite large, if it is owned by a commercial or governmental organization. In the latter case, a great many of the entries may be associated with the e-mail addresses of the thousands of employees of the institution, while several, tens, or hundreds may be associated with the name servers of lower-level zones. Often, institutions will register multiple domain names (e.g., nas.edu and nationalacademies.org) that point to the IP address of the same server, enabling access to it under different domain names.
3.5.2 Institutional Framework of the Second- and Third-Level Domains
The effective operation of the second- and third-level domains requires that three functions be performed:
-
Selecting the organizations to register second-level domains,
-
Registering second-level domains, and
-
Resolving second-level domain name conflicts.
The principal organizations participating in this institutional framework are ICANN, the TLD registries, the registrars, and the organizations that provide dispute resolution services. Although many of the organizations at this level are commercial, numerous not-for-profit and governmental organizations play an active role as well.
Selecting the Organizations to Register Domains
In many cases, especially in the ccTLDs and some of the gTLDs, only the registry carries out the registration of second- or third-level domains. However, in a 1998 white paper76 the DOC, responding to a policy goal of privatizing and increasing competition in the market for domain name registration, recommended opening the business of registering lower-level names in gTLDs to competition. It subsequently amended its agreement with NSI, then the operator of the .com, .org, and .net registries, to require it to develop a system of multiple registrars and put it into opera-
tion in 1999. The DOC designated ICANN as the organization that would oversee the establishment of the Shared Registration System (SRS) and would be responsible for establishing and implementing a system for registrar accreditation. The SRS and registrar accreditation began operation in 1999. Before the multiple registrar system, NSI charged $35 per year for registrations in its domains. At the beginning of 2005, registrations in those domains in the United States could be obtained for less than $10 per year.77
Under the terms of their agreements with ICANN, gTLD registries are required to permit registrars to provide Internet domain name registration services within their top-level domains. In addition, these agreements regulate the price that registries can charge registrars—the “wholesale price,” with the current regulated price being a maximum of $6 per year per registrant. One can think of the regulation of the wholesale price as intended to constrain the exercise of market power by registries and the requirement for competing registrars as intended to constrain the retail “margin.”
To the extent that regulation of the wholesale price is intended to limit the exercise of market power in the wholesale market, however, it is not entirely obvious why the wholesale price that can be charged by new gTLDs, especially new gTLDs that are intended to serve diverse users, must be regulated.78 Indeed, increased future competition, especially as the number of gTLDs is expanded, might reduce or eliminate the need to regulate the wholesale price that VeriSign or other registries can charge. But if regulation of the wholesale price is intended to prevent registries from exploiting existing customers that may be locked in, there may be a continuing need to regulate wholesale rates even if the registry market were to become more competitive. The significance of lock-in will depend on the importance of switching costs, the flow of new registrants relative to the existing stock, and on whether registries can discriminate between new and existing registrants.
There were in February 2005 more than 460 registrars from more than 20 countries accredited to register domain names in 1 or more of the 10 eligible gTLD domains.79 Many of them have decided to operate, at least in part, as wholesalers and suppliers of registrar services; those operations have enabled many agents to sell domain names without any rela-
|
77 |
For example, in February 2005, godaddy.com was offering .com registrations for $8.95. |
|
78 |
Some specialized TLDs might continue to have market power even if the total number of TLDs were very large. |
|
79 |
For the current list, see the ICANN site at <http://www.icann.org/registrars/accredited-list.html>. |
tionship with, or accreditation by, ICANN. Although most ccTLDs use authorized agents, many ccTLDs have adopted the notion of multiple registrars, and many ICANN-accredited registrars also register ccTLD second-level domain names.
ICANN accredits registrars through an open application process. Any organization wishing to become an ICANN-accredited registrar must complete a detailed application concerning its technical and business qualifications and pay a $2500 application fee. If approved by ICANN, the applicant must execute the standard Registrar Accreditation Agreement80 and pay a yearly accreditation fee that is $4000 for the first TLD and $500 for each additional TLD for which the registrar is accredited. In addition, the registrar must pay a quarterly accreditation fee to cover a portion of ICANN’s operating expenses. The fee is based, in part, on the registrar’s share of registrations in the TLDs for which it is accredited. Registrars that are accredited by ICANN must also enter into accreditation agreements with the registries in the TLDs in which they want to register domains. Those agreements specify, among other things, the fees to be paid to the registries for each registration. As noted above, a ceiling is imposed on that fee structure by ICANN for the gTLDs that have signed agreements with ICANN.
The ICANN Registrar Accreditation Agreement imposes certain requirements on registrars. The registrar is obligated to (1) submit specified information81 for each registrant to the registry; (2) enable public Internet access to a file of information about registrants—the Whois file—both in query and bulk access form; (3) maintain a file of all registrant information submitted to the registry; (4) regularly submit a copy of the file to ICANN or to an escrow agent; (5) comply with consensus policies established by ICANN; and (6) have for the resolution of name disputes a policy and procedures that comply with ICANN’s Uniform Dispute Resolution Policy. (See “Resolving Domain Name Conflicts” below.) However, some of the newer gTLD agreements anticipate the possibility of “thick” registries, for example, ones in which Whois and similar data are maintained by the registry, not the registrars. This changes requirement (2) and has some impact on the others.
Registering Domain Names
Registration of second-level (or third-level) domain names occurs according to different processes in the different types of TLDs. For the 10
|
80 |
A copy of the agreement can be found at <http://www.icann.org/registrars/ra-agreement-17may01.htm>. |
|
81 |
See Box 3.6. |
gTLDs that use accredited registrars and for a number of ccTLDs—for example, Great Britain, Australia, Canada, and Denmark—registrars compete to sell second-level domain names in the TLDs they represent. They are free to set whatever fees they like, subject only to competitive market forces and their obligations to pay registration fees to the registries. For the .edu, .gov, .mil, .int, and .arpa gTLDs, as well as for most ccTLDs, registration by members of the restricted group occurs directly at the registries.
The registrar stage of the DNS process appears to be quite competitive, with entry being relatively easy82 and competition taking place along a number of dimensions. Registrars for the same registry compete with one another for the patronage of registrants83—what is sometimes called intra-brand competition—with competition being based on both the prices and the services offered. These services include the efficiency with which registrations take place as well as value-added services that may be bundled with registration.84 Switching registrars within a given registry is not particularly difficult, but there have been complaints that registrars have not always responded promptly to requests for switching and that some registrars have aggressively and misleadingly solicited other registrars’ customers. In addition, domain name theft has been one of the problems associated with inadequate procedures and security measures put in place by the registrars of domain names. In such cases, a third party fraudulently claims to be the registrant in order to have the domain name transferred to its ownership.85 There have also been instances of fraud charges against domain name registries and registrars of domain names.
The SnapNames State of the Domain report listed 148 registrars in the CNO domains (.com, .net, and .org) in the first quarter of 2003.86 How-
|
82 |
This competition is facilitated by the Shared Registration System protocol, which allows registrars to enter names directly in registries. |
|
83 |
This is not to say that registrars for different TLDs do not also compete with one another, a form of interbrand competition. In addition to registering new domain names, registrars also participate in the secondary market for domain names, acting as brokers, as well as in assisting registrants in applying for expired names. |
|
84 |
SnapNames reported that GoDaddy, a registrar, gained 70,000 registrants in a month when it launched its free online tax preparation software, presumably available only to its registrants. See the next section for a discussion of value-added services, some of which are provided by firms that are not registrars. |
|
85 |
In April 2004, the original operator of sex.com received a $15 million settlement from VeriSign because its registrar service had incorrectly transferred ownership of the name to a fraudulent claimant. |
|
86 |
SnapNames.com, Inc., State of the Domain, First Quarter 2003, May 13, 2003, available at <http://www.sotd.info/sotd/content/documents/SOTDQ103.pdf>. The SnapNames report showed over 150 ICANN-accredited registrars operational at that time (pp. 31-34). |
ever, “market shares” in these domains were skewed, with the VeriSign registrar (now Network Solutions)87 having more than 25 percent of all registrations in .com—which was, however, a significant decline from its 40 percent share only 15 months earlier;88 Tucows having about 10 percent; Register.com having approximately 9 percent; and GoDaddy having somewhat over 6 percent. Thus, the share of the “market” controlled by the top four firms in .com—the four-firm concentration ratio—was about 52 percent.89 Seven other registrars each had more than 1 percent of all .com registrations. (More recent data were not available at the time of this writing.)
The situation was somewhat different in the then newly opened .biz domain according to the SnapNames State of the Domain, first quarter 2003 report. Although the VeriSign registrar (Network Solutions) was the market leader, its share was only about 19 percent, 6 percent less than its share in the .com domain. Other registrars with shares in excess of 6 percent were Register.com (10 percent), Tucows (9 percent), and Melbourne IT (6 percent),90 so that the four-firm concentration ratio here was only about 44 percent. SnapNames reports that there were 127 registrars of .biz names. As a result of the wide disparity in the sizes of the various domains, Network Solution’s approximately 25 percent share of .com was about 5.8 million names, while its approximately 19 percent share of .biz was only about 170,000 names.91
Finally, although registrars charge the same prices to all registrants, some registrars offer a back-order service under which, for a fee, they will track the expiration of a desired domain name and attempt to register it immediately if the registration lapses. However, multiple registrars may be trying electronically to register the same name at the instant it becomes
|
87 |
VeriSign sold its registrar, Network Solutions, to a private investment company for about $100 million in October 2003. |
|
88 |
SnapNames.com, Inc., State of the Domain, January 2002, February 26, 2002. |
|
89 |
The quotation marks around “market” and “market shares” are intended to indicate that no claim is being made that registrar services in the .com domain constitute a relevant antitrust market. SnapNames reported that the top 10 registrars had about 75 percent of the market in the first quarter of 2003, down from about 91 percent at the end of 2001. |
|
90 |
Recall that Melbourne IT is part of a joint venture with NeuStar, the operator of the .biz registry. |
|
91 |
For further discussion of market issues and presentation of market data, see “Generic Top Level Domain Names: Market Development and Allocation Issues,” Organisation for Economic Co-operation and Development, Directorate for Science, Technology and Industry, Committee for Information, Computer and Communications Policy, Working Party on Telecommunication and Information Service Policies, July 13, 2004, available at <http://www.oecd.org/dataoecd/56/34/32996948.pdf>. |
available. The one that tries at just the right instant wins the prize. Because of this chance element, consumers often enter back orders with multiple registrars. In March 2002, ICANN asked VeriSign to conduct a 12-month trial of a single wait-listing service, which would take just one order—at a $24 fee directly from the consumer—for an expiring name on a first-come, first-served basis. Thus, from the consumer’s side, the need to use multiple registrars would be eliminated, but from the registrar’s side, the opportunity to derive additional revenue would be lost. On July 15, 2003, a coalition of name registrars filed a lawsuit against ICANN seeking to block the launch of VeriSign’s global waiting list for domain names.92 At its March 2004 meeting, ICANN’s board voted to seek the DOC’s agreement to its approval of VeriSign’s 1-year trial of the wait-listing service.
Resolving Domain Name Conflicts
One of the most difficult institutional roles that the operation of the DNS requires is the resolution of conflicts among competing claimants for domain names. These conflicts arise for a number of reasons that are discussed in detail in Section 2.5. The one that has attracted the most attention is the use of trademarked words in domain names, which is covered in “Trademark Conflicts” in Section 2.5.2. Although domain names can be used for a number of legitimate purposes other than as an address for a World Wide Web site, such as identifying a host, an e-mail server, an FTP site, and so on, the vast majority of the disputes involving domain names are associated with their very visible use in association with World Wide Web sites. Conflicts can also arise over names in which individuals, organizations, or governments claim a proprietary interest other than a trademark.
Whatever the source, the practical use of the DNS, which assumes that every domain name will be registered to one and only one entity, cannot proceed without some means for resolving conflicting claims for the same name. In the early days of the Internet, before strong financial and political interests were involved, such conflicts were handled informally, usually on a first-come, first-served basis, and they still are in many ccTLDs.93 However, as domain names appeared on the signposts on the World Wide Web and in e-mail addresses, and some gained visibility and potentially great value, the need to use more formal processes became
|
92 |
See Susan Kuchinskas, Embittered Registrars Sue Embattled ICANN, July 15, 2003, available at <http://siliconvalley.internet.com/news/print.php/2235661>. |
|
93 |
See, for example, the terms and conditions for the .uk registry available at <http://www.nic.uk>. |
evident. This was especially true for .com at first, and then for .net and .org as they were more widely marketed to general users. For the reasons described in Section 2.5.1, they were the most visible names on signposts on the Web.
Possible Remedies to Conflicts Over Names
There are basically two approaches to resolving conflicts over rights to names: one approach incorporates policies and regulations into the actual administration of the naming system and its assignment rules. The other approach relies on dispute resolution mechanisms that are external to naming system administration.
Internal Remedies. In a completely internalized naming system administration, a single manager owns the naming system and decides who is entitled to which name. Hence there are no rights conflicts. Public or quasi-public naming systems, such as the DNS, can also attempt to link the assignment of names to strict policies and regulations. The available techniques include imposing policies on the assignment of names at the point of registration, name reservations94 or exclusion, and so-called sunrise proposals.
Policies Imposed at the Point of Registration. Such policies must rely on rules or procedures to determine eligibility for a name. It is difficult to mechanize such rules. Thus, prior review of registration is likely to be expensive and slow if it is administered manually and prone to be crude and unfair if it is not.
Name Exclusions. Name exclusions withdraw specific names or entire classes of names from the available database. For a time, Network Solutions did not allow registration of six of the Federal Communication Commission’s “seven dirty words” in the domain name space.95 The World Intellectual Property Organization (WIPO) recommended eliminating a list of “famous” trademarks from the DNS database and reserving their use to the trademark holder.96 ICANN has provided all of its
|
94 |
The deployment of internationalized domain names involves new processes and challenges with respect to the reservation of names to prevent some conflicts over domain names. See Section 5.6.3 for discussion. |
|
95 |
For example, see “Seven Dirty Words,” Wikipedia online encyclopedia, available at <http://en.wikipedia.org/wiki/Seven_dirty_words>. |
|
96 |
See “The Problem of Notoriety: Famous and Well-Known Marks,” in The Mangement of Internet Names and Addresses: Intellectual Property Issues, First Report of WIPO Internet Domain Name Process, April 30, 1999, available at <http://wipo2.wipo.int/process1/rfc/3/interim2_ch4.html>. |
newly authorized registries with a list of reserved names that consisted of names and acronyms of organizations related to the IETF and ICANN.97
Name exclusion is an effective method of protecting the reserved names from abuse, but it is also a crude instrument, and in a global, public name space its crudeness raises significant public policy concerns. With-drawing words from circulation is in effect a form of automated censorship. Exclusions do not make any distinction between legitimate and illegitimate users; they simply make it impossible to use the names. A rigid exclusion deprives these organizations of the right to register domain names corresponding to their acronyms or trademarks. Exclusions and other regulations are less significant when they are part of the practice of a private naming system, where the owner can be assumed to have property rights over the naming system as a whole. Such exclusions also ignore the fact that certain words have a particular meaning only in a particular language. A “dirty” word in English may have no such meaning in another language.
Sunrise Proposals. Sunrise proposals, in general, establish a period at the start-up of a new name space within the DNS during which certain entities may register names in which they have established rights (e.g., famous trademarks) before the space is opened for public registration.
External Remedies. External methods of resolving rights conflicts include litigation through the courts or alternative dispute resolution procedures, such as the ICANN Uniform Domain Name Dispute Resolution Policy (UDRP), which is discussed below. The advantage of these methods is that they are based on case-specific analysis. Thus, they are sensitive to the specific facts of the conflict and can employ “soft” interpretive principles to adjudicate a dispute. Their disadvantage, of course, is that they are more time-consuming and expensive, and litigation is subject to jurisdictional limitations that may not match the scope of the affected naming system. Litigation is particularly expensive and cumbersome, although it offers a reliably neutral tribunal in many countries. Alternative dispute resolution techniques such as the UDRP greatly reduce the cost of external dispute resolution but sacrifice thoroughness in compiling and verifying facts, and their rapid procedures can put respondents at a disadvantage.
|
97 |
For the list of reserved names, see ICANN, “Appendix K, Schedule of Reserved Names,” available at <http://www.icann.org/tlds/agreements/unsponsored/registry-agmt-appk26apr01.htm>. |
Remedies to Conflicts Over Names in the DNS
Since the remedies to domain name conflicts differ somewhat between the gTLDs and the ccTLDs, each is described separately below.
gTLDs. Although there are other uses of trademarks with international spillover effects, second-level domains in gTLDs are unusual in the extent to which they are visible in almost every jurisdiction in the world, with the resulting difficulty in making either geographic or sectoral distinctions. Ordinarily, the same trademarks can be used in a single geographic region so long as they are in different economic sectors where confusion is unlikely. On the Internet such distinctions cannot be made. As a result, the question arises as to the means to be used to make decisions about domain name conflicts and disputes that cross national and business sector boundaries and, since such decisions inevitably involve matters of commercial or political or social importance, to ensure that those decisions are regarded as legitimate and enforced. Normally, trademark and related disputes are resolved by the courts of the nation in which they arise, and those in many nations have shown themselves capable of handling domain name disputes. In addition, the United States has passed specific legislation at both the federal and the state levels addressing the rights of trademark owners to domain names. (These are discussed further below.) As noted above, however, legal proceedings can become expensive and time-consuming. Therefore, many in the Internet community felt the need for a less expensive and quicker means of resolving domain name disputes.
Uniform Domain Name Dispute Resolution Policy. An answer, implemented by ICANN in December 1999, based on a recommendation from WIPO, was the Uniform Domain Name Dispute Resolution Policy. The UDRP has been adopted, as ICANN requires, by all registrars in the .aero, .biz, .com, .coop, .info, .museum, .name, .net, and .org top-level domains, as well as voluntarily by managers of several global ccTLDs, such as .tv, .cc, and .ws. In addition, managers of other ccTLDs, such as .ca, have adopted their own policies based on modified versions of the UDRP.
The policy takes effect through agreements between registrars (or other registration authorities) and their registrants. Each registrant agrees to be bound by the provisions of the policy when it registers its domain name.98 In agreeing to the registration agreement, the registrant also must
|
98 |
The policy conditions, examples of bad-faith actions, and other provisions listed below are paraphrased from the UDRP text available at <http://www.icann.org/dndr/udrp/policy.htm>. |
represent that to its knowledge its registration of the domain name does not infringe any third party’s rights, nor is it for an unlawful purpose, nor will it be used in violation of any applicable laws or regulations.
By registering the domain name, the registrant is then bound by the policy to submit to a mandatory administrative proceeding if a complainant asserts that:
-
Registrant’s domain name is identical or confusingly similar to a trademark or service mark in which the complainant has rights; and
-
Registrant has no rights or legitimate interests in respect of the domain name; and
-
Registrant’s domain name has been registered and is being used in bad faith.
The complainant must demonstrate all three of these conditions for the complainant to prevail.
The policy asserts examples of actions that would demonstrate bad faith that include registering and using the domain name:
-
For the purpose of transferring the registration to the complainant, or to one of its competitors, for more than the documented out-of-pocket costs of the domain name; or
-
To prevent the owner of the trademark or service mark from using the mark in a domain name (provided that registrant engaged in a pattern of such conduct); or
-
Primarily for the purpose of disrupting the business of a competitor; or
-
Intentionally to attract, for commercial gain, Internet users to registrant’s Web site or other online location, by creating a likelihood of confusion with the complainant’s mark on registrant’s Web site or location.
It also describes circumstances that would enable the registrant to demonstrate its rights and legitimate interests in the domain name. These are as follows:
-
Before any notice to registrant of the dispute, its use of, or demonstrable preparations to use, the domain name or a name corresponding to the domain name in connection with a bona fide offering of goods or services; or
-
Registrant has been commonly known by the domain name, even if it has acquired no trademark or service mark rights; or
-
Registrant is making a legitimate noncommercial or fair use of the domain name, without intent for commercial gain, to misleadingly divert consumers, or to tarnish the trademark or service mark.
The mandatory proceeding—which is electronically based—must be held before an accredited and administrative-dispute-resolution provider that has been approved by ICANN.99 The complainant selects the provider and is required to pay the fees, except in the case when the registrant elects to expand the panel from one to three panelists, in which case the fee is split. The registrar, the registry, and ICANN are not parties to a UDRP proceeding. However, during a UDRP proceeding, the registrar does confirm that the domain name has been registered by the respondent named in the proceeding and is required to execute the outcome of a decision. The only remedy available to the complainant through the proceeding is cancellation or transfer of the domain name.
As of May 10, 2004, 9377 proceedings involving 15,710 domain names had been brought under the UDRP.100 Two-thirds (6262) of these proceedings had resulted in a transfer of the disputed domain name to the complainant or in a cancellation of the domain name. Approximately one-fifth (1892) had resulted in a decision for the respondent, and approximately one-tenth (971) of the proceedings had been disposed without decision or terminated. There were 931 proceedings pending. The 15,710 domain names that had been disputed in 4 years represent 0.03 percent of the more than 46 million domain names registered in the gTLDs subject to the UDRP.
Approximately 60 percent of these proceedings have been filed with WIPO, approximately 33 percent have been filed with the National Arbitration Forum (NAF), approximately 6 percent were filed with eResolution,101 and approximately 0.7 percent have been filed with the Center for Public Resources Institute for Dispute Resolution (CPR). The Asian Domain Name Dispute Resolution Centre (ADNDRC) began operation in February 2002.
|
99 |
The approved providers are listed at <http://www.icann.org/dndr/udrp/approvedproviders.htm>. There were four approved providers in February 2005. |
|
100 |
ICANN, “Statistical Summary of Proceedings Under Uniform Domain Name Dispute Resolution Policy,” January 30, 2004; latest version available at <http://www.icann.org/udrp/proceedings-stat.htm>. |
|
101 |
eResolution ceased operating as a dispute-resolution provider for ICANN in late November 2001. |
FIGURE 3.3 UDRP filings as of April 30, 2004. NOTE: With respect to gTLD UDRP filings commencing during the period from December 1999 through October 2003, data were obtained from the ICANN Web site at <http://www.icann.org/udrp/proceedings-list.htm>. With respect to such filings commencing during the period from November 2003 through April 2004, data were obtained directly from the Asian Domain Name Dispute Resolution Centre Web sites at <http://www.adndrc.org/adndrc/bj_home.html> and <http://www.adndrc.org/adndrc/hk_home.html>, the Center for Public Resources Institute for Dispute Resolution Web site at <http://www.cpradr.org/ICANN_Cases.htm>, the National Arbitration Forum Web site at <http://www.arb-forum.com/domains/decisions.asp>, and the World Intellectual Property Organization Arbitration and Mediation Center Web site at <http://arbiter.wipo.int/domains/statistics/index.html>. Specialized domain name dispute resolution proceedings (e.g., Start-up Trademark Opposition Policy (STOP) and the usTLD Domain Name Dispute Resolution Policy (USDRP)) have been excluded from these statistics.
Over time, there has been a decline in the number of UDRP proceedings filed. As shown in Figure 3.3, the number of UDRP proceedings filed each month has been steadily decreasing since August 2000.
WIPO explained this decline as suggesting that “an expedited online dispute resolution service has been effective in dissuading Internet pirates from hijacking names.”102 It may also be partly the conse-
|
102 |
WIPO, “WIPO Continues Efforts to Curb Cybersquatting,” Press Release PR/2002/303, February 26, 2002, available at <http://www.wipo.org/pressroom/en/releases/2002/p303.htm>. |
quence of working through the backlog of cases that UDRP faced upon start-up and entering a more normal steady-state condition. To some extent, as well, it may reflect a change in the attitudes of trademark owners, some of whom may have come to feel that their interests are not jeopardized by every similar domain name, which are not worth the cost and effort to maintain. The decline in cases might also be attributed, in part, to learning by cybersquatters about avoiding a finding of bad faith against them.
As a first step in a policy development process, in 2003, ICANN prepared a report that lists many of the procedural and substantive issues that have been raised about the UDRP.103
Start-up Registrations. The UDRP was designed to handle an ongoing rate of domain name conflicts arising in already established gTLDs. However, several of the seven new gTLDs have faced unique issues when they entered the start-up phase. Specifically, under the terms of their contracts with ICANN, they needed a process by which intellectual property rights holders could challenge bad-faith claimants in advance of open registration in order to avoid a rush of cybersquatters followed by a heavy demand on the UDRP process as intellectual property holders asserted their rights. The four most significant—.biz, .info, .name, and .pro—each adopted somewhat different policies, but all are adopting or have a UDRP-like dispute resolution policy.
ccTLDs. Most ccTLD registries, and their agents and registrars when they exist, publish policies about who is eligible to register in the second-level domain, or in its third-level domains when they are open for direct registration. These policies generally also cover the resolution of conflicts over domain names. Where the TLD limits itself to individuals and organizations that have an association with the country, many potential conflicts are readily addressed through national administrative, regulatory, and judicial institutions. For example, matters of trademark priority are handled through the national regulatory and legal systems, and corporations may have defensible rights only in the names that are legally registered.
|
103 |
See ICANN, “Staff Manager’s Issues Report on UDRP Review,” August 1, 2003, available at <http://www.icann.org/gnso/issue-reports/udrp-review-report-01aug03.htm>. ICANN also set up a committee to consider WIPO’s proposed amendments to the UDRP. ICANN has not made the committee’s report public. |
U.S. Legislation. The United States has passed legislation at both the federal and the state levels addressing the rights of trademark owners to domain names.
Federal—The ACPA: On November 29, 1999, President Clinton signed into law the Anti-cybersquatting Consumer Protection Act (ACPA), which provided trademark owners with a further cause of action that was specifically directed to domain names.104 Under the ACPA, a trademark owner can bring a civil action against a person if that person has a bad-faith intent to profit from a mark and registers, traffics in, or uses a domain name that, in the case of a mark that is distinctive, is identical or confusingly similar to that mark; or in the case of a famous mark, is identical or confusingly similar to or dilutive of that mark; or is a trademark, word, or name protected by law.105 Mere registration of such a domain in bad faith may be sufficient to violate the trademark owner’s rights under the ACPA; there is no further requirement for any use of the domain name in association with any goods or services.
Under the ACPA, factors affecting the judgment of bad faith include, but are not limited to, whether (1) the registrant holds any intellectual property rights in the name; (2) the domain name consists of the registrant’s name; (3) the domain name was used in connection with the bona fide offering of any goods or services; (4) the domain name was used in a way that could be viewed as a bona fide noncommercial or fair use; (5) the domain name was intended to divert consumers from the mark owner’s online location; (6) the registrant offered to sell the domain name to the mark owner without having used it in a bona fide manner; (7) the registrant provided false contact information in the registration form; (8) the registrant acquired multiple domain names that are identical or similar to the trademarks of others; and (9) the domain name incorporates a mark that is not distinctive and famous.
The ACPA also created a cause of action for individuals with respect to domain names. Specifically, a domain name registrant can be held liable if the domain name consists of, or is substantially and confusingly similar to, the name of another living person and the domain name has been registered without that person’s consent with the specific intent to profit from the name by selling it for financial gain. This particular cause of action, however, is not available for domain name registrations that occurred prior to the ACPA’s enactment date.
With respect to remedies, the ACPA provided that a court may award injunctive relief, including forfeiture, cancellation, or transfer of the do-
main name. In addition, if the registration, trafficking, or use of the domain name occurred after the ACPA’s enactment date, a plaintiff can elect to recover, instead of actual damages and profits, an award of statutory damages in the amount of $1,000 to $100,000 per domain name (as the court considers just).
Furthermore, if personal jurisdiction over the domain name registrant cannot be obtained, the trademark owner could file an in rem civil action106 against the domain name itself in the judicial district of the domain name registrar, domain name registry, or other domain name authority that registered or assigned the domain name. However, the ACPA limits the remedies in an in rem action to forfeiture, cancellation, or transfer of the domain name.
States: California, Hawaii, and Louisiana also passed laws that address the registration, sale, and use of domain names within that state and provide for civil remedies in state courts for violations of these laws.
Foreign Legislation. Relatively few countries have chosen to address the rights of trademark holders in domain names in the same legislative manner as the United States. The European Union (EU) has relied largely on new telecommunications laws coordinated at the EU level to provide for the regulation of domain names at the national level. For example, in Spain, the General Telecommunications Act (1998) was modified in July 2001 to impose a number of conditions on the registration of domain names under the ccTLD .es, including a requirement that a domain name to be registered be somehow related to the trademark or name of the company undertaking the registration. In other countries, the judicial process, rather than the legislative process, has been relied on to address conflicts between domain names and trademarks. Since at least 1997, courts within the United Kingdom have been prohibiting the registration of domain names that conflict with trademarks. In 1998, the Delhi High Court in India likewise extended its form of common law trademark protection to domain names, as did the Tribunal de Grande Instance of Draguignan in France. Many ccTLDs, 42 in all, including a number from the EU, have opted to rely on a form of alternative dispute resolution policy.107 Likewise, the new .eu ccTLD will apply the following rules regarding registrations:
-
Governments may reserve geographical and geopolitical names.
-
In a 4-month sunrise phase, “prior rights” holders and public bodies can register .eu domain names before the general public can do so.
|
106 |
An in rem action is taken against property directly, in contrast to an action against people (e.g., the owners of a given piece of property). |
|
107 |
See <http://arbiter.wipo.int/domains/cctld/index.html> for an example. |
-
Two months before the sunrise phase starts, technical and administrative measures will be published in detail.
-
In the first 2 months of the sunrise phase, registered national and European Community trademarks and geographical indications as well as names and acronyms of public bodies can be registered as .eu domain names by the holder/public body.
-
Two months later, other “prior rights” holders can also register .eu domain names, but only as far as they are protected under national law in the member state where they are held. This provision concerns unregistered trademarks, trade names, business identifiers, company names, family names, and distinctive titles of protected literary and artistic works.
-
There will be an alternative dispute resolution procedure in place (similar to ICANN’s “Uniform Domain Name Dispute Resolution Policy” UDRP).
-
After the sunrise phase, the domain names will be registered according to the first-come, first served-principle.
3.5.3 Assessment
Conclusion: The tens of millions of registered second- and third-level domains are operated by individuals with a broad spectrum of capabilities. It is notable that the DNS has been able to function effectively and reliably despite this range of operator capabilities.
Conclusion: The UDRP is a unique cross-border, electronically based process that has resolved thousands of disputes over domain names without the expense and potential delay of court proceedings.
The issues of dispute resolution and appropriate Whois balance are examined in Chapter 5, where the alternative approaches are described and the committee’s recommendations presented.
3.6 SUMMARY
Conclusion: The domain name technical system reliably and effectively handles the billions of queries it receives every day. The institutions that manage it perform the required functions adequately, in many cases without direct compensation.
Conclusion: The DNS technical system can continue to meet the needs of an expanding Internet. Early in the committee’s assessment it became apparent that it would not be fruitful to consider alternate naming systems. As noted, the DNS operates quite well for its intended purpose and
has demonstrated its ability to scale with the growth of the Internet and to operate robustly in an open environment. Moreover, significantly increased functionality can be achieved though applications—such as navigation systems—built on the DNS, or offered independently, rather than through changing the DNS directly. Hence, the need did not seem to be to replace the DNS but rather to maintain and incrementally improve it. Furthermore, given the rapidly increasing installed base and the corresponding heavy investments in the technical system and the institutional framework, the financial cost and operational disruption of changing to a replacement for the DNS would be extremely high, if even possible at all.
Yet, despite this better than passing grade, the committee’s assessments have identified a number of significant technical and institutional issues whose effective resolution is critical to the DNS’s successful adaptation to the demands on it. Chapters 4 and 5 address those issues.









































































