
4
The Centrality of Standards
Standards are the most important element in the science education system because they make explicit the goals around which the system is organized, thus providing the basis for coherence among the various elements. They guide the development of curriculum, the selection of instructional resources, and the choices of teachers in setting instructional priorities and planning lessons. They are the basis for developing assessments, setting performance levels, and judging student and school performance. Standards are also the reference point for reporting performance to educators and the public and for focusing school improvement efforts. The No Child Left Behind Act (NCLB) requires states to have science standards of high quality, although it says relatively little about what characterizes standards of high quality.
Under NCLB the word “standards” refers to both content standards and achievement standards. NCLB requires states to develop challenging academic standards of both types, and the law describes them as follows (U.S. Department of Education, 2004, p. 1):
Academic content standards must specify what all students are expected to know and be able to do; contain coherent and rigorous content; and encourage the teaching of advanced skills.
Academic achievement standards must be aligned with the State’s academic content standards. For each content area, a State’s academic achievement standards must include at least two levels of achievement (proficient and advanced) that reflect mastery of the material in the State’s academic content standards, and a third level of achievement (basic) to provide information about the progress of lower-achieving students toward mastering the proficient and advanced levels
of achievement. For each achievement level, a State must provide descriptions of the competencies associated with that achievement level and must determine the assessment scores (“cut scores”) that differentiate among the achievement levels.
Thus, content standards describe the knowledge and skills students should attain, and achievement levels indicate the adequacy of performance that is expected at different levels of competence.
It is important to note that the role of standards in the NCLB context differs somewhat from the role envisioned for standards by those who developed national standards for science education. The National Science Education Standards (NSES) and the Benchmarks for Science Literacy (American Association for the Advancement of Science, 1993) were written to present “a vision of science education that will make scientific literacy for all a reality in the 21st century” (National Research Council, 1996, p. ix).
To serve as the basis for curriculum materials, instructional strategies, and assessments at the classroom, district, and state levels, state standards must provide richer, more focused, and more detailed descriptions than those contained in either the NSES or the benchmarks.1 The standards contained in these documents—and those in most state standards documents—are written primarily as lists of propositional statements that describe the scientific ideas students should learn. They rarely articulate the knowledge and skills that students need to understand them. To fulfill their role of guiding curriculum, instruction, and assessment, standards need to better describe the knowledge, understandings, and abilities that are necessary to attain the standard, the prerequisite standards on which each standard is built, and the subsequent standards to which each contributes.
This chapter begins with an overview of existing state science content standards. It continues with an examination of key features of high-quality content standards and research-based strategies for organizing and elaborating the standards for practitioners. The chapter concludes with an overview of achievement standards and issues related to setting achievement levels for systems of assessment.
STATE SCIENCE STANDARDS
To obtain an overview of current state science standards, the committee examined samples of science standards from states that had developed them as of January 2004. We also reviewed the work of other organizations, such as the Council of Chief State School Officers, Mid-continent Research for Education
and Learning, Achieve, Inc., the Fordham Foundation, the American Federation of Teachers, and Editorial Projects in Education, which produces the annual Quality Counts reports for Education Week.
Variation Among States
In our review, we found that existing state science standards vary widely in organization, format, breadth, and depth. Many standards do not reflect current knowledge of how students learn and develop scientific understanding or the fact that science is a network of mutually supporting ideas and practices that develop cumulatively. Indeed, it is difficult to compare one set of standards to another because they are organized and presented in such different ways. This occurs because, as Archibald (1998, p. 4) notes, “There is no standard language or model for content standards.”
State standards vary considerably in terms of features that affect their usefulness for developing curriculum materials, planning instruction, and creating assessments. While all state standards contain recognizable descriptions of academic content, these descriptions differ in important ways. One of the most important differences is in the specific content that states expect students to know. Some state standards focus on declarative and procedural knowledge—that is, knowing scientific facts, formulas, and principles and making accurate measurements and computations. These standards usually include such words as “define,” “describe,” “identify,” or “state.” Other standards include schematic or strategic knowledge—that is, posing scientific questions, designing investigations, and developing explanations and arguments. These standards may include such words as “explain,” “analyze,” “justify,” “predict,” “compare,” and “support.”
Another important difference is the scope of the basic content units that are included. Some standards describe topics broadly; others describe content in more specific, small units. Standards also differ in terms of the grade ranges that are used to locate content. Some descriptions are specific to a single grade level; others cover two- or three-year grade spans. States that use the latter approach must, under NCLB, specify grade-level content expectations for every grade in the span. The committee concurs with this requirement, noting that without it there could be a tendency for curriculum and instruction to focus more heavily on topics covered in years in which students would be assessed rather than on the full range of knowledge and skills contained in the standards.
The descriptions of content have many other differences. For example, some state standards establish priorities by identifying selected concepts or topics as of greatest importance, but most states give no guidance about the relative importance of topics, tacitly implying that everything mentioned is of equal importance. Likewise, few states make any attempt to limit the scope of their standards on the basis of an analysis of available instructional time. Some standards documents indicate interconnections among topics and attempt to integrate related
components of science, but this is not the norm. Illinois explicitly attends to these interconnections in organizing its standards; state goal 12 reads, “[Students will] understand the fundamental concepts, principles and interconnections of the life, physical and earth/space sciences.”2 Only a few state standards attempt to show how scientific topics are related to material in other disciplines, such as mathematics. New Jersey science standard number 5.3, for example, states: “All students will integrate mathematics as a tool for problem-solving in science, and as a means of expressing and/or modeling scientific theories.”3
While most state science standards are limited to descriptions of science content, some go further to describe aspects of content that are relevant to teaching and learning. For example, some standards give suggestions regarding lesson structure (how scientific information is organized and presented) or instructional approach (how teachers interact with students about science content). Some standards include helpful information about the structure and transmittal of scientific knowledge, and a few describe desired student attitudes toward science. In addition, some standards contain assessment-related information, such as conditions for student performance (how students demonstrate their scientific understanding). This information is helpful both for teachers and assessment designers. Box 4-1 includes a small portion of the Rhode Island science standards that illustrates this point.
Finally, there are some useful features that the committee found in only a few state standards, such as examples of real-world contexts in which scientific principles apply. Many of these examples are found in the elementary or early middle grades. Delaware and Nevada both provide such contexts in their science standards. The standards of one or two states contain lists of required or expected scientific terminology. For example, Utah’s standards include lists of science language that students should understand and use in meeting specific standards. Box 4-2 includes a portion of the Utah state science standards in which guidance is given to teachers on important terminology that students should learn and be able to use. Some states make explicit the connections between the science standards and the curriculum. For example, Florida requires publishers to align textbooks with the state standards. An increasing number of states, including Alaska, Florida, and Indiana, also include in their standards student understanding about the history of science or the role of science in contemporary society.
The one general principle that emerged from the committee’s review of state science standards is the importance of clear, thorough, understandable descriptions. For standards to play a central role in assessment and accountability systems, they must communicate clearly to all the stakeholders in the system—
|
2 |
See http://www.isbe.state.il.us/ils/science/word/goal12.doc [12/12/04]. |
|
3 |
See http://www.state.nj.us/njded/cccs/s5_science.htm#53 [12/8/04]. |
|
BOX 4-1 Here is an example of a state science standard that includes examples of classroom work and assignments that might be suitable. Performance expectations are suggested, and each standard includes an “embedded assessment” and a summative assessment. By the end of the eighth grade, all students will know that the sun is a mediumsized star located near the edge of a disk-shaped galaxy (Milky Way) of stars, part of which can be seen as a glowing band of light that spans the sky on a very clear night. The universe contains many billions of galaxies, and each galaxy contains many billions of stars. To the naked eye, even the closest of these galaxies is no more than a dim, fuzzy spot. Suggested Activity: Visit planetarium, contact NASA for computer program, pictures, etc. Help students locate the Milky Way and prominent galaxies in the night sky. Embedded Assessment: Look at photographs, identify the differences between a galaxy and a star. Summative Assessment: Using a diagram of our own galaxy and the approximate position of our solar system, explain the phenomenon known as the Milky Way. Theme: Systems Process: Developing Explanatory Frameworks NASA Space Grant Program Center located at Brown University (863-2889) has celestial maps and other resources available for teachers. SOURCE: http://ridoe.net/standards/frameworks/science/default.htm. |
teachers, assessment developers, students, parents, and policy makers—what students are expected to know and be able to do. In other words, they must be elaborated.
Other Evaluations of State Science Standards
Besides conducting our own examination of sample science standards, the committee relied on two comprehensive reviews by other groups that provide a good starting point for thinking about the features of high-quality standards. The reviews were conducted by the American Federation of Teachers (AFT) and the Fordham Foundation; each used its own criteria for making judgments about the
quality of standards.4 The AFT reviewed state content standards in English, mathematics, science, and social studies in 1996 and updated this review in 1999 and 2001 (American Federation of Teachers, 1996, 1999, 2001). The AFT review criteria have evolved from one review to the next, but they typically involve a small number of broad themes that are applicable to all four subject areas. The principal criteria are that standards should define core content, be organized by grade level, provide sufficient detail, and address both content and skills. The AFT reviews also examine curricula, assessments, and accountability systems separately, and some of the evaluative criteria that are applied to these other components are also relevant to standards.
The Fordham Foundation commissioned content experts to review content standards in English, history, geography, mathematics, and science using subject-specific criteria (Finn and Petrilli, 2000). Instead of the few, broad criteria used by the AFT, the Fordham Foundation used 25 detailed criteria, ranging from the structure and organization of the standards to the specific science content and cognitive demand—what, exactly, students were expected to do (Lerner, 1998, 2000). The Fordham review was done from the perspective of a scientist “who has no official connection with K–12 education,” whereas the AFT reports were written from the perspective of science educators.
These reviews produced markedly different results. In some cases, the same state received a top grade in one review and a bottom grade in another, according to an Education Week story (Olson, 1998). This contradiction points to a divergence of views about what students should know and be able to do, as well as to a divergence of views about how this information should be communicated to educators and the public.
Regardless of the criteria that were used, all the evaluations found considerable variation in quality among state standards. While the reviews showed that the states made progress in improving their standards over time, the most recent evaluations still found room for improvement. In a paper written for the National Education Goals Panel, Archibald (1998) described the state of content standards as one of “startling variety.”
Other groups have suggested criteria for developing or reviewing content standards and frameworks (Education Week, 2004; the National Education Goals Panel, 1993; Blank and Pechman, 1995; Pacific Research Institute, 2004, available at http://www.pacificresearch.org/pub/sab/educat/ac_standards/main.html). Although these efforts provide additional ideas about the features of good standards, they do not lead to any convergence of opinion.
|
BOX 4-2 This standard for a first-year biology course provides guidance to teachers on the specific terminology that students need to learn and use to indicate mastery of a set of standards. Objective 1: Summarize how energy flows through an ecosystem.
Objective 2: Explain relationships between matter cycles and organisms.
|
HIGH-QUALITY SCIENCE STANDARDS
What should effective standards look like? NCLB contains no specific requirements concerning the format in which science standards should be presented, what topics they should emphasize, or how detailed they should be. The law leaves to states the prerogative to develop standards in their own ways and to develop their own consensus views of what students should know and be able to do in science. Because of the central role of standards in both the education and the assessment systems, review and revision of standards documents should be the impetus for substantive discussion among educators, parents, and others, about priorities for science learning.
Objective 3: Describe how interactions among organisms and their environment help shape ecosystems.
Science language that students should use: —predator-prey, symbiosis, competition, ecosystem, carbon cycle, nitrogen cycle, —oxygen cycle, population, diversity, energy pyramid, consumers, producers, —limiting factor, competition, decomposers, food chain, biotic, abiotic, community, —variable, evidence, inference, quantitative, qualitative. |
After reviewing the evaluations of the AFT, the Fordham Foundation, and the Council for Basic Education, Archibald (1998, p. 5) proposed that the evaluation of standards needs a “theory of design for content standards that would link purpose, content and organization.” While this remains an unrealized goal, the committee suggests that a first step in this direction is to derive a set of guidelines for standards that can help identify the essential features that standards should possess. It would be very inefficient for each state to develop such a theory of design on its own. Education policy and research organizations could assist states by bringing together experts and state education leaders to develop guidance on the structure of quality science standards. The U.S. Department of Education also
might provide some guidance to states, not on the content of their science standards, which they are prohibited by law from doing, but on the nature and characteristics of well-formulated science standards. We note here that this discussion relates primarily to content standards; issues specific to achievement standards are discussed at the end of the chapter.
Content Standards Must Support Accountability Actions
In a standards-based accountability system such as NCLB, content standards are the explicit reference point for action. Rather than serving as loose guides, content standards must be a consistent reference point, as the U.S. Constitution is for the nation’s judicial system. State content standards define what students should know and, therefore, what teachers should teach. They also are used for developing assessments and setting achievement targets that will be used to judge student achievement, identifying successful and unsuccessful schools and districts, reporting to the public, triggering interventions (including reorganizations and reconstitutions), and issuing sanctions and rewards. In addition, standards are the reference point for developing improvement strategies to enhance curriculum and instruction and to make school and district operations more effective. Although science is not currently included in the NCLB accountability requirements, it may be in the future; moreover, states may use results from science assessments for their own accountability purposes. The committee assumes that because the results from state science assessments will be publicly reported, they will become part of the accountability system, even if the results are not included in calculations of adequate yearly progress.
Key Features of Content Standards
The committee has compiled a list of characteristics that science content standards should have. Science content should:
-
be clear, detailed, and complete;
-
be reasonable in scope;
-
be rigorously and scientifically correct;
-
have a clear conceptual framework;
-
be based on sound models of student learning; and
-
describe performance expectations and identify proficiency levels.
Each of the characteristics is described below, and examples of current state standards are used to illustrate many of them.5 We were unable to identify any complete set of state science standards that meets all of the criteria we describe. We did, however, find examples of standards that embody one or more of these
features, and we use them to illustrate some key points, although they may fall short in other regards. It was not possible to include examples from all of the state standards that meet a particular criterion, and many examples could be found of other state standards that meet many of the criteria we discuss. Similarly, our including a state’s standards in this document does not constitute an endorsement by the committee of that state’s standards as a whole.
Clear, Detailed, and Complete
To serve as the basis for curriculum development, the selection of instructional resources, and related activities, science standards must describe the desired outcomes of instruction in clear, detailed, and complete terms. Clarity is important because curriculum developers, textbook and materials selection committees, and others need to develop a shared understanding of the outcomes their efforts are designed to promote. If the standards are incomplete—for example, if they omit important aspects of science—the curriculum will contain similar gaps. We do not suggest that, to be complete, standards should include everything that is known about student learning in this area. That would be both impractical (since it would lead to encyclopedic standards documents) and impossible (since understanding of student science learning is still developing). Rather, we suggest that the standards should reflect careful judgment about which aspects of science students need to learn. One means of paring this very large domain down to a manageable size to serve as targets for instruction and assessment is described by Popham et al. (2004) (see Chapter 2, the instructionally supportive design team model).
However, completeness means more than covering the important science content. It also means providing enough information to communicate a standard well. For example, a complete description of a standard should include as much information as possible about related concepts and principles that are necessary for students to develop an understanding of the standard, prerequisite knowledge that students will need, subsequent knowledge that will build on the standard, expectations for student performance that demonstrates mastery of the standard, and connections to related standards. Sufficient detail is necessary to enable educators to determine whether potential curriculum units and materials promote the goals that the standards are supposed to represent. This is best communicated by concrete examples of student work at all levels of achievement.
In addition, the standards must provide a complete description of the domain of science as a school subject. If standards are incomplete, they will not provide a common reference for all users. One way that standards can be incomplete is by using broad, general, or vague language that leaves interpretation to the individual. This defeats the purpose of having standards. When describing student performance objectives, if standards use precise terms, indicating whether students are expected to know, explain, communicate about, compare, differenti-
ate among, analyze, explore, design, construct, debate, or measure, they are far more useful. California’s science standards, although they describe the content to which students should be exposed, do not make clear what it is that students must be able to do to demonstrate mastery of the standards (see Box 4-3). Merely indicating that students will “know” a given topic is not enough.
Science standards must be clearly written so that they are understandable to science educators, parents, and policy makers. The American Federation of Teachers (1996) said standards should use “clear explicit language … firmly rooted in the content of the subject area, and … detailed enough to provide significant guidance to teachers, curriculum and assessment developers, parents, students
|
BOX 4-3 The California standards are specific about content, but the language and the lack of clarification about what it means to “know” make the standards an inadequate guide for curriculum or assessment. Plate Tectonics and Earth’s Structure 1. Plate tectonics accounts for important features of Earth’s surface and major geologic events. As a basis for understanding this concept:
SOURCE: http://www.human-landscaping.com/BA_collaboratory/standards.html. |
and others who will be using them.” The Consortium for Policy Research in Education (1993) described this quality as “sufficient precision” to be used for the intended functions.
Reasonable in Scope
The pressure for clarity and completeness has to be balanced against the reality of the school day and year. The consensus-building process that is used to develop standards can result in an unrealistically large document. The tendency to resolve disagreements about priorities by including more things in the standards should be counterbalanced by a realistic appraisal of the limitations dictated by the length of the school day and year. If the standards contain more material than can be covered in a year, administrators and teachers become de facto standard setters by virtue of their choice of textbooks, curriculum materials, and lessons.
Efforts should be made to restrict the scope of standards. Furthermore, since it is difficult to know exactly how much content can be covered in the available time, it is important to indicate priorities among topics to give guidance to teachers and assessment developers who have to make choices.
If the scope of science content has to be limited, it should favor overarching principles and powerful ideas that have explanatory power within and across scientific disciplines—the “big ideas” of science discussed in earlier chapters. Standards developers should not let content area specifics overwhelm broader understandings. An example from the Washington state standards demonstrates a good way to meet this criterion (see Box 4-4).
Rigorous and Scientifically Correct
To support curriculum-related functions, science standards must be rigorous and scientifically correct. Since standards are the reference point that guides other elements of the system, errors and omissions in the standards will be replicated in curricula, instruction, and assessments. Rigor also entails a focus on important scientific understandings rather than trivial facts or formulas in isolation. The standards should reflect the manner in which scientific knowledge is organized, so that curricula can be structured in appropriate ways.
State science content standards should be accurate in describing the nature of science and scientific investigation, and they should be thorough in covering the basic principles in the fields they address. Lerner (1998, p. 3) objects to standards that are mere lists of facts because “lists tend to obscure the profound importance of the theoretical structure of science.”
A Clear Conceptual Framework
Standards should embody a clear conceptual framework that shows how scientific knowledge is organized into disciplines, how large principles subsume
|
BOX 4-4 These standards specify precisely what students should be expected to do to demonstrate mastery of the standards. EALR 1—Systems: The student knows and applies scientific concepts and principles to understand the properties, structures and changes in physical, earth/space, and living systems. Component 1.1 Properties: Understand how properties are used to identify, describe, and categorize substances, materials, and objects and how characteristics are used to categorize living things.
SOURCE: Office of Superintendent of Public Instruction, http://www.k12.wa.us/curriculumInstruct/Science/default.aspx. |
||||||||||||||
smaller concepts, and how facts and observations support scientific theories. The framework also should reflect the way science is understood by students and how their understanding develops over time. In addition, the framework should be coherent—the content should be presented in a logical order; there should be connections between the standards for one year and the next (whether standards are written at every grade level or in grade-level bands); there should be connections among curriculum, instruction, and assessment and the standards; and the progression of content should be developmentally appropriate for the students.
Standards should have a clear internal structure to provide a framework for developing curriculum and organizing instruction, as well as to provide a reference point for reporting student results. Topics should be organized into conceptually coherent units that make sense to stakeholders. Standards also should convey which subscores are meaningful in terms of the content domain. It may be adequate to report a single judgment for all of science, but more detailed information about subtopics or subdomains can shed more light on the developmental trajectory of a student. Subtopic results can show where a student is having difficulty, and they also can reveal patterns of difficulty among individuals or groups of students that point to a need for curricular or instructional improvements. If results are to be used by teachers to improve instruction, their content has to be organized in ways that will be helpful to them.
Sound Models of Student Learning
Effective standards should reflect what is known about how students learn science. For example, content should be organized in the standards to match the way students actually develop scientific understanding. Similarly, it would be a mistake to establish a standard that research had shown was inaccessible to most students of a given age.
To the extent possible, the standards should reflect what is known about how students learn science. For example, standards should clarify the way understanding builds on prior knowledge and experience. Similarly, standards can illustrate the way ideas are applied in multiple contexts as a basis for developing deeper understanding. When appropriate, standards should explicitly mention the kinds of cognitive tools that characterize the work of scientists and the ways in which students learn science. As states begin to elaborate standards for specific audiences, they should think about other learning principles that are particularly relevant for instructional planning, such as the importance of interactions with peers and experts in developing understanding through collaborative work.
Another function of standards is to support instructional planning and the setting of instructional priorities. In a standards-based system, teachers should refer directly to standards documents, as well as to the curriculum and instructional resources, to decide what to teach and how to teach it. Thus, standards become directly relevant to instructional decisions.
Describe Performance Expectations and Identify Proficiency Levels
If content standards are to fulfill their role of supporting assessment development and the setting of achievement standards, they must describe examples of performance expectations for students in clear and specific terms. Moreover, it is helpful if the central standards document suggests the basis on which distinctions between levels of proficiency can be made, even before specific decisions are made about how the achievement standards will be set. An exhaustive description of every performance level for every standard is unrealistic. However, if the developers of content standards have clear beliefs about aspects of scientific knowledge and skills that should be associated with basic, proficient, and advanced performance, they should indicate this as a guideline for the setting of achievement levels.
ELABORATING STANDARDS FOR PRACTITIONERS
To be effective, state science standards need to be more thorough and thoughtful than most are at present. However, that does not mean that science content standards alone would be adequate to serve the needs of teachers, test developers, students, parents, and policy makers. Supplementary material must be developed to help communicate the standards widely and to elaborate on them for practitioners, policy makers, and others. Users of the standards need guidance in applying them, in part because research has not answered every conceivable question; standards will, and should, inevitably leave room for judgment at the school district, school, and classroom levels. Each state will develop its own strategy for elaboration, based on its existing resources, but it is important that the elaboration process be as inclusive as possible, so that all relevant stakeholders become familiar with the standards. It is also important that the supplementary materials be designed to “stretch” the standards to meet the needs of different audiences. A few examples illustrate the type of materials we have in mind.
The state may need to elaborate on the standards to help teachers apply the curriculum and develop instructional plans that link the standards. These materials may contain references to approved curricula, suggested lesson activities, and sources of supplemental lesson materials, and they would certainly contain examples of student work that satisfy the standards. They may also contain information about the prior knowledge and experiences that students need to learn the information embodied in a given standard, sources of difficulty that students commonly encounter with the content, common misconceptions that they hold about the topic, connections between this standard and others in science, and connections between this standard and standards in other disciplines. There is no common label to describe such elaborations, but a good descriptive term might be standards-based lesson support. As teachers work with students, particularly as they assess student understanding in class, they will learn more about the prior
knowledge and experience students need to master a given standard, the sources of difficulty students have, and relevant misconceptions. This knowledge should be shared with others as part of an ongoing process of elaboration. Ultimately, it should find its way back into revisions of the standards themselves.
For test developers, the state may need to provide a measurement-oriented document that focuses on the content that has high priority for assessment, the manner in which student understanding should be determined, the balance among presentation options, constraints regarding test administration and scoring, and reporting requirements. Standards-based assessment guidelines would be a suitable label for such a document. It would contain information on which to build more detailed assessment blueprints or specifications. It also would contain necessary background information required to develop a request for proposals for an assessment contractor.
The committee suggests that states consider, as they elaborate on their standards, a model that can be used not only for organizing and elaborating standards but also as the conceptual framework for assessment. We have described why systems for science education and assessment should be organized around the big ideas of science. These central principles can be introduced early and progressively refined, elaborated, and extended throughout schooling. Organizing standards around these central principles and developing learning progressions make clear what could be taken as evidence at different grade levels that students are developing as expected and building a foundation for future learning.
Organizing standards around big ideas represents a fundamental shift from the more traditional organizational structure that many states now use, in which standards are grouped under discrete topic headings. In reorganizing their standards, states may find that they will need to add to, elaborate on, delete, or revise some standards to better represent the kinds of scientific knowledge and understandings that are the basis for these big ideas. This process is likely to mean a shift in state standards from broad coverage to deep coverage around a relatively small set of foundational concepts that can be progressively refined, elaborated, and extended.
The committee recognizes the challenges inherent in trying to organize standards in this way. It is a time-consuming process that requires the combined expertise of science teachers, scientists, curriculum developers, and experts with knowledge of how children learn in specific domains of science. The strand maps in the Atlas for Science Literacy (American Association for the Advancement of Science, 2001) may provide a useful starting place for thinking about state-level learning progressions (Figure 4-1). These maps show how students’ understanding of the ideas and skills that lead to literacy in science, mathematics, and technology grow over time. Each map contains explicit connections to ideas represented on other maps, as understanding these connections is a critical part of developing science literacy.
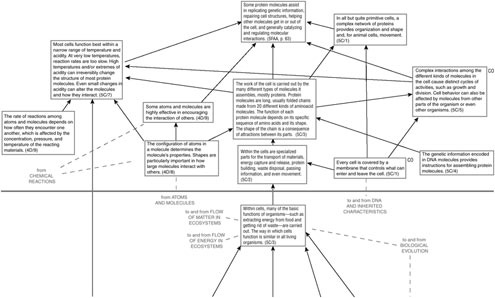
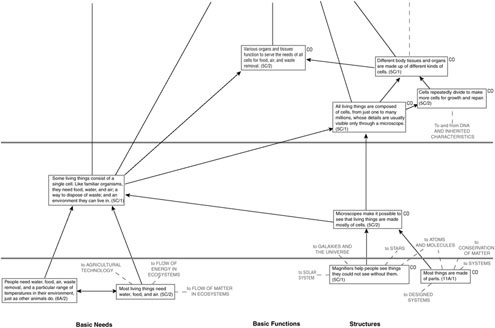
ACHIEVEMENT STANDARDS
The term “standards” is often used loosely in a way that does not distinguish between content and achievement standards. However, both kinds of standards are important, and they must work together. We turn now to some issues that relate to the setting and use of achievement standards. Achievement standards are means of defining levels of performance. Because there are a variety of ways to set them, they can take a variety of forms. In some contexts—licensure tests for airline pilots and surgeons, for example—they are used to mark a minimum level of acceptable performance. In other settings, more general descriptions of performance that sort students into achievement levels, such as basic, proficient, and advanced, are used. Achievement standards are important for many reasons:
-
They provide teachers with targets for instruction by specifying what, and how much, students must be able to do to demonstrate mastery of the content standards and the achievement level that is called for.
-
They provide clear directions to test developers about the kinds of performance situations and tasks that will be used to make judgments about student proficiency.
-
They provide a tool for evaluating the alignment between standards and assessments that is more precise than an analysis of the content match between the two.
-
They help standard setters by suggesting the basis on which judgments about levels of proficiency should be made.
-
They provide a framework for aggregating data drawn from different sources of information to document performance.
-
They help to clarify for the public what it means for a student to be classified at a particular level.
Before considering the NCLB requirements for achievement standards, it is useful to note the different ways in which the term “achievement standard” is used. To test developers and psychometricians, an achievement standard is represented by the point on a test score scale that separates one level of achievement from another (a passing score from a failing one, for example). To educators involved in the development of curriculum and instruction, the term can mean a description of what a student knows and can do to demonstrate proficiency on a standard. To others, it can mean examples of student work that illustrate a particular level of performance. Hansche (1998) defines achievement standards (which he refers to as performance standards) as a system that includes performance levels (labels for each level of achievement), performance descriptors (narrative descriptions of performance at each level), exemplars of student work that illustrate the full range of performance at each level of achievement, and cut scores that differentiate among the achievement levels. The key characteristics
|
BOX 4-5 Performance standards clearly differentiate among levels. Performance descriptors should be easy to apply to collections of student work. When they apply the descriptors for the performance levels, teachers, parents, and students should clearly see why certain sets of student exemplars or student profiles are assigned to one performance level and not to another. Performance standards are grounded in student work but not tied to the status quo. The system should reflect the major concepts and accomplishments that are essential for describing each level of performance. Student work that reflects the diverse ways in which various students demonstrate their achievement should be used to inform the descriptions during various stages of development, illustrating where students should be as a result of the educational process rather than where they are now. Performance standards are built by consensus. The system of standards must be arrived at by the constituency who will use them. It must be built around agreed-upon statements of a range of achievement with regard to student performances. Not only should teachers and students understand the standards, but the “end users,” such as colleges and universities, technical schools, and employers, should also understand what performance standards mean for them. Performance standards are focused on learning. Performance descriptors should provide a clear sense of increased knowledge and sophistication of skills. Descriptors that simply specify “more advanced” at each successive level are not particularly useful. The “more” should be clearly described or defined to show progression of learning. Cut scores on assessments must be based on this learning, and exemplars of student work should illustrate learning at each level. SOURCE: Hansche (1998). Reprinted by permission of the Council of Chief State School Officers. |
that systems of achievement standards should have, as conceived by Hansche, are shown in Box 4-5.
Three of the four components of the assessment system—labels, descriptors, and exemplars—should be created before assessments are developed. Bond (2000) argues that test development can be improved if test developers are given copies of the achievement standard descriptors and exemplars of what satisfactory performance looks like before test development begins. Test developers can use the content specifications, the assessment framework, and the performance descriptors to create items that assess all levels of performance.
The cut score—the numerical cutoff marking the divide between levels of performance deemed acceptable for particular purposes—is defined in the context of a particular instrument and is usually developed after the assessment is
administered and scored. NCLB requires that states develop science achievement standards by the 2005–2006 school year, but does not require states to set cut scores until after they administer their first science assessments in 2007–2008.
Establishing Achievement Levels
Current methods for setting achievement levels fall into two categories: test-based methods and student-based methods. Test-based methods are those in which judgments are based on close examination of individual items or tasks that help to refine understanding of the performance of students who fall close to the border between two achievement levels. Student-based methods, by contrast, are procedures by which judgments are made about the skills or knowledge (or both) displayed by sample groups of students, generally by teachers who know them well. Methods that combine the test-based and student-based approaches also have been developed (Haertel and Lorie, 2004; Wilson and Draney, 2002). Each is likely to yield somewhat different results and no single method is recognized as the best for all circumstances (Jaeger, 1989).
Variability in Achievement Standards
While the language of standards-based reform has focused on setting high standards and helping all students move toward those levels, definitions of proficiency are not consistent from state to state or, in some cases, from district to district. For example, one study found that definitions of proficiency range from the 70th percentile or higher to as low as the 7th percentile. In other words, in one state, 30 percent of students in a particular grade may be identified as proficient in a subject, while in a neighboring state, 93 percent are identified as proficient. Such stark contrasts are likely to indicate that expectations—and perhaps the purposes of testing—are different in the two states, not that students in one state are vastly more competent in the assessed domain than students in the other. Judgment is a key part of the standard-setting process, and the variability this introduces must be factored into planning. Different groups of human beings will not produce exactly comparable results using the same process, and this source of error variance must be taken into account in the process by which the results are validated (Linn, 2003). In one study in which the standards set by independent but comparable panels of judges were evaluated, the percentages of students identified as failing ranged from 9 to 30 percent on the reading assessment and from 14 to 17 percent on the mathematics assessment (Jaeger, Cole, Irwin, and Pratto, 1980).
The method chosen to set achievement standards will also have an impact on the standards. An early study in which independent samples of teachers set standards using one of four methods showed considerable variability in the levels set (Poggio, Glasnapp, and Eros, 1981). On a 60-item reading test, the percentage of students who would have failed ranged from 2 to 29 percent across the standard-
setting methods. Some researchers have suggested that variability can be minimized if multiple methods are used in setting achievement standards and a panel then uses these results to set the final standards.
Establishing the Validity of Achievement Standards
A critical aspect of the standard-setting process is the collection of evidence to support the validity of the standards and the decisions that are made in using them (Kane, 2001). A first step in doing this is to examine the coherence of the standard-setting process—that is, the standard-setting methods should be consistent with the design of the assessment and the model of achievement underlying the assessment program (Kane, 2001). Evidence regarding the soundness of the design and implementation of the standard-setting study is needed; this could include reviews of the procedures used for selecting and training judges and for crafting descriptors for the achievement levels. Researchers advocate that descriptors for the achievement levels be developed before the cut scores are established so that the judges have a clear definition of each of the levels.
Evidence of the extent of internal inconsistency, or variability, in judgments is needed as well. Variability among judges can be examined at the different stages of the standard-setting process. For example, after training, judges can be asked to independently set cut scores in the first round of the process. Each judge can then be provided with information on the cut scores set by other judges; after a group discussion, the judges can be asked to review their own cut scores and make any modifications they deem necessary. The variability of the judges can also be examined after this second round. Judges can be shown impact data (demonstrating the effects of setting cut scores at particular levels, for example) and then be asked to discuss how this affects their chosen cut scores. Afterward they could have another opportunity to make modifications to their cut scores if they wish. The variability can be examined again at this point.
The consistency of the standards set by independent sets of judges representing the same constituencies should also be evaluated. This would require forming independent panels of comparably qualified judges to set standards under the direction of comparable leaders using the same method, procedures, instructions, and materials. The variance in the standards set by the independent panels provides a measure of the error present with panels and standard-setting leaders (Linn, 2003). Supplementary data should also be collected regarding the judges’ level of satisfaction with the standard-setting process as well as their degree of confidence in the resulting cut scores. Surveys and interviews can provide these data.
Evidence of external validity is also needed. NCLB requires states to participate in biennial administrations of the state-level National Assessment of Educational Progress (NAEP) in reading and mathematics at grades 4 and 8. In the near future, states will also be able to participate in administrations of NAEP in sci-
ence, which will allow them to use these results in evaluating the stringency of their achievement standards.
Setting Achievement Standards for a System of Assessments
Although there are many different ways to set achievement standards, further options are needed. The most common methods used to set achievement levels, such as the modified Angoff or bookmark methods, were designed for use on a single test. Although the committee did not evaluate them, we identified several methods for setting achievement standards when multiple measures are used. These methods include the body of work method (Kingston, Kahl, Sweeney, and Bay, 2001); the judgmental policy capturing method (Jaeger, 1995) and the construct mapping method (Wilson and Draney, 2002). All of these methods have been tried with some success on a limited scale; however, this is an area in which research is clearly needed, as states will need help in implementing standard-setting strategies or systems of assessment that include multiple measures of student achievement.
QUESTIONS FOR STATES
In responding to the requirements of NCLB, states will need to review their science standards and the documents that serve to elaborate the standards, and they may need to modify them in significant ways. We urge states to use the principles outlined in this chapter as a guide, and we pose questions that states can use as they consider possible improvements to their science standards.
Question 4-1: Have the state’s science standards been elaborated to provide explicit guidance to teachers, curriculum developers, and the state testing contractors about the skills and knowledge that are required?
Question 4-2: Have the state’s science standards been reviewed by an independent body to ensure that they are reasonable in scope, accurate, clear, and attainable; reflect the current state of scientific knowledge; focus on ideas of significance; and reflect current understanding of the ways in which students learn science?
Question 4-3: Does the state have in place a regular cycle (preferably no longer than 8 to 10 years) for reviewing and revising its standards, during which time is allowed for development of new standards as needed; implementation of those standards; and then evaluation by a panel of experts to inform the next iteration of review and revision? Has the state set aside resources and developed both long-and short-term strategies for this to occur?






















