
Commercializing Auditory Neuroscience
LLOYD WATTS
Audience Inc.
Mountain View, California
In a previous paper (Watts, 2003), I argued that we now have sufficient knowledge of auditory brain function and sufficient computer power to begin building a realistic, real-time model of the human auditory pathway, a machine that can hear like a human being. Based on extrapolations of computational capacity and advancements in neuroscience and psychoacoustics, a realistic model might be completed in the 2015–2020 time frame. This ambitious endeavor will require a decade of work by a large team of specialists and a network of highly skilled collaborators supported by substantial financial resources. To date, from 2002 to 2006, we have developed the core technology, determined a viable market direction, secured financing, assembled a team, and developed and executed a viable, sustainable business model that provides incentives (expected return on investment) for all participants (investors, customers, and employees), in the short term and the long term. So far, progress has been made on all of these synergistic and interdependent fronts.
SCIENTIFIC FOUNDATION
The scientific foundation for Audience Inc. is a detailed study of the mammalian auditory pathway (Figure 1), completed with the assistance of eight of the world’s leading auditory neuroscientists. Our approach was to build working, high-resolution, real-time models of various system components and validate those models with the neuroscientists who had performed the primary research.
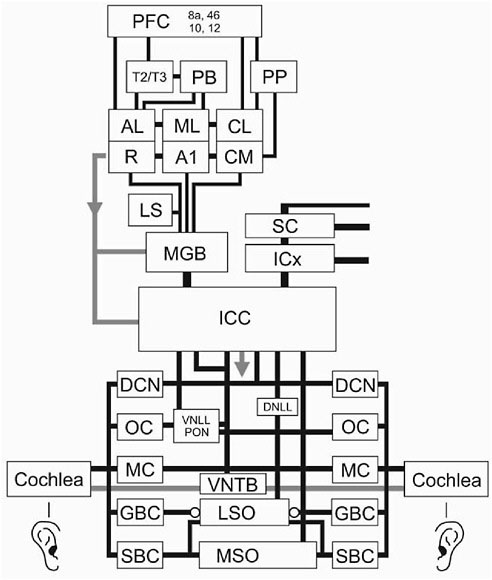
FIGURE 1 A highly simplified diagram of the mammalian auditory pathway. Adapted from Casseday et al., 2002; LeDoux, 1997; Oertel, 2002; Rauschecker and Tian, 2000; and Young, 1998.
The basic model-building began in 1998 and continued through 2002, just when personal computers crossed the 1 GHz mark, which meant that, for the first time in history, it was possible to build working, real-time models of real brain-system components, in software, on consumer computer platforms. Early demonstrations in 2001 and 2002 included high-resolution, real-time displays of the cochlea; binaural spatial representations, such as interaural time differences (ITDs) and interaural level differences (ILDs); high-resolution, event-based
correlograms; and a demonstration of real-time, polyphonic pitch detection, all based on well-established neuroscience and psychoacoustic findings.
MARKET FOCUS AND PRODUCT DIRECTION
In the early years of the company, we explored many avenues for commercialization. After a two-year sojourn (from 2002 to 2004) into noise-robust speech recognition, we re-assessed the market and determined that the company’s greatest commercial value was in the extraction and reconstruction of the human voice, a technology that could be used to improve the quality of telephone calls made from noisy environments. This insight was driven by the enormous sales in the cell-phone market and the need for cell-phone users to be heard clearly when they placed calls from noisy locations. At that point, work on speech recognition was de-emphasized, and the company began to focus in earnest on commercializing a two-microphone, nonstationary noise suppressor for the mobile telephone market.
TECHNOLOGY
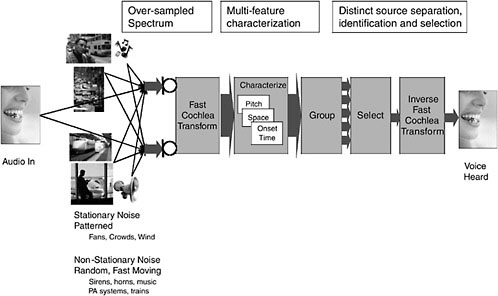
Figure 2 is a block diagram of Audience’s cognitive audio system, which is designed to extract a single voice from a complex auditory scene. The major elements in the system are: Fast Cochlea Transform™ (FCT), a characterizatio process, a grouping process, a selection process, and Inverse FCT.
-
FCT provides a high-quality spectral representation of the sound mixture, with sufficient resolution and without introducing frame artifacts, to allow the characterization of components of multiple sound sources.
-
The characterization process involves computing the attributes of sound components used by human beings for grouping and stream separation. These attributes include: pitches of constituent, nonstationary sounds; spatial location cues (when multiple microphones are available), such as onset timing and other transient characteristics; estimation and characterization of quasistationary background noise levels; and so on. These attributes are then associated with the raw FCT data as acoustic tags in the subsequent grouping process.
-
The grouping process is a clustering operation in low-dimensionality spaces to “group” sound components with common or similar attributes into a single auditory stream. Sound components with sufficiently dissimilar attributes are associated with different auditory streams. Ultimately, the streams are tracked through time and associated with persistent or recurring sound sources in the auditory environment. The output of the grouping process is the raw FCT data associated with each stream and the corresponding acoustic tags.
-
The selection process involves prioritizing and selecting separate auditory sound sources, as appropriate for a given application.
-
Inverse FCT telephony applications involve reconstructing and cleaning up the primary output of the system to produce a high-quality voice. Inverse FCT converts FCT data back into digital audio for subsequent processing, including encoding for transmission across a cell-phone channel.
TECHNICAL DETAILS
Fast Cochlea Transform™
FCT, the first stage of processing, must have adequate resolution to support high-quality stream separation. Figure 3 shows a comparison of the conventional fast Fourier transform (FFT) and FCT. In many applications, FFT is updated every 10 ms, giving it coarse temporal resolution, as shown in the right half of the FFT panel. FCT is updated with every audio sample, which allows for resolution of glottal pulses, as necessary, to compute periodicity measures on a performant basis as a cue for grouping voice components.
Because of the way FFT is often configured, it provides poor spectral resolution at low frequencies; very often, the following processor (such as a back-
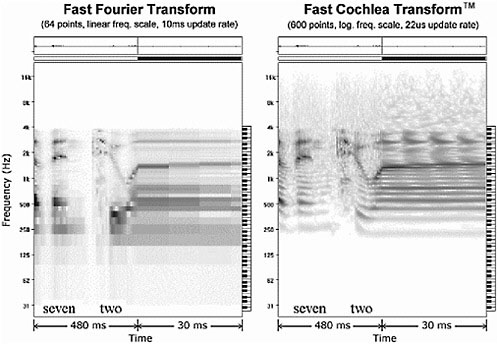
FIGURE 3 Comparison of fast Fourier transform and Fast Cochlea Transform™. Source Audience Inc.
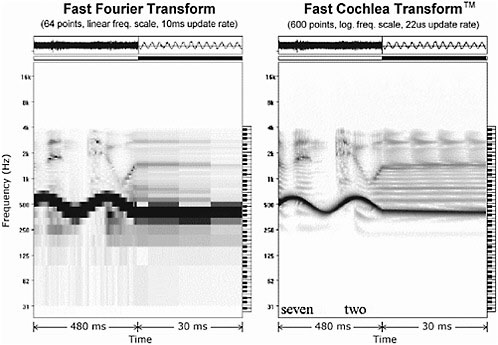
FIGURE 4 Multistream separation demonstration (speech + siren). Note that the Fast Cochlea Transform creates a redundant, oversampled representation of the time-varying auditory spectrum. We have found this is necessary to meet the joint requirements of perfect signal reconstruction with no aliasing artifacts, at low latency, with a high degree of modifiability in both the spectral and temporal domains. Source: Audience Inc.
end speech recognizer) is only interested in a smooth estimate of the spectral envelope. FCT, however, is designed to give high-resolution information about individual resolved harmonics so they can be tracked and used as grouping cues in the lower formants.
High resolution is even more important in a multisource environment (Figure 4). In this example, speech is corrupted by a loud siren. The low spectro-temporal resolution of the frame-based FFT makes it difficult to resolve and track the siren, and, therefore, difficult to remove it from speech. The high spectro-temporal resolution of FCT makes it much easier to resolve and track the siren as distinct from the harmonics of the speech signal. The boundaries between the two signals are much better defined, which results in high performance in the subsequent grouping and separation steps.
Characterization Process
The polyphonic pitch algorithm is capable of resolving the pitch of multiple speakers simultaneously and detecting multiple musical instruments simulta-
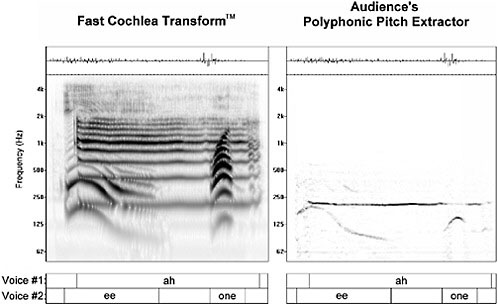
FIGURE 5 Polyphonic pitch for separating multiple simultaneous voices. Source: Audience Inc.
neously. Figure 5 shows how the simultaneous pitches of a male and female speaker are extracted. Spatial localization is valuable for stream separation and locating sound sources, when stereo microphones are available. Figure 6 shows the response of binaural representations to a sound source positioned to the right of the stereo microphone pair.
Figure 7 shows an example of stream separation in a complex audio mixture (voice recorded on a street corner with nearby conversation, noise from a passing car, and ringing of a cell phone) in the cochlear representation. After sound separation, only the voice is preserved.
Inverse Fast Cochlea Transform
After sound separation in the cochlear (spectral) domain, the audio waveform can be reconstructed for transmission, playback, or storage, using the Inverse FCT. The Inverse FCT combines the spectral components of the FCT back into a time-domain waveform.
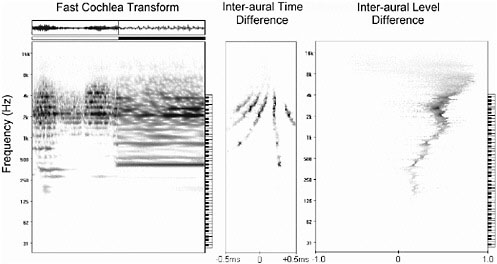
FIGURE 6 Response of the cochlear model and computations of ITD and ILD for spatial localization. Source: Audience Inc.

FIGURE 7 Separation of a voice from a street-corner mixture, using a handset with real-time, embedded software. Top panel: mixture of voice with car noise, another voice, and cell-phone ring-tone. Bottom panel: isolated voice. Source: Audience Inc.
PRODUCT DIRECTION
So far, the company’s product direction has remained true to the original goal of achieving commercial success by building machines that can hear like human beings. Along the way, we have found points of divergence between what the brain does (e.g., computes with spikes, uses slow wetware, does not reconstruct audio) and what our system must do to be commercially viable (e.g., compute with conventional digital representations, use fast silicon hardware, provide inverse spectral transformation). In general, however, insights from our studies of the neuroscience and psychoacoustics of hearing have led to insights that have translated into improved signal-processing capacity and robustness.
PRODUCT IMPLEMENTATION
In the early days of the company, I assumed it would be necessary to build dedicated hardware (e.g., integrated circuits or silicon chips) to support the high computing load of brain-like algorithms. Therefore, I advised investors that Audience would be a fabless semiconductor company with a strong intellectual property position (my catch-phrase was “the nVidia of sound input”). Because the project was likely to take many years and implementation technology changes quickly, Paul Allen, Microsoft cofounder and philanthropist, advised us in 1998 to focus on the algorithms and remain flexible on implementation technology (personal communication, 1998). Eight years later, in 2006, his counsel continues to serve the company well.
As we enter the market with a specific product, we are finding acceptance for both dedicated hardware solutions and embedded software solutions, for reasons that have less to do with computational demands than with the details of integrating our solution into the existing cell-phone platform (e.g., the lack of mixed-signal support for a second microphone). So, the company is a fabless semiconductor company after all, but for very different reasons than I expected when the company was founded in 2000.
REFERENCES
Casseday, J., T. Fremouw, and E. Covey. 2002. Pp. 238–318 in Integrative Functions in the Mammalian Auditory Pathway, edited by D. Oertel, R. Fay, and A. Popper. New York: Springer-Verlag.
LeDoux, J.E. 1997. Emotion circuits in the brain. Annual Review of Neuroscience 23: 155–184.
Oertel, D. 2002. Pp. 1–5 in Integrative Functions in the Mammalian Auditory Pathway, edited by D. Oertel, R. Fay, and A. Popper. New York: Springer-Verlag.
Rauschecker, J., and B. Tian. 2000. Mechanisms and streams for processing of “what” and “where” in auditory cortex. Proceedings of the National Academy of Sciences 97(22): 11800–11806.
Watts, L. 2003. Visualizing Complexity in the Brain. Pp. 45–56 in Computational Intelligence: The Experts Speak, edited by D. Fogel and C. Robinson. New York: IEEE Press/John Wiley & Sons.
Young, E. 1998. Pp. 121–158 in The Synaptic Organization of the Brain, 4th ed., edited by G. Shepherd. New York: Oxford University Press.
FURTHER READING
Bregman, A. 1990. Auditory Scene Analysis. Cambridge, Mass.: MIT Press.
Shepherd, G. 1998. The Synaptic Organization of the Brain, 4th ed. New York: Oxford University Press.










