
1
Assessment: Software Systems and Dependability Today
The software industry is, by most measures, a remarkable success. But it would be unwise to be complacent and assume that software is already dependable enough or that its dependability will improve without any special efforts.
Software dependability is a pressing concern for several reasons:
-
Developing software to meet existing dependability criteria is notoriously difficult and expensive. Large software projects fail at a rate far higher than other engineering projects, and the cost of projects that deliver highly dependable software is often exorbitant.
-
Software failures have caused serious accidents that resulted in death, injury, and large financial losses. Without intervention, the increasingly pervasive use of software may bring about more frequent and more serious accidents.
-
Existing certification schemes that are intended to ensure the dependability of software have a mixed record. Some are largely ineffective, and some are counterproductive.
-
Software has great potential to improve safety in many areas. Improvements in dependability would allow software to be used more widely and with greater confidence for the benefit of society.
This chapter discusses each of these issues in turn. It then discusses the committee’s five observations that informed the report’s recommendations and findings.
COST AND SCHEDULE CHALLENGES IN SOFTWARE DEVELOPMENT
For many years, international surveys have consistently reported that less than 30 percent of commercial software development projects are finished on time and within budget and satisfy the business requirements. The exact numbers are hard to discern and subject to much discussion and disagreement, because few surveys publish their definitions, methodologies, or raw data. However, there is widespread agreement that only a small percentage of projects deliver the required functionality, performance, and dependability within the original time and cost estimate.
Software project failure has been studied quite widely by governments, consultancy companies, academic groups, and learned societies. Two such studies are one published by the Standish Group and another by the British Computer Society (BCS). The Standish Group reported that 28 percent of projects succeeded, 23 percent were cancelled, and 49 percent were “challenged” (that is, overran significantly or delivered limited functionality).1 The BCS surveyed2 38 members of the BCS, the Association of Project Managers, and the Institute of Management, covering 1,027 projects in total. Of these, only 130, or 12.7 percent, were successful; of the successful projects, 2.3 percent were development projects, 18.2 percent maintenance projects, and 79.5 percent data conversion projects—yet development projects made up half the total projects surveyed. That means that of the more than 500 development projects included in the survey, only three were judged to have succeeded.
The surveys covered typical commercial applications, but applications with significant dependability demands (“dependable applications,” for short) show similar high rates of cancellation, overrun, and in-service failure. For example, the U.S. Department of Transportation’s Office of the Inspector General and the Government Accountability Office track the progress of all major FAA acquisition projects intended to modernize and add new capabilities to the National Airspace System. As of May 2005, of 16 major acquisition projects being tracked, 11 were over budget, with total cost growth greater than $5.6 billion; 9 had experienced schedule delays ranging from 2 to 12 years; and 2 had been deferred.3 Software is cited as the primary reason for these problems.
An Air Force project that has been widely studied and reported illustrates the difficulty of developing dependable software using the methods currently employed by industry leaders. The F/A-22 aircraft has been under development since 1986. Much of the slow pace of development has been attributed to the difficulty of making the complex software dependable.4 The instability of the software has often been cited as a cause of schedule delays5,6 and the loss of at least one test aircraft.7 The integrated avionics suite for the F/A-22 is reported to have been redesigned as recently as August 2005 to improve stability, among other things.8
The similarly low success rates in both typical and dependable applications is unsurprising, because dependable applications are usually developed using methods that do not differ fundamentally from those used commercially. The developers of dependable systems carry out far more reviews, more documentation, and far more testing, but the underlying methods are the same. The evidence is clear: These methods cannot dependably deliver today’s complex applications, let alone tomorrow’s even more complex requirements.
It must not be forgotten that creating dependable software systems itself has economic consequences. Consider areas such as dynamic routing in air traffic control, where there are not only significant opportunities to improve efficiency and (arguably) safety, but also great risks if automated systems fail.
DISRUPTIONS AND ACCIDENTS DUE TO SOFTWARE
The growing pervasiveness and centrality of software in our civic infrastructure is likely to increase the severity and frequency of accidents that can be attributed to software. Moreover, the risk of a major catastrophe in which software failure plays a part is increasing, because the growth in complexity and invasiveness of software systems is not being matched by improvements in dependability.
Software has already been implicated in cases of widespread economic disruption, major losses to large companies, and accidents in which
|
4 |
Michael A. Dornheim, 2005, “Codes gone awry,” Aviation Week & Space Technology, February 28, p. 63. |
|
5 |
Robert Wall, 2003, “Code Red emergency,” Aviation Week & Space Technology, June 9, pp. 35-36. |
|
6 |
General Accounting Office, 2003, “Tactical aircraft, status of the F/A-22 program: Statement of Allen Li, director, Acquisition and Sourcing Management,” GAO-33-603T, April 2. |
|
7 |
U.S. Air Force, “Aircraft accident investigation,” F/A-22 S/N 00-4014. Available online at <http://www.airforcetimes.com/content/editorial/pdf/af.exsum_f22crash_060805.pdf>. |
|
8 |
Stephen Trimble, 2005, “Avionics redesign aims to improve F/A-22 stability,” Flight International, August 23. |
hundreds of people have been killed. Accidents usually have multiple causes, and software is rarely the sole cause. But this is no comfort. On the contrary, software can (and should) reduce, rather than increase, the risks of system failures.
The economic consequences of security failures in desktop software have been severe to date. Several individual viruses and worms have caused events where damage was assessed at over $1 billion each—Code Red was assessed at $2.75 billion worldwide9—and two researchers have estimated that a worst-case worm could cause $50 billion in damage.10 One must also consider the aggregated effect of minor loss and inconvenience inflicted on large numbers of people. In several incidents in the last few years, databases containing the personal information of thousands of individuals—such as credit card data—were breached. Security attacks on personal computers are now so prevalent that according to some estimates, a machine connected to the Internet without appropriate protection would be compromised in under 4 minutes,11 less time than it takes to download up-to-date security patches.
In domains where attackers may find sufficient motivation, such as the handling of financial records or the management of critical infrastructures, and with the growing risk and fear of terrorism and the evolution of mass network attacks, security has become an important concern. For example, as noted elsewhere, in the summer of 2005, radiotherapy machines in Merseyside, England, and in Boston were attacked by computer viruses. It makes little sense to invest effort in ensuring the dependability of a system while ignoring the possibility of security vulnerabilities. A basic level of security—in the sense that a software system behaves properly even in the presence of hostile inputs from its environment—should be required of any software system that is connected to the Internet, used to process sensitive or personal data, or used by an organization for its critical business or operational functions.
Automation tends to reduce the probability of failure while increasing its severity because it is used to control systems when such control is beyond the capabilities of human operators without such assistance.12
|
9 |
See Computer Economics, 2003, “Virus attack costs on the rise—Again,” Figure 1. Available online at <http://www.computereconomics.com/article.cfm?id=873>. |
|
10 |
Nicholas Weaver and Vern Paxson, 2004, “A worst-case worm,” Presented at the Third Annual Workshop on Economics and Information Security (WEIS04), March 13-14. Available online at <http://www.dtc.umn.edu/weis2004/weaver.pdf>. |
|
11 |
Gregg Keizer, 2004, “Unprotected PCs fall to hacker bots in just four minutes,” Tech Web, November 30. Available online at <http://www.techweb.com/wire/security/54201306>. |
|
12 |
N. Sarter, D.D. Woods, and C. Billings, 1997, “Automation surprises,” Handbook of Human Factors/Ergonomics, 2nd ed., G. Salvendy, ed., Wiley, New York. (Reprinted in N. Moray, ed., Ergonomics: Major Writings, Taylor & Francis, Boca Raton, Fla., 2004.) |
Aviation, for example, is no exception, and current trends—superairliners, free flight, greater automation, reduced human oversight in air-traffic control, and so on—increase the potential for less frequent but more serious accidents. High degrees of automation can also reduce the ability of human operators to detect and correct mistakes. In air-traffic control, for example, there is a concern that the failure of a highly automated system that guides aircraft, even if detected before an accident occurs, might leave controllers in a situation beyond their ability to resolve, with more aircraft to consider, and at smaller separations than they can handle. There is also a legitimate concern that a proliferation of safety devices itself creates new risks. The traffic alert and collision avoidance system (TCAS), an onboard collision avoidance system now mandatory on all commercial aircraft,13 has been implicated in at least one near miss.14
Hazardous Materials
The potential for the worst software catastrophes resulting in thousands of deaths lies with systems involving hazardous materials, most notably plants for nuclear power, chemical processing, storing liquefied natural gas, and other related storage and transportation facilities. Although software has not been implicated in disasters on the scale of those in Chernobyl15 or Bhopal,16 the combination of pervasive software and high risk is worrying. Software is used pervasively in plants for monitoring and control in distributed control systems (DCS) and supervisory control and data acquisition (SCADA) systems. According to the EPA,17 123 chemical plants in the United States could each expose more than a million people if a chemical release occurred, and a newspaper article reports that a plant in Tennessee gave a worst-case estimate of 60,000 people facing death or serious injury from a vapor cloud formed by an
|
13 |
For more information on TCAS, see the FAA’s “TCAS home page.” Available online at <http://adsb.tc.faa.gov/TCAS.htm>. |
|
14 |
N. Sarter, D.D. Woods, and C. Billings, 1997, “Automation surprises,” Handbook of Human Factors/Ergonomics, 2nd ed., G. Salvendy, ed., Wiley, New York. (Reprinted in N. Moray, ed., Ergonomics: Major Writings, Taylor & Francis, Boca Raton, Fla., 2004.) |
|
15 |
See the Web site “Chernobyl.info: The international communications platform on the long-term consequences of the Chernobyl disaster” at <http://www.chernobyl.info/>. |
|
16 |
See BBC News’ “One night in Bhopal.” Available online at <http://www.bbc.co.uk/bhopal>. |
|
17 |
See U.S. General Accounting Office, 2004, “Federal action needed to address security challenges at chemical facilities,” Statement of John B. Stephenson before the Subcommittee on National Security, Emerging Threats, and International Relations, Committee on Government Reform, House of Representatives (GAO-04-482T), p. 3. Available online at <http://www.gao.gov/new.items/d04482t.pdf>. |
accidental release of sulfur dioxide.18 Railways already make extensive use of software for signaling and safety interlocks, and the use of software for some degree of remote control of petrochemical tanker trucks (e.g., remote shutdown in an emergency) is being explored.19
Aviation
Smaller but still major catastrophes involving hundreds rather than thousands of deaths have been a concern primarily in aviation. Commercial flight is far safer than other means of travel, and the accident rate per takeoff and landing, or per mile, is extremely small (although accident rates in private and military aviation are higher). Increasing density of airspace use and the development of airliners capable of carrying larger numbers of passengers pose greater risks, however.
Although software has not generally been directly blamed for an aviation disaster, it has been implicated in some accidents and near misses. The 1997 crash of a Korean Airlines 747 in Guam resulted in 200 deaths and would almost certainly have been avoided had a minimum safe altitude warning system been configured correctly.20 Several aircraft accidents have been attributed to “mode confusion,” where the software operated as designed but not as expected by the pilots.21 Several incidents in 2005 further illustrate the risks posed by software:
-
In February 2005, an Airbus A340-642 en route from Hong Kong to London suffered from a failure in a data bus belonging to a computer that monitors and controls fuel levels and flow. One engine lost power and a second began to fluctuate; the pilot diverted the aircraft and landed safely in Amsterdam. The subsequent investigation noted that although a backup slave computer was available that was working correctly, the failing computer remained selected as the master due to faulty logic in the software. A second report recommended an independent low-fuel warning system and noted the risks of a computerized management system
|
18 |
See James V. Grimaldi and Guy Gugliotta, 2001, “Chemical plants feared as targets,” Washington Post, December 16, p. A01. |
|
19 |
See “Tanker truck shutdown via satellite,” 2004, GPS News, November. Available online at <http://www.spacedaily.com/news/gps-03zn.html>. |
|
20 |
For more information, see the National Transportation Safety Board’s formal report on the accident. Available online at <http://www.ntsb.gov/Publictn/2000/AAR0001.htm>. |
|
21 |
See NASA’s “FM program: Analysis of mode confusion.” Available online at <http://shemesh.larc.nasa.gov/fm/fm-now-mode-confusion.html>; updated August 6, 2001. |
-
that might fail to provide crew with appropriate data, preventing them from taking appropriate actions.22
-
In August 2005, a Boeing 777-200 en route from Perth to Kuala Lumpur presented the pilot with contradictory reports of airspeed: that the aircraft was overspeed and at the same time at risk of stalling. The pilot disconnected the autopilot and attempted to descend, but the auto-throttle caused the aircraft to climb 2,000 ft. He was eventually able to return to Perth and land the aircraft safely. The incident was attributed to a failed accelerometer. The air data inertial reference unit (ADIRU) had recorded the failure of the device in its memory, but because of a software flaw, the unit failed to recheck the device’s status after power cycling.23
-
In October 2005, an Airbus A319-131 flying from Heathrow to Budapest suffered a loss of cockpit power that shut down not only avionics systems but even the radio and transponder, preventing the pilot from issuing a Mayday call. At the time of writing, the cause has not been determined. An early report in the subsequent investigation noted, however, that an action was available to the pilots that would have restored power, but it was not shown on the user interface due to its position on a list, and a software design that would have required items higher on the list to be manually cleared in order for that available action to be shown.24
Perhaps the most serious software-related near miss incident to date occurred on September 14, 2004. A software system at the Los Angeles Air Route Traffic Control Center in Palmdale, California, failed, preventing any voice communication between controllers and aircraft. The center is responsible for aircraft flying above 13,000 ft in a wide area over southern California and adjacent states, and the outage disrupted about 800 flights across the country. According to the New York Times, aircraft violated minimum separation distances at least five times, and it was only due to onboard collision detection systems (i.e., TCAS systems) that no collisions actually occurred. The problem was traced to a bug in the software, in which a countdown timer reaching zero shut down the system.25 The
|
22 |
See Air Accidents Investigation Branch (AAIB) Bulletin S1/2005–SPECIAL (Ref: EW/ C2005/02/03). Available online at <http://www.aaib.dft.gov.uk/cms_resources/G-VATL_Special_Bulletin1.pdf>. |
|
23 |
See Aviation Safety Investigation Report—Interim Factual, Occurrence Number 200503722. November 2006. Available online at <http://www.atsb.gov.au/publications/investigation_reports/2005/AAIR/aair200503722.aspx>. |
|
24 |
See AAIB Bulletin S3/2006 SPECIAL (Ref. EW/C2005/10/05). Available online at <http://www.aaib.dft.gov.uk/cms_resources/S3-2006%20G-EUOB.pdf>. |
|
25 |
L. Geppert, 2004, “Lost radio contact leaves pilots on their own,” IEEE Spectrum 41(11):16-17. |
presence of the bug was known, and the FAA was in the process of distributing a patch. The FAA ordered the system to be restarted every 30 days in the interim, but this directive was not followed. Worryingly, a backup system that should have taken over also failed within a minute of its activation. This incident, in common with the hospital system failure described in the next section, illustrates the greater risk that is created when services affecting a large area or many people are centralized in a single system, which then becomes a single point of failure.
Medical Devices and Systems
Medical devices such as radiation therapy machines and infusion pumps are potentially lethal. Implanted devices pose a particular threat, because although a single failure affects only one user, a flaw in the software of a device could produce failures across the entire population of users. Safety recalls of pacemakers and implantable cardioverter-defibrillators due to firmware (that is, software) problems between 1990 and 2000 affected over 200,000 devices, comprising 41 percent of the devices recalled and are increasing in frequency.26 In the 20-year period from 1985 to 2005, the FDA’s Maude database records almost 30,000 deaths and almost 600,000 injuries from device failures.27
In a study the FDA conducted between 1992 and 1998, 242 out of 3,140 device recalls (7.7 percent) were found to be due to faulty software.28 Of these, 192—almost 80 percent—were caused by defects introduced during software maintenance.29 The actual incidence of failures in medical devices due to software is probably much higher than these numbers suggest, as evidenced by a GAO study30 that found extensive underreporting of medical device failures in general.
|
26 |
William H. Maisel, Michael O. Sweeney, William G. Stevenson, Kristin E. Ellison, Laurence M. Epstein, 2001, “Recalls and safety alerts involving pacemakers and implantable cardioverter-defibrillator generators,” Journal of the American Medical Association 286:793-799. |
|
27 |
FDA, 2006, Ensuring the Safety of Marketed Medical Devices: CDRH’s Medical Device Postmarket Safety Program. January. |
|
28 |
Insup Lee and George Pappas, 2006, Report on the High-Confidence Medical-Device Software and Systems (HCMDSS) Workshop. Available online at <http://rtg.cis.upenn.edu/hcmdss/HCMDSS-final-report-060206.pdf>. |
|
29 |
In addition, it should be noted that delays in vendor testing and certification of patches often make devices (and therefore even entire networks) susceptible to worms and other malware. |
|
30 |
GAO, 1986, “Medical devices: Early warning of problems is hampered by severe underreporting,” U.S. Government Printing Office, Washington, D.C., GAO publication PEMD-87-1. For example, the study noted that of over 1,000 medical device failures surveyed, 9 percent of which caused injury and 37 percent of which had the potential to cause death or serious injury, only 1 percent were reported to the FDA. |
Indeed, software failures have been responsible for some notable catastrophic device failures, of which perhaps the best known are failures associated with radiotherapy machines that led to patients receiving massive overdoses. The well-documented failure of the Therac-25, which led to more than five deaths between 1985 and 1987, exposed not only incompetence in software development but also a development culture unaware of safety issues.31 A very similar accident in Panama in 200132 suggests that these lessons were not universally applied.33
As software becomes more pervasive in medicine, and reliance is placed not only on the software that controls physical processes but also on the results produced by diagnostic and scanning devices, the opportunity for software failures with lethal consequences will grow. In addition, software used for data management, while often regarded as noncritical, may in fact pose risks to patients that are far more serious than those posed by physical devices. Most hospitals are centralizing patient records and moving toward a system in which all records are maintained electronically. The failure of a hospital-wide database brings an entire hospital to a standstill, with catastrophic potential. Such failures have already been reported.34
An incident reported by Cook and O’Connor is indicative of the kinds of risks faced. A software failure in a pharmacy database in a tertiary-care hospital in the Chicago area made all medication records inaccessible
|
31 |
See Nancy Leveson and Clark S. Turner, 1993, “An investigation of the Therac-25 accidents,” IEEE Computer 26(7):18-41. |
|
32 |
See International Atomic Energy Agency (IAEA), 2001, “Investigation of an accidental exposure of radiotherapy patients in Panama: Report of a team of experts,” International Atomic Energy Agency, Vienna, Austria. Available online at <http://www-pub.iaea.org/MTCD/publications/PDF/Pub1114_scr.pdf>. |
|
33 |
A number of studies have investigated challenges related to infusion devices. See R.I. Cook, D.D. Woods, and M.B. Howie, 1992, “Unintentional delivery of vasoactive drugs with an electromechanical infusion device,” Journal of Cardiothoracic and Vascular Anesthesia 6:238-244; M. Nunnally, C.P. Nemeth, V. Brunetti, and R.I. Cook, 2004, “Lost in menuspace: User interactions with complex medical devices,” IEEE Transactions on Systems, Man and Cybernetics—Part A: Systems and Humans 34(6):736-742; L. Lin, R. Isla, K. Doniz, H. Harkness, K. Vicente, and D. Doyle, 1998, “Applying human factors to the design of medical equipment: Patient controlled analgesia,” Journal of Clinical Monitoring 14:253-263; L. Lin, K. Vicente, and D.J. Doyle, 2001, “Patient safety, potential adverse drug events, and medical device design: A human factors engineering approach,” Journal of Biomedical Informatics 34(4):274-284; R.I. Cook, D.D. Woods, and C. Miller, 1998, A Tale of Two Stories: Contrasting Views on Patient Safety, National Patient Safety Foundation, Chicago, Ill., April. Available online at <http://www.npsf.org/exec/report.html>. |
|
34 |
See, for example, Peter Kilbridge, 2003, “Computer crash: Lessons from a system failure,” New England Journal of Medicine 348:881-882, March 6; Richard Cook and Michael O’Connor, “Thinking about accidents and systems,” forthcoming, in K. Thompson and H. Manasse, eds., Improving Medication Safety, American Society of Health-System Pharmacists, Washington, D.C. |
for almost a day. The pharmacy relied on this database for selecting and distributing medications throughout the hospital and was only able to continue to function by collecting paper records from nurses’ stations and reentering all the data manually. Had the paper records not been available, the result would have been catastrophic. Although no patients were injured, Cook and O’Connor were clear about the significance of the event: “Accidents are signals sent from deep within the systems about the sorts of vulnerability and potential for disaster that lie within.”35
In many application areas, effectiveness and safety are clearly distinguished from each other. In medicine, however, the distinction can be harder to make. The accuracy of the data produced by medical information systems is often critical, and failure to act in a timely fashion can be as serious as failure to prevent an accident. Moreover, the integration of invasive devices with hospital networks will ultimately erase the gap between devices and databases, so that failures in seemingly unimportant back-office applications might compromise patient safety. Networking also makes hospital systems vulnerable to security attacks; in the summer of 2005, radiotherapy machines in Merseyside, England36 were attacked by a computer virus. In contrast to the problem described above, this attack affected availability, not the particular treatment delivered.
Computerized physician order entry (CPOE) systems are widely used and can reduce the incidence of medical errors as well as bring efficiency improvements. The ability to take notes by computer rather than by hand and instantly make such information available to others of the medical team can save lives. The ability to record prescriptions the minute they are prescribed, and the automated checking of these prescriptions against others the patient is taking, reduces the likelihood of interactions. The ability to make a tentative diagnosis and instantly receive information on treatment options clearly improves efficiency. But one study37 suggests that poorly designed and implemented systems can actually facilitate medication errors. User interfaces may be poorly designed and hard to use, and important functions that once, before computerization, were implemented by other means may be missing. Moreover, users can
|
35 |
Richard Cook and Michael O’Connor, “Thinking about accidents and systems,” forthcoming, in K. Thompson and H. Manasse, eds., Improving Medication Safety, American Society of Health-System Pharmacists, Washington, D.C., p. 15. Available online at <http://www.ctlab.org/documents/ASHP_chapter.pdf>. |
|
36 |
BBC News, 2005, “Hospital struck by computer virus,” August 22. Available online at <http://news.bbc.co.uk/1/hi/england/merseyside/4174204.stm>. |
|
37 |
Ross Koppel, Joshua P. Metlay, Abigail Cohen, Brian Abaluck, A. Russell Localio, Stephen E. Kimmel, and Brian L. Strom, 2005, “Role of computerized physician order entry systems in facilitating medication errors,” Journal of the American Medical Association 293(10):1197-1203. |
become reliant on the information such systems provide, even to the point of using it for invalid purposes (for example, using doses in the pharmacy database to infer normative ranges).
The usability of medical information systems is an important consideration as poor usability may not only lead to accidents but may also reduce or even eliminate efficiency gains and lower the quality of care. If an information system is not designed to carefully represent complex traditional procedures in digital form, information may be lost or misrepresented. Moreover, avenues for data entry by physicians need to ensure that the physicians are able to pay sufficient attention to the patient and pick up any subtle cues about the illness without being distracted by the computer and data entry process.
Many of these challenges might stem from organizational control issues—centralized and rigid design that fails to recognize the nature of practice,38 central rule-making designed to limit clinical choices, insurance requirements that bin various forms of a particular condition in a way that fails to individualize treatment, and insufficient assessment after deployment. However, technology plays a role in poorly designed and inefficient user interfaces as well. Although the computerization of health care can offer improvements in safety and efficiency, care is needed so that computerization does not undermine the safety of existing manual procedures. In the medical device industry, for example, while many of the largest manufacturers have well-established safety programs, smaller companies may face challenges with respect to safety, perhaps because they lack the necessary resources and expertise.39
Infrastructure
By enhancing communication and live data analysis, software offers opportunities for efficiency improvements in transportation and other infrastructure. Within a decade or two, for example, traffic flow may be controlled by extensive networks of monitors, signals, and traffic advisories sent directly to cars.40 A major, sustained failure of such a system might be catastrophic. For critical functions such as ambulance, fire, and police services, any failure has catastrophic potential. The failure of even
|
38 |
See Kathryn Montgomery, 2006, How Doctors Think, Clinical Judgment and the Practice of Medicine, Oxford University Press, Oxford, United Kingdom. |
|
39 |
A recent FDA report estimates that there are about 15,000 manufacturers of medical devices and notes that “these small firms may lack the experience to anticipate, recognize, or address manufacturing problems that may pose safety concerns.” Ensuring the Safety of Marketed Medical Devices: CDRH’s Medical Device Postmarket Safety Program, January 2006. |
|
40 |
See ongoing work at <http://www.foresight.gov.uk/Intelligent_Infrastructure_Systems/Index.htm>. |
one component, such as the dispatch system, can have significant repercussions; the infamous collapse of the London Ambulance System41 demonstrated how vulnerable such a system is just to failures of availability.
Software is a key enabler for greater fuel efficiency; modern cars rely heavily on software for engine control, and in some cars, control is largely by electrical rather than mechanical means. However, software flaws might cause a car to fail to respond to commands or even to shut down entirely. Whereas mechanical failures are often predictable (through evidence of wear, for example), software failures can be sudden and unexpected and, due to coupling, can have far-reaching effects. In 2005, for example, Toyota identified a software flaw that caused Prius hybrid cars to stall or shut down when traveling at high speed; 23,900 vehicles were affected.42
In the realm of communications infrastructure, advances in telecommunications have resulted in lower costs, greater flexibility, and huge increases in bandwidth. These improvements have not, however, been accompanied by improvements in robustness. Cell phone networks have a different—not necessarily improved—vulnerability posture than conventional landline systems, and even the Internet, despite its redundancies, may be susceptible to failure under extreme load.43 The disaster on September 11 and Hurricane Katrina were both exacerbated by failures of communication systems.44
Defense
The U.S. military is a large, if not the largest, user of information technology and software. Failures in military systems, as one might expect, can have disastrous consequences:
A U.S. soldier in Afghanistan used a Precision Lightweight GPS Receiver—a “plugger”—to set coordinates for an air strike. He then saw
|
41 |
D. Page, P. Williams, and D. Boyd, 1993, Report of the Inquiry into the London Ambulance Service, Communications Directorate, South West Thames Regional Health Authority, London, February. Available online at <http://www.cs.ucl.ac.uk/staff/A.Finkelstein/las/lascase0.9.pdf>. |
|
42 |
Sholnn Freeman, 2005, “Toyota attributes Prius shutdowns to software glitch,” Wall Street Journal, May 16. Available online at <http://online.wsj.com/article_print/SB111619464176634063.html>. |
|
43 |
For a discussion of how the traditional landline phone system and the Internet manage congestion and other issues, see National Research Council, 1999, Trust in Cyberspace, National Academy Press, Washington, D.C. Available online at <http://books.nap.edu/catalog.php?record_id=6161>. |
|
44 |
For more information on communications relating to September 11, 2001, see National Research Council, 2003, The Internet Under Crisis Conditions: Learning from September 11, The National Academies Press, Washington, D.C. Available online at <http://books.nap.edu/catalog.php?record_id=10569>. |
that the “battery low” warning light was on. He changed the battery, then pressed “Fire.” The device was designed, on starting or resuming operation after a battery change, to initialize the coordinate variables to its own location.45
It was reported that three soldiers were killed in this incident.46 The error appears to have been the result of failing to consider the larger system when defining the safety properties that guided the design of the software. Hazard analysis should have revealed the danger of transmitting the location of the plugger as the destination for a missile strike, and once the hazard had been identified, it would be straightforward to specify a system property that required (for example) that the specified target be more than some specified (safe) distance away, and that this be checked by the software before the target coordinates are transmitted.
Defense systems with high degrees of automation are inherently risky. The Patriot surface-to-air missile, for example, failed with catastrophic effect on several occasions. An Iraqi Scud missile hit the U.S. barracks in Dhahran, Saudi Arabia, in February 1991, killing 28 soldiers; a government investigation47 found that a Patriot battery failed to intercept the missile because of a software error. U.S. Patriot missiles downed a British Tornado jet and an American F/A-18 Hornet in the Iraq war in 2003.
Distribution of Energy and Goods
Software failures could also interrupt the distribution of goods and services, such as gasoline, food, and electricity. An extended blackout during wintertime in a cold area of the United States would be an emergency. The role of software in the blackout in the Northeast in 2003 is complicated, but at the very least it seems clear that had the software monitoring system correctly identified the initial overload, it could have been contained without leading to systemwide failure.48
Apart from experiencing functional failures or design flaws, software is also vulnerable to malicious attacks. The very openness and ubiquity that makes networked systems attractive exposes them to attack by van-
|
45 |
From page 83 in Michael Jackson, 2004, “Seeing more of the world,” IEEE Software 21(6):83-85. Available online at <http://mcs.open.ac.uk/mj665/SeeMore3.pdf>. |
|
46 |
Vernon Loeb, 2002, “‘Friendly fire’ deaths traced to dead battery: Taliban targeted, but US forces killed,” Washington Post, March 24, p. A21. |
|
47 |
GAO, 1992, Patriot Missile Software Problem, Report of the Information Management and Technology Division. Available online at <http://www.fas.org/spp/starwars/gao/im92026.htm>. |
|
48 |
See Charles Perrow, 2007, The Next Catastrophe: Reducing our Vulnerabilities to Natural, Industrial, and Terrorist Disasters, Princeton University Press, Princeton, N.J., Chapter 7. |
dals or criminals. The trend to connecting critical systems to the Internet is especially worrying, because it often involves placing in a new and unknown environment a program whose design assumed that it would be running on an isolated computer. In the summer of 2005, two separate incidents were reported wherein radiotherapy systems were taken offline because their computers were infected by viruses after the systems had been connected to the Internet.49 Numerous studies and significant research have been carried out in software and network security. This report does not focus on the security aspects of dependability, but analysis of the security aspects of a system should be part of any dependability case (see Chapter 2 for a discussion of dependability cases generally, and see Chapter 3 for more on security).
Voting
There have been many reports of failures of software used for electronic voting, although none have been substantiated by careful and objective analysis. But there are few grounds for confidence, and some of the most widely used electronic voting software has been found by independent researchers to be insecure and of low quality.50 In the 2006 election in Sarasota County, Florida, the outcome was decided by a margin of 363 votes, yet over 18,000 ballots cast on electronic voting machines did not register a vote. A lawsuit filed to force a revote cites, among other things, the possibility of software malfunction and alleges that the machines were improperly certified.51
PROBLEMS WITH EXISTING CERTIFICATION SCHEMES
Evidence for the efficacy of existing certification schemes is hard to come by. What seems certain, however, is that experience with certification varies dramatically across domains, with different communities of users, developers, and certifiers having very different perceptions of certification. A variety of certification regimes exist for software in particular application domains. For example, the Federal Aviation Authority (FAA) itself certifies new aircraft (and air-traffic management) systems that include software, and this certification is then relied on by the cus-
|
49 |
BBC News, 2005, “Hospital struck by computer virus,” August 25. Available online at <http://news.bbc.co.uk/1/hi/england/merseyside/4174204.stm>. |
|
50 |
See Avi Rubin et al., 2004, “Analysis of an electronic voting system,” IEEE Symposium on Security and Privacy, Oakland, Calif., May. Available online at <http://avirubin.com/vote.pdf>. |
|
51 |
See the full complaint online at <http://www.eff.org/Activism/E-voting/florida/sarasota_complaint.pdf>. |
tomers who buy and use the aircraft; whereas the National Information Assurance Partnership (NIAP) licenses third-party laboratories to assess security software products for conformance to the Common Criteria (CC).52 Some large organizations have their own regimes for certifying that the software products they buy meet their quality criteria, and many product manufacturers have their own criteria that each version of their product must pass before release. Few, if any, existing certification regimes encompass the combination of characteristics recommended in this report: namely, explicit dependability claims, evidence for those claims, and a demand for expertise sufficient to construct a rigorous argument that demonstrates that the evidence is sufficient to establish the validity of the claims.
On the one hand, in the domain of avionics software, the certification process (and the culture that surrounds it) is held in high regard and is credited by many for an excellent safety record, with software implicated in only a handful of incidents. On the other hand, in the domain of software security, certification has been a dismal failure: New security vulnerabilities appear daily, and certification schemes are regarded by developers as burdensome and ineffective.
Security Certification
Security certification standards for software were developed initially in response to the needs of the military for multilevel-secure products that could protect classified information from disclosure. Concern for security in computing is now universal. The most widely recognized security certification standard is the CC. In short, since CC is demanded by some government agencies, it is widely applied; however better criteria would make it more effective and less burdensome.
Like its predecessors, the CC is a process in which independent government-accredited evaluators conduct technical analyses of the security properties of—typically—commercial off-the-shelf (COTS) IT products and then certify the presence and quality of those properties. The CC model allows end users or government agencies to write a protection profile that specifies attributes of the security features of a product (such as the granularity of access controls and the level of detail captured in audit
logs) and the level of security assurance of a product, as determined by the quality of its design and implementation.
The CC characterizes assurance at one of seven levels, referred to as Evaluation Assurance Levels or EAL 1 (the lowest) through 7 (the highest). Each higher EAL requires more structured design documentation (and presumably more structured design), more detailed documentation, more extensive testing, and better control over the development environment. At the three highest levels of assurance (EALs 5-7), formal specification of system requirements, design, or implementation is mandated.
With a handful of exceptions,53 COTS products complete evaluations only at the lowest four levels of assurance (EALs 1-4). Commercial vendors of widely used software have not committed either to the use of formal methods or to the extensively documented design processes that the higher levels of the CC require. Typical vendor practice for completing evaluation is to hire a specialized contractor who reviews whatever documentation the vendor’s process has produced as well as the product source code and then produces the documentation and associated tests that the CC requires. The vendor often has the option of excluding problematic features (and code) from the “evaluated configuration.” A separate contractor team of evaluators (often another department of the company that produces the evidence) then reads the documentation and reviews the test plans and test results. At EALs 1-4, the assurance levels applied to COTS products, the evaluators may conduct a penetration test to search for obvious vulnerabilities or at the Enhanced Basic level for other flaws (both criteria as defined in the CC documents).54 If the evaluators find that all is in order, they recommend that the responsible government agency grant CC certification to the product as configured. In the United States, the National Security Agency employs validators who are government employees or consultants with no conflicts of interest to check the work of the evaluators.
Because the CC certification process focuses on documentation designed to meet the needs of the evaluators, it is possible for a product to complete CC evaluation even though the evaluators do not have a deep understanding of how the product functions. And because the certification process at economically feasible evaluation levels focuses on the functioning of the product’s security features even while real vulnerabilities can occur in any component or interface, real-world vulnerability
|
53 |
The smartcard industry has embraced higher levels of evaluation, and many smartcard products have completed evaluation at EAL 5. Of more than 400 evaluated products other than smartcards listed at <http://www.commoncriteriaportal.org>, only 7 have completed evaluation at EAL 5 or higher. |
|
54 |
See CC Evaluation Methodology manuals versions 2.3 and 3.1, respectively. |
data show that products that have undergone evaluation fare no better (and sometimes worse) than products that have not.55
While the CC evaluation of security features gives users some confidence that the features are appropriate and consistent, most users would logically assume that a product that had completed evaluation would have fewer vulnerabilities (cases in which an attacker could defeat the product’s security) than a product that had not been evaluated. Sadly, there is no evidence that this is the case.
CC evaluation does not necessarily correlate with the observed rate of vulnerability, as the following examples illustrate. The first example, which a member of the committee participated in at Microsoft, considers the relative effectiveness of CC evaluation and other measures in reducing security vulnerabilities in two Microsoft operating system versions. Microsoft’s Windows 2000 was evaluated at the highest evaluation level usually sought by commercial products (EAL 4), a process that cost many millions of dollars and went on for roughly 3 years after Windows 2000 had been released to customers. However, Windows 2000, as fielded, experienced a large number of security vulnerabilities both before and after the evaluation was completed. A subsequent Windows version, Windows Server 2003, was subject to an additional series of pragmatic steps such as threat modeling and application of static analysis tools during its development. These steps proved effective, with the result that the (thenunevaluated) Windows Server 2003 experienced about half the rate of critical vulnerabilities in the field as its CC-evaluated predecessor.56 Some 18 months later, a CC evaluation against the same set of requirements as for Windows 2000 was completed for Windows Server 2003. The evaluation was useful insofar as it demonstrated the operating system contained a relatively complete set of security features, However, Microsoft’s assessment was that the vulnerability rate of Windows Server 2003 was better than that of Windows 2000 because of a reduced incidence of errors at the coding level, a level well below the level at which it is scrutinized by the CC evaluation. Another example is a recent comparison57 of the vulnerability rates of database products, which indicated that a product
|
55 |
See, for example, the National Vulnerability Database online at <http://nvd.nist.gov/> and a list of evaluated products at <http://www.commoncriteriaportal.org/public/consumer/index.php?menu=5>. |
|
56 |
For information on security vulnerabilities and fixes, see the Microsoft Security Bulletin Web site at <http://www.microsoft.com/technet/security/current.aspx>. |
|
57 |
See David Litchfield, 2006, “Which database is more secure? Oracle vs. Microsoft,” an NGS Software Insight Security Research (NISR) publication. Available online at <http://www.databasesecurity.com/dbsec/comparison.pdf>. The National Vulnerability Database at <http://nvd.nist.gov/> also provides information on this topic. |
that had completed several CC evaluations actually experienced a higher vulnerability rate than one that had completed none.
These data, and comparable data on other classes of products, demonstrate that completion of CC evaluations does not give users confidence that evaluated products will show lower vulnerability rates than products that have not been evaluated. While evaluation against a suitable protection profile ensures completeness and consistency of security features, most users would expect (incorrectly) that CC evaluation is an indicator of better security, which they equate with fewer vulnerabilities.
The problem with CC goes beyond the certification process itself. Its fundamental assumption is that security certification should focus on security components—namely, components that implement security features, such as access control. This is akin to evaluating the security of a building by checking the mechanisms of the door locks. Software attackers, like common burglars, more often look for weaknesses in overall security—for example, for entry points that are not guarded. In computer security jargon, an evaluation should consider the entire attack surface of the system. The CC community is well aware of these problems and has discussed them at length. Unfortunately, the newly released CC version 3 does not show any significant change of direction.
Avionics Certification
Avionics systems are not certified directly but are evaluated as part of the aircraft as a whole. In the United States, when the regulations governing aircraft design were initially developed, avionics systems were implemented in hardware alone and did not incorporate software. The introduction of software into civilian aircraft beginning in the 1970s exposed inadequacies in the regulations relating to avionics: They could not be readily applied to software-based systems. In 1980, a special committee (SC-145) of the Radio Technical Commission for Aeronautics (RTCA) was created to develop guidelines for evaluating software used on aircraft. It was composed of representatives of aircraft manufacturers and avionics manufacturers, members of the academic community, aircraft customers, and certifiers. The committee released its report, Software Considerations in Airborne Systems and Equipment Certification (RTCA DO-178), in 1982. The document was subsequently revised, and the present 1992 version, DO-178B, eventually became the de facto standard worldwide for software in civilian aircraft. In Europe, it is known as ED-12B and is published by the European equivalent of RTCA, the European Organisation for Civil Aviation Equipment (EUROCAE).58
|
58 |
More information on the work of EUROCAE is available online at <http://www.eurocae.org/>. |
DO-178B classifies software using the FAA’s five failure levels to characterize the impact of that particular software’s failure on an aircraft59—ranging from Level A (catastrophic) to Level E (no effect on the operational capability of an aircraft)—and prescribes more stringent criteria at higher levels. DO-178B tends to focus more on eliminating defects than on preventing their introduction in the first place. The desire to make DO-178B widely acceptable also made it imprecise, and evaluations have yielded very different results when conducted by different organizations or government agencies. For example, there are very few detailed requirements for standards and checklists contained within DO-178B. Where one evaluator may be satisfied to check against a set of criteria in a checklist or standard, another may document numerous deficiencies based on his or her own experience, and DO-178B cannot be used to adjudicate between the two different results.60 A dearth of skilled personnel with a stable body of knowledge and capable of delivering consistent interpretations has exacerbated the situation. Evaluators were typically drawn from industry, but despite having good practical experience, they rarely had any formal qualifications in software engineering. To reduce variability, additional explanatory guidance and procedures were developed, and certifiers were given special training. These steps have led to a more prescriptive approach and have resulted in better standardization.
At least in comparison with other domains (such as medical devices), avionics software appears to have fared well inasmuch as major losses of life and severe injuries have been avoided. However, this is not in itself evidence that any or all of the processes prescribed by the DO-178B standard are necessary or cost effective. To give one example, DO-178B lays down criteria for structural coverage of the source code during testing depending on the criticality of the component. The unstated purpose is to establish that requirements-based testing has ensured that all source code has been completely exercised with a rigor commensurate with the hazard associated with the software. Without considerable negotiation, no other approaches are allowable. However, in one published study, detailed analysis and comparison of systems that had been certified to Levels A or B of DO-178B showed that there was no discernible differ-
|
59 |
Adapted from Jim Alves-Foss, Bob Rinker, and Carol Taylor, undated, “Merging safety and assurance: The process of dual certification for FAA and the Common Criteria.” Available online at <http://www.csds.uidaho.edu/comparison/slides.pdf>. |
|
60 |
This was documented in the following NASA report: K.J. Hayhurst, C.A. Dorsey, J.C. Knight, N.G. Leveson, and G.F. McCormick, 1999, “Streamlining software aspects of certification: Report on the SSAC survey.” NAS/TM-1999-209519, August, Section 3, observations 1, 3, 4, 5 (p. 45). The report is available online at <http://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/19990070314_1999110914.pdf>, and an overview of the SSAC process is available online at <http://shemesh.larc.nasa.gov/ssac/>. |
ence between the two levels in the remaining level of anomalies in the software, and that these anomalies included many serious, safety-related defects.61 The main difference between Level A (software that could lead to a catastrophic failure) and Level B (software whose failure would at most be severely hazardous) is that Level A calls for requirements-based testing to be shown to provide MCDC coverage of the software. This suggests that MCDC test coverage (at least as carried out on the software examined in the lessons learned study mentioned above62) does not significantly increase the probability of detecting any serious defects that remain in the software.
Medical Software Certification
Medical software, in contrast to avionics software, is generally not subject to uniform standards and certification. The Food and Drug Administration (FDA) evaluates new products in a variety of ways. Some are subject to premarket approval (PMA), which is “based on a determination by FDA that the PMA contains sufficient valid scientific evidence to assure that the device is safe and effective for its intended use(s).”63 Other classes of products are subject to premarket notification, which requires manufacturers to demonstrate that the product is substantially equivalent to, or as safe and effective as, an existing product. The FDA’s requirements for this procedure are minimal.64 They center on a collection of guidance documents that outline the kinds of activities expected and suggest consensus standards that might be adopted. The larger manufacturers often voluntarily adopt a standard such as the International Electrotechnical Commission’s (IEC’s) 61508,65 a standard related to the functional safety
|
61 |
Andy German and Gavin Mooney, 2001, “Air vehicle software static code analysis— Lessons learnt,” Proceedings of the Ninth Safety-Critical Systems Symposium, Felix Redmill and Tom Anderson, eds., Springer-Verlag, Bristol, United Kingdom. |
|
62 |
In the study cited above, few survey respondents found MCDC testing to be effective—it rarely revealed errors according to 59 percent and never revealed them at all according to 12 percent. That survey (which had a 72 percent response rate) also found that 76 percent of respondents acknowledged inconsistency between approving authorities; only 7 percent said that the guidance provided was ample (with 33 percent deeming it insufficient and 55 percent barely sufficient); and 75 percent found the cost and time for MCDC to be substantial or nearly prohibitive. The committee is not aware of results suggesting significant changes in the ensuing years. |
|
63 |
See the FDA’s “Device advice” on premarket approval. Available online at <http://www.fda.gov/cdrh/devadvice/pma/>. |
|
64 |
The FDA’s guidance on premarket notification is available online at <http://www.fda.gov/cdrh/devadvice/314.html>. |
|
65 |
For more information on IEC 61508, see <http://www.iec.ch/zone/fsafety/pdf_safe/hld.pdf>; for information on ISA S84.01, see <http://www.isa.org/>. |
of electrical/electronic/programmable electronic-safety-related systems, or its U.S. equivalent, ISA S84.01. The certification process itself typically involves a limited evaluation of the manufacturer’s software process.
The consensus standards contain a plethora of good advice and are mostly process-based, recommending a large collection of practices. They emphasize “verification” repeatedly, but despite the safety-critical nature of many of the devices to which they are applied, they largely equate verification with testing (which, as explained elsewhere in this report, is usually insufficient for establishing high dependability) and envisage no role for analysis beyond traditional reviews. The FDA’s guidance document,66 like the IEC’s, has a lengthy section on testing techniques and discusses how the level of criticality should determine the level of testing. It recognizes the limitations of testing and suggests the use of other verification techniques to overcome these limitations, but it does not specify what these might be.
OPPORTUNITIES FOR DEPENDABLE SOFTWARE
Analyses of the role of software in safety-critical systems often focus on their potential to cause harm. It is important to balance concern about the risks of more pervasive software with a recognition of the enormous value that software brings, not only by improving efficiency but also by making systems safer. Software can reduce the risk of a system failure by monitoring for warning signs and controlling interventions; it can improve the quality and timeliness of information provided to operators; and it can oversee the activities of error-prone humans. Software can also enable a host of new applications, tools, and systems that can contribute to the health and well-being of the population.
Without better methods for developing dependable software, it may not be possible to build the systems we would like to build. When software is introduced into critical settings, the benefits must obviously outweigh the risks, and without convincing evidence that the risk of catastrophic failure is sufficiently low, society may be reluctant to field the system whatever the benefits may be. In the United States, the threat of litigation may raise the bar even higher, since failing to deploy a new system that improves safety is less likely to result in damage claims than deploying a system that causes injury.
To illustrate these issues, we consider the same two domains: air transportation and medicine.
|
66 |
FDA, 2002, General Principles of Software Validation; Final Guidance for Industry and FDA Staff, January 11. Available online at <http://www.fda.gov/cdrh/comp/guidance/938.html>. |
Air Transportation
Software already plays a critical role in air transportation, most notably in onboard avionics and in air-traffic management. Dependable software will be a linchpin of safe air transport in the coming decades, in two areas in particular.67 First, efforts to enhance aviation functionality, such as plans for (1) new avionics systems that incorporate full-authority digital engine controllers (FADECs) to manage large engines and monitor their performance and (2) flight-deck and ground-based automation to support free flight, will rely heavily on software.
Second, there are efforts to improve aviation safety by employing automation in the detection and mitigation of accidents.68 The category of accident responsible for most fatalities involving commercial jetliners is “controlled flight into terrain” (CFIT), in which the pilot, usually during takeoff or landing, inadvertently flies the aircraft into the ground. Collisions between planes during ground operations, takeoff, and landing also merit attention; a runway incursion in the Canary Islands in 1977 resulted in one of the worst accidents in aviation history, with 583 fatalities. While such accidents are not common, they pose significant risk.
Software can help prevent both kinds of accident, with—for example— ground proximity warning systems and automatic alerts for runway incursions. Software can also be used to defend against mechanical failures: the Aircraft Condition Analysis and Management System (ACAMS) uses onboard components and ground-based information systems to diagnose weaknesses and communicate them to maintainers.
Medicine
Software is crucial to the future of medicine. Although computers are already widely used in hospitals and doctors’ offices, the potential benefits of IT in patient management have been garnering increased attention of late. The ready availability of information and automated record keeping can have an impact on health care that goes far beyond efficiency improvements. Each year, an estimated 98,000 patients die from preventable medical errors.69 Many of these deaths could be prevented by software. CPOE systems, for example, can dramatically reduce the rate
|
67 |
This section is based on information provided in John C. Knight, 2002, “Software challenges in aviation systems,” Lecture Notes in Computer Science 2434:106-112. |
|
68 |
See, for example, the NASA Aviation Safety Program. Available online at <http://www.aerospace.nasa.gov/programs_avsp.htm>. |
|
69 |
Institute of Medicine, 2000, To Err Is Human: Building a Safer Health System, National Academy Press, Washington, D.C. Available online at <http://books.nap.edu/catalog.php?record_id=9728>. |
of medication errors by eliminating transcription errors. Although media attention tends to focus on the more exciting and exotic applications of software, a wider and deeper deployment of existing IT could have a profound effect on health care.70 Computerization alone, however, is not sufficient; a highly dependable system with adequate levels of decision support is needed.71
The ability of software to implement complex functionality that cannot be implemented at reasonable cost in hardware makes new kinds of medical devices possible, such as heart and brain implants and new surgical tools and procedures. An exciting example of the potential of software to improve medical treatment is image-guided surgery, in which images produced by less recent technologies such as MRI can be synchronized with positioning data, allowing surgeons to see not only the physical surfaces of the area of surgery but also the internal structure revealed by prior imaging. A neurosurgeon removing a tumor aims to remove as much tumor material as possible without causing neurological damage; better tools allow less conservative but safer surgery. Obviously, the software supporting such a tool is critical and must be extraordinarily dependable.
OBSERVATIONS
This study raised a host of questions that have been asked many times before in the software engineering community and beyond but have still to be satisfactorily answered. How dependable is software today? Is dependability getting better or worse? How many accidents can be attributed to software failures? Which development methods are most cost-effective in delivering dependable software? Not surprisingly, this report does not answer these questions in full; answering any one of them comprehensively would require major research. Nevertheless, in the course of investigating the current state of software development and formulating its approach, the committee made some observations that inform its recommendations and reflect on these questions.
Observation 1: Lack of Evidence
Studies of this sort do not have the resources to perform their own data collection, so they rely instead on data collected, analyzed, and interpreted by others. Early on in this study, it became clear that very little information was available for addressing the most fundamental questions about software dependability.
Incomplete and unreliable data about software failures and about the efficacy of different approaches to the development of software make objective scientific evaluation difficult if not impossible. When software fails, the failures leave no evidence of fractured spars or metal fatigue to guide accident investigators; execution of software rarely causes changes to the software itself. Investigating the role of software in an accident needs a full understanding of the software design documents, the implementation, and the logs of system events recorded during execution, yet this expertise may be available only to the manufacturer, which may have a conflict of interest.
Failures in a complex system often involve fault propagation and complex interactions between hardware components, software components, and human operators. This makes it very difficult to precisely determine the impact of software on a system failure. Complex interactions and tight coupling not only make a system less reliable but also make its failures harder to diagnose. There are a number of compendia of anecdotal failure reports, most notably those collected by the Risks Forum,72 which for many years has been gathering into a single archive a wide variety of reports of software-related problems, mostly from the popular press. The accident databases maintained by federal agencies (for example, the National Transportation Safety Board) include incidents in which software was implicated. But detailed analyses of software failures are few and far between, and those that have been made public are mostly the work of academics and researchers who based their analyses on secondary sources.
The lack of systematic reporting of significant software failures is a serious problem that hinders evaluation of the risks and costs of software failure and measurement of the effectiveness of new policies or interventions. In traditional engineering disciplines, the value of learning from failure is well understood,73 and one could argue that without this feedback loop, software engineering cannot properly claim to be an engineer-
|
72 |
See The Risks Digest, a forum on risks to the public in computers and related systems moderated by Peter G. Neumann. Available online at <http://catless.ncl.ac.uk/risks>. |
|
73 |
See, for example, Henry Petroski, 2004, To Engineer Is Human, St. Martin’s Press, New York; and Matthys Levy and Mario Salvadori, 1992, Why Buildings Fall Down, W.W. Norton & Company, New York. |
ing discipline at all. Of course, many companies track failures in their own software, but there is little attention paid by the field as a whole to historic failures and what can be learned from them.
This lack of evidence leads to a range of views within the broader community. The essential question is, If mechanisms for certifying software cannot be relied on, should the software be used or not? Some believe that absent evidence for dependability and robust certification mechanisms, a great deal of caution—even resistance—is warranted in deploying and using software-based systems, since there are risks that systems will be built that could have a catastrophic effect. Others observe that systems are being built, that software is being deployed widely, and that deployment of robust systems could in fact save lives, and they argue that the risk of a catastrophic event is worth taking. From this perspective, effects should focus not so much on deciding what to build, but rather on providing the guidance that is urgently needed by practitioners and users of systems. Accordingly, the lack of evidence has two direct consequences for this report. First, it has informed the key notions that evidence be at the core of dependable software development, that data collection efforts are needed, and that transparency and openness be encouraged so that those deploying software in critical applications are aware of the limits of evidence for its dependability and can make fully informed decisions about whether the benefits of deployment outweigh the residual risks. Second, it has tempered the committee’s desire to provide prescriptive guidance—that is, the approach recommended by the committee is largely free of endorsements or criticisms of particular development approaches, tools, or techniques. Moreover, the report leaves to the developers and procurers of individual systems the question of what level of dependability is appropriate, and what costs are worth incurring in order to obtain it.
Observation 2: Not Just Bugs
Software, according to a popular view, fails because of bugs: errors in the code that cause the software to fail to meet its specification. In fact, only a tiny proportion of failures due to the mistakes of software developers can be attributed to bugs—3 percent in one study that focused on fatal accidents.74 As is well known to software engineers (but not to the general public), by far the largest class of problems arises from errors made in the eliciting, recording, and analysis of requirements. A second large class of problems arises from poor human factors design. The two classes are
related; bad user interfaces usually reflect an inadequate understanding of the user’s domain and the absence of a coherent and well-articulated conceptual model.
Security vulnerabilities are to some extent an exception; the overwhelming majority of security vulnerabilities reported in software products—and exploited to attack the users of such products—are at the implementation level. The prevalence of code-related problems, however, is a direct consequence of higher-level decisions to use programming languages, design methods, and libraries that admit these problems. In principle, it is relatively easy to prevent implementation-level attacks but hard to retrofit existing programs.
One insidious consequence of the focus on coding errors is that developers may be absolved from blame for other kinds of errors. In particular, inadequate specifications, misconceptions about requirements, and serious usability flaws are often overlooked, and users are unfairly blamed. The therapists who operated the radiotherapy system that failed in Panama, for example, were blamed for entering data incorrectly, even though the system had an egregious design flaw that permitted the entry of invalid data without generating a warning, and they were later tried in court for criminal negligence.75 In several avionics incidents, pilots were blamed for issuing incorrect commands, even though researchers recognized that the systems themselves were to blame for creating “mode confusion.”76
Understanding software failures demands a systems perspective, in which the software is viewed as one component of many, working in concert with other components—be they physical devices, human operators, or other computer systems—to achieve the desired effect. Such a perspective underlies the approach recommended in Chapter 3.
Observation 3: The Cost of Strong Approaches
In the last 20 years, new techniques have become available in which software can be specified and designed using precise notations and subsequently subjected to mechanized analysis. These techniques, often referred to as “formal methods,” are believed by many to incur unreasonable costs. While it may be true that formal methods are not economical when only the lowest levels of dependability are required, there is some evidence that as dependability demands increase, an approach that includes formal specification and analysis becomes the more cost-effective
|
75 |
See Deborah Gage and John McCormick, 2004, “We did nothing wrong,” Baseline, March 4. Available online at <http://www.baselinemag.com/article2/0,1540,1543571,00.asp>. |
|
76 |
See NASA, 2001, “FM program: Analysis of mode confusion.” Available online at <http://shemesh.larc.nasa.gov/fm/fm-now-mode-confusion.html>. |
option. This section presents some data in support of this claim and gives a simple economic analysis showing how the choice between a traditional approach and a strong approach (one that incorporates formal methods) might be made.
Traditional software development approaches use specification and design notations that do not support rigorous analysis, as well as programming languages that are not fully defined or that defeat automated analysis. Traditional approaches depend on human inspection and testing for validation and verification. Strong approaches also use testing but employ notations and languages that are amenable to rigorous analysis, and they exploit mechanical tools for reasoning about properties of requirements, specifications, designs, and code.
Traditional approaches are generally less costly than strong methods for obtaining low levels of dependability, and for this reason many practitioners believe that strong methods are not cost-effective. The costs of traditional approaches, however, can increase exponentially with increasing levels of dependability. The cost of strong approaches increases more slowly with increasing dependability, meaning that at some level of dependability strong methods can be more cost-effective.77
Whether software firms and developers will use traditional or strong approaches depends, in part, on consumer demand for dependability. The following exercise discusses the consumer-demand-dependent conditions under which firms and developers would choose either the traditional or the strong approach and the conditions under which it would be sensible, from an economics and engineering perspective, to switch back to the traditional approach.
|
77 |
Peter Amey, 2002, “Correctness by construction: Better can also be cheaper,” CrossTalk Magazine, The Journal of Defence Software Engineering, March. Available online at <http://www.praxis-his.com/pdfs/c_by_c_better_cheaper.pdf>. This paper describes the savings that are repeatedly made by projects that use strong software engineering methods. On p. 27, Amey asks How … did SPARK help Lockheed reduce its formal FAA test costs by 80 percent? The savings arose from avoiding testing repetition by eliminating most errors before testing even began…. Most high-integrity and safety-critical developments make use of language subsets. Unfortunately, these subsets are usually informally designed and consist, in practice, of simply leaving out parts of the language thought to be likely to cause problems. Although this shortens the length of rope with which the programmers may hang themselves, it does not bring about any qualitative shift in what is possible. The use of coherent subsets free from ambiguities and insecurities does bring such a shift. Crucially it allows analysis to be performed on source code before the expensive test phase is entered. This analysis is both more effective and cheaper than manual methods such as inspections. Inspections should still take place but can focus on more profitable things like “does this code meet its specification” rather than “is there a possible data-flow error.” Eliminating all these “noise” errors at the engineer’s terminal greatly improves the efficiency of the test process because the testing can focus on showing that requirements have been met rather than becoming a “bug hunt.” |
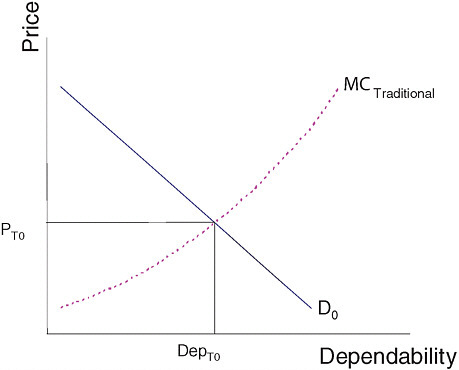
FIGURE 1.1 Equilibrium price and dependability with perfect competition and traditional software approaches.
Consumers have some willingness to pay for dependability. Like any other good, the more costly dependability is, the less of it consumers, who have limited resources, will purchase. Figure 1.1 shows this downward-sloping demand (D0) for dependability: At low prices for dependability, consumers will purchase a lot of it; at high prices, they will purchase less. It is costly, meanwhile, for suppliers to increase dependability. The marginal cost of supplying different levels of dependability using traditional approaches is depicted by the line labeled “MCTraditional.” With perfect competition, the market will reach an equilibrium in which firms supply dependability, DepT0, at the price PT0.
Next, consider the introduction of strong software engineering approaches (Figure 1.2). Consumers still have the same willingness to pay for dependability, but the costs of supplying any given amount of it now depend on whether the firm uses traditional approaches or strong engineering approaches, with the cost structure of the latter depicted in the figure by the curve labeled “MCStrong.”
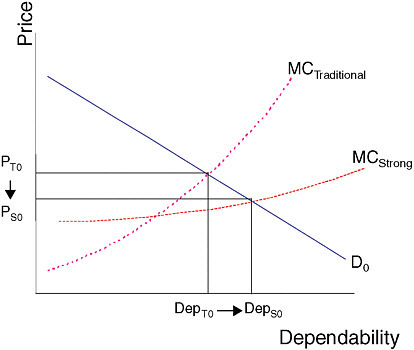
FIGURE 1.2 Lower equilibrium price and higher dependability with strong engineering approaches.
Consumers have the same demand profile for dependability as they had before, but the curve intersects the strong software cost profile at a different point, yielding a new equilibrium at higher dependability (DepS0) and lower price (PS0).78 It is a new equilibrium because, in a perfectly competitive market, firms that continue to use traditional approaches would be driven out of business by firms using strong approaches.
Lower prices and higher dependability are not necessarily the new equilibrium point. The new equilibrium depends crucially on the slopes and location of the demand and cost curves. For some goods, consumers might not be willing to pay as much for a given level of dependability as they might for other goods. Figure 1.3 depicts this demand profile as D1. In this scenario, firms will continue to use traditional approaches, with the equilibrium DepT1 at a price of PT1. No rational firm would switch to strong approaches if consumer demand did not justify doing so.
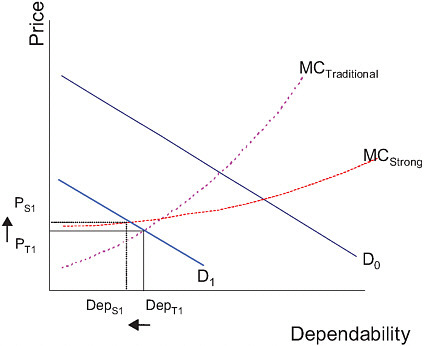
FIGURE 1.3 Consumer demand for dependability is decreased; there is no switch to strong approaches in equilibrium.
Observation 4: Coupling and Complexity
In Normal Accidents,79 Perrow outlines two characteristics of systems that induce failures: interactive complexity, where components may interact in unanticipated ways, perhaps because of failures or just because no designer anticipated the interactions that could occur; and tight coupling, wherein a failure cannot be isolated but brings about other failures that cascade through the system. Systems heavy with software tend to have both attributes. The software may operate as designed, and the component it interfaces with may be performing within specifications, but the software design did not anticipate unusual, but still permissible, values in the component. (In one incident, avionics software sensed the pilot was performing a touch-and-go maneuver; this was because the wet tarmac did not allow the wheels to turn, so they skidded. The pilot was trying to land but the control assumed otherwise and would not let him deceler-
ate.80) Or, the component may be used in a way not anticipated by the software specifications, or a newer model of the component is introduced without realizing how the software might affect it. (Both were true in the case in the Ariane 5 rocket failure. It was destroyed by the overflow of a horizontal velocity variable in a reused Ariane 4 component that was to perform a function not even required by Ariane 5.81) Complicated software programs interact with other complicated software programs, so many unexpected interactions can occur. Trying to find a single point of failure is often fruitless.
The interactive character of software and the components it interfaces with is, quite literally, tightly coupled, so faulty interactions can easily disturb the components linked to it, cascading the disturbance. Modularity reduces this tendency and reduces complexity. Redundant paths increase reliability; while they increase the number of components and the amount of software, this does not necessarily increase the interactive complexity and certainly not the coupling.
The problem of coupling and complexity is exacerbated by the drive for efficiency that underlies modern management techniques. It is common to use software systems in an attempt to increase an organization’s efficiency by eliminating redundancy and shaving margins. In such circumstances, systems can tend to be drawn inexorably toward the dangerous combination of high complexity and high coupling. Cook and Rasmussen explain this phenomenon and illustrate its dangers in the context of patient care.82 In one incident they describe, for example, a hospital allowed surgeries to begin on patients expected to need intensive care afterwards on the assumption that space in the intensive care unit would become available; when it did not, the surgery had to be terminated abruptly. In another incident, when a computer upgrade was introduced, the automated drug delivery program of a large hospital was disrupted for more than 2 days, neccesitating the manual rewriting of drug orders for all patients. All backup tapes of medication orders were corrupted “because of a complex interlocking process related to the database management software that was used by the pharmacy application. Under particular circumstances, tape backups could be incomplete in ways that
|
80 |
See Main Commission Accident Investigation—Poland, 1994, “Report on the accident to Airbus A320-211 aircraft in Warsaw on 14 September 1993.” Available online at <http://sunnyday.mit.edu/accidents/warsaw-report.html>. |
|
81 |
See J.L. Lions, 1996, “ARIANE 5: Flight 501 failure,” Report by the Inquiry Board. Available online at <http://www.ima.umn.edu/~arnold/disasters/ariane5rep.html>. |
|
82 |
R. Cook and J. Rasmussen, 2005, “Going solid: A model of system dynamics and consequences for patient safety,” Quality and Safety in Health Care 14(2):130-134. |
remained hidden from the operator.”83 There was no harm to patients, but the disruption and effort required to mitigate it were enormous.
It is also well known that the operator interfaces to complex software systems are often so poorly designed that they invite operator error.84 However, there is a more insidious danger that derives from a lack of confidence in systems assurance—namely, systems that might best be largely autonomous are instead dubbed “advisory” and placed under human supervision. For a human to monitor an automated system, the automation must generally expose elements of its internal state and operation; these are seldom designed to support an effective mental model, so the human may be left out of the loop and unable to perform effectively.85 Such problems occur frequently in systems that operate in different modes, where the operator has to understand which mode the system is in to know its properties. Mode confusion contributing to an error is exemplified by the fatal crashes of two Airbus 320s—one in Warsaw in 1993 and one near Bangalore in 1990.86 Systems thinking invites consideration of such combinations (sometimes called “mixed initiative systems”) in which the operator is viewed as a component and the overall system design takes adequate account of human cognitive functions.
These concerns do not necessarily militate against the use of software, but they do suggest that careful attention should be paid to the risks of interactive complexity and tight coupling and the advantages of modularity, buffering, and redundancy; that interdependences among components of critical software systems should be analyzed to ensure that modes of
failure are well understood; and that failures are localized to the greatest extent possible. Developers and procurers of software systems should also keep in mind that there are likely to be trade-offs of various sorts between the goals of efficiency and safety and that achieving appropriate safety margins may exact a cost in reduced efficiency and perhaps also in reduced functionality and automation. At the same time, the clarification and simplification that meeting most safety requirements demands may also improve efficiency. Recent work on engineering resilience suggests ways to dynamically manage the trade-off and ways to think about when to sacrifice efficiency for safety.87
Observation 5: Safety Culture Matters
The efficacy of a certification regimen or development process does not necessarily result directly from the technical properties of its constituent practices. The de facto avionics standard, DO178B, for example, although it contains much good advice, imposes (as explained above) some elaborate procedures that may not have a direct beneficial effect on dependability. And yet avionics software has an excellent record with remarkably few failures, which many in the field credit to the adoption of DO178B.
One possible explanation is that the strictures of the standard and the domain in which system engineers and developers are working have collateral effects on the larger cultural framework in which software is developed beyond their immediate technical effects. The developers of avionics software are confronted with the fact that many lives depend directly on the software they are constructing and they pay meticulous attention to detail. A culture tends to evolve that leads developers to act cautiously, to not rely on intuition, and to value the critiques of others.
Richard Feynman, in his analysis of the Challenger disaster,88 commented on similar attitudes among software engineers at NASA:
The software is checked very carefully in a bottom-up fashion…. But completely independently there is an independent verification group, that takes an adversary attitude to the software development group, and
|
87 |
See, for example, D.D. Woods, 2006, “Essential characteristics of resilience for organizations,” in Resilience Engineering: Concepts and Precepts, E. Hollnagel, D.D. Woods, and N. Leveson, eds., Ashgate, Aldershot, United Kingdom; D.D. Woods, 2005, “Creating foresight: Lessons for resilience from Columbia,” in Organization at the Limit: NASA and the Columbia Disaster, W.H. Starbuck and M. Farjoun, eds., Blackwell, Malden, Mass. |
|
88 |
Richard P. Feynman, 1986, “Appendix F—Personal observations on the reliability of the shuttle,” In Report of the Presidential Commission on the Space Shuttle Challenger Accident, June. Available online at <http://science.ksc.nasa.gov/shuttle/missions/51-l/docs/rogers-commission/Appendix-F.txt>. |
tests and verifies the software as if it were a customer of the delivered product…. A discovery of an error during verification testing is considered very serious, and its origin studied very carefully to avoid such mistakes in the future.
To summarize then, the computer software checking system and attitude is of the highest quality. There appears to be no process of gradually fooling oneself while degrading standards so characteristic of the Solid Rocket Booster or Space Shuttle Main Engine safety systems.
An organizational culture that encourages and supports such attitudes is called a “safety culture,” and it is widely recognized as an essential ingredient in the engineering of critical systems. At the same time, it is important to recognize that a strong safety culture, while necessary, is not sufficient. As Feynman noted in the same analysis: “One might add that the elaborate system could be very much improved by more modern hardware and programming techniques.” A safety culture and the processes that support it need to be accompanied by the best technical practices in order to achieve desired dependability.89
Establishing a good safety culture is not an easy matter and requires a sustained effort. The task is easier in the context of organizations that already have strong safety cultures in their engineering divisions and in industries that have organizational commitments to safety (and pressure from consumers to deliver safe products).90 The airline industry is a good example. The large companies that produce avionics software have a long history of engineering large-scale critical systems. There is a rich assemblage of organizations and institutions with an interest in safety; accidents are vigorously investigated; standards are strict; liabilities established; and its customers are influential and resourceful. In his book on accident
|
89 |
The safety culture alone may prevent the deployment of dangerous systems, but it may exact an unreasonably high cost. NASA’s avionics software for the space shuttle, for example, is estimated to have cost roughly $1,000 per line of code (Dennis Jenkins, “Advanced vehicle automation and computers aboard the shuttle.” Available online at <http://history.nasa.gov/sts25th/pages/computer.html>, updated April 5, 2001). Using appropriate tools and techniques can help reduce cost (see previous discussion of the cost of strong approaches). Studies of some systems developed by Praxis, for example, show that software was obtained with defect rates comparable to the software produced by the most exacting standards, but at costs not significantly higher than for conventional developments (Anthony Hall, 1996, “Using formal methods to develop an ATC information system,” IEEE Software 13(2):66-76). It is not clear how widely these results could be replicated, but it is clear that conventional methods based on testing and manual review become prohibitively expensive when very high dependability is required. |
|
90 |
For a comprehensive discussion of the role of safety culture in a variety of industries, see Charles Perrow, 1999, Normal Accidents, Princeton University Press, Princeton, N.J. |
investigation,91 Chris Johnson lists a dozen public and nonprofit organizations concerned with software reliability in the industry (and notes the lack of incident reporting even there). A strong safety culture has not been as widespread in some other domains.
Standards and certification regimes can play a major role in establishing and strengthening safety cultures within companies. The processes they mandate contribute directly to the safety culture, but there are important indirect influences also. They raise the standards of professionalism, the abilities they demand leads to the weeding out of less-skilled engineers, and they call for a seriousness of purpose (and a willingness to perform some laborious work whose benefit may not be immediately apparent). The need to conform to a standard or obtain certification imposes unavoidable costs on a development organization. One engineer interviewed by the committee explained that in his department (in a large U.S. computer company), the fact that managers were forced to spend money on safety made them more open and willing to consider better practices in general and somewhat counterbalanced the tendency to focus on expanding the feature set of a product and hurrying the product to market.
|
91 |
C.W. Johnson, 2003, Failure in Safety-Critical Systems: A Handbook of Accident and Incident Reporting, University of Glasgow Press, Glasgow, Scotland. Available online at <http://www.dcs.gla.ac.uk/~johnson/book/>. |



































