
INTRODUCTION
Comparative effectiveness research (CER) is composed of a broad range of activities. Aimed at both individual patient health and overall health system improvement, CER assesses the risks and benefits of competing interventions for a specific disease or condition as well as the system-level opportunities to improve health outcomes. To meet the ultimate goal of providing information that is useful to guide the healthcare decisions of patients, providers, and policy makers, the work required includes conducting primary research (e.g., clinical trials, epidemiologic studies, simulation modeling); developing and maintaining data resources in order to conduct primary research, such as registries or databases for data mining and analysis, or to enhance the conduct of other types of clinical research; and synthesizing and translating a body of existing research via systematic reviews and guideline development methods. To ensure the best return on investment in these efforts, work is also needed to advance the development of new or refined study methodologies that improve the efficiency and relevance of research as well as reduce its costs. Similarly, to guide the overall clinical research enterprise in the efficient production of information of true value to healthcare decision makers requires the identification of priority research questions that need to be addressed, the coordination of the various aspects of evidence development and translation work, and the provision of technical assistance, such as study design and validation.
The papers that follow provide an overview of the nature of the work required, noting lessons learned about the known benefits of the country’s
capacity and experience, and illustrating opportunities to improve care through capacity building. Emerging from these papers is the notion that although a number of diverse, innovative, and talented organizations are engaged in various aspects of this work, additional efforts are needed. Gains in efficiency are possible with improved coordination, prioritization, and attention to the range of methods that can be employed in CER.
Two papers provide a sense of the potential scope and scale of the necessary CER. Erin Holve and Patricia Pittman from AcademyHealth estimate that approximately 600 comparative effectiveness studies were ongoing in 2008, including head-to-head trials, pragmatic trials, observational studies, evidence syntheses, and modeling. Costs for these studies range broadly, but cluster according to study design. Challenges to develop the workforce needed for CER suggest the need for greater attention to infrastructure for training and funding researchers. Providing a sense of the overall need for comparative effectiveness studies, Douglas B. Kamerow from RTI International discusses the work of a stakeholder group to develop a prioritization process for CER topics and some possible criteria for prioritizing evidence needs. This process yielded 16 candidate research topics for a national inventory of priority CER questions. Possible pitfalls of such an evaluation and ranking process are discussed.
Three papers provide an overview of the work needed to support, develop, and synthesize research. Jesse A. Berlin and Paul E. Stang from Johnson & Johnson survey data resources for research, and discuss how appropriate use of data and creative uses of data collection mechanisms are crucial to help inform healthcare decision making. Given the described strengths and limitations of available data, current systems are primarily resources for the generation and strengthening of hypotheses. As the field transitions to electronic health records (EHRs) however, the value of these data could dramatically increase as targeted studies and data capture capabilities are built into existing medical care databases. Richard A. Justman, from the United Health Group, discusses the challenges of evidence synthesis and translation as highlighted in a recent Institute of Medicine (IOM) report (2008). Limitations of evidence synthesis and translation have led to gaps, duplications, and contradictions; and, key findings and recommendations from a recent IOM report provide guidance on infrastructure needs and options for systematic review and guideline development. Eugene H. Blackstone, Douglas B. Lenat, and Hemant Ishwaran from the Cleveland Clinic discuss five foundational methodologies that need to be refined or further developed to move from the current siloed, evidence-based medicine (EBM) to semantically integrated, information-based medicine and on to predictive personalized medicine—including reengineered randomized controlled trials (RCTs), approximate RCTs, semantically exploring disparate
clinical data, computer learning methods, and patient-specific strategic decision support.
Finally, Jean R. Slutsky from the Agency for Healthcare Research and Quality (AHRQ) provides an overview of organizations conducting CER activities and reflects on the importance of coordination and technical assistance capacities to bridge these activities. Particular attention is needed as to which functions might be best supported by centralized versus local, decentralized approaches
THE COST AND VOLUME OF COMPARATIVE EFFECTIVENESS RESEARCH
Erin Holve, Ph.D., M.P.H., Director; Patricia Pittman, Ph.D.,
Executive Vice President, AcademyHealth
Overview
In the ongoing discussion about CER, there has been limited understanding of the current capacity for conducting CER in the United States. This report intends to help fill this gap by providing an environmental scan of the volume and the range of costs of recent CER. This work was funded by the California HealthCare Foundation. Current production of CER is not well understood, perhaps due to the relatively new use of the term, or perhaps as a result of fragmented funding streams.
Comparative Effectiveness Research Environmental Scan
This study sought to determine whether there is a significant body of CER under way so that policy makers interested in improving outcomes can plan appropriate initiatives to bolster CER in the United States. This study does not catalog the universe of CER because existing data sources are limited by the way that research databases are developed. However, it is a first attempt to assess the approximate volume and cost of CER.
The study focused on four major objectives:
- Identify a typology of CER design.
- Characterize the volume of research studies that address comparative effectiveness questions.
- Provide a range of cost estimates for conducting comparative effectiveness studies by type of study design.
- Gather information on training to support the capacity to produce CER.
These efforts relied on three modes of data collection. The first phase included the development of a framework of study designs and topics. The second consisted of a structured search of research projects listed in two databases: www.clinicaltrials.gov and Health Services Research Projects in Progress (HSRProj),1 a database of health services research projects in progress. The third consisted of in-person and telephone interviews with 25 research organizations identified as leaders in comparative effectiveness studies. The number, type, and costs of studies were noted, although only studies cited by funders were included in the estimates of volume because of the possibility of double-counting studies cited by both researchers and funders. Interviews were used to triangulate information on costs and the relative importance of different designs.
An important study limitation was that it was not possible to cross-reference the databases and the interviews. As a result, although these sources are comparable, they should not be aggregated.
In an initial focus group with experts on CER, a definition of CER was developed to guide the project. Though many definitions of CER have been developed,2 this project relies on the following:
- CER is a comparison of the effectiveness of the risks and benefits of two or more healthcare services or treatments used to treat a specific disease or condition (e.g., pharmaceuticals, medical devices, medical procedures, other treatment modalities) in approximate real-world settings
- The comparative effectiveness of organizational and system-level strategies to improve health outcomes is excluded from this definition, as is research that is clearly “efficacy” research. This means that studies that compare an intervention to placebo or to usual care were excluded from our counts.
The expert panel also developed a framework of research designs to make it possible to categorize findings systematically. For the purposes of this study there was general agreement that there are three primary research categories3 applicable to CER:
_______________
1 HSRProj may be accessed at www.nlm.nih.gov/hsrproj/ (accessed September 22, 2010).
2 In a recent report from the Congressional Budget Office, the authors state that comparative effectiveness is “simply a rigorous evaluation of the impact of different treatment options that are available for treating a given medical condition for a particular set of patients” (CBO, 2007). An earlier report by the Congressional Research Service makes an additional distinction that comparative effectiveness is “one form of health technology assessment” (CRS, 2007).
3 During the interviews we attempted to identify research by more specific types, asking questions about pragmatic trials, registry and modeling studies, and systematic reviews.
- head-to-head trials (including pragmatic trials);
- observational studies (including registry studies, prospective cohort studies, and database studies); and
- syntheses and modeling (including systematic reviews).4
Clinicaltrials.gov is the national registry of data on clinical trials, as mandated by the Food and Drug Administration (FDA) reporting process required for drug regulation. Clinicaltrials.gov includes more than 53,000 study records and theoretically provides a complete set of information on all clinical trials of drugs, biologics, and devices subject to FDA regulations (Zarin and Tse, 2008). While the vast majority of trials included in clinicaltrials.gov are controlled experimental studies, there are some observational studies as well.
HSRProj is a database of research projects related to healthcare access, cost, and quality as well as the performance of healthcare systems. Some clinical research may be included in HSRProj if it is focused on effectiveness. HSRProj includes a variety of public and private organizations but only a limited number of projects funded by private or industry sources.
A search was conducted in www.clinicaltrials.gov for phase 3 and phase 4 observational and interventional studies. Phase 4 studies were narrowed by searching only for studies containing the term effectiveness. Studies that were explicitly identified as efficacy studies or those that did not include at least two active comparators were excluded. The HSRProj database was also searched for studies on effectiveness. Because HSRProj does not differentiate between study design phases, a search was also conducted by the types of studies identified in the framework. The studies identified through the process of searching both databases were then searched by hand in order to identify projects that met the definition of CER.
The interview phase of the project included in-person and telephone interviews with research funders and researchers who conduct CER. An initial sample of individuals funding and conducting CER were contacted in response to recommendations by the focus group panel, and these initial
_______________
4 Observational research studies include a variety of research designs but are principally defined by the absence of experimentation or random assignment (Shadish et al., 2002). In the context of CER, cohort studies and registry studies are generally thought of as the most common study types. Prospective cohort studies follow a defined group of individuals over time, often before and after an exposure of interest, to assess their experience or outcomes (Last, 1983), while retrospective cohort studies frequently use existing databases (e.g., medical claims, vital health records, survey records) to evaluate the experience of a group at a point or period in time.
Registry studies are often thought of as a particular type of cohort study based on patient registry data. Patient registries are organized systems using observational study methods to collect patient data in a uniform way. These data are then used to evaluate specific outcomes for a population of interest (Gliklich and Dreyer, 2007).
contacts in turn recommended other respondents—a “snowball” sample. In total, 35 individuals representing 25 research funders or research organizations participated in the project.5
Findings
For the project, 689 comparative effectiveness studies were identified in clinicaltrials.gov and HSRProj. Of these the vast majority are “interventional trials” listed on clinicaltrials.gov; specifically, they are phase 3 trials that compare two or more treatments “head to head,” have real-world elements in their study design, and do not explicitly include efficacy in their description of the study design. Only 19 studies are phase 4 post-marketing studies that compare multiple treatments. Seventy-three CER projects were identified in HSRProj. The process of manually searching project titles confirmed that most studies in this database were observational research, although a handful of studies were specifically identifiable as registry studies, evidence synthesis, or systematic reviews.
The interviews with funders identified 617 comparative effectiveness studies, of which approximately half were observational studies (prospective cohort studies, registry studies, and database studies). Research syntheses (reviews and modeling studies) and experimental head-to-head studies also represent a significant proportion of research activities.
Neither clinicaltrials.gov nor HSRProj publish funding amounts, so interviews with funders and researchers are the sole source of data on cost. As would be expected across the range of study designs covered, there is an extremely broad array of cost for CER studies. However, despite the range, cost estimates provided in the interviews did tend to cluster, particularly by study type. While the cost of conducting head-to-head randomized trials was extremely broad, including studies as costly as $125 million, smaller trials tended to range from $2.5 million to $5 million and larger studies from $15 million to $20 million.
Likewise, the range of cost for observational studies was extremely broad but tended to cluster (Table 2-1). While large prospective cohort studies cost $2 million to $4 million, large registry studies cost between $800,000 and $6 million, with most examples falling at the higher end of this range, although a few were substantially less. Retrospective database studies tended to be less expensive and cost on the order of $100,000
_______________
5 Though an initial group of potential respondents was identified as funders of CER, it was often necessary to speak with multiple individuals to find the appropriate person or group responsible for CER within the organization’s portfolio. For this reason the response rate among individuals is lower than might be expected for a series of key informant interviews. Thirteen organizations were identified that did not suggest they received funding for CER from other sources. This subset is used as the sample of organizations that fund or self-fund CER.
TABLE 2-1 Costs of Various Comparative Effectiveness Studies
|
|
||
|
Type of Study |
Cost |
|
|
|
||
|
Head to head |
Randomized controlled trials: Smaller Larger |
$2.5m–$5m $15m–$20m |
|
|
||
|
Observational |
Registry studies Large prospective cohort studies Small retrospective database studies |
$2m–$4m $800k–$6m $100k–$250k |
|
|
||
|
Synthesis |
Simulation/modeling studies Systematic reviews |
$100k–$200k $200k–$350k |
|
|
||
to $250,000. Systematic reviews and modeling studies tended to be less expensive and have a far narrower range of cost, in part because these studies were based on existing data, with many falling between $100,000 to $200,000. It is important to note, however, that this may not include the cost of procuring data. Systematic reviews cluster around a range of $200,000 to $350,000.
There are, of course, additional activities and costs of involving stakeholders in research agenda setting as well as prioritizing, coordinating, and disseminating research on CER that are not included here.6 These important investments will need to be considered in the process of budgeting for CER.7
_______________
6 Examples of activities designed to prioritize and coordinate research activities include the National Cancer Institute’s CER Cancer Control Planet (http://cancercontrolplanet.cancer.gov/), which serves as a community resource to help public health professionals design, implement, and evaluate CER-control efforts (NCI, 2007). Within the the Agency for Healthcare Research and Quality, the prioritization and research coordination efforts for comparative effectiveness studies are undertaken as part of the Effective Health Care Program. Translation and dissemination of CER findings is handled by the John M. Eisenberg Clinical Decisions and Communications Science Center, which aims to translate research findings to a variety of stakeholder audiences. No budget information is readily available for the Eisenberg Center activities.
7 Examples of stakeholder involvement programs include two programs at the FDA focused on involving patient stakeholders, the Patient Representative Program and the comparative
Finally, the interviews also shed light on two subjects discussed at this workshop (IOM, 2008): (1) the need for additional training in the methods and conduct of CER; and (2) the need to bring researchers together to discuss the relative contributions of RCTs and observational studies in the context of CER.
While interviewees generally commented that they have some capacity to respond to an increase in the demand for CER, some noted that they have had difficulty finding adequately trained researchers to conduct such research. For the moment, training programs are limited primarily to research trainees working with AHRQ’s evidence-based practice centers and the Developing Evidence to Inform Decisions about Effectiveness (DEcIDE) network. Respondents also mentioned two postdoctoral training programs designed to teach researchers how to conduct effectiveness research. The Duke Clinical Research Institute (DCRI) offers a program for fellows and junior faculty. Fellows studying clinical research may take additional coursework and receive a masters of trial services degree in clinical research as part of the Duke Clinical Research Training Program. The Clinical Research Enhancement through Supplemental Training (CREST) program at Boston University is the second program mentioned. CREST trains researchers in aspects of clinical research design, including clinical epidemiology, health services research (HSR), biobehavioral research, and translational research. Both the DCRI and CREST programs have a strong emphasis on clinical research using both randomized experimental study designs and observational designs.
Other funding for training includes the National Institutes of Health (NIH) K30 awards to support career development of clinical investigators and to develop new modes of training in theories and research methods. The program’s goal is to produce researchers capable of conducting patient-oriented research on epidemiologic and behavioral studies and on outcomes or health services research (NIH, 2006). As of January 2006, the Office of Extramural Affairs lists 51 curriculum awards funded through the K30 mechanism. In November 2007 AHRQ released a Special Emphasis Notice
_______________
effectiveness research Drug Development Patient Consultant Program (Avalere Health, 2008; FDA, 2009). Other examples of stakeholder involvement programs include the National Institute for Occupational Safety and Health–National Occupational Research Agenda program, the American Thoracic Society Public Advisory Roundtable, and the National Institutes of Health director’s Council of Public Representatives (COPR). These efforts can represent a sizeable investment in order to assure stakeholder involvement among the potentially diverse group of end users. For example, the COPR is estimated to cost approximately $350,000 per year (Avalere Health, 2008). From an international perspective, the UK’s National Institute for Health and Clinical Excellence (NICE) allocates approximately 4 percent of their annual budget (approximately $775,000) in NICE’s Citizen’s Council and for their “patient involvement unit” (NICE, 2004).
for Career Development (K) Grants focused on CER (AHRQ, 2007). Four career awards are slated to support the development, generation, and translation of scientific evidence by enhancing the understanding and development of methods used to conduct CER.
The challenge of filling the “pipeline” of researchers working on comparative effectiveness is exacerbated by what many of the interviewees viewed as a fundamental philosophical difference between researchers who were academically trained in observational research and those who are trained on the job to conduct clinical trials. Several respondents noted that these differences likely arise because the majority of researchers are trained in either observational study methods or randomized trials, but rarely both. In addition, as noted by Hersh and colleagues,8 there are many unknowns related to assessing the workforce needs for CER, including the unresolved definitional issues and scope of comparative effectiveness. As noted by Hersh, the proportion of CER that is focused on randomized trials, observational research, and syntheses has strong implications for the number of researchers (and the type of training) that will be needed. For this reason it is important to track research production and funding for CER in order to anticipate future needs.
Some respondents noted that differences in training manifest themselves in disagreements about the benefits of various observational study designs. Nevertheless, most individuals interviewed as part of this study felt that RCTs, observational studies (including registry studies, prospective cohort studies, and quasi-experiments), and syntheses (modeling studies and systematic reviews) are complementary strategies to generate useful information to improve the evidence base for health care. Furthermore, many participants agreed that, as CER evolves, it will be critical to develop a balanced research portfolio that builds on the strengths of each study type. To facilitate this balance, some of the interviews, as well as many comments at the IOM’s Roundtable on Value & Science-Driven Health Care (IOM, 2008) suggest that training opportunities to bridge gaps in language and methods used by researchers may be helpful in creating a balanced portfolio of CER.
Conclusion
Findings from this study indicate that there is a greater volume of ongoing CER than may initially have been supposed. The cost of conducting this research varies greatly, although it tends to cluster by type of study.
_______________
8 Hersh, B., T. Carey, T. Ricketts, M. Helfand, N. Floyd, R. Shiffman, and D. Hickam. A framework for the workforce required for comparative effectiveness research. See Chapter 4 of this publication.
The range of studies that are currently being conducted and the cost variation by study type have implications for the mix of activities that may be undertaken by an entity focused on CER. Furthermore, as identified in the interviews, assuring sufficient research capacity to conduct CER is likely to require an investment in multidisciplinary training, with an emphasis on bridging the gap between awareness of the strengths and limitations of randomized trials, observational study designs, and syntheses.
INTERVENTION STUDIES THAT NEED TO BE CONDUCTED
Douglas B. Kamerow, M.D., M.P.H.
Chief Scientist, Health Services and Policy Research, RTI International,
and Professor of Clinical Family Medicine, Georgetown University
Overview
CER compares the impact of different treatments for medical conditions in a rigorous, practical manner. At the request of the IOM’s Roundtable on Value & Science-Driven Health Care, IOM staff convened in 2008 a multisectoral working group to create a national priority assessment inventory. Their charge was to set criteria for choosing appropriate CER topics and then to nominate and review example topics for needed research. An abridged summary of the report is presented in Appendix B. Appendixes C and D, respectively, are the recommended priority CER studies proposed in 2009 by the IOM Committee on Comparative Effectiveness Research Prioritization and the Federal Coordinating Council for Comparative Effectiveness Research.
Introduction
CER has been defined as “rigorous evaluation of the impact of different options that are available for treating a given medical condition for a particular set of patients,” (CBO, 2007) and “the direct comparison of existing healthcare interventions to determine which work best for which patients and which pose the greatest benefits and harms” (Slutsky and Clancy, 2009). Broadly construed, this type of research can involve comparisons of different drug therapies or devices used to treat a particular condition as well as comparisons of different modes of treatment, such as pharmaceuticals versus surgery. It can also be used to compare different systems or locations of care and varied approaches to care, such as different intervals of follow-up or changes in medication dosing levels for a particular condition. CER also may be used to investigate diagnostic and
preventive interventions. All of these studies may include an evaluation of costs as well as an assessment of clinical effectiveness.
Comparative assessment research is especially valuable now, in an era of unprecedented healthcare spending and large, unexplained variations in care for patients with similar conditions. The IOM’s Roundtable on Value & Science-Driven Health Care set a goal for the year 2020 that 90 percent of clinical decisions will be supported by accurate, timely, and up-to-date clinical information that reflects the best available evidence. Currently, there is insufficient evidence about which treatments are most appropriate for certain groups of patients and whether or not those treatments merit their sometimes significant costs. The healthcare community requires improved evidence generation that will address how different interventions compare to one another when applied to target patient populations. CER provides the opportunity to ground clinical care in a foundation of sound evidence.
The current system usually ensures that when a new drug or device is made available, there is evidence to show its effectiveness compared to a placebo in ideal research conditions—that is, its efficacy. But there is often an insufficient body of evidence demonstrating its relative effectiveness compared to existing or alternative treatment options, especially in real-world settings. This limited scope of information increases the likelihood that clinical decisions are not based on evidence but rather on local practice style, institutional tradition, or physician preference. Although the numbers vary, some estimate that less than half—perhaps well less than half—of all clinical decisions are supported by sufficient evidence (IOM, 2007). This lack of evidence also leads to substantial geographic variations in care, further supporting the idea that patients may be subjected to treatments that are unnecessarily invasive—or not aggressive enough—for a variety of conditions. These variations in care partly explain healthcare spending differences across geographic regions that cannot be fully accounted for by price differences or illness rates. Geographic variations in treatment approach are often greater when there is less agreement within the medical community about the appropriate treatment. Variation in treatment approach for a variety of conditions is of significant concern because it has not been demonstrated that areas with higher levels of spending—where presumably patients are treated with more aggressive or expensive options or with simply more treatment—have significantly better health outcomes than areas with lower levels of spending.
The Institute of Medicine and Comparative Effectiveness
The IOM’s Roundtable on Value & Science-Driven Health Care recognized the importance of furthering CER to ensure that all clinical deci-
sions are based on sound evidence. The participants at the Roundtable’s July 2007 meeting of sectoral stakeholders concluded both that current resources to support head-to-head assessments of treatment options are not optimal and that a stronger consensus is needed on the priorities and approaches for assessing the comparative clinical effectiveness of health interventions. Participants at this meeting identified the need for the development of what they initially termed a “national problem list” to illustrate key evidence gaps and to prompt discussions leading to national studies.
National Priority Assessment Inventory
After initial work was done by IOM staff, the proposed project was renamed the National Priority Assessment Inventory. A working group was convened to serve as a steering committee for the project. Nominees for the working group were sought from IOM Roundtable stakeholders representing the different participating sectors—patients, caregivers, integrated care delivery organizations, insurers, regulators, employees and employers, clinical investigators, and healthcare product developers. The working group was composed of physicians and researchers representing different specialties and perspectives, coming from academia, government, private practice, medical specialty societies, and industry. The working group was given three tasks to accomplish in a series of conference calls involving either the entire group or only certain individuals:
- Review and refine selection criteria for identifying and evaluating needed research.
- Solicit and nominate candidate research topics.
- Review and comment on the final list of pilot topics.
Selection Criteria
The working group initially discussed and refined criteria that could be used to identify and evaluate candidate research topics. The final five selection criteria are listed in Box 2-1.
The first criterion selected was the importance of the conditions being treated or prevented. The working group wanted to concentrate on research for problems that were serious, common, or costly. Though not wanting to set quantitative cutoffs, they felt it was important that the studies chosen involved conditions that would be clearly recognized as important by clinicians, policy makers, and patients.
Second, effective treatments or preventive interventions needed to be available for the chosen conditions. Reasonable alternative treatments and resulting variations in practice are basic requirements for CER. Alternatives to be compared could include different drugs, different treatment modalities
BOX 2-1
Selection Criteria to Identify and Evaluate Research Topics
- Importance of the conditions
- Effective treatments or preventive interventions available
- Current knowledge about the relative effectiveness not definitive
- Research must be feasible and realistic
- The selection process should yield a heterogeneous group of topics
(drugs, devices, surgery, etc.), different preventive interventions, or different settings and systems of care.
Third, current knowledge about the relative effectiveness of alternative treatments or modalities must not be definitive, so that uncertainty exists in treatment selection for different settings and populations. In short, while an existing body of research is clearly necessary, unresolved questions should still exist.
Fourth, research to answer selected questions must be feasible and realistic. A head-to-head trial or data analysis that could improve knowledge and guide decision making should be practical to perform, without major design or financial barriers.
Fifth, the work group agreed that this pilot selection process should yield a heterogeneous group of topics. The final topic list was intended to provide examples of treatment, prevention, and HSR on a variety of conditions, using several different modes of treatment, and for conditions in differing demographic groups.
Selection Process
Candidate topics were solicited in a number of ways. Working group members suggested many topics from their respective clinical and administrative experience; they also asked colleagues for suggestions. IOM staff generated topics from prior work they had done as well as from outside sources. A prioritized list of 100 Medicare research priorities generated by the Medicare Evidence Development and Coverage Advisory Committee was also reviewed, as was a list of 14 priority conditions created for AHRQ’s Effective Health Care Program. A special effort was made to identify topics related to the care of children because so much effort is usually concentrated on adults and the elderly.
After this nomination process, about two dozen potential topics and studies were classified by condition, applicable population, type of treatment, setting, and other categories, and then were discussed by the working group. Staff began to evaluate the candidate topics by doing literature searches to determine available literature and feasibility. In an informal iterative process performed with the working group, the list was reduced to 16 topics. This list was then circulated to sectoral representatives for comments, and in July 2008 it was discussed and approved by members of the Roundtable on Value & Science-Driven Health Care. Staff then did further literature reviews and wrote brief summaries of the final example topics.
The 16 study topics are listed in Table 2-2 and are categorized by type of study, condition, and age group. As mentioned previously, the topics were chosen in part to provide examples from each of the categories in these tables.
Study Topic Summaries
Sixteen study topic summaries are included in Appendix B of this publication. All of the summaries are organized in the same manner:
- description of the condition or problem,
- available treatments or interventions,
- current evidence about the treatments or interventions,
- issues needing research and conclusions, and
- brief list of references.
Lessons Learned from This Project
The original, perhaps naïve, intent of this project was to produce a list of the 20 or so “best” or “most important” comparative effectiveness studies that need to be done immediately. However, evaluating and ranking studies proved to be difficult to do. Some nominations were impractical or difficult to operationalize; for others, evidence was not available. Ranking topics by potential national costs of the condition would skew the rankings toward common and expensive adult problems and leave childhood problems out entirely. Comparing topics is often an “apples vs. oranges” exercise, and common metrics are not always available. The process did, however, produce some clear lessons learned:
Much research needs to be done. It was not difficult to gather nominations and information about research that has the potential to make a real difference in costs and outcomes. It bears repeating that the topics chosen are just examples of questions that need to be answered.
Stakeholders should be consulted. A process without input and review
TABLE 2-2 The Comparative Effectiveness Studies Inventory Project Identified 16 Candidate Topics for Comparative Effectiveness Research
| Study Topic | Study Type | Age Group | Condition |
| Treatment of attention deficit hyperactivity disorder in children: drugs, behavioral interventions, no prescription | Comparative effectiveness treatment studies across modalities | Children | Mental diseases |
| Treatment of acute thrombotic/embolic stroke: clot removal, reperfusion drugs | Comparative effectiveness treatment studies across modalities | Adults | Heart and vascular diseases |
| Treatment of chronic atrial fibrillation: drugs, catheter ablation, surgery | Comparative effectiveness treatment studies across modalities | Adults | Heart and vascular diseases |
| Treatment of chronic low back pain | Comparative effectiveness treatment studies across modalities | Adults | Neurological diseases |
| Gamma knife surgery for intracranial lesions vs. surgery and/or whole brain radiation | Comparative effectiveness treatment studies across modalities | Adults | Neurological diseases |
| Treatment of localized prostate cancer: watchful waiting, surgery, radiation, cryotherapy | Comparative effectiveness treatment studies across modalities | Adults | Cancer |
| Diagnosis and prognosis of breast cancer using genetic tests: human epidermal growth factor receptor 2 and others | Diagnostic studies | Adults | Cancer |
| Over-the-counter drug treatment of upper respiratory tract infections in children | Drug–drug and drug–placebo treatment studies | Children | Respiratory disorders |
| Drug treatment of depression in primary care | Drug–drug and drug–placebo treatment studies | Adults | Mental disorders |
| Study Topic | Study Type | Age Group | Condition |
| Drug treatment of epilepsy in children | Drug–drug and drug–placebo treatment studies | Children | Neurological diseases |
| Use of erythropoiesis-stimulating agents in the treatment of hematologic cancers | Drug–drug and drug–placebo treatment studies | Adults | Cancer |
| Outcomes of percutaneous coronary interventions in hospitals with and without onsite surgical backup | Health services/systems studies | Adults | Heart and vascular diseases |
| Screening hospital inpatients for methicillin-resistant Staphylococcus aureus infection | Preventive interventions | Adults | Infectious diseases |
| Tobacco cessation: nicotine replacement agents, oral medications, combinations | Preventive interventions | Adults | Preventive interventions |
| Prevention and treatment of pressure ulcers | Surgical studies | Adults | Dermatological diseases |
| Inguinal hernia repair: open vs. minimally invasive | Surgical studies | Adults | Surgical disorders |
NOTE: Study topics are categorized by study type, age group, and condition.
SOURCE: Kamerow, 2009.
by a broad set of stakeholders risks missing important topics as well as not obtaining different perspectives on all nominated topics. Clinicians ask one kind of question; payers and employers often have different concerns. All perspectives need to be considered in nominating, vetting, and ultimately deciding on research topics. That said, some topics nominated by stakeholders were not confirmed as being important or practical after literature reviews.
Research questions need to be carefully defined. Once general topics had been selected, literature reviews often found either too much or
not enough evidence to support a call for further research. Topics were often reoriented as a result of the state of the evidence, being narrowed, expanded, or abandoned according to what the evidence said.
Different types of studies are needed. Three types of comparative assessment studies are often described. The gold standard for CER is a prospective, randomized head-to-head trial comparing specific treatments or interventions for a condition. Such trials, however, can be expensive and usually take time to complete. In some cases, the extant literature is sufficient to assess comparative effectiveness, and systematic reviews with or without formal meta-analysis can be created from data taken from previous studies. This type of study is usually the fastest to complete. Finally, existing clinical and payment data systems can sometimes be analyzed to compare the effectiveness of drugs or devices without collecting new data. These studies can also be done relatively rapidly. It was often difficult to determine from the state of the literature which type of comparative effectiveness study was appropriate for each of the nominated topics.
An explicit, transparent process is important. Significant funding will be necessary to undertake these studies. Unlimited funding is never available, of course, and there will be limits on the number of projects that can be initiated simultaneously, so priorities must be assigned. While the external validity of this selection and ranking processes has not been proven, the face validity of the process will be important for continued stakeholder support.
Continuous updating is important. Advances and new data appear all the time, so frequent updates of literature reviews will help make sure that the topics selected still need research.
Prioritizing topics is very difficult. As mentioned above, ranking studies by their importance is difficult to do in a manner that is equitable. The burden of suffering caused by a condition, expressed in prevalence or mortality rates, can be determined for many conditions, but it is skewed by greater prevalence of disease in older populations. Taking into account the years of productive life lost can help to correct for some of the age bias, but such calculations do not necessarily reflect costs. Treatment cost data are biased towards conditions whose treatments involve expensive devices or drugs. And so on.
“Indication creep” is challenging to assess. Often drugs or devices that have been proven effective for one indication or condition will be used to treat other, related problems without strong evidence. Questions then arise about their effectiveness for the new indication. Are de novo studies required, or can results from research on similar problems be extrapolated to apply?
Systematic reviews and evidence-based guidelines are important and helpful, as are expert-written editorials. Staff found that medical journal
editorials accompanying research articles often provided a good orientation for subjects being considered. When available, systematic reviews and meta-analyses helped in the assessment of what is known and what needs to be done. Evidence-based clinical practice guidelines were also useful, especially when they included research agendas that emerged from the guideline creation process.
The distinction between efficacy and effectiveness is an important one. More often than not, clinical trials and the resulting meta-analyses report on work done in academic centers with highly selected patients. Except for some very recent trials, most do not include minority or gender diversity. This limits the ability to extrapolate from trial or meta-analysis findings to real-world populations.
Much more needs to be done. This effort is only a preliminary step in setting criteria and providing examples of CER. In several instances a single test or technology was discussed as an example of several needed study topics and areas. A much larger and more comprehensive assessment process is needed to create a truly national inventory of needed research.
CLINICAL DATA SETS THAT NEED TO BE MINED
Jesse A. Berlin, Sc.D., Vice President, Epidemiology; and
Paul E. Stang, Ph.D., Senior Director, Epidemiology,
Johnson & Johnson Pharmaceutical R&D9
Overview
Information is like fish: It’s better when it’s fresh.
Healthcare delivery, by virtue of the evolving ability of systems to capture and store data and the intense interest in analyzing those data, is poised for transformation. The key to the transformation will be how the data and analyses are used to inform decisions to improve health. If successful, the system can be transformed into a learning health system that will provide high-quality data to inform decisions made by policy makers, healthcare providers, and patients, who can then use the same data collection and analytic tools to assess the impact of those decisions. The critical elements needed to transform health care and to create a “learning organization” (Senge, 1990) include experimentation with new approaches, learning from personal and corporate past experience, learning from best practices of
_______________
9 The authors would like to acknowledge the insightful comments of Michael Fitzmaurice on earlier drafts.
others, efficient and rapid knowledge transfer, and a systematic approach to problem solving.
This model has been recast for health care by Etheredge (2007), who espouses the value of observational research in medical care data as a laboratory for testing hypotheses and undertaking research to inform rapid learning and improve the efficiency of healthcare delivery in the United States in addition to addressing a number of other information gaps. However, the current capacity and data resources are only capable of filling the short-term needs and therefore represent a modest initial step toward informing better healthcare decision making. The contribution of electronic data collection to achieving the vision of the learning health system will be directly related to the quality, breadth, and depth of the data capture.
The basic contention underlying this paper is that appropriate use of existing data and creative uses of existing data collection mechanisms will be crucial to operationalizing the above elements, the end result of which will be improvement of healthcare decision making in the near term. With this goal in mind, the strengths and limitations of currently available administrative data to address questions of comparative effectiveness (and safety) will be explored, and additional ways in which the existing infrastructure for these databases might be used to support further data collection efforts, perhaps more specifically targeted, will be proposed.
Currently Available Healthcare Databases:
Claims and Electronic Health Records
Most existing healthcare databases were created for purposes other than research. Currently, payers (including managed care organizations, insurance companies, employers, and governments) use data to track expenditures for multiple purposes. This gives rise to the so-called claims or claims-based databases that contain the coded transactional billing records between a clinician and an organization that allow the healthcare provider to be reimbursed for a given patient. In parallel, the details of the patient–clinician interaction contained within the medical record have slowly been moving from paper to computers, giving rise to EHRs, which can also be aggregated into a database. The EHR may, in some cases, represent all of the care provided to a given patient by an institution or staff health maintenance organization, but in other cases it may represent just that portion of care rendered by the individual clinician with the EHR. The Mayo Clinic, long the keeper of extensive longitudinal paper “dossier” medical records, now uses an electronic system. The General Practices Research Data (GPRD) based in the United Kingdom and records from Kaiser Permanente and the Henry Ford Health Systems are a few other examples of these
EHR databases. These data reflect not only the patient–clinician interaction but also the underlying healthcare delivery system (and its idiosyncrasies).
Existing secondary data sets, such as those listed in Box 2-2, offer a number of advantages for research. Studies are inexpensive and can be done quickly, relative to the cost of doing a clinical study, because the data have already been collected and organized into a database; the data reflect healthcare decisions and outcomes as they were actually made (vs. the artificial constructs of an RCT); and each database represents an identifiable and quantifiable source population, i.e., a “denominator” for the calculation of event rates and mean values. By virtue of reflecting actual, real-world clinical practice, these databases also offer improved external validity relative to RCTs.
Despite all of these advantages for research, secondary data have several important limitations and obvious gaps. For claims data, research would be restricted to coded diagnoses, some of which may be erroneous, may be part of an active workup (e.g., the code may be MI [myocardial infarction], but the interaction was part of a “rule-out” MI), or may omit a code altogether because it is not required for billing (e.g., one of four active problems during the visit). Some relevant data may not have been collected or consistently recorded, particularly those potential confounding factors that may be associated with the choice of therapy and with the outcome of interest. The absence of these data may be critical when making comparisons between specific therapeutic options, as they may strongly influence the study results or the conclusions drawn, but they cannot be managed in the design or analysis of these databases. The problem of confounding of comparisons between therapeutic options is why randomization is such a powerful aspect of clinical trials. Unfortunately, many existing databases lack consistent capture of such factors as smoking status, alcohol consumption, use of over-the-counter (OTC) medications; even weight and height are not always routinely captured in these databases (Box 2-2). As an example, Ilkhanoff and colleagues (2005) used a case-control study that included interview-based primary data collection from participants to show that adjustment for confounding factors not captured in electronic databases—e.g., smoking, family history, years of education—had a substantial impact on estimates of relative risk for MI associated with non-aspirin, non-steroidal anti-inflammatory drug (NANSAID) use, relative to nonusers. The inability of databases to capture OTC use of NANSAIDs and OTC aspirin use also had marked effects on study findings.
There is also a general lack of longitudinality in the patient record that reflects the current healthcare system. Loss to follow-up occurs because people are constantly changing healthcare systems or coverage, either as part of the annual choices provided by employers or because their eligibility for
BOX 2-2
Examples of Existing Healthcare Databases
Healthcare delivery systems: Kaiser Permanente, Group Health Cooperative of Puget Sound, Geisinger Health System, Henry Ford Health System, Rochester Epidemiology Project (Mayo Clinic)
Aggregated claims: PharMetrics, Marketscan (Thompson-Medstat)
Electronic medical record systems independent of a single healthcare delivery system: General Practice Research Database (united Kingdom), The Health Improvement Network (based in the united Kingdom), General Electric (Centricity), Cerner
Hospital: Premier, Cerner
Government-managed or -funded programs: Medicaid, Centers for Medicare & Medicaid Services (Medicare), Veteran’s Administration, Department of Defense
U.S. government surveys: National Health and Nutrition Examination Survey, Medical Expenditure Panel
Specialty data and registries: Surveillance, Epidemiology, and End Results (Cancer Registry), Food and Drug Administration spontaneous adverse event database (voluntary drug adverse event reports), the Nordic countries linkable registries (Sweden, Denmark)
Canadian provincial databases: Saskatchewan, Manitoba, Régie de l’Assurance Maladie du Québec
Prescription-tracking databases: IMS Health, Verispan
coverage changes. About 10 to 20 percent of patients in a given insurance database may leave a given plan during a given year. Having a unique identification number that follows a given patient across all interactions with the healthcare system would alleviate this problem with longitudinality, but it is clear there are appropriate concerns about confidentiality that such a system would trigger.
Finally, there are entire segments of the population and healthcare system that are poorly represented in these data. The interactions of the 49
million Americans without healthcare coverage are essentially lost to the current system since there is no ability to link individual patients with a unique identification number. Similarly, elderly people and those in institutions are essentially overlooked in most analyses because of lack of access to their clinical data, even though these are the very groups that are most at risk for poor coordination of care and less favorable outcomes.
Studying Benefits and Risks in Existing Healthcare Data: Information Asymmetry
Because the data source represents a clinical interaction, any retrospective research will be limited to events that could be characterized as part of the coded or detailed physician interaction. In general, the benefits of treatment are more common than the risks, but unlike risk, benefits are poorly represented in these data sources, as they do not fit into the current diagnostic vernacular. Many of the benefits of treatment (e.g., reduction in blood pressure, improvement in mood or quality of life, return to full mobility, fewer number of seizures per month, reduced symptoms of schizophrenia) are not clinical diagnoses, and they are not usually captured in databases because they cannot be represented in coded claims. It is not always known what impact these other measures have on more serious events, nor is it known how their importance is perceived by patients and providers. The claims do capture use-based measures (e.g., switching drugs, changes in emergency department use, hospitalizations), and the data would include reductions in clinical events (e.g., myocardial infarction). Conversely, most potential harms from therapies are clinical events and would be captured in clinical encounter data (e.g., agranulocytosis, hepatitis, renal failure).
In the context of comparative effectiveness studies, differences in effectiveness (usually considered to be benefits) between two treatments, especially between two drugs in the same class, may be small in magnitude. Evaluating such small differences in effects absolutely requires strong control over potential confounding variables if internal validity is to be maintained. If one fails to control confounding variables, the observed differences in effects (or safety) could be misleading, as they might represent differences in the underlying characteristics of patients exposed to one or the other product rather than true differences in effect between the products. Several efforts, including the Developing Evidence to Inform Decisions about Effectiveness (DEcIDE) network and the Centers for Education and Research on Therapeutics, both of which were set up by AHRQ and the Observational Medical Outcomes Partnership from the Foundation for the NIH, are under way to better understand the strengths and limitations of these databases, the performance characteristics of the methods, and the
ability to use them as the initial line of surveillance for potential safety issues.
Because these databases reflect care as it is really delivered, generally without the consistent screening and capture of information that exists in a clinical trial, variability and uncertainty can be high. Erkinjuntti and colleagues offer a striking example in which the prevalence of dementia in a single Canadian cohort of patients varied from 3.1 to 29.1 percent simply by applying different accepted case definitions of dementia (Figure 2-1) (Erkinjuntti et al., 1997). With secondary data it is unclear what diagnostic criteria (if any) were applied in the clinical setting to arrive at a diagnosis, and there are other measures that are either inherently prone to variability, such as blood pressure, or are subjective in nature, such as the Tanner score. When measures are highly variable and taken outside the context of a carefully controlled study with standardized measurement techniques, it will often be more difficult to detect differences in these measures between treatment approaches. By engaging the clinician directly at the point of data entry, the record system itself can help standardize the capture of data, can solicit additional detail, or can push summary information and links to additional resources.
Existing databases are generally considered to be reasonably complete with respect to determining “exposure” to particular drugs (and, to a lesser
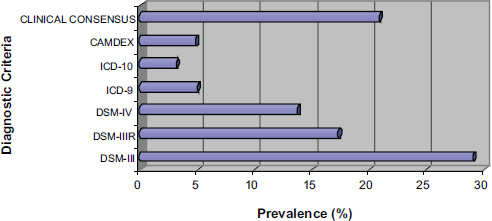
FIGURE 2-1 The prevalence of dementia across different diagnostic criteria in the same Canadian cohort.
NOTE: CAMDEX = Cambridge Mental Disorders of the Elderly Examination;
DSM = Diagnostic and Statistical Manual of Mental Disorders; ICD = International Classification of Diseases.
SOURCE: Derived from data in Erkinjuntti et al. (1997).
extent, medical devices) (Strom, 2005). However, databases capture only the prescription of a medication (from EHR) or, at most, the prescription plus the dispensing of the prescription (from pharmacy records or billing). The databases do not (cannot) capture whether the drug was actually used or, if used, whether it was used correctly.
While there are a number of challenges in the use of current databases to address questions of comparative effectiveness, it is still possible to learn from current efforts to inform further designs and improvements in the capture of data, governance, and methods. The current systems can best be thought of as hypothesis generating and, potentially, hypothesis strengthening; it is unclear to what extent they can be considered definitive sources of data for confirmation. In some respects, current systems represent databases in search of a question. As the field transitions to EHRs, some of the issues with coding mentioned above will be dramatically reduced, and the value and impact of these data and the evolving methods will improve. The ability to link a patient across data sets will further strengthen the capacity of the data sets to provide more definitive answers, increasing the value of these data sets; the appearance of prompted “pop-ups” to collect or refine data at the point of entry will similarly increase the value of the data sets. Real value will come from the ability to use the EHR system as a data collection vehicle for randomized studies in the populations covered by the data sources. This concept is expanded in the following section.
Looking Ahead
Given the limitations of working with available databases, it seems likely that more robust data collection at the clinical interface would improve insights from, and the quality of, observational databases. Accumulating higher-quality data could help provide insight into current practice and help improve care. Simply adding flags to denote “rule-out” diagnoses would help researchers to better distinguish actual events from clinical workup. Similarly, with respect to general hospitalization data where much effort is focused (because of its high costs), if a separate diagnostic list of those findings was included at the time of admission (rather than the existing discharge diagnoses only), it would have a major impact on the ability to track and determine risks and effectiveness of hospital-based occurrences. Finally, as more devices are implanted, physically coding (e.g., with bar codes) the individual devices with a unique identification would facilitate future identification and the tracking of safety and outcomes. The ongoing Centers for Medicare & Medicaid Services (CMS) payments to hospitals and physicians for reporting quality data and for improved performance on
quality measures may be an appropriate mechanism to help motivate and implement such changes.
However, the innovation that holds the greatest potential for informing change in health care will be the ability to use the existing data infrastructure and healthcare delivery system to take advantage of randomization at points of clinical equipoise to generate new insights into interventions and their outcomes. There are many possible innovative approaches, but the focus here is specifically on the idea of “designing studies into the database.”
In general terms, the goal is to increase the power of the existing data collection through the EHR by enhancing data collection with special data collection forms, e.g., screens that pop up on a computer in the physician’s office for patients who match a specific set of criteria. The basic idea is to tailor additional aspects of data collection (as would be done in a separately designed and implemented primary study) within the context of an existing data collection system. This increases the possibility of going one step further by conducting large simple randomized studies (also called naturalistic or real-world trials) by “randomizing into the database,” a concept that was first described by Sacristan and coworkers (1997) and later employed by Mosis and colleagues in the Dutch Integrated Primary Care Information database (Mosis et al., 2005a, 2005b). Their findings suggest that the technical infrastructure existed but that the requirements for recruitment in general practice for this particular study were inconsistent with the flow of patient care and were too time consuming (Mosis et al., 2006). At a high level, this would again involve the use of a computer in the clinician’s office that, when a patient meeting certain criteria presents, would generate a special screen asking the clinician whether or not he or she is willing to randomize that patient.
This model is being revived across the United Kingdom in the Research Capability Programme in the Connecting for Health initiative, which includes educating the public on the importance of participating in clinical trials as a way of contributing to medical knowledge and advancement. Making such trials practical in the context of primary care may well require either structural changes in the process of care, in order to facilitate patient and physician participation, or adjustments to how these trials are conducted, so that the interruptions to the usual process of care are minimized. Various scenarios might be considered as far as when, in the course of care, computerized “prompts” would be presented to the clinician: during periodic reviews of new data, for example, vs. when a patient presents for any reason vs. when a patient presents with specific symptoms vs. when a prescription for one of the study drugs is written. These various scenarios have potentially very different implications for the acceptability of the trial
to the clinician. Research is ongoing in the UK GPRD to test the feasibility of “randomized trials within the database.”10
The significance is that the same clinical data capture can be used as data capture for randomized (or observational) studies. The database provides part of the infrastructure for conducting a targeted study, thereby reducing time and costs while engaging the clinician in the process. This approach will require a variety of steps if it is to be feasible: modifying the existing infrastructure to produce new data collection tools and integrate those into existing systems, training clinicians to use the new systems, and perhaps even training clinicians in the principles of clinical epidemiology, so that they might better appreciate the value of research based in actual clinical settings.
The discussion so far has focused on data collection aimed at specific research questions. However, capturing the data at the physician–patient interface may have a number of other potential applications beyond contributing to larger trials. Data on individual physician practices and outcomes from specific encounters could form a foundation for single-physician-focused efforts that would allow practitioners to see and track what works and what doesn’t, not just for their own patients but for all (similar) patients in the database, and to do a better job of understanding their own treatment decisions and the impact of those decisions. It is essential that data flow not be unidirectional. This concept of data flowing back to practitioners and informing future practice is captured in Figure 2-2. This is consistent with the views expressed by others (Etheredge, 2007; Stewart et al., 2007) and would be the foundation of a learning health system.
To overcome barriers generated by the structure of the healthcare system (particularly in the United States) and the dispersion of healthcare data, a broader view of data collection and integration is required. Comprehensive health records capturing all of the clinical encounters with a given patient will require an infrastructure to link across databases (issuing a unique patient identifier to enable this linkage), perhaps to include the personal health record maintained by the patient himself or herself. This generates more than just information technology (IT) requirements. For example, one must consider privacy concerns, particularly in the United States with its Health Insurance Portability and Accountability Act (HIPAA) regulations. Making links across hospitals, claims, electronic medical records, and other data sources will be best accomplished by using unique personal identifiers (e.g., social security numbers), which would require a reexamination of the country’s HIPAA and protected personal information culture.
An investment in workforce and methods will also be required to realize the full benefit of these changes to the data and IT infrastructure.
_______________
10 See http://www.gprd.com/home/default.asp (accessed September 22, 2010).
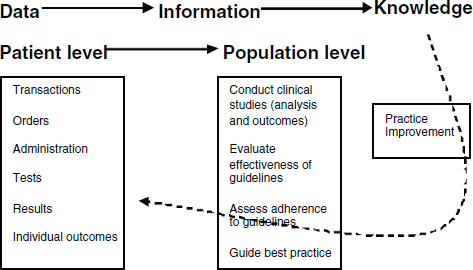
FIGURE 2-2 Data flow in a learning system.
SOURCE: Reprinted with permission from Anceta American Medical Group Association’s Collaborative Data Warehouse.
Clinicians will need to be provided with more training to make sure they understand how their contribution of quality data directly affects the value of the information that they and others can retrieve. A variety of specialists, including informaticians, methodologists, and epidemiologists, will also be required to assure that there are continuing improvements to the systems.
Sharing of de-identified, individual-level, clinical trials data could provide an incredibly rich source of data to investigators. Again, however, doing so presents challenges because of privacy and informed consent concerns. Strict de-identification, required under HIPAA, is a time-consuming and costly activity (as opposed to the use of limited data sets from which certain key identifiers have been stripped). Safety analyses of erthyropoietin-stimulating agents are currently being conducted by the Cochrane Hematological Malignancies Group. For this effort, data have been provided by multiple sponsors of trials, including three pharmaceutical companies. There are other ongoing consortia of many types. For example, a Duke/FDA/Industry Cardiac Safety Research Consortium exists, the purpose of which is to create an electrocardiogram (ECG) library from clinical trials that could be used to identify early predictors of cardiac risk (Cardiac Risk ECG Library). Thus there is ample precedent for successful collaborative efforts across academic, government, and private sectors, with the success of each resting on the ability to amass data from a number of different sources.
The comments thus far have focused, at least implicitly, on pharma-
ceuticals, but it is important to remember that comparative effectiveness questions also arise with respect to medical devices. Currently, as far as is known, none of the administrative databases that are publicly available (usually for a fee) can distinguish among devices by manufacturer, so, for example, one may know a coronary stent was used, but much would be unknown, including which company made that stent and specific details around the individual stent (e.g., manufacturing lot number).
Summary
Data can be powerful and, one hopes, represent truth. Existing databases are currently most useful for paying bills and reflecting medical treatment. For research, the most useful applications of administrative data to date have been to support the analysis of potential safety issues. Although a number of statistical methods are available for controlling potential confounders, their contribution may be limited by the availability and accuracy of the required data. This lack of sufficiently detailed information on confounding factors is potentially a bigger problem than any challenges related to statistical methods when studying small-magnitude differences in the effectiveness of two therapies. Existing databases generally lack specific information on effectiveness, except when effectiveness can be represented in terms of clinical events.
Although not necessarily optimal, there are rational options that would improve the existing data collection system and its usefulness to both clinician and researcher. In particular, further development of a system at the point of care that records information, prompts the clinician for additional information, and provides insight and summarization back to the clinician should improve the quality of care by making critical data directly available when the clinician is making treatment decisions. This feedback loop is a critical link in the development of a learning health system that functions both for direct patient care and for the development of a research infrastructure that will help improve quality.
Future directions may include a mix of data quality and infrastructure efforts. Simple data-side adjustments that would improve the usefulness of these data (e.g., a “rule-out” flag that would signal more directly a clinician’s intent rather than leave others to misinterpret a code as an occurrence, a hospital admission findings list, unique identification numbers on all implanted devices) would be smaller steps that could generate huge returns in the quality of patient care. The ultimate goal is to begin both building targeted studies and enhanced data capture capabilities into the framework of existing medical care databases as well as making information flow both from and to healthcare providers in a way that is immediately beneficial and effective in informing their care of the patient.
KNOWLEDGE SYNTHESIS AND TRANSLATION THAT NEED TO BE APPLIED11
Richard A. Justman, UnitedHealthcare
EBM is now the mantra of physicians, consumers, purchasers of health care, regulators, payers, and others who want to know which medical test or treatment works best. Unfortunately, an agreed-upon infrastructure to determine which treatment works best does not exist today. In fact, although everyone agrees that it is a good idea to follow the principles of EBM in deciding which treatment works best, there is no such agreement on the standards of clinical evidence to be used in a given situation. A national system for grading clinical evidence does not exist. This creates an interesting conundrum for persons who want answers to specific questions.
For example, a patient with localized prostate cancer seeking information on which treatment would be best for him is likely to obtain different answers depending upon whether he asks a primary care physician, a urologist, or a radiation oncologist. In fact, an asymptomatic 50-year-old man cannot even obtain definitive answers about whether he should be screened for prostate cancer with an inexpensive, readily available blood test for prostate-specific antigen.
Physicians seeking information based upon grades of clinical evidence face a similar dilemma. For example, microvolt T-wave alternans is an office-based test that predicts the risk of life-threatening cardiac arrhythmia. The American College of Cardiology grades the evidence supporting its use as grade 2a (Zipes et al., 2006). A physician seeking information about the use of bevacizumab to treat breast cancer will learn that the National Cancer Care Network drug compendium grades the evidence supporting its use as grade 2a. However, the definitions of grade 2a given by these two highly respected professional organizations do not match.12
_______________
11 Note: This section is adapted from portions of Knowing What Works in Health Care: A Roadmap for the Nation, a report of the Institute of Medicine Committee on Reviewing Evidence to Identify Highly Effective Clinical Services (IOM, 2008).
12 American College of Cardiology: “Evidence level IIa: conditions for which there is conflicting and/or a divergence of opinion about the usefulness/efficacy or a procedure or treatment. Weight of evidence/opinion is in favor or usefulness/efficacy” (Hunt, et al., 2005). National Comprehensive Cancer Networks (NCCN) Category 2A: “The recommendation is based on lower-level evidence, but despite the absence of higher-level studies, there is uniform consensus that the recommendation is appropriate. Lower-level evidence is interpreted broadly, and runs the gamut from phase 2 to large cohort studies to case series to individual practitioner experience. Importantly, in many instances, the retrospective studies are derived from clinical experience of treating large numbers of patients at a member institution, so NCCN Guidelines panel members have firsthand knowledge of the data. Inevitably, some recommendations must address clinical situations for which limited or no data exist. In these instances the congruence of experience-based judgments provides an informed if not confirmed direction for optimizing
Institute of Medicine Committee to Identify
Highly Effective Clinical Services
In June 2006 the Robert Wood Johnson Foundation asked the Institute of Medicine to do the following:
- Recommend an approach to identifying highly effective clinical services.
- Recommend a process to evaluate and report on clinical effectiveness.
- Recommend an organizational framework for using evidence reports to develop recommendations on appropriate clinical applications for specified populations.
The imperative behind this request derives from the need to constrain healthcare costs, which have been rising faster than the consumer price index without a commensurate improvement in health outcomes; the need to reduce the idiosyncratic geographic variation in the use of healthcare services; the need to improve clinical quality, including health outcomes; the need to give consumers information they need to make healthcare choices; and the need to help purchasers of health care and payers to decide which services to include in their benefit designs.
Clinical Safety and Effectiveness: Current State
While there are multiple avenues available today to help consumers, physicians, and others decide which treatments are safe and effective, they all have significant limitations. In addition, the lack of a national comparative effectiveness architecture leaves the current state replete with gaps, duplications, and contradictions, as noted below (see also Table 2-3).
The FDA reviews the safety and effectiveness of medications. However, comparative effectiveness studies are not required as part of this review, so users lack information on which medication works best for a particular disease scenario. Another division of the FDA, the Center for Devices and Radiological Health (CDRH) reviews medical devices. The level of review performed by the CDRH is determined by the classification of the device. In any event, head-to-head trials and long-term outcome studies are not required in order to approve a medical device for marketing. Physicians commonly prescribe both medications and medical devices for other than the labeled indications (“off label” prescribing). This sometimes leads to
_______________
patient care. These recommendations carry the implicit recognition that they may be superseded as higher-level evidence becomes available or as outcomes-based information becomes more prevalent” (NCCN, 2008).
conflicting and confusing results. For example, bevacizumab is labeled for treatment of breast cancer. It is not labeled for treatment of age-related macular degeneration (AMD). Yet the evidence for improved vision in persons with AMD is stronger than the evidence of prolonged survival for women with breast cancer.
Multiple organizations perform systematic reviews of medical tests and treatments, including the Cochrane Collaboration; Hayes, Inc.; the ECRI Institute; and the Blue Cross Blue Shield Technology Evaluation Center. These respected organizations provide excellent systematic reviews of available clinical evidence. However, many of the topics they review are new or emerging technologies, so there is insufficient information from which valid conclusions can be drawn. Two of these organizations provide brief reports of new technologies, but the lack of available evidence makes these reports of limited use to persons who must make treatment decisions today.
Various agencies of the federal government have performed systematic reviews of available clinical evidence. Two such organizations, the National Center for Health Care Technology and the Office of Technology Assessment, did so in the past, but no longer do so. AHRQ now contracts with evidence-based practice centers to complete systematic reviews. These reports are uniformly excellent, but they address only a small number of topics about which consumers and physicians need to know. AHRQ also maintains the National Guideline Clearinghouse, a repository of clinical practice guidelines developed by other organizations. The Department of Veterans Affairs (VA), CMS, and the NIH provide information about the safety and effectiveness of medical treatments in different ways. However, they, too, lack the infrastructure to offer comprehensive information about the comparative effectiveness of health services.
Professional specialty societies and health plans, among others, develop clinical practice guidelines. Some of these guidelines provide excellent reviews of clinical evidence, noting both the strength of the evidence and the strength of the recommendations they make. Other guidelines are less fastidious in their review of evidence, relying instead on a consensus of expert opinion.
It is not clear how much is spent annually on researching the safety and effectiveness of medical treatments. However, it is likely to be less than $2 billion (IOM, 2007). This is considerably less than 1 percent of the total dollars spent annually on health care.
Deficiencies of the Current State of Comparative Effectiveness Review
As noted above, some systematic reviews of clinical evidence and some clinical practice guidelines lack scientific rigor, relying instead on a con-
TABLE 2-3 Duplicated Efforts by Selected Health Plans and Technology Assessment Firms, 2006
| Type of Service | Health Plans | Technology Assessment Firms |
||||||
| United Healthcare | Kaiser Permanente | Aetna | WellPoint | Hayes, Inc. | Technology Evaluation Center |
ECRI Institute | ||
| Screening | ||||||||
| Genetic testing to predict breast cancer recurrence | √ | √ | √ | √ | √ | √ | √ | |
| Proteomic testing for ovarian cancer | √ | √ | √ | √ | √ | |||
| Virtual (computed tomography [CT]) colonoscopy | √ | √ | √ | √ | √ | √ | √ | |
| Disease management | ||||||||
| Ambulatory blood pressure monitoring | √ | √ | √ | √ | √ | √ | √ | |
| Intermittent intravenous insulin therapy | √ | √ | √ | √ | √ | |||
| Diagnosis | ||||||||
| CT angiography for suspected coronary artery disease | √ | √ | √ | √ | √ | √ | √ | |
| Microvolt T-wave alternans | √ | √ | √ | √ | √ | √ | √ | |
| Wireless capsule endoscopy | √ | √ | √ | √ | √ | √ | √ | |
| Treatment | |||||||
| Brachytherapy for various cancers: breast, ovarian, and prostate cancer and brain tumors | √ | √ | √ | √ | √ | √ | √ |
| Dysfunctional uterine bleeding and fibroids | √ | √ | √ | √ | √ | √ | √ |
| Fallopian tube occlusion for permanent contraception | √ | √ | √ | √ | √ | ||
| Growth factor–mediated lumbar spinal fusion | √ | √ | √ | √ | √ | ||
| Intracoronary brachytherapy | √ | √ | √ | √ | √ | √ | √ |
| Minimally invasive surgery for low back pain | √ | √ | √ | √ | √ | √ | √ |
| Photodynamic therapy for Barrett’s esophagus and esophageal cancer | √ | √ | √ | √ | √ | √ | |
| Vagus nerve stimulation for intractable depression | √ | √ | √ | √ | √ | √ | √ |
| Devices | |||||||
| Artificial total disc replacement for lumbar and cervical spine | √ | √ | √ | √ | √ | √ | √ |
| Cochlear implants | √ | √ | √ | √ | √ | √ | |
| Total artificial heart | √ | √ | √ | √ | √ | √ | |
| Total hip resurfacing arthroplasty | √ | √ | √ | √ | √ | √ | √ |
NOTE: Not all reviews are comprehensive assessments. Agency for Healthcare Research and Quality evidence-based practice centers have reviewed 5 of the 20 topics listed (ambulatory blood pressure monitoring, CT angiography, proteomic testing for ovarian cancer, spinal fusion for low back pain, and uterine fibroids). The Kaiser Permanente entries represent all Kaiser regions.
SOURCE: IOM, 2008.
sensus of expert opinion rather than clinical evidence as the basis of their conclusions.
The body of clinical evidence for some health services in which consumers and physicians are interested may be weak or totally lacking. Two examples are the treatment of chronic wounds, an issue of vital importance to an aging population, and the nonsurgical treatment of uterine fibroids. Moreover, as noted earlier, there is no nationally agreed-upon method for rating clinical evidence or the strength of recommendations.
Bias and conflict of interest on the part of experts further complicate the understanding of the conclusions that can be drawn from available clinical evidence. Bias may be unintentional. For example, physicians trained in nonsurgical specialties may be more oriented toward medical treatments than surgical treatments. Actual conflicts of interest, such as physicians who are paid consultants to device manufacturers or pharmaceutical companies, make it difficult to discern whether the conclusions physicians draw about clinical evidence are truly independent conclusions.
Finally, the multiple clinical guidelines available for the treatment of the same condition frequently make differing recommendations. The Infectious Disease Society of America and the International Lyme and Associated Diseases Society make different recommendations concerning prolonged antibiotic use to treat neuroborreliosis (IDSA, 2006; ILADS Working Group, 2004). Similarly, different professional specialty societies related to allergies make different recommendations regarding the type of allergy immunotherapy to be used on atopic persons.
Recommendations by the Institute of Medicine Committee on Reviewing Evidence to Identify Highly Effective Clinical Services
To address the deficiencies noted above and in fulfillment of the charge to the IOM by the Robert Wood Johnson Foundation, a Committee on Reviewing Evidence to Identify Highly Effective Clinical Services (HECS) was convened. This committee was composed of persons with different perspectives on health care, including academic physicians, researchers, epidemiologists, health economists, consumers, payers, device manufacturers, physician groups, and others.
In Knowing What Works in Health Care: A Roadmap for the Nation (IOM, 2008), the committee made the following recommendations:
- Congress should direct the Secretary of Health and Human Services to designate a single entity to ensure production of credible, unbiased information about what is known and not known about clinical effectiveness.
- The Secretary of Health and Human Services should appoint a Clinical Effectiveness Advisory Board to oversee the Program.
- The Program should develop standards to minimize bias for priority setting, evidence assessment, and recommendations development.
- The Program should appoint a Priority Setting Advisory Committee to identify high-priority topics.
- The Program should develop evidence-based methodologic standards for systematic reviews, including a common language for characterizing the strength of evidence.
- The Program should assess the capacity of the research workforce to meet the Program’s needs; if necessary, it should expand training opportunities in systematic review and CER methods.
- Groups developing clinical guidelines should use the Program’s standards.
- An effort should be made to minimize bias by balancing competing interests, publishing conflict of interest disclosures, and prohibiting voting by members with material conflicts.
- Stakeholders should preferentially use clinical recommendations according to the Program’s standards.
Role of a Priority Setting Advisory Committee
Anticipating significant demand for comparative effectiveness reports, a Priority Setting Advisory Committee (PSAC) will be necessary to review requests for clinical effectiveness information from stakeholders and to stratify them for review. To meet the needs of a large and varied group of stakeholders, priority setting must be open, transparent, efficient, and timely. Suggested criteria for priority setting include the improvement of health outcomes, reduction in the burden of illness and health disparities, elimination of undesirable variations, and reduction in the economic burden of disease and treatment of disease. Members of the PSAC should have a broad range of expertise and interests. Finally, the committee must be constituted in such a way as to minimize bias and to identify and address potential conflict of interest among committee members (IOM, 2008).
Conceptual Framework for Assessing Clinical Evidence
The IOM HECS committee recommended a hybrid approach to assessing clinical evidence that included developing a new infrastructure for evaluating evidence through systematic review and using existing structures for the development of clinical guidelines. Research study designs would include RCTs, cohort studies, case-control studies (identifying factors that may contribute to a medical condition by comparing a group of patients
who have that condition with a group of patients who do not), cross-sectional studies (observing some subset of a population of items all at the same time, so that groups can be compared at different ages with respect to independent variables), and case reviews. Systematic review of clinical evidence requires a common language to identify and assess the quality of individual studies, to critically appraise the body of evidence, and to develop qualitative or quantitative synthesis. Finally, clinical guidelines would be written using common language for stating the strength of clinical evidence and the strength of recommendations (IOM, 2008).
A systematic review investigates the characteristics of the patient population, care setting, and type of provider; the intervention, including the route of administration, dose, timing, and duration; the comparison group; outcome measures and timing of assessments; quality of the evidence (risk of bias, sample sizes, quantitative results and analyses, including an examination of whether the study estimates of effect are consistent across studies); and the effect of potential sources of study heterogeneity, if relevant (IOM, 2008).
Infrastructure requirements include funding, staffing, and stakeholder involvement; common agreement on the hierarchy of clinical evidence; a body of evidence sufficient to allow for systematic review; capability of satisfying the needs of different stakeholders, including consumers, physicians, purchasers of health care, and payers, among others; a repository for evidence reports; a process for systematic updating and revision; and an infrastructure sufficient to compare different treatments (IOM, 2008).
Review of Emerging Treatments
All of the foregoing assumes that questions will be directed toward health services sufficiently mature to accumulate a body of clinical evidence sufficient for systematic review. However, it is likely that many questions will arise about new or emerging treatments for which a significant body of published clinical evidence does not exist. The committee recommends that an infrastructure be developed allowing for brief reports that address what is known about emerging treatments, identify the salient questions that must be addressed, acknowledge the gaps in evidence, and articulate the opportunities for future research (IOM, 2008). Such brief reports would be also be useful in addressing rare diseases and conditions, treatments for conditions with no known effective treatment, and health services for which comparative effectiveness trials are unlikely to be completed in the short term.
Some avenues to synthesize evidence in order to address such health services include clinical trials and CMS Coverage with Evidence Devel-
opment. Other protocol-specified prospective data collection programs address similar questions.
Examples of new or emerging treatments worthy of such review are easy to identify. They include accelerated partial breast irradiation to accompany lumpectomy in the treatment of localized breast cancer, bevacizumab to treat age-related wet macular degeneration, endovascular repair of thoracic aortic aneurysm, intracerebral stenting for the prevention of stroke, endobronchial values as an alternative to lung volume reduction surgery to treat emphysema, bronchial thermoplasty to treat moderate-to-severe asthma, and injectable bulking agents to treat vesicoureteral reflux in children.
Final Comments
Given the amount spent on health care in the United States, consumers of health services, professionals who provide those services, and purchasers who pay for them are entitled to know what works and what does not. They are entitled to know which health services are definitely beneficial, which are likely to be beneficial, which have insufficient evidence supporting their use to know if they are beneficial, and which services in common use today are known to be of no benefit or, worse, that are actively harmful. Persons making choices on which treatments to use should understand the range of treatments available to them, including advantages, harms, and alternatives. However, despite the plethora of information available today, such a “single source of truth” does not exist. The foregoing comments represent one attempt at defining the knowledge synthesis necessary to answer these vital questions.
METHODS THAT NEED TO BE DEVELOPED
Eugene H. Blackstone, M.D., Douglas B. Lenat, Ph.D., and
Hemant Ishwaran, Ph.D.
Cleveland Clinic
Overview
RCTs and their meta-analyses are generally agreed to provide the highest-level evidence for comparative clinical effectiveness of clinical interventions and care. However, today cost and complexity impede nimble, simple, inexpensive designs to test the numerous therapies for which a randomized trial is well justified. Further, it is impossible, unethical, and prohibitively expensive to randomize “everything.”
To fill this gap, balancing-score methods coupled with rigorous study design can approximate randomized trials. They are less controlled but
use real-world observational clinical data. They may provide the only way to test therapies when it is impossible to conceive of or conduct RCTs. Although a number of their important features remain to be understood and refined, they are comparatively inexpensive and use readily available electronically stored data. Interestingly, although the intent of EBM is to reduce practice variance, this methodology draws its power from heterogeneity of care.
Unfortunately, a longitudinal birth-to-death patient-centric health record, populated largely with discrete values for variables that would be useful for both streamlined randomized and balancing-score-based clinical trials, has not been brought to fruition. Instead, clinical information remains locked in narrative, mostly within segregated institutional silos. But a new methodology is emerging both to elegantly link these silos and to provide a population-centric view of clinical data for analysis: semantic representation of data. Meaning is emphasized rather than lexical syntax. This has the promise of transforming EBM into information-based medicine. Its elements include storage of patient data as nodes and arcs of graphs that can seamlessly link disparate types of data across medical silos, from genomics to outcomes, and, in theory, across venues of care to create a virtual longitudinal health record, to say nothing of the completely longitudinal personal health record. What is required are (1) a rich ontology of medicine, the taxonomy component of which is enough to enable semantic searching, and the formal knowledge base component, which is enough to permit—even today—natural language query of complex patient data (that is, separating logical understanding of query from the need to understand underlying data schemata); (2) a worldwide effort to assemble this ontology and the assertions that make it useful; and (3) intelligent agents to assist discovery of unsuspected relationships and unintended adverse (or surprisingly beneficial) outcomes.
But if such clinically rich data were available, especially a massive amount, could they be put to effective use? Computer-learning methods such as bootstrap aggregation (bagging), boosting, and random forests are algorithmic, as opposed to the traditional model-based methods that are computationally fast and can reveal complex patterns in patient genomic and phenotypic data. These methods refocus attention from “goodness of fit” to a given set of data to prediction error for new data. Methods like this are needed to propel the country yet another step toward personalized medicine.
Thus the results of trials, approximate trials, and automated discovery need to be transformed from static publications to dynamic, patient-specific medical decision support tools (simulation). Although such methodologies are widely used for institutional assessment and ranking, they need to lead
to clinically rich, easily used, real-time tools that integrate seamlessly with the computer-based patient record.
This article highlights five foundational methodologies that need to be refined or further developed to provide an infrastructure to learn which therapy is best for which patient. They are representative of those needed for progression from current siloed EBM to semantically integrated information-based medicine and on to predictive personalized medicine. The five methodologies can be grouped into three categories:
1. Evidence-based
• Reengineering RCTs
• Approximate RCTs
2. Information-based
• Semantically interpreting, querying, and exploring disparate clinical data
• Computer learning methods
3. Personalized
• Patient-specific strategic decision support
Reengineering Randomized Controlled Trials
Following intense preliminary work, several cardiac surgical centers began designing a randomized trial to answer a simple question: Is surgical ablation of nonparoxysmal atrial fibrillation accompanying mitral valve disease effective at preventing the return of the arrhythmia? It took a short time—weeks—to design this study, but then it had to be vetted through committees, review boards, and the FDA, leading to multiple revisions, additions, and mounting complexity. The case report form became extensive and required considerable human abstraction of information from clinical records to complete. Two core laboratories were needed and competitively bid. After more than 2 years, the trial was launched. From inception to completion, the trial is likely to take 5 years at a minimum. The cost of what was intended to be a simple, easily deployed trial will be about $2 million; large multi-institutional, multinational trials may cost upwards of 10 times this figure.
Designing and executing RCTs like this has become one of the most demanding of human feats. It may not compare with climbing Mt. Everest, but it is close. A major reason to climb this mountain is that RCTs remain the gold standard for EBM. They are purpose designed, have endured ethical scrutiny, ensure concurrent treatment, capture highest-quality data, and have adjudicated end points. Their data meet the statistical assumptions of the methods used to analyze them.
Yet, like the trek up Everest, the design and conduct of an RCT is filled with pitfalls that need to be bridged. The following six areas are among those that must be addressed if RCTs are to achieve the kind of cost effectiveness that evidence-based medical practice requires in the future: complexity, data capture, generalizability, equipoise, appropriateness, and funding.
Complexity
A deep pitfall of the current practice of RCTs is what John Kirklin, pioneer heart surgeon, called “the Christmas Tree Effect”: ornamenting trials with unnecessary variables rather than keeping them elegantly simple and focused. Every additional variable increases the cost and difficulty of the trials, which reduces available resources, limiting the number of trials that can be performed. Nonessential complexity constructs a barrier to progress when instead a bridge is needed. In reengineering RCTs, data collection should be focused on the small number of variables that directly answer the question posed. A series of elegant, scientifically sound, clinically relevant, simple, focused trials will provide more answers more quickly than bloated multimillion-dollar trials that are justified as providing enormous riches of high-quality data for later (observational) data exploration.
Second, rapid development of simple pilot trials on clinically important questions should be encouraged, to be followed with simple, definitive trials. The National Heart, Lung, and Blood Institute has put into place a number of disease- and discipline-specific networks of centers devoted to simple RCTs. This is an important step forward. Two observations: (1) The trials being designed are simple only in the number of patients enrolled, not in design; funding would be better spent on highly focused, extremely simple RCTs. (2) There is no plan for funding pivotal trials based on clinical outcomes rather than surrogate and composite end points that stem from these pilot trials (Fleming and DeMets, 1996). Perhaps the focus should, therefore, shift to funding a mix of simple, inexpensive pilot trials and simple but definitive trials.
Third, adding administrative and bureaucratic complexity to many RCTs is needed for investigational device exemptions and new drug exemptions from the FDA. This introduces considerable delay by an organization that should itself promote efficient study designs focused on safety and efficacy. The heterogeneity of institutional review board requirements adds further administrative burden.
Fourth, to “survive,” design and conduct of RCTs has become a “business” that is increasingly specialized and complex and distanced from the practice of medicine. Physicians with good questions believe they cannot attempt to scale the mountain. It was not always this way, and patient
recruitment suffers from it because patients’ personal physicians are often no longer advocates for clinical trials. Again, simplification is key to bridging this chasm.
All four of these complexities argue for applying a kind of symbolic sensitivity analysis when an RCT is designed, eliminating variables that are more decorative than functional.
Data Capture
RCT technology as practiced today makes little use of discrete data elements acquired as part of clinical practice. Available computer-based clinical data could and should be used for patient screening, recruiting, and data gathering. With electronic patient records composed of “values for variables” (discrete data elements), one could electronically identify patients meeting eligibility criteria for trials, generating alerts so that healthcare providers could be on the front line of informing patients about a trial germane to their treatment. Insofar as possible, patient data, including end points, should be retrieved directly from the electronic patient record. Instead, study coordinators today laboriously fill out case report forms, translating from medical records. Reducing the data-gathering burden would not only reduce complexity and cost but also bring trials more into the sometimes messy reality of clinical practice—the very environment for which inferences about clinical effectiveness from the trial are to be made. Admittedly, redundant data abstraction, end point adjudication, and core laboratories all contribute to incrementally improving the quality of trial data, but it is questionable whether the improvements justify the accompanying costs, their impeding the climb, and permitting more climbs.
Generalizability
RCTs often focus on patient subgroups (usually the lowest-risk patients, ostensibly to reduce potential confounding and for which equipoise is unquestioned, rather than the spectrum of disease observed in the community (Beck et al., 2004). Yet results of these restrictive trials typically are extrapolated to the entire spectrum, a practice that may be treacherous no matter what the trial shows. One of the first large, costly trials sponsored by the NIH was the Coronary Artery Surgery Study of the late 1970s and early 1980s (NHLBI, 1981). About 25,000 patients were entered into a registry of patients with coronary artery disease, but only 780 were randomized (Blackstone, 2006). Yet treatment inferences from the study were applied to a broad spectrum of patients with coronary artery disease (Braunwald, 1983). Although it can be argued that pilot studies should be conducted in the patient subgroups most likely to demonstrate a treatment difference
(so-called enriched trials), these studies should be used to aid developing inclusive trials of adequate power. Just as the data acquired from clinical practice is often taken too lightly today, the data acquired from these restricted RCTs is often taken too seriously, when in truth both of these turn out in hindsight to be no more—and no less—than valuable heuristics (Ioannidis, 2005).
Equipoise
Among physicians’ areas of expertise and responsibility is the task of selecting the right treatment for the right patient at the right time. Surgeons call this “indications for operation.” This is the antithesis of equipoise. Thus, a number of important trials have been stopped or considerably protracted for lack of enrollment. Across time periods, nationalities, and schools of thought, each physician will follow his or her own generally consistent but somewhat idiosyncratic set of rules for deciding appropriate treatment. Thus, whenever one examines clinical practice, considerable variance is seen. This gives hope that equipoise on important medical dilemmas might be found at times. However, it also suggests the possibility of capitalizing on practice heterogeneity to conduct studies that approximate RCTs, as described later in this text, rather than seeking artificial, unnatural equipoise.
Appropriateness
Most investigators developing RCTs concentrate on efficacy. Studies are powered for anticipated (often overly optimistic) efficacy, but rarely focus on short- or long-term safety. This is even true of trials conducted for FDA approval. Indeed, for cardiovascular devices, the track record of mandated FDA safety surveillance is dismal. It usually involves a small cohort of patients for whom there is little power to detect increased occurrence of adverse events, and it generally employs a follow-up time too short to detect untoward effects of long-term device implantation. Rare adverse effects caused by long-term exposure to devices (or pharmaceuticals) may go undetected for a long time, but when they are finally detected they incite public anger, recalls, and withdrawals of effective drugs and devices (Nissen, 2006). This reaction might be avoided if a proper surveillance program were in place with impartial analysis of data, possibly assisted by the computer learning technology discussed later in this paper. The factual reporting of findings and a measured response could convince industry, the public, regulators, and even skeptics that the process is transparent and timely (Blackstone, 2005).
Are all the clinical trials that are being performed actually necessary?
Just because a trial can be mounted is no reason to initiate inappropriate trials. At the end of the appropriateness scale is the proverbial parachute trial. Not only will there not be a randomized trial of efficacy of parachutes, there is no compelling reason to do such a trial; magnitude of the effect is too large and logically obvious, although we concede that logic can trip us up. Many trials are expected at the outset to show no difference in efficacy, and yet futile trials are done, often because a regulatory body has required it. Many equivalency, nonsuperiority, and noninferiority trials could be replaced by objective performance criteria and an intense surveillance program (Grunkemeier et al., 2006).
Funding
Typically, the costs of new pharmaceutical and device trials are borne by industry sponsors, with their attendant actual and potential conflicts of interest. Relative to this, only a small number of trials are sponsored by the NIH. Yet in an evidence-based medical system, the obvious benefactors are health insurers, and to a lesser extent the pharmaceutical and device manufacturers. Shouldn’t insurers be interested in sponsoring clinically relevant RCTs, including making data available from the trials to the scientific community or at least bearing the patient costs of RCTs?
Approximate Randomized Clinical Trials
What effect does chronic exposure to urban pollution have on the risk of developing pulmonary disease or cancer? What is the effect of socioeconomic status on response to therapy? What is the effect on long-term outcomes of complete versus incomplete coronary revascularization? What is the effect of chronic atrial fibrillation on stroke? Can severe aortic stenosis be managed medically rather than surgically? Is the radial artery a good substitute for the right internal thoracic artery for bypass of the circumflex coronary system? These are but a few questions for which an evidence basis is needed. Some may be answerable with cluster randomized trials (Donner and Klar, 2000). Others require epidemiologic studies, and none seem readily amenable to randomized trials. It is not possible to randomize gender, disease states, environmental conditions, choice of ancestry, or healthcare organizations in local communities. It would be unethical to randomize patients to placebo or to incomplete or sham surgery when at least knowledge at the present time, if not solid data, indicates that to do so is unsafe. Thus, there is no knowledge in the modern era about the untreated natural history of certain diseases, such as critical aortic stenosis, hypoplastic left heart syndrome, transposition of the great arteries, untreated renal failure, unset fractures, untreated acute appendicitis, or jumping out of an airplane
without a parachute. Yet clinical decisions are made on incomplete evidence or flawed logic every day. Is it possible to do better than guessing? Is there an alternative to “randomizing everything?”
When literature comparing nonrandomized treatment groups is scrutinized, the natural response is to think, “They are comparing apples and oranges” (Blackstone, 2002). This is because in real-life clinical practice there remains wide variance in practice (that is, selection bias), and this results in noncomparable groups. If it is impossible to randomize patients or impractical or unethical, or if it can be demonstrated that one cannot draw a clean, causal inference even from a randomized trial (such as a trial that inextricably confounds treatment with the skill of the person implementing the treatment), is there a way to exploit the heterogeneity of clinical practice to make better comparisons that are closer to apples to apples? Basically, the goal would be to discover within the heterogeneity of practice the elements of selection bias and account for these to approximate a randomized trial.
A quarter century ago, Rosenbaum and Rubin (1983) introduced the improbable notion that observational data can be thought of as a broken randomized trial (Rubin, 2007), with an unknown key to the treatment allocation process. They proposed that the propensity of a patient to receive treatment A versus B be estimated statistically (for example, by logistic regression) to find that key. In its simplest form, a quantitative estimate of propensity for one versus the other treatment is calculated for each patient (propensity score) from the resulting statistical analysis and used for apples-to-apples comparisons (Blackstone, 2002; Gum et al., 2001; Sabik et al., 2002).
How does a single number, the propensity score, seemingly magically achieve a balance of patient characteristics that makes it appear as if an RCT had been performed (for that is exactly—and surprisingly—what it does)? It does so by matching patients with similar propensity to receive treatment A. A given pair of propensity-matched patients may have quite dissimilar characteristics but similar propensity scores. A set of such pairs, however, is well matched (Figure 2-3). What distinguishes these patients from those in an RCT is that at one end of the spectrum of propensity scores, only a few who actually received treatment A match those who actually received treatment B, and at the other end of the spectrum, only a few patients who actually received treatment B match those who received treatment A. Thus, balance in patient characteristics is achieved by unbalancing n along the spectrum of propensity scores (Figure 2-4). The generic idea is called balancing score technology, which can be extended from two treatments to multiple treatments, or even to balance continuous variables, such as socioeconomic status or age (Rosenbaum and Rubin, 1983).
Unlike an RCT in which the allocation mechanism (randomization)
FIGURE 2-3 Comparison of patient characteristics before mitral valve repair (black bars) or replacement (unshaded bars). Unadjusted values are depicted in A and propensity-matched patients in B.
NOTE: COPD = chronic obstructive pulmonary disease; LVEF = left ventricular ejection fraction; NYHA = New York Heart Association.
is known explicitly and equally distributes both known and unknown factors, propensity score methods can at best account for only those selection factors that have been measured and recorded, not for those that are unknown. Thus claims of causality, which are strong with RCTs, are weaker with propensity-based methods. This considerable disadvantage is, however, offset in a number of ways: (1) innumerable treatments can be studied at low cost based on heterogeneity of practice and availability of clinically rich data and (2) treatments or characteristics that cannot be randomized (e.g., gender, place of birth, treating facility, presence of
FIGURE 2-4 Achieving balance of clinical features by unbalancing n. Shown are two groups of patients that have been divided according to increasing quintile of propensity score. Notice at low propensity scores, the numbers of group 1 patients dominate over those of group 2, and at the other extreme, the numbers of group 2 patients dominate over those of group 1. Within each quintile, patient characteristics are well matched between groups, but these characteristics progressively change across quintiles (for example, low-risk profile in quintile 1 and high-risk profile in quintile 5).
disease) can be analyzed. Thus, there is broad applicability for a relatively inexpensive method.
It is important to say, however, that relying on clinical practice data alone is potentially irresponsible, biased, and dangerous, much like standing on untested terrain that may turn out to be thin ice, and patterns may turn out later to be artifactual “false peaks.” However, these techniques may play a valuable role as a heuristic for helping to point RCTs in promising directions when that is possible and as better evidence than apples-to-oranges comparisons when it is not.
Taking yet another step backward, it has been claimed that traditional multivariable analysis is equally accurate in making risk-adjusted nonrandomized comparison (Sturmer et al., 2006). The problem, however, is that until now, there has been no independent support for this claim. It may be right more than 80 percent of the time, but what about the other 20 percent? Propensity-based methods provide this independent assessment. In addition, they also permit comparison when important clinical outcomes occur at a low frequency by supplying a single risk-adjustment variable: the propensity score (Cepeda et al., 2003).
Propensity methodology (and balancing scores in general) should be
elevated further. First, because propensity models are predictive ones (predicting which treatment was selected), the computer learning approach presented later in the text could be exploited to account for possibly complex interactions among selection factors. Second, comparisons based on clinically rich vs. administrative vs. electronically available laboratory databases should be tested for relative value. Third, the most appropriate method of comparing outcomes after propensity matching remains controversial and probably requires developing new statistical tests.
Semantically Interpreting, Querying, and Exploring Disparate Clinical Data
Computerized Patient Records
In 1991 the Institute of Medicine described what it called the computer-based patient record (CPR) (Barnett et al., 1993; IOM, 1991). Its creators envisioned a birth-to-death, comprehensive, longitudinal health record that contained not just narrative information but also values for variables (discrete data) to allow the record to be active, generating medical alerts, displaying trends, providing meaningful patient-level clinical decision support, and facilitating clinical research. It would not be simply an electronic embodiment of the paper-based medical record, which is what they believed the emerging electronic medical record (EMR) was.
The need for a CPR is, if anything, more acute today than it was in the early 1990s because of the increased complexity of care, the aging of the population with multiple chronic diseases, and the multiplicity of care venues from shopping malls to acute care facilities to clinics to large hospitals, to say nothing of OTC medications and a proliferation of alternative and complementary therapies, public awareness of clinical outcomes, the need to track unanticipated complications of therapy across time, and a cumbersome built-in redundancy of clinical documentation for reimbursement.
The originators recognized most of the same impediments to implementing such a system as still exist, not the least of which was that medical education would need to be altered to train a new generation of physicians how to use this new technology optimally.
What has not been clear to developers of EMRs is how discrete data might provide the underpinnings for a learning medical system. Nor did those who were willing to give up pen and ink and adopt the electronic record demand discrete data gathering as a by-product of patient care. Thus, before describing various methods that exploit discrete medical data, it is important to ask why discrete data is an asset and envision what could be done with this asset. For individual care, discrete data can be used to generate smart alerts based on the real-time assessment of data by algo-
rithms, care plans, or models developed on the basis of past experience. For informed patient consent, patient-specific predicted outcomes of therapy can be displayed based on models that are risk adjusted for individual patient comorbidities and intended therapeutic alternatives (see the later section, “Patient-Specific Decision Support”). From a population-centric vantage point, discrete data can provide outcomes and process measures for quality metrics and necessary feedback for improving patient care. This is in part because discrete data can make possible the automated compiling of quality outcomes and process measures along with variables needed for proper risk adjustment. Discrete data assist institutions in responding to clinical trials eligibility specifications to determine feasibility of studies and provide historical outcomes for estimating sample sizes. In addition, discreet data could alert physicians that a patient being seen satisfies all eligibility criteria for a clinical trial. Discrete data coupled with an intelligent query facility can be used to identify patient cohorts for observational clinical studies and approximate clinical trials. They provide the observational data for developing propensity scores, balancing scores, and conducting studies of comparative clinical effectiveness. If a true longitudinal record is created, then discrete data may identify adverse events and the substrate by which unsuspected correlated events may be identified, quite possibly with the use of artificial intelligence and computer learning techniques.
Computer-Based Patient Record Efforts at the University of Alabama at Birmingham
Kirklin and Blackstone, then at the University of Alabama at Birmingham (UAB), recognized the formidable barriers to the CPR and in October 1993 embarked on a $23 million proof-of-concept CPR in partnership with IBM. Initially, they sought an object model of medicine. Two simultaneous efforts to accomplish this resulted in the same conclusion: There is no object model of medicine because “everything is related to everything.” Requirements for complex relationships coupled with the extensibility needed to keep pace with rapid medical advancement, assimilation of disparate types of data, provisions for examining data from multiple vantage points (e.g., viewing diabetes from the vantage points of genetics, anatomy, endocrinology, laboratory medicine, pharmacology, and other medical perspectives), and the feeding of computer systems without slowing patient care were huge challenges. IBM brought to the table experts in a host of different types of databases and concluded that nothing existed that would satisfy the IOM’s vision of an active CPR. However, a novel vision for a system emerged from the collaboration that would be infinitely extensible, self-defining, active, secure, and fast (response time less than 300 milliseconds to those using the system clinically). It required that the container hold-
ing the data know nothing of its content and thus be schemaless. Rather, values for variables themselves needed to be surrounded by their context (metadata) (Kirklin and Vicinanza, 1999). Such a system was built on the IBM-transaction processing facility platform, the same as used at that time by airlines and banking. Its major unsolved problem, however, was cross-patient (population centric vs. patient centric) queries: In theory, an infinitely extensible, comprehensive, centralized data store could take an infinite time to query.
Semantic Representation of Data and Knowledge
Meanwhile, computer scientists at Stanford University (Abiteboul et al., 1997) and the University of Pennsylvania (Buneman et al., 2000) were developing methods to query semistructured (schemaless) data stored as directed acyclic graphs (DAGs). We recognized that the storage format of our UAB data could also be considered DAGs and be queried by the techniques those investigators were developing. Blackstone’s move to Cleveland Clinic in late 1997 provided the opportunity to pursue development of the CPR, but in the test bed of a highly productive cardiovascular clinical research environment. Clinical researchers know, of course, that discrete data are required for statistical analysis, and for the preceding 25 years, human abstractors at the clinic had laboriously extracted data elements from narratives for every patient undergoing a diagnostic or interventional cardiac procedure, resulting in the Cardiovascular Information Registry. We also found that other investigators at the clinic had developed more than 500 clinical data registries, often containing redundant, unadjudicated, non-quality-controlled data about various aspects of medicine—even of the same patient—stored in disparate clinical silos, such as orthopedics, cardiology, oncology, and ophthalmology. For the most part, these registries did not communicate with one another.
We therefore continued our work in developing what we then called a semantic database that, like any DAG representation, could be extended infinitely, was self-defining, and was also self-reporting by use of intelligent agents. Some 15 years and $50 million later, we at last have a technology that can underlie an extensible multidisciplinary CPR without the need for special integration, because it is natively integrated. Each data element in such a system is a node or an arc that connects nodes (databases) in a graph resource description framework), along with context and meaning (knowledge base). Additional nodes represent medical concepts and these are all linked. Each node has an address just like an Internet in a thimble. The Internet analogy is not an empty one. The infrastructure for the World Wide Web (Cleveland Clinic is 1 of some 400+ organizations worldwide that make up the World Wide Web Consortium) is the prime example of a
container that is ignorant of content, has all the properties of a DAG, and can easily be extended to assimilate new concepts that have never before entered the mind of humankind. Our test data set for cardiovascular surgery contains 23 million nodes (terms) and 93 million relationships (statements) representing 200,000 patients.
What are the advantages of such graph structures besides infinite extensibility? First, medical taxonomies, such as those of Systematized Nomenclature of Medicine (SNOMED) (Schulz et al., 2009) or the National Library of Medicine’s metathesaurus (UMLS [unified medical language system]) (Thorn et al., 2007), underlie the data model and enable semantic searches. An investigator can search for patients and their data without knowing anything about underlying data structure. Specifically, this is achieved by separating semantics from the underlying syntax, in much the same spirit as the vision for the semantic web (Berners-Lee et al., 2001). Rather than being confined to lexical searches for information, a semantic web search is based on meaning. An example of this is the contrast between a dictionary based on meaning, such as the American Heritage Dictionary (Pickett, 2000), and one based on lexical definitions, such as Merriam-Webster (Merriam-Webster Dictionary, 2004). Thus, a heart attack, myocardial infarction, MI, acute myocardial infarction, AMI, and the variety of ways this medical concept may be expressed in both language and specific idiosyncratic syntax in a given database, are all recognized as a meaningful single semantic concept. Conversely, when the meaning of a term (such as myocardial infarction) changes, there is no semantic confusion because at the semantic level those are separate terms (Thygesen et al., 2007). There is a many-to-many mapping between lexical terms and their semantic denotations; the latter are the loci of medical knowledge.
Second, patients’ graphs are connected by a data model to both general and medical ontologies, not just controlled term lists or taxonomies. These ontologies are built on a skeleton of taxonomically arranged concepts, but they contain as many—and as sophisticated—assertions about those concepts as are needed to compose an adequate model of an area of practice (Buchanan and Shortliffe, 1984). Think of an orthopedic ontology: It contains not only a taxonomy of all the bones in the body, but also assertions about them, such as “the knee bone’s connected to the thigh bone, and the thigh bone’s connected to the hip bone” (Weeks and Bagian, 2000), the type of joints between them, relative sizes, and so on.
Third, because natural language queries that seem clear to human investigators are fraught with ambiguous terms and grammatical constructions (e.g., attachment of prepositional phrases), pronouns, elisions, and metaphors, the knowledge represented in rich ontologies (vs. a taxonomy) suffices—barely—to permit investigators to ask database questions in natural language rather than in the language of a database expert. For the last
few years, Cleveland Clinic has collaborated with Douglas B. Lenat and his group in Austin, Texas, who, for the last 24 years, have built a top-down ontology of general concepts that starts with “thing” at the top and goes all the way down to such domain-specific concepts as “kidney” and “dialysis,” and millions of general rules and facts that interrelate and, therefore, partially define those terms and model a portion of human knowledge (Lenat and Guha, 1990). Not surprisingly, to cope with divergence across humans’ models of the world, that ontology—Cyc—required its knowledge base to be segmented into locally consistent (but only locally consistent) contexts. Since 2007 a group of us from Cleveland Clinic and Cycorp have worked together to tie low-level medical ontology concepts to the general Cyc ontology of things.
An investigator can now type into a Semantic Research Assistant™ a simple English sentence such as “Find patients with bacteremia after a pericardial window.” Although complete automatic parsing of realistically large and complex investigator queries is still far beyond today’s state-of-the-art artificial intelligence software (Lenat, 2008), one thing that is possible today, and which the current system does, is to successfully extract entities, concepts, and relations from the text as it understands the meaningful fragments of the query. These fragments are understood as logical clauses (in the system’s formal representation), each of which is translated into a short, comprehensible English phrase and presented to the investigator. The investigator selects those fragments believed to be relevant, at which time an amazing thing happens almost every time: There is only a single semantically meaningful combination of those fragments, and only a single query that makes sense, given common sense constraints, domain knowledge constraints, and discourse pragma. Combining the fragments entails, for example, deciding which variables from each fragment unify with variables from other fragments, or whether they represent separate entities, and deciding whether each variable should be quantified existentially or universally, and in what order. The full query is then assembled, an English paraphrase of it is presented to the investigator, and a SPARQL translation of it is presented to the semantic database, which returns answers that are displayed to the investigator. Often, in the course of this process, some clauses that were not explicitly included by the investigator can be suggested; at other points in the process, the investigator may tweak the query by replacing a term with one of its generalizations or siblings or descendants in the ontology.
Fourth, a semantic-ontology approach also permits truly intelligent patient search of medical concepts. This is becoming increasingly important as patients seek out information about their medical conditions. A patient might type into a medical semantic search engine, “I have a racing heart.” The semantic search engine produces a number of hits that don’t include
NASCAR racing but rather tachycardias, such as atrial fibrillation, presenting the patient with definitions and treatment options.
What now needs to be developed to implement semantic databases and knowledge bases for intelligent search of all of medicine is a comprehensive formal ontology of medicine. This will require a worldwide effort. Already some of this is going on. For example, the Cardiovascular Gene Ontology provides full annotation for genes associated with cardiac disease processes.13
In the future such systems may actively ask relevant questions about correlations and trends within longitudinal records by means of true artificial intelligence. Automated intelligent agents could assist in discovering unsuspected relationships, unintended adverse outcomes, and surprising beneficial effects (AAAI, 2008). It could be central to realizing a learning medical system, a key component of what 21st-century medicine must become.
Computer Learning Methods
As much as one can dream of a longitudinal database that might permit innovative research for information-based medical care, it is important to ask, “If we actually had these data, would we know what to do with them?” One useful way to look at the issue is to use a “trees and woods” analogy in which individual patients, their data, and their genes are like the individual trees, and groups of patients or populations are the woods (Blackstone, 2007). The expression “Ye can’t see the wood for the trees” (Heywood, 1546) implies that there may be patterns in the wood that can be discerned by overview that are not visible by attention paid only to individual trees. Here is an example: If one sits on the sidelines of an Ohio State University football game, one can only see individual band members playing at half-time and their feet moving around. But from an aerial view, one can see the band is in formation spelling the word Ohio. Patterns in medical data represent the general ways that patients react to their disease or treatment. They are the incremental risk factors, the modulators, or the surrogates for underlying disease and treatment mechanisms (Kirklin, 1979).
The rapidly developing science of computer learning promises methods far more robust than traditional statistical methods for discovering these patterns (Breiman, 2001). Many of them are based on multiple bootstrap samples (Diaconis and Efron, 1983; Efron, 1979, 1982; Efron and Tibshirani, 1986), each of them analyzed and aggregated (Breiman, 1996). This can be illustrated by analyzing 15 potential risk factors for death after
_______________
13 See http://www.geneontology.org/GO.cardio.shtml (accessed September 8, 2010).
mitral valve surgery. These are designated A through O in panel A in Figure 2-5, which shows the first five bootstrap analyses. The tall vertical bars designate variables identified in each analysis. Note that no analysis yields identical risk factors. But now consider a running average of these results (Figure 2-5, panel B). Notice the running average of these unstable results progressively reveals a clear pattern: Variables A, C, D, I, and J are signal, and the rest are noise (Figure 2-5, panel C).
Imagine extending this concept. For example, at each iteration the algorithm could average the contribution of a predictor based on its appearance in previous iterations (boosting)—an adaptive weighted average (Bartlett et al., 2004; Freund and Schapire, 1996; Friedman, 2001, 2002). Bagging produces an average, but unlike boosting, it uses the same weight for each iteration.
Other computer learning techniques are being developed, such as Bayesian analysis of variants for Microarray methodology, which is being used to discover empiric gene expression profiles that are highly predictive for colorectal cancer recurrence (Ishwaran and Rao, 2003; Ishwaran et al., 2006). Unsupervised hierarchical bootstrap clustering almost completely separates patients experiencing cancer recurrence from those whose cancer has not recurred. What is important to recognize is that these methods solve the problem of having a large number of parameters (P) compared to number of individuals (n), a key factor in genomic analysis and research.
These methods are still in their infancy; many are based on computer-intensive methods such as bootstrap sampling or random forest technology. Variables may be selected by importance value (Breiman, 1996, 2001; Ishwaran, 2007) or by signal-to-noise ratios rather than by traditional P values, which become progressively less useful as n becomes large. Prediction error is minimized rather than maximizing goodness of fit.
An important feature of all ensemble learners is that they are computationally highly parallelizable—either for large-scale parallel computers or for grid computing. This may become important as researchers start looking at a huge number of patients, when speed of computation for clinical inferencing may be of the essence.
Patient-Specific Strategic Decision Support
Finally, to come full circle, consider personalized medicine. Joel Verter once said that RCTs are “sledgehammers, not fine dissecting instruments.” Medicine needs to head toward fine dissecting instruments, toward personalized strategic decision support. With n = 1, a new paradigm of RCT needs to be developed for genomic-based personalized medicine (Balch, 2006).
Consider a 59-year-old man with ischemic cardiomyopathy and anterior MI resulting in left ventricular aneurysm. He has an ejection fraction
of 10 percent; 4+ mitral valve regurgitation; extensive coronary artery disease, including 90 percent left anterior descending coronary artery stenosis; and multiple comorbidities. Should the recommended therapy be continued medical treatment, coronary artery bypass graft (CABG), CABG plus mitral valve anuloplasty, a Dor operation, or cardiac transplantation? This complex information is too multidimensional for assimilation by the human mind. It calls for a cognitive prosthesis (Reason, 1999). Ideally, this patient’s data would be entered automatically by a CPR into a strategic decision aid and the long-term expected survival would be depicted for multiple alternative therapies along with uncertainty limits, although not all therapies may be applicable.
Locked in the medical literature even today are static risk factor equations that could be used in dynamic mode for strategic decision support for a patient such as this (Levy et al., 2006). Random forest technology also can generate outcome risk estimates for individual patients by “dropping” their characteristics down a forest of trees, where they will land at a specific node in each tree with patients having similar characteristics and known outcome. Results of all patients at each node become the average ensemble predicted outcome for an individual patient. Thus, it is possible to imagine that in the future there will be methods by which patient-specific prediction of outcomes are generated and alternative therapies compared for patient decision support.
A library of modules must be developed for constructing strategic decision aids such as this. These in turn must be coupled to values for variables in a CPR so that no human intervention is required to depict comparable predictions of results. Then it must be prospectively verified that the simulated results match actual outcomes. The medical record thus becomes an active revealing and learning tool.
FIGURE 2-5 Example of automated variable selection by bootstrap aggregation (bagging). Fifteen variables labeled A through O are depicted as potential predictors of death after mitral valve surgery. In column A, analyses of five bootstrap samples are shown. Tall bars indicate the variable was selected at P < .05, and gaps represent variables not selected. Variables A and D were selected in all cases, but otherwise the analyses appear to be unique. Panel B shows a running average of these five analyses. Variables A, D, I, and J were selected more often than others. Panel C shows averages of 10, 50, 100, 250, and 1,000 bootstrap analyses. Notice that no variable was selected 100% of the time, and all 15 were selected at one time or another. But if variables appearing in 50% or more analyses are considered reliable risk factors, then variables A, C, D, I, and J fit that criterion of “signal,” and the rest are “noise.”
Summary
Moving beyond today’s Mt. Everest level of difficulty, RCTs need to become more nimble and simple to better reflect the real world and to have their financing restructured. Heterogeneity in practice facilitates approximate randomized trials via propensity score methods that are inexpensive and widely accessible but which require patient-level clinical data stored as discrete values for variables. Emerging semantic technology can be exploited to integrate currently disparate, siloed medical data—responding to investigators’ complex queries and patients’ imprecise ones—and in the near future holds the promise to automate discovery of unsuspected relationships and unintended adverse or surprisingly beneficial outcomes. A next generation of analytic tools for revealing patterns in clinical data should build on successful methods developed in the discipline of machine learning. Both new knowledge learned and resulting algorithms should be transformed into strategic decision support tools. These are but a few concrete examples of methods that need to be developed to provide an infrastructure to determine the right treatment for the right patient at the right time.
Resources Needed
What resources are needed to develop this infrastructure?
Reengineering Randomized Controlled Trials
The cost of an NIH-sponsored simple trial appears to be in the range of $2 million, but multi-institutional, multinational large trials driven by clinical end points can consume 10 times that figure. If one uses $100 million as a metric, this means 5 to 50 such trials of therapy can be supported. Considering all the therapies of medicine for which the evidence base is weak, it is clear that demanding gold-standard RCTs for everything is unaffordable. The cost of RCTs that are highly focused, ethically unambiguous, and feasible could be brought down to a quarter, perhaps even a tenth, of this figure based on practical experience. This will require maximum use of electronic patient records, consisting of values for variables, and quite specifically longitudinal surveillance data to study the long-term side effects of therapies.
Approximate Randomized Controlled Trials
The NIH and National Science Foundation (NSF) should join forces and solicit 3-year methodology grants of approximately $250,000 per year,
10 per year. For this $7.5 million investment, a strong understanding of how best to use nonrandomized data would emerge. With this would come production of publicly available statistical software.
If rich discrete clinical data were available for analysis, a typical study using these methods for nonrandomized comparison would cost approximately $75,000. The cost would double if extensive integration of data was necessary, possibly over healthcare networks. For $100 million, it would be possible to conduct more than 1,000 such approximate randomized trials. This could have a major impact on acquiring what might be called “silver-level” evidence for practice.
Semantically Integrating, Querying, and Exploring Disparate Clinical Data
Based on several years of work, it seems that developing a comprehensive ontology of medicine—a new framework for analysis across disparate medical domains—will cost about 1 hour of time per term for an analyst, programmer, and clinical expert. One need not start from scratch, but can exploit SNOMED, UMLS, and other term lists and ontologies to start the process. Assuming that 100,000 terms would need to be defined in this fashion, that the wages would be $300 per hour, and that 25 ontologists would be needed, this work could be completed in 2 years at a cost of $36 million. This would include the software that must be programmed to implement a global effort in rallying medical experts to this task.
Computer Learning Methods
Knowledge discovery in medicine involves both methodologic development and applications. These should go hand in hand in this new field because it would accelerate the development of methods as they encounter problems requiring further methodologic work. The NSF has begun an initiative called Cyber-Enabled Discovery and Innovation (Jackson, 2007). This began with a $52 million first-year budget and is intended to ramp up $50 million per year and finish within 5 years for a total of $750 million. It would be useful to add $10 million per year for direct application to biomedicine, for a total sustained level for these activities within 5 years of $50 million.
Patient-Specific Strategic Decision Support
Costs in this area are largely for developing software, including the interfaces to EMR systems. This could be done for approximately $10 million. One could envision every study of clinical effectiveness having a
patient-specific prediction component built into it. Again, based on experience doing this, approximately $25,000 per study would be required to adapt and test the software and couple it with EMRs for decision support. It is also likely that at some point, the FDA may become involved with tools such as this and would introduce regulations that are more costly to meet than those of performing the studies.
COORDINATION AND TECHNICAL ASSISTANCE THAT NEED TO BE SUPPORTED
Jean R. Slutsky, Director, Center for Outcomes and Evidence,
Agency for Healthcare Quality and Research
Overview
CER as a concept and reality has grown rapidly in the past 5 years. While it builds on an appreciation for the role of technology assessment, comparative study designs, and the increased role of health information technology to gather evidence and distribute it to the point of care, the capacity and infrastructure for this research has received less targeted attention. Understanding the landscape of organizations and health systems undertaking CER is challenging but essential. Without knowing what capacities and infrastructure currently exist, rational strategic planning for the future cannot be done. It is also important to address which functions can be most effective if they are centralized, which are most effective if they are local or decentralized, and how different activities relate to each other in a productive way. This paper will explore the practical realities of what exists now, what is needed for the future, and how the needs of the country’s diverse healthcare system for CER can best be met.
The Agency for Healthcare Research and Quality Perspective
AHRQ plays a significant role in CER. Under a mandate included in Section 1013 of the Medicare Prescription Drug, Improvement, and Modernization Act of 2003, AHRQ is the lead agency for CER in the United States. AHRQ conducts health technology assessment at the request of CMS and analyzes data and suggests options for coverage with evidence development (CED) and post-CED data collection. AHRQ also provides translation of CER findings, promotes and funds comparative effectiveness methods research, and funds training grants focused on comparative effectiveness. AHRQ has an annual budget of over $300 million ($372 million for 2009), and received funds specifically for work on CER ($30
million and $50 million in 2008 and 2009, respectively).14 AHRQ has built a flexible, dynamic infrastructure for CER that includes 41 research centers nationwide with more than 160 researchers. The program includes K awards for career development such as the Mentored Research or Clinical Scientist Development awards, and Independent Scientist awards. AHRQ has also funded methods research that heretofore had not been funded except on an ad hoc basis. AHRQ has also put concentrated funding into the translation of CER findings.
Given the pressing need for evidence, it is important to keep in mind the high costs of precision. It costs money to conduct precise studies that answer detailed questions, which speaks to the importance of not only priority setting but also understanding that this is an important and difficult task.
In the United States, the landscape for CER is, for the most part, very well intentioned. All parties engaged in this work want to do the right thing and see what works best for patients in the United States and elsewhere. Nonetheless, current efforts are too ad hoc in nature. There are no adequate organizing principles, except for those outlined in Section 1013, where language in the legislation focuses on setting priorities, having transparent processes, involving stakeholders, and having a translation component. The effect is that in the United States there is essentially only a very limited capacity to conduct CER and to translate that research into meaningful and useful applications. The United States is not accustomed, nor organized effectively, to conduct this type of research. In part, this is because the system tends not to grow researchers who have the capacity to move beyond what might be described as a parochial mind set regarding the types of research study designs, a mind set which has limited the capacity to readily generate hypotheses and study designs appropriate for CER. Generally, researchers do not involve stakeholders to the extent that is required for research aimed at generating information to guide end users such as patients and physicians. A key shift needed in the current approach to research is to involve patients and other key stakeholders, such as industry and health plans, in the formulation of questions for investigation and in study design.
As mentioned above, AHRQ is currently conducting CER under legislative mandate. Other federal agencies also conducting CER include the NIH, CMS (CED), and the VA; some have done so for decades. In the private sector, health plans and industry are also engaged in CER. In addition, CER-focused public–private partnerships are starting to form, as are private–private partnerships. Unlike other forms of research, CER will most certainly require the kinds of partnerships that are now emerging.
_______________
14 See http://www.ahrq.gov/about/budgtix.htm (accessed September 8, 2010).
There are a number of common pitfalls in CER. One of the most significant failures is that comparative effectiveness studies are not designed in ways that capture meaningful end points as well as longitudinal and relevant outcomes—end points that would be meaningful not only to patients but also to decision makers. There are also significant issues about the applicability of the CER studies that are conducted, and the work we do for CMS is reflective of the need for research conducted in patients representative of the Medicare population. The elderly tend not to be studied in rigorous trials to the extent that children are, although AHRQ has begun to address this discrepancy through, for example, work for the Medicaid and State Children’s Health Insurance programs. There is also a failure to clinically address relevant heterogeneity and biological heterogeneity as well. Finally, there are also responsibility issues, as evidenced in discussions of “who pays and who stays” when the need for an important study has been noted. There is currently discussion of such issues on Capitol Hill.
Today’s reality in CER, therefore, can be summarized as follows. There is general sentiment that CER can be a positive thing if it is done fairly, is well designed, and is transparent. This is important because of the potential impact of CER on many different sectors—not just patients, but also industry and health plans. If CER is not conducted in a way that stakeholders can understand—and, importantly, in a way by which they have input into the process—it could happen that CER does not have the impact, in terms of improving health outcomes, that everyone hopes it will have. As AHRQ discovered in developing the Section 1013 healthcare program, involving stakeholders early, listening to them, and involving them throughout the process through to the end and implementation of the findings, is critically important.
Another issue with CER today is that there is no agreement on the best methods for setting priorities. Everyone tries to set priorities finds that reaching consensus is hugely difficult. In part that is because the process of setting such priorities tends to revert to personal or narrowly defined considerations. If a consensus is to be reached, rather than thinking about individual priorities, it will be important to instead learn to focus on national priorities. Experience shows, however, that such priority shifting is difficult.
Another aspect of the reality of CER today that has been disappointing is that there has been less emphasis on designing good studies than on just the concept of CER. A great deal of time is spent talking about where CER should live, what it should look like, and how it should be funded, but there has tended not to be adequate discussion about how to conduct CER most effectively from a methodological and implementation standpoint. Further discussion is needed on both sides of this issue—discussion not only about which box CER lives in, if you will, but about what’s inside the box.
Once a decision to perform a CER study is made, finding a payer or a funder for the research component is difficult. Obviously, with a budget of $30 million AHRQ cannot be the sole funder of many of these studies. Regardless, the reality is that the challenges related to funding lead to less rigorous and less innovative study designs. Somehow the issue of how different players collaborate to fund these studies must be addressed. Otherwise, the rigorous study designs needed to move this field forward will never be developed.
Successes, however, make the fundamental concept of CER worthwhile. Among the successes, for example, are cases where CER uncovered findings that exceeded expectations. Successes also include what might be considered negative findings, where research results proved to be not good news for certain subpopulations but still provided findings that were not previously known. Whether findings from CER are viewed as positive or negative, the overarching consideration is that they inform how care is provided.
Conclusions
In closing, it will be important to be mindful of several critical factors while developing the infrastructure necessary to advance CER. First, more coordination is needed in setting priorities. Much has been learned from individual efforts that have taken place both within government and outside government. What is needed now is to capitalize on these lessons learned and to begin moving forward together in a more coordinated way to reach consensus in the setting of priorities for CER. A more systematic approach to the conduct of CER is also warranted, if only because CER tends to receive a smaller slice of research funding and so it will be important to be systematic and strategic in spending limited funds effectively. Coordination is imperative.
A stronger emphasis on training, methods, and translation is also needed. These three factors are separate, but they are not inseparable. Enhanced education is necessary to train the next generation of researchers on the methodologies of new research designs and on methods of translating research findings in ways that are actionable, understandable, and not leading with blunt-edge decisions. At the same time, there needs to be more robust training targeted to help next-generation investigators work effectively with all relevant stakeholders. More funding is needed, specifically for well-designed studies that meet priorities, that are not underpowered and that address meaningful health outcomes. Further, more public–private partnerships are needed to move CER forward from an implementation standpoint and to resolve some of the funding problems that heretofore have hindered CER. Finally, more training is needed on the use of findings to avoid inappropriate or unintended consequences. Too often, the defini-
tion of success is whether the results of a given study were published in a peer-reviewed journal. That focus needs to be shifted to the true heart of the matter, which is how the findings can best be used in practice and how they are relevant to decision makers.
As to the future of CER, public–private funding and participation is a critical necessity for CER to go forward. More effort is needed to develop designs and protocols that more efficiently and effectively answer CER questions. This would encompass not merely conducting new methodological research but also working with stakeholders and users of research as well as people affected by the research. Public–private funding and participation is a necessity. Finally, there are a number of important issues that will take a global approach that need to be addressed. Training on research design and translation must become an accepted use of healthcare dollars. Wide attention to vastly improved priority setting, at macro and micro levels, is also necessary. Transparency across participation is important, so no one gets unequal access and everyone is at the table. Improved technical assistance for conducting and implementing CER will also be critical to success.
REFERENCES
AAAI (Association for the Advancement of Artificial Intelligence). 2008. Fall symposium on automated scientific discovery. November 7-9, 2008. Arlington, VA.
Abiteboul, S., D. Quass, J. McHugh, J. Widom, and J. L. Wiener. 1997. The Lorel query language for semistructured data. International Journal of Digital Libraries 1:68-88.
AHRQ (Agency for Healthcare Research and Quality). 2007. Special emphasis notice: AHRQ announces interest in career development (K) grants focused on comparative effectiveness research. http://grants.nih.gov/grants/guide/notice-files/NOT-HS-08-003.html (accessed August 5, 2010).
Avalere Health. 2008. Patient and clinician participation in research agenda setting: Lessons for future application. Washington, DC: Avalere Health.
Balch, C. M. 2006. Randomized clinical trials in surgery: Why do we need them? Journal of Thoracic and Cardiovascular Surgery 132(2):241-242.
Barnett, G. O., R. A. Jenders, and H. C. Chueh. 1993. The computer-based clinical record—Where do we stand? Annals of Internal Medicine 119(10):1046-1048.
Bartlett, P. L., P. J. Bickel, P. Buhlmann, and Y. Freund. 2004. Discussions of boosting papers, and rejoinders. Annals of Statistics 32:85-134.
Beck, J., P. J. Esser, and M. B. Herschel. 2004. Why clinical trials fail before they even get started: The “frontloading” process. Quality Assurance Journal 8(1):21-32.
Berners-Lee, T., J. Hendler, and O. Lassila. 2001. The semantic web: A new form of web content that is meaningful to computers will unleash a revolution of new possibilities. Scientific American May 17:1-18.
Blackstone, E. H. 2002. Comparing apples and oranges. Journal of Thoracic and Cardiovascular Surgery 123(1):8-15.
———. 2005. Could it happen again? The Bjork-Shiley convexo-concave heart valve story. Circulation 111(21):2717-2719.
———. 2006. Consort and beyond. Journal of Thoracic and Cardiovascular Surgery 132(2): 229-232.
———. 2007. From trees to wood or wood to trees? Journal of Surgical Research 147: 59-60.
Braunwald, E. 1983. Effects of coronary-artery bypass grafting on survival. Implications of the randomized coronary-artery surgery study. New England Journal of Medicine 309(19):1181-1184.
Breiman, L. 1996. Bagging predictors. Machine Learning 24:123-140.
———. 2001. Statistical modeling: The two cultures. Statistical Science 16:199-231.
Buchanan, B. G., and E. H. Shortliffe, eds. 1984. Rule based expert systems: The mycin experiments of the Stanford heuristic programming project. Reading, MA: Addison-Wesley.
Buneman, P., M. Fernandez, and D. Suciu. 2000. UnQL: A query language and algebra for semistructured data based on structural recursion. Very Large Database Journal 9:76-110.
CBO (Congressional Budget Office). 2007. Research on the comparative effectiveness of medical treatments. Publication No. 2975. Washington, DC: CBO. http://www.cbo.gov/ftpdocs/88xx/doc8891/12-18-ComparativeEffectiveness.pdf (accessed September 3, 2010).
Cepeda, M. S., R. Boston, J. T. Farrar, and B. L. Strom. 2003. Comparison of logistic regression versus propensity score when the number of events is low and there are multiple confounders. American Journal of Epidemiology 158(3):280-287.
Congressional Research Service (CRS). 2007. Comparative clinical effectiveness and cost-effectiveness research: Background, history, and overview. Washington, DC: CRS.
Diaconis, P., and B. Efron. 1983. Computer-intensive methods in statistics. Scientific American June 1:116-130.
Donner, A., and N. Klar. 2000. Design and analysis of cluster randomization trials in health research. New York: Oxford University Press.
Efron, B. 1979. Bootstrap methods: Another look at the jackknife. Annals of Statistics 7:1-26.
———. 1982. The jackknife, the bootstrap and other resampling plans. Monograph. Philadelphia, PA: Society for Industrial and Applied Mathematics.
Efron, B., and R. Tibshirani. 1986. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Statistical Science 1:54-77.
Erkinjuntti, T., T. Ostbye, R. Steenhuis, and V. Hachinski. 1997. The effect of different diagnostic criteria on the prevalence of dementia. New England Journal of Medicine 337(23):1667-1674.
Etheredge, L. 2007. A rapid-learning health system. Health Affairs 26:w107-w118.
FDA (Food and Drug Administration). 2009. Patient participation in FDA regulatory issues. http://www.fda.gov/ForConsumers/ByAudience/ForPatientAdvocates/PatientInvolvement/default.htm (accessed August 5, 2010).
Fleming, T. R., and D. L. DeMets. 1996. Surrogate end points in clinical trials: Are we being misled? Annals of Internal Medicine 125(7):605-613.
Freund, Y., and R. E. Schapire. 1996. Experiments with a new boosting algorithm. Proceedings of the International Conference on Machine Learning July:148-156.
Friedman, J. H. 2001. Greedy function approximation: A gradient boosting machine. Annals of Statistics 29:1189-1232.
———. 2002. Stochastic gradient boosting. Computational Statistics & Data Analysis 38: 367-378.
Gliklich, R. E., and N. A. Dreyer, eds. 2007. Registries for evaluating patient outcomes: A user’s guide. Rockville, MD: Agency for Healthcare Research and Quality.
Grunkemeier, G. L., R. Jin, and A. Starr. 2006. Prosthetic heart valves: Objective performance criteria versus randomized clinical trial. Annals of Thoracic Surgery 82(3):776-780.
Gum, P. A., M. Thamilarasan, J. Watanabe, E. H. Blackstone, and M. S. Lauer. 2001. Aspirin use and all-cause mortality among patients being evaluated for known or suspected coronary artery disease: A propensity analysis. Journal of the American Medical Association 286(10):1187-1194.
Heywood, J. 1546. A dialogue conteynyng the nomber in effect of all the prouerbes in the englische tongue.
Hunt, S. A., W. T. Abraham, M. H. Chin, A. M. Feldman, G. S. Francis, T. G. Ganiats, M. Jessup, M. A. Konstam, D. M. Mancini, K. Michl, J. A. Oates, P. S. Rahko, M. A. Silver, L. W. Stevenson, C. W. Yancy, E. M. Antman, S. C. Smith, Jr., C. D. Adams, J. L. Anderson, D. P. Faxon, V. Fuster, J. L. Halperin, L. F. Hiratzka, A. K. Jacobs, R. Nishimura, J. P. Ornato, R. L. Page, B. Riegel, American College of Cardiology, American Heart Association Task Force on Practice Guidelines, American College of Chest Physicians, International Society for Heart and Lung Transplantation, and Heart Rhythm Society. 2005. ACC/AHA 2005 guideline update for the diagnosis and management of chronic heart failure in the adult. American Heart Association 112:145-235.
IDSA (Infectious Diseases Society of America). 2006. Frequently asked questions about Lyme disease. http://www.idsociety.org/lymediseasefacts.htm (accessed August 5, 2010).
ILADS (International Lyme and Associated Diseases Society) Working Group. 2004. Evidence-based guidelines for the management of Lyme disease. Expert Review of Anti-Infective Therapy 2(1):S1-S13. http://www.ilads.org/files/ILADS_Guidelines.pdf (accessed August 5, 2010).
Ilkhanoff, L., J. D. Lewis, S. Hennessy, J. A. Berlin, and S. E. Kimmel. 2005. Potential limitations of electronic database studies of prescription non-aspirin non-steroidal anti-inflammatory drugs (NANSAIDS) and risk of myocardial infarction (MI). Pharmacoepidemiological Drug Safety 14(8):513-522.
Ioannidis, J. P. 2005. Why most published research findings are false. PLoS Medicine 2(8): e124.
IOM (Institute of Medicine). 1991 The computer-based patient record: An essential technology for health care. Washington, DC: National Academy Press.
———. 2007. Learning what works best: The nations need for evidence on comparative effectiveness in health care. http://www.iom.edu/ebm-effectiveness (accessed August 5, 2010).
———. 2008. Knowing what works in health care: A roadmap for the nation. Washington, DC: The National Academies Press.
Ishwaran, H. 2007. Variable importance in binary regression trees and forests. Electronic Journal of Statistics 1:519-537.
Ishwaran, H., and J. S. Rao. 2003. Detecting differentially expressed genes in microarrays using Bayesian model selection. Journal of the American Statistical Association 98:438-455.
Ishwaran, H., J. S. Rao, and U. B. Kogalur. 2006. Bamarray: Java software for Bayesian analysis of variance for microarray data. BMC Bioinformatics 7(1):59.
Jackson, A. 2007. Cyber-enabled discovery and innovation. Notices of the American Mathematical Society 54:752-754.
Kamerow, D. 2009. Comparative effectiveness studies inventory project. Washington, DC: A commissioned activity for the IOM Roundtable on Value & Science-Driven Health Care.
Kirklin, J. W. 1979. A letter to Helen (Presidential address). Journal of Thoracic and Cardiovascular Surgery 78(5):643-654.
Kirklin, J. W., and S. S. Vicinanza. 1999. Metadata and computer-based patient records. Annals of Thoracic Surgery 68(3 Suppl.):S23-S24.
Last, J., ed. 1983. A dictionary of epidemiology. New York: Oxford University Press.
Lenat, D. B. 2008. The voice of the turtle: Whatever happened to AI? Artificial Intelligence Magazine 29(2):11-22.
Lenat, D. B., and R. V. Guha. 1990. Building large knowledge-based systems: Representation and inference in the Cyc project. Reading, MA: Addison-Wesley.
Levy, W. C., D. Mozaffarian, D. T. Linker, S. C. Sutradhar, S. D. Anker, A. B. Cropp, I. Anand, A. Maggioni, P. Burton, M. D. Sullivan, B. Pitt, P. A. Poole-Wilson, D. L. Mann, and M. Packer. 2006. The Seattle heart failure model: Prediction of survival in heart failure. Circulation 113(11):1424-1433.
Merriam-Webster Dictionary. 2004. Springfield, MA: Merriam-Webster.
Mosis, G., B. Koes, J. Dieleman, B. Stricker, J. van der Lei, and M. C. Sturkenboom. 2005a. Randomised studies in general practice: How to integrate the electronic patient record. Informatics in Primary Care 13(3):209-213.
Mosis, G., A. E. Vlug, M. Mosseveld, J. P. Dieleman, B. C. Stricker, J. van der Lei, and M. C. Sturkenboom. 2005b. A technical infrastructure to conduct randomized database studies facilitated by a general practice research database. Journal of the American Medical Informatics Association 12(6):602-607.
Mosis, G., J. P. Dieleman, B. Stricker, J. van der Lei, and M. C. Sturkenboom. 2006. A randomized database study in general practice yielded quality data but patient recruitment in routine consultation was not practical. Journal of Clinical Epidemiology 59(5):497-502.
NCCN (National Comprehensive Cancer Networks). 2008. About the NCCN clinical practice guidelines in oncology. Available at http://www.nccn.org/professionals/physician_gls/about.asp (accessed September 8, 2010).
———. 2009. NCCN drugs & biologics compendium. http://www.nccn.org/professionals/drug_compendium/content/contents.asp (accessed September 8, 2010).
NCI (National Cancer Institute). 2007. Cancer care outcomes research and surveillance consortium. http://outcomes.cancer.gov/cancors (accessed May 30, 2009).
NHLBI (National Heart, Lung, and Blood Institute). 1981. National Heart, Lung, and Blood Institute coronary artery surgery study. A multicenter comparison of the effects of randomized medical and surgical treatment of mildly symptomatic patients with coronary artery disease, and a registry of consecutive patients undergoing coronary angiography. Circulation 63(6 Pt. 2):I1-I81.
NICE (National Institute for Health and Clinical Excellence). 2004. Summary budget statement. www.nice.org.uk/niceMedia/pdf/boardmeeting/brdsep04item12.pdf (accessed July 31, 2004).
NIH (National Institutes of Health). 2006. K30 clinical research curriculum award. http://grants.nih.gov/training/k30.htm?sort=inst#list (accessed January 17, 2006).
Nissen, S. E. 2006. Adverse cardiovascular effects of rofecoxib. New England Journal of Medicine 355(2):203-205.
Pickett, J. P., ed. 2000. The American heritage dictionary of the English language, 4th ed. Boston, MA: Houghton Mifflin.
Reason, J. 1999. Human error. Cambridge, MA: Cambridge University Press.
Rosenbaum, P. R., and D. B. Rubin. 1983. The central role of the propensity score in observational studies for causal effects. Biometrika 70:41-55.
Rubin, D. B. 2007. The design versus the analysis of observational studies for causal effects: Parallels with the design of randomized trials. Statistics in Medicine 26(1):20-36.
Sabik, J. F., A. M. Gillinov, E. H. Blackstone, C. Vacha, P. L. Houghtaling, J. Navia, N. G. Smedira, P. M. McCarthy, D. M. Cosgrove, and B. W. Lytle. 2002. Does off-pump coronary surgery reduce morbidity and mortality? Journal of Thoracic and Cardiovascular Surgery 124(4):698-707.
Sacristan, J. A., J. Soto, I. Galende, and T. R. Hylan. 1997. A review of methodologies for assessing drug effectiveness and a new proposal: Randomized database studies. Clinical Therapeutics 19(6):1424-1517.
Schulz, S., B. Suntisrivaraporn, F. Baader, and M. Boeker. 2009. SNOMED reaching its adolescence: Ontologists’ and logicians’ health check. International Journal of Medical Informatics 78(Suppl. 1):S86-S94.
Senge, Peter M. 1990. The fifth discipline: The art and practice of the learning organization. New York: Doubleday.
Shadish, W., T. Cook, and D. Campbell. 2002. Experimental and quasi-experimental designs for generalized causal inference. Boston, MA: Houghton Mifflin.
Slutsky, J., and C. Clancy. 2009. AHRQ’s effective health care program: Why comparative effectiveness matters. American Journal of Medical Quality 24:67-70.
Stewart, W. F., N. R. Shah, M. J. Selna, R. A. Paulus, and J. M. Walker. 2007. Bridging the inferential gap: The electronic health record and clinical evidence. Health Affairs 26(2): w181-w191.
Strom, B. L. 2005. Overview of automated data systems in pharmacoepidemiology. In Pharmacoepidemiology, 4th ed., edited by B. L. Strom. Chichester, UK: John Wiley and Sons.
Sturmer, T., M. Joshi, R. J. Glynn, J. Avorn, K. J. Rothman, and S. Schneeweiss. 2006. A review of the application of propensity score methods yielded increasing use, advantages in specific settings, but not substantially different estimates compared with conventional multivariable methods. Journal of Clinical Epidemiology 59(5):437-447.
Thorn, K. E., A. K. Bangalore, and A. C. Browne. 2007. The UMLS knowledge source server: An experience in Web 2.0 technologies. AMIA Annual Symposium Proceedings 2007:721-725.
Thygesen, K., J. S. Alpert, and H. D. White. 2007. Universal definition of myocardial infarction. Journal of the American College of Cardiology 50(22):2173-2195.
Weeks, W., and J. Bagian. 2000. Developing a culture of safety in the Veterans Health Administration. Effective Clinical Practice 3:270-276.
Zarin, D. A., and T. Tse. 2008. Medicine: Moving toward transparency of clinical trials. Science 319(5868):1340-1342.
Zipes, D. P., A. J. Camm, M. Borggrefe, A. E. Buxton, B. Chaitman, M. Fromer, G. Gregoratos, G. Klein, A. J. Moss, R. J. Myerburg, S. G. Priori, M. A. Quinones, D. M. Roden, M. J. Silka, C. Tracy, S. C. Smith, Jr., A. K. Jacobs, C. D. Adams, E. M. Antman, J. L. Anderson, S. A. Hunt, J. L. Halperin, R. Nishimura, J. P. Ornato, R. L. Page, B. Riegel, J. J. Blanc, A. Budaj, V. Dean, J. W. Deckers, C. Despres, K. Dickstein, J. Lekakis, K. McGregor, M. Metra, J. Morais, A. Osterspey, J. L. Tamargo, and J. L. Zamorano. 2006. ACC/AHA/ESC 2006 guidelines for management of patients with ventricular arrhythmias and the prevention of sudden cardiac death: A report of the American College of Cardiology/American Heart Association task force and the European Society of Cardiology committee for practice guidelines (Writing committee to develop guidelines for management of patients with ventricular arrhythmias and the prevention of sudden cardiac death). Journal of the American College of Cardiology 48(5):e247-e346.


































































