
5
Toward a Comprehensive Assessment of Federal Research and Development Investment
The preceding chapters have defined the need for this study, identified user issues, discussed methods for improving the current system in the short term, and laid out a plan for the design and implementation of a new system. This chapter begins by considering the future of collection of federal research and development (R&D) spending data in the context of a “science of science” analysis framework, which is evolving to address the needs of science policy analysts and decision makers for R&D spending information. These needs were identified in the workshop the panel held as part of its data-gathering activities (see Appendix C). Many of these needs require bringing together federal funding information from across the federal government, as is now the task of the federal funds and federal support surveys. In addition, they require data on R&D spending outcomes, the role of federal R&D spending in fostering innovation, and the “capacity of the science enterprise to contribute to the wide array of social goals that justifies society’s investment in science” (Sarewitz, 2007, p. 1).
This chapter also considers novel, cutting-edge approaches, such as data federation, automatic text, and linkage analysis that could help enrich the information attainable from administrative sources. This chapter suggests several medium- and long-term initiatives that the Division of Science Resources Statistics (SRS) of the National Science Foundation (NSF) should consider as a basis for modernizing the federal R&D data system.
SCIENCE OF SCIENCE METRICS
The needs and opportunities for improved data and methods for making and analyzing science and technology policies are the principal focus of the NSF Science of Science and Innovation Policy (SciSIP) Program. SciSIP aims to foster the development of relevant knowledge, theories, data, tools, and human capital. According to the agency’s description, “the SciSIP program underwrites fundamental research that creates new explanatory models, analytic tools and datasets designed to inform the nation’s public and private sectors about the processes through which investments in science and engineering (S&E) research are transformed into social and economic outcomes. SciSIP’s goals are to understand the contexts, structures and processes of S&E research, to evaluate reliably the tangible and intangible returns from investments in R&D, and to predict the likely returns from future R&D investments within tolerable margins of error and with attention to the full spectrum of potential consequences” (National Science Foundation, 2008c).
Metrics from such sources as the federal funds and federal support surveys are essential inputs to such analysis. To further develop the vision of a new science of science policy, which was originally articulated by John H. Marburger III, the former director of the Office of Science and Technology Policy and presidential science adviser, the National Science and Technology Council Interagency Task Group developed “The Science of Science Policy: A Federal Research Roadmap” (National Science and Technology Council and Office of Science and Technology Policy, 2008). The roadmap document points out the importance of public investments in science, technology, and innovation but notes that a rationale for scientific investment decisions has insufficient theoretical and empirical bases. The roadmap calls for the development of more rigorous tools, methods, and data to help arrive at sound and cost-effective investment strategies.
The portfolio of statistics prepared by SRS is central to these science and innovation policy initiatives. However, the development of an infrastructure for the science of science and innovation policy cannot be accomplished by SRS alone. It will require contributions from academic research and from a multitude of other federal agencies and departments. The workshop summary in Appendix C describes the kind of information that users need to support an assessment of science and innovation policy. In addition to the current input indicators that are offered by the federal funding data, these needs include output indicators (e.g., publications, graduate students, citations, patents) that support “return on investment” studies and other science policy analyses. To best take advantage of the dynamic nature of these investments, the data would need to be retrievable in new ways. Ideally, it should be possible to select a bar graph, a geospa-
tial region, or a field of S&E, and to delve deeply into the data to see the specific projects funded by different agencies or to see the papers, patents, or products that resulted.
A new data system to support monitoring and analyzing science and innovation policy would require the ability to bring together data at the contract, project, program, and activity levels. The data should be supported by standards of transparency, accountability, and comparability, as well as an infrastructure that permits the linking of data records across agencies.
A FEDERATED SYSTEM OF SCIENCE INVESTMENT POLICY-RELEVANT DATA
This federated database of the future would require that major units of analysis (projects) be supported by unique and persistent data identifiers. The unique identifiers for major projects would include not only grants and contracts, but also papers, patents, people, authors, institutions, and countries, as well as geographic locations, R&D or R&D plant, character of work, and field of science. Plus, records will have to be interlinked—authors would be linked to their respective institutions as well as to all of their papers and funding; papers would be linked to other citing or cited papers; and contracts, grants, and papers would be linked to the fields of science that they represent. This would require the development of a data federation system that would be able to link data records across agency boundaries and would be supported by tools that enable searching and integrating very large databases.
The federated system would have new ways of accessing the data. A management system for the persistent identification of the content of digital networks has been developed by a group of international registration agencies in the Digital Object Identifier (DOI) System. The DOI identifiers, or names, are unique and interoperable from system to system. The DOI names are strings of information about an object backed up by descriptive metadata (Paskin, 2009).
The federated system would incorporate the Semantic Web (Berners-Lee, Hendler, and Lassila, 2001), which is based on standards developed by the World Wide Web Consortium (W3C). The Semantic Web uses uniform resource identifiers (URIs) as globally unique, persistent identifiers. URIs are defined in the resource description framework (RDF1), as is the representation of URI relationships and attributes, using “triples.” A triple describes the data in a sentence-like fashion. Some common links are rdf:seeAlso to refer to related records, owl:sameAs to indicate record identity, or foaf:knows to interlink records of people who know each other.
|
1 |
Available: http://www.w3.org/RDF/. |
Sets of triples can be stored in a single file or distributed across the entire web. SPARQL (Sparql Protocol and RDF Query Language),2 another W3C standard, makes it possible to query Semantic Web data using SQL-like syntax. RDF relationships can also be embedded into standard web pages using RDFA (Resource Description Framework in Attributes).3 In this way, browsers or search engines can extract structured data.
Semantic Web standards such as RDF Schema (RDFS)4 and the Web Ontology Language (OWL)5 make it possible to exchange ontologies, which specify the semantics of the terminology and relationships used in RDF descriptions. Ontologies also enable reasoning, or inference of new triples based on existing data. Another W3C language that should be considered is the Simple Knowledge Organization System (SKOS). This language is particularly tailored to the development of taxonomies and thesauri, being based on a KOS thesaurus standard. It is now being used by many of the U.S. national libraries, including the Library of Congress. SKOS may be especially appropriate for some of the administrative data reporting issues faced in developing a modernized retrieval system for federal grant and contract actions.6
eXtensible Markup Language (XML) is another tool that adds structure, although it does not add meaning to records. It permits data providers and users to create their own “tags” or labels that annotate web pages or content on web pages. In the case of R&D investment data, tags could be developed through XML technology to locate words or phrases that identify a contract or grant as pertaining to a class of research or development, as well as other information, such as a field associated with the object identified as research and development.
The Linking Open Data (LOD) community project led by the World Wide Web Consortium Semantic Web Education and Outreach Group (W3C SWEO)7 shows the power of exposing, sharing, and connecting data via dereferenceable uniform resource identifiers (URIs) on the web.8 Data sets federated via LOD vary from Wikipedia data (DBPedia, wikicompany), to geographical data (e.g., Geonames, World Factbook, Eurostat), to news data (e.g., BBC News), and recently to government data (e.g., U.S. Census Data, GovTrack). The number of interlinked data sets is growing rapidly—from over 500 million RDF triples in May 2007 to around 20 billion RDF
|
2 |
Available: http://www.w3.org/TR/rdf-sparql-query/. |
|
3 |
Available: http://www.w3.org/TR/xhtml-rdfa-primer/. |
|
4 |
Available: http://www.w3.org/TR/rdf-schema/. |
|
5 |
Available: http://www.w3.org/TR/owl-features/. |
|
6 |
Available: http://www.w3.org/2004/02/skos/. |
|
7 |
Available: http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData. |
|
8 |
URIs are used in the World Wide Web to identify resources. Using a standardized protocol such as HTTP, they can “dereferenced” to obtain information about the resource. |
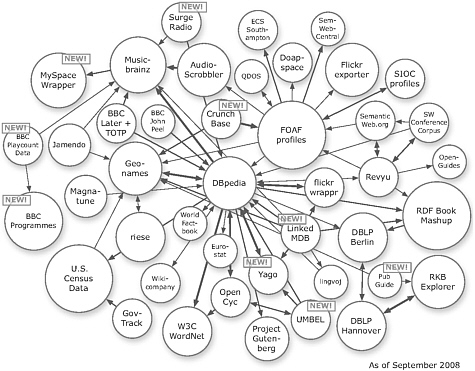
FIGURE 5-1 Linking open data sources.
SOURCE: Linking Open Data W3C SWEO community project. Available: http://esw.w3.org/topic/SweoIG/TaskForces/CommunityProjects/LinkingOpenData.
triples in September 2008. Figure 5-1 illustrates the diversity and number of data sets federated by the LOD project.
Several of the government data sets that have already been converted to RDF format and interlinked within the LOD project are relevant for monitoring the health of S&E, such as U.S. Census Data, GovTrack, Eurostat, and the World Factbook. Other existing data sets, such as SRS funding data, the www.data.gov, and the www.USAspending.gov files, have already been or could be easily converted into RDF format and interlinked to other LOD data sets via RDF links, improving the coverage and utility of the data for analysis of R&D investments.
One important aspect of this work is that about 80-90 percent of the required data unification and data interlinkage can be done automatically. The remaining 10-20 percent of data correction needs to be done by the creators of the objects—the funding agencies that changed award-naming conventions or the principal investigators who best know the subject matter of their grants and contracts. Hence, it will be necessary to support
and encourage data acquisition, editing, and annotation by the applicants and recipients of the grants and contracts and the agencies that fund them. A system used in the Air Force Research Laboratories, using JIFFY R&D program management software, has provided such an automated tool for managing program execution. Importantly, the JIFFY system provides a common repository for data elements related to several different functions of the laboratories.9
A major data federation project that assembles data on academic research and researchers in the United States and other countries is the Community of Science (COS), a product of ProQuest. The COS Scholar Universe has access to information on more than 2 million researchers in over 200 disciplines and 9 countries. The information about scholars is linked to their publications in other databases.10
An international example is the free admission Lattes Database compiled and served by the National Council for Scientific and Technological Development in Brazil.11 The site provides access to around 1,100,000 researcher curricula and about 4,000 institutions in Brazil, including education, business, nonprofit private, and government organizations. Researchers in Brazil were asked to log in to Lattes to ensure that their data are complete and correct with the incentive that these data would soon be used in funding decision making. The result is acclaimed to be one of the cleanest researcher databases in existence today.
The Lattes Database was further interlinked with data from other institutions, such as SciELO, LILACS, SCOPUS, Crossref, and university databases, to increase its coverage and quality. Many institutions in Brazil use the Lattes Database to retrieve data about their teachers, researchers, students, and employees. They interlink the data with their own information systems, generating internal indicators of scientific and technological production or using the data in support of the implementation of management policies.12
A number of other countries have created their own databases. Among them are the Directory Database of Research and Development Activities (ReaD) in Japan13 and the Italian Network for Innovation and Technology Transfer to Small and Medium Sized Enterprises (RIDITT).14 ReaD is a database service designed to promote cooperation among industry, academia, and government by collecting and providing scientific information on research institutes, researchers, research projects, and research resources
|
9 |
Available: http://www.stormingmedia.us/32/3280/A328024.html. |
|
10 |
Available: http://www.refworks-cos.com/GlobalTemplates/RefworksCos/cosschuniv.shtml. |
|
11 |
Available: http://lattes.cnpq.br/english. |
|
12 |
Available: http://lattes.cnpq.br/english/conteudo/acordos.htm. |
|
13 |
Available: http://read.jst.go.jp/index_e.html. |
|
14 |
Available: http://www.riditt.it/page.asp?page=faq&action=detail&IDObject=122. |
in Japan. RIDITT is an initiative aimed at improving the competitiveness of small- and medium-sized enterprises by strengthening the supply of services for innovation and technology transfer and the creation of new high-tech enterprises. It is promoted by the Italian Ministry for Economic Development and managed by the Italian Institute for Industrial Promotion.
If the Office of Management and Budget (OMB) were to oversee implementation of a similar system, over time, the federated system of science and innovation policy–relevant data could encompass a majority of U.S. scholarly data. Given the value and importance of these data, the system should not be owned by a private entity but should be developed using federal funds and hosted by a governmental institution, such as the National Library of Medicine or the National Institute of Standards and Technology. If such a system existed, the job of SRS to provide innovative data on S&E would be significantly enhanced.
Obtaining Fields of Science and Engineering Information in the Future
Many of the currently used science taxonomies are manually compiled for specific domains of science. Examples are the National Library of Medicine’s Medical Subject Headings (MeSH) thesaurus, the Computer Retrieval of Information on Scientific Projects (CRISP) thesaurus, and the National Cancer Institute’s thesaurus. As the amount, complexity, and diversity of relevant data grow, it becomes more and more difficult to ensure that manually compiled structures truly match the stream of data they aim to organize.
Text analysis techniques, such as the Topic Model by Griffith and Steyvers (2004), can be applied here. The techniques read a large volume of text, for example, all NIH awards for a certain year, and set a parameter that states the number of desired topics (typically around 500). An algorithm then compiles a list of unique words that occur in the award texts. Using Latent Dirichlet Allocation by Blei, Ng, and Jordan (2003), a topic model then computes and outputs two probability matrices: “awards × topics” and “unique words × topics.” The topic model has been successfully applied to all 2007 NIH awards and to data sets as large as Medline (about 18 million papers).15
Recent work on mapping knowledge domains (Börner, Chen, and Boyack, 2003; Shiffrin and Börner, 2004) uses citation links to study and communicate the structure and dynamics of science at the local and global levels. Wagner and Leydesdorff have used new tools emerging from network science to better understand international collaborations at the subfield level (Wagner and Leydesdorff, 2005). Klavans and Boyack recently
|
15 |
The 2007 mapping is shown as a visual browser at http://scimaps.org/maps/nih/2007. |
compared 20 existing maps of science (Klavans and Boyack, 2009). Some of the maps were compiled by hand, others automatically, using very different data sets and approaches. They had three basic visual forms: hierarchical, centric, and noncentric (or circular). The authors found that a circular “consensus map” generated from consensus edges occurs in at least half of the input maps. The ordering of areas in the consensus map is as follows: Mathematics is (arbitrarily) placed at the top of the circle, followed clockwise by physics, physical chemistry, engineering, chemistry, earth sciences, biology, biochemistry, infectious diseases, medicine, health services, brain research, psychology, humanities, social sciences, and computer science. The link between computer science and mathematics completes the circle. If the lowest weighted edges are pruned from this consensus circular map, the result is a hierarchical map stretching from mathematics to social sciences. This result is valuable, as it supports the argument that a general structure of science can be derived from very different data sources using different approaches.








