
3
National Science Foundation Options, Decision, and Impact
This chapter addresses the issues and options that the National Science Foundation (NSF) considered when it faced a decision about how best to balance protection for and access to information from the Survey of Earned Doctorates (SED). It discusses the decision that the agency came to after its extensive outreach program. Using information provided by NSF in a paper prepared especially for this workshop (National Science Foundation, 2009), this chapter assesses the impact of the decision in terms of the ability to protect data and the capacity to make useful data available to data users.
A BALANCING ACT
The objective of the NSF strategy for disclosure protection, according to Stephen Cohen, is to balance data utility and disclosure risk. As NSF tries to make the data more useful and accessible to data users, the risk of disclosure of confidential information also tends to increase (see Figure 3-1). At the zero/zero point, there is no disclosure risk, nor is there any utility. Releasing all information creates an exceptionally high disclosure risk. Cohen submitted that the issue for the statistical agency is where to draw the line.
For NSF, there is a tension between the usefulness of its published products and the pledge of confidentiality that is tied to a legislative mandate. It is a balancing act for all of the NSF surveys that are collected under
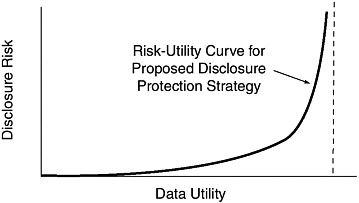
FIGURE 3-1 Balancing data utility and disclosure risk.
SOURCE: Presentation of Stephen Cohen, SED Workshop, May 27, 2009. Adapted from Duncan, Keller-McNulty, and Stokes (2001).
a pledge of confidentiality, but it is even more complicated in the case of SED because of the nature of the data that are collected.
The survey collects a mixture of information on the education, socioeconomic characteristics, and plans of doctorate recipients. Some data are more sensitive than others. For example, some of the information collected would generally be considered public knowledge, such as the type and field of the doctoral recipient’s degree. This information is widely disclosed in university graduation programs, announcements, and publications. The information can also be readily gleaned from various databases of dissertations—such as ProQuest and dissertations.com—which identify the authors of dissertations, their institutions, and other possibly identifying information, such as the date of the dissertation.
Some of the information collected would be considered by many people to be very private and personal and thus sensitive. Such information includes birth year, citizenship status at graduation, country of birth and citizenship, disability status, graduate and undergraduate educational debt, postgraduation plans (e.g., work, postdoctorate or other study, training), sources of financial support during graduate school, and salary of next position. Because the individual responses are protected by NSF and the contracted collection organization, the National Opinion Research Center (NORC), the data are published only in tabular form at high levels of aggregation.
There would be little concern over the protection of sensitive informa-
tion except for the fact that some statistical tables, which are included in an annual publication series, Doctorate Recipients from United States Universities: Summary Report (also known as the Interagency Summary Report), involve cross-tabulations of multiple variables and produce data cells with small counts. In addition, NORC has traditionally generated a number of additional standard tabulations of data when ordered by interested parties. These “on order” tabulations include the Race/Ethnicity, Gender, and Fine Field of Study Tables (called here the REG tables). The REG tables report national-level counts of doctorate recipients by fine field of doctorate, gender, race/ethnicity, and citizenship. The survey contractor also has produced on-demand tabulations of the SED data customized to the requester’s research specifications. These sets of tables have been released with data based on very small cell counts and were judged to be especially at risk of disclosure.
DECISION TO SUPPRESS CELLS IN TABULATIONS
The publication of new guidelines for the Confidential Information Protection and Statistical Efficiency Act by the Office of Management and Budget (2007) triggered a review by the staff of the Division of Science Resources Statistics (SRS) of the data protection across all of its surveys that collect confidential data. Based on its review, SRS concluded that, to protect the confidentiality of information provided by respondents to the SED and to apply a consistent policy across all SRS surveys, it was necessary to alter procedures for releasing data from the SED. Data suppression methods, which involve replacing data cells that are deemed sensitive to potential disclosure with a suppression symbol, had previously been used only sparingly in the survey. At this time, data suppression was applied broadly to a large number of tables in the 2006 Interagency Summary Report and, for the first time, to the 2006 REG tables. In response to a question, Cohen stated that the decision to suppress the data was preemptive; that is, there had been no complaints about the old policy that resulted in publication of fine field cells, but the agency had received undocumented feedback from users of other NSF surveys that there were concerns about the potential for disclosure of confidential information.
The publication of the suppressed 2006 REG tables and 2006 Interagency Summary Report generated a strong negative response from the SED data user community concerning diminished access to information about underrepresented minorities. As discussed in Chapter 4 of this sum-
mary, users believe that the loss of this information would harm programs to increase minority participation in particular degree fields.
The community voiced frustration with SRS for implementing the additional confidentiality protections without first consulting with, or at least informing, the relevant stakeholder groups. These stakeholder groups include universities, government agencies, and associations that use SED race/ethnicity data for planning, preparing funding proposals, tracking progress, measuring impacts, fulfilling specific federal, state, and institutional reporting requirements, and many other activities that have as their objective an increase in the representation of currently underrepresented minorities in science and engineering fields.
The reaction of NSF to the response of stakeholders was immediate, Cohen reported. NSF reissued the 2006 Interagency Summary Report and 2006 REG tables using its earlier level of confidentiality protection, acknowledging that the user community had not been notified or involved in discussions of changes in the release of the 2006 data. The agency also set about to explore alternative disclosure protection strategies that would maximize the reporting of REG data and simultaneously meet the requirements of protecting the confidentiality of information provided by respondents.
At the same time, the agency initiated efforts to learn about the data needs and uses of the SED data user community. It undertook to sponsor three activities to solicit stakeholder feedback that would inform its efforts. The disclosure protection strategy options are discussed below. The initiatives to elicit stakeholder input are reported in Chapter 4.
DISCLOSURE LIMITATION OPTIONS
Cell suppression as a strategy to protect against disclosure of confidential information can be a complex and iterative process. For example, when cells that are considered to be sensitive to potential disclosure (based on counts that fall below a predetermined threshold) are suppressed, additional cells may also be affected. They may be subject to something called “complementary cell suppression,” a situation in which the values of the suppressed sensitive cells could still be calculated as a residual between the published values of other cells and the unchanged marginal totals in the table. In complementary suppression, nonsensitive cells also are suppressed in order to preclude the possibility of deriving the value of the sensitive cell.
With regard to complementary suppression, Cohen referred to recent
work of Lawrence Cox, which was circulated at the workshop (Cox, 2008). Cox pointed out problems with the use of complementary cell suppression. In his view, “suppression sacrifices both confidential and nonconfidential data, forcing potentially significant degradation in data quality and usability.” These effects are often compounded because mathematical relationships induced by suppression tend to produce “over-protected solutions.”
Another disclosure limitation option that is sometimes used by statistical agencies is data perturbation, which involves adding positive and negative values drawn randomly from a probability distribution to microdata records, so that the sum of the “noise” equals zero (i.e., the positive and negative values cancel) and high-level aggregate totals are not affected. Controlled rounding, in which the values of individual data cells in a statistical table are altered, again without affecting the marginal totals in the table, is another perturbation scheme. NSF did not consider data perturbation a viable option because of the interest of some SED data users in tracking small cells of race/ethnicity data; precision of the data in small cells is very important to these users.
The more traditional solution for statistical agencies is to aggregate data cells along a data dimension until cell values become sufficiently large to make it very difficult to identify the individuals whose data are presented in the cells. Indeed, Cohen reported that, on the basis of these considerations, NSF determined that the data aggregation approach was the most promising.
Cohen outlined three alternatives that were developed and tested by NSF to aggregate the SED data in the REG tables by their three major components: race/ethnicity categories, fine field of degree, and year of degree award:
-
The first alternative would be to combine the racial/ethnic groups into a “minorities” total. In this option, the degree counts for black, Hispanic, and American Indian/Alaska Native doctorate recipients would be lumped into a category called “underrepresented minorities” and that total would be published for fine fields in which there were 25 or more degree recipients. This alternative would have the advantage of providing a consistent taxonomy of fields over time, but it would mask data on individual minority groups.
-
A second alternative would be to aggregate by racial/ethnic categories and fine field of degree, again establishing a minimum degree count of 25 or more in the year. This option would have the same limita-
-
tion as the first option, but it could also result in the publication of fewer fine fields.
-
A third alternative would be to aggregate across years by combining 2, 3, or 4 years together. This option would permit publication of much more detail for racial/ethnic groups and by fine fields of degree, but it would aggregate the data over a number of years, eliminating the long series of annual observations and resulting in a gap period in which data could not be published while additional year(s) of data were being obtained.
NSF evaluated these alternatives against the objective of maximizing the level of detail reported on race/ethnicity/gender by fine field of degree while still protecting personally identifiable information provided by SED respondents. In the user input sessions reported in Chapter 4, all of these options were found to be wanting in some fashion. However, the option that would involve aggregation across years, thus preserving information about specific minority groups and detailed fields, was generally considered to be the least disruptive for the purposes to which the users put the data. The user groups also recommended that SRS explore aggregating fine field of degree using the Classification of Instructional Programs (CIP) taxonomy. The CIP is the official, general-purpose taxonomy of education programs maintained and periodically updated by the National Center for Education Statistics of the U.S. Department of Education. The recommendation of aggregating across years was based upon the options presented by NSF at the user outreach meetings, which had not developed detailed CIP aggregation proposals at that time.
DATA PROTECTION STRATEGY
Mark Fiegener, SED survey manager, discussed the strategy that, after consideration of user feedback, SRS finally adopted. The chosen option switches the focus of the disclosure protection strategy from suppression based on counts in individual cells to counts in domains—in this case, field of degree. The approach follows the principles used in releasing microdata sets for small geographic areas: data about small geographic areas are released if population totals (domain counts) are sufficiently large and, for individual data points that may have unusual or potentially unique characteristics in the geographic area, if additional criteria are met. The application of these principles to the REG tables for SED implies that it would be safe to pub-
lish race/ethnicity and gender detail about a particular field of degree if the population of research doctorates in that field is sufficiently large.
As reported by Fiegener, the solution that considers domain counts was eventually adopted by NSF with the rationale that it would preserve the ability to identify the racial/ethnic groups that comprise the underrepresented minority population. The key would be to use aggregation rather than cell suppression methods to protect the confidentiality of respondent data. Aggregation would permit reporting of small counts and the display of data cells that contain fewer than 5 doctoral recipients by adopting rules that would minimize the risk of reidentification.
The key to this methodology, Fiegener went on, is to publish detail only when the population is large enough to preclude individual reidentification. “Large” came to be defined as fine fields of degree in which 25 or more doctorates are awarded in a given year. For these fine fields, NSF will display counts of doctorate recipients (even counts of fewer than 5, including zero) in all REG tables. Likewise, fields of degree in which fewer than 25 doctorates are awarded in a given year will not be displayed separately; they will be aggregated for that year in all REG tables with “related” fine fields, so that degree counts in combined fields are at least 25.
The selection of a cutoff point of 25 was questioned by workshop participants. A justification for its selection was provided later in the workshop by Cohen, who stated that 25 was selected because the number of racial/ethnic categories published is 5, and NSF made the judgment call that 5 times the cell count would be a comfortable compromise between making the data useful and affording protection for the confidentiality of the data.
In the afternoon session, Mary Frase, SRS deputy director, reported that slightly less than 4 percent of all degrees in 2006 were in fields that had fewer than 25 degrees awarded. Although this accounted for about a quarter of all fields, most of the small fields were well below the 25 threshold. The small size of these fields tends to minimize the adverse analytical impact of the data suppression policy that is being implemented.
This methodology may also introduce issues with small fields that may meet, exceed, or fail to meet the cutoff of 25 on a year-to-year basis. NSF was encouraged, in the afternoon session, to conduct some research on patterns of movement around the threshold by fields based on past experiences. To limit the possibility of inadvertent disclosures based on the possibility of fine fields that are near the threshold becoming subject to possible disclosure because they would meet or fail to meet the cutoff from year-to-year, NSF
|
BOX 3-1 Aggregation Rules Aggregation Rule 1: When two or more below-threshold fine fields share a 4-digit Classification of Instructional Program (CIP) code,* aggregate the degree counts from these fine fields into one or more aggregated fields that have above-threshold degree counts. Aggregation Rule 2: When a below-threshold fine field does not share a 4-digit CIP code with any other below-threshold fine field, but does share a 4-digit CIP with an above-threshold fine field, aggregate the degree count from the below-threshold fine field with an above-threshold fine field, and, if there are multiple possible aggregation candidates, aggregate with the above-threshold field that has the smallest degree count. Aggregation Rule 3: When a single below-threshold fine field does not share a 4-digit CIP code with any other below- or above-threshold fine field, aggregate the degree count from the below-threshold fine field with the appropriate “other fields” category within the same major field. Aggregation Rule 4: When multiple below-threshold fine fields do not share 4-digit CIP codes with any other below- or above-threshold fine fields, and the total of the degree counts exceeds the minimum count |
plans to reassess the fine fields selected for aggregation on a 3-year cycle. The 3-year review would permit assessment of the risk of disclosure on an on-going basis and afford the opportunity to add new fields and emerging fields on a scheduled basis.
The actual aggregation of fine fields will be guided by the CIP taxonomy. In some cases, it is expected that CIP guidance may be equivocal, and NSF subject-area experts will then be consulted for recommendations about appropriate aggregation partner(s) for particular fine fields of degree. Aggregation choices based on NSF observations of special circumstances that cropped up when applying the methodology to 2006 data were codified into six “aggregation rules.” The rules specify how below-threshold fields will be aggregated under different circumstances (see Box 3-1).
In discussing the potential application of these aggregation rules,
|
threshold, aggregate the degree counts from the below-threshold fine fields together into a new “combined fields” category within the same major field. Aggregation Rule 5: When a below-threshold fine field shares a 4-digit CIP code with all other fine fields in its major field, the CIP code cannot determine the appropriate aggregation partner. In this case, advice from field experts will be sought to determine the best aggregation partner(s) for the below-threshold field. If no aggregation partners are deemed appropriate and there are multiple such fields, the below-threshold fine fields will be aggregated into a new “combined fields” category if the total of degree counts rise above the threshold, as specified in Aggregation Rule 4, and will be aggregated into “other fields” if there is a single such field or the combined degree counts of multiple fields remain below-threshold, as in Rule 3. Aggregation Rule 6: When an “other field” is below the minimum count threshold after all the other aggregation rules have been applied, aggregate the “other field” with the “general field,” if there is one. The degree counts in this “general-other” combined field—or in a below-threshold “other field” without an associated “general field”—will be displayed if the total degree count exceeds five. |
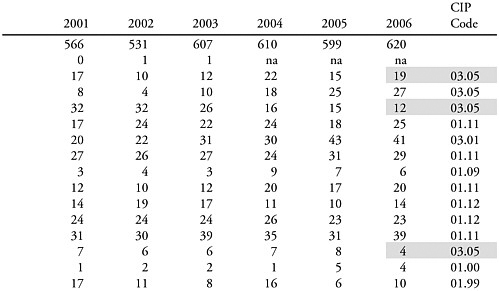
Fiegener mentioned several illustrative tabulations to show the impact of applying the various rules. An example was given applying Aggregation Rule #1: When two or more below-threshold fine fields share a 4-digit CIP code, aggregate the degree counts from these fine fields into one or more aggregated fields that have above-threshold degree counts in Table 1a of the SED published tables for 2006. In the example, NSF could combine forest sciences and biology, forestry and related sciences, and wood science and pulp/paper technology fine fields (the shaded items shown in Table 3-1) into a combined field based on the shared CIP code (0305), forestry and other related science. This CIP field would yield the minimum count of 25 doctorates and would be deemed to be publishable.
In response to a question, Fiegener stated that NSF plans to re-compute and reconsider the aggregations anew each year. For example, if there were
TABLE 3-1 Application of the CIP Aggregation Rule to Agricultural Fields
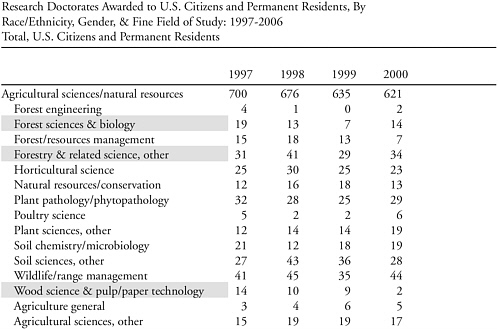
an explosion in Ph.D.s in a fine field in a year following a year in which there were too few to warrant separate publication, the year in which the 25 threshold was met would be published. When fields decline, the fields would become susceptible to aggregation into higher level CIP fields.
Over time, Fiegener believes that NSF will gain experience and learn to present the data better. For example, for cases in which the CIP does not lead to a clear aggregation decision, NSF would call on internal experts in the various fields of science to advise on appropriate aggregations, thus serving as a further mechanism for rationalizing the decisions. It is expected that in-house subject-matter experts can provide unbiased advice on aggregation decisions. Over time, the decisions based on this advice could be codified, turned into metadata, and used as the basis for future decisions.
|
|
|
Endowment for the Humanities/U.S. Department of Education/U.S. Department of Agriculture/National Aeronautics and Space Administration, Survey of Earned Doctorates, 2006. |
Fiegener further reported that NSF is still seeking outside input on what to do about fields in which the number of degrees could meet or be above the publication threshold but that would consist of degrees granted by a very small number of institutions. This would increase the risk of reidentification of degree recipients because they came from a limited number of institutions. In 2006, there were 14 fields in which 25 or more doctorates were awarded by fewer than 20 institutions. In fact, in that same year, there was one field of study—art education—in which 11 or fewer institutions offered doctorate degrees; 9 of the 25 art education doctoral degrees were awarded by just one institution. In these special cases, NSF plans to provide detailed published notes regarding the aggregation decisions to inform data users.
The issue of volatility in the availability of data series was also discussed. The output of doctorate degrees in some fields varies widely by year, so in one year the number may meet the threshold for publication and in the next may fail to meet it. Again, to assist users, NSF plans to publish detailed notes outlining the reason for the elimination of data series.












