
6
Evaluating Evidence
|
KEY MESSAGES
|
The previous chapter describes an expanded perspective on the types of evidence that can be used in decision making for interventions addressing obesity and other complex, systems-level population health problems. It presents a detailed typology of evidence that goes beyond the traditional simple evidence hierarchies that have been used in clinical practice and less complex public health interventions. This chapter focuses on the question of how one judges the quality of different types of evidence in making decisions about what interventions to undertake. The question is an important one not only because many of the interventions required to address obesity are complex, but also because the available evidence for such interventions comes from studies and program
evaluations that often are purposely excluded from systematic reviews and practice guidelines, in which studies are selected on the basis of the conventional hierarchies.
In the L.E.A.D. framework (Figure 6-1), one begins with a practical question to be answered rather than a theory to be tested or a particular study design (Green and Kreuter, 2005; Sackett and Wennberg, 1997). A decision maker, say, a busy health department director or staff member, will have recognized a certain problem or opportunity and asked, “What should I do?” or “What is our status on this issue?” Either of these questions may be of interest only to this decision maker for the particular social, cultural, political, economic, and physical context in which he/she works, and the answer may have limited generalizability. This lack of generalizability may lead some in the academic community to value such evidence less than that from randomized controlled trials (RCTs). However, data that are contextually relevant to one setting are often more, not less, relevant and useful to decision makers in other settings than highly controlled trial data drawn from unrepresentative samples of unrepresentative populations, with highly trained personnel conducting the interventions under tightly supervised protocols (see Chapter 3 for further discussion).
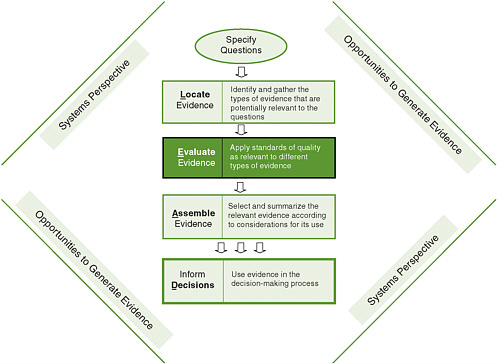
FIGURE 6-1 The Locate Evidence, Evaluate Evidence, Assemble Evidence, Inform Decisions (L.E.A.D.) framework for obesity prevention decision making.
NOTE: The element of the framework addressed in this chapter is highlighted.
The types of evidence that are used in local decision making, including the policy process, extend beyond research to encompass politics, economics, stakeholder ideas and interests, and general knowledge and information (see Chapter 3), and the decision maker needs to take a practical approach to incorporating this evidence into real-life challenges. Working from this expanded view of what constitutes relevant evidence and where to find it (Chapter 5), this chapter describes an approach for evaluating these different types of evidence that is dependent on the question being asked and the context in which it arises.
Before proceeding, it is worth emphasizing that the L.E.A.D. framework is useful not only for decision makers and their intermediaries but also for those who generate evidence (e.g., scientists, researchers, funders, publishers), a point captured by the phrase “opportunities to generate evidence” surrounding the steps in the framework (Figure 6-1). In fact, a key premise of the L.E.A.D. framework is that research generators need to give higher priority to the needs of decision makers in their research designs and data collection efforts. To this end, the use of the framework and the evaluation of evidence in the appropriate context will identify gaps in knowledge that require further investigation and research.
This chapter begins by reviewing several key aspects of the evaluation of evidence: the importance of the user perspective, the need to identify appropriate outcomes, and the essential role of generalizability and contextual considerations. After summarizing existing approaches to evaluating the quality of evidence, the chapter describes the general approach proposed by the committee. Finally, the chapter addresses the issue of the trade-offs that have to be made when the available evidence has limitations for answering the question(s) at hand—a particular concern for those who must make decisions about complex, multilevel public health interventions such as obesity prevention.
A USER’S PERSPECTIVE
The approach of “horses for courses” (Petticrew and Roberts, 2003) emphasizes that what constitutes best evidence varies with the question being addressed and that there is no value in forcing the same type of evidence to fit all uses. Once the question being asked is clear, users of the L.E.A.D. framework must either search for or generate (see Chapter 8) the kinds of evidence that will be helpful in answering that question. The next chapter describes how to assemble the evidence to inform decisions. For situations in which the evidence is inadequate, incomplete, and/or inconsistent, this chapter suggests ways to blend the best available evidence with less formal sources that can bring tacit knowledge and the experience of professionals and other stakeholders to bear.
A large number of individual questions can, of course, be raised by those undertaking efforts to address obesity or other complex public health challenges. Petticrew and Roberts (2003) place such questions into eight broad categories: effectiveness
(Does this work?), process of delivery (How does it work?), salience (Does it matter?), safety (Will it do more good than harm?), acceptability (Will people be willing to use the intervention?), cost-effectiveness (Is it worth buying this service?), appropriateness (Is this the right service/intervention for this group?), and satisfaction (Are stakeholders satisfied with the service?). To this categorization the committee has added such questions as How many and which people are affected? and What is the seriousness of the problem? In Chapter 5, the committee adopts this approach but places these questions in the broad categories of “Why,” “What,” and “How” and gives a number of examples for each category (Tables 5-1 through 5-3).
Certain types of evidence derived from various study designs could be used to answer some of these questions but not others (Flay et al., 2005). For example, to ascertain the prevalence and severity of a condition and thus the population burden, one needs survey or other surveillance data, not an RCT. To ascertain efficacy, effectiveness, or cost-effectiveness, an RCT may be the best design. To understand how an intervention works, qualitative designs may be the most valuable and appropriate (MacKinnon, 2008). To assess the organizational adoption and practitioner implementation and maintenance of a practice, longitudinal studies of organizational policies and their implementation and enforcement (i.e., studies of quality improvement) may be needed.
As discussed in previous chapters, to assess interventions designed to control obesity at the community level or in real-world settings, RCTs may not be feasible or even possible, and other types of evidence are more appropriate (Mercer et al., 2007; Sanson-Fisher et al., 2007; Swinburn et al., 2005). To apply the terminology adopted for this report (Chapter 5) (Rychetnik et al., 2004), for “Why” (e.g., burden of obesity) or in some cases “How” (e.g., translation of an intervention) questions, RCTs are not the appropriate study design. The same may be true even for some “What” questions (e.g., effectiveness of an intervention) that lend themselves more to formal intervention studies.
Also as discussed in previous chapters, decision makers need to recognize the interrelated nature of factors having an impact on the desired outcome of complex public health interventions. They should view an intervention in the context in which it will be implemented, taking a systems perspective (see Chapter 4). Such a perspective, which evolved from an appreciation of the importance of effectiveness in real-world conditions or natural settings (Flay, 1986), is clearly needed when decision makers evaluate generalizability, as well as level of certainty, in judging the quality of evidence (Green and Glasgow, 2006; Rychetik et al., 2004; Swinburn et al., 2005).
IDENTIFICATION OF APPROPRIATE OUTCOMES
Appropriate outcomes may be multiple and may be short-term, intermediate, or long-term in nature. Regardless, they should be aligned with user needs and interests. For policy makers, for example, the outcomes of interest may be those for which they
will be held accountable, which may or may not be directly related to reductions in obesity. In a political context, policy makers may want to know how voters will react, how parents will react, what the costs will be, or whether the ranking of the city or state on body mass index (BMI) levels will change. Health plan directors may want evidence of comparative effectiveness (i.e., comparing the benefits and harms of a competitive intervention in real-world settings) to make decisions on coverage. In any situation with multiple outcomes, which is the usual case, trade-offs may have to be made between these outcomes. For example, an outcome may be cost-effective but not politically popular or feasible. Further discussion of trade-offs can be found later in the chapter.
Logic models are helpful in defining appropriate evaluation outcomes and providing a framework for evaluation. For a long-term outcome, a logic model is useful in defining the short-term and intermediate steps that will lead to that outcome. Outcomes can be goals related to the health of the population (e.g., reduced mortality from diabetes), structural change (e.g., establishment of a new recreation center), a new policy (e.g., access to fresh fruits and vegetables in a Special Supplemental Nutrition Program for Women, Infants, and Children [WIC] program), or others. A recent report by the Institute of Medicine (IOM) (2007) introduces a general logic model for evaluating obesity prevention interventions (for children) (see Chapter 2, Figure 2-2) and applies it specifically to distinct end users, such as government and industry (see Figures 6-2 and 6-3, respectively). This model takes into account the
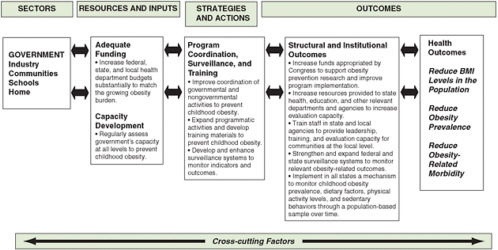
FIGURE 6-2 Evaluation framework for government efforts to support capacity development for preventing childhood obesity.
SOURCE: IOM, 2007.
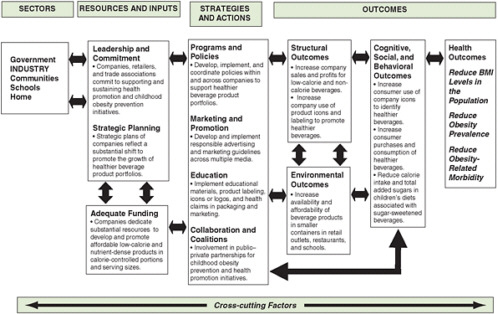
FIGURE 6-3 Evaluation framework for industry efforts to develop low-calorie and nutrient-dense beverages and promote their consumption by children and youth.
SOURCE: IOM, 2007.
interconnected factors that influence the potential impact of an intervention. It facilitates the identification of resources (e.g., funding), strategies and actions (e.g., education, programs), outcomes (e.g., environmental, health), and other cross-cutting factors (e.g., age, culture, psychosocial status) that are important to obesity prevention for particular users.
GENERALIZABILITY AND CONTEXTUAL CONSIDERATIONS
Existing standards of evidence formulate the issue of generalizability in terms of efficacy, effectiveness, and readiness for dissemination (Flay et al., 2005). From this perspective, among the questions to be answered in evaluating whether studies are more or less useful as a source of evidence are the following: How representative were the setting, population, and circumstances in which the studies were conducted? Can the evidence from a study or group of studies be generalized to the multiple settings, populations, and contexts in which the evidence would be applied? Are the interventions studied affordable and scalable in the wide variety of settings where they might
be needed, given the resources and personnel available in those settings? For decision makers, the generalizability of evidence is what they might refer to as “relevance”: Is the evidence, they ask, relevant to our population and context? Answering this question requires comparing the generalizability of the studies providing the evidence and the context (setting, population, and circumstances) in which the evidence would be applied.
Glasgow and others have called for criteria with which to judge the generalizability of studies in reporting evidence, similar to the Consolidated Standards of Reporting Trials (CONSORT) reporting criteria for RCTs and the Transparent Reporting of Evaluations with Nonrandomized Designs (TREND) quality rating scales for nonrandomized trials (Glasgow et al., 2006a). Box 6-1 details four dimensions of generalizability (using the term “external validity”) in the reporting of evidence in most efficacy trials and many effectiveness trials and the specific indicators or questions that warrant consideration in judging the quality of the research (Green and Glasgow, 2006).
EXISTING APPROACHES TO EVALUATING EVIDENCE
The most widely acknowledged approach for evaluating evidence—one that underlies much of what is considered evidence of causation in the health sciences—is the classic nine criteria or “considerations” of Bradford Hill (Hill, 1965): strength of association, consistency, specificity, temporality, biological gradient, plausibility, coherence, experiment, and analogy. All but one of these criteria emphasize the level of causality, largely because the phenomena under study were organisms whose biology was relatively uniform within species, so the generalizability of causal relationships could be assumed with relative certainty.
The rating scheme of the Canadian Task Force on the Periodic Health Examination (Canadian Task Force on the Periodic Health Examination, 1979) was adopted in the late 1980s by the U.S. Preventive Services Task Force (USPSTF) (which systematically reviews evidence for effectiveness and develops recommendations for clinical preventive services) (USPSTF, 1989, 1996). These criteria establish a hierarchy for the quality of studies that places professional judgment and cross-sectional observation at the bottom and RCTs at the top. As described by Green and Glasgow (2006), these criteria also concern themselves almost exclusively with the level of certainty. “The greater weight given to evidence based on multiple studies than a single study was the main … [concession] to external validity (or generalizability), … [but] even that was justified more on grounds of replicating the results in similar populations and settings than of representing different populations, settings, and circumstances for the interventions and outcomes” (Green and Glasgow, 2006, p. 128). The Cochrane Collaboration has followed this line of evidence evaluation in its systematic reviews, as has the evidence-based medicine movement (Sackett et al., 1996) more generally in its almost exclusive favoring of RCTs (see Chapter 5). As the Cochrane
|
Box 6-1 Quality Rating Criteria for External Validity Reach and Representativeness
Program or Policy Implementation and Adaptation
Outcomes for Decision Making
Maintenance and Institutionalization
SOURCE: Green, L. W., and R. E. Glasgow, Evaluation and the Health Professions 29(1), pp. 126-153, Copyright © 2006 by SAGE Publications. Reprinted by permission of SAGE Publications. |
methods have been extended to nonmedical applications, greater acceptability of other types of evidence has been granted, but reluctantly (see below). More recently, the Campbell Collaboration (see Sweet and Moynihan, 2007) attempted to take a related but necessarily distinctive approach to systematic reviews of more complex interventions addressing social problems beyond health, in the arenas of education, crime and justice, and social welfare. The focus was on improving the usefulness of systematic reviews for researchers, policy makers, the media, interest groups, and the broader community of decision makers. The Society for Prevention Research has extended efforts to establish standards for identifying effective prevention programs and policies by issuing standards for efficacy (level of certainty), effectiveness (generalizability), and dissemination (Flay et al., 2005).
The criteria of the USPSTF mentioned above were adapted by the Community Preventive Services Task Force, with greater concern for generalizability in recognition of the more varied public health circumstances of practice beyond clinical settings (Briss et al., 2000, 2004; Green and Kreuter, 2000). The Community Preventive Services Task Force, which is overseeing systematic reviews of interventions designed to promote population health, is giving increasing attention to generalizability in a standardized section on “applicability.” Numerous textbooks on research quality have tended to concern themselves primarily with designs for efficacy rather than effectiveness studies, although the growing field of evaluation has increasingly focused on issues of practice-based, real-time, ordinary settings (Glasgow et al., 2006b; Green and Lewis, 1986, 1987; Green et al., 1980). Finally, in the field of epidemiology, Rothman and Greenland (2005) offer a widely cited model that describes causality in terms of sufficient causes and their component causes. This model illuminates important principles such as multicausality, the dependence of the strength of component causes on the prevalence of other component causes, and the interactions among component causes.
The foregoing rules or frameworks for evaluating evidence have increasingly been taken up by the social service professions, building not just on biomedical traditions but also on agricultural and educational research in which experimentation predated much of the action research in the social and behavioral sciences. The social service and education fields have increasingly utilized RCTs, but have faced growing resistance to their limitations and the “simplistic distinction between strong and weak evidence [that] hinged on the use of randomized controlled trials …” (Chatterji, 2007, p. 239; see also Hawkins et al., 2007; Mercer et al., 2007; Sanson-Fisher et al., 2007), especially when applied to complex community interventions.
Campbell and Stanley’s (1963) widely used set of “threats to internal validity (level of certainty)” for experimental and quasi-experimental designs were accompanied by their seldom referenced “threats to external validity (generalizability).” “The focus on internal validity (level of certainty) was justified on the grounds that without internal validity, external validity or generalizability would be irrelevant or misleading, if not impossible” (Green and Glasgow, 2006, p. 128). These and other issues
concerning the level of certainty and generalizability are discussed in greater detail in Chapter 8.
A PROPOSED APPROACH TO EVALUATING THE QUALITY OF SCIENTIFIC EVIDENCE
Scientists have always used criteria or guidelines to organize their thinking about the nature of evidence. Much of what we think we know about the causes of obesity and the current obesity epidemic, for example, is based on the evaluation of evidence using existing criteria. In thinking about the development of a contemporary framework to guide decision making in the complex settings of public health, however, the committee decided to advance a broader view of appropriate evaluation criteria. As described in 2005 in a seminal report from the Institute of Medicine (IOM), these decisions need to be made with the “best available evidence” and cannot wait for the “best possible evidence” or all the desirable evidence to be at hand (IOM, 2005, p. 3). The L.E.A.D. framework should serve the needs of decision makers focused on the obesity epidemic, but can also provide guidance for those making decisions about complex, multifactorial public health challenges more generally.
The starting point for explaining the committee’s approach to evaluating the quality of evidence for obesity prevention is the seven categories of study designs and different sources of evidence presented in Chapter 5. In Table 6-1, this typology is linked to criteria for judging the quality of evidence, drawing on the concept of “critical appraisal criteria” of Rychetnik and colleagues (Rychetnik et al., 2002, 2004). Generally speaking, different types of evidence from different types of study designs are evaluated by different criteria, all of which can be found in the literature on evaluating the quality of each type of evidence. In all cases, high-quality evidence avoids bias, confounding, measurement error, and other threats to validity whenever possible; however, other aspects of quality come into play within the broader scope of evidence advanced by the L.E.A.D. framework.
Users of the L.E.A.D. framework can refer to any of the various criteria for high-quality evidence depending on the source of evidence they have located, following the guidance provided in Chapter 5 as well as the references cited in Table 6-1. This process requires some time and effort by an individual or multidisciplinary group with some expertise in evaluating evidence. Despite the availability of the criteria listed in Table 6-1, making judgments about the quality of evidence can still be challenging. One recommended approach is the eight-step process advanced by Liddle and colleagues (1996):
-
“Select reviewers(s) and agree on details of the review procedure.
-
Specify the objective of the review of evidence.
-
Identify strategies to locate the full range of evidence including unpublished results and work in progress.
-
Classify the literature according to general purpose and study type.
TABLE 6-1 A Typology of Study Designs and Quality Criteria
|
Sources of Evidence (research designs, tools, and methods for evidence gathering) |
Existing Criteria for Assessing Quality of Evidence |
|
Nonexperimental or Observational Studies |
Can be assessed by criteria grouped by Liddle et al. (1996): |
|
|
|
|
|
Transparent Reporting of Evaluations with Nonrandomized Designs (TREND) is a new attempt to establish criteria for nonrandomized intervention studies that has produced a preliminary statement of criteria for judging such studies (Des Jarlais et al., 2004). |
|
Experimental and Quasi-experimental Studies |
Can be graded by assessment of study design, selection bias, confounding; blinding; data collection and classification of outcomes, follow-up, withdrawal and drop-out, and analysis (Rychetnik et al., 2002, as outlined by the Oxford-based Public Health Resource Unit). |
|
|
Quality of an RCT is based on (Higgins and Green, 2009): |
|
|
|
|
|
Study design is evaluated by levels of evidence (as in those of the Canadian Task Force on the Periodic Health Examination or the Task Force on Community Preventive Services and the U.S. Preventive Services Task Force [USPSTF]). Criteria for the USPSTF are summarized by Harris et al. (2001) and updated by Pettiti et al. (2009). |
|
Qualitative Research |
Standardized quality criteria have not been agreed upon, but should reflect the distinctive goals of the research. As an example of criteria, quality may be determined by the audit trail of processes and decisions made and the credibility of the study methods (Rychetnik et al., 2002, Table 3): |
|
|
|
|
Mixed-Method Experimental Studies |
Quality criteria for mixed-method research derive from the quality criteria used for quantitative and qualitative designs separately. A 15-point checklist of criteria for mixed-method research and mixed studies reviews is presented by Pluye et al. (2009). Three points on which mixed-method research can be judged are: |
|
|
|
|
Sources of Evidence (research designs, tools, and methods for evidence gathering) |
Existing Criteria for Assessing Quality of Evidence |
|
Evidence Synthesis Methods |
Questions to consider when appraising a systematic review include (Public Health Resource Unit, 2006): |
|
|
|
|
Parallel Evidence |
Quality is determined by the underlying study designs of the parallel evidence sources in the same way that it is determined for the primary evidence. |
|
Expert Knowledge |
Questions to consider when appraising expert knowledge include (World Cancer Research Fund and American Institute for Cancer Research, 2007): |
|
|
|
|
|
A description of the computer-based Delphi Method for utilizing expert knowledge reliably is provided by Turoff and Hiltz (1996). |
|
|
A description of procedures used to quantify expert opinion (using specialized software) is in Garthwaite et al. (2008). |
-
Retrieve the full version of evidence available.
-
Assess the quality of the evidence.
-
Quantify the strength of the evidence.
-
Express the evidence in a standard way.” (pp. 6-7).
Step 6 includes checklists for assessing the quality of studies depending on their design and purpose (Liddle et al., 1996).
Most biomedical researchers are familiar with the quality criteria that have been used for experimental and observational epidemiological research, but less so with those used for qualitative studies. Quality is not addressed for qualitative research in the checklists offered by Liddle and colleagues (1996), but can be assessed using
the same broad concepts of validity and relevance used for quantitative research. However, these concepts need to be applied differently to account for the distinctive goals of such research, so defining a single method for evaluation is not suggested (Cohen and Crabtree, 2008; Patton, 1999). Mays and Pope (2000) summarize “relativist” criteria for quality, similar to the criteria of Rychetnik and colleagues (2002) (see Table 6-1), that are common to both qualitative and quantitative studies. Others have since reported on criteria that can be used to assess qualitative research (Cohen and Crabtree, 2008; Popay et al., 1998; Reis et al., 2007). In addition, guidance on the description and implementation of qualitative (and mixed-method) research, along with a checklist, has been provided by the National Institutes of Health (Office of Behavioral and Social Sciences Research, 2000).
Criteria also exist for evaluating the quality of systematic reviews themselves, whether they are of quantitative or qualitative studies (Goldsmith et al., 2007). In addition to the criteria of the Public Health Resource Unit (2006) listed in Table 6-1, a detailed set of criteria has been compiled by the Milbank Memorial Foundation and the Centers for Disease Control and Prevention (CDC) (Sweet and Moyniham, 2007).
As noted earlier, expert knowledge is frequently considered to be at the bottom of traditional hierarchies that focus on level of certainty, such as that used by the USPSTF. However, expert knowledge can be of value in evaluating evidence and can also be viewed with certain quality criteria in mind (Garthwaite et al., 2008; Harris et al., 2001; Petitti et al., 2009; Turoff and Hiltz, 1996; World Cancer Research Fund and American Institute for Cancer Research, 2007). The Delphi Method was developed to utilize expert knowledge in a reliable and creative way that is suitable for decision making and has been found to be effective in social policy and public health decision making (Linstone and Turoff, 1975); it is a “structured process for collecting and distilling knowledge from a group of experts” through questionnaires interspersed with controlled feedback (Adler and Ziglio, 1996, p. 3). If these quality criteria are taken into account and conflicts of interest are identified and minimized, decision making can benefit substantially from the considered opinion of experts in a particular field or of practitioners, stakeholders, and policy makers capable of making informed judgments on implementation issues (e.g., doctors, lawyers, scientists, or academics able to interpret the scientific literature or specialized forms of data).
Finally, in addition to the main sources of evidence included in Table 6-1, other sources may be of value in decision making. Many are not independent sources, but closer to a surveillance mechanism or a tool for dissemination of evidence. They include simulation models, health impact assessments, program or policy evaluations, policy scans, and legal opinions. For instance, health impact assessments (described in more detail in Chapter 5, under “What” questions) formally examine the potential health effects of a proposed intervention (Cole and Fielding, 2007). An example is Health Forecasting (University of California–Los Angeles School of Public Health, 2009), which uses a web-based simulation model that allows users to view evidencebased descriptions of populations and subpopulations (disparities) to assess the poten-
tial effects of policies and practices on future health outcomes. Another such source, policy evaluations, allows studies of various aspects of a problem to be driven by a clear conceptual model. An example is the International Tobacco Control Policy Evaluation Project, a multidisciplinary, multisite, international endeavor that aims to evaluate and understand the impact of tobacco control policies as they are implemented in countries around the world (Fong et al., 2006). These sources may provide evidence for which there are quality criteria to consider, but are not addressed in detail here.
WHEN SCIENTIFIC EVIDENCE IS NOT A PERFECT FIT: TRADE-OFFS TO CONSIDER
Trade-offs may be involved in considering the quality of various types of evidence available to answer questions about complex, multilevel public health interventions (Mercer et al., 2007). Randomization at the individual level and experimental controls may remain the gold standard, but as pointed out above, these methods are not always possible in population health settings, and they are sometimes counterproductive with respect to the artificial conditions used to implement randomization and control procedures. Therefore, some of the advantages of RCTs may have to be traded off to obtain the best available evidence for decision making. Because no one study is usually sufficient to support decisions on public health interventions, the use of multiple types of evidence (all of good quality for their design) may be the best approach (Mercer et al., 2007), a point further elaborated upon in Chapter 8.
REFERENCES
Adler, M., and E. Ziglio. 1996. Gazing into the oracle: The Delphi method and its application to social policy and public health. London, UK: Jessica Kingsley.
Briss, P. A., S. Zaza, M. Pappaioanou, J. Fielding, L. Wright-De Aguero, B. I. Truman, D. P. Hopkins, P. D. Mullen, R. S. Thompson, S. H. Woolf, V. G. Carande-Kulis, L. Anderson, A. R. Hinman, D. V. McQueen, S. M. Teutsch, and J. R. Harris. 2000. Developing an evidence-based Guide to Community Preventive Services—methods. American Journal of Preventive Medicine 18(1, Supplement 1):35-43.
Briss, P. A., R. C. Brownson, J. E. Fielding, and S. Zaza. 2004. Developing and using the Guide to Community Preventive Services: Lessons learned about evidence-based public health. Annual Review of Public Health 25:281-302.
Campbell, D. T., and J. C. Stanley. 1963. Experimental and quasi-experimental designs for research. Chicago: Rand McNally.
Canadian Task Force on the Periodic Health Examination. 1979. The periodic health examination. Canadian Medical Association Journal 121(9):1193-1254.
Chatterji, M. 2007. Grades of evidence: Variability in quality of findings in effectiveness studies of complex field interventions. American Journal of Evaluation 28(3):239-255.
Cohen, D. J., and B. F. Crabtree. 2008. Evaluative criteria for qualitative research in health care: Controversies and recommendations. Annals of Family Medicine 6(4):331-339.
Cole, B. L., and J. E. Fielding. 2007. Health impact assessment: A tool to help policy makers understand health beyond health care. Annual Review of Public Health 28:393-412.
Des Jarlais, D. C., C. Lyles, and N. Crepaz. 2004. Improving the reporting quality of nonrandomized evaluations of behavioral and public health interventions: The TREND statement. American Journal of Public Health 94(3):361-366.
Flay, B. R. 1986. Efficacy and effectiveness trials (and other phases of research) in the development of health promotion programs. Preventive Medicine 15(5):451-474.
Flay, B. R., A. Biglan, R. F. Boruch, F. G. Castro, D. Gottfredson, S. Kellam, E. K. Moscicki, S. Schinke, J. C. Valentine, and P. Ji. 2005. Standards of evidence: Criteria for efficacy, effectiveness and dissemination. Prevention Science 6(3):151-175.
Fong, G. T., K. M. Cummings, R. Borland, G. Hastings, A. Hyland, G. A. Giovino, D. Hammond, and M. E. Thompson. 2006. The conceptual framework of the International Tobacco Control (ITC) Policy Evaluation Project. Tobacco Control 15(Supplement 3): iii1-iii2.
Garthwaite, P. H., J. B. Chilcott, D. J. Jenkinson, and P. Tappenden. 2008. Use of expert knowledge in evaluating costs and benefits of alternative service provisions: A case study. International Journal of Technology Assessment in Health Care 24(3):350-357.
Glasgow, R., L. Green, L. Klesges, D. Abrams, E. Fisher, M. Goldstein, L. Hayman, J. Ockene, and C. Orleans. 2006a. External validity: We need to do more. Annals of Behavioral Medicine 31(2):105-108.
Glasgow, R. E., L. M. Klesges, D. A. Dzewaltowski, P. A. Estabrooks, and T. M. Vogt. 2006b. Evaluating the impact of health promotion programs: Using the RE-AIM framework to form summary measures for decision making involving complex issues. Health Education Research 21(5):688-694.
Goldsmith, M. R., C. R. Bankhead, and J. Austoker. 2007. Synthesising quantitative and qualitative research in evidence-based patient information. Journal of Epidemiology and Community Health 61(3):262-270.
Green, L. W., and R. E. Glasgow. 2006. Evaluating the relevance, generalization, and applicability of research: Issues in external validation and translation methodology. Evaluation & the Health Professions 29(1):126-153.
Green, L. W., and M. W. Kreuter. 2000. Commentary on the emerging Guide to Community Preventive Services from a health promotion perspective. American Journal of Preventive Medicine 18(1 Supplement 1):7-9.
Green, L. W., and M. W. Kreuter. 2005. Health program planning: An educational and ecological approach. 4th ed. New York: McGraw-Hill.
Green, L. W., and F. M. Lewis. 1986. Measurement and evaluation in health education and health promotion. Palo Alto, CA: Mayfield Publishing Company.
Green, L., and F. M. Lewis. 1987. Data analysis in evaluation of health education: Towards standardization of procedures and terminology. Health Education Research 2(3):215-221.
Green, L. W., F. M. Lewis, and D. M. Levine. 1980. Balancing statistical data and clinician judgments in the diagnosis of patient educational needs. Journal of Community Health 6(2):79-91.
Harris, R. P., M. Helfand, S. H. Woolf, K. N. Lohr, C. D. Mulrow, S. M. Teutsch, and D. Atkins. 2001. Current methods of the U.S. Preventive Services Task Force: A review of the process. American Journal of Preventive Medicine 20(3, Supplement):21-35.
Hawkins, N. G., R. W. Sanson-Fisher, A. Shakeshaft, C. D’Este, and L. W. Green. 2007. The multiple baseline design for evaluating population-based research. American Journal of Preventive Medicine 33(2):162-168.
Higgins, J. P. T., and S. Green (editors). 2009. Cochrane handbook for systematic review of interventions, Version 5.0.2 [updated September 2009]. The Cochrane Collaboration, 2008. http://www.cochrane-handbook.org (accessed December 13, 2009).
Hill, A. B. 1965. The environment and disease: Association or causation. Proceedings of the Royal Society of Medicine 58:295-300.
IOM (Institute of Medicine). 2005. Preventing childhood obesity: Health in the balance. Edited by J. Koplan, C. T. Liverman, and V. I. Kraak. Washington, DC: The National Academies Press.
IOM. 2007. Progress in preventing childhood obesity: How do we measure up? Edited by J. Koplan, C. T. Liverman, V. I. Kraak, and S. L. Wisham. Washington, DC: The National Academies Press.
Liddle, J., M. Williamson, and L. Irwig. 1996. Method for evaluating research and guideline evidence. Sydney: NSW Health Department.
Linstone, H. L., and M. Turoff. 1975. The Delphi method: Techniques and applications. Reading, MA: Addison-Wesley.
MacKinnon, D. P. 2008. An introduction to statistical meditation analysis. New York: Lawrence Erlbaum Associates.
Mays, N., and C. Pope. 2000. Qualitative research in health care: Assessing quality in qualitative research. British Medical Journal 320(7226):50-52.
Mercer, S. L., B. J. DeVinney, L. J. Fine, L. W. Green, and D. Dougherty. 2007. Study designs for effectiveness and translation research: Identifying trade-offs. American Journal of Preventive Medicine 33(2):139-154.
Office of Behavioral and Social Sciences Research. 2000. Qualitative methods in health research: Opportunities and considerations in application and review. Produced by the NIH Culture and Qualitative Research Interest Group, based on discussions and written comments from the expert working group at a workshop sponsored by the Office of Behavioral and Social Sciences Research. Bethesda, MD: Office of Behavioral and Social Sciences Research.
Patton, M. Q. 1999. Enhancing the quality and credibility of qualitative analysis. Health Services Research 34(5, Part 2):1189-1208.
Petitti, D. B., S. M. Teutsch, M. B. Barton, G. F. Sawaya, J. K. Ockene, and T. Dewitt. 2009. Update on the methods of the U.S. Preventive Services Task Force: Insufficient evidence. Annals of Internal Medicine 150(3):199-205.
Petticrew, M., and H. Roberts. 2003. Evidence, hierarchies, and typologies: Horses for courses. Journal of Epidemiology and Community Health 57(7):527-529.
Pluye, P., M. P. Gagnon, F. Griffiths, and J. Johnson-Lafleur. 2009. A scoring system for appraising mixed methods research, and concomitantly appraising qualitative, quantitative and mixed methods primary studies in mixed studies reviews. International Journal of Nursing Studies 46(4):529-546.
Popay, J., A. Rogers, and G. Williams. 1998. Rationale and standards for the systematic review of qualitative literature in health services research. Qualitative Health Research 8(3):341-351.
Public Health Resource Unit. 2006. Critical appraisal skills programme (CASP). Making sense of evidence. http://www.phru.nhs.uk/Doc_Links/S.Reviews%20Appraisal%20Tool.pdf (accessed December 17, 2009).
Reis, S., D. Hermoni, R. Van-Raalte, R. Dahan, and J. M. Borkan. 2007. Aggregation of qualitative studies—from theory to practice: Patient priorities and family medicine/general practice evaluations. Patient Education and Counseling 65(2):214-222.
Rothman, K. J., and S. Greenland. 2005. Causation and causal inference in epidemiology. American Journal of Public Health 95(Supplement 1):S144-S150.
Rychetnik, L., M. Frommer, P. Hawe, and A. Shiell. 2002. Criteria for evaluating evidence on public health interventions. Journal of Epidemiology and Community Health 56(2):119-127.
Rychetnik, L., P. Hawe, E. Waters, A. Barratt, and M. Frommer. 2004. A glossary for evidence based public health. Journal of Epidemiology and Community Health 58(7):538-545.
Sackett, D. L., and J. E. Wennberg. 1997. Choosing the best research design for each question. British Medical Journal 315(7123):1633-1640.
Sackett, D. L., W. M. C. Rosenberg, J. A. M. Gray, R. B. Haynes, and W. S. Richardson. 1996. Evidence based medicine: What it is and what it isn’t. British Medical Journal 312(7023):71-72.
Sanson-Fisher, R. W., B. Bonevski, L. W. Green, and C. D’Este. 2007. Limitations of the randomized controlled trial in evaluating population-based health interventions. American Journal of Preventive Medicine 33(2):155-161.
Sweet, M., and R. Moynihan. 2007. Improving population health: The uses of systematic reviews. New York: Milbank Memorial Fund and Centers for Disease Control and Prevention.
Swinburn, B., T. Gill, and S. Kumanyika. 2005. Obesity prevention: A proposed framework for translating evidence into action. Obesity Reviews 6(1):23-33.
Turoff, M., and S. R. Hiltz. 1996. Computer-based Delphi process. In Gazing into the oracle: The Delphi method and its application to social policy and public health, edited by M. Adler and E. Ziglio. London, UK: Jessica Kingsley. Pp. 56-85.
University of California–Los Angeles School of Public Health. 2009. Health forecasting. http://www.health.forcasting.org (accessed November 9, 2009).
USPSTF (U.S. Preventive Services Task Force). 1989. Guide to clinical preventive services. Baltimore, MD: Lippincott Williams & Wilkins.
USPSTF. 1996. Guide to clinical preventive services. 2nd ed. Baltimore, MD: Williams & Wilkins.
World Cancer Research Fund and American Institute for Cancer Research. 2007. Food, nutrition, physical activity, and the prevention of cancer: A global perspective. Washington, DC: American Institute for Cancer Research.


















