
3
Field Evaluation Experiences in Other Areas
Field evaluations are performed to one degree or another in many other areas besides intelligence and counterintelligence, sometimes effectively and sometimes not. Five speakers in two separate sessions discussed their experiences with field evaluation in other areas with an eye toward offering takeaway lessons that could be applied to the field of intelligence.
EDUCATION
The field of education has many parallels with intelligence: its practitioners have a large body of accepted methods, many of which have not been rigorously field tested; new methods are regularly introduced, many of them based on behavioral science research, but, again, a large percentage are never carefully evaluated in the field; and the practitioners tend to trust their own experience-based judgment over research findings that may be contradictory. Grover Whitehurst, who served as the first director of the Institute of Education Sciences in the U.S. Department of Education (ED), described the experiences of ED during his tenure1 in attempting to subject educational programs to rigorous evaluation, emphasizing randomized controlled trials (RCTs).
“There are always barriers to generalizing from one field to another or from one agency to another,” he said. “I am acutely aware of that. But I think there may be some lessons learned in other federal agencies about the production and use of research that could be applicable to intelligence.”
Whitehurst, now a senior fellow of government studies and director of the Brown Center on Education Policy at the Brookings Institution in Washington, began his presentation by commenting that education has a history of not knowing much about what it is doing. In 1971, for example, a RAND Corporation group set out to discover which educational practices were well supported by research and came to the conclusion that there was essentially no evidence to show that any educational methods worked. Almost three decades later, a report by the National Research Council reached a very similar conclusion (National Research Council, 1999). So there had been very little progress in 30 years.
A 2007 review of all federal investments in science or mathematics education listed 105 programs with statutory funding authority of $3 billion a year (U.S. Department of Education, 2007). According to Whitehurst, when the Office of Management and Budget instructed each of those programs to submit any evaluations they had of the effectiveness of their investments, the only positive results that anyone could find came from four small research grants, such as one in which an education researcher at Carnegie Mellon University had evaluated a technique for teaching students the principles underlying experiments and found it to be effective.
The lack of validation was not limited to the education programs in science and mathematics, Whitehurst said. It was an issue throughout the federal government. For instance, when he attended an Education and Training Conference at the Department of Labor, in preparation for the meeting, he searched through reports from the Government Accountability Office for information on education and training programs that the Department of Labor had sponsored. He could not find a single evaluation of any recent program that contained rigorous evidence that the program had had an effect.
One of the main reasons that so few RCTs of federal programs are carried out, Whitehurst said, is that there are few people in the agencies who understand the importance of evaluating programs. He described serving on a committee organized by the White House science office to study what needed to be done to improve the evaluation of science, technology, engineering, and mathematics programs. As part of that process the committee members met with representatives of various federal agencies involved in funding such programs and asked them to describe the programs they wished to expand and to discuss their evaluation plans for
those programs. What became clear to the committee members, he said, was just how little understanding there is in many federal agencies of the importance of asking whether an investment is actually working.
“So there is a strong sense,” he said, “that for federal agencies to do a better job in producing knowledge about the effectiveness of their own program activities, they need people embedded in the agency who understand the importance of doing that, who have the credentials and a position in the agency that enable their aesthetic to have some impact.”
Over the past decade, there was a move in this direction at ED, and, as a result, an increasing number of effective evaluations were performed on ED-sponsored programs. In 2000, Whitehurst said, there were 17 evaluations of ED programs, but only one of these evaluations had a randomized design that made it possible to rigorously answer questions about the effect of the program. Instead, an evaluation was more likely to be based on such things as surveys sent to principals asking if they thought the funding they received had been helpful. Not surprisingly, such evaluations generally found evidence of a positive effect.
In more recent years, ED has moved toward the use of randomized trials to measure the effect of programs or, if a randomized trial was not feasible, using the best available approach. There is now an emphasis on comparative effectiveness trials, measuring the effects of different approaches against each other. As an example, Whitehurst described an evaluation of four elementary school mathematics curricula; the research found that the difference between the most effective and the least effective of those curricula was equivalent to almost a half-year of learning over the course of a school year. And since the costs of the different programs were about equal, that is a valuable finding—one that would not have been possible to reach without a well-designed comparative effectiveness evaluation.
Today, Whitehurst said, ED has a list of 70 programs and practices that have a strong evidentiary base behind them and that have been shown to have a positive effect on student outcomes.
How did ED turn things around and start to evaluate programs rigorously and regularly? There were a number of factors, Whitehurst said. First, in 2002-2003 Congress created the Institute of Education Sciences. Because the institute was given a degree of independence that its predecessor agency did not have, it was able to attract knowledgeable people to perform good research and protect that research from outside pressures. There was also more money provided for randomized controlled trials.
The experience at ED offers a number of lessons for the intelligence community or for any group that wishes to begin evaluating methods and techniques in a rigorous way, Whitehurst said.
One of the things that makes a difference is money. Without a predict-
able supply of funding, researchers will not get involved, nor will they train graduate students in the area.
The methods used in the research also matter, he said. “If we are going to try to answer a question that policy makers are supposed to run with, it is important to have an answer that they can stand on, and not one that in many cases will be incorrect.” One of the things that ED has studied, for instance, is how to arrive at the right answer with a variety of methods. The more rigorous the method, the more quickly one can come to a conclusion that can be depended on. Other methods require replication and aggregation to overcome the potential errors and omissions and arrive at a reliable answer.
One problem that ED faced was that the quality of the research on education varied tremendously, Whitehurst said. Part of the solution was the establishment of the What Works Clearinghouse by the ED’s Institute of Education Sciences. The clearinghouse assesses the quality of research and confers its imprimatur on those studies it sees as being sufficiently rigorous.
Independence matters. In government there is generally strong pressure to support policy. Policy makers decide on policy, and they do not appreciate evidence that their favored policies do not work. Thus an agency that is producing knowledge needs to have a certain amount of independence to be able to resist the pressures to come up with conclusions that support policy.
Finally, he said, people matter. It is important to have people involved who understand science and who are committed to the value of the scientific effort and its integrity. One approach to doing this is to get the academic research community involved, and the way to do this is to provide stable funding with a reasonable peer review process.
CRIMINAL JUSTICE
In her presentation, Cynthia Lum, deputy director of the Center for Evidence-Based Crime Policy (CEBCP) at George Mason University, discussed the current state of field evaluations in two areas of criminal justice: policing and counterterrorism. In neither area is the field evaluation of methods and technologies yet standard practice, although such evaluation is much closer to reality in one of the areas than in the other.
In most police departments today, Lum said, decisions about policing practices and policies are not based on scientific evidence but instead are made on a case-by-case basis, using personal experience, anecdotes, even bar stories as a guide. The individuals making the decisions fall back on their own judgment, guesses, hunches, feelings, and whims, while being influenced by various outside forces, such as political pressure, lobbying
by special interest groups, social crises, and moral panics. “That is the reality,” Lum said. “The context of decision making is not crime, it is police organizational culture [and] things that have nothing to do with crime.”
That is slowly changing, however. There is a growing emphasis on what is called “evidence-based policing,” which is the practice of basing police policies and procedures on scientific evidence about what works best. Many of the ideas for evidence-based policing were laid out in a 1998 article by Lawrence Sherman (Sherman, 1998), now the director of the Jerry Lee Centre of Experimental Criminology and the Police Executive Programme at Cambridge University in England. Sherman talked about using various data accumulated by police departments, such as maps of crime patterns and information about repeat offenders, combined with scientific methods of deduction and objective evaluations of programs to shape police policies and methods. The goal was to replace subjective judgments with scientific conclusions about what works best in determining what police practices should be.
Over the past decade there has been a slowly growing acceptance in police departments of the importance of this scientific approach to policing, Lum said. The aspect of evidence-based policing of greatest relevance to the workshop is, of course, the scientific evaluation of different policing practices. Such evaluation is beginning to be done, Lum said, but its pace of adoption varies greatly according to what is being evaluated.
For example, very few of the new technologies being used in policing—things like license plate recognition technology, crime mapping, mobile computer terminals, and DNA field testing—have been evaluated for effectiveness. They are tested to see if they work as they are supposed to—to determine, for instance, if the license plate recognition systems actually do recognize license plates accurately—but almost nothing has been done anywhere to test if these technologies are effective in, say, reducing crime rates. “I actually don’t know of any very high-quality evaluations in police technology,” Lum said. Evaluations currently being completed by the Police Executive Research Forum and by CEBCP are looking at whether license plate recognition systems have any effect on reducing auto theft—which is what they are intended to do—but these are the first studies of their kind, so far as Lum knows. Most technology “evaluations” have examined whether the technology physically works or is faster, but not necessarily more effective, she said.
However, there have been quite a few evaluations of various policing interventions, such as hot spot policing, crackdowns, raids on crack houses, and other actions designed to reduce the frequency and severity of crimes. Lum and her colleagues have assembled, in an “Evidence-
Based Policing Matrix,”2 a set of 92 evaluations of policing interventions that were judged to be medium to high quality. Many of the studies were randomized controlled trials or “high-level quasi-experiments,” Lum said, and they looked at a variety of outcomes, such as crime rates, recidivism, even police legitimacy.
More generally, she said, there is reason to be optimistic that there will be more and more high-quality evaluations of policing practices in the future. The reason for such optimism is that a research infrastructure already exists in the area of policing that can be used for the generation of scientific evidence and objective evaluations.
This research infrastructure exists in large part, she said, because of the efforts of a number of pioneering researchers who spent their careers working to build relationships and trust with police officers and departments around the country. Because of their efforts, there are police chiefs and officers in many police departments who recognize the value of evidence-based policing and of performing evaluations and who therefore are willing and able to cooperate with policing researchers.
A second important part of the research infrastructure is the knowledge base, exemplified by the 92 evaluations of interventions that Lum and colleagues collected. Such a knowledge base is vital in determining what questions to ask, what areas to focus on in developing better evidence, and where to spend research funds.
The research infrastructure also includes advances in information technology that are being applied to policing. Lum mentioned, for instance, that she works with a geographic information system that allows her to map the locations of tens of thousands of crimes very quickly and easily.
Finally, shifts in police culture have been vital in developing and using this research infrastructure. Not only are an increasing number of police chiefs and officers recognizing the value of science and research to their jobs, but police research groups, such as the Police Foundation and the Police Executive Research Forum, are receptive to working with academic criminologists. Those in the policing community are more understanding of the value of embedding a criminologist in a police department, for example, and the professional groups are now working to translate the criminological research for their members and to explain its importance.
In contrast to the situation with regard to policing, Lum said, the research infrastructure and the evidence base for counterterrorism work are almost nonexistent. “It is very weak and very small.”
Since the September 11, 2001, terrorist attacks there has been a tremendous investment into the counterterrorism area. Funding has been shifted
into the area, much of it from policing and emergency management, along with new funding, and there has been a great deal of discussion about tools and technologies to prevent and counter terrorism as well as new policies and laws intended to make terrorist attacks less likely to succeed. At the same time, there has been a surge in publications about various counterterrorism subjects, such as airport screening and metal detectors, detection devices for biological or chemical weapons, emergency response preparedness, hostage negotiation, and many others.
In 2006 Lum and two colleagues published a systematic review of the literature on counterterrorism (Lum, Kennedy, and Sherley, 2006). They surveyed more than 20,000 articles written about terrorism and counter-terrorism. Of all of those articles, Lum said, only seven contained evaluations that satisfied minimal requirements for methodological quality. In other words, although there has been a torrent of literature in the area, much of it discussing new technologies and practices for dealing with terrorism, almost none of it offers useful evaluations of these technologies and practices.
Even more disturbing, Lum said, is the fact that there is almost no research infrastructure in the counterterrorism area to support an evaluation agenda. Many of the studies are done by the same people using the same datasets that are just added to over the years, allowing the researchers to analyze and reanalyze them from varying perspectives. Thus, despite the large number of publications, the evidence base is inadequate.
There are also few research pioneers in this area, Lum said, and most of them tend to focus on such things as the causes of terrorism, the psychology of terrorism, and the groups behind terrorism. There is far more work done in such areas than in addressing the question of whether various interventions work.
One reason that the area of counterterrorism, unlike policing, has so few evaluation studies is the fact that terrorist activities, unlike criminal activities, are rare. Thus researchers have relatively little information to work with. Researchers also sometimes find it difficult to obtain the clearance they need to gain access to information, and relatively few research relationships have been developed between practitioners and researchers.
Furthermore, Lum said, she has found that the leadership culture in counterterrorism is not focused on science or on the role that science could play in counterterrorism. Nor are there any third parties that can play the kind of role that the Police Foundation or the Police Executive Research Forum plays in advancing the evaluation of policing practices.
Finally, there is little or no government support for evaluation research. Much of government funding is instead focused on the causes of terror-
ism and descriptions of relevant technologies rather than information about interventions. This is exacerbated by a lack of discourse or rhetoric about evaluation or science as they apply to counterterrorism methods.
HEALTH SCIENCES
In the next presentation, Lisa Colpe, a senior scientist and epidemiologist at the National Institute of Mental Health, described a pair of mental health surveys that illustrate the importance of including up-front evaluation criteria in research studies.
One of the ways to study the epidemiology of a mental illness in the general population is to conduct surveys of people at home or in other specific settings. But the people responding to such surveys will usually give researchers only a limited amount of time to ask their questions, so the surveys must be designed to detect the signs of illness with a set of questions that is much shorter than the standard clinical questionnaire. Depression, for example, is normally diagnosed in a doctor’s office after a lengthy examination and interview, but researchers who are interested in determining the prevalence of depression in the general population must develop an abbreviated questionnaire that can predict with a certain accuracy which of the respondents has depression.
Colpe described a recent survey that she and a group of colleagues conducted to look for serious mental illness in the general population. By definition, a serious mental illness is characterized by the presence of a mental disorder combined with significant functional impairment. The researchers developed two scales for use in the survey, one that indicated the presence of mental distress and the other that measured the degree of functional impairment. By combining sets of responses from the two scales, they could acquire a measure of the prevalence of severe mental disorders in the study population.
It was then necessary to compare the measure of mental disorder derived from the survey responses with the measure of mental distress derived from standard clinical interviews. In particular, psychologists use the Structured Clinical Interview for DSM-IV disorders, or SCID, to detect the presence of a clinically significant mental disorder; the researchers needed to calibrate their survey responses with the SCID responses so that they could be sure they were compatible.
The process was straightforward. The researchers took a sample of 750 people who had answered the survey questions and assessed them clinically with both the SCID and the Global Assessment of Functioning Scale, which is a standard measure of impairment. With these measures they could assess which of the 750 subjects had a serious mental illness
according to clinical standards and then examine how well these particular subjects were identified by the set of questions in the questionnaire.
In particular, Colpe said, they found that not every item on the questionnaire had the same predictive weight in picking out those subjects with a serious mental illness according to clinical criteria. A statistical analysis allowed them to assign different weights to the survey questions to get the most predictive power from the questionnaire. “What we were looking for,” she said, “was a cut point where we were happy with the estimate that we were getting by evening out false positives and false negatives and coming up with an estimate of serious mental illness that could be applied to the greater survey.” By applying those numbers to all 45,000 adults who took part in the survey, they were able to get estimates of the prevalence of serious mental illness throughout the United States because the survey sample was chosen to be nationally representative.
This validation will be carried out continuously, Colpe said, because the survey itself is an annual one. The researchers carrying out the survey will routinely select a small subgroup of survey respondents to be given a full clinical evaluation so that the validation remains current.
It is important to build this sort of validation or calibration into larger surveys, Colpe said. Even when researchers believe they understand their measures, it is possible for those measures to vary in unexpected ways. For example, the answers that people give to survey questions will often vary depending on whether the questions and answers are given orally or in written form. “People respond differently to sensitive items about their mental health if they are being asked by a grandmotherly type sitting across the table versus if they are able to answer the questions on a computer or in some way that is a little more discreet.”
Colpe also described an international collaboration, the World Mental Health Survey Initiative, carried out by researchers in 28 countries located in all the different regions of the world and surveying a total of more than 200,000 people. The goal of the survey was to estimate the prevalence of various mental disorders, the accompanying societal burdens, the rates of unmet needs, and the treatment adequacy in the different nations. One of the major challenges was making sure that the results would be comparable from country to country.
It began with the design of the study. All of the participating countries agreed to one universal design in which there would be nationally or regionally representative household surveys. The various countries also agreed to use the same training and quality control protocols as well as the same processes to translate the survey instrument into the different languages. Finally, all of the countries agreed to do clinical validation studies of the sort described above that would be used to validate the responses on the surveys. As a result, Colpe said, the differences that the
survey uncovered among countries were likely to be reflective of real differences rather than being artifacts created by differences in how the surveys were carried out in the various countries.
“The bottom line message,” Colpe said, “is that you have got to plan on the evaluation from the beginning of the study as you design the study, so you are well positioned to do comparisons across studies or conduct pre- and postintervention program analysis.”
LEGAL SYSTEM
Over the past two decades there has been a great deal of testing and evaluation of one particular aspect of the U.S. legal system—the use of eyewitness identifications. Christian Meissner, an associate professor of psychology and criminal justice at the University of Texas at El Paso, provided an introduction to the general field of psychology and law, which includes the specific topic of eyewitness recall identification, and discussed how research has helped lead to reforms of the legal system.
The area of psychology and law, Meissner explained, includes experimental psychologists with social, cognitive, developmental, and clinical backgrounds who conduct basic and applied research with the goal of helping improve the legal system. The field has evolved and expanded over the past 100 years. One of the earliest practitioners was Hugo Munsterberg, often considered the father of applied psychology. In 1908 Munsterberg published On the Witness Stand, which explored some of the psychological factors that could affect the outcome of trials, such as the variability of eyewitness testimony and the phenomenon of false confessions (Munsterberg, 1908). Now considered a landmark, at the time the book was controversial and soured the relationship between experimental psychologists and the legal profession for many years, Meissner said.
So despite Munsterberg’s pioneering contributions, there was little sustained research in the field for nearly 50 years. Part of the reason, Meissner said, was simply that psychologists did not have the methods or theories that allowed them to contribute to the legal system. It was not until the 1950s, for instance, that cognitive and social psychology began to be developed. By the 1960s psychologists were starting to apply cognitive and social theories to the real world and, in particular, to the legal system, but it has only been in the past two or three decades that this work has kicked into high gear.
The trigger for much of this work, Meissner said, was the first case of DNA exoneration, which occurred in 1989. Indeed, there were three separate cases in 1989 in which DNA evidence was used to prove the innocence of someone who had been convicted by the criminal justice system. “This was a really important moment in our field,” Meissner
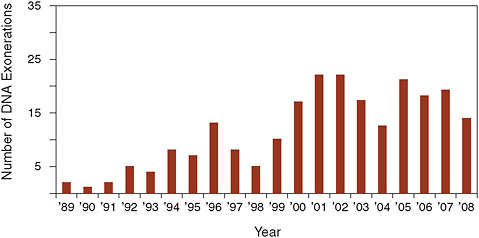
FIGURE 3-1 DNA exonerations in the United States.
NOTE: The Innocence Project regularly updates these numbers, which have grown even more since the workshop. For the most recent figures, see http://www. innocenceproject.org/know.
SOURCE: Innocence Project (2009a). Reprinted with permission.
said, “because it provided impetus not only for further research but also for reform.” Since that time, according to data from the Innocence Project, the total number of people proved to have been wrongfully convicted through DNA exoneration has grown to more than 240 (see Figure 3-1), including 17 on death row.
A variety of studies were carried out to determine the various causes of wrongful conviction, Meissner said, and they have found that mistaken eyewitness identification played a role in about 80 percent of the cases (see Figure 3-2). That shocked the legal system, he said, and led to a great deal of research into witness identification and efforts on validating its use.
The research on eyewitness memory has actually been going on in earnest since the late 1960s and early 1970s, and today the literature includes hundreds of studies on interviewing witnesses and eyewitness identification. These studies include such research as laboratory studies on face recognition and more formal studies of eyewitness performance, such experiments in which a witness observes an event and later is asked to report what happened.
In investigating eyewitness reports, Meissner said, a key distinction is between system variables and estimator variables. System variables are those that are controlled by the system. They include such things as the ways that interviews are conducted, the ways that identification lineups
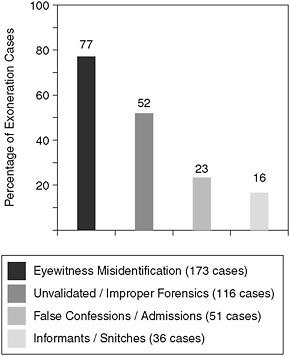
FIGURE 3-2 Contributing causes of wrongful convictions in the first 225 DNA exonerations.
NOTE: Total is more than 100 percent because wrongful convictions can have more than one cause.
SOURCE: Innocence Project (2009b). Reprinted with permission.
are created and administered, and the types of instructions that witnesses are provided. Research on these variables is important because it can help identify ways that the system can be modified to reduce the inaccuracies of witnesses and provide more reliable results.
Estimator variables, by contrast, are those over which the system has no control but that can still affect witness memory. Meissner offered several examples: How good a view did the witness get? How long did the witness have to study the person’s face? What was the length of time between the witness viewing the suspect and the witness providing an identification? It is important to understand these variables as well, Meissner said, not to change the system but to aid in assessing the reliability of a witness.
One of the key facts about the research on eyewitness performance is the fact that it has taken a multimethodological approach, Meissner said. It has included well-controlled experimental studies done in laboratories in which key variables were manipulated and the outcome observed. It
has included a variety of field experiments, such as a situation in which the participants actually went into a convenience store and experienced something and were asked about it later or in which the participants were put in the role of a clerk at a convenience store or a bank who is passed phony bills and then later asked to identify the person who passed the counterfeit money. It is possible to control a number of the variables in these situations, so they can be considered quasi-experimental. There have also been archival studies, in which researchers looked back at real cases and attempted to determine the factors that influenced whether a person was selected as a suspect. More recently there have been evaluations in which researchers looked at how changes in policy affect indicators that are important for the legal community.
Ultimately, Meissner said, this research has led to the development of a number of procedures to improve eyewitness identification. For example, interviewing protocols have been developed that dramatically increase the amount of correct information that witnesses recall without causing concomitant increases in errors. Researchers have also proposed a number of improvements in identification procedures, such as how best to construct a lineup, the use of double-blind administration in carrying out lineup identifications, the best way to give instructions to witnesses, and the use of confidence assessments in determining how sure witnesses are of their identifications.
An important fact to note about this body of research, Meissner said, is the sheer amount of it. There have been a number of meta-analytic reviews of the studies. Indeed, there has been so much research in some areas that two or three meta-analyses have been done.
The research is not without some controversy, however. Meissner described a technique, the sequential lineup, developed in 1985 by Rod Lindsay and Gary Wells (Lindsay and Wells, 1985). The idea behind the sequential lineup is that instead of showing a witness a group of six people or photographs all at one time, the witness would be presented with the people or photos one at a time, and at each point the witness has to determine whether or not this is the person who had been seen. The first couple of studies done by Lindsay and Wells found a dramatic drop in misidentifications but no significant drop in correct identifications. The technique looked to be a major improvement.
However, subsequent studies found that the technique produced not only a drop in false identifications but also a drop in correct identifications. The technique was not making witnesses more discriminating; it was making them more conservative in their identifications. They were less likely to identify any given individual, either the guilty person or an innocent one. The findings have led to controversy about whether sequential lineups should be used. They would probably lead to fewer innocent
people being found guilty, but they might also reduce the likelihood that guilty parties would be identified.
The larger point, Meissner said, is that if additional research had not been done after the early papers were published, the sequential lineup technique might well have been implemented widely, and it would only have been much later, after subsequent research was done, that it became clear what the costs of the technique really were.
In 1996, the American Psychology–Law Society commissioned a white paper by a group of leading eyewitness researchers, which made recommendations for changing the system (Wells et al., 1998). At around the same time, the National Institute of Justice (NIJ) produced a report on the first 28 cases of DNA exoneration, 25 of which involved mistaken eyewitness identification (Connors et al., 1996). Those two documents in turn led to the formation of an NIJ working group composed of researchers, prosecutors, defense attorneys, law enforcement investigators, and others in the criminal justice system who worked to provide a set of best practices for collecting evidence from eyewitnesses. The document produced by that group, Eyewitness Evidence: A Guide for Law Enforcement, was published in 1999 (Technical Working Group for Eyewitness Evidence, 1999). Four years later, the NIJ published an accompanying training manual, Eyewitness Evidence: A Trainer’s Manual for Law Enforcement (Technical Working Group for Eyewitness Evidence, 2003).
One of the morals of this story, Meissner said, is that it is important for researchers to follow through to the end of the process—the actual training of the people who will put recommended practices into effect. “Sometimes when you develop procedures in the lab or even in the field,” he said, “when they get implemented they get changed.” Furthermore, they can get changed in ways that compromise the validity of the technique. So this is an important consideration for anyone discussing field evaluation: not only is it important to do the research and see that the findings are implemented, but also the findings must be implemented in the way they were intended.
However, Meissner concluded, the reports are just recommendations; although they serve as an example of best practices in the field, they do not have the force of law. And today the majority of law enforcement jurisdictions still have not changed their procedures. Thus, although the work on eyewitness identification has been a success in terms of the research, the evaluation, and the consensus recommendations, widespread success in implementation remains unseen.
HUMAN FACTORS
In his presentation, Eduardo Salas, a professor at the Institute for Simulation and Training at the University of Central Florida, described the field of human factors engineering and how various technologies for enhancing human performance are evaluated in the field.
Human factors is the study of humans and their capabilities and limitations, Salas said. The understandings developed from the science are applied to the design and deployment of different systems and tasks. Every device that a person uses, from an automobile to an iPod, has been shaped by human factors engineers, he said.
A closely related field is organizational psychology, which is the study of people and groups at work. Its basic application is to make organizations more effective. “This is a science that basically resides in human resources departments,” Salas said, adding that anyone who has been interviewed by a human resources specialist or who has taken an assessment as part of applying for a job has been touched by an organizational psychologist.
Human factors scientists and organizational psychologists have a long history of working in fields in which errors can have drastic consequences: the military, hospitals, and the aerospace and nuclear industries. Because the stakes are so high, it pays to think carefully about how the design of devices and of organizations can make mistakes less likely.
Historically, Salas said, the military has driven much of the development in human factors and organizational psychology. During both world wars, technologies were introduced without being empirically validated for use with humans, and in many cases it was discovered too late that the technologies did not work particularly well. There was also a growing need for systems that would be usable no matter who was operating them. Thus the military began to invest in research on human factors and organizational psychology, and today the military funds much of the basic and applied research in the field.
Besides the military, medical communities today are investing a great deal in the field. There is particular interest in encouraging teamwork. At the same time, everyone wants to be sure that the various approaches being adopted actually work, Salas said. “Every CFO [chief financial officer] in every hospital is being asked the question: before I roll this out, tell me if this works. What is the evidence that you have? If you spend eight million dollars in peak training for 14,000 employees, will it work, and will patients be safe?” Evaluations are thus a vital part of the field.
Human factors and organizational psychology offer a large variety of products, Salas said. These include tools and devices, principles, strategies, methods, guidelines, and theories, and all of them are evaluated to some degree. Clients naturally want to know what the evidence is that
something will work, he said, and that pushes the human factors and organizational psychology community to do a great deal of evaluation and evidence-based reporting.
There are two primary approaches to evaluating the products, Salas said: usability analysis and training evaluation typology. Usability analysis uses human factors principles to evaluate a system and tailor it to a user, and training evaluation typology uses principles from organizational psychology and human factors to ensure that a user is able to actually use the system or perform the task and has acquired the necessary competencies.
Usability Analysis
Salas then spent the next several minutes of his presentation describing usability analysis in greater detail. “It is an iterative process that engages the user little by little in the design and the development and implementation of whatever product we are coming up with,” he said. Its focus is on the system and how the user interacts with it, with the goal of improving the usefulness and effectiveness of the product.
One usability analysis, for example, focused on a problem with a particular model of car: it kept rear-ending other automobiles. The analysts came up with a variety of possible reasons, such as visibility issues, control issues, or even bad brakes. Then they tested the vehicle with different users and different tasks. What they discovered was that the gas pedal and brake were too close and kept getting pushed at the same time.
A more familiar example, Salas said, is the existence of the third brake light that has become standard on cars. “That came from a usability study done by human factors psychologists.” It was found to be more noticeable to people following in other cars, thus reducing the chance of an accident when a car has to stop suddenly.
A variety of usability analyses could have application to the intelligence field, Salas said. They include evaluations of data visualization, mobile devices, wearable systems, informatics, automated decision aids, and virtual environments for military intelligence.
Five methodologies are used in usability analysis, ranging from very simple and straightforward, with the user not necessarily involved, all the way to field testing. Heuristic evaluation is the simplest and most informal. In it, usability experts judge whether a particular system fits established heuristics, like speak the user’s language, be consistent, minimize memory load, be flexible and efficient, and provide progressive levels of detail. This approach is quick, low in cost, and often very effective, but users are generally not involved, so there is no user insight.
A second methodology is the cognitive walkthrough. It involves an
expert or group of experts taking on the role of the user and stepping methodically through the process of using the system. It can identify the goals, problems, and actions of the user, Salas said, and it is best used early in the usability life cycle with rapid prototypes. It has the benefit that it provides a virtual view of the user without actually having to involve one; its weakness is also that it doesn’t actually involve users, because experts may miss some things that an inexperienced user unfamiliar with the system would pick up on.
The third methodology is the use of interviews with both end users and experts. This can be done in the form of focus groups, and its goal is to determine user needs and goals. If the product is already in use, the interviews can be used to determine common problems and issues from the user’s perspective. The benefit of this approach is that there is direct user contact; the disadvantages are that it can be logistically complicated, and it might not be appropriate for a particular community.
The fourth methodology is the thinking-aloud protocol. This is similar to the cognitive walkthrough, except that it involves an actual user doing an actual task. The user is asked to narrate his or her thoughts while performing the task: “I need to copy this file, so I am going to look for the clipboard function…. Maybe it’s under ‘Edit’ like on Windows…. Oh, here’s a button.” The purpose is to identify the user’s goals, actions, and problems during actual use. “You would be surprised how much information you get out of this,” Salas said. “We have a lot of evidence to show that experts cannot articulate what they know very clearly” because they know what they are doing so well that it becomes automatic. One can often learn much more by following the thought processes of users rather than experts.
The last methodology is field testing. Observing a system deployed in the field offers a researcher less control of the variables and less influence on the task, but it makes it possible to get information and insights that cannot be gained in any other way. However, field testing is expensive and difficult to perform, and its lessons may not generalize to all communities.
Training Evaluation
The second basic approach to evaluating human factors products focuses not so much on the interaction of system and user as on the effectiveness of a particular training approach for a given system. Most training evaluations follow a five-level model called Kirkpatrick’s typology, which has been in use since the 1950s (see Figure 3-3).
The first level is a simple measurement of trainees’ reactions: Did they like the training? What do they plan to do with what they have learned?
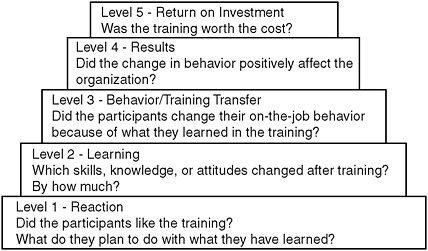
FIGURE 3-3 Kirkpatrick’s model of training evaluation.
SOURCE: Kirkpatrick (1994). Reprinted with permission of the publisher. From Evaluating training programs: The four levels, copyright © 1994 by D.L. Kirkpatrick, Berrett-Koehler, Publishers, Inc., San Francisco, CA. All rights reserved. www.bkconnection.com.
It is the easiest and least expensive to collect, since it is basically reaction data pulled from people after a training session. “The problem is that several meta-analyses have shown the industry stops there,” Salas said. A lot of people feel that if the user likes the device and the training, that’s good enough, and it’s okay to go ahead with putting the device in the field. The problem is that research has shown that there is very little correlation between the positive reactions of people to training and how much they have actually learned. So the fact that someone liked the instructor, liked the setting, and liked the material does not mean that the person got any real benefit from the training.
Thus it is important to move to Level 2, which measures learning. Which skills, knowledge, or attitudes changed after training? By how much? This is usually measured by a multiple-choice or some other type of test. It costs more than the first level and takes more time, but industry is moving in this direction because the evidence-based movement has convinced people of the value of getting actual data.
Level 3 focuses on behavioral changes: Did the participants change their on-the-job behavior because of what they learned in the training? This is the whole point of the training, Salas notes—people are supposed to take what they have learned and transfer it to the performance of their
jobs. Measuring such behavioral changes is significantly more expensive than measuring the acquisition of new knowledge, but it is important for organizations to know.
Level 4 looks even further and focuses on results: Did the change in behavior positively affect the organization? In a hospital, for example, the question might be whether patients are safer because of the training the hospital staff has received. Behavioral changes do not matter if they don’t have positive results for the organization.
In the airline industry, for example, all flight crews have to be given teamwork training on the theory that this will lead to better performance and, ultimately, fewer accidents. And simulations do indeed show that this crew training has the desired results. But after 30 years of such training, Salas said, no correlation has been found between the training and reduced accidents. Still, the Federal Aviation Administration mandates the training.
Level 5 looks at return on investment: Was the training worth the cost? In the discussion session following his presentation, he described a Level 5 evaluation he had done for the financial firm UBS. He used a methodology called utility analysis, which, if followed systematically, makes it possible to obtain a dollar value for an intervention. However, it is based on a number of assumptions, one of which is that it is possible to assign a value to a person’s performance by using interviews with supervisors. And generally speaking, Salas said, Level 5 analyses in industry are done very poorly. “It is done basically to satisfy the bean counters.”
Despite the general weakness of the Level 5 evaluations, Salas said that people in the area of human factors and organizational psychology generally have a good sense of what is required for effective training evaluations. It is a very robust approach, it is systematic, it is very diagnostic, and it identifies which training works, which doesn’t, and what can be done about it.
LESSONS
After the presentations of the five case studies, the presenters and other workshop participants spent some time discussing the broader lessons to be learned from these examples. Salas in particular provided some lessons from operations research.
First, Salas said, one very important fact about operations research is that, after decades of development, scientists know how to validate systems and strategies. There are still problems that can affect validation, such as the lack of leadership or bureaucratic issues, but the field has developed a set of methodologies that are theoretically driven, practical, relevant—and that work. “They are not perfect, I don’t think they will ever
be perfect, but I think we know how to validate systems when humans [are] in the loop.”
Twenty-five years of experience have taught him that for field evaluations of any kind to work, five things are needed, Salas said. The first is a mandate or a champion or leadership that recognizes the importance of what is being done. Evaluations take a long time, so a stable base to work from is important.
The second requirement is resources. Without money and workers, nothing can get done.
The third requirement is access to subject-matter experts, the people most knowledgeable about what is being evaluated. The problem is that these people tend to be very busy, and few of them want to spend their time talking about what they’re doing rather than getting it done.
The fourth is metrics. It is vital to be able to measure the key factors in a system.
Finally, science. It is important to know how to perform evaluations in the most scientifically valid way possible.
Another lesson, Salas said, is that nobody likes evaluations. The reason is the common perception that an evaluation is looking for bad news. People will act as though they are in favor of an evaluation but then not cooperate fully when it starts. “We need a culture that can accept poor results and do something about it” rather than resist the people who are coming up with the results.
Lum focused on the importance of a research infrastructure that can be used to support the use and generation of evaluations. If such an infrastructure already exists for a field, it is something to capitalize on and take advantage of. “In counterterrorism, for example, there isn’t that much evaluation research, but Christopher Koper (from the Police Executive Research Forum) and I suggest putting all the criminal justice studies into the Crime Prevention Matrix that we developed for policing and trying to glean from it some generalizations that might be applicable to counterterrorism,” she said. “It is not the best, but it is all we have. So we are trying to build on something, some knowledge, in order to come to some conclusion about what might work in different areas.”
If there is not already an infrastructure in a field, creating such an infrastructure should be a focus. Without one, it will be difficult to develop a system of field evaluations.
In response to a question from Robert Fein, Lum said that the NIJ had moved away from its earlier focus on evaluations.3 The institute, particularly its science and technology division, is more focused on process evaluations and technology efficiencies. For example, in looking at
license plate readers, the main focus has been on the question of how well they work in reading license plates. There is still little understanding of whether the technology will help reduce auto theft, which was the major purpose of the technology.
In responding, Fein commented that the leadership of any institute is critical in terms of determining what it actually does. It appears to some that NIJ shifted quite dramatically from the late 1970s to the present in terms of a focus on evaluation. Yes, Lum said, there was a time when the institute was pushing for randomized controlled experiments, and then there was a time when that was not the case. Recently has there been a return to more evidence-based practices, under the current administration, and evaluation is getting much more attention.






















