
7
Perspectives on Innovation
INTRODUCTION
Health information technology (HIT) is a rapidly developing field propelled by continual innovation. Participants in this session were invited to give informal remarks based on their observations of the workshop as well as personal experiences. These comments are summarized briefly in this chapter. The papers point to the need for novel approaches to the aggregation of health data to improve population health, offer observations on challenges and opportunities given the current state of HIT, and provide perspective on the opportunities afforded by the vast quantities of health and health-related information collected by individuals and available on the web.
Drawing from the assertion that population health is more than the aggregation of individual disease and, therefore, an understanding that population health cannot simply be gleaned by aggregating patient care data, Population and Public Health Information Services’ Daniel Friedman advocates for the creation of a U.S. population health record. He emphasizes that while the United States has large amounts of publicly accessible population-level disease-related data, challenges for population health include a lack of that same level of granularity for functional status and well-being as well as problems of data integration and integrity. In order to address these issues he proposes the establishment of a single source of population health data backed by an overarching data model and theoretical framework. Data would be drawn from a number of different sources including those not typically integrated with clinical data, such as environmental sampling and census data.
In her remarks Molly Coye, formerly from the Public Health Institute (now the University of California, Los Angeles), identifies what she sees as three areas of opportunity for HIT innovation. Citing the need to improve the current state of clinical decision support she suggests areas where innovation could help meet this goal: how to recognize and deal with incorrect or missing data, integration of a single patient’s data from multiple sources, and how to turn data into clinical guidance. Dr. Coye cites the need for research to be integrated into care processes and for evidence generated to be fed back in a continuous, seamless process that supports informed, shared decision making. Lastly, she points to the movement of healthcare delivery to integrated models—such as accountable care organizations—which increase the need for remote data collection, diagnosis, consultation, and treatment. Dr. Coye concludes by stressing that many of these challenges are social rather than technical in nature, and therefore successful approaches will need to take into account the complex character of these systems.
The growing prevalence of personal information ecologies provides the context for the remarks made by the Institute of the Future’s Michael Liebhold. He notes that these ecologies are composed of digital artifacts not only related to health and fitness, but also to social activities, media use, and even civic life. Mr. Liebhold observes that citizens are ready and willing to collect and share their health information and, with the encouragement of industry and employers, to become more actively involved in their own health. However, effectively integrating information from all of these sources in a meaningful way presents a formidable challenge. Technologies such as those that underlie the semantic web hold much promise, but still face challenges, especially in the areas of privacy and security. Looking to the future, Mr. Leibhold notes the need for methods to curate web-based health information, for interoperable health app stores, and for the development of a web of linked, open healthcare information and knowledge interoperability.
CONCEPTUALIzING A U.S. POPULATION HEALTH RECORD
Daniel J. Friedman, Ph.D.
Population and Public Health Information Services
This paper presents a concept for a U.S. population health record (PopHR), an idea initially presented in a recent article coauthored with Gib Parrish (Friedman and Parrish, 2010). Before presenting the concept of a PopHR, it is necessary to define population health. Our definition is the level and distribution of disease, functional status, and well-being of a population. This definition focuses on (a) functional status and well-being as well as disease; and (b) the level and distribution of each, allowing for knowledge of disparities and equity.
Based on this definition, it becomes equally important to be explicit about what constitutes a population. We use the definition: all of the inhabitants of a given country or area taken together. In this definition, an area can be a province, state, neighborhood, city, or town and can include groups within the overall geography such as demographically bounded groups.
Health care is just one of many influences on population health. Influences such as the context of the population (natural environment, cultural context, political context) and community attributes (social and collective lifestyles, the environment, economic structures, education) all have a bearing on the health of a population. Simply put, population health is more than the aggregation of individual disease. As a result, the aggregation of patient care data provides only an incomplete understanding of population health.
Healthcare Data and Population Health
The United States has many blessings when it comes to population health data. We have rich disease-level data which allow researchers to look at causes of death, birth rates, and cancer prevalence down to the census track. However, we also have some burdens—what you cannot see at the local level is functional status and well-being. The level of granularity we have for causes of death does not exist for depression, disabling lower-back injuries, etc.
We are also blessed by a large amount of publicly accessible, web-based population-level disease data. Currently, roughly 28 states have web-based systems that provide public access to population health data. These systems vary in quality, but some are quite exceptional—employing sophisticated statistics and providing access to two dozen or more datasets. Additionally, the Department of Health and Human Services (HHS) has roughly two dozen web-based population health data systems that are publicly accessible. With so many different websites, datasets are often duplicative, resulting in different definitions for statistical measures or different definitions for the same variables.
The Population Health Record
These burdens could all be solved—not to mention the current benefits enhanced—if there was a single easily accessible source with an overarching data model and theoretical framework. This is the motivation behind a PopHR. The PopHR focuses on populations, not on individuals; it focuses on population health as defined above; and it focuses on the influences on population health enumerated above. Thus, we define PopHR as a repository of statistics, measures, and indicators regarding the state of and influ-
ences on the health of a defined population, in computer-processable form, stored and transmitted securely, and accessible by multiple authorized users.
Framework
Successfully developing a PopHR will require an explicit population health framework that includes a schematic representation of factors that will potentially influence population health. There are many different versions of this type of framework, with an example shown in Figure 7-1. Building the model around population health and not the individual health of members of the population will remedy gaps in our current knowledge such as functional status and well-being.
Information Model and Content
A logical and agreed upon information model will also be necessary for achieving a PopHR. As opposed to an individualized population health records system absent standards, adopting a standardized and agreed upon information model will reduce the burden of overlapping and inconsis-
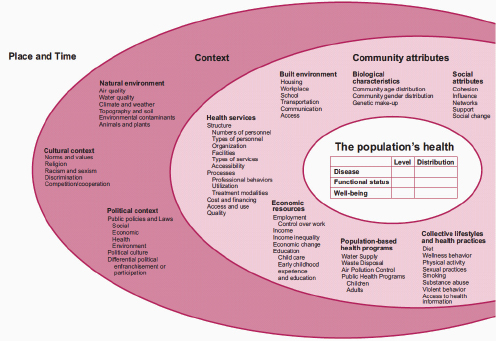
FIGURE 7-1 Influences on population health.
SOURCE: Friedman et al. (2005).
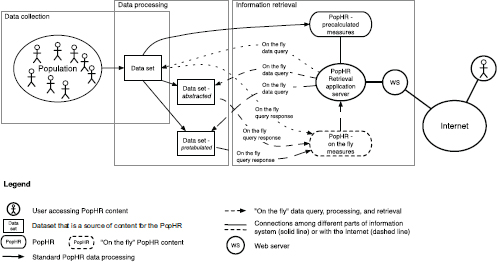
FIGURE 7-2 PopHR and PopHR system showing collection, processing, and retrieval of information content from a PopHR.
SOURCE: Friedman and Parrish (2010).
tently defined variables. A good example of such a model is the Australian Institute for Health and Welfare National Data Model and its more recent metadata directory called Meteor.1 It is also important to consider information content. The PopHR would need to include information on health, and the determinants of health, from existing data sources such as ongoing population surveys; public health surveillance systems; environmental sampling; Medicare claims; and population census. These data sources could be either geographically or individually based, but would be aggregated to the population level in the PopHR—a process enabled by a standardized information model.
Conceptual Model
Figure 7-2 presents a conceptual model of a PopHR. Data for the population are collected using various methods—surveys, environmental monitoring, and abstraction of health records—and compiled and processed to form a population dataset. The dataset is then analyzed to produce a set of population health measures which are stored in the PopHR for later retrieval. To increase retrieval efficiency and speed, the PopHR system might use intermediate datasets in which one or more large datasets would be reduced in size by either selectively removing infrequently used data elements to form
___________________
1 See www.aihw.gov.au/publications/hwi/nhimv2 (accessed March 2, 2011).
TABLE 7-1 Possible System Architectures for a Population Health Record (PopHR)
| Model | Information Storage | Information Retrieval |
| 1 | Centralized | Centralized |
| 2 | Distributed | Centralized |
| 3 | Centralized | Distributed |
| 4 | Distributed | Distributed |
| SOURCE: Friedman and Parrish (2010). | ||
an “abstracted dataset,” or pre-tabulating and indexing the dataset on frequently retrieved data elements. In response to a user query of the PopHR, the PopHR system would retrieve information from either the PopHR with precalculated measures (a standard PopHR information retrieval), or one or more primary or intermediate datasets (an “on the fly” PopHR information retrieval). For some queries a combination of standard and “on the fly” retrievals might be necessary. The retrieved information would then be synthesized into a response and communicated to the user via the Internet.
Implementation
There are various types of system architectures that could be employed in a PopHR system (Table 7-1). In order to successfully implement a PopHR it will be useful to start with the most practical model, and then build to the nimblest and most versatile. In the near term (1 to 5 years) efforts should focus on developing a population health framework and logical information model as well as implementing Model 1 with core functionalities. Doing so will require leveraging the existing HHS web-based query systems. Efforts should be made to inventory the existing work and develop a logical information model and metadata directory for these datasets.
As time progresses, efforts can be made to shift to more advanced models—focusing first on developing and implementing Model 3 with core and enhanced functionalities, and then on doing the same for Model 4.
ACCELERATING INNOVATION OUTSIDE THE PRIVATE SECTOR
Molly J. Coye, M.D., M.P.H.
Public Health Institute (formerly)
University of California, Los Angeles
Currently there is tremendous innovation going on in the private sector, but we could be doing more to foster innovation in the public sector and
at academic centers. This paper will address three challenges—which are not so much daunting as exciting—facing the healthcare system that can become loci for innovative projects. The first is decision support. Currently, we are very far away from the goal of not just producing an array of data but actually producing information that leads to change in the behavior of clinicians and patients. The second concerns consolidating a health information technology (HIT)-supported national knowledge base with parallel efforts in effectiveness research. This too is far off, but the Patient-Centered Outcomes Research Institute has the potential to help drive innovation. Finally, we will be undertaking these efforts to build the digital infrastructure amidst pivotal transformations in delivery of health care. While this certainly provides opportunities, we must also remain conscious of the context of the Patient Protection and Affordable Care Act (ACA) if these efforts are to be successful.
Decision Support
Decision support centers are turning healthcare data into healthcare information. The limitations of our current decision support systems have been very well described: they are klugy, physician-centric, and many physicians resist using them—often for good reason. Innovation in decision support will need to move through three stages: avoiding bad decisions caused by faulty or nonexistent data, integrating streams of data to provide optimally accurate and specific data, and supporting better decisions with clinical guidance. Many organizations are actively involved in work on all of these stages, with considerable progress being made on the first. However, the second—to have data about the same patient coming from multiple locations so that decisions are based on the most accurate and specific data—is proving more elusive and will likely remain a challenge for some time. While the meaningful use rules are encouraging progress, the third stage will require that every point-of-care decision is informed not by data, but by clinical guidance—again, turning data into information.
In order to activate innovation in decision support we need to do more to stimulate the development of small, close-to-the-ground decision support tools that will actually be used by physicians. To achieve this, it is necessary to develop explicit clinical performance benchmarks in consultation with physicians. Furthermore, it will be necessary to collaborate in design with employers and health plans to ensure that there is a business case for use. Unless providers who use these systems are rewarded for doing so, widespread adoption will be hard to achieve.
Comparative Effectiveness Research
Attempting to integrate HIT and comparative effectiveness research carries with it the unfortunate consequence of creating disillusionment. If we are able to build transparency about how little evidence base there is for much of our decisions into clinical decision support—and are transparent to patients on this risk, too—we risk considerable disillusionment. This could be ameliorated by integrating clinical research with the care encounter. Bill Press has outlined a possible approach to this situation (Press, 2009). In his model, when a patient comes to see a physician, the quality of evidence for different diagnostic and therapeutic options is arrayed as probabilities—the probability the diagnostic option will reveal, or the therapeutic option will resolve, the problem at hand. When the patient makes a decision—which, it should be noted, will be a shared and informed decision—the clinical encounter becomes part of a rolling clinical trial. As a result, the probabilities evolve as the results of individual encounters and treatments are recorded and reported. The result is a learning system, where evidence is continually generated and refined, and then fed back to clinicians and patients to promote informed, shared decision making.
The level of patient-fostered engagement in this approach is crucial to promote innovation. If patients can be convinced of the benefits in such a system they will not only be eager to participate, but will begin to demand such capabilities from the healthcare system. With consumer demand we might be able to accelerate work on the technical, political, social, and economic dimensions of facilitating the rich exchange of data necessary to enable such a system. This is an area of opportunity for academic medical centers (because of informatics resources) and large medical groups (because of capitated care and large databases) to design closed-loop learning systems that continually utilize data to evolve clinical understanding. Developing and refining this concept in small cases will begin to demonstrate the utility to the general public, stimulating larger efforts.
Remote Models of Care
The third challenge facing health care is the reconfiguration of the health delivery system toward integrated care models (such as accountable care organizations) as a result of ACA. One of the defining characteristics of these new delivery system models will be the remote nature of care. Functions, not just data, will be liberated and redistributed. Furthermore, we will likely see the rise of long-distance—or remote—diagnosis, consultation, and treatment. This will require advanced health information exchange between and among organizations. The evolution will be a fluid process, but it will also be rough. Considerable time and resources are being invested
in the idea of distributed health information exchange, but this issue will continue to be a continual source of difficulty.
The challenge will not be so much technical, as it will be political and economic. Consequently, the Office of the National Coordinator for Health Information Technology (ONC) should partner with the most advanced systems using telemedicine, tele-ICU, tele-emergency and telehealth technologies to understand how the structures, regulations, and processes that we are setting up now facilitate, or complicate, delivering networked care.
Conclusion
Addressing these challenges will test the limits of data integration with electronic health records that live inside separate enterprises and support learning and the dissemination of principles gleaned from data exchange. Ultimately, successful approaches to these challenges will emerge from treating them as complex systems. Solutions will not involve rules and laws, but will be centered on processes for solving complex and evolving problems.
COMBINATORIAL INNOVATION IN HEALTH
INFORMATION TECHNOLOGY
Michael Liebhold
Institute for the Future
The topic of this paper—combinatorial innovation—comes from a concept introduced by Google chief economist Hal Varian. He postulates that there is currently enough innovation available such that we do not have to invent anything new to create disruption. This paper will begin by addressing many elements that already exist today, but that in combination can be disruptive, and then move on to a discussion of work going on at the Institute for the Future as well as some priorities moving forward.
Capturing Personal Health Data
Discussions on the digital infrastructure for a learning health system tend to focus on clinical information ecologies and the notion of standardized and interoperable electronic health records (EHRs). Much attention, not to mention recent legislation, concerns the linkage between evidence-based science and an interoperable EHR, but this is really only half the picture. Something that is commonly ignored is personal information ecologies.
Citizens are constantly creating digital artifacts. These are not just health and fitness related, but come from their social life, shopping, media
use, vocational activities, and civic life. There is enormous interest—not just in the healthcare community but across communities—in managing these digital artifacts. Doing so will necessitate a holistic program which, fortunately, has been acknowledged by the current administration. The recently released a multiagency recommendation for a national identity and security2 that advocates for a federated model for identity management as an important step in harnessing the potential of these data.
When discussing patient engagement in health information technology, many argue that only a minority of people will collect their data and want to use it in their personal health record. Our indicators suggest that this is not going to be the case. In the Silicon Valley, leading companies like Intel, Cisco, Google, and others are providing real incentives for people to get involved with their own data—body mass index, blood pressure, cholesterol—and take control over their own health. This is viewed as a corporate health issue, making it reasonable to assume that it can spread to populations at large.
There are also growing stores of health-related information that many people do not normally consider. For example, since many people now carry GPS devices in their pocket, we can mine those data and forecast kinds of behaviors and activities in particular locations. Furthermore, some individuals are beginning to wear sensors—not just for their health but for fitness. In fact, there is a lot of new research in the area of using mobile devices as hubs for a wearable network of sensors.
Making Sense of Captured Data
All of these new technologies generate a surplus of information. We do not need all of the information, just the right information. Consequently, we need to combine or orchestrate information, devices, and infrastructure on a continual, real-time basis to deliver the right information to the patient/clinician at the right time. Fortunately, we are well on our way to doing so. In online social networks, we are seeing the rise of social graphs—a schematic that visualizes the kinds of linkages and relationships between people on a dynamic and real-time basis. This technique is based on a very common semantic web framework called Resource Description Framework (RDF), a simple grammar for describing relationships in terms of the subject, predicate, and object.
RDF is also the basis for almost all semantic web applications used for health information exchange. Soon, we will have a population of 500 million people who have a semantic web description of their relationships,
___________________
2 See http://www.whitehouse.gov/blog/2010/06/25/national-strategy-trusted-identitiescyberspace (accessed March 3, 2010).
opening up unprecedented opportunities for data mining and sophisticated inference on a real-time and continuous basis. Of course there are problems with privacy and security if you put your data out there in a universal infrastructure—and there is a lot of work to be done on that front—but the opportunity is immense.
Institute for the Future
In this new climate there are several major contact points that need to be kept in mind: the relationship of our personal health information and the public health commons, the relationship of our personal information and contextual health information, the relationship of our clinical information and contextual health, and the relationship of the scientific evidence base with the clinical information. All of these pairs of relationships have to be explored as a coherent system, and at the Institute for the Future we are looking at what can be achieved with massive computing capability and an abundance of rich data.3
The examples discussed above are the types of technologies our teams have been working with—most recently in a project called Healthcare 2020—to develop tools for precise clinical health information and adaptive health coaching. The result would be that your mobile device would know, for example, that you are not supposed to drink and therefore advise you against going to a bar. Similarly, if you are a diabetic it could coax you to stay away from McDonald’s and, instead, go for a run. With technologies like these we can optimize our health spans, not just prevent morbid conditions.
Priorities Moving Forward
As this field continues to grow, there will need to be a certification process for curating public health information on the web. With so many individuals getting health information on the web from dubious sources, there is a new stewardship role that has to be fulfilled. The government could take a leadership position and come up with standards to certify aggregators and curators of information on the web. Furthermore, the federal government can prime the pump by opening an interoperable health app store, providing tools for consumers to collect, report, generate, and analyze their health, behavioral, dietary, and fitness data. Finally, as these concepts are still in development, support for the development of a deep healthcare web of linked open data and open frameworks for knowledge interoperability, the roles and practices for real-time sensor data, and re-
___________________
3 For more information, see http://www.iftf.org/health (accessed March 3, 2011).
search on therapeutic health information patterns are all needed if we are to harness the power of digital information for improvements in health and health care.
REFERENCES
Friedman, D. J., and R. G. Parrish. 2010. The population health record: Concepts, definition, design, and implementation. Journal of the American Medical Informatics Association 17(4):359-366.
Friedman, D. J., E. L. Hunter, and R. G. Parrish. 2005. Health statistics: Shaping policy and practice to improve the population’s health. New York: Oxford University Press.
Press, W. H. 2009. Bandit solutions provide unified ethical models for randomized clinical trials and comparative effectiveness research. Proceedings of the National Academy of Sciences 106(52):22387-22392.












