
3
Federal Surveys
For the most part, estimates of children’s health insurance coverage are based on one of three federal household surveys, although several other federal surveys collect data periodically that assist in understanding the extent and quality of health insurance coverage. The three major surveys are (1) the American Community Survey (ACS), (2) the Current Population Survey Annual Social and Economic Supplement (CPS ASEC), and (3) the National Health Interview Survey (NHIS). (The attributes of these three major surveys are summarized in Table 3-1, and are discussed below.) Two other surveys are referenced here because they, too, collect insurance coverage information: the Survey of Income and Program Participation (SIPP) and the Medical Expenditure Panel Survey-Household Component (MEPS-HC).
NATIONAL HEALTH INTERVIEW SURVEY
Kenney and Lynch report a general consensus that the NHIS produces the most valid coverage estimates (Chapter 8, in this volume).1 The NHIS is a multipurpose health survey conducted by the National Center for Health Statistics (NCHS), Centers for Disease Control and Prevention (CDC), and is the principal source of information on the health of the civil-
|
1 |
Results from the Medicaid Undercount project suggest that underreporting of Medicaid/CHIP is lower in the NHIS than the CPS (see http://www.census.gov/did/www/snacc/ [September 2010]). |
TABLE 3-1 Comparison of the Attributes of Three Sources of Coverage Estimates
|
Strengths |
Limitations |
|
American Community Survey |
|
|
|
|
Current Population Survey |
|
|
|
|
National Health Interview Survey |
|
|
|
|
Combined |
|
|
|
|
SOURCE: Kenney and Lynch (Chapter 8, in this volume) and workshop discussion. |
|
ian, noninstitutionalized, household population of the United States. The NHIS has been conducted continuously since 1957; the data are collected for NCHS by the Census Bureau (National Center for Health Statistics, 2010). The NHIS is collected in four segments that are weighted, sepa-
rately, to February 1, May 1, August 1, and November 1 of the survey year, then combined to create a single annual weight in the public-use file, with an effective reference date of mid-June (see Chapter 10, in this volume).
Because the NHIS is a health-focused survey, it includes many features to aid respondents in understanding the coverage question and recalling details required to correctly answer it. Kenney and Lynch consider the NHIS features that may strengthen validity to include
-
the area sample frame;
-
a well-trained interview staff that work exclusively on this survey;
-
a fairly high response rate;
-
usually an in-person interview;
-
a knowledgeable respondent (i.e., adults are encouraged to report on coverage for children if they are familiar or to talk about it with the person most familiar with the coverage of household members);
-
a questionnaire that defines concepts and probes respondent memory as it collects information;
-
breadth of content on other health-related data, which potentially helps respondents understand distinctions between coverage types and their type;
-
asking about coverage source at the time of the survey, which is associated with lower measurement error;
-
asking about Medicaid and CHIP using state-specific names;
-
a low level of item nonresponse on insurance sequence;
-
asking for many details about coverage, which may help define relevant concepts or distinguish different types of coverage (e.g., type of managed care, copayments, deductibles, need for referrals) and help respondent recall coverage details;
-
asking about periods without coverage and when the child last had coverage (for use in estimating full-year uninsurance) and why it stopped (potentially helping the person to recall more details required to determine their true coverage status);
-
verifying no Medicaid for children with no reported coverage;
-
asking about citizenship, place of birth, and family relationship, which are some of the important variables needed to simulate eligibility in Medicaid and CHIP;
-
asking about medical visits and other uses of coverage or evidence of acting uninsured;
-
asking for the name of the insurance plan so the name can be matched to a list of insurance plans by state in a postcollection data processing phase and used to recode misreported coverage type; and
-
having been in production for many years and with attention to maintaining a credible time series.
The authors caution that there are also important limitations for using the NHIS to monitor coverage. The most problematic of these is the sampling design, which limits the geographic and other subpopulation estimates that are possible as well as raising validity questions. First, the sample size is too small to produce precise annual state (and substate) estimates for most states. Second, most states have only a very small number of primary sampling units, a fact that raises a concern about the representativeness and precision of the state-level estimates produced by the survey. Third, because of data confidentiality concerns, access to state identifiers is available only through data centers.
The ability to use the NHIS to simulate Medicaid/CHIP eligibility is also limited by the quality of the income data, as well as the possible underreporting of the Medicaid/CHIP information coverage, despite all the efforts to measure coverage accurately. The NHIS is also limiting because of the timing of the data release and what is excluded from the published estimates. There is an early release that enables some important coverage evaluations before the survey is fully prepared; however, it is still about 9 months after the interviews are completed, it does not include published estimates for children ages 0-18 separately, and it does not provide valid estimates by income.
CURRENT POPULATION SURVEY
The CPS ASEC has historically played an important role in monitoring coverage. Besides being a relatively large survey that uses high-quality data collection methods, it is an income- and employment-focused survey and is considered by the Census Bureau to have the most valid data on those domains, which are integral for eligibility simulations and other coverage-related analyses. It is the source of the national poverty estimates.
Kenney and Lynch suggest that features that may strengthen validity include
-
the area frame;
-
a well-trained interview staff working exclusively on this survey;
-
telephone and in-person interviews;
-
high response rates;
-
a sample size that is large enough for precise state estimates for large states annually;
-
family-level questioning about coverage source, which helps get more coverage reported in large households;
-
state-specific names and separate questions about Medicaid and CHIP;
-
other probes and definitions (military coverage, direct purchase);
-
a question on directly purchased coverage that emphasizes that it is not related to a current or former employer;
-
asking for detailed information about coverage, including who is the policy holder, who is covered by the same policy, who is covered by someone outside the household, and employer contributions;
-
asking several times about any other type of coverage not yet talked about;
-
verifying the absence of insurance coverage;
-
logical coverage edits performed by the Census Bureau to correct some likely reporting errors;
-
asking about citizenship, place of birth, family relationship, supports from people outside the household, firm size, as well as income and employment-related factors, which are some of the important variables needed to simulate eligibility in Medicaid and CHIP;
-
asking about health status;
-
having been in production for many years and with attention to maintaining a credible time series; and
-
the release of estimates and public-use files with state identifiers 5-6 months after the data are collected.
The CPS ASEC has limitations as well, the most critical of which for purposes of monitoring coverage is the known measurement error with the coverage questions because of confusion, recall bias, and other issues with the retrospective reference period (Pascale et al., 2009).
The list of limitations suggested by Kenney and Lynch goes on: it has a small sample size for many individual states, even when averaged over 3 years, which makes state estimates highly variable; the imputations for missing income and health insurance data (fully 30 percent of the CPS income data is imputed) are developed on a national basis and do not take account of state differences; income is underreported, particularly for the low-income population, which may contribute to overestimates of children eligible for CHIP; there are errors in recalling periods of health insurance coverage, so that estimates of children with no coverage at any time during the previous year may be biased upward; and children, particularly girls and minorities, are undercovered.
The extent to which nonsampling errors in the CPS were a problem for fund allocations, such as underreporting of income and health insurance and undercoverage of the population, depended on the extent to which the various sources of error differed among states and thereby
under- or overcompensated particular states in terms of their CHIP allotments relative to other states.
As a result of these limitations, the CPS has greater apparent underreporting of Medicaid/CHIP coverage and considerable uncertainty about what the estimates mean, compared with other surveys (Davern et al., 2009). In addition, the sample size and the number of primary sampling units is small in many states, which raises concerns about the representativeness and precision of the state estimates.
Historically there has also been concern about bias in the imputation process for coverage variables; however, new imputations are being implemented at the Census Bureau to address this problem (Davern et al., 2007). The CPS is also missing information about access to, need for, and use of health services and spending. The 9-month lag between the end of the calendar year reference period and the release of the published estimates and edited data limits the ability to track coverage in real time; however, the estimates and data are more timely if they are interpreted as representing some time closer to the interview data in March (just 6 months before the release). The published estimates are also limiting because they do not include children ages 0-18.
AMERICAN COMMUNITY SURVEY
ACS, an annual survey designed to provide intercensal estimates of the information previously collected on the decennial census long form, added information on health insurance coverage in 2008. Although the ACS is a new resource for monitoring children’s health insurance coverage, it has a number of important strengths relative to the other surveys, the most important of which is its very large sample and its sample frame (which samples every county and census tract). The large sample size allows for 1-year coverage estimates for areas with a population of 65,000 or more; 3-year coverage estimates for areas with populations of 20,000 or more; and 5-year coverage estimates for all statistical, legal, and administrative entities. Thus, it is possible to put together a variety of substate estimates, including service areas consisting of public-use microdata areas, counties, metropolitan areas, and the like. It is quite timely, in that estimates and public-use files with state identifiers are released 8-9 months after the end of the survey period, implying an average lag between data collection and data release of 14-15 months. In addition, although most data are collected by mail, the ACS has very high response rates (98 percent).
The health insurance coverage question was asked for the first time in 2008 and is asked for each person in the household. The respondent is
instructed to report each person’s current coverage by marking “yes” or “no” for each of the eight types of coverage listed in the question:
Is this person CURRENTLY covered by any of the following types of health insurance or health coverage plans? Mark “Yes” or “No” for EACH type of coverage in items a–h.
-
Insurance through a current or former employer or union (of this person or another family member)
-
Insurance purchased directly from an insurance company (by this person or another family member)
-
Medicare, for people 65 and older, or people with certain disabilities
-
Medicaid, Medical Assistance, or any kind of government-assistance plan for those with low incomes or a disability
-
TRICARE or other military health care
-
VA (including those who have ever used or enrolled for VA health care)
-
Indian Health Service
-
Any other type of health insurance or health coverage plan—Specify [Includes a space to write-in a response to subpart h]
Since the ACS coverage data are new as of 2008, the survey cannot provide an extended preperiod for studying trends in children’s coverage prior to the adoption of policy changes related to the Children’s Health Insurance Program Reauthorization Act (CHIPRA). In addition, reliable data will not be available immediately for smaller local areas because, as noted above, the Census Bureau publishes ACS single-year estimates for areas with a population of 65,000 or more, 3-year estimates for areas with populations of 20,000 or more, and 5-year estimates will be published for all statistical, legal, and administrative entities. This means that the first 3-year estimates will be released in 2011, and the first 5-year estimates will be released in 2013.
Moreover, research is just now being conducted on the validity of the ACS estimates. Although overall the unadjusted ACS estimates of uninsured children were close to the CPS estimates, they were somewhat higher than the NHIS estimates for the same period, and reports of direct purchase of insurance on the ACS are very high. A major limitation of the survey is that it is conducted primarily by mail (56 percent), which means that most respondents complete the survey without the aid of an interviewer.
Another major concern is that the coverage question is limited. It includes no distinction among Medicaid, CHIP, and other sources of government insurance. Several times during the workshop, the ACS was criticized for not permitting the inclusion of state-specific names for Medicaid
or CHIP. In response to a suggestion that they be added, David Johnson told workshop participants that earmarking questions on the ACS to a particular state is nearly impossible for the Census Bureau because of the cost of sending out tailored surveys by state. However, this information was made available to interviewers in the computer-assisted telephone interviewing (CATI) and computer-assisted personal interviewing (CAPI) modes starting in 2009. There was some discussion about the cost-effectiveness of tailoring the questionnaire and some interest in studying the costs and benefits of such an enhancement.
Another ACS limitation is that there is only one itemized list of coverage types (rather than a detailed series of patterned questioning, defining, and probing, as in the NHIS and the CPS), which could also introduce more measurement error in the reporting of coverage type. Also of concern is the absence of a statement that insurance purchased directly should not have anything to do with a current or former employer as well as the absence of questions about coverage details (managed care, premiums, employer contributions). In addition, the ACS does not include a verification of uninsurance or questions about duration of uninsurance.
Another concern with the 2008 ACS estimates is that there was less postcollection processing on the ACS to remedy possible reporting errors, compared with the NHIS (which collects the name of the person’s plan and then uses it to reclassify coverage type) and the CPS (which uses other coverage-related information collected about the person or family to reclassify coverage on a logical basis).
In her presentation, Joanna Turner suggested that this latter concern shows up in the treatment of nonresponse imputation and editing of the new coverage question. Although 73 percent of respondents had a complete item response (that is, a “yes” or “no” to each of the first seven types), 23.2 percent had a partial response (responded to at least one, but not all items), and 3.8 percent left all items blank. Response patterns varied among the collection modes. Mail respondents were the least likely to provide complete item response, at 58.1 percent, and those interviewed through CATI and CAPI were the most likely to give complete item response, at 96.1 percent. This pattern reflects both differences in the instruments and differences in the composition of people in each mode.
When respondents do not complete an item, a series of rules determine a response that is imputed to the record. If a respondent marked “yes” to one and only one of the types and all other subparts were left blank, the types associated with the blanks were assumed to be and assigned values of “no.” For example, if a respondent marked “yes” for employer-provided coverage (subpart a) and left the rest blank, the edited final response for that person would be a “yes” for employer- or union-based coverage and a “no” for all of the others: direct purchase,
Medicare, Medicaid, military health care, veterans, and Indian Health Service. This process turned some partial responses into complete responses, and they were not considered imputed. This editing choice was the result of analysis of respondents to the paper form. The weighted allocation rate—the percentage of people who had an answer to at least one of the health insurance types, obtained through a procedure called hot-deck imputation—was 9.7 percent for 2008. (The ACS edits for nonresponse did not use a rules-based assignment of health insurance coverage, called coverage or consistency edits. In the ACS, these types of edits are being implemented in the 2009 tabulations.)
The ACS has a number of other content limitations. In particular, family relationship information is not directly available for analysis, making it much more difficult to identify health insurance units for eligibility simulations; there is no information on the child’s general health status or the parents’ firm size. And although the ACS sample is very large and its published estimates cover a variety of important geographic areas (e.g., congressional districts), the sample released for public-use data is smaller and excludes many geographic identifiers, making it more difficult to track meaningful coverage changes for smaller states and smaller subgroups, short of gaining access to a census data center (which requires a comprehensive application that takes several months and must meet stringent requirements).
MEDICAL EXPENDITURE PANEL SURVEY, HOUSEHOLD COMPONENT
The Medical Expenditure Panel Survey (MEPS) has two major components: the Household Component (MEPS-HC), which provides data from individual households and their members supplemented by data from their medical providers, and the Insurance Component, which is a separate survey of employers that provides data on employer-based health insurance. MEPS-HC collects data from a sample of families and individuals in selected communities across the United States, drawn from a nationally representative subsample of households that participated in the prior year’s NHIS. During the household interviews, MEPS collects detailed information for each person in the household on the following: demographic characteristics, health conditions, health status, use of medical services, charges and source of payments, access to care, satisfaction with care, health insurance coverage, income, and employment. It is a panel design, that is, there are several rounds of interviewing covering 2 full calendar years, making it possible to determine how changes in respondents’ health status, income, employment, eligibility for public and private insurance coverage, use of services, and payment for care are related (Agency for Healthcare Research and Quality, 2010).
The health insurance section of the MEPS collects extensive information about private health insurance obtained through an employer, direct purchase of private insurance plans, and public health insurance programs, including on Medicare, Medicaid/CHIP, Medicaid waiver programs, TRICARE, Veterans Administration coverage, and other government programs. It identifies the household members covered by health insurance, type of plan, name of each plan, nature of coverage under each plan, duration of coverage, and who pays various costs for the policy premiums.
The MEPS has some technical anomalies that should be taken into account, according to Thomas Selden. In response to a question, he suggested that users use the full-year MEPS file to analyze coverage because the full year aligns on poverty and the point-in-time file does not. The point-in-time estimates from the MEPS are very high partly because the Agency for Healthcare Research and Quality changed the sample frame along with the NHIS and revised the computer software used to administer the computer-assisted interviewing. Their research has identified, not a major reason for the difference, but rather many small influences.
SURVEY OF INCOME AND PROGRAM PARTICIPATION
The SIPP is currently designed to collect source and amount of income, labor force information, program participation and eligibility data, and general demographic characteristics to measure the effectiveness of existing federal, state, and local programs, among other purposes. It is a household panel, that is, the survey design is a continuous series of national panels, with sample size ranging from approximately 14,000 to 36,700 interviewed households, each of which ranges in duration from 2.5 to 4 years. The SIPP sample is a multistage stratified sample of the U.S. civilian noninstitutionalized population. Beginning with the 2004 version, the SIPP collects point-in-time (“last 4 months”) information on participation in CHIP, although it does not reference state CHIP by name, so there may be some confusion about the program. The most recent data from the SIPP is for the year 2008. Johnson reported at the workshop that the program is undergoing a redesign, in which the Census Bureau is testing moving from collection three times a year to once a year, in the process asking the respondents to complete a calendar indicating when they have received the benefits. The tests, he reported, are promising in terms of the rates reported.
SURVEY COVERAGE ESTIMATES
Turner stated that, in terms of national estimates of coverage rates, the results from the three major sources are very similar. The ACS health
insurance coverage rate was 84.9 percent, not statistically different from the NHIS rate of 85.2 percent. This high level of consistency is a good sign for the ACS, which is conceptually similar to the NHIS, as they both measure current coverage. The CPS ASEC health insurance coverage rate was 84.6 percent. Although the statistical test of the difference between the ACS and the CPS ASEC showed evidence of difference, these two estimates do not appear meaningfully different—both round to 85 percent of the population. Both the ACS and the CPS ASEC estimate 90.1 percent of children have health insurance coverage, and the NHIS estimates that 91.0 percent of children have health insurance coverage.
Looked at another way, however, the three surveys show quite different results on how many children are uninsured at a point in time or throughout the year. Kenney and Lynch reported that, for 2008, the most recent year for which official estimates are available from each of these surveys, the number of uninsured children aged 0-17 at a particular point in time ranges from 6.6 million on the NHIS to at least 10.7 million on the MEPS (Turner et al., 2009). The unadjusted CPS and ACS published estimates are both 7.3 million for children aged 0-17 in 2008, whereas they are 8.2 million and 8.1 million, respectively, for the more policy-relevant 0-18 population (Turner et al., 2009).
The most recent year for which full-year estimates of uninsurance are available for more than one survey (assuming the CPS estimate is not a valid measure of full-year uninsurance) is 2007, and they show a range from 3.7 million in the NHIS to 7.9 million in the MEPS (Agency for Healthcare Research and Quality, 2009; Turner et al., 2009). Not only is there disagreement about how many children lack health insurance coverage at a particular point in time nationally, but state-level estimates also vary across surveys (Blewett and Davern, 2006; Turner et al., 2009).
In his presentation, Michael Davern put the estimates into further perspective, drawing on the data on uninsurance for the total population, which is free from some of the issues affecting the estimates of children. Estimates of the percentage and number of people under age 65 who were uninsured throughout 2002 ranged from 17.2 percent (43.3 million) in the CPS to 8.1 percent (20.4 million) in the SIPP. These differences raise some interesting analytical questions:
-
Is the range in all-year uninsured coverage estimates common in other domains (poverty, employment, education)?
-
Why is all-year uninsured an outlier?
-
Is the difference among the surveys’ rates in all-year uninsured consistent across important covariates of health insurance coverage?
-
Is the CPS consistently like a “point-in-time estimate”?
To address these issues, he examined health insurance coverage estimates as well as other domains that the four national surveys have in common, to see if a common pattern comes through cross-tabulations. The estimates were, as much as possible, anchored to calendar year 2002, but different survey timing caused him to use the 2003 CPS, the 2001 SIPP panel, the 2002 NHIS, and the 2001 MEPS panel. The results of the comparisons for the age group 0-65 years are shown on Table 3-2, which was contained in Davern’s PowerPoint presentation.
From this table, Davern observed that the all-year uninsured estimates are an outlier among the other domains examined. The three surveys with an explicit point-in-time estimate are much closer, well within the range of usual survey to survey variation. Furthermore, the CPS is consistently the outlier, with the highest rates of all-year uninsured across the domains examined. His findings suggest that the degree of difference can become dramatic for important policy-relevant groups. For example, the CPS estimate is that 33.6 percent of those below poverty lack insurance, whereas for the SIPP it is 18 percent. As Davern pointed out, this difference is dramatic. This range of 15.7 percentage points is considerably higher than the 9.1 percent difference in the overall estimate. For those whose incomes are over 400 percent of the poverty level, the difference between the SIPP and the CPS narrows to only 5.6 percent points. The difference between the CPS estimate and other all-year uninsured estimates is seen to vary considerably across important domains of poverty, age, race, and education as well. He observed that the CPS is not a reliable measure of all-year uninsured, mainly because it does not perform consistently. He ascribes this partly to the fact that asking people to remember what insurance coverage they had 16 months ago is a difficult cognitive task, especially for programs like Medicaid or CHIP, in which they may be more likely to move on and off the program than in other types of insurance coverage.
Going on to compare the CPS estimate with the NHIS point-in-time estimate across domains, Davern sees significant differences in 27 of 38 domains, with the NHIS showing a consistently lower point-in-time estimate except in two domains—other race and Supplemental Security Income receipt. The MEPS point-in-time estimate across domains shows significant differences in 13 of 38 domains compared with the CPS estimate, indicating that the MEPS moves in a fairly similar fashion to the CPS. Finally, the SIPP point-in-time estimate across domains shows significant differences in 26 of 36 domains, and with the SIPP there is not a very a strong degree of consistency across domains. (Sometimes the SIPP is higher—for children under age 18—and sometimes lower—for adults aged 19-64.)
Davern suggested that, for policy reasons, the fact that persons do not have to be uninsured for 16 months in order to be eligible for state
TABLE 3-2 Comparisons for the Age Group 0-65 Years
CHIP or Medicaid means that point-in-time estimates are more reliable in helping to understand who is actually uninsured and who is potentially eligible for a program today, rather than who is among the long-term uninsured. In response to a question, Johnson reported that the Census Bureau has tested a point-in-time question on the CPS and is evaluating the response, with the thought of replacing the all-year estimate with a point-in-time one.
This analysis underscores Davern’s observation that the CPS is a very poor measure of all-year uninsurance. Interpreting it as something it was not designed to measure should be done cautiously. There may be a number of causal factors leading the CPS to mimic a point-in-time measure that may not always track an explicit point-in-time measure in a time series. Known causes include editing, imputation, and recall errors. His bottom line is that using the CPS as a point-in-time measure is reasonable (but cautioned), but using it as an all-year measure is not (see Figure 3-1).
|
MEPS |
SIPP |
||
|
Estimate (%) |
Difference (%) |
Estimate (%) |
Difference (%) |
|
12.9 |
4.3 |
8.1 |
9.1 |
|
17.9 |
−0.7 |
15.9 |
1.3 |
|
12.2 |
0.5 |
n/a |
n/a |
|
87.8 |
−0.5 |
n/a |
n/a |
|
8.4 |
−0.5 |
8.6 |
−0.7 |
|
91.6 |
0.5 |
94.1 |
0.7 |
|
4.5 |
0.0 |
4.9 |
−0.4 |
|
17.0 |
−4.1 |
12.9 |
−0.1 |
|
31.3 |
−2.3 |
28.4 |
0.6 |
|
24.1 |
5.5 |
31.7 |
−2.2 |
|
16.8 |
2.0 |
17.6 |
1.1 |
|
10.9 |
−1.1 |
9.3 |
0.5 |
|
20.1 |
3.3 |
19.3 |
4.1 |
|
12.2 |
−2.9 |
10.6 |
−1.4 |
|
67.7 |
−0.4 |
70.0 |
−2.7 |
QUALITY OF THE INCOME DATA FROM THE MAJOR FEDERAL SURVEYS
The quality of estimates of health insurance coverage of children, particularly for purposes of CHIP, relies on the quality of the income data collected from the household, which plays a key role in the development of estimates of poverty and low-income status. The paper by John Czajka (Chapter 10, in this volume) suggests that, although much attention is being focused on the quality of these new estimates of health insurance coverage as a major factor in the choice between the CPS or the ACS, the quality of the income data collected in the ACS may be equally important in determining the ultimate viability of the ACS as a source of annual estimates of low-income children and low-income uninsured children.
The CPS, Czajka pointed out, is the official source of annual estimates of income and poverty in the United States, whereas the ACS collects more limited information on personal income and does so through a questionnaire that two-thirds of the sample completes without the assistance of an interviewer and submits by mail. Policy analysts also have reason to be interested in the ACS as a potential data source for a wide variety of analyses of state and local variation in health insurance coverage, and income is likely to play a key role in many such analyses. For such appli-
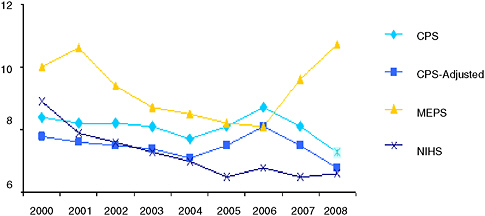
FIGURE 3-1 Trends among the surveys in the number of children (under 18 years) who are uninsured for entire year (CPS) and point-in-time (MEPS and NHIS) (in millions).
SOURCES: CPS–Current Population Survey, 2001-2009; CPS-Adjusted–Davern (2010); MEPS–MEPS-HC online tables, Table 5 (multiple years); NHIS–Cohen et al. (2007).
cations, the demands placed on the ACS income data are likely to exceed those that must be met in providing satisfactory estimates of low-income children.
Given these potential uses of the ACS and the current limitations, do the ACS income data measure up to the CPS sufficiently well to warrant their use in producing the mandated annual estimates of low-income children and low-income uninsured children? His paper reviews income measurement and other features that differentiate the CPS, the ACS, and the NHIS, presenting findings from two empirical analyses comparing the surveys.2
Czajka contends that the CPS defines the measurement of annual income and poverty estimates for the United States since it is the official source of such data. Income in the CPS is defined as pretax money income as measured in the survey; the CPS family is two or more persons living
in the same household and related by blood, marriage, or adoption; and the CPS defines residence rules, which affect who is included in a given family. The CPS collects data on the presence of more than 50 sources of income and captures up to 24 annual dollar amounts for each sample member aged 15 and older. The reported incomes of individual family members at the time of the interview are summed to obtain a measure of total family income for the preceding calendar year. By contrast, the ACS collects income for up to eight sources for each sample person aged 15 and older, combining many sources for which the CPS collects separate reports. The NHIS collects total family income from a single question asked of the family respondent. Earnings from employment are collected from all persons aged 18 and older, but this is separate from and not reconciled with reported family income.
There are other differences. The CPS and the NHIS responses are based on income for the previous calendar year, whereas the ACS asks about income for the past 12 months. The ACS income data during a given calendar year span a 23-month period centered on December of the prior year because, for persons completing the survey at the beginning of the year, the past 12 months are January through December of the prior year; for persons completing the survey at the end of the year, the past 12 months are December of the prior year through November of the current year. The Census Bureau must adjust the ACS data to make them comparable.3 These and other differences described in the Czajka paper add up to differences in the survey estimates of income and thus poverty. In some respects, the results are fairly close. Czajka points out that aggregate income ranges from $6.12 trillion in the NHIS to $6.47 trillion in the CPS—a spread of just 5 percent. This means that in a single question the NHIS captures 95 percent as much total income as the CPS, and the ACS, with a simple instrument filled out primarily by respondents rather than a trained interviewer, captures 98 percent as much total income as the CPS.
However, Czajka makes the point that distributions are important, and there are important differences when income collected by these three
surveys is examined by quintile. Although the ACS aggregates are within a percentage point of the CPS aggregates (both above and below) through the first three quintiles, they drop to 98 and 97 percent of the CPS in the fourth and fifth quintiles, respectively. The NHIS captures only 85 percent as much total income as the CPS (and the ACS) in the bottom quintile.
The differences show up in the poverty rates produced by each of the surveys. The CPS and the ACS yield poverty rates of 12.2 percent and 12.5 percent, respectively, but the NHIS estimates a somewhat higher poverty rate—14.7 percent. Likewise, estimates of children in low-income families from the CPS and the ACS lie very close to each other, whereas the NHIS finds somewhat more. Interestingly, for purposes of comparing the number of children in families likely to be eligible for CHIP and improved benefits under the Patient Protection and Affordable Care Act, the estimates of near-poor children vary from 14.9 to 15.4 million or 21.1 to 21.5 percent across the three surveys.
In his paper and presentation, Czajka drew out of these comparisons several implications of using the different surveys as a source of income and poverty data. Despite differences in measurement, “the ACS produces estimates of income and health insurance coverage that look strikingly similar to those obtained from the CPS” (see Chapter 10), giving support to the use of the ACS to develop direct estimates of low-income uninsured children at the state level and even lower levels of geography. As income is disaggregated, however, some consequential differences emerge owing to collection methods and reference periods. The longer reference period in the ACS means that it tends to lag the CPS in response to changes in the economy, an important issue when assessing the change in health insurance coverage of low-income children in response to the business cycle.
Finally, when it comes to income data, nonresponse and rounding are important considerations. Czajka stated that for both the CPS and the NHIS, about a third of total income is imputed. The CPS imputes a “staggering” figure of 63 percent of the dollars for asset income. The allocation rate for the ACS is only about half of what it is for the CPS. Rounding is important when comparing the survey results. Czajka illustrates the impact of rounding in work that found that close to one-third of the ACS earnings responses are exactly divisible by $5,000. This has important implications when using the data to simulate program eligibility because the data are artificially affected by cutoff points.
SUMMARY
Several observations with regard to the major federal surveys were made by the presenters and are summarized here. Perhaps the most sig-
nificant is that differences in the estimates of health insurance coverage among the three major current sources are not analytically significant. The CPS, the ACS, and the NHIS all produced coverage estimates that rounded to 85 percent in 2008.
The choice of which data source to use largely depends on the question that is asked, since they have different features related to sample size, level of detail used in questions collecting information about coverage, other subjects asked about, characteristics of the interview, and postcollection processing that affect their estimates of health insurance coverage. For example, if the need is for a point-in-time estimate, the user would turn to the ACS, whereas the CPS yields an all-year view of coverage. Each of the surveys has limitations when it comes to monitoring coverage, so Kenney and Lynch suggest that it is important to benchmark key estimates to other surveys.
Some sophisticated analysis by the State Health Access Data Assistance Center, using an “enhanced” CPS series, gives an approximation of what future estimates might look like. Turner reported that the 2008 estimates showed an ACS estimate of 14.6 percent uncovered, which was nearly identical to the NHIS 14.8 percent and actually identical to the CPS rate. On the basis of this work, she observed that the ACS estimates of health insurance coverage looked reasonable, and, when the logical edits are implemented for 2009, it is possible that the ACS estimate of uninsured may be nearly identical to the “best” NHIS estimate for overall coverage.
Much work needs to be done to improve the precision of the survey-based estimates of uninsured children, including modifying questionnaires, enhancing content, and expanding what is available in public-use files, improving clarity of published estimates, improving documentation, giving data users more information about reasons for differences in survey estimates, expanding state-level data on access and service use, and editing cases with misreported coverage. Many of the presenters emphasized conducting targeted methodological research, building bridges between the surveys so they could benefit from the strengths of one another, and providing data users more information for analyzing and possibly further adjusting data.


















