
2
Cyberinfrastructure
DEFINING “CYBERINFRASTRUCTURE”
In 2003 the National Science Foundation’s (NSF’s) Blue-Ribbon Advisory Panel on Cyber Infrastructure issued a report, Revolutionizing Science and Engineering Through Cyber Infrastructure, that defined “cyberinfrastructure” as the “infrastructure based upon distributed computer, information and communication technology” (NSF, 2003, p. 5). Over the 7 years since that report was published, experience has taught us a great deal about what it takes to build and operate successful cyberinfrastructure (CI) for scientific research communities. The primary lesson learned is that it is not sufficient to focus on technology. A successful combustion CI will require the following:
-
Deep engagement of the leading scientists in the field, who will supply the models, algorithms, software, data, and other tools that are to be shared through the CI and who will exploit those shared resources to advance combustion research and development (R&D);
-
A critical mass of information technology and scientific domain professionals, ideally all at a single location, to manage and guide the CI;
-
Resources not only for doing calculations but also for implementing and sustaining a detailed and long-range plan to store and curate the product data so that they can be mined for insight by others in the community;
-
Strategy, plans, and resources to foster and coordinate the retention and sharing of experimental data, whether virtual or centralized, some of which might be created only through the prodding of the CI managers;
-
A serious commitment and involvement by the research community; and
-
A sustained funding model that balances investments in advancing high-risk activities with funds needed to operate a dependable infrastructure that provides the community backbone.
This report refers to all of these elements (hardware, software, data, and personnel) as “the cyberinfrastructure.”
Building, operating, and maintaining such a community CI requires a coordinated effort that is fully integrated with the research and engineering vision and roadmap of the community. By its very nature, a CI is a multifaceted entity that spans technology and sociology. In fact, the primary value that a CI can provide to the combustion community is to bridge the disparate subcommunities (kineticists, fluid dynamicists, industrial designers, and so on), and so, by definition, it must be broad and encompassing. This bridging will be achieved by the use of the CI, necessitated by its value to individual researchers. A CI can also require large investments. Although one of the main goals of any community CI is to facilitate the sharing of data and information, an effective community CI also requires the sharing of resources and the adoption of common tools and methodologies. This entire endeavor can be accomplished only through strong leadership, long-term planning and funding, commitment to cultural changes, and methodical execution.
The operation of a CI for scientific and engineering research requires the use of a business model for getting the operation funded and for allocating the funds, strategic decision making about which technologies should be used and/or adopted, and a strong and effective executive management. In addition to these functions, building a community CI needs one or more skillful “technology evangelists” who can build support for the CI and a community vision. In order for these components to be effected, there must be a model for how the community functions. Chapter 3 sketches this model for community functioning in broad terms, but an early step in creating a CI for combustion would entail a more detailed exposition of the resources that exist and a characterization of the flows of information through the community, from basic researchers all the way to designers of combustion systems.
The leaders of the combustion CI must take responsibility for sparking a cultural transformation, because the CI can succeed only if the com-
munity truly embraces this new model for carrying out R&D. At the same time, those leaders must deal with the cultural transformation caused or triggered by the CI. The foundation for a successful community CI is a culture of sharing that is anchored in mutual trust and respect and a focus on goals that are larger than those required just for creating publishable results. The community CI enables and promotes sharing within and across subcommunities, and membership in the CI assumes an acceptance of this culture of sharing and of mutual goals.
As has been demonstrated by other communities, establishing a community CI can have a transformative impact on all involved. However, by the very nature of a transformative force, building a community CI will require the implementation of “painful” decisions. Some groups will have to give up “ownership” of software tools, computing capabilities, data, or other hallmarks of being a special resource—in some cases because of redundancy and in some cases because of quality or openness. In other words, you cannot have a revolution and keep everyone happy.
The CI of the combustion community cannot operate in a vacuum. It will have to interact with other CIs and leverage cyber tools and methodologies developed by other communities. National CIs such as the Open Science Grid1 and the NSF TeraGrid2 offer services and computing resources, whereas community CIs provide data and tools. The external CIs also offer help in steering the community CI in the rapidly changing (and in many cases confusing) landscape of hardware and software technologies. Learning from the experience of others and understanding the inherent trade-offs of emerging technology can make the difference between success and failure for a community CI. However, the combustion CI might use extant CIs as models, but it would require its own unique structure. The data requirements, resource requirements, and interconnectivities, as discussed in Chapters 3 and 4, differ in substantial ways from those of the CIs built for other science and technology areas. The field of combustion science is extremely diverse in many aspects (areas, methodologies, size, and so on). As a lower bound on size, the Combustion Institute had 2,000 to 3,000 members in 2004, although these numbers represent only active researchers, and most people are actively doing research only for a short portion of their careers. The memberships of other organizations—such as the International Association for Fire Safety Science, the American Institute of Aeronautics and Astronautics, the American Society of Mechanical Engineers, and the chemistry societies of many nations—have many additional active combustion researchers. In addition, many people working in industrial positions developing
|
1 |
See www.opensciencegrid.org. Accessed June 21, 2010. |
|
2 |
See www.teragrid.org. Accessed June 21, 2010. |
fuel, power, or engine research can be considered within the combustion community.
To meet its diverse challenges, a community CI requires a wide spectrum of innovative capabilities and technology that have emerged in the past decade, including the following:
-
Advances in high-performance computing (discussed in the subsection below entitled “The Petascale Frontier and the Exascale Challenge”);
-
The emergence of data and their analysis as a fourth paradigm of computing (Hey et al., 2009);
-
Information and computation grids that link distributed research centers into a single fabric (discussed in the next section, “Building a Community Cyberinfrastucture as Distributed Collaboration”); and
-
The use of collaboration and Web technology to create domain data portals for education and outreach (discussed in the subsection below entitled “Science Gateways”).
There is a tendency to think that the most important step in building a CI for a community is to acquire a lot of hardware and network it together. However, the actual costs of owning and operating information resources for a research community are in fact dominated by space, cooling, power, and, most important, people. Although federal funding agencies have been willing to provide capital costs for acquiring computing hardware, they often defer to the host institutions to staff, power, and maintain this hardware. This means that many major computational infrastructure projects are funded without a long-term sustainability model to support the most important asset—the human talent that keeps the CI functioning on behalf of the scientific mission. This talent is also responsible for interfacing the CI with the science applications to form effective end-to-end capabilities that leverage the community CI and tailor the CI to support the changing R&D needs. The committee believes that “sustainability” is an attribute of the projected combustion CI that is at least as important as its technical attributes and that sustainability is driven by the CI’s human resource needs. At least two prior examples of a CI in the combustion community declined in usefulness—in spite of striking early success—because they were not sustained well (see Chapter 3 in this report). Any plan that is developed must include clear provision for sustainability.
The importance of well-designed and well-tested software infrastructure for building the core of the community CI platform is another major, and often overlooked, category in the total cost of a successful CI. Soft-
ware that must be used by large research communities and evolve over long time periods must be well designed and reliable. Unfortunately, building reliable software is very hard, and most members of the combustion community are not trained as professional software engineers and may not be rewarded professionally for creating efficient and reliable software. Yet, these scientists are often put in the position of trying to build the software framework needed to support a productive CI. The result is that much software—components that are critical for enabling and accelerating progress in data- and computation-intensive science, such as faster algorithms, data-analysis and visualization tools, middleware, and so on—exists as fragile, “homegrown” products that are difficult to share and which might not work without attention from the person who created the software (that person might have been a graduate student or postdoctoral researcher who has since left). It should be said that such homegrown software does have the potential advantage of being tuned to the researcher’s particular needs rather than being more generic. However, that potential advantage does not normally offset the disadvantages. The tendency for homegrown software can also lead to redundant efforts, with the result that the community has multiple versions of software serving a limited number of purposes and none of them being of high quality.
As research collaborations have become large, distributed, and complex, the reliability of the infrastructure has become a critical issue. Without reliability, users lose trust in the system and abandon it; at the least, users must take time that would otherwise be devoted to research in order to reuse someone else’s products. When researchers cannot get what they need from the shared infrastructure, they develop their “one-off ad hoc” cyber tools. A CI team that included some dedicated computer scientists and greater use of well-established commercial or open-source platforms (with modest customization) could help address these issues. In addition, the combustion community should agree on a set of community codes to be included in the CI and maintained by CI staff. This difficult issue must be resolved before finalizing the CI architecture, as the acceptance of an existing platform will undoubtedly require compromises in the functionality of the resulting infrastructure, and the trade-offs between these compromises and the ease of use and maintenance of the infrastructure should be clearly understood.
The sharing of software infrastructure, computing resources, and data is often more of a social challenge than a technical one. In the case of software infrastructure, there is a reluctance to use software from another group because there may be no assurance of its sustained support. Also, building a trusting relationship among the different groups involved in contributing to a software stack requires an incremental process that cannot be accomplished in a short time and requires long-term commit-
ment from all parties involved. Federal funding agencies have also been reluctant to fund software maintenance and sustainability. Unless software is an extremely general-purpose product, the critical mass of users needed to attract an open-source community committed to supporting and improving it will not be realized. Commercial vendors will not adopt and support software unless there is a business model sufficiently robust to generate profits. For this reason as well, the CI must have sustainable government support.
Data sharing is a different problem. Because of the publication value of their data, some scientists would rather “share their toothbrush than share their data.” However, there is a great deal of community data which, if made available in an easily accessible manner, could accelerate scientific progress. The National Institutes of Health has policies that require some data from funded research be made public.3 Although this is an enlightened policy, there are no standard mechanisms to provide the metadata4 to make the data reusable; and building repositories that are robust enough to keep the data alive and available is a substantial CI challenge.
The sharing of processing, storage, and networking resources brings its own unique set of challenges. Such sharing requires policies that are easy to define, implement, and verify in order to control who can use what, how much, and when. Dependable and scalable mechanisms are needed to implement these policies in an environment that crosses the boundaries of administrative domains, technologies, and computing models.
Two aspects of data that are of special importance are their provenance and the control of access. Thus, an underpinning component of any shared infrastructure is identity management, as the “owner” of each request to a data item, software component, or computing resource must be authenticated before the request can be considered for authorization. In the same way that the data and information cannot flow without a network, they also cannot flow without a community-wide authentication system. When intercommunity boundaries need to be crossed, the community authentication system must be capable of supporting the mechanisms needed to facilitate the secure and well-managed mapping of identities. The community also needs to develop processes and procedures to assign memberships and roles to individuals.
Given that investment in a community CI can be significant, it may
|
3 |
See www.nsf.gov/bfa/policy/dmp.jsp. Accessed October 15, 2010. |
|
4 |
“Metadata” refers to data about data. The term applies mainly to electronically archived data and is used to describe the definition, structure, and administration of data files with all of their contents in context in order to ease the further use of the captured and archived data. |
result in a reduction in the funding levels of other activities. Even if this is not the case and the CI funding is “new” money, some community members will consider this money as money that would have been available for their work and is now wasted on CI. It is critical to demonstrate value (return on investment) early. There are many advantages to starting with a small set of engaged customers rather than starting with an overly ambitious “We will build it and they will come” attitude. Winning over the community for a large-scale investment that is labeled as “infrastructure” rather than “high-risk/high-return science” is not an easy task, especially when a significant fraction of the investment (software and people) is not as visible as a big piece of hardware. Unless members of the community experience the value of the CI investment, they will not support the activity. Many scientists and engineers are frustrated with the ever-shifting landscape of cyber technologies, always promising that the next “hot (hardware and/or software) technology” is the “dream technology,” while offering very little (if any) help to transition to it.
BUILDING A COMMUNITY CYBERINFRASTRUCTURE AS DISTRIBUTED COLLABORATION
The most important elements of a community CI are the research groups that build the tools and generate the data that support progress in the discipline. A successful CI depends on sustained support for these central groups. But the communities involved in the CIs described below evolved from small communities; they did not start as large ones.
There are many examples of this evolution in the United States, Europe, and Asia. The National Center for Atmospheric Research5 and Unidata6 are primary centers for atmospheric research in the United States. These closely aligned organizations are persistent and provide both computation and data resources shared by the whole community. Other large groups, such as the Storm Prediction Center,7 consist of important specialists who augment the strength of the central facilities; other individual groups work with resources provided by the entire network of resources. As shown in the Figure 2.1, the structure of an overall community CI is a multilevel grid of researchers, specialty centers, and centralized resource providers. The high-energy physics community CI is similar, with central facilities at the European Organization for Nuclear Research8 and Fermilab.9 Large Hadron Collider (LHC) data are distributed to a national com-
|
5 |
See www.ncar.ucar.edu. Accessed June 21, 2010. |
|
6 |
See www.unidata.ucar.edu. Accessed June 21, 2010. |
|
7 |
See www.spc.noaa.gov. Accessed June 21, 2010. |
|
8 |
See public.web.cern.ch. Accessed June 21, 2010. |
|
9 |
See www.fnal.gov. Accessed June 21, 2010. |
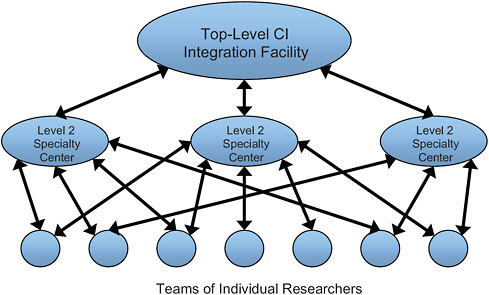
FIGURE 2.1 A typical cyberinfrastructure (CI) organizational chart.
munity of researchers through a multilevel network of data providers. The National Radio Astronomy Observatory10 provides a similar central organization for the widely distributed radio astronomy community. In each case the technology of CI ties the community CI together.
In Chapter 4, this structure, represented in Figure 2.1, is specialized to the combustion research community.
THE CHALLENGES FACING A COMBUSTION CYBERINFRASTRUCTURE
As the technology of CI has evolved, so has the way that it has been used in science. Until the late 1990s, the use of CI in science was dominated by very large scale numerical simulations done on supercomputers. Innovation was centered on new approaches to parallelizing families of important applications. As the ability to solve more and more complex problems grew, two phase transitions emerged in the way that computational scientists work:
-
Computation moved into multiscale simulations. This change often resulted in applications that required a multidisciplinary team of scientists. The applications became more heterogeneous in struc-
|
10 |
See www.nrao.edu. Accessed June 21, 2010. |
-
ture, and special middleware11 was needed to manage them. The teams of scientists working on a problem often lived in different locations, so the CI had to include scientific modes of telepresence and collaboration technology.
-
The analysis of data became as important as simulation. An increase in online storage, together with the proliferation of digital instrument streams from sensors in laboratory experiments as well as semi-static data from databases, simulation output, and the World Wide Web, created new CI challenges. New forms of artificial intelligence based on Bayesian statistical methods created revolutionary new ways to discover knowledge from massive data collections in fields such as bioinformatics and natural language translation. The LHC (the largest physics experiment ever devised) is creating the largest data-analysis challenge ever attempted, and the development and maintenance of the associated CI are major components of that project.
The subsections that follow describe the technology challenges that define the frontier of CI in research and education.
The Petascale Frontier and the Exascale Challenge
Combustion-systems modeling is clearly a complex multiscale, multiphysics problem, as described in Chapter 3. Chemical reactions in a combustion device evolve on a nanometer, femtosecond scale, whereas an engine operates at the scale of meters and minutes. It is not feasible to capture this range of scales in a single simulation. Instead, combustion scientists use a range of distinct computational tools along with experimental data, each appropriate to a particular regime, to build models that can be used for simulations at larger scales. Chemical reactions are determined from the synthesis of a broad range of disparate data and simulation tools based on quantum mechanical methodologies such as models for Schrödinger’s equation. Fundamental flame properties are determined through a combination of simulations of the Navier-Stokes equations and laboratory flame experiments. Behavior of combustion systems requires complex multiphysics models centered on either Reynolds-averaged or Large-Eddy-Simulations approaches for turbulent computational fluid dynamics (CFD) modeling.
Over the past 20 years, each major increase in computing capabil-
ity—from gigaflops to teraflops to, now, petaflops12—has led to higher-and-higher-fidelity models of combustion processes, with current models contributing materially to understanding combustion chemistry and physics as well as contributing to the design of more efficient, less polluting combustion devices. However, a great many approximations are still necessary, even on the most advanced supercomputers, and future advances in combustion science will continue to require access to the most powerful computers available as well as to advanced science and engineering codes and applications that can fully exploit the capabilities of these computers.
As new architectures are developed and deployed, a new generation of combustion science software will be required. This next generation of software will need to be more than simply numerical algorithms for solving the core chemistry and physics models needed for combustion. It will also need to encompass new approaches for data analysis and visualization, with an emphasis on making the results of simulations available to the larger community.
In addition, as new architectures evolve, there is a growing consensus that how simulation is approached and what software tools are needed to exploit these architectures fully will have to be rethought at a fundamental level. For exascale computing systems, an international planning activity is currently underway13 to assess the short-term, medium-term, and long-term software and algorithmic needs of applications for petascale and exascale systems, and to develop a roadmap for software and algorithms on extreme-scale systems. The opportunities provided by petascale and exascale computers for advancing combustion science and engineering are great; however, major investments in software will be required to take full advantage of these new capabilities. In addition, policy issues will need to be addressed, and resources will be required to enable the effective use of these capabilities by academic and industrial researchers.
Cyberinfrastructure and Digital Research Collections
Descriptions of what a CI can do for science are vivid and compelling, with many exemplary cases emerging across domains, as evidenced in a report from the National Science Foundation (NSF, 2008). The advances are profound, but so too are the uncertainties about how to continue to invest in and build a CI in ways that will provide broad support while also enhancing research capabilities for particular research communities
|
12 |
“Petascale” refers to computing systems that reach a performance of 1015 floating point operations per second. “Exascale” is a 1,000-fold increase over petascale. |
|
13 |
See http://www.exascale.org/iesp/Main_Page. Accessed December 10, 2010. |
and the work of individual scientists. Supporting and advancing a CI for combustion science need to proceed in step with more global CI development, given the ultimate aim—value-added systems and services that can be widely shared across scientific domains, both supporting and enabling large increases in multi- and interdisciplinary science while reducing the duplication of effort and resources (adapted from the wording in the report of the Blue-Ribbon Advisory Panel on Cyberinfrastructure; see NSF, 2003).
In the general discourse on CIs, the coordination of research data and tools tends to be glossed over as an inevitable trend. But it is often the case that advances in technical capabilities proceed apace while a constellation of underlying social dimensions hinder the growth and use of collections of digital resources. Problems vary across disciplinary cultures, and they are more pronounced in domains that do not have established practices to support the open exchange of publications, software, or data (Kling and McKim, 2000), as is the case with combustion research. Although the present report is concerned with a CI that encompasses more than just data repositories and services, the issues surrounding data are particularly instructive. As seen in the NSF report Understanding Infrastructure: Dynamics, Tensions, and Design, many basic CI development challenges are “principally about data: how to get it, how to share it, how to store it, and how to leverage it” for scientific discovery and learning (Edwards et al., 2007, p. 31).
Evolution of Data Collections
The three categories of data collection identified in the report of the National Science Board (2005) entitled Long-Lived Digital Data Collections: Enabling Research and Education in the 21st Century provide a framework for considering how digital repositories for combustion research may evolve.
-
Research collections are the most localized, usually associated with a single investigator or a small laboratory, with limited application of standards, perhaps no intention to archive data over time, and little funding for the management of data. A fundamental aim of the proposed combustion CI is to move beyond this type of distributed, ad hoc approach.
-
Resource collections are the next step up in coordination, developed for a community of researchers, with standards sometimes developed within the community, but funding sources tend to be variable and unstable.
-
Reference collections support broad and sometimes diverse com-
-
munities, conform to well-established standards, and tend to have long-term funding streams from multiple sources.
The Protein Data Bank14 is the archetype of this last category, reference collections, with its—
-
Sophisticated data structures and descriptive vocabularies for protein structures,
-
Experimental processes,
-
Administrative metadata,
-
Highly evolved discovery and access functions, and
-
Data validation and security processes (Westbrook et al., 2003; Berman et al., 2003).
As the combustion community works toward reference-level infrastructure, the stages of development will likely follow the path of past successful infrastructures, evolving through the integration of localized systems into a larger functioning network (Edwards et al., 2007). In essence, this course of development brings together (virtually or physically) research-level collections into resource collections to provide the foundation for a more comprehensive reference collection. Table 2.1 captures the relevant features of various structures for data retention and sharing.
Data-Curation Aims and Challenges
Accessible and functional data collections are essential research assets that, if developed through systematic curation principles and methods, will grow not just in size but also in value. Here, “data curation” is defined as the active and ongoing management of data through its life cycle of value to society. This process includes data archiving and digital preservation, but also active appraisal, management, and accountability, provision of context and linkages, and support for reuse and integration (Rusbridge et al., 2005). Data-curation services maintain data integrity and enable data discovery, retrieval, and use over time through a range of activities for identification, selection, authentication, representation, preservation, and other processes that span the entire life cycle of data from production to archiving and reuse. The integration and reuse of data will not happen within a community, however, without a culture of data sharing. At this point in time in combustion research and many other sciences, data sharing is not a commonplace practice or expectation. As is common in many other sciences, data sharing functions more like a cot-
|
14 |
See www.pdb.org. Accessed June 21, 2010. |
TABLE 2.1 Data Sharing Frameworks and Implications
|
Aspect |
Approach |
Characteristics |
Implications for Data Producers |
|
Structure |
Centralized |
Single host location |
Deposition services |
|
|
|
Normalized format |
Coordinated acquisition location |
|
|
|
|
Normalized format |
|
|
Federated |
Single access point |
Limited to participants |
|
|
|
|
Enforced data standards |
|
|
Distributed |
Individual points of access |
Local responsibility for storage |
|
|
|
|
Control of format |
|
Access |
Open |
Unlimited access and reuse |
Not an option for sensitive data sets |
|
|
Hybrid |
Access control as needed |
Ability to restrict access and use |
|
|
|
|
Management of sensitive data |
|
|
Controlled |
Registration and permissions required |
Controlled sharing |
|
|
|
|
Minimized risks |
|
Management |
Local |
Case-by-case decisions |
Control retained |
|
|
|
Potential inconsistency |
Maintenance and distribution burden |
|
Central |
Governance by committee or central authority |
Policy-driven options for control |
|
|
SOURCE: Adapted from Pinowar et al. (2008). |
|||
|
Implications for Data Consumers |
Considerations for Developers, Service Providers, and Stakeholders |
|
High visibility |
Easier coordination of development and maintenance than with other approaches |
|
Optimized retrieval |
|
|
|
Best for common data types |
|
Enabled browsing |
|
|
|
Requires sustained funding and personnel |
|
Same attributes as with centralized approach, but with more complex oversight |
More complex infrastructure than for centralized structure |
|
|
Requires proactive work with participants |
|
|
Requires sustained funding and personnel |
|
Low visibility |
No control or formal coordination |
|
More difficult retrieval than for other approaches |
Rarely maintained for the long term |
|
Complications with interpretation, consistency, integration, and sustainability |
|
|
No barriers to participation |
Maximizes potential reuse |
|
Some barriers to access |
Requires coordination |
|
Access can be complex, time-consuming |
Accommodates needs for privacy and security |
|
Ad hoc, inequitable access |
Can support gradual transition to more open sharing over time |
|
Guidelines for access and use |
Enables consistency |
|
|
Potential for building community consensus and standards |
tage industry activity, with exchange based on professional relationships and personal communication, and in which actual sharing with anyone other than close, trusted collaborators is negotiated on a case-by-case basis (Cragin et al., 2010).
Much enthusiasm is voiced for the “open data” movement in the flurry of reports from scientific agencies and in the popular scientific press, but studies of data practices point to some of the key obstacles that would be faced in the development of CI capabilities for combustion research. For example, as might be expected, scientists are less inclined to share data that require a laborious data-collection process (Borgman et al., 2007) or which have not been fully mined yet for research results. A recent study across 12 scientific research areas (Cragin et al., 2010) found that willingness to share tends to increase as data are cleaned, processed, refined, and analyzed in the course of research, and particularly after results from data have been published. However, it is not unusual for scientists to withhold data, even within collaborative groups, and to devise strategies to guard against inappropriate use or erroneous interpretation of their data. Moreover, data-sharing enthusiasts can turn into skeptics if they experience some kind of infringement as they begin making their data publicly available. More generally, repositories will not attract contributors unless they have effective access and use policies, with embargo systems to enforce waiting periods before the release of data; also, attribution requirements are of primary importance to many scientists.
Analysis of the roles and functions of nascent public data collections has indicated that criteria-based policies are needed for deposition, sharing, and quality control (Cragin and Shankar, 2006). Policies associated with curation services are complex, as they need to accommodate differences in sharing behaviors and norms, which vary at the subdiscipline level (Research Information Network, 2008), while they also encourage data deposit and use. Since sharing practices are also directly influenced by early experiences, the first steps must be carefully thought out so that early adopters become advocates.
As with all aspects of CI, problems with standards are always looming. There is no consensus on the optimal unit for representing and organizing data, and it can vary within a domain and based on the aims of the depositor or user. This issue is further complicated by the fact that the most presentable or easily analyzed version of a data set may not be the most valuable for preservation over the long term, especially if it is to be integrated or reused by researchers for new types of analysis or in a different discipline (Cragin et al., 2010). Valid interpretation and application by others will require systematic tracking of provenance, determination of the proper targets for archiving and preservation, and consistent appli-
cation of standards for data capture and for descriptive and contextual metadata. Quality metadata are a linchpin for functioning cyberinfrastructure, but the problems associated with generating metadata have been nearly intractable in many efforts to federate digital resources. As noted by Edwards et al. (2007, p. 31):
[F]unders have exhorted their grantees to collect and preserve metadata—a prescription that has, for the same number of years, been routinely ignored or under-performed. The metadata conundrum represents a classic mismatch of incentives: while of clear value to the larger community, metadata offers little to nothing to those tasked with producing it and may prove costly and time intensive to boot.
Even in fields where data sharing is accepted practice, the burden of generating contextual metadata to ensure understanding and valid application of data cannot be absorbed by the typical researcher. Scientists rarely have the time or skills needed to prepare data for public sharing (Research Information Network, 2008), resulting in the need for investment in metadata production, preferably at the point of data generation, and a high level of resources directed to supporting functions during the acquisition and ingestion stages of curation (Beagrie et al., 2008).
Filling Data Gaps
A combustion CI also needs to be concerned with filling data gaps, which is not required of some other computational infrastructures referred to above. Models and simulations used for combustion R&D need data as inputs and later for validation, and not all of those data are intrinsically interesting to experimentalists. A full model of combustion might track 1,000 chemical species and require millions of chemical parameters as inputs (see Chapter 3 of this report). Traditional research funding might not be available to provide all of those parameters, and proposals to determine them experimentally might, in many cases, be ranked as low in scientific interest. In other cases, the parameters of real interest for combustion research might be quite difficult to determine experimentally; experimentalists can work with other species to more conveniently examine the underlying science, but the combustion modeler cannot be satisfied with such analogous data.
Thus, for a combustion CI, it should be considered how to provide incentives to fill some gaps in data. Values computed from first principles might someday be feasible, or grants to support “nonglamorous” data collection might be part of the CI plan. Identifying which gaps to fill is in itself a challenging problem.
Aligning with the Combustion Community
To build a CI that supports and advances research, collections need to be aligned with the research process, recognizing that the archiving and access of resources for educational purposes may require different approaches. Nonetheless, shared digital collections can serve a range of functions, all of which have their policy challenges. Some high-value functions for the combustion community include the registration and certification of data sets and an awareness of research production trends, features that have often emerged as unintended outcomes of repository development rather than by design. There is a real opportunity in CI planning to exploit these capabilities to the fullest.
Certain aspects of the field of combustion research make it clearly appropriate as a target for CI development and suggest that a combustion CI has a high probability of benefit and success. These favorable aspects are inherent characteristics of the discipline—not the kind of factors that can be engineered from the outside or imposed by technical structures or policies. The first important factor is the high mutual dependence among subfields. The second is the variation in core problems and methods. Fields with these characteristics are particularly well positioned to capitalize on information exchange systems and likely to have high levels of adoption (Fry, 2006). Moreover, researchers who rely on large bodies of data for modeling and simulation have been early and effective users of public data-repository services. Thus, the combustion community is a relatively low-risk, high-payoff target for a systematic, field-wide approach to collecting, curating, and mobilizing digital collections through a CI.
Known problems in the conceptualization and implementation of distributed, collaborative efforts do pose some risk, however. Areas that need particular attention in supporting combustion research include coordination and cohesion within the community, participation and membership in CI activities, leadership of the initiative over time, the building of trust with all stakeholders, and the translation of the needs of researchers and the technical capabilities of the CI across various disciplinary cultures.
It has been shown that coordination among numerous research sites can hinder collaborative efforts more than the number of disciplines involved, but multiple coordination and communication tactics are effective in improving the management of activities over space and time (Cummings and Kiesler, 2005). Cohesion is essential to building and maintaining effective virtual organizations (NSF, 2008), and it can be strengthened with various techniques, which include making participants’ identities explicit and promoting collective activities in the virtual space.
Transparency of leadership, authority, and accountability are necessary and can build trust early on in the development of a community CI. Overcoming distrust after it is established is a much more difficult hurdle. Co-activity across distributed partners is another important strategy that can take the form of training, evaluation, or policy development. Ease of access and participation are key to realizing wide adoption, since more casual interaction (or lurking) is an important way for newcomers to gain entrée to a community of practice (Lave and Wenger, 1991).
Growth and sustainability over time will require a plan for recruiting potential participants with valuable data and software assets for combustion research, as well as researchers in cognate communities who may contribute to or benefit from a combustion CI. Historically, the technologies that provide the foundation for infrastructure have tended to be developed by groups of self-selected experts and enthusiasts for purposes customized for their goals, and whose technological expertise continually increases during the process of development (Edwards et al., 2007, p. 31). The transition from separate, local systems to a pervasive CI will require attracting and supporting the broad range of researchers in combustion and other related scientific disciplines, including more junior scientists and engineers, and those who are more novice users of networked and shared digital resources. Participation can be most readily extended through existing social networks, but attention to incentives for encouraging contributions from more disconnected groups can bring in valuable data, technologies, techniques, resources, and expertise for solving combustion research problems. As linkages and complexity increase, there is a continual need for the translation of requirements and contributions across the fields represented in the growing user base. Translation is also a necessity on the technical side of development, to align data formats, vocabularies, and ontologies for interoperability and integration across domains.
The committee notes that many of the data-curation and -management issues brought up in this section have been anticipated by the NSF through its Sustainable Digital Data Preservation and Access Network Partner (DataNet). Following is a brief description of this project from its prospectus:
Science and engineering research and education are increasingly digital and increasingly data-intensive. Digital data are not only the output of research but provide input to new hypotheses, enabling new scientific insights and driving innovation. Therein lies one of the major challenges of this scientific generation: how to develop the new methods, management structures and technologies to manage the diversity, size, and complexity of current and future data sets and data streams. This solicitation
addresses that challenge by creating a set of exemplar national and global data research infrastructure organizations (dubbed DataNet Partners) that provide unique opportunities to communities of researchers to advance science and/or engineering research and learning.15
MEASURING PROGRESS
Many features and dimensions of a CI can be measured. The subsection below on “NanoHUB” illustrates some of these measures. But benchmarks of real value and impact are difficult and can only be determined over time with good baselines in place. For combustion research, there may be a range of aims particularly worthy of assessment, including the amount of reuse of data and software, new collaborations, citations across subcommunities, the fraction of the research community that uses the CI, and reductions in the amount of time that researchers spend on software and in finding data. The field is still in its infancy, and the means for identifying and measuring such things as results produced with shared data, incentives for participation, quality criteria for data sets, optimal levels of metadata production, and many other issues will need to be resolved in order to optimize the CI to produce the best benefits for the combustion community at large. Sharing of “best practices” with other community CIs would be helpful in this regard.
EXPANDING ACCESS TO THE COMMUNITY
As the combustion community considers the role that cyberinfrastructure might play in its future, certain questions should be asked. On the one hand, are there common data repositories, large-scale instruments, or specialized simulation capabilities that the community as a whole relies on? If so, a compelling case for a shared CI that unites and empowers the community could be made. Or, on the other hand, is the field more characterized by a very wide range of smaller-scale research? If so, a nanoHUB-like model may make sense. Whichever course is taken, a clear understanding of development and support costs should be a starting point. Before launching a costly and extended technology-development effort, one should also examine existing technology platforms that might be leveraged. Below, two of the most prominent platforms that the combustion community might consider as components of its CI are briefly examined: science gateways, represented by the nanoHUB, and cloud computing. The development effort will also require leveraging and link-
|
15 |
Available at http://www.nsf.gov/pubs/2007/nsf07601/nsf07601.htm. Accessed on December 6, 2010. |
ing to existing facilities such as supercomputing centers and networks of the NSF and the Department of Energy.
Science Gateways
A “science gateway” is a Web-hosted environment for providing users with discipline-specific tools, collaboration, and data. Science gateways usually take the form of a Web portal similar to that of an online bank, an airline, or other retailer. Once the user completes an authentication step (“signs in”), the portal provides the user with his or her personal data and tools to manage the data. In the case of a science gateway, the portal provides access to domain application data as well as tools to manage, generate, and visualize the data. The NSF Tera-Grid project has a very successful ongoing science gateway program. The program has 32 gateway portals, which represent the disciplines of atmospheric science, biochemistry, and molecular structure and function, biophysics, chemistry, earth sciences, astronomy, cosmology, geography, integrative biology and neuroscience, language, cognition and social behavior, neutron science, and materials research. Features common to most gateways include the following: tools for work flow management, so that applications can be rapidly composed from existing components; the ability to personalize the gateway; extensive documentation; and help-desk processes. The TeraGrid organization has a small staff of professionals available to help set up a portal for a science gateway. The staff provides information on best practices for security, job submission to the TeraGrid supercomputers, data management, and Grid protocols. The staff also provides illustrations on how to turn a standard command-line-driven application into a science work flow component.
There are several challenges to making a science gateway a success. Often science gateways are initially funded as an outreach component of a larger grant. They are built by science team members and not by professional developers. Those who build such gateways often start with predetermined concepts of how the software should be built and installed and are not interested in building on the success of others. These gateways seldom integrate well with the TeraGrid security and job-submission protocols. However, with the success of some of the more established gateways, such as nanoHUB and the HUBzero software, more robust portals have emerged. Running a successful portal requires a hosting infrastructure and full-time staff to support it. The greatest challenge comes when the initial funding runs out. TeraGrid has only had limited resources to help with continued support and to keep the portal run-
ning; the application community must devote resources, often from other grants, to keep it alive.
NanoHUB
The Network for Computational Nanotechnology (NCN) was launched in 2002 by the National Science Foundation with an objective of accelerating the evolution of nanoscience to nanotechnology and a vision for using what is now called CI to enable new ways for the community to work, learn, and collaborate. A major goal was to lower barriers to the use of simulation in newly emerging fields of research, thereby fostering collaborations between experimentalists and computational experts and promoting the use of live simulations in education. Toward that goal, the NCN created nanoHUB.org, a science gateway where users log on, access research-grade software being developed by their colleagues in nanotechnogy, run interactive simulations, and view the results online, with no need to download, install, support, and maintain software. A powerful open-source software development platform, rappture.org, makes it easy for developers to create and deploy new codes and to equip them with friendly interfaces designed for nonexperts. The underlying technology platform, HUBzero, now powers eight different “hubs” in various scientific and engineering disciplines and is being readied for an open-source release.16
At its core, a “hub” is a Web site built with familiar open-source packages—a Linux system running an Apache Web server with a Lightweight Directory Access Protocol17 for user logins, PHP18 Web scripting, Joomla!19 content-management system, and a MySQL20 database for storing content and usage statistics. The HUBzero software builds on that infrastructure to create an environment in which researchers, educators, and students can access tools and share information.
The signature service of a hub is its ability to deliver interactive, graphical simulation tools through an ordinary Web browser. Unlike a portal, the tools in a hub are interactive; users can zoom in on a graph, rotate a molecule, probe isosurfaces of a three-dimensional volume interactively, and so on, without having to wait for a Web page to refresh.
|
16 |
See HUBzero.org. Accessed December 10, 2010. |
|
17 |
A Lightweight Directory Access Protocol is an Internet protocol that e-mail and other programs use to look up information from a server. |
|
18 |
PHP is a widely used general-purpose scripting language that is especially well suited for Web development. |
|
19 |
Joomla! is an open-source content-management-system platform for publishing content on the Web. |
|
20 |
MySQL is a relational database management system. |
Users can visualize results without having to reserve time on a supercomputer or wait for a batch job to engage. Users can deploy new tools without having to rewrite special code for the Web. The HUBzero tool execution and delivery mechanism is based on Virtual Network Computing (VNC).21 Any tool with a graphical user interface can be installed on the hub and deployed within a few hours. For legacy tools and other codes without a graphical interface, an interface can be quickly created by using HUBzero’s associated Rappture22 toolkit. The Rappture interface helps to set up jobs and visualize results. The jobs themselves can be dispatched to the TeraGrid, the Open Science Grid, and other participating cluster resources. Using this architecture, the nanoHUB has brought more than 100 different simulation tools online in just a few years, with more tools currently under development. In addition to providing for online simulation, the nanoHUB has also become a major platform for disseminating new research methods and new approaches to education in nanotechnology.
Richard Hamming, the founder of the Association for Computing Machinery, famously said: “The purpose of computing is insight—not numbers.” Some of the most popular resources on nanoHUB.org are tutorials, short courses, and full-semester courses that convey new ways of treating the new problems and possibilities associated with nanoscience and technology. Online research seminars (also available as podcast seminars), tutorials, and courses attract a high percentage of nanoHUB users. Complementing the online simulations, seminars, and courses is a set of services for supporting users and resource contributors along with services to manage the development and deployment of software and related services. Content ratings and tagging, citations, wikis and blogs, user-managed groups, and usage metric collection and reporting are also part of the HUBzero infrastructure.
More than 154,000 people (60 percent outside the United States) make use of nanoHUB services each year. More than 1,800 science and education resources have been created, and the nanoHUB has been cited in 575 research publications. As of the 2009-2010 academic year, 320 classes at
130 institutions have used the nanoHUB, including all top 50 U.S. engineering schools.23
The nanoHUB is still a work in progress, but some lessons have been learned and some software potentially usable by a broader community has been developed. The nanoHUB science gateway has proven to be an effective platform for knowledge dissemination by experts, for education by self-learners, and for the promotion of collaborations between computational experts and experimentalists. The nanoHUB cannot yet be considered to be an online user facility, and it does not yet address the needs of the serious computational scientist. It does well at the dissemination of new research methods—especially those that are concretely instantiated in a simulation tool that often meets the needs of experimentalists and promotes collaboration with them.
As the field matures, computational demands are increasing, and the nanoHUB is being challenged to make cloud computing work for a community of people focused on solving problems and exploring ideas rather than on computational science per se. Still, the value of small-scale computational tools should not be underestimated. In fact, a recent survey on how scientists use computers concludes:
[I]f funding agencies, vendors and computer science researchers really want to help working scientists do more science, they should invest more in conventional small-scale computing. Big-budget supercomputing projects and e-science grids are more likely to capture magazine covers, but improvements to mundane desktop applications, and to the ways scientists use them, will have more real impact. (Wilson, 2009, p. 360)
An interesting and unanticipated development has been the use of the nanoHUB as a forum for innovative new approaches to teaching concepts in nanoscience and technology. For instance, the initiative “Electronics from the Bottom Up” at the nanoHUB is an effort to rethink the teaching of nanotechnology beginning at the molecular level and working up to the macroscopic level. The collection of courses in this initiative attracts approximately 25,000 people per year. Other examples in teaching innovation include efforts to cross disciplinary boundaries. For example, the educational materials on electronic biosensors are specifically designed to make use of the concepts that electrical engineering students understand while teaching them the relevant concepts from biology. Such multidisciplinary courses are rare, and the people who can develop them well
are also rare. Because of this, deploying these kinds of courses online for self-learners can have great impact for a community.
Cloud Computing
Science gateways and portals provide a Web interface to scientific data and data-analysis tools. These tools are traditionally hosted on small servers that sit in a researcher’s laboratory. This is a reasonable solution as long as the number of users is small. However, if the gateway becomes popular, this method of supporting it becomes less realistic. Cloud computing uses the resources of a large, industrial-scale data center to provide scalable, reliable access to data storage and computational resources. The commercial data center provider charges on a pay-as-you-go basis. If a person only uses one server and a small database, that person is only charged for that service. However, the data center will automatically add servers and capacity as demand for anyone’s Web site grows. The name “cloud computing” comes from the idea that the application provider no longer needs to support or maintain the infrastructure; it is a “cloud” of remote resources. The concept is an evolution of the Web-server-hosting industry combined with the infrastructure that was built for large online business such as Web search. Companies such as Google, Microsoft, Amazon, Yahoo!, e-Bay, and IBM have together deployed millions of servers, and they have realized that they can easily provide this massive infrastructure as a service to aid their customers.
Cloud computing is still very new, and its use in scientific applications is just beginning. The NSF has sponsored the Cluster Exploratory (CLuE) program to encourage researchers to experiment with clouds provided by IBM, Google, and others. More recently the NSF announced the Computing in the Cloud program in collaboration with Microsoft. As part of President Obama’s initiative to improve government efficiency, the General Services Administration has just introduced Apps.gov, a federal cloud resource for business applications, productivity tools, information technology services, and social media applications.
Cloud computing is not intended to replace traditional supercomputing. At first glance, the architecture of a modern supercomputer and a cloud data center are similar; however, they are optimized for different uses. Supercomputers are designed to support massively parallel simulations for which processors operate in tight synchronization. Cloud data centers support loosely coupled, massively parallel access to large volumes of data and millions of concurrent users. While these two architectures may converge in the years ahead, there are still many applications of both in modern digital science.
SCIENTIFIC WORK FLOW
As science has become more multidisciplinary and voluminous data of different types are more readily available, the nature of the scientific software application has changed from tasks carried out by monolithic FORTRAN programs to those accomplished by complex collections of preprocessors, applications, postprocessors, databases, and visualization tools. The scientific community has recognized that the orchestration of these tasks, known as work flow management, which often has to be applied to hundreds or thousands of input scenarios, is best accomplished by an automated process. A work flow system is a type of programming tool that was invented in the commercial sector to manage large, complex, business-critical processes. In the sciences, work flow systems are used to automate the process of taking scientific input data and moving it to storage, scheduling it for any required preprocessing so that it may be used as initial conditions for large simulations, running the simulations and postprocessing the results. This is especially important when the same sequence of tasks must be accomplished for hundreds of different input data collections.
In the early 2000s, a number of scientific work flow tools were developed (Taylor et al., 2007). For example, a work flow tool has been used to orchestrate the large-scale data movement, data transformations, and visualization in large, turbulent-combustion computations (Chen et al., 2009). By 2005, there were over a dozen different work flow systems designed for specific disciplines. Many were very similar in function, and few were built based on proven industry standards. Each discipline insisted that its requirements were different, and the tools that emerged were often so specialized that they could not be used in a new context. As of this writing, only a few scientific work flow tools remain, and the sustainability of those is questionable. The private sector now provides work flow systems suitable for scientific applications. In some cases a commercial system may be provided at no cost to researchers. In other cases a few standards-based, open-source tools have a large enough user base to be sustained. But, as with much of the successful open-source software, the programmers maintaining it are provided by companies who have a business interest in seeing it continue.
It is entirely possible that there will emerge a single scientific work flow system with enough flexibility to support most science domain challenges. The funding agencies, working with partners in the private sector, can help make this happen. However, this outcome would take an effort by each scientific community to abandon software developed by that community for a particular purpose and to adopt software, possibly developed by other communities for related purposes.
REFERENCES
Beagrie, N., J. Chruszcz, and B. Lavoie. 2008. Keeping Research Data Safe: A Cost Model and Guidance for UK Universities. Bristol, United Kingdom. Joint Information Systems Committee. Available at http://www.jisc.ac.uk/publications/reports/2008/keepingresearchdatasafe.aspx. Accessed December 10, 2010.
Berman, H., K. Henrick, and H. Nakamura. 2003. “Announcing the Worldwide Protein Data Bank.” Nature Structural Biology 10(12):980.
Borgman, C.L., J.C. Wallis, and N. Enyedy. 2007. “Little Science Confronts the Data Deluge: Habitat Ecology, Embedded Sensor Networks, and Digital Libraries.” International Journal of Digital Libraries 7(1-2):17-30.
Chen J.H., A. Choudhary, B. de Supinski, M. DeVries, E.R. Hawkes, S. Klasky, W.K. Liao, K.L. Ma, J. Mellor-Crummey, N. Podhorszki, R. Sankaran, S. Shende, and C.S. Yoo. 2009. “Terascale Direct Numerical Simulations of Turbulent Combustion Using S3D.” Computational Science and Discovery, Vol. 2.
Cragin, M.H., and K. Shankar. 2006. “Scientific Data Collections and Distributed Collective Practice.” Computer Supported Cooperative Work 15(2/3):185-204.
Cragin, M.H., C.L. Palmer, J.R. Carlson, and M. Witt. 2010. “Data Sharing, Small Science, and Institutional Repositories.” Philosophical Transactions of the Royal Society A. 368(1926):4023-4038.
Cummings, J.N., and S. Kiesler. 2005. “Collaborative Research Across Disciplinary and Organizational Boundaries.” Social Studies of Science 35(5):703-722.
Edwards, P.N., S.J. Jackson, G.C. Bowker, and C.P. Knobel. 2007. Understanding Infrastructure: Dynamics, Tensions, and Design. Report of a Workshop on History and Theory of Infrastructure: Lessons for New Scientific Cyberinfrastructures. Arlington, Va.: National Science Foundation. Available at http://hdl.handle.net/2027.42/49353. Accessed December 10, 2010.
Fry, J. 2006. “Scholarly Research and Information Practices: A Domain Analytic Approach.” Information Processing and Management 42(1):299-316.
Hey, T., S. Tansley, and K. Tolle, eds. 2009. The Fourth Paradigm: Data-Intensive Scientific Discovery. Redmond Wash.: Microsoft Press.
Kling, R., and G. McKim. 2000. “Not Just a Matter of Time: Field Differences and the Shaping of Electronic Media in Supporting Scientific Communication.” Journal of the American Society for Information Science and Technology 51(14):1306-1320. Available at http://xxx.lanl.gov/ftp/cs/papers/9909/9909008.pdf. Accessed December 10, 2010.
Lave, J., and E. Wenger. 1991. Situated Learning: Legitimate Peripheral Participation. Cambridge: University of Cambridge Press.
National Science Board. 2005. Long-Lived Digital Data Collections: Enabling Research and Education in the 21st Century. Available at http://www.nsf.gov/pubs/2005/nsb0540/. Accessed January 18, 2011.
NSF (National Science Foundation). 2003. Revolutionizing Science and Engineering Through Cyber Infrastructure: Report of the National Science Foundation Blue-Ribbon Advisory Panel on Cyberinfrastructure. Arlington, Va.: National Science Foundation. Available at http://www.nsf.gov/cise/sci/reports/atkins.pdf. Accessed December 10, 2010.
NSF. 2008. Beyond Being There: A Blueprint for Advancing the Design, Development, and Evaluation of Virtual Organizations. Final report from Workshops on Building Virtual Organizations. Arlington, Va.: National Science Foundation.
Pinowar, H.A., M.J. Becich, H. Biolfsky, and R.S. Crowley. 2008. “Toward a Data Sharing Culture: Recommendation for Leadership from Academic Health Centers.” Public Library of Science Medicine 5(9):e183.
Research Information Network. 2008. RI News Issue 5. Available at http://www.rin.ac.uk/resources/print-newsletter/rinews-issue-5-summer-2008. Accessed January 18, 2011.
Rusbridge C., P. Burnhill, and S. Ross. 2005. “The Digital Curation Centre: A Vision for Digital Curation.” In From Local to Global: Data Interoperability—Challenges and Technologies. Available at http://eprints.erpanet.org/82/01/DCC_Vision.pdf. Accessed December 19, 2010.
Taylor, I., E. Deelman, D. Gannon, and M. Shields, eds. 2007. Workflows for e-Science. New York, N.Y.: Springer Press.
Westbrook, J., F. Zukang, L. Chen, Y. Huanwang, and H.M. Berman. 2003. “The Protein Data Bank and Structural Genomics.” Nucleic Acids Research 31(1):489-491.
Wilson, G. 2009. “How Do Scientists Really Use Computers?” American Scientist, Vol. 97, p. 360.



























