
Report of the Panel on Atmosphere-Ionosphere-Magnetosphere Interactions
8.1 SUMMARY OF AIMI SCIENCE PRIORITIES AND IMPERATIVES FOR THE 2013-2022 DECADE
Informed by observations and modeling efforts that have occurred during the past decade, there is increasing recognition among scientists of the atmosphere-ionosphere-magnetosphere (AIM) system as a complex and active element of space weather, and as a region where important science questions with broad applicability across our solar system can be answered. Earth’s space environment, or geospace, is unique in many ways: the interconnected behavior of the plasma and neutral gas in the AIM system, the strong signature of lower atmospheric conditions in space, and the development of massive plasma structures with embedded variability at multiple scales are just a few examples. The pursuit toward understanding energy transfer and physical manifestations in near-Earth space has yielded and will continue to offer insights into fundamental processes that occur at other planets and bodies in our solar system and indeed throughout the universe. There are also practical reasons to study the AIM system. The space-based assets for observation and communication of human activities all operate in geospace and therefore must be designed or otherwise protected from the hazards and unpredictability that this energetic, nonlinear system produces. Advances in scientific understanding of the AIM system enable the development of a capability for the prediction of geospace conditions.
In this chapter, the decadal survey’s Panel on Atmosphere-Ionosphere-Magnetosphere Interactions (AIMI) articulates its science goals and aspirations for the decade ahead and suggests an implementation strategy to achieve that vision. Building on the significant accomplishments of the previous decade, the panel presents an interlinked and achievable research program to address the most compelling science questions in the field. Summarized below are the AIMI panel’s science priorities, imperatives, and recommendations to the survey committee for the 2013-2022 decade.
The three major AIMI science priorities for the 2013-2022 decade are as follows:
AIMI Science Priority 1. Determine how the ionosphere-thermosphere system regulates the flow of solar energy throughout geospace.
AIMI Science Priority 2. Understand how tropospheric weather influences space weather.
AIMI Science Priority 3. Understand the plasma-neutral coupling processes that give rise to local, regional, and global-scale structures and dynamics in the AIM system.
These priorities emerge from the five AIMI science goals described in Section 8.4, “Science Goals and Priorities for the 2013-2022 Decade,” and from the panel’s assessment of the resources required to address them, and lead to the following imperatives:
AIMI Imperative 1. Close a critical gap in the NASA Heliophysics Systems Observatory with a mission that determines how solar energy drives ionospheric-thermospheric variability and that lays the foundation for a space weather prediction capability.
AIMI Imperative 2. Provide a broad and robust range of space-based, suborbital, and ground-based capabilities that enable frequent measurements of the AIM system from a variety of platforms, categories of cost, and levels of risk.
AIMI Imperative 3. Integrate data from a diverse set of observations across a range of scales, coordinated with theory and modeling efforts, to develop a comprehensive understanding of plasma-neutral coupling processes and the theoretical underpinning for space weather prediction.
AIMI Imperative 4. Conduct a theory and modeling program that incorporates accumulated understanding and extends the legacy of observations into physics-based models that are utilized for new scientific insight and operational specification and forecast capabilities.
These imperatives represent a balanced strategy for addressing the panel’s priority science; they are not listed in any particular order. The requirements underlying the imperatives span five categories: spaceflight missions; Explorers, suborbital, and other platforms; ground-based facilities; theory and modeling; and enabling capabilities. Priorities within each of these categories are summarized in turn below.
No new NASA missions are under development or are currently planned for the future that address any of the AIMI science priorities articulated above. This deficiency represents an acute imbalance in the study of the Sun-Earth system that impedes researchers’ ability to resolve complex AIM system behavior that impacts geospace dynamics and the operation of ground- and space-based assets on which society depends. A critical AIMI imperative therefore is that a mission addressing the response of the ionosphere-thermosphere (IT) system to variable forcing be put forth as the highest priority of the solar and space physics decadal survey.
The most compelling AIM science questions of the coming decade are best addressed with a Geospace Dynamics Constellation (GDC) mission nominally consisting of six identical satellites in high-latitude equally spaced circular orbits, with the goal of understanding how winds, temperature, composition, chemistry, charged particles, and electric fields interact to regulate the observed global response of the IT. This mission will also provide new insights into the IT response to dynamical coupling with the lower atmosphere. If this mission must be delayed at all due to budgetary constraints, then a revitalized heliophysics
instrument and technology development program must support GDC’s implementation later in this decade. In that case, the AIMI panel suggests that the DYNAMIC (Dynamical Neutral Atmosphere-Ionosphere Coupling) mission be put forth as the decadal survey’s number-one priority for the 2013-2022 decade. DYNAMIC is a pair of satellites in low-Earth orbits separated by 6 hours of local time, carrying the instruments to measure the critical energy inputs to the AIM system from the spectrum of waves entering from below. Although the primary focus is to understand how lower-atmosphere variability drives IT variability, DYNAMIC will also measure important properties of the IT response to variable magnetospheric forcing.
Additional NASA missions that address another high-priority science challenge of the next decade— understanding the two-way interaction between the ionosphere-thermosphere and the magnetosphere—are also described in this chapter. These missions and the associated science are also potential candidates for the Explorer program.
8.1.2 Explorers, Suborbital, and Other Platforms
The relative proximity of the AIM system makes it amenable to observational strategies involving a wide variety of platforms. This attribute is a significant strength in crafting a program that is responsive to budgetary realities and to the changing climate of programmatic risk factors. The following AIMI panel priorities reflect this crucial flexibility:
• Explorer program enhancement (highest priority). Enhance the Heliophysics Explorer line to execute a broad range of science missions that can address important AIMI science challenges. Mission classes should range from a tiny Explorer that takes advantage of miniaturized sensors and alternative platforms and hosting opportunities, up to a medium Explorer that could address multiple science challenges for the decade.
• Constellations of satellites. Develop the means to effectively and efficiently implement constellation missions, including proactive development of small-satellite capabilities and miniaturized sensors and pursuit of cost-effective alternatives such as commercial constellations.
• Suborbital research. Maintain a strong suborbital research program. Continue development of observatory-class capabilities, such as a high-altitude sounding rocket and long-duration balloons, and expand funding for science payload development for these platforms.
• Strategic hosted payloads. Develop a strategic capability to make global-scale AIMI imaging measurements from host spacecraft, notably those in high Earth orbit and geostationary Earth orbit, as is currently done in support of solar (GOES SXT) and magnetospheric (TWINS, GOES, LANL) research.
New ground-based instrumentation and associated research programs can also address an array of AIMI science questions in this decade. These facilities will play a major role in an overall strategy to understand the origins of plasma-neutral structures over local (tens to hundreds of kilometers), regional (hundreds to thousands of kilometers), and global scales (thousands to tens of thousands of kilometers), as well as the interactions between structures over these different scales. In particular, several prospective facilities are particularly compelling for advancing AIMI panel science priorities:
• Autonomous American sector network. Develop, deploy, and operate a network of 40 or more autonomous observing stations extending from pole to pole through the (North and South) American lon-
gitudinal sector. The network nodes should be populated with heterogeneous instrumentation capable of measurements, including winds, temperatures, emissions, scintillations, and plasma parameters, for study of a variety of local and regional ionosphere-thermosphere phenomena over extended latitudinal ranges.
• Whole-atmosphere lidar observatory. Create and operate a lidar observatory capable of measuring gravity waves, tides, wave-wave and wave-mean flow interactions, and wave dissipation and vertical coupling processes from the stratosphere to 200 km. Collocation with a research facility such as an incoherent scatter radar (ISR) installation would enable study of a number of local-scale plasma-neutral interactions relevant to space weather.
• NSF medium-scale research facility program. The above two facilities are candidates for support by the NSF Geospace Program and would require that a medium-scale (~$40 million to $50 million) research facility funding program be instituted at NSF to fill the gap between the Major Research Instrumentation (MRI; <$4 million) and Major Research Equipment and Facilities Construction (MREFC; >$100 million) programs.
• Southern-Hemisphere expansion of incoherent scatter radar (ISR) network. In addition to the two facilities listed above, expansion of the now proven Advanced Modular Incoherent Scatter Radar (AMISR) technology to southern polar latitudes (i.e., Antarctica) would provide for the first-ever view of detailed ionosphere processes in the southern polar hemisphere, thus contributing a critical missing component to the Heliophysics Systems Observatory.
• Ionospheric modification facilities. Fully realize the potential of ionospheric modification techniques through colocation of modern heating facilities with a full complement of diagnostic instruments including incoherent scatter radars. This effort requires coordination between NSF and DOD agencies in the planning and operation of existing and future ionospheric modification facilities.
Cross-scale coupling processes are intrinsic to AIM system behavior. Phenomena and processes that are highly structured in space and time (e.g., wave dissipation, turbulence, electric field fluctuations) can produce effects (e.g., wind circulations, chemical transport, Joule heating, respectively) over much larger scales. At the same time, larger-scale phenomena create local conditions that can either promote or suppress development of rapidly changing structures at small spatial scales (e.g., instabilities and turbulence). The observational strategies presented in this report place high priority on understanding how local, regional, and global-scale phenomena couple to produce observed responses across scales. These strategies call for complementary development of theory and numerical modeling capabilities that enable comprehensive treatment of cross-scale coupling processes, together with new data synthesis technologies that combine multiple, hetero-scale data sources into a common framework for understanding critical aspects of the AIM system.
Therefore, to support the synergistic program of space-based investigations and ground-based facilities, the AIMI panel has the following priorities regarding theory and modeling:
• Model development. Comprehensive models of the AIM system would benefit from the development of embedded grid and/or nested model capabilities, which could be used to understand the interactions between local- and regional-scale phenomena within the context of global AIM system evolution.
• Theory. Complementary theoretical work would enhance understanding of the physics of various-scale structures and the self-consistent interactions between them.
• Assimilative capabilities. Comprehensive models of the AIM system would benefit from developing assimilative capabilities and would serve as the first genre of space weather prediction models.
Further priorities concerning theory and modeling are provided in Section 8.5.4, “Theory and Modeling.”
The missions and initiatives described above require additional capabilities and infrastructure that enable cheaper and more frequent measurements of the AIM system, that transform measurements into scientific results, that maintain the health of the scientific community, and that serve the needs of 21st-century society. These enabling capabilities (i.e., working group priorities) fall into the following categories:
• Innovations: technology, instruments, and data systems;
• Theory, modeling, and data exploitation;
• Research to operations, and operations to research; and
• Education and workforce.
The panel’s priorities in these areas are detailed in Section 8.5.5, “Enabling Capabilities.”
8.2 MOTIVATIONS FOR STUDY OF ATMOSPHERE-IONOSPHERE-MAGNETOSPHERE INTERACTIONS
Electromagnetic radiation from the Sun is the source of energy for photosynthesis and life. However, the Sun’s other energetic outputs produce conditions and events that can be disruptive and even catastrophic to society. Hurricanes and tornadoes are examples of extreme and dangerous terrestrial weather events that occur on the surface of Earth. But our planet is also embedded in the streaming plasma and magnetic field of the Sun’s outer corona (Figure 8.1), which can lead to hazardous weather in space with similarly catastrophic consequences. Although Earth’s magnetic field serves as a protective cocoon that is difficult for the Sun’s plasma and magnetic field to penetrate, transmission of a few percent of this energy into near-Earth space can produce large effects.
Reconnection between the magnetic fields of the Sun and Earth causes electric fields, currents, and energetic particles to be created. The source of magnificent auroral displays, energetic particles, can penetrate satellite electronics and solar cells and disrupt or sometimes even terminate their operation. Electric currents flowing through the auroral ionosphere heat the atmosphere and produce global changes in upper-atmosphere density that make it difficult to predict the future locations of satellites and potential collisions between them. Electrical connections between the near-Earth space environment and the ionosphere can also disrupt the operation of communications and navigation systems, and cell phones, and even induce dangerous levels of currents in the U.S. power distribution system. Energetic particle precipitation into the upper atmosphere can also initiate a chain of events that lead to massive depletions of stratospheric ozone in the polar regions. These are only a few of the consequences that emerge from a complex web of interactions occurring within this active region called geospace and that motivate us to understand our home in the solar system (M1) and to predict the changing space environment and its societal impact (M2).1
The focus of the AIMI panel and the subject of this chapter is the region of geospace where atmosphere-ionosphere-magnetosphere interactions occur. That region extends from roughly the top of the stratosphere (at about 50 km) to several thousand kilometers, where the presence of the neutral atmosphere ceases to exert any significant control over the system. As will be discussed in more detail in this chapter, this
________________________
1 The motivations referred to in this section are those outlined in the introduction to Part II of this report: M1. Understand our home in the solar system; M2. Predict the changing space environment and its societal impact; M3. Explore space to reveal universal physical processes.
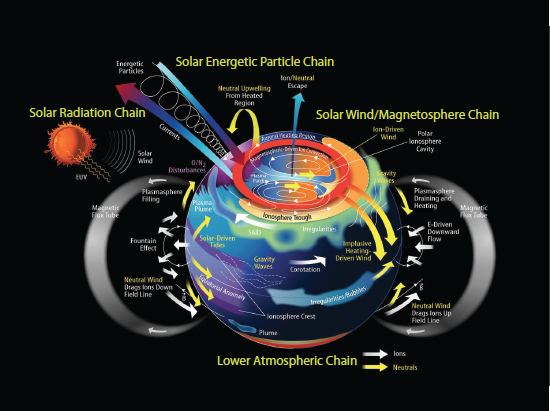
FIGURE 8.1 A depiction of the atmosphere-ionosphere-magnetosphere (AIM) system and the major processes that occur within that system. Absorption of short-wavelength solar radiation accounts for a large fraction of the heat input. Energetic particles, mostly from the magnetosphere, enhance the ionospheric conductance at high latitudes and modify the electrical currents that flow between the ionosphere and magnetosphere. Magnetospheric convection imposes electric fields that drive currents in the lower part of the ionosphere and set the ionospheric plasma into motion at higher altitudes, with a portion escaping into geospace and beyond. These injections of energy drive a global thermospheric circulation that redistributes heat and molecular species upwelling from the heated regions and also excites a spectrum of waves that redistribute energy both locally and globally. Planetary waves, tides, and gravity waves propagate upward from the lower atmosphere, deposit momentum into the mean circulation, and generate electric fields via the dynamo mechanism in the lower ionosphere. Dynamo electric fields are also created by disturbance winds. Neutral winds and electric fields from these combined sources redistribute plasma over local, regional, and global scales and sometimes create conditions for instability and production of smaller-scale structures in neutral and plasma components of the system. SOURCE: Courtesy of Joe Grebowsky, NASA Goddard Space Flight Center.
region of geospace possesses several distinguishing characteristics that define it as a domain for compelling scientific inquiry and warrant the attention of a decadal survey with an explicit focus on solar and space physics’ connections to a technological society. Notably, this region serves as a “final link” in the transfer of energy within the solar-terrestrial chain. The primary drivers for variability in the region consist of direct solar energy in the form of extreme ultraviolet (EUV) and ultraviolet (UV) radiation, solar energy
transformed into the charged particles and fields that permeate the magnetosphere, and solar-driven waves propagating upward from the lower atmosphere (see Figure 8.1).
Responses to these drivers are determined by interacting dynamical, chemical, and electrodynamic processes that occur over a wide range of spatial and temporal scales, and moreover are strongly influenced by the presence of a strong magnetic field. Often these processes involve nonlinearity and feedback, and it is thus evident that this complex system can often exhibit emergent behavior.2 In fact, scientific investigations of this geospace region resolve and interpret the system’s response to variable forcing, and ultimately unravel the complex chains of events leading to the observed, emergent behavior. (Several examples of emergent behavior are provided in this chapter.) Given this complexity, one can appreciate the difficulties of predicting the variability of neutral and plasma densities to the accuracies required to support orbital, reentry, communications, and navigation systems in operational settings. Thus, as this chapter unfolds, it will become evident that the study of atmosphere-ionosphere-magnetosphere interactions presents challenging scientific problems that are fundamental to understanding planetary atmospheres and exospheres and that underlie the ability to predict environmental conditions that serve operational needs. In addition, the processes studied in this context can often be translated to other planetary bodies, and in this way geospace serves as a local laboratory to reveal and study universal physical processes (M3).
The following section of this chapter summarizes the main scientific achievements of the past decade, reflecting back on the recommendations of the previous decadal survey. This lays the foundation for the subsequent section, which sets forth the science agenda for 2013-2022. The section after that addresses the various assets, resources, and strategies needed to advance AIM science most productively and presents a prioritized program for doing so.
8.3 SIGNIFICANT ACCOMPLISHMENTS OF THE PREVIOUS DECADE
Understanding of atmosphere-ionosphere-magnetosphere (AIM) interactions has advanced through a number of vigorous programs, ranging from national, international, and multiagency programs to smaller-scale programs. Examples of programs that have helped shape the research landscape over the past decade are NASA’s Living with a Star (LWS) and Heliophysics Geospace Science programs, the NASA TIMED Solar-Terrestrial Probe, the NASA IMAGE Mid-size Explorer (MIDEX) mission, the NASA FAST Small Explorer (SMEX) mission, the NASA THEMIS MIDEX mission, the NASA AIM SMEX mission, and the U.S. Air Force (USAF) C/NOFS mission; the NASA Sounding Rocket Program; the National Space Weather Program; the NSF-sponsored SHINE, GEM, CEDAR, and small-satellite programs and their international counterparts; the NSF major research initiative (MRI) and science and technology centers (STCs); numerous DOD activities; international satellite programs, such as CHAMP, GRACE, and COSMIC; and international science programs, such as CAWSES. These various programs have supported satellite and ground-based instruments and the related data analysis, theory, and modeling efforts. Research models and data assimilation schemes have advanced operational space weather prediction and created new models of the Sun-Earth system using a systemic and holistic perspective: Center for Integrated Space Weather Modeling (CISM), Community Coordinated Modeling Center (CCMC), NCAR Whole Atmosphere Community Climate Model (WACCM) development, and solar wind/magnetosphere models coupled with ionosphere/thermosphere global circulation models. Through these targeted programs and the critically important base programs funded by NSF, NASA, NOAA, and DOD, important scientific progress has been made, helping us to clarify needs and identify priorities that form the basis of this panel report.
________________________
2 Emergent behavior results from the interaction of a large number of system components that could not have been anticipated on the basis of the properties of components acting individually.
New supporting technologies, not specifically targeted for AIM research, have also significantly contributed to the field’s advancement in the past decade. These include cyberinfrastructure, advanced communications, improved sensors, networking technology, increases in computing power, precision navigation systems, and small satellites. Complementing this technology growth were planned developments in space-borne and ground-based missions, major research instrumentation and facilities development, data assimilation schemes, and whole-atmosphere model development. These technological advancements help accelerate scientific endeavors and enable new science areas to be investigated and understood. The emergence of relocatable incoherent scatter radars (ISRs) based on electronically steerable antenna arrays is an excellent example. These NSF-supported advanced modular ISRs (AMISRs) can be steered on a pulse-to-pulse basis, allowing the simultaneous acquisition of information from multiple directions. The rapid steering capabilities of AMISR-class ISRs provide a unique capability for supporting AIM science objectives. For instance, these instruments can be used to construct three-dimensional views of the evolving plasma state within a volume traversed by a satellite or rocket.
Model development has been facilitated by major advances in instrumentation and measurement techniques, experimental facilities, and observing networks, which are starting to provide unprecedented volumes of data on processes operating across AIM. Together with concurrent progress in computational techniques, these advances have enabled the development of ever more sophisticated, multidimensional models of geospace. These models, along with data assimilation schemes, offer the promise of greater insights into the physical processes at work and improved ability to forecast disruptive events and their potential impacts.
Development of numerical models that extend from Earth’s surface to the thermosphere/ionosphere has made significant breakthroughs during the past decade. These whole-atmosphere models are able to generate atmospheric disturbances, such as sudden stratospheric warming and quasi-biennial oscillation internally without having to impose artificial forcing, and to investigate their dynamical and electrodynamical coupling to the upper atmosphere in a self-consistent manner. Models that couple the magnetosphere and the ionosphere/thermosphere have reached the maturity to include feedback interaction between thermospheric neutrals and magnetospheric plasmas, as well as mass and momentum exchanges within geospace. In addition, physics-based data assimilation models of the global ionosphere have been developed that are capable of assimilating multiple data types, for example, to reconstruct the electron density configuration during storms. These models are now running routinely in a test-operational mode for space weather specification.
The adoption and implementation of a systems approach are more realizable today with the rapid expansion of multidimensional databases, increasing computational capabilities and sophistication of numerical tools, and emergence of new sensor technologies. Complementing these technological advancements have been new scientific discoveries that are rooted in a systems perspective of AIM science. What has emerged from this past research is the recognition that many of the natural coupling processes within AIM are linked through system complexity processes of feedback, nonlinearity, instability, preconditioning, and emergent behavior. The following examples of significant accomplishments of the previous decade reflect this overarching recognition.
8.3.1 Magnetosphere-Ionosphere Coupling
A recent discovery in AIM science comes from a fortuitous combination of new measurement capabilities. The explosive increase in the global distribution of GPS receivers both on the ground and in space and the flight of the NASA IMAGE mission to image Earth’s magnetosphere-ionosphere (MI) showed a completely new view of ionospheric/magnetospheric coupling during storms. Global GPS maps of ionospheric
density showed, for the first time, large-scale dense plumes of plasma extending from middle latitudes to the auroral zone at the onset of magnetic storms (Figure 8.2). During such events, plasmaspheric imaging of He+ ions by IMAGE showed corresponding structures in the inner magnetosphere, where plasma was sheared away from the plasmasphere and advected toward the magnetopause. The plasmaspheric structure was never expected to appear in the ionosphere, and the discovery points to a process critical to enhancing auroral ion outflow during storms. Further research results from NASA’s FAST and IMAGE satellites revealed that storm-enhanced ionosphere plasma feeds outflows of ionospheric ions into a tornado-like cusp funnel, powered by Alfvén waves generated by the solar wind-magnetosphere interaction. Evidence is accumulating that energy in these small-scale Alfvénic current filaments is deposited over a range of spatial and temporal scales and is converted to heat and momentum through ion-neutral interactions.
These findings highlight the importance of feedback through the AIM system where magnetospherixscally imposed electric fields redistribute ionospheric plasma, fueling the flux of outflowing ions to the magnetosphere. The outflows, especially heavy-ion outflows, can overwhelm reconnection mass loss in the plasma sheet and, effectively, reduce the cross-polar-cap potential and the concomitant ionospheric electric fields. In some instances, emergent behavior results whereby ~3-hour planetary-scale (sawtooth)
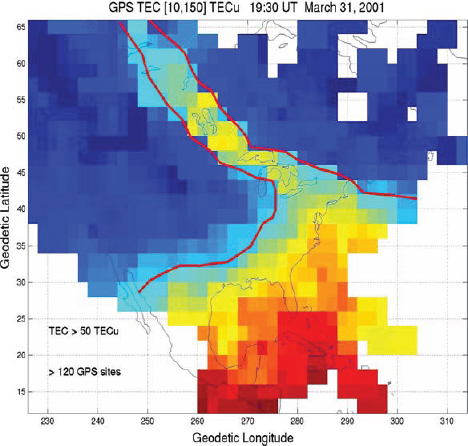
FIGURE 8.2 Storm-enhanced plasma density signatures in total electron content (TEC) observed on March 31, 2001. These are believed to be connected to plasmashere erosion and driven by subauroral electric fields from the inner magnetosphere. SOURCE: J.C. Foster, P.J. Erickson, A.J. Coster, J. Goldstein, and F.J. Rich, Ionospheric signatures of plasmaspheric tails, Geophysical Research Letters 29(13):1-1, doi:10.1029/2002GL015067, 2002. Copyright 2002 American Geophysical Union, reproduced by permission of American Geophysical Union.
oscillations in the magnetosphere are observed. These occur when the MI system is strongly driven by a steady solar wind and seem to rely on superfluent nightside outflows of ionospheric O+.
The past decade marked the 23rd solar cycle on modern record. Notable events included a number of powerful geomagnetic storms, two separate sunspot maxima, and a very deep solar minimum. With observations from an array of space- and ground-based instruments unprecedented in their capabilities, solar cycle 23 is the first cycle since the initial detection of coronal mass ejections (CMEs) in the early 1970s in which a complete record of CMEs, coronal hole distributions, and solar wind data are all available over the whole cycle. The availability of simultaneous space- and ground-based data covering the Sun-Earth space has made solar cycle 23 solar storms and geomagnetic activity one of the best sets of events to analyze. It has been possible to assemble atmospheric, ionospheric, magnetospheric, interplanetary, and solar data on 88 CME storms during solar cycle 23. Many more events of enhanced geomagnetic activity were observed during this cycle associated with corotating interaction regions (CIRs)/high-speed solar wind streams (HSS) related to low-heliolatitude distributions of persistent coronal holes.
A few of the CME storms were considered “great” storms that led to unexpected or emergent behavior in the AIM system. Ionosphere observations indicated the emergence of a daytime super-fountain effect lifting the ionosphere to new heights and increasing its total electron content by as much as 250 percent. Also observed were very large amplitude traveling ionospheric disturbances (Figure 8.3), new ionosphere layers, and very different behavior in equatorial plasma irregularities.
The atmosphere responded with dramatic changes in neutral composition, winds, temperature, and mass density. Thermosphere mass density at 400 km increased by over 400 percent during these great storms while experiencing exceptionally fast recovery times, indicating a unique overcooling effect. The CIR/HSS storms were predominant during the declining and minimum phase of the solar cycle, producing an entirely different response in the AIM system. Where CME storms lasted a few days and were episodic, CIR/HSS storms lasted for more than a week and recurred for many solar rotations—in some instances sustaining common periodicities for an entire year. This has led to the discovery in atmosphere and ionosphere data sets of pervasive periodicities at subharmonics of the ~27-day solar rotation period during solar cycle 23 (Figure 8.4). Unfortunately, although CHAMP, COSMIC, and ground-based platforms provided new discoveries in terms of total neutral and plasma density responses of the AIM system to the various solar disturbances noted above, only sparse measurements were made of the key parameters (e.g., winds, plasma drifts, neutral and ion composition) needed to understand these responses. It is a high-priority goal of the next decade to gain this understanding.
8.3.3 Meteorology-AIM Coupling
One of the most exciting developments in recent years has been a new realization of the direct and strong impact of tropospheric weather and climate on the upper atmosphere and ionosphere. The connection has been elicited, first, from measurements of the ionospheric density near the equator by NASA IMAGE and TIMED satellites, showing large changes in the structure of the ionosphere on seasonal timescales. This signature has subsequently been observed in upper-thermospheric composition and temperature. The clear correspondence demonstrated in this confluence of efforts has energized the study of atmospheric wave coupling to space plasma. Other observations and model studies have unequivocally revealed that Earth’s IT system owes a considerable amount of its longitudinal, local time, seasonal-latitudinal, and day-to-day variability to atmospheric waves that begin near Earth’s surface and propagate into the upper atmosphere.
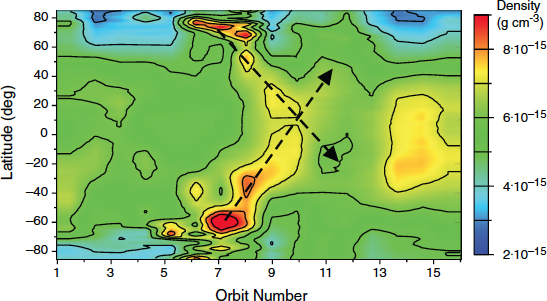
FIGURE 8.3 Illustration of traveling atmospheric disturbances seen in densities near 400 km near local noon measured by the accelerometer on the Challenging Mini-Satellite Payload (CHAMP) satellite, in connection with a geomagnetic disturbance on day 308 of 2003. The data are obtained at nearly constant longitudes about every 1.5 hours, i.e., the time between consecutive “passes” or “orbits” of the satellite. The disturbance was initiated between pass 6 and 7 and took roughly 4.5 hours to reach the equator from both polar/auroral regions. The southward-propagating disturbance appears to pass into the Southern Hemisphere. Researchers do not know the behaviors of these disturbances in other local time sectors, or how dissipation of this disturbance has modified the mean state of the ionosphere-thermosphere system. SOURCE: Courtesy of Sean Bruinsma, Centre National d’Études Spatiales.
Waves propagating upward from the lower atmosphere contribute about equally to the energy transfer in the IT system as direct solar energy in the form of EUV and UV radiation and reprocessed solar energy in the form of particles and fields from the magnetosphere. This unexpected and new realization is important for the space weather of the IT system. It is becoming increasingly clear that understanding wave driving from below is critical for predicting large- and small-scale structures in the IT system, such as ionospheric scintillations important to communication and navigation, and for testing and improving models for orbit propagation and collision warnings.
8.3.4 AIM Coupling and Global Change
Earth is changing, and there are compelling and urgent needs for society to expand and develop basic science research to assess and answer society’s concerns in the area of climate change. There is sufficient evidence to believe that any climate change connected to changes in solar activity may involve chemical and dynamical pathways through the upper and middle atmosphere. Furthermore, long-term evolution-
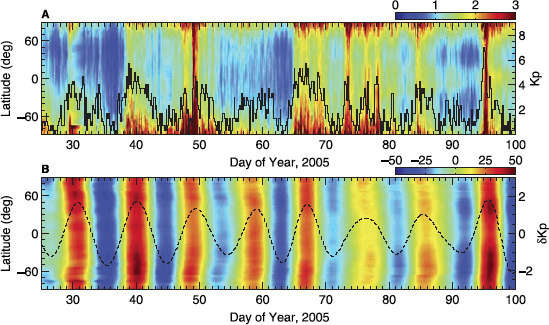
FIGURE 8.4 Quasi-9-day periodicity in the thermosphere densities as a result of recurring high-speed solar wind streams (and associated recurrent geomagnetic activity) originating from longitudinally distributed solar coronal holes. (A) Latitude versus time variations of CHAMP neutral densities (in units of 1012 kg/m3) during days 25-100, 2005. The solid black line denotes the Kp values, corresponding to the right-hand scale. (B) Percent of the band-pass filter density residuals to 11-day running mean during days 25-100, 2005. The band-pass filter was centered at the period of 9 days, with half-power points at 6 and 12 days. The perturbations in Kp obtained from the same band-pass filter are superimposed in the lower panel (dashed line, right-hand scale). SOURCE: J. Lei, J.P. Thayer, J.M. Forbes, E.K. Sutton, and R.S. Nerem, Rotating solar coronal holes and periodic modulation of the upper atmosphere, Geophysical Research Letters 35:L10109, doi:10.1029/2008GL033875, 2008. Copyright 2008 American Geophysical Union, reproduced by permission of American Geophysical Union.
ary change in Earth’s atmosphere may alter short-term system variability or multiscale temporal response in the AIM system. Studies of these effects have been newly undertaken in the recent decade, with some remarkable findings.
The AIM system can serve as a conduit or amplifier of externally induced climate drivers, coupling different regions via radiative, dynamical, and chemical feedbacks. These pathways are shown schematically in Figure 8.5. Through these feedback processes remote regions highly driven by solar influences are linked to the troposphere.
Yet how and to what extent solar and magnetospheric variability affects atmospheric conditions and climate in such an interconnected system remains an open question. A clear link between space weather and ozone destruction is contained in the large fluxes of aurorally produced nitric oxide (NO) that are observed moving downward into the stratosphere within the winter polar vortex. The circulation of air within the vortex confines the NO to dark high latitudes and rapidly transports it to lower altitudes before
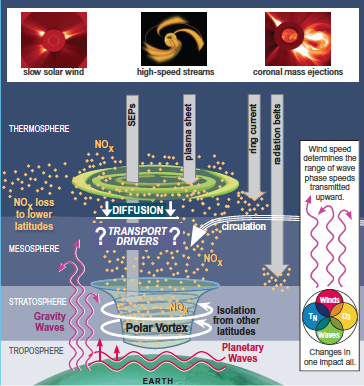
FIGURE 8.5 Schematic of the intertwined pathways that link space weather variability to atmospheric coupling. SOURCE: Courtesy of Cora E. Randall, University of Colorado, Boulder; Janet U. Kozyra, University of Michigan, Ann Arbor; and Scott M. Bailey, Virginia Institute of Technology.
it can be destroyed by sunlight. Once in the stratosphere, NO catalytically destroys ozone as the vortex breaks up, influencing temperature and circulation over a broad region in the middle atmosphere. But whether or not the effects of these fluxes are strong enough to be transmitted into the troposphere through resulting large-scale changes in atmospheric circulation remains unknown.
Long-term change in the lower and middle atmosphere can also drive change in the AIM system. For instance, a systematic decrease by several percent per decade in thermosphere mass density is now evident in the record of satellite orbit decay measured since the beginning of the space age. An effect predicted in the 1980s, this change is thought to arise largely in response to the increase in atmospheric CO2 that acts as a radiative cooler in the upper atmosphere, diametric to its role in the lower atmosphere. This is not itself an effect of the change in climate in the lower atmosphere, but rather a human-influenced change in the upper. An important practical consequence for society is that a less dense upper atmosphere lengthens the residence time of orbital debris.
The AIM community has thus begun to undertake investigations of “space climate.” Studies of space climate deal with determining and understanding the average behavior of the coupled geospace system and
the elements of that system. The typical behavior of geospace, on a variety of spatial and temporal scales, is of interest to the research and applications community. Gradual changes in solar activity, solar wind, EUV radiation, and Earth’s magnetic field each play a significant role in defining the longer-term variation in the geospace environment. For instance, long-term changes in Earth’s magnetic field are occurring and producing measurable changes in the ionosphere. From the solar irradiance perspective, the latest solar minimum, from late 2007 to mid-2009, marks the lowest solar EUV fluxes (and heating rates) of the longest duration in the past four solar cycles. This “super-minimum” produced unprecedented low temperatures in the ionosphere and a contracted thermosphere that none of the current numerical models were able to predict or reproduce. This low solar minimum was also accompanied by a weaker than normal interplanetary magnetic field, cosmic rays at record high levels, high tilt angle of the solar dipole magnetic field, and low solar wind pressure. All of these solar surface, solar wind, and interplanetary parameters constitute a change in the space climate and played an integral role in how the AIM system evolved and responded. These differences also had important practical consequences for satellite operations, space debris/hazard prediction, ionospheric forecasts, and airline operations.
AIM science is global in nature. International cooperation is thus a key component of the AIMI panel’s decadal plan. One of the more important entities for coordinating these international efforts is the Scientific Committee on Solar-Terrestrial Physics (SCOSTEP). SCOSTEP currently sponsors the Climate and Weather of the Sun-Earth System (CAWSES) program. CAWSES was initiated in 2004 as a 5-year program and was extended into a second phase dubbed CAWSES-II covering the period 2008-2012. The CAWSES-II program focuses on four science questions: (1) What are the solar influences on Earth’s climate? (2) How will geospace respond to an altered climate? (3) How does short-term solar variability affect the geospace environment? and (4) What is the geospace response to variable waves from the lower atmosphere?
A successful example of international collaboration in space benefiting AIM science is the COSMIC (Constellation Observing System for Meteorology Ionosphere and Climate) project. While the project is jointly sponsored by Taiwan and the United States, its scientific benefits extend to all nations. Since its launch in 2006, the COSMIC mission has observed the tidal influence on total electron content (TEC) and F-region ionosphere, wave-4 signatures in the topside ionosphere/plasmasphere, and a geographically fixed (with the Weddell Sea) ionospheric anomaly, and it is demonstrating the complex structure in ionosphere F-region density and peak altitude.
Contributions also come from serendipitous opportunities. One such example is that from international geodesy programs. The German Challenging Minisatellite Payload (CHAMP) and NASA/German Gravity Recovery and Climate Experiment (GRACE) missions led to improved estimates of the thermosphere mass density and winds from the need to better model and understand Earth’s gravity field and its spatial and temporal variability. These thermosphere measurements have led to several discoveries and new insights into the AIM system, such as a neutral density cusp enhancement, an equatorial thermosphere anomaly, tides in the upper thermosphere, and periodic expansion of the thermosphere gas associated with coronal hole distributions on the Sun.
8.3.6 Current and Future Programs
Solving the compelling, remaining mysteries of AIM science requires a continued commitment to a space, ground, and modeling effort. Current and future programs and interagency activities provide context
and the boundary conditions for AIM efforts. These include NASA’s ACE, SDO, and STEREO missions for studying the Sun and solar wind, and NASA’s RBSP (renamed the Van Allen Probes) for studying Earth’s radiation belts. The NASA TIMED mission continues to provide valuable IT science, as does the USAF C/NOFS satellite, which was placed in a unique, low-inclination orbit where its instruments gather data related to the unstable equatorial ionosphere. NASA’s Sounding Rocket Program supports a variety of cutting-edge investigations in the ionosphere, thermosphere, and mesosphere focused on solving outstanding science questions at high, middle, and low latitudes. International programs such as ESA’s SWARM and GOCE missions and Canada Space Agency’s e-POP payload on its CASSIOPE satellite will further contribute to AIM science and enrich international collaboration. The NSF AMISR-class incoherent scatter radars are currently deployed near Poker Flat, Alaska (PFISR), and Resolute Bay, Canada (RISR), the latter consisting of two full radar faces, one funded through an international collaboration with Canada. Plans are being developed to deploy an additional radar in Antarctica and to relocate the PFISR facility to La Plata, Argentina, a location magnetically conjugate to Arecibo. NSF also supports the AMPERE project, which utilizes the engineering magnetometers aboard the Iridium communications network to resolve field-aligned magnetospheric currents in the auroral zone.
8.4 SCIENCE GOALS AND PRIORITIES FOR THE 2013-2022 DECADE
The range of intellectually stimulating science questions that arise within the purview of atmosphere-ionosphere-magnetosphere interactions is enormous. However, there are a subset whose connections to the needs of a 21st-century society make them compelling; it is on this basis that the panel defined the science challenges articulated in this section. Moreover, they also form an integral part of the key science goals (see Chapter 1) that this solar and space physics decadal survey has set forth as its prime agenda.
Before proceeding, it is useful to consider the ionosphere-thermosphere from a systems perspective and to describe what aspects of the system behavior need to be understood in order to advance toward a predictive capability. Figure 8.1 provides a useful reference. First, it must be understood how energy and momentum inputs from the magnetosphere are spatially and temporally distributed in the polar and auroral regions, and how the global IT system responds to these inputs. Equally important, it must be understood how energy and momentum are transferred from the lower atmosphere into the IT system, and what this means in terms of IT spatial and temporal variability. Key to the above, it must further be understood how internal processes transform and transfer energy and momentum within the system, regulate responses to external forcing, and control the formation of regional and local structures in both neutral and ionized constituents. The consequences of two-way interactions between the IT system and the magnetosphere must also be considered. In this context, it must be understood how the high-latitude IT system moderates the transfer of energy from the solar wind and magnetosphere and how the inner magnetosphere and plasmasphere interact with the mid-latitude ionosphere and drive its variability.
Achieving the above level of understanding is a multidecade task. The AIMI panel has, however, narrowed the scope of aspirations to five AIMI science goals that have the potential to be comprehensively addressed with current technologies or those under development, and within the 2013-2022 decade. These are enumerated in Figure 8.6 and are expanded on throughout the remainder of this section. In addition, Figure 8.6 maps AIMI science goals into the decadal survey’s key science goals 1-4, and the text below explains these mappings further. Finally, the following section sets forth a prioritized set of strategies to address these challenges.
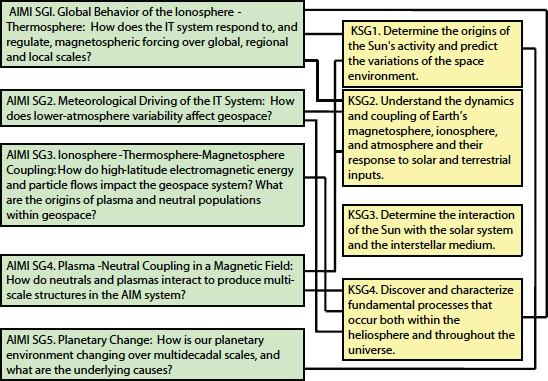
FIGURE 8.6 Five AIMI science goals for the 2013-2022 decade and how they map into the decadal survey’s key science goals 1-4.
8.4.1 AIMI Science Goal 1. Global Behavior of the Ionosphere-Thermosphere
How does the IT system respond to, and regulate, magnetospheric forcing over global, regional, and local scales?
At high latitudes, the AIM system directly impacts magnetospheric dynamics through conductivity changes, current closure, and ion outflow. Spatially confined energy input from the magnetosphere can quickly be redistributed to the ionized and neutral gases over much larger scales. A response of the system can occur at locations well removed from the input. Determination of changes in the system that are imposed externally and changes resulting from the internal system response is required to understand the geo-effectiveness of the interaction of the planet with the solar wind. In other words, the ionosphere-thermosphere system both adjusts to the varying input from above, and also feeds back and regulates this exchange.
Inter-hemispheric differences address the asymmetric closure of currents, as well as local ionospheric structuring and electric fields. Indeed, the dissimilarities present in the simultaneously measured magnetic
perturbations and derived currents shown in Figure 8.7 may be due to the differences in the high-latitude neutral density and plasma environments, which affect both the return currents in the aurora and the field-aligned potentials that accelerate the particles that create the visible aurora. The compelling science questions that researchers must answer are these: How do field-aligned currents, precipitation, conductivity, neutral winds and density, and electric fields organize a self-consistent, electrodynamic/hydrodynamic
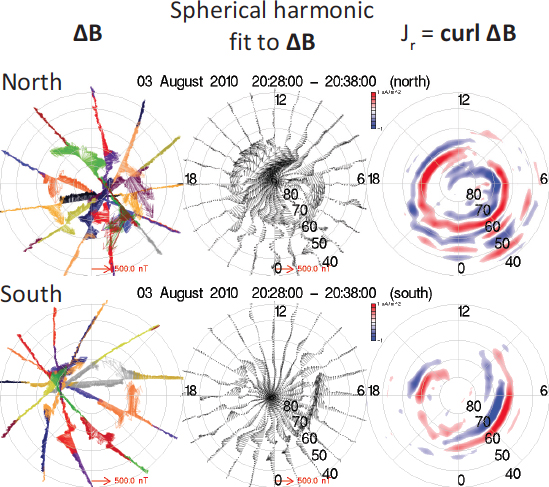
FIGURE 8.7 Simultaneous measurements of currents gathered in the northern and southern polar regions showing a striking difference in the current patterns and hence of energy input. Differences in ionospheric conductivity play an important role in the closure of magnetospheric currents and may have a profound influence on magnetospheric current closure, as the ionosphere and magnetosphere interact to regulate the response of geospace to solar wind input. SOURCE: Active Magnetosphere and Planetary Electrodynamics Response Experiment (AMPERE), Johns Hopkins University, Applied Physics Laboratory.
system at high latitudes? How does such a varying, spatially structured environment feed back on and modify field-aligned current and electric potential patterns imposed from the magnetosphere?
High-latitude heating (mainly below 200 km) causes N2-rich air to upwell, and strong winds driven by this heating transport N2 equatorward, which then mixes with ambient O in unknown ways (Figure 8.8).
IT constituents are controlled by gravity, diffusion, chemical reactions, and bulk transport. It is essential to understand how these processes determine global responses in O and N2 after heating occurs at high latitudes. Since these disturbances are superimposed on a solar EUV-driven circulation system that is mainly ordered in a geographic coordinate frame that varies with local time and season, the interactions can be complex, and IT responses are very different depending on prevailing conditions. The relative abundances of O and N2 are fundamental to understanding local plasma densities and total mass densities, both of which are key parameters underlying space weather forecast needs. The question then remains, How do winds, temperature, and chemical constituents interact to produce the observed global neutral and plasma density responses of the IT system?
Since the B field plays a major role in controlling the distribution of ionospheric plasma, and since ion-neutral collisions can serve to decelerate or accelerate the neutral gas, the ionospheric plasma can in many ways regulate the IT response to magnetospheric forcing. This occurs mainly through the redistribu-
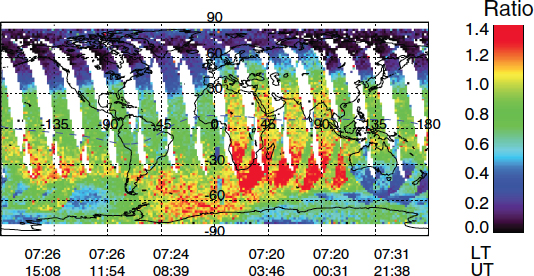
FIGURE 8.8 This image from the Thermosphere-Ionosphere-Mesosphere Energetic and Dynamics (TIMED)/Global Ultraviolet Imager (GUVI) instrument provides the height-integrated O/N2 density ratio for a single moderately disturbed day in April 2002. This picture varies considerably from day to day, but is available only at a single local time on any given day. Without coincident global measurements of neutral winds, temperature, and total mass density and some measure of localized heating, the causes and consequences of this composition variability cannot be ascertained. The Geospace Dynamics Constellation mission, described below in this chapter, will enable researchers to understand the relationships between these variables and, moreover, will provide this information simultaneously as a function of local time in a single day. SOURCE: Courtesy of Johns Hopkins University, Applied Physics Laboratory.
tion of plasma by electric fields. For instance, in connection with a sudden storm commencement, eastward penetrating electric fields can lift the equatorial ionosphere and accelerate the neutral gas through removal of the drag effect of the ions. A similar effect can occur at middle latitudes when equatorward winds push the plasma up magnetic field lines, lessening the drag on the zonal winds. Large redistributions of plasma occur as the result of subauroral electric fields that couple the inner magnetosphere and plasmasphere to the mid-latitude ionosphere (Figure 8.9). Disturbance winds below 200 km generate electric fields through the dynamo mechanism, which then redistribute plasma that affects the wind system at higher altitudes. As discussed below, there are also tidal-driven electric fields that redistribute plasma as a function of local time, longitude, and season and that modify the interaction between the plasma and neutral components of the IT system. The key question is, How do plasma and neutrals interact to produce the observed response of the IT system, including hemispheric and longitudinal asymmetries?
At high latitudes the IT system and the magnetosphere are engaged in a two-way interaction with each other. Energetic particles from the magnetosphere ionize the upper atmosphere, creating complex conductive pathways that regulate the flow of current from the magnetosphere. Electric fields guide the flow of
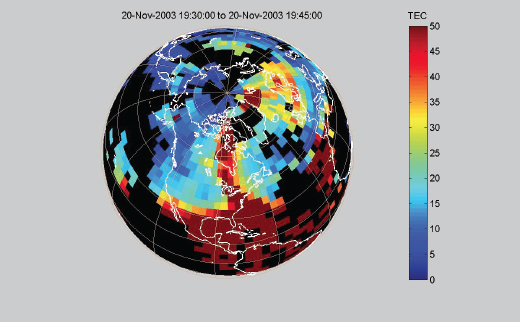
FIGURE 8.9 Storm-enhanced plasma density signatures in total electron content (TEC) observed on November 20, 2003. These signatures are believed to be connected to plasmasphere erosion and driven by subauroral electric fields from the inner magnetosphere. Strong plasma density gradients are observed over North America, the details of which could be observed by a network of ground-based observatories. Spatial and temporal evolution of the global structure would be well observed by a constellation of satellites making in situ measurements. SOURCE: A. Coster and J. Foster, Space weather impacts of the subauroral polarization stream, Radio Science Bulletin 321:28-36, 2007. Copyright 2007 Radio Science Press, Belgium, for the International Union of Radio Science (URSI), used with permission.
currents within the ionosphere, leading to Joule heating that depends on the spatial and temporal variability of the E fields as well as their absolute magnitudes. The peak altitude of Joule heating in turn determines the response time of the global thermosphere to this energy input. Energetic particles also initiate a chemical pathway to create nitric oxide, which regulates the response and recovery of the neutral atmosphere through radiative cooling. Local heating of the IT system and ionospheric flows from lower latitudes (see Figure 8.9) serve as sources of O+ to the magnetosphere, which then regulates how the magnetosphere transfers solar wind energy to the IT system (see further details on magnetosphere-IT interactions under “AIMI Science Goal 3”).
The interactions and feedbacks that occur between energy deposition, dynamics, radiative cooling, energetic particles, electric fields, and plasma and neutral constituents and temperatures are how the global IT system regulates its response to magnetospheric forcing, and how it also regulates the response of the magnetosphere to solar wind forcing. The complexity of the AIM system is such that emergent behaviors occur, sometimes involving coupling across spatial and temporal scales (see further details under “AIMI Science Goal 4”).
The AIMI panel concluded that a major goal of the coming decade, therefore, is to understand how regulation of the IT system occurs, and how connectivity between multiple scales arises within this regulation process.
Making the required coincident multi-parameter measurements of the system over local, regional, and global scales poses major challenges in terms of observational strategies. Strategies that employ an optimal combination of ground-based, suborbital and space-based platforms involving innovative in situ and remote-sensing instrumentation will be required. The panel’s implementation strategies are presented in the section “Implementation Strategies and Enabling Capabilities” below.
8.4.2 AIMI Science Goal 2. Meteorological Driving of the IT System
How does lower-atmosphere variability affect geospace?
Numerous observational and modeling studies conducted since the 2003 decadal survey have unequivocally revealed that the IT system owes much of its longitudinal, local-time, seasonal-latitudinal, and day-to-day variability to meteorological processes in the troposphere and stratosphere. The primary mechanism through which energy and momentum are transferred from the lower atmosphere to the upper atmosphere and ionosphere is through the generation and propagation of waves (Figure 8.10).
Owing to rotation of the planet, periodic absorption of solar radiation in local time (LT) and longitude (e.g., by troposphere H2O and stratosphere O3) excites a spectrum of thermal tides having periods and zonal (east-west) wavenumbers (or harmonics) defined by the planetary rotation period and longitudinal variability, respectively. Surface topography and unstable shear flows arising due to solar forcing excite planetary waves (PWs) and gravity waves (GWs) extending from planetary to very small (approximately tens to hundreds of kilometers) spatial scales and periods ranging from 2 to 20 days down to minutes. The absorption of solar radiation at the surface and the subsequent release of latent heat of evaporation in convective clouds radiate additional thermal tides, GWs, and other classes of waves. Those waves that propagate vertically grow exponentially with height into the more rarified atmosphere, ultimately achieving large amplitudes. Some parts of the wave spectrum achieve convective instability, spawning additional waves or turbulence. Other parts of the wave spectrum are ultimately dissipated by molecular diffusion in the 100- to 150-km-height region, and some fraction of those waves penetrate all the way to the base of the exosphere (ca. 500-600 km). Along the way, nonlinear interactions between different wave types occur, modifying the interacting waves and giving rise to secondary waves. Finally, the IT wind perturbations
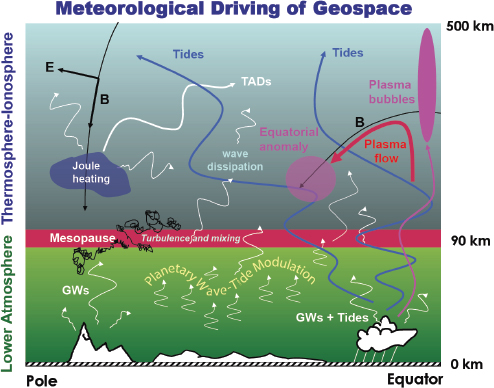
FIGURE 8.10 Schematic of the various mechanisms through which lower-atmosphere processes influence the ionosphere and thermosphere. See text for details. SOURCE: Courtesy of Jeffrey M. Forbes, University of Colorado, Boulder, and David Fritts, Colorado Research Associates.
carried by the waves can redistribute ionospheric plasma, either through the electric fields generated via the dynamo mechanism, or directly by moving plasma along magnetic field lines (Figure 8.11).
Although the presence and importance of waves are without dispute, the relevant coupling processes operating within the neutral atmosphere, and between the neutral atmosphere and ionosphere, involve a host of multiscale dynamics that are not understood at present. The connection between tropical convection and modification of the ionosphere described above is just one example of emergent behavior that typifies the coupling between the lower atmosphere and the IT system. Below, the panel presents its analysis of what are the most pressing science questions that must be addressed on this topic in the coming decade, particularly with respect to developing a capability to predict the space weather of the IT system.
A first and fundamental question is, How does the global wave spectrum evolve temporally and spatially in the thermosphere? The TIMED, CHAMP, and GRACE missions provide approximately 2-month average tidal climatologies below 110 km and above 400 km, respectively (Figure 8.12), but with little information on the intervening region where the tidal and gravity wave spectra evolve with height, dissipate,
FIGURE 8.11 The 10-day-mean structure in electron density (m-3) at 400 km measured by the CHAMP satellite. The 3-4 maxima in longitude are believed to result from electric fields generated by longitude-dependent atmospheric tides in the dynamo region, with possible contributions from associated composition variations and possibly in situ north-south winds. However, no electric field, wind, or composition measurements were available to understand the interplay between these quantities that results in the displayed structure. Satellite-based measurements are urgently needed to resolve this and many other similar issues in IT science. SOURCE: N.M. Pedatella, J.M. Forbes, and J. Oberheide, Intra-annual variability of the low-latitude ionosphere due to nonmigrating tides, Geophysical Research Letters 35:L18104, doi:10.1029/2008GL035332, 2008. Copyright 2008 American Geophysical Union. Reproduced by permission of American Geophysical Union.
and give up momentum to the mean circulation. What are needed are observations between about 100 and 200 km that include the critical dynamo region where electric fields are generated, and that would, moreover, make it possible to answer the question, How does the mean thermosphere state respond to wave forcing? Observations of both the mean state and of the waves are required to elucidate how the waves dissipate, how they relate to the background flow and thermal structure, and how their effects can be parametrized in general circulation models.
It is important to measure the tidal PWs, and GWs together, to be able to understand the interactions between them. For instance, PWs do not penetrate much above 100 km, but instead are thought to impose their periodicities on the IT system by modulating the tidal and GW parts of the spectrum that do penetrate to higher altitudes. This raises the following questions: How are GWs modulated by PWs and tides, and do they effectively map these structures to higher altitudes? and By what mechanisms are electric fields and plasma drifts generated in the dynamo region at PW periods? As one example, recent measurements reveal the fascinating result that stratospheric warmings significantly alter the state of the IT system: a prevailing theory is that enhanced quasi-stationary PWs common to these dynamical events interact nonlinearly with existing tides to produce secondary tides that propagate globally and generate dynamo electric fields in the ionosphere. The electric field subsequently redistributes ionospheric plasma, dramatically changing TEC gradients that are known to degrade communications and navigation systems. This emergent behavior in the system, once completely understood, has the potential to dramatically improve ionospheric predictions
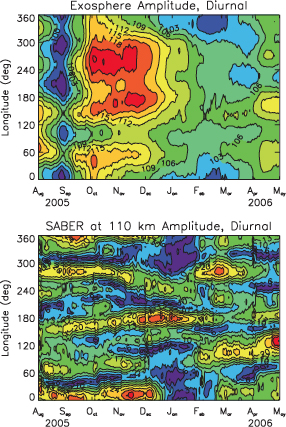
FIGURE 8.12 Equatorial diurnal tidal temperature amplitudes as a function of longitude and month from August 2005 to May 2006. (Top) Exosphere temperatures, ranging from 97 K (maroon) to 121 K (red). (Bottom) SABER temperatures at 110 km, ranging from 3 K (maroon) to 27 K (orange). The diurnal tidal spectrum evolves with height, with the larger-scale waves penetrating to 400 km, while the shorter-scale waves are absorbed at intervening altitudes, giving up their energy and momentum to the mean atmosphere. Researchers know very little about how the tidal, planetary wave, and gravity wave spectra evolve with height and modify the mean thermal and dynamical structure of the thermosphere. SOURCE: J.M. Forbes, S.L. Bruinsma, X. Zhang, and J. Oberheide, Surface-exosphere coupling due to thermal tides, Geophysical Research Letters 36:L15812, doi:10.1029/2009GL038748, 2009, Copyrighgt 2009 American Geophysical Union, reproduced by permission of American Geophysical Union.
since the peak of the ionospheric response occurs several days after the stratospheric warming. In addition, first-principles modeling predicts a thermospheric warming in response to the stratospheric warmings, and resulting changes in thermospheric winds and density that impact satellite drag.
The above wave-plasma interactions focus on electric fields generated by the dynamo mechanism, but one must ask: What other processes compete with dynamo electric fields to modify and redistribute plasma in the F region (~200-600 km)? Recent studies, in fact, show that winds associated with tides that
penetrate to high altitudes can significantly modify ionospheric peak heights at low latitudes. Variations in composition also accompany tidal dynamics, thereby introducing chemical influences on ionospheric production and loss with large effects in scale and magnitude. Finally, breaking gravity waves are thought to provide the turbulent mixing at the base of the thermosphere (ca. 90-100 km) that determines the geographical and temporal variation of the turbopause altitude, and hence that of the O/N2 ratio at higher altitudes. How does the turbopause vary in space and time, and what are the causes and consequences? remains one of the outstanding fundamental questions in aeronomy, and one that can conceivably be addressed in the next decade.
Gravity waves have often been cited as the source for small-scale plasma variability, but the absence of coordinated observations of neutral waves and ionospheric perturbations in the right altitude regions has greatly impeded progress. In particular, a long-standing question that must be answered in the next decade if significant progress is to be made in understanding and predicting how small-scale plasma structures interfere with radio propagation is, What is the role of gravity waves in “seeding” equatorial Rayleigh-Taylor instabilities that lead to plasma bubbles (depletions)?
One hypothesis suggests that the interaction between in situ gravity waves and the steep bottom-side plasma gradient of the post-sunset equatorial ionosphere generates alternating east and west electric fields that can excite this instability. Another theory requires gravity-wave winds only in the E region, which generate electric fields that couple to the F layer. In addition, the tidal and mean wind fields modulate the accessibility of gravity waves to these ionosphere regions, and moreover contribute to instability onset and suppression criteria, and to instability growth rates. Thus, the interactions between small, local, and regional-scale plasma-neutral coupling phenomena are all involved in this complex but highly relevant emergent behavior in the system. Resolving this problem requires high-resolution measurements of neutral and plasma parameters with high spatial and temporal resolution over the 100- to 300-km height region, and further development of the relevant theories and models.
Finally, lightning is known to generate low-frequency electromagnetic waves called whistlers, which can induce precipitation of radiation belt particles into the opposite hemisphere and enhance lower ionosphere densities there. Lightning events also accelerate electrons to very high energies and create strong electric fields in the mesosphere. Gamma-ray flashes observed from space (e.g., from RHESSI) may indeed result from the deceleration of very energetic electrons due to collisions with atmospheric molecules. Luminous optical manifestations of these events are referred to variously as sprites, elves, or blue jets (Figure 8.13). All of these processes raise questions about chemical modification of the mesosphere and electrodynamic coupling between the troposphere, the ionosphere, and all of geospace through these energetic lightning events.
The AIMI panel concluded that a major goal of the coming decade is to understand how tropospheric weather drives space weather.
8.4.3 AIMI Science Goal 3. Ionosphere-Thermosphere-Magnetosphere Coupling
How do high-latitude electromagnetic energy and particle flows impact the geospace system?
What are the origins of plasma and neutral populations within geospace?
The IT-magnetosphere interaction at high latitudes is catalyzed by convective flows, which transport and mix plasma and neutral gases across subauroral, auroral, and polar regions, and by magnetic field-aligned flows of plasma and electromagnetic energy, which couple the collisionless magnetosphere to the collisional ionosphere-thermosphere boundary layer. Researchers now recognize that the active response
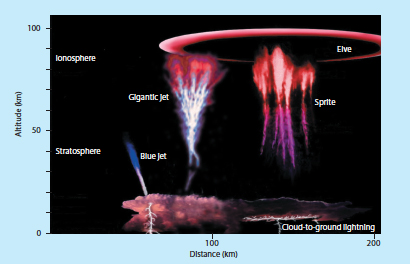
FIGURE 8.13 Illustration of transient luminous events (including elves, sprites, and jets) that occur at stratospheric and mesospheric/lower-ionospheric altitudes and are directly related to electrical activity in underlying thunderstorms. Effects on the upper atmosphere and ionosphere of transient electric fields, electromagnetic waves, and high-energy electrons produced by these events remain unknown. SOURCE: Reprinted by permission from Macmillan Publishers Ltd: Nature, V.P. Pasko, Atmospheric physics: Electric jets, Nature 423:927-929, 2003, doi:10.1038/423927a. Copyright 2003.
of the IT to solar wind-magnetosphere forcing, together with the response of the collisionless high-latitude region spanning the topside ionosphere and the low-altitude magnetosphere up to altitudes of ~104 km, introduces feedback and coupling between IT and magnetosphere system elements. Determining the processes that control this coupling is critical in understanding geospace dynamics and for development of accurate predictive capabilities. Knowledge of auroral acceleration processes and of auroral electrodynamics derived from satellite missions such as FAST, POLAR, and IMAGE is now fairly mature, but placing these processes in the context of IT-magnetosphere system dynamics is forcing the need to confront larger-scope questions: How is electromagnetic energy converted to particle energy? What controls the conversion rates and the spatial-temporal distributions of Joule heating, particle precipitation, and ionospheric outflows at high latitudes? How do these distributions and their spatial gradients, combined with neutral-wind feedback, regulate ionosphere-thermosphere-magnetosphere dynamics?
Answering these questions over the next decade will require combining model results with new multipoint in situ and remote-sensing measurements. The relationships are shown schematically in Figure 8.14.
Measurements at two or more points along magnetic flux tubes in the collisionless region above the topside ionosphere will be required to determine the mechanisms through which electromagnetic energy is converted to particle energy, and their rates; conjugate measurements at lower altitudes are essential for determining the impacts of precipitating and outflowing particles on the ionosphere and thermosphere and, in turn, the influence of the resulting IT activity on the source populations of outflowing ions and on the development of gradients (for example, in conductivity) that moderate electrical current flow and electro-
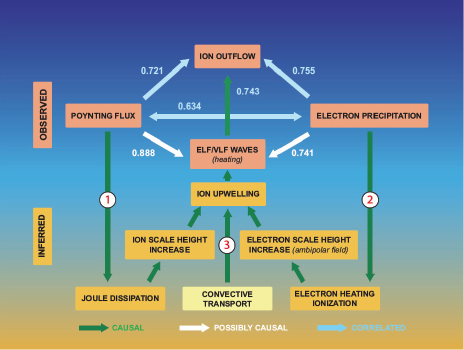
FIGURE 8.14 Observed correlations from FAST satellite data and inferred causal relationships among ionosphere-thermosphere-magnetosphere processes leading to the outflow of ionospheric ions. Researchers lack firm empirical knowledge of the relative importance of the inferred processes, all of which occur in the ionosphere. The observed correlations from FAST satellite data suggest causal relationships, but determining causality among these processes requires, at a minimum, two-point measurements along magnetic flux tubes. SOURCE: Adapted from R.J. Strangeway, R.E. Ergun, Y.-J. Su, C.W. Carlson, and R.C. Elphic, Factors controlling ionospheric outflows as observed at intermediate altitudes, Journal of Geophysical Research 110:A03221, doi:10.1029/2004JA01082, 2005. Copyright 2005 American Geophysical Union. Modified by permission of American Geophysical Union.
magnetic energy conversion and absorption. Combining optical measurements with in situ measurements is needed to provide contextual information, in particular, how locally inferred acceleration processes influence, and are influenced by, larger-scale structure and dynamics. The synthesis required to connect these measurements with solar wind and magnetospheric drivers will require development and application of increasingly realistic models for global and regional dynamics.
Without the photo-ionization present in the dayside ionosphere, the nightside ionosphere is susceptible to structuring and modulation by variable fluxes of charged particles precipitating from the magnetosphere. Gradients in the resulting ionization cause ionospheric currents to be diverted into field-aligned currents. Recent studies have revealed the unexpected possibility that the accompanying ionospheric flow structures are mirrored in the plasma sheet by the formation of fast flow channels and by steep plasma pressure gradients in the outer ring current. These ionospheric flow structures form at steep gradients in ionospheric conductivity, which remains one of the most poorly diagnosed and vitally important ionospheric variables.
While empirical models of electron precipitation have become increasingly sophisticated, knowledge of the associated conductivity dynamics on spatial scales down to 1 km is still lacking. Even less is known about conductivity enhancements due to ionospheric turbulence—effects that have been theoretically predicted to be capable of doubling the total height-integrated conductivity during disturbed geomagnetic conditions. A compelling question is thus, What are the spatial and temporal scales of ionospheric structure and associated conductivity that determine energy deposition, plasma and neutral flows, and electrical current flow in the ionosphere-thermosphere interaction?
Plasma of ionospheric origin mixes with solar wind plasma to populate the plasma sheet, ring current, and plasmasphere. During episodic events such as storms and substorms, the presence of ionospheric plasma in these regions can be a controlling factor in geospace dynamics. For example, dense, convecting plasmaspheric plumes are thought to modulate dayside magnetic reconnection upon contacting the magnetopause. What are the processes that cause the plume structure to appear as storm-enhanced densities in the ionosphere? Ionospheric outflows emerging from the dayside cleft ion fountain and nightside Alfvénic acceleration regions can dominate both the density and the pressure of the plasma sheet during superstorms and the energy density of the ring current. Plasma in the inner magnetosphere is composed of protons and He+ and O+ ions of ionospheric origin. The relative abundance of these ions influences the plasma wave intensities that are responsible for the scattering and loss of radiation belt electrons. Recognition that ionospheric plasma is a critical agent in regulating the geospace system is accompanied by the humbling reality that researchers do not know what controls the abundance or distribution of ionospheric plasma in the magnetosphere. How does the flow of ionospheric plasma into the magnetosphere during storms change as a result of IT plasma and neutral redistributions?
The AIMI panel concluded that an additional major goal of the coming decade is to understand how the IT and magnetosphere interact to regulate their coupled response to solar wind forcing.
8.4.4 AIMI Science Goal 4. Plasma-Neutral Coupling in a Magnetic Field
How do neutrals and plasmas interact to produce multiscale structures in the AIM system?
An intriguing aspect of the IT system is the transfer of energy and momentum that occurs between the plasma and neutral components of the system, and how electric and magnetic fields serve to accentuate and sometimes moderate this interchange. The pathways through which ions and neutrals interact are of course fundamental to space physics, as they occur all over our solar system. Addressing the compelling science questions described within previous sections also presents many opportunities to employ the IT system as a local laboratory to expand understanding of plasma-neutral coupling processes that have broad applicability across the solar system. In particular, these interactions occur over local, regional, and global scales, and in many cases cross-scale coupling exists. Some insight into the range of topics that can be addressed is provided in the following section, which begins with the low latitudes and then moves toward the polar regions.
The equatorial IT system represents a rich laboratory for investigation of plasma-neutral coupling in the presence of a magnetic field. The unique features are the quasi-horizontal orientation of the B field, the plasma instabilities that arise from this configuration, the ability of winds to generate electric fields through the E- and F-region dynamo mechanisms, the change in plasma-neutral collision frequency with height, the unimpeded ability of neutral winds to move plasma along field lines, and the relatively rapid change in magnetic inclination with latitude. Combined with a variety of chemical processes, interactions between the plasma and neutral gases in the above environment produce emergent behaviors in the neutral and plasma densities, their bulk motions, and their temperatures. One example of emergent structures in neutral density is provided in Figure 8.15.
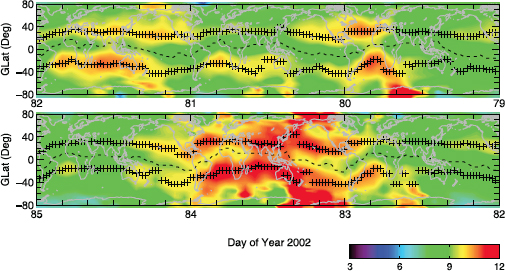
FIGURE 8.15 Neutral mass density (kg/m3) structures measured by the accelerometer on the CHAMP satellite near 400 km and 1800 local time during days 79-85, 2002. The universal time day runs from right to left, so as to display the data on top of geographic maps. Crosses (dashed lines) mark the locations of the equatorial temperature anomaly (ETA) crests (troughs). Magnetic activity was mostly quiet, except on day 83 when Kp reached values of 4-6. The longitudinal alignment of the ETA trough and crests suggests a connection with a magnetic coordinate system and hence with plasma densities. Researchers do not know how quiet-time and disturbance wind, electric field, and composition variations interacted to produce the observed changes. With just single-satellite sampleing, tmporal variations cannot be separated from longitude variations; moreover, measurements are made only at two local times. A constellation of satellites would remove the longitude-universal time ambiguity and would reveal how these structures varied in local time. SOURCE: J. Lei, J.P. Thayer, and J.M. Forbes, Longitudinal and geomagnetic activity modulation of the equatorial thermosphere anomaly, Journal of Geophysical Research 115:A08311, doi:10.1029/2009JA015177, 2010. Copyright 2010 American Geophysical Union. Reproduced by permission of American Geophysical Union.
The longitudinal alignment is reminiscent of the plasma feature referred to as the equatorial ionization anomaly (EIA), but the EIA maxima are less widely spaced in latitude and do not respond to changes in geomagnetic activity to the same degrees as do the neutral structures. Although theories exist that involve plasma and neutral transport and temperature and density responses due to adiabatic heating and cooling terms in the thermodynamic equation, the absence of coincident wind, temperature, electric field, and composition measurements over a range of spatial and temporal scales precludes a definitive interpretation.
What is needed to dispel speculation are simultaneous measurements of neutral and ion densities, temperatures, winds, and plasma drifts (E fields) so that physical connections can be explored and model simulations can be constrained. The measurement and modeling strategies proposed in the section “Implementation Strategies and Enabling Capabilities” will do exactly this. In fact, the proposed measurements will enable investigation of several low-latitude phenomena whose origins can be elucidated only through simultaneous multi-parameter measurements. These phenomena include, for instance, the equatorial temperature and wind anomaly, the midnight temperature maximum, the post-sunset atmospheric jet,
terminator waves, and atmospheric superrotation. In summary, the overarching question that captures most low-latitude IT phenomena is thus, How are gas temperatures and densities at low latitudes modified by momentum transfer between neutrals and ions in the presence of a magnetic field?
Middle latitudes serve as a laboratory for different kinds of plasma-neutral interactions that also exhibit emergent behavior. For instance, consider the TEC and 6,300 Å airglow emissions depicted in Figure 8.16. The TEC data are obtained from a network of ground-based GPS receivers, and airglow measurements are obtained from ground-based all-sky imagers. The spontaneous emission of 6,300 Å airglow at nighttime originates from excited atomic oxygen atoms that result from the dissociative recombination of molecular ions with electrons. Similar TEC measurements have been made using a GPS receiver network over the continental United States. The depicted waves, which are predominantly south-westward propagating, are thought to originate as neutral density waves at high latitudes, which then interact with the mid-latitude ionosphere to create the observed structures; however, the occurrence of these waves is curiously unrelated to level of magnetic activity.
It is hypothesized that the southwestward directionality of the waves, at least at nighttime, is aligned in the direction of weakest Joule damping as predicted by the Perkins instability. This hypothesis is supported by measurements that indicate the existence of electric fields within the wave structures, which are
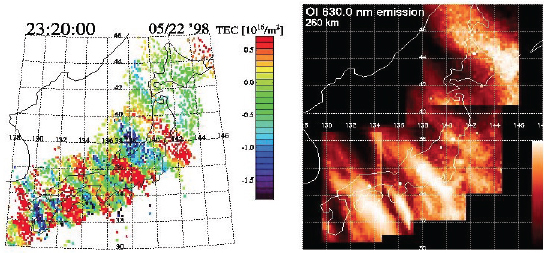
FIGURE 8.16 Two-dimensional distribution of total electron content (TEC) (left) and 6,300 Å airglow emission (right) near midnight over Japan on May 22, 1998, during passage of a traveling ionospheric disturbance. The TEC measurements were obtained using an array of GPS receivers, and the airglow measurements were made with five all-sky charge-coupled device cameras. The airglow emission is from excited neutral atomic oxygen atoms produced as a result of dissociative recombination of molecular ions and electrons. Note that the maxima in TEC mostly correspond with the airglow peaks, consistent with this interpretation. A North American ground-based observing network would enable investigation of these and many other regional-scale space weather phenomena involving fundamental plasma-neutral coupling processes, while a complementary satellite mission would provide insights into coupling on a global scale. SOURCE: A. Saito et al., Traveling ionospheric disturbances detected in the FRONT Campaign, Geophysical Research Letters 28(4):689-692, 2001. Copyright 2001 American Geophysical Union. Reproduced by permission of American Geophysical Union.
thought to arise from winds blowing across Pedersen conductivity gradients associated with the waves. It also appears that the physics behind the ionospheric manifestation of the waves may be different during nighttime and daytime, and that their directionality varies with season. This may reflect different generation mechanisms and/or the influence of the background large-scale wind circulation on the wave propagation. Note that explanation of this phenomenon involves coupling between instability, local, regional, and global-scale processes in ways that scientists do not understand, leading to the question, How do plasmas and neutrals interact across local, regional, and global scales to produce the operationally important density variations referred to as space weather?
Plasma-neutral interactions at high latitudes are strongly coupled to solar wind and magnetospheric dynamics. This coupling is regulated to a large extent by the ionospheric conductance, which is dependent on the ion and neutral gas densities. Despite their importance in the AIM interaction, the spatial distributions of these densities and their time variability are among the most poorly measured parameters of the IT system. Consequently, the interplay between neutral and ionized gas constituents and electromagnetic activity are not well understood. At high latitudes, ion motions driven by the interaction of Earth with the solar wind provide the strongest forcing to the neutral atmosphere. The temporal and spatial scales of the neutral atmosphere response are quite different at different altitudes and quite different from those imposed by the driver. The driven neutral gas motions persist long after the driving fields change, and the neutral gas convects and diffuses well beyond the region of ion forcing. This complex interaction changes the energy deposited in the atmosphere, which causes changes in the global temperature, composition, and density that cannot yet be predicted. For example, in both the cusp region and its counterpart in the night-side ionospheric convection throat, the average mass density of the neutral atmosphere near the F-region peak is observed to be significantly higher than that predicted by the empirical reference thermosphere (MSIS90) (Figure 8.17).
This discrepancy has stimulated a search for the causative mechanisms. The neutral density enhancements are statistically collocated with observed regions of soft electron precipitation, Joule heating, ion upflows and outflows, dispersive Alfvén waves, and small-scale field-aligned currents. Determining cause and effect among these variables and advancing an operational capability to predict regional enhancements in neutral density will require simultaneous, multivariable measurements in the topside and bottomside ionosphere. Model results indicate that thermospheric upwelling strongly influences the scale height of O+ ions in the topside ionosphere and their escape flux into the magnetosphere. Thus the population of the magnetosphere by ionospheric outflows is also dependent on plasma-neutral interactions. Breakthroughs in the next decade in understanding the dynamic interaction between the magnetosphere and the IT system must therefore confront the question, How do activities in neutral and ionized gases and electromagnetic fields interact to produce observed magnetic field-aligned structure and motions of the thermosphere and ionosphere?
The AIMI panel concluded that a major goal of the 2013-2022 decade is to understand the plasma-neutral coupling processes that give rise to local, regional, and global-scale structures in the AIM system, particularly those relevant to society.
8.4.5 AIMI Science Goal 5. Planetary Change
How is our planetary environment changing over multidecadal scales, and what are the underlying causes?
The preceding discussions indicate why achieving an understanding of how the whole atmosphere system is coupled to the geospace environment remains a singular challenge for AIM research. Addressing
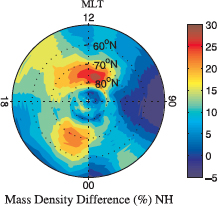
FIGURE 8.17 Magnetic-latitude and local-time distribution of a 1-year average of the percent difference between the thermospheric mass density derived from CHAMP satellite measurements and MSIS90 at 400-km altitude in the northern polar region during quiet conditions (Kp = 0-2). Model ionospheric convection streamlines are superposed. Large differences occur in the cusp and midnight sectors. SOURCE: Adapted from H. Liu, H. Lühr, V. Henize, and W. Köhler, Global distribution of the thermospheric total mass density derived from CHAMP, Journal of Geophysical Research 110:A04301, doi:10.1029/2004JA010741, 2005. Copyright 2005 American Geophysical Union. Reproduced by permission of American Geophysical Union.
this challenge will provide vital information not only on the variability of Earth’s near-space environment, but also on terrestrial climate variability and change.
Human activities, particularly the introduction of greenhouse gases (e.g., CO2 and CH4) into the atmosphere, are changing the global climate. One of the many manifold demonstrations that the change in Earth’s climate is due to the rise in CO2 concentrations is that the lower atmosphere is warming while the upper atmosphere is cooling. This demonstrable fact is fully consonant with the well-understood role of CO2 as an effective radiator of energy in the upper atmosphere. A systematic decrease by several percent per decade near 400-km altitude in thermosphere mass density has recently been identified, evident in the record of satellite orbit decay measured since the beginning of the space age (Figure 8.18).
One result of an increase in the average temperature in the lower atmosphere is that the amount of water vapor, and consequently the available latent heat, may increase. Possible consequences include changes in the strength of the lower-atmosphere tides that, as noted above, modify the longitudinal structure of the ionosphere. Gravity wave, Kelvin wave, and planetary wave fluxes are also likely to be affected. Given recent findings of an El Niño-Southern Oscillation-related signature in low-latitude ionospheric structure, scientists should expect its structure to change in response to other climate changes in the lower atmosphere. Another aspect of lower-atmosphere changes is an expected increase in the number of severe storms. If ionospheric instabilities are seeded by tropospheric gravity waves propagating into the upper atmosphere, this may have an impact on the frequency of these events. Another source of gravity waves is the flow of tropospheric winds over topographic features. If lower atmospheric circulation patterns are altered, this too may change the spectrum and frequency of occurrence of gravity waves, and ionospheric instabilities.
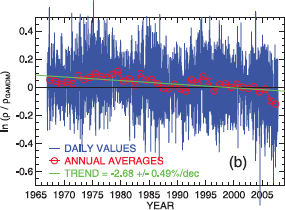
FIGURE 8.18 Analyses of decades of satellite drag data indicate a long-term trend of decreasing thermosphere densities. SOURCE: J.T. Emmert, J.M. Picone, and R.R. Meier, Thermospheric global average density trends, 1967-2007, derived from orbits of 5000 near-Earth objects, Geophysical Research Letters 35:L05101, doi:10.1029/2007GL032809, 2008. Copyright 2008 American Geophysical Union. Reproduced by permission of American Geophysical Union.
Model simulations and decades of observations indicate that changes in ozone and greenhouse gases have produced long-term changes in the wind fields of the stratosphere and mesosphere that serve as the environment through which tropospherically excited waves propagate. Waves propagating through the middle atmosphere and into the base of the thermosphere (ca. 100 km) must therefore also undergo change, and this is confirmed by trends seen in long-term wind and magnetic perturbations between 80 and 120 km observed from the ground. Since dissipation of waves in this region helps drive the mean circulation of the mesosphere and lower thermosphere, these effects must feed back to modify the circulation system that resulted in the changed wave spectrum in the first place. In addition, there is the question of downward control and whether the adiabatic heating and cooling effects of the wave-driven vertical motion field extend far enough down in altitude to have practical consequences.
One of the most spectacular signatures of the coupling of the lower and upper atmosphere is the existence of polar mesospheric clouds (PMCs). These water ice clouds at the edge of space (~84 km) are seen in the summer hemisphere. Stratospheric and mesospheric water vapor is created largely through the oxidation of methane (CH4). Water vapor is trapped at the tropopause while methane is mixed into the upper atmosphere, thus changing the hydrogen chemistry of the upper atmosphere. Local temperature is also key to the existence of PMCs, and at these altitudes is determined largely by the adiabatic heating and cooling accompanying the wave-driven circulation discussed above. In the coming decade, the AIM community will build on the work of previous missions like the NASA Aeronomy of Ice Mission and the Thermosphere Ionosphere Mesosphere Energetics and Dynamics (TIMED) mission to understand how geospace is influenced by the lower atmosphere.
One of the urgent, unresolved heliophysics questions is how feedback processes in the Earth system amplify the effects of small changes in solar energy output, leading to disproportionately large changes in atmospheric parameters. The atmospheric response to energetic particle precipitation (EPP) is a key
component of this unexplored frontier and provides a natural means of probing the coupling mechanisms that redistribute solar and magnetospheric energy at Earth. Determining how redistribution of precipitating particle energy influences atmospheric composition and structure, and how nonlinear coupling processes amplify these impacts beyond those expected from the absolute energy input, would represent a fundamental advance in heliophysics.
Coupling of different regions via radiative, dynamical, and chemical feedbacks controls weather and climate throughout the atmosphere. Through these feedback processes the remote regions highly driven by solar influences are linked to the troposphere where human activities are concentrated. Yet how solar and magnetospheric variability affects atmospheric conditions and climate in such an interconnected system remains an open question. Only with a deeper understanding of the natural variability, and of the way external influences perturb the coupling processes, will researchers be able to model this complex system and thereby develop a predictive capability for future generations.
EPP refers to energetic electrons and protons impinging on Earth’s atmosphere after they have been accelerated by solar and magnetospheric activity. Figure 8.5 in the section above titled “Significant Accomplishments of the Previous Decade” depicts current, incomplete understanding of the atmospheric response to EPP. Solar magnetic variability produces changes both in irradiance and in the plasmas and magnetic fields that permeate interplanetary space, driving space weather at Earth. The resulting EPP occurs at all times during the solar cycle but has different characteristics depending on particle sources, which are broadly associated with different geomagnetic activity levels. Through ionization and dissociation EPP produces NO and NO2, collectively referred to as NOx, the primary catalytic destroyer of ozone (O3) in most of the stratosphere. NOx produced by EPP (EPP-NOx) can be created directly in the stratosphere by high-energy particles, or in the mesosphere and lower thermosphere (MLT) by lower-energy particles. EPP-NOx descends from the MLT into the stratosphere during the polar winter (see Figure 8.19, for example). The downward transport is controlled by an unknown combination of diffusion, large-scale circulation, and confinement in the polar vortex, with winds and waves modifying these elements.
NOx is an atmospheric coupling agent because of its impact on O3, either through the NOx catalytic loss cycle, or by interfering with other catalytic O3 loss cycles. Changes in O3 can alter temperature gradients, and thereby influence circulation. Perturbations to these three entities are intertwined and can trigger nonlocal changes, e.g., by perturbing propagation of waves to the upper atmosphere or weather and climate in the lower atmosphere. Thus EPP-NOx-induced perturbations in O3 are communicated via effects on temperature and circulation upward to the MLT and potentially downward to the troposphere, thereby triggering the redistribution of particle energy throughout the atmosphere. These results suggest a mechanism for EPP indirectly affecting even tropospheric climate, evidence for which is provocative but tenuous. Tropospheric perturbations themselves—either natural or human-induced—can be communicated to the middle and upper atmosphere, thereby altering the atmospheric response to EPP. The coupling pathways described here form a critical yet poorly understood link between heliophysical forcing and Earth’s climate system. A complete description of the Sun-Earth system requires understanding of the pathways by which EPP transmits signals of solar magnetic variability through Earth’s atmosphere, specifically the amplifying coupling processes triggered by EPP-NOx. It is then important to ask: How do EPP-initiated chemical changes translate to thermal and dynamical changes throughout the atmosphere?
The AIMI panel concluded that a major goal for the upcoming decade is to determine how our planetary environment is changing over multi-decadal scales, and to understand how the changes are embodied in or transmitted through the AIM system.
This goal triggers two major implications. First, long-term observations that provide the best information about the degree of change, and that best serve to constrain models, must be protected if scientists are to understand and predict long-term change in the AIM system. Second, fundamental processes and
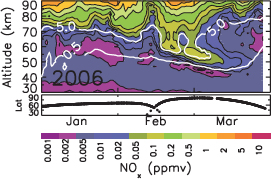
FIGURE 8.19 ACE measurements of NOx (color contours) during the Northern Hemisphere winter of 2006. White lines are CO mixing ratios, a tracer that indicates descent. The origin of the NOx is energetic particle precipitation. In 2006, meteorological conditions were favorable for NOx descent. The upper-stratosphere vortex was particularly strong, trapping the NOx in the polar region as it descended farther into the stratosphere where it has a longer chemical lifetime. SOURCE: Adapted from C.E. Randall et al., Enhanced NOx in 2006 linked to strong upper stratospheric Arctic vortex, Geophysical Research Letters 33:L18811, 2006. Copyright 2006 American Geophysical Union. Modified by permission of American Geophysical Union.
mechanisms that underlie long-term change, such as wave-mean flow interactions, must be identified and understood. The latter are also important in terms of understanding and predicting the behavior of the AIM system over the short term, and toward this end wave coupling between the lower and upper atmosphere has emerged in this panel report as one of a few core high-priority research areas for the future decade.
The AIMI panel’s science priorities for the 2013-2022 decade are presented here. These overarching priorities reflect, and to an extent cut across, the science goals discussed above. The panel’s strategy for addressing these science priorities reflects the need to allocate scarce resources optimally and the desire for a program that will have high societal benefit. The science priorities for 2013-2022 are as follows:
1. Determine how the ionosphere-thermosphere system regulates the flow of solar energy throughout geospace.
2. Understand how tropospheric weather influences space weather.
3. Understand the plasma-neutral coupling processes that give rise to local, regional, and global-scale structures and dynamics in the AIM system.
8.5 IMPLEMENTATION STRATEGIES AND ENABLING CAPABILITIES
The following section focuses on strategies and enabling capabilities to address the AIMI science goals outlined in the previous section, with particular emphasis on the three science priorities just enumerated. The AIMI panel’s four imperatives as summarized in Section 8.1 fall under the categories of spaceflight
missions; Explorers, suborbital, and other platforms; ground-based facilities; theory and modeling; and enabling capabilities. Priorities within each are indicated below.
As stated previously, the nature of AIM science is that it requires a synergistic complement of space-based and ground-based observational approaches with complementary theory and modeling activities. However, there are no NASA missions in development or approved for development that address these priorities, and therefore there is a void in the current capacity to understand the solar-terrestrial system and to contribute to the space weather needs of 21st-century society. It is the AIMI panel’s view that the Heliophysics Systems Observatory should be continued with a mission that determines how solar energy drives ionosphere-thermosphere variability, and that lays the foundation for a space weather prediction capability. There are two complementary notional missions that are put forth as the panel’s highest-priority imperatives to satisfy this need: GDC and DYNAMIC. Out of the many different means of measuring the AIM system, they are representative of the types of missions that will provide the needed global view unattainable in any other way (i.e., Explorer-class missions, which are less costly). GDC (a large-class mission) and DYNAMIC (a moderate-class mission) are described immediately below. Some level of detail is provided to enable the reader to understand the scope of mission required to achieve its science goals and to relate this to the broad cost categories described in Chapter 1 of this report. Thus, although some details are provided, these missions are not prescriptive; the AIM community will ultimately decide on the optimal implementation to achieve the science goal. Two additional notional missions, ESCAPE (Energetics, Sources and Couplings of Atmosphere-Plasma Escape) and MAC (Magnetospheric-Atmosphere Coupling), are also described below; each addresses very high priority science topics (i.e., regulation of the IT-magnetosphere interaction and fundamental plasma processes).
8.5.1.1 GDC (Geospace Dynamics Constellation) Mission (Intermediate Class)
Overview
Assuming resources enable a new start early in the decadal survey interval, the AIMI panel sees the Geospace Dynamics Constellation (GDC) as the optimal way to significantly advance both solar-terrestrial and AIM science. GDC would be a fundamental contributor to the Heliophysics Systems Observatory while also enabling measurements that are highly relevant for research aimed at understanding and developing a predictive capability for space weather. The primary focus of GDC is to gather the necessary data to reveal how the IT operates as a system and how it regulates its response to external forcing. With current and foreseeable technologies, this requires a robust, systematic observation approach using in situ probes to gather data at all local times and latitudes simultaneously. Furthermore, these satellites must gather data at sufficiently low altitudes where both the neutral and ionized gases are sufficiently dense and inherently coupled.
The observational problem is that such global dynamics cannot be captured by a single satellite regardless of the number of its instrument probes. When averaged over a sufficiently long period of time, data from a single satellite provides a useful climatology as a function of latitude and longitude. However, such data are static and do not show the physical coupling inherent in the continuously adjusted density contours and velocity patterns (dynamics) that, by their very nature, respond at all local times to the interconnected processes that define the AIM system. On the other hand, a constellation of identical, multiple satellites in low Earth orbit, such as proposed here as the Geospace Dynamics Constellation, would provide the necessary global, simultaneous observations covering all latitudes and local times while orbiting Earth in
TABLE 8.1 Geospace Dynamics Constellation (GDC) Science and Relevance to Space Weather
|
|
||||
| Solar and Space Physics Motivations | 1 | Understand Our Home in the Solar System | ||
| 2 | Predict the Changing Space Environment and Its Societal Impact | |||
| 3 | Explore Space to Reveal Universal Physical Processes | |||
|
|
||||
| GDC Primary Objective | Characterize and understand how the ionosphere-thermosphere behaves as a system, responding to, and regulating, solar wind/magnetosphere energy input. | |||
| GDC Measurements and Description | Gather simultaneous, global measurements of plasma and neutral gases and their dynamics, and magnetosphere energy/mass input, using 4-6 multiple platforms in 80° inclination, circular orbits (320 to 450 km) equally spaced in local time. | |||
|
|
||||
| GDC Science Objectives | GDC Scientific Merit | GDC Space Weather Relevance | ||
|
|
||||
| Understand the dynamic, energy/ momentum exchange between ionized/ neutral gases at high latitudes and their coupling and feedback to the magnetosphere and solar wind. | Will determine how the global IT system participates as an active element in the evolution of storms. | Enable prediction of how high-latitude structures in the ionosphere and thermosphere are driven by magnetosphere input and then propagate to mid and low latitudes. | ||
| Determine the global response to the AIM system to magnetic activity and storms. | GDC will determine how winds, temperature, and chemical constituents interact to produce the observed global neutral and plasma density responses of the global IT system. Simultaneous measurements of global neutral and plasma parameters will for the first time provide all of the information required to expose how changes in the system at different locations are related. |
Enable prediction of how neutral and plasma densities and motions respond to magnetic activity and storms. | ||
| Determine the influence of forcing from below on the ionosphere/ thermosphere system. | GDC will measure the global variability of thermosphere tides on a day-to-day basis for the first time. GDC will show how waves/tides of tropospheric origin contribute to the mean structure, dynamics, and electrodynamics of the ionosphere and upper thermosphere. |
Provide a means to predict how the ionosphere and thermosphere will react to strong tidal and gravity wave forcing from below. | ||
|
|
||||
circular orbits within the altitude region (300-450 km) at high inclination. Table 8.1 summarizes the science objectives, scientific merit, and space weather relevance of GDC, and how it relates to motivations and related questions of the current decadal survey.
Mission Configuration
The basic approach of GDC is straightforward: a suite of six satellites will gather simultaneous, global measurements of key ionospheric and thermospheric parameters using identical instruments on high-inclination platforms, executing circular orbits along planes evenly distributed in local time. Each satellite includes an identical suite of notional instruments, as listed in Table 8.2. The instruments include those that measure the neutral and ionized gases and their motions and hence are used to fully describe the global dynamics of the co-existing ionized and neutral fluids that define the IT system. Also included are a magnetometer and energetic particle detector in order to measure energy and momentum drivers from the magnetosphere. The satellites, in their final configuration, will have circular orbits that are initially at 450 km. The satellites will then slowly decay in altitude due to atmospheric drag. When the altitude decays
TABLE 8.2 Geospace Dynamics Constellation (GDC) Key Parameters to Be Measured from Space
|
|
||||
| Notional Instrument | Key Parameters | Nominal Altitude (km) | ||
|
|
||||
| Ion Velocity Meter (includes RPA) | Vi, Ti, Ni, broad ion composition | 300-400 | ||
| Neutral Wind Meter (NWM) | Un, Tn, Nn, broad neutral composition | 300-400 | ||
| Ionization Gauge | Neutral density | 300-400 | ||
| Magnetometer | Vector B, Delta B, currents | 300-400 | ||
| Electron Spectrometer | Electron distributions, pitch angle (0.05 eV to 20 keV) | 300-400 | ||
NOTE: All instruments have extensive flight heritage.
to about 320 km, each satellite will then use on-board propulsion to re-boost to 450 km, a maneuver that will be completed in a single orbit. Such a re-boost is a routine maneuver expected to be required approximately once every 6 months, depending on solar activity.
The nominal plan for GDC is to have six identical satellites that will spread into six equally spaced orbital planes separated by 30° longitude, thus providing measurements at 12 local times (LTs), with a resolution of 2 hours of LT, as shown in Figure 8.20a. The satellites will nominally have an inclination of 80°, in order to use precession to help separate the local time planes, while maintaining adequate coverage of the high-latitude region.
Three main orbital configurations were considered by the AIMI panel:
1. Spacecraft fully spread out in latitude to provide continuous, global coverage (see Figure 8.20a);
2. Spacecraft configured as an “armada” with simultaneous, dense coverage at high latitudes alternating between polar cap regions every 45 minutes (Figure 8.20b); and 4.
3. Satellites configured to orbit in two separated three-satellite armadas, such that three are in the Northern Hemisphere while three are in the Southern Hemisphere, providing simultaneous coverage of both polar regions every 45 minutes (Figure 8.20c).
Both configuration 2 and configuration 3 gather consolidated measurements at the mid- and low latitudes, with simultaneous crossings of the equator by all six satellites every 45 minutes (Figure 8.20d), while the entire globe is sampled every 90 minutes at 12 local times (as is the case for configuration 1). The panel notes that only minimal amounts of propulsion are needed to alternate between these configurations and that the “station keeping” time to change and maintain these configurations is very short.
Initial Deployment Phase and Operational Strategy
The most cost-effective launch approach (given available launchers) would be to launch all six satellites with one launcher. In this case, the satellites are first placed in a highly elliptical orbit plane (e.g., with perigee of 450 and apogee of 2,000 km) with an 80° inclination. As they then precess, these satellites will spread out in equally separated local time planes (requiring ~12 months). Note that propulsion can be used to decrease this deployment time. In this scenario, the apogee of one satellite is immediately lowered to provide an initial 450-km circular orbit, while the remaining five satellites precess in local time. After about 2.5 months, in which the satellites have precessed 30 degrees in local time, a second satellite orbit is changed to 450 km circular. The process continues until all six are spread out equally and converted to 450-km circular orbits. During the time required to establish the final distribution in local time of the six satellites, this initial observing phase permits “pearls-on-a-string” observations by the satellites along
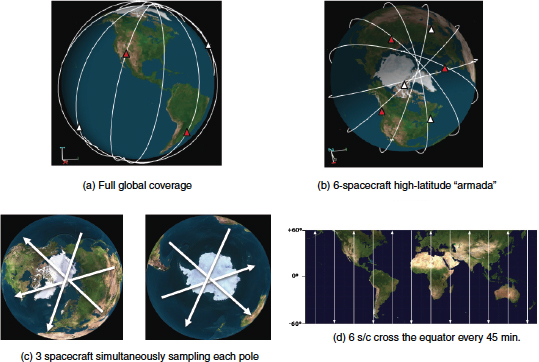
FIGURE 8.20 Various orbital configurations and sampling options offered by a six-satellite constellation. SOURCE: (a-c) Orbital configurations courtesy of the Aerospace Corporation using Earth images provided by Living Earth, Inc. (d) NASA Goddard Space Flight Center.
highly elliptical orbits that will gather data that will address important science questions under AIMI science goals 2, 3, and 4, in addition to science goal 1, thus cutting across all three AIMI science priorities for the 2013-2022 decade.
Baseline Mission and Possible Descope
The GDC baseline mission can fully meet its science objectives with a complement of six satellites as discussed above. These satellites will gather data along six orbit planes, sampling 12 local times with 2-hour spacing, providing continuous global measurements as they orbit Earth every 90 minutes. This temporal coverage is sufficient for studies of large-scale processes at high latitudes and is more than adequate to resolve major changes to the IT system during magnetic storms, whose main phases typically last 6-8 hours. The longitude/local time coverage of six satellites is sufficient to resolve tidal and planetary wave effects, including the resolution of terdiurnal tides. Another advantage of six satellites is that three can be placed in the Northern Hemisphere high-latitude region, while three are simultaneously observing in the Southern Hemisphere high-latitude region, providing data that address inter-hemispherical asymmetries and energy input along six local time planes within each polar region. In addition, six satellites can be launched by one
launcher (in a manner similar to the launch and separation of the six COSMIC satellites on one launcher), and operations and telemetry transmissions are very straightforward. If the estimated cost of the nominal GDC configuration with six satellites falls outside of available budget limits, the panel also considered a GDC constellation with only four satellites. In this case, the prime GDC science objectives can still be met, yet in a less robust sense. Coverage becomes more regional and less local, because only eight local time planes can be supported. Nevertheless, such an observing scenario would provide important strides forward in understanding of the AIM system.
Expected Outcomes
The IT constellation proposed here will provide a major advance in the field of heliophysics, addressing fundamental physical processes and providing a new level of understanding of geospace. Specifically, through its global and simultaneous measurements of interconnected state variables, GDC will provide (1) breakthroughs in understanding of feedbacks between field-aligned currents, ion drifts (electric fields), conductivities, neutral densities, and winds that result from the interaction between the atmosphere-ionosphere and the magnetosphere; (2) fundamental discoveries of global ion-neutral coupling and feedback processes active in the geospace-atmosphere system; (3) unprecedented knowledge about how the ionosphere-thermosphere system at global, regional, and local scales responds to variations in solar EUV irradiance, tropospheric forcing, and solar wind (magnetospheric) driving; and (4) the data required to advance space weather models of the AIM system to the next level of sophistication.
8.5.1.2 DYNAMIC (Dynamical Neutral Atmosphere-Ionosphere Coupling) Mission (Moderate Class)
Overview
A highly compelling, complementary, and somewhat less expensive way to advance knowledge of the AIM system would be to devote a mission to answering the question, How does lower-atmosphere variability affect geospace? The primary goal of DYNAMIC is to address wave coupling with the lower atmosphere, and to come to near-closure on understanding how lower-atmosphere variability drives neutral and plasma variability in the IT system. It concentrates on revealing and understanding the processes (i.e., wave dissipation, mean-flow interactions) that underlie the transfer of energy momentum into the IT system (especially within the critical 100- to 200-km-height regime) and the thermosphere and ionosphere variability that these waves incur at higher altitudes.
Mission Configuration
The above science focus translates to a mission involving instruments that remotely sense the lower and middle thermosphere while also collecting in situ data at higher altitudes. A key mission driver is the need to address atmospheric thermal tides, which demand measurements over all local times. Since satellites generally take weeks to months to precess through 24 hours of local time, one therefore must trade latitude coverage against local time precession rate, or possibly consider multiple satellites. To include important wave sources at high latitudes such as weather systems and stratospheric warmings, and moreover to separate aurorally generated waves from those originating in the lower atmosphere, a high-inclination (75°-90°) satellite is required. However, for these orbital inclinations, 24-hour local time precession occurs over a time period that exceeds that of important variability that needs to be captured. Taking these factors into account, the preferable strategy is two identical satellites in 80° inclination orbits at 600-km altitude, with their orbital planes spaced about 6 hours apart in local time. Assuming measurements are made at four local times over all longitudes in one day, all zonal (longitudinal) components of the diurnal (24-hour) tide would be fully characterized once per day, and semidiurnal (24-hour) tides as well as the diurnal mean
TABLE 8.3 DYNAMIC Key Parameters to Be Measured from Space
|
|
||
| Instrument | Key Parameters | Altitude Range |
|
|
||
| Limb Vector Wind and Temperature Measurement WIND (1 unit includes 2 telescopes) | Vn(z) - vector T (z) | 80-300 km 80-300 km |
| Far Ultraviolet Imager (FUV) | Altitude profiles: O, N2, O2, H, O+ | 110-300 km |
| Maps: Q, Eo, O/N2, O+, bubbles | 200-600 km | |
| Ion Velocity Meter (IVM) | Vi | In situ |
| Neutral Wind Meter (NWM) | Vn - vector | In situ |
| Ion Neutral Mass Spectrograph (INMS) | O+, H+, He+ O, N 2, O2, H, He | In situ |
NOTE: The IVM, NWM, and INMS are on the ram and anti-ram sides of the spacecraft. Only one operates at a time.
All instruments have extensive flight heritage. Technology investments will improve performance and provide additional capabilities.
would be acquired about once every 20 days. Gravity waves would be measured throughout each orbit, and planetary waves would easily be extracted with 1-day resolution. With the exception of semidiurnal tides, all wave-wave interactions could be explored, and on a 20-day timescale the interactions between the wave field and the mean state could be explored. In situ plasma and neutral responses at 600 km to these wave inputs would be measured over similar timescales.
Table 8.3 lists the key parameters that have to be measured to achieve the main objectives and science questions defining the mission, which are tabulated in Table 8.4. Table 8.3 assumes an instrument to measure horizontal winds and temperatures from about 80 to 250 km, day and night, with horizontal and vertical resolutions on the order of 100 km and 2-10 km, depending on height. Instruments consisting of flight heritage components approaching this capability are thought to exist at TRL 5,3 but flight test opportunities are required to establish their true capabilities. A flight-tested FUV imager already exists, and this would provide key measurements of neutral and ionized constituents in the lower and middle thermosphere regime. In situ instruments exist to make the required in situ measurements of neutral and ion composition, winds, and drifts, but further technology developments are underway to enhance performance and reduce size, power, and weight; it is important that these technology developments be supported, given that these types of instruments are likely to be flown on almost any terrestrial or planetary ionosphere-thermosphere mission.
It is important to note that while DYNAMIC’s primary focus is to address the question of meteorological driving of geospace, the orbital sampling and instruments that are flown also address several of the science questions of GDC. For instance, the composition, temperature, and wind measurements will enable understanding of the relative roles of upwelling, advection, and thermal expansion in determining latitude-time evolution of the O/N2 ratio during changing geomagnetic conditions, which affects total mass density and plasma density concentrations. Measurement of winds, plasma drifts, and plasma densities at high latitudes will lead to estimates of Joule heating, as well as to estimates of a number of other plasma-neutral interactions at high and low latitudes. In addition, the simultaneous measurement of lower-thermosphere winds and plasma drifts at higher altitudes (or, equivalently, electric fields) will enable delineation of the disturbance dynamo in addition to the tidal-driven dynamo.
________________________
3 For an explanation of technology readiness levels, see J.C. Mankins, NASA Advanced Concepts Office, Office of Space Access and Technology, “Technology Readiness Levels: A White Paper,” April 6, 1995; available at http://www.hq.nasa.gov/office/codeq/trl/trl.pdf.
TABLE 8.4 DYNAMIC Science and Relevance to Space Weather
|
|
||||
| Solar and Space Physics Motivations | 1 Understand Our Home in the Solar System | |||
| 2 Predict the Changing Space Environment and Its Societal Impact | ||||
| 3 Explore Space to Reveal Universal Physical Processes | ||||
|
|
||||
| DYNAMIC Primary Objective | Characterize and understand how the lower atmosphere drives IT variability. | |||
| DYNAMIC Secondary Objectives | Characterize and understand the IT response to change magnetosphere forcing Neutral-plasma interactions in the presence of a magnetic field | |||
| DYNAMIC Measurements and Description | Key neutral and ion state variables; high-resolution remote sensing and in situ Cost category A, 2 spacecraft mission, orthogonal circular 80° LEO orbits | |||
|
|
||||
| DYNAMIC Science Questions | DYNAMIC Scientific Merit | DYNAMIC Space Weather Relevance | ||
|
|
||||
| How and to what extent do waves from the lower atmosphere determine the variability and mean state of the IT system? | “Meteorological influences from below” is a new discovery and a fundamental problem; come to closure on this question. | Enable prediction of large- and small-scale structures in the ionosphere and thermosphere driven by waves. Enable prediction of regions that would seed ionospheric instabilities. |
||
| How does the global wave spectrum evolve in the thermosphere, and how does the mean thermosphere state respond to this wave forcing? | Wave coupling, dissipation, and forcing are fundamental to all planetary atmospheres. Defining and understanding the mean state of the IT system is a fundamental question. |
How the IT system responds to variable forcing depends on the mean state of the system. | ||
| How do neutral-plasma interactions produce neutral and ionospheric density changes over local, regional, and global scales? | Provide the first comprehensive view of the dynamo process over multiple scales. Understand how chemical processes, winds and electric fields combine to drive ionosphere variability. |
Provide knowledge of plasma gradients and other spatial and temporal variability key to radio-based operational needs. | ||
| What is the role of gravity waves in “seeding” equatorial Rayleigh-Taylor instabilities that lead to plasma bubbles (depletions)? | Cross-scale plasma-neutral processes in the equatorial ionosphere are fundamental. Dispel existing controversies on the origins of plasma bubbles that lead to plasma irregularities and radio scintillations. |
Develop the basis for forecasting ionospheric scintillations. | ||
| What is the relative importance of thermal expansion, upwelling, and advection in defining total mass density changes? | This question is fundamental to understanding the global IT response to magnetospheric forcing. | Develop a better physical basis for empirical drag prediction models. | ||
|
|
||||
8.5.1.3 ESCAPE (Energetics, Sources and Couplings of Atmosphere-Plasma Escape) Mission (Medium Class)
Overview
With the recognition that outflows of ionospheric ions can have profound effects on the AIM system, it has become abundantly evident that understanding of the outflow process is severely lacking, especially during episodic space weather events when O+ ion outflows become superfluent. An important step forward in remedying this deficiency can be accomplished with a dual spacecraft mission identified here as ESCAPE. Its configuration and its instrumentation resemble those of the SWMI panel mission MISTE, but, with its closer vertical separations and lower-altitude apogee, ESCAPE achieves relatively high-accuracy magnetic
alignments at altitudes below the ion baropause (~2,000-km altitude), where upflowing ionospheric ions become sufficiently energized to escape coulomb collisions and gravity. The primary goal of the ESCAPE mission is to answer the question, How are ionospheric outflows energized?
Despite the many successes of satellite missions devoted to the physics of auroral and polar-region particle acceleration, the physical processes of conversion of electromagnetic energy into particle energy, the evolution of energy conversion and particle acceleration along magnetic field lines, and the control of ionospheric outflows by plasma-neutral interactions are yet to be discovered because two spacecraft have never been accurately positioned along magnetic field lines while measuring ionized and neutral gas properties and simultaneously imaging the aurora at their ionospheric footpoints. A key aspect of such measurements, relevant to space weather prediction, is to determine how the outflow flux and other properties such as composition, density, and energy vary with electromagnetic and precipitating particle energy inputs into the outflow source region; e.g., the efficiency of energy conversion may be quantitatively expressed as an intensive transport relation between electromagnetic energy flux and particle energy flux. Such relationships are crucial elements of simulation models of AIM dynamics, yet little reliable information is available on their form.
By combining two-point ESCAPE measurements with solar wind and interplanetary magnetic field measurements; ground-based radar, lidar, imaging, and TEC measurements; and global geospace simulations, the ESCAPE mission can also address two related, global questions directly aligned with AIMI panel science priorities 1 and 3: How do interplanetary and AIM conditions control outflows, their distributions, and fluxes? How does the AIM system respond to ionospheric outflows?
ESCAPE science objectives and their connections to the heliophysics decadal survey science themes are summarized in Table 8.5, together with assessments of the mission’s scientific merit and relevance to space weather applications.
TABLE 8.5 ESCAPE Science and Relevance to Space Weather
|
|
||||
| Solar and Space Physics Motivations | 1 Understand Our Home in the Solar System | |||
| 2 Predict the Changing Space Environment and Its Societal Impact | ||||
| 3 Explore Space to Reveal Universal Physical Processes | ||||
|
|
||||
| ESCAPE Primary Objective | Determine how ionospheric outflows are energized, the processes controlling their fluxes and distributions, and how they affect the AIM system. | |||
| ESCAPE Orbital Configuration and Key Measurements | Acquire FUV auroral images and in situ measurements of charged particles, neutral gases, and electromagnetic fields at two points along magnetic flux tubes using 2 spacecraft in 84° inclination, coplanar elliptic orbits with collinear lines of apsides, 180° phase difference in apogees. Two orbital phases: (1) topside perigee, 500 km × 2,500 km orbits; (2) bottomside perigee, 200 km × 2500 km orbits. | |||
|
|
||||
| ESACPE Science Objectives | ESCAPE Scientific Merit | ESCAPE Space Weather Relevance | ||
|
|
||||
| Understand how ionospheric outflows are energized. | Promises breakthroughs in physics of charged-particle acceleration, plasma-neutral interactions, and planetary atmospheric escape. | Proved transport relations needed in geospace forecast models: out flow responses as functions of drivers. | ||
| Understand how interplanetary and AIM conditions control outflows, their distributions and fluxes. | Determines causal mechanisms of upper atmospheric, ionospheric variability, and planetary outflows. | Develop outflow climatology: empirical basis for predicting IT disturbances, magnetosphere mass compsition. | ||
| Determine how the AIM system responds to ionospheric outflows. | Resolves wave and particle couplings between collisional and collisionless media and their regulation of AIM system dynamics. | Enable prediction of IT cavitation, upwelling in outflow processes: affects drag prediction and radio propagation. | ||
|
|
||||
TABLE 8.6 Key Parameters to Be Measured by ESCAPE
|
|
|||
| Package | Instrument | Key Parameters | |
|
|
|||
| Fields | Double probe | Vector E, δE (dc to 8 MHz) | 3D |
| Magnetometer | Vector B, δB (dc to 8 MHz) | 3D | |
| Langmuir probe | Plasma density, temperature | ||
| Plasma | Thermal particle spectrometers | Ion, electron core distribution (0.1-20 eV) | ~3D |
| Superthermal particle | e-, H+, He+, He++, O+ distributions (5 eV-30 keV) | 2D | |
| Gas | Ionization gauge | Neutral density | |
| Neutral wind sensor | Vector winds (within ±1000 m/s) | ||
| Mass spectrometer | Ion, neutral composition: O+, H+, He+, O, N2, O2, H, He | ||
| Remote | FUV imager—1356, LBH-S | Auroral Q, E0; O/N2 (30° FOV, 0.5° res., <1 min) | |
| Ionospheric sounder | Electron density profile | ||
NOTE: Versions of all instruments have extensive flight heritage.
Mission Configuration
ESCAPE achieves the necessary measurements with two identically instrumented, three-axis stabilized spacecraft (MISTE employs despun platform segments), nominally in 84°-inclination, coplanar elliptical orbits with collinear lines of apsides and apogees of the two spacecraft 180° out of phase. The perigee of the nominal initial orbits (500 km × 2,500 km) is in the topside ionosphere. When one spacecraft is at higher altitude, it measures electromagnetic and precipitating particle energy inputs and properties of outflowing ions, while the magnetically aligned low-altitude spacecraft measures the properties of the ion and neutral gas source region and physical attributes of the energy conversion process. A wide range of vertical separations is achieved, including over the equatorial ionosphere, as the lines of apsides complete a full rotation in about 4.5 months. With additional propellant, the perigees of the spacecraft are lowered midway through the mission from 500 km to 200 km, thereby providing source region measurements in the bottomside ionosphere during the second orbital phase (200 km × 2,500 km) of the mission.
Table 8.6 lists the key parameters that are required to achieve closure of primary mission science. The cost envelope of the complete ESCAPE mission is estimated to be like that of a mid-range Solar Terrestrial Probe. It achieves many science targets of the 2009 Heliophysics Roadmap STP#5 called ONEP (Origins of Near-Earth Plasmas). Descoped versions of ESCAPE would carry fewer instruments and could be designed for a single orbital phase. As an example, if the mission were configured for only the higher-altitude perigee phase (500 km × 2,500 km), one or more of the neutral-gas instruments might be eliminated. With compromises in the time resolution of FUV images, both spacecraft could also be deployed as spinning platforms, which would lessen the instrument complexity and mass overhead required for dc electric, dc magnetic, and thermal particle measurements. Further descopes might include eliminating one or both imagers and/or the ionospheric sounder. A suitably descoped but still scientifically vital ESCAPE mission would likely fit in the Medium-class Explorer program envelope.
8.5.1.4 MAC (Magnetosphere-Atmosphere Coupling) Mission (Medium Class)
Overview
Recent advances resulting from studies of Earth’s upper and lower atmosphere and magnetosphere have revealed the importance of the dynamic connection between these regions. At high latitudes the ionosphere
and thermosphere interact with energy inputs from the magnetosphere that can be characterized by the field-aligned Poynting flux and the flux of the precipitating charged particles. Variations in these inputs are expected to be among the largest sources of variability in the ionosphere and thermosphere. However, they are poorly understood and poorly represented in global models due largely to the inability so far to identify the most important spatial and temporal scales that characterize the interaction. Magnetospheric energy inputs, which can vary with timescales of a few minutes and be input over spatial scales of 100 km, are redistributed as heat and momentum in the ionosphere and thermosphere, producing changes in the dynamics and effective conductance over spatial scales of thousands of kilometers and temporal scales of many hours. Changes in the neutral atmosphere dynamics and conductance also change the internally generated electric fields and the coupling processes to the magnetosphere. Thus the ability to specify the energy input and view the dynamic state of a large volume at middle and high latitudes over time periods ranging from less than 1 minute to many tens of minutes is necessary to determine how magnetosphere-atmosphere coupling processes affect the behavior of both regions.
This challenge can be efficiently met with a Magnetosphere-Atmosphere Coupling (MAC) mission. With two spacecraft spaced in the same orbit in the ionosphere and a single satellite imaging the sampled volume from high altitude, it is possible to identify coherent spatial features in the input drivers from the magnetosphere and the temporal and spatial scales over which the ionosphere and thermosphere respond. The MAC mission objective, science questions, and their connections to the heliophysics decadal survey science motivations are summarized in Table 8.7, together with assessments of the mission’s scientific merit and relevance to space weather applications.
Mission Configuration
MAC provides the necessary measurements with two identically instrumented, three-axis stabilized spacecraft, nominally in the same circular orbit with altitude near 400 km and inclination 78°. Each space-
TABLE 8.7 MAC Science and Relevance to Space Weather
|
|
||||
| Solar and Space Physics Motivations | 1 Understand Our Home in the Solar System | |||
| 2 Predict the Changing Space Environment and Its Societal Impact | ||||
| 3 Explore Space to Reveal Universal Physical Processes | ||||
|
|
||||
| MAC Primary Objective | Determine how magnetosphere-atmosphere coupling processes determine the behavior of both regions. | |||
| MAC Orbital Configuration and Key Measurements | Two spacecraft in the same 400 km circular orbit with 78° inclination and having variable separations varying from 30 seconds to ½-orbit period. Each measures the neutral and charged gas properties and the electromagnetic and particle energy inputs. One satellite in 400 km × 12,000-km orbit with 63.5° inclination images the volume sampled by the lower altitude satellite at high latitudes with spatial resolution better than 100 km. | |||
|
|
||||
| MAC Science Objectives | MAC Scientific Merit | MAC Space Weather Relevance | ||
|
|
||||
| Determine the spatial and temporal scales over which electromagnetic energy is delivered to the atmosphere. | A major feedback in the coupling between the magnetosphere and the AIM. | Critical to development of accurate predictions for satellite drag and ground induced currents. | ||
| Establish the critical spatial and temporal scales for ion neutral coupling processes that feedback to the magnetosphere. | The link between spatial scale and temporal persistence determines the heat and momentum transfer. | Applications to the development of ionospheric irregularities and atmospheric heating. | ||
| Understand the roles of winds and conductivity in the penetration of magnetospheric drivers to low latitudes. | Established the link between magnetospheric drivers and AIM drivers. | Critical for the assessment of interplanetary influences on the appearance of plasma structures at low latitudes. | ||
|
|
||||
TABLE 8.8 Key Parameters to Be Measured by MAC
|
|
||
| Notional Instrument | Key Parameters | |
|
|
||
| LEO Thermal Ions (in situ) | Ion velocity vector (±3,000 km/s) Ion temperature 300-10,000 K Major ion composition (H+, O+) Total ion concentration | |
| LEO Neutral Gas (remote sensing 100 km to 350 km) | Neutral wind vector profile (±800 m/s) O/N2 density profile | |
| LEO Fields (in situ) | Magnetic field perturbation vector Electric field vector | |
| LEO Particles (in situ) | Pitch angle/energy distribution Ions and electrons 30 eV to 30 keV | |
| HEO FUV Imaging 1356, LBH-S, LBH-L | Auroral images ~100 km spatial resolution, ~3 minute cadence | |
|
|
||
craft has propulsion that allows small adjustments in the orbit eccentricity, allowing the satellites to fly in a “string-of-pearls” configuration with controlled temporal separations that vary from 0 seconds to ½-orbit period. Each spacecraft will measure the electromagnetic energy flux and the precipitating energetic particle flux incident to the atmosphere with a temporal resolution of 1 second or better. The same satellites will measure the ion and neutral density and dynamics at altitudes between 100 km and 400 km, thus allowing the response of the atmosphere to the energy inputs to be specified. Spatial and temporal ambiguities will be resolved by identifying spatial features from cross-correlation between the two LEO measurement sets and establishing coherence of the identified features through FUV imaging in the same volume from a high-altitude satellite in a 400 km × 12,000 km orbit with a 63.4° inclination (Table 8.8).
8.5.2 Explorers, Suborbital, and Other Platforms
The relative proximity of the AIM system makes it amenable to observational strategies involving a wide variety of platforms. This attribute is a significant strength in crafting a program that is responsive to budgetary realities and to the changing climate of programmatic risk factors.
8.5.2.1 Explorer Program Enhancement
The NASA Explorer program has long been instrumental in the advancement of AIM science. The Orbiting Geophysical Observatory missions, Atmospheric Explorers, and Dynamic Explorers opened whole new areas of scientific inquiry into the physics and chemistry of the AIM regions. Later missions such as IMAGE (Imager for Magnetopause to Aurora Global Exploration) and Aeronomy of Ice in the Mesosphere have provided system-level information on the behavior of the magnetosphere effective in the upper atmosphere and ionosphere, and the conditions at the boundary between the atmosphere and space, respectively. These notable achievements could be followed by an Explorer mission that investigates the coupling of energy between the regions or the development of large-scale structures and emergent behavior in the system. The ESCAPE and MAC missions are two such examples provided in this chapter.
Budgetary pressures require missions to stay on schedule and respect firm cost caps. These are hallmarks of the Explorer program, whose PI-led missions have historically performed in line with budgetary requirements. Explorers are not “too big to fail,” and technical, schedule, and cost risks can be, and have been, identified early. The Explorer office holds reserves at the program level and can thus better control
costs and apply fixes in individual cases as they arise on particular missions. All of these aspects of the program support a scientifically broad approach where no mission can impose the risk of cancellation on others because it experiences unforeseen cost increases. A budget line enhancement to return the Heliophysics Explorer program to a level that allows for timely, focused science missions, with a range of scales including the MIDEX, would enable significant new advances toward the AIMI panel’s top goals. The panel notes that reorganizing the STP and LWS lines to accommodate a more robust Explorer program may well make the difference between being able to support three versus two heliophysics missions for the decade. The AIMI panel supports an enhancement of the Heliophysics Explorer budget line to accomplish a broad range of science missions that can address important AIMI science challenges. The mission classes should range from a tiny Explorer that takes advantage of miniaturized sensors and alternative platforms and hosting opportunities, up to a Medium Explorer that could address multiple science challenges for the decade.
8.5.2.2 Constellations of Satellites
The importance of AIM system interactions with neighboring systems above and below dictates the need for a global-scale view of AIM system responses to various drivers. Such views will be enabled by satellite constellations with a range of capabilities in terms of state variable measurements, spatial coverage, and sampling cadence. NASA will benefit from developing innovative technologies; having methods to cost, launch, and implement multisatellite/platform programs; and working with the science community to address the challenges presented by satellite constellation missions.
Small satellites for AIMI science have proved successful and offer a unique perspective on achieving specific AIMI science objectives cheaply (thus the panel’s strong support for a tiny Explorer). This path offers low-cost satellites in ad hoc constellations, expendable platforms for exploratory research, opportunities for workforce development, and potential commercial collaborations. NASA and NSF are encouraged to jointly explore opportunities to augment, or to otherwise complement, the NSF program for CubeSat-based science missions for space weather and atmospheric research.
The AIMI panel supports development of the means to effectively and efficiently implement constellation missions, including proactive development of small-satellite capabilities and miniaturized sensors, and pursuit of cost-effective alternatives such as commercial constellations. NASA, in partnership with other agencies where advantageous, is best suited to lead this effort.
8.5.2.3 Suborbital Research
Low-cost access to space via rockets and balloons is a valuable program to the AIM community that has reached a level of maturity enabling sophisticated instrumentation and new science. Present funding for science payloads is inadequate and should be increased to take advantage of the new, near-space-observatory-class capabilities being developed. The sounding rocket program has been particularly fruitful in advancing science, training and educating students, and developing technologies. It is essential that this program be protected from infringement from other programs, including proposed low-cost orbiting platforms. Without a critical mass needed to maintain core capabilities and a small, dedicated cadre of engineers, the efficiencies of scale for maintaining the low-cost sounding rocket program would evaporate and the many key advantages of the program to NASA, including the unique research capabilities it offers to the nation, would be lost.
The AIMI panel supports maintaining a strong suborbital research program by continuing development of observatory-class capabilities such as a high-altitude sounding rocket and long-duration balloons, and expanding funding for science payload development for these platforms.
8.5.2.4 Strategic Hosted Payloads
A simple review of the plethora of robust and useful measurements from NOAA’s powerful GOES platform demonstrates the possibilities that continuous observations of select scientific parameters can provide. For example, GOES provides in situ measurements of the magnetic field, energetic particles, and solar emissions. These data are primarily for space weather applications, but they provide important information for research studies as well. In the past decade, a vision for other AIMI instruments in geosynchronous orbit has grown to include imagers of the IT system at wavelengths tuned to the science target. Such observations offer compelling, continuous observations of the IT system over large regions on Earth. The hosting of payloads in these orbits offers a cost-effective way to make a critical measurement for AIMI science that would otherwise be allocated to an Explorer, LWS, or STP mission. Conversely, strategic observations in place reduce the costs of future missions that require the measurements for closure, just as most AIMI missions benefit scientifically from upstream solar wind measurements.
The AIMI panel supports development of a strategic capability to make global-scale AIMI imaging measurements from host spacecraft, notably those in high Earth orbit and geostationary Earth orbit, as is currently done in support of solar (GOES SXT) and magnetospheric (TWINS, GOES, LANL) research.
The spaceflight missions discussed in the previous sections will be greatly enhanced by the acquisition of measurements from ground-based and suborbital platforms that leverage the inherent synergy between these different means of accessing the AIM system. Ground-based instruments have an advantage in that all local times are viewed every day. Thus, the physics and evolutionary aspects of waves, electric fields, and plasma structures can be explored over much shorter timescales than from space. Ground-based remote sensing techniques and suborbital platforms are also capable of accessing regions of the atmosphere and space that are not easily probed by orbital vehicles. On the other hand, these types of observations do not provide the global view that is demanded by several of the science questions enumerated above.
AIMI science priorities regarding ground-based facilities are aimed mainly at advancing the knowledge base regarding cross-scale coupling at local and regional scales, since this area of study is fertile ground for scientific discovery, while at the same time addressing aspects of the IT system that hold societal relevance. Thus, very significant contributions to all of the AIMI science goals described in the section titled “Science Goals and Priorities for the 2013-2022 Decade” would be addressed by the imperatives put forth below. Specific areas of contribution are noted.
8.5.3.1 Autonomous American Sector Network
As described in the section “Science Goals and Priorities for the 2013-2022 Decade,” AIMI science goal 4 seeks to understand how neutrals and plasmas interact to produce multiscale structures. An example of propagating structures over Japan is shown in Figure 8.16, but such structures also exist over the United States (Figure 8.21). At both locations they propagate in the southeastward direction during daytime until mid-afternoon, switching to southwestward in the late afternoon and evening. A distributed array of ground-based instruments extending from pole to pole and with regional (i.e., continental United States) concentrations would significantly advance understanding of hemispheric variability in these and other anomalies (e.g., the plasma plumes illustrated in Figure 8.10) arising from plasma-neutral interactions in the geospace system. Although a global sensor network is the ultimate vision, focusing the network initially
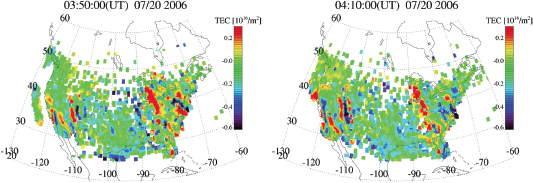
FIGURE 8.21 Two snapshots of total electron content (TEC) perturbations from Global Positioning System measurements, 20 minutes apart, over the continental United States. These are nighttime traveling ionospheric disturbances similar to those depicted in Figure 8.16 and discussed under “Science Goals and Priorities for the 2013-2022 Decade,” in the section titled “AIMI Science Goal 4.” SOURCE: Adapted from T. Tsugawa, Y. Otsuka, A.J. Coster, and A. Saito, Medium-scale traveling ionospheric disturbances detected with dense and wide TEC maps over North America, Geophysical Research Letters 34:L22101, doi:10.1029/2007GL031663, 2007. Copyright 2007 American Geophysical Union. Modified by permission of American Geophysical Union.
in the American longitudinal sector would leverage existing NSF infrastructure investments, providing an achievable goal for the coming decade.
Such a sensor network would provide significant insight into the causes of ionospheric variability relevant to space weather operational needs. One such example is the challenge of predicting and removing errors of ionospheric origin associated with the GPS-based Wide Area Augmentation System (WAAS), which was developed by the Federal Aviation Administration (FAA) to become the primary means of civil air navigation. Of particular interest are the integrity and availability of the WAAS LPV (Localizer Performance with Vertical Guidance) phase of flight that provides vertical guidance to aircraft, enabling descent to 200-250 feet above a runway (LPV approaches are equivalent to the instrument landing systems installed at many runways today). Besides loss of lock on GPS satellites owing to, e.g., signal scintillations due to plasma structures, loss of vertical navigation capability occurs due to lack of knowledge of plasma density gradients and their impact on position accuracy. High-resolution assimilative models can potentially go a long way toward ameliorating the uncertainties underlying such operational problems, but the phenomena responsible for the plasma gradients must be understood so that the correct physics and observational parameters are represented in the model. The network proposed above, and the development of embedded grid and assimilative first-principles models (see below), will represent critical steps forward in this area.
The concept of a globally distributed facility augments the current approach of clustering small, dissimilar instruments around a few large facility-class assets (e.g., ISR facilities, ionospheric heater facilities, rocket launch facilities). There is synergy between this concept and initiatives to deploy AMISR facilities in Antarctica, Argentina, and other locations. The concept also has potential synergy with NSF’s emerging small-satellite initiative, which may lead to a complementary network (or constellation) of distributed AIMI
sensors in space. The “seamless” assimilation of distributed measurements from ground and from space is at the heart of the heterogeneous facility concept discussed in Appendix C
AIMI Priority: Develop, deploy, and operate a network of 40 or more autonomous observing stations extending from pole to pole through the (North and South) American longitudinal sector. The network nodes should be populated with heterogeneous instrumentation capable of measuring such features as winds, temperatures, emissions, scintillations, and plasma parameters for study of a variety of local and regional ionosphere-thermosphere phenomena over extended latitudinal ranges.
8.5.3.2 Whole-Atmosphere Lidar Observatory
One of the most fundamental and least-understood topics in upper-atmosphere research concerns the vertical evolution of the wave spectrum from the troposphere to the lower and middle thermosphere (ca. 100-200 km) where many of the waves are dissipated. As waves propagate into the more tenuous upper atmosphere, they grow in amplitude exponentially with height; this leads to nonlinear interactions causing energy to cascade between wave scales, and to convective instability resulting in turbulence and mixing of chemical constituents, and deposition of wave momentum into the mean flow (Figure 8.22).
The curious result that the summer mesopause is the coldest region of Earth’s atmosphere is due to the downwelling (adiabatic cooling) associated with a global meridional circulation that is gravity wave driven. Recent modeling efforts demonstrate that gravity wave–mean flow and nonlinear interactions can also lead to secondary generation of waves that then propagate to even higher altitudes. How gravity waves are dissipated and drive the mean circulation and thermal structure of the thermosphere remains unclear. In addition, gravity waves interact with longer-period tides and planetary waves and modify their vertical
FIGURE 8.22 Gravity wave vertical structures seen in electron densities by the Poker Flat Incoherent Scatter Radar (PFISR) on December 13, 2006. The scale is in terms of percent perturbation relative to the mean; maximum electron density perturbations at the lowest altitudes exceed 20 percent. These authors attribute observed accelerations of the mean thermosphere winds to dissipation of the waves. SOURCE: S.L. Vadas and M. Nicolls, Temporal evolution of neutral, thermospheric winds and plasma response using PFISR measurements of gravity waves, Journal of Atmospheric and Solar-Terrestrial Physics 71:740-770, 2009.
propagation characteristics. All of these processes are subgrid processes in general circulation models of the AIM system, and their macroscopic effects need to be parameterized in such models before the influences on the mean state can be determined.
A significant impediment to further progress has been the lack of adequate observations. However, measurements of neutral gas properties from the lower atmosphere to the mid-thermosphere are within the current reach of lidar technologies. The combination of Rayleigh and resonance lidars is currently able to observe winds and temperatures from the ground to 105 km, albeit with signal-to-noise ratio (SNR) that is marginal for advancing the state of knowledge. Large-aperture telescopes and more powerful lasers are the natural remedy for limited SNR in lidar. Previous campaigns using resonance lidar techniques have demonstrated the scientific utility of using large telescope apertures of 3.5 meters at Starfire Optical Range, New Mexico, and the Air Force facility on Haleakala, Hawaii, with correlative passive optics, meteor radars, and rocket payloads to achieve desired resolutions to advance mesosphere and lower thermosphere science. A further demonstration of possibilities using large-aperture telescopes is shown in Figure 8.23, provided by a resonance lidar team working on sodium guide star studies. A 6-meter, zenith-pointing telescope comprising a spinning mercury mirror was coupled to a sodium lidar system and revealed amazing detail in MLT instability structures, identified as Kelvin-Helmholtz billows evident at the base of the sodium layer, at a temporal resolution of 60 milliseconds and a spatial resolution of 15 meters.
The available laser power has also increased exponentially over the years and, when combined with a large-aperture telescope, enables retrieval of winds and temperatures well into the thermosphere using the proven Rayleigh lidar technique. A lidar simulation based on a laser transmitter of 325 watts at 750 pulses per second and an 8-meter telescope can retrieve neutral temperatures at 200 km with 10 percent error at a range resolution of 5 km with 1-hour integration. Obviously the temporal and spatial resolution improves exponentially as altitude decreases, leading to unprecedented measurements of neutral gas properties in
FIGURE 8.23 Large-aperture Na atomic density lidar measurements at 60-millisecond and 15-meter resolution showing detailed Kelvin-Helmholtz structures at the base of the layer. SOURCE: T. Pfrommer, P. Hickson, and C.-Y. She, A large-aperture sodium fluorescence lidar with very high resolution for mesopause dynamics and adaptive optics studies, Geophysical Research Letters 36:L15831, doi:10.1029/2009GL038802, 2009. Copyright 2009 American Geophysical Union. Reproduced by permission of American Geophysical Union.
the thermosphere and mesosphere. Recent lidar developments are also providing new possibilities for observations in the thermosphere. A helium resonance lidar is under development to probe the resonance structure of metastable helium in the upper atmosphere. If the lidar demonstrated, wind and temperatures would be derivable from altitudes well above 200 km. The technological advances expected with this program will also help lead to future developments of a lidar system in space for upper-atmosphere research.
AIMI Priority: Create and operate a lidar observatory capable of measuring gravity waves, tides, wave-wave and wave-mean flow interactions, and wave dissipation and vertical coupling processes from the stratosphere to 200 km. Collocation with a research facility such as an incoherent scatter radar (ISR) installation would enable study of a number of local-scale plasma-neutral interactions relevant to space weather.
8.5.3.3 Southern Hemisphere Expansion of Incoherent Scatter Radar (ISR) Network
ISR is an extraordinarily powerful AIMI diagnostic, able to remotely sense the fundamental state parameters of the ionospheric plasma (Ne, Te, Ti, Vi) as a function of range and time. Through the use of ancillary models, higher-order parameters can also be resolved, including conductance, ion composition, Joule heating, electric current systems, and neutral wind fields. The emergence of electronically steerable ISRs in the previous decade has provided a major step forward in AIMI science. The Advanced Modular ISR (AMISR) facilities have demonstrated enormous capabilities to study the ionosphere with unprecedented resolution and precision. One example is provided in Figure 8.22, illustrating the capability of the Poker Flat AMISR (PFISR) to observe the ionospheric signatures of gravity waves in the critical 100- to 300-km-altitude region. A second example is provided in Figure 8.24, illustrating the capability of an AMISR to measure ionospheric flow fields and ion temperatures over small spatial and temporal scales.
FIGURE 8.24 Composite image showing auroral forms, F-region ion temperature, and F-region ion flows, illustrating the local reduction in electric field in the vicinity of an auroral activation—a consequence of the polarization response of the ionosphere to the increased conductivity produced by the auroral precipitation. SOURCE: J. Semeter, T. W. Butler, M. Zettergren, C.J. Heinselman, and M.J. Nicolls, Composite imaging of auroral forms and convective flows during a substorm cycle, Journal of Geophysical Research 115:A08308, doi:10.1029/2009JA014931, 2010. Copyright 2010 American Geophysical Union. Reproduced by permission of American Geophysical Union.
In addition to boasting low operation and maintenance costs, low power requirements, and a highly robust architecture, the AMISR facilities offer an extraordinary degree of experimental flexibility that has not yet been fully realized. For instance, during the 2009 International Polar Year, the PFISR facility was configured to record a vertical profile every 15 minutes for the entire year. This low-duty cycle mode was interleaved seamlessly with other experiments. Figure 8.25 shows an epoch analysis of ionospheric effects caused by corotating interaction regions extracted from these data.
AMISR facilities deployed in the Southern Hemisphere and in the southern polar regions will contribute significantly to understanding of inter-hemispheric variability that serves as the focus of the longitudinal sensor network proposed above. Collocation of the proposed whole-atmosphere lidar with such a deployment will lead to further advances in AIMI science by elucidating wave-plasma and plasma-neutral interactions over a range of scales, as well as contributing to understanding of the spatial and temporal evolution of Joule heating. Thus, with successful AMISR deployments at Poker Flat (PFISR) and at Resolute Bay (RISR), and planned deployments in Argentina and Antarctica, attention over the next decade should turn to developing technologies and strategies to fully exploit the emerging ISR network to address AIMI panel science priorities.
AIMI Priority: Develop and deploy phased-array ISR facilities in the Southern Hemisphere including Antarctica, and develop the technologies and strategies to enable autonomous, extended, and coordinated operation of these facilities.
AIMI Priority: Create a medium-scale research facility program at NSF. The above facilities are candidates for support by the NSF Geospace program and would require that a medium-scale (~$40 million to $50 million) research facility funding program be instituted at NSF to fill the gap between the Major Research Instrumentation (MRI; <$4 million) and Major Research Equipment and Facilities Construction (MREFC; >$100 million) programs.
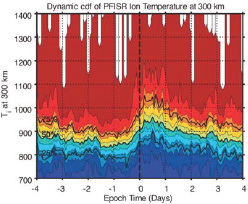
FIGURE 8.25 Epoch analysis of ion temperature affected by the arrival of corotating interaction regions over the course of a year, extracted from AMISR low-duty-cycle measurements. SOURCE: J.J. Sojka, R.L. McPherron, A.P. van Eyken, M.J. Nicolls, C.J. Heinselman, and J.D. Kelly, Observations of ionospheric heating during the passage of solar coronal hole fast streams, Geophysical Research Letters 36:L19105, doi:10.1029/2009GL039064, 2009. Copyright 2009 American Geophysical Union. Reproduced by permission of American Geophysical Union.
8.5.3.4 Ionospheric Modification Facilities
Ionospheric modification using high-frequency (HF) radio transmitters, or “heaters,” provides a powerful tool for exploring the physics of the upper atmosphere from the ground. Heating facilities treat the ionosphere as a “laboratory without walls,” providing insight into complicated plasma physics processes that occur elsewhere in the cosmos but that are difficult or impossible to explore in the laboratory. Ionospheric heaters affect the propagation of radio signals; they generate airglow and radio emissions that can be observed from the ground; they create plasma density irregularities that can be studied using small coherent scatter radars; they provide access to chemical rate constants that are otherwise hard to quantify; they accelerate electrons, mimicking auroral processes; and finally, they modify plasma density and electron and ion temperatures and enhance the plasma and ion lines observed by incoherent scatter.
The DOD operates and maintains the world’s largest ionospheric modification facility, HAARP, near Gakona, Alaska. HAARP is not collocated with an incoherent scatter radar, and so its full potential has not been realized since the phenomena it creates cannot be fully diagnosed. Figure 8.26 shows an image of an artificial aurora created at the HAARP facility. Another ionospheric modification facility is under construction at the Arecibo Radio Observatory. While this facility will be modest in power compared to HAARP, its collocation with Arecibo, the world’s most sensitive incoherent scatter radar, raises the prospect of discovery science in the areas of artificial and naturally occurring ionospheric phenomena.
The Arecibo heater came about through close collaboration between DOD and NSF. The AIMI panel regards this kind of interagency cooperation as a model to be followed for the utilization of existing ionospheric modification facilities as well as the planning and development of new ones.
AIMI Priority: Fully realize the potential of ionospheric modification techniques through collocation of modern heating facilities with a full complement of diagnostic instruments including incoherent scatter radars. This effort requires coordination between NSF and DOD agencies in the planning and operation of existing and future ionospheric modification facilities.

FIGURE 8.26 Artificial aurora induced by high-power HF radiation from the HAARP heater facility. The rayed structures are about 100 meters in width and are aligned with the geomagnetic field. SOURCE: E. Kendall, R. Marshall, R.T. Parris, A. Bhatt, A. Coster, T. Pedersen, P. Bernhardt, and C. Selcher, Decameter structure in heater-induced airglow at the High-frequency Active Auroral Research Program facility, Journal of Geophysical Research 115:A08306, doi:10.1029/2009JA015043, 2010. Copyright 2010 American Geophysical Union. Reproduced by permission of American Geophysical Union.
As noted in numerous examples within this chapter, cross-scale coupling processes are intrinsic to IT system behavior. That is, phenomena highly structured in space and time (e.g., wave dissipation, turbulence, electric field fluctuations) can produce effects (e.g., wind circulation, chemical transport, Joule heating, respectively) over much broader scales. By the same token, larger-scale phenomena create local conditions that can seed development of rapidly changing structures at small spatial scales (e.g., instabilities and turbulence). The current state of affairs is that parameterizations are formulated to approximate the bulk effects of small-scale phenomena in global models whose spatial and temporal resolutions preclude inclusion of physics at smaller scales. Often such parameterizations make ad hoc assumptions about the governing physics and coupling between scales, and are usually artificially tuned to yield results in global-scale models that agree better with observations.
The observational strategies suggested in this report, which place high priority on understanding how local, regional, and global-scale phenomena couple to produce observed responses at all scales, call for complementary development of theory and numerical modeling capabilities that enable self-consistent treatment of cross-scale coupling processes. The fundamental physics of small-scale phenomena needs to be developed and understood, and numerical simulations performed that validate theories and explore parameter space dependencies. These models need to be embedded in regional-scale models so that two-way interactions are self-consistently addressed, and regional-scale models need to be nested at strategic locations within global models to enable cross-scale coupling processes and their implications to be truly understood and emulated.
Finally, researchers know well from terrestrial weather forecasting the concept of assimilating real-time data to nudge the solutions of physics-based models toward the observed state of the system. Global weather models assimilate data of various types over the globe to provide local, regional, and global forecasts as part of our daily lives. A similar path needs to be followed for the IT system to attain a true space weather forecast capability. During the next decade, assimilative models for the IT need to be developed, and such models need to be explored to reveal the types and distributions of measurements that provide optimal characterizations of the system at local, regional, and global scales.
In summary, and as an indication of its priorities for progress in theory and modeling, the AIMI panel notes that:
• Comprehensive models of the AIM system would benefit from the development of embedded grid and/or nested model capabilities, which could be used to understand the interactions between local- and regional-scale phenomena within the context of global AIM system evolution.
• Complementary theoretical work would enhance understanding of the physics of various-scale structures and the self-consistent interactions between them.
• Comprehensive models of the AIM system would benefit from developing assimilative capabilities and would serve as the first genre of space weather prediction models.
The missions and initiatives outlined above will not be successful if there is not an infrastructure of additional capabilities that enable cheaper and more frequent measurements of the AIM system, that transform measurements into scientific results, that maintain the health of the scientific community, and that serve the needs of 21st-century society. These enabling capabilities (i.e., working group imperatives) fall into the following categories: innovations: technology, instruments, and data systems; theory, modeling,
and data exploitation; research to operations and operations to research; and education and workforce, and are detailed below.
8.5.5.1 Innovations: Technology, Instruments, and Data Systems
Key Instrument Development
Principal among the challenges presented to AIM science is a description of the neutral wind over the altitude range from 90 km to 300 km where a transition from a collision-dominated to a magnetized atmosphere occurs. Neutral-wind instrument development for space is a high priority for AIM science. The panel notes that reductions in mass, power, and volume of AIM space sensors would increase the effectiveness of small-satellite missions. Similarly, early action in instrument and technology development reduces the risk of unanticipated cost growth. Performed alongside a revitalized Explorer program, a new heliophysics instrument and technology development program would thus be highly complementary and support rapid scientific advancement.
AIMI Priority: An expanded instrument development program to enable new observational advances that can reduce cost risk and threats when implemented as part of satellite missions.
Data Access
The AIM community uses a wide variety of heterogeneous data sets that sample regions throughout the geospace system and are collected by space- and ground-based instruments, some of them in networks or arrays. The synthesis of data sets within arrays, with other data sets, and with global and regional models to explore frontier science issues is a major challenge for the future. The Solar and Space Physics Information System (SSPIS) was created to enable access to, and digital searching of, the many distributed data resources managed or utilized by NASA. It currently consists of a set of VxOs providing access to distributed data sets with space data model descriptors. New search-and-analysis technologies that make use of these core capabilities are now possible with a potential for significantly enhancing AIM research. In the near future SSPIS will face major challenges in providing data services for manipulation, visualization, and storage of terabyte data sets and model outputs. The development and the implementation of new capabilities are extremely slow given the minimal funding levels of the program (only 1 percent of the NASA heliophysics budget). VxOs have developed to the point that software tools can now be built by end users to support scientific studies that could not conceivably have been performed before. For geospace regions that are populated by heterogeneous sensors, this is an important capability for revealing the processes that drive the development of structure and change in the AIM system.
AIMI Priority: Create enhanced VxOs and interactive data access for system-level understanding.
8.5.5.2 Theory, Modeling, and Data Exploitation
Programmatic Support
High-priority AIMI science described throughout this chapter focuses on multiscale coupling, emergence, nonlinear dynamics, and system-level behaviors. This focus sets new requirements for research programs, computational technologies, and data analysis needs. Discovery science in all these areas requires a means of understanding global connections, sometimes across vast distances or very disparate spatial or temporal scales, while at the same time developing a deep understanding of the individual regions and
processes that are elements of these connections. Coupling within the AIM system and with other elements in the Sun-Earth system spans timescales from seconds to centuries and serves to refocus efforts in understanding global change and the role of solar variability in climate. Tackling planetary change and space climate issues is dependent on the availability of historical data sets and continuity in observations of key AIM parameters like atmospheric temperatures, composition and cooling rates, and solar inputs like spectral irradiance and interplanetary magnetic field. Finally, the future of assimilative modeling in space weather prediction rests on a continuing supply of near-real-time observations of the AIM system that provide information on large-scale features like the auroral zone and equatorial electrojet as well as small-scale gradients relevant to the triggering of ionospheric instabilities.
Advances in computer power and speed have reached the point that self-consistent simulations of multiscale coupling in the AIM system are already possible. Existing peta-scale computers have reached 300,000 cores, and powerful mega-core computers are expected in the next decade to provide the computational equivalent of 1 million to 10 million CPU cores. These computational advances will drive a revolution in the realism of simulations and the ability to reproduce the self-consistent global signatures of small-scale processes. These advances in modeling in a very real sense parallel the innovations in observational programs that are high-priority targets in this chapter. An investment in a range of technological capabilities is needed to take full advantage of these powerful computational resources, including new multiscale, multiphysics algorithms (such as adaptive mesh refinement), computational frameworks that couple physics across disparate time and spatial scales, innovative ways to mine, visualize, and analyze massive amounts of data produced by the next generation of multiscale simulations, and data assimilation technologies essential to improve space weather forecasting tools.
These requirements and technological advances compel the following:
AIMI Priority: Establish a re-balanced and expanded Research and Analysis Program with the following elements:
• Solar and space physics (heliophysics) science centers, a new program of interdisciplinary centers (heliophysics scientists with computational experts) that leverages the power of peta-scale computers to create powerful physics-based multiscale models of the AIM system and its coupling to other regions, alongside parallel efforts in data assimilation and data fusion. Similar interdisciplinary theory and modeling efforts in the range of $1.5 million to $5 million per year over 3 to 5 years’ duration but not focused specifically on geospace are funded through NSF through its Frontiers in Earth System Dynamics, and AFOSR through its Multidisciplinary Research Program of the University Research Initiative program. NASA funds smaller-scale modeling efforts within the strategic capabilities category in the Living with a Star Targeted Research and Technology program. Given the large costs of these programs, it may work best if NASA, NSF, and AFOSR coordinate their funding of these multidisciplinary programs in order to avoid duplication and ensure that essential projects are funded.
• A strengthened NASA theory program that supports critical-mass groups responding to new theoretical challenges in AIM science using a wide variety of research approaches.
• An enhanced data analysis program (attached to satellite missions and ground-based facilities) that provides a level of support needed to convert new and archived AIM observations into knowledge and understanding.
• An upgraded R&A program that is a reasonable fraction of the overall AIM budget to make sure that expenditures in the program are converted to major advances in science.
AIM Data Environment
The innovative observational and modeling programs described in this chapter will provide essential new information about how the AIM system works. However, this information will be embedded in the relationships between data sets as well as within the individual data sets themselves. It will be buried in petabytes of simulation data and in large volumes of heterogeneous data from new and ongoing space missions, from major new ground-based facilities, from suborbital platforms, and from arrays of ground-based all-sky cameras, lidars, radars, magnetometers, GPS receivers, ionosondes, imagers, and other instruments. There must be a parallel effort to develop the tools needed to convert the volumes of data into new knowledge about the AIM system. The challenge is to combine these heterogeneous data sources, housed in archives distributed around the world, into new browse summaries and new data products that contain information about AIM system behaviors in addition to the regional and process information contained in the individual data sets themselves. In turn, this global view will provide needed context for the interpretation of small-scale features and local observations.
Because of these requirements, new efforts in data exploitation and data synthesis are essential ingredients for the future of the AIM research environment. As data sources grow in size and complexity, exploiting the data requires being able to (1) locate specific pieces of information within a large distributed set of worldwide data archives, (2) manipulate and visualize the data while retaining knowledge of version information and all supporting analysis programs, and (3) combine data sources to create new data products while maintaining linkages back to the original data sources. This is where the development of data synthesis capabilities is essential. In the face of constrained budgets, much of this effort can be accomplished by using robust and sustainable commercial off-the-shelf (COTS) technologies that keep pace with new developments. To make heliophysics data “findable” by these commercial technologies requires the development of standard text-based metadata descriptors. Much of the groundwork for this capability has taken place in the last few years with the creation of an array of virtual observatories and the continuing development and implementation of the international Space Physics Archive Search and Extract (SPASE) data model.
The full and complete implementation of SPASE opens the way for the development of an array of shared software tools for essential capabilities in data mining, pattern recognition, statistical analyses, data visualization, and so on, both on the client side and on the server side in the case of large data volumes. Virtual observatories also enable the development of tools that require detailed information about instruments not easily obtained by individual investigators. One example is the calculation of common volumes in which in situ and remote-sensing measurements are made or in which space- and ground-based observations intersect.
AIMI Priority: Develop a data environment that preserves important elements of the current heliophysics data environment, while expanding the capabilities in directions that enhance data exploitation to maximize the scientific value of the data sets.
Data Synthesis
Essential to many of the AIM science frontiers identified in this chapter is the ability to synthesize information from multiple data sets into new knowledge about the AIM system. This includes, for example, mapping between geospace data sets using magnetic fields from continuously running magnetohydrodynamic simulations, browse products that superpose observations along satellite tracks onto global patterns from constellations or imagers, maps that combine information from a large number of individual ground-based instruments into global views, and combinations of ground- and space-based observations that address space-time ambiguities, among others.
AIMI Priority: Explore new data synthesis technologies to leverage the many types of AIM data into new knowledge of the AIM system required for accelerating progress on AIM system science frontiers.
Heterogeneous Data Sets
To accomplish AIM goals in the coming decade, a data environment is needed that draws together new and archived satellite and ground-based geospace data sets from U.S. agencies as well as international partners. This effort is needed to obtain the best possible coverage of the geospace system and describe its evolution over time. This data environment should also provide access to operational space weather data sets, climatological data sets, archived simulation outputs, and the latest technological advances in digital searching, storage, and retrieval and in data mining, fusion, and assimilation, as well as client-side and server-side data manipulation and visualization. These ground and space assets represent a large investment and are vital for the system science goals of the AIM program. The full value of that investment will be realized only if adequate funding is provided. The present Solar and Space Physics Information System (SSPIS) could naturally form the core of this program. The valuable multiagency and international efforts to unify standards and increase interoperability through agreements on data and metadata formats and communication protocols started under the SSPIS program must be an essential component of this effort.
AIMI Priority: Increase investment in the acquisition, archiving, and ease of use of geospace data sets.
Long-Term Data Sets
NASA and NSF should identify essential long-term data sets and pursue maintenance and preservation through funding within the heliophysics data environment activities and related NSF data archives. Some of this data, not in digital formats yet, is in danger of being irretrievably lost. A larger problem is the continuity of key long-term data sets, for example, solar spectral irradiance and 30 years of particle precipitation on operational satellites. Mechanisms do not yet exist to continue such data sets except by competing against new satellite missions. New mechanisms must be established to add instrumentation where possible on rides of opportunity and to partner with other agencies to re-establish space environment monitors on key operational satellite payloads.
AIMI Priority: Establish mechanisms for maintenance and continuity of essential long-term data sets.
Laboratory Experiments
Modeling planetary atmospheres and interpreting information in airglow and auroral emissions from Earth’s atmosphere, planetary bodies, and comets requires detailed knowledge of differential cross sections and of reaction rates. The extraction of information about planetary environments from these emissions and the design of new and innovative remote-sensing instrumentation are dependent on accurate cross-section information. Laboratory experiments are a primary source of this information and have a long history of advancing the discovery of fundamental processes in all of these environments. Critical information on rates and cross sections for key atomic and molecular processes is still lacking. One particular example where cross-section information is highly uncertain and has impeded progress is oxygen ion precipitation and backsplash during extreme space weather events.
AIMI Priority: Establish a program of laboratory experiments joint between NSF, NASA, and DOE that includes measurements of key cross sections and reaction rates.
8.5.5.3 Research to Operations and Operations to Research
Research is the foundation for future improvements in space weather services. Ionospheric models are just now beginning to reach maturity at a level that can benefit space weather customers. But at the same time, there is a major decline in support for the development and improvement of models, which are critical to operational entities.
Furthermore, model development aimed at improving forecasts requires a dedicated effort focused on validation and verification. Also, in order to quantify a model’s performance, there is a need to establish a standard set of metrics for space weather products. Under NASA, NSF, NOAA, and AFOSR sponsorship, a standard set of metrics and a skill score most appropriate for a given space weather application need to be selected that would reflect operational needs. Metrics and skill score should also be used to quantify progress with each new model version.
To reduce “the valley of death” that separates research models and operational systems, the AIMI panel suggests that operational and research agencies fund open-source models. Open-source operational models have the potential to minimize the cost of transitioning research models to operations and of maintaining the models.
AIMI Priority: Improve the effectiveness and level of support for model development, validation, and transition to operation.
Existing and planned assets that are routinely used for purposes other than space weather often have capabilities that could be utilized to return valuable space science measurements. With minimal investment, important data can be obtained from these instruments. One very-low-cost example includes tasking on a daily basis the Altair radar at Kwajalein to measure ionospheric parameters (electron density and plasma irregularities). This can easily be done during short periods interlaced between scheduled radar target acquisitions. These measurements would also benefit the users of the Altair system by providing a method to detect and forecast possible scintillation problems that could affect the radar data.
AIMI Priority: Seek high-leverage opportunities for acquiring new measurements.
It is widely recognized that space environment data provided by NOAA and DOD operational satellites for almost four decades are essential to AIMI science. Data from these satellites are of fundamental importance for space weather forecasting. They are among the most often used data sets for space science research on ionosphere/magnetosphere coupling. In addition, they are essential for studying long-term climatic changes in geospace. The following three-part imperative follows:
AIMI Priority: Leverage national investments in operational satellite data for scientific progress: (1) NOAA and DOD should maintain the space environment sensing capability that has provided data for almost four decades and should continue to acquire observations from low-Earth-orbit satellites of particle precipitation, ion drifts, ion density, and magnetic perturbations similar to those measured from POES and DMSP. (2) Open data policies should be negotiated with DOD, DOE, and other agencies (that also safeguard national security concerns). (3) DOD, NOAA, and NASA should coordinate the archiving of these data sets, making data accessible and creating tools that provide for ease of use. The present Solar and Space Physics Information System could naturally form the core of this program.
8.5.5.4 Education and Workforce
The AIM community recognizes the increasing need to promote education and training in all aspects of space science and space technology. At the same time, few educational institutions have the breadth within their faculty, or the student numbers within a department, to facilitate a complete AIM curriculum. Thus it is important to afford the opportunity for students and faculty to participate in programs that bring together varying expertise from different institutions in intensive training sessions in order to fill this pedagogical gap. NSF, NASA, and DOD should continue to support the development and execution of summer schools and workshops to provide a full spectrum of instruction in geospace science and technology. This effort is considered essential to the proper development of the next generation of space scientists and engineers. NSF should continue its Faculty Development in Space Sciences program, which provides an incentive for universities to hire faculty in geospace research. The federal government should revise export control policies to exempt basic space research from government restrictions such as those mandated under ITAR.
AIMI Priority: As described above, expand and promote education and training opportunities to develop the future generation of AIM scientists and engineers.




























































