
FINDING THE BOUNDARIES: WHEN DO DIRECT SURVEY ESTIMATES MEET SMALL-AREA NEEDS?
This session focused on the topic of producing estimates in situations in which only a small amount of information is available or there are other limitations, such as physical, temporal, or conceptual boundaries that make direct estimation difficult. In the first presentation, Robert Fay (Westat) discussed the boundaries between direct estimation and model-based small-area estimation. He noted that model-assisted estimation (Särndal, Swensson, and Wretman, 1992) can be viewed as an intermediate point between the traditional design-based approaches and model-based estimation. For the purposes of his talk, however, he included model-assisted estimation as part of direct estimation.
Theories of design-based sampling (Neyman, 1934; Hansen, Hurwitz, and Madow, 1953), although robust and useful in many applications, are based on the asymptotic properties of large samples. However, in practice, researchers are often dealing with moderate-size samples, and even in the case of large samples, the subdomains of interest are often represented by small samples. What constitutes a sufficiently large sample size depends on the intended use of the data, and this is an important question because it determines whether direct estimation is adequate for a specific task.
Fay recalled the 1976 Survey of Income and Education (SIE), which was conducted one time only, with the goal of producing state-level estimates of children ages 5-17 in poverty, with a 10 percent coefficient of variation. Because its sample was approximately three times as large as the Current Population
Survey (CPS), the SIE generally achieved this target reliability, which was considerably better than what the CPS offered, particularly in small states. Even when reliability targets were negotiated in advance, however, the impact of sampling error on the face validity of the estimates was more pronounced than survey designers anticipated. Although the SIE met the target reliability requirements, the state of Alabama protested the large decrease in its poverty rate since the preceding census. The use of small-area models to correct data problems of this type was not yet an established practice at the time.
In some situations, model-based small-area estimation represents a necessary alternative to direct estimation. Some of the earliest examples of small-area estimation include postcensal population estimates from the Census Bureau and economic series produced by researchers at the Bureau of Economic Analysis, even though these precedents use slightly different paradigms.
Several of the basic model-based approaches to small-area estimation emerged decades ago, including:
- synthetic estimation (Gonzalez and Waksberg, 1973; Levy and French, 1977; Gonzalez and Hoza, 1978),
- area-level models (Fay and Herriot, 1979),
- structure preserving estimation (Purcell and Kish, 1980), and
- unit-level models (Battese, Harter, and Fuller, 1988).
These basic approaches were followed by a number of refinements, such as mean square estimation and hierarchical Bayes approaches, he noted. Even as these model-based approaches expanded, researchers pointed out that model-assisted estimators could represent a viable alternative in some situations (Särndal and Hidiroglou, 1989; Rao, 2003).
Fay mentioned some reviews of early applications: Small Area Statistics: An International Symposium (Platek et al., 1987) and Indirect Estimators in U.S. Federal Programs (Schaible, 1996), which was based on a 1993 Federal Committee on Statistical Methodology report and includes examples of practice from several agencies. A basic resource on theory for scholars starting out in this area is the classic Small Area Estimation (Rao, 2003). Another useful review of theory is Small Area Estimation: An Appraisal (Ghosh and Rao, 1994).
It is clear that even though the theory of model-based small-area estimation has been available for decades and a number of researchers have expanded the theory, the number of applications is not yet large. Possible reasons are that model-based estimates are more difficult to produce, replicate, and combine with other estimates than direct estimates. Model-based estimates are also more difficult to document and explain to data users. For example, even when estimates of error are produced for an annual series of small-area estimates, users are typically unable to answer other questions from the published information,
such as what reliability is achieved by averaging small-area estimates for a given area over multiple years.
Some have argued that, although experimentation with model-based estimates should be encouraged, more caution should be exercised when deciding whether to publish them because they are often not equivalent in quality to the direct estimates typically published by government agencies. One approach is to clearly distinguish them from other statistical products. Fay referred to the example of the United Kingdom and the existence of experimental versus official statistics. In the United States, model-based estimates have, in some cases, been published and endorsed. The arguments for doing so are especially strong when the data produced are more informative than any other alternatives available to users, particularly when the estimates are able to meet a legally mandated need.
One example is the Current Population Survey, including its Annual Social and Economic Supplement (ASEC). The original CPS sample design was developed with national labor force objectives in mind. The first-stage design comprised strata of self-representing primary sampling units (PSUs), mostly large counties, and non-self-representing strata, each composed of PSUs of one or more smaller counties, from which one, or sometimes two, PSUs were selected at random. Because the design was originally guided by its national objectives, non-self-representing strata typically crossed state lines.
In 1973 publication began of average annual unemployment for some of the states, accomplished by a quasi-modeling that involved collapsing strata and reweighting PSUs to compensate for effects of the national stratification. The sample was soon expanded to produce estimates of annual unemployment meeting the criterion of a 10-percent coefficient of variation in each of the states (for an underlying unemployment rate of 6 percent). To avoid continuing the quasi-modeling approach, in 1984 the design was changed to state-based stratification as part of the survey redesign, which eliminated the need for these adjustments.
The ASEC supplement in the CPS has been the source of a number of small-area applications, including the Small Area Income and Poverty Estimates (SAIPE) Program, which provides income and poverty estimates for states, counties, and school districts. SAIPE is an example of a program that fills mandated needs. Considering the small CPS sample size for the target areas, the SAIPE program was quite ambitious and largely successful (National Research Council, 2000).
After the American Community Survey (ACS) was launched, the SAIPE program moved from the CPS to the ACS because of the larger ACS sample size. The ACS includes approximately 2 million interviewed households per year. The ACS pools data over 1-, 3-, and 5-year periods to produce estimates. Although the 5-year estimates produce data for the smallest publishable geographic areas, the SAIPE program currently models the 1-year ACS estimates, most of which
are not publicly released, to increase the timeliness of the data, and relies on small-area models in place of averaging over time to reduce the relative impact of sampling error. It will be interesting to assess the trade-offs related to the different releases after two or three sets of 5-year ACS estimates become available. It will also be of interest to observe whether the sampling variability of the ACS will encourage a new series of small-area applications to replace the ACS direct estimates for some uses.
Fay mentioned another case study that is worth following closely: Canada’s National Household Survey (NHS), which replaces the mandatory long questionnaire that one in five households used to receive as part of the Canadian population census. Although details are still emerging, the current plans for a voluntary survey partially integrated into the census are likely to result in lower response rates and higher variances compared with previous censuses. The case of the NHS could become an unplanned experiment in what happens when data become less reliable than users have grown to expect.
Fay also briefly mentioned his work as part of a Westat team commissioned by the National Center for Health Statistics to evaluate options for averaging several years of data from the National Health and Nutrition Examination Survey (NHANES) to produce quasi-design-based estimates for the state of California. The products will be both a weighted file and an approach to estimate the variance of the estimates.
Looking ahead, Fay predicted that the area on the boundary between traditional design-based survey estimates and small-area estimates will probably grow in importance because there is an increasing demand for subnational estimates, surveys costs are rising, and modeling tools represent a possible route for incorporating existing administrative records into the estimates. Review of the case studies presented and similar ones can help guide the evolution of policy on the use of small-area estimation at federal statistical agencies.
USING SURVEY, CENSUS, AND ADMINISTRATIVE RECORDS DATA IN SMALL-AREA ESTIMATION
William Bell (Census Bureau) discussed strategies of combining data from several sources—sample survey, census, and administrative records—to produce small-area estimates. To illustrate these procedures, he used examples from the Census Bureau’s Small Area Income and Poverty Estimates Program, which combines data from different sources to provide income and poverty estimates that are more current than census information for states, counties, and school districts. Specifically, SAIPE relies on
- direct poverty estimates from the ACS (and previously the CPS),
- prior census long-form sample poverty estimates,
- tax data from the Internal Revenue Service (IRS),
- information from Supplemental Nutrition Assistance Program (SNAP) records, and
- demographic population estimates.
All data sources, including the ones used for SAIPE, are subject to various types of error, and these must be taken into consideration when making decisions about how the data can best be combined. Bell mentioned some of the main types of error affecting data sources:
- sampling error (the difference between the estimate from the sample and what would be obtained from a complete enumeration done the same way),
- nonsampling error (the difference between what would be obtained from a complete enumeration and the population characteristic of interest), and
- target error (the difference between what a data source is estimating—its target—and the desired target).
Table 6-1 shows error types most likely to affect survey, census, and administrative records data, although all three data sources could include all three types of errors. “Census” data may or may not have sampling error, depending on whether they refer to the complete enumeration or to data from a prior census sample (also known as the census long form). The distinction is important for modeling purposes.
Both the ACS and the CPS provide data suitable to produce estimates of poverty, albeit in slightly different ways, Bell said. Their weaknesses are that they are subject to large sampling error for small areas, particularly the CPS. The census estimates have negligible (state level) or low (most counties) sampling error, but the estimates become gradually more outdated after the census income year, which is essentially a form of target error. For administrative records, sampling error is usually not a concern, but the data are subject to nonsampling error, and they are not collected with the specific goal of measuring poverty, which leads to a form of target error (for SAIPE’s purposes). In particular, the IRS tax data leave out many low-income people who do not need
TABLE 6-1 Typical Sources of Error for Different Data Sources
| Data Source | Error | ||||||||||||||||||
| Sampling | Nonsampling | Target | |||||||||||||||||
| Sample survey | X | X | |||||||||||||||||
| Census | Maybe | X | X | ||||||||||||||||
| Administrative records | X | X | |||||||||||||||||
SOURCE: Workshop presentation by William Bell.
to file tax returns, while in the case of SNAP, the qualifications for the program are different from the determination of poverty status and not everyone who is eligible participates.
Taking into consideration the errors described, there are different options for combining these data sources, Bell said. Suppose yi is a survey estimate of desired population quantity Yi for area i, and zi is a related quantity from another, independent data source. The question is how to combine yi and zi to produce an improved estimator of Yi.
One option for combining the data sources is to take ![]() with
with ![]() and
and ![]() . This assumes that the estimates from the two surveys, yi and zi, are both unbiased estimates of the target, Yi, which rarely happens in practice.
. This assumes that the estimates from the two surveys, yi and zi, are both unbiased estimates of the target, Yi, which rarely happens in practice.
An alternative is to take a weighted average of the estimates with weights instead proportional to the mean squared errors (MSEs): ![]() with
with ![]() and
and ![]() . This assumes that the mean squared errors are known, or equivalently the biases are known, which is also rare in practice.
. This assumes that the mean squared errors are known, or equivalently the biases are known, which is also rare in practice.
One could take one of these estimates, yi, and use it to define the target—in other words, assume that it is unbiased. One can then use ordinary least squares regression to adjust zi to provide an unbiased predictor of ![]() , where syn indicates a synthetic estimator.
, where syn indicates a synthetic estimator.
For a more formal modeling approach (Fay and Herriot, 1979), the following structure is assumed:
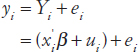
where:
yi = direct survey estimate of population target Yi for area i
ei = sampling errors that are assumed to be independently distributed with a normal N(0, vi) distribution, with vi assumed known
xi = vector of regression variables for area i
β = vector of regression parameters
ui = area i random effects (model errors), which are assumed to be independent and identically distributed according to N![]() and independent of ei.
and independent of ei.
To illustrate this with an example from SAIPE, Bell discussed the state poverty rate model for children ages 5-17. The direct survey estimates, yi, were originally from the CPS (three-year averages) but have since been replaced with single-year estimates from the ACS. The regression variables for each state include a constant or intercept term and
- a “pseudo poverty rate” for children, calculated based on the adjusted gross income and the number of child exemptions on the tax return;
- the tax “nonfiler” rate, which is the percentage of the population not represented on tax returns;
- the SNAP participation rate, which is the number of participants in the program divided by the population estimate; and
- census data in one of two forms, either the estimated state poverty rate for school-age children ages 5-17, or residuals from regressing previous census poverty estimates for ages 5-17 on other elements of xi for the census year.
One generally has reasonable estimates of the sampling variances, ni. If one also had estimates of ![]() , their sum would provide an estimate of the variances of the yi. Since the various sampling errors and random effects are independent, the estimated covariance matrix for the yi is
, their sum would provide an estimate of the variances of the yi. Since the various sampling errors and random effects are independent, the estimated covariance matrix for the yi is ![]() , with the off-diagonal terms equal to zero given the assumed independence. Using this covariance matrix, we could estimate β using weighted least squares as follows:
, with the off-diagonal terms equal to zero given the assumed independence. Using this covariance matrix, we could estimate β using weighted least squares as follows:
![]()
where y = (yi,…,ym)’ and X is m x r with rows ![]() .
.
Turning things around, given the νi and some initial estimates of β, one could estimate ![]() using the method of moments, maximum likelihood estimation, REML, or through a Bayesian approach. (One might iterate from an initial estimate of β by setting the
using the method of moments, maximum likelihood estimation, REML, or through a Bayesian approach. (One might iterate from an initial estimate of β by setting the ![]() equal to some initial value.)
equal to some initial value.)
It would then be possible to combine the direct survey estimates and the regression estimates using the best linear unbiased prediction (BLUP) as follows:
![]()
where ![]() .
.
Bell said that a way to think about how the data are being used for small-area modeling and prediction assumes that there is a regression function that describes the variation of the mean in the target from state to state as a function of ![]() . It then follows that
. It then follows that ![]() so the fitted regression can be thought of as a predictor of the target yi. For example, if there is only one regression variable, zi, plus an intercept, then
so the fitted regression can be thought of as a predictor of the target yi. For example, if there is only one regression variable, zi, plus an intercept, then ![]() . The model fitting makes a linear adjustment to the data source zi, which otherwise has target error. After the adjustment, the fitted linear function of zi can be used to better predict Yi.
. The model fitting makes a linear adjustment to the data source zi, which otherwise has target error. After the adjustment, the fitted linear function of zi can be used to better predict Yi.
The BLUP is the weighted average of two predictors of the target, the
direct estimate and the regression fit, where the weights are inversely proportional to the variances of the errors in the two predictors, that is,
![]()
To illustrate the improvements in accuracy resulting from this modeling, Bell compared the approach of regressing the CPS poverty rate for children ages 5-17 on the pseudo poverty rate from tax records with the Fay-Herriot model, with one regression variable (the pseudo poverty rate), and with the SAIPE production model that brings in other regression variables.
Using data from 2004, let yi = CPS 5-17 poverty rates and zi = pseudo poverty rate for children. Regressing yi on zi using ordinary least squares gives the synthetic predictor
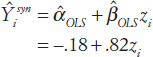
The analogous Fay-Herriot model is yi =Yi + ei. In contrast to the OLS model, here weighted least squares are used, weighting inversely proportional to Var(yi), to estimate the regression coefficients. Then the regression estimates are combined with the direct estimates, weighting the regression estimates inversely proportional to ![]() and the direct estimates inversely proportional to νi.
and the direct estimates inversely proportional to νi.
Table 6-2 shows the mean squared errors of the two predictors for four states. The synthetic predictor is worse than the direct estimate, except in the case of Mississippi. The mean squared errors for the Fay-Herriot model with one regressor are lower than the variances of the direct estimates. The improvement is larger in the states with smaller samples and higher sampling variances, as is typical in this context. The last column in the table shows the weights that are applied to the direct estimate. For example, in California, approximately 80 percent of the weight is for the direct estimate—in other words, the model prediction is going to be very close to the direct estimate in this state.
TABLE 6-2 Prediction Mean Squared Errors (MSE) for 2004 Poverty Rates for Children Ages 5-17 Based on the Current Population Survey Target and the Fay-Herriot Model with One Regressor (FH1)
| State | ni | vi | MSE (Ŷisyn) | MSE(Yi|y, FH1) | hi | ||||||||||||||
| California | 5,834 | 1.1 | 7.7 | .9 | .80 | ||||||||||||||
| North Carolina | 1,274 | 4.6 | 4.7 | 2.3 | .50 | ||||||||||||||
| Indiana | 904 | 8.1 | 9.0 | 3.4 | .36 | ||||||||||||||
| Mississippi | 755 | 12.0 | 6.3 | 3.9 | .26 | ||||||||||||||
SOURCE: Workshop presentation by William Bell.
TABLE 6-3 Prediction Mean Squared Errors (MSE) from the Fay-Herriot Model with One Regressor Compared to Those of the Full SAIPE Production Model
| State | vi | MSE(Yi|y, FH1) | MSE(Yi|y, full model) | hi | |||||||||||||||
| California | 1.1 | .9 | .8 | .61 | |||||||||||||||
| North Carolina | 4.6 | 2.3 | 2.0 | .28 | |||||||||||||||
| Indiana | 8.1 | 3.4 | 2.0 | .18 | |||||||||||||||
| Mississippi | 12.0 | 3.9 | 2.9 | .13 | |||||||||||||||
SOURCE: Workshop presentation by William Bell.
Table 6-3 compares the MSEs of the one-regressor Fay-Herriot model to the MSEs for the full SAIPE production model. The mean squared errors are lower with the full model, and, again, the difference is bigger in the case of smaller states, where the predictions are less able to rely on the direct estimates.
Bell also discussed an extension of the Fay-Herriot model to a bivariate version, which can be used for modeling two statistics simultaneously. The targets in the two equations are different in this case, and there are procedures for model fitting and prediction that can potentially improve the estimates for both quantities. The bivariate model is written
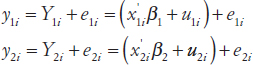
This approach is useful when there are estimates of ostensibly the same characteristic from two independent surveys, such as the state poverty rates for the 5-17 age group from the CPS and the ACS. It can also be used for estimates of two related characteristics from one survey, such as the poverty rates for the 5-17 and 18-64 age groups from the CPS, or for estimates of the same characteristic but for two time points, such as poverty rates for the 5-17 age group from this year and last year’s CPS.
In cases in which there are two estimates of ostensibly the same characteristic from two surveys, researchers have to decide which of the two estimates defines the target (as being the expectation of one of the estimates). One way to think about this is to consider which of the two surveys is suspected of having lower nonsampling error. If both estimates are thought to have similar levels of nonsampling error, then one may let the direct estimate that has lower sampling variance define the target, and to try to improve that estimate by modeling.
If one of the two estimates has some sort of “official” status, then this estimate could define the target. In any case, the bivariate model will utilize
the regression variables and the estimates from the other survey to predict the specified target. This adjusts for bias due to differential nonsampling and target error between the two survey estimates, but it does not address any bias in the survey estimate that is used to define the target.
The approach to generating the SAIPE income and poverty estimates is fairly unusual in the federal statistical system. Yet the estimates are widely used for administering federal programs and allocating federal funds. In Bell’s view, there were several factors that contributed to the acceptance of the model-based estimates among data users. First, the modeling relies on high-quality data sources that can generate good-quality estimates. Second, the time was right for this initiative when the Improving America’s Schools Act was passed in 1994, requiring the allocation of Title 1 education funds according to updated poverty estimates for school districts for the 5-17 age group, unless the model-based estimates were deemed “inappropriate or unreliable.” In addition, a panel of the Committee on National Statistics that reviewed SAIPE methods and initial results also recommended that the model-based estimates be used (National Research Council, 2000).
ROLE OF STATISTICAL MODELS IN FEDERAL SURVEYS: SMALL-AREA ESTIMATION AND OTHER PROBLEMS
Trivellore Raghunathan (University of Michigan) discussed research areas in which model-based estimation represents an ideal tool that allows researchers to use data for purposes beyond what they were intended for. He noted that there has been a recent increase in the complexity of research conducted using data from federal surveys. The data available from a single survey often do not meet these complex research needs, and the answer is often a model-based approach that can synthesize and integrate data from several surveys. Some of the arguments for combining data sources include
- extending the coverage,
- extending the measurement,
- correcting for nonresponse bias,
- correcting for measurement error, and
- improving precision.
Raghunathan presented four examples from his own work. The first one involved combining estimates from the National Health Interview Survey (NHIS) and the National Nursing Homes Survey (NNHS), with the goal of improving coverage. The variables of interest were chronic disease conditions. Data were available from both surveys for 1985, 1995, and 1997. The initial strategy was a design-based approach, treating the two surveys as strata. Current work involves Bayesian hierarchical modeling to obtain subdomain
estimates for analysis of health disparity issues based on education and race (Schenker et al., 2002; Schenker and Raghunathan, 2007).
Another project involved matching respondents from the NHIS and the NHANES on common covariates involving a propensity score technique. The NHIS collects data about disease conditions in a self-reported format, which raises concerns about underreporting due to undiagnosed disease conditions, especially among those least likely to have access to medical care. The NHANES has a self-report component, but it also collects health measurements. This allowed the researchers to model the relationship between the self-reported data and clinical measures in the NHANES and then to impute “no” responses to questions about disease conditions in the NHIS using the model from the NHANES. After applying this correction to the NHIS, many of the relationships “became more reasonable.” Current work focuses on extending the approach to several years of data and on obtaining small-area estimates of undiagnosed diabetes and hypertension (Schenker, Raghunathan, and Bondarenko, 2010).
The third project combined data from two surveys with the goal of providing small-area estimates of cancer risk factors and screening rates to the National Cancer Institute (NCI). In the past, NCI has relied on the Behavioral Risk Factor Surveillance System (BRFSS) to construct these estimates. However, the BRFSS is a telephone survey that faces increasing challenges associated with uneven landline coverage and low response rates. Raghunathan and his colleagues combined the BRFSS data with data from the NHIS, which covers both telephone and nontelephone households and has higher response rates.
The technique selected for this study was a hierarchical model, treating NHIS data as unbiased estimates and BRFSS data as potentially biased estimates. These assumptions were made because of the face-to-face mode and higher response rates in the case of the NHIS. The telephone household estimates from the NHIS and the telephone household estimates from the BRFSS were used to correct for nonresponse bias associated with the nontelephone households and then produce a model-based estimate for all counties.
Although in the past the concept of nontelephone households was understood to mean households without a telephone, it is becoming increasingly important to distinguish between households that do not have a telephone at all and households that do not have a landline but do have a cell phone, because the demographic characteristics of these two types of households are different. The model thus becomes a four-variate model.
Raghunathan mentioned that although the NHIS and the BRFSS are both surveys of the Centers for Disease Control and Prevention, accomplishing the data sharing still involved substantial work. A predecessor to this project, which involved linking data from the National Crime Victimization Survey and the Uniform Crime Reporting Survey, also experienced challenges related to confidentiality and privacy restrictions. Raghunathan emphasized that these are
issues with which the federal statistical system will have to grapple in research of this type.
Raghunathan’s current project involves developing an alternative to the current National Health Expenditure Accounts. The goal is to study the relationship between health care expenditures and population health, with a focus on specific elements, such as disease prevalence and trends; treatment, intervention, and prevention effectiveness; and mortality, quality of life, and other health outcomes. The relationships are examined using Bayesian network modeling, and microsimulations are performed to evaluate hypothetical alternative scenarios.
Given that no existing data set contains all of the desired measures, Raghunathan and his colleagues are working on combining data from a variety of sources. For example, the team identified 120 disease categories with major impact on expenditures. Related data for subsets of diseases are available from
- Self-report sources: NHIS, NHANES, Medical Expenditure Panel Survey (MEPS), Medicare Current Beneficiary Survey (MCBS),
- Clinical measures: NHANES, and
- Claims: MEPS, MCBS.
Although information on past and current disease conditions is available from self-report data, the claims data represent current conditions, so to combine the information, both types of data are converted to a measure of whether the person ever had the disease. For example, Figure 6-1 shows the information available from the MCBS and the NHANES. Respondents are matched on the covariates and then the missing self-report in the MCBS is imputed, so that the overall self-report rates in the two surveys agree.
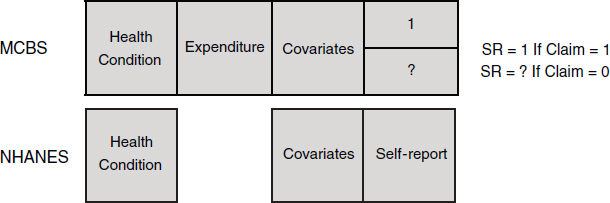
FIGURE 6-1 Data layout for the Medicare Current Beneficiary Survey (MCBS) and the National Health and Nutrition Examination Survey (NHANES).
SOURCE: Workshop presentation by Trivellore Raghunathan.
Raghunathan concluded by saying that although there are a lot of challenges related to the portability of information from one survey to another, including differences in the data collection instruments, protocols, and timing, often combining several data sets is the best option. When data from multiple sources are synthesized, statistical modeling and an imputation framework are particularly useful tools to create the necessary infrastructure. However, data sharing has to be made easier for these types of approaches to be successful. In an ideal world, all data collection would be part of a large matrix, with a unified sampling frame and complementary content that could be filled in by different agencies or researchers working on different pieces.
Roderick Little started the discussion by saying that the term “design-based” theory of sampling conflates the design aspects of the work with the analysis aspects, and that it is perhaps more appropriate to think of it as design-based theory of inference. Little described himself as a modeler and an advocate of what he calls “calibrated Bayes,” in which the design and the repeated sampling aspects come into the assessment of the model rather than into the actual inference (Little, 2006). This approach makes it possible to avoid “inferential schizophrenia” between being design-based or model-based. He prefers to think of everything as models, and, in that sense, the design-based model can be described as a saturated fixed-effects model, in which one does not make strong structural assumptions, so there are no random effects. One can also consider unsaturated hierarchical models, so to the extent that there are any distinctions, they are in terms of the different types of models.
Little argued that hierarchical models are the right way to think about this conceptually. The advantage of hierarchical models is that it is not necessary to use either the direct estimates or the model-based estimates, because they provide a compromise between the direct estimate from the saturated model and the model-based estimate from the unsaturated model. Fay’s discussion of SAIPE illustrates how it is possible to get estimates for different areas, some borrowed mostly from direct estimates and some from the model-based estimates.
In some cases, Bayes modeling may be a little better because it does a better job with the uncertainty and the variance components. While the calibrated approach is a weighted combination of the two, the weights can be poorly estimated, and in simulation studies the calibrated approach can provide worse inference than the model-based approach when the hierarchical model is reasonable. Little finished by stating that the challenge is to come up with some kind of index of what he called structural assumption dependence. For example, when the weights allocated to the model get too high, it might be possible to use that as a criteria for whether to publish an estimate.
Other aspects of this include how well the model is predicting and the extent to which the model is highly parametric. He said that research is needed to develop the right indices.
Fay responded that he will have to think about some of Little’s points, but that he wanted to defend the need for a boundary because it is a practical tool for statistical agencies. The number of people who can implement the design-based theory of inference is much larger than those with the skills described by Little, so that represents a very practical boundary. Identifying the boundary will help those who have to decide whether they want to pursue a small-area application that requires considerable effort and buildup of staff. In response, Little responded that, since this is a forward-looking workshop, the emphasis is not on how things are now, but on thinking about how things might be in the future.
Graham Kalton asked Raghunathan whether using Medicare administrative records was considered when producing estimates about the population ages 65 and older. Raghunathan responded that he is a “scavenger for information,” using as much data as he can find, and he did explore the Medicare claims information, which is now part of the administrative data used for the fourth project he discussed. He agreed that the quality of the auxiliary data is very important in order to borrow strength for small-area estimation. In his third project, he and his team worked hard on obtaining county-level data from a wide variety of sources, not only census data, but also marketing data and data about how active the public health department is.
He added that they also went through a lot of soul searching in terms of whether the estimates are publishable. They had a meeting at the Centers for Disease Control and Prevention with state health department representatives and presented the estimates. Most said that the numbers looked reasonable. The few who did not, also came around after they went back and thought about it. The fact is that researchers have to rely on the best information available to solve a particular problem, and the modeling framework provides an opportunity to move forward with research on these topics.
Raghunathan commented that in some areas of statistics modeling is widely used, but the techniques are less common in the survey field. He argued that the distinctions made by survey researchers between model-based, model-assisted, and design-based approaches are not particularly helpful. In his research, they relied on the latest computational and statistical developments in the field as a whole, and that allowed them to solve the problems at hand. Quoting George Box, he said that all models are wrong, but some are useful. Viewing models as a succinct summary of the information available and using that to make projections about the population helps scientific areas, such as health policy, move forward.
Regarding Fay’s presentation, Kalton commented that state stratification makes a lot of difference if state-level small-area estimates are of interest, as
they were in the California case discussed. A related issue is the number of sampled PSUs in each small area; if there is not a sizable number of PSUs in an area, direct variance estimates will be too imprecise, leading to the need to model the variances.
Fay responded that the problem of degrees of freedom raised was a common one. The NHANES has certainly lived with few degrees of freedom before. In the case of the eight years of data in California, about half of the PSUs were self-representing, which means a lot of degrees of freedom for that half of the population. The study did poorly in the remaining part of the state. He agreed that a distinction can be made between design-based estimation and design-based inference, adding that the variances may have to proceed out of some form of generalization. This was true for the CPS case as well, because for the averages it was only a guess what the true variances were.
Kalton quoted Gordon Brackstone, former assistant chief statistician at Statistics Canada, who many years ago said that the problem with small-area estimates is that the local people know better, and they will always challenge model-based estimates that appear wrong. Kalton said that it turns out that the local people do not necessarily know better, and that surprisingly they tend to react to the estimates presented by constructing a rationalization for why the estimates are correct. At least early on, there were not a lot of challenges to the SAIPE estimates.
Bell said that he believes that when Kalton spoke of large errors, he was referring to the school district estimates and also some counties. The issue was the paucity of the data they had at the school district level. In the case of the estimates that the panel chaired by Kalton was reviewing (National Research Council, 2000), the updates were coming from the county level, and there were no school district level updates, so the quality of those estimates was not as good as the data that were available for higher levels of geography. The general principle is that the smaller the area, the worse the data are going to be, and that is an issue. In recent years, SAIPE has also brought in IRS data, but the program is not always able to assign the tax returns to school districts.
Regarding challenges, Bell commented that they are continuing to get challenges, although he does not deal with them directly himself. Often they come from very small school districts, where it is easier for the locals to have a good sense of what is going on. Occasionally the challenges make reference to other data, such as free and reduced price lunch data, a situation that indicates that there is some confusion, given that these are not the same as the poverty estimates. There were also a lot of challenges based on the 2000 census data, using the census numbers to estimate the school district to county shares of poverty and making reference to what the previous estimates were. Generally, data users compare the current estimates to something else, and they tend to react when they see a large discrepancy, even though it is clearly possible that the other estimate was incorrect. Sometimes they have a legitimate case and it
is clear that the estimates are far enough out of line, but Bell and his team are not correcting for statistical errors.
Little referred back to Fay and Raghunathan’s points about the skills needed to conduct these types of analysis, arguing that it does not help to think about survey sampling as a field separate from the general statistical community in which models are being taught. Zaslavsky added that if the general feeling is that there are not enough people who can do this type of analysis, then it is important to think about the implications for new directions in training.
Fay said that this debate has been going on for many years, and the concern about model-based estimation has always been that data users cannot understand the complex techniques and are suspicious of what is going on “behind the curtain.” But if data users really understood what is involved with design-based estimation, for example, postsurvey adjustment and variance estimation, they would be concerned about that as well.
He thinks it would be useful for researchers to continue to pursue this research and talk to the data users in contexts similar to that described by Raghunathan. To the extent that researchers are able to communicate their methods and demonstrate a commitment to accuracy, it is likely that data users will embrace these techniques, in the same way they accepted the classical estimators that they do not fully understand.
















