
6
Teaching and Assessing for Transfer
The prior chapters have established transfer as the defining characteristic of deeper learning; discussed the importance of cognitive, intrapersonal, and interpersonal skills for adult success; and expanded our description of deeper learning, including both the process of deeper learning and its manifestation in the disciplines of English language arts, mathematics, and science. This chapter takes the argument one step further by reviewing research on teaching for transfer. The first section discusses the importance of specifying clear definitions of the intended learning goals and the need for accompanying valid outcome measures if we are to teach and assess for transfer. Accepting that there are limitations in the research, the next section describes emerging evidence indicating that it is possible to support deeper learning and development of transferable knowledge and skills in all three domains. The third section then summarizes what is known about how to support deeper learning and the development of transferable cognitive competencies, identifying features that may serve as indicators that an intervention is likely to develop these competencies in a substantial and meaningful way. The fourth section then discusses what is known about how to support deeper learning in the intrapersonal and interpersonal domains. The fifth section returns to issues of assessment and discusses the role of assessment in support of deeper learning. The final section offers conclusions and recommendations.
THE NEED FOR CLEAR LEARNING GOALS AND VALID MEASURES
Educational interventions may reflect different theoretical perspectives on learning and may target different skills or domains of competence. In all cases, however, the design of instruction for transfer should start with a clear delineation of the learning goals and a well-defined model of how learning is expected to develop (National Research Council, 2001). The model—which may be hypothesized or established by research—provides a solid foundation for the coordinated design of instruction and assessment aimed at supporting students’ acquisition and transfer of targeted competencies.
Designing measures to evaluate student accomplishment of the particular learning goals can be an important starting point for the development process because outcome measures can provide a concrete representation of the ultimate student learning performances that are expected and of the key junctures along the way, which in turn can enable the close coordination of intended goals, learning environment characteristics, programmatic strategies, and performance outcomes. Such assessments also communicate to educators and learners—as well as designers—what knowledge, skills, and capabilities are valued (Resnick and Resnick, 1992; Herman, 2008).
An evidence-based approach to assessment rests on three pillars that need to be closely synchronized (National Research Council, 2001, p. 44):
- A model of how students represent knowledge and develop competence in a domain
- Tasks or situations that allow one to observe student performance relative to the model
- An interpretation framework for drawing inferences from student performance
Developing that first pillar—a model of the learning outcomes to be assessed—offers a first challenge in the assessment of cognitive, intrapersonal, and interpersonal competencies. Within each of these three broad domains, theorists have defined and conducted research on a wealth of individual constructs. In the previous chapters, we noted that the research literature on cognitive and noncognitive competencies has used a wide variety of definitions, particularly in the intrapersonal and interpersonal domains. In Chapter 2, we suggested certain clusters of competencies within each domain as the targets of assessment and instruction and offered preliminary definitions. Questions remain, however, about the implications of these definitions. For example, the range of contexts and situations across which the learning of these competencies should transfer remains unclear.
A second challenge arises from the existing assessment models and methodologies used to observe and interpret students’ responses relative to these constructs. It is widely acknowledged that most current large-scale measures of educational achievement do not do a good job of reflecting deeper learning goals in part because of constraints on testing formats and testing time (Webb, 1999; also see Chapter 7). While a variety of well-developed exemplars exist for constructs in the cognitive domain, those for intrapersonal and interpersonal competencies are less well developed. Below, we briefly discuss examples of measures for each domain of competence. (For a fuller discussion of this topic, see National Research Council, 2011a.)
Measures of Cognitive Competence
Promising examples of measures focused on important cognitive competencies can be found in national and international assessments, in training and licensing tests, and in initiatives currently under way in K-12. One example is the computerized problem-solving component of the Programme for International Student Assessment (PISA), which is scheduled for operational administration in 2012 (National Research Council, 2011b). In this 40-minute test, items are grouped in units around a common problem, which keeps reading and numeracy demands to a minimum. The problems are presented within realistic, everyday contexts, such as refueling a moped, playing on a handball team, mixing elements in a chemistry lab, and taking care of a pet. The difficulty of the items is manipulated by increasing the number of variables or the number of relationships that the test taker has to deal with.
Scoring of the items reflects the PISA 2012 framework, which defines four processes that are components of problem solving: (1) information retrieval, (2) model building, (3) forecasting, and (4) monitoring and reflecting. Points are awarded for information retrieval, based on whether the test taker recognizes the need to collect baseline data and uses the method of manipulating one variable at a time. Scoring for the process of model building reflects whether the test taker generates a correct model of the problem. Scoring of forecasting is based on the extent to which responses to the items indicate that the test taker has set and achieved target goals. Finally, points are awarded for monitoring and reflecting, which includes checking the goal at each stage, detecting unexpected events, and taking remedial action if necessary.
Another promising example of assessment of complex cognitive competencies, created by the National Council of Bar Examiners, consists of three multistate examinations that jurisdictions may use as one step in the
process of licensing lawyers.1 The three examinations are the Multistate Bar Examination (MBE), the Multistate Essay Examination (MEE), and the Multistate Performance Test (MPT). All are paper-and-pencil tests that are designed to measure the knowledge and skills necessary to be licensed in the profession and to ensure that the newly licensed professional knows what he or she needs to know in order to practice. These overarching goals—as well as the goals of the individual components summarized briefly below—reflect an assumption that law students need to have developed transferable knowledge that they will be able to apply when they become lawyers.
The purpose of the MBE is to assess the extent to which an examinee can apply fundamental legal principles and legal reasoning to analyze a given pattern of facts. The questions focus on the understanding of legal principles rather than on memorization of local case or statutory law. The MBE consists of 60 multiple-choice questions and is administered over an entire day.
The purpose of the MEE is to assess the examinee’s ability to (1) identify legal issues raised by a hypothetical factual situation; (2) separate material that is relevant from that which is not; (3) present a reasoned analysis of the relevant issues in a clear, concise, and well-organized composition; and (4) demonstrate an understanding of the fundamental legal principles relevant to the probable resolution of the issues raised by the factual situation. This test lasts for 6 hours and consists of nine 30-minute questions.
The goal of the MPT is to assess the fundamental skills of lawyers in realistic situations by asking the candidate to complete a task that a beginning lawyer should be able to accomplish. It requires applicants to sort detailed factual materials; separate relevant from irrelevant facts; analyze statutory, case, and administrative materials for relevant principles of law; apply relevant law to the facts in a manner likely to resolve a client’s problem; identify and resolve ethical dilemmas; communicate effectively in writing; and complete a task within time constraints. Examinees are given 90 minutes to complete each task.
These and other promising examples each start with a strong model of the competencies to be assessed; use simulated cases and scenarios to pose problems that require extended analysis, evaluation, and problem solving; and apply sophisticated scoring models to support inferences about student learning. The PISA example, in addition, demonstrates the dynamic and interactive potential of technology to simulate authentic problem-solving situations.
The PISA problem-solving test is one of a growing set of examples that use technology to simultaneously engage students in problem solving and assess their problem-solving skills. Another example is SimScientists, a
___________________
1The following description of the three examinations relies heavily on Case (2001).
simulation-based curriculum unit that includes a sequence of assessments designed to measure student understanding of ecosystems (Quellmalz, Timms, and Buckley, 2010). The SimScientists summative assessment is designed to measure middle school students’ understanding of ecosystems and scientific inquiry. Students are presented with the overarching task of describing an Australian grassland ecosystem for an interpretive center and respond by drawing food webs and conducting investigations with the simulation. Finally, they are asked to present their findings about the grasslands ecosystem.
SimScientists also includes elements focusing on transfer of learning, as described in a previous NRC report (National Research Council, 2011b, p. 94):
To assess transfer of learning, the curriculum unit engages students with a companion simulation focusing on a different ecosystem (a mountain lake). Formative assessment tasks embedded in both simulations identify the types of errors individual students make, and the system follows up with graduated feedback and coaching. The levels of feedback and coaching progress from notifying the student that an error has occurred and asking him or her to try again, to showing the results of investigations that met the specifications.
Students use this targeted, individual feedback to engage with the tasks in ways that improve their performance. As noted in Chapter 4, practice is essential for deeper learning, but knowledge is acquired much more rapidly if learners receive information about the correctness of their results and the nature of their mistakes.
Combining expertise in content, measurement, learning, and technology, these assessment examples employ evidence-centered design and are developing full validity arguments. They reflect the emerging consensus that problem solving must be assessed as well as developed within specific content domains (as discussed in the previous chapter; also see National Research Council, 2011a). In contrast to these examples, many other current technology-based projects designed to impact student learning lack a firm assessment or measurement basis (National Research Council, 2011b).
Project- and problem-based learning and performance assessments that require students to engage with novel, authentic problems and to create complex, extended responses in a variety of media would seem to be prime vehicles for measuring important cognitive competencies that may transfer. What remains to be seen, however, is whether the assessments are valid for their intended use and if the reliability of scoring and the generalizability of results can achieve acceptable levels of rigor, thereby avoiding validity and reliability problems of complex performance assessments developed in the past (e.g., Shavelson, Baxter, and Gao, 1993; Linn et al., 1995).
Measures of Intrapersonal and Interpersonal Competence
As is the case with interpersonal skills, many of the existing instruments for the measurement of intrapersonal skills have been designed for research and theory development purposes and thus have the same limitations for large-scale educational uses as the instruments for measuring interpersonal skills. These instruments include surveys (self-reports and informant reports), situational judgment tests, and behavioral observations. As with the assessment of interpersonal competencies, it is possible that evidence of intrapersonal competencies could be elicited from the process and products of student work on suitably designed complex tasks. For example, project- or problem-based performance assessments theoretically could be designed to include opportunities for students to demonstrate metacognitive strategies or persistence in the face of obstacles. Student products could be systematically observed or scored for evidence of the targeted competencies, and then these scores could be counted in student grades or scores on end-of-year accountability assessment. To date, however, strong design methodologies, interpretive frameworks and approaches to assuring the score reliability, validity, and fairness have not been developed for such project- or problem-based performance assessments.
There are few well-established practical assessments for interpersonal competencies that are suitable for use in schools, with the exception of tests designed to measure those skills related to formal written and oral communication. Some large-scale measures of collaboration were developed as part of performance assessments during the 1990s, but the technical quality of such measures was never firmly established. The development of those assessments revealed an essential tension between the nature of group work and the need to assign valid scores to individual students. Today there are examples of teacher-developed assessments of teamwork and collaboration being used in classrooms, but technical details are sketchy.
Most well-established instruments for measuring interpersonal competencies have been developed for research and theory-building or for employee selection purposes, rather than for use in schools. These instruments tend to be one of four types: surveys (self-reports and informant reports), social network analysis, situational judgment tests, or behavioral observations (Bedwell, Salas, and Fiore, 2011). Potential problems arise when applying any of these methods for large-scale educational assessment, to which stakes are often attached. Stakes are high when significant positive or negative consequences are applied to individuals or organizations based on their test performance, consequences such as high school graduation, grade-to-grade promotion, specific rewards or penalties, or placement into special programs.
Stakes attached to large-scale assessment results heighten the need for the reliability and validity of scores, particularly in terms of being resistant to fakeability. Cost and feasibility also are dominant issues for large-scale assessments. Each of the instrument types has limitations relative to these criteria. Self-report, social network analysis, and situational judgment tests, which can provide relatively efficient, reliable, and cost-effective measures, are all subject to social desirability bias—the tendency to give socially desirable and socially rewarded rather than honest responses to assessment items or tasks. While careful design can help to minimize or correct for social desirability bias, if any of these three types of assessment instruments were used for high-stakes educational testing, social desirability bias would likely be heightened.
Behavioral ratings, in contrast, present challenges in assuring reliability and cost feasibility. For example, if students’ interpersonal skills are assessed based on self, peer, or teacher ratings of student presentations of portfolios of their past work (including work as part of a team), a number of factors may limit the reliability and validity of the scores. These include differences in the nature of the interactions reflected in the portfolios for different students or at different times; differences in raters’ application of the scoring rubric; and differences in the groups with whom individual students have interacted. This lack of uniformity in the sample of interpersonal skills included in the portfolio poses a threat to both validity and reliability (National Research Council, 2011a). Dealing with these threats to reliability takes additional time and money beyond that required for simply presenting and scoring student presentations.
Collaborative problem-solving tasks currently under development by PISA offer one of the few examples today of a direct, large-scale assessment targeting social and collaboration competencies; other prototypes are under development by the ATC21S project and by the military. The quality and practical feasibility of any of these measures are not yet fully documented. However, like many of the promising cognitive measures, these rely on the abilities of technology to engage students in interaction, to simulate others with whom students can interact, to track students’ ongoing responses, and to draw inferences from those responses.
Summary
In summary, there are a variety of constructs and definitions of cognitive, intrapersonal, and interpersonal competencies and a paucity of high-quality measures for assessing them. All of the examples discussed above are measures of maximum performance rather than of typical performance (see Cronbach, 1970). They measure what students can do rather than what they are likely to do in a given situation or class of situations. While
measures of maximum performance are usually the focus in the cognitive domain, typical performance may be the primary focus of measures for some intrapersonal and interpersonal competencies. For example, measures of dispositions and attitudes related to conscientiousness, multicultural sensitivity, and persistence could be designed to assess what students are likely to do (typical performance). In comparison to measures of maximum performance, measures of typical performance require more complex designs and tend to be less stable and reliable (Patry, 2011).
Both the variety of definitions of constructs across the three domains and the lack of high-quality measures pose challenges for teaching, assessment, and learning of 21st century competencies. They also pose challenges to research on interventions designed to impact student learning and performance, as we discuss below.
EMERGING EVIDENCE OF INSTRUCTION THAT PROMOTES DEEPER LEARNING
Despite the challenges posed by a lack of uniform definitions and high-quality measures of the intended performance outcomes, there is emerging evidence that cognitive, intrapersonal, and interpersonal competencies can be developed in ways that promote transfer. The most extensive and strongest evidence comes from studies of interventions targeting cognitive competencies, but there is also evidence of development of intrapersonal and interpersonal competencies. The research includes studies encompassing how people learn in formal, informal, and workplace learning environments, as discussed further below.
Evidence from Interventions in Formal Learning Environments
As illustrated by the examples in the previous chapter, some classroom-based interventions targeting specific cognitive competencies have also, through changes in teaching practices, fostered development of intrapersonal and interpersonal competencies. The students learn through discourse, reflection, and shared experience in a learning community. For example, Boaler and Staples (2008) note the following:
The discussions at Railside were often abstract mathematical discussions and the students did not learn mathematics through special materials that were sensitive to issues of gender, culture, or class. But through their mathematical work, the Railside students learned to appreciate the different ways that students saw mathematics problems and learned to value the contribution of different methods, perspectives, representations, partial ideas and even incorrect ideas as they worked to solve problems. (p. 640)
Both the mathematics knowledge and skills and the positive dispositions toward mathematics and feelings of self-efficacy in mathematics developed by these students appear to be durable and transferable, as nearly half of the students enrolled later in calculus classes and all indicated plans to continue study of mathematics.
In the domain of English language arts, Guthrie, Wigfield, and their colleagues developed an instructional system designed to improve young students’ reading by improving their motivation and self-regulation as well as their use of cognitive and metacognitive strategies (Guthrie et al., 1996, 2004; Guthrie, McRae, and Klauda, 2007; Wigfield et al., 2008; Taboada et al., 2009). Several empirical studies found this intervention to be successful in improving the performance of young readers, reflecting gains in the cognitive knowledge and skills that were the primary targets of the intervention (Guthrie et al., 2004). The young students involved in the intervention showed greater engagement in reading both in school and outside of school (Wigfield et al., 2008). These findings suggest that the students not only developed the intrapersonal competencies of motivation and self-regulation but also transferred these competencies to their reading in the contexts of both school and home.
There is also some evidence that intrapersonal and interpersonal competencies can be effectively taught and learned in the classroom. In the past, interventions often focused on reducing or preventing undesirable behaviors, such as antisocial behavior, drug use, and criminal activities. Increasingly, however, intervention programs are designed instead to build positive capacities, including resilience, interpersonal skills, and intrapersonal skills, in both children and families. In a recent review of the research on these new skill-building approaches—including meta-analyses and numerous randomized trials—a National Research Council committee (2009b) concluded that effectiveness has been demonstrated for interventions that focus on strengthening families, strengthening individuals, and promoting mental health in schools and in healthcare and community programs.
Durlak et al. (2011) recently conducted a meta-analysis of school-based instructional programs designed to foster social and emotional learning. They located 213 studies that targeted students aged 5 to 18 without any identified adjustment or learning problems, that included a control group, and that reported sufficient data to allow calculation of effect sizes. Almost half of the studies employed randomized designs. More than half (56 percent) were implemented in elementary school, 31 percent in middle school, and the remainder in high school. The majority were classroom based, delivered either by teachers (53 percent) or by personnel from outside the school (21 percent). Most of the programs (77 percent) lasted less than a year, 11 percent lasted 1 to 2 years, and 12 percent lasted more than 2 years.
The authors analyzed the effectiveness of these school-based programs in terms of six student outcomes in the cognitive, intrapersonal, and interpersonal domains: social and emotional skills, attitudes toward self and others, positive social behaviors, conduct problems, emotional distress, and academic performance. Measures of these outcomes included student self-reports; reports and ratings from a teacher, parent, or independent rater; and school records (including suspensions, grades, and achievement test scores). Overall, the meta-analysis showed statistically significant, positive effect sizes for each of the six outcomes, with the strongest effects (d = 0.57) in social and emotional skills.2 These positive effects across the different outcomes suggest that students transferred what they learned about positive social and emotional skills in the instructional programs, displaying improved behavior throughout the school day.
Among the smaller group of 33 interventions that included follow-up data (with an average follow-up period of 92 weeks), the effects at the time of follow up remained statistically significant, although the effect sizes were smaller. These findings suggest that the learning of social and emotional skills was at least somewhat durable.
An even smaller subset of the reviewed studies included measures of academic performance. Among these studies the mean effect size was 0.27, reinforcing the interconnectedness of learning across the cognitive, intrapersonal, and interpersonal domains.
One promising example showing that interventions can develop transferable intrapersonal competencies is Tools of the Mind, a curriculum used in preschool and early primary school to develop self-regulation, improve working memory, and increase adaptability (Diamond et al., 2007). It includes activities such as telling oneself aloud what one should do, dramatic play, and aids to facilitate memory and attention (such as an activity in which a preschooler is asked to hold a picture of an ear as a reminder to listen when another preschooler is speaking). A randomized controlled trial in 18 classrooms in a low-income urban school district indicated that the curriculum was effective in improving self-regulation, classroom behavior, and attention. The documented improvement in classroom behavior suggests that the young children transferred the self-regulation competencies they learned through the activities to their daily routines. The intervention also improved working memory and cognitive flexibility, further illustrating
___________________
2In research on educational interventions, the standardized effect size, symbolized by d, is calculated as the difference in means between treatment and control groups, divided by the pooled standard deviation of the two groups. Following rules of thumb suggested by Cohen (1988), an effect size of approximately 0.20 is considered “small,” approximately 0.50 is considered “medium,” and approximately 0.80 is considered “large.” Thus, the effect size of 0.57 on social and emotional skills is considered “large” or “strong.”
the links across the cognitive, intrapersonal, and interpersonal domains (Barnett et al., 2008).
Because of the closely intertwined nature of cognitive, intrapersonal, and interpersonal competencies an intervention targeting learning and skill development in one domain can influence other domains, as illustrated by a study included in the Durlak et al. (2011) meta-analysis. Flay et al. (2006) conducted a randomized controlled trial of the Positive Action Program—a drug education and conflict resolution curriculum with parent and community outreach—in 20 elementary schools in Hawaii. Although the intervention was focused on social and emotional competencies, it had large, statistically significant effects on mathematics (an effect size of 0.34) and reading achievement (0.74).
Evidence from Interventions in Informal Learning Environments
Studies of informal learning environments provide more limited evidence that cognitive, intrapersonal, and interpersonal competencies can be taught in ways that promote deeper learning and transfer. Informal learning takes place in a variety of settings, including after-school clubs, museums, science centers, and homes, and it includes a variety of experiences, from completely unstructured to highly structured workshops and educational programs. Informal learning activities may target a range of different learning goals, including goals determined by the interests of individual learners (National Research Council, 2011b). These characteristics of informal learning pose challenges both to clearly identifying the goals of a particular informal learning activity and to a careful assessment of learners’ progress toward those goals—essential components of any rigorous evaluation (National Research Council, 2009a). Despite these challenges, research and evaluation studies have shown, for example, that visitors to museums and science centers can develop a deeper understanding of a targeted scientific concept through the direct sensory or immersive experience provided by the exhibits (National Research Council, 2009a).
Somewhat stronger evidence that informal learning environments can develop important competencies emerges from evaluations of structured after-school programs with clearly defined learning goals. Durlak, Weissberg, and Pachan (2010) conducted a meta-analysis of after-school programs designed to promote social and emotional learning among children and youth. They located 68 studies of social and emotional learning programs that included both a control group and measures of postintervention competencies, and they analyzed data on three categories of outcomes:
- feelings and attitudes (child self-perception and school bonding);
- indicators of behavioral adjustment (positive social behaviors, problem behaviors, and drug use); and
- school performance (achievement test scores, school grades, and school attendance).
Overall, the programs had a positive and statistically significant impact on participants’ competencies, with the largest mean effects in self-confidence and self-esteem, increases in positive social behaviors and decreases in problem behaviors, and increases in achievement test scores. The only outcomes for which effects were not statistically significant were school attendance and drug use.
In structured after-school settings, as in the in-school environment, a few examples illustrate the potential of technology- and game-based approaches to develop transferable knowledge and skills. For example, an evaluation of the Fifth Dimension—an informal after-school computer club that incorporates games—showed positive effects on students’ computer literacy, comprehension, problem solving, and strategic efficiency (Mayer et al., 1999). However, the use of technology must be carefully structured to support transferable learning, as we discuss further below.
Parenting Interventions
Because informal learning and skill development begins at birth, and because parents strongly influence this process, some interventions target parents’ cognitive, intrapersonal, and interpersonal competencies as a route to helping children develop these competencies. Parenting interventions are a route to boosting the competencies and improving the behavior of struggling children (Magnuson and Duncan, 2004). When considering interventions to develop parenting competencies:
It is useful to distinguish between parenting education and parenting management training. Parenting education programs seek to boost parents’ general knowledge about parenting and child development. Information is provided in conjunction with instrumental and emotional support. Home visitation programs for new mothers and parent-teacher programs are perhaps the most familiar examples. Management training programs are designed for parents of children with diagnosed problem behavior, usually conduct disorders. Clinical therapists teach parents concrete behavioral strategies designed to improve their children’s behavior. Typically, parents are taught how to reinforce their child’s positive behavior and punish negative behavior appropriately. Evaluation evidence on parenting management programs is much more positive than the evidence on parent education programs. (Magnuson and Duncan, 2004, p. 206)
There is a substantial experimental literature on the efficacy of home visitation programs. The most successful (and expensive) of these programs is the nurse/family partnership model developed by David Olds (Olds, Sadler, and Kitzman, 2007). Meta-analyses of its evaluations show some positive effects on certain parent and child outcomes, such as reductions in child maltreatment and visits to emergency rooms, but it is less clear whether such programs affect school readiness skills (Sweet and Appelbaum, 2004). The long-term impacts on school readiness are inconsistent, but the evidence suggests that there could be very modest effects on children’s social adjustment and cognitive competencies.
Evidence from Workplace Learning Environments
Another area yielding emerging evidence that interventions can develop transferable competencies is the body of literature in industrial and organizational psychology that focuses on the transfer of learning from organizational training programs to the workplace. This research has been summarized in a number of recent reviews and meta-analyses (e.g., Ford and Weissbein, 1997; Burke and Hutchins, 2008; Cheng and Hampson, 2008; Baldwin, Ford, and Blume, 2009; Blume et al., 2010; Grossman and Salas, 2011).
U.S. employers invest heavily in employee training, spending an estimated $46 billion to $54 billion per year when employee salaries during training time are included (Mikelson and Nightingale, 2004).3 This investment reflects a belief that training will transfer to improvements in job performance. Although Georgenson (1982) is often cited as estimating that only 10 percent of training experiences transfer from the training classroom to the work site, he did not, in fact, make such an estimate (Fitzpatrick, 2001). In recent years, a number of researchers have sought to measure the actual extent of transfer from training to on-the-job performance, to characterize what is transferred, and to identify the conditions promoting transfer. To measure the extent of transfer, researchers often turn to the Kirkpatrick model for evaluating the effectiveness of training (Kirkpatrick and Kirkpatrick, 2006). This model includes four levels of effectiveness: (1) trainees’ immediate reactions after a training session, (2) learning, (3) changes in on-the-job behavior, and (4) results (return on training investment).
___________________
3It is difficult to estimate total employer training investments, partly because most employers do not carefully account for training costs (Mikelson and Nightingale, 2004). In addition, there have been no systematic national surveys since those conducted by the U.S. Census Bureau in 1994 and 1997. More recent surveys, such as those conducted by the American Society for Training and Development (2009), include the most training-intensive firms, causing an upward bias in the results.
In a meta-analysis of the effects of organizational training, Arthur et al. (2003) proposed that transfer takes place if the training is found to be effective at any or all of the levels from (2) through (4) of the framework, such that:
(a) learning is demonstrated through pretraining and posttraining tests of trainees’ knowledge and skills (which may include cognitive, intrapersonal, and interpersonal competencies);
(b) improvements in on-the-job behavior are demonstrated through changes in pre- and post-training performance measures; or
(c) results are demonstrated through calculations of organizational return on investment.
The authors found that the training had significant, positive effects for each of these three levels of the evaluation framework: d = .63, .62, and .62 for learning, behavior, and results, respectively. They concluded that training does indeed transfer.
Attention has shifted recently from whether training transfers to which conditions specifically enhance the transfer of training. A convenient framework for characterizing those conditions is Baldwin and Ford’s model of transfer (Baldwin and Ford, 1988; Ford and Weissbein, 1997; Baldwin, Ford, and Blume, 2009). The model proposes that three categories of factors influence transfer: trainee characteristics, training design, and work environment. Baldwin and Ford (1988) proposed that the key trainee characteristics promoting transfer are cognitive ability, personality, and motivation, while the key training design features include following the principles of learning, correctly sequencing the training, and providing appropriate training content. The key work environment features that promote transfer include supervisor and peer support for the training and opportunities to use the training on the job (see Figure 6-1).
A meta-analysis of 89 studies conducted by Blume et al. (2010) examined these various factors and found positive relationships between transfer and several of them, including the trainee characteristics of cognitive ability and motivation (as well as conscientiousness) and support within the work environment. The authors also examined moderators of these relationships and found that the above factors predicted transfer more strongly when the training content focused on “open” skills, such as leadership development, rather than on “closed” skills, such as how to use a particular type of computer software. Transfer was also promoted to the extent that the training environment and the transfer environment (the job) were similar. This latter finding reflects the research from learning sciences discussed in Chapter 4, which found that transfer is enhanced when the original learning
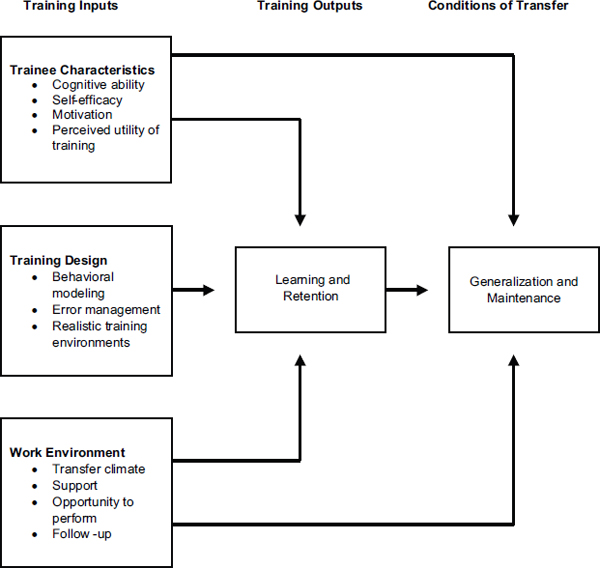
FIGURE 6-1 A model of the transfer process.
SOURCE: Grossman and Salas (2011). Reprinted with permission from John Wiley and Sons.
situation and the new learning situation have similar underlying principles (e.g., Singley and Anderson, 1989).
Because the Blume et al. (2010) meta-analysis included studies that varied in terms of the content of the training being evaluated, the research design, and the evaluation methods, it is informative to supplement that report’s findings with information obtained using other methodologies. Burke and Hutchins (2008) surveyed training professionals about best practices and identified several factors thought to contribute to effective transfer. The most important were supervisory support, coaching, opportunities to perform what was learned in training, interactive training, measurement of
transfer, and job-relevant training. These survey findings are consistent with the empirical studies of the predictors of transfer.
Grossman and Salas (2011) conducted a comprehensive review of the meta-analyses and other research reviews with the purpose of extracting
the strongest, most consistent findings from the literature in order to help organizations, and even researchers, identify the “bottom line” … [and to] serve as a valuable complement to Burke and Hutchins’s (2008) practice-based paper. (p. 117)
Within the category of trainee characteristics, Grossman and Salas confirmed the importance of cognitive ability, self-efficacy, and motivation for facilitating transfer of training to the job. They suggested that goal-setting was well established as a means to increase motivation and that transfer was facilitated when learners understood the relevance of the training to the job. These findings reinforce the findings from cognitive research and the studies of educational interventions showing that intrapersonal competencies, including motivation, enhance learning and transfer.
Grossman and Salas also discussed training design and concluded that the elements that most strongly facilitate transfer include behavior modeling, error management (an increasingly popular training strategy of allowing trainees to make errors and providing error management instructions), and realistic training environments (e.g., on-the-job training and the use of low- and high-fidelity simulations).
Concerning the work environment, the authors found that the transfer climate was the most important factor influencing transfer (Grossman and Salas, 2011). This finding is supported by the meta-analyses from Colquitt, LePine, and Noe (2000) and Blume et al. (2010). Specifically, Grossman and Salas found that transfer is facilitated when the trainee’s workplace prompts the use of the new competencies learned in training and when trainees are given goals, incentives, feedback, and the opportunity to practice the competencies. Two other features of the work environment shown to play an important role in facilitating transfer were supervisor support (which included such things as recognition, encouragement, rewards, and modeling) and peer support. These findings were similar to those of Blume et al. (2010). Still other features of the work environment that were found to play a role in facilitating transfer were the opportunity to perform the learned competencies with minimal delay, posttraining follow-up, and feedback. Figure 6-1 presents a summary of the factors affecting transfer that was originally developed by Baldwin and Ford (1988) and later modified by Grossman and Salas to reflect their findings.
Research on Team Training. Evidence that cognitive, intrapersonal, and interpersonal skills can be taught and learned also emerges from research on team training in organizations, although this research does not focus specifically on questions of transfer. In a recent meta-analysis of the research on team training, Salas et al. (2008) analyzed data from 45 studies of team training, focusing on four types of outcomes that cut across the three domains: (1) cognitive outcomes, such as declarative and procedural knowledge of work tasks; (2) affective outcomes, such as feelings of trust and confidence in team members’ ability; (3) team processes, such as communication, coordination, strategy development, self-correction, and assertiveness; and (4) team performance, such as quantity, quality, accuracy, and efficiency. This variety of outcome measures reflects the variety of goals of team training interventions, which often target multiple cognitive, intrapersonal, and interpersonal competencies. These goals are based on the assumption that team training transfers within and across domains so that knowledge of work tasks, for example, is applied in ways that improve task (and team) performance. Salas and his colleagues found statistically significant, positive correlations between the training interventions and each of the four outcomes, with the highest correlation being for team processes (i.e., training targeting development of intrapersonal and interpersonal competencies).
INSTRUCTIONAL DESIGN PRINCIPLES FOR TRANSFER—COGNITIVE DOMAIN
While the evidence discussed above and in Chapters 4 and 5 indicates that various cognitive competencies are teachable and learnable in ways that promote transfer, we noted in Chapter 5 that such instruction remains rare in U.S. classrooms; few effective strategies and programs to foster deeper learning exist. Research and theory suggest a set of principles that can guide the development of such strategies and programs, as discussed below. It is important to note that the principles are derived from research that has focused primarily on transfer of knowledge and skills within a single topic area or domain of knowledge (see Box 6-1).
How can instructors teach in ways that promote transfer? Addressing this seemingly simple question has been a central task of researchers in learning and instruction for more than a century, and within the past several decades, a number of useful advances have been made toward providing evidence-based answers (Mayer, 2008; Mayer and Alexander, 2011). Evidence-based guidelines for promoting deeper learning (i.e., learning of transferable knowledge) have been offered by a recent task force report from the Association for Psychological Science (Graesser, Hakel, and Halpern, 2007), a guidebook published by the Institute of Education
BOX 6-1
Deeper Learning Across Topics or Disciplines
Most of the research to date on deeper learning has focused on learning within a single discipline, often investigating how children learn a specific topic, procedure, or strategy. This focus reflects the limited success of earlier efforts to develop generic knowledge or skills that could be widely transferred or applied across disciplines, topics, or knowledge domains. In science, for example, early research sought to clarify children’s understanding of scientific experimentation by presenting them with “knowledge-lean” tasks about causes and effects that required no prior knowledge of relevant science concepts. However, such methods were criticized, and further research clearly demonstrated that children’s prior knowledge plays an important role in their ability to formulate a scientific question about a topic and design an experiment to test the question (National Research Council, 2007). Current research presents children with “knowledge-rich” tasks, recognizing that their causal reasoning is closely related to their prior knowledge of the question or concept to be investigated.
Only a few studies have examined transfer across disciplines, topics, or contexts. For example, Bassok and Holyoak (1989) studied transfer of learning in algebra and physics, focusing on problems with identical underlying structures but different surface features—arithmetic-progression problems in algebra and constant-acceleration problems in physics. High school and college students were first trained to solve such problems, either in algebra or physics, and then were presented with word problems that used either content from the domain in which they were trained or content based on an unfamiliar domain. The algebra students, whose training included the information that the problems were broadly applicable, were very likely to spontaneously recognize that physics problems involving velocity and distance could be addressed using the same equations. These students recognized the applicability to physics, regardless of whether they had learned arithmetic-progression problems using word problems focusing on several different types of content (e.g., growth of savings accounts, height of a human pyramid) or had learned using word problems focusing on a single type of content—i.e., money problems. In contrast, students who had learned to solve constant-acceleration problems in physics almost never recognized or transferred this approach to solve the algebra problems. The authors note that the algebra-focused students were able to “screen out” the domain-specific content of the word problems, while the physics-focused students had been taught that the physical concepts involved in word problems were critical to the applicability of the equations. Bassok and Holyoak concluded that although expertise is generally based on content-specific knowledge, it may be possible to teach some mathematical procedures in a way that enables students to transfer these procedures across content domains; they called for further research to explore such possibilities.
Studies such as these provide some clues about how to support transfer of learning across specific knowledge domains, but much further research is needed to clarify whether, and to what extent, it may be possible to teach students in ways that promote deeper learning and transfer across disciplines or broad content domains.
SOURCE: Created by the committee.
Sciences (Pashler et al., 2007), and a review of problem-solving transfer in the Handbook of Educational Psychology (Mayer and Wittrock, 2006).
Before describing various research-based principles for instructional design, it is worth noting that recent research on teaching and learning reveals that young children are capable of surprisingly sophisticated thinking and reasoning in science, mathematics, and other domains (National Research Council and Institute of Medicine, 2009; National Research Council, 2012). With carefully designed guidance and instruction, they can begin the process of deeper learning and development of transferable knowledge as early as preschool. As noted in Chapters 4 and 5, this process takes time and extensive practice over many years, suggesting that instruction for transfer should be introduced in the earliest grades and should be sustained throughout the K-12 years as well as in postsecondary education. Thus, the principles discussed below should be seen as broadly applicable to the design of instruction across a wide array of subject matter areas and across grade levels spanning K-16 and beyond.
Research-Based Methods for Developing Transferable Knowledge
Using Multiple and Varied Representations of Concepts and Tasks
Mayer (2009, 2011b) has shown, based on 11 experimental comparisons, that adding diagrams to a text (or adding animation to a narration) that describes how a mechanical or biological system works can increase student performance on a subsequent problem-solving transfer test by an average of more than one standard deviation. Allowing students to use concrete manipulatives to represent arithmetic procedures has been shown to increase transfer test performance both in classic studies in which bundles of sticks are used to represent two-column subtraction (Brownell and Moser, 1949) and in an interactive, computer-based lesson in which students move a bunny along a number line to represent addition and subtraction of signed numbers (Moreno and Mayer, 1999).
Research suggests that the use of multiple and varied representations is also effective in informal learning environments. For example, a recent National Research Council (2009a) study found that visitors to museums and science centers commonly report developing a deeper understanding of a concept through the concrete, sensory, or immersive experiences provided by the exhibits. One investigation reported in this study found that children who interacted purposefully with exhibits about magnetism gained conceptual understanding of the concept of magnetism (Rennie and McClafferty, 2002).
While adding diagrams or animations to text can enhance learning and transfer, researchers have found that how multimedia learning environments are designed strongly influences their effectiveness. Based on dozens
of experiments leading to his theory of multimedia learning, Mayer (2009) has identified 12 principles of multimedia design that can enhance transfer (see Box 6-2).
Encouraging Elaboration, Questioning, and Self-Explanation
Chi and colleagues have shown that, in both book-based and computer-based learning environments, students learn more deeply from reading a science text if they are prompted to explain the material to themselves aloud as they read (Roy and Chi, 2005; Fonseca and Chi, 2011). Research has investigated how different types of questioning techniques promote deeper learning (Graesser and Person, 1984; Graesser, D’Mello, and Cade, 2011), indicating that some successful tutoring techniques include asking why, how, what if, what if not, and so what. As noted in the previous chapter, carefully designed questions posed by teachers and fellow students, such as asking students to justify their answers, have been shown to support deeper learning in mathematics (Griffin, 2005; Boaler and Staples, 2008) and science (Herrenkohl et al., 1999). Asking the learner to summarize the material in a text can also lead to deeper learning (Pressley and Woloshyn, 1995; Mayer and Wittrock, 1996). Finally, research on the testing effect shows that students learn better when they test themselves (without feedback) on material that they have just read than when they study it again; this is true both with paper-based materials (Roediger and Karpicke, 2006) and with online multimedia lessons (Johnson and Mayer, 2009).
There is evidence that this method also supports learning for transfer in designed informal science learning centers (e.g., zoos, museums, and aquariums). Exhibits can be designed to encourage learners to pose questions to themselves and others, helping them think abstractly about scientific phenomena (National Research Council, 2009a). When parents provide explanations of science exhibits to their children, they may help them link the new information to their previous knowledge. How exhibits are designed appears to influence the number and kinds of questions visitors ask.
Engaging Learners in Challenging Tasks, with Supportive Guidance and Feedback
For more than 40 years, research has repeatedly shown that asking students to solve challenging problems in science and other disciplines without appropriate guidance and support (i.e., pure discovery) is ineffective in promoting deep learning (Shulman and Keislar, 1966; Mayer, 2004; de Jong, 2005; Kirchner, Sweller, and Clark, 2006). In contrast, asking students to solve challenging problems while providing appropriate and specific cognitive guidance along the way (i.e., guided discovery) can be a useful
BOX 6-2
Principles of Multimedia Design for Deeper Learning
Principles for Reducing Extraneous Processing (thinking unrelated to the learning goal)
- Coherence principle: Exclude extraneous words, pictures, and sounds.
- Signaling principle: Add cues to highlight the organization of essential material.
- Redundancy principle: Graphics with narration are more effective than graphics with narration and on-screen text.
- Spatial contiguity principle: Place corresponding words and pictures close together on the page or screen.
- Temporal contiguity principle: Present corresponding words and pictures simultaneously rather than successively.
Principles for Managing Essential Processing (thinking related to the learning goal)
- Segmenting principle: Present lesson in user-paced segments.
- Pretraining principle: Present names and characteristics of key concepts in advance of the main lesson.
- Modality principle: Use graphics and narration, rather than animation and on-screen text.
Principles for Managing Generative Processing (thinking that enables deeper learning)
- Multimedia principle: Use words and pictures, rather than words alone.
- Personalization principle: Use words in a conversational style.
- Voice principle: Narration should be spoken with a friendly human voice rather than a voice produced by a machine.
- Image principle: Adding a speaker’s image does not necessarily enhance learning.
Boundary Conditions
The series of experiments also indicated that the effectiveness of these design principles for supporting deeper learning are limited by two boundary conditions. First, some design effects are stronger for low-experience learners than for high-experience learners, which Mayer (2009) refers to as the individual-differences condition. Second, the effects of applying the principles are stronger for multimedia lessons with highly complex content than for those with less complex content and are also stronger for fast-paced presentations than for slow-paced presentations.
SOURCE: Adapted from Mayer (2009).
technique for promoting deep learning (de Jong, 2005; Tobias and Duffy, 2009). For example, there is no compelling evidence that beginners deeply learn science concepts or processes by freely exploring a science simulation or game (National Research Council, 2011b), but including guidance in the form of advice, feedback, prompts, and scaffolding (i.e., completing part of the task for the learner) can promote deeper learning in beginners (de Jong, 2005; Azevedo and Aleven, 2010).
Providing guided exploration and metacognitive support also enhances learning for transfer in informal settings. Based on its review of the research on informal science learning, a National Research Council committee (2009a) recommended that science exhibits and programs be designed with specific learning goals in mind and that they provide support to sustain learners’ engagement and learning. For example, exhibits and programs should “prompt and support participants to interpret their learning experiences in light of relevant prior knowledge, experiences, and interests” (p. 307). There is emerging evidence that designing simulations to enable guided exploration, with support, enhances deeper learning of science (National Research Council, 2011b).
Teaching with Examples and Cases
A worked-out example is a step-by-step modeling and explanation of how to carry out a procedure, such as how to solve probability problems (Renkl, 2005, 2011). Under appropriate conditions, students gain deep understanding when they receive worked-out examples as they begin to learn a new procedural skill, both in paper-based and computer-based venues (Sweller and Cooper, 1985; Renkl, 2005, 2011). In particular, deep learning is facilitated when the problem is broken into conceptually meaningful steps which are clearly explained and when the explanations are gradually taken away with increasing practice (Renkl, 2005, 2011).
Priming Student Motivation
Deep learning occurs when students are motivated to exert the effort to learn, so another way to promote deep learning is to prime student motivation (Schunk, Pintrich, and Meece, 2008; Summers, 2008; Wentzel and Wigfield, 2009). Research on academic motivation shows that students learn more deeply when they attribute their performance to effort rather than to ability (Graham and Williams, 2009), when they have the goal of mastering the material rather than the goal of performing well or not performing poorly (Anderman and Wolters, 2006; Maehr and Zusho, 2009), when they expect to succeed on a learning task and value the learning task (Wigfield, Tonks, and Klauda, 2009), when they have the belief that they
are capable of achieving the task at hand (Schunk and Zimmerman, 2006; Schunk and Pajares, 2009), when they believe that intelligence is changeable rather than fixed (Dweck and Master, 2009), and when they are interested in the learning task (Schiefele, 2009). There is promising evidence that these kinds of beliefs, expectancies, goals, and interests can be fostered in learners by, for example, peer modeling techniques (Schunk, Pintrich, and Meece, 2008) and through the interventions described in Chapter 4 (Yaeger and Walton, 2011). Elementary school students showed increased self-efficacy for solving subtraction problems and increased test performance after watching a peer demonstrate how to solve subtraction problems while exhibiting high self-efficacy (such as saying, “I can do that one” or “I like doing these”) versus control conditions (Schunk and Hanson, 1985). As discussed in Chapter 4, research has shown that, in a responsive social setting, learners can adopt the criteria for competence they see in others and then use this information to judge and perfect the adequacy of their own performance (National Research Council, 2001).
Although informal learning environments are often designed to tap into learners’ own, intrinsic motivations for learning, they can also prime and extend this motivation. For example, to prime motivation and support deeper learning in structured informal science learning environments (e.g., zoos, aquariums, museums, and science centers), research suggests that science programs and exhibits should
- be interactive;
- provide multiple ways for learners to engage with concepts, practices, and phenomena within a particular setting; and
- prompt and support participants to interpret their learning experiences in light of relevant prior knowledge, experiences, and interests (National Research Council, 2009a, p. 307).
Similarly, research suggests that to prime learners’ motivation for the difficult task of learning science through inquiry, simulations and games should provide explanatory guidance, feedback, and scaffolding; incorporate an element of narrative or fantasy; and allow a degree of user control without allowing pure, open-ended discovery (National Research Council, 2011b).
Using Formative Assessment
The formative assessment concept (discussed further below) emphasizes the dynamic process of using assessment evidence to continually improve student learning; this is in contrast to the concept of summative assessment, which focuses on development and implementation of an instrument to
measure what a student has learned up to a particular point in time (National Research Council, 2001; Shepard, 2005; Heritage, 2010). Deeper learning is enhanced when formative assessment is used to: (1) make learning goals clear to students; (2) continuously monitor, provide feedback, and respond to students’ learning progress; and (3) involve students in self- and peer assessment. These uses of formative assessment are grounded in research showing that practice is essential for deeper learning and skill development but that practice without feedback yields little learning (Thorndike, 1927; see also Chapter 4).
Research on each of the six major instructional approaches to teaching for transfer discussed above helps to pinpoint the boundary conditions for each instructional method, including for whom, for which learning contexts, and for which instructional objectives.
Promoting Deeper Learning Through Problem-Based Learning: An Example
One curriculum model that incorporates several of the methods described above is problem-based learning (PBL). PBL approaches represent learning tasks in the form of rich extended problems that, if carefully designed and implemented, can engage learners in challenging tasks (problems) while providing guidance and feedback. They can encourage elaboration, questioning, and self-explanation and can prime motivation by presenting problems that are relevant and interesting to the learners. While a variety of different approaches to PBL have been developed, such instruction often follows six key principles (Barrows, 1996):
- Student-centered learning
- Small groups
- Tutor as a facilitator or guide
- Problems first
- The problem is the tool to achieve knowledge and problem-solving skills
- Self-directed learning
Two recent meta-analyses of the research on interventions following these principles suggest that PBL approaches can support deeper learning and transfer. Gijbels et al. (2005) focused on empirical studies that compared PBL with lecture-based instruction in higher education in Europe (with most of the studies coming from medical education). The meta-analysis identified no significant difference in the understanding of concepts between students engaged in PBL and those receiving lecture-based instruction. However, students in the PBL environments demonstrated
deeper understanding of the underlying principles that linked the concepts together. In addition, students in the PBL environments demonstrated a slightly better ability to apply their knowledge than students in the lecture-based classes. As noted in the previous chapter, two hallmarks of deeper learning are that it develops understanding of underlying principles and that it supports the application of knowledge—i.e., transfer.
More recently, Strobel and van Barneveld (2009) conducted a meta-synthesis of eight previous meta-analyses and research reviews that had compared PBL approaches with traditional lecture-based instruction. They found that how learning goals were defined and assessed in the various individual studies affected the findings about the comparative effectiveness of the two different approaches. When the learning goal was knowledge, and assessments were focused on short-term retention, traditional approaches were more effective than PBL, but when knowledge assessments focused on longer-term retention (12 weeks to 2 years following the initial instruction), PBL approaches were more effective. Furthermore, when learning goals were related to transfer or application of knowledge, PBL approaches were more effective. Two particular learning goals were identified by the authors as showing such advantages: performance, as measured by supervisor ratings of medical students’ clinical practice, and mixed knowledge and skill (including application of knowledge). Although PBL appears promising, more extensive and rigorous research is needed to determine its effectiveness in supporting deeper learning.
Design Principles for Teaching Problem-Solving and Metacognitive Strategies
Problem solving and metacognition are important competencies that are often included in lists of 21st century skills. Problem-solving and metacognitive strategies differ in several respects. Problem solving typically involves applying sets of procedures organized as strategies that allow persons to tackle a range of new tasks and situations within some performance domain such as how to simplify an algebraic equation or summarize a text, and they represent one of the five types of transferable knowledge discussed in Chapter 4 (see Table 4-3). Metacognition refers to a person’s ability to select, monitor, manage, and evaluate cognitive processing during the learning or performance of a cognitive task. Metacognitive strategies are higher-level methods for managing one’s thinking and reasoning while learning or performing a task. Metacognitive strategies may play a central role in people’s ability to transfer—that is, in people’s ability to solve new problems and learn new things. The ability to apply metacognitive strategies when learning is a key dimension of self-regulated learning, as discussed in Chapter 4. Recent research advances have specified metacognitive
strategies, determined their role in solving problems in mathematics (e.g., Griffin, 2005) and other disciplines, and illuminated how to teach them. These advances reflect the central role of metacognition in the development of transferable 21st century competencies.
There are five main issues to consider in developing transferable strategies for effective problem solving and metacognition: determining what to teach, how to teach, where to teach, when to teach, and how long to teach (Mayer, 2008).
What to Teach
In determining what to teach, the first question one must answer is whether competency in problem solving or metacognition is based on improving the mind in general as a single monolithic ability or on acquiring a collection of smaller component skills. Early in the history of psychology and education the varying beliefs about the nature of cognitive ability were epitomized by the opposing approaches of Galton (1883) and Binet (1962). Galton proposed that cognitive ability was a unitary construct best measured by reaction time tasks and perceptual discrimination tasks. Later research showed that Galton’s battery of cognitive measures did not correlate strongly with such measures of intellectual ability as school grades (Sternberg, 1990). In contrast, when Binet was charged with developing a test to predict academic success in the Paris school system, he conceptualized cognitive ability as a collection of small component skills and pieces of knowledge that could be learned, and his test was successful in predicting school success.
Similarly, modern psychometric approaches to human cognitive ability that are based on factor analyses of large batteries of cognitive tests reveal that there are many small component factors to cognitive ability rather than a single general ability factor (Carroll, 1993; Willis, Dumont, and Kaufman, 2011). And research-based cognitive theories of intelligence are based on the idea that cognitive performance on academic tasks depends on a collection of smaller cognitive and metacognitive processes rather than on a single mental ability (Mayer, 2010; Hunt, 2011). Although conventional wisdom among laypeople may hold that intellectual ability is a single monolithic ability, research on testing and individual differences in information processing suggests that intellectual ability is best seen as a collection of smaller component skills. It follows that cognitive strategy instruction should focus on helping students develop a collection of clearly defined component skills and learning how to assemble and integrate them rather than on improving their minds in general.
How to Teach
On the issue of how to teach, a key question is whether instruction should focus on the product of problem solving (i.e., getting the right answer) or on the process of problem solving (i.e., the thinking that goes into getting the right answer). Three research-based instructional techniques for the teaching of problem-solving and metacognitive strategies are modeling, prompting, and apprenticeship. In modeling the learner observes an expert perform the task, usually with commentary so that the learner receives a step-by-step explanation for why each step is taken. Modeling generally takes the form of worked-out examples that can be printed in books, presented on computer screens, or presented live by an expert. In prompting, the learner is given a problem to solve along with questions and hints about the reasons for carrying out various actions. For example, in self-explanation methods, the learner is asked to explain aspects of his or her cognitive processing while solving a problem. Because such explanations require reflection on one’s own thinking and learning, these methods help learners develop metacognitive strategies.
In a classic study, Bloom and Broder (1950) taught college students how to solve problems on exams in college subjects such as economics by asking them to think aloud as they solved a problem, watch a model think aloud as he solved the problem, and then compare their thought processes with that of the model problem solver. Several hours of training based on this modeling of effective problem-solving processes resulted in significant improvements in exam scores as compared to a control group that did not receive this training. Modeling of the cognitive processes of successful problem solvers has been a component in the development of several successful problem-solving programs, as indicated in assessments of the Productive Thinking Program (Olton and Crutchfield, 1969; Mansfield, Busse, and Krepelka, 1978), Instrumental Enrichment (Feuerstein, 1980), and Project Intelligence (Hernstein et al., 1986; Nickerson, 2011).
Apprenticeship teaching and learning methods can help learners understand and apply the process of problem solving. In apprenticeship, a mentor or teacher models problem solving by describing how he or she approaches the process, coaches by providing guidance and tips to the learner who is carrying out a task, and scaffolds by directly performing or eliminating difficult parts of the task that the learner is unable to perform (Mayer and Wittrock, 2006). One example of apprenticeship methods is reciprocal teaching, as when students and a teacher took turns discussing strategies for increasing reading comprehension (Palincsar and Brown, 1984; Brown and Palincsar, 1989). Students who engaged in reciprocal teaching demonstrated a much larger gain in reading comprehension scores than students
who learned reading with conventional methods, as the reciprocal teaching method helped them to solve problems they encountered while reading text.
Azevedo and Cromley (2004) identified several metacognitive strategies that are commonly used in the learning of new material, including planning, monitoring, using strategies, managing, and enjoying. Planning refers to the development of a plan for learning, and it includes activating relevant prior knowledge. Monitoring refers to recognizing when one does or does not comprehend something and figuring out what needs to be clarified. Using strategies involves determining when to use various learning strategies, such as taking notes, writing summaries, and generating drawings. Managing involves using time wisely, such as seeking help when needed. Enjoying involves expressing interest in the material. In short, a reasonable conclusion is that instructional methods should focus on the processes of problem solving and metacognition rather than solely on the final products of those processes.
Where to Teach
On the issue of where to teach, the key issue is whether problem-solving and metacognitive strategies should be learned in a specific domain or in a general way. Early in the history of educational psychology Thorndike sought to test the conventional wisdom of the day, which held that certain school subjects such as Latin and geometry helped to develop proper habits of mind—general ways of thinking that applied across disciplines (Thorndike and Woodworth, 1901; Thorndike, 1932). For example, in a classic study, Thorndike (1923) found that students who had learned Latin and students who had not learned Latin showed no differences in their ability to learn a new school subject: English. Combined with numerous other studies showing a lack of general transfer, these results led Thorndike to conclude that transfer is always specific—that is, the elements and relations in the learned material must be the same as the elements and relations in the to-be-learned material. Research on problem-solving and metacognitive expertise supports the idea that competency tends to be domain specific, as discussed in Chapter 4. People who are experts in solving problems in one domain are not able to transfer their problem-solving skill to other domains (de Groot, 1965; Ericsson et al., 2006). As noted above, research has shown that children’s ability to solve problems in science is dependent on their prior knowledge of the topic or concept under study (National Research Council, 2007). These findings suggest that strategy instruction should be conducted within the specific context in which the problems will be solved (i.e., embedded within specific disciplines) rather than as a general stand-alone course.
When to Teach
On the subject of when to teach, the key question is whether problem-solving strategies should be taught before or after lower-level skills are mastered. Although the research base is less developed on this question, there is converging evidence that novices can benefit from training in high-level strategies. For example, in writing instruction students can be taught how to communicate with words—by dictating to an adult, for example, or by giving an oral presentation or being allowed to write with misspelled words and improper grammar—before they have mastered lower-level skills such as spelling and punctuation (Bereiter and Scardamalia, 1987; De La Paz and Graham, 1995). In observational studies of cognitive apprenticeship, beginners successfully learn high-level skills through a process of assisted performance (Tharp and Gallimore, 1988) in which they are allowed to attempt parts of complex tasks before than have mastered basic skills. These findings suggest that higher-order thinking skills can be learned along with lower-order ones early in the instructional process.
How Long to Teach
On the fifth issue, how long to teach, the main question is what the role should be of prolonged, deliberate practice in learning problem-solving strategies. Research on the development of expertise indicates that “high degrees of competence only come through extensive practice” (Anderson and Schunn, 2000, p. 17) and that learners need feedback that explains how to improve (Shute, 2008; Hattie and Gin, 2011). For example, students were found to develop expert-like performance in troubleshooting electronic and mechanical equipment if they spent 20-25 hours with a computer simulation in which they received immediate and focused feedback (Lesgold, 2001). In case studies, Ericsson and colleagues have found a close relationship between the development of professional expertise and the amount of deliberate practice—intensive practice at increasingly more challenging levels—even among learners with equivalent talent (see, e.g., Ericsson, 2003). Although programs that require only a few hours of work can produce improvements in problem-solving skill, the development of expert problem-solving skill requires years of deliberate practice.
Research indicates that extended time and practice also enhances learning in informal settings. For example, the National Research Council (2009a) recommends that designers of science exhibits and programs support and encourage learners to extend their learning over time, noting that “learning experiences in informal settings can be sporadic and … without support, learners may not find ways to sustain their engagement with science or a given topic.”
BOX 6-3
Issues in Teaching Cognitive and Metacognitive Skills
- What to teach: Focus on a collection of small component skills rather than trying to improve the mind as a single monolithic ability.
- How to teach: Focus on the learning process (through modeling, prompting, or apprenticeship) rather than on the product.
- Where to teach: Focus on learning to use the skill in a specific domain rather than in general.
- When to teach: Focus on teaching higher skills even before lower skills are mastered.
- How long to teach: Focus on deliberate practice to develop expertise.
SOURCE: Adapted from Mayer (2008).
Summary
Research and theory to date suggest answers to each of the five questions posed above (see Box 6-3). They suggest that instructors should teach component skills and their integration rather trying to improve the mind in general; should focus on the processes of problem solving and metacognition (through modeling or prompting) rather than solely on product; should focus on using the strategies in a specific context rather than in general; should focus on learning problem-solving and metacognitive strategies before or while lower-level skills are mastered; and should focus on prolonged, deliberate practice and application rather than one-shot deals.
Summary: Developing Transferable Cognitive Competencies
A persistent theme in research on learning and teaching for transfer concerns the situated nature of learning. That is, it is not fruitful to try to teach high-level thinking skills in general; rather, transferable knowledge is best learned within the disciplinary situations or sets of topics within which the knowledge will be used. In the previous chapter, we explored learning and teaching for transfer within three disciplines—English language arts, mathematics, and science. Within each discipline, the kinds of teaching techniques for transferable knowledge are adapted to the particular subject matter by such means as using multiple representations, encouraging questioning and self-explanation, providing guidance and support during exploration, teaching with examples, and priming motivation. The examples included in that chapter (Herrenkohl et al., 1999; Griffin, 2005) provide
straightforward evidence that pure discovery (or unassisted inquiry) is not a particularly effective instructional method and that a more effective approach involves a combination of explicit instruction and guided exploration with metacognitive support.
Similarly, the disciplinary goals discussed in the previous chapter vary in how they approach the teaching of cognitive competencies. On the topic of what to teach, each discipline focuses on competencies that are important for the particular subject matter—such as discourse structures for argumentation and the interpretation of evidence in science, problem solving in mathematics, and comprehension of text in English language arts. On the issue of how to teach, each discipline adapts various techniques, including the modeling of thinking processes within discipline-specific tasks. On the subject of where to teach, high-level strategies are taught within discipline-specific situations rather than as general strategies. On the question of when to teach, each discipline teaches high-level content along with more basic, foundational content rather than waiting for basic skills to be mastered first. Finally, on the subject of how long to teach, each discipline views disciplinary learning as a long-term learning progression in which major competencies are learned at increasingly more sophisticated levels over the course of schooling—such as the way in which learning to read or write becomes more sophisticated and adapted for specific purposes.
INSTRUCTIONAL DESIGN PRINCIPLES—INTRAPERSONAL AND INTERPERSONAL DOMAINS
The research on instruction that directly targets intrapersonal and interpersonal learning goals is less extensive and rigorous than the research on instruction targeting cognitive learning goals. Although the limited evidence base poses a challenge to identifying specific principles of instructional design to advance intrapersonal and interpersonal knowledge and skills, there is suggestive evidence that some of the principles for instruction in the cognitive domain may be applicable to instruction in these two other domains.
In their meta-analysis of studies of after-school social and emotional learning programs described above, Durlak, Weissberg, and Pachan (2010) analyzed the studies’ findings related to eight outcomes clustered into three categories, as follows:
- Feelings and attitudes (child self-perceptions, bonding to school)
- Behavioral adjustment (positive social behaviors, problem behaviors, drug use)
- School performance (achievement test scores, grades, attendance)
Based on prior research, the authors identified four practices thought to work together in combination to enhance the effectiveness of such programs:
- A sequenced, step-by-step training approach
- Emphasizing active forms of learning, so that youth can practice new skills
- Focusing specific time and attention on skill training
- Clearly defining goals, so that youth know what they are expected to learn
Among the programs evaluated in the studies, 41 followed all four of the research-based practices listed above, while 27 did not follow all four. The group of programs that followed the four practices showed statistically significant mean effects for all outcomes (including drug use and school attendance), while the group of programs that did not follow all four practices did not yield significant mean effects for any of the outcomes. These findings support the authors’ hypothesis that the four research-based practices work best in combination to support the development of intrapersonal and interpersonal skills.
In a more recent meta-analysis of school-based social and emotional learning programs, Durlak et al. (2011) reviewed 213 studies, examining findings of effectiveness in terms of six outcomes:
- Social and emotional skills
- Attitudes toward self and others
- Positive social behaviors
- Conduct problems
- Emotional distress
- Academic performance
When the authors considered the findings in terms of the four research-based practices identified in their earlier study (Durlak, Weissberg, and Pachan, 2010), they found that the group of programs that followed all four of these recommended practices showed significant effects for all six outcomes, whereas programs that did not follow all four practices showed significant effects for only three outcomes (attitudes, conduct problems, and academic performance). The authors also found that the quality of implementation mattered. When programs were well conducted and proceeded according to plan, gains across the six outcomes were more likely.
These four practices are similar to some of the research-based methods and design principles described above for supporting deeper learning in the cognitive domain. For example, the earlier discussion identified the
method of encouraging elaboration, questioning, and self-explanation as an effective way to support deeper learning of cognitive skills and knowledge. Similarly, the research on teaching social and emotional skills suggests that active forms of learning that include elaboration and questioning—such as role playing and behavioral rehearsal strategies—support deeper learning of intrapersonal and interpersonal skills and knowledge. These active forms of social and emotional learning provide opportunities for learners to practice new strategies and receive feedback.
The research on social and emotional skills indicates that it is important for teachers and school leaders to give sufficient attention to skill development, with a sequential and integrated curriculum providing opportunities for extensive practice. This echoes two findings about teaching cognitive skills: (1) teaching should be conducted within the specific context in which problems will be solved—in this case, social and emotional problems; and (2) the development of expert problem-solving skill requires years of deliberate practice. Providing adequate time and attention for skill development in the school curriculum appears to enhance the learning of intrapersonal and interpersonal skills. Finally, the research on social and emotional learning—like the research on cognitive learning—indicates that establishing explicit learning goals enhances effectiveness (Durlak et al., 2011). Just as the research on instruction for cognitive outcomes has demonstrated that learners need support and guidance to progress toward clearly defined goals (and that pure “discovery” does not lead to deep learning), so, too, has the research on instruction for social and emotional outcomes.
Research on team training also provides suggestive evidence that certain instructional design principles are important for the deeper learning of intrapersonal and interpersonal skills. In their meta-analysis, Salas et al. (2008) analyzed the potential moderating influence that the content of the team-training interventions had on outcomes. They identified three types of content: primarily task work; primarily teamwork (i.e., communication and other interpersonal skills); and both task work and teamwork. Their results suggest that when the goal is performance improvement the content makes little difference. However, for process outcomes (i.e., the development of intrapersonal and interpersonal skills that facilitate effective teamwork) and affective outcomes, teamwork and mixed-content training are associated with larger effect sizes than training focused on task work. The finding that, in situations when the goal is to improve team processes, focusing training content on teamwork skills improves effectiveness provides further support for the design principle that instruction should focus on clearly defined learning goals. The authors caution, however, that this conclusion is based on only a small number of studies.
ASSESSMENT OF AND FOR DEEPER LEARNING
Earlier in this chapter we discussed the need for clear learning goals and valid measures of important student outcomes, be they cognitive, intrapersonal, or interpersonal. Thus any discussion of issues related to the use of assessment to promote deeper learning presupposes that concerns about what to assess, how to assess, and how to draw valid inferences from the evidence have been addressed. These concerns must be addressed if assessment is to be useful in supporting the processes of teaching and learning. In this section we focus on issues related to how assessment can function in educational settings to accomplish the goal of supporting and promoting deeper learning.
Since its beginning, educational testing has been viewed as a tool for improving teaching and learning (see, for example, Thorndike, 1918), but perspectives on the ways that it can best support such improvement have expanded in recent years. Historically the focus has been on assessments of learning—the so-called summative assessments—and on the data they can provide to support instructional planning and decision making. More recently, assessment for learning—the so-called formative assessment—has been the subject of an explosion of interest, spurred largely by Black and Wiliam’s 1998 landmark review showing impressive effects of formative assessment on student learning, particularly for low-ability students. A more recent meta-analysis of studies of formative assessment showed more modest, but still significant, effects on learning (Kingston and Nash, 2011).
The formative assessment concept emphasizes the dynamic process of using assessment evidence to continually improve student learning, while summative assessment focuses on development and implementation of an assessment instrument to measure what a student has learned up to a particular point in time (National Research Council, 2001; Shepard, 2005; Heritage, 2010).
Both types of assessment have a role in classroom instruction and in the assessment of deeper learning and 21st century skills, as described below. (The role of accountability testing in the development of these skills is treated in Chapter 7.)
Assessments of Learning
Assessments of learning look back over a period of time (a unit, a semester, a year, multiple years) in order to measure and make judgments about what students have learned and about how well programs and strategies are working—as well as how they can be improved. Assessments of learning often serve as the starting point for the design of instruction and teaching because they make explicit for both teachers and students what is
expected and they provide benchmarks against which success or progress can be judged. For the purpose of instruction aimed at deeper learning and development of 21st century skills, it is essential that such measures (1) fully represent the targeted skills and knowledge and a model of their development; (2) be fair in enabling students to show what they know; and (3) provide reliable, unbiased, and generalizable inferences about student competence (Linn, Baker, and Dunbar, 1991; American Educational Research Association, American Psychological Association, and the National Council for Measurement in Education, 1999). In other words, the intended learning goals, along with their development, the assessment observations, and the interpretative framework (National Research Council, 2001) must be justified and fully synchronized.
When this is the case, the results for individual students can be useful for grading and placing students, for initial diagnoses of learning needs, and, in the case of students who are academically oriented, for motivating performance. Aggregated at the class, school, or higher levels, results may help in the identification of new curriculum and promising practices as well as in the assessment of teaching strategies and the evaluation of personnel and institutions.
Assessment for Learning: Formative Assessment
In contrast to assessments of learning that look backward over what has been learned, assessments for learning—formative assessments—chart the road forward by diagnosing where students are relative to learning goals and by making it possible to take immediate action to close any gaps (see Sadler, 1989). As defined by Black and Wiliam (1998), formative assessment involves both understanding and immediately responding to students’ learning status. In other words, it involves both diagnosis and actions to accelerate student progress toward identified goals.
Such actions may be teacher directed and coordinated with a hypothesized model of learning. Actions could include: teachers asking questions to probe, diagnose, and respond to student understanding; teachers asking students to explain and elaborate their thinking; teachers providing feedback to help students transform their misconceptions and transition to more sophisticated understanding; and teachers analyzing student work and using results to plan and deliver appropriate next steps, for example, an alternate learning activity for students who evidence particular difficulties or misconceptions. But the actions are also student centered and student directed. A hallmark of formative assessment is its emphasis on student efficacy, as students are encouraged to be responsible for their learning, and the classroom is turned into a learning community (Gardner, 2006; Harlen, 2006). To assume that responsibility, students must clearly understand what
learning is expected of them, including its nature and quality. Students receive feedback that helps them to understand and master performance gaps, and they are involved in assessing and responding to their own work and that of their peers (see also Heritage, 2010).
The importance of the teacher’s role in formative assessment was demonstrated by the recent meta-analysis by Kingston and Nash (2011). The authors estimated a weighted mean effect size of 0.20 across the selected studies. However, in those studies investigating the use of formative assessment based on professional development that supported teachers in implementing the strategy, the weighted mean effect size was 0.30. Formative assessment occurs hand in hand with the classroom teaching and learning process and is an integral component of teaching and learning for transfer. It embodies many of the principles of designing instruction for transfer that were discussed in the previous section of this chapter. For example, formative assessment includes questioning, elaboration, and self-explanation, all of which have been shown to improve transfer. Formative assessment can provide the feedback and guidance that learners need when engaged in challenging tasks. Furthermore, by making learning goals explicit, by engaging students in self- and peer assessment, by involving students in a learning community, and by demonstrating student efficacy, formative assessment can promote students as agents in their own learning, which can increase student motivation, autonomy, and metacognition as well as collaboration and academic learning (Gardner, 2006; Shepard, 2006). Thus, formative assessment is conducive to—and may provide direct support for—the development of transferable cognitive, intrapersonal, and interpersonal skills.
A few examples suggest that teachers and students can enhance deeper learning by drawing on the evidence of their learning progress and needs provided by the formative assessment embedded within simulations and games. One such example, SimScientists, was described above. Another example, called Packet Tracer, was developed for use in the Cisco Networking Academy, which helps prepare networking professionals by providing online curricula and assessments to public and private education and training institutions throughout the world. In the early years of the networking academy, assessments were conducted by instructors and consisted of either hands-on exams with real networking equipment or else multiple-choice exams. Now Packet Tracer has been integrated into the online curricula, allowing instructors and students to construct their own activities and students to explore problems on their own. Student-initiated assessments are embedded in the curriculum and include quizzes, interactive activities, and “challenge labs”—structured activities focusing on specific curriculum goals, such as integration of routers within a computer network. Students use the results of these assessments to guide their online learning activities
and to improve their performance. A student may, with instructor authorization, access and re-access an assessment repeatedly.
Formative and Summative Assessment: Classroom Systems of Assessment
Assessments of learning and for learning (summative and formative assessments) can work together in a coherent system to support the development of cognitive, intrapersonal, and interpersonal skills. If they are to do so, however, the assessments must be in sync with each other and with the model of how learning develops. Figure 6-2 shows the interrelationships among components of such a model. The model features explicit learning goals for targeted cognitive, intrapersonal, and interpersonal competencies and poses a sequential and integrated approach to their development, as supported by the literature (see, for example, Durlak and Weissburg, 2011).
In Figure 6-2, the benchmarks represent critical juncture points in progress toward the ultimate goals, while the formative assessment represents the interactive process between the teachers and students and continuous data that facilitate student progress toward the junctures and ultimate goals.
FIGURE 6-2 A coherent assessment system.
SOURCE: Adapted from Herman (2010a).
Formative Assessment: Teacher Roles and Practices
The coherent assessment system depicted in Figure 6-2 depends on formative assessment to facilitate student progress. Herman has described formative assessment as follows (2010b, p. 74):
Rather than imparting knowledge in a transmission-oriented process, in formative assessment teachers guide students toward significant learning goals and actively engage students as assessors of themselves and their peers. Formative assessment occurs when teachers make their learning goals and success criteria explicit for students, gather evidence of how student learning is progressing, partner with students in a process of reciprocal feedback, and engage the classroom as a community to improve students’ learning. The social context of learning is fundamental to the process as is the need for classroom culture and norms that support active learning communities—for example, shared language and understanding of expected performance; relationships of trust and respect; shared responsibility for and power in the learning process. Theorists (Munns and Woodward, 2006) observe that enacting a meaningful process of formative assessment influences what students perceive as valued knowledge, who can learn, who controls and is valued in the learning process.
Yet formative assessment itself involves a change in instructional practice: It is not a regular part of most teachers’ practice, and teachers’ pedagogical content knowledge may be an impediment to its realization (Heritage et al., 2009; Herman, Osmundson, and Silver, 2010). These and other challenges related to teaching and assessing 21st century competencies are discussed in Chapter 7. In that chapter, we reach conclusions about the challenges and offer recommendations to overcome them.
CONCLUSIONS AND RECOMMENDATIONS
The research literature on teaching and assessment of 21st century competencies has examined a plethora of variously defined cognitive, interpersonal, and interpersonal competencies, Although the lack of uniform definitions makes it difficult to identify and delineate the desired learning outcomes of an educational intervention—an essential first step toward measuring effectiveness—emerging evidence demonstrates that it is possible to develop transferable competencies.
- Conclusion: Although the absence of common definitions and quality measures poses a challenge to research, emerging evidence indicates that cognitive, intrapersonal, and interpersonal competencies can be taught and learned in ways that promote transfer.
The emerging evidence on teaching and learning of cognitive, intrapersonal, and interpersonal competencies builds on a larger body of evidence related to teaching for transfer. Researchers have examined the question of how to design instruction for transfer for more than a century. In recent decades, advances in the research have begun to provide evidence-based answers to this question. Although this research has focused on acquisition of cognitive competencies, it indicates that the process of learning for transfer involves the interplay of cognitive, intrapersonal, and interpersonal competencies, as reflected in our recommendations for design of instruction and teaching methods:
- Recommendation 3: Designers and developers of instruction targeted at deeper learning and development of transferable 21st century competencies should begin with clearly delineated learning goals and a model of how learning is expected to develop, along with assessments to measure student progress toward and attainment of the goals. Such instruction can and should begin with the earliest grades and be sustained throughout students’ K-12 careers.
- Recommendation 4: Funding agencies should support the development of curriculum and instructional programs that include research-based teaching methods, such as:
- Using multiple and varied representations of concepts and tasks, such as diagrams, numerical and mathematical representations, and simulations, combined with activities and guidance that support mapping across the varied representations.
- Encouraging elaboration, questioning, and explanation—for example, prompting students who are reading a history text to think about the author’s intent and/or to explain specific information and arguments as they read—either silently to themselves or to others.
- Engaging learners in challenging tasks, while also supporting them with guidance, feedback, and encouragement to reflect on their own learning processes and the status of their understanding.
- Teaching with examples and cases, such as modeling step-by-step how students can carry out a procedure to solve a problem and using sets of worked examples.
- Priming student motivation by connecting topics to students’ personal lives and interests, engaging students in collaborative problem solving, and drawing attention to the knowledge and skills students are developing, rather than grades or scores.
- Using formative assessment to: (a) make learning goals clear to students; (b) continuously monitor, provide feedback, and respond to students’ learning progress; and (c) involve students in self- and peer assessment.
The ability to solve complex problems and metacognition are important cognitive and intrapersonal competencies that are often included in lists of 21st century skills. For instruction aimed at development of problem-solving and metacognitive competencies, we recommend:
- Recommendation 5: Designers and developers of curriculum, instruction, and assessment in problem solving and metacognition should use modeling and feedback techniques that highlight the processes of thinking rather than focusing exclusively on the products of thinking. Problem-solving and metacognitive competencies should be taught and assessed within a specific discipline or topic area rather than as a stand-alone course. Teaching and learning of problem-solving and metacognitive competencies need not wait until all of the related component competencies have achieved fluency. Finally, sustained instruction and effort are necessary to develop expertise in problem solving and metacognition; there is simply no way to achieve competence without time, effort, motivation, and informative feedback.
Most of the available research on design and implementation of instruction for transfer has focused on the cognitive domain. We compared the instructional design principles and research-based teaching methods emerging from this research with the instructional design principles and research-based teaching methods that are beginning to emerge from the smaller body of research focusing on development of intrapersonal and interpersonal skills, identifying some areas of overlap and similarities.
- Conclusion: The instructional features listed above, shown by research to support the acquisition of cognitive competencies that transfer, could plausibly be applied to the design and implementation of instruction that would support the acquisition of transferable intrapersonal and interpersonal competencies.
The many gaps and weaknesses in the research reviewed here, particularly the lack of common definitions and measures, and the limited research in the intrapersonal and interpersonal domains limit our understanding of how to teach for transfer across the three domains.
- Recommendation 6: Foundations and federal agencies should support research programs designed to fill gaps in the evidence base on teaching and assessment for deeper learning and transfer. One important target for future research is how to design instruction and assessment for transfer in the intrapersonal and interpersonal domains. Investigators should examine whether, and to what extent, instructional design principles and methods shown to increase transfer in the cognitive domain are applicable to instruction targeted to the development of intrapersonal and interpersonal competencies. Such programs of research would benefit from efforts to specify more uniform, clearly defined constructs and to produce associated measures of cognitive, intrapersonal, and interpersonal competencies.










































