
4
Issues and Opportunities in the Emergence of Large Health-Related Datasets
KEY SPEAKER THEMES
Madigan
• Complexity of health information surpasses the ability of clinicians and current “evidence-based” models.
• Large health-related datasets can produce more accurate predictive models.
• Bias presents an enormous challenge to observational research but there are strategies to mitigate its impact.
McCall
• Understanding what works best for whom requires a nuanced understanding of cause and effect.
• Advances in mathematics, coupled with access to large datasets, have the potential to allow researchers to discover cause-effect relationships rather than correlations.
• Research should focus on insights rather than analytics in order to come up with causal structure rather than static answers.
The emergence of large health-related datasets—from sources such as large health systems, payers, pharmacy benefit managers, etc.—have the potential to transform the clinical effectiveness research enterprise. Realizing the potential requires mathematical methods that handle the scale of data, as well as an appreciation of the biases and limitations inherent to each data source. David Madigan, Professor and Chair of the Department of Statistics at Columbia University, discussed the challenge of bias in large datasets, and strategies and methods to more appropriately address bias in observational clinical outcomes research. Carol McCall, Chief Strategy Officer at GNS Healthcare, focused on new mathematical approaches that allow nuanced insights to be derived from large datasets.
THE CHALLENGE OF BIAS IN LARGE HEALTH-RELATED DATASETS
David Madigan began his presentation by focusing on the current clinical decision framework, which revolves around evidence-based medicine and clinical judgment. He told the story of a cardiologist deciding whether or not a patient should receive angioplasty. Using a risk assessment algorithm from the Framingham study, the doctor assigned a 10-year risk of developing coronary heart disease using the following variables: age, total cholesterol, smoking, high-density lipoprotein (HDL), and blood pressure. According to Madigan, this is evidence-based medicine in 2012. A multitude of other health related data—other lab results, family history, medication, other health issues—is ignored in this analysis. This is where, ideally, clinical judgment comes in. The cardiologist should use the evidence-based recommendation, coupled with the other variables, to make an appropriate decision. Madigan argued that in the face of this much information it is infeasible for a human being to do optimal decision making.
With the right statistical techniques, however, large health-related datasets can begin to answer these questions. Madigan cited the work of the Observational Medical Outcomes Partnership (OMOP), which has medical records for roughly 200 million individuals. Within this database, he speculated, there might be 30,000 individuals like the patient described above. This information can be used to make inferences about the course of care more precisely than those made by physicians. At its heart, Madigan stated, these are issues of predictive modeling. The way that “big data” can help improve care is by aiding the development of good predictive models.
According to Madigan, the data for these types of analyses exist. There are several databases with large quantities of patient-level data. The limitation is that, currently, there are no satisfactory methodologies to build
reliable predictive models. One challenge is the inherent bias of the data being used. Madigan laid out the various stages in the data collection and research process at which bias can be introduced into a data set (Figure 4-1).
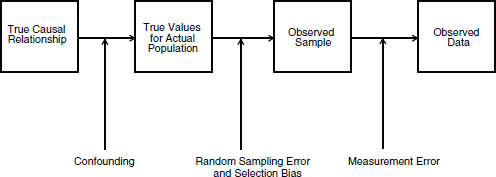
FIGURE 4-1 Sources of bias in clinical datasets.
SOURCE: Reprinted with permission from Phillips, 2003.
Bias alone is not the problem. In fact, it is unavoidable. The larger problem is that current observational research with large datasets does not acknowledge the limitations that bias places on results. Madigan noted that, generally, the issues of bias and measurement error are only paid lip service in the peer-reviewed literature for observational clinical outcomes research. Articles will often state potential limitations, but fail to discuss the implications. There are profound data quality issues when using large observational datasets and, according to Madigan, the current practice for observational research does little about it.
To demonstrate the consequence of bias he presented some data from the OMOP database. OMOP researchers ran self-controlled case series analysis for a variety of drugs across each of the 10 component OMOP databases. The results demonstrated extreme heterogeneity. For 20 of the 50 drug-event pairs studies, the drug-event relationship went from being statistically significant in the positive direction to statistically significant in the negative direction depending on which database was used. This heterogeneity has profound implications for the generalizability of published outcomes research.
Madigan concluded his presentation by focusing on strategies that confront these challenges of bias and data quality. One critical strategy is sensitivity analysis. He acknowledged that sound statistical methods and software for sensitivity analysis currently exist. These methods look at sources of biases and run various “what-if” scenarios to give a sense of how robust findings are. He suggested that sensitivity analysis ought to be an absolute requirement for the publication of observational studies.
The other strategy to improve the quality and utility of retrospective outcomes research is to establish operating characteristics of observational studies. Madigan argued that currently there is no good understanding of the quality and reliability of this type of research. For example, if a study arrives at a certain relative risk, how close is that relevant risk to the truth if it were to be reproduced with different data? Similarly, when studies report 95 percent confidence intervals, how close are those to the truth? Madigan noted that OMOP researchers have found that across databases, reported 95 percent confidence intervals often have only roughly 50 percent coverage. There is a need, he stressed, to study this science empirically in order to get a handle on how well it actually works and how likely the results are to be the truth.
MOVING FROM ANALYTICS TO INSIGHTS
Carol McCall posed that the principal challenge in health care today is the ability to create a deep and dynamic understanding of what works best for whom. She noted that while there are currently many areas of redesign and improvement in health care—aligning business models, transforming care models, building infrastructure—all of these changes implicitly assume that there is access to evidence and an understanding of what works for whom. The sustainability of all of these efforts demands something new: a nuanced understanding of cause and effect in health care.
According to McCall, three developments have made it possible to analyze vast amounts of data to generate actionable medical evidence. The first is Moore’s law, the doubling of computing capacity approximately every 2 years, which gave rise to big data and big-data technologies. The second is that health care data is becoming much more liquid. The third, which she noted as the lynchpin, is a revolution in mathematics, led by Judea Pearl, which has mathematized causality, opening a paradigm shift in analytics. Previously, the problem with big data was that the bigger it got, the more correlations were found. McCall stressed that correlation is a truism. Data is correlated, always higher or lower, but it always exists, and it is not the same as causation. This new calculus of causality, however, allows researchers to discover cause-effect relationships and generate evidence from big data (Pearl, 2009).
The fundamental difference of this type of approach is that it focuses on insights rather than analytics. Through these types of mathematical methods, she notes, researchers are left with causal structure rather than a static answer. This structure can be interrogated to answer a variety of important questions such as what data is needed to resolve existing uncertainty, an insight that can guide next data investments and be used to tailor research strategies. Furthermore, this type of structure allows researchers to
run counterfactuals, interrogate and investigate much more quickly, and go beyond situations where they already know the answer. This ability to make predictions and quickly assess results is at the core of a learning health system. Clinicians and researchers can predict an outcome, observe what happens, compare it against experience, and adjust future care protocols in response. And this can all happen rapidly.
With the mathematical methods in place, McCall noted, the priorities for big data analytics and evidence generation are shifting. Since mathematics can be scaled to any level and performed on any data set, the challenge now is finding data sources that are comprehensive and up to date. She underscored the need to link and share data from a variety of sources, such as pharmaceutical companies, hospitals, pharmaceutical benefit managers and payers. With data coming from several sources, there is also the need to understand context, and metadata take on an added importance.
REFERENCES
Pearl, J. 2009. Causality: Models, reasoning and inference. New York: Cambridge University Press.
Phillips, C. V. 2003. Quantifying and reporting uncertainty from systematic errors. Epidemiology 14(4):459-466.






