
Computer and Semiconductor Technology Trends and Implications
Computing and information and communications technology has had incredible effects on nearly every sector of society. Until recently, advances in information and communications technology have been driven by steady and dramatic gains in single-processor (core) speeds. However, current and future generations of users, developers, and innovators will be unable to depend on these improvements in computing performance.
In the several decades leading up to the early 2000s, single-core processor performance doubled about every 2 years. These repeated performance doublings came to be referred to in the popular press as “Moore’s Law,” even though Moore’s Law itself was a narrow observation about the economics of chip lithography feature sizes.1 This popular understanding of Moore’s Law was enabled by both technology—higher clock rates, reductions in transistor size, and faster switching via fabrication improvements—and architectural and compiler innovations that increased performance while preserving software compatibility with previous-generation processors. Ongoing and predictable improvements in processor performance created a cycle of improved single-processor performance followed by enhanced software functionality. However, it is no longer possible to increase performance via higher clock rates, because of power and heat dissipation constraints. These constraints are themselves manifestations of more fundamental challenges in materials science and semiconductor physics at increasingly small feature sizes.
A National Research Council (NRC) report, The Future of Computing Performance: Game Over or Next Level?,2 explored the causes and implications of the slowdown in the historically dramatic exponential growth in computing performance and the end of the dominance of the single microprocessor in computing. The findings and recommendations from that report are provided in Appendix D. The authoring committee of this report concurs with those findings and recommendations. This chapter draws on material in that report and the committee’s own expertise and discusses the technological challenges to sustaining growth in computing performance and their implications for computing and innovation. The chapter concludes with a discussion of the implications of these technological realities for United States defense. Subsequent chapters have a broader emphasis, beyond technology, on the implications for global technology policy and innovation issues.
1.1 Interrelated Challenges to Continued Performance Scaling
The reasons for the slowdown in the traditional exponential growth in computing performance are many. Several technical drivers have led to a shift from ever-faster single-processor computer chips as the foundation for nearly all computing devices to an emphasis on what have been called “multicore” processors—placing
_______________
1The technological and economic challenges are intertwined. For example, Moore’s Law is enabled by the revenues needed to fund the research and development necessary to advance the technology. See, for example, The Economic Limit to Moore’s Law – IEEE Transactions on Semiconductor Manufacturing, Vol. 24, No. 1, February 2011.
2NRC, The Future of Computing Performance: Game Over or Next Level?, Washington, D.C.: The National Academies Press (available online at http://www.nap.edu/catalog.php?record_id=12980.
multiple processors, sometimes of differing power and/or performance characteristics and functions, on a single chip. This section describes those intertwined technical drivers and the resulting challenges to continued growth in computing performance. This shift away from an emphasis on ever-increasing speed has disrupted what has historically been a continuing progression of dramatic sequential performance improvements and associated software innovation and evolution atop a predictable hardware base followed by increased demand for ever more software innovations that in turn motivated hardware improvements. This disruption has profound implications not just for the information technology industry, but for society as a whole. This section first describes the benefits of this virtuous cycle—now ending—that we have depended on for so long. The technical challenges related to scaling nanometer devices, what the shift to multicore architectures means for architectural innovation, programming explicitly parallel hardware, increased heterogeneity in hardware, and the need for correct, secure, and evolvable software are then discussed.
1.1.1 Hardware-Software Virtuous Cycle
The hardware and performance improvements described above came with a stable programming interface between hardware and software. This interface persisted over multiple hardware generations and in turn contributed to the creation of a virtuous hardware-software cycle (see Figure 1-1). Hardware and software capabilities and sophistication each grew dramatically in part because hardware and software designers could innovate in isolation from each other, while still leveraging each other’s advances in a predictable and sustained fashion. For example, hardware designers added sophisticated out-of-order instruction issue logic, branch prediction, data prefetching, and instruction prefetching to the capabilities. Yet, even as the hardware became more complex, application software did not have to change to take advantage of the greater performance in the underlying hardware and, consequently, achieve greater performance on the software side as well.
Software designers were able to make grounded and generally accurate assumptions about future capabilities of the hardware and could—and did—create software that needed faster, next-generation processors with larger memories even before chip and system architects actually were able to deliver them. Moreover, rising hardware performance allowed software tool developers to raise the level of abstraction for software development via advanced libraries and programming models, further accelerating application development. New, more demanding applications that only executed on the latest, highest performance hardware drove the market for the newest, fastest, and largest memory machines as they appeared.
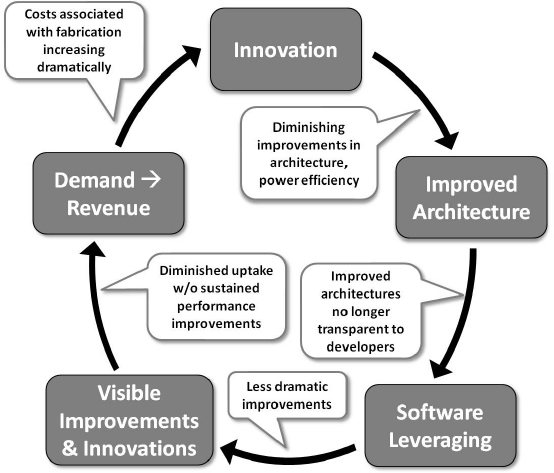
FIGURE 1-1 Cracks in the hardware-software virtuous cycle. SOURCE: Adapted from a 2011 briefing presentation on the Computer Science and Telecommunications Board report The Future of Computing Performance: Game Over or Next Level?
Another manifestation of the virtuous cycle in software was the adoption of high-level programming language abstractions, such as object orientation, managed runtimes, automatic memory management, libraries, and domain-specific languages. Programmers embraced these abstractions (1) to manage software size, sophistication, and complexity and (2) to leverage existing components developed by others. However, these abstractions are not without cost and rely on system software (i.e., compilers, runtimes, virtual machines, and operating systems) to manage software complexity and to map abstractions to efficient hardware implementations. In the past, as long as the software used a sequential programming interface, the cost of abstraction was hidden by ongoing, significant improvements in hardware performance. Programmers embraced abstraction and consequently produced working software faster.
Looking ahead, it seems likely that the right choice of new abstractions will expand the pool of programmers further. For example, a domain specialist can become a programmer if the language is intuitive and the
abstractions match his or her domain expertise well. Higher-level abstractions and domain-specific toolkits, whether for technical computing or World Wide Web services, have allowed software developers to create complex systems quickly and with fewer common errors. However, implicit in this approach has been an assumption that hardware performance would continue to increase (hiding the overhead of these abstractions) and that developers need not understand the mapping of the abstractions to hardware to achieve adequate performance.3 As these assumptions break down, the difficulty in achieving high performance from software will rise, requiring hardware designers and software developers to work together much more closely and exposing increasing amounts of parallelism to software developers (discussed further below). One possible example of this is the use of computer-aided design tools for hardware-software co-design. Another source of continued improvements in delivered application performance could also come from efficient implementation techniques for high-level programming language abstractions.
1.1.2 Problems in Scaling Nanometer Devices
Early in the 2000s, semiconductor scaling—the process of technology improvement so that it performs the same functionalities at ever smaller scales—encountered fundamental physical limits that now make it impractical to continue along the historical paths to ever-increasing performance.4 Expected improvements in both performance and power achieved with technology scaling have slowed from their historical rates, whereas implicit expectations were that chip speed and performance would continue to increase dramatically. There are deep technical reasons for (1) why the scaling worked so well for so long and (2) why it is no longer delivering dramatic performance improvements. See Appendix E for a brief overview of the relationship between slowing processor performance growth and Dennard scaling and the powerful implications of this slowdown.
In fact, scaling of semiconductor technology hit several coincident roadblocks that led to this slowdown, including architectural design constraints, power limitations, and chip lithography challenges (both the high costs associated with patterning smaller and smaller integrated circuit features and with fundamental device physics). As described below, the combination of these challenges can be viewed as a perfect storm of difficulty for microprocessor performance scaling.
With regard to power, through the 1990s and early 2000s the power needed to deliver performance improvements on the best performing microprocessors grew from about 5–10 watts in 1990 to 100–150 watts in 2004 (see Figure 1-2). This increase in power stopped in 2004, because cooling and heat dissipation proved inadequate. Furthermore, the exploding demand for portable devices, such as phones, tablets, and netbooks, increased the market importance of lower-power and energy-efficient processor designs.
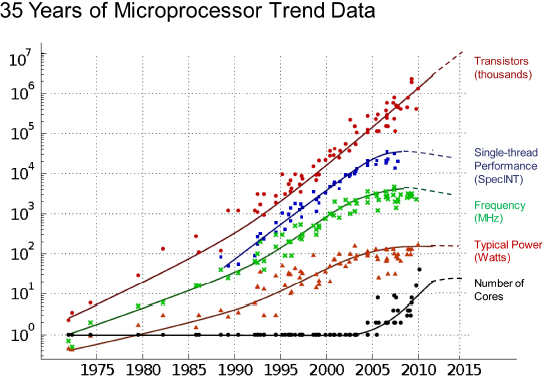
FIGURE 1-2 Thirty five years of microprocessor trend data. SOURCE: Original data collected and plotted by M. Horowitz, F. Labonte, O. Shacham, K. Olukotun, L. Hammond, and C. Batten. Dotted-line extrapolations by C. Moore: Chuck Moore, 2011, “Data processing in exascale-class computer systems,” The Salishan Conference on High Speed Computing, April 27, 2011. (www.lanl.gov/orgs/hpc/salishan)
In the past, computer architects increased performance with clever architectural techniques such as ILP (instruction-level parallelism through the use of deep pipelines, multiple instruction issue, and speculation) and memory locality (multiple levels of caches). As the number of transistors per unit area on a chip continued to increase (as predicted by Moore’s Law), microprocessor designers used these transistors to, in part, increase the potential to exploit ILP by increasing the number of instructions executed in parallel (IPC, or instructions per
_______________
3Such abstractions may increase the energy costs of computation over time; a focus on energy costs (as opposed to performance) may have led to radically different strategies for both hardware and software. Hence, energy-efficient software abstractions are an important area for future development.
4In “High-Performance Processors in a Power-Limited World,” Sam Naffziger reviews the Vdd limitations and describes various approaches (circuit, architecture) to future processor design given the voltage scaling limitations: Sam Naffziger, 2006, “High-performance processors in a power-limited world,” Proceedings of the IEEE Symposium on VLSI Circuits, Honolulu, HI, June 15–17, 2006, p. 93–97.
clock cycle).5 Transistors were also used to achieve higher frequencies than were supported by the raw transistor speedups, for example, by duplicating logic and by reducing the depth of logic between pipeline latches to allow faster clock cycles. Both of these efforts yielded diminishing returns in the mid-2000s. ILP improvements are continuing, but also with diminishing returns.6
Continuing the progress of semiconductor scaling—whether used for multiple cores or not—is now dependent on innovation in structures and materials to overcome the reduced performance scaling traditionally provided by Dennard scaling.7
Continued scaling also depends on continued innovation in lithography. Current state-of-the-art manufacturing uses a 193-nanometer wavelength to print structures that are only tens of nanometers in size. This apparent violation of optical laws has been supported by innovations in mask patterning and compensated for by increasingly complex computational optics. Future lithography scaling is dependent on continued innovation.
1.1.3 The Shift to Multicore Architectures and Related Architectural Trends
The shift to multicore architectures meant that architects began using the still-increasing transistor counts per chip to build multiple cores per chip rather than higher-performance single-core chips. Higher-performance cores were eschewed in part because of diminishing performance returns and emerging chip power constraints that made small performance gains at a cost of larger power use unattractive. When single-core scaling slowed, a shift in emphasis to multicore chips was the obvious choice, in part because it was the only alternative that could be deployed rapidly. Multicore chips consisting of less complex cores that exploited only the most effective ILP ideas were developed. These chips offered the promise of performance scaling linearly with power. However, this scaling was only possible if software could effectively make use of them (a significant challenge). Moreover, early multicore chips with just a few cores could be used effectively at either the operating system level, avoiding the need to change application software, or by a select group of applications retargeted for multicore chips.
With the turn to multicore, at least three other related architectural trends are important to note to understand how computer designers and architects seek to optimize performance—a shift toward increased data parallelism, accelerators and reconfigurable circuit designs, and system-on-a-chip (SoC) integrated designs.
First, a shift toward increased data parallelism is evident particularly in graphics processing units (GPUs). GPUs have evolved, moving from fixed-function pipelines to somewhat configurable ones to a set of throughput-oriented “cores” that allowed more successful general-purpose GPU (GP-GPU) programming.
Second, accelerators and reconfigurable circuit designs have matured to provide an intermediate alternative between software running on fixed hardware, for example, a multicore chip, and a complete hardware solution such as an application-specific integrated circuit, albeit with their own cost and configuration challenges. Accelerators perform fixed functions well, such as encryption-decryption and compression-decompression, but do nothing else. Reconfigurable fabrics, such as field-programmable gate arrays (FPGAs), sacrifice some of the performance and power benefits of fixed-function accelerators but can be retargeted to different needs. Both offer intermediate solutions in at least four ways: time needed to design and test, flexibility, performance, and power.
Reconfigurable accelerators pose some serious challenges in building and configuring applications; tool chain issues need to be addressed before FPGAs can become widely used as cores. To use accelerators and reconfigurable logic effectively, their costs must be overcome when they are not in use. Fortunately, if power, not silicon area, is the primary cost measure,
_______________
5Achieved application performance depends on the characteristics of the application’s resource demands and on the hardware.
6ILP improvements are incremental (10–20 percent), leading to single-digit compound annual growth rates.
7According to Mark Bohr, “Classical MOSFET scaling techniques were followed successfully until around the 90nm generation, when gate-oxide scaling started to slow down due to increased gate leakage” (Mark Bohr, February 9, 2009, “ISSCC Plenary Talk: The New Era of Scaling in an SOC World”) At roughly the same time, subthreshold leakage limited the scaling of the transistor Vt (threshold voltage), which in turn limited the scaling of the voltage supply in order to maintain performance. Since the active power of a circuit is proportional to the square of the supply voltage, this reduced scaling of supply voltage had a dramatic impact on power. This interaction between leakage power and active power has led chip designers to a balance where leakage consumes roughly 30 percent of the power budget. Several approaches are being undertaken. Copper interconnects have replaced aluminum. Strained silicon and Silicon-on-Insulator have provided improved transistor performance. Use of a low-K dielectric material for the interconnect layers has reduced the parasitic capacitance, improving performance. High-K metal gate transistor structures restarted gate “oxide” scaling with orders of magnitude reduction in gate leakage. Transistor structures such as FinFET, or Intel’s Tri-Gate have improved control of the transistor channel, allowing additional scaling of Vt for improved transistor performance and reduced active and leakage power.
turning the units off when they are not needed reduces energy consumption (see discussion of dark and dim silicon, below).
Third, increasing levels of integration that made the microprocessor possible four decades ago now enable complete SoCs. They combine most of the functions of a motherboard onto a single chip, usually with off-chip main memory. These processors integrate memory and input/output controllers, graphics processors, and other special-purpose accelerators. These (SoC) designs are widely used in almost all devices, from servers and personal computers to smartphones and embedded devices.
Fourth, power efficiency is increasingly a major factor in the design of multicore chips. Power has gone from a factor to optimize in the near-final design of computer architectures to a second-order constraint to, now, a first-order design constraint. As the right side of Figure 1-2 projects, future systems cannot achieve more performance from simply a linear increase in core count at a linear increase in power. Chips deployed in everything from phones, tablets, and laptops to servers and data centers must take into account power needs.
One technique for enabling more transistors per chip at better performance levels without dramatically increasing the power needed per chip is dark silicon. Dark silicon refers to a design wherein a chip has many transistors, but only a fraction of them are powered on at any one time to stay within a power budget. Thus, function-specific accelerators can be powered on and off to maximize chip performance. A related design is dim silicon where transistors operate in a low-power but still-useful state. Dark and dim silicon make accelerators and reconfigurable logic more effective. However, making dark and dim silicon practical is not easy, because adding silicon area per chip always raises cost, even if the silicon only provides value when it is on. This also presents significant software challenges, as each heterogeneous functional unit requires efficient code (e.g., this may mean multiversion code, as well as compilers and tool chains designed for many variations). Thus, even as dark and dim silicon become more widely adopted, using them to create value is a significant open challenge.
Moreover, emerging transistors have more variability than in the past, due to variations in the chip fabrication process: Some transistors will be faster, while others are slower, and some use more power and others use less. This variability is emerging now, because some aspects of fabrication technology (e.g., gate oxides) are reaching atomic dimensions. Classically, hardware hid almost all errors from software (except memory errors) with techniques (such as guard bands) that conservatively set parameters well above a mean value to tolerate variation while creating the illusion of error-free hardware. As process variation grows relative to mean values, guard bands become overly conservative. This means that new errors will be exposed more frequently to software, posing software and system reliability challenges.
1.1.4 Game Changer: Programming for Explicitly Parallel Commodity Hardware
The advent of multicore chips changes the software interface. Sequential software no longer becomes faster with every hardware generation, and software needs to be written to leverage parallel hardware explicitly. Current trends in hardware, specifically multicore, might seem to suggest that every technology generation will increase the number of processors and, accordingly, that parallel software written for these chips would speed up in proportion to the number of processors (often referred to as scalable software).
Reality is not so straightforward. There are limits to the number of cores that can usefully be placed on a chip. Moreover, even software written in parallel languages typically has a sequential component. In addition, there are intrinsic limits in the theoretically available parallelism in some problems, as well as in their solution via currently known algorithms. Even a small fraction of sequential computation significantly compromises scalability (see Figure 1-3), compromising expected improvements that might be gained by additional processors on the chip.
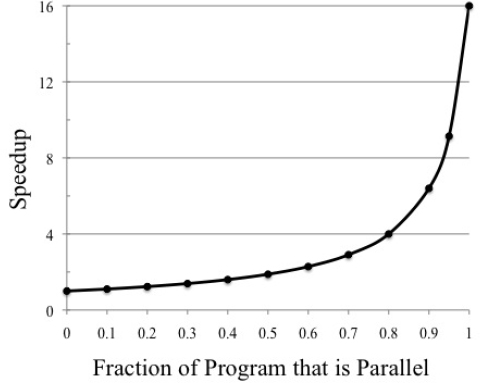
FIGURE 1-3 Amdahl’s Law example of potential speedup on 16 cores based on the fraction of the program that is parallel.
As part of ongoing research programs, it will be important to analyze the interplay among the available parallelism in applications, energy consumption by the resulting chip (under load with real applications), the performance of different algorithmic formulations, and programming complexity.
In addition, most programs written in existing parallel languages are dependent on the number of hardware processors. Further developments in parallel software are necessary to be performance portable, that is, it should execute on a variety of parallel computing platforms and should show performance in proportion to the number of processors on all these platforms without modifications, within some reasonable bounds.
Deeply coupled to parallelism is data communication. To operate on the same data in parallel on different processors, the data must be communicated to each processor. More processors imply more communication. Communicating data between processors on the same chip or between chips is costly in power and time. Unfortunately, most parallel programming systems result in programs whose performance heavily depends on the memory hierarchy organization of the processor. Where the data is located in a system directly affects performance and energy. Consequently, sequential and even existing parallel software is not performance portable to successive generations of evolving parallel hardware, or even between two machines of the same generation with the same number of processors if they have different memory organizations. Software designers currently must modify software for it to run efficiently on each multicore machine. The need for such efforts breaks the virtuous cycle described above and makes building and evolving correct, secure, and performance-portable software a substantial challenge.
Finally, automatic parallelization systems, which seek to transform a sequential program into a parallel programmer without programmer intervention, have mostly failed. Had they been successful, programmers would be able to write in a familiar sequential language and yet still see the performance benefits of parallel execution. As a result, research now focuses on programmer-specified parallelism.
1.1.5 Heterogeneity in Hardware
As mentioned above, not only are technology trends leading designers and developers of computer hardware to focus on multicore systems, but they are also leading to an emphasis on specialization and heterogeneity to provide power, performance, and energy efficiency. This specialization is a marked contrast to previous approaches. GPUs are an example of hardware specialization designed to be substantially more power efficient for a specific workload. The problem with this trend is three-fold.
First, hardware specialization can only be justified for ubiquitous and/or high-value workloads due to the high cost of chip design and fabrication. Second, creating software that exploits hardware specialization and heterogeneity closely couples hardware and software—such coupling may be good for performance, power, and energy, but it typically sacrifices software portability to different hardware, a mainstay expectation in computing over many decades.
Third, the lead time needed for effective software support of these heterogeneous devices may reduce the time they can be competitive in the marketplace. If it takes longer to deliver the tools (compilers, domain-specific language, and so on) than it takes to design and deliver the chip, then the tools will appear after the chip, with negative consequences.8 This problem, however, is not new. For example, by holding the IA-32 instruction set architecture relatively constant across generations of hardware, software could be delivered in a timely manner. Designing and building a software system for hardware that does not exist, or is not similar to prior hardware, requires well-specified hardware-software interfaces and accurate simulators to test the software independently. Because executing software on simulators requires tens to thousands of more time than executing on actual hardware, software will lag hardware without careful system and interface design. In summary, writing portable and high-performance software is hard, making such software parallel is harder, and developing software that can exploit heterogeneous parallel architectures is even harder.
1.1.6 Correct and Secure Software that Evolves
Performance—in the sense of ever-increasing chip speed—is not the only critical demand of modern application and system software. Although performance is fungible and ever-faster computer chips can be used to enable a variety of functionality, software is the underpinning of virtually all our economic, government, and military infrastructure. Thus, the criticality of Secure, Parallel Evolvable, Reliable, and Correct software cannot be overemphasized. This report uses the term SPERC software to refer to these software properties.
_______________
8The same is true for hardware-software co-design efforts. Success in co-design requires that both the hardware and software be delivered at roughly the same time. If the software lags behind the hardware, it diminishes the strategy’s effectiveness.
Achieving each of these desirable SPERC software properties is difficult in isolation, and each property is still the subject of much research. In an era where new technologies—at all levels of the system—appear quickly, yet the rate of hardware performance improvement is slowing, an alternative to the virtuous cycle described earlier is essential. Rather than remaining oblivious to hardware shifts, new approaches and methodologies are needed that allow our complex software systems to evolve nimbly, using new technologies and adapting to changing conditions for rapid deployment. This flexibility and rapid adaptation will be key to continued superiority, for all large-scale enterprises, including military and defense needs.
In addition to flexibility and nimbleness, as the world becomes more connected, building software that executes reliably and guarantees some security properties is critical. For example, modern programming systems for languages such as PHP, JavaScript, Java, and C#, while more secure than native systems because of their type and memory safety, do not guarantee provably secure programs. For example, mainstream programming models do not yet support concise expression of semantic security properties such as “only an authenticated user can access their own data,” which is key to proving security properties. Even recipes of best practices for secure programming remain an open problem.
Finally, functional correctness remains a major challenge. Designing and building correct parallel software is a daunting task. For example, static verification is the process that analyzes code to ensure that it guarantees certain properties and user-defined specifications. Static verification of even basic properties of sequential software in some cases cannot be decided, and computing approximations often involves exponential amounts of computation to analyze properties on all programming paths. Evaluating the same properties in parallel programs is even harder, since the analysis must consider all possible execution interleaving of concurrent statements in distinct parallel tasks. Current practice sometimes verifies small critical components of large systems, but for the most part, executes the program on a variety of test inputs (testing) to detect errors. Correctness and security demands on software may trump performance in some cases, but applications will typically need to combine these properties with high performance and parallelism.
Even assuming that there are programming models that establish a solid foundation for creating SPERC software, adoption will be a challenge. Commodity and defense software will need to be created or ported to use them. The enormous investment in legacy software and the large cost of porting software to new languages and platforms will be a barrier to adoption.
1.2 Future Directions for Hardware and Software Innovation
Section 1.1 outlined many of the technological challenges to continued growth in computing performance and some of the implications (e.g., the shift to multicore and increased emphasis on power efficiency.) This section provides a brief overview of current hardware and software research strategies for building and evolving future computer systems that seek continued improvements to high performance and energy efficiencies.
1.2.1 Advanced Hardware Technology Options
Earlier sections of this chapter described issues that have hindered continued scaling of modern semiconductor technology and some of the current innovations in materials and structures that have allowed continued progress. All are variations on historical approaches. Are there more radical innovations that may deliver future improvements? In principle, yes, but there are daunting challenges.
Transistors built from alternative materials such as germanium (Ge) and Group III–V materials, such as gallium arsenide, indium phosphide, indium arsenide, and indium antimonide, promise improved power efficiency,9 but only by about a factor of two, as they also suffer from the same threshold voltage limits, and limit on-supply voltage scaling inherent in current complementary-symmetry metal-oxide semiconductor technologies.
Advances in packaging technology continue, and some of those offer promise for power and performance improvements. For example, 3D stacking and through-silicon vias are being explored for some SoC designs. The primary limitation for 3D stacking of memory, however, is capacity (i.e., only limited dynamic random-access memory can be placed in the stack).
Finally, more exotic alternatives to the use of electrons as the “tokens,” coupled with an energy barrier as the control—the method used by all modern computer chips—are under investigation.10 Although all of these
_______________
9Donghyun Kim, Tejas Krishnamohan, and Krishna C. Saraswat, 2008, “Performance Evaluation of 15nm Gate Length Double-Gate n-MOSFETs with High Mobility Channels: III–V, Ge and Si,” The Electroch. Soc. Trans. 16(11): 47–55.
10K. Bernstein, R. Calvin, W. Porod, A. Seabaugh, and J. Welser, 2010, “Device and Architecture Outlook for Beyond CMOS Switches,” Proceedings of the IEEE 98(12): 2169–2184.
technologies show potential, each has serious challenges that need to be resolved through continued fundamental research before they could be adopted for high-volume manufacturing.
1.2.2 Prospects for Performance Improvements
In the committee’s view, there is no “silver bullet” to address current challenges in computer architecture and the slowdown in growth in computing performance. Rather, efforts in complementary directions to continue to increase value, that is, performance, under power constraints, will be needed. Early multicore chips offered homogeneous parallelism. Heterogeneous cores on a single chip are now part of an effort to achieve greater power efficiency, but they present even greater programming challenges.
Efforts to advance conventional multicore chips and to create more power-efficient core designs will continue. On one hand, researchers will continue to explore techniques that reduce the power used by individual cores without unduly sacrificing performance. In turn, this will allow placement of more cores on each chip. Researchers could also explore radical redesigns of cores that focus on power first, for example, by minimizing nonlocal information movement through spatially aware designs that limit communication of data (see Section 1.1.4).
GP-GPU computing, in particular, and vector and single-instruction multiple-data operation, in general, offer promise for specific workloads. Each of these reduce power consumption by amortizing the cost of dealing with an instruction (e.g., fetch and decode) across the benefit of many data manipulations. All offer great peak performance, but this performance can be hard to achieve without deep expertise coupling algorithm and architecture, hardly a prescription for broad programmability. Moreover, software that runs on such chips must allocate work to cope with allocating work to heterogeneous computing units, such as throughput-oriented GPUs and latency-oriented conventional central processing units, highlighting the need for advances in software and programming methodologies as described earlier.
More heterogeneity will arise from expanded use of accelerators and reconfigurable logic, described earlier, that is needed for increased performance under power constraints. Accelerators are so-named because they can accelerate performance. While this is true, recent work shows that the greater benefit of accelerators may be in reducing power.11 However, accelerator effectiveness can be blunted by the overheads of communicating control and data to and from accelerators, especially if someone seeks to offload even smaller amounts of work to expand the availability of off-loadable work. Reconfigurable designs, such as FPGAs, described earlier, may provide a middle ground, but they are not yet easily programmable. Similarly, SoCs combine specialized accelerators on a single chip and have had great success in the embedded market, such as smartphones and tablets. As SoCs continue to proliferate, the challenge will be simplifying software and hardware design and programmability while maximizing performance and power efficiency.
Moreover, communication at all levels—close, cross-chip, off-chip, off-board, off-node, offsite—must be minimized to save energy. For example, moving operands from a close-by register file can use energy comparable to an operation (e.g., floating-point multiply-add), while moving them from cross- or off-chip uses tens to hundreds of times more energy. Thus, a focus on reducing computational energy without a concomitant focus on reducing communication is doomed to have limited effect.
Finally, a reconsideration of the hardware-software boundary may be in order. While abstraction layers hide complexity at each boundary, they also hide optimization and innovation possibilities. For decades, software and hardware experts innovated independently on opposite sides of the instruction set architecture boundary. Multicore chips began the end of the era of separation. Going forward, co-design is needed, where chip functionality and software are designed in concert, with repeated design and optimization feedback between the hardware and software teams. However, since the software development cycle typically significantly lags behind the hardware development cycle, effective co-design will also require more rapid deployment of effective tools in a timescale commensurate with the specialized hardware if its full functionality is to be realized.
1.2.3 Software
Creating software systems and applications for parallel, power-constrained computing systems on a single chip requires innovations at all levels of the software-hardware design and engineering stack: algorithms, programming models, compilers, runtime
_______________
11Rehan Hameed, Wajahat Qadeer, Megan Wachs, Omid Azizi, Alex Solomatnikov, Benjamin C. Lee, Stephen Richardson, Christos Kozyrakis, and Mark Horowitz, 2010, "Understanding Sources of Inefficiency in General-Purpose Chips," Proceedings of the 37th International Symposium on Computer Architecture (ISCA), Saint-Malo, France, June 2010.
systems, operating systems, and hardware-software interfaces.
One strategy for addressing the challenges inherent to parallel programming is to first design application-specific languages and system software and then seek generalizations. The most successful examples of parallelism come from distributed search systems, Web services, and databases executing on distinct devices, as opposed to the challenge of parallelism within a single device (chip) that is addressed here. Parallel algorithm and system design success stories include MapReduce12 for processing data used in search, databases for persistent storage and retrieval, and domain-specific toolkits with parallel support, such as MATLAB. Part of their success is rooted in providing a level of abstraction in which programmers write sequential components, while the runtime and system software implement and manage the parallelism. On the other hand, GPU programming is also a success story, but when used for game engineering development, for instance, it relies on expert programmers with deep knowledge of parallelism, algorithm-to-hardware mappings, and performance tuning. General-purpose computing on GPUs does not require in-depth knowledge about graphics hardware, but does require programmers to understand parallelism, locality, and bandwidth—general-purpose computing primitives.
More research is needed in domain-specific parallel algorithms, because most applications are sequential. Sequential algorithms are almost never appropriate for parallel systems. Expressing algorithms in such a way that they satisfy the key SPERC properties and are performance portable across different parallel hardware and generations of parallel hardware requires investment and research in new programming models and programming languages.
These programming models must enable expert, typical, and potentially naïve programmers to use parallel hardware effectively. Since parallel programming is extremely complex, the expertise necessary to effectively work in this realm is currently only within reach of the most expert programmers, and the majority of existing systems are not performance portable. A key requirement will be to create modular programming models that make it possible to encapsulate parallel software in libraries in such a way that (1) they can be reused by many applications and (2) the system adapts and controls the total amount of parallelism that effectively utilizes the hardware, without over- or undersubscription. Mapping applications, which use these new models, to parallel hardware will require new compiler, runtime, and operating system services that model, observe, and reason, and then adapt to and change dynamic program behaviors to satisfy performance and energy constraints.
Because power and energy are now the first-order constraint in hardware design, there is an opportunity for algorithmic design and system software to play a much larger role in power and energy management. This area is a critical research topic with broad applicability.
1.3 The Rise of Mobile Computing, Services, and Software
Historically, the x86 instruction set architecture has come to dominate the commercial computing space, including laptops, desktops, and servers. Developed originally by Intel and licensed by AMD, the commercial success of this architecture has either eliminated or forced into smaller markets other architectures developed by MIPS, HP, DEC, and IBM, among others. More than 300 million PCs are sold each year, most of them powered by x86 processors.13 Further, since the improvement in capabilities of single-core processors started slowing dramatically, nearly all laptops, desktops, and servers are now shipping with multicore processors.
Over the past decade, the availability of capable, affordable, and very low-power processor chips has spurred a fast rise in mobile computing devices in the form of smartphones and tablets. The annual sales volume of smartphones and tablets already exceeds that of PCs and servers.14 The dominant architecture is U.K.based ARM, rather than x86. ARM does not manufacture chips; instead it licenses the architecture to third parties for incorporation into custom SoC designs by other vendors. The openness of the ARM architecture has facilitated its adoption by many hardware manufacturers. In addition, these mobile devices now commonly incorporate two cores, and at least one SoC vendor has been shipping four-core designs in volume since early 2012. Furthermore, new heterogeneous big- and small-core designs that couple a higher performance, higher power core with a lower performance, lower power core have recently been announced.15 Multicore chips are now ubiquitous across the entire range of computing devices.
_______________
12In 2004, Google introduced the software framework, MapReduce, to support distributed computing on large datasets on clusters of computers.
13See http://www.gartner.com/it/page.jsp?id=1893523. Last accessed on February 7, 2012.
14See http://www.canalys.com/newsroom/smart-phones-overtake-client-pcs-2011. Last accessed on February 7, 2012.
15See www.tegra3.org; http://www.reuters.com/article/2011/10/19/arm-idUSL5E7LJ42H20111019. Last accessed on June 25, 2012.
The rise of the ARM architecture in mobile computing has the potential to adjust the balance of power in the computing world as mobile devices become more popular and supplant PCs for many users. Although the ARM architecture comes from the United Kingdom, Qualcomm, Texas Instruments, and NVIDIA are all U.S.-based companies with strong positions in this space. However, the shift does open the door to more foreign competition, such as Korea’s Samsung, and new entries, because ARM licenses are relatively inexpensive, allowing many vendors to design ARM-based chips and have them fabricated in Asia.
However, just as technical challenges are changing the hardware and software development cycle and the software-hardware interface, the rise of mobile computing and its associated software ecosystems are changing the nature of software deployment and innovation in applications. In contrast to developing applications for general-purpose PCs—where any application developer, for example, a U.S. defense contractor or independent software vendor, can create software that executes on any PC of their choosing—in many cases, developing software for mobile devices imposes additional requirements on developers, with “apps” having to be approved by the hardware vendors before deployment. There are advantages and disadvantage to each approach, but changes in the amount and locus of control over software deployments will have implications for what kind of software is developed and how innovation proceeds.
A final inflection point is the rise of large-scale services, as exemplified by search engines, social networks and cloud-hosting services. At the largest scale, the systems supporting each of these are larger than the entire Internet was just a few years ago. Associated innovations have included a renewed focus on analysis of unstructured and ill-structured data (so-called big data), packaging and energy efficiency for massive data centers, and the architecture of service delivery and content distribution systems. All of these are the enabling technologies for delivery of services to mobile devices. The mobile device is already becoming the primary personal computing system for many people, backed up by data storage, augmented computational horsepower, and services provided by the cloud. Leadership in the technologies associated with distributed cloud services, data center hardware and software, and mobile devices will provide a competitive advantage in the global computing marketplace.
Software innovations in mobile systems where power constraints are severe (battery life directly affects user experience) are predicted to use a different model than PCs, in which more and more processing is performed in the “cloud” rather than on the mobile device. A flexible software infrastructure and algorithms that optimize for network availability, power on the device, and precision are heralding a challenging ecosystem.
Fundamental to these technologies are algorithms for ensuring properties such as reliability, availability, and security in a distributed computing system, as well as algorithms for deep data mining and inference. These algorithms are very different in nature from parallel algorithms suitable for traditional supercomputing applications. While U.S. researchers have made investments in these areas already, the importance and commercial growth potential demand research and development into algorithmic areas including encryption, machine learning, data mining, and asynchronous algorithms for distributed systems protocols.
Semiconductor scaling has encountered fundamental physical limits, and improvements in performance and power are slowing. This slowdown has, among other things, driven a shift from the single microprocessor computer architectures to homogenous and now heterogeneous multicore processors, which break the virtuous cycle that most software innovation has expected and relied on. While innovations in transistor materials, lithography, and chip architecture provide promising opportunities for improvements in performance and power, there is no consensus by the semiconductor and computer industry on the most promising path forward.
It is likely that these limitations will require a shift in the locus of innovation away from dependence on single-thread performance, at least in the way performance has been achieved (i.e., increasing transistor count per chip at reduced power). Performance at the processor level will continue to be important, as that performance can be translated into desired functionalities (such as increased security, reliability, more capable software, and so on.) But new ways of thinking about overall system goals and how to achieve them may be needed.
What, then, are the most promising opportunities for innovation breakthroughs by the semiconductor and computing industry? The ongoing globalization of science and technology and increased—and cheaper—access to new materials, technologies, infrastructure, and markets have the potential to shift the U.S. competitive advantage in the global computing ecosystem, as well as to refocus opportunities for innovation in the computing space. In addition, the computing and semiconductor
industry has become a global enterprise, fueled by increasingly competitive overseas semiconductor markets and firms that have made large and focused investments in the computing space over the last decade. The possibility of new technological approaches emerging both in the United States and overseas reinforces the critical need for the United States to assess the geographic and technological landscape of research and development focused on this and other areas of computer and semiconductor innovation.












