
3- Attribution and Credit: Beyond Print and Citations
Johan Bollen1
Indiana University
The main focus of my work is not on citations, let alone data citations, but on computational methods to study scientific communication by analyzing very large-scale usage data. This is quite different from citation data, but how we organize and analyze our data is probably a useful and worthwhile perspective to contribute here.
When researchers talk about data citations, the assumption is that a citation has value. But why is it valuable? It is valuable because it defines a notion of credit and attribution in scientific communication. It is the mechanism by which one author explicitly indicates that he or she has been influenced by the thinking or the work of another author. Citations are very strongly grounded in the tradition of printed scientific paper, but we are thinking about data now, and data is much more difficult to cite in that context. The main problem here is that technology has fundamentally changed scholarly communication, and in fact even how scholars think, but scholarly review and assessment are still stuck in the paper era (e.g., peer review, print, citations, journals) that we have known since the late 19th century. However, if you look at how scholarly communication has been evolving over just the past 10 to 15 years, most of it has moved online. Most of my colleagues are on Twitter and Facebook now. One of the ways that they communicate their science is by posting tweets that make references to their papers and data. In other words, the way they publish has fundamentally changed.
This is also true for my own experience. When I write a paper the first thing I do is to deposit it in my web site or in an archive. The community then finds its way to my paper and if people find errors, they will provide extensive feedback, through, for example, a blog post. So, in addition to publishing my papers online, they are also “peer reviewed” online. The whole notion here is that the entire spectrum of scholarly communication is moving online. Before, it seemed to be occurring mostly within the confines of the traditional publication system.
If you look at scholarly assessment, however, it seems like it has skipped that evolution nearly entirely. Therefore, I think that we need to talk about changing scholarly assessment beyond the traditional way of doing things, to systems that can actually keep up with the changes in the scholarly communication process.
Figure 3-1 shows that publication data and citation data are the end-product of a long chain of scholarly activities. Usage data can be harvested for each of the antecedent activities, such as when authors read the scholarly literature as part of their research, submission, and peer- review process.
______________________
1 Presentation slides are available at http://www.sites.nationalacademies.org/PGA/brdi/PGA_064019.
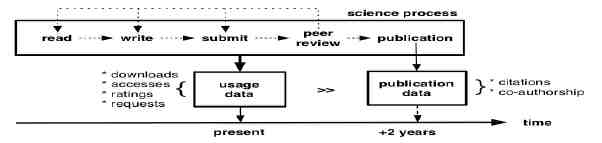
FIGURE 3-1 Data for assessing scholarly communication.
For that reason we have looked at applications of usage data for scholarly assessment. The main promise of usage data is that it can be recorded for all digital scholarly content (e.g., papers, journals, preprints, blog postings, data, chemical structures, software), not just for 10,000 journals and not only for peer-reviewed, scholarly articles. It provides extensive information on types of user behavior, sequences, timing, context, and clickstreams. It also reflects the behavior of all users of scholarly information (e.g., students, practitioners, and scholars in domains with different citation practices). Furthermore, interactions are recorded starting immediately after publication; that is, the data can reflect real-time changes (see Figure 3-1). Finally, usage data offers very large-scale indicators of relevance—billions of interactions recorded for millions of users by tens of thousands of scholarly communication services.
However, there are significant challenges with usage data. These include:
(1) Representativeness: usage data is generally recorded by a particular service for its particular user community. To make usage data representative of the general scholarly community, i.e. beyond the user base of a single service, we must find ways to aggregate usage data across many different services and user communities.
(2) Attribution and credit: a citation is an explicit, intentional expression of influence, i.e., authors are explicitly acknowledging which works influence their own. Usage data constitutes a behavioral, implicit measurement of how much “attention” a particular scholarly communication item has garnered. The challenge is thus to turn this type of behavior, implicit, clickstream data into metrics reflecting actual scholarly influence.
(3) Community acceptance: whereas an entire infrastructure is now devoted to the collation, aggregation and disposition of citation data and statistics, usage data remains largely unproven in terms of scholarly impact metrics or services, due to a lack of applications and community services. The challenge here is to create a framework to aggregate, collate, normalize, and process usage data that the community can trust and from which we can derive trusted metrics and indicators.
Enter the Metrics from Scholarly Usage of Resources (MESUR) project! The MESUR project was funded by the Andrew W. Mellon Foundation in 2006 to study science itself from large- scale usage data. The project was involved with large-scale usage data acquisition, deriving
structural models of scholarly influence from said usage data, and surveying a range of impact metrics from the usage and citation it collected.
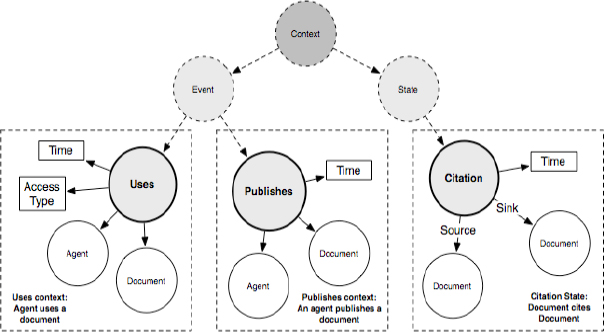
FIGURE 3-2 Modeling the scholarly communication process — the MESUR ontology.2
So far, the MESUR project has collected more than one billion usage events3 from publishers, aggregators and institutions serving the scientific community. These include: BioMedCentral, Blackwell, the University of California, EBSCO Publishing, Elsevier, Emerald, Ingenta, J- STOR, the Los Alamos National Laboratory, Zetoc project of the University of Manchester, Thomson, the University of Pennsylvania, and the University of Texas.
This data provided to the project has to conform to specific requirements, which were fortunately met by all our providers. In particular, we required that the data had an anonymous but unique user identifier, unique document identifiers, data and time of the user request to the second, an indicator of the type of request, and a session identifier, generated by the provider’s server, which indicates whether the same user accesses other documents within the same session.
The latter is an important element of the MESUR approach. We are not just interested in total downloads, but their context, the structural features of how people access scholarly communication items over time. We therefore required session identifiers, meaning that if users access a document at a particular time, they are assigned a session identifier before they move on to the next document. They maintain this session identifier throughout their movement from one
______________________
2 Marko A Rodriguez, Johan Bollen and Herbert Van de Sompel. A Practical Ontology for the Large-Scale Modeling of Scholarly Artifacts and their Usage, In Proceedings of the Joint Conference on Digital Libraries 2007, Vancouver, June 2007.
3 Data from more than 110,000 journals, newspapers and magazines, along with publisher-provided usage reports covering more than 2,000 institutions, is being ingested and normalized in MESUR’s databases, resulting in large- scale, longitudinal maps of the scholarly community and a survey of more than 40 different metrics of scholarly impact.
document to the next. As a result we can reconstruct so-called clickstreams and model how people move from one document to the next in any particular session. Because we have that kind of data, we can track how users collectively move from one article or journal to the next, and map the collective flow of “scientific traffic.” Such a map is shown in Figure 3-3 and was published in PLoS ONE in 2009.4
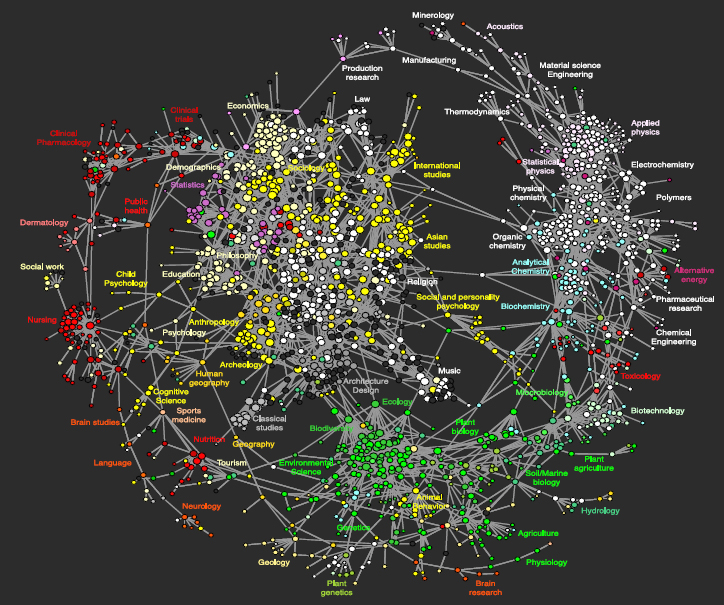
FIGURE 3-3 Visualization of MESUR clickstream data showing how users move from one journal to the next in their online access behavior. Each circle represents a journal. Journals are connected by a line if they frequently cooccur in user clickstreams.
Looking at the map we can see a rich tapestry of scholarly connections woven by the collective actions of users who express their interests in the sequence by which they move from one article and journal to the next in their online explorations. Although from our data we cannot prove that any individual user actually followed a certain path, we can say that it reflects the fact that users
______________________
4 Bollen J, Van de Sompel H, Hagberg A, Bettencourt L, Chute R, et al. (2009) Clickstream Data Yields High- Resolution Maps of Science. PLoS ONE 4 (3): e4803. doi:10.1371/journal.pone.0004803.
collectively felt these journals are related somehow, leading to the formation of clusters of interests which do not always coincide with traditional domain classifications, cf., the position of psychology journals in this map.
Once we have derived a network structure of related journals from usage data, as shown in Figure 3-3 we can use it to perform the same kind of scholarly assessment analysis that is now commonly conducted on the basis of citation data, and the resulting citation networks. We can actually calculate how important a journal is to the structure of the network, and use it as a measure of scholarly influence or impact.
This is what the MESUR project has done. We surveyed nearly forty different impact metrics, most based on social network analysis. We calculated one half of the metrics from our usage network, and the other half from a citation network that we derived from the Journal Citation Reports. Most usage-based network metrics had a citation-based counterpart. We also added several existing citation-based metrics that are not necessarily based on a citation network, such as the journal’s h-index and its Impact Factor. Each of these metrics, depending on whether they were based on usage data or citation data, and their method of calculation, will reflect a different perspective of scholarly impact in the journal rankings it produces. For example, some metrics will indicate how centrally located a journal is in the usage network and serve as an indication of its general impact according to patterns of journal usage. We can also calculate a journal’s “betweenness centrality,” i.e., how often users or citations pass through the particular journal on their way to another journal from another one. This may be construed as an indication of the journal’s interdisciplinary nature, its ability to bridge different areas and domains of interest in the usage and citation network vs. how popular or well connected it is in general. Each metric by virtue of its definition will have something different to say about a journal’s scholarly impact, and can furthermore be calculated from either usage networks or citation networks, offering even more perspectives on the complex notion of scholarly impact. A comparison of all of these metrics was published in PLoS ONE in 2009, and yielded a model of the main dimensions along which scholarly impact can fluctuate.5
We are also working on a number of online services to make our results accessible to the public. As mentioned, the problem with this kind of usage data is that people have a hard time accepting its validity since citation data is so ingrained. Usually, I get arguments such as “You may have nice results, but I don’t believe it.” A public, open, freely available service will allow people to play with the data and results themselves and might make them more community accepted.
Finally, I want to mention that we secured new funding in 2010 from the Andew W. Mellon Foundation to develop a generalized and sustainable framework for a public, open, scholarly assessment service based on aggregated large-scale usage data, which will support the evolution of the MESUR project to a community-supported, sustainable scholarly assessment framework. This new phase of the project will focus on four areas in developing the sustainability model:
______________________
5 Bollen J, Van de Sompel H, Hagberg A, Chute R (2009) A Principal Component Analysis of 39 Scientific Impact Measures. PLoS ONE4 (6): e6022. doi:10.1371/journal.pone.0006022.
financial sustainability, legal frameworks for protecting data privacy, technical infrastructure and data exchange, and scholarly impact. It will integrate these four areas to provide the MESUR project with a framework upon which to build a sustainable structure for deriving valid metrics for assessing scholarly impact based on usage data. Simultaneously, MESUR’s ongoing operations will be continued with the grant funding and expanded to ingest additional data and update its present set of scholarly impact indicators.
I would like to end my presentation by highlighting the following interesting initiatives and some relevant publications.
Initiatives:
• Microsoft/MSR: http://www.academic.research.microsoft.com/
• Altm etrics:http://www.altmetrics.org/
• Mendeley-based analytics: using Mendeley’s bookmarking and reading data to rank articles.
• Publisher-driven initiatives:Elsevier’s SciVal, mapping of science: http://www.elsevier.com/wps/find/authored_newsitem.cws_home/companynews05_01743
• Google Scholar: http://www.scholar.google.com/
• Science of Science Cyberinfrastructure: http://www.sci.slis.indiana.edu/ (Katy Borner at Indiana University)
Relevant Publications by the Presenter:
• Johan Bollen, Herbert Van de Sompel, Aric Hagberg, Luis Bettencourt, Ryan Chute, Marko A. Rodriguez, Lyudmila Balakireva. Clickstream data yields high-resolution maps of science. PLoS One, March 2009.
• Johan Bollen, Herbert Van de Sompel, Aric HagBerg, Ryan Chute. A principal component analysis of 39 scientific impact measures. arXiv.org/abs/0902.2l83
• Johan Bollen, Marko A. Rodriguez, and Herbert Van de Sompel. Journal status. Scientometrics, 69 (3), December 2006 (arxiv.org:cs.DL/0601030)
• Johan Bollen, Herbert Van de Sompel, and Marko A. Rodriguez. Towards usage-based impact metrics: first results from the MESUR project. In Proceedings of the Joint Conference on Digital Libraries, Pittsburgh, June 2008.
• Marko A. Rodriguez, Johan Bollen and Herbert Van de Sompel. A Practical Ontology for the Large-Scale Modeling of Scholarly Artifacts and their Usage, In Proceedings of the Joint Conference on Digital Libraries, Vancouver, June 2007.
• Johan Bollen and Herbert Van de Sompel. Usage Impact Factor: the effects of sample characteristics on usage-based impact metrics. (cs.DL/0610154)
• Johan Bollen and Herbert Van de Sompel. An architecture for the aggregation and analysis of scholarly usage data. In Joint Conference on Digital Libraries (JCDL2006), pp. 298-307, June 2006.
• Johan Bollen and Herbert Van de Sompel. Mapping the structure of science through usage. Scientometrics, 69 (2), 2006.
• Johan Bollen, Herbert Van de Sompel, Joan Smith, and Rick Luce. Toward alternative metrics of journal impact: a comparison of download and citation data. Information Processing and Management, 41 (6): 1419-1440, 2005.
This page intentionally left blank.








