
26- Standards and Data Citations
Todd Carpenter1
National Information Standards Organization
Standards are very familiar in the distribution of information, even if we do not recognize them. They are things that we rely on every day. We probably do not give them much thought. However, when we pick up a book, we are really picking up an incredibly standardized object. Everything from page numbers, table of contents, an index, cataloging information, title pages, organization structures, paper acidity, binding, paper sizes, ink, colors, font sizes, even the spelling of the words themselves are all best practices derived from the mass production of book publishing. These practices have developed over time and have been adapted to provide more efficient discovery and distribution of content.
One challenge posed by our current environment and the transformation to digital content distribution is that a lot of the practices that have been resolved for decades have changed radically in this new digital environment. If we think about page numbers, for example, they do not really mean anything in the flow of a digital text, where you can size the font up to 96 points and a page might only have two or three words on it. So, how one cites those particular words within such a mutable digital object is certainly a problem.
As I envision the citation of the future, it is no longer a string of words and textual descriptions of how to discover a referenced item. We are moving toward an era when a citation will likely be one or more identifiers for the specific information being referenced.
The information distribution ecosystem is moving toward standardizing around a number of key identifiers. These identifiers provide us with actionable answers to a variety of questions: What is this thing? What is its relationship to other things? Who created it? What is it packaged with? How can I locate it? If we can create a citation structure that is built on actionable links to entities that have additional information stored in accessible registries, there is great potential to aid discovery and distribution of information. After all, an actionable network of linkable text citations was, in part, the rationale for creating the entire World Wide Web and its follow-on the Semantic Web.
One of the barriers to establishing this network infrastructure is that the machines needed to intermediate this world for us do not talk the way that human beings do. They rely on structure and markup and are not able to easily gloss over errors in coding, syntax, or semantics. However, they are incredibly well suited to navigating a structured world with incredible efficiency. This fact has implications on the access, use, and citation of data. Instead of using a text-formatted description of an information resource, an identifier-based citation format, built on universally adopted standards, could build upon and unleash the opportunities in our machine-intermediated world.
______________________
1 Presentation slides are available at http://www.sites.nationalacademies.org/PGA/brdi/PGA_064019.
We are almost to a point where we have identifiers for all of the elements of a citation. Identifier standards exist, or are being developed, for names (ORCID or ISNI), affiliations (Institutional Identification, I2), publications (ISBN or ISSN), collections (ISCI), and persistent URLs (DOI, ARC, or PURL), and dates. Each of these standards could be incorporated into actionable URIs and those URIs, along with the associated metadata, could be served to the community as part of linked data stores. The implications of this shift of meaningful connections and machine references to a wealth of additional information could be tremendous. For example, an unambiguous name identifier could bring a user more than just the name of the referenced the author; it could also provide links to everything else this author has published. Another link in that URI-based citation could connect to everything else in this package or collection.
On several occasions during this meeting, we discussed the development of the Open Researcher and Contributor Identification (ORCID) initiative whose goal is to establish a unique identifier for each researcher in the scholarly communication process. This project is closely related to the International Standard Name Identifier (ISNI) standard (ISO 27729). This standard was recently approved for publication and it defines an identifier for any “parties” involved in the content creation process across all media. Both of these initiatives will probably launch in 2012 and will provide us a great opportunity for uniquely identifying content contributors and clearly distinguishing between people with the same or similar names. NISO’s own Institutional Identifier (I2) project will be utilizing the ISNI and its infrastructure to identify institutions and to provide metadata about them, including its links to parent or sub-organizations, such as departments. Combining these new identifiers with existing standards, such as the ISBN or ISSN, we are approaching a time where all of the information in a citation can be replaced with URIs.
So, when we talk about standards for data citation, what do we mean? There are a variety of things we could standardize that are related to, for example, discovering the data locating it, describing it, sharing it, preserving it, and for interoperating with it. But which are the most important to pursue? The problem with setting priorities is that each person or each field has different challenges and needs. What is a critical issue for one community is of secondary or tertiary concern to another. Here is my list of the things that I believe is being a high priority for good citations in a digital world:
1- Disambiguation of the item.
2- Location of the item (either in physical or digital form or both).
3- Attribution and disambiguation of the author.
4- Ability to reuse and preserve.
You may think there are other priorities; for example, ontologies and terminologies, privacy issues, rights and intellectual property issues, database size and complexity, and refresh pace and update frequency.
Identifying the most critical needs is really the first step. Mark Parsons said it well yesterday: if we can solve 80 percent of our problems with an 80/20 solution, we should do that. In large part, that is what standards do. Perhaps the data citation group that organized this meeting should spend some time focusing on which issues are secondary to the bigger goal of sharing data and then focus its attention on those things most critical to creating a culture of digital data citation.
Focusing on the core problem does provide a great deal of benefit even if it does not solve every issue for every community. One good example of this is the Dublin Core metadata standard, which is widely used. Communities have been trying to develop a better schema for how to describe content, metadata, and bibliographic information and they keep going back to the Dublin Core and extending its basic model. The Dublin Core metadata set contains all the critical elements and that same approach is probably how we should start. Perhaps what we need is a good framework of data elements that define core and secondary sets of metadata for describing data or data sets, which may be applicable in across a range of communities and leave the proper display question to each individual community.
The problem with most standards is not that they are bad ideas or that there is not sufficient thought that went into their development. Frequently, the problem stems from a limited amount of follow-up or commitment to promoting adoption. The point at which most standards fail is after consensus is reached. The failure point is often in the standard’s adoption—or better said in the absence of adoption.
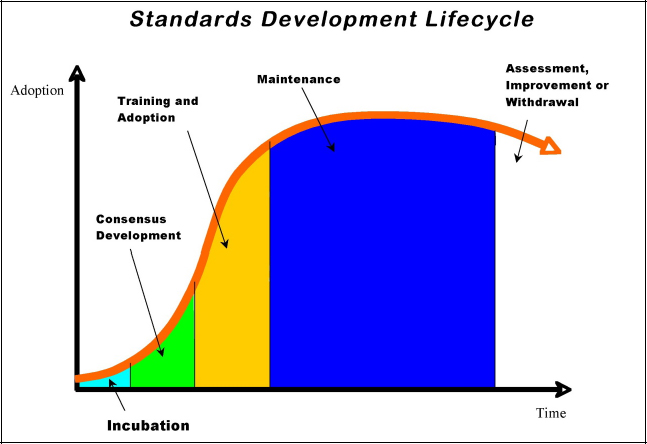
FIGURE 26-1 The standards development lifecycle.
Much like the sales adoption cycle of any other product, standards go through a lifecycle process of slow growth, growing adoption, broad acceptance, then eventual decline, which leads to revision or withdrawal. Figure 26-1 is a graph of the life cycle of a standard with adoption on the vertical axis and time on the horizontal axis. Projects start out in incubation stage, where a small group of people are interested in trying to solve a problem. Then there is a period of consensus development, where people become aware of the project and agree on the solution.
Unfortunately, far too many standards development processes stop at this stage. Group members might say or think, “We have developed the schema, so let us publish it, and then we are done.” But the problem is that getting people to use a standard is the most difficult part of the process. Just as with the latest technology product, in order for it to reach mass-market appeal, it needs promotion, marketing, and encouragement to get people to use it. So, we need to spend a lot of time, effort, and energy on these later stages to make a standard succeed. If we do come up with a standard data citation format, schema for metadata about data sets, or publication policies, and after we have obtained consensus on the citation structure, we have to invest time and effort in getting people to actually use it.
Finally, I want to reflect on who is the audience for the project we are developing? “Who” is one of the most critical questions regarding the adoption of a standard or best practice that has been developed. Among those who need to be deeply engaged in data citation standards adoption are researchers, educators, data centers, publishers, promotion tenure committees, administrators, funding agencies, consumers of the data, and repositories. Among the challenges as we move forward is ensuring that we have engaged the right communities to ensure that what we have done here and what we will continue to do over the next year will get adopted? I think that is probably the biggest challenge facing us now, as it is with any standards development organization, or any standards community.




