
5- Maintaining the Scholarly Value Chain: Authenticity, Provenance, and Trust
Paul Groth1
VU University of Amsterdam, The Netherlands
I think the following quote is important. It is from Jeff Jarvis2:
In content, as creation becomes overabundant and as value shifts from creator to curator, it becomes all the more vital to properly cite and link to sources […]. Good curation demands good provenance. […] Provenance is no longer merely the nicety of artists, academics, and wine makers. It is an ethic we expect”.
I agree that this is an ethic that we expect and that is one of my motivations for doing research on provenance.
I am a computer scientist. One of the design principles that computer scientists adopt a separation of concerns. I think that when we talk about data citation, we need to be very careful about separating concerns. This lack of separation of concerns occurs because when we speak about data citation we adopt practices from the way we cite traditionally. My goal is to convince you that we can do better.
Let me give you an example. The figure below is a standard reference from an older famous paper in the field of artificial intelligence titled “A Truth Maintenance System"3.

FIGURE 5-1 A reference from the article, “A Truth Maintenance System.”
This reference contains a lot of information. It tells you where to find this article. It gives you a search term to help you find it in libraries or in Google. It also helps with provenance. For example, it gives information about the person who wrote this paper and that it appeared in a book called the Fourth Proceedings of IJCAI, as identified in Figure 5-2.
______________________
1 Presentation slides are available at http://sites.nationalacademies.org/PGA/brdi/PGA_064019
2 Jeff Jarvis, media company consultant and associate professor at the City University of New York’s Graduate School of Journalism, in “The importance of provenance”, on his BuzzMachine blog, June, 2010.
3 Jon Doyle, A truth maintenance system, Artificial Intelligence, Volume 12, Issue 3, November 1979, Pages 231-272, ISSN 0004-3702, 10.1016/0004-3702 (79)90008-0.

FIGURE 5-2 Provenance information with a reference.
Furthermore, the reference helps with making trust interpretations. For example, I personally know that Pat, the author, is a good person. This means that I should follow this citation because I know this person is trustworthy. Or maybe, I should follow the citation because it is at the International Joint Conference on Artificial Intelligence and I happen to have background knowledge about artificial intelligence to know that this is a top conference in the field. So, again, I think I trust this piece and think it can be used in my work. The point is that in this one simple citation and its corresponding reference, we were provided with information about four different things: information to lookup the paper, its identity, provenance information, and trust. However, giving this same reference to a computer changes things completely.
I think that for data citation we need to try to address all of these different areas separately. We need identity and we need provenance, but provenance is not part of making persistent identifiers. It is something separate. Once we have provenance, we can start computing trust metrics. Different people have different ideas about what they trust, but based on where the material comes from and describing how the experiments were produced we can compute different kinds of trust metrics. Finally, over the top of all this, once we have identifiers, once we have some information about where the material comes from and how it was produced, once we have these trust metrics, we can build good search engines.
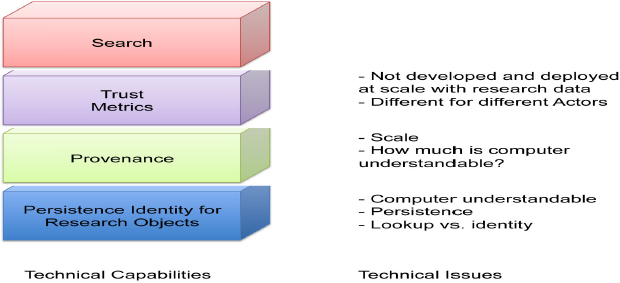
FIGURE 5-3 Technical capabilities Vs. Technical issues.
Each area is a different concern and there are some technical issues with each one. For identity, we have already heard about computer understandability, about identity persistence and also the notion of lookup versus identity. Whether we need to put together or pull apart, lookup and identity, I do not know.
For provenance, we need to deal with the issue of scale. One data point can have hundreds of gigabytes of provenance. I remember when I did my Ph.D., I was doing provenance work and I had a result that was one number with one gigabyte of provenance information associated with it. So scale is a huge issue here, especially how much of this is computer understandable? Right now most of what we say about provenance of data is encoded in text that people can read, but increasingly we encode in the form of computational workflows or in other computer reasonable formats.
It is important to note, that trust is different than provenance. Provenance can be viewed as a platform on which we can develop different ways of determining trust. I think we need to develop this platform trust metrics separately. We also need to develop scalable algorithms for calculating these trust metrics. Finally, I think trust is different for different actors and, right now, we do not have that clear a conception of it. So this also requires more work. For example, for my many data applications, I may trust everything because statistically it does not matter. However, for something that my tenure or promotion package is based on, maybe I want a different, higher level of trust.
To conclude, this is my appeal: Citation does not have to contain everything. When we talk about data citation, we should not try to include everything possible in the citation or reference. Maybe all we need is simple pointers that are understandable by machines. The final thought I want to leave you with is that we can build it. We have the technology and I do not think we are far off. I will end with some references:
W3C Provenance Incubator Final Report:
http://www.w3.org/2005/Incubator/prov/XGR-prov-20101214/.
W3C Provenance Working Group Standardization Activity:
http://www.w3.org/2011/prov/wiki/Main_Page.
Surveys of provenance and trust:
Donovan Artz and Yolanda Gil. A Survey of Trust in Computer Science and the Semantic Web, Journal of Web Semantics, Volume 5, Issue 2, 2007.
Rajendra Bose and James Frew. Lineage Retrieval for Scientific Data Processing: A Survey. ACM Computing Surveys, Volume 37, Issue 1, 2005).
J. Cheney, L. Chiticariu and W.-C. Tan. Provenance in databases: Why, where and how, Foundations and Trends in Databases, 1 (4):379-474, 2009.
David DeRoure, Replacing the Paper: The Twelve Rs of the e-Research Record: http://www.blogs.nature.com/eresearch/2010/11/27/replacing-the-paper-the-twelve-rs-of-the-e-Research-Record
Juliana Freire, David Koop, Emanuele Santos, Claudio Silva. Provenance for Computational Tasks: A Survey, Computing Science and Engineering, Vol 10, No 3, pp 11-21, 2008.
Luc Moreau, The Foundations for Provenance on the Web, 2010, Foundations and Trends® in Web Science: Vol. 2: No 2-3, pp 99-241. http://www.dx.doi.org/10.1561/1800000010
Yogesh L. Simmhan, Beth Plale, Dennis Gannon. A survey of data provenance in e-science. ACM SIGMOD Vol 34, No 3, 2005. See also a longer version.
DISCUSSION BY WORKSHOP PARTICIPANTS
Moderated by John Wilbanks
PARTICIPANT: I did not get the distinction between usage data, citation data, and bibliography data. Can you please define these terms?
DR. BOLLEN: The least we can say about usage data is that someone paid attention to a particular resource, whereas with citations, it is an explicit public statement of someone indicating that they have been influenced or impacted by someone else’s work. In our statistics, it is sometimes obvious that some materials are used a lot but never cited and vice versa. When we raise this data usage issue, we also talk about data downloads and access, and we are focusing on aspects that are somehow measurable.
PARTICIPANT: I believe I got your distinction between usage data and citation data, but I think that this is not well developed. We might need to make a distinction between citation and usage of data versus citation and usage of literature.
PARTICIPANT: I think that the issue of data citation has two components: technical and sociocultural. We still have questions related to how we write a citation for a dataset, and there are some technical challenges in terms of space or in terms of the style of writing the citation for a given dataset. However, are we focusing too much only on the technical challenges? The real challenge is the culture of citing datasets and providing a proper citation. We therefore need to focus on both the technical and the social and cultural challenges.
DR. MINSTER: There is a well-known trick to put the subtle error in one of your papers and then everybody is going to cite your publication. You can do the same with data. If we stop insisting that every single granule of a database should have its own identifier and be quoted by those who use it, it would be in the interest of the data provider to just give miniscule granules.
PARTICIPANT: Why can I not point to every piece of data at the smallest granularity possible?
DR. BOLLEN: Fair enough, but if you rely on this mechanism to provide people with recognition, advancement, tenure, things like this, the small cites are not very useful.
PARTICIPANT: This question is for Dr. Bollen. Did you put your usage data in your tenure package?
DR. BOLLEN: Yes, I did. I had a couple of pages showing some statistics on my papers. PARTICIPANT: Did you make the raw data available?
DR. BOLLEN: No. I could not do that because of the agreement that we have to sign with the rights holder. This issue is always a big challenge and a big responsibility.
PARTICIPANT: One of the great things about print citations is that they are notation dependent. In the past, if you happened to work at a university, you knew how to go to the library and look
up a journal title and get it. Those practices survived hundreds of years, and I worry sometimes that if we revert to just URIs and require that it should be de-referenced, we are losing something very important from the old model. Do you have any thoughts about this tradeoff between location and dependence on simplicity?
DR. BOLLEN: This is a good question. The best answer I heard this morning was that when you want to deal with regularity, you have to retrieve the same dataset that somebody else used. Maybe storing separately the data and the dataset of the query is the right way to do it. Then you can say, “in this research, I have used the output of this query on that dataset".
PARTICIPANT: Where would I find the dataset? Where do I look?
DR. BOLLEN: The dataset should be findable by URI on the web, no matter where it is, although some providers may require enormous granules or miniscule granules. Having that as the output of the query would be a reasonable thing to do.
DR. GROTH: I think this is one of the places where we may have to sacrifice because of the scale we are talking about. The reason we can look at a normal citation and find it in the library is because there is lots of background information about what all the pieces of a citation mean. In the data area, it is not that clear. We had a great example of what a possible data citation could look like in a paper, but we already have been told that it is too much work. If we think about the scale we are talking about, then URLs may even be too much work. So we have to sacrifice this location independence.
DR. VAN DE SOMPEL: I am in favor of the HTTP URIs in this case. I have some reasons for that. One, we get an entire infrastructure that is freely available. We can get all the new developments free rather than having to reinvent the wheel. In order to get closer to what we refer to as longevity of identifiers similar to what we have in print, I am actually in favor of having an accession number that is not protocol based, like the DOI or an ARK identifier as introduced by the California Digital Library. It is just a unique string that you carry with you into the future. I call this technology independent. You can print it on paper. Then you basically instantiate that non-protocol identifier and use the protocol of the moment. So, even if all those citations become invalid at one point because HTTP goes away, there will be ways to recover that information and transpose it to the next protocol. Plus, if indeed HTTP is going to become obsolete at some point, there are going to be services to migrate us from one to the other. We just have to rely on that. So, yes I am now in favor of using HTTP URIs, but probably under the condition that the non-protocol string identifier exists also.
DR. BOLLEN: I share that concern. There is definitely going to be some problem in this area. I am not a specialist on identifiers, but a lot of this seems to me to be an artifact of the technology that we have at our disposal right now. If we had machine intelligence that could, in essence, unpack the kind of information that we use, none of this would be an issue.
PARTICIPANT: However, humans do create identifiers.
DR. BOLLEN: This involves a lot of background knowledge and implicit information. The reason why we are coming up with these machine identifiers specifically, however, is because the machines are not capable of accessing that information.
DR. SPERBERG-MCQUEEN: We should not overestimate the power of human contextual information. Bear in mind that in difficult cases, in particular in identifying musical compositions, we always use catalog notes. You do not refer to a piece by Mozart without a peripheral number precisely because context does not suffice for average use in those situations.
PARTICIPANT: Dr. Minster, you referred to something being “properly cited.” What did you mean by that?
DR. MINSTER: I used “properly cited” in a loose way, but I believe it has two purposes. The first purpose is to give appropriate credit to the person who actually created the data, analyzed them, calibrated them, or did whatever was necessary before they become public. The second is for someone else to be able reuse these data and do his/her own analysis.
PARTICIPANT: I have another question for Dr. Minster. What did you mean by “data publication?” Are you talking about fixing data in time or printing it on paper? Or are you talking about just making it available in some other form? Or are you actually talking about a publication like a data journal?
DR. MINSTER: No, I do not mean a data journal, but I do mean something that may have a versioning capacity. For instance, if we want to refer to a book, we have to say which edition we want. That is the same thing about data. There is another aspect, however, which I am not sure how to solve. In our world today, we trust the gold standard for scientific publication: peer review. I do not know how one would do a dataset peer review. This is something that might have to be invented in the future.
PARTICIPANT: Does citation have anything to do with peer review? That is the thing that I do not really get. Just being able to point to something formally and give it credit should be fine. We need to be able to do that first and then we may need new mechanisms for peer review of data.
DR. MINSTER: The question was about publication, however. I have a hard time accepting the concept of citable publication without some kind of quality control, either peer review or an equivalent mechanism.
PARTICIPANT: When a database comes out, it is often transformed before it is published. That transformation can then be done later by a third party and, in fact, there could be a whole new data chain. At what level of granularity does it make sense to track this into a machine- understandable form so that we can say, “I am looking at this transformation of this data by this person?”
DR. GROTH: I have worked with people who track the provenance of data at the operating system level. I think it is the decision of scientists. There is no hard and fast rule for that.
DR. MINSTER: In my field of geophysics, more and more datasets are the output of a large computer program and, in that case, provenance is a real issue because we have to say which version of the code we used, on what machine, and using what operating system.
DR. VAN DE SOMPEL: I agree with Paul Groth that this is a more curatorial decision. I am not an expert in this area, but it seems to me that we can hold on to all the provenance or workflows
that have taken place. The question, though, is do we also need to hold on to all intermediate versions of the data? Are these workflows still relevant when we do not have the underlying data anymore? Maybe they are because we can figure out what had happened even though the source data are gone.
DR. GROTH: In general, if we have un-deterministic data, we can throw away the intermediate data. But if we have un-deterministic data or information, we cannot throw away steps because we cannot reproduce them. We did some work in astronomy, where we put everything on a virtual machine and anyone could just re-execute everything. It was fine because we had all the input data and everything could be reproduced.
DR. CALLAGHAN: I want to respond to Paul Groth’s comment on the relationship between data publication and data citation. I think that we need to have citation before we can have data publication. This is because the way we are looking at publishing data (i.e., actual formal journal publishing with the associated peer review arrangements) is to give it that cited stamp of quality. We cannot do that unless the dataset that is being peer reviewed is findable, static, a host of other things, and is persistent.
I work for a data center and we do what some people might consider data publishing. It gets a bit confusing because we have two levels of publishing. There is publishing that involves making labels, handing it out to the web, and the like. We call it publishing with a small “p”. Then there is publishing that carries all the connotations of scientific peer review, quality, persistence, and so on. We call that publishing with a big “P.” I view citation of data as occurring somewhere between those two. So, from my point of view, citation means that as data centers, we are making some judgments about the technical quality of the datasets. We cannot say anything about the scientific quality of the data because that is for the domain experts and the scientific peer review process to decide.
DR. GROTH: When we use a citation in a journal article, I know that in geography, for example, they only cite things that are peer reviewed. In computer science, however, if you examine the articles produced by the logic community of practice, they cite their own technical reports because their proofs are so long that they cannot put them in the paper itself. So, I think we need to allow for citation of the small “p” and that should be the same mechanism for the citation of the big “P.”
DR. CALLAGHAN: I have a quick point related to the granularity issue and citing a small part of the dataset. The way I think about it is that we do not need to have a DOI or a URI for every word in a book, for example. We cite the books and some location information at the end, such as page number, paragraph number, or something similar. That is the analogy I would think of when it comes to citing a portion of the dataset. We cite a dataset as a whole, but we can also provide extra information to locate the specific part of the data that we want to reference.
DR. VAN DE SOMPEL: That is exactly the formulation that I showed on my presentation slides, which I feel is also the most generic approach to this: use the identifier of the entire thing and in addition use an annotation (with an identifier) to express which part of the thing is of concern. All of this is easier when using HTTP URIs, including ones that carry DOIs or ARK identifiers, because a whole range of capabilities comes freely with HTTP.
MS. CARROLL: We got separated from the publication and citation issues, and I would like to get back to them. I think we have to have a common understanding of what we are talking about when it comes to publication. I think the division between scholarly articles and technical reports is a good analogy. The vast majority of datasets that people want are like technical reports rather than like scholarly journal articles. So, let us not lose sight of those little “p’s".
DR. VAN DE SOMPEL: I agree and I would like to reiterate that peer reviewing in the classic way is not going to be scaleable in the area of small “p.”
MR. WILBANKS: I think it is also important to note that even in the big “P,” traditional peer review is starting to change. Recently, we started to see articles getting published that are only reviewed for scientific validity, without attempting to judge input in advance. This is not just in the library science area; it is in Nature and is used by some other publishers.
DR. CALLAGHAN: I think that what is really important is how people actually use the material, regardless of whether it has gone through a formal review process or not. If we are looking to the future and how people are collaborating and communicating, that whole formal scholarly review and the metrics of it should be reconsidered.
DR. BOLLEN: That is exactly the point. I think that within the next 10 or 15 years, we will see the momentum of building new systems and mechanisms and that the traditional big “P” publication process will be slowly but surely replaced by new approaches.
MR. PARSONS: Continuing on this peer review theme, one of the things that I think is critical in this area is training in relation to the concept of data citation. I have been pushing data citation for more than a decade and only recently, in the last couple of years, has the issue really taken off. The scholarly literary mechanisms will likely transform, but also let us be honest and admit that academia is an incredibly conservative institution. It does not transform quickly and one of the reactions I have gotten in pushing data citation is that the data producers do not want the data to be cited. They want the paper about the data to be cited, because they get more credit for that.
PARTICIPANT: Just a quick clarification, Dr. Bollen. I thought that all of the materials you were studying were big “P” publication.
DR. BOLLEN: Yes, we were heavily focused on cross-validation of our results and the only comparable datasets that we had were citation statistics, which do focus on big “P” publications.
I am not expert on persistent identifiers, but I feel that these issues were working themselves out into the larger community by mechanisms that are very difficult to anticipate at this particular point. I think they will be very different from the publication and the scholarly communication mechanisms that we have seen in the past. This is my personal experience and that is true for my students. That is also true for all of my colleagues. A lot of the material that they publish these days is distributed primarily online, and is reviewed primarily online by the general community and not by an editor or a committee of three or four reviewers. I see this phenomenon coming into play when it comes to datasets that are increasingly made publicly available, but not in any systematic way anytime soon.
DR. GROTH: I have three comments. One, I think that we need a simple and straightforward way to point to small “p” and big “P” datasets. Two, once we have that, we can use it as the basis for building more complicated systems around provenance and later on, trust. So, let us start with the simple task first. Finally, we may need some standard ways to make citations look nice in the back of our papers.
DR. MINSTER: It is a sad reality that some of our colleagues work very hard to produce the datasets and they get no credit. Once we have done a piece of work and published it with a big “P,” it ends up in a journal or in a book. How often is it that you get somebody to hack the book and change the contents of, for example, Science magazine online? I just do not see this happening. In datasets, however, this could happen all the time and therefore it is very important to have trusted repositories.
This page intentionally left blank.












