
5
Gene Regulation
Gene Control: Transcription Factors and Mechanisms
Since the elucidation of the double-helix structure of deoxyribonucleic acid (DNA) in 1953, biologists have been racing to understand the details of the science of genetics. The deeper they penetrate into the workings of the DNA process, however, the more complexity emerges, challenging the early optimism that characterizing the structural mechanisms would reveal the entire picture. It now appears likely that life within an organism unfolds as a dynamic process, guided by the DNA program to be sure, yet not subject to clockwork predictability. One of the most intriguing questions involves the very first step in the process, how the DNA itself delivers its information to the organism. At the Frontiers symposium, a handful of leading genetic scientists talked about their research on transcription—the crucial first stage in which RNA molecules are formed to deliver the DNA's instructions to a cell's ribosomal protein production factories. The discussion was grounded in an overview by Robert Tjian, who leads a team of researchers at the Howard Hughes Medical Institute and teaches in the Department of Molecular and Cell Biology at the University of California's Berkeley campus.
Eric Lander of the Whitehead Institute at the Massachusetts Institute of Technology organized the session "to give a coordinated picture of gene control in its many different manifestations, both the different biological problems to which it applies and the different methods people use for understanding it." The goal was to try to
provide the "nonbiologists at the symposium with a sense of how the genome knows where its genes are and how it expresses those genes."
Possibly no other scientific discovery in the second half of the 20th century has had the impact on science and culture that elucidation of DNA's structure and function has had. The field of molecular biology has exploded into the forefront of the life sciences, and as its practitioners rapidly develop applications from these insights, new horizons appear continuously. The working elements of genetics, called genes, can now be duplicated and manufactured, and then reintroduced into living organisms, which generally accept them and follow their new instructions. Recombinant DNA technology and gene therapy promise to change not only our view of medicine, but also society's fundamental sense of control over its biological fate, perhaps even its evolution.
HOW DNA WORKS
Despite the significance of modern genetics, many of its fundamentals are still not widely understood. A summary of what has been learned about DNA might serve as a useful introduction to the discussion on transcription and gene expression:
-
The heritable genetic information for all life comes in the form of a molecule called DNA. A full set of a plant's or an animal's DNA is located inside the nucleus of every cell in the organism. Intrinsic to the structure of the DNA molecule are very long strings composed of so-called base pairs, of which there are four types. A gene is a segment of this string that has a particular sequence of the four base pairs, giving it a unique character. Genes are linked one after another, and the string of DNA is carried on complex structures called chromosomes, of which there are 23 pairs in humans. Researchers put the number of discrete genes in humans at about 100,000. To clarify the concept of DNA, Douglas Hanahan from the University of California, San Francisco, invoked the metaphor of a magnetic tape, "which looks the same throughout, but has within it (or can have) discrete songs composed of information." A gene can thus be likened to a particular song.
-
The general outline of this picture was known by the early 1950s, but even the electron microscope had not revealed exactly how the DNA molecule was structured. When British biophysicist Francis Crick and American molecular biologist James Watson first proposed the double-helix structure for DNA, a thunderclap echoed throughout molecular biology and biochemistry. Much more than just a
-
classification of structure, it was a revelation whose implications opened up a vast area of exploration. Why so momentous? Because that structure facilitates DNA's role and function to such an extent that the whole process of decoding and eventually altering the basic genetic information was suddenly glimpsed by drawing the curtain back on what has come to be known as the alphabet of life.
-
The structure of DNA was at once realized to be dramatically suggestive of how the molecule actually functions to store and deliver coded information. By weak chemical bonding between complementary bases—adenine with thymine and cytosine with guanine, and each pair vice versa—the hereditary store of information in all life forms takes shape as a coded sequence of simple signals. The signals are arranged in the double-helix structure discovered by Watson and Crick. Picture two strands of rope side by side, each with a string of chemical bases along its length (Figure 5.1). When a base on the first rope is adenine (A), the base opposite it on the other rope
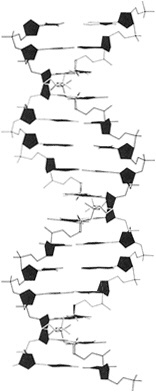
Figure 5.1 Skeletal model of double-helical DNA. The structure repeats at intervals of 34 angstroms, which corresponds to 10 residues on each chain. (From p. 77 in BIOCHEMISTRY 3rd edition, by Lubert Stryer. Copyright © 1975, 1981, 1988 by Lubert Stryer. Reprinted by permission from W.H. Freeman and Company.)
-
will be thymine (T). Also conversely, if thymine appears on one strand, adenine will be found opposite on the other strand. The same logic applies to analogous pairings with cytosine (C) and guanine (G). These base pairs present the horizontal connection, as it were, by their affinity for a weak chemical bond with their complementary partner on the opposite strand. But along the vertical axis (the rope's length), any of the four bases may appear next. Thus the rope—call it a single strand, either the sense strand or the antisense strand—of DNA can have virtually any sequence of A, C, G, and T. The other strand will necessarily have the complementary sequence. The code is simply the sequence of base pairs, usually approached by looking at one of the strands only.
-
In their quest to explain the complexity of life, scientists next turned to deciphering the code. Once it was realized that the four nucleotide bases were the basic letters of the genetic alphabet, the question became, How do they form the words? The answer was known within a decade: the 64 possible combinations of any given three of them—referred to as a triplet—taken as they are encountered strung along one strand of DNA, each delivered an instruction to "make an amino acid."
-
Only 20 amino acids have been found in plant and animal cells. Fitting the 64 "word commands" to the 20 outcomes showed that a number of the amino acids could be commanded by more than one three-letter "word sequence," or nucleotide triplet, known as a codon (Figure 5.2). The explanation remains an interesting question, and so far the best guess seems to be the redundancy-as-error-protection theory: that for certain amino acids, codons that can be mistaken in a "typographical mistranslation" will not so readily produce a readout error, because the same result is called for by several codons.
-
The codons serve, said Hanahan "to transmit the protein coding information from the site of DNA storage, the cell's nucleus, to the site of protein synthesis, the cytoplasm. The vehicle for the transmission of information is RNA. DNA, the master copy of the code, remains behind in a cell's nucleus. RNA, a molecule whose structure is chemically very similar to DNA's, serves as a template for the information and carries it outside the cell's nucleus into the cytoplasm, where it is used to manufacture a given sequence of proteins.
Once the messenger transcript is made, its translation eventually results in the production (polymerization) of a series of amino acids that are strung together with peptide bonds into long, linear chains that in turn fold into interesting, often globular molecular shapes due to weak chemical affinities between and among various amino acids.
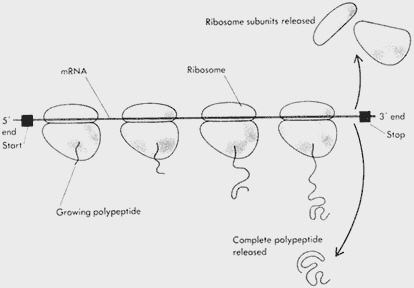
Figure 5.2 (A) Diagram of a polyribosome. Each ribosome attaches at a start signal at the 5' end of a messenger RNA (mRNA) chain and synthesizes a polypeptide as it proceeds along the molecule. Several ribosomes may be attached to one mRNA molecule at one time; the entire assembly is called a polyribosome.
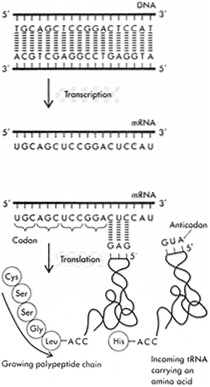
(B) Transcription and translation. The nucleotides of mRNA are assembled to form a complementary copy of one strand of DNA. Each group of three is a codon that is complementary to a group of three nucleotides in the anti-codon region of a specific transfer (tRNA) molecule. When base pairing occurs, an amino acid carried at the other end of the tRNA molecule is added to the growing protein chain. (Reprinted with permission from Watson et al., 1987, p. 84. Copyright © 1987 by The Benjamin/Cummings Publishing Company, Inc.)
These steps are chemically interesting, but the mystery that compelled the scientists at the Frontiers symposium surrounds the initial transcript that is created by a species of ribonucleic acid called messenger RNA (mRNA). Tjian's overview, "Gene Regulation in Animal Cells: Transcription Factors and Mechanisms," touched on much of the above background and presented some of the basic issues scientists are exploring as they probe the mRNA process. His colleagues in the session on gene regulation each described intriguing findings based on their studies of regulation in various organisms: Arnold Berk, from the University of California, Los Angeles, in viruses; Kevin Struhl, from the Harvard Medical School, in yeast; Ruth Lehmann, from the Whitehead Institute, in the fruit fly; and Hanahan, in mice. They explained their work to the symposium and suggested how its implications may help to clarify human genetics and fill in the larger picture of how life operates.
THE ROLE OF DNA
Noncoding DNA—Subtlety, Punctuation, or Just Plain Junk?
Scientists cannot say for certain whether the majority of noncoding genes that do not seem to say simply "make this string of amino acids," are saying anything at all. Tjian has heard a lot of speculation on this question: "Most people in the field agree that only a very small percentage of the human genome is actually coding for . . . the proteins that actually do all the hard work. But far be it for me to say that all that intervening sequence is entirely unimportant. The fact is we don't know what they do." He notes an interesting phenomenon among scientists, observing that while "some people call it junk," others like himself ''would rather say 'I don't know.''' Rather than dismissing the significance of this undeciphered DNA, he and others mentally classify it as Punctuation that is modifying and influencing the transcript. "There is clearly a lot of punctuation going on, yet still the question arises: Why do amphibians have so much more DNA than we do? Why does the simple lily have so much DNA, while the human—clearly just as complicated in terms of metabolic processes—doesn't seem to need it? Actually, a lot of people wonder about whether those sequences are perhaps there for more subtle differences—differences between you and me that at our present stage of sophistication may be too difficult to discern."
Eric Lander, responding to the curiosity about excess or junk genes, pointed out that the question often posed is, If it is not useful, why is it there? He continued, "From an evolutionary point of view, of
course, the relevant question is exactly the reverse: How would you get rid of it? It takes work by way of natural selection to get rid of things, and if it is not a problem, why would you junk it? That is really the way life is probably looking at it." Vestigial traits are not uncommon at the higher rungs of the evolutionary ladder, pointed out Lander, whereas "viruses, for example, are under much greater pressure to compete, and do so in part by replicating their DNA efficiently."
However, the astounding intricacy, precision, and timing of the biological machinery in our cells would seem to suggest to Tjian and others that the nucleotide base sequences in between clearly demarcated coding genes do have a vital function. Or more likely, a number of functions. Now that the questions being posed by scientists mapping the genome are starting to become more refined and subtle, the very definition of a gene is starting to wobble. It is often convenient to conceptualize genes as a string of discrete pearls—or an intertwined string following the double-helix metaphor—that are collected on a given chromosome. But Tjian reinforces the significance of the discovery that much less than half of the base sequences are actually coding for the creation of a protein.
He is searching for the messages contained in the larger (by a factor of three or four) "noncoding" portion of the human genome. Mapping is one thing: eventually with the aid of supercomputers and refined experimental and microscopy techniques to probe the DNA material, an army of researchers will have diagrammed a map that shows the generic, linear sequence of all of the nucleotide base pairs, which number about 3 billion in humans. For Tjian, however, that will only be like the gathering of a big pile of puzzle pieces. He is looking to the next stage, trying to put the puzzle together, but from this early point in the process it is difficult to say for certain even what the size and shape of the individual pieces look like. He knows the title of the assembled picture: "How the DNA governs all of the intricate complexities of life."
One early insight is proving important and echoes revelations uncovered by scientists studying complex and dynamical systems: each of the trillion cells in a human is not an autonomous entity that, once created by the DNA, operates like a machine. Life is a process, calling for infinitely many and infinitely subtle reactions and responses to the conditions that unfold. The formal way of clarifying this is to refer to the actual generic sequence of bases in an organism as its genotype, and the actual physical life form that genotype evolves into as the phenotype. The distinction assumes ever more significance when the effects of interacting dynamic phenomena on a system's evolution are considered. A popular slogan among biologists
goes: evolution only provides the genotype; the phenotype has to pay the bills. Tjian and his colleagues strongly suspect that, on the cellular level—which is the level where molecular biologists quest and where DNA eventually produces its effects—the instructions are not merely laid down and then run out like a permanently and deterministically wound-up clock. Most of the noninstinctive—that is, other than biochemically exigent and predictable—functions performed within the cell must have a guiding intelligence, and that intelligence must be coded in the DNA. And these modern geneticists are most compelled by the very functions that begin the process, translating the DNA's program into action.
The Central Dogma of Biology
Not long after Crick and Watson made their celebrated discovery, they pursued their separate researches, and Crick was among those given the most credit for helping to unravel the code itself. In the process, it became clear that DNA was not really an actor at all, but rather a passive master copy of the life plan of an organism's cells. Crick was responsible for what came to be called the central dogma of biology—the sequence of steps involved in the flow of information from the DNA master plan through to the final manufacture of the proteins that power the life process (Figure 5.3).
Molecular biologists and biochemists have uncovered a number of fascinating and unexpected phenomena at each of these distinct steps. But the transcript made at the first step is understandably critical, because somehow the proper part of the enormous DNA master plan—the correct gene or sequence of genes—must be accessed, consulted, and translated for transmission to the next step. Thus the major questions of transcription—often referred to as gene expression—draw the attention of some of the world's leading geneticists, including Tjian and his colleagues at the symposium's gene regulation session, who explained how they probe the mRNA process experimentally in search of answers.
A cell has many jobs to do and seems to be programmed to do them. Moreover, the cell must react to its environment and thus is constantly sensing phenomena at its cell membrane with receptors designed for the task, and then transmitting a chemically coded signal to the nucleus. Processing this information, to continue the metaphor, requires a software program, and undoubtedly the program is located in the genes. It is the job of the transcription machinery to find the proper part of the genome where the needed information is located. Conceptually, two categories of signals may be received,
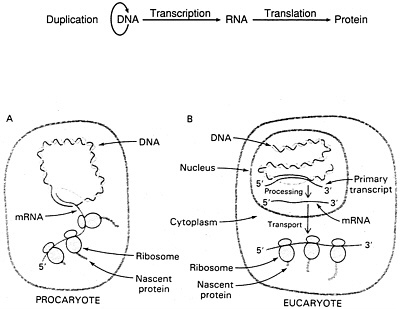
Figure 5.3 (Top) Pathway for the flow of genetic information referred to in 1956 by Francis Crick as the central dogma. The arrows indicate the directions proposed for the transfer of genetic information. The arrow encircling DNA signifies that DNA is the template for its self-replication. The arrow between DNA and RNA indicates that all cellular RNA molecules are made on ("transcribed off") DNA templates. Correspondingly, all proteins are determined by ("translated on") RNA templates. Most importantly, the last two arrows were presented as unidirectional; that is, RNA sequences are never determined by protein templates, nor was DNA then imagined ever to be made on RNA templates. (Reprinted with permission from Watson et al., 1987, p. 81. Copyright © 1987 by The Benjamin/Cummings Publishing Company, Inc.). (Bottom) Transcription and translation are closely coupled in procaryotes (A), whereas they are spatially and temporally separate in eucaryotes (B). In procaryotes, the primary transcript serves as mRNA and is used immediately as the template for protein synthesis. In eucaryotes, mRNA precursors are processed and spliced in the nucleus before being transported to the cytosol. [After J. Darnell, H. Lodish, and D. Baltimore. Molecular Cell Biology (Scientific American Books, 1986), p. 270.] (From p. 716 in BIOCHEMISTRY 3rd edition, by Lubert Stryer. Copyright © 1975, 1981, 1988 by Lubert Stryer. Reprinted by permission from W.H. Freeman and Company.)
though probably in the same form. One could be thought of as preprogrammed; for example, when a cell begins to die its natural death, it must be replaced, and a full new set of DNA must be created for the progeny cell. Such a DNA replication event is biologically predictable, and thus it could conceivably be anticipated within the program itself. But a different sort of signal is probably far the more numerous sort: a need to respond to something exigent, a reaction—to some extracellular event or to an intracellular regulatory need—that requires a response. With this latter sort of signal, the RNA-transcribing enzyme, RNA polymerase, is somehow able to search out the proper part of the DNA library where the needed information is stored, copy it down by transcription, and then deliver the transcript to the next step in the process, which will move it outside the nucleus to the ribosomes. These have been described as the production factory where the body's proteins are actually assembled using yet another variant of RNA, ribosomal RNA (rRNA). Again, the central dogma.
TRANSCRIPTION FACTORS
Tjian believes the key to unravelling the complexities of the code lies in understanding how the messenger RNA transcript is crafted. Since the chemical rules by which RNA polymerase operates are fairly well understood, he is looking for more subtle answers, related to how the protein finds the proper part or parts of the genome—that is, the gene or genes that need to be consulted at the moment. His research indicates that the answer most likely will involve at least several phenomena, but his target at the moment is a collection of proteins called transcription factors. Since timing is also a crucial component of the transcription process, geneticists are trying to understand how the rapid-fire creation of proteins is coordinated: not only where, but when. This is because the ultimate product, the long polypeptide chains that make up the body's proteins, are linear as they are built. This long string, when conceived as the product of a program, can be seen as the sequential order in which the proteins are called for and assembled, because they are strung together one after another by chemical bonding in a long chain in one direction only. The ribosomal cell factories pump out proteins at the rate of over 30 per second. An only slightly fanciful example: if the RNA polymerase is moving down the DNA chain, and at 1.34 seconds the code says UCA (serine), at 1.37 seconds it says ACG (threonine), and then at 1.40 it says GCA (alanine), there cannot be a delay in reading the UCA, or the proteins will not be laid down in the proper se-
quence, and the protein sequence and therefore the resultant polypeptide chain will be different, and the whole system will break down.
Thanks to the electron microscope, Tjian was able to provide moving pictures of the transcription process in action. Almost all the actors in this drama are proteins in one form or another; the primary substance responsible for making the transcript is a complex protein called RNA polymerase II. RNA polymerase II is a multisubunit enzyme composed of approximately 10 different polypeptides.
The first step is to clear the DNA strand of associated chromatin components so that the RNA polymerase can get at it. The DNA molecule in a eukaryote is wrapped up in a complex of proteins called histones, which have to be cleared off the DNA template. Then the two complementary strands are locally unwound, and the RNA polymerase starts to move along one strand to create the transcript. By reading nucleotide bases it is actually building a complementary strand of mRNA, by producing the base that chemistry calls for. The mRNA transcript is actually a copy—with the substitution of uracil for thymine, the RNA domain's one primary change—of the DNA's sense strand, which is merely standing by while the formerly coupled antisense strand, its chemical complement or counterpart, is being used as a template (Figure 5.4). The template does not produce
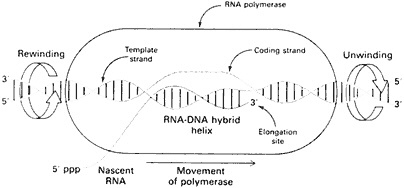
Figure 5.4 Model of a transcription bubble during elongation of the RNA transcript. Duplex DNA is unwound at the forward end of RNA polymerase and rewound at its rear end. The RNA-DNA hybrid helix rotates in synchrony. (From p. 710 in BIOCHEMISTRY 3rd edition, by Lubert Stryer. Copyright © 1975, 1981, 1988 by Lubert Stryer. Reprinted by permission from W.H. Freeman and Company.)
an exact copy but uses basic chemistry to create a complementary copy of the antisense strand, ergo an exact copy of the sense strand.
Tjian concentrates not on the chemical events themselves, but rather on how the RNA polymerase somehow knows where to go to begin and then where to end the transcript. The basic terrain he is exploring—the proteins called transcription factors—has signposts like promoter and enhancer regions, and introns and extrons, to guide this search for the "where" of transcription. The roles these regions play are largely unknown, and they offer a rich terra incognita for the molecular biologist and biochemist with a pioneering curiosity. As Tjian put it, "RNA polymerase is rather promiscuous" and not capable of discriminating discrete parts of the genome. It is the transcription factors that "seem to be designed to recognize very subtle differences in the DNA sequence of the template and can easily discriminate a real piece of information from junk. Their resolving power is very high," he said. Used as probes, they allow geneticists to home in on a piece of DNA as small as 6 to 8 nucleotides in length.
Drawing Lessons from Simpler Organisms
As Arnold Berk put it: "What are the punctuation marks?" Berk has done some important work on this question by probing a much simpler genome in a particular species of virus called adenovirus type 2, one of the 100 or so viruses that give humans colds. This diversity of known cold viruses allows Berk to deduce that "this is why you get a cold every year." Since a single exposure is sufficient to create a permanent immunity to its effect, it is comparatively safe to work with it in the laboratory. As compared to the 3 billion base pairs in the human genome, the adenovirus has only about 36,000. The logical inference is that—even though the virus does not have to perform differential calculus or ponder the philosophical and scientific implications of chaos theory—it has a more efficient genome. That is, there is a smaller proportion of junk or extra (that is, unidentified as to its clear function) DNA in the viral genome. "It grows well in the laboratory, it is convenient to work with," and its transcription behavior should be comparatively lucid.
The strategy of the virus, when it manages to get inside a host cell, is to exploit the cell's capacity to transcribe and translate DNA. The DNA of the virus says something like, "Make more of these." Instructions that say "make proteins" are obviously not hard to find, since they are the heart of any DNA code. But since it has been revealed that, in the human and most other genomes, so much other
curious DNA is present, the virus cannot simply find a generic, "make more of these" instruction sequence. The virus must locate one or a series of very specific transcription factors that it can use to subvert the host cell's original genetic program for its own purpose, which is self-replication. If it can find the right place to go, it wins. For, as Berk says, "the cell cannot discriminate between the viral DNA and its own DNA, and it reads this viral DNA, which then instructs the cell to basically stop what it is doing and put all of its energy into producing thousands of copies of this virion."
Berk's experiment takes full advantage of the relative simplicity of the viral genome. The experimental goal is to elucidate in the DNA sequence a so-called promoter region—the "punctuation mark," he explained, "which instructs transcription factors and RNA polymerase where to begin transcribing the DNA." Because "some of these control regions that tell the polymerase where to initiate are very much simplified compared to the control regions you find for cellular genes," Berk has been able to home in on the promoter region for the E1B transcription unit. This process illustrates one of the basic genetic engineering protocols.
Because of the simplicity of the viral genome, he and his team began by narrowing the target area down to a point only 68 base pairs beyond a previously mapped gene region. To target even closer, they next constructed mutants by removing or altering small base regions on successive experimental runs. The process of trial and error eventually locates the precise sequence of bases that works, that is, initiates transcription in the host cell. The result is the clarification of a particular promoter region on the viral genome, more knowledge about the transcription factors that interact with this promoter region, and, hopes Berk, some transferable inferences about the structure and function of more complicated promoter regions in animal cells.
Exploring the Details of Binding Protein to DNA
One of the first hurdles in performing laboratory experiments like the ones Berk and Tjian described is actually getting a sufficient quantity of transcription factor proteins to work with. "They are very elusive because they are produced in minute quantities in the cell, along with hundreds of thousands of different other proteins, and you have to be able to fish these particular proteins out and to study their properties," explained Tjian. However, since their structure includes a surface that recognizes a chemical image of a DNA sequence, experimenters can manufacture synthetic DNA sequences,
by trial and error, that eventually match the profile of the protein they are trying to isolate and purify. These DNA affinity columns are then attached to a solid substrate and put into a chemical solution. When a solution with thousands of candidate proteins is washed past these tethered DNA strings that geneticists refer to as binding sites, the targeted transcription factor recognizes its inherent binding sequence and chemically hooks on to the probe. Once the transcription factor is in hand, it can be analyzed and duplicated, often by as much as a factor of 105 in a fairly reasonable amount of laboratory time.
Tjian illustrated another method of doing binding studies, that is, isolating the small region of the DNA sequence that actually contacts and binds the transcription factor. The first step is to tag the DNA gene region by radioactive labeling and then to send in the transcription factor to bind. Next, one tries to probe the connection with "attacking agents, small chemicals or an enzyme that cuts DNA." The bound protein literally protects a specific region of the DNA from chemical attack by these agents and thus allows the detailed mapping of the recognition site. "Gel electrophoresis patterns can actually tell, to the nucleotide, where the protein is interacting" (Figure 5.5).
After some years now of experience with binding studies, Tjian and other molecular biologists have begun to recognize certain signatures , structures that seem to indicate transcription factor binding domains. One of the most prominent are the so-called zinc fingers, actually a specific grouping of amino acids that contains a zinc molecule located between cysteine and histidine residues. Over and over again in binding studies, analysis of complex proteins showed Tjian this "recognizable signpost . . . a zinc finger," which, he and his colleagues surmised, "very likely binds DNA." Subsequent analysis showed that it was, in fact, usually embedded in the effective binding domain. In this very specialized area of research, Tjian called this discovery "an extremely powerful piece of information" that has led to the cataloging of a large family of so-called zinc-finger binding proteins. Another similar binding signature they call a helix-turn-helix, or a ''homeodomain.''
Using the Power of Genetics to Study Transcription
Biochemist Kevin Struhl described for symposium participants some of the various methods used in his laboratory's work with yeast, an organism whose relative simplicity and rapid reproducibility make it a good candidate for studies of the transcription process. "As it
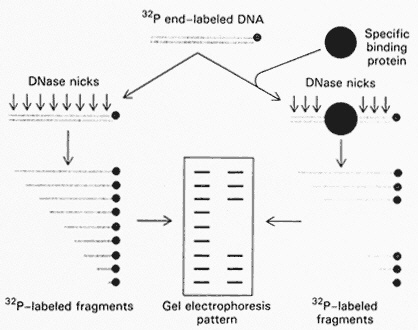
Figure 5.5 Footprinting technique. One end of a DNA chain is labeled with 32 p. This labeled DNA is then cutat a limited number of sites by DNase I. The same experiment is carried out in the presence of a protein that binds to specific sites on DNA. The bound protein protects a segment of DNA from the action of DNase I. Hence, certain fragments will be absent. The missing bands in the gel pattern identify the binding site on DNA. (From p. 705 in BIOCHEMISTRY 3rd edition, by Lubert Stryer. Copyright © 1975, 1981, 1988 by Lubert Stryer. Reprinted by permission from W.H. Freeman and Company.)
turns out," Struhl pointed out, "the basic rules of how transcription works are really fundamentally the same in yeast and in humans and all eukaryotic species."
One genetic approach researchers have used in yeast to try to identify some of the key proteins involved in transcription involves isolating mutants whose properties differ in some respect from those of the normal organism. "In yeast cells," he explained, "one can easily isolate mutants that do or do not grow under certain circumstances. . . . The aim is to try to understand the biology of some particular process, for example, a cell's response to starvation conditions," by identifying mutants that do not display a particular prop
erty and then checking experimentally to see if absence of a "normal" or unmutated gene accounts for absence of that property in the cell. "The basic idea," he continued, ''is to first look at the function of an organism and to identify a variant that cannot perform it. Getting a function and a mutant is a first step in discovering which gene is actually involved in regulating the property being studied, and then in learning about the transcription factors that regulate expression of the gene."
Another method, gene replacement, was described by Struhl as a "very powerful technique to identify all the different parts of the gene and what it is doing." He explained: "To put it in simple terms, the process is analogous to going into a chromosome with scissors, cutting out a gene, and then replacing it with one that the researcher has created in a test tube." The result is "a real, intact cell . . . that can be analyzed to learn what the result of that gene is."
A third technique, developed in Struhl's laboratory and now widely used in the study of transcription, is one that he called reverse biochemistry. The researcher essentially carries out in a test tube what normally happens in a cell. Struhl pointed out that one "can actually take the DNA in a gene, use the appropriate enzymes to synthesize RNA and the protein [it encodes] in a test tube, . . . and then test to see exactly what the protein does." An advantage is that purification procedures required for work with unsynthesized proteins can be bypassed. In addition, a protein that is synthesized in a test tube can also be treated with radioactive label, which in turn enables many interesting related experiments.
A final technique mentioned by Struhl is used to figure out how much information there is in a particular genetic function, or, more specifically, how much DNA a specific DNA-binding protein actually recognizes," and what, really, is being recognized. DNA is synthesized so that the 23 base pairs are in a completely random sequence. Because DNA can be isolated only in minute quantities, "every single molecule [thus synthesized] is a different molecule in terms of its sequence," Struhl explained. A DNA-binding protein, GCN4, is put on a column and the completely random mixture of sequences is then passed through the column. Separating what is bound by GCN4 from what is not bound and then sequencing the result "gives a statistically valid description of what the protein is actually recognizing," Struhl said. In the case of GCN4, what the protein recognizes is the statistical equivalent of 8 1/2 base pairs worth of information. "The important point,'' Struhl summed up, "is that this random selection approach can be used for many other things besides simply DNA binding. . . . If [for example] you put this random segment of
DNA into the middle of your favorite gene . . . you can ask all kinds of questions about how much specificity, in terms of nucleic acids, is needed to carry out a particular function of interest."
Activation—Another Role of Transcription Factors
Tjian reminded the symposium audience that "transcription factors have to do more than just bind DNA. Once bound to the right part of the genome, they must program the RNA polymerase and the transcriptional accessory proteins to then begin RNA synthesis," and to do so, moreover, with exquisite temporal finesse. Experiments indicate that an altogether different part, as Tjian puts it, "the other half" of the transcription factor protein, does this, probably by direct protein-to-protein interaction, triggering regulation on or off, up or down. A powerful insight from these studies is that transcription factor proteins seem to consist of at least two modules, one for binding and one for activation. The modular concept has been borne out experimentally as to both structure and function. Molecular biologists have been able to create hybrid proteins, mixing the binding domain from one gene with the activation domain from another. Fortunately, signatures have also been detected that often indicate the presence and location of these activation domains. One such signature is a particularly high concentration within a certain protein of the amino acid glutamine, and another is a similar cluster of proline molecules. Though they do not know how this concentration may actually trigger the transcription process, geneticists have some confidence that the signature does encode for the activation domain of the transcription protein.
The accumulated value of these discoveries begins to suggest the figure from the ground. And though biology does not yet have a good model for how transcription factors do all of their work, a catalog of signatures is a vital foundation for such a model. Such a catalog "tells you two things," said Tjian, "first, that not all binding [and/or activation] domains use the same architecture, and second, that there is tremendous predictive value in having identified these signatures, for you can then say with some confidence whether a new gene that you may have just discovered is doing one of these things and by which motif."
These binding and activation domain studies also suggest another feature of transcription factors that Tjian referred to as topology. Even though these polypeptide chains may be hundreds of molecules in length and are created in a linear progression, the chain itself does not remain strung out. Rather it tends to coil up in complicated but
characteristic ways, with certain weak chemical bonds forming the whole complex protein into a specific shape. When this complexity of shape is imposed onto the DNA template, experiment shows that a given protein—with a presumably specific regulatory function—may make contact with other proteins located at several different places hundreds or thousands of bases apart. As Tjian said, "Specific transcription factors don't just all line up in a cluster near the initiation site, but can be scattered all over." The somewhat astounding results of such topographic studies suggest that the molecules somehow communicate and exert "action at a distance," he said, adding that their effects are synergistic. That is, molecules at a proximal site are causing a certain effect, but when other distant molecules that are nonetheless part of the same or related transcription factor complex make contact, the activity at the proximal site is enhanced. Electron and scanning microscopy confirms these spatially complex interactions, the implications of which would seem to suggest a fertile area of inquiry into the overall process of transcription. As Tjian pointed out, "This gives you tremendous flexibility in generating a much larger combinatorial array of regulatory elements, all of which can feed into a single transcription unit. You can begin to appreciate the complexity and, also, the beauty of this transcription factor regulatory system."
Notwithstanding the complexity and continual reminders of what they do not know, geneticists have established some basic rules that seem to govern transcription activation. A line of exceptionally active and hardy human cells called He-La cells have proven very manipulable in vitro and indicate that in all transcription events, a "basal complex" must first be established. Many genes seem to present a so-called TATA (indicating those particular bases) box to initiate the binding process. The TATA box-binding protein alights first on the gene, and then another specific molecule comes along, and then another, in a characteristic sequence, until what Tjian called the "basic machinery," or basal complex, has been assembled. From this point onward in the transcription process, each gene likely has a specific and unique scenario for attracting specific proteins and transcription factors, but will already have constructed the generic, basal complex to interact chemically with them (Figure 5.6).
The Transcription Factor in Development
Thus far, most of the experiments described rely on the basic chemistry of transcription to indicate how it may work. Arnold Berk's mutant strategy, however, suggests that another mark of the effect of
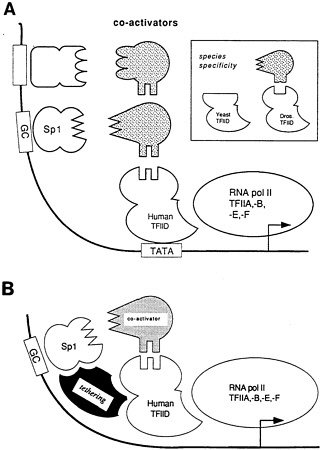
Figure 5.6 Coactivator and tethering models for transcriptional activation by Sp1. (A) A model for trans-activation through coactivators. This model proposes that specific coactivators (stippled) function as adaptors, each serving to connect different trans-activating domains into the general initiation complex, possibly to the TATA binding protein TFIID. These coactivators are not any of the basal initiation factors (THIIA-THIIF), which in this diagram are grouped together. The coactivator may be subunits of a larger complex that includes the TATA binding protein. Although not depicted by this model, the putative TFIID target may have multiple surfaces to accommodate coactivators from a number of trans-activators. (B) Tethering model for Sp1 activation of TATA-less templates. At TATA-less promoters, Sp1 requires a novel tethering activity (shown in black) distinct from the coactivators (stippled) to recruit the basal initiation factors. This model shows the tethering factor interacting with the TATA binding factor TFIID since its function replaces the TATA box and it copurifies with TFIID. However, the tethering activity could be interacting with other components of the basal transcription complex and bypassing the need for the TFIID protein. (Reprinted with permission from Pugh and Tjian, 1990, p. 1194. Copyright © 1990 by Cell Press.)
transcription factors is their success or failure as indicated by the genes they normally influence. These genes often code for characteristics that are clearly manifest in the species under examination, and if a mutant can be developed that at least survives long enough to be analyzed, important inferences about transcription can be developed. Several of the session's scientists described how genetics makes creative use of recombinant DNA technology to alter and study the expression of genes in the embryo and the developing organism.
Transcription factors are proteins that tend to influence the expression of genes in the mRNA stage. But since the point has been made that organisms—even at the cellular level—grow and evolve dynamically in a process that involves their environment, geneticists also look through the lens of developmental embryology to see if transcription factors may be involved in interactions other than simply those inside the cell nucleus.
Ruth Lehmann addressed the question of "how we get from a single cell to an organism" and revealed to the symposium some of the broad outlines of how genes may be turned on and off as the organism develops in the embryo and after birth. She and her colleagues study the fruit fly Drosophila, another favorite species for genetic experimenters. This species lends itself readily to experimentation because it has a manageable number of fairly distinct features, and is very hardy in surviving and manifesting some rather extreme mutations. "The complexity of the larval morphology is in striking contrast to the almost homogeneous appearance of the egg cell," Lehmann pointed out. After birth, the segments from anterior to posterior—head, thorax, and abdomen—are distinct.
Lehmann and her colleagues have asked how the undifferentiated fertilized egg cell uses its genetic information to create a segmented animal. Are distinct factors for the development of each body segment prelocalized in specific egg regions during oogenesis, or is a single factor, which is present at different concentrations throughout the egg, responsible for establishing body pattern?
By pricking the egg and withdrawing cytoplasm from various egg regions, Lehmann showed that two factors, one localized to the anterior and another concentrated at the posterior pole of the egg cell, establish body pattern in the head-thorax and abdominal regions, respectively. These factors are deposited in the egg cell by the mother during oogenesis. Genes that encode these localized signals were identified on the basis of their mutant phenotypes. For example, females that fail to deposit the anterior factor into the egg cell produce embryos that are unable to develop a head and thorax. Thus body pattern is established by distinct factors that become distribut-
ed in a concentration gradient from their site of initial localization, and these factors act at a distance.
One of these factors, "bicoid," which is required for head and thorax development, has been studied in the greatest detail in Christiane Nusslein-Volhard's laboratory at the Max-Planck-Institut in Tübingen, Germany. During oogenesis, bicoid RNA is synthesized by the mother and becomes tightly localized to the anterior pole of the egg cell. The protein product of bicoid RNA, however, is found in a concentration gradient that emanates from the anterior pole and spans through two-thirds of the embryo. Bicoid protein encodes a transcription factor that activates several embryonic target genes in a concentration-dependent manner; cells in the anterior of the embryo, which receive a high level of bicoid, express a different set of genes than do cells that are further posterior, which receive lower levels of bicoid.
The various studies on maternal genes in Drosophila show that no more than three maternal signals are required for specification of pattern along the longitudinal axis, and that one factor is necessary for the establishment of dorsoventral pattern. Thus a small number of signals are required to make pattern formation. The complexity of the system increases thereafter as each signal activates a separate pathway that involves many components. Although it is known that many of these components are transcription factors, it is unclear how these different factors work in concert to orchestrate the final pattern.
IS CANCER GENE-ENCODED GROWTH GONE AWRY?
Hanahan reminded the symposium scientists that "mammalian organisms are composed of a diverse set of interacting cells and organs." Like Lehmann, he is interested in connecting gene expression to how the organism develops and functions. "Often," he said, "the properties of individual cell systems are only discernible by studying disruptions in their functions, whether natural or induced." He is exploring abnormal development and disease, primarily cancer, using transgenic mice that pass on to newborn progeny an altered piece of DNA especially crafted by the genetic scientist in vitro. The next generation of animals can then be studied as the genetic expression of the altered DNA plays itself out over time during development—both in embryogenesis and as the animal matures. "Transgenic mice represent a new form of perturbation analysis," said Hanahan, ''whereby the selective expression of novel or altered genes can be used to perturb complex systems in ways that are informative about their development, their functions, and their malfunctions.''
The process once again utilizes the bipartite character of genes already discussed, namely that "genes are composed of two domains: one for gene regulatory information and one for protein coding information." Hanahan first prepares his manufactured gene, known as a hybrid. The gene regulatory domain he designs as it would occur in a normal mouse, but the protein coding domain he takes from an oncogene, so-called because it is known to induce cancer. Next, he removes fertilized eggs from a normal mouse, introduces his hybrid gene with a very fine capillary pipette, and then reimplants this injected embryo back into a foster mother that goes on to give birth to what is defined as a transgenic mouse, that is, one that is carrying an artificially created gene. When the transgenic mouse mates with a normal mouse, about half of the second-generation mice inherit a set of DNA that now includes this new gene, still recognized by its regulatory information as a normal gene but whose protein instructions code for cancer growth. As Hanahan put it, "Half of the progeny of this mating carry the hybrid oncogene. Every one of those dies of tumors. Their normal brothers and sisters live normal lives."
Beyond proving that oncogenes are heritable, and that only the protein coding portion is necessary to cause cancer in the offspring, Hanahan found some other suggestive patterns. First, although an affected mouse has this deadly oncogene throughout its DNA and thus in every cell of its body, only some of the cells develop tumors. Second, the tumors that do develop arise at unpredictable times during the course of the mouse's life. "From this we infer that there are other, rate-limiting events in tumors," and that simply possessing the gene does not predict whether and especially when a cell will develop into a tumor, Hanahan emphasized. All of the cells must be classified as abnormal, but they seem to undergo what he referred to as a sort of dynamic evolution as the organism ages. He has seen this phenomenon in several different environments. For example, even if all 10 mammary glands of a transgenic mouse express an oncogene, the offspring mice inevitably, and reproducibly, develop only one tumor, on average.
With an insulin gene promoter, he has observed the "cancer gene" expressed in all of the insulin-producing cells of the islets of the pancreas at 3 weeks, but only half of these islets begin abnormal proliferation 4 weeks later. At 9 weeks, another phenomenon is seen that Hanahan believes may be more than coincidental, that is, an enhanced ability to induce the growth of new blood vessels, called angiogenesis. Of the 400 islands of cells expressing the oncogene, one-half show abnormal cell proliferation, yet the percentage of full-blown tumors is only about 2 percent. Prior to solid tumor forma-
tion, a few percent of the abnormal islets demonstrate an ability to induce the proliferation of new blood vessels. Thus the genes that control angiogenesis become a strong suspect for one of the other rate-limiting factors that control cancer growth. Hanahan said these findings are "consistent with what we suspected from the studies of human cancers: while oncogenes clearly induce continuous cell proliferation, the abnormal proliferative nodules are more numerous than the tumors, and precede them in time. There is evidence that the induction of new blood vessel growth is perhaps a component in this latter process resulting in a malignant tumor." But angiogenesis is likely only one of at least several rate-limiting secondary events.
The dynamic evolution theory thus entails the premise that cells acquire differential aberrant capabilities as they mature. These differences could come from other DNA-encoded information in different genes altogether, but not until the hybrid oncogene is introduced to initiate the process does the system then evolve cancerously. Other suspected traits, like the ability to induce blood vessel growth, probably relate to dynamic phenomena of cells in normal development or in their actions. Some cancer cells seem able to ignore and trample over their neighbors, while others seem able to actively subvert their adjoining and nearby cells into aberrant behavior. Some cancer cells show a propensity to migrate more readily. Hanahan and his colleagues are looking at these phenomena and how they may be expressed. "Can we prove these genetically?" he asked, and went on to suggest that from such studies scientists hope to derive cancer therapy applications in humans. Although extremely suggestive, the implications are not yet clear. Cancer is a disease of uncontrolled cell growth. Many of the transcription factors have a role in regulating protein production. Many of these same transcription factors can act as oncogenes. Thus a key to unlocking the mysteries of cancer could be understanding in greater detail how the transcription factors actually influence the rate of protein production.
The oncogene studies provide yet another interesting and suggestive finding. Tjian reminds us that one of the important functions of genes is to provide information to respond to what amount to ecological crises for the cell. Most cells are equipped with receptors of one sort or another at their membrane. When some chemical or other physical stimulus arrives at a chosen receptor, a chain reaction begins in the cytoplasm of the cell in order to get the message into the nucleus, presumptively to consult the DNA master plan (by a process as mysterious as it is speculative) for a reaction. The routes through the cytoplasm are called transduction pathways, and it turns out that many of the transcription factors Tjian and others have been
studying serve to mark these pathways. One particular protein is called AP1, which in other studies has been revealed as an oncogene. Said Tjian: "Nuclear transcription factors are also nuclear oncogenes. They have the potential when their activities or their functions are perverted to cause uncontrolled growth and neoplasia. The discovery that this family of regulatory proteins is actually an oncogene was greatly aided by the analysis of the yeast protein GCN4 that was largely the work of Kevin Struhl and Jerry Fink."
LIFE ITSELF
In less than four decades, standing on the platform erected by Crick and Watson and a number of others, the genetic sciences of molecular biology and biochemistry have developed the most important collection of ideas since Darwin and Wallace propounded the theory of evolution. To say that these ideas are revolutionary belabors the obvious: science is in the process of presenting society with a mirror that may tell us, quite simply, how to build and repair life itself, how to specify and alter any form of life within basic biological constraints. Recombinant DNA technology promises applications that pose fundamental bioethical questions. Taken together with the advances made in modeling the brain, these applications point to a future where natural organic life may one day become chemically indistinguishable from technology's latest model.
This future, however, is only a shimmering, controversial possibility. The geneticists at the Frontiers symposium were united in their humility before the hurdles they face. Discoveries continue to mount up. The halls of genetics, reported Eric Lander, are a most exciting place to be working, and that excitement has led to a unity of biological disciplines not evident a decade ago. But as Ruth Lehmann warned, cloning a gene is a far cry from figuring out how it works. It is that puzzle, seen especially through the lens of mRNA transcription, that she and her colleagues are working on. Whether it will remain a maze with ever finer mapping but no ultimate solution is for history to say, but the search is among the most exciting in modern science.
BIBLIOGRAPHY
Mitchell, Pamela J., and Robert Tjian. 1989. Transcriptional regulation in mammalian cells by sequence-specific DNA binding proteins. Science 245:371–378.
Pugh, Franklin B., and Robert Tjian. 1990. Mechanism of transcriptional activation by Spl: Evidence for coactivators. Cell 61:1187–1197.
Stryer, Lubert. 1988. Biochemistry. Third edition. Freeman, New York.
Watson, James D., Nancy H. Hopkins, Jeffrey W. Roberts, Joan Argetsinger Steitz, and Alan M. Weiner. 1987. Molecular Biology of the Gene. Fourth edition. Volumes I and II. Benjamin/Cummings Publishing, Menlo Park, Calif.
RECOMMENDED READING
Beardsley, Tim. 1991. Smart genes. Scientific American 265:86–95.
Johnson, Peter F., and Stephen L. McKnight. 1989. Eukaryotic transcriptional regulatory proteins. Annual Review of Biochemistry 58:799–839.
Ptashne, Mark, and Andrew A.F. Gann. 1990. Activators and targets. Nature 346:329–331.
Sawadogo, Michele, and Andre Sentenac. 1990. RNA polymerase B (II) and general transcription factors. Annual Review of Biochemistry 59:711–754.

























