
Appendix F
Science, Technology, and Innovation Databases and Heat Map Analysis
Leland Wilkinson and Esha Sinha1
The panel assembled and analyzed underlying data on research and development (R&D), science and technology (S&T), human capital, and innovation to determine the following:
- What are the primary indicators that are necessary for the National Center for Science and Engineering Statistics (NCSES) to disseminate, and are they produced by traditional or frontier methods? To address this question, cluster analysis, primarily a heat map tool, was used together with knowledge gleaned from the literature on the performance of science, technology, and innovation (STI) indicators. Reference is made to the National Science Board’s Science and Engineering Indicators (SEI) biennial publication when appropriate, but this analysis is not a full review of the SEI publication.
- What are the redundant indicators that NCSES does not need to produce going forward? These indicators might be low performers; highly correlated with other, more useful indicators; or measures that are gathered by other organizations. NCSES could target these indicators for efficiency gains while curating the statistics that are in demand but reliably produced elsewhere.
This appendix describes the main data on R&D, S&T, human capital, and innovation that the panel assembled and analyzed. It is divided into four sections. The first two sections contain descriptions of data sources from NCSES and other international statistical organizations. The third section presents the heat map analysis, citing the literature on methodological underpinnings of this technique. The final section gives observations based on this analysis. Not all of the data sources described were analyzed, because it was not feasible to investigate such a wide variety of data culled from various sources. Only databases of the five main STI data providers were analyzed: NCSES; OECD; Eurostat; the United Nations Educational, Scientific and Cultural Organization (UNESCO); Institute of Statistics (UIS); and Statistics Canada. Indicators published in the SEI 2012 Digest were also analyzed.
ASSEMBLED DATA
National Center for Science and Engineering Statistics
NCSES communicates its S&T data through various publications, ranging from InfoBriefs to Detailed Statistical Tables (DSTs) derived using table generation tools. The three table generation tools—the Integrated Science and Engineering Resource Data System (WebCASPAR), the Scientists and Engineers Statistical Data System (SESTAT), and the Survey of Earned Doctorates (SED) Tabulation Engine (National Center for Science and Engineering Statistics, 2013b)—are each supported by application-specific database systems. The Industrial Research and Development Information System (IRIS) is an additional searchable database of prepopulated tables.
- WebCASPAR hosts statistical data for science and engineering (S&E) at U.S. academic institutions (National Science Foundation, 2012e). This database is compiled from several surveys, including:
____________________
1Esha Sinha, CNSTAT staff, compiled the data used in the heat map analysis. Leland Wilkinson, panel member, initially ran the heat map program, based on an algorithm that he developed. Sinha then ran several versions of the program on different datasets and over several different time periods. She presented the results of the heat map analysis to the panel during its April 2012 panel meeting. She subsequently ran more sensitivity analyses to ensure the stability of the results. Panel member John Rolph reviewed the work, concluding that the statistical analysis was sound and potentially instructive as an indicators prioritization exercise that NCSES might perform in the future.
— SED2/Doctorate Records File;
— Survey of Federal Funds for Research and Development;
— Survey of Federal Science and Engineering Support to Universities, Colleges, and Nonprofit Institutions;
— Survey of Research and Development Expenditures at Universities and Colleges/Higher Education Research and Development Survey;
— Survey of Science and Engineering Research Facilities;
— National Science Foundation (NSF)/National Institutes of Health (NIH) Survey of Graduate Students and Postdoctorates in Science and Engineering; and
— National Center for Education Statistics (NCES) data sources—Integrated Postsecondary Education Data System (IPEDS):
- IPEDS Completions Survey;
- IPEDS Enrollment Surveys;
- IPEDS Institutional Characteristics Survey (tuition data); and
- IPEDS Salaries, Tenure, and Fringe Benefits Survey.
- SESTAT (National Science Foundation, 2013d) is a database of more than 100,000 scientists and engineers in the United States with at least a bachelor’s degree. This is a comprehensive data collection on education, employment, work activities, and demographic characteristics, covering 1993 to 2008.3 The SESTAT database includes data from:
— the National Survey of College Graduates (NSCG);
— the National Survey of Recent College Graduates (NSRCG);
— the Survey of Doctorate Recipients (SDR); and
— an integrated data file (SESTAT).
- IRIS (National Center for Science and Engineering Statistics, 2013a) is a database containing industrial R&D data published by NSF from 1953 through 2007. It comprises more than 2,500 statistical tables, which are constructed from the Survey of Industrial Research and Development (SIRD). It is, therefore, a databank of statistical tables rather than a database of microdata of firm-specific information. The data are classified by Standard Industrial Classification and North American Industrial Classification codes (as appropriate), and by firm size, character of work (basic, applied, development), and state. Employment and sales data for companies performing R&D are also included in IRIS.
The data outlined above focus on academic and industrial R&D expenditures and funding and on human capital in S&T. NCSES conducts five surveys to capture R&D support and performance figures for various sectors of the economy. The National Patterns of Research and Development Resources series of publications presents a national perspective on the country’s R&D investment. R&D expenditure and performance data are available, as well as employment data on scientists and engineers. The National Patterns data are useful for international comparisons of R&D activities, and they also report total U.S. R&D expenditures by state. The data series span 1953 through 2011 and are a derived product of NCSES’s above-referenced family of five active R&D expenditure and funding surveys:
- Business Research and Development and Innovation Survey (BRDIS; for 2007 and earlier years, the industrial R&D data were collected by the SIRD);
- Higher Education Research and Development Survey (HERD; for 2009 and earlier years, academic R&D data were collected by the Survey of Research and Development Expenditures at Universities and Colleges);
- Survey of Federal Funds for Research and Development;
- Survey of Research and Development Expenditures at Federally Funded R&D Centers (FFRDCs); and
- Survey of State Government Research and Development.4
The SEI biennial volume is another notable contribution from NCSES, published by the National Science Board. It not only contains tables derived from the table generation tools described above but also amalgamates information from NCSES surveys, administrative records such as patent data from government patent offices, bibliometric data on publications in S&E journals, and immigration data from immigration services. For example, tables on the U.S. S&E
____________________
2SED data on race, ethnicity, citizenship, and gender for 2006 and beyond are available in the SED Tabulation Engine. All other SED variables are available in WebCASPAR except for baccalaureate institution. For more details on the WebCASPAR database, see https://webcaspar.nsf.gov/Help/dataMapHelpDisplay.jsp?subHeader=DataSourceBySubject&type=DS&abbr=DRF&noHeader=1.
3Data for 2010 were released in 2013.
4For details on each of these surveys, see http://nsf.gov/statistics/question.cfm#ResearchandDevelopmentFundingandExpenditures [November 2012]. A sixth survey, the Survey of Research and Development Funding and Performance by Nonprofit Organizations, was conducted in 1973 and for the years 1996 and 1997 combined. The final response rate for the 1996-1997 survey was 41 percent (see http://www.nsf.gov/statistics/nsf02303/sectc.htm). This lower-than-expected response rate limited the analytical possibilities for the data, and NSF did not publish state-level estimates. The nonprofit data cited in National Patterns reports either are taken from the Survey of Federal Funds for Research and Development or are estimates derived from the data collected in the 1996-1997 survey. See National Science Foundation (2013c, p. 2), which states: “Figures for R&D performed by other nonprofit organizations with funding from within the nonprofit sector and business sources are estimated, based on parameters from the Survey of R&D Funding and Performance by Nonprofit Organizations, 1996-97.”
labor force are generated using data from the American Community Survey, the Current Population Survey (U.S. Census Bureau), SESTAT, and Occupational Employment Statistics (Bureau of Labor Statistics) (National Science Board, 2012a, Table 3-1, p. 3-8).
Along with information on U.S. R&D capacity and outputs, the SEI Digest 2012 contains analysis of the data. The SEI indicators can be classified as follows (National Science Board, 2012b) (see Box F-1): (1) global R&D and innovation; (2) U.S. R&D funding and performance; (3) U.S. R&D federal portfolio; (4) science, technology, engineering, and mathematics (STEM) education; (5) U.S. S&E workforce trends and composition; (6) knowledge outputs; (7) geography of S&T; and (8) country characteristics.
BOX F-1
NCSES’s STI Indicators
1 Global research and development (R&D) and innovation
- Worldwide R&D expenditure by regions and countries
- Average annual growth of R&D expenditure for the U.S., European Union (EU), and Asia-10 economies
- Annual R&D expenditure as share of economic output (R&D/gross domestic product [GDP])
- R&D testing by affiliation, region/country
- U.S. companies reporting innovation activities
- Exports and imports of high-tech goods
2 U.S. R&D funding and performance (including multinationals and affiliates)
- U.S. R&D expenditure by source of funds (including venture capital)
- Types of U.S. R&D performed
- Types of U.S. R&D performed by source of funds
- U.S. academic R&D expenditure by source of funds
3 U.S. R&D federal portfolio
- U.S. federal R&D expenditure by type of R&D
- U.S. federal support for science and engineering (S&E) fields
- U.S. federal R&D budget by national objectives
- U.S. federal R&D spending on R&D by performer
- Federal research and experimentation tax credit claims by North American Industrial Classification System (NAICS) industry
- Federal technology transfer activity indicators
- Small Business Innovation Research (SBIR) and Technology Innovation Program
4 Science, technology, engineering, and mathematics (STEM) education (most measures have demographic breakouts)
- Average mathematics and science scores of U.S. students (National Assessment of Educational Progress [NAEP] and Programme for International Student Assessment [PISA])
- Teacher participation, degrees, and professional development
- High school students taking college classes
- First university degrees in natural sciences and S&E fields by country/region
- S&E degrees, enrollments, and related expenditures—associate’s, bachelor’s, master’s, doctoral
- Doctoral degrees in natural sciences and S&E fields by country/region
- Distance education classes
5 U.S. S&E workforce trends and composition
- Individuals in S&E occupations and as a percentage of the U.S. workforce
- S&E work-related training
- Unemployment rate for those in U.S. S&E occupations
- Change in employment from previous year for those in STEM and non-STEM U.S. jobs
- Women and underrepresented minorities in U.S. S&E occupations
- Foreign-born percentage of S&E degree holders in the United States by field and level of S&E degree
6 Knowledge outputs
- S&E journal articles by region/country
- Engineering journal articles as a share of total S&E journals by region/country
- Citations in the Asian research literature to U.S., EU, and Asian research articles
- Patents and citations of S&E articles in United States Patent and Trademark Office (USPTO) patents
- U.S. patents granted to non-U.S. inventors by region/ country/economy
- Share of U.S. utility patents awarded to non-U.S. owners that cite S&E literature
- Value added of knowledge and technology
7 Geography of S&T
- Location of estimated worldwide R&D expenditure
- Average annual growth rates in number of researchers by country/economy
- Value added of high-tech manufacturing by region/ country
- Exports of high-tech manufactured goods by region/ country
- Cross-border flow of R&D funds among affiliates
- State S&T indicators
8 Country characteristics
- Macroeconomic variables
- Public attitudes toward and understanding of S&T
SOURCE: National Science Board (2012b).
The primary conclusions of the SEI Digest are drawn from the indicators outlined above and are supported by more detailed STI data collected by NCSES. The list of variables is presented in Table F-1. Because of space limitations, it was not possible to highlight in this table the fact that most of the information in the SEI—such as assessment scores, S&E degrees, individuals in S&E occupations, R&D expenditures and their various components, federal R&D obligations, patents, and venture capital—is available at the state level.
OECD
R&D statistics generated by OECD are based on three databases: Analytical Business Enterprise Research and Development (ANBERD), Research and Development Statistics (RDS), and Main Science and Technological Indicators (MSTI).
The ANBERD database presents annual data on industrial R&D expenditures. These data are broken down by 60 manufacturing and service sectors for OECD countries and selected nonmember economies. The reported data are expressed in national currencies as well as in purchasing power parity (PPP) U.S. dollars, at both current and constant prices. Estimates are drawn from the RDS database and other national sources. ANBERD is part of the Structural Analysis Database (STAN) family of industrial indicators produced by the Science, Technology, and Industry directorate at OECD.
The RDS database covers expenditures by source of funds, type of costs, and R&D personnel by occupation (in both head counts and full-time equivalents [FTEs]). This database is the main source of R&D statistics collected according to the guidelines set forth in OECD’s Frascati Manual (OECD, 2002). It covers R&D expenditures by sector of performance, source of funds, type of costs, and estimates of R&D personnel and researchers by occupation (in both head counts and FTEs). It also includes data on government budget appropriations or outlays on R&D (GBAORD) (OECD, 2013b). Data are provided to OECD by member countries and observer economies through the joint OECD/ Eurostat International Survey on the Resources Devoted to R&D. Series are available from 1987 to 2010 for 34 OECD countries and a number of nonmember economies. Information on sources and methods used by countries for collecting and reporting R&D statistics is provided in the Sources and Methods database.
OECD’s MSTI publication provides indicators of S&T activities for OECD member countries and seven nonmember economies (Argentina, China, Romania, Russian Federation, Singapore, South Africa, and Chinese Taipei). Going back to 1981, MSTI includes indicators on financial and human resources in R&D, GBAORD, patents, technology balance of payments, and international trade in R&D-intensive industries (see http://www.oecd.org/sti/msti).
OECD Patent Database comprises information on patent applications from the European Patent Office (EPO) and the United States Patent and Trademark Office (USPTO), as well as patent applications filed under the Patent Cooperation Treaty (PCT) that designate the EPO and Triadic Patent Families.5 The EPO’s Worldwide Patent Statistical (PATSTAT) database is the primary source of these data. The following patent statistics are available on OECD’s statistical portal: patents by country and technology fields (EPO, PCT, USPTO, Triadic Patent Families); patents by regions and selected technology fields (EPO, PCT); and indicators of international cooperation in patents (EPO, PCT, USPTO). OECD has developed four different sets of “raw” patent data for research and analytical purposes, which may be downloaded from its server. OECD also provides tables on biotechnology indicators (see http://www.oecd.org/innovation/innovationinsciencetechnologyandindustry/keybiotechnologyindicators.htm).
At present, no standard OECD database covers innovation statistics based on the Oslo Manual. The reason for this is the difficulty of comparing results based on different survey methodologies, particularly those used by countries that follow the Eurostat Community Innovation Survey (CIS) model questionnaire and those used by non-European Union (EU) countries that implement the same concepts and definitions in different ways. Ad hoc data collection on selected innovation indicators has been carried out in recent years, and the results have been published in the STI Scoreboard and other related publications.
UNESCO Institute of Statistics
UIS collects its STI data from approximately 150 countries and territories. It has also partnered with three organizations to acquire additional data: on 25 Latin American countries, from the Network on Science and Technology Indicators—Ibero-American and Inter-American (RICYT); on 40 OECD member states and associated countries, from OECD; and on 7 European countries, from Eurostat. UIS conducts a biennial R&D survey, which is administered to the office responsible for national S&T policy or statistics of United Nations (UN) member nations. Even though the survey is administered every 2 years, the questionnaire items request annual information for the previous 5 years. Therefore, the data series is available for 1996 to 2010. A major accomplishment of UIS is that it adapted survey instruments and methodologies and developed other key indicators that are suited to the needs of developing countries. The aim was to enable those countries to apply concepts of the Frascati Manual that would in turn produce comparable S&T statistics across nations. The UIS S&T survey not only collects data on R&D expenditures but also elicits information on researchers involved in R&D. The survey uses a standardized occupational classification of researchers: “professionals
____________________
5See http://www.oecd.org/sti/inno/oecdpatentdatabases.htm for more details and links to sources of these data.
engaged in the conception or creation of new knowledge, products, processes, methods, and systems and also in the management of the projects concerned” (OECD, 2002, p. 93). The classification includes Ph.D. students who are involved in R&D activities.
In 2011, UIS conducted a pilot survey on innovation in the manufacturing sector. Countries surveyed were Brazil, China, Colombia, Egypt, Ghana, Indonesia, Israel, Malaysia, the Philippines, the Russian Federation, South Africa, and Uruguay. The survey included both technological and nontechnological innovation. Survey items were (1) firms involved in innovation, (2) cooperative arrangements, and (3) factors hampering innovation.
Eurostat
Eurostat is the European Commission’s statistical office. Its main function is to provide statistical information on European nations to the European Commission. The main themes of Eurostat’s statistical portfolio are policy indicators; general and regional statistics; economy and finance; population and social conditions; industry, trade, and services; agriculture and fisheries; external trade, transport, environment, and energy; and STI. Within the STI theme, there are five domains:
- Research and development—Data are collected from national R&D surveys using definitions from the Frascati Manual (OECD, 2002).
- CIS—Data originate from the national CIS on innovation activity in enterprises that are based on the Oslo Manual (OECD-Eurostat, 2005).
- High-tech industry and knowledge-intensive services—Various origins and methodologies are used; statistics are compiled at Eurostat.
- Patents—Data originate from the patent database PATSTAT, hosted by EPO. PATSTAT gathers data on applications from the EPO and from about 70 national patent offices around the world (mainly USPTO and the Japan Patent Office); statistics are compiled at Eurostat.
- Human resources in S&T—Data are derived at Eurostat from the EU Labour Force Survey (LFS) and the Data Collection on Education Systems (UOE) according to the guidelines in the Canberra Manual (OECD, 1995).
Statistics Canada
Statistics Canada is the Canadian federal statistical agency with a mandate under the Statistics Act:
(a) to collect, compile, analyze, abstract and publish statistical information relating to the commercial, industrial, financial, social, economic and general activities and condition of the people;
(b) to collaborate with departments of government in the collection, compilation and publication of statistical information, including statistics derived from the activities of those departments;
(c) to take the census of population of Canada and the census of agriculture of Canada as provided in this Act;
(d) to promote the avoidance of duplication in the information collected by departments of government; and
(e) generally, to promote and develop integrated social and economic statistics pertaining to the whole of Canada and to each of the provinces thereof and to coordinate plans for the integration of those statistics.6
The Canadian Socio-economic Information Management System (CANSIM) is a socioeconomic database of Statistics Canada and contains data tables from censuses and 350 active surveys. Data are provided under various subjects, such as the system of national accounts, labor, manufacturing, construction, trade, agriculture, and finance.
There are four areas within S&T:
1. R&D—Statistics on R&D expenditures and funding are collected by six surveys focused on various performing and funding sectors:
a. Research and Development in Canadian Industry
b. Research and Development of Canadian Private Non-Profit Organizations
c. Provincial Research Organizations
d. Provincial Government Activities in the Natural Sciences
e. Provincial Government Activities in the Social Sciences
f. Federal Science Expenditures and Personnel, Activities in the Social Sciences and Natural Sciences
2. Human resources in S&T—Data on personnel engaged in R&D are derived from the Federal Science Expenditures and Personnel, Activities in the Social Sciences, and Natural Sciences surveys.
3. Biotechnology—Currently inactive, the 2005 Biotechnology Use and Development Survey provided information on innovation by biotechnology companies.
4. Innovation—CANSIM includes tables from the 2003 and 2005 survey cycles of the Survey of Innovation. Jointly with Industry Canada and Foreign Affairs and International Trade Canada, Statistics Canada conducted the first Survey of Innovation and Business
____________________
6Available: http://www.statcan.gc.ca/edu/power-pouvoir/aboutapropos/5214850-eng.htm [July 2013].
TABLE F-1 Subtopics of Science, Technology, and Innovation Data Produced by Agencies/Organizations, Showing Level of Detail and Unique Variables
| Agency/Organization | Total R&D | Industrial R&D | Academic R&D | Federal R&D | GBAORD | Nonprofit R&D |
| NCSES (NB: Statistics on R&D expenditure and SEH degrees available by state) | Total R&D by performer and funder, character of work | Industrial R&D by funder, character of work, NAICS classification, company size | Academic R&D by funder, character of work; entities and subrecipients of academic R&D | Federal R&D by funder, character of work | R&D obligations and outlays by character of work and performing sector; reported in Science and Engineering Indicators only | Nonprofit R&D by funder, character of work, S&E field, extramural entity, type of nonprofit organization |
| NCSES and NSB | Total R&D by performer and funder, character of work, country/economy | Industrial R&D by funder, NAICS classification, company size; R&D performed by multinational companies, foreign affiliates | Academic R&D in S&E and non-S&E fields | Federal R&D by major socioeconomic objectives, country/region | Federal obligations for R&D and R&D plant by agency, performer, character of work | Domestic R&D performed by private nonprofit sector, domestic R&D funded by private nonprofit sector |
| Statistics Canada | GERD by performer and funder | BERD by funding sector | HERD | GOVERD by socioeconomic objectives, type of science, com onents | Private nonprofit R&D by funder | |
| OECD | GERD by performer, funder, field of science, socioeconomic objectives | BERD by funding sector, type of cost, size class, field of science, performing industry | HERD, HERD financed by industry | GOVERD, GOVERD financed by industry | GBAORD by socioeconomic objectives | GERD performed by private nonprofit sector |
| Eurostat (NB: Almost all data available at regional level) | GERD by funding source, sector of performance, type of cost, socioeconomic objectives, field of science | BERD by funding source, type of cost, size class, economic activity | HE intramural expenditure by funding source, type of cost, field of science, socioeconomic objectives | Government intramural expenditure by funding source, sector of performance, type of cost, socioeconomic objectives, field of science | GBAORD by socioeconomic objectives | GERD performed by private nonprofit sector; GERD funded by private nonprofit sector |
| UNESCO | GERD by performing sector and funding sector, field of science, character of work | GERD performed by business enterprise sector; GERD funded by business enterprise sector | GERD performed by higher education sector; GERD funded by higher education sector | GERD performed by private nonprofit sector; GERD funded by private nonprofit sector | ||
| Agency/Organization | Technology BOP and International Trade in R&D-Intensive Industries | Patents and Venture Capital | R&D Personnel, Scientists and Engineers | Science, Engineering, and Health Degrees; Assessment Scores | Innovation | Public Attitudes Toward Science and Technology |
| NCSES (NB: Statistics on R&D expenditure, SEH degrees available by state) | Scientists and engineers by gender, age, race/ethnicity, level of highest degree, occupation, labor force status, employment sector, primary/secondary work activity, median annual salaries | Graduate students, doctorate holders, postdoctorates, nonfaculty research staff by gender, race/ethnicity, citizenship, academic field, Carnegie classification; SEH doctorates by gender, age, race/ethnicity, occupation, labor force status, employment sector, primary/secondary work activity, postdoctoral appointments, median annual salaries | Product and process innovation by NAICS classification | |||
| NCSES and NSB | U.S. trade balance in research, development, and testing services by affiliation; exports of high-technology and manufactured products by technology level, product, region/country/economy; global value added by type of industry; ICT infrastructure index; U.S. high-technology microbusinesses | USPTO patents granted by selected technology area, region/country/economy; patenting activity in clean energy and pollution control technologies; patents granted by BRIC nations by share of resident and nonresident inventors; patent citations to S&E articles by patent technology area, article field; patenting activity of employed U.S.trained SEH doctorate holders; U.S. venture capital investment by financing stage and industry/technology; venture capital disbursed per $1,000 of GDP; venture capital deals as a percentage of high-technology business establishments; venture capital disbursed per venture capital deal by state | Workers in S&E and STEM occupations by MSA, occupation category, educational background, R&D work activities, age, ethnicity/race; scientists and engineers reporting international engagement by demographic characteristics, education, employment sector, occupation, salary, work-related training; foreign-born workers in S&E occupations by education level | SEH doctorate holders by gender, race/ethnicity, field of doctorate, sector of employment, academic appointment, salary, unemployment rate; S&E doctorate recipients and full-time S&E graduate students by source, primary mechanism of support, Carnegie classification; foreign recipients of U.S. S&E doctorates by field, country/economy of origin; field switching among postsecondary students; time taken to receive an S&E doctorate; community college attendance among recent recipients of S&E degrees by sex, race/ethnicity, degree level, degree year, citizenship status; NAEP assessment scores in mathematics and science; advanced placement exam taking by public school students | Small Business Innovation Research funding per $1 million of GDP by state | Media coverage, news stories by topic area; correct answers to S&T and S&T-related questions by gender and country/region; public perceptions of various occupational groups’ contribution to society and public policy-making process; public assessment/opinion of stem cell research and environmental problems; source of information for S&T issues |
| Agency/Organization | Total R&D | Industrial R&D | Academic R&D | Federal R&D | GBAORD | Nonprofit R&D |
| Statistics Canada | Intellectual property commercialization by higher education sector; intellectual property management by federal department and agency | Researchers, support staff, technicians by R&D performing sector and type of science; federal personnel engaged in S&T by activity, type of science, S&T component | University degrees, diplomas, and certificates granted by program level and Classification of Instructional Programs, gender, immigration status | Innovation activities; product and process innovation; degree of novelty; hampering factors of and obstacles to innovation; important sources of information; cooperation arrangements; innovation impacts; methods of protection; geomatic activities | ||
| OECD | BOP—payments and receipts; trade—imports and exports by R&D-intensive industries | Patent applications, Triadic Patent Families, patents in selected technologies by region, international cooperation | R&D personnel by field of science, sector of performance, qualification; researchers by sector of performance and gender | Graduates by field and level of education; PISA scores in science and mathematics | ||
| Eurostat (NB: Almost all data available at subnational level) | Trade in high-tech industries and knowledge-intensive sectors within EU and ROW; employment in these sectors by gender, occupation, educational qualification, mean earnings | Patent applications at USPTO and EPO by priority year and sector, ownership of patents, patent citations; European and international copatenting, Triadic Patent Families | Human resources in S&T, R&D personnel, and researchers by gender, field of science, sector of performance, qualification; citizenship of researchers in government and higher education sector | Doctorate holders by gender, activity status; employed doctorate holders by gender, sector, occupation, field of science, job mobility | Innovation activities; product and process innovation; degree of novelty; hampering factors of and public funding for innovation; important sources of information; cooperation arrangements; environmental innovation; objectives of innovation; impacts of innovation; methods of protection; employees in innovation sector | |
| UNESCO | R&D personnel and researchers (FTE and head count) by gender, performing sector, educational qualification, field of science; technicians and other supporting staff by performing sector | Innovation in manufacturing sector—firms involved in innovation; cooperation arrangements; hampering factors of innovation; available for 12 nations | ||||
NOTES: BERD = business enterprise expenditure on research and development; BOP = balance of payments; BRIC = Brazil, Russia, India, and China; EPO = European Patent Office; EU = European Union; FTE = full-time equivalent; GBAORD = government budget appropriations or outlays for research and development; GDP = gross domestic product; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on research and development; HE = higher education; HERD = higher education expenditure on research and development; ICT = information and communication technology; MSA = metropolitan statistical area; NAEP = National Assessment of Educational Progress; NAICS = North American Industry Classification System; NSB = National Science Board; NCSES = National Center for Science and Engineering Statistics; PISA = Programme for International Student Assessment; R&D = research and development; ROW = rest of the world; S&E = science and engineering; SEH = science, engineering, and health; STEM = science, technology, engineering, and mathematics; UNESCO = United Nations Educational, Scientific and Cultural Organization; USPTO = United States Patent and Trademark Office.
SOURCES: Adapted from BRDIS, see http://www.nsf.gov/statistics/industry/ [November 2012]. Federal Funds, see http://www.nsf.gov/statistics/fedfunds/ [November 2012]. R&D Expenditure at FFRDCs, see http://www.nsf.gov/statistics/ffrdc/ [November 2012]. HERD, see http://www.nsf.gov/statistics/herd/ [November 2012]. Science and Engineering State Profiles, see http://www.nsf.gov/statistics/pubseri.cfm?seri_id=18 [November 2012]. S&E I 2012, see http://www.nsf.gov/statistics/seind12/tables.htm [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012]. Statistics Canada, CANSIM, see http://www5.statcan.gc.ca/cansim/a33?lang=eng&spMode=master&themeID=193&RT=TABLE [November 2012].
Strategy (SIBS) in 2010. Information was collected from enterprises for the period 2007-2009, and survey estimates were published in 2011. SIBS data are not available in CANSIM.
World Intellectual Property Organization (WIPO)
WIPO is a specialized UN agency focused on intellectual property—patents, trademarks, copyrights, and design. It collects data by sending questionnaires to the intellectual property offices of 185 member states. It produces annual statistics on patents, utility models, trademarks, industrial designs, and plant varieties, thus creating a comprehensive national database of intellectual property. Some of the data series for particular nations go back to 1885.
Innovation Data from Other U.S. Agencies
Apart from NCSES, other U.S. agencies collect innovation statistics, ranging from patents and trademarks to grants and federal awards (see Table F-2):
- USPTO—Three datasets are available from USPTO—the Patent Assignments Dataset, Trademark Casefile Dataset, and Trademark Assignments Dataset. As their names suggest, these datasets comprise ownership and changes in ownership for USPTO-granted patents and trademarks.
- Economic Research Service (ERS), U.S. Department of Agriculture (USDA)—In 2013, ERS began fielding its first Rural Establishment Innovation Survey, which is aimed at business establishments funded through USDA’s Rural Development Mission Area. The purpose of the survey is threefold: to collect information on the adoption of innovative practices and their contribution to firm productivity; to discover how participation in federal, state, and local programs aids the growth of rural business units; and to determine usage of available local and regional assets, such as workforce education and local business associations, by rural business units.
- NIH, NSF, and the White House Office of Science and Technology Policy—Science and Technology for America’s Reinvestment: Measuring the Effect of Research on Innovation, Competitiveness, and Science (STAR METRICS) is a multiagency venture that relies on the voluntary participation of science agencies and research institutions to document the outcomes of science investments for the public. Currently, more than 90 institutions are participating in the program. The STAR METRICS data infrastructure contains recipient-based data that include information on contract, grant, and loan awards made under the American Recovery and Reinvestment Act of 2009.
- NSF—The U.S. government’s research spending and results webpage provides information on active NSF and National Aeronautics and Space Administration (NASA) awards, such as awardees, funds obligated, and principal investigator.
- National Institute of Standards and Technology (NIST), Department of Commerce (Anderson, 2011)—NIST has been responsible for preparing the Department of Commerce’s report on technology transfer utilization. The Federal Laboratory (Interagency) Technology Transfer Summary Reports cover federal laboratories and FFRDCs. They contain data tables on patent applications, invention licenses, cooperative R&D agreements, and R&D obligations, both extramural and intramural.
- Small Business Administration (SBA)—The Small Business Innovation Research (SBIR) program and the Small Business Technology Transfer (STTR) program fall under the administration of the SBA’s Technology Program Office. These programs award more than $2 billion each year to small high-tech businesses.7 The SBA-Tech.net website includes a searchable database on federal R&D funds/awards by agency, category, and state.
- Department of Energy (DOE)—DOE’s visual patent search tool allows users to collect information on issued U.S. patents and published patent applications that result from DOE funding.
Data collected by federal statistical agencies, either through surveys or from administrative databases, contain rich information on various economic and social issues. Most of this information is used by private corporations and educational institutions (sometimes the agencies themselves) that either present the data in a comprehensive fashion or develop tools for dissemination and analysis. Some of those efforts are outlined below:
- Google—On its website, Google hosts a bulk download tool that allows users to download data tables on patents and trademarks issued by USPTO.
- NIH, NSF, and the White House Office of Science and Technology Policy—Applications of the STAR METRICS data platform include the Portfolio Explorer Project, a tool for examining public research award information by topic, region, institution, and researcher. STAR METRICS currently uses four tools to view scientific portfolios (Feldman, 2013b):
— The Portfolio Viewer provides information on proposals, awards, researchers, and institutions by program level and scientific topic.
____________________
7For details, see http://www.sba.gov/about-sba-services/7050 [July 2013].
TABLE F-2 Innovation Data from U.S. Agencies Other Than NCSES
| Agency | Database/Survey/Data Collection Mechanism | Indicator/Data Items | Time Period |
| United States Patent and Trademark Office (USPTO) | Patent Assignments Dataset | Patent assignments and change of ownership of patents that are granted by USPTO | 2010 onward |
| Trademark Casefile Dataset | Trademarks granted by USPTO | 1884-2010 | |
| Trademark Assignments Dataset | Change of ownership of trademarks granted by USPTO | 2010 onward | |
| Economic Research Service, U.S. Department of Agriculture | Rural Establishment Innovation Survey | Inventory of innovation activities; use of technology by labor force, establishment, and community characteristics; factors hampering innovation; funding source for innovation; applications for intellectual property and trademarks; sources of information on new opportunities | First survey cycle was conducted in 2013 |
| National Institutes of Health, National Science Foundation, and White House Office of Science and Technology Policy | STAR METRICS | Recipient-based data containing information on contract, grant, and loan awards made under the American Recovery and Reinvestment Act of 2009 | 2009-2012 |
| National Science Foundation | Research Spending and Results | Recipient-based data containing information on awards made by the National Science Foundation and the National Aeronautics and Space Administration | 2007 onward |
| National Institute of Standards and Technology, U.S. Department of Commerce | Federal Laboratory (Interagency) Technology Transfer Summary Reports | Patent applications, invention licenses, cooperative R&D agreements, R&D obligations—extramural and intramural | 1987-2009 |
| Small Business Administration | Small Business Innovation Research (SBIR) and Small Business Technology Transfer (STTR) programs | Federal R&D funds/awards by agency, category, and state | 1983-2012 |
| U.S. Department of Energy NB: Information available at the state, county, and municipal levels, as well as from utilities and nonprofits | Energy Innovation Portal—Visual Patent Search Tool | Issued U.S. patents and published patent applications that are created using Department of Energy funding | 1979 onward |
| Advanced Manufacturing Office—State Incentives and Resource Database | Energy-saving incentives and resources available for commercial and industrial plant managers | ||
SOURCES: USPTO databases, see http://www.gwu.edu/~gwipp/Stuart%20Graham%20020712.pdf. Rural Development, USDA, see http://www.gpo.gov/fdsys/pkg/FR-2011-06-22/html/2011-15474.htm. STAR METRICS, see https://www.starmetrics.nih.gov/Star/Participate#about. Research Spending and Results, see https://www.research.gov/research-portal/appmanager/base/desktop?_nfpb=true&_eventName=viewQuickSearchFormEvent_so_rsr. Federal Laboratory (Interagency) Technology Transfer Summary Reports, see http://www.nist.gov/tpo/publications/federal-laboratory-techtransfer-reports.cfm. SBIR and STTR, see http://www.sbir.gov/. Energy Innovation Portal, see http://techportal.eere.energy.gov/. Advanced Manufacturing Office, see http://www1.eere.energy.gov/manufacturing/.
— The Expertise Locator provides information on proposals and coprincipal investigators related to different topic areas to make it possible to locate researchers working on that topic.
— The Patent Viewer provides data on patents from NSF grantees.
— The Map Viewer offers a geographic tool for viewing NSF investments by institution and topic.
- DOE—DOE’s Green Energy Data Service contains bibliographic data for patents relating to various forms of green energy (e.g., solar, wind, tidal, bio-energy) resulting from research sponsored by DOE and predecessor agencies.
- Indiana University—Innovation in American Regions is a project funded in part by the U.S. Commerce Department’s Economic Development Administration. The research is conducted by the Purdue Center for Regional Development, Indiana University, Kelley School of Business. The web tools available to users are the Innovation Index, Cluster Analysis, and Investment Analysis. The Innovation Index is a weighted index of indicators based on four components—human capital, economic dynamics, productivity and employment, and economic well-being. Cluster Analysis depicts occupation and industry clusters for any state, metro area, micro area, district, or county in the nation. Investment Analysis provides various kinds of information to aid regional investors.
- Innovation Ecologies Inc.—The Regional Innovation Index is a single data platform consisting of a host of indicators from various sources. The indicators measure venture capital, labor inputs, personal income, education and training, globalization, Internet usage, R&D inputs, universities, quality of life, knowledge, employment outcomes in firms and establishments, social and government impacts, and innovation processes.
Innovation Data from Private Sources
A number of educational institutions and corporate organizations collect and disseminate innovation data (see Table F-3):
- University of California, Los Angeles (UCLA)—Zucker and Darby (2011) developed the COMETS (Connecting Outcome Measures in Entrepreneurship Technology and Science) database. COMETS is an integrated database of principal investigators, dissertation writers and advisers, inventors, and employees at private-sector firms. COMETS data can be used to trace government expenditures on R&D from the initial grant through knowledge creation, translation, diffusion, and in some cases commercialization.
- Association of University Technology Managers (AUTM)—AUTM has been conducting licensing surveys on U.S. and Canadian universities, hospitals, and research institutions since 1991. Twenty years of data from participating institutions are placed in Statistics Access for Tech Transfer (STATT), a searchable and exportable database. It contains information on income from, funding source of, staff size devoted to, and legal fees incurred for licensing; start-ups that institutions created; resultant patent applications filed; and royalties earned.
- Association of Public and Land-grant Universities (APLU), Commission on Innovation, Competitiveness, and Economic Prosperity (CICEP)—APLU is involved in creating new metrics with which to measure the economic impact of universities at the regional and national levels. APLU’s CICEP has been working to identify and investigate the efficacy of potential metrics in the areas of human capital and knowledge capital. Indicators being investigated range from unfunded agreements between universities and industry (e.g., material transfer agreements, nondisclosure agreements), to student engagement in economic activities, to the impacts of technical assistance provided by universities to various actors in the region’s economy.
- Harvard University—Patent Network Dataverse (Feldman, 2013a) is an online database created and hosted by the Institute for Quantitative Social Science at Harvard University. This is a “virtual web archive” that has, among other things, matched patents and publication data. Researchers use Dataverse to publish, share, reference, extract, and analyze data.
- PricewaterhouseCoopers and the National Venture Capital Association—The MoneyTree Report is published quarterly and is based on data provided by Thomson Reuters. The report contains data on venture capital financing, including the companies that supply and receive the financing.
- Venture capital database—CB Insights, Venture Deal, Grow Think Research, and Dow Jones VentureSource have venture capital databases that profile venture capital firms and venture capital-financed firms.
TYPES OF INFORMATION CAPTURED BY VARIOUS STI DATABASES
STI data can be broadly categorized into three distinct subtopics:
1. R&D expenditure—Total R&D activity in a nation can be further broken down into:
— Total R&D expenditure or gross domestic expenditure on R&D (GERD),
TABLE F-3 Innovation Product Data from Private Sources
| Agency | Database/Survey/Data Collection Mechanism | Indicator/Data Items | Time Period |
| University of California, Los Angeles | Connecting Outcome Measures in Entrepreneurship, Technology, and Science (COMETS) database | Integrates data on government grants, dissertations, patents, and publicly available firm data; currently contains information on patents granted by the U.S. Patent and Trademark Office (USPTO) and on National Science Foundation (NSF) and National Institutes of Health (NIH) grants | 2007-2012 |
| Association of University Technology Managers | Statistics Access for Tech Transfer (STATT) | Academic licensing data from participating academic institutions: licensing activity and income, start-ups, funding, staff size, legal fees, patent applications filed, royalties earned | 1991-2010 |
| Association of Public and Land-grant Universities—Commission on Innovation, Competitiveness, and Economic Prosperity | New Metrics to Measure Economic Impact of Universities | Relationship with industry: agreements, clinical trials, sponsored research, external clients Developing the regional and national workforce: student employment, student economic engagement, student entrepreneurship, alumni in workforce Knowledge incubation and acceleration programs: success in knowledge incubation and acceleration programs, ability to attract investments, relationships between clients/program participants and host university | Pilot conducted in spring 2012 with 35 participating institutions |
| Harvard University | Patent Network Dataverse: U.S. Patent Inventor Database | Patent coauthorship network | 1975 onward |
| PricewaterhouseCoopers and National Venture Capital Association | Money Tree Report | Venture capital firms and firms receiving financing: quarterly and yearly investment amounts, number of deals by industry, stage of development, first-time financings, clean technology, and Internet-specific financings | Quarterly data, 1st quarter 1995 onward |
| CB Insights, Venture Deal, Grow Think Research, Dow Jones VentureSource | Venture Capital Database | Profile of venture capital firms and venture capital-financed firms | |
SOURCES: COMETS Database, see http://scienceofsciencepolicy.net/?q=node/3265. STATT database, see http://www.autm.net/source/STATT/index.cfm?section=STATT. APLU Economic Impact, see http://www.aplu.org/page.aspx?pid=2693. Patent Network Dataverse, see http://thedata.harvard.edu/dvn/dv/patent. Money Tree Report, see https://www.pwcmoneytree.com/MTPublic/ns/index.jsp. Venture Capital databases, see http://www.cbinsights.com/;http://www.venturedeal.com/; http://www.growthinkresearch.com/; https://www.venturesource.com/login/index.cfm?CFID=2959139&CFTOKEN=53e4cab1e600d5d-9089-411f-a010-949554ae0978.
— Business R&D expenditure or business enterprise expenditure on R&D (BERD),
— Academic R&D expenditure or higher education expenditure on R&D (HERD),
— Federal R&D expenditure,
— Government intramural expenditure on R&D (GOVERD),
— Government budget appropriations or outlays on R&D (GBAORD), and
— R&D performed and/or funded by nonprofit organizations.
2. Human capital/human resources in S&T—It comprises human capital in S&T, including individuals in S&T occupations and those with degrees in S&T fields. Most of the above-mentioned agencies/organizations produce statistics on both subgroups. The variables reported are:
— total R&D personnel;
— researchers;
— technicians;
— other supporting staff;
— scientists and engineers;
— number of degrees in science, engineering, and health (SEH) fields; and
— number of graduates in S&E fields.
3. Innovation—Statistics on business innovation are being collected by NCSES through BRDIS. NCSES has released two InfoBriefs (NSF 11-300 and NSF
12-307) that provide information on technologically innovative firms and usage of methods for protecting intellectual property, both by North American Industrial Classification System (NAICS) classification. Data in both InfoBriefs were gathered from the 2008 BRDIS. BRDIS focuses on technological innovation (product and process) and was inspired by Eurostat’s CIS, which looks at both technological and nontechnological innovation. Similarly, Statistics Canada’s SIBS contains many elements borrowed from the CIS. To some extent, this ensures that questions across the three surveys align, and may be helpful for international data comparisons. As the survey results become available, it will be possible to answer the question of whether the data across all three surveys are truly comparable; for now, however, it is too early to say. The subtopics within innovation statistics stem from sections/questions in survey questionnaires and can divided into nine categories:8
- type of innovation activity—product, process, organizational, marketing;
- innovation activity and expenditure;
- turnover due to innovative products;
- objectives of innovation;
- sources of information on innovation;
- cooperation in innovation activity;
- factors hampering innovation activity;
- government support/public funding for innovation; and
- innovation with environmental benefits.
Table F-1, presented earlier, outlines the level of detail available in the STI data produced by NCSES, Statistics Canada, OECD, Eurostat, and UNESCO. Unique variables produced by these agencies—those not available from other organizations—are highlighted in the table.
Even though agencies and other organizations try to produce STI statistics covering the subtopics, some of them clearly have an advantage over others in certain areas. Staff of the Committee on National Statistics looked at the concentration of agencies and other organizations in various subtopics (see Figures F-1 and F-2). The metric used in these figures is the percentage of tables produced on a particular subtopic relative to the total tables generated by the STI database. Using Eurostat’s statistics database as an example, it has 330 tables on various STI subtopics (see Table F-1). Of those, 9 tables show GERD values of member nations disaggregated by economic activity, costs, and so on. Similarly, there are 40 tables on R&D personnel and their various attributes, which brings the percentage of tables on the R&D personnel subtopic to 12 percent (40 divided by 330). A separate figure was created for NCSES to avoid confusion. As seen in Figures F-1 to F-3, STI data produced by NCSES are oriented toward scientists and engineers and SEH degrees; Statistics Canada and Eurostat focus more on innovation topics, and OECD and UNESCO on researchers.
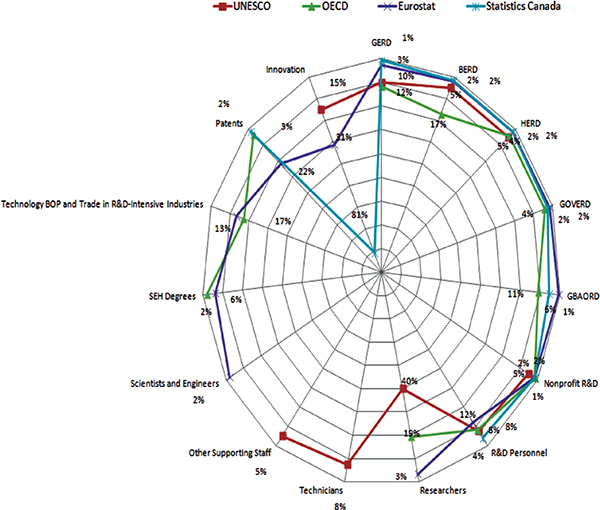
FIGURE F-1 Subtopics of science, technology, and innovation data produced by agencies/organizations other than the National Center for Science and Engineering Statistics.
NOTES: The scale is in reverse order. As one moves closer to the epicenter, the value increases. BERD = business enterprise expenditure on R&D; BOP = balance of payments; GBAORD = government budget appropriations or outlays for research and development; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on R&D; HERD = higher education expenditure on research and development; R&D = research and development; SEH = science, engineering, and health; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: Adapted from UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012.] Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012]. Statistics Canada, CANSIM, see http://www5.statcan.gc.ca/cansim/a33?lang=eng&spMode=master&themeID=193&RT=TABLE [November 2012].
METHODOLOGY
The panel used cluster analysis, which includes multidimensional scaling (MDS), and a heat map tool to understand the redundancy in the main S&T indicators produced by the above-mentioned organizations/agencies. Although MDS and the heat map are not exclusive approaches to analyzing STI data, they are among many possible paths to understanding the issue of redundancy in the multitude of variables published by various agencies and organizations. Both methods
____________________
8Subtopics in the CIS.
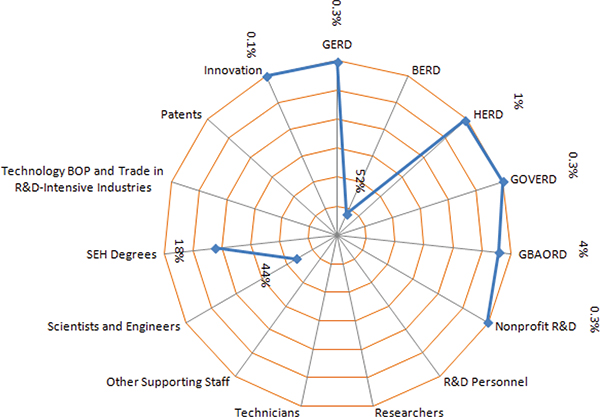
FIGURE F-2 Subtopics of science, technology, and innovation data produced by the National Center for Science and Engineering Statistics.
NOTES: The scale is in reverse order. As one moves closer to the epicenter, the value increases. BERD = business enterprise expenditure on R&D; BOP = balance of payments; GBAORD = government budget appropriations or outlays for research and development; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on R&D; HERD = higher education expenditure on research and development; R&D = research and development; SEH = science, engineering, and health. SOURCES: Adapted from BRDIS, see http://www.nsf.gov/statistics/industry/ [November 2012]. Federal Funds, see http://www.nsf.gov/statistics/fedfunds/ [November 2012]. R&D Expenditure at FFRDCs, see http://www.nsf.gov/statistics/ffrdc/ [November 2012]. HERD, see http://www.nsf.gov/statistics/herd/ [November 2012]. Science and Engineering State Profiles, see http://www.nsf.gov/statistics/pubseri.cfm?seri_id=18 [November 2012].
offer wide-ranging applications in various fields and have helped researchers gain some amount of understanding of the dataset on which they are working.
Generally, cluster analysis9 is a collection of methods for finding distinct or overlapping clusters in data. It is an analytic procedure for grouping sets of objects into subsets that are relatively similar among themselves. In a broad sense, there are two methods of clustering—hierarchical and partitioning. With hierarchical methods, small clusters are formed that merge sequentially into larger and larger clusters until only one remains, resulting in a tree of clusters. Partitioning methods split a dataset into a set of discrete clusters that are nonhierarchical in nature because they do not fit into a tree or hierarchy. Different numbers of clusters on the same dataset can result in different partitioning that may overlap. To produce clusters, there must be some measure of dissimilarity or distance among objects. Similar objects should appear in the same cluster and dissimilar objects in different clusters. Different measures of similarity produce different hierarchical clusterings. If there are two vectors consisting of values on p features of two objects, popular distance measures are:10
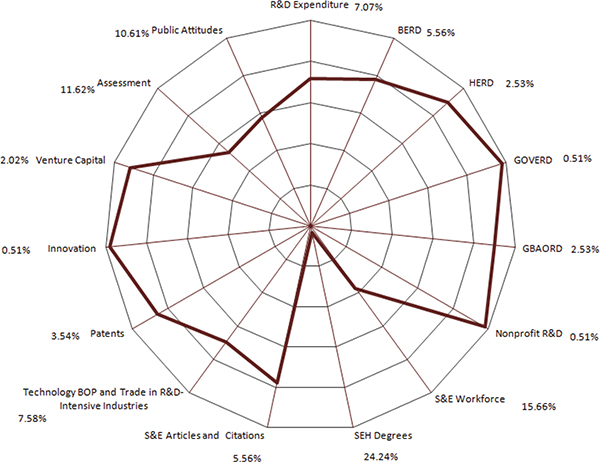
FIGURE F-3 Subtopics of science, technology, and innovation indicators published in Science and Engineering Indicators 2012 Digest.
NOTES: The scale is in reverse order. As one moves closer to the epicenter, the value increases. BERD = business enterprise expenditure on R&D; BOP = balance of payments; GBAORD = government budget appropriations or outlays for research and development; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on R&D; HERD = higher education expenditure on research and development; R&D = research and development; S&E = science and engineering; SEH = science, engineering, and health.
SOURCE: Adapted from Science and Engineering Indicators 2012, see http://www.nsf.gov/statistics/seind12/tables.htm.
- Euclidean—the square root of the sum of squared elementwise differences between the two vectors;
- City Block—the sum of absolute differences between the two vectors;
- cosine—the inner product of the two vectors divided by the product of their lengths (norms);
- Pearson 1—the Pearson correlation between two vectors; and
- Jaccard—the sum of the mismatches between the elements of one vector and the elements of the other.
____________________
9For examples of the broad analytical capabilities of cluster analysis, see Feser and Bergman (2000) on industrial clusters, Myers and Fouts (2004) on K-12 classroom environments for learning science, and Newby and Tucker (2008) in the area of medical research.
10This explanation of distance measures and linkage methods is based on the Data Analysis output of AdviseStat (see http://www.skytree.net/products-services/adviser-beta/ [December 2012]).
Euclidean distances are sensitive to differences between values because the differences are squared, and larger differences carry more weight than small. City Block distances are similarly sensitive to differences between values, but these differences are not squared. In contrast with Euclidean or City Block distances, cosine-based distances are invariant to scaling—multiplying all values by a constant will not change cosine distance. Pearson-based distances are invariant to scaling and location—adding a constant to the values will not change these distances. Jaccard distances are based only on mismatches of values and are invariant under one-to-one recodings of unique values. All of these measures are real (metric) distances; they obey the metric axioms.11
Multidimensional Scaling
The panel used MDS models to discover which sets of indicators are more similar to each other and to help in arriving at a set of primary and derivative indicators. Table F-1 and Figure F1, presented earlier, show the great number of variables capturing numerous pieces of STI information. From the viewpoint of an agency or organization, it is important to understand which indicators are necessary for addressing key policy questions and in turn make the production of STI variables more efficient. Various applications of MDS are documented by Young and Hamer (1987). MDS is frequently applied to political science data, such as voting preferences. For example, Minh-Tam and colleagues (2012) used MDS to embed the network of capital cities of European nations based on their pairwise distances (Minh-Tam et al., 2012; Nishimura et al., 2009).
The original motivation for MDS was to fit a matrix of dissimilarities or similarities to a metric space. Since its origins, however, MDS has had many other applications. A popular use is to compute a distance matrix on the columns of a rectangular matrix using a metric distance function (Euclidean, cosine, Jaccard, power, etc.). The result is that MDS projects the original variables into a low-dimensional (usually 2-dimensional) space. This approach is an alternative to principal components analysis. If the projection is intrinsically nonlinear for a given dataset, MDS can provide a better view than principal components.
Young (2013, p. 1) describes the process as follows:
Multidimensional scaling (MDS) is a set of data analysis techniques that display the structure of distance-like data as a geometrical picture. It is an extension of the procedure discussed in scaling…. MDS pictures the structure of a set of objects from data that approximate the distances between pairs of the objects…. Each object or event is represented by a point in a multidimensional space. The points are arranged in this space so that the distances between pairs of points have the strongest possible relation to the similarities among the pairs of objects. That is, two similar objects are represented by two points that are close together, and two dissimilar objects are represented by two points that are far apart.
Given a configuration of points in a metric space, one can compute a symmetric matrix of pairwise distances on all pairs of points. By definition, the diagonal of this matrix is zero, and the off-diagonal elements are positive. Now suppose a condition is inverted. One has an input matrix X and wants to compute a distance matrix Y containing the coordinates of points in the metric space using the distance formula provided by the metric. A general formula for a distance metric is:
dijp = ∑ar | Xia – Xja |P, (p ≥ 1), Xi ≠ Xj
where there are r dimensions, where Xia is the coordinate of point i on dimension a, and where Xi is an r-element row vector from the ith row of the n by r matrix X containing the coordinates Xia of all n points on all r dimensions. For dij to satisfy all of the properties of a metric, dij must be positive. Therefore, only the positive root of dij must be used in determining dij. This is known as a Minkowski model. Three special cases of the Minkowski model are of primary interest. One of these is the Euclidean model, which is obtained when the Minkowski exponent (p) is 2. The second is the city block or taxicab model; when p = 1, dij is simply the sum of absolute difference in the coordinates of the two points. When p is infinitely large, the Dominance model is obtained.
The MDS analysis in this report uses the Euclidean model, as described earlier in this chapter. For the application to STI indicators, the input matrix X needed to be symmetric, which refers to Xia = Xai. Since the input matrix was not symmetric initially, a matrix of correlation coefficients of the variables in the analysis was used.12
Heat Map
Another notable method is cluster heat maps. In certain fields, the analyst wants to cluster rows and columns of a matrix simultaneously. The popular display is called the cluster heat map.13 Wilkinson and Friendly (2009) describe heat map analysis as follows:
The cluster heat map is a rectangular tiling of a data matrix with cluster trees appended to its margins. Within a relatively compact display area, it facilitates inspection of row, column,
____________________
11Metric axioms are: Identity, where distance (A, A) = 0; Symmetry, where distance (A, B) = distance (B, A); and Triangle Inequality, where distance (A, C) ≤ distance (A, B) + distance (B, C). See http://www.pigeon.psy.tufts.edu/avc/dblough/metric_axioms.htm [July 2013].
12For more details on the derivation of the Euclidean model from the general formula for a distance metric, see Young and Hamer (1987, p. 87).
13The whole explanation of clustering methods is taken from “A Second Opinion on Cluster Analysis,” Whitepaper on a Second Opinion, downloaded from the AdviseAnalystics website (https://adviseanalytics.com/advisestat [December 2012]).
and joint cluster structure. Moderately large data matrices (several thousand rows/columns) can be displayed effectively on a higher-resolution color monitor, and even larger matrices can be handled in print or in megapixel displays.
The heat map also orders the variables such that similar variables are closer to each other. Cluster heat maps are built from two separate hierarchical clusterings on rows and columns, and as a consequence, each rests on the same foundation that one-way hierarchical clustering involves.
ANALYSIS
STI databases consist of variables, some of which measure R&D expenditures, some the numbers of scientists and engineers, others the amount of trade taking place, and so on. As there is no uniform scale for all of these variables (dollar figures and actual counts), the panel decided to use Pearson distance, which is 1 − the Pearson correlation between two vectors. Therefore, if a correlation is negative, the distance will be greater than 1. For standardized variables (z-scores), 1 − Pearson is equivalent to Euclidean distance. One can also conclude that hierarchical clustering depends on linkage methods. These methods determine how the distance between two clusters is calculated. They are:
- single—distance between the closest pair of objects, one object from each group;
- complete—distance between the farthest pair of objects, one object from each group;
- average—average of distances between all pairs of objects, one object from each group;
- centroid—distance between the centroids of the clusters;
- median—distance between the centroids of the clusters weighted by the size of the clusters; and
- Ward—increase in the within-cluster sum of squares as a result of joining two clusters.
Once distances between clusters have been computed, the closest two are merged. Single linkage tends to produce long, stringy clusters, whereas complete linkage tends to produce compact clusters. Ward clustering usually produces the best hierarchical trees when the clusters are relatively convex and separated. Since the panel believes Ward linkage is the best all-around method, it was used for this analysis.
To analyze STI data, the panel used hierarchical clustering, cluster heat map, and MDS methods. For purposes of analysis, we used the statistics program AdviseStat, an expert system for statistics akin to an intelligent analytics advisor. In the cluster analysis, we used Pearson correlations as the similarity measure, and the hierarchical clustering used Ward linkage. Variables were standardized before similarities were computed. Standardizing puts measurements on a common scale and prevents one variable from influencing the clustering because it has a larger mean and/or variance. In general, standardizing makes overall level and variation comparable across measurements. As mentioned above, comprehensive evaluation of STI variables leads to scale issues as variables capture different types of information. Hence, it is necessary to put the variables in a common scale.
The analysis consisted of three segments, depending on the type of data. OECD, UNESCO, and Eurostat collect STI information from member nations; NCSES and Statistics Canada collect similar information from a single nation. Analyzing variables from all five databases would be intractable. Therefore, it was necessary to separate the analysis into two groups—many nations and single nation. In the many nations analysis, we concentrated on (1) variables from OECD, UNESCO, and Eurostat and (2) indicators from the SEI 2012 Digest. The single nation analysis has two components: (1) U.S. R&D expenditures and funding as published by NCSES, OECD, UNESCO, and Eurostat and (2) U.S. R&D human capital as published by NCSES, OECD, UNESCO, and Eurostat. The third segment focused on innovation data published by NCSES, Eurostat, and Statistics Canada. The conclusions and observations from the analysis are summarized below.
Many Nations Analysis
This analysis is restricted to OECD, UNESCO, and Eurostat as their databases contain data on more than one nation. As mentioned earlier, the data series of OECD and Eurostat go back to 1981, while that of UNESCO begins in 1996. Here again, the data were divided into two parts. The first part of the analysis focused on main S&T variables from the three databases for 1996 to 2011 (see Figures F-4, F-5, and F-6). The second part of the analysis was based on a subset of those variables, for which information was available going back to 1981, and hence was restricted to OECD and Eurostat (see Figures F-7, F-8, and F-9). The selected variables are listed in Table F-4. It should be noted that this is not an exhaustive list of all the variables available in the three databases. Early in the analysis, the panel took a “kitchen sink” approach whereby the analysis was run on all variables. We ran into multiple clusters, as many of the variables are tabs of a main variable. For example, “number of foreign citizen female researchers in government sector” is a subset of “number of female researchers.” As can be seen in Table F-1, the number of variables that can be gleaned from a single subtopic is large; for example, Eurostat’s STI database contains at least 180 variables on human resources in S&T. The aim of the cluster analysis and MDS is to understand what redundancy exists in main S&T variables, and our analysis was therefore restricted to the selected variables shown in Table F-4 that address various subtopics. The variable names start with EURO, OECD, or UN, denoting the S&T database to which the variables belong. It should not be assumed that the excluded variables are unimportant—Chapter 3 of this report
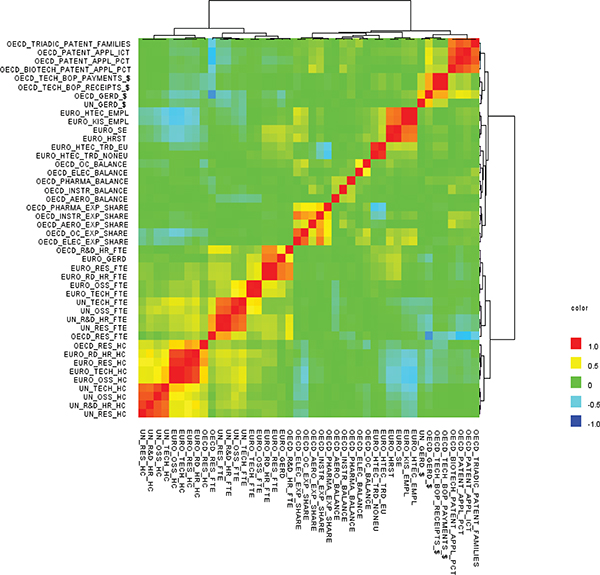
FIGURE F-4 Heat map of main science and technology variables from OECD, UNESCO, and Eurostat databases.
NOTES: AERO = aerospace industry; BOP = balance of payments; ELEC = electronic industry; EMPL = employment; EU = European Union; EURO = Eurostat; EXP = export industry; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; HRST = human resources in science and technology; HTECH = high technology; ICT = information and communication technology; INSTR = instrument industry; KIS = knowledge-intensive services; NONEU = non-European Union; OC = office machinery and computer; OSS = other supporting staff; PCT = Patent Cooperation Treaty; PHARMA = pharmaceutical industry; R&D = research and development; RD = R&D; RES = researchers; SE = science and engineering; TRD = Trade; UN = United Nations; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: Panel analysis and UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012].
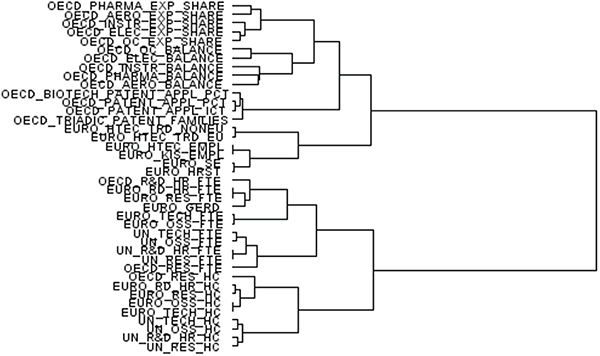
FIGURE F-5 Hierarchical cluster of main science and technology variables from OECD, UNESCO, and Eurostat databases.
NOTES: AERO = aerospace industry; ELEC = electronic industry; EMPL = employment; EU = European Union; EURO = Eurostat; EXP = export industry; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; HRST = human resources in science and technology; HTECH = high technology; ICT = information and communication technology; INSTR = instrument industry; KIS = knowledge-intensive services; NONEU = non-European Union; OC = office machinery and computer; OSS = other supporting staff; PCT = Patent Cooperation Treaty; PHARMA = pharmaceutical industry; R&D = research and development; RD = R&D; RES = researchers; SE = science and engineering; TRD = trade; UN = United Nations; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: Panel analysis and UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012].
points out that they have a crucial role in answering policy questions. We also encountered the problem of missing data, especially in the UNESCO dataset. As described earlier, the UNESCO database consists of 216 nations, but the set is reduced to 80 if one excludes those countries for which the number of time series is limited. For the second part of the analysis, the number of observations was reduced still further to 52 nations. It is important to understand that we attempted to make our analysis as comprehensive as possible by merging information from three databases, but that effort was hampered by the unavailability of data in certain cases.
In addition to reviewing redundancy in statistics produced by UNESCO, OECD, and Eurostat, the panel expanded the analysis to include data taken from SEI 2012. The online version of SEI 2012 is available at http://www.nsf.gov/statistics/seind12/start.htm. The site provides access to tables and figures used in the digest. These tables and figures provide information on the United States, the EU, Japan, China, other selected Asian economies (the Asia-8: India, Indonesia, Malaysia, the Philippines, Singapore, South Korea, Taiwan, and Thailand), and the rest of the world. A more detailed breakdown is available in the appendix tables.14 Because the digest is intended to inform the reader of broad trends, the source data for the figures and tables do not show a continuous time series.15 Note that this is not a review of everything that is in SEI 2012, because many tables and figures are used to highlight findings and conclusions. As pointed out in the introduction to SEI 2012:
The indicators included in Science and Engineering Indicators 2012 derive from a variety of national, international, public, and private sources and may not be strictly comparable in a statistical sense. As noted in the text, some data are weak, and the metrics and models relating them to each other and to economic and social outcomes need further development. Thus, the emphasis is on broad trends; individual data points and findings should be interpreted with care.
____________________
14Detailed appendix tables are available at National Science Foundation (2012c).
15For example, see Table 6-6 on p. 6-41 in the S&E 2012 Digest (National Science Board, 2012b).
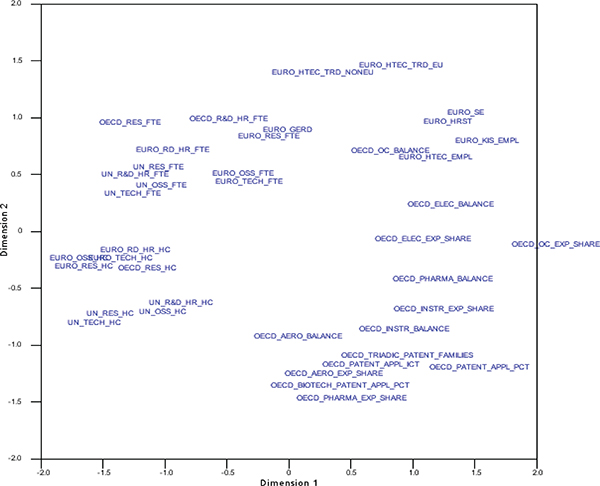
FIGURE F-6 Multidimensional scaling of main science and technology variables from OECD, UNESCO, and Eurostat databases.
NOTES: EMPL = employment; EU = European Union; EURO = Eurostat; EXP = export; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; HRST = human resource in science and technology; HTECH = high technology; ICT = information and communication technology; KIS = knowledge-intensive services; NONEU = non-European Union; OC = office machinery and computer; OSS = other supporting staff; PHARMA = pharmaceutical industry; PCT = Patent Cooperation Treaty; R&D = research and development; RD= R&D; RES = researchers; SE = science and engineering; TRD = trade; UN = United Nations; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: Panel analysis and UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012].
Table F-5 shows a list of indicators used in the panel’s analysis. Every effort was made to be as congruent as possible with the list outlined earlier. Because this is a many nations analysis, not all the indicators are included in the table, because many were specific to the United States.
Single Nation Analysis: International Comparability and Human Capital in Science and Engineering
International Comparability
Complying with the Frascati Manual, NCSES reports R&D expenditures by performer and funder (see Table F-6). For comparability purposes, NCSES reports GERD for the United States in National Patterns, the SEI, and various InfoBriefs. Categorization of R&D expenditures by government priorities provides a broad picture of the distribution of R&D activities and a basis for international comparisons (National Science Foundation, 2010b). The standards for collecting data on socioeconomic objectives were introduced in the third edition of the Frascati Manual (OECD, 2002). Godin (2008) points out that the third edition of the manual expanded the scope of the previous edition to include research on the social sciences and humanities and place greater emphasis on “functional” classifications, notably the distribution of R&D by “objectives.” The Frascati Manual
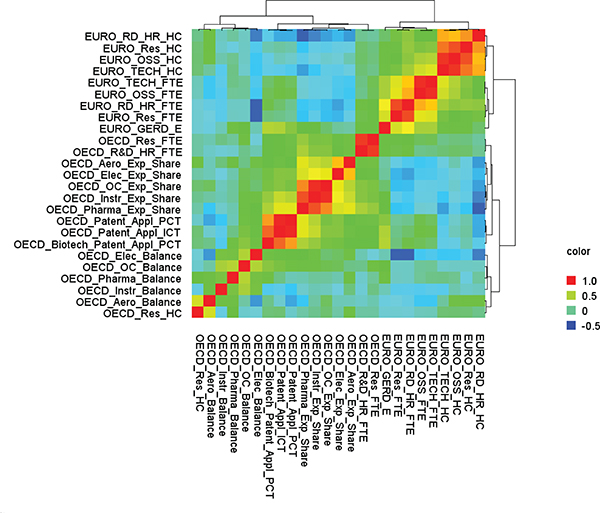
FIGURE F-7 Heat map of main science and technology variables from OECD and Eurostat databases.
NOTES: E = European currency unit; EURO = Eurostat; EXP = export; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; ICT = information and communication technology; OC = office machinery and computer; OSS = other supporting staff; PCT = Patent Cooperation Treaty; R&D = research and development; RD = R&D.
SOURCES: Panel Analysis and UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012].
recommends collecting performer-reported data in all sectors for two priorities: (1) defense and (2) control and care of the environment. In Table 4-23 of the SEI 2012 Digest, U.S. GBAORD values are reported by socioeconomic objectives for 1981, 1990, 2000, and 2009. The agency publishes those figures using special tabulations because aggregate R&D funding data from federal agencies are already allocated to various socioeconomic objective categories, but performer-based R&D totals are not. BRDIS does intermittently survey companies to report their R&D performance for defense purposes and for environmental protection applications, even though the latter category is not fully compliant with the Frascati Manual. Along with GBAORD, Eurostat and OECD report GERD by socioeconomic objectives. The Frascati Manual also recommends that major fields of S&T be adopted as the functional fields of a science classification system. This classification should be used for R&D expenditures of the governmental, higher education, and private nonprofit sectors; if possible for the business enterprise sector; and for personnel data in all sectors (OECD, 2007). OECD,
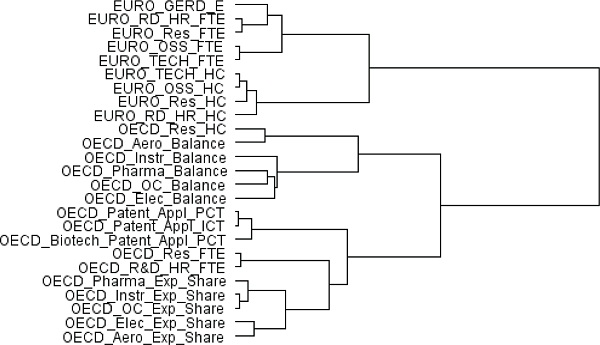
FIGURE F-8 Hierarchical cluster of main science and technology variables from OECD and Eurostat databases.
NOTES: E = European currency unit; EURO = Eurostat; EXP = export; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; ICT = information and communication technology; OC = office machinery and computer; OSS = other supporting staff; PCT = Patent Cooperation Treaty; R&D = research and development; RD = R&D.
SOURCES: Panel analysis and UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012].
Eurostat, and UNESCO publish GERD figures by fields. NCSES publishes academic expenditures by S&E subfields. The original targets for categorization of R&D expenditures by socioeconomic objectives and fields of science were GBAORD and HERD, respectively. Revisions of the Frascati Manual have expanded the scope of the categorization to include all kinds of R&D expenditures.
Table F-6 shows total R&D expenditure and its components for the United States as published by NCSES and other international organizations. Figures F-10 and F-11 show the results of the cluster analysis performed on the data in Table F-6.
Human Capital in Science and Engineering
NCSES produces a multitude of STI human capital variables, as seen in Table F-7:16
- Scientists and engineers—Scientists and engineers are individuals who satisfy one of the following criteria: (1) have ever received a U.S. bachelor’s or higher degree in an S&E or S&E-related field, (2) hold a non-S&E bachelor’s or higher degree and are employed in an S&E or S&E-related occupation, and (3) hold a non-U.S. S&E degree and reside in the United States.
- Doctoral scientists and engineers—Doctoral scientists and engineers are scientists and engineers who have earned doctoral degrees from U.S. universities and colleges.
- Bachelor’s and master’s degrees in S&E—Estimates of recent college graduates in S&E fields were generated from the biennial NSRCG, which provides information about individuals who recently obtained bachelor’s or master’s degrees in an SEH field. As the NSRCG was a biennial survey, it collects information for two academic years; therefore, the estimates of S&E bachelor’s and master’s degrees produced from the NSRCG are for two consecutive academic years. NCSES also requests special tabulations from NCES on S&E bachelor’s, master’s, and doctoral degrees, which are published in Women, Minorities and Persons with Disabilities in Science and Engineering.
- Doctorate recipients—Doctorate recipients are individuals who received a doctoral degree from a U.S. institution in an SEH field.
____________________
16Definitions of these terms are found on NCSES’s website at http://www.nsf.gov/statistics.
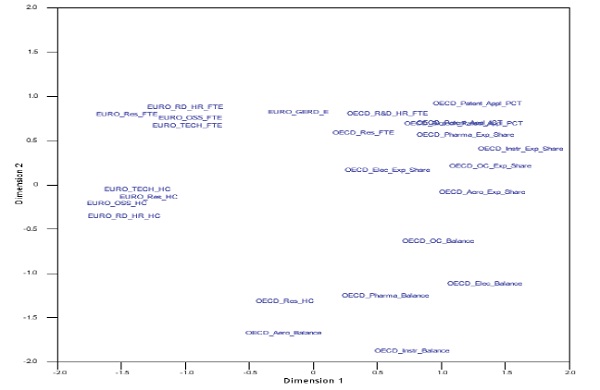
FIGURE F-9 Multidimensional scaling of main science and technology variables from OECD and Eurostat databases.
NOTES: EMPL = employment; EU = European Union; EURO = Eurostat; EXP = export; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; HRST = human resources in science and technology; HTECH = high technology; ICT = information and communication technology; KIS = knowledge-intensive services; NONEU = non-European Union; OC = office machinery and computer; OSS = other supporting staff; PCT = Patent Cooperation Treaty; PHARMA = pharmaceutical industry; R&D = research and development; RD = R&D; RES = researchers; SE = science and engineering; TRD = trade; UN = United Nations; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: Panel analysis and UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database European Union, 1995-2013 [November 2012].
- Graduate students in S&E—Graduate students in S&E are those who have been enrolled for credit in any SEH master’s or doctorate program in the fall of the survey cycle year.
- Postdoctorates in S&E—Postdoctorates are defined as individuals who (1) hold a recent doctorate or equivalent, a first-professional degree in a medical or related field, or a foreign equivalent to a U.S. doctoral degree and (2) have a limited-term appointment primarily for training in research or scholarship under the supervision of a senior scholar in a unit affiliated with a GSS17 institution.
- Nonfaculty researchers—Doctorate-holding, nonfaculty researchers are defined as individuals involved principally in research activities who are not postdoctorates or members of a faculty.
Relative to NCSES, other organizations/agencies do not publish a large set of human capital variables, but they capture information on certain R&D occupations (see Table F-1) that were missing from NCSES’s surveys very recently. OECD produces statistics on R&D personnel and researchers. In accordance with the Frascati Manual, R&D personnel include all persons employed directly in R&D activities, as well as those providing direct services, such as R&D managers, administrators, and clerical staff, while researchers are professionals engaged in the conception or creation of new knowledge, products, processes, methods, and systems and in the management of the projects concerned. Eurostat defines human resources in S&T as people who fulfill one of the following conditions:
____________________
17NSF/NIH Survey of Graduate Students and Postdoctorates in Science and Engineering at http://www.nsf.gov/statistics/srvygradpostdoc/ [December 2012].
TABLE F-4 Selected Science and Technology Variables from OECD, UNESCO, and Eurostat Database Used in the Panel’s Analysis
| Variable Label | Variable |
| EURO_GERD | Gross domestic expenditure on R&D (millions of current PPP dollars) |
| EURO_HRST | Human resources in science and technology |
| EURO_HTEC_EMPL | Employment in high-tech sectors |
| EURO_HTEC_TRD_EU | Trade with EU partners in high-tech sectors |
| EURO_HTEC_TRD_NONEU | Trade with non-EU partners in high-tech sectors |
| EURO_KIS_EMPL | Employment in high-tech knowledge-intensive services |
| EURO_OSS_FTE | Other supporting staff—full-time equivalent |
| EURO_OSS_HC | Other supporting staff—head count |
| EURO_RD_HR_FTE | R&D personnel—full-time equivalent |
| EURO_RD_HR_HC | R&D personnel—head count |
| EURO_RES_FTE | Researchers—full-time equivalent |
| EURO_RES_HC | Researchers—head count |
| EURO_SE | Scientists and engineers |
| EURO_TECH_FTE | Technicians—full-time equivalent |
| EURO_TECH_HC | Technicians—head count |
| OECD_AERO_BALANCE | Trade balance: aerospace industry (millions of current dollars) |
(1) successfully completed education at the third level in an S&T field of study; and
(2) were not formally qualified as above, but are employed in S&T occupations in which the above qualifications are normally required.18
Eurostat refers to scientists and engineers as persons who use or create scientific knowledge and engineering and technological principles, i.e., persons with scientific or technological training who are engaged in professional work on S&T activities and high-level administrators and personnel who direct the execution of S&T activities. UNESCO publishes information on researchers, technical professionals, and other supporting staff. OECD, Eurostat, and UNESCO produce human capital statistics by head count and FTEs.
Table F-7 shows various human capital variables for the United States that are published by NCSES and other international organizations. Figures F-12 and F-13 show results of the cluster analysis performed on the data in Table F-7. Doctoral scientists and engineers is the only NCSES variable that is closely related to the variables reported by Eurostat and OECD.
Single Nation Analysis: Innovation Statistics—Levels versus Percentages
Table F-8 provides a comparative view of innovation data by industry classification that are available from the three surveys on innovation—the CIS, BRDIS, and Canada’s Survey of Innovation. SIBS 2009 has more recent data on the status of innovation activity in Canada, but the data are not available by industry classification; hence the 2003 Survey of Innovation data are presented here. NCSES data cover the period 2006-2008, because companies were asked to report on innovation activity for those years. The EU innovation data are taken from CIS 2006 and 2008. In Tables 1 and 2 of InfoBrief NSF 11-300, data on firms producing innovative products and processes are presented as percentages—for example, the percentage of innovative firms reporting that they produced a new/significantly improved product. This is also the case with innovation data produced by Statistics Canada, while data from the CIS are available in both level and percentage form. Staff of the Committee on National
____________________
18See http://epp.eurostat.ec.europa.eu/cache/ITY_SDDS/Annexes/hrst_st_esms_an1.pdf, page 1 [December 2012].
| Variable Label | Variable |
| OECD_AERO_EXP_SHARE | Export market share: aerospace industry |
| OECD_BIOTECH_PATENT_APPL_PCT | Number of patents in the biotechnology sector—applications filed under the PCT (priority year) |
| OECD_ELEC_BALANCE | Trade balance: electronic industry (millions of current dollars) |
| OECD_ELEC_EXP_SHARE | Export market share: electronic industry |
| OECD_GERD_$ | Gross domestic expenditure on R&D (millions of current PPP dollars) |
| OECD_INSTR_BALANCE | Trade balance: instruments industry (millions of current dollars) |
| OECD_INSTR_EXP_SHARE | Export market share: instruments industry |
| OECD_OC_BALANCE | Trade balance: office machinery and computer industry (millions of current dollars) |
| OECD_OC_EXP_SHARE | Export market share: office machinery and computer industry |
| OECD_PATENT_APPL_ICT | Number of patents in the ICT sector—applications filed under the PCT (priority year) |
| OECD_PATENT_APPL_PCT | Number of patent applications filed under the PCT (priority year) |
| OECD_PHARMA_BALANCE | Trade balance: pharmaceutical industry (millions of current dollars) |
| OECD_PHARMA_EXP_SHARE | Export market share: pharmaceutical industry |
| OECD_R&D_HR_FTE | R&D personnel—full-time equivalent |
| OECD_RES_FTE | Researchers—full-time equivalent |
| OECD_RES_HC | Researchers—head count |
| OECD_TECH_BOP_PAYMENTS_$ | Technology balance of payments: payments (millions of current dollars) |
| OECD_TECH_BOP_RECEIPTS_$ | Technology balance of payments: receipts (millions of current dollars) |
| OECD_TRIADIC_PATENT_FAMILIES | Number of Triadic Patent Families (priority year) |
| UN_GERD_$ | Gross domestic expenditure on R&D (millions of current PPP dollars) |
| UN_OSS_FTE | Other supporting staff—full-time equivalent |
| UN_OSS_HC | Other supporting staff—head count |
| UN_R&D_HR_FTE | R&D personnel—full-time equivalent |
| UN_R&D_HR_HC | R&D personnel—head count |
| UN_RES_FTE | Researchers—full-time equivalent |
| UN_RES_HC | Researchers—head count |
| UN_TECH_FTE | Technicians—full-time equivalent |
| UN_TECH_HC | Technicians—head count |
NOTES: AERO = aerospace industry; APPL = application; BOP = balance of payments; ELEC = electronic industry; EMPL = employment; EU = European Union; EURO = Eurostat; EXP = export market share; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; HC = head count; HR = human resources; HRST = human resources in science and technology; HTECH = high technology; ICT = information and communication technology; INSTR = instruments industry; KIS = knowledge-intensive services; NONEU = non-European Union; OC = office machinery and computer; OSS = other supporting staff; PCT = Patent Cooperation Treaty; PHARMA = pharmaceutical industry; PPP = purchasing power parity; R&D = research and development; RD = R&D; RES = researchers; SE = science and engineering; TECH = technicians; TRD = trade; UN = United Nations; UNESCO = United Nations Educational, Scientific and Cultural Organization.
Statistics manipulated the available data in Table 1 of NSF 11-300 and converted percentage figures into levels; the results are shown in Table F-8. Survey results from Canada’s 2003 Survey of Innovation, which are available in CANSIM, are problematic to interpret as it is often difficult to understand what the denominator is. In some data tables, it is clear that the denominator is innovative firms, while for other tables the user must guess. One can calculate the total number of innovative firms receiving tax credits or total number of innovative firms reporting customers as an important source of innovation information if information on total innovative firms is available. Hence, staff of the Committee on National Statistics could not convert percentage figures into levels in the case of innovation data from CANSIM. It would be useful if more information on the surveyed population, such as total population, sample size, and response rate, were readily available. This information needs to be published by industry classification, as is evident from Tables F-8 and F-9.19
OBSERVATIONS
Many Nations Analysis
Figures F-4 to F-6 show a cluster heat map, a hierarchical cluster tree, and the multidimensional scaling of a Pearson correlation matrix, respectively. The input matrix consists of the main S&T variables from the OECD, UNESCO, and Eurostat databases. The red and orange squares along the diagonal of the heat map in Figure F-4 show that those variables are very closely related to each other, and either they could be merged, or the most well-behaved and consistent variables among them could be selected. Figures F-5 and F-8 show clusters of variables. Broadly speaking, human resource variables form one category and trade variables another. Figures F-6 and F-9 show sets of variables that are either similar or dissimilar. In these two figures, the dimensions have no interpretation, and one is looking for clusters of variables that would indicate they belong together. Strong correlation patterns are observed in the variables on researchers, technicians, and other supporting staff. These variables are closely grouped together. Moreover, within these variables, those produced by the same organization
____________________
19For further information, see Lonmo (2005, Table 1).
TABLE F-5 Science and Engineering Indicators from SEI 2012 Digest Used in the Panel’s Analysis
| Indicator Label | Indicator |
| RD_%_GDP | R&D expenditures as a share of economic output = R&D as percentage of GDP |
| Deg_NatSci | First university degrees in natural sciences |
| Deg_Eng | First university degrees in engineering |
| Doct_NatSci | Doctoral degrees in natural sciences |
| Doct_Eng | Doctoral degrees in engineering |
| S&E_Art | S&E journal articles produced |
| Eng_Share_S&E_Art | Engineering journal articles as a share of total S&E journal articles |
| Res_Art_Int_CoAuthor | Percentage of research articles with international coauthors |
| Share_Citation_Int_Lit | Share of region’s/country’s citations in international literature |
| Global_HighValue_Patents | Global high-value patents |
| Export_Comm_KIS | Exports of commercial knowledge-intensive services |
| HighTech_Exports | High-technology exports |
| Trade_Balance_KIS_IntAsset | Trade balance in knowledge-intensive services and intangible assets |
| VA_HighTech_Manu | Value added of high-technology manufacturing industries |
| VA_Health_SS | Global value added of health and social services |
| VA_Educ | Global value added of education services |
| VA_Whole_Retail | Global value added of wholesale and retail services |
| VA_Real_Estate | Global value added of real estate services |
| VA_Transport_Storage | Global value added of transport and storage services |
| VA_Rest_Hotel | Global value added of restaurant and hotel services |
NOTES: GDP = gross domestic product; KIS = knowledge-intensive services; R&D = research and development; RD = R&D; S&E = science and engineering.
SOURCE: Panel analysis and Science and Engineering Indicators 2012, see http://www.nsf.gov/statistics/seind12/tables.htm [November 2012].
are more similar. Clusters of subtopics are also observed. Expenditure variables, trade variables, and patent variables are more similar to variables within their group. This shows that variables on a subtopic relay similar information; i.e., they are proxy variables. For example, if an analyst is looking at predictor variables for a regression model and is unable to obtain data on technical staff, then researchers can substitute. In some ways, this relieves the burden on statistical agencies/ offices trying to follow the Frascati Manual’s recommendations. Even if they fall short in collecting certain variables, similar information can be gleaned from other variables on the same topic.
Single indicators highlighted for each subtopic as primary indicators are not shown here, as that would lead to conjecture. Nations should decide which variables to collect depending on ease of collection and budgetary constraints. The panel is not asserting that statistical offices around the world should stop collecting detailed S&T data, as the utility of variables is not limited to the ability to feed them into a regression model. National statistical offices collect detailed STI information through surveys and/or by using administrative records to answer specific policy questions, such as the mobility of highly skilled labor, the gender wage gap in S&T occupations, and the amount of investment moving into certain S&T fields. It can be said that the S&T community is interested in understanding the progress of nations in attracting the best talent, or the broad careers pursued by Ph.D. holders in particular fields, or the R&D investment in environmental projects. The main concern faced by the panel was the unavailability of detailed data as main variables undergo disaggregation. Apart from OECD and Eurostat member countries, the rest of the world has yet to keep pace in terms of capturing STI information in accordance with recommendations of the Frascati and Oslo Manuals. OECD and Eurostat have been frontrunners in pursuing valuable information, and they should be commended for their efforts. At the same time, the panel is not critical of non-OECD and non-Eurostat nations, as both data collection agencies and respondents must undergo a learning process to provide such fine data in a consistent fashion.
Figures F-14 to F-16 show a cluster heat map, a hierarchical cluster tree, and the multidimensional scaling of a Pearson correlation matrix, respectively. The input matrix consists of S&E indicators from the SEI 2012 Digest. The red and orange squares along the diagonal of the heat map show that those variables are very closely related to each other, and either they could be merged, or the most well-behaved and consistent variables among them could be selected. Figure F-15 shows clusters of indicators; Figure F-16 shows sets of indicators that are either similar or dissimilar. In these two figures, the dimensions have no interpretation, and one is looking for clusters of variables that would indicate they belong together. Indicators representing the service sector are observed to be highly correlated with each other. Indicators denoting first university degrees are closely grouped together. The same conclusion can be drawn for indicators on generation of S&E knowledge (articles and citations). Therefore, clusters of subtopics are observed, similar to those observed for STI variables from the OECD, Eurostat, and UNESCO databases. Certain indicators, such as R&D as
TABLE F-6 Statistics on U.S. R&D Expenditure Produced by NCSES, UNESCO, OECD, and Eurostat (in millions of current dollars)
| National Center for Science and Engineering Statistics—National Patterns of R&D Resources | ||||||||
| Indicator | Total R&D Expenditure | Industry-Performed R&D | Industry FFRDC-Performed R&D | Federally-Performed R&D | Universities and Colleges-Performed R&D | University and College FFRDC-Performed R&D | Nonprofit-Performed R&D | Nonprofit FFRDC-Performed R&D |
| Variable Name Year | NCSES_RD | NCSES_RD_IND | NCSES_RD_IND_FFRDCS | NCSES_RD_FED | NCSES_RD_UC | NCSES_RD_UC_FFRDCS | NCSES_RD_NP | NCSES_RD_NP_FFRDCS |
| 1981 | 72292 | 50425 | 1385 | 8605 | 7085 | 2484 | 1784 | 524 |
| 1982 | 80748 | 57166 | 1484 | 9501 | 7603 | 2544 | 1915 | 536 |
| 1983 | 89950 | 63683 | 1585 | 10830 | 8251 | 2840 | 2176 | 585 |
| 1984 | 102244 | 73061 | 1739 | 11916 | 9154 | 3243 | 2511 | 620 |
| 1985 | 114671 | 82376 | 1863 | 13093 | 10308 | 3616 | 2761 | 655 |
| 1986 | 120249 | 85932 | 1891 | 13504 | 11540 | 3973 | 2867 | 541 |
| 1987 | 126360 | 90160 | 1995 | 13588 | 12807 | 4287 | 3013 | 509 |
| 1988 | 133881 | 94893 | 2122 | 14342 | 14221 | 4581 | 3213 | 510 |
| 1989 | 141891 | 99860 | 2195 | 15231 | 15634 | 4756 | 3669 | 547 |
| 1990 | 151993 | 107404 | 2323 | 15671 | 16939 | 4894 | 4126 | 636 |
| 1991 | 160876 | 114675 | 2277 | 15249 | 18206 | 5120 | 4652 | 696 |
| 1992 | 165350 | 116757 | 2353 | 15853 | 19388 | 5259 | 4993 | 748 |
| 1993 | 165730 | 115435 | 1965 | 16531 | 20495 | 5289 | 5267 | 749 |
| 1994 | 169207 | 117392 | 2202 | 16355 | 21607 | 5294 | 5599 | 758 |
| 1995 | 183625 | 129830 | 2273 | 16904 | 22617 | 5367 | 5827 | 808 |
| 1996 | 197346 | 142371 | 2297 | 16585 | 23718 | 5395 | 6209 | 772 |
| 1997 | 212152 | 155409 | 2130 | 16819 | 24884 | 5463 | 6626 | 821 |
| 1998 | 226457 | 167102 | 2078 | 17362 | 26181 | 5559 | 7332 | 843 |
| 1999 | 245007 | 182090 | 2039 | 17851 | 28176 | 5652 | 8207 | 993 |
| 2000 | 267983 | 199961 | 2001 | 18374 | 30705 | 5742 | 9734 | 1465 |
| 2001 | 279755 | 202017 | 2020 | 22374 | 33743 | 6225 | 11182 | 2192 |
| 2002 | 278744 | 193868 | 2263 | 23798 | 37215 | 7102 | 12179 | 2319 |
| 2003 | 291239 | 200724 | 2458 | 24982 | 40484 | 7301 | 12796 | 2494 |
| 2004 | 302503 | 208301 | 2485 | 24898 | 43122 | 7659 | 13394 | 2644 |
| 2005 | 324993 | 226159 | 2601 | 26322 | 45190 | 7817 | 14077 | 2828 |
| 2006 | 350162 | 247669 | 3122 | 28240 | 46955 | 7306 | 13928 | 2943 |
| 2007 | 376960 | 269267 | 5165 | 29859 | 49010 | 5567 | 14777 | 3316 |
| 2008 | 403040 | 290681 | 6346 | 29839 | 51650 | 4766 | 16035 | 3724 |
| 2009 | 400458 | 282393 | 6446 | 30901 | 54382 | 4968 | 17531 | 3835 |
| UNESCO | |||||
| Indicator | GERD | GERD Performed by Business Enterprise Sector | GERD Performed by Government Sector | GERD Performed by Higher Education Sector | GERD Performed by Private Nonprofit Sector |
| Variable Name Year | UN_GERD | UN_GERD_BEP | UN_GERD_GOVP | UN_GERD_HEP | UN_GERD_PNPP |
| 1996 | 197792 | 142371 | 25504 | 2378 | 6209 |
| 1997 | 212709 | 155409 | 25801 | 24873 | 6626 |
| 1998 | 226934 | 167102 | 26320 | 26171 | 7341 |
| 1999 | 245548 | 182090 | 27041 | 28165 | 8252 |
| 2000 | 268121 | 199961 | 27685 | 30693 | 9782 |
| 2001 | 278239 | 202017 | 31358 | 33731 | 11133 |
| 2002 | 277066 | 193868 | 33647 | 37202 | 12349 |
| 2003 | 289736 | 200724 | 35703 | 40470 | 12839 |
| 2004 | 300293 | 208301 | 36567 | 43128 | 12297 |
| 2005 | 323047 | 226159 | 38526 | 45197 | 13164 |
| 2006 | 347809 | 247669 | 39573 | 46983 | 13584 |
| 2007 | 373185 | 269267 | 40472 | 49021 | 14425 |
| 2008 | 398194 | 289105 | 42225 | 51163 | 15701 |
| OECD | ||||||
| Indicator | GERD | BERD | GBAORD | GOVERD | HERD | GERD Performed by Nonprofit Sector |
| Variable Name Year | OECD_GERD | OECD_BERD | OECD_GBAORD | OECD_GOVERD | OECD_HERD | OECD_GERD_PNPP |
| 1981 | 72750 | 50425 | 33735 | 13455 | 7085 | 1784 |
| 1982 | 81166 | 57166 | 36115 | 14482 | 7603 | 1915 |
| 1983 | 90403 | 63683 | 38768 | 16294 | 8251 | 2175 |
| 1984 | 102874 | 73061 | 44214 | 18149 | 9154 | 2511 |
| 1985 | 115219 | 82376 | 49887 | 19775 | 10308 | 2761 |
| 1986 | 120562 | 85932 | 53249 | 20222 | 11540 | 2867 |
| 1987 | 126667 | 90160 | 57069 | 20686 | 12807 | 3013 |
| 1988 | 134202 | 94893 | 59106 | 21877 | 14220 | 3213 |
| 1989 | 142226 | 99860 | 62115 | 23065 | 15632 | 3669 |
| 1990 | 152389 | 107404 | 63781 | 23923 | 16936 | 4126 |
| 1991 | 161388 | 114675 | 65897 | 23858 | 18203 | 4652 |
| 1992 | 165835 | 116757 | 68398 | 24700 | 19385 | 4993 |
| 1993 | 166147 | 115435 | 69884 | 24956 | 20489 | 5267 |
| 1994 | 169613 | 117392 | 68331 | 25024 | 21598 | 5599 |
| 1995 | 184077 | 129830 | 68791 | 25813 | 22608 | 5827 |
| 1996 | 197792 | 142371 | 69049 | 25504 | 23708 | 6209 |
| 1997 | 212709 | 155409 | 71653 | 25801 | 24873 | 6626 |
| 1998 | 226934 | 167102 | 73569 | 26320 | 26171 | 7341 |
| 1999 | 245548 | 182090 | 77637 | 27041 | 28165 | 8252 |
| 2000 | 268121 | 199961 | 83613 | 27685 | 30693 | 9782 |
| 2001 | 278239 | 202017 | 91505 | 31358 | 33731 | 11133 |
| 2002 | 277066 | 193868 | 103057 | 33647 | 37202 | 12349 |
| 2003 | 289736 | 200724 | 114866 | 35703 | 40470 | 12839 |
| 2004 | 300293 | 208301 | 126271 | 36567 | 43128 | 12297 |
| 1005 | 325936 | 226159 | 131259 | 40378 | 45190 | 14209 |
| 1006 | 350923 | 247669 | 136019 | 42256 | 46955 | 14043 |
| 2007 | 377594 | 269267 | 141890 | 44474 | 49010 | 14843 |
| 2008 | 403668 | 290681 | 144391 | 45246 | 51650 | 16091 |
| 2009 | 401576 | 282393 | 164292 | 47118 | 54382 | 17683 |
| 2010 | 148448 | |||||
| Eurostat | ||||||
| Indicator | GERD | BERD | GBAORD | GOVERD | HERD | GERD Performed by Nonprofit Sector |
| Variable Name Year | EURO_GERD | EURO_BERD | EURO_GBAORD | EURO_GERD_GOVP | EURO_GERD_HEP | EURO_GERD_PNPP |
| 1982 | 72750 | 50425 | 33735 | 13455 | 7085 | 1784 |
| 1082 | 81166 | 57166 | 36115 | 14482 | 7603 | 1915 |
| 1983 | 90403 | 63683 | 38768 | 16294 | 8251 | 2175 |
| 1984 | 102874 | 73061 | 44214 | 18149 | 9154 | 2511 |
| 1985 | 115219 | 82376 | 49887 | 19775 | 10308 | 2761 |
| 1986 | 120562 | 85932 | 53249 | 20222 | 11540 | 2867 |
| 1987 | 126667 | 90160 | 57069 | 20686 | 12807 | 3013 |
| 1988 | 134202 | 94893 | 59106 | 21877 | 14220 | 3213 |
| 1989 | 142226 | 99860 | 62115 | 23065 | 15632 | 3669 |
| 1990 | 152389 | 107404 | 63781 | 23923 | 16936 | 4126 |
| 1991 | 161388 | 114675 | 65897 | 23858 | 18203 | 4652 |
| 1992 | 165835 | 116757 | 68398 | 24700 | 19385 | 4993 |
| 1993 | 166147 | 115435 | 69884 | 24956 | 20489 | 5267 |
| 1994 | 169613 | 117392 | 68331 | 25024 | 21598 | 5599 |
| 1995 | 184077 | 129830 | 68791 | 25813 | 22608 | 5827 |
| 1996 | 197792 | 142371 | 69049 | 25504 | 23708 | 6209 |
| 1997 | 212709 | 155409 | 71653 | 25801 | 24873 | 6626 |
| 1998 | 226934 | 167102 | 73569 | 26320 | 26171 | 7341 |
| 1999 | 245548 | 182090 | 77637 | 27041 | 28165 | 8252 |
| 2000 | 268121 | 199961 | 83613 | 27685 | 30693 | 9782 |
| 2001 | 278239 | 202017 | 91505 | 31358 | 33731 | 11133 |
| 2002 | 277066 | 193868 | 103057 | 33647 | 37202 | 12349 |
| 2003 | 289736 | 200724 | 114866 | 35703 | 40470 | 12839 |
| 2004 | 300293 | 208301 | 126271 | 36567 | 43128 | 12297 |
| 2005 | 323047 | 226159 | 131259 | 38526 | 45197 | 13164 |
| 2006 | 347809 | 247669 | 136019 | 39573 | 46983 | 13584 |
| 2007 | 373185 | 269267 | 141890 | 40472 | 49021 | 14425 |
| 2008 | 398194 | 289105 | 144391 | 42225 | 51163 | 15701 |
| 2009 | 164292 | |||||
| 2010 | 148448 | |||||
NOTES: BERD = business enterprise expenditure on research and development; EURO = Eurostat; FFRDC = federally funded research and development center; GBAORD = government budget appropriations or outlays for research and development; GDP = gross domestic product; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on research and development; HERD = higher education expenditure on research and development; IND = industry; NCSES = National Center for Science and Engineering Statistics; NP = nonprofit; PNPP = private nonprofit performed; R&D = research and development; RD = R&D; UC = universities and colleges; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: National Science Foundation (2012). National Patterns of R&D Resources: 2009 Data Update. NSF 12-321. National Center for Science and Engineering Statistics. Available: http://www.nsf.gov/statistics/nsf12321/ [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database [November 2012].
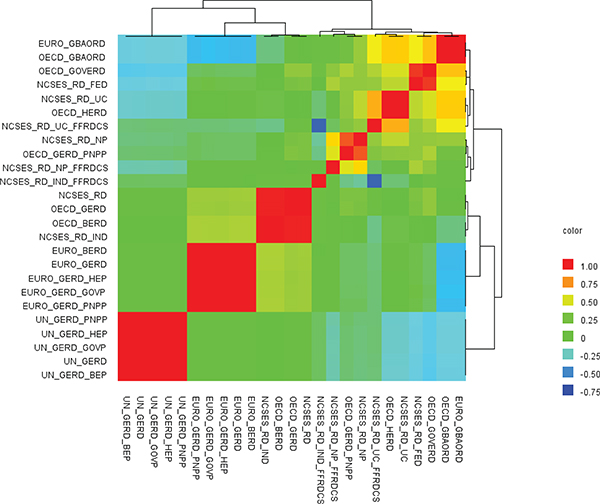
FIGURE F-10 Heat map of U.S. R&D expenditure variables from various STI databases.
NOTES: BEP = business enterprise performed; BERD = business enterprise expenditure on research and development; EURO = Eurostat; FFRDCs = federally funded R&D centers; GBAORD = government budget appropriations or outlays for research and development; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on research and development; GOVP = government sector performed; HEP = higher education sector performed; HERD = higher education expenditure on research and development; IND = industry; NCSES = National Center for Science and Engineering Statistics; NP = nonprofits; PNPP = private nonprofit performed; RD = research and development; UC = universities and colleges.
SOURCES: Panel analysis and National Science Foundation. (2012). National Patterns of R&D Resources: 2009 Data Update. NSF 12-321. National Center for Science and Engineering Statistics, available: http://www.nsf.gov/statistics/nsf12321/ [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database [November 2012].
a share of GDP, global high-value patents, doctoral degrees in engineering, and doctoral degrees in natural science are not strongly correlated with other indicators. Hence within the set of indicators analyzed, these four indicators stand apart. The reader should not assume that these indicators are unique, because the list of indicators analyzed here is small. The uniqueness might not hold if more indicators were included in the input matrix.
Single Nation Analysis
The clusters shown in Figures F-10 and F-11 are not surprising, as sector-specific expenditure variables are clustered together; i.e., business R&D expenditure figures are similar to each other irrespective of the data source. The same conclusion can be drawn for figures on expenditures on federal R&D, nonprofit R&D, and academic R&D.
Eurostat, OECD, and UNESCO report numbers of FTE researchers for the United States, but it is not clear how that number is calculated. NCSES and NCES report head counts of S&E human resources. Therefore, a disparity is seen in
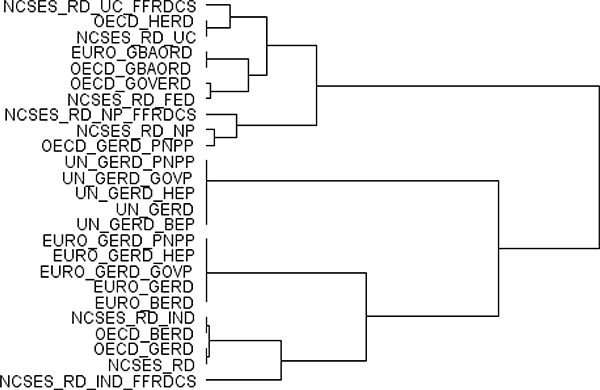
FIGURE F-11 Cluster map of U.S. R&D expenditure variables from various STI databases.
NOTES: BEP = business enterprise performed; BERD = business enterprise expenditure on research and development; EURO = Eurostat; FFRDCs = federally funded R&D centers; GBAORD = government budget appropriations or outlays for research and development; GERD = gross domestic expenditure on research and development; GOVERD = government intramural expenditure on research and development; GOVP = government sector performed; HEP = higher education sector performed; HERD = higher education expenditure on research and development; IND = industry; NCSES = National Center for Science and Engineering Statistics; NP = nonprofit; PNPP = private nonprofit performed; RD = research and development; UC = universities and colleges.
SOURCES: Panel analysis and National Science Foundation (2012). National Patterns of R&D Resources: 2009 Data Update. NSF 12-321. National Center for Science and Engineering Statistics, available: http://www.nsf.gov/statistics/nsf12321/ [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database [November 2012].
the metric that is reported, as U.S. head counts represent the supply of human capital not necessarily involved in R&D. FTE researchers show the contribution of labor hours to the R&D process; hence it is important for a researcher or an S&T policy maker to understand that different data sources may appear to report the same thing, but this usually is not the case. Figures F-12 and F-13 show that variables representing head counts are not strongly correlated with FTE researchers. One advantage of having so many variables is that as a user, one can select among them depending on the question being addressed. Table F-5 shows that the whole set of variables produced by NCSES is an attempt at capturing different segments of the S&E population, which range from scientists to medical researchers. Figures F-12 and F-13 show that variables from NCSES and NCES are clustered together, with variables reporting the same indicator being more strongly correlated (see the cluster of doctorate recipients, graduate students [NCSES], and doctoral degrees [NCES]). This suggests the possibility that NCSES may be overproducing some of the S&E human capital variables. As previously mentioned, however, agencies produce variables to answer particular policy questions. The end result is a trade-off between efficiency and addressing user needs. It is commendable that NCSES has been able to satisfy academicians and policy analysts alike, but a more resourceful approach is required under current budgetary conditions.
The panel would also like to highlight the efforts of NCSES to comply more closely with the recommendations of the Frascati Manual. The Survey of Industrial Research and Development (SIRD) (the old industrial survey) questionnaire contained items on FTE R&D scientists and engineers only. NCSES decided to resolve this data gap by including questions on researchers (FTE) and R&D personnel (head count) by gender; occupation (scientists and engineers, technicians, support staff); and location, including foreign locations. With the new data, it is possible to generate tabs, for example, on female technicians working in Belgium. The Survey of Research and Development Expenditures at Universities and Colleges (the old academic survey) contained a serious data gap in terms of information on R&D personnel in the academic sector. In 2010, NCSES began using the HERD survey to collect researcher and R&D personnel head counts. The HERD redesign investigation process indicated that collecting FTE data would be highly problematic,
whereas collecting principal investigator data appeared to be rather reasonable. Therefore, obtaining information on FTE researchers or R&D personnel in the academic sector still is not possible, but one can obtain head counts of researchers, principal investigators, and R&D personnel.
One point that came to the panel’s attention is that NCSES does not publish its main STI indicators on a single webpage. For national R&D expenditures, a user accesses National Patterns, while for human capital in S&E, one must generate tables from SESTAT. For further detail on academic R&D expenditures, WebCASPAR serves as a more useful tool. IRIS contains historical data tables on industrial R&D expenditures. SESTAT data feed into various NCSES publications, including (1) Characteristics of Scientists and Engineers in the U.S.; (2) Characteristics of Doctoral Scientists and Engineers in the U.S.; (3) Doctoral Scientists & Engineers Profile; (4) Characteristics of Recent College Grads; (5) Women, Minorities, and Persons with Disabilities in Science and Engineering; and (6) various InfoBriefs. It is difficult to find summary tables that combine information across all five publications. WebCASPAR contains detail on SEH degrees that is not available in SESTAT. When staff of the Committee on National Statistics downloaded STI databases of other agencies/organizations, they had an easier task because all variables were available on a single webpage.
TABLE F-7 Statistics on U.S. Science and Engineering Human Resources Produced by NCSES, NCES, UNESCO, OECD, and Eurostat
| Indicator | National Center for Science and Engineering Statistics | |||||||
| SESTAT | WEBCASPAR | |||||||
| Scientists and Engineers | Doctoral Scientists and Engineers | S&E Bachelor’s Degree Recipients | S&E Master’s Degree Recipients | S&E Doctorate Recipients (Includes Medical and Other Life Sciences) | SEH Graduate Students | SEH Postdoctorates | SEH Nonfaculty Research Staff | |
| Variable Name Year | SE | DSE | RCG_BACH | RCG_MAST | DOCREP_SE | GRADSTUD | POSTDOC | NONFACULTY_RES_STAFF |
| 1990 | 23823 | 452113 | 29565 | 5255 | ||||
| 1991 | 308500 | 57000 | 25060 | 471212 | 30865 | 5478 | ||
| 1992 | 25785 | 493522 | 32747 | 5482 | ||||
| 1993 | 11615200 | 513460 | 348900 | 73200 | 26640 | 504304 | 34322 | 6001 |
| 1994 | 27500 | 504399 | 36377 | 6209 | ||||
| 1995 | 12036200 | 542540 | 354450 | 74750 | 27864 | 499640 | 35926 | 6534 |
| 1996 | 354450 | 74750 | 28564 | 494079 | 37107 | 6604 | ||
| 1997 | 12530700 | 582080 | 371500 | 78500 | 28650 | 487208 | 38481 | 6722 |
| 1998 | 371500 | 78500 | 28773 | 485627 | 40086 | 7100 | ||
| 1999 | 13050800 | 626700 | 379150 | 80050 | 27338 | 493256 | 40800 | 7573 |
| 2000 | 379150 | 80050 | 27557 | 493311 | 43115 | 7879 | ||
| 2001 | 656550 | 468850 | 123350 | 27,069 | 509607 | 43311 | 7531 | |
| 2002 | 468850 | 123350 | 26263 | 540404 | 45034 | 7906 | ||
| 2003 | 21647000 | 685300 | 521833 | 138967 | 26916 | 567121 | 46728 | 8473 |
| 2004 | 521833 | 138967 | 27993 | 574463 | 47240 | 9075 | ||
| 2005 | 521833 | 138967 | 29768 | 582226 | 48555 | 9527 | ||
| 2006 | 22630000 | 711800 | 467000 | 102000 | 31774 | 597643 | 49343 | 10814 |
| 2007 | 467000 | 102000 | 33974 | 619499 | 50840 | 10752 | ||
| 2008 | 10204000 | 752000 | 34926 | 631489 | 54164 | 13747 | ||
| 2009 | 35562 | 631645 | 57805 | 14059 | ||||
| 2010 | 35253 | 632652 | 63415 | |||||
| Indicator | National Center for Science and Engineering Statistics | ||||||
| Women, Minorities and Persons with Disabilities in Science and Engineering | International Organizations | ||||||
| UNESCO | OECD | Eurostat | |||||
| S&E Bachelor’s Degrees | S&E Master’s Degrees | S&E Doctoral Degrees | Researchers (FTE) | Researchers (FTE) | Researchers in Business Enterprise Sector (FTE) | Researchers (FTE) | |
| Variable Name Year | BACH_SE | MAST_SE | DOC_SE | UN_RES_FTE | OECD_RES_FTE | EURO_RES_BEMPOCC_FTE | EURO_RES_PERSOCC_FTE |
| 1990 | 329094 | 77788 | 22868 | 758500 | |||
| 1991 | 337675 | 78368 | 24023 | 981659 | 776400 | 981659 | |
| 1992 | 355265 | 81107 | 24675 | 772000 | |||
| 1993 | 366035 | 86425 | 25443 | 1013772 | 766600 | 1013772 | |
| 1994 | 373261 | 91411 | 26205 | 757300 | |||
| 1995 | 378148 | 94309 | 26536 | 1035995 | 789400 | 1035995 | |
| 1996 | 384674 | 95313 | 27243 | 859300 | |||
| 1997 | 388482 | 93485 | 27232 | 1159908 | 1159908 | 918600 | 1159908 |
| 1998 | 390618 | 93918 | 27278 | 997700 | |||
| 1999 | 25933 | 1260920 | 1260920 | 1033700 | 1260920 | ||
| 2000 | 398622 | 95683 | 25966 | 1293582 | 1293582 | 1041300 | 1293582 |
| 2001 | 400435 | 99,528 | 25453 | 1320305 | 1320305 | 1060000 | 1320096 |
| 2002 | 415983 | 99650 | 24254 | 1342454 | 1342454 | 1075300 | 1342454 |
| 2003 | 442755 | 108355 | 25425 | 1430551 | 1430551 | 1156000 | 1430551 |
| 2004 | 458658 | 119296 | 26573 | 1384536 | 1384536 | 1111300 | 1384536 |
| 2005 | 470214 | 120870 | 28561 | 1375304 | 1375304 | 1097700 | 1375304 |
| 2006 | 478858 | 120999 | 30452 | 1414341 | 1414341 | 1135500 | 1414341 |
| 2007 | 485772 | 120278 | 32588 | 1412639 | 1412639 | 1130500 | 1412639 |
| 2008 | 496168 | 126404 | 33359 | ||||
| 2009 | 505435 | 134517 | 33284 | ||||
NOTES: BACH = bachelor’s degrees; BEMPOCC = business enterprise sector; DOCREP = doctorate recipients; DSE = doctoral scientists and engineers; EURO = Eurostat; FTE = full-time equivalent; GRADSTUD = graduate students; MAST = master’s degrees; PERSOCC = researchers FTE; POSTDOC = postdoctorates; RCG = recent college graduates; RES = researchers; S&E = science and engineering; SEH = science, engineering, and health; SESTAT = Scientists and Engineers Statistical Data System; UN = United Nations; UNESCO = United Nations Educational, Scientific and Cultural Organization.
SOURCES: WebCASPAR, see https://webcaspar.nsf.gov [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB [November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database [November 2012].
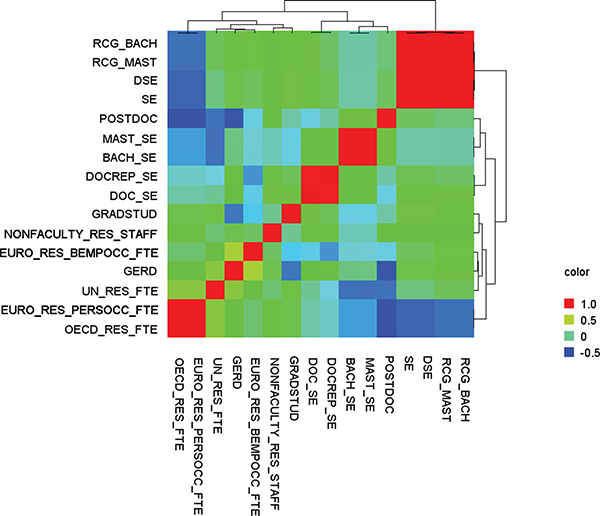
FIGURE F-12 Heat map of U.S. human capital variables from various STI databases.
NOTES: BACH = bachelor’s degrees; BEMPOCC = business enterprise sector; DOC = doctorate; DOCREP = doctorate recipients; DSE = doctoral scientists and engineers; EURO = Eurostat; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; GRADSTUD = graduate students; MAST = master’s degrees; PERSOCC = researchers FTE; RCG = recent college graduates; RES = researchers; SE = science and engineering; UN = United Nations.
SOURCES: Panel analysis and WebCASPAR, see https://webcaspar.nsf.gov [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database [November 2012].
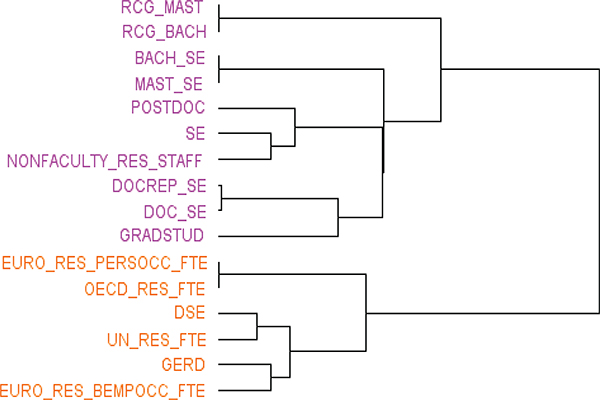
FIGURE F-13 Cluster map of U.S. human capital variables from various STI databases.
NOTES: BACH = bachelor’s degrees; BEMPOCC = business enterprise sector; DOC = doctorate; DOCREP = doctorate recipients; DSE = doctoral scientists and engineers; EURO = Eurostat; FTE = full-time equivalent; GERD = gross domestic expenditure on research and development; GRADSTUD = graduate students; MAST = master’s degrees; PERSOCC = researchers FTE; RCG = recent college graduates; RES = researchers; SE = science and engineering; UN = United Nations.
SOURCES: Panel analysis and WebCASPAR, see https://webcaspar.nsf.gov [November 2012]. UNESCO, see http://www.uis.unesco.org/ScienceTechnology/Pages/default.aspx [November 2012]. OECD, see http://stats.oecd.org/Index.aspx?DataSetCode=MSTI_PUB November 2012]. Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database [November 2012].
TABLE F-8 Innovation Statistics from NCSES (2006-2008) and Statistics Canada (2003)
| United States: National Center for Science and Engineering Statistics | |||||||
| Industry Classification | 2006-2008: Number of Companies Who Answered Yes to Innovating | ||||||
| Any Good/Service | Goods | Services | Any Process | Mfgr./Production Methods | Logistic/Delivery/Distribution Methods | Support Activities | |
|
Manufacturing industries, 31–33 |
27962 | 22878 | 12710 | 27962 | 22878 | 8897 | 16523 |
|
Food, 311 |
1547 | 1456 | 455 | 1547 | 1183 | 546 | 637 |
|
Beverage/tobacco products, 312 |
204 | 156 | 72 | 180 | 108 | 72 | 96 |
|
Textile/apparel/leather and allied products, 313–16 |
1159 | 915 | 549 | 1098 | 793 | 427 | 732 |
|
Wood products, 321 |
549 | 366 | 305 | 976 | 793 | 183 | 366 |
|
Chemicals, 325 |
2419 | 1947 | 1062 | 2006 | 1298 | 1003 | 1180 |
|
Pharmaceuticals/medicines, 3254 |
675 | 360 | 405 | 630 | 270 | 405 | 480 |
|
Other, 325 |
1760 | 1584 | 660 | 1364 | 1012 | 616 | 704 |
|
Plastics/rubber products, 326 |
1464 | 1281 | 671 | 1708 | 1464 | 488 | 915 |
|
Nonmetallic mineral products, 327 |
702 | 594 | 270 | 756 | 594 | 216 | 432 |
|
Primary metals, 331 |
357 | 273 | 231 | 399 | 357 | 84 | 231 |
|
Fabricated metal products, 332 |
4176 | 2871 | 2349 | 5742 | 4959 | 1305 | 3132 |
|
Machinery, 333 |
3120 | 2760 | 1320 | 2880 | 2520 | 600 | 1800 |
|
Computer/electronic products, 334 |
3150 | 3010 | 1260 | 2310 | 1820 | 770 | 1260 |
|
Computers/peripheral equipment, 3341 |
336 | 282 | 156 | 276 | 186 | 114 | 126 |
|
Communications equipment, 3342 |
408 | 408 | 168 | 264 | 200 | 56 | 136 |
|
Semiconductor/other electronic components, 3344 |
675 | 625 | 250 | 625 | 475 | 175 | 350 |
|
Navigational/measuring/electromedical/control instruments, 3345 |
1534 | 1508 | 624 | 1040 | 936 | 416 | 572 |
|
Other, 334 |
185 | 175 | 65 | 70 | 50 | 15 | 50 |
|
Electrical equipment/appliance/components, 335 |
1036 | 1008 | 308 | 784 | 672 | 336 | 588 |
|
Transportation equipment, 336 |
1512 | 1350 | 594 | 1242 | 972 | 270 | 810 |
|
Motor vehicles/trailers/parts, 3361–63 |
792 | 726 | 264 | 726 | 627 | 99 | 462 |
|
Aerospace products/parts, 3364 |
288 | 261 | 171 | 225 | 144 | 63 | 180 |
|
Other, 336 |
455 | 403 | 156 | 325 | 195 | 104 | 208 |
|
Furniture/related products, 337 |
1092 | 1014 | 468 | 1482 | 936 | 390 | 936 |
|
Manufacturing nec, other 31–33 |
5302 | 4097 | 2892 | 5543 | 4097 | 1687 | 3374 |
|
Nonmanufacturing industries, 21–23, 42–81 |
113432 | 42537 | 99253 | 113432 | 28358 | 42537 | 85074 |
|
Information, 51 |
6930 | 3696 | 5775 | 4620 | 1617 | 2310 | 3696 |
|
Software publishers, 5112 |
3080 | 2320 | 2240 | 2120 | 760 | 880 | 1720 |
|
Telecommunications/Internet service providers/Web search portals/data processing services, 517–18 |
2331 | 945 | 2142 | 1386 | 441 | 693 | 1260 |
|
Other, 51 |
1548 | 516 | 1419 | 1290 | 516 | 903 | 774 |
|
Finance/insurance, 52 |
4472 | 559 | 4472 | 4472 | 559 | 1118 | 3913 |
|
Real estate/rental/leasing, 53 |
3430 | 2940 | 2450 | 2940 | 980 | 980 | 2940 |
|
Professional/scientific/technical services, 54 |
22568 | 10416 | 20832 | 20832 | 6944 | 8680 | 17360 |
|
Computer systems design/related services, 5415 |
6790 | 3880 | 5820 | 4850 | 1552 | 1358 | 4462 |
|
Scientific R&D services, 5417 |
1023 | 744 | 682 | 806 | 465 | 186 | 434 |
|
Other, 54 |
15110 | 6044 | 13599 | 15110 | 6044 | 6044 | 12088 |
|
Health care services, 621–23 |
18350 | 5505 | 16515 | 14680 | 5505 | 5505 | 12845 |
|
Nonmanufacturing nec, other 21–23, 42–81 |
55968 | 27984 | 46640 | 65296 | 18656 | 18656 | 46640 |
| Canada: Statistics Canada | ||||||
| Industry Classification | 2003: Percentage of Business Units | |||||
| Both Product and Process Innovators | Innovators | Process Innovators | Process Innovators Only | Product Innovators | Product Innovators Only | |
|
Air transportation [481] |
22.4 | 36.7 | 32.7 | 10.2 | 26.5 | 4.1 |
|
Airport operations [48811] |
17.1 | 46.3 | 41.5 | 24.4 | 22.0 | 4.9 |
|
Cable and other program distribution [5175] |
42.8 | 66.5 | 42.8 | 0 | 66.5 | 23.7 |
|
Computer and communications equipment and supplier wholesaler-distributors [4173] |
28.2 | 65.1 | 37.3 | 9.1 | 56.0 | 27.8 |
|
Computer systems design and related services [54151] |
35.4 | 87.2 | 42.0 | 6.6 | 80.6 | 45.2 |
|
Contract drilling (except oil and gas) [213117] |
14.3 | 32.1 | 17.9 | 3.6 | 28.6 | 14.3 |
|
Data processing, hosting, and related services [5182] |
50.0 | 72.4 | 63.8 | 13.8 | 58.6 | 8.6 |
|
Electronic and precision equipment repair and maintenance [8112] |
18.4 | 53.3 | 33.4 | 15.1 | 38.3 | 19.9 |
|
Engineering services [54133] |
21.1 | 55.3 | 32.0 | 10.9 | 44.5 | 23.4 |
|
Environmental consulting services [54162] |
32.8 | 67.3 | 45.9 | 13.1 | 54.2 | 21.4 |
|
Geophysical surveying and mapping services [54136] |
14.6 | 57.8 | 41.4 | 26.8 | 31.0 | 16.4 |
|
Industrial design services [54142] |
27.6 | 53.9 | 31.3 | 3.7 | 50.2 | 22.5 |
|
Information and communication technology (ICT) service industries |
37.2 | 78.2 | 44.1 | 6.9 | 71.3 | 34.1 |
|
Internet service providers [518111] |
58.2 | 75.4 | 61.2 | 3 | 72.4 | 14.2 |
|
Interurban and rural bus transportation [4852] |
18.8 | 43.8 | 25 | 6.3 | 37.5 | 18.8 |
|
Management consulting services [54161] |
26.5 | 44.1 | 35 | 8.5 | 35.7 | 9.1 |
|
Management, scientific and technical consulting services [5416] |
26.6 | 47.1 | 35.9 | 9.2 | 37.8 | 11.2 |
|
Office and store machinery and equipment wholesalers-distributors [41791] |
37.2 | 61.8 | 42.7 | 5.5 | 56.3 | 19.1 |
| Canada: Statistics Canada | ||||||
| Industry Classification | 2003: Percentage of Business Units | |||||
| Both Product and Process Innovators | Innovators | Process Innovators | Process Innovators Only | Product Innovators | Product Innovators Only | |
|
Office machinery and equipment rental and leasing [53242] |
30.0 | 52.6 | 37.7 | 7.7 | 44.9 | 14.9 |
|
Other machinery, equipment and supplies wholesaler-distributors [4179] |
26.0 | 63.8 | 33.7 | 7.7 | 56.1 | 30.1 |
|
Other scientific and technical consulting services [54169] |
23.8 | 52.2 | 35.1 | 11.3 | 40.9 | 17.2 |
|
Other support activities for mining [213119] |
20.0 | 34.5 | 29.1 | 9.1 | 25.5 | 5.5 |
|
Other telecommunications [5179] |
||||||
|
Port and harbour operations [48831] |
20.7 | 41.4 | 41.4 | 20.7 | 20.7 | 0 |
|
Rail transportation [482] |
0 | 53.3 | 33.3 | 33.3 | 20 | 20 |
|
Research and development in the physical, engineering and life sciences [54171] |
32.2 | 68.1 | 44.3 | 12.1 | 56.1 | 23.9 |
|
Research and development in the social sciences and humanities [54172] |
21.2 | 60.1 | 50.5 | 29.3 | 30.8 | 9.6 |
|
Satellite telecommunications [5174] |
62.7 | 100 | 73.7 | 11.1 | 88.9 | 26.3 |
|
Scientific research and development services [5417] |
30.1 | 66.6 | 45.5 | 15.4 | 51.3 | 21.1 |
|
Software publishers [5112] |
53.1 | 94.3 | 59.3 | 6.2 | 88.1 | 35.0 |
|
Support activities for forestry [1153] |
10.3 | 28.7 | 25.0 | 14.7 | 13.9 | 3.6 |
|
Surveying and mapping (except geophysical) services [54137] |
23.6 | 51.2 | 48.2 | 24.6 | 26.6 | 3.0 |
|
Telecommunications resellers [5173] |
29.4 | 74.5 | 29.4 | 0 | 74.5 | 45.0 |
|
Testing laboratories [54138] |
20.0 | 51.9 | 33.5 | 13.5 | 38.4 | 18.4 |
|
Truck transportation [484] |
10.9 | 25.7 | 20.8 | 9.9 | 15.8 | 5.0 |
|
Water transportation [483] |
8.3 | 20.8 | 16.7 | 8.3 | 12.5 | 4.2 |
|
Web search portals [518112] |
||||||
|
Wired telecommunications carriers [5171] |
57.8 | 75.4 | 60.5 | 2.6 | 72.8 | 15.0 |
|
Wireless telecommunications carriers (except satellite) [5172] |
43.5 | 60.0 | 49.1 | 5.6 | 54.4 | 10.9 |
SOURCES: Adapted from National Science Foundation (2010). NSF Releases New Statistics on Business Innovation. NSF 11-300. National Center for Sci - ence and Engineering Statistics, available: http://www.nsf.gov/statistics/infbrief/nsf11300/ [November 2012]. Statistics Canada, Adapted from CANSIM Table 358-00321, 2 Survey of Innovation, selected service industries, percentage of innovative business units [November 2012].
TABLE F-9 Innovation Statistics from Eurostat, 2006 and 2008
| European Union: Eurostat | ||||||
| 2006: Number of Enterprises with Type of Innovation | ||||||
| Industry Classification | Technological Innovation | Novel Innovators, Product Only | Novel Innovators, Process Only | Introduced Organizational/Marketing Innovation | ||
| Agriculture, forestry and fishing | ||||||
| Mining and quarrying | 1402 | 239 | 559 | 652 | ||
| Manufacturing | 158629 | 35531 | 42018 | 76297 | ||
| Electricity, gas, steam and air conditioning supply | 2340 | 228 | 1191 | 1233 | ||
| Water supply; sewerage, waste management and remediation activities Construction | 19202 | 6528 | 7809 | 1751 | ||
| Wholesale and retail trade; repair of motor vehicles and motorcycles | 42233 | 7413 | 18292 | 15994 | ||
| Transportation and storage | ||||||
| Accommodation and food service activities | ||||||
| Information and communication | ||||||
| Financial and insurance activities | ||||||
| Real estate activities | ||||||
| Professional, scientific and technical activities | ||||||
| Administrative and support service activities | ||||||
| Hotels and restaurants | 5422 | 1306 | 2999 | 333 | ||
| Transport, storage and communication | 24702 | 4304 | 7301 | 13065 | ||
| Financial intermediation | 8792 | 1416 | 2200 | 4847 | ||
| Real estate, renting and business activities | 22748 | 4849 | 6395 | 6442 | ||
| Industry Classification | 2008: Number of Enterprises with Type of Innovation | |||||
| Innovation Activity | Technological Innovation Only | Innovation Activity | Novel Innovator, Product Only | Novel Innovators, Process Only | ||
|
Agriculture, forestry and fishing |
2799 | 1223 | 579 | 524 | 862 | |
|
Mining and quarrying |
4072 | 595 | 523 | 181 | 648 | |
|
Manufacturing |
446126 | 50774 | 39981 | 36255 | 44047 | |
|
Electricity, gas, steam and air conditioning supply |
4919 | 541 | 792 | 208 | 682 | |
|
Water supply; sewerage, waste management and remediation activities |
13891 | 1785 | 1719 | 702 | 1784 | |
|
Construction |
42042 | 9470 | 17805 | 3716 | 11230 | |
|
Wholesale and retail trade; repair of motor vehicles and motorcycles |
75102 | 12742 | 30184 | 7422 | 14042 | |
|
Transportation and storage |
72156 | 6310 | 12699 | 2822 | 8501 | |
|
Accommodation and food service activities |
15062 | 2492 | 6628 | 939 | 2048 | |
|
Information and communication |
27343 | 5300 | 4337 | 6748 | 2874 | |
|
Financial and insurance activities |
28580 | 1655 | 3065 | 1948 | 2483 | |
|
Real estate activities |
2631 | 361 | 1198 | 327 | 588 | |
|
Professional, scientific and technical activities |
19809 | 4521 | 5565 | 2978 | 3870 | |
|
Administrative and support service activities |
7909 | 1563 | 3557 | 910 | 1947 | |
|
Hotels and restaurants |
||||||
|
Transport, storage and communication |
||||||
|
Financial intermediation |
||||||
|
Real estate, renting and business activities |
||||||
SOURCES: Eurostat, see http://epp.eurostat.ec.europa.eu/portal/page/portal/science_technology_innovation/data/database[November 2012].
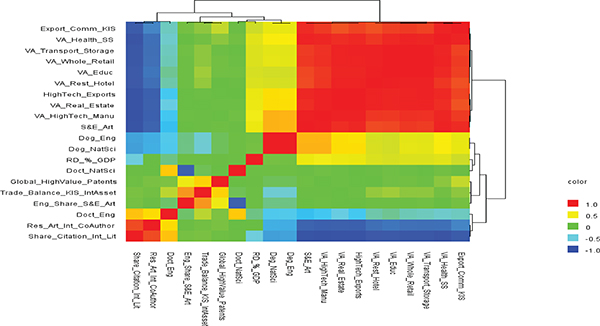
FIGURE F-14 Heat map of science and engineering indicators from SEI 2012 Digest.
NOTE: GDP = gross domestic product; KIS = knowledge-intensive services; RD = research and development; S&E = science and engineering; SS = social services; VA = global value added. SOURCE: Panel analysis and Science and Engineering Indicators 2012, see http://www.nsf.gov/statistics/seind12/tables.htm [November 2012].
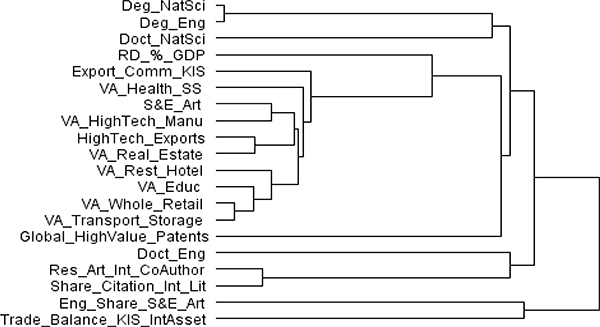
FIGURE F-15 Hierarchical cluster of science and engineering indicators from SEI 2012 Digest.
NOTES: GDP = gross domestic product; KIS = knowledge-intensive services; RD = research and development; S&E = science and engineering; SS = social services; VA = global value added.
SOURCE: Panel analysis and Science and Engineering Indicators 2012, see http://www.nsf.gov/statistics/seind12/tables.htm [November 2012].
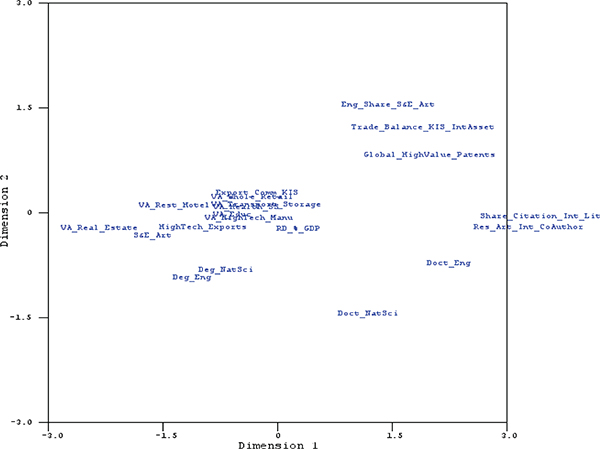
FIGURE F-16 Multidimensional scaling of science and engineering indicators from SEI 2012 Digest.
NOTES: GDP = gross domestic product; KIS = knowledge-intensive services; RD = research and development; S&E = science and engineering; SS = social services; VA = global value added.
SOURCE: Panel analysis and Science and Engineering Indicators 2012, see http://www.nsf.gov/statistics/seind12/tables.htm [November 2012].
This page intentionally left blank.












































