
8
Evaluating the Quality of Performance Measures: Criterion-Related Validity Evidence
Investigations of empirical relationships between test scores and criterion measures (e.g., training grades, supervisor ratings, job knowledge test scores) have long been central to the evaluation and justification of using test scores to select and classify personnel in both civilian and military contexts. Such investigations, commonly known as criterion-related validity studies, seek evidence that performance on criteria valued by an organization can be predicted with a useful degree of accuracy from test scores or other predictor variables. The implications of a criterion-related validity study depend only secondarily, however, on the strength of the statistical relationship that is obtained. They depend first and foremost on the validity and acceptance of the criterion measure itself.
As summarized by the Office of the Assistant Secretary of Defense —Force Management and Personnel (1987), the program of criterion-related validity studies conducted by the Services in the past was generally based on the statistical relationship between aptitude test scores (i.e., the ASVAB) and performance in military training. Performance in basic and technical training has been the traditional criteria with which the Services validate their selection and classification measures because the data are credible, reasonably reliable, and available.
Training criteria are certainly relevant to the mission of the Services. Failures in training are expensive, and a logical case can be made that training outcomes should be related to performance on the job. The weak-
ness of training outcomes, however, is that they tend to be primarily scores on paper-and-pencil tests of cognitive knowledge that do not tap many of the important aspects of job proficiency, such as psychomotor ability or problem-solving skills (Office of the Assistant Secretary of Defense—Force Management and Personnel, 1987:1-2).
Concerns about the criterion measures that were most commonly used to validate the ASVAB in the past provided much of the motivation for the JPM Project, the goals of which, as has been noted, “are to (1) develop prototype methodologies for the measurement of job performance; and (2) if feasible, link enlistment standards to on-the-job performance” (Office of the Assistant Secretary of Defense—Force Management and Personnel, 1987:3). Realization of the first of these goals would make possible the use of measures of job performance in criterion-related validity studies, the results of which are a necessary, albeit not sufficient, condition for realizing the second goal of the project.
OVERVIEW OF CRITERION-RELATED VALIDATION
Criterion Constructs: Measurement and Justification
Given an adequate criterion measure, the criterion-related test validation paradigm—though subject to a variety of technical complications that will be considered below—is conceptually straightforward. Basically, empirical evidence is needed to establish the nature and degree of relationship between test scores and scores on the criterion measure. But the opening phrase of this paragraph assumes away the “criterion problem,” which is the most fundamental problem in criterion-related validation research. Indeed, as Gottfredson (Vol. II:1) points out, it is one of the most important but most difficult problems of personnel research.
Some 40 years ago, Thorndike (1949) defined the “ultimate criterion” as “the complete final goal of a particular type of selection or training ” (p. 121). Thorndike's ultimate criterion is an abstraction that is far removed from actual criterion measures. The notion of the ultimate criterion, however, provides a useful reminder that measures that can be realized in practice are only approximations of the conceptual criteria of interest. The value of a criterion-related study depends on the closeness of the criterion measure to this conceptual ultimate criterion.
The conceptual criterion of interest for the JPM Project is actual on-the-job performance. The reasons for this choice are evident. Among the justifications that might be presented for the use of a test to select or classify applicants, none is apt to be more persuasive or intuitively appealing than the demonstration that test scores predict actual on-the-job performance. Like Thorndike's ultimate criterion, however, actual on-the-job performance
is not something that can be simply counted or scored and then correlated with test scores. Rather, as described in Chapter 4, Chapter 6, and Chapter 7, measures of job performance must be developed and justified. They must be accepted as valid, reliable, and relevant to the goals of the Services before they can serve as the criteria by which the validity of aptitude tests will, in turn, be judged. It is for these reasons that previous chapters have devoted so much attention to the development, validation, and assessment of the reliability of job performance measures.
There is no need to repeat the discussion of previous chapters regarding the evaluation of the quality of criterion measures. However, two threats to the validity of any criterion measure deserve special emphasis here and will guide the discussion of specific criterion measures in subsequent sections. Criterion contamination occurs when the criterion measure includes aspects of performance that are not part of the job or when the measure is affected by “construct-irrelevant ” (Messick, 1989) factors that are not part of the criterion construct. Criterion deficiency occurs when the criterion measure fails to include or underrepresents important aspects of the criterion construct.
Criterion contamination and criterion deficiency are illustrated by training criteria, whose weaknesses were acknowledged by the Office of the Assistant Secretary of Defense—Force Management and Personnel (1987). Training grades, which are based largely on written tests of cognitive knowledge about the job, may be contaminated by a greater dependence on certain cognitive abilities, such as verbal ability, than is true of actual on-the-job performance. And training measures may be deficient if they leave out tasks that require manipulation of equipment that may be crucial to successful job performance. Concerns about possible criterion contamination and deficiency are not limited to measures of training performance. A hands-on job performance measure, for example, might lack validity because it represents only a small, or atypical, fraction of the important tasks that an individual is required to perform on the job (criterion deficiency). Ratings of the adequacy of performance of a hands-on task might be influenced by irrelevant personal characteristics, such as race, gender, or personal appearance (criterion contamination).
Criterion contamination is most serious when construct-irrelevant factors that influence the criterion measure are correlated with the predictors. Similarly, criterion deficiency is most serious when the criterion measure fails to include elements of job performance that are related to the predictor constructs (Brogden and Taylor, 1950). Of particular concern are situations in which criterion deficiency or contamination “enhance[s] the apparent validity of one predictor while lowering the apparent validity of another” (Cronbach, 1971:488). An understanding of predictor constructs and criterion constructs is necessary to evaluate these possibilities.
Predictor-Criterion Relationships
The relationship between a predictor and a criterion measure may be evaluated in a variety of ways (see, e.g., Allred, Vol. II). Correlation coefficients are often used to express the relationship, but a more basic summary is provided by simple tables and graphs. In the most basic form, the data of a criterion-related validation study using a single test and a single criterion measure consist of pairs of test and criterion scores for each person or counts of the number of times each combination of test and criterion scores occurs.
Consider, for example, a simple hypothetical situation with three levels of test scores (low, middle, and high) and four levels of criterion performance (unacceptable, adequate, above average, and superior). Pairs of test and job performance criterion scores are obtained for a sample of 400 individuals. The number of people with each possible combination of test and criterion scores is shown in Table 8-1. This simple table contains all the information about the relationship between the test scores and the criterion measure. With such a small number of possible scores on the test and the criterion, this basic two-way table can also be used to summarize the findings. For example, individuals with low test scores are most likely to have performance on the criterion that is unacceptable (47 of 100 compared with 16 of 200 with test scores in the middle range or 2 of 100 for those with high test scores). Similarly, the percentage of individuals with high test scores who had superior criterion performance scores (15 percent) is nearly twice that of the total group (33 of 400, or about 8 percent) and 7.5 times as great as that of individuals with low test scores (2 percent).
Such simple frequencies provide the basis for constructing another useful summary of the data, known as an expectancy table. “Such a table reports the estimated probability that people with particular values on a test, or on a combination of predictors, will achieve a certain score or higher on the criterion” (Wigdor and Garner, 1982:53). The expectancy table corresponding to the Table 8-1 frequencies is shown as Table 8-2. As can be seen, almost all individuals with high test scores (98 percent) are predicted to
TABLE 8-1 Frequency of Test and Criterion Score Combinations
|
Criterion Performance |
Test Score |
|||
|
Low |
Middle |
High |
Total |
|
|
Superior |
2 |
16 |
15 |
33 |
|
Above average |
11 |
24 |
30 |
65 |
|
Adequate |
40 |
144 |
53 |
237 |
|
Unacceptable |
47 |
16 |
2 |
65 |
|
Total |
100 |
200 |
100 |
400 |
TABLE 8-2 Illustrative Expectancy Table: Estimated Probability of a Particular Level of Job Performance Given a Particular Test Score
|
Criterion Performance |
Test Score |
||
|
Low |
Middle |
High |
|
|
Superior |
2 |
8 |
15 |
|
Above average or better |
13 |
20 |
45 |
|
Adequate or better |
53 |
92 |
98 |
have adequate or better criterion performance and nearly half of them (45 percent) are predicted to have performance that is above average or superior. And almost half (47 percent; 100 percent minus the 53 percent predicted to have adequate or better performance) of the individuals with low test scores would be expected to perform at an unacceptable level.
In addition to demonstrating a relationship, an expectancy table makes it obvious that even when the relationship is relatively strong, as in the illustrative example, there will be errors of prediction. Although the vast majority of individuals with high test scores would be expected to have adequate criterion performance, 2 percent would still be expected to perform at an unacceptable level. Similarly, 2 percent of the individuals with low test scores would be expected to have superior performance on the criterion.
If the criterion categories of unacceptable, adequate, above average, and superior used for the example in Table 8-1 were given score values of 1, 2, 3, and 4, respectively, a mean score on the criterion measure for individuals in each of the three test score categories could be easily computed (Table 8-3). The tendency shown in Table 8-1 and Table 8-2 for individuals with higher test scores also to have higher performance on the criterion than their counterparts with lower test scores is again apparent in Table 8-3. What is lost, however, is an indication of the degree of error in the predicted performance (e.g., the fact that 2 percent of the individuals with low test scores had superior criterion performance).
A variety of tabular and graphical summaries similar in general nature to the above tables can be useful in summarizing relationships between test scores and criterion measures. Scatter diagrams and tables or figures show
TABLE 8-3 Mean Criterion Scores for the Total Sample and for Groups with Low, Middle, and High Test Scores
|
Test Score |
||||
|
Low |
Middle |
High |
Total Sample |
|
|
Criterion mean |
1.68 |
2.20 |
2.58 |
2.16 |
ing the spread as well as the average criterion scores of individuals with specified levels of test scores are particularly useful. See Allred (Vol. II) for a detailed discussion of these and other related techniques.
Although graphs and tables have considerable utility, more concise statistical summaries are more typical and can also be useful for certain purposes. The most common statistical summaries of criterion-related validity results are correlation coefficients and regression equations. A correlation coefficient summarizes in a single number ranging from −1.0 to 1.0 the degree of relationship between test scores and a criterion measure (or between other pairs of variables). A correlation of .0 indicates that there is no linear relationship between the two sets of scores, while a correlation of 1.0 (or −1.0) indicates that there is a perfect positive (or negative) relationship.
For simplicity, only linear relationships are considered here. Linear relationships are commonly assumed and widely used in criterion-related validity studies. It is important, however, to keep in mind the possibility that relationships are nonlinear; a variety of techniques is available to investigate the possibility of nonlinearity (see, e.g., Allred, Vol. II).
The correlation between test scores and scores on the criterion for the data in Table 8-1 is .40. In practice, an observed correlation (validity coefficient) of this magnitude between test scores and scores on a criterion would not be unusual.
A linear regression equation expresses the relationship between the test and the criterion scores in terms of a predicted level of criterion score for each value of the test score (low = 1, middle = 2, and high = 3). For the example in Table 8-1, the regression equation is as follows: predicted criterion score = 1.265 + .45 × the test score. Thus, the predicted criterion scores are 1.72, 2.16, and 2.62 for individuals with test scores of 1, 2, and 3, respectively. These predicted values may be compared with the mean criterion scores of 1.68, 2.20, and 2.58 for the three respective score levels (see Table 8-3). The small differences between the two sets of values are due to the use of a linear approximation in the regression equation.
This general overview has ignored a number of complications that must be considered in criterion-related validity studies. For example, the effects of the reliability of the criterion measure, the effects of basing coefficients only on samples of job incumbents who have already been selected on the basis of test scores and successful completion of training, and the possibility that validities and predictive equations may differ as a function of subgroup (e.g., men and women or blacks, whites, and Hispanics)—are all important considerations in a criterion-related validity study. Issues of how multiple criterion measures should be combined, the degree of generalization of validities across jobs, and the degree to which different combinations of predictors yield different validities across jobs are also critical considerations. Some of these complications are considered in this chapter.
Because they are better dealt with in the specific context of the JPM Project, we now turn to a discussion of some of the specifics of the project that are most relevant to an evaluation of the criterion-related validity evidence.
THE NATURE AND INTERRELATIONSHIPS OF CRITERION MEASURES
As discussed in previous chapters, hands-on performance measures are viewed as providing the “benchmark data to evaluate certain surrogate (less expensive, easier to administer tests and/or existing performance information) indices of performance as substitutes for the more expensive, labor intensive hands-on job performance” (Office of the Assistant Secretary of Defense—Force Management and Personnel, 1987:3). Consequently, the quality of hands-on measures takes on special importance within the context of the JPM Project.
It is reasonable to consider hands-on performance measures as benchmarks only to the degree that they are valid and reliable measures of job performance constructs. The threats to validity of criterion contamination and criterion deficiency apply as much to hands-on measures as to alternative criterion measures, such as job knowledge tests, ratings, or administrative records. As is also true of other types of measures, the quality of hands-on measures also depends on the reliability of the measures, that is, the degree to which the scores that are obtained can be generalized across test administrators, tasks, and administration occasions. Further, as Gottfredson (Vol. II) has noted, “job performance can be measured in many ways, and it is difficult to know which are the most appropriate, because there is generally no empirical standard or ‘ultimate' criterion against which to validate criterion measures.” Thus, it is important to consider the strengths and weaknesses of each of the criterion measures investigated in the JPM Project as well as their relationship.
Hands-On Measures
The development of hands-on measures and the evaluation of their reliability and content representativeness were discussed in previous chapters. Here our focus is the construct validity (see Chapter 4) of the measures. The scoring weights given to steps and tasks, the correlations of part-scores with total scores, and the correlations of hands-on measures with other criterion and predictor measures —all contribute to the evaluation of the construct validity of a hands-on measure. Consider, for example, the hands-on measures developed for the occupational specialty (MOS) of Marine Corps infantry rifleman. The total hands-on test score (TOTAL) for an infantry rifleman consisted of a weighted sum of the score from the hands-on basic
infantry core (CORE) and scores obtained from MOS-unique (UNIQUE1) and supplementary (UNIQUE2) tasks (Mayberry, 1988). The CORE was a weighted sum of scores obtained from tasks in 12 basic infantry duty areas. The UNIQUE1 task involved live fire with a rifle; the UNIQUE2 task consisted of more advanced versions of two of the tasks in CORE (squad automatic weapon and tactical measures).
The task weights, test-retest reliabilities, correlations of task scores with the hands-on TOTAL score, and correlations of task scores with GT, the General Technical aptitude area composite from the ASVAB used for classification into infantry occupational specialties, are shown in Table 8-4. The pattern of correlations of task scores with the TOTAL is consistent with what would be expected from knowledge of the scoring weights and the test-retest reliabilities. The land navigation task score, for example, would be expected to have a relatively high correlation with the TOTAL
TABLE 8-4 Task Scoring Weights, Test-Retest Reliabilities, and Correlations with Hands-On Total Score (TOTAL) and General Technical (GT) Aptitude Area Composite (Marine Infantry Rifleman)
hands-on score because it is one of the two basic infantry duty area tasks with the highest-scoring weights and it has the highest test-retest reliability. The observed correlation of .64 between land navigation and TOTAL is consistent with this expectation. The fact that rifle, live fire, has the highest correlation (.66) with TOTAL of any of the tasks despite its marginal test-retest reliability is due in part to the fact that it has the largest weight for any single task used to define TOTAL. As noted in Table 8-4, UNIQUE1, which is the single rifle live fire task, has a weight of .25 in the computation of TOTAL. The CORE score, which is given a weight of .60 in computing TOTAL, is a composite based on 12 tasks; the UNIQUE2 score, with a weight of .15, is a composite based on 2 tasks.
From an inspection of the correlations of the task scores with TOTAL and a review of the actual measures for each duty area, it is clear that TOTAL measures a relatively complex job performance construct. It involves a combination of tasks that depend heavily on cognitive knowledge of duty area responsibilities (e.g., land navigation, tactical measures 1 and 2, nuclear, biological, chemical (NBC) defense, and communications). TOTAL is also strongly related to tasks requiring complex psychomotor skills, most notably live fire with a rifle. This apparent complexity and the differential dependency of subtasks on cognitive ability are supported by an inspection of the correlations of the task scores with GT, the General Technical ASVAB composite score. As would be expected, tasks judged to have a greater cognitive component have relatively high correlations with GT, and the duty areas that generally involve manipulation of weapons (rifle, live fire, squad automatic weapon 1 and 2, and hand grenades) have correlations of less than .20 with GT.
It is evident that the predictive validity that can be obtained using scores based on the ASVAB for the Marine infantry rifleman MOS depends not only on the way in which hands-on task measures are obtained but the way in which an overall composite hands-on score is defined. Increasing the relative weight that is given to such tasks as land navigation and tactical measures could be expected to increase the criterion-related validities of ASVAB composites. Conversely, increasing the relative weight that is given to such tasks as rifle, live fire, and squad automatic weapon would be expected to decrease ASVAB validities.
We do not mean to suggest that the Marines should use weights other than the ones reported in Table 8-4. Those weights are based on judgments of subject matter experts regarding the importance of each task to the job of a marine rifleman. The point is, however, that, before a hands-on measure is accepted as a benchmark or even as the most important criterion measure to consider, it is critical that the construct validity of the hands-on measure be evaluated and the relevance of the construct as measured to the mission of the Service be judged.
Job Knowledge Tests
Written job knowledge tests are sometimes used as performance criteria. Compared with hands-on performance tests, they are relatively inexpensive to construct, administer, and score. The rationale for using written tests as a criterion measure is generally based on a showing of content validity (using job analyses to justify the test specifications) and on arguments that job knowledge is a necessary, albeit not sufficient, condition for adequate performance on the job. Some have suggested more elaborate justifications for paper-and-pencil tests of job knowledge. Hunter (1983, 1986), for example, has argued that very high correlations between job knowledge and job performance measures are to be expected (on the assumption that knowing how and being able to do something are much the same) and has reported estimated correlations based on corrections for reliability and range restriction as high as .80 between job knowledge and work-sample measures of job performance. Such estimates are obtained only after substantial adjustments for reliability and range restriction, however, and those adjustments depend on strong assumptions. Moreover, as noted by Wigdor and Green (1986:98), written tests “require a much greater inferential leap from test performance to job performance” than do job-sample tests.
Paper-and-pencil job knowledge tests are widely criticized as criterion measures on the grounds of contamination and deficiency. The written format itself introduces a factor of vocabulary-grammar-verbal facility into the performance test that may not be a part of the job—or, even if relevant to the job, not the object of measurement. In multiple-choice tests, a small set of alternatives is identified for the examinee, a situation that is unlikely to be reproduced in the actual work setting. The major deficiency, of course, is that such tests do not deal directly with the ability to perform a task.
One problem involved in using a written test as a criterion measure is particularly pertinent to the JPM Project. The fact that the ASVAB is also a paper-and-pencil test means that all aspects that are common to such tests will lead to high correlations between the predictor and the criterion. This represents a special evaluation problem; because the predictor and the criterion are similarly contaminated, the degree of correlation may be spurious.
Correlations of job knowledge tests with other criterion measures, particularly with hands-on job performance measures, take on particular importance due to the concern about criterion contamination that may be correlated with the predictor test scores. Results reported for 15 specialties/ratings (9 Army, 4 Marine Corps, and 2 Navy) for which hands-on performance measures and written job knowledge tests were administered are shown in Table 8-5. As can be seen, the correlations are consistently positive, ranging from .35 to .61. These correlations demonstrate that job knowledge tests are significantly related to hands-on performance measures. The degree of
relationship would appear to be even stronger if adjustments were made for the less-than-perfect reliabilities of both measures. For example, the estimated reliability (relative G coefficient) for the hands-on measure for machinist's mates in the engine room is .72 (Laabs, 1988; see also the results in Table 6-3 for 2 examiners and 11 tasks). Adjusting the .43 correlation in Table 8-5 for the .72 reliability of the hands-on measure and an assumed job knowledge test reliability of .85 would yield a corrected correlation of .55. Increases of a similar order of magnitude might reasonably be expected for the other correlations in Table 8-5.
Even with adjustments for reliability, the correlations between job knowledge and hands-on job performance tests would remain substantially less than 1.0. Thus, as would be anticipated, the two criterion measures do not measure exactly the same constructs. In other words, using a strict standard of equivalence, job knowledge tests are not interchangeable with hands-on performance tests. Compared with other variables, however, the link be
TABLE 8-5 Correlations of Paper-and-Pencil Job Knowledge Test Scores With Hands-On Job Performance Total Score
|
Service |
Specialty (MOS/Rating) |
Correlation |
|
Army |
Infantryman |
.44 |
|
Cannon crewman |
.41 |
|
|
Tank crewman |
.47 |
|
|
Radio teletype operator |
.56 |
|
|
Light wheel vehicle/power generator mechanic |
.35 |
|
|
Motor transport operator |
.43 |
|
|
Administrative specialist |
.57 |
|
|
Medical specialist |
.46 |
|
|
Military police |
.37 |
|
|
Marine Corps |
Infantry assaultman |
.49 |
|
Infantry machinegunner |
.61 |
|
|
Infantry mortarman |
.55 |
|
|
Infantry rifleman |
.52 |
|
|
Navy |
Machinist's mate (engine room) |
.43 |
|
Machinist's mate (generator room) |
.39 |
|
|
Radioman |
.54 |
|
|
SOURCES: Army results are based on Hanser's report to the Committee on the Performance of Military Personnelat the September 1988 workshop in Monterey, Calif. The Marine Corpsresults are based on tables provided for the September 1988 workshop.The Navy results are based on Laabs's report at that workshop andOffice of the Assistant Secretary of Defense (1987:45-46). |
||
tween the two types of measures is relatively strong. If it could also be shown that decisions about the choice of predictor variables and the rules used for selection and classification would be unchanged due to the choice between these two types of criterion measures, then a case might be made that paper-and-pencil job knowledge tests are adequate surrogates for the more expensive hands-on performance tests.
Interviews
Although interviews have been used most often in selecting and classifying workers, they can also be used to assess job proficiency. A worker is asked how he or she would perform a particular task, perhaps with appropriate equipment and tools at hand, and the oral responses provide evidence about the knowledge the worker can bring to bear on executing the task.
As a criterion measure, interviews are apt to be both deficient and contaminated. A person may be able to describe what would be done, for example, without being able actually to perform the task. Interview results may also be affected to a greater degree than actual performance by personality characteristics and verbal facility.
To minimize potential criterion bias due to contamination and deficiency, the interview procedures that were investigated by the Air Force as part of the JPM Project were designed to be highly structured and task specific. The Air Force task interviews were conducted in conjunction with the handson testing. Together, the hands-on tasks and the interview tasks defined an overall performance test, called a walk-through performance test (WTPT). By combining the interview, or show-and-tell performance tasks, with tasks requiring actual hands-on performance, it was possible to cover more tasks, even if indirectly, in a given period of time and to test tasks that were too dangerous, time-consuming, or expensive for hands-on testing.
Correlations between the hands-on and the interview portions of the WTPT for three Air Force specialties are shown in Table 8-6. As was true of the
TABLE 8-6 Correlations Between Interview and Hands-On Portions of Walk-Through Performance Tests (WTPT) and Correlations of Parts With Total WTPT Scores in Three Air Force Specialties
|
Correlations |
|||
|
Specialty |
Interview and Hands-on |
Interview and WTPT Total |
Hands-on and WTPT Total |
|
Air traffic control |
.81 |
.96 |
.91 |
|
Avionic communications |
.57 |
.80 |
.92 |
|
Jet engine mechanic |
.54 |
.81 |
.90 |
job knowledge tests, the correlation between the interview and the hands-on portions suggests that they measure similar (but not identical) constructs. If it can be shown that decisions about prediction systems would not be affected by the choice of technique, the walk-through interview tasks might make reasonable surrogates for the hands-on tasks, especially in the case of the air traffic control specialty.
Ratings
Ratings by supervisors are the most widely used criterion in industrial personnel research. They are relatively easy to collect and thus are less disruptive of ongoing activities than other measures. Ratings, however, are likely to be deficient because of people's tendency to give global ratings, no matter how detailed the questionnaire. They are also likely to be contaminated by personal attitudes or individual likings. To combat these amply documented inadequacies, researchers in recent years have designed the behaviorally anchored rating scale, which provides behavioral descriptions of the kind of performance associated with each value on the rating scale.
The subjective nature of ratings also raises concerns about possible systematic biases due to rater and ratee race/ethnic group membership and gender. Research summarized by Landy and Farr (1983), for example, led them to conclude that there is a tendency for raters “to give same-race ratees higher ratings, although the degree of [racial] integration in the setting may affect this” (p. 142).
All of the Services have developed rating scales and used them in the research conducted in conjunction with the JPM Project. Behaviorally anchored ratings scales were developed for use not only by supervisors, but also by peers and by the individuals being rated (self-ratings). Ratings of job-specific and general performances and behaviors were obtained.
The correlations of MOS-specific ratings with total hands-on performance scores were lower than the correlations of paper-and-pencil job knowledge tests with hands-on total scores for each of the nine occupational specialties for which the Army obtained hands-on measures. As shown in Table 8-7, the correlations of ratings with TOTAL ranged from a low of .18 to a high of .28 for the nine Army occupational specialties. These numbers can be compared with the range of .35 to .57 reported in Table 8-5 for the corresponding correlations between job knowledge test scores and hands-on total scores. Although the correlations of supervisory ratings and hands-on performance shown in Table 8-7 for the Navy and Air Force jobs are somewhat higher in some cases than those obtained for the Army jobs, they are still lower than the correlations of interview or job knowledge test scores with hands-on performance measures.
In general, it appears that ratings are not the best available surrogate for
TABLE 8-7 Correlations of Job-Specific Ratings of Performance With Hands-On Job Performance Total Scores
|
Specialty (MOS)/Rating/AFS |
Correlation |
|
Army |
|
|
Infantryman |
.28 |
|
Cannon crewman |
.25 |
|
Tank crewman |
.27 |
|
Radio teletype operator |
.28 |
|
Light wheel vehicle/power generator mechanic |
.18 |
|
Motor transport operator |
.24 |
|
Administrative specialist |
.22 |
|
Medical specialist |
.22 |
|
Military police |
.28 |
|
Navy |
|
|
Machinist's mates (engine room) |
|
|
Supervisor ratings |
.33 |
|
Peer ratings |
.45 |
|
Self ratings |
.43 |
|
Machinist's mates (generator room) |
|
|
Supervisor ratings |
.19 |
|
Peer ratings |
.13 |
|
Self ratings |
.18 |
|
Radioman |
|
|
Supervisor ratings |
.35 |
|
Peer ratings |
.09 |
|
Air Force |
|
|
Air traffic control operator |
|
|
Supervisor dimensional ratings |
.15 |
|
Peer dimensional ratings |
.21 |
|
Self dimensional ratings |
.14 |
|
Avionics communications |
|
|
Supervisor dimensional ratings |
.37 |
|
Peer dimensional ratings |
.30 |
|
Self-dimensional ratings |
.26 |
|
Jet engine mechanic |
|
|
Supervisor dimensional ratings |
.32 |
|
Peer dimensional ratings |
.39 |
|
Self-dimensional ratings |
.14 |
| SOURCES: The Army results are based on Hanser's report to the Committee on the Performance of Military Personnel at the September 1988 workshop in Monterey, Calif. The Navy results are based on Laabs's report and Office of the Assistant Secretary of Defense—Force Management and Personnel (1987:45-46). Air Force results are based on tables prepared for the Monterey workshop. | |
hands-on performance. However, ratings may, as suggested by other results reported by the Army (Campbell et al., 1987; McHenry et al., 1987; Zeidner, 1987) tap performance constructs (e.g., effort and leadership, personal discipline, and physical fitness and military bearing) that are not assessed by hands-on measures but that are of importance to the Services.
Training Criteria
The advantages and disadvantages of training measures have already been discussed. Since training criteria generally have relied on paper-and-pencil tests, they share many of the characteristics of job knowledge tests. When taken from administrative records, training grades may also suffer from problems caused by an individual's multiple attempts at the tests used to determine course grades. Training grades are also equivocal if they are the product of self-paced instruction or are based on group performance.
The Army investigated the use of specially constructed school knowledge tests as part of its larger study of job performance (Project A). These tests were designed to cover the domain of content covered in the training classes for the nine occupational specialties for which ratings, job knowledge tests, and hands-on performance measures were used. The school knowledge tests, thus, were limited in content to topics covered in training classes, whereas the job knowledge tests included areas that might be dealt with in on-the-job training.
The correlations of school knowledge test scores with job knowledge test scores and with hands-on performance were reported by Campbell et al. (1987) as part of large correlation matrices involving 24 to 30 criterion measures per occupational specialty (Table 8-8).
TABLE 8-8 Correlations of School Knowledge Test Scores With Job Knowledge and Hands-On Performance
|
Army Specialty |
Job Knowledge |
Hands-on Performance |
|
Infantryman |
.65 |
.40 |
|
Cannon crewman |
.65 |
.36 |
|
Tank crewman |
.64 |
.23 |
|
Radio teletype operator |
.72 |
.39 |
|
Light wheel vehicle power generator mechanic |
.63 |
.37 |
|
Motor transport operator |
.43 |
.28 |
|
Administrative specialist |
.73 |
.58 |
|
Medical specialist |
.67 |
.44 |
|
Military police |
.40 |
.14 |
As might be expected, the correlations between the school knowledge and job knowledge tests are higher than the correlations between school knowledge and hands-on performance for each occupational specialty. For all but two of the nine occupational specialties (motor transport operators and military police), the correlation of school knowledge and job knowledge scores is greater than .60. Although none of the correlations of the school knowledge test scores with the hands-on performance measures reaches .60, school knowledge and hands-on performance scores are clearly related.
RELATIONSHIPS BETWEEN PREDICTORS AND CRITERION MEASURES
Predictor Constructs
ASVAB
The ASVAB is the primary predictor for the JPM Project. It consists of 10 paper-and-pencil cognitive tests, which are combined into various composites by the Services for use in screening and classifying applicants. Table 8-9 lists the 10 ASVAB subtests and provides a brief description of the test contents.
As the table shows, the ASVAB includes a variety of types of test items that are intended to measure a range of cognitive abilities. Factor analyses (e.g., Hunter et al., 1985; McHenry et al., 1987) suggest that the 10 ASVAB subtests measure four broad abilities. The four correlated factors and the subtests that define each factor are (1) verbal ability (defined by WK, PC, and GS), (2) quantitative ability (defined by AR and MK), (3) technical ability (defined by EI, MC, and AS), and (4) perceptual speed (defined by NO and CS). These four broad ability factors have substantial intercorrelations with each other.
Other Predictors
The cognitive abilities measured by the ASVAB are known to provide relatively good prediction of training criteria. These cognitive abilities might also be expected to be related to certain types of hands-on performance. However, with an expanded definition of job performance, it might also be anticipated that prediction could be improved by adding predictors that measure a wider array of constructs. Notably absent from the ASVAB in the way of cognitive measures, for example, are any measures of spatial ability. Also missing, since the ASVAB consists only of cognitive tests, are any measures of psychomotor ability, personality, or interest.
Some experimental predictor measures were included in the research programs
TABLE 8-9 Subtests of the Armed Services Vocational Aptitude Battery
|
Subtest |
Code |
Contents |
|
General science |
GS |
High school level physical, life, and earth sciences |
|
Arithmetic reasoning |
AR |
Arithmetic word problems |
|
Word knowledge |
WK |
Identification of synonyms and the best meaning of words in context |
|
Paragraph comprehension |
PC |
Questions regarding information in written passages |
|
Numerical operations |
NO |
Speeded numerical calculations |
|
Coding speed |
CS |
Speeded use of a key assigning numbers to words |
|
Auto shop and information |
AS |
Automobile, tools, and shop terminology and practices |
|
Mathematics knowledge |
MK |
High school mathematics, including algebra and geometry |
|
Mechanical comprehension |
MC |
Use of mechanical and physical principles to visualize how illustrated objects work |
|
Electronics information |
EI |
Electricity and electronics, including circuits, inductance, capacitance, and devices such as batteries and amplifiers |
of the individual Services that were related to the JPM Project. In addition to the ASVAB, for example, the Army's Project A included a wide range of experimental measures of spatial ability, perceptual/psychomotor ability, vocational interest, and temperament/personality. It was anticipated that the interest and personality measures would be useful additions to the ASVAB for purposes of predicting such criteria as attrition, discipline, and leadership. The measures of spatial, perceptual, and psychomotor ability were expected to aid more in the prediction of hands-on performance measures.
In the Army's research, six spatial ability tests (Assembling Objects, Map, Mazes, Object Rotation, Orientation, and Figural Reasoning) were combined to form a single spatial ability composite score (McHenry et al.,
1987). In addition, 10 computer tests defined a total of 21 perceptual-psychomotor scores. These computer tests included such diverse tasks as simple reaction time, short-term memory, target tracking, target shooting, and cannon shooting. The 21 scores from the computer tests were used to define 6 perceptual-psychomotor composite scores: (1) psychomotor, (2) complex perceptual speed, (3) complex perceptual accuracy, (4) number speed, (5) simple reaction time, and (6) simple reaction accuracy (McHenry et al., 1987). The perceptual-psychomotor composites and the spatial composite were combined with 4 composites from the ASVAB (verbal, quantitative, technical, and speed) to provide a total of 11 cognitive composite scores for purposes of prediction. To these, 13 noncognitive composite scores were added as potential predictors based on the Assessment of Background and Life Experiences (ABLE), the Army Vocational Interest Career Examination (AVOICE), and the Job Orientation Blank (JOB).
Problems in Linking Predictor and Criterion Constructs
Correlations of predictor scores and scores on a criterion measure are affected by the facts that criterion measures are always less than perfectly reliable and that the correlations can be computed only for people who have been selected for the job and are still on the job at the time the criterion scores are obtained. Low reliability of a criterion measure attenuates the observed correlation between a predictor and the criterion measure. Predictor-criterion correlations are also reduced in magnitude when they are based on a sample of job incumbents who have been selected for the job on the basis of the predictor or a related variable and, therefore, have predictor scores with reduced variability.
Criterion Reliability
According to classical test theory, the correlation of a test with a criterion measure cannot be greater than the square root of the product of their reliabilities. An estimate of what the correlation would be if both measures were perfectly reliable is obtained from the ratio of the observed correlation to the square root of the product of the reliabilities of the two measures. This ratio is known as the “correction for attenuation” (see, e.g., Lord and Novick, 1968).
Although the reliability of the predictor test and the criterion affect the correlation, it is the latter reliability that is generally of greater concern, for two reasons. First, the instruments used as predictors tend to have higher reliability values than the typical criterion measures. For example, the reliability of a well-constructed cognitive test is often approximately .90; at that level, dividing an observed correlation by the square root of the test
reliability will have only a small effect. An observed correlation of .40, for example, would be increased by only .02, to .42, if an adjustment was made for a test reliability of .90. But criterion reliabilities are often substantially lower than those of predictor tests. Hence, adjustments for the unreliability of criterion measures can have a more substantial effect. Second, and more important, predictor and criterion unreliability have differing implications for understanding the predictive power in applied settings. Selection and classification decisions are made on the basis of actual predictor test scores, which are always less than perfectly reliable. Adjusting the predictor score for unreliability would give an inflated notion of the accuracy of the score in practice. Failing to adjust the criterion score for unreliability, however, would result in an underestimate of the actual predictive value of the predictor test in applied settings.
Although adjusting for criterion unreliability is desirable in theory, at least three problems arise in practice. First, appropriate estimates of reliabilities are often unavailable. Second, and more important, predictor and criterion unreliability have differing implications in applied settings. If the question were, “How well does ability predict performance?” we might correct for the effects of unreliability of both predictor and criterion. And if the question were simply, “How well does our particular measure of ability predict our particular measure of performance?”then no corrections are pertinent. But in practice, selection and classification decisions are made on the basis of scores on a particular measure of ability, which is always less than perfectly reliable, but the intent is to predict performance in general. Adjusting the correlation for predictor unreliability would give an inflated notion of the accuracy of the score at hand. However, failing to adjust the correlations for criterion unreliability would result in an underestimate of the actual predictive value of the particular test for performance in general. Finally, adjustments lead to less stable statistical estimates (large standard errors of estimate). Because the direction and magnitude of the effect of unreliability are known, however, the effect can be taken into consideration without actually computing adjusted estimates. For example, if investigations of reliability suggest that the criterion reliability is between .65 and .80, it can be assumed that the observed test-criterion correlations are deflated by a factor of about .10 to .20 percent. In any event, given the limitations of the adjustments, it is important that unadjusted estimates be reported along with adjusted ones if adjustments are made.
Range Restriction
Ideally, correlations for a criterion-related validity study would be based on a random sample of all applicants. Applicants are the population for which the test will presumably be used to make decisions. Hence, the value
of the test is best judged in terms of that group. In practice, however, it is almost never possible to base a criterion-related validity study on anything other than an already selected group of people who were chosen for the job and have stayed on the job long enough for the criterion measure to be obtained.
As discussed by Dunbar and Linn (Vol. II), the effects of this selection, commonly known as range restriction, can be complex and, at times, severe. The test that appears to have the highest correlation with a criterion measure in a selected sample is not necessarily the same as the test that would have the highest correlation in an unselected group or a group that was selected on another basis. Indeed, in complex selection situations, the sign of a validity coefficient can even be reversed (see Linn, 1983).
The JPM Project scientists recognized the problem of range restriction and included adjustments for it in calculating validity coefficients. That decision was reasonable. It is also important, however, to report both unadjusted and adjusted coefficients, because the adjustments depend on assumptions that are only approximated in practice. For example, when the assumption of linearity is violated, the correction may be too large or too small depending on whether the slope of the regression tends to increase or decrease at the upper end of the test score distribution. See Dunbar and Linn (Vol. II) for a more detailed discussion of the implications of this and other violations of assumptions.
Summary of Relationships Between Predictors and Criterion Measures
Prediction of Hands-On Performance
The Office of the Assistant Secretary of Defense—Force Management and Personnel (1989) summarized the validity of the AFQT for predicting the hands-on performance measures of the JPM Project in its January 1989 report to the House Committee on Appropriations. Uncorrected correlations between these two variables and correlations that were corrected for range restriction were reported for 23 occupational specialties (8 Air Force, 9 Army, 4 Marine Corps, and 2 Navy). Both sets of correlations are shown in Table 8-10. Also shown in the table are the corrected validities of the appropriate aptitude area (AA) composite for the hands-on performance total scores for the two Services (Army and Marine Corps) whose correlations were included in the 1989 report to the House Committee on Appropriations.
As can be seen, the uncorrected correlations range from a low of .10 to a high of .49; the median value is .26. After correcting for range restriction, the range is from .13 to .67 and the median is .38. The aptitude area
TABLE 8-10 Correlations of Armed Forces Qualification Test (AFQT) and Appropriate Aptitude Area (AA) Composite With Hands-On Performance Total Scores (TOTAL)
composites have higher corrected validities than the corresponding corrected validities of the AFQT in all 13 Army and Marine Corps specialties. The median corrected validity for these 13 specialties is .50, compared with a median of .46 for the AFQT (also corrected for range restriction) with the same 13 specialties. The uncorrected correlations for the aptitude area composites were not reported.
The distributions of the 23 uncorrected and 23 corrected AFQT validities are shown in Table 8-11. The stem-and-leaf plot to left of center displays the uncorrected validity coefficients. The leaf of 9 next to the stem of .4, for example, indicates that the uncorrected correlation between the AFQT and the hands-on performance total score was .49 for 1 of the 23 occupational specialties (Marine Corps machinegunner, see Table 8-10). The stem-and-leaf plot to the right of center displays the distribution of correlations after corrections for range restriction have been made.
Although the AFQT is not the optimal predictor that might be obtained from the ASVAB, much less with the addition of new predictors to the ASVAB, it is evident from the global summary of the validity results shown in Table 8-11 that the AFQT has a positive relationship with hands-on performance in all 23 occupational specialties that were studied. The median corrected correlation of .38 represents a degree of relationship that has
TABLE 8-11 Stem-and-Leaf Plots of Uncorrected and Corrected Correlations Between the AFQT and Hands-On Performance Total Scores
|
Correlations |
||
|
Uncorrected |
Corrected* |
|
|
Leaf |
Stem |
Leaf |
|
.6 |
667 |
|
|
.6 |
||
|
.5 |
5 |
|
|
.5 |
13 |
|
|
9 |
.4 |
6699 |
|
0 |
.4 |
|
|
85 |
.3 |
5689 |
|
4322 |
.3 |
14 |
|
98865 |
.2 |
79 |
|
4332 |
.2 |
1 |
|
7 |
.1 |
556 |
|
32000 |
.1 |
3 |
|
Median Correlations .26 |
.38 |
|
|
*Corrected for range restriction. |
||
considerable practical utility for the Services (Brogden, 1946; Brown and Gheselli, 1953; Schmidt et al., 1979).
Based on the results summarized in Table 8-10, the ASVAB has a useful degree of validity for predicting hands-on performance in the occupational specialties studied. The validity coefficients, while generally somewhat lower than validities that have been reported using school or job knowledge tests as criterion measures, are consistently positive and in most cases are high enough to have practical value for purposes of selection and classification. There clearly is a substantial degree of variability across specialties in the validity of the ASVAB for predicting hands-on performance. However, some of that variability is to be expected simply as the result of sampling error. Moreover, in all 13 Army and Marine Corps specialties for which validities for aptitude area composites were reported, the correlations corrected for range restriction were .20 or higher.
Job Experience
The 1989 report to the House Committee on Appropriations by the Office of the Assistant Secretary of Defense—Force Management and Personnel also covered relationships between hands-on performance and time-in-service. The AFQT scores were broken down into four score ranges (Categories I-II, IIIA, IIIB, and IV). Time-in-service was also divided into four categories (1 to 12 months, 13 to 24 months, 25 to 36 months, and 37+ months). Average hands-on performance total scores were then computed for each of the 16 cells corresponding to the 4 AFQT categories and 4 time-in-service categories.
Figure 8-1 shows a plot of the average hands-on performance score as a function of time for each of the four AFQT score ranges. The results are based on the aggregation of the hands-on performance data for 7,093 Service personnel across all 23 jobs for which validity data were reported in Table 8-10. For each job, the hands-on performance scores were first transformed to a standard scale with an overall mean of 50 and overall standard deviation of 10. Those scores were then aggregated across jobs to compute the means displayed in Figure 8-1.
As can be seen in the figure, the hands-on scores increase with level of experience for all four AFQT score ranges. The figure also shows that the level of performance is positively related to AFQT score category at each of the four levels of job experience. The mean hands-on performance score for personnel with the highest AFQT scores (Category I-II), for example, is slightly higher during the first year than the mean performance of personnel with the lowest AFQT scores after more than three years (37+ months) of job experience. That is, the lowest aptitude group never reaches the initial performance level of the highest aptitude group.
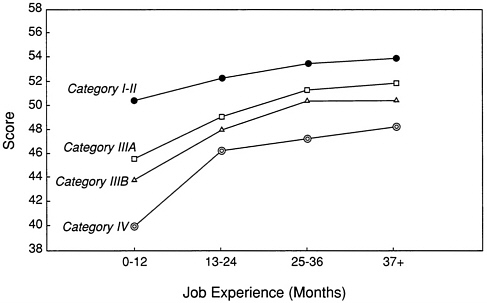
FIGURE 8-1 Mean hands-on total scores by AFQT category and job experience. SOURCE: Based on Office of the Assistant Secretary of Defense—Force Management and Personnel (1991:2-4).
The results in Figure 8-1 are quite global. The pattern of increasing hands-on performance with experience and with AFQT score is quite consistent with the detailed results that are reported for each of the 23 jobs.
Hands-On Versus Job Knowledge Criterion Measures
As discussed above, job knowledge tests were generally found to have substantial, albeit less than perfect, correlations with the hands-on performance measures (see Table 8-5). Job knowledge tests have a number of potential advantages as criterion measures. They are easy to administer and, compared with hands-on performance measures, they are relatively inexpensive. Because they are paper-and-pencil tests, however, job knowledge tests raise concerns about criterion contamination and criterion deficiency.
Questions about criterion deficiency can be addressed in part by analyzing the strength of the relationship between the job knowledge test scores and hands-on performance measures, such as those summarized in Table 8-5. Job analyses and content analyses of the tests can also be used to evaluate the degree to which the tests represent knowledge that is judged to be necessary for successful job performance. In general, the strength of the relationship between the job knowledge tests and hands-on performance measures in the JPM Project appears adequate to support some uses of the
job knowledge tests as criterion measures. Assuming that the results of content and job analyses also support the use of the job knowledge tests, the primary remaining issue is that of criterion contamination.
Since job knowledge tests and the ASVAB depend on the results of paper-and-pencil, multiple-choice testing formats, it might be expected that this common method variance would inflate the correlation between the two types of measures. Comparisons of the uncorrected predictive validities of the appropriate aptitude area composite on the ASVAB using job knowledge tests and hands-on performance measures are provided in Figure 8-2 for the nine Army and four Marine Corps occupational specialties for which
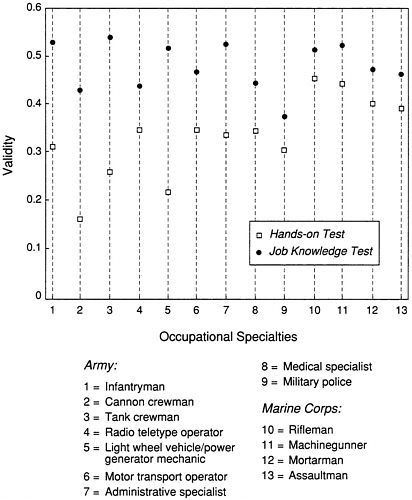
FIGURE 8-2 Aptitude area validities for hands-on and job knowledge tests for 13 occupational specialties. SOURCE: Based on table of correlations provided as part of the common data analysis plan, Monterey, Calif., September, 1988.
both criterion measures were obtained. Consistent with the expectation based on the argument of common method variance, the validity is higher for the job knowledge test criterion measure than for the hands-on criterion measure in all 13 occupational specialties.
Although the differences shown in the figure are sometimes relatively large, a given aptitude area composite appears to have a useful degree of validity for both criterion measures in all 13 jobs. Thus, it would appear that validation studies using job knowledge tests as criterion measures can provide useful indications of the predictive validity of ASVAB scores for military jobs. What results such as those shown in Figure 8-2 do not reveal, however, is the extent to which the use of one criterion measure rather than the other is likely to lead to different decisions about the best predictor for a given job. More detailed analyses of the expanded predictor sets are needed to answer such questions.
New Predictors
To investigate additional predictors, the Army used five composite job performance factors derived from the approximately 270 variables gathered from each soldier (Figure 8-3). These performance constructs are called (1) Core Technical Proficiency, (2) General Soldiering Proficiency, (3) Effort and Leadership, (4) Personal Discipline, and (5) Physical Fitness and Military Bearing (Campbell, 1986; Sadacca et al., 1986; Wise et al., 1986, McHenry et al., 1987). Core Technical Proficiency corresponds most closely to the hands-on performance total score, but it includes job knowledge and school knowledge test results. General Soldiering Proficiency also includes hands-on tasks and job and school knowledge tests. The remaining three criterion constructs are based mainly on ratings and some administrative records (see, e.g., Campbell et al., 1987).
Cognitive tests provided the best prediction for the General Soldiering Proficiency and Core Technical Proficiency criterion measures. Spatial ability and perceptual-psychomotor ability measures provided some incremental validity over that obtained from the four ASVAB aptitude composites (verbal, quantitative, and technical ability and perceptual speed) against these two criterion measures. For example, the average incremental validity for spatial ability based on correlations corrected for range restriction and adjusted for shrinkage was .02 for Core Technical Proficiency and .03 for General Soldiering Proficiency (McHenry et al., 1987). The temperament/ personality, interest, and preference measures did not add much to the validity of the ASVAB for predicting those two criterion measures.
For the remaining three dimensions of performance (Effort and Leadership; Personal Discipline; Physical Fitness/Military Bearing), the noncognitive predictors not only added to the predictive validity of the ASVAB, but in

some cases also had the highest validities of any of the predictors. Together, the ASVAB and the noncognitive predictors had higher validity than either had alone.
Predictor and Criterion Measure Construct Similarities
The corrected validities of the four ASVAB aptitude factors for one of the Marine Corps specialties (rifleman) are shown in Figure 8-4 using hands-on total scores and job knowledge test scores as the criterion measures. As would be expected, the validities are somewhat higher for each of the aptitude factors when job knowledge test scores serve as the criterion than when hands-on total scores are used. Of greater interest, however, is the relatively larger variation in the validities obtained for the four aptitude composites in predicting hands-on performance than in predicting job knowledge test scores. For the job knowledge test, any of the three nonspeeded apti
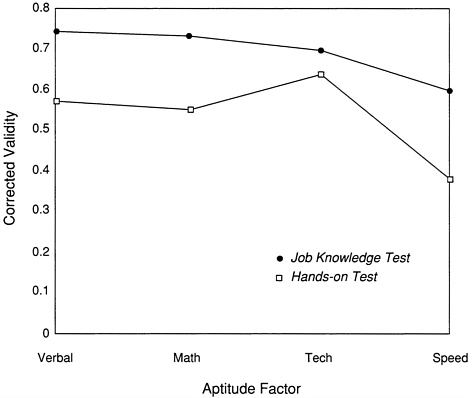
FIGURE 8-4 Validities (corrected for range restriction) of ASVAB aptitude factors for hands-on total scores and job knowledge test scores: Marine rifleman. SOURCE: Based on Mayberry (1988).
tude factors (verbal, quantitative, or technical ability) yields about equally good prediction. By a very small amount, the technical factor actually has the lowest validity and the verbal factor the highest among the three nonspeeded aptitude factors. With the hands-on measure, the variation in the validities is not only greater, but the highest validity is obtained using the technical factor.
The greater variation in the validities of the aptitude factors for the hands-on measure than for the job knowledge test shown for Marine rifleman in Figure 8-4 was also observed for the other three Marine Corps specialties (machinegunner, mortarman, and assaultman) included in the JPM Project. This greater variation in validities for hands-on measures is consistent with prior expectations. The lower verbal load of the hands-on measure and greater dependence on technical aspects of job performance result in relatively higher validities for the technical aptitude factor and relatively lower validities for the verbal factor. Such a change in the pattern of validities supports the construct validity of the hands-on measures. It also enhances the likelihood of finding variations in the patterns of validity coefficients from one job to another.
Job-to-Job Differences in Validities
In addition to demonstrating that the predictor tests have a useful degree of validity for predicting hands-on performance, it is of interest to determine the degree of differential validity and differential prediction. Unfortunately, the terms differential validity and differential prediction are used to refer to the variation in validities (or in prediction equations for various tests from one job to another) and to the degree to which validities (or predictions) for a given job differ for identifiable subgroups of the population (e.g., men and women or minority and majority group members). To avoid this possible confusion, we speak of job-to-job differences in validities or differences in prediction equations (discussed in the next section), rather than using the shorter and more traditional labels of differential validity and prediction.
Demonstrating that the ASVAB has a useful degree of validity for hands-on criterion measures in all military jobs would be sufficient if the ASVAB was used only for making selection decisions. The degree to which the pattern of predictive validities of the ASVAB subtests varies from one job to another is also important, however, for purposes of making classification decisions. Classification would be facilitated by finding that different sets of subtests provide the best prediction of performance for different jobs. If the subtests have identical validities for all jobs, then the same people will have the highest predicted performance in all jobs. However, if the pattern of validities varies from job to job, then the people who have the highest
predicted performance on one job will not necessarily have the highest predicted performance on another job, and by differential assignment to jobs the overall performance across jobs can be enhanced.
Using training criteria, the differences in validities from job to job that have been obtained for the ASVAB over the years have been relatively modest. It was expected that the lack of greater variation in the pattern of validities across jobs might be partially due to the substantial general cognitive component in all of the nonspeeded ASVAB tests and in the training criterion measures. Assuming that the hands-on criterion measures reflect greater differentiation between jobs than the more cognitive training measures, it might therefore be expected that the pattern of validities would be more variable from job to job with hands-on measures than had been previously obtained using training measures. Greater variation in validities and in predictions might also be expected with an expanded set of predictors that included spatial and psychomotor tests.
Three of the Army occupational specialties can be used to illustrate job-to-job difference in validities. Observed (uncorrected) validities of the eight nonspeeded ASVAB tests with total hands-on score as the criterion measure are shown for the infantryman, light wheel vehicle/power generator mechanic, and administrative specialist occupations in Figure 8-5. Reading from left to right in the figure, the tests are arranged as follows: The first three tests (General Science, Word Knowledge, and Paragraph Comprehension) are indicators of the verbal aptitude factor, the next two (Arithmetic Reasoning and Mathematics Knowledge) are indicators of the quantitative factor, and the final three (Auto/Shop, Mechanical Comprehension, and Electronics Information) are indicators of the technical factor.
For the infantryman job, the validities for the eight tests are all relatively similar in magnitude, ranging from a low of .20 for Electronics Information and Word Knowledge to a high of .27 for General Science and Mechanical Comprehension. The pattern of validities for the two other jobs shown in the figure is much more differentiated. The three verbal tests and two math tests have relatively low validities in comparison with the three technical tests for mechanics. As might be expected, the Auto/Shop test has the highest validity (.26) for mechanics, followed by Mechanical Comprehension (.20) and Electronics Information (.19). Moving from mechanics to administrative specialists, there is a marked, and intuitively reasonable, shift in the pattern of validities. The three technical tests that provide the best prediction for mechanics have the lowest validities among the eight nonspeeded tests for administrative specialists. The two math tests have the highest validities (.31 for Mathematics Knowledge and .30 for Arithmetic Reasoning) for administrative specialists.
The contrasting patterns of validity coefficients for the three jobs in the figure suggest that there are some job-to-job differences in validities and
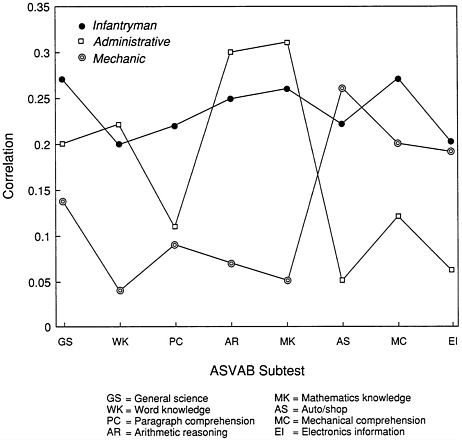
FIGURE 8-5 Correlations of ASVAB tests with hands-on total scores for three Army occupational specialties. SOURCE: Based on correlations provided by the Army for the common data analysis plan, Monterey, Calif., September 1988.
predictions that can be capitalized on for purposes of making differential assignments of personnel to jobs. These three jobs were selected to illustrate differences in patterns, however. Many jobs have more similar patterns of validities. Moreover, these simple comparisons are no substitute for more comprehensive analyses (yet to be reported by each of the Services) that identify the best predictive composites for the hands-on measures of each of the military jobs investigated and evaluate the utility of the predictive composites when used operationally to place personnel in different specialties.
FAIRNESS ANALYSIS
The discussion now turns to group differences in predictor test scores and in job performance scores. Implementation of the Civil Rights Act of
1964 challenged psychologists to develop analyses to assess the fairness of tests. As government policy focused on providing equal employment opportunity to groups formerly kept out of the economic mainstream, it was quickly realized that reliance on test scores without regard to group membership can have substantial adverse consequences because there are sizable differences in average tests scores among various population groups. Hence the need was felt to find out whether these differences in average test scores are related to real performance differences or are artifactual.
The now-conventional fairness analysis focuses on whether selection tests like the ASVAB function in the same way for different population groups, wherein it examines two questions: whether the correlations of test scores with on-the-job criterion measures differ by racial or ethnic group or gender; and whether predictions of criterion performance from test scores differ for employees who are of different racial or ethnic identity or gender. Both of these questions take test scores as their point of departure. Recently, an additional perspective on fairness has been advocated (Hartigan and Wigdor, 1989) that looks beyond whether the predictor test functions in the same way for specified groups. This approach asserts that realized job performance is the object of fundamental interest and works from performance scores back to what the predictor scores should look like. One of the important issues to emerge from this perspective on fairness concerns the size of group differences in job performance compared with group differences in predictor scores. Each of these aspects of test fairness is discussed below in turn.
Group-to-Group Differences in Prediction Systems
Although limited in various respects described below, data provided by the Services permit us to describe the degree of similarity that scores on current forms of the ASVAB have in predicting hands-on performance and job knowledge criteria for minorities and nonminorities and for men and women. The analyses presented in this section provide some insight into the magnitude of group-to-group differences in prediction systems, as well as some appreciation of the complexity of this differential prediction problem.
The principal limitation of the data on subgroup prediction systems involving hands-on performance measures is the large degree of sampling error that exists due to small sample sizes in the focal groups of the comparisons, minorities and women. Table 8-12 illustrates this problem. Seven of 21 occupational specialties had complete hands-on performance data for fewer than 25 minority recruits. The problem is somewhat worse for the hands-on measures for the gender comparisons. The size of the focal group is less of a concern with the job knowledge criterion, but even here the regression estimates in the focal group are based on far fewer observations
TABLE 8-12 Number of Studies by Focal Group Sample Size for Current ASVAB Differential Prediction Data
|
Sample Size in Focal Group Knowledge |
Hands-on Performance |
Job |
|
Race comparisons |
||
|
Fewer than 25 |
7 |
2 |
|
25 to 75 |
8 |
5 |
|
75 or more |
6 |
6 |
|
Gender comparisons |
||
|
Fewer than 25 |
6 |
0 |
|
25 to 75 |
7 |
5 |
|
75 or more |
3 |
2 |
|
SOURCE: Data submitted to the Committee on the Performance of MilitaryPersonnel. |
||
than in the comparison groups. This degree of instability in the results for women and minorities should be kept in mind in evaluating the group-to-group differences presented in this section.
It should also be remembered that validity correlations will differ depending on the heterogeneity of the group scores. When one group has substantially less variance on either variable in the correlation, the size of the correlation will be smaller, even if, from a regression perspective, the test is equally predictive for both groups. Also, when one group has a considerably lower mean value on the predictor, and there is a substantial degree of selectivity for the job, the selection will impinge more strongly on the group with the lower mean; corrections for range restriction, which are typically made on the total population, might be inappropriate unless the same regression system is applicable to both groups.
Comparisons between minorities and nonminorities and between women and men are discussed separately below.
Minority Group Comparisons
Validity Coefficients Although comparisons of correlations can be quite misleading when concern centers on entire prediction systems, they are nevertheless useful when concern centers on groups for which it may be hypothesized that the predictor has no utility in selection. Table 8-13 summarizes correlations between criterion measures and selection composites used by the Services. (One occupational specialty with only three black
TABLE 8-13 Weighted Average Correlations Between ASVAB Predictors and Job Performance Criteria for Black and Nonminority Samples
|
Predictor Criterion |
Number of Studies |
Blacks |
Nonminorities |
||
|
N |
Avg. R |
N |
Avg. R |
||
|
Selection composite |
|||||
|
Hands-on |
21 |
1,487 |
.22 |
5,557 |
.29 |
|
Job knowledge |
12 |
1,304 |
.26 |
4,485 |
.43 |
|
AFQT |
|||||
|
Hands-on |
20 |
1,118 |
.14 |
4,303 |
.17 |
|
Job knowledge |
11 |
935 |
.20 |
3,231 |
.38 |
|
NOTE: Average correlations using within-group sample sizes as weights. SOURCE: Data submitted to the Committee on the Performance of MilitaryPersonnel. |
|||||
recruits in the validation sample was excluded from this analysis). When viewed in this global manner, these results reveal the already-noted fact that validities tend to be higher when a written job knowledge test is used as the criterion as opposed to a hands-on measure of performance (due at least in part to method effects). However, the average correlations for blacks and nonminorities are much more similar in magnitude when the hands-on measure serves as the criterion (.22 and .29 as compared with correlations of .26 and .43 on the written test). For both criteria, the average predictive validity of the selection test is lower for minorities, but only markedly so when another written test serves as the criterion. Although there is substantial variability in the size of the difference from one job specialty to another, scatterplots of correlations that had been transformed to Fisher's Z's showed that, in the majority of cases, when a predictor lacked utility for minorities, its utility for nonminorities was also questionable.
Prediction Equations The comparisons of prediction equations consider only cases for which a measure of hands-on performance served as the criterion. These were the only data in which all four Services were represented. Customary procedures were followed in this evaluation of group-to-group differences in prediction equations. The sections that follow discuss standard errors of estimates and regression slopes and intercepts, in that order, followed by direct comparisons of predicted scores using the within-group and combined-group equations.
Throughout this section, the results of the differential prediction analyses that were provided by the four Services for this study are presented without regard to the levels of statistical significance observed in individual analyses. Rather than base decisions about the extent of prediction differences
among groups on individual studies, this section attempts to describe general trends that can be seen from a description of observed results from all pertinent studies. To discourage potentially misleading overinterpretations of these trends, results from studies with particularly small samples of recruits in the focal group of a comparison are identified.
Standard Errors of Prediction Studies of group-to-group differences in prediction systems have generally found regression equations to yield more accurate predictions of performance for nonminorities and women than for minorities and men (Linn, 1982). The use of hands-on performance criteria in the JPM Project, as opposed to paper-and-pencil tests, does not appear to have altered that finding to any great extent. The stem-and-leaf plot in Table 8-14 shows the distribution of ratios of mean-squared errors of prediction for blacks and nonminorities. Ratios based on samples of fewer than 25 blacks are shown in regular type, others in boldface type. Ratios above 1.0 are cases in which prediction for blacks is less accurate than those for nonminorities. Thus, in 13 of 20 occupational specialties the errors of prediction for blacks were larger than those for nonminorities, given the selection composite as predictor. The same picture emerges when the AFQT
TABLE 8-14 Stem-and-Leaf Plot of Ratios of Mean-Squared Errors of Prediction for Blacks and Nonminorities
|
Leaf |
Stem |
Leaf |
||
|
1.8 |
Predictions for Blacks |
|||
|
5 |
1.7 |
4 |
Less Accurate |
|
|
1.6 |
||||
|
1.5 |
||||
|
6 |
1.4 |
|||
|
0 |
1.3 |
29 |
||
|
2 |
1.2 |
125 |
||
|
8653 |
1.1 |
27 |
||
|
AFQT |
50 |
1.0 |
046899 |
Selection Composite |
|
8530 |
.9 |
47 |
||
|
631 |
.8 |
23 |
||
|
7 |
.7 |
9 |
||
|
9 |
.6 |
7 |
||
|
.5 |
||||
|
3 |
.4 |
|||
|
.3 |
Predictions for Blacks |
|||
|
.2 |
9 |
More Accurate |
||
|
NOTE: Leaves in boldface type are based on samples of 25 or more black recruits. SOURCE: Based on data submitted to the Committee on the Performanceof Military Personnel. |
||||
is the predictor. However, the largest differences were for jobs with small sample sizes in the black cohort. Thus, the stable values in the table suggest relatively minor group differences in the accuracy of prediction.
Slopes and Intercepts Hypothesis tests of group-to-group differences in slopes were conducted for all occupational specialties with appropriate data. The t-ratios on which such tests were based are shown in the stem-and-leaf plot in Table 8-15. In this plot, t-ratios based on the selection composite form leaves to the right. Those based on the AFQT form leaves to the left. Positive t-ratios indicate that the slope for blacks was steeper than the slope for nonminorities. (There seemed to be no pattern that would indicate that the regression line for blacks was systematically flatter than that for nonminorities, as might be expected from other comparisons of this type; see Linn, 1982; Hartigan and Wigdor, 1989).
As the values in the table indicate, the t-ratios for slope differences between blacks and nonminorities tend to be larger in absolute value when the AFQT is the predictor variable in the equation. When the selection composite is the predictor, no slope differences are significant at the 10 percent level. Many of the t-ratios in the plot are instances in which the significance test had very low power due to the small sample of black recruits (Drasgow and Kang, 1984). If one were to argue that the alpha level for these tests should be raised to guard against Type II errors (here, concluding the slopes are the same when, in fact, they are not), only two slope differences involving the selection composite would be significant at the 25
TABLE 8-15 Stem-and-Leaf Plot of T-Ratios for Differences Between Slopes for Blacks and Nonminorities
|
Leaf |
Stem |
Leaf |
||
|
0 |
2. |
|||
|
7 |
1. |
8 |
||
|
10 |
1. |
023 |
||
|
9865 |
0. |
5699 |
||
|
AFQT |
320 |
0. |
13 |
Selection Composite |
|
10 |
−0. |
022233 |
||
|
−0. |
6 |
|||
|
100 |
−1. |
001 |
||
|
86 |
−1. |
5 |
||
|
−2. |
||||
|
85 |
−2. |
|||
|
NOTE: Leaves in boldface type are based on samples of 25 or more black recruits. SOURCE: Based on data submitted to the Committee on the Performance of Military Personnel. |
||||
percent level. However, 5 of 20 slopes differences would be judged significant at the 10 percent level when the AFQT is the predictor.
The contrasting results of tests for slope differences provide a useful illustration of the possible effects of selection on the outcome of a differential prediction study. Because the AFQT is not an explicit selection variable in this context (see Dunbar and Linn, Vol. II), it is possible that the more frequent slope differences are at least a partial artifact of differing degrees of range restriction in the comparison groups. The fact that the two largest slope differences for the selection composite were from jobs with nonsignificant slope differences for the AFQT is consistent with this hypothesis of a selection effect.
Given the above results regarding slopes, within-group intercepts in jobs in which slopes were not significantly different at the 25 percent level were recalculated based on a pooled estimate of the slope. For each job, the intercept for blacks was subtracted from that for nonminorities, and the difference was divided by the standard deviation of the criterion in the black sample. These standardized differences between intercepts are given in the stem-and-leaf plot shown as Table 8-16. Although in most cases small in magnitude, the intercept differences do show a trend found in previous differential prediction studies toward positive values (Linn, 1982; Houston and Novick, 1987), which implies that the use of prediction equations based on the pooled sample in these jobs would result in overprediction of black performance more often than not. However, the amount of overprediction
TABLE 8-16 Stem-and-Leaf Plot of Ratios of Standardized Differences Between Intercepts for Blacks and Nonminorities
|
Leaf |
Stem |
Leaf |
||
|
2 |
1. |
|||
|
1. |
1 |
|||
|
0. |
||||
|
6 |
0. |
|||
|
AFQT |
4 |
0. |
45 |
Selection Composite |
|
333322 |
0. |
2223 |
||
|
11110 |
0. |
000011 |
||
|
1 |
−0. |
011111 |
||
|
2 |
−0. |
|||
|
−0. |
||||
|
NOTE: Leaves in boldface type are based on samples of 25 or more black recruits.
SOURCE: Based on data submitted to the Committee on the Performance of Military Personnel. |
||||
that would typically be found appears to be smaller than in previous studies, which have used less performance-oriented criterion variables.
Criterion Predictions Perhaps a more complete picture of the magnitude of group-to-group differences in regression lines can be obtained by examining the actual criterion predictions made by group-specific and pooled-group equations. Such differences were calculated for each occupational specialty at three points on the predictor scale: one standard deviation below the black mean (−1 SD), the mean in the black sample, and one standard deviation above the black mean (+1 SD). Means and standard deviations of these differences (expressed in black standard deviation units) were calculated for groups of studies based on the size of the black sample. The results are shown in Table 8-17.
Three features of the results in the table should be noted. First, all average differences in the table are positive, which reflects once again the fact that the combined-group equations, on average, lead to overprediction of black performance (i.e., predictions that are somewhat higher on average than the performance achieved by blacks with particular scores on predictor variables). Second, the largest differences in the table tend to be those that are the least stable with respect to sampling (from jobs with data on fewer than 25 black recruits). And third, the differences tend to be larger when the AFQT is the predictor. This last result, again, may well be due to the fact that the AFQT is not an explicit selection variable for most jobs; hence, group differences in this case are confounded by differing degrees of range restriction in the comparison groups.
TABLE 8-17 Standardized Differences Between Predicted Scores from Black and Pooled Equations
|
Black Sample Size |
Selection Composite |
AFQT |
|||||
|
−1SD |
Mean |
+1SD |
−1 SD |
Mean |
+1 SD |
||
|
Fewer than 25 |
(Avg.) |
.12 |
.17 |
.22 |
.20 |
.27 |
.34 |
|
(SD) |
.37 |
.44 |
.56 |
.38 |
.47 |
.67 |
|
|
Between 25 and 75 |
(Avg.) |
.08 |
.07 |
.05 |
.12 |
.08 |
.04 |
|
(SD) |
.14 |
.11 |
.20 |
.17 |
.18 |
.33 |
|
|
More than 75 |
(Avg.) |
.07 |
.10 |
.13 |
.07 |
.15 |
.23 |
|
(SD) |
.10 |
.09 |
.11 |
.10 |
.09 |
.20 |
|
| SOURCE: Based on data submitted to the Committee on the Performance of Military Personnel. | |||||||
The Performance-Based Focus on Fairness
As we have seen in the previous analyses, there are small differences in the accuracy of prediction of job performance from test scores for blacks and nonminorities, but for practical purposes the same regression lines predicted performance about as well for both groups. Remembering always the thinness of the data for the black job incumbents, we observe that the ASVAB appears to fulfill that particular definition of fairness. However, this analysis does not address imperfect prediction per se as it affects the lower-scoring group. A comparison of the relative size of group differences on the predictor and criterion measures is illuminating.
Table 8-18 summarizes the mean differences between the scores of black and nonminority enlisted personnel on the AFQT and two types of criterion measure, a written job knowledge test and the hands-on performance test. In these figures, a negative difference indicates that the average black job incumbent scored below the average nonminority job incumbent by the given number of standard deviation units. The average group differences in scores across the 21 studies was −.85 of a standard deviation on the AFQT, −.78 of a standard deviation on the job knowledge test, and −.36 of a standard deviation on the hands-on test. In addition to these mean differences, the stem-and-leaf plot in Table 8-19, which compares group differences on hands-on and job knowledge criterion measures, shows that the entire distribution of differences on the hands-on criterion is shifted in a direction that indicates greater similarity between blacks and nonminorities on the more concrete and direct measure of job performance.
To the extent that we have confidence in the hands-on criterion as a good measure of performance on the job, these findings strongly suggest that scores on the ASVAB exaggerate the size of the differences that will ultimately be found in the job performance of the two groups. These results are in line with results for the private sector, as recently reviewed in Fairness in Employment Testing (Hartigan and Wigdor, 1989), which found an average score difference of 1 standard deviation between blacks and whites on the General Aptitude Test Battery compared with a one-third standard deviation on the criterion measure (typically, supervisor ratings). One might interpret the JPM Project results as meaning that the initial edge given nonminorities as a group by somewhat higher general aptitudes (as measured by verbal and mathematical reasoning tests) is greatly reduced by experience on the job. Note, however, that the written job knowledge test used as the second criterion measure in this analysis exhibits only a small diminution in the size of the average group differences. Since the AFQT and the job knowledge test are both paper-and-pencil multiple-choice tests, a strong method effect seems to be involved. This issue goes well beyond the JPM Project; it calls for the attention of the measurement profession as a whole.
TABLE 8-18 Stem-and-Leaf Plot of Standardized Differences Between: (a) Mean AFQT and Job Knowledge Criterion Performance of Black and Nonminority Enlisted Personnel and (b) Mean AFQT and Hands-On Criterion Performance of Black and Nonminority Enlisted Personnel
TABLE 8-19 Stem-and-Leaf Plot of Standardized Differences Between Mean Criterion Performance of Black and Nonminority Enlisted Personnel
Gender Comparisons
Data on the differences between prediction systems for men and women in military occupational specialties are limited not only by the small number of female recruits in individual jobs, but also by the number of jobs for which the relevant data are available. Accordingly, only general discussion of apparent trends in these data is possible.
Validity Coefficients Weighted average correlations between ASVAB predictors and performance criteria for men and women are shown in Table 8-20. As was true in the comparisons based on race, the average correlation is higher when the criterion is a written test than when the criterion is a direct measure of performance. However, the dominant feature of these data is the markedly higher average correlation between the AFQT and hands-on performance among women. In addition, and unlike the black/nonminority comparison, there seems to be no clear relationship between the size of the group difference between validity coefficients and the type of criterion variable.
Regression Equations Standard errors of estimate, slopes, and intercepts from the regressions of hands-on performance on the ASVAB selection composite were examined in the 16 occupational specialties for which data
TABLE 8-20 Weighted Average Correlations Between ASVAB Predictors and Performance Criteria for Samples of Men and Women
on male and female recruits were available. Although the results from individual jobs were quite mixed, when viewed as a whole the data do suggest some inconsistencies with previous findings from gender comparisons of this type.
In general, the accuracy of prediction, as measured by the standard error of estimate, was similar for men and women. In 10 of the 16 jobs, predictions were more accurate among women than among men. This is generally consistent with findings reported by Linn (1982) in educational contexts and by Dunbar and Novick (1988) in a military training context. In instances in which the standard errors of estimate were markedly different in magnitude, sampling error appeared to be a likely cause of the difference.
Comparisons of slopes and intercepts showed mixed results. Whereas the typical finding in studies of differential prediction by gender is that slopes among samples of women are steeper than among samples of men, half of the jobs in the current data showed the opposite trend. One might suspect that the use of a performance criterion rather than a written test of job knowledge might account for this discrepancy with previous studies. However, even among the seven jobs that provided criterion data from a test of job knowledge, there were four in which the slope in the samples of women was flatter than it was in the samples of men.
A second and perhaps more notable contrast with the findings of previous studies is the difference between intercepts in instances in which slopes were judged to be similar. In 8 of 12 such instances, the intercept of the regression equation in the female sample was smaller than that of the male sample. Such findings would imply that the use of a combined prediction equation for men and women in these instances would result in the overprediction of female performance on the hands-on criterion, that is, female recruits
would be predicted to perform better than they actually would. This finding is counter to the results summarized by Linn (1982), in which the dominant trend was for the criterion performance of women to be underpredicted by the use of a combined equation.
Whether this contrast can be attributed to the use of the hands-on performance criterion is only suggested by results from the seven specialties that also used a job knowledge test as the criterion. Among those seven, five showed intercept differences that would suggest underprediction of female performance on the test of job knowledge, a result more in line with the literature on gender differences in prediction systems. Given the inconsistencies reported here, further investigations of prediction differences between men and women in the military should continue to examine the role of the criterion in the interpretation of such differences.
CONCLUSION
The JPM Project has succeeded in demonstrating that it is possible to develop hands-on measures of job performance for a wide range of military jobs. The project has also shown that the ASVAB can be used to predict performance on these hands-on measures with a useful degree of validity. With the addition of measures of spatial ability and perceptual-psychomotor abilities to the ASVAB, some modest increments in the prediction of hands-on performance could be obtained. Noncognitive predictors, however, are apt to be useful for purposes of predicting criteria such as discipline and leadership but are unlikely to improve the prediction of actual hands-on job performance.
Although the 23 jobs studied to date in the JPM Project are relatively diverse, many more jobs were not included in the research than were. The validation task that remains to be accomplished is to develop a means of generalizing the results for these 23 jobs to the full range of jobs in the Services. Each Service is currently conducting research that seeks to accomplish this task (Arabian et al., 1988).
Another task that remains to be accomplished, building on these results, is to link enlistment standards to job performance. The Department of Defense is currently conducting research that seeks “to develop a method or methods for linking recruit quality requirements and job performance data” (Office of the Assistant Secretary of Defense —Force Management and Personnel, 1989:8-1). The hands-on job performance data are a critical aspect of that effort.











































