
1
Psychological Testing and the Challenge of the Criterion
INTRODUCTION
The United States is the world's largest user of standardized tests and test products and Americans are, without doubt, among the most tested of people. By one recent estimate, there are 20 million school days of standardized testing per year in elementary and high schools. It is common for major transition points in schooling and in working life to be marked by some sort of standardized test or assessment procedure. Beginning with the assessment of school readiness among preschoolers, the individual faces a long succession of tests designed to do such things as establish grade-level progress; diagnose learning difficulties; track pupils; allocate places in special programs or magnet schools; provide a measure of institutional accountability; ensure that those receiving a high school diploma have achieved minimum levels of competency; screen applicants for admission to college, training programs, the military, or entry-level jobs; and, in many lines of work, certify the achievement of mastery levels for advanced or specialized positions.
Just as school systems have found standardized tests useful tools for organizing and monitoring the education enterprise, so in the world of work tests have assumed important sorting and gatekeeping functions. In traditional societies, hereditary social status largely determines one's occupational niche. The growth of industrial economies with diverse job demands
and large population concentrations has tended to substitute individual capability for family, class, and the like as the formal criterion for allocating jobs. Particularly in America, with its great tides of ambitious immigrants and unusually strong attachment to the idea that one can make one's future, sorting on the basis of ability has come in the twentieth century to have widespread appeal.
Testing is the primary means of competitive selection in federal, state, and municipal merit systems, an outgrowth of the reformist beliefs of the Progressive Era that ability and not political cronyism should be the grounds for selection into the civil service. Many private-sector employers look to tests of general or specialized abilities as an important part of human resource management; widespread concern in the business community about the shortcomings of American education has in recent years increased the attraction of testing among employers who hope to maintain their competitive advantage through more effective personnel selection. Labor unions depend on tests like the Department of Labor's General Aptitude Test Battery to screen candidates for apprenticeship programs. The lifting of mandatory retirement laws in recent years under the Age Discrimination Act of 1965 could well mean an increased use of tests to assess employees ' continued ability to perform up to standard on the job—a kind of retirement readiness testing.
Testing has, in other words, become a visible and influential force in American life—and to an extent not found in other Western, industrialized societies. The predominant technology, which is about as old as the airplane and as little understood by most people, is the work of psychologists who thought to develop a science of the mind for the solution of social problems.
AMERICAN TESTING TECHNOLOGY
In the words of one early historian of mental testing, American psychology “inherited its physical body from German experimentalism, but got its mind from Darwin” (Boring, 1929:494). By 1900, evolution had quite captured the American imagination and that meant, in psychology, an emphasis on individual differences. The study of individual differences is above all a measurement science; in the early decades of this century, the mental test became its primary measurement tool.
There have been a good number of studies of the intellectual antecedents of standardized ability testing, from the first generation chronicles of Peterson (1925), Pinter (1923), Young (1923), and the aforementioned Boring to recent studies by historians (e.g., Kevles, 1985; Hale, 1980; Fass, 1980; Sokal, 1987), which, with the benefit of distance, provide greater insight into the cultural and intellectual context in which the testing movement
grew up. We need not repeat in any detail the influence of Wilhelm Wundt's laboratory techniques for the precise measurement of mental operations such as memory or reaction time; or the development by Galton, Pearson, and finally Spearman of powerful statistical techniques for expressing the distribution of human abilities; or indeed, the crucial work of Alfred Binet and Lewis Terman in translating mental measurement from an experimental into an applied science.
It is essential, however, to appreciate that psychological testing in its American manifestation is a combination of high science and practical purpose, of experimentalism and the correlation coefficient on one hand and human resource management on the other.
The Science of Testing
The psychometric approach to human abilities owes as much to physics as to philosophy. In an interesting brief analysis of Spearman's seminal treatise, The Abilities of Man (1927), Irvine and Berry (1988) describe the derivation of the correlational technology of tests and testing from the laws of statics, that is, the study of forces on bodies at rest. They present a diagram drawn from a popular late-Victorian physics school book illustrating the principle that a system is in equilibrium around a fixed point or fulcrum when the sum of the products of force times the distance from the fixed point is zero (reproduced as Figure 1-1 below).
In classical test theory, the fulcrum is the group mean, and individual ability—Spearman actually calls it mental energy—is expressed as a test
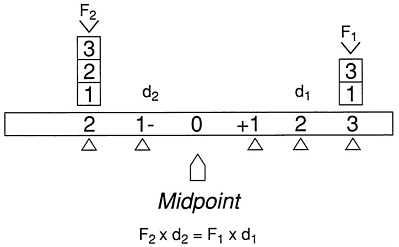
FIGURE 1-1 Moments around a fixed point. SOURCE: Loney (1890). Reprinted in Irvine and Berry (1988).
score's relative distance from the mean. As in physics, the distribution of individuals' abilities are moments around a point, and all the deviations from the mean sum to zero. Moreover, Pearson's product-moment correlation, which is the heart of test validation, is an average value expressing the amount of consistent deviation from the means that the same group of people shows on two measures. As Irvine and Berry conclude, psychological testing in America “takes physics and moments around a point not just as an analog, but as a model for an exact science of the mind” (1988:11).
Despite Spearman's efforts, there was not in the early years, nor has there since emerged a unified theory of intellect or ability that has informed the science of mental measurement. If mental testing is not wholly atheoretical, E.L. Thorndike's quip that “intelligence is the thing that psychologists test when they test intelligence,” (reported in Murphy, 1929:354-355) reflects the profession's relative unconcern with what intelligence is in any epistemological sense. The promoters of psychological testing have invested their energies in and rested their claims on test development, on careful measurement under standardized conditions, on developing statistical techniques for the precise quantitative expression of values, and on correlational analysis to establish the validity of the test results. As in many other areas of economic and social research, the persuasive power of numbers has proved to be very great, and society at large rapidly became the laboratory for this science of the mind.
Practical Applications
With the invention of the group-administered multiple-choice test during World War I, the psychology of individual differences found its metier: mass testing, standard procedures to eliminate irrelevant sources of variation, and a response format that lends itself to the quantification of results. Despite its many limitations and periodic public attacks, the multiple-choice test remains the dominant mode of testing to this day, not only because it fitted the empirical mode, but because it provided society with much-needed tools for organizing and ordering its members.
Twentieth-century America has been characterized by increasingly heterogeneous and transient populations. The emergence of modern industrial society in the late nineteenth century, with its hunger for cheap labor, brought massive immigration; the population increased by 68 percent in the 30 years between 1890 and 1920. Schools were deluged with children—Tyack (1974) reported that the high school population grew by 711 percent in these years—and in addition to sheer increase in numbers, educators had to figure out how to deal with children of many different lingual and cultural backgrounds. Industrial production brought with it new demands for regularity in attendance and work habits, care in the use of machinery, and technical
skills. Employers, plagued by high rates of labor turnover and industrial accidents, increasingly turned their attention to the more efficient selection and management of personnel (Hale, 1980: Chapter 10). Social dislocation and the movement of peoples did not end with the immigration restrictions imposed in the 1920s. The great internal migrations from East to West and South to North, particularly in the years after World War II, continued the attenuation of tradition, local ties, mutual knowledge, and shared values as social binding agents.
Standardized multiple-choice testing arose and prospered in this context because it appeared to offer an efficient and objective way to classify masses of people on the basis of ability.1 Group testing via the now ubiquitous multiple-choice item was introduced as a bold experiment in military selection and classification during World War I, and thereby cemented the future of testing as an important instrument of pedagogy, employee selection, and, ultimately, of public policy.
The Army Alpha and Beyond
If World War I and the Army Alpha brought mental testing into the American mainstream, it was Robert M. Yerkes above all others who brought testing to the problem of military screening. As early as 1908, Alfred Binet had urged the testing of conscripts to eliminate defectives; careful scientist that he was, he cautioned that preliminary trials would be necessary to see if the test eliminated those individuals actually found to be inefficient in the Army (Peterson, 1925:292). But Yerkes and his colleagues on the American Psychological Association Committee on Examination of Recruits had a more ambitious vision of the contribution of testing to the war effort. In May of 1917, less than one month after America's entry into the war, he wrote that “we should not work primarily for the exclusion of intellectual defectives, but rather for the classification of men in order that they may be properly placed in the military service” (quoted in Kevles, 1968:567).
This goal is all the more remarkable when one remembers that Yerkes and his colleagues had little precedent to guide them. In 1917, as Goodenough (1949) pointed out, almost nothing was known about measuring the intelligence of the normal adult. Yet, under the auspices of the Psychology Committee of the National Research Council, which the National Academy of Sciences created in 1916 to mobilize the scientific community to serve the war effort, Yerkes, Lewis Terman, and five other psychologists set out to develop an intelligence test that could be used to screen large groups of
|
1 |
That testing has also been the conveyer of some of the more distasteful myths of Social Darwinism and has been used to justify cultural and racial bias (Kevles, 1985) is an aspect of the story that should not be forgotten. |
men quickly and efficiently. It was Terman and Walter V. Bingham who convinced Yerkes to approve group testing and Terman's student, Arthur Otis, whose work on a group test system provided the inspiration for the multiple-choice format (Von Mayrhauser, 1987; Samelson, 1987). This was the origin of the famous Army Alpha. By late summer the secretary of war had authorized experimental trials, and the results were compelling enough that, on Christmas Eve 1917, universal testing of all enlisted men, draftees, and officers was approved.
In a remarkably short period of time a corps of military psychologists was in place, a school was established at Fort Oglethorpe, Georgia, to train test administrators so that examining procedures would be uniform down to tone of voice and speed of delivery, and, by May of 1918, 200,000 men were being tested per month at 24 Army camps around the country. (The detail of the program can be found in Yerkes, 1921; Kevles, 1968; and Reed, 1987.)
Yerkes and his mental testers were by no means universally accepted by military officials (Kevles quotes General Hugh Johnson's later remarks about the “mental meddlers”). There was a tension between the professional army and the professional psychologists, between experience and expertise that has continued to mark the relationship of military officials and the social scientists who would provide them with “objective tools” to guide decision making. Yet the testing program proved itself useful enough to survive three investigations and, before the end of the war, some 1,750,000 men took the Army Alpha or the Beta, the version for those unable to read English.
Although historians have cast doubt on the extent to which the program contributed to the war effort (Reed, 1987), the testing of one and three-quarter million soldiers during World War I established psychological testing and the intelligence quotient (IQ) in the public consciousness. In a way that could scarcely have been envisioned prior to the war, group multiple-choice tests were looked on as tools for the solution of problems of a practical character. In 1921, the developers of the Army Alpha published a revised version called the National Intelligence Test. Within two years almost 1,400,000 copies were sold, and by 1923 a total of 40 different intelligence tests were available nationally (Freeman, 1926; Fass, 1980). Yerkes and Lewis Terman also joined forces after the war to promote the differentiated school curriculum, based on intelligence tests, and found themselves at the crest of the tide. In a very few years, intelligence tests were adopted in schools all over the country to help sort and track and counsel students in the course of education best suited to their abilities.
The Army test of general intelligence also stimulated the interest of the College Board in the possible use of psychological testing for college admissions in place of written essays covering various subjects. An advisory
committee, including Yerkes and Carl C. Brigham, was asked to look into the question and, as a consequence, the Scholastic Aptitude Test—now a cultural icon—was born in 1926 (Angoff, 1971). Employers too showed increased interest in personnel testing, and both general and job-specific aptitude testing became quite common, if not as widespread as standardized multiple-choice testing in the schools. For all of these purposes, testing was widely accepted as a legitimate means of making decisions about the aptitude or abilities of normal people. As a kind of scientific Solomon, the standardized ability test provided a means of reconciling equality of opportunity with the realities of limited educational, employment, and, ultimately, economic opportunities. (There has, of course, been controversy about the technical and social assumptions of testing from the beginning. Walter Lippmann's series of articles in the New Republic, published in the early 1920s, remains among the most eloquent statements of misgiving about the grandiosity of the testers' claim to measure important and complex human characteristics with brief written tests and the likelihood that the technology would end up thwarting rather than enhancing equity and social mobility. See, for example, Wigdor and Garner, 1982; Block and Dworkin, 1976; for more recent arguments, Madaus and Kellaghan, 1991; Darling-Hammond, 1991.)
In the following decades, technical aspects of test construction and validation received a great deal of attention as widespread use revealed threats to precision of measurement. Procedures were developed to calibrate the difficulty level of tests so that there was consistency from year to year in, for example, college admissions tests. The need to validate tests, to show that the abilities or skills being measured are relevant to education or employment decisions being made, was recognized early and often, at least by testing professionals. Techniques were developed for assessing the reliability or consistency of measurements, for revealing the factor structure of test batteries, for expressing multivariate relationships.
But for all that aptitude or ability testing has been an American preoccupation since the 1920s, providing “a powerful organizing principle, a way of ordering perceptions, and a means for solving pressing institutional and social problems” (Fass, 1980), comparatively little systematic attention has been devoted over the years to understanding and measuring the kinds of human performance that tests are commonly used to predict. Employers use tests to hire workers, hoping thereby to build a more effective work force. Medical and law schools use entrance tests to determine who will have the opportunity to enter training for those professions. Yet very little is known about the performance of a good doctor or lawyer—or car mechanic for that matter. How, then, can the employer or educator know whether the test scores at hand are meaningful for the decisions being made? By and large, the public has been content to see test scores as a reflection of intelligence
or ability and to find in these general concepts a sufficient connection to performance. Applied psychologists quickly came to know that things are more complicated than that when employment tests failed pretty consistently in the 1920s to predict which employees would be the more successful performers. Internal documents of the period show the staff of Walter Bingham's Personnel Research Bureau rather painfully aware of the weakness of the employment tests they were developing for clients (Kraus, 1986). So little success was had in relating IQ test scores to executive and managerial success—indeed, Bingham and Davis reported a negative correlation—that the enterprise was thrown into momentary disarray (Super and Crites, 1962).
THE CRITERION PROBLEM IN VALIDATION RESEARCH
In fact, it has turned out to be far easier to develop sophisticated test instruments and statistical techniques for analyzing the degree of correspondence between the distribution of test scores and the distribution of criterion scores than to find adequate measures of performance to use as criteria in judging the relevance of the tests. Although the criterion problem also exists in educational testing, it has been more frequently raised with regard to employment tests. For the most part, industrial and organizational psychologists and their institutional clients have used measures of convenience such as training grades or supervisor ratings as a surrogate for job performance, concentrating, as Rains Wallace (1965) put it, “on criteria that are predictable rather than appropriate.”
The dangers inherent in using inadequate performance measures were brought into focus in Captain John Jenkins' report (1950) on the tests used to select and classify Navy and Army air crews during World War II. The experience of those years merits some retelling, for it shows both the great value of standardized testing procedures for marshaling human resources to the war effort, and sobering limitations as well.
When Germany occupied France in June of 1940, the War Department announced plans to select and train 7,000 pilots and 3,600 bombardiers and navigators. It was well known to military planners that in the period 1926-1935, when eligibility for air cadet training was based on an educational requirement (two years of college) and a stringent physical requirement, some 61 percent had flunked out of flight training (DuBois, 1947). Under threat of war, it was rapidly decided to supplement the physical test with psychological tests for selection and for classification into the three air crew specialties: pilot, navigator, and bombardier. Large numbers of psychologists were brought into the Naval Aviation Program and the Army Air Force (AAF) Classification Program, both to develop new selection and classification tests and to conduct validation research. DuBois reports that,
at full strength, more than 1,000 Army aviation psychologists and psychological assistants worked in research and examining units, largely in test development, administration, scoring, records, and reports.
The World War II aviation psychology programs were—and are—considered one of the triumphs of applied psychology. As the war progressed, more and more reliance was placed on psychological testing to make selection and classification decisions. A robust research program supported the test batteries. The AAF classification battery, for example, went through nine revisions between its introduction in early 1942 and 1945 as a result of research findings.
It is important to remember how massive a buildup the military faced. The AAF air crew training program in effect in the fall of 1941 called for the production of 30,000 pilots a year. Given the dismal statistics on completion of training during the interwar years and the pressing need to enlist, train, and produce combat-ready air crews, it is perhaps not surprising that in both Services the criterion against which the selection and classification tests were validated was completion of advanced training. And this was not an insignificant basis for judging the relevance of the tests. Validation of the AAF classification battery included the study of a control group of 1,311 men, constituting a representative sample of the total group of applicants for air crew training, who were sent into pilot training with no requirements as to aptitude or temperament. Figure 1-2, reproduced from DuBois (1947), tells a dramatic story. Slightly more than 70 percent of the control group was eliminated. Of those in the lowest score category on the pilot classification battery (stanine 1),2 100 percent were eliminated from the training program. In contrast, only 23.9 percent of those with the highest standard score (stanine 9) failed to complete the training course.
Clearly the pilot classification battery was a powerful predictor of success and failure in pilot training in the Army Air Force. But success in training may well have no bearing on combat proficiency.
Psychologists in the Navy aviation program, under the leadership of Captain John Jenkins, spent a good deal of time thinking about the problem of developing better performance criteria, criteria that would show whether the selection and classification tests were identifying the good combat pilots or just pilots with the characteristics needed to succeed in training (Jenkins, 1946). Fairly well into the war, Jenkins and his group were able to launch one effort to develop a measure of combat effectiveness. To try to establish the elements of success in combat flying, interviews of active combat pilots were begun in the Pacific fleet in 1943; in the fall of 1944, after more than a year of exploratory work and instrument development, full-scale data
|
2 |
“Stanine” derives from Standard Nine, a normalized transformation in 9 steps of a weighted raw-score composite of several different tests. |
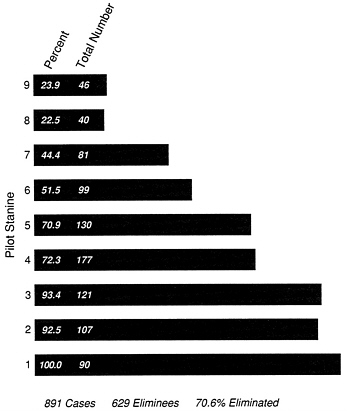
FIGURE 1-2 Elimination rate of experimental group for pilot stanines (elimination for flying deficiency, fear, or own request). SOURCE: DuBois (1947).
collection began. The method chosen to obtain combat criterion data was a nomination procedure, administered to groups of pilots in combat areas, who were asked to make their nominations in writing. Aircraft carrier pilots, for example, were asked to name:
-
Two men, living or dead, known to you, on whom you would be glad to fly wing, if assigned to another air group, (high group)
-
Two men, living or dead, whom you would not wish to have flying wing on you, if assigned to another air group, (low group)
Subjects were also asked to fill out checklists giving reasons for their nominations, the checklists having been developed from free response interviews with over 800 pilots who had completed at least one tour of combat duty.
A total of 2,872 experienced combat pilots in the Pacific theater was involved in the final study, and the names of 4,325 nominees were obtained. Of these, 40 percent were nominated more than once. The analysis of the data, begun by Captain Jenkins and his Combat Criterion Program team,
was completed and written up after his death by the National Research Council Committee on Aviation Psychology, chaired by M.S. Viteles.
The sobering conclusion of the report: “. . . it can be said with little equivocation that consideration of the indices of relationship between tests and the combat criterion measures . . . indicates that none of the tests . . . devised to predict success in training, gave evidence of predicting the combat criterion measures to any marked degree”3 (Jenkins, 1950:256).
Evolution of the Criterion Problem
Summing up the lessons of World War II in his 1946 article entitled “Validity For What?” Jenkins wrote that psychologists had learned that criterion measures are neither given of God, nor just to be found lying around. Test validation is not “a simple technical problem . . . . [T]he criterion itself may provide the psychologist with as great a technical challenge as the procedures incident to the assembly of good predictors” (1946:98).
The years since have shown just how great a challenge. The description and measurement of job performance has been a central theme of postwar psychological and organizational research. There has been fruitful discussion of the nature of job performance and the range of possible performance criteria, with distinctions being made between natural and constructed measures, between concrete and conceptual approaches to performance, or along such dimensions as optimal versus ordinary performance. Some researchers have concentrated their efforts on defining job performance in terms of outcomes, some have examined job behaviors, and others, building on the work of Walter V. Bingham in the 1920s and 1930s, have studied personality traits such as leadership qualities or initiative as correlates of successful performance.
Various types of performance measure have been studied. These include natural measures, such as production or sales records, absenteeism, or accident rates, and constructed measures, including work samples and the ubiquitous rating scale in its many variants. Job analysis has always received a good deal of attention (Gael, 1984, 1988), and the 1970s saw a number of large-scale efforts to develop taxonomies of human performance (see Fleishman and Quaintance, 1984).
Captain Jenkins remarked in 1946 that a review of the literature published between 1920 and 1940 would turn up hundreds of articles on the
|
3 |
The report drew the same conclusion about the Army Air Force combat criterion program, which investigated the relationship between test variables and a number of combat criteria in the categories of strike photo studies, administrative action studies, and ratings of combat effectiveness. |
construction of predictors, but almost total silence on the subject of the criteria to be predicted. A review of the literature since 1950 would reveal, not hundreds, but thousands of articles on criterion development and validation. Yet in summarizing the previous 30 years of research, Landy and Farr (1983) concluded that accurate measurement of work performance remains elusive and the criterion problem is as vexing as ever.
Performance Appraisal
The research experience with rating instruments is illustrative. Supervisor ratings have been (and remain) the most common criterion measure for the validation of selection tests outside the military, because they are readily available or easily obtainable, because they are an inexpensive source of performance data, and because they are plausible to the client—it makes sense that supervisors would be able to make reasonable judgments about the performance of workers for whom they are responsible. But performance ratings have always been held suspect by measurement experts because they depend on human judgment, with the attendant threats of subjectivity.
Until 1980, the primary focus of research on performance ratings was the rating instrument, its measurement properties, and standardization of raters to reduce error. An enormous amount of professional energy was expended on the quantitative expression of rating error and the control of error variance through improvements in rating technology. There is a vast literature on performance appraisal (see Landy and Farr, 1983; Milkovich and Wigdor, 1990; Bernardin and Beatty, 1984; Bernardin, 1989), which documents the attempts of researchers to quantify the various sources of rating error. Among the most frequently studied are the problems of halo, which refers to the tendency of raters to give an employee similar grades on purportedly separate and independent dimensions of job performance; leniency, the tendency to give employees higher ratings that their work warrants; restriction in range, which describes the tendency of raters to give similar ratings to all employees; and unreliability, which is an index of the tendency of raters to make erratic or inconsistent judgments about employee performance.
The ample documentation of these departures from precise and accurate measurement inspired many attempts to find a technological fix—that is, to design rating instruments that would control the problems. A variety of innovations in scale format were experimented with. The early graphic scales presented the rater with a continuum on which to rate a particular trait or behavior of the employee. Some scales presented mere numerical anchors:
|
Leadership: |
1 |
2 |
3 |
4 |
Others present adjectival descriptions at each anchor point:
|
Leadership: |
1 |
2 |
3 |
4 |
|
poor |
satisfactory |
exceeds expectations |
outstanding |
Many scholars attributed the measurement error characteristic of graphic scales to the limited amount of definition and guidance they provided the rater either on the nature of the underlying dimension or on the meaning of the scale points along the continuum.
In response, the behaviorally anchored rating scale (BARS) was developed. The seminal work on BARS was done by Smith and Kendell in 1963, and there have been many further experiments. Although performance is still presented on a continuum in this rating mode, behavioral descriptions are presented at each anchor point to help clarify the meaning of the performance dimensions and to calibrate all raters' definitions of what constitutes good and poor performance. The methods used to develop the behaviorally anchored scales were consciously designed by researchers to form a strong link between the critical behaviors in accomplishing a specific job and the instrument created to measure those behaviors. Hence scale development is based on a careful job analysis and the identification by job experts of examples of effective and ineffective performance.
An even more elaborate attempt to control rater error is seen in the mixed standard scale developed by Blanz and Ghiselli (1972). This format is designed to be proactive in preventing rater bias. The graphic continuum and the definitions of the performance dimensions of interest (e.g., leadership, attention to detail, perseverance) are eliminated from the rating form. Instead, good, average, and poor examples of behavior are developed for each of the dimensions to be assessed and the rating form presents a random ordering of all the behavioral descriptions. The rater's task is to indicate whether an employee's performance is equal to, better than, or worse than the behavioral example presented. The actual performance score for each dimension is calculated by someone other than the rater.
The results of these innovations in rating format have been disappointing. Although the research findings are not entirely consistent, the consensus of professional opinion is that variations in scale type and rating format do not have a consistent, demonstrable effect on halo, leniency, reliability, or other sources of error or bias in performance ratings (Jacobs et al., 1980; Landy and Farr, 1983; Murphy and Constans, 1988; Milkovich and Wigdor, 1990:149). No doubt a great deal was learned, and everyday practice in applied settings has benefited —but improvements in job analysis, scale development, scale format, and rater training, whatever else they accomplished, did not bring dramatic improvements in measurement precision.
As a consequence, many industrial and organizational psychologists turned
their attention in the 1980s from the rating instrument to the cognitive processes of the person doing the rating. The motive remains the same as in earlier research, that is, to enhance the accuracy of ratings of employee performance through the elimination, or at least the diminution, of rater bias or error. By understanding how evaluators process performance information and by what heuristic their judgments are stored in memory, the researchers with a cognitive bent hoped to come up with devices for improving those judgments.
One of the early findings of the work on the cognitive processes of raters is that, whether the rating instrument is cast in terms of behaviors or personal traits, evaluators appear to draw on trait-based cognitive models of an employee's performance, and that these general impressions substantially affect the evaluator's memory and judgment of actual work behaviors (Landy and Farr, 1983; Murphy et al., 1982; Ilgen and Feldman, 1983; Murphy and Jako, 1989; Murphy and Cleveland, 1991). The prescriptions for improvement growing out of this line of research concentrate, not on innovations in rating format, but on increasing the physical proximity of the rater to the employees to be rated so there is increased observation of actual work performance; training raters in systematic observation; encouraging the use of aides-mémoire such as performance diaries; and, in the expert systems mode, training in the heuristics used by successful evaluators. But once again, the innovations have failed to show dramatic or consistent improvements in measurement precision.
The most recent developments in the research on performance ratings represent a departure from the psychometric lines of inquiry that have dominated testing and criterion research. A number of industrial psychologists have begun to move away from the traditional view of performance appraisal as a measurement problem. Rather than treating it as a measurement tool, they have begun to look on performance appraisal as a social and communication process (Murphy and Cleveland, 1991; see Milkovich and Wigdor, 1990:145). From this perspective, the other uses of performance appraisal in organizational settings —for improving employee understanding of organizational goals, communicating a sense of fair play in the distribution of rewards and penalties, increasing communication between managers and employees—take center stage. Forty years of research on performance rating technology appear to have led at least some researchers to doubt that the large improvements in accuracy and precision that were at one time anticipated will be forthcoming.
The Importance of the Criterion Issue
The full importance of the criterion issue was only slowly recognized by psychologists, and it is safe to say that the problem is largely unappreciated by employers, educators, test takers, and others who use or are affected by
test scores. In part this is because the statistical assumptions that underlie testing technology are complicated; most people are not conversant with correlational analysis or regression analysis and furthermore do not understand the extent to which the statistical procedures provide the meaning in this approach to human abilities. In part, it is because most people think that test scores have some inherent meaning. The nomenclature surrounding testing—ability tests, vocational aptitude tests, intelligence tests—has masked the degree to which meaning is derived, not from a deep understanding of what ability or intelligence is, but from the calculation of external relationships among variables of interest, e.g., the consistency with which the distribution of individuals' test scores around the mean is replicated on a criterion measure. The failure to fully recognize the seriousness of the criterion problem is also due in part to the sheer difficulty in most settings of coming up with an adequate criterion that is measurable and not prohibitively expensive to develop. The performance rating continues to be the most common criterion used in validation research as a matter of expediency.
The truth of the matter is that standardized testing, for all its efficiencies, cannot perform the rational and objective sorting functions that Americans expect it to unless test publishers and institutional users are willing to put as much thought and effort into the criteria used in the validation process as is put into the tests themselves. This is as necessary in educational settings, in which tests are called on to group and screen students, monitor educational progress, and evaluate schools, as it is of the use of tests in business and industry.
In a speech to his colleagues at the 1964 annual meeting of the American Psychological Association, Rains Wallace argued that, at the very least, it behooves industrial psychologists to show that their services do no harm (Wallace, 1965:411):
The possibility of this macabre event has been soft-pedaled. Somehow, we seem to have convinced our clients, and even ourselves, that the application of our selection techniques is, at worst, neutral in its effect. This is probably the reason that we are allowed and allow ourselves to install selection tests . . . by which prospective employees are rejected for initial employment, even though we have no evidence that those rejected are any different from those who are employed in potential [for] success [in] the job.
The costs of using tests that cannot be shown to be substantially related to appropriate and adequate performance criteria are twofold. First, of course, is the unfairness to individuals who lose out on job or education opportunities, doubly unfair under a system that advertises itself as an objective means of selecting on the basis of merit. Second are the larger social costs. If the examinations used to decide who shall be admitted to medical school tap only scientific knowledge and not clinical or diagnostic skills, medical research may prosper, but everyday treatment may well be found wanting. If employ
ers put resources into selection procedures that eliminate a large percentage of applicants on dubious grounds, not only have they wasted the costs of the personnel selection program, but they have also lost potentially successful employees. Few have the luxury of an overabundance of qualified workers in their applicant pool. If the policy maker reaches decisions about the health of the education enterprise on the basis of data from tests designed to evaluate basic skills mastery, no matter how suitable the tests for the latter purpose, those decisions are likely to misguided.
The search for new and better measures of job performance has not, of course, been limited to the performance evaluation strategies described above. The major innovation of the 1980s has been the systematic study of the hands-on job-sample test. Applied psychologists have always considered the job sample the most compelling performance measure in the abstract, but they have seldom found it a practical alternative because of the high costs of development and administration. If for no other reason, the military research described in this volume represents a significant contribution to the art and science of ability testing and test validation because it has made a serious, conscientious attempt to construct, administer, and interpret the criterion measure that comes closest to actual job performance, the hands-on job-sample test.
The importance of the military project goes well beyond the attempt to construct a particular type of performance measure that had been too much ignored in the past. There have been few large-scale research projects devoted to the criterion question in the broadest sense. The Joint-Service Job Performance Measurement/Enlistment Standards (JPM) Project, which is the subject of this book, is the exception. Following the example set during two world wars, the military launched an ambitious study of the job performance of first-term enlisted personnel in which the four Services among them constructed and administered some 16 distinct types of measures of job proficiency in a sample of military jobs. As Linda Gottfredson points out in her paper in the companion volume to this report, the JPM Project has brought the tests and measurement field to a new frontier: for the first time, a variety of alternative measures that were designed to serve the same purpose can be evaluated and compared. The experience of the JPM Project—from job analysis to the construction of hands-on and other measures, to the very complicated task of trying to analyze an enormous data base that includes a fairly comprehensive set of input and performance measures—will bring the problem of validating the criterion a long step forward and promises over time to yield a deeper understanding of the meaning and proper interpretation of test scores.
The chapters that follow provide a description of this important initiative, a discussion of the policy needs it is designed to serve, and, in conclusion, a look at the challenges raised for the next generation of performance measurement.
















