
4
The Development of Job Performance Measures
Most studies that attempt to link applicant characteristics to job success assume a perfectly reliable and valid job performance criterion (e.g., supervisory ratings) and seek predictors of that criterion (e.g., ability tests, educational attainment). The JPM Project made no such assumption. Rather, it focused on the construction of criterion measures that capture job performance in order to validate already available predictors and to justify selective entrance standards. The central goal was to design and develop a measure of job performance with high fidelity to the actions performed on the job for a sample of military jobs. This measure was expected to “look like” the job to job incumbents, supervisors, and policy makers; to represent the important aspects of the job; and to exclude extraneous requirements that might inflate or depress the true relation between the ASVAB and the criterion —military job performance.
It was an ambitious undertaking, with lessons to be learned at every step of the way. Because so few precursors existed in the published literature, the Service research teams had to work out the nuts and bolts of constructing hands-on performance measures of sufficient psychometric robustness for the intended use. In this chapter, we draw on the methods used by the Services to illustrate the difficulties inherent in any serious attempt at performance measurement in employment or educational settings.
JOB PERFORMANCE AS A CONSTRUCT
The measurement of job performance might appear to be relatively straightforward, particularly for military jobs, which have specified training requirements and on-the-job responsibilities. The apparent simplicity, however, is misleading. Job performance is not something that can be readily pointed to or simply counted. Except for the most highly routinized jobs, in which the measurement of a person 's performance is almost a by-product of doing the job, what we call job performance for operational purposes is an abstraction from objective reality—its functional definition is a product of constructions or concepts developed for particular purposes, such as personnel selection and classification, training, performance-based compensation decisions, or test validation.
There are a number of obvious and not-so-obvious hazards that confront the analyst who would construct a definition of job performance for any given occupation. Even if it were possible to follow a sample of job incumbents for several weeks, videotaping each worker's every action, and then testing the consequences of each action (e.g., did the valve leak; did the wires used to secure screws come loose after X hours of jet engine vibration), the observations would not automatically suggest a useful concept of the job nor necessarily produce an adequate measurement of job performance. Some critical job tasks may be performed only very occasionally and might easily elude the observer. Or they may occur only in crisis situations and thus defy easy interpretation. Some critical job tasks may be difficult to observe directly—complex troubleshooting tasks, for example, are performed largely within the mind. Furthermore, the outcomes of an individual's task performance may depend on a wide variety of environmental factors, such as the state of repair of the equipment used, the actions of coworkers, or, as every sales representative and military recruiter knows, the state of the economy. Even if one had a wealth of observational data, however, this would not resolve the difficult conceptual issues regarding what aspects of job performance to measure, how each aspect should be measured, or how the measures should be combined.
In other words, a job is not a fact of nature to be stumbled upon and classified. In order to speak about a job, it is necessary to construct a conception of the job. In order to assess job performance, it is necessary to translate that conception into measurable bits. And in order to evaluate the quality of job performance measurements, it is necessary to demonstrate the validity of construct interpretations —that is, to defend the appropriateness of the construct for the purpose at hand and to show that an incumbent's performance on the measure is representative of performance on the job.
The purpose of this chapter is to describe the steps involved in the development of job performance measures, and in particular the hands-on job
sample measures that characterize the JPM Project. We describe methods used by the Services to: (a) define the universe of job tasks and their performances, (b) reduce that universe to a manageable number and kind of tasks, and (c) create performance measures based on task samples.
STEPS IN DEVELOPING JOB PERFORMANCE MEASURES
The design and development of a job performance measure begins with the specification of job content and ends with the development of test items from a reduced set of tasks/actions to be included in the performance measure (Guion, 1979; Laabs and Baker, 1989). More specifically, design and development of job performance measures follow a process of progressive refinement of the job construct, involving:
-
Definition of the Job Content Universe. This initial examination of a job involves the enumeration and description of all tasks that comprise the job, as well as the corresponding acts (behaviors) needed to carry them out (Guion, 1977).
-
Definition of the Job Content Domain. The job content universe is all inclusive. It is likely to contain redundant or overlapping tasks, tasks rapidly being made obsolete by technological change or job restructuring, and tasks performed in only a few locations. At this stage, the total universe is distilled to a smaller set of tasks that comprise the “essential” job.
-
Specification of the Domain of Testable Tasks. Further refinement of the domain of interest is made for reasons relating to testing. Financial constraints, for example, might call for the elimination of tasks requiring the use of expensive equipment and for which no simulators are available. Safely considerations might preclude some tasks.
-
Development of Performance Measures. At this point, a sample of job-tasks that are amenable to testing are translated into test items.
This sequence provides a framework for describing and evaluating the approaches and variations in approaches taken by the Services in developing performance assessments.
THE JOB CONTENT UNIVERSE
A job may be described by a set of tasks and the behavior needed to perform them, including the knowledge and skills underlying that behavior. These tasks and behaviors in the job content universe are enumerated through a job analysis.
Four approaches have been used to analyze jobs. One method, task analysis, was the central component of the JPM job analyses. The specifics
of the task analysis varied from one Service to another because of differences in task definition, in the level of detail at which tasks were described, and in the extent to which only observable or both observable and cognitive behavior was accounted for. The second method, trait analysis, identifies the human abilities necessary to successfully complete the tasks on the job. The third method, task-by-trait analysis, embodies both of these (Guion, 1975; Wigdor and Green, 1986). The fourth approach, cognitive task analysis, goes beyond specifying abstract traits to identify the cognitive components involved in successfully performing a task in a conceptual and procedural system. We describe these methods and how the Services use them in the sections that follow.
Task Analysis
A task is commonly defined as a well-circumscribed unit of goal-directed job activity with a discernable beginning and end. It is generally performed within a short period of time, but it may be interrupted and it may share time with other tasks. Some tasks may be performed by individuals, others by a team.
The beginning of a task is signaled by a cue or stimulus that tells a person to perform the task. These cues may be embedded in training material or a written procedure, specified by a supervisor, triggered by the completion of a preceding task, or called for by some displayed item of information such as a warning light. The task is completed when the goal is reached.
Task analysis is carried out by analysts who may observe the job, perform some of the tasks, interview job incumbents and supervisors, collect job performance information from incumbents and supervisors by questionnaire, or do some combination of these (Landy, 1989). The most common method is to observe the job and collect data by taking notes or filling out a checklist or questionnaire regarding tasks that appear important. A second method is to collect information in interviews or with questionnaires from large numbers of incumbents and supervisors.
The analysis results in a written record comprised of descriptive statements enumerating the behaviors exhibited in the performance of the job tasks. These descriptive statements may take the form of a simple sentence consisting of a person who performs a job (e.g., rifleman), an action verb (e.g., lifts, aims, pulls), and an object (e.g., the weapon, the trigger). The analysis also identifies the starting conditions, the actions required to reach the task goal, the goal itself, and each person by job title or name involved in performing the task (e.g., supervisor, operator, technician).
These statements are often translated into tabular form. Each task is entered in a row divided into successive subject-verb-object columns. Additional columns may be used to enter enabling attributes and conditions
and other information related to tasks, such as task importance as judged by subject matter experts. Sometimes tasks are subdivided into steps, each step describing the detailed actions necessary to achieve the task's goal.
The Marine Corps' use of task analysis illustrates one approach taken in the JPM Project. The Marine Corps found its task analysis ready-made in training doctrine (Mayberry, 1987). Its individual training standards (ITS) defined the tasks that were required of each Marine in a job and the level of competence to which the tasks were to be performed. The ITS also defines the pay grade level associated with the job. More specifically, the ITS divides a job (e.g., basic infantry) into mini jobs called duty areas (e.g., grenade launcher), which, in turn, are divided into tasks (e.g., inspect grenade launcher; maintain launcher; zero grenade launcher; engage targets; engage targets with limited visibility). The process of performing a task, for example, engage target, is specified by a set of subtasks, as are the performance standards. The ITS, then, provides the definitive statement of the tasks that comprise each and every Marine Corps job (Figure 4-1).

FIGURE 4-1 Individual training standards for one task of the M203 grenade launcher duty area. SOURCE: Mayberry (1987:16).
The ITS, however, provides only limited information about the behaviors required to carry out a job. To complete the task analysis, the Marine Corps researchers identified the major activities relevant to each of the subtasks. The five tasks in the duty area called grenade launcher, for example, were broken down into 12 subtasks, which among them included 19 behavioral elements (Figure 4-2). These behavioral elements (verbs in a task description) were themselves further defined by the steps required to carry them out (Figure 4-3). Taken together, then, the tasks and subtasks defined by the ITS and their behavioral elements and steps defined by a detailed task analysis constituted the job content universe for each of the Marine Corps jobs.
While no other Service has Individual Training Standards, they all have elaborate task inventory systems. The Air Force, for example, used its Comprehensive Occupational Data Analysis Program, CODAP (Christal, 1974) to define a job content universe for developing performance measures. CODAP is a collection of data management programs that assemble, quantify, organize, and summarize information obtained from job analyses. Task inventories for each Air Force specialty have been compiled (and regularly updated) since the 1970s by job analysts who observed people at work, actually performed parts of the job themselves, and interviewed job incumbents and supervisors. From this collection of information, a questionnaire was developed for each job specialty to collect specific background and task performance information from job incumbents and supervisors.
The questionnaire for jet engine mechanics, for example, consists of no fewer than 587 questions; the first 28 address background information, and the remaining 559 address task performance information (Table 4-1). The questionnaire data are entered into CODAP periodically; information can be obtained on which tasks are performed in what amount of time by whom (incumbent, supervisor), at which work station, and on what aircraft. In this way, the job of jet engine mechanic is described exhaustively.
Trait Analysis and Task-by-Trait Analysis
Trait analysis is predicated on the notion that a great deal could be learned about a job by knowing what personal attributes—abilities, traits, and skills—enable an incumbent to successfully perform that job. In early applications of trait analysis, expert judgments about underlying abilities were translated into tests used in employee selection. Shortly after the end of World War II, trait analysis was abandoned in favor of the less direct, yet seemingly more empirical, criterion-related validity analysis. Criterion-related validity analysis attempted to predict job performance by “blind empiricism”: analysts sought a set of ability tests that significantly discriminated between the performance of job experts and job novices. This approach led to a proliferation of new tests but did little to increase understanding of the underlying behavioral foundation of job performance.
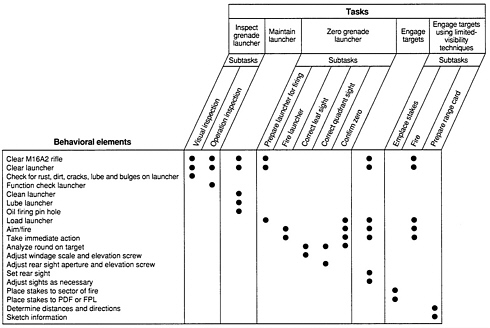
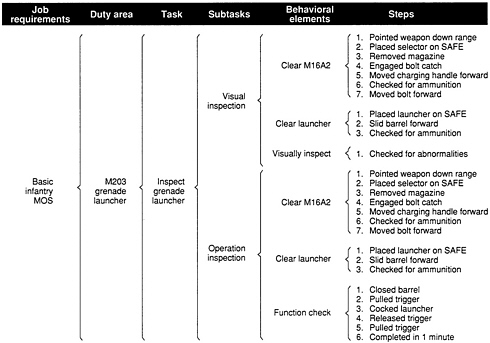
TABLE 4-1 Jet Engine Mechanic Job Inventory: Selected Items
|
Background Information |
|
|
9. |
How do you find your job (Extremely dull ... Extremely interesting)? |
|
21. |
Indicate the function which best describes where you work in your present job. Choose only one response (Accessory Repair, Afterburner Shop, ..., Balance Shop, ..., Flow Room) |
|
26. |
Indicate any test equipment or special tools you use in your present job (I do not, ..., Bearing Cleaners, ..., Carbon Seal Testers, ..., Freon Testers, ..., Variable Vane Pumps, ..., “Yellow Box” Testers) |
|
Task Information: Check Tasks Performed and Fill in Time Spent When Requested |
|
|
A. |
Organizing and Planning 1. Assign personnel to duty positions 21. Plan work assignments |
|
B. |
Directing and Implementing 26. Advise maintenance officers on engine maintenance activities 55. Supervise Apprentice Turboprop Propulsion Mechanics 62. Write correspondence |
|
C. |
Inspecting and Evaluating 63. Analyze workload requirements 70. Evaluate maintenance management information and control systems |
|
D. |
Training 86. Administer tests 100. Evaluate OJT trainees |
|
E. |
Preparing and Maintaining Forms, Records, and Reports 109. Cut stencils 116. Maintain engine master roster listings |
|
F. |
Performing Quality Control Functions 145. Inspect areas for foreign object damage matter 149. Observe in-process maintenance |
|
G. |
Performing Flightline Engine Maintenance Functions 158. Adjust gearbox oil pressure 163. Compute engine thrust or efficiency on trim pads 186. Remove or install engines in aircraft |
|
H. |
Performing In-Shop Engine Maintenance Functions 203. Inspect engine oil seals 229. Prepare engines for shipment 247. Remove or install turbine rotors |
|
I. |
Performing Balance Shop Functions 249. Assemble compressor units 255. Measure blade tip radii |
|
SOURCE: U.S. Air Force (1980). |
|
Today, pure trait analysis is rarely used. Rather, trait analysis is used in combination with task analysis in one of two ways: (a) generic task-by-trait analysis and (b) local task-by-trait analysis.
Generic Task-by-Trait Analysis
The generic approach assumes that any task can be decomposed into a parsimonious set of human abilities. Each task is analyzed by job analysts or subject matter experts who attempt to link task performance with underlying traits or abilities. A job, then, would be described by the smallest set of human abilities that underlie the performance of its constituent tasks. Conceptually, generic attribute analysis results in a profile of necessary and desirable attributes needed to perform the job successfully. An early example is Lipmann's (1916) psychograph, the first formal and widely used job analysis instrument. It contained 148 questions related to human traits necessary for success in any of 121 occupations. Thus, for example, the job of quiller (a job in a cotton mill that dealt with keeping yarn supplied and knitting machines running smoothly) was thought to require a particular pattern of mental abilities (Figure 4-4). Those abilities were posited after observation of the job by a trained observer, who then rated the job on each of the 148 traits using a 5-point scale of importance from “negligible” to “utmost” importance (Viteles, 1932).
In recent years, Fleishman's research has carried on the task-by-trait line of analysis. Called the ability requirements approach, the Fleishman taxonomy has been developed in both laboratory and field settings and has been revised and refined over 30 years (Fleishman, 1975; Fleishman and Quaintance, 1984). The objective of the work has been to define a parsimonious set of ability factors in psychomotor, physical, cognitive and perceptual domains, then to develop a rating scale methodology by means of which the ability requirements of tasks could be described as a basis for classifying these tasks. The Fleishman taxonomy currently consists of some 52 abilities; Table 4-2 shows a selection of general abilities, each accompanied by three definitional anchors representing levels of that ability. Subject matter experts and job analysts can compare the ability requirements of the job they are studying to the definitional anchors.
In practice, task analysis usually precedes trait analysis. Critical tasks or broader task groups are identified so that the job analyst can then apply trait analysis either to all tasks or only a subset of the most important of them. The human abilities are then collapsed across tasks to obtain a final, parsimonious profile of the abilities required by the job. Thus, when completed, the analysis provides a picture of the job from both the task and trait perspectives.
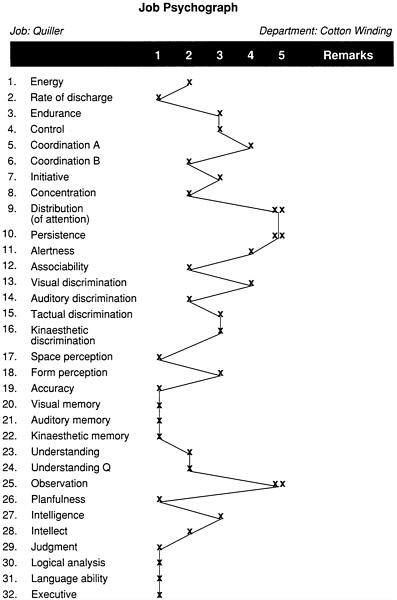
TABLE 4-2 Ability Requirement Scales: Tasks Representing Different Ability Categories
|
1. |
Written Comprehension Understand an instruction book on repairing a missile guidance system. Understand an apartment lease. Read a road map. |
|
2. |
Problem Sensitivity Recognize an illness at an early stage of a disease when there are only a few symptoms. Recognize from the mood of prisoners that a riot is likely to occur. Recognize that an unplugged lamp won't work. |
|
3. |
Speed of Closure Interpret the patterns on the weather radar to decide if the weather is changing. Find five camouflaged birds in a picture. While listening to the radio, recognize and start to hum an old song after hearing only the first few lines. |
|
4. |
Visualization Anticipate your opponent's as well as your own future moves in a chess game. Know how to cut and fold a piece of paper to make a cube. Imagine how to put paper in the typewriter so the letterhead comes out at the top. |
|
5. |
Reaction Time Hit back the ball which has been slammed at you in a ping-pong game. Duck to miss being hit by a snowball thrown from across the street. Start to apply brakes on your car 1 second after the light turns red. |
|
6. |
Finger Dexterity Play a classical flamenco piece on the guitar. Untie a knot in a long-awaited package. Put coins in a parking meter. |
|
7. |
Time Sharing As air traffic controller, monitor a radar scope to keep track of all inbound and outbound planes during a period of heavy, congested traffic. Monitor several teletypes at the same time in a newsroom. Watch street signs and road while driving 30 miles per hour. |
|
8. |
Stamina Bicycle 20 miles to work. Mow a small yard. Walk around the block. |
|
9. |
Depth Perception Thread a needle. Operate a construction crane. Judge which of two distant buildings is closer. |
|
10. |
Sound Localization Locate someone calling your name in the midst of crowd. Find a ringing telephone in an unfamiliar apartment. Take legal dictation. |
|
SOURCE: Fleishman and Quaintance (1984:Appendix C). |
|
Local Task-by-Trait Analysis
Rather than using a predetermined set of human abilities such as the Fleishman taxonomy, job analysts may develop a list or taxonomy for the particular job at hand. Such an analysis might be created through discussions with subject matter experts or by combining attributes from other ability lists that seem to bear on the current analysis. Examples of local trait-by-task analysis can be found in the JPM Project. In their analysis of jobs, the Army research team developed a list of attributes considered important to job performance (Figure 4-5). This list is actually a combination of attribute labels from several distinct taxonomies, including Fleishman's. In part, the Army's list reflects the broader nature of the Army's research, which was committed to exploring alternative predictors of service success and, as a result, had an interest in predictor as well as criterion development. In addition, the list reflects the Army's interest not only in the attributes that related to the can-do aspect of performance (i.e., possession of requisite knowledge, skills, and abilities) but also in the will-do aspect (i.e., possession of attitudinal, affective, motivational, and habitual personal attributes).
FIGURE 4-5 Local taxonomy for attribute analyses.
Cognitive Task Analysis
An emerging technology, too new to be employed in the JPM Project, is a modern version of task-by-trait analysis called cognitive task analysis (Glaser et al., Vol. II; Lesgold et al., 1990). Like task analysis, cognitive task analysis segments jobs into tasks; like trait analysis, it examines the human abilities underlying performance. Where it differs from the traditional task-by-trait analysis is that the giant leap from observed behavior to psychological traits/abilities underlying job performance is replaced by a careful analysis and empirical testing of the procedural and contextual knowledge used by an individual in performing job tasks.
Cognitive task analysis concentrates on both observable performance and on the individual's mental representation of the task. Specifically, it leads to a description of the knowledge an individual possesses about a task and the rules the individual uses in applying that knowledge to performing the task. For purposes of analysis, knowledge is divided into two general categories: procedural knowledge—the content of the individual's technical skills—and contextual/background knowledge used in applying skills to task performance.
Procedural knowledge is composed of the individual's mental representation of (1) the goals and subgoals of the task, (2) the procedures for performing the task, and (3) the rules followed in selecting and applying procedures to the achievement of task goals and subgoals. Contextual/ background knowledge is defined, in part, by the depth of the individual's understanding of the content of the task—whether the individual has an explicit or implicit representation of the task's goal structure, whether the individual knows the basic principles and theories—and the sophistication of mental models and metaphors that have been developed to guide task performance.
Research by Glaser et al. and Lesgold et al. suggests significant differences in the ways novices and experts represent a task. These differences are characterized by variations in depth of knowledge, familiarity with task goals and content area principles, and level of goal orientation in problem solving. According to Glaser et al. (Vol. II:7):
In particular, we know that the knowledge of experts is highly procedural. Facts, routines, and job concepts are bound by rules for their application, and to conditions under which this knowledge is useful. . . . The functional knowledge of experts is related strongly to their knowledge of the goal structure of a problem. Experts and novices may be equally competent at recalling small specific items of domain-related information, but proficient people are much better at relating these events in cause-and-effect sequences that reflect the goal structures of task performance and problem solution.
The primary purposes of distinguishing between the mental representations of experts and novices are: (1) to define effective performance, (2) to design training programs targeted to instilling in novices the knowledge representations of experts, and (3) to develop computer-based expert systems that will function effectively as advisers to both novices and experts. With advances in technology, a greater proportion of job tasks are relying on higher cognitive processes rather than on rote learning of procedures—that is, lower-level jobs are being replaced by automation. These changes suggest that assessing the cognitive processes of an individual is becoming a more important part of specifying what is meant by effective task performance. As a result, cognitive task analysis is likely to play a significant role in future research on job analysis.
Current procedures for performing cognitive task analysis are time-consuming and expensive. Subject matter experts cannot do cognitive task analyses of their own mental processing because much of their expertise is automatic. For the most part, the analysis process is conducted by “knowledge engineers,” and their standard method is to have the expert critique the performance of a novice—iterative critiques lead to a refined understanding on the part of the knowledge engineer. A need for the future is to develop a clear set of rules and practices for cognitive task analysis—at the present time it is more of an art than a science.
Glaser et al. (Vol. II) undertook a cognitive task analysis of expert and novice electronics technicians performing an avionics troubleshooting task. One of their goals was to create a task analysis that directly reflected experts' views of which cognitive activities were critical to effective trouble-shooting. Luckily they found one subject matter expert who had extensive experience in observing novice performance. He was able to point out (p. 16):
It was not a big chore to specify all of the steps that an expert would take as well as all of the steps that any novice was at all likely to take in solving even very complex troubleshooting problems. That is, even when the task was to find the source of a failure in a test station that contained perhaps 40 feet . . . of printed circuit boards, cables, and connectors, various specific aspects of the job situation constrained the task sufficiently that the effective problem space could be mapped out.
In the end, between 55 and 60 key decision points could be identified in the troubleshooting task. The research team constructed 45 questions that could be asked of the job incumbent as he or she performed the task. The responses to these questions were used to map out the conceptual and procedural knowledge used to complete the task (Figure 4-6). In this way, the incumbent's plan for finding the fault in the circuit was made explicit. The

results provide a strong basis for evaluating the job performance of an incumbent as well as diagnosing the need for specific types of training.
Characteristics of Job Tasks and Traits
A job analysis is not yet complete when the universe of tasks and traits has been enumerated. Not all tasks, for example, contribute in the same way to the job. Some require more training time than others, some are performed more frequently than others, some are more important to job success than others, and some engender more errors than others. Consequently, in characterizing a job and constructing a measure of performance on that job, it is necessary to go beyond task and behavior descriptions and evaluate tasks according to such characteristics as frequency, difficulty, and importance. Such information further describes the job and also permits the weighting of tasks in selecting them for inclusion in a job performance measure. In this section, we consider some of the alternative dimensions on which tasks or traits might be evaluated and the consequences of using each.
Importance
Certainly, one would be interested in distinguishing tasks along some continuum of importance or criticality. The importance might refer to the position of a single task in a larger domain of tasks that make up the job, or it might refer to the contribution of a particular knowledge, skill, or ability (i.e., trait) in a larger domain of personal attributes that define the full set of resources that a worker might bring to a task (or job). For example, a firefighting task involving fire suppression is more important than one involving the cleaning of equipment. Similarly, for the job of firefighter, the attribute known as stamina or cardiovascular endurance is more important than the attribute known as finger dexterity. In the military setting, a task involving the repair of an electronic circuit controlling fuel flow to a jet engine would probably be more important than a task related to cleaning repair equipment after every use.
Frequency
In addition to importance, one might be interested in whether the task is performed frequently relative to other tasks or if the attribute is used frequently relative to other attributes. In the case of the firefighter position described above, equipment maintenance tasks are performed more frequently than fire suppression tasks. Similarly, the attribute of verbal comprehension is more frequently required in activities than is deductive reasoning.
Similarly, the jet engine mechanic may replace washers and O-rings much more frequently than circuit boards.
Difficulty
Independent of importance and frequency, one might investigate the relative difficulty involved in completing a task or applying a knowledge, skill, or ability. Another way of addressing the same issue might be to examine the level at which the task must be performed or the extent to which the attribute must be developed to be useful in the job. To remain with the firefighter example, it seems clear that suppressing a chemical fire is more challenging than suppressing a brush fire. With respect to personal attributes, it seems true that problem sensitivity must be developed to a considerably greater extent than eye-hand coordination. For the jet engine mechanic, troubleshooting and diagnostics may be considerably more difficult than routine maintenance.
Modifiability
Often, a worker will receive training after being hired. Thus, when considering attributes required for success, one is often interested in the extent to which a task is required immediately after placement on a job rather than after some period of on-the-job training. Similarly, the job analyst might be interested in knowing if an attribute is likely to be modifiable through training or if the skill in question will be part of a training program. Those attributes least modifiable might be more central to the job analysis than those easily changed, particularly when those attributes are also central to job success.
Variability
From both the task and attribute perspective, it is often useful to identify those tasks or attributes for which the differences among incumbents are likely to be the greatest. This is important, for example, if the purpose is to make selection decisions (but not if the purpose is to assess job mastery). Tasks or attributes for which there is little variability are of limited value from the perspective of personnel selection. This follows from the psychometric foundation for prediction: the greater the variance in predictor and criterion, the higher the potential empirical relationship between the two. Conversely, if either the criterion or predictor variable is constant (or nearly so), there will be no (or little) chance of demonstrating a relationship between the two and there will be little utility in using the predictor to make selection decisions.
Other Characteristics
It is possible to think of other characteristics that might play a role in job analysis, but they would be less common and might relate more to the situation than the job analysis procedures generally. As an example, in some situations one might introduce the notion of contribution to profitability if the environment was a highly competitive one with narrow profit margins. Similarly, in an environment in which personal danger and safety were at issue, one might consider the extent to which a task was dangerous or the extent to which the possession of a particular attribute might reduce risk to a worker or colleague or consumer —a safety dimension. One might also consider the extent to which a task or attribute is an aspect of many jobs rather than only one or a few jobs. This might be called a commonality dimension. Finally, one might consider the effect that a radical change in environment might have on a task or an attribute. Consider the differences between a precomputer and postcomputer workplace. As another example, consider the sophisticated firing mechanisms in modern tanks that permit one to fire the cannon while the tank is in motion. This was a radical departure from previous weapon systems that required the tank to come to a stop (and assume a position of maximum vulnerability in the process) before firing the cannon. Aside from providing the air-conditioned comfort enjoyed by computers and tank crewman alike, the combat environment in the new tanks places a premium on rapid response to computer-generated targeting information.
This kind of consideration is of particular importance in the context of the JPM Project. A central point of discussion has been wartime versus peacetime conditions. The question that might be asked with respect to job tasks or personal attributes is the extent to which they become more or less important in conditions of open conflict. In the private sector, an equivalent concern might be a midyear budget reduction for an industrial unit or the threat of a corporate takeover. The question of tasks and attributes that become more or less important under hostile conditions was a central issue in the planning for the JPM Project, since the purpose of the armed forces is to be prepared to fight a war, not simply to maintain equipment during peacetime conditions.
The JPM Definition of the Job Content Universe
The JPM Project did not break new ground in identifying and analyzing tasks that comprise a job content universe. Instead, project scientists carried out a traditional job analysis. For several reasons, trait analysis did not play a major role in the project. First, the Air Force CODAP system and its variants provided the Services with an available knowledge base for task
based job analysis. Sheer time and cost considerations made it expedient to use the existing system and data. In addition, the credibility or face validity of the criterion measures to be developed was inordinately important. The misnorming incident described earlier led some legislators and military policy makers to question the value of the ASVAB. Hence a central premise in the JPM Project was that a good behavioral criterion measure was the necessary condition for demonstrating the predictive value of the ASVAB. Project planners wanted to stay as close as possible to concrete job performance in order to allay the apprehensions of policy makers. Although any project faces financial and contextual constraints, the failure to pursue a task-by-trait analysis has some unfortunate consequences. It is important to keep in mind the value of the task-by-trait approach for predictor development, for construct validation, and for theory building. In general, the most informative job analysis will embrace both facets of performance: the tasks inherent in jobs and the enabling human traits or attributes that produce successful performance of those tasks.
DEFINING THE DOMAIN OF INTEREST
The job content universe is likely to contain more tasks than can or should be incorporated into a job performance measure. For example, the universe may contain tasks that duplicate one another, or are judged by subject matter experts to be trivial or so dangerous that using them in a job performance measure cannot be justified, or are so expensive that if an error is made, the cost far exceeds the information value (e.g., damaging a jet engine). The art and science of job performance measurement consist in good part in the finesse with which the essential job (whose definition may well depend on the measurement goals) is distilled from the total universe of possible tasks.
There are many possible approaches to specifying the domain of interest. The Marine Corps, for example, reduced the content universe to the domain of testable tasks by identifying behavioral elements shared in common by different tasks. The rationale was that “sampling of test content with regard only to tasks may be somewhat misleading because one cannot explicitly identify the specific behaviors that are being measured or assure that all behaviors relevant to the performance of the job are even being tested” (Mayberry, 1987:17). To identify behavioral elements, a detailed task analysis was carried out, and job experts constructed behavioral elements—”generic verb-noun statements denoting identifiable units of performance that underlie the performance of the ITS (Individual Training Standards) tasks” (p. 17). Thus, across the tasks comprising the grenade launcher duty area, a parsimonious set of behavioral elements was identified. The domain of interest for the grenade launcher was then defined by five tasks and a set of behavioral elements common to one or more of the tasks (see Figure 4-2).
The Air Force took a different approach. For each job studied there was occupational survey data available organized as a list of tasks, each with information on the percentage of incumbents performing the task, relative time spent on the task, time required to learn the task, and the importance of training to mastery of the task.
The list of tasks was reduced using complex decision rules. For the job of jet engine mechanic the rules were as follows:
-
Select tasks that are included in the Plan of Instruction (training curriculum) or that are performed by at least 30 percent of first-term incumbents.
-
Group tasks into clusters that will facilitate ease of development of hands-on measures.
-
Weigh clusters in terms of relative importance.
-
Determine percentage of tasks within a cluster to be selected for further consideration.
-
Select tasks on the basis of learning or performance difficulty.
The Navy's approach to task selection depended heavily on the use of experts to reduce the initial task universe. As an example, for the Navy rating of radioman, the job analysis began with a list of 500 tasks that defined the job content universe. This list was generated by examining prior job analyses, reviewing training material, interviewing first-term incumbents and their supervisors, and observing on-the-job performance. Only tasks performed exclusively by first-term radiomen were included in the initial list.
At this point, a series of individuals and groups examined and modified the list, as follows:
-
Two senior staff members of the training facility for radiomen deleted (a) tasks not performed by first-term radiomen, (b) those performed Navy-wide and not specifically by radiomen, (c) military tasks (such as standing for inspection), and (d) administrative tasks (such as maintaining a bulletin board; Laabs and Baker, 1989).
-
This reduced list of tasks was then examined by 17 radioman supervisors, who combined subtasks into larger complete tasks and separated broad, general tasks into more specific tasks. In addition, they reworded tasks so that all tasks were written at the same level of specificity. This refinement reduced the list from 500 to 124 task statements.
When steps 1 and 2 were completed, a questionnaire using the 124 statements was developed and sent to 500 first-term radiomen and 500 supervisors. The radiomen rated statements on the basis of frequency of perfor
mance and complexity. The supervisors rated the statements on the basis of importance for mission success and the percentage of time the task was performed incorrectly (an index of difficulty). The process by which a final sample of 22 tasks was selected for the radioman hands-on test is described in Chapter 7 (see also Laabs and Baker, 1989).
Approaches to Task Sampling
As indicated above, various decision rules were employed by the Services to reduce and refine the universe of tasks in a job to a subset of candidates for hands-on criterion development. Although such decision rules may be more or less reasonable, this trimming of the content universe of necessity creates interpretive difficulties. The problem is to draw a sample of tasks while preserving the ability of the job performance measure to reflect an incumbent's performance on the entire job.
At the extremes, there are two distinctly different sampling strategies that might be adopted. The first is to sample randomly from all tasks that define the job in question. An alternative would be to select tasks in some purposive way to represent certain a priori parameters. It is the second strategy that best characterizes the JPM Project. The question becomes whether this purposive task selection plan describes performance (through the hands-on medium) in a way that satisfies the goals of the JPM Project. To put the question more directly: Did the method of task selection for hands-on development create a definition of job performance that would permit one to conclude reasonably from a significant ASVAB validity demonstration that someone who did better on the ASVAB would do better on the job? A second, perhaps more intimidating issue is related to the linking of enlistment standards to job performance (and the desired mix of performance). Did the tasks chosen for hands-on test performance permit the assessment of the extent to which requisite performance mixes would be realized, i.e., could one be safe in inferring that a particular mix of CAT I through IV recruits would produce an acceptable mix of eventual performance? To the extent that the tasks chosen were not representative of relevant aspects of the job, both of these inferences (validity and performance mix) would be in jeopardy. In Chapter 7, we consider this issue of task sampling at some length. For purposes of this chapter, however, it should be kept in mind that the manner by which we create definitions of job success (including our operational definitions of success—i.e., the hands-on tests) will ultimately determine the strength of the inferences that can be made. If the tasks selected for hands-on development are not representative in some important way, then the technical and administrative qualities of those measures are almost irrelevant.
Specification of Test Content
By whatever route the sample of tasks is drawn, it defines the range of “stimulus materials” and acceptable responses that might be used to construct a job performance measure, as well as the alternative methods that might be used to score performance. Stimulus material refers to the items —tasks, problems, questions, situations—that might be presented in the performance test (e.g., using a grenade launcher). The form of probable or permissible responses refers to the steps, problem solutions, answers, or actions taken in response to the stimulus material (e.g., the steps required to load, aim, adjust sights, and fire a grenade launcher). The method of scoring the responses might entail counting the number or proportion of steps successfully completed in carrying out a task, or the number of correct answers to a set of questions, or an expert's evaluation of a verbal description of a procedure provided by the incumbent.
Guion (1979:23) provides an example of test content specification using a mapping sentence (following Hively et al., 1968) that completely specifies the test domain for electronics repair tasks:
Given (diagnostic data) about a malfunction in (product), and given (conditions), candidate must (locate and replace) malfunctioning (part) with the work or response evaluated by (method of observation or scoring).
Test content specification also identifies the modifications needed to translate the stimulus material and responses into a standardized form for measurement purposes (Guion, 1979).
Task Editing
Inevitably the domain of testable tasks contains a number of tasks that are trivial or repetitive that would, if included, provide little information about job performance and take up precious testing time. For example, the total time required for the Marine Corps to test the tactical measures duty area was estimated at 368 minutes. “Two-thirds of this time would be required for the subtask of ‘construct fighting hole.' Certainly, there are required techniques and specifications for digging fighting holes and these concepts could be tested, but actually digging a hole would not be an efficient use of testing time” (Mayberry, 1987:24). All of the Services eliminated such tasks.
Moreover, some tasks involved equipment that, if damaged, would be expensive to fix or replace. Such was the case in the Air Force' s performance test for jet engine mechanics. The solution was to create an assessment format that circumvented the problem, in this case a walk-through performance test. The walk-through performance test “has as its foundation
the work sample philosophy but attempts to expand the measurement of critical tasks to include those tasks not measured by hands-on testing . . . through the addition of an interview testing component. . . .” (Hedge et al., 1987:99).
The interview portion of the test has the incumbent explain the step-by-step procedures he or she would use to complete a task. The interview is conducted in a show-and-tell manner that permits the incumbent to visually and verbally describe how a step is accomplished (e.g., that bolt must be turned five revolutions). “For example, an interview item may test incumbents' ability to determine the source of high oil consumption . . . . While the incumbent is explaining how to perform the task, the test administrator uses a checklist to indicate whether the steps necessary for successful performance are correctly described and scores overall performance on a 5-point scale” (Hedge et al., 1987:100).
Finally, tasks may need to be translated into test items in a way that eliminates dangerous elements. For example, all Services eliminated some “live fire” subtasks and only one, the Marine Corps, included any such subtasks. The Army infantryman task cluster “to shoot” included all of the components other than firing the weapons: load, reduce stoppage, and clear an M60 machine gun; perform maintenance on M16A1 rifle; prepare a Dragon for firing, and so on.
In sum, the domain of testable tasks is not synonymous with the job content universe. Some tasks may have to be eliminated entirely for want of practical assessment procedures. All remaining tasks (perhaps with associated behaviors or, in a task-by-trait system, with relevant traits) need editing for testing purposes. The “stuff” of the performance measure, the content of the test, is distilled from the domain representing job content. This entails a further reduction of the original job content universe, the universe to which, ultimately, decision makers will draw inferences from the job performance measurement. As can be seen, there is a fine art to the science of performance measurement.
An Example: Marine Corps Infantryman
Mayberry (1987) provides a good summary of the entire process beginning with job universe specification and ending with the development of a job performance measure for the infantryman occupation. The job content universe is specified by Marine Corps doctrine through its Individual Training Standards (ITS) and its Essential Subject Tasks (EST), the former specifying job-related tasks and the latter basic tasks required of all Marines. In order to accomplish the reduction of the job as a whole to a sample of that job, a series of disaggregations was adopted. First, the researchers adopted the ITS designation of 13 duty areas for the basic infantry job (e.g., land
navigation, tactical measures, M16A2 rifle, communications, grenade launcher, hand grenades) each with its tasks, subtasks, and behavioral elements specified (e.g., Figure 4-2 and Figure 4-4). This job content universe was reduced in size to the job content domain by applying the following rules of elimination (Mayberry, 1987:21):
-
The subtask is hazardous or expensive, such as live firing of most weapons (except the M16A2 service rifle) and crossing a contaminated area for the NBC [Nuclear-Biological-Chemical] duty area.
-
Experts judge that the subtask provides little or no information. This [criterion] was applied to trivial or repetitive subtasks (it did not translate into the exclusion of simple subtasks).
From the job content domain, a set of tasks/behavioral elements was sampled with the constraint that “Total testing time for the . . . [basic infantry portion of the test] will be limited to about four hours” with the testing time for any duty area ranging from 10 to 30 minutes (Mayberry, 1987:21). To accomplish the sampling, several steps had to be carried out. First, heterogeneous tasks and subtasks had to be defined as discrete units with clearly defined boundaries and limits of about equal size. Yet “[j]obs can not readily be decomposed into discrete and independent units of performance. . . . The solution involves extensive analyses to refine the tasks into equivalent performance units that are amenable to sampling . . .” (Mayberry, 1987:20). This was accomplished using job experts.
The second step in sampling focused on deciding how much time to allocate to each duty on the performance measure. To this end, job experts' ratings of importance and criticality were collected. Testing time was allocated to each duty area according to its importance ranking. Duty area served as a stratification variable for drawing a weighted random sample of subtasks (Mayberry, 1987:25):
To maximize test content coverage across the behavioral elements [e.g., see Figure 4-4], each subtask . . . was weighted with respect to its behavioral elements. . . . For the first round of . . . sampling . . ., the sampling weight for each subtask was merely the number of behavioral elements that it contained. The subtasks with the greatest number of behavioral elements had the highest likelihood of being sampled.
Sampling weights for the remaining subtasks were then recomputed so that a second subtask could be sampled . . . . Random sampling of weighted subtasks continued until the testable units exhausted the allotted testing time for the duty area [p. 27].
The selection of subtasks established the general test content domain. Next, a detailed analysis was done of each subtask. This analysis revealed
the exact steps necessary for performance of the subtask. These steps became the actual go/no go or pass/fail test items. For example, the task “inspect the grenade launcher” includes the subtask “visual inspection,” which is broken down into the following steps that were translated into the scorable units of the hands-on test:
Clearing the M16A2
-
pointing the weapon down range
-
placing the selector on SAFE
-
removing the magazine
-
engaging the bolt catch
-
moving the charging handle forward
-
checking for ammunition
-
moving the bolt forward
Clearing the Launcher
-
placing the launcher on SAFE
-
sliding the barrel forward
-
checking for ammunition
The criteria used to screen tasks and subtasks (see above) were also applied to the steps required to accomplish each of the subtasks in the sample. Steps were deleted “if they were hazardous or too expensive to test or, in the opinion of job experts, provided little or no information concerning one's proficiency level” (Mayberry, 1987:25). The remaining “testable” subtask units were reviewed by both job experts and incumbents to ensure that what remained was representative of the subtask on the job.
Since each subtask test had a different number of steps, the individual 's score was determined as the percentage of steps successfully completed. These subtask scores were then weighted according to the relative importance of the duty area that they represented. Note that neither subtasks nor steps were differentially weighted. Each step and each subtask counted equally in the determination of hands-on scores. The performance test, then, was composed of a stratified, weighted, and “pruned” random sample of subtasks from the basic infantry job in the Marine Corps.
This description of the Marine Corps method of test construction is useful for illustrative purposes. First, it was clear that for administrative reasons they had limited time available for testing. For the grenade launcher duty area, task analysis indicated that the subtask of “maintaining the grenade launcher” was estimated at 32 minutes. Since there were 13 duty areas in the basic infantry job and a total of 4 hours to be allocated for testing (with a constraint of 10-30 minutes for testing an entire duty area), this subtask occupied too much time for inclusion. The actual time allotted to
testing a single duty area depended on the relative importance of that duty area (as judged by subject matter experts) and the number of subtasks into which the duty area could be decomposed. Thus, an important duty area (e.g., land navigation in the basic infantry job) with a substantial number of subtasks (16) would be allocated 30 minutes of testing time in the hands-on test but a less important duty area (e.g., use of the night vision device) with a small number of subtasks (5) might be allocated only 10 minutes. Keep in mind, however, that every duty area was measured. The difference was in the amount of time allocated to the duty area in the hands-on test and the percentage of subtasks in the duty area sampled.
SCORING HANDS-ON TESTS
Test items in the JPM Project were designed to be scorable using a go/no go format. That is, each task or partial task was broken down into some number of steps that an observer could evaluate dichotomously. The scoring sheet for each task listed a sequence of steps, with a place beside each step to indicate go or no go. A critical requirement of the hands-on assessment format is that it requires that the test administrator be able to see whether the step was performed correctly.
Scoring Performance on Tasks
Deciding how to compute an overall score for a given task required the JPM researchers to consider a number of small but important points. One of these had to do with the importance of sequence to task performance. Often the list of steps on the scoring sheet mirrored the steps found in the technical manual for the occupational specialty. The question of whether the exact sequence had to be followed was task dependent. In some cases, any change in sequence meant a no go for that step and perhaps for the remainder of the task because in real time the lapse would result in, for example, erroneous judgments (e.g., if pressure gauges were read in the wrong order).
Similarly, procedural rules have to be established for when to abort a test item. In some instances, if a step has been done incorrectly, the remainder of the task cannot, or for reasons of safety should not, be attempted. In the JPM Project, if the step could be easily done or corrected by the test administrator (who in most cases was an expert in the job), it was done and the administrator proceeded with the remaining steps. Otherwise, the task was aborted.
Perhaps the most important decision to be made is how to derive a score from performance on the task's constituent steps. The score might be defined as the number of successive correct stages before the first error or
before some critical step. Or the task score might be computed as the proportion of steps done correctly—this strategy was followed for the most part in the JPM Project. It has the benefit of expressing task performance on a standard scale even though tasks vary greatly in the number of steps they include. Within this framework it would also be possible to weight steps differentially on the grounds that some steps are more critical than others, although this was not typically done in the JPM Project.
Computing Test Scores
In arriving at a score that is to be an informative indicator of performance on the job, two issues present themselves. First is the question of combining scores from various parts of the test. Second is the question of what constitutes a “passing” score.
For a concrete example, consider the tank crew position in the Army. The current hands-on test includes several task clusters. One set of tasks involves using the radio, another navigating, and a third using the cannon. Suppose an individual did well on the first two yet poorly on the third. How is that person to be described psychometrically? How many and which tasks must the individual “pass” in order to be considered competent as a tank crewman?
There are three operational scoring models that might be considered in combining task scores. We label these models the compensatory model, the noncompensatory model, and the hybrid model. The compensatory model allows for an individual to make up for a poor performance in one area with a good performance in another. Task performance can be scored either dichotomously (pass/fail) or continuously. In the former case, a pass might be defined as correctly performing two of three tasks; this means that failure on any one task could be compensated by a pass on the other two. A tank crewman might have serious difficulties operating the radio but be proficient in navigation and engaging the target with the cannon and still be considered to have passed the hands-on test. Simply averaging the task scores to obtain a total proportion of steps performed successfully is another form of the compensatory model.
A noncompensatory model implies that an individual must reach an acceptable level in each and every task. In the hybrid model, there is some limited compensation but also some sine qua non requirements. It might be reasonable to assume that each crewman must be able to adequately perform two of the tasks involved in tank operation and that these tasks are logically associated. Thus, we might require the crewman to be proficient at either radio operations or navigation and proficient at either driving operations or cannon operations. In this instance, radio operations could compensate for navigation (or vice versa) and driving could compensate for
cannon operations, but an individual who was proficient in neither radio nor navigational operations would not pass, regardless of how good that person was on driving and cannon operation tasks. In this model, the individual receives a discrete score (i.e., pass or fail) on each of the events.
These models illustrate the types of decisions that must be made in coming to some final determination of how performance will be represented psychometrically. Of course, the actual impact of the models will vary widely in terms of how many test takers would be considered competent. The noncompensatory models are more demanding (i.e., fewer individuals will be considered competent); the continuous score compensatory model is the least demanding or restrictive; and the hybrid model occupies the middle ground.
In addition to choosing a method of combining task scores, it would also be possible to weight tasks differentially, depending on criticality or difficulty. The Marine Corps studied the possibility of differential weighting in combining live-fire task scores with other infantry tasks. In that event, the differential weighting schemes were not thought to add enough to the reliability or validity of the performance measure to warrant the extra complications of execution and of interpreting the test scores.
These scoring issues are not peculiar to the JPM Project. Whenever there are multiple pieces of information about an individual that must be combined, similar choices must be made. In the current case, however, the importance of these decisions is more substantial as a result of the necessity to make statements and inferences about competency and performance standards.
CONCLUSION
The JPM Project set out to measure proficiency in job performance. A job was defined as a collection of tasks and associated behaviors. After eliminating redundant, hazardous, time-consuming or expensive tasks, a small set of representative tasks was selected from which to constitute each job performance measure. Traditional task analysis from documents and task inventories was used to identify job tasks, break them down into subtasks, and specify the individual steps required to accomplish the task. The individual steps in the task constituted the units that were scored, typically as go or no go. In general, task scores were computed as the proportion of steps successfully completed; performance on the test was an aggregate (usually a sum) of the task scores.
The methods used to analyze the jobs, select tasks, and construct and score the hands-on tests representing these jobs inevitably raise questions about the extent to which the tests accurately represent the essence of the job. It is clear from descriptions of the strategies of the four Services that
the job analysis and task selection were driven by test construction goals, in particular by the desire to identify tasks that would be amenable to hands-on testing. Furthermore, in most instances, small groups of individuals made decisions about what tasks would be included in the final task domain. Each Service used a different set of decision rules and a different set of parameters for assembling the tasks that would define the occupational specialties in question.
For the most part, the Services relied on the judgment of subject matter experts to characterize the importance, criticality, and frequency of job tasks. These judgments were used to select tasks that would ensure that the job performance measures “look like” the job. When subject matter experts are used, particularly as respondents to questionnaire items, there are always the concerns about completeness of coverage and carefulness of response. Perhaps the most striking finding by several Services was that subject matter experts disagreed considerably in their judgments. In part, this disagreement arises out of local definitions of a job—those aspects of the job that are most closely attended to and therefore best understood by the subject matter expert. Variations in job definition reemphasize the point made earlier that the essence of a job is in some sense a negotiated essence, and that great care is needed in defining the construct and testing it against alternative interpretations.
With some exceptions, the JPM Project is characterized by a purposive sampling approach to task selection, which on at least one occasion deteriorated into ad hoc selection by policy makers. Moreover, in progressing from task descriptions to the development of hands-on tests, a number of limiting criteria were imposed, including the time to perform the task, safety considerations, cost of equipment, etc. As a result, the potential lack of representativeness at the task description level was compounded at the level of hands-on test design.
After examining this process, one is left with some uneasiness regarding the extent to which the essence of each job has been articulated. To be sure, each of the processes employed by each of the Services was a useful heuristic device, helping them to achieve a foundation for test development. This was certainly a manifest goal of the project. However, in the ideal case, the job would not have been defined in terms of what was amenable to a particular testing format. If the essence of the job is in some sense a negotiated essence, it was negotiated in this instance with goals unrelated to job description in mind. As a result, some might find it difficult to accept the proposition that performance on these measures can be extrapolated to overall job performance. It is also likely that each Service discovered a different essence by virtue of the use of different methodologies and different decision rules for task selection and test development.
A further concern is raised by the absence of any consistent attempt to
determine the human attributes that might contribute to the successful accomplishment of each task or task group. The specification of attributes was less important to the JPM Project than it might have been in a developmental validation study in which new predictors were being constructed. But the decision to ignore attributes had its costs. For purposes of a more general discussion of job analysis, prediction, and construct validity, it is fair to say that a full attribute analysis would prove valuable in building a theory of job performance. It is through such a broadened perspective that results become more widely useful and generalizable—and generalizability of JPM results to other military jobs has proved to be a very difficult matter. It is useful to know more than the fact of a correlation between a predictor and criterion—one needs to know the reason for that correlation. One also needs to know which attributes that are useful on the job are tapped by the test under consideration. We need to know as much as possible about the constructs involved in both the criterion and the predictor. Of course, researchers can return to the JPM data and flesh out the attributes in greater detail. The results of the project would then make a greater contribution to the personnel research community as a whole rather than the more limited (but equally important) military accession community.
The JPM Project is not alone in depending on task analysis as the major component of job analysis. Task analysis is a common method in the private sector as well. It is tempting to speculate why task analysis techniques are given primacy over attribute analysis. One possibility may be that modern job analysis techniques were most frequently applied to jobs having a low cognitive composition; as a result, the job consisted of what was observed. This luxury is not available for cognitively loaded jobs, however, or for the cognitive components of work dominated by physical action. Regardless of the reason for this state of affairs, it is clear that job analysts have given little attention to human attributes in their job analysis strategies.
The JPM Project data base provides researchers the opportunity to restore this balance between tasks and attributes. As an example, it seems clear that the project's data base will permit a careful articulation of the relationships between the attributes represented by the 10 subtests of the ASVAB and the various facets of performance (measured by both hands-on tests and other devices). In addition, several of the Services (most notably the Army) have developed additional predictors to supplement the ASVAB. These enhanced attribute data sets could lead the way to an enriched understanding of the construct of job performance.
These observations and questions are raised not so much as criticisms of the JPM Project, but to convey the complexities of performance-based assessment, complexities insufficiently understood and as yet incompletely addressed.






























