
4
Project Descriptions: Work and Collaboration
A number of SciSIP researchers have explored the ways in which scientists work and collaborate and the influences that shape their work and their careers. These researchers have brought the tools and perspectives of various disciplines to bear in analyses of team functioning, scientific creativity, the experience of Native American researchers, and other related topics.
SOCIAL AND COGNITIVE PROCESSES IN TEAM INNOVATION
Susannah Paletz, University of Pittsburgh
Susanna Paletz observed that most science and engineering innovation is the result of team collaborations. Nine of the top 10 scientific discoveries highlighted by Time Magazine between 2007 and 2010 were made by teams, not individuals, she pointed out, adding that “you basically can’t do scientific discovery alone at this point.” One reason for this is the importance of collaboration among specialists from different disciplines, who ordinarily do not publish in the same journals or attend the same conferences. Many government agencies recognize the importance of cross-disciplinary work, she noted. In the wake of the BP oil spill, for example, engineers, microbiologists, economists, and even social workers needed to collaborate to try to manage all aspects of the damage that was caused.
The diversity of knowledge a team can bring to a task is widely regarded as having great potential for innovation, but, according to Paletz, research on clear connections between diversity and team performance has been weak and has produced inconsistent findings. Simply putting a multidisciplinary team together is not sufficient, she observed, because “sometimes they succeed and sometimes they fail spectacularly.” One of the problems with the existing research is that it focuses on the input variable (disciplinary diversity) and the outputs (e.g., publications, supervisor ratings, solutions to problems), without examining the processes by which outcomes are produced by teams. The research that has examined processes has relied primarily on self-reports from team members. There are numerous mediators and moderators, however, that influence what teams produce, Paletz noted, adding that “we don’t really understand what the teams are actually doing.”
Paletz and her colleagues developed a theory to describe the functioning of team structures, social processes, and cognitive processes, and to account for team innovative divergent and convergent outcomes (Paletz and Schunn, 2010). She described research they have done to explore the elements of their theoretical structure. For example, they addressed the role of uncertainty and analogy, which she defined as transferring
information from a domain one knows to another domain in which there is a problem one wants to solve (Chan, Paletz, and Schunn, 2012). Someone who wants to design a tube that can transport liquid but does not know much about possible materials to use might think about strong but flexible materials used in other contexts (e.g., Christensen and Schunn, 2007). Analogous ideas might come from within the same general domain or a completely different one, such as when materials engineers studied the way geckos’ feet allow them to adhere to vertical surfaces and adapted the mechanism to develop new adhesives. Thus, teams with members with diverse training and experiences will collectively have deeper and broader knowledge structures to rely on, Paletz explained, and thus likely be more successful problem solvers.
Paletz and her colleagues explored these processes using records of informal problem-solving conversations that took place among the more than 100 scientists who collaborated on the NASA Rover mission. The researchers coded the conversations using social and cognitive variables at the utterance, or clause level. In one analysis, they established the degree of uncertainty the speakers expressed before, during, and after considering an analogy as they solved a problem. The researchers found that the introduction of a problem-solving analogy tended to reduce uncertainty (Chan et al., 2012).
They also examined the different sorts of conflicts teams might have at the clause level: task conflicts about the matter at hand; process conflicts about scheduling, plans, priorities, and the like; and relationship conflicts, in which participants dislike one another or react negatively to another’s manner. Some conflicts have more negative emotion associated with them than others. The researchers found that the relationship between conflict and analogies is complex. The introduction of analogies from within a domain (both elements of the analogy are within the same domain) tended to spark both task and process conflicts, which may be constructive. On the other hand, process and negative conflicts, but not task-relevant conflicts, significantly preceded within-discipline analogies, but not within-domain (very close) or very distant analogies (Paletz, Schunn, and Kim, 2013).
Paletz noted that the environment can influence the sorts of conflicts that develop and whether they are mostly constructive or not. According to Paletz, “some places really encourage dissent and encourage disagreement and create what’s called psychological trust so that you can disagree without feeling like it’s going to get personal. And that’s of course where disagreement is going to be the most useful.”32
OPTIMIZING EXAMPLE DISTANCE TO IMPROVE ENGINEERING IDEATION
Chris Schunn, University of Pittsburgh
Chris Schunn presented his research on the creativity process in engineering design processes. His main premise is that analogies to nature or other human designs are frequently cited as major sources of innovative ideas in engineering. Schunn argued that little is known about how to efficiently find the right analogies. One complicating factor
________________
32For more details on this research, see Chan, Paletz, and Schunn (2012); Christensen and Schunn (2007); Paletz and Schunn (2010); and Paletz, Schunn, and Kim (2013).
is that the space of possible analogies is quite large. For example, just restricting to the U.S. Patent database, there are ~107 patents to consider.
One approach to organizing a search through possible analogies is to put possible sources into a structure. But on what should basis the structure be developed—logic, lexical, or conceptual? Schunn and his colleague used a new Bayesian approach developed by Griffiths, Kemp, and Tennenbaum (2008) to empirically discover the structure in data. Their process allowed them to “bottom-up discover” that color is best represented as a wheel, animals as a tree structure, and the U.S. Supreme Court as a line. Schunn’s research team augmented this approach using Latent Semantic Analysis developed by Landauer, Foltz, and Laham(1998) to capture the basic semantics of text in patent descriptions. They then used Kemp and Tennenbaum’s algorithm to determine which kind of structure best organizes the data. It turns out a tree structure provides a good fit to the text similarity data.
Schunn then explained how they tested the approach on an actual engineering design problem: design a device to collect energy from human motion. They took a random set of “mechanical” patents from the U.S. Patent database and organized them using their algorithm. As part of the experiment, they used 72 undergraduate mechanical engineers, who were randomly assigned to one of three different conditions:
Near: see 5 patents considered close to the design problem in the semantic tree Far: see 5 patents considered far from the design problem in the semantic tree Control: given no patents prior to being asked to solve the problem
Design solutions that were generated by the experimental subjects were coded for both novelty and quality.
Describing the findings of his project, Schunn said that the “Far” condition did worse than the “Control” or the “Near” conditions on both aspects of assessment—novelty and quality. This finding was the reverse of a previous study by his team, for which they used hand-selected patents instead of randomly chosen patents for their experiment (see Chan et al., 2011). To understand the difference in outcomes, Schunn and his colleagues added the previously used hand-selected patents to their 45 randomly selected patents, and re-ran the algorithm. They discovered that their near and far hand-selected patents were all closer to the design problem than the randomly selected patents that had been organized into relatively near and far. Thus, they essentially identified an inverted U-shape in the design quality and novelty data: very near patents are of no help, medium-distance patents can be useful, but very far patents are also of no help.
In conclusion, Schunn remarked that the result of his work expands notions of distance beyond the simple near/far binary distinction that is commonly used. His study also provides an objective distance function that can be used in research and practice to guide optimal analogy searches.33
________________
33For more details on this research, see: Fu, Chan, Schunn et al. (2013); Fu, Chan, Cagan et al. (2013); and Chan et al. (2011).
LAB-BASED SOCIO-TECHNICAL COLLABORATIONS
Erik Fisher, Arizona State University
Erik Fisher observed that scientists and engineers are increasingly coming under pressure not just to produce societal benefits and contribute to economic growth, but also to consider societal and ethical factors as they make decisions in their work. “This is a relatively new type of discourse in science policy,” he remarked, and it is known as the socio-technical integration mandate. This mandate differs from others that have affected scientists, in that it puts the burden on scientists and engineers to participate in the integration work themselves, rather than simply taking note of ethical, legal, or societal implications of their work. An example of this sort of formal policy, Fisher explained, is the U.S. Nanotechnology Act of 2003, which calls on scientists to integrate research on the societal, ethical, and environmental implications of research and development in the field of nanotechnology. This requirement was unprecedented at the time the law was written, in Fisher’s view, but similar policies have been pursued in other countries.
This approach is a switch from thinking about the effects of policies on scientific choices to thinking about the effects of scientific choices on policy outcomes. Legislators “… are essentially saying that scientific and technological trajectories are in part the aggregate result of numerous individual decisions and choices that scientists make,” Fisher explained. The authors of the nanotechnology legislation and other similar laws and policies acknowledge, however, that, as Fisher noted, “well, maybe this isn’t even possible,” because it is a new way of thinking about science.
In response, researchers have begun to explore what is possible in this regard. Fisher described a project called Socio-Technical Integration Research (STIR), which is a coordinated set of studies of laboratories in which researchers examine the capacity of scientists to integrate broader societal concerns into their work in response to the pressures on them to do so. This work involved 27 laboratories within 14 countries, located in North America, Western Europe, and East Asia. Social scientists were “embedded” in these laboratories for 12-week periods to engage in interdisciplinary collaborations with scientists and engineers in order to identify and reflect on societal issues, and also to document the results.
The project was grounded in a theoretical model of decision making in a laboratory setting termed “midstream modulation,” Fisher explained. The model reflects the fact that laboratory scientists factor many dimensions, including ethical ones, into their thinking, but that they are not trained to do this in an explicit way. Thus, in the STIR project, the embedded social scientists observed the decision making and challenged the laboratory practitioners to think more explicitly about the social context in which work fits. The social scientists used a protocol for midstream modulation that essentially asks the laboratory scientists questions such as: “What opportunities are you responding to? What are the considerations that are going into your response? What are the different alternatives you have to move forward? And where do you think this is going and why might it matter, who will care about the decisions that you make?”
Often, Fisher explained, at the beginning of these experiences, the scientists do not recognize that their work involves decision making, but as the questioning highlights the decisions they do make, they begin to see their work “through the social scientific lens.” He suggested that, in many cases, the scientists began to make decisions more
deliberately as a result of this experience and recognized environmental and safety concerns they had not previously seen. They made changes in experimental procedures and waste disposal, for example, and even found new ways to adapt research procedures in ways they had not thought were viable. Several of the changes lasted or took place after the social scientists left the laboratories, Fisher noted, such as altering the direction of a research project, instituting collaborative decision-making processes, or developing public outreach programs. In other cases, tradeoffs were examined more deliberatively but tensions remained unresolved.
More important than changes in material practice, for Fisher, were the changes in the laboratory scientists’ thinking. Prior to one study, most industrial researchers who participated indicated that the integration of societal concerns was not one of their core professional obligations, whereas by the end of the study, all agreed that it was. Fisher noted that many scientists and policy makers believe that this sort of integration is not possible, or that if it were possible, it would be undesirable. Not only would it undermine the scientific process, some believe, it would “slow down research and development.” In his view, the STIR project has demonstrated both that socio-technical integration is possible and that it has utility: “It aids scientific creativity and expands decision making.” Making science more responsive to societal concerns and demands also enhances its public value, he added.
Fisher closed with the observation that the laboratory is not just an instrument of policy, but also a policy actor, and that “the decisions made in the laboratory have implications for policy outcomes.” Science is largely self-governed, he noted, which has been a barrier to previous attempts to institute socio-technical integration, “because science is set up to protect itself from societal concerns.” But the mechanisms of self-governance are also “powerful forces for deciding what and how and when to consider and respond to societal questions that are normally taboo.” Scientific research can contain the potential for “explosive conflicts,” he added. The function of socio-technical integration is to “bring these conflicts to the fore more often, more regularly, at multiple levels, not just after commercialization in public debates and in regulatory decisions, but at the site of knowledge creation.”34
Gary Bradshaw, Mississippi State University
Gary Bradshaw observed that something remarkable happened between approximately 1000 AD and 1900 AD that is visible in graphs of many different phenomena. He showed the similarity of graphs of world coal output, energy use, sugar consumption, speed of transportation, life expectancy, gross world product, and world population over the past 200,000 years: each was essentially flat for most of the period and then abruptly veered upward, virtually at a right angle. “You cannot fit even an exponential function” to this sort of graph, he pointed out, “so what happened?” Clearly, there were dramatic developments in manufacturing, agriculture, medicine, transportation, and other areas, more or less at the same time.
________________
34For more details on this research, see Fisher and Schuurbiers (2013); Flipse, van der Sanden, and Osseweijer (2012); and Rodríguez, Fisher, and Schuurbiers (2013).
Focusing on the period between 1000 AD and 1900 AD, Bradshaw pointed to several key developments (see Figure 4-1). Population began its sharp increase, and the increase for gross world product was even sharper. Three events that fueled the industrial revolution occurred within this period: the founding of the Royal Society of London for Improving Natural Knowledge in 1660, the publication of Galileo’s first book (1638),35 and the invention of the steam engine in 1775. Galileo’s work was important because “the science that predates Galileo wasn’t experimental in the sense that we understand today,” Bradshaw explained. Galileo recognized the importance of precise measurements; invented instruments with which to record data, such as the water clock, ruler, thermometer, and telescope; and introduced the idea of a scientific report that included a description of the methods used in the investigation.
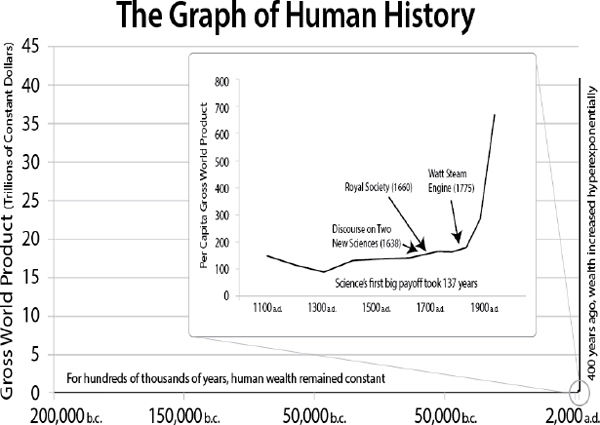
FIGURE 4-1 The Graph of Human History.
SOURCE: Presentation to SciSIP Policy Investigators’ Conference by Gary Bradshaw, 2012.
________________
35Discourses and Mathematical Demonstrations Relating to Two New Sciences, available at http://oll.libertyfund.org/?option=com_staticxt&staticfile=show.php%3Ftitle=753 [January 2014].
The sharp turns in the graphs demonstrate the value of this contribution, Bradshaw explained, noting that “99.66 percent of the gross world product is attributable to science.” The development of the steam engine, which grew out of 10 years of experimentation, was “the first big payoff.” Many scientific findings, however, lie “inert” for a long time before they are applied. For example, incandescence was demonstrated in 1802, but it was not until 75 years later that Thomas Edison developed a practical light bulb, while the Wright brothers applied research that was 100 years old in inventing a workable airplane. In both of these cases, experimental research was needed to build on the basic science that supported the invention.
These examples illustrate an idea that remains relevant today, Bradshaw suggested. Experimental research provides the foundation for technological developments (such as the current transition from incandescent light bulbs to more energy-efficient ones), but basic science has value undiminished by time. “Nearly every moment of our lives we exploit 200-, 300-, even 400-year old science,” he noted, and the opportunity for many technological improvements lies in currently “inert” science. Many scientists are not particularly skilled at recognizing the commercial applications of their findings because their job is to make the discoveries. Some companies are good at tracking scientific developments, but much that has commercial potential is missed.
Improving the science-to-technology pipeline is an important policy goal, in Bradshaw’s view. One possible way to accomplish that would be to provide governmental support for efforts to transition science to practical applications. “In many areas, there is little or no corporate support for transitioning inert science into valuable technologies,” he said. Bradshaw closed with his own view of science funding, which is that governments invest modest amounts of money in scientific research, “often with the belief that these investments will have immediate economic benefits.” The scientific evidence for this belief is “patchy,” he added, though “hundreds of thousands of years of human experience demonstrate conclusively that science has both near-term and long-term benefits.” These benefits have had a profound impact on individual and societal wealth. “The fastest way to exploit science for economic benefit is to leverage inert science,” he asserted.
Jan Youtie, Georgia Institute of Technology
Jan Youtie observed that research on highly creative scientists tends to focus on individual abilities, article citations, or the prestige rankings of universities, while less attention has been paid to the effects of career and organizational factors on scientists’ creative performance. These are important though, in her view, because policy interventions can more easily address the structures that affect scientists’ career paths than other factors. She and her colleagues explored policy and management interventions that affect scientists’ careers in two fields—human genetics and nanotechnology—in the United States and in European countries.
Youtie and her colleagues began with a consideration of how to define scientific creativity and identified five ways in which it might be expressed, shown in Table 4-1.
TABLE 4-1 Types of Scientific Creativity
| Type of Scientific Creativity | Examples |
| Formulation of new ideas that open a new cognitive frame or bring theoretical claims to a new level of sophistication | Theories of specific relativity (physics) Einstein (1905) |
| Discovery of new empirical phenomena that stimulate development of new theories | Biodiversity and the theory of evolution (biology) Darwin (1859) |
| Development of new methodology for empirically testing theoretical problems | Factor analysis and theory on mental abilities (psychology) Spearman (1904, 1927) |
| Invention of novel instruments that open up new search perspectives and research domains | Scanning tunnel microscopy and nanotechnology (physics) Binnig and Rohrer (1982) |
| New synthesis of previously dispersed ideas into general theoretical laws that permit analysis of diverse phenomena in a common cognitive frame | General systems theory (biology, cybernetics, sociology) Bertalanffy (1949); Ashby (1956); Luhmann (1984) |
SOURCE: Presentation to SciSIP Principal Investigators’ Conference by Jan Youtie, 2012; adapted by Youtie based on Heinze et al. (2007).
They used this definition in a survey of active scientists, including some who are widely cited and are also journal editors in the two fields, and asked them to nominate highly creative researchers. Using these nominations and prize awards, they identified 76 scientists who met the criteria for high creativity. They then looked for scientists who had very similar characteristics (e.g., subject area, year of first publication, number of publications, subject area, productivity in first 6 years) early in their careers but who had not achieved the same degrees of recognition to serve as a control group. They requested CVs from scientists in both groups in order to identify matches for comparison.
Youtie and her colleagues developed models of early and mid-career pathways they hoped would accurately predict the differing outcomes for the target and control groups. Variables for the early career stage included time to earning a degree, having a postdoctoral appointment, international experience, and the like. For the mid-career stage, the variables included time to achieving tenure, number of total and nonacademic positions held, number and diversity of grants received, and collaborations.
The comparisons of the U.S. and European experiences highlighted both differences and similarities at both stages, Youtie reported. For example, moving quickly through schooling and up the promotion ladder is beneficial everywhere, but more so in
the United States; in Europe having international educational experiences has more weight than it has in the United States. Interdisciplinary training is more highly valued in the United States than in Europe, as are professional prizes and opportunities to work in nonacademic jobs. These results, Youtie concluded, suggest that more streamlined doctoral requirements would particularly benefit U.S. researchers, while expanded international opportunities would particularly benefit European ones. Both groups, she added, would benefit from more access to mentors who could offer guidance about career choices.36
PRIVACY AT AN INTERDISCIPLINARY RESEARCH INSTITUTE
Noah Weeth Feinstein, University of Wisconsin, Madison
According to Noah Weeth Feinstein, many scholars of science and science policy have concluded that contemporary science is different in significant ways from what came before it. One key difference lies in perspectives on treating research as public or private. Citing an influential book on the subject, The New Production of Knowledge (Gibbons et al., 1994), Feinstein noted that some “make the claim that contemporary science … is both somehow more public—in the sense that it has greater social relevance, takes place in the context of application, and has greater or different forms of accountability—and also somehow more private, in [its] organizational heterogeneity, the mix of public and private institutions [involved], and the emphasis on time to market.”
Feinstein and his colleagues investigated this tension in the context of a single institution, the Wisconsin Institutes for Discovery,37 which resulted from the combined efforts of the University of Wisconsin, Madison, the Wisconsin Alumni Research Foundation, and a private donor to create an organization that would be responsive to the evolving nature of science. The founding of the institutes was inspired in part by the political controversy over stem cell research—the University of Wisconsin had been a leader in this type of research, and was concerned about maintaining its leadership in foundational research if there were new restrictions on research using stem cells. The design of the building was also a critical aspect of the plan for the institution. The building houses two research organizations: a private, nonprofit institute focused on biomedical research and a public university-affiliated institute. It also contains a large, open, and publicly accessible space called the “Town Center,” which occupies the ground floor.
Feinstein and his colleagues used oral history interviews, archival materials, and media coverage of the Wisconsin Institutes for Discovery to compare the institutes’ goals with the actual experiences of those who have worked there and those involved in the institutes’ early development. They began with the Town Center, which houses a café and restaurant and other spaces for collaboration. It was planned to allow university undergraduates and the general public to interact with the investigators in the building. The actual research is carried out on upper floors not accessible to the public or to most University of Wisconsin staff, faculty, and students. The space on the upper floors is also
________________
36For more details on this research, see Heinze et al. (2007); Youtie, Shapira, and Rogers (2009); and Youtie et al. (2013).
37For more information, see http://discovery.wisc.edu/discovery [January 2014].
divided between the public and private research entities, and there are legal restrictions on the types of research that can be carried out in particular zones. Even on the private side, where certain restrictions on stem cell research do not apply, there are limits on the sorts of collaborations with private industry that are permitted, Feinstein added.
Using these and other examples, Feinstein and colleagues argue that organizational divisions have been established between the general public and all of the scientists, between non-institute scientists and institute scientists, and between the scientists associated with each of the institutes housed in the building. Depending on one’s perspective, the same scientist can be both a member of the private, inaccessible community of science and a member of the public, excluded from the work of a particular institute. In short, there was not a single clear barrier between private and public science, but rather multiple lines that may be drawn in different ways. Although the creation of the institutes was intended to bridge barriers between public and private, it has had the perverse effect of creating a new set of barriers as well.38
ETHNIC COMPOSITION OF RESEARCH TEAMS
Richard Freeman and Wei Huang, Harvard University
The pool of scientific researchers has grown increasingly diverse. As Richard Freeman explained, large numbers of foreign-born scientists have immigrated to the United States as students, post-doctoral researchers, and fully qualified scientists. Published papers are increasingly likely to have multiple co-authors, and, in particular, collaboration among international colleagues has increased. Freeman and Wei Huang explored the ethnic composition of collaborative scientific teams and its relation to team productivity. They calculated the extent to which U.S.-based researchers tend to work with colleagues of the same ethnic background and whether that tendency influences the impact factor of the journal and citations to papers.
Freeman and Huang examined papers published between 1985 and 2008with two, three, or four authors in the Web of Science dataset that covers all of the science and mathematics disciplines. Using a tool for linking last names to ethnicities, they calculated the difference between the actual proportion of author teams with shared ethnicity and the proportion that would be found if the co-authorship were based on a random drawing.
Freeman noted that collaboration that leads to co-authorship of published articles could be thought of as a search process in which researchers seek out potential collaborators who are most likely to improve their work. He compared the process to the dating market, noting that the potential collaborators a researcher might meet will vary by geographic location, field of study, degree of seniority, and other factors. People might have a tendency to work with people who are like them because they are more likely to meet such people than other people, or because they share interests or find it easier to communicate. According to Freeman, if researchers choose collaborators based on shared preferences, the result may be lower productivity, whereas if they do so based on ease of communication, the result may be higher productivity.
Freeman and Huang developed an index of homophily, the formal name for the “bird of a feather flock together” tendency to associate with others of the same
________________
38For more details on this research, see Kleinman, Feinstein, and Downey (2012).
background in various activities. They found a substantial degree of homophily in the authorship of scientific papers. Far more researchers work with people of the same ethnicity within detailed scientific fields than would be expected if researchers of different ethnicities met by chance and randomly chose to work together. Table 4-2 shows their calculations for papers with three authors. The first column gives the actual percentage of papers on which authors of the given ethnicities all had the same ethnicity. The second column gives the expected percentage of papers in which all three authors had the same ethnicity if authorship were randomly chosen from the ethnic distribution of all authors. The ratios above one in the third column show statistically significant homophily.
Freeman and Huang also explored the relation between homophily and the impact factor of the journal in which scientists published a paper and the frequency with which their papers were cited. The impact factor was lower when all authors were of the same ethnicity. Citations were also lower, though the relation was mediated in part by the impact factor of the journal. Looking at other characteristics of papers and authors that affected impact factors and citations, Freeman and Huang found that research teams with different addresses and that referred to more articles produced papers that were published in better journals and had higher impact factors.
TABLE 4-2 Comparison of Actual Percentage of Authors of Same Ethnicity with Expected Percentage, Based on Random Selection of Authors, in Three-Authored Papers
| Ethnic Group | Percentage of All 3-Authored Papers with All Authors of Same Ethnicity | Expected Percentage Based on Random Draw of Authors from Ethnic Distribution of All Authors | Ratio of Actual to Expected Percentages (> 1 ⃗ homophily) |
|
|
|||
| English | 13.34 | 11.30 | 1.18 |
| Chinese | 1.24 | 0.09 | 13.32 |
| European | 0.22 | 0.16 | 1.35 |
| Hindi | 0.31 | 0.02 | 15.44 |
| Hispanic | 0.07 | 0.01 | 14.27 |
| Japanese | 0.09 | 0.00 | 205.53 |
| Korean | 0.20 | 0.00 | 117.68 |
| Russian | 0.30 | 0.00 | 16.64 |
| Eight groups | 18.20 | 11.58 | 1.57 |
|
|
|||
NOTES: Based on 569,305 papers with three authors in WOS, 1985-2008. Ethnic group Vietnamese not reported due to small numbers. Ratios calculated by taking statistics to 5th decimal places (not given in this table).
SOURCE: Presentation to the SciSIP Principal Investigators’ Conference by Richard Freeman, 2012.
The implication is that the more diverse the research team—by addresses as well as ethnic mix—and the more diverse or wider the knowledge base as indicated by references, the more successful the paper was. Finally, they also found that the publication record of the first and last authors in a paper also contributed to its impact factor and the number of citations it received.
SCIENTISTS’ CAREER CHOICES AND TRAJECTORIES
Rajshree Agarwal, University of Maryland
Rajshree Agarwal described two studies she and her colleagues have done on career choices that face young scientists. Both studies were intended to shed light on a tension that has developed between the worlds of academic and industrial research. Some in the academic world have suggested that industrial researchers cannot be expected to produce “breakthrough ideas,” she explained, while from the industrial side, some perceive that “academia has failed us.” In this context, young scientists are deciding between careers focused on basic research—the pursuit of knowledge for its own sake—and applied research—intended to meet a recognized need. She and her colleagues used survey and other data available from the NSF Scientists and Engineers Statistical Data System (SESTAT)39 to explore the choices these young people make, the factors that influence them, and their earnings trajectories.
Career paths are not strictly orthogonal with respect to academic versus industry location of work, Agarwal noted. More than 21 percent of scientists who have academic positions focus on applied science; on the other hand, 13 percent of those with jobs in industry focus on basic science. She and her colleagues found that young researchers with “a preference for non-monetary returns” tend to choose academic jobs over industry jobs, but not necessarily to choose basic science over applied science. Ability is another factor in this sorting, with higher ability researchers choosing basic over applied research if they are in academic jobs, but not necessarily doing so if they are in industry jobs. Moreover, researchers doing these two types of work are much more likely to collaborate with one another if they are in industry jobs than if they are in academic ones. She suggested that policies to better support young researchers making career choices, and to break down academic silos, would be beneficial.
In general, Agarwal explained, earnings do not closely track the simple choice between basic and applied research. Earnings are typically lower in academia than in industry, in part because there is a higher preference for non-monetary returns among academic researchers. Also, earnings between basic and applied researchers in academia diverge, but are very similar in industry, in part because the greater collaboration across research types in industry causes both types of researchers to benefit from higher productivity.
In a second study, Agarwal and her colleagues examined the gender gap in earnings, with women who work full time currently earning just over 80 percent of what
________________
39SESTAT is a project of the National Center for Science and Engineering Statistics; for more information, see http://www.nsf.gov/statistics/sestat/ [January 2014].
their male counterparts earn.40 Agarwal noted that in analyses that controlled for factors such as ability, demographics, and family status, the gender gap is higher in academia than in industry. While the gender gap is lowest at the start of careers in both work places, the divergence in academia over time is greater than in industry. She noted several possible explanations, including that women in academia may have fewer career options when they are striving to coordinate with a partner’s career, that childrearing responsibilities may disproportionately affect academic women’s careers particularly when experienced in the pre-tenure years, that “good old boy” networks may be more persistent in academia, and that women in academia may be more likely to be segregated into lower paying sectors than those in industry.41
SKILLED IMMIGRANTS AND INNOVATION
Eric Stuen, University of Idaho
The United States has been a global leader in research and development, both within the university system and in high-tech industries, observed Eric Stuen, but many have wondered why that is so given the deficiencies in its education system. He noted the possible connection between the nation’s leadership in these areas and the large increase in enrollment of foreign students in U.S. Ph.D. programs between 1980 and 1995. The presence of these students could have influenced research outcomes, and many may also have stayed on in this country as researchers and recruited colleagues. Overall, Stuen estimated, one-third of Ph.D. students in science and engineering are foreign born and two-thirds are U.S. born. He also commented that 62 percent of foreign-born students on temporary visas remain in the United States 5 years after completing their degrees.42
Stuen observed that some have criticized programs designed to attract and support foreign students who want to study in the United States on several grounds.43 After the September 11, 2001, terrorist attacks, he noted, the U.S. Congress placed limitations and checks on student visas that were considered after that date. Current immigration bills under consideration would expand access to work visas and green cards, which indirectly encourages enrollment in Ph.D. programs. Thus, Stuen and his colleagues explored the impact of enrolling different sorts of students in Ph.D. programs and how visa and scholarship programs can best support research in the United States.
Stuen and his colleagues used a knowledge production function to link research inputs and outcomes and to identify enrollment fluctuations and attempt to link them to macro-level influences, such as China’s lifting of restrictions on study abroad in the 1980s. They culled a variety of sources for data, including enrollments, publications and
________________
40Data are from the Bureau of Labor Statistics; see http://www.bls.gov/cps/cpswom2011.pdf [January 2014].
41For more details on this research, see Agarwal and Ohyama (2013); and Agarwal, Ding, and Ohyama (no date).
42This statistic comes from M.G. Finn (2012), the only scholar to study long-term stay rates with credible data. Stay rates of Ph.D. students vary widely depending on their country of origin, from only 5 percent from Saudi Arabia to 89 percent from China. See http://orise.orau.gov/files/sep/stay-rates-foreign-doctorate-recipients-2009.pdf [January 2014].
43See Finn (2012). One such program is the federal Fulbright foreign student program; see http://foreign.fulbrightonline.org [January 2014].
citations, and research and development expenditures. The researchers developed a model that was able to predict enrollment for U.S. and international students and found only statistically insignificant differences between foreign students and U.S. students in terms of the number of publications and citations that resulted from their enrollment. A second central finding was that foreign students whose enrollment was more sensitive to fluctuations in income, and hence more likely to be on scholarship, contribute more to research productivity than those who likely pay their own way.
Stuen concluded, first, that both international and domestic Ph.D. students contribute to science and that financial support for them has high returns. Second, he concluded that major reductions in programs designed to attract and support foreign science students would harm the scientific capacity of U.S. universities. Specifically, he added, the current visa policy that requires applicants who wish to study in the United States to demonstrate financial means hurts scientific productivity in the United States.44
FOREIGN-BORN STUDENTS WHO RETURN TO THEIR HOME COUNTRIES
Megan MacGarvie, Boston University
The United States educates a large share of the world’s scientists, explained Megan MacGarvie, and in many fields foreign-born students are now the majority. She and her colleagues examined the results when these foreign-born students leave the United States once they have earned their degrees. She noted several possibilities. Students who return to their home countries may make research contributions to these countries and promote the diffusion of ideas around the world, but lose their links to the research community in the United States. If the research community in their home countries is not as productive as that in the United States, their contributions may be muted. There is likely a loss to the United States when these students leave: domestic scientists lose connections with scientists in other countries, and the nation loses the contributions of researchers who have traditionally been among the most productive.
Since its inception in 1946, the Fulbright Foreign Student Program has brought more than 128,146 students to U.S. graduate programs, MacGarvie explained. These students receive J-1 student visas that require them to spend 2 years in their home countries before applying for a permanent or work visa in the United States. Moreover, many countries have programs that require or encourage those who study abroad to return home after they earn their degrees. Students affected by these policies tend to spend about twice as much time abroad after earning their degrees as other foreign students do.
MacGarvie and her colleagues used citations of academic papers as an indicator of influence. They used those data, along with other data about a pool of 488 Fulbright scholars from around the world and from a variety of science and engineering fields, to determine whether those who were subject to the return requirement were cited more or less frequently by authors in their home countries and by authors in the United States than those not subject to such requirements. Analyzing the data using a variety of controls, they found that a key variable was the income status of the student’s home country. Thus, low-income countries reaped a significant benefit from the return
________________
44For more details on this research, see Stuen, Mobarak, and Maskus (2012); Maskus, Mobarak, and Stuen (2013); and Stuen (2013).
requirement, in terms of influence on their own research communities. On the other hand, the students from low-income countries affected by the return requirement ultimately had reduced productivity, compared with their peers. To be more effective, MacGarvie suggested, return requirements should be paired with policies designed to support research productivity in low-income countries. However, she suggested, there are likely additional unmeasured benefits in terms of improved access to scientific knowledge in lower-income home countries.
U.S. RESEARCHERS IN INTERNATIONAL COLLABORATIONS
Susan Cozzens, Georgia Institute of Technology
There is growing capacity in both science and engineering in many parts of the world, but “no country can really do it all by themselves anymore,” Susan Cozzens observed. In her view, there are strong incentives for researchers around the world to learn from one another, and her research focused on the role that U.S. researchers are playing in international research collaborations, and the effects on them. The U.S. research workforce itself is quite international, she noted, and research teams include many people who were born outside the United States. U.S. researchers do less cross-border collaboration than those from other countries, though they report that they learn as much as their partners from such collaborations.
Cozzens and her colleagues investigated international collaboration in two fields—laboratory-based biofuels research and neutron-scattering research. They reviewed papers published between 2003 and 2009, conducted interviews with 60 researchers, and conducted an online survey of more than 2,500 researchers in the two fields (two-thirds were in the field of neutron scattering). Biofuels research became very popular in the early 2000s, Cozzens explained, and there are significant research centers in this area outside the United States. Neutron-scattering research is based on the use of large instruments, so it is primarily affluent countries that build the equipment needed to run the experiments.
There were no significant differences in the basic characteristics of the researchers from the two fields within the study pool, Cozzens noted. Among those in both fields, between 50 and 60 percent were born in the United States, and most were employed at universities, government laboratories, or other research institutions. In both fields the respondents were approximately 80 percent male and 20 percent female. These researchers work in fairly large teams, with a median team size of 12 for the biofuels researchers and 10 for neutron scattering; the teams generally have more than 40 percent international participation. In both fields, the amount of international experience researchers had before earning their degrees varied by country of origin and other factors, but by the time they become senior researchers, the vast majority had such experience. In both fields, however, U.S. researchers have among the lowest rates of international experience compared with those from other developed countries.
Cozzens noted that theoretical work suggests two primary reasons for researchers to collaborate. They might seek out the most powerful and influential collaborator they can find, which would likely result in asymmetric collaborations, or they might seek knowledge they cannot secure through their normal networks. The individuals she
interviewed tended to match two categories well: the survey respondents engaged in situations in which either junior researchers were seeking new knowledge and skills or equal partners were seeking complementary knowledge and skills. The researchers, however, generally reported having learned as much from their collaborations as their team members did, regardless of their own status. Cozzens noted that the finding that research collaborations are often characterized by equal learning suggests that the theoretical model might need to be expanded.
Kimberly TallBear, University of California, Berkeley, and University of Texas, Austin
Kimberly TallBear conducted a study to answer the question of whether increased participation in science by Native American researchers will result in research that is more inclusive of and accountable to a broader sector of society and also more rigorous, or whether the result will simply be a more diverse population of researchers but no change in concepts or approaches. She used several kinds of sources and methods to explore this question, including a review of literature on the participation of Native Americans in science, demographic data from professional associations, interviews,45 and participant observations at scientific meetings and training venues.
TallBear explained that her general approach is to explore both scientific communities and Native American communities as having cultural, bureaucratic, and knowledge-producing functions. She sees these similarities as a way to bridge gaps between them and to undercut a common view of science and society as separate and potentially conflicting entities. Because TallBear’s own heritage is Native American, her research background has been shaped by concerns about the potential influence of scientific research on Native Americans and their tribes. She was also able to draw on her relationships with other Native American scientists and professional societies in conducting this work, which helped her identify those who actively identified with their heritage.
TallBear described a few conclusions from her work about characteristics that Native American bioscientists share. They “emphasize their situatedness,” she explained, by which she meant that because they are often the first in their families, or even their communities, to go to a university, those communities may have little familiarity with scientific practice. At the same time, however, moral support from their families and communities is often key to their persistence. Many say, she added, that mentoring from older peers with “a Native way of looking at things” has also been a key support.
Native American scientists may also respond in unexpected ways to moral and cultural challenges, TallBear added. For example, Native American scientists may be uncomfortable with killing animals for research and prefer to use animals that have died of natural causes. Many also grow up with strong traditions that treat certain animals or objects as “profane.” Owls, for example, are viewed as profane—a bad omen to be
________________
45TallBear noted that, to date, she has interviewed members of the Dena or Navajo people, Ojibwa or Anishinabe, Seneca, Eastern Band of Cherokee, Colville, Laguna Pueblo, Yurok, Ohlone, and Onondaga tribes.
avoided—by the Navajo, so research involving owl pellets presents a challenge for scientists of that background. The Navajo also have strict rules about interacting with dead bodies, which has caused some science students to determine that they could not attend medical school. However, TallBear added, it has been possible for some to accept dissection of both humans and animals if the work is done “thoughtfully and with appropriate respect.” Indigenous scientists have in some cases worked with other tribe members to create new ceremonies to address these ethical concerns.
In general, TallBear found, Native American scientists are able to travel effectively between reservation settings and university research laboratories. She used her interviews to ask about the congruence, and lack thereof, between traditional knowledge practice and university science. Many responded initially that the two are incompatible, but, when pressed, “acknowledge that there are elements of traditional knowledge that are very akin to the scientific method.” What is most difficult for them to navigate are the social differences. In science there is “an ethic of individual inquiry and a right to knowledge,” she noted, whereas those who develop traditional knowledge “have to be called and recognized by other medicine people,” because of the spiritual element of the knowledge base.
TallBear concluded that Native American scientists have the incentive to develop scientific methods that are less destructive than they might otherwise be. Because scientific narratives have authority in policy making, she added, “it is prudent [for Native American scientists] to have a voice in the construction” of those narratives. At the same, Native American scientists “can contribute research questions, hypotheses, methods, and ethical approaches that are consonant with [their] cultural practices and knowledge priorities, rather than shaped solely by non-tribal research priorities and Western bioethical assumptions.”
ORGANIZATIONAL SIZE AND DISCONTENTS
Jerald Hage, University of Maryland, College Park
Aleia Clark, U.S. Census Bureau
Jonathan Mote, George Washington University
Gretchen Jordan, 360 Innovation
Jerald Hage and his colleagues explored the influence of organizational size in six federally funded research laboratories. These laboratories are key components of the national innovation system and therefore for the economy, but the sites also provide unique opportunities to study sociological problems from a distinctive angle.
The original research design started with 75 research projects in six programmatic research areas: biology, chemistry, alternative energies, material sciences, and geosciences, as well as some interdisciplinary projects. The projects were selected with the aid of senior division managers in six national laboratories: three small (under 2,000 scientists), two medium (2,000 to 4,000 scientists), and one large (over 4,000 scientists). Hage and his colleagues encountered resistance from the laboratories’ leadership and from the scientists themselves, but were ultimately able to collect at least two responses each on a specially designed research environment survey for 57 projects. Response rates
varied by laboratory size, from 38 percent for the large ones to 64 percent for the small ones.
Hage summarized a variety of findings across a number of major areas of research: research activities, work satisfaction, learning, management qualities, and lab strategy. Across the six programmatic research areas, there were considerable differences in the amount of time allocated to basic research. For example, scientists involved in material sciences spent 44 percent of their time on research, while those in chemistry spent only one-quarter of their time. Time spent on seeking research funding was more than he had expected, ranging from 9 percent (alternative energy and material sciences) to 19 percent (chemistry). Despite these differences across programmatic areas, the larger the laboratory, the less time was spent on research and the more time was spent on seeking outside funding and on internal administration.
Not only did the scientists in the larger labs spend less time conducting research, but also organizational size actually affected the nature of the research process. Irrespective of programmatic area, scientists in the larger laboratories reported that their projects had less time for creativity, freedom to explore new ideas, and to take risks. Furthermore, these scientists wished that they had more time for these activities as measured by a discrepancy index measuring the difference between preferred and actual time allocations. In contrast, the programmatic research area had a strong impact on the different ways in which scientists learned. But despite this, scientist at the larger size labs also reported receiving less critical thought and greater discontent as measured by the discrepancy index. Consistent with this negative effect, managers were perceived to provide less technical value in the larger laboratories.
Not unexpectedly, the larger laboratories, even controlling for both intrinsic and extrinsic rewards, have less work satisfaction. Researchers engaged in interdisciplinary work were the most likely to score high on the satisfaction measures, while the scientists who have been in their jobs longest were the least satisfied. One might have expected that the larger laboratories would have more resources, but it appears that as reported by the scientists, they do not. This is another cause of less work satisfaction. One potential explanation for the larger laboratories having fewer resources and thus the necessity for external support is the scientists do not perceive that they are pursing innovative strategies likely to gain more resources. These findings, in Hage’s view, demonstrate some important disadvantages to large laboratories: as he suggested, “it is time to rethink laboratory size.” However, clearly more research is needed to further explore differences in laboratory structure and strategy by research area.
COMMUNITY ECOLOGY FOR INFORMATION TECHNOLOGY (IT) INNOVATION
Ping Wang, University of Maryland, College Park
Some innovations become very popular and reshape the landscape of information technology, noted Ping Wang, while others do not. Wang and his colleagues used a database of innovations they have been building, the Science and Technology Innovation Concept Knowledge-based (STICK: stick.ischool.umd.edu) to explore why some innovations are so influential. Social media, big data, and cloud computing are just a few
of the innovations that are popular now, he noted. Most share a wavelike trajectory in popularity—moving rapidly from being unknown to a peak, and then declining almost as quickly—but some have much higher peaks than others.
Wang and his colleagues focused on cloud computing to investigate this pattern. The National Institute of Standards and Technology has defined cloud computing as “a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction” (Mell and Grance, 2011). A diverse community is needed to support cloud commuting, Wang explained, including platform providers, application providers, adopters, public and private investors, researchers, analysts, consultants, and others, as well end users. “The general public is a stakeholder,” he added, and media organizations are also heavily involved. Wang and his colleagues used ideas drawn from organizational ecology theory to explore the evolution of this community.
A process known as legitimization, Wang explained, describes the way in which an innovation and its community gain legitimacy. As the innovation gains legitimacy, more people and organizations join the community—and as more join, the legitimacy increases. After a certain amount of expansion, however, the community resources may be stretched thin and the crowding will cause competition. At this point, the rate at which new members join the community will drop off.
Communities of comparable size will vary in their popularity, Wang added, and thus other factors, such as community structure or the efficiency of community resource utilization, may explain that difference. He turned to a new theoretical model, scale-free network theory, to explore possibilities. A scale-free network, he explained, such as the flight route map of an airline, has hubs, or nodes, that are connected to many other points, while other points are not so well connected. This model is “highly efficient in diffusing innovation, information, rumors, or viruses,” whereas a system with more randomly distributed nodes, none of which is better connected than others, is not. Thus, if two different innovation communities have comparable degrees of crowding but one is a scale-free network and the other is not, the negative effect of competition will be smaller for the scale-free one. Wang and his colleagues hypothesized that the more scale-free a community, the higher the rate of entry of new members into that community.
To test that hypothesis, they collected news articles about cloud computing published over a 5-year period and used automated tools to identify the organizations that were members of the cloud computing community. They used NodeXL, a free Excel add-on program, to construct a model of the interconnections within the community and identify clusters of connections that represent competitive and collaborative relationships among companies, investors, researchers, and so forth. Over time, the number of organizations involved and the clusters grew, and the network structure also became more complex.
Wang and his colleagues used the rate of new entries in a community as the dependent variable, the density dependence model (the dependence of community dynamics on community density) to represent the legitimization and competition in the cloud computing community, and the degree to which the community is scale-free to represent its efficiency of resource utilization. They looked at the entry rate over a 5-year period and found that it correlated positively with legitimacy and degree to which the
community was scale-free, but negatively with competition. Overall, Wang noted, this model of community function explains more than 70 percent of the variance in entry rate over time.
Wang concluded from this work that ecology theory, conventionally applied to explain dynamics of individual industries, is applicable even to an innovation community that involves multiple industries. He believes that the approach they used, drawing on what is discussed and mentioned about innovations in published articles, or discourse analysis, is a useful way to capture the flow of ideas and resources across industries. Combining this analysis with crowdsourcing, natural language processing, and information visualization, he added, helped them to take the innovation discourse analysis to a larger scale.46
______________
46For more detail on this research, see Sun and Wang (2012); and Shneiderman et al. (2012).




















