
3
PARALLEL COMPUTATION
COMPUTATION AND SUPERCOMPUTERS
Computation has played a central and critical role in mechanics for more than 30 years. Current supercomputers are being used to address challenging problems throughout the field. The Raveche Report1 covers a broad range of disciplines. Nevertheless, it cites specific accomplishments where supercomputers have had profound impact in mechanics, such as the two-orders-of-magnitude reduction in the number of wind tunnel models tested, design of artificial heart valves with minimal degradation, and design and manufacture of efficient mechanical devices with respect to heat and mass transfer. Other problems described as being "ripe for impact" include full aircraft flow analysis, turbulent flow simulation, composite materials design, understanding phase transitions, polymeric materials design, and analysis of multiphase and particulate flows. For instance, solution of the Euler equations of compressible flow about a complete aircraft would greatly enhance vehicle design capabilities and dramatically reduce the time from design conception to fabrication and testing. Dependence on complex, time-consuming, and expensive wind tunnel testing would be greatly reduced. Turbulent flow simulations would lead to a fundamental physical understanding of the mechanisms involved in turbulence. This, in turn, would lead to more realistic turbulence models that could enhance vehicle stability, control, and performance.
Solutions to these problems could be obtained in approximately 1 hour on a computer having 10G Flop (1010 floating point operations per second) performance and 100 million
words of memory, which places it barely out of the range of current supercomputer capabilities. Algorithmic advances and hardware innovation notwithstanding, a greater reliance on parallelism will be needed to solve many of the complex problems addressed in this report.
Parallel computation involves a program's division into tasks that can be executed concurrently by several processing units. A task can be a single instruction, a group of instructions such as a loop, or a procedure. While theoretical models of parallel computation have focused on a hypothetical computer known as a parallel random access machine (PRAM), available hardware is quite varied. For present purposes, hardware will be classified as either a shared- or a distributed-memory computer; however, systems are becoming increasingly complex and such a simple division is not appropriate in many situations.
Shared-memory systems involve several processors connected to a common memory by a high-speed bus, for example. In principle, each processor has equal access to any data element; however, with current technology, communication delays develop when too many processors are involved. Hierarchical memory systems where each processor has a local memory cache have improved performances somewhat, but it is believed that architectures of this type are limited to tens or hundreds, rather than thousands, of processors.
Current supercomputers employ a limited form of parallelism based on a shared memory. Processors generally have vector capabilities, thus utilizing a mixture of coarse-and fine-grained parallelism. So-called graphics supercomputers that offer computational performance with superior visual display capabilities in a workstation are also of shared-memory design.
Systems having a more massive level of parallelism have had memory distributed among each of several processors. Each processor and its local memory are connected through a network to a limited number of other processing elements. For present purposes, a processing element shall refer to a processor with its local memory and input/output connections to the network. Various network topologies are available; the most popular include two-dimensional grids and hypercubes. Processing elements in a grid are located at vertices and have network connections to their nearest north, east, west, and south neighbors. With a hypercube-connected network, 2d processing element located at the vertices of a d-dimensional cube are connected along the d edges emanating from each vertex. Thinking Machines Corporation's Connection Machine, for example, has a 512-megabyte memory distributed uni-
formly among 65,536 one-bit processors. Each 16 processors form the vertices of a 12-dimensional hypercube, and pairs of 16-processor clusters share a floating-point unit.
Processors on the Connection Machine operate synchronously in lock step or single instruction, multiple data (SIMD) fashion with a separate control unit dictating the instruction to be executed simultaneously on all processors. MasPar Corporation's recently introduced MP-1 is another SIMD machine having 16,384 four-bit processing elements, each having network connections to its nearest eight neighbors. Hypercube-connected asynchronous or multiple instruction, multiple data (MIMD) systems with as many as 10 dimensions (1,024 processors) have been available for some time. With each processor executing its own program, balancing computation and communication is critical. In fact, load balancing is the major programming problem on MIMD computers.
Past and likely future advances in processor speed and memory are traced in Figure 3.1. This forecast, which appears to be reasonable given straight forward developments of semiconductor devices, suggests that Teraflop (1012 floating point operations per second) performance will be available by the mid-1990s.
Additional architectural advances will provide platforms for greater experimentation and vastly increased performance. Massively parallel MIMD systems have been described recently in the literature. Systems placing a greater reliance on hierarchies of parallelism will emerge. For example, a likely compromise between the flexibility of an MIMD system and HP LaserJet Series IIHPLASEII.PRSy of processors connected to a global memory with each processor being a medium-grained network of fine-grained vector processors. Software management of such complex systems will be a major challenge of the 1990s.
Originally poor on high-performance systems, software environments have been improving steadily. Parallel versions of Lisp, C++, and Fortran-77, for example, are available on the Connection Machine. Most systems offer at least one high-level language having some parallel programming enhancements and some parallel debugging tools. Research on new parallel computing languages is continuing; however, software is still the greatest bottleneck in parallel computation. A lack of standards, robust and rich programming structures, software development tools, and debugging aids has discouraged widespread use. Left alone, this situation will become even more critical as increasingly complex hardware systems emerge.
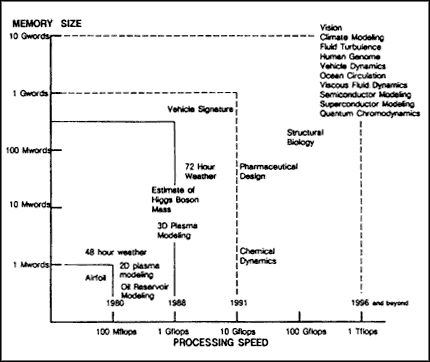
Figure 3.1 Some grand challenges of high-performance computing and their projected computational requirements (from the Federal High-Performance Computing Program).2
The greatest advances in computing performance have, and will continue to come from, algorithmic innovation. The fast Fourier transform, adaptive hp-refinement, and fast multipole method are but three examples. Systems and pressor software must improve so scientists and engineers do not have to divert a great deal of time from their primary disciplinary goals in order to understand the nuances of parallel programming. With this accomplished, algorithmic breakthroughs will occur more frequently.
THE FEDERAL HIGH-PERFORMANCE COMPUTING PROGRAM
Several studies conducted during the 1980s, terminating with the Raveche Report and the FCCSET (Federal Coordinating Council for Science, Engineering, and Technology) Report,3 addressed the need for the United States to maintain superiority in high-performance computing. As a result, the Bush administration introduced the Federal High-Performance Computing (HPC) Program in 1989.4 The HPC Program calls for increasing the current $500 million funding level for high-performance computing by $150 million during the first year to $600 million by year five. Intimately connected with parallel computation, the HPC Program clearly addresses several issues central to computational mechanics. Listed among their "grand challenges" are climatology, turbulence, combustion, vehicle design, oil recovery, oceanography, and viscous flow. Progress in these areas, made possible by advanced parallel computing systems and software, will result in enhanced productivity, greater efficiency of engineering systems, and increased scientific knowledge.
Research Opportunities
The greatest success in algorithm development for parallel computers has been the solution of linear algebraic systems. Techniques and software exist for solving dense and
sparse systems on a variety of architectures. Relative to this, parallelization of other portions of computational mechanics problems is in its infancy.
Experimentation with procedures for solving solid and fluid mechanics problems on massively parallel SIMD arrays has had some degree of success. For problems of moderate size, one could associate an element, computational cell, or node of the mesh with an individual processor of the parallel system. With computing systems having the concept of virtual processors, this strategy would be viable for problems of arbitrary size. However, as previously noted, the network connections of the computer may not be rich enough to support a convenient mapping of elements or nodes onto processors. Problems using uniform meshes and finite difference approximations are, naturally, simpler to map to SIMD or MIMD networks than are formulations using unstructured grids having general connections. One technique for solving unstructured-grid finite element problems on a SIMD array uses a two-step procedure with an initial mapping of elements of the mesh onto processors followed by a second mapping of the nodes onto processors for the solution of the linear system. Another approach utilizes an underlying uniform tree structure associated with the grid to create a mapping. Nevertheless, there is a great deal more work to be done, and mapping the discrete problem to the computational topology continues as a major unsolved problem. This situation will be further exacerbated by the emergence of new architectures with different network connections.
Adaptive finite difference and finite element methods employing automatic mesh (h-type) refinement, order (p-type) enrichment, and/or mesh redistribution (r-type refinement) are among the most efficient and robust procedures for solving mechanics problems on serial computers. Optimal adaptive enrichment strategies can even produce exponential convergence rates as problem sizes increase (cf. Figure 1.2). Very little has been done, however, to develop parallel adaptive procedures. Factors limiting progress include reliance on nonuniform unstructured meshes, variable-order methods, and dynamic data structures such as trees. The efficiency afforded by adaptivity will always be important at some level and would permit solving problems that could not be solved with uniform structures. Furthermore, complex three-dimensional geometries will place a greater emphasis on adaptive mesh refinement and order enrichment rather than on a priori mesh generation and order specification.
Adaptive procedures typically use hierarchical data structures that contain suitable parallel constructs. Procedures
for mapping such trees to some parallel architectures are known, for example, and used in computer vision and computer-aided design. Use of these procedures with adaptive techniques has begun and, while much more remains to be done, there is some cause for optimism. Rapidly convergent hp-refinement procedures use different combinations of mesh refinement and order enrichment locally and seem more suited to MIMD computation than to execution on a computer operating in lock-step fashion. Many mesh redistribution techniques often include global influences and also seem to be more appropriate for MIMD computation. Envisioned MIMD computer systems containing clusters of SIMD arrays may overcome some of these difficulties, but efficient processor utilization and load balancing remain challenging issues to the successful parallel implementation of adaptive hp- and r-refinement procedures.
A 10-dimensional hypercube-connected MIMD computer has approximately the same bit-processing capability as the largest SIMD arrays. Software environments on MIMD computers, however, are less developed than those on SIMD computers due to the greater complexity involved in distributing control structures. Model mechanics problems involving wave propagation, compressible flow, and elastic deformation have been solved with great success; but realistic problems with embedded heterogeneities such as heterogeneous materials, phase transitions, and elastic-plastic responses present difficulties similar to those described for parallel adaptive procedures. Computation on SIMD systems will be inefficient due to large variations in local response, and computation on MIMD systems will require complicated load balancing.
Solution-based reliability measures provided by a posteriori error estimation could potentially serve as metrics for balancing processor loading. Physically motivated domain decomposition, whereby asymptotic or other approximate analyses are used to estimate the computational effort needed in various portions of the problem domain, are another possible means of load balancing that should be explored further.
Education, Experimentation, and Access
Researchers in computational mechanics must be educated and have access to promising advanced systems as soon as they become available. Undue reliance should not be placed on existing systems, and conclusions regarding the superiority of one architectural design relative to another should not be
drawn too quickly. Software developed with a lack of standardization and a lack of input from the engineering community can only hinder progress and further discourage the use of parallel systems. Interdisciplinary cooperation is clearly needed. Parallel programming constructs and languages must strive for standardization and portability. New computing languages must have capabilities rich enough to address complexities commonly found in computational mechanics.
Access to supercomputers has been improved considerably by the construction of national and regional networks and the funding of computational research sponsored by the National Science Foundation supercomputing centers. However, relatively few engineers have access to more massive and experimental parallel computing systems. Current massively parallel systems are the prototypes of future computers, and their use is now vital toward achieving the algorithmic breakthroughs that will provide necessary performance improvements. Although less expensive than production supercomputers, massively parallel systems are still costly and, as noted, have a more complex programming environment. Use should increase with the availability of smaller hardware systems at reduced cost and with expected improvements in software systems and tools. Scaled-down SIMD systems still provide hundreds to thousands of processors and thus have a reasonable degree of parallelism. Cost is declining to the point where individual research groups can afford to purchase systems.
Computation is peripherally involved in most mechanics curricula and is a central part of others; however, parallel programming in education is rare. Courses emphasizing parallel programming design and methodology must be developed now in order to meet the engineering challenges of the future. Programs should emphasize the interdisciplinary nature of the subject and include studies in mechanics, computer science, and numerical analysis. Appropriate computer science courses should give students a knowledge of parallel algorithm design, programming languages, data bases, operating systems, architectures, and algorithm analysis. Computational experimentation is essential. Hardware must either be available locally or conveniently accessible via networks. Software must be developed to illustrate the fundamental concepts and encourage algorithmic experimentation without undue reliance on frustrating semantic details or architectural idiosyncrasies. Programs will undoubtedly begin at the graduate level; however, undergraduate exposure to parallel computation should not be delayed.
Much of the future of high-performance computing lies in massive parallelism and, although present parallel systems
may bear little resemblance to their successors, experience gained now is vital to developing new algorithms and solution strategies, building a knowledge base, and developing and designing new architectures. Steps must be taken to provide increased access to parallel systems of moderate and massive proportions. Moderately sized systems having modest cost may be distributed widely. They are important for education, experimentation, software development, and establishment of a local cadre of expertise. They will accelerate learning of the more complicated programming methodology and greatly stimulate interdisciplinary interaction. Large systems at remote centers may be used for production and testing of scalability or parallel algorithms.









