
Serendipitous Data and Future Statistical Software.
Paul F. Velleman
Cornell University
Modern statistics is usually considered to have first appeared around the beginning of this century in a form that resembled its scientific father more than its mathematical mother.
As statistics matured during the middle of this century, statisticians developed mathematical foundations for much of modern statistics. Along the way they developed methods that were optimal in some sense. For example, maximum likelihood statistics--which, when applied under the most commonly used assumptions, include the most commonly used methods--have many properties that make them the best choice when certain assumptions about the model and the data are true. Data from suitably designed and suitably randomized studies were the focus of data analysis based on these insights.
However, much real-world data is serendipitous. By that I mean that it arises not from designed experiments with planned factors and randomization, nor from sample surveys, but rather as a by-product of other activities. Serendipitous data reside in databases, spreadsheets, and accounting records throughout business and industry. They are published by government and trade organizations. They arise as a by-product of designed studies when unexpected patterns appear but cannot be formally investigated because they are not part of the original protocol. Serendipitous data forms the basis for some sciences and social sciences because it is, for the moment, the best we can do.
Concern with optimal properties of statistics follows the traditions of mathematics in which elegant results are valued for their internal consistency and completeness but need not relate directly to the real world. By contrast, a scientist would reject even the most elegant theory for the small sin of failing to describe the observed world. Traditional statistics are often inappropriate for serendipitous data because we cannot reasonably make the assumptions they require. Much of the technology of classical statistics and of traditional statistics software is designed to analyze data from designed studies. This is a vital function, but it is not sufficient for the future.
In his landmark paper, “The Future of Data Analysis,” John Tukey identified the difference between mathematical and scientific statistics, and called for a rebirth of scientific statistics. To quote Lyle Jones, the editor of Volumes III and IV of Tukey's Collected Works [Jones, 1986, p. iv],
The publication was a major event in the history of statistics. In retrospect, it marked a turning point for statistics that elevated the status of scientific statistics and cleared the path for the acceptance of exploratory data analysis as a legitimate branch of statistics.
Through Tukey's work, and that of others, data analysis that follows the paradigms of scientific statistics has been called Exploratory Data Analysis (EDA). Recently, EDA and the statistical graphics that often accompany it have emerged as important themes of computer-based statistical data analysis. An important aspect of these advances is that, contrary to traditional methods, they do not require data from designed experiments or random samples; they can work with serendipitous data. By examining the differences in these two philosophies of statistical data analysis, we can see important trends in the future of statistics software.
All statistical data analyses work with models or descriptions of the data and the data's relationship to the world. Functional models describe patterns and relationships among variables. Stochastic models try to account for randomness and error in the data in terms of probabilities, and provide a basis for inference. Traditional statistical analyses work with a specified functional model and an assumed stochastic model. Exploratory methods examine and refine the functional model based on the data, and are designed to work regardless of the stochastic model.
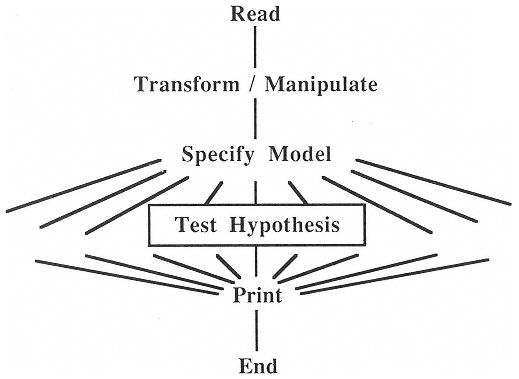
Statistics software has traditionally supported mathematical statistics. The data analyst is expected to specify the functional model before the analysis can proceed. (Indeed, that specification usually identifies the appropriate computing module.) The stochastic model is assumed by the choice of analysis and testing methods. Statistics packages that support these analyses offer a large battery of tests. They avoid overwhelming the typical user because a typical path through the dense thicket of choices is itself relatively simple.
The many branches in this design (Figure 1) encourage modularity, which in turn encourages a diversity of alternative tests and the growth of large, versatile packages. Most of the conclusions drawn from the analysis derive from the hypothesis tests. Printing (in Figure 1) includes plotting, but simply adding graphics modules to such a program cannot turn it into a suitable platform for EDA. For that we need a different philosophy of data analysis software design.
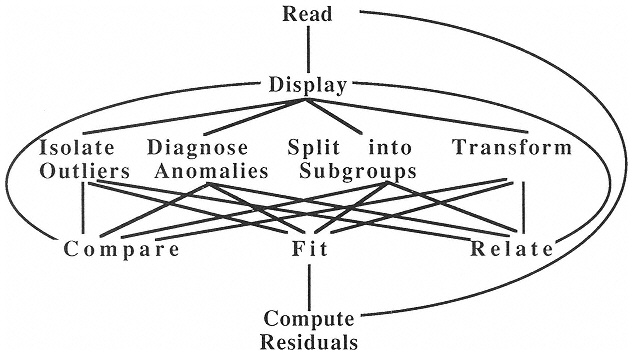
Software to support scientific statistics must support exploration of the functional model and be forgiving of weak knowledge of the stochastic model. It must thus provide many plots and displays, offer flexible data management, be highly interconnected, and depend on methods other than traditional hypothesis tests to reveal data structure. A schematic might look like Figure 2. Note that there is no exit from this diagram. Most of the paths are bi-directional, and many are omitted. The data analyst learns about the data from the process of analysis rather than from the ultimate hypothesis test. Indeed, there may never be a hypothesis test.
Software to support scientific statistics is typically not modular because each module must communicate with all the others. The complexity can grow factorially. It is thus harder to add new capabilities to programs designed for scientific statistics because they cannot simply plug in as new modules. However, additions that are carefully designed benefit from the synergy of all capabilities working together.
The user interface of such software is particularly important because the data analyst must “live” in the computing environment while exploring the data and refining the
functional model (rather than simply passing through on a relatively straight path, as would be typical of traditional packages).
The ideals of mathematical and scientific statistics are two ends of a continuum. Good statistics software can fit almost anywhere along this continuum. However, it is probably impossible for any one program to serve both ends well. Any program rich enough in statistics methods and options to meet the needs of classical statistics will find it hard to offer the directness, speed, and integration required for data exploration.
Where is Statistical Software Going?
Many programs are moving to fill the middle ranges of the continuum. Programs such as SPSS, SAS, and Systat that were once geared to the extreme mathematical statistics end of the spectrum now appear in versions for desktop computers, and more flexible interfaces and better graphics have begun to be developed. Programs such as S, Data Desk, and X-Lisp Stat that pioneered in the data analysis end of the spectrum have had more capabilities added so that they no longer concentrate only on data exploration and display.
Nevertheless, I do not believe that we will all meet in the middle.
Innovations in Computing Will Offer New Opportunities
Computing power will continue to grow, and new data analysis and graphics methods will develop to take advantage of it. Many of these will extend scientific statistics more than mathematical statistics, although both kinds of data analysis will improve.
As operating systems become more sophisticated, it will become increasingly common (and increasingly easy) to work with several programs, using each for what it does best and moving data and results among them freely. Thus, for example, one might open a favorite word processor, a presentation graphics program, a traditional mathematical statistics program, and a scientific data analysis program. One would then explore and graph data in the data analysis program, copying results to and writing commentary in the word processor. One might then move to the mathematical statistics program for specialized computations or specific tests available only there (again copying results to the word processor). Finally, the presentation graphics program could be used to generate a few displays to illustrate the major points of the analysis, and those displays again copied to the word processor to complete the report. Development in this direction will be good
for statistical computing. There will be less pressure on statistics programs to be all things to all people, and more encouragement to define a role and fill it well. It will be easier to develop new innovative software because the practical barriers that make it difficult to develop and introduce new statistics software will be lower.
Networking will also improve dramatically, making it easier to obtain data from a variety of sources. Much of this data will be serendipitous, having been collected for other purposes. Nonetheless, additional data are likely to enhance analysis and understanding.
Challenges for Statistical Software
There are a number of clear challenges facing someone with the goal of producing better statistics software. First, it takes a long time to design and implement a statistics package. Common wisdom is that 10 person-years is minimum, but the major packages have hundreds of person-years invested. Second, the user community is diverse. No matter what is in a package, someone will have a legitimate reason to want something slightly different. Many of these requests are reasonable, yet a package that meets all of them may satisfy nobody. Third, full support of software is difficult and expensive. While documentation can now be produced with desktop publishing, it is still very hard to design and write. Finally, designing and programming for multiple platforms often means designing for the lowest common capabilities. What may be worse, many of the difficulties arising in writing portable software affect capabilities of particular interest to modern computer-based data analysis, such as the speed and look of graphics, methods of efficient and effective data management, and the design and implementation of the user interface.
Is the Commercial Marketplace the Best Source of Statistical Software Innovation?
I answer this question in the affirmative. Software developed in academia or research facilities has rarely reached usefulness or ready availability without being commercialized. Commercial software continues to be innovative (although it also tends to copy the innovations of others). Commercial software is usually safer to use because the inevitable bugs and errors are more likely to get fixed. I also believe that the marketplace has shown a general ability to select statistics software. “Survival of the fittest” has been known to kill off some good programs, but weak packages tend to survive only in niche markets even when large sums are spent on advertising and marketing.
Nevertheless, commercial software development is a chancy business, demanding an
unusual combination of skill, knowledge, and luck. The most innovative interface designers may lack the specialized knowledge to program a numerically stable least squares or to get the degrees of freedom right for an unbalanced factorial with missing cells. The best algorithms may be hidden behind an arcane command language or burdened with awkward data management.
We need to encourage innovation, but we also need to protect users from software that generates wrong results or encourages bad data analyses.
What Can We Do to Encourage Innovation?
To encourage innovations, we should encourage small players. While I have great respect for the giants of the statistics software industry, I think that monopoly rarely promotes innovation.
Developing standards that make it easier to work with several packages will also encourage innovation. For example, we need a better standard for passing tables of data among programs while preserving background information such as variable name, case label, units, and formats. Some might argue that we should work toward a unified interface for working with statistics software, but I believe that this would stifle innovation.
We can reduce the need to re-invent. For someone with a new idea about data analysis or graphics, it can take an inordinate amount of time and effort to implement standard algorithms that are already known. Books such as Numerical Recipes [Press et al., 1986] help for some scientific applications, but have little for statistics. For advanced statistical methods, Heiberger's book Computing for the Analysis of Designed Experiments [Heiberger, 1990] stands alone.
I support the trend toward using multiple programs. If a new concept can be proved in a relatively small, focused program and used readily with established programs, it will be easier to develop, distribute, and use. Users could then move data in and out of the program easily, continuing their analysis in their other preferred packages. Programs focused on a particular approach or audience (e.g., time series, quality control, econometrics) could integrate in this way with more established programs.
The pace of innovation could be speeded if we could convince academia that the creation of innovative software is a legitimate intellectual contribution to the discipline. We can attract fresh talent to statistical computing only if we provide publication paths and professional rewards. The Journal of Computational and Graphical Statistics, begun recently by the American Statistical Association, the Institute of Mathematical Statistics, and the Interface Foundation, and other new journals in this field may help here. Some university copyright regulations also penalize software development relative to authoring books or papers, but there is no consistency from school to school. We could work to establish standard policies that promote rather than stifle software innovation.
What Can We Do to Ensure Quality?
Software reviewing is difficult and still haphazard. We need to recruit competent reviewers and encourage reviews that combine informed descriptions of a package's operation style, reasonable checks of its correctness, and well-designed studies of its performance. All complex software has bugs and errors. Responsible developers want to hear of them so they can be fixed. But people tend to believe that if the program doesn't work, it must be their fault (“After all, it's published, it's been out for so long someone must have noticed this before, computers don't make mistakes …”). We need to encourage users to recognize, document, and report bugs and errors.
A library of tested algorithms can help reduce errors. New programs always have errors. (So do old ones, but--we hope--fewer and less serious ones.) By providing tested programs and stable algorithms we can reduce the incidence of bugs and errors. Even if the algorithm is reprogrammed, it helps to have a benchmark for testing and debugging.
What Can We Do to Promote Progress?
-
We must encourage those who have serendipitous data to examine it. (Typical thinking: “I don't have any data … well, I do have personnel records, sales records, accounting records, expenses, materials costs … but that's not data.”)
-
We must teach scientific statistics as well as mathematical statistics.
-
We must encourage innovation.
References.
Heiberger, R., 1990, Computing for the Analysis of Designed Experiments, John Wiley & Sons, New York.
Jones, L. (ed.), 1986, The Collected Works of John W. Tukey, Vols. III and IV, Wadsworth Advanced Books & Software, Monterey, Calif.
Press, W.H., B.P. Flannery, S.A. Teukolsky, and W.T. Vetterling, 1986, Numerical Recipes, The Art of Scientific Computing, Cambridge University Press, New York.








