
Appendix A
Pilot Test of the IOM Model
In July 1991, five members of the Committee on Priorities for Health Technology Assessment and Reassessment convened to pilot-test the committee's model for priority setting. The version they tested was designated the convened pilot; a second mailed pilot test provided clam for a comparison of the results obtained by each method, convening and mailing. The purpose of the pilot testing was (1) to test the methodology, (2) to compare results of the two groups to judge whether a mail process was a reasonable substitute for a convened group, and (3) to use the experience of both groups to improve the model.
Each group used a consensus process to assign weights to the six criteria that the full committee had chosen at an earlier meeting; group members also assigned criterion scores by vote for the three subjective criteria (a seventh criterion was later added by the committee). In addition, the convened group estimated missing data where needed to assign criterion scores for objective data. The mailed pilot test used the criterion definitions developed by the convened group to weight the criteria and provided criterion scores for the three subjective criteria.
In addition to the weighting and criterion scoring activities, each group listed the ethical, legal, and social problems that contributed to their rating of that criterion. This report compares the products of both groups and draws conclusions about implementation of the model.
METHODS
Topics and Data for Priority Setting
To prepare for the pilot test, study staff sampled 11 conditions and technologies from a rank-ordered list of 20 topics produced during the IOM/ CHCT pilot study (IOM, 1990f). Using stratified random sampling, the first- and twentieth-ranked conditions or technologies were sampled first. Nine additional topics were then sampled between the top and bottom of the group using a table of random numbers.
Conditions and technologies were defined more specifically than in the IOM/CHCT study to facilitate data gathering. These definitions required a designation of whether the condition or technology was to include prevention, screening, diagnosis, or treatment; the level of severity; the care settings; and the anatomical site or sites of interest. For instance, ''cardiovascular disease'' in the IOM/CHCT study was further defined for this pilot test as "treatment of coronary artery disease severe enough to consider revascularization but not treatment of post-myocardial infarction." Thus, the individual topics in the pilot test were a subset of the topics listed in the IOM/CHCT report but not strictly comparable to them.
Before the meeting, staff compiled data on each condition and technology and provided the pilot-test group with a summary describing each condition, a list of alternative technologies to be considered, and data relevant to each condition.
Although the groups were small (each had six members), they included clinicians and individuals experienced in quantitative and health services research and technology assessment, and public policymaking.
Criteria
The following six criteria were to be weighted and given criterion scores:
-
burden of illness (per patient with the disease)
-
cost (expenditures/person/year)
-
prevalence (rate/1,000 in the general population)
-
practice variations (coefficient of variation)
-
potential of the assessment to improve health outcomes
-
potential of the assessment to resolve ethical, legal, or social (ELS) issues.
Mailed pilot-test respondents were given instructions about how to assign weights and subjective scores for each criterion. After the pilot test was completed, the committee further refined the definitions of each criterion (see Chapter 4).
Criterion Weighting
The pilot group voted to take one criterion—the ELS criterion, which in some respects was considered the least important—and use it to anchor the bottom end of the weighting scale. Each member of the group then assigned weights to the remaining five criteria relative to his or her perception of the importance of the rating of ELS ("How much more important is criterion X than ELS?"). The group discussed individual weights and voted again. The mean weights that were computed following this round were used for the remainder of the pilot test. The mailed pilot test group had only one round of voting.
Criterion Scoring
Convened Pilot
Objective Criterion Scores.
The group reviewed the data that the staff had assembled and discussed which data were pertinent to the criteria. After ensuring that measures were used consistently among conditions and technologies, the group estimated missing data for the three objective criteria—prevalence, costs, and practice variations.
Subjective Criterion Scores. Each member of the convened pilot group independently rated the conditions and technologies on burden of illness, potential to improve outcomes, and potential to resolve ELS issues. The group then discussed their scores and had an opportunity to make adjustments (such adjustment occurred in 27 of 135 separate ratings for the convened group). The ratings for each condition, as would be expected, showed regression to the mean. Mean scores for each criterion were entered in the quantitative model to calculate priority scores.
Mailed Pilot
Objective Criterion Scores. The mailed pilot test group was not asked to provide objective criterion scores. Consequently, in order to compare priority scores for both groups, the analysis used the criterion scores that the convened pilot group assigned to each criterion (as well as the convened pilot criterion weights) to compute priority scores for both groups on the objective criteria.
Subjective Criterion Scores. Members of both groups rated each of the three subjective criteria based on summary descriptive material about each condition and technology and available data on burden of illness. Each respondent indicated the reasoning behind his or her rating for ELS issues.
RESULTS
Feasibility
The convened group concluded that its model was feasible. Staff time required to assemble data for each condition was approximately 1 day. Although many data were missing or expressed in noncomparable units, the group found that the criteria could be operationally defined and that its combined experience was sufficient to estimate data (although with the understanding that a full implementation of the model would require more complete data).
Improvements in the Model
Pilot testing led the committee to extensive deliberation about the criterion definitions and their appropriate units, and to the addition of one criterion, for a total of seven. The committee also considered and further clarified the composition of the panels for weighting the criteria and for creating subjective and objective criterion scores.
Comparison of Convened and Mailed Methods
Three questions might be asked about the two methods. First, how much dispersion was there around the mean for each group (within-group differences)? Second, how much did criterion scores differ when developed by a group process or by an individualized mail process without feedback (between-group differences)? Third, how much do differences in subjective scores contribute to differences in priority scores?
Criterion Weights
The first analysis addressed the differences between the two pilots in mean criterion weights and their dispersion. Figure A.1 shows the mean criterion weights and their standard deviations for the six members of the convened pilot group. Figure A.2 shows the mean criterion weights and standard deviations derived by the mailed pilot group. Overall, the mailed pilot group assigned higher individual criterion weights and had a greater range of weights relative to the ELS criterion than were assigned by the
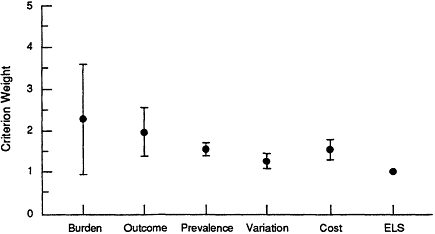
Figure A.1 Mean criterion weights and their standard deviations for the convened pilot group; ELS=ethical, legal, and social (issues).
convened group. Within the mailed group, the highest ranking criterion—likelihood of an assessment changing health outcomes—reached a mean rating of 3.7; the highest weight assigned by the convened group was only 2.25 for burden of illness.
Criterion Scores
Between-Group Comparisons. Criterion scores for the three subjective criteria (burden of illness, likelihood of an assessment changing health outcomes, and probability of resolving an ELS issue) were compared for each condition or technology. Overall, the mailed pilot group rated conditions higher (22 of 33 conditions were rated higher by the mailed pilot), although a sign test was not significant (X2 = 3.67; Snedecor and Cochran, 1967).
Within-Group Dispersion of Responses. Standard deviations for each criterion score were also compared using a sign test. Here, the findings are striking, if not predictable. In 26 of 33 possible ratings, the standard deviations for the mailed group are larger, in many cases considerably larger, than for the convened group. Using the sign test to compare the number of condition and technology pairs in which one or the other group had a higher deviation in their ratings yields X2 = 10.93 (p <<.001).
Taken together, the two sign tests indicated that despite small numbers of respondents (six in each group), the mailed pilot group had a signifi-
cantly greater dispersion in responses, compared with the convened group, and rated each condition higher for most criteria.
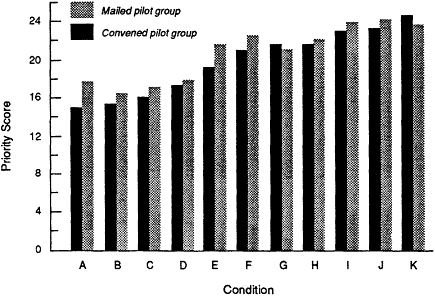
Priority Scores
Observed Priority Scores (see Figure A.3). For the objective criteria, the mailed pilot used the criterion weights and objective criterion scores derived by the convened pilot group. Thus, the two groups differ only on the subjective ratings. As in the assigning of criterion weights, the priority scores of the mailed pilot group were higher than those of the convened group for each condition. Relative priority scores for the two groups, however, were comparable. As can be seen in Figure A.3, scores for the top three conditions or technologies were approximately the same, as were scores for the bottom four.
Sensitivity of Priority Scores to Changes in Subjective Criterion Scores. The second analysis addressed the effect of a change in the subjective ratings on the resulting priority score. Given that the mailed pilot yielded greater variations in response, what effect do these variations have on the final priority score?
It is useful to examine how the model behaves when criterion scores vary (Figure A.4). To test how changes in subjective ratings affect the final priority score, one can hold constant the criterion weights and the objective
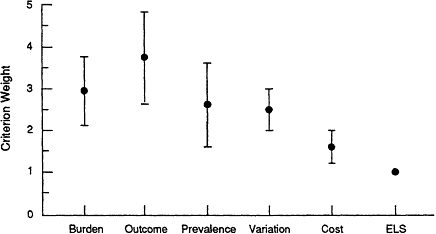
Figure A.2 Mean criterion weights and their standard deviations for the mailed pilot group; ELS=ethical, legal, and social (issues).
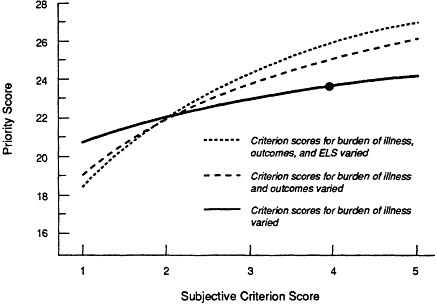
criterion scores and vary first one, then two, and finally all three subjective ratings from their minimum to maximum values.
The solid circle in Figure A.4 shows the observed priority score of 23.6 for a debilitating chronic condition for which burden of illness was rated 4, outcomes 2, and ELS 1.9. The overlying curve shows the effect on the priority score when the rating for burden of illness is changed to 1, 2, 3, and 5.
The second curve (the dashed line) shows the result of varying two subjective ratings simultaneously; the third curve (the dotted line) shows the result of varying all three ratings. When all three ratings are varied from 1 to 5, the expected priority scores range from 18.45 to 26.9, which is equivalent to the 8.5-point range observed in this exercise for all the conditions considered (15.7-24.2). From this, one may draw conclusions about how the quantitative model behaves: although priority scores are robust (e.g., resistant to change caused by extremes in individual ratings), substantial changes in the mean criterion score for a given condition affect the final priority score.
IMPLICATIONS OF THE PILOT TESTS FOR THE IOM MODEL
Neither group reported difficulties in assigning criterion weights, although the group surveyed by mail reported difficulty in assigning subjective criterion scores for individual conditions or technologies. They attributed their difficulties to uncertainty about applying the criteria to specific conditions as well as about the scope of the technologies to include. Other problematic factors were incomplete data, some instances of data that were not expressed in comparable units, and lack of familiarity with a given clinical condition.
Criterion weights assigned by the convened group showed less dispersion (particularly after group discussion) than did those assigned by the mailed pilot group. Although members of the mailed pilot group received revised definitions of each criterion, the definitions were briefly stated and did not include applied examples. Individual mailed pilot criterion scores varied more widely and tended to be higher than the scores of the convened pilot group. The greater variation in response is easily explained by lack of group consensus about the meaning of the criteria or a chance to discuss and vote again, but it is not clear why the scores of the mailed pilot group tended to be higher. Despite these differences, and perhaps of greater interest, both groups rated burden of illness and outcome high relative to the other criteria. They also rated prevalence, practice variations, and cost above ELS issues.
Criterion Scores
The convened group derived objective criterion scores using a combination of the data provided by staff and their expertise and knowledge of the clinical conditions. The group needed to perform less estimation for prevalence and clinical practice variations than for costs. It should be noted that estimates of burden of illness must, at this time, be largely subjective. Although mortality data are readily available, health status measures that include functional status scores for a given clinical condition are still quite sparse in the clinical literature and require both clinical familiarity and patient- and family-based information.
Both the convened group and the mailed pilot group assigned scores to subjective criteria. Following the first round of ratings, the convened group used a Delphi process that focused on outlier ratings, differences in their interpretation of a criterion, and different features of the condition, patient populations, or social issues that each person had considered. In particular, ELS issues identified by group members varied widely.
For example, in explaining a high rating for the ELS criterion on cardiovascular procedures, one person cited the published differences in procedure rates for blacks and whites and what this implied about inequality of access. Another individual, who gave a rating of I to ELS issues, explained, "I seriously doubt new technology is as important as prevention." In considering the burden of illness from cataracts, one person persuaded the group that untreated cataracts could mean the difference between living independently and requiring nursing home care. Another person considered the burden to society of highway accidents related to cataract-impaired drivers. Considerations of treatment of alcoholism raised many social issues—for example, fetal alcohol syndrome, special at-risk populations, co-addiction, and issues related to insurance coverage for risky behavior. In considering intensive care units (ICUs), one member of the group focused on identifying the appropriate populations for ICU care, another on the implications of life-sustaining therapy for the terminally ill. In another example, considerations related to depression included underdiagnosis, depression associated with unemployment, the rising rate of teenage suicide, and side effects of medications. In some cases, the panel agreed that the issue was interesting but not relevant to setting priorities for technology assessment; in other cases, scores were adjusted as a result of the discussion.
The mailed pilot group, which did not have a second round of ratings, reported much more difficulty than the convened group in assigning ratings; the mailed group also had many more missing ratings. Respondents cited, in particular, lack of familiarity with the clinical condition and difficulty in understanding how to apply the criteria. One possible reason for the difference between the two groups is that the convening process gave individuals
more confidence in assigning ratings (although not necessarily greater accuracy) in the face of almost complete uncertainty.
Although the number of individuals in each group was small, the two pilot tests suggest that implementation of the model will require very clear and careful descriptions of the criteria as well as several rounds of voting and discussion conducted in conference or by other methods to establish criterion weights. Some criteria, such as prevalence, are familiar to many people but are used in this model in specific ways, particularly when referring to procedures and screening technologies. Other criteria, such as burden of illness, are unfamiliar and require a clear definition to ensure that group members use them comparably.
The committee drew several conclusions from its pilot tests. First, the model is feasible, but those implementing it will need to establish a method (e.g., a training session or other form of education) to ensure a common understanding of the criteria. Second, there is considerable merit to using a two-stage group method that first anchors the ends of a given subjective criterion for a given candidate list and then assigns scores within these extremes. Third, it will be critical to establish the reliability of the criterion weighting process to ensure that the process is informed and stable—as well as efficient. Fourth, the model should be modified on the basis of use and experience. Aspects of validity include the reasonableness of the product and its acceptability to and employment by intended users. The committee's pilot test began this process of evaluation and modification, but it must be continued by the model's users.










