
3.
Approximate Counting Via Markov Chains
David Aldous
University of California at Berkeley
ABSTRACT
For large finite sets where there is no explicit formula for the size, one can often devise a randomized algorithm that approximately counts the size by simulating Markov chains on the set and on recursively defined subsets.
3.1 Exact and Approximate Counting
For a finite set S, there is a close connection between
-
having an explicit formula for the size |S| and
-
having a bounded-time algorithm for generating a uniform random element of S.
As an elementary illustration, we all know that there are n! permutations of n objects. From a proof of this fact, we could write down an explicit 1-1 mapping f between the set of permutations and the set A = {(a1 , a2, ... , an): ![]() . Then we could simulate a uniform random permutation by first simulating a uniform random element a of A and then computing f(a). Conversely, given an algorithm that was guaranteed to produce a uniform random permutation after k(n) calls to a random number generator, we
. Then we could simulate a uniform random permutation by first simulating a uniform random element a of A and then computing f(a). Conversely, given an algorithm that was guaranteed to produce a uniform random permutation after k(n) calls to a random number generator, we
could (in principle) analyze the working of the algorithm in order to calculate the chance p of getting the identity permutation. Then we can say that the number of permutations equals 1/p.
But now suppose we have a hard counting problem for which we cannot find an explicit formula for |S|. The purpose of this chapter is to describe a remarkable technique for constructing randomized algorithms that count S approximately. This technique, developed in recent years, has two ingredients. The first idea is that in some settings, having an algorithm for generating an approximately uniform random element of S can be used re-cursively to estimate approximately the size |S|. We illustrate this with two examples in the next section. The second idea is that we can obtain an approximately uniform random element of S by running a suitable Markov chain on state-space S for sufficiently many steps. This idea and the particular chains used in the two examples are discussed in §3.3. The latter idea is fundamentally similar to the use of Markov chains in the Metropolis algorithm, which underlies the simulated annealing algorithm discussed in Chapter 2. The difference is that here we seek to simulate a uniform distribution rather than a distribution that is deliberately biased towards minima of a cost function. Our Markov chains are simpler to analyze and permit rigorous discussion of polynomial-time convergence issues that seem too hard for rigorous treatment in the context of simulated annealing.
3.2 Recursive Estimation of Size
Example: Volume of a Convex Set (Dyer et ah, 1989, 1991). Consider the problem of estimating the volume vol(K) of a convex set K in n-dimensional space, for large n. Suppose we are told that ![]() , where B(r) is the ball of radius r = r(n). It is believed that there is no polynomial-time deterministic algorithm to approximate vol(K). But suppose we have a means of simulating, at unit cost, a random point in K whose distribution is approximately uniform. Specify some subset K1 with
, where B(r) is the ball of radius r = r(n). It is believed that there is no polynomial-time deterministic algorithm to approximate vol(K). But suppose we have a means of simulating, at unit cost, a random point in K whose distribution is approximately uniform. Specify some subset K1 with ![]() and for which vol(K1)/vol(K) is not near 0 or 1. Then by simulating m random points in K and counting the proportion p(1) that fall within K1,
and for which vol(K1)/vol(K) is not near 0 or 1. Then by simulating m random points in K and counting the proportion p(1) that fall within K1,
Now specify a decreasing sequence of such convex subsets
that will have length L = O(n log r). Then as above we can estimate each ratio vol(Ki)/vol(Ki-1) as p(i), and finally
How accurate is this approximation? The elementary mathematics of random sampling shows that the sampling error at each step is O(m-1/2 ). So by choosing m to be a large multiple of L2, the sampling error in (3.1) is made small. Note this makes the total cost O(L3). The remaining issue is to find a way of simulating an approximately uniform point in K with bias o(1/L), where bias is formalized in (3.2). We return to this issue in the next section.
Example: Matchings in a Graph (Sinclair and Jerrum, 1989).> Fix a graph G with n vertices. In graph-theory terminology, two edges are independent if there is no common vertex, and a matching is a set of independent edges. Let M(G) be the set of all matchings of G. How can we estimate |M(G)|, the number of matchings? Let us show how to do so, given a method of simulating approximately uniform random matchings.
Enumerate the vertices as s1, s2, ... , sn. Let Gi be the subgraph obtained by deleting s1, ... , si. If we could simulate a random matching ![]() that was exactly uniform (i.e., equally likely to be each of the |M(G)| matchings), then
that was exactly uniform (i.e., equally likely to be each of the |M(G)| matchings), then
So given a method of simulating an approximately uniform matching, we can do m such simulations and record the proportion p(1) of these m simulations in which s1 is not an edge of the random matching. Then
Similarly, do m simulations of an approximately uniform random matching in Gi-1, and use the proportion p(i) in which si is not an edge of the matching as an estimator of |M(Gi)|/|M(Gi-1)|. This argument, analogous to (3.1), leads to
These examples share a self-reducibility property formalized in Sinclair and Jerrum (1989). Informally, we can relate the size of the set S under
consideration to the size of a smaller set S1 of the same type. The examples illustrate the first idea stated in §3.1. That is, with self-reducible sets an algorithm for generating an approximately uniform random element can be used recursively to estimate approximately the size |S|.
Three points deserve mention:
-
In the two examples, the self-reducibility property was exact. The reader will rightly suspect that such examples are rare. But the method has been successfully applied where there is only some cruder notion of reducibility, for instance to the problems of approximating the permanent (Jerrum and Sinclair, 1989) and of counting regular graphs (Jerrum and Sinclair, 1988).
-
We should emphasize the point of the product-form estimators: they enable us to estimate exponentially small probabilities in polynomial time. Thus in the first example both vol(K)/vol(B(r)) and vol(B(1))/ vol(K) are typically O(r-n), so to estimate the ratio in one step would require simulating O(rn) points instead of O(nlog r)3 points.
-
In principle, we could combine this self-reducibility technique with any method of simulating approximately uniform elements of the set, not just the Markov chain method in the next section. But in practice no other methods are known for the examples where the technique has been successful.
3.3 The Markov Chain Method of Simulating a Probability Distribution
This method is a specialization of the Metropolis algorithm described in Chapter 2 on simulated annealing. Suppose we want to simulate the uniform probability distribution π on a large finite set S. Suppose we cau define a Markov chain (picture a randomly moving particle) on states S whose stationary distribution is π. After running the chain for a sufficiently large number of steps, the position of the particle will be approximately uniform. The simplest way to define such a chain is to define a regular graph structure with vertex-set S. In this graph setting, let the Markov chain be a simple random walk on the graph, at each step moving from the current vertex s to a vertex s' chosen uniformly from the neighbors of s.
We now describe graphs for our two examples. To fit the first example into this framework, we discretize in the obvious way, replacing the convex set K by its intersection ![]() with the lattice of edge-length δ, for some small δ. By simulating random walk on S for sufficiently many steps, we will get to a point approximately uniform in S, and hence approximately uniform in K.
with the lattice of edge-length δ, for some small δ. By simulating random walk on S for sufficiently many steps, we will get to a point approximately uniform in S, and hence approximately uniform in K.
In the second example, construct a Markov chain as follows. From a matching ![]() , move to a new matching
, move to a new matching ![]() as follows:
as follows:
-
Pick an edge (v, w) of G at random.
-
If (v, w) is an edge of
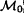 , delete it.
, delete it. -
If v and w are singletons of
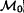 , add the edge (v, w).
, add the edge (v, w). -
Otherwise, v (say) is a singleton and w is in an edge (w, u) of
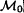 : delete the edge (w, u) and add the edge (v, w).
: delete the edge (w, u) and add the edge (v, w).
After sufficiently many steps, the random matching will have approximately uniform distribution.
3.4 Estimating Mixing Times
There is a glaring gap to bridge before we can use the Markov chain method as an honest randomized algorithm. In the simplest use of this method, we will run the chain for some number k of steps and employ the final state as our "approximately uniform" random element. But how many steps are enough? To justify algorithms, we need bounds on a mixing time such as τ1 or τ2 below, which formalize the intuitive idea of "number of steps until the distribution is approximately the stationary distribution, independent of starting position." The classical elementary theory of Markov chains says that, under natural conditions (irreducible, aperiodic), the distribution of k steps converges as ![]() to the stationary distribution π. But proofs of this elementary general result do not lead to useful bounds on in particular examples. The invention of approximate counting, as well as other Markov chain applications such as card-shuffling (Bayer and Diaconis, 1992; Diaconis, 1988) and queueing theory (Blanc, 1988), have motivated recent work of the mathematical issue of estimating mixing times.
to the stationary distribution π. But proofs of this elementary general result do not lead to useful bounds on in particular examples. The invention of approximate counting, as well as other Markov chain applications such as card-shuffling (Bayer and Diaconis, 1992; Diaconis, 1988) and queueing theory (Blanc, 1988), have motivated recent work of the mathematical issue of estimating mixing times.
In the context of approximate counting, we have some flexibility in the exact choice of the Markov chain, and it is usually possible and very convenient to choose the chain to be reversible, that is, to satisfy π(i)P(i, j) =
π(j)P(j, i) for all states i, j. A classical way of formalizing rates of convergence is via the second-largest eigenvalue λ < 1 of the transition matrix P. This leads to one definition of mixing time as
Another definition of mixing time, more directly applicable in our setting, uses the time taken to make the maximal bias small:
It is easy to show that after mτ1 steps the bias is at most 2e-m, so that a bound on τ1 enables us to specify confidently a number of steps guaranteed to reduce the bias sufficiently in our applications to approximate counting.
There are several other possible definitions of mixing times, and easy general inequalities giving relations between them. The real issue is not the choice of definition but the development of widely applicable techniques that enable some mixing time to be bounded. One interesting technique is to relate mixing times to the quantity
From a bound on c(P), one can use Cheeger's inequality (e.g., Sinclair and Jerrum, 1989) to bound τ2 and then obtain the desired bound on τ1. Such results are theoretically appealing in that c(P) relates to the "geometry" of the chain, and (for simple random walk on a graph G) to isoperimetric inequalities on G, a quantity of intrinsic graph-theoretic interest. On the other hand, it is usually hard to estimate c(P) well. Diaconis and Stroock (1991) argue that to get upper bounds on τ2 one can do as well by a direct use of a distinguished paths method. For each pair of states, one specifies a path connecting them, seeking to minimize the number of times any fixed edge is used: one can then bound τ2 in terms of the maximal "probability flow" along any edge. This is still an active research area, and doubtless further techniques will be developed.
We said that the simplest use of this method was to run the chain for some prespecified number of steps and employ the final state as our "approximately uniform" random element. As described in §3.2, this process is then repeated m times (say) in order to calculate the proportion of these m final values that fall in a given subset. Many variations are possible. For
instance, instead of the m repetitions one could run the chain for the same total time but estimate the desired probability of a subset by looking at the proportion of all times (except an initial segment) that the chain spent in the subset. This is likely to give somewhat of an improvement in practice, though in principle may be no better (Aldous, 1987).
3.5 Conclusion
The topic of approximate counting is still under vigorous development. Let us close with one direction for future research. In addition to the familiar counting problems from the theory of combinatorial algorithms, there are a range of interesting problems arising from physics. We mentioned that the Markov chain method was just a specialization of the Metropolis algorithm for simulating a given probability distribution by inventing a suitable Markov chain. Physicists have long used that algorithm for simulation but typically have been unable to justify rigorously the results of the simulation by proving bounds on the mixing time. For instance, physicists have studied self-avoiding random walks rather intensely by simulation and by nonrigorous mathematical methods. A celebrated open problem is to prove a polynomial-time bound for the mixing time in some algorithm for simulating self-avoiding walks in three dimensions: equivalently, to give a polynomial-time randomized algorithm for approximately counting the number of self-avoiding walks of length n. Bringing together the users of randomized algorithms in physics and the ''theoretical'' researchers in computer science promises to be a fruitful collaboration.
References
Aldous, D.J. (1987), On the Markov chain simulation method for uniform combinatorial distributions and simulated annealing, Probah. Eng. Inform. Sci. 1, 33-46.
Bayer, D., and P. Diaconis (1992), Trailing the dovetail shuffle to its lair, Ann. Appl. Probab. 2, to appear.
Blanc, J.P.C. (1988), On the relaxation times of open queueing networks, in Queueins Theory and Its Applications, CWI Monographs 7, North-Holland, New York, 235-259.
Diaconis, P. (1988), Group Representations in Probability and Statistics , Institute of Mathematical Statistics, Hayward, Calif.
Diaconis, P., and D. Stroock (1991), Geometric bounds for eigenvalues of Markov chains, Ann. Appl. Probab. 1, 36-61.
Dyer, M., A. Frieze, and R.. Kannan (1989), A random polynomial time algorithm for approximating the volume of convex bodies, in Proc. 21st ACM Symp. on Theory of Computing, ACM Press, New York, 375-381.
Dyer, M., A. Frieze, and R. Kannan (1991), A random polynomial time algorithm for approximating the volume of convex bodies, J. Assoc. Comput. Mach. 38, 1-17.
Jerrum, M., and A. Sinclair (1988), Fast uniform generation of regular graphs, Theor. Comput. Sci. 73, 91-100.
Jerrum, M., and A. Sinclair (1989), Approximating the permanent, SIAM J. Comput. 18, 1149-1178.
Sinclair, A., and M. Jerrum (1989), Approximate counting, uniform generation and rapidly mixing Markov chains, Inform. Comput. 82, 93-133.








